Go 構造体
構造体は異なる型のデータグループを保存でき、複合型です。Go はクラスと継承を捨て、コンストラクタも捨て、意図的にオブジェクト指向の機能を弱めています。Go は伝統的な OOP 言語ではありませんが、OOP の要素を持ち、構造体とメソッドを通じてクラスをシミュレートできます。以下は構造体の簡単な例です。
type Programmer struct {
Name string
Age int
Job string
Language []string
}宣言
構造体の宣言は非常に簡単です。例を以下に示します。
type Person struct {
name string
age int
}構造体自体とその内部のフィールドは、大文字小文字の命名規則に従って公開されます。同じ型の隣接フィールドについては、型を繰り返し宣言する必要はありません。
type Rectangle struct {
height, width, area int
color string
}TIP
構造体フィールドを宣言する際、フィールド名はメソッド名と重複できません。
初期化
Go にはコンストラクタが存在しません。ほとんどの場合、以下の方法で構造体を初期化します。初期化時は map のようにフィールド名を指定してからフィールド値を初期化します。
programmer := Programmer{
Name: "jack",
Age: 19,
Job: "coder",
Language: []string{"Go", "C++"},
}ただし、フィールド名を省略することもできます。フィールド名を省略する場合、すべてのフィールドを初期化する必要があります。通常、この方法は推奨されません。可読性が非常に悪いためです。
programmer := Programmer{
"jack",
19,
"coder",
[]string{"Go", "C++"}}初期化プロセスが複雑な場合は、構造体を初期化するための関数を作成できます。以下のように、これをコンストラクタと理解できます。
type Person struct {
Name string
Age int
Address string
Salary float64
}
func NewPerson(name string, age int, address string, salary float64) *Person {
return &Person{Name: name, Age: age, Address: address, Salary: salary}
}ただし、Go は関数とメソッドのオーバーロードをサポートしていないため、同じ関数やメソッドに異なるパラメータを定義することはできません。構造体を複数の方法で初期化したい場合は、複数のコンストラクタを作成するか、options パターンの使用を推奨します。
オプションパターン
オプションパターンは Go 言語で非常に一般的なデザインパターンで、より柔軟に構造体を初期化でき、拡張性が高く、コンストラクタの関数シグネチャを変更する必要もありません。以下のような構造体があると仮定します。
type Person struct {
Name string
Age int
Address string
Salary float64
Birthday string
}PersonOptions 型を宣言します。これは *Person 型のパラメータを受け取ります。これはポインタである必要があります。クロージャ内で Person に値を代入する必要があるためです。
type PersonOptions func(p *Person)次にオプション関数を作成します。これらは通常 With で始まり、戻り値はクロージャ関数です。
func WithName(name string) PersonOptions {
return func(p *Person) {
p.Name = name
}
}
func WithAge(age int) PersonOptions {
return func(p *Person) {
p.Age = age
}
}
func WithAddress(address string) PersonOptions {
return func(p *Person) {
p.Address = address
}
}
func WithSalary(salary float64) PersonOptions {
return func(p *Person) {
p.Salary = salary
}
}実際に宣言されたコンストラクタのシグネチャは以下の通りで、可変長 PersonOptions 型のパラメータを受け取ります。
func NewPerson(options ...PersonOptions) *Person {
// options を優先的に適用
p := &Person{}
for _, option := range options {
option(p)
}
// デフォルト値の処理
if p.Age < 0 {
p.Age = 0
}
......
