gmp
Go 言語の最大の特徴の 1 つは、並行処理へのネイティブサポートです。わずか 1 つのキーワードでコルーチンを開始できます。以下の例が示す通りです。
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Go 言語のコルーチンは非常に簡単に使用でき、開発者は追加の作業をほとんど行う必要がありません。这也是它受欢迎的原因之一。しかし、シンプルさの背後には、シンプルではない並行スケジューラが支えています。その名前は皆さんが多かれ少なかれ聞いたことがあるでしょう。主な参加者がそれぞれ G(コルーチン)、M(システムスレッド)、P(プロセッサ)の 3 つのメンバーで構成されているため、GMP スケジューラとも呼ばれています。GMP スケジューラの設計は Go 言語ランタイム全体の設計に影響を与えており、GC、ネットワークポーラーなど、可以说它就是整个语言最核心的一块。もしそれについて一定の理解があれば、今後の仕事で役立つことがあるかもしれません。
歴史
Go 言語の並行スケジューリングモデルは完全にオリジナルではなく、多くの前人の経験と教訓を吸収し、絶え間ない発展と改良を経て現在の姿になりました。影響を受けた言語は以下の通りです。
- Occam -1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
最も大きな影響を与えたのは、ホールが 1978 年に発表した CSP(Communicate Sequential Process)に関する論文です。この論文の基本的な考え方は、プロセスとプロセスが通信を通じてデータを交換するというものです。上記のいくつかのプログラミング言語はすべて CSP の考え方の影響を受けており、Erlang は最も典型的なメッセージ指向プログラミング言語です。有名なオープンソースメッセージキューリングミドルウェアである RabbitMQ は Erlang で作成されています。現在では、コンピュータとインターネットの発展に伴い、並行サポートはほぼ現代言語の標準装備となっています。CSP の考え方を組み合わせた Go 言語が誕生しました。
スケジューリングモデル
まず GMP を構成する 3 つのメンバーを簡単に紹介します。
- G、Goroutine、Go 言語のコルーチンを指します
- M、Machine、システムスレッドまたはワーカースレッド(worker thread)を指し、オペレーティングシステムによってスケジューリングされます
- P、Processor、CPU プロセッサを指すのではなく、Go 自身が抽象化した概念で、システムスレッド上で動作するプロセッサを指します。これを通じて各システムスレッド上のコルーチンをスケジューリングします。
コルーチンはより軽量なスレッドで、規模が小さく、必要なリソースも少なく、作成と破棄とスケジューリングのタイミングは Go 言語ランタイムによって完了し、オペレーティングシステムではないため、その管理コストはスレッドよりもはるかに低くなります。ただしコルーチンはスレッドに依存しており、コルーチン実行に必要なタイムスライスはスレッドから来ており、スレッドのタイムスライスはオペレーティングシステムから来ています。異なるスレッド間の切り替えには一定のコストがかかるため、コルーチンがスレッドのタイムスライスをどのようにうまく利用するかが設計の鍵となります。
1:N
問題を解決する最良の方法は問題を無視することです。スレッド切り替えにコストがかかるなら、直接切り替えなければよいのです。すべてのコルーチンを 1 つのカーネルスレッドに割り当てると、コルーチン間の切り替えのみが発生します。
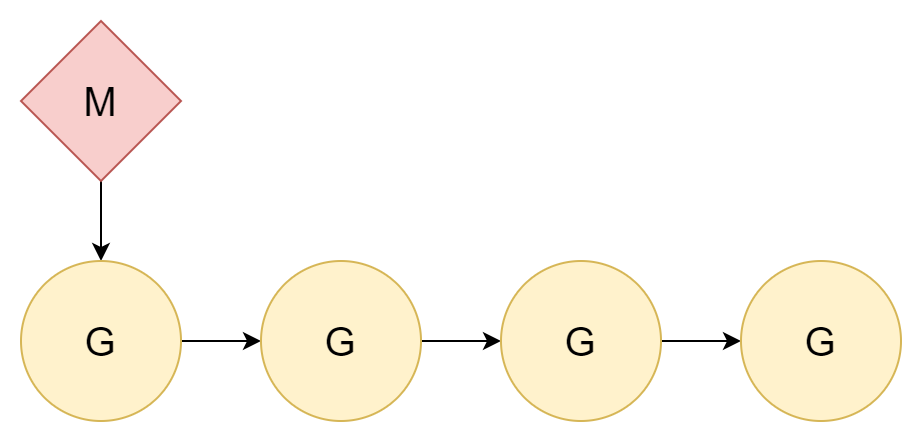
スレッドとコルーチンの関係は 1:N です。これには非常に明白な欠点があります。現代のコンピュータはほとんどがマルチコア CPU であり、このような割り当てではマルチコア CPU のパフォーマンスを十分に活用できません。
N:N
別の方法として、1 つのスレッドが 1 つのコルーチンに対応し、1 つのコルーチンがそのスレッドのすべてのタイムスライスを楽しめ、複数のスレッドもマルチコア CPU のパフォーマンスを活用できます。ただし、スレッドの作成と切り替えコストは比較的高く、1 対 1 の関係ではコルーチンの軽量という利点を十分に活かせません。
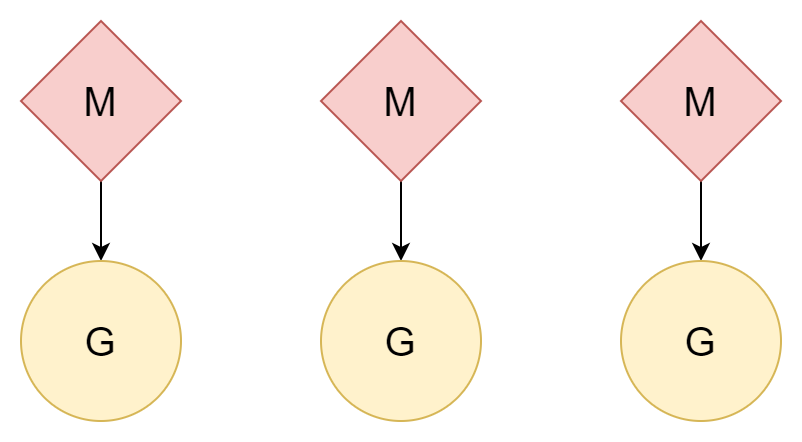
M:N
M 個のスレッドが N 個のコルーチンに対応し、M は N よりも小さいです。複数のスレッドが複数のコルーチンに対応し、各スレッドは若干のコルーチンに対応し、プロセッサ P がコルーチン G がスレッドのタイムスライスをどのように使用するかをスケジューリングします。この方法は比較的良い方法で、Go が現在まで継続して使用しているスケジューリングモデルです。
M はプロセッサ P に関連付けられた後にのみタスクを実行できます。Go は GOMAXPROCS 個のプロセッサを作成するため、実際にタスク実行に使用できるスレッド数は GOMAXPROCS 個です。デフォルト値は現在のマシンの CPU 論理コア数で、手動で値を設定することもできます。
コードを通じて
runtime.GOMAXPROCS(N)を変更し、実行時に動的に調整できます。呼び出し後直接 STW します。環境変数
export GOMAXPROCS=Nを設定します。静的です。
実際の状況では、M の数は P の数よりも多くなります。実行時に他のタスク(システムコールなど)を処理する必要があるためです。最大値は 10000 です。