return p
}これにより、異なる初期化の要件に対して 1 つのコンストラクタで完了し、異なる Options 関数を渡すだけで済みます。
func main() {
pl := NewPerson(
WithName("John Doe"),
WithAge(25),
WithAddress("123 Main St"),
WithSalary(10000.00),
)
p2 := NewPerson(
WithName("Mike jane"),
WithAge(30),
)
}関数型オプションパターンは多くのオープンソースプロジェクトで見られます。gRPC Server の初期化方法もこのデザインパターンを採用しています。関数型オプションパターンは複雑な初期化に適しています。パラメータが単純な場合は、通常のコンストラクタを使用することを推奨します。
組み合わせ
Go では、構造体間の関係は組み合わせを通じて表現されます。明示的な組み合わせと匿名の組み合わせがあり、後者は継承に似ていますが、本質的には変化はありません。例えば:
明示的な組み合わせ
type Person struct {
name string
age int
}
type Student struct {
p Person
school string
}
type Employee struct {
p Person
job string
}使用する際は、明示的にフィールド p を指定する必要があります。
student := Student{
p: Person{name: "jack", age: 18},
school: "lili school",
}
fmt.Println(student.p.name)匿名の組み合わせは、明示的にフィールドを指定する必要がありません。
type Person struct {
name string
age int
}
type Student struct {
Person
school string
}
type Employee struct {
Person
job string
}匿名フィールドのデフォルト名は型名です。呼び出し者はその型のフィールドとメソッドに直接アクセスできます。最初の方式よりも便利ですが、それ以外には違いはありません。
student := Student{
Person: Person{name: "jack",age: 18},
school: "lili school",
}
fmt.Println(student.name)ポインタ
構造体ポインタの場合、参照解除せずに構造体のコンテンツに直接アクセスできます。例を以下に示します。
p := &Person{
name: "jack",
age: 18,
}
fmt.Println(p.age,p.name)コンパイル時に (*p).name、(*p).age に変換されます。実際には参照解除が必要ですが、コーディング時に省略でき、一種の構文糖衣です。
タグ
構造体タグはメタプログラミングの一種で、リフレクションと組み合わせることで多くの奇妙な機能を実現できます。形式は以下の通りです。
`key1:"val1" key2:"val2"`タグはキーと値のペアで、スペースで区切られます。構造体タグのフォールトトレランスは非常に低く、正しい形式で構造体を記述しないと、正常に読み取れなくなります。ただし、コンパイル時にはエラーは発生しません。以下は使用例です。
type Programmer struct {
Name string `json:"name"`
Age int `yaml:"age"`
Job string `toml:"job"`
Language []string `properties:"language"`
}構造体タグの最も一般的な用途は、さまざまなシリアライゼーション形式での別名の定義です。タグの使用はリフレクションと組み合わせることで、その機能を完全に発揮できます。
メモリアライメント
Go 構造体フィールドのメモリ分布はメモリアライメントの規則に従います。これにより CPU のメモリアクセス回数を減らせますが、その分メモリ使用量が増えます。これは空間と時間のトレードオフの一種です。以下のような構造体があると仮定します。
type Num struct {
A int64
B int32
C int16
D int8
E int32
}これらの型のバイト数を以下に示します。
int64は 8 バイトint32は 4 バイトint16は 2 バイトint8は 1 バイト
この構造体のメモリ使用量は 8+4+2+1+4=19 バイトでしょうか。もちろんそうではありません。メモリアライメントの規則によると、構造体のメモリ使用量は少なくとも最大フィールドの整数倍で、不足分は埋められます。この構造体で最大なのは int64 で 8 バイトです。メモリの分布は以下の図のようになります。
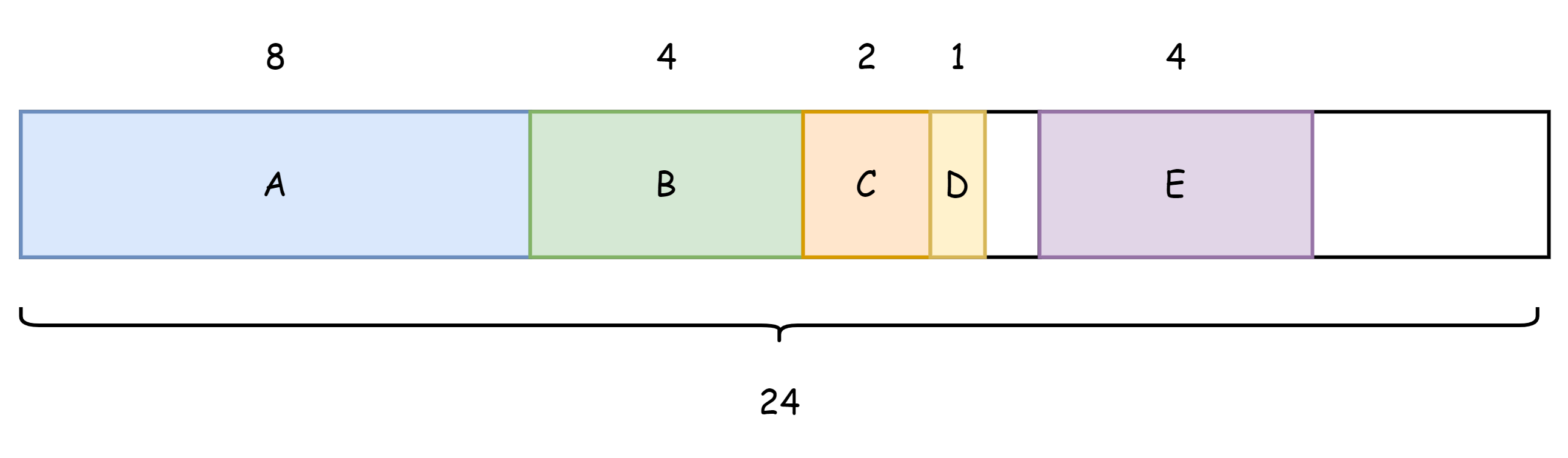
実際には 24 バイト使用され、そのうち 5 バイトは無駄です。
次にこの構造体を見てみましょう。
type Num struct {
A int8
B int64
C int8
}上記の規則を理解すると、この構造体も 24 バイトを使用することがすぐにわかります。フィールドは 3 つしかありませんが、14 バイトも無駄になっています。

ただし、フィールドの順序を以下のように変更できます。
type Num struct {
A int8
C int8
B int64
}これにより、メモリ使用量は 16 バイトになり、6 バイトの無駄で、8 バイトのメモリ浪費を削減できます。
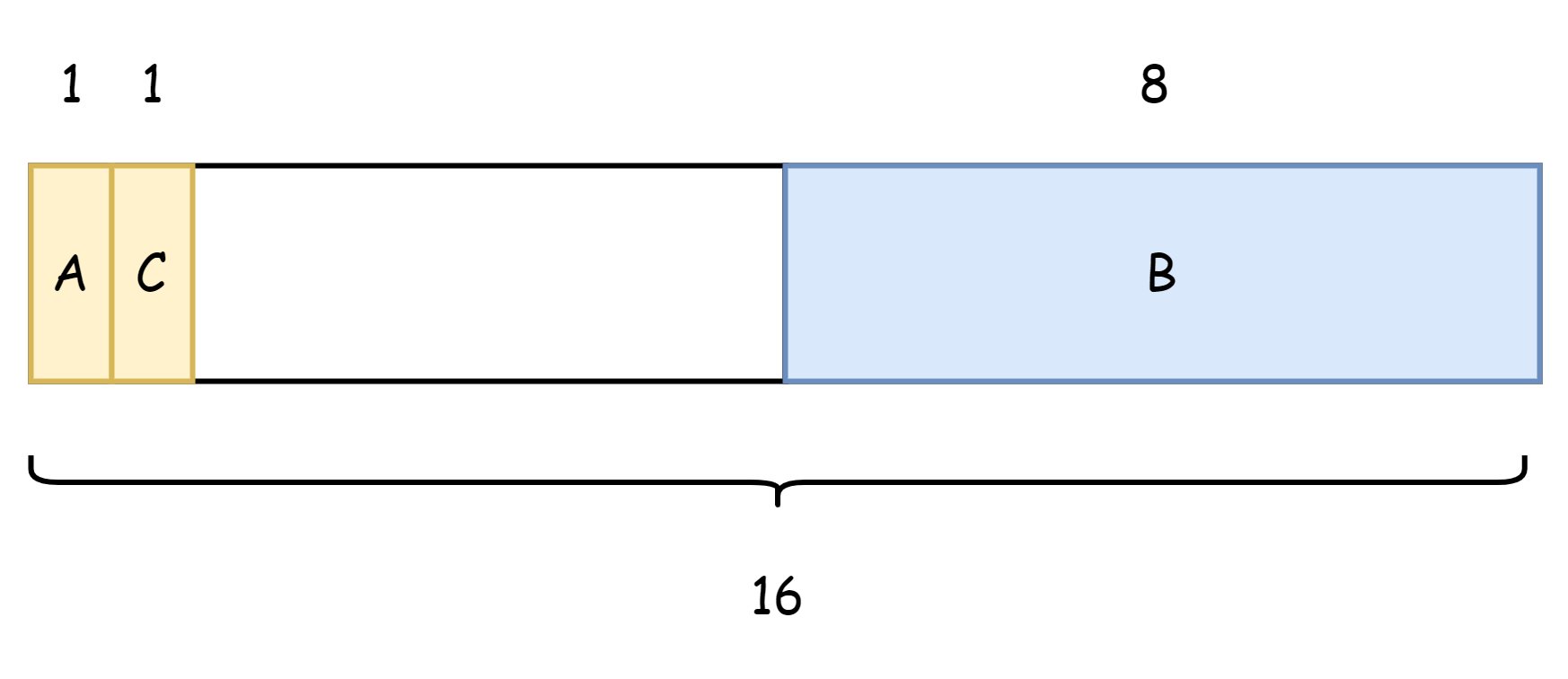
理論的には、構造体フィールドを合理的な順序で配置することで、メモリ使用量を削減できます。ただし、実際のコーディングでは、このようにする必要は必ずしもありません。メモリ使用量の削減において実質的な向上をもたらすとは限らず、開発者の負担とメンタルモデルを増加させるだけです。特にビジネスロジックでは、構造体フィールド数が数十または数百に達する可能性があります。そのため、理解するだけで十分です。
TIP
本当にこの方法でメモリを節約したい場合は、以下の 2 つのライブラリをご覧ください。
これらはソースコード内の構造体をチェックし、構造体フィールドを計算して再配置し、構造体のメモリ使用量を最小化します。
空構造体
空構造体はフィールドを持たず、メモリを占有しません。unsafe.Sizeof 関数を使用して占有バイト数を計算できます。
func main() {
type Empty struct {}
fmt.Println(unsafe.Sizeof(Empty{}))
}出力
0空構造体の使用場面は多岐にわたります。例えば、前述したように map の値型として使用し、map を set として使用したり、チャネルの型として使用して通知のみのチャネルを示したりできます。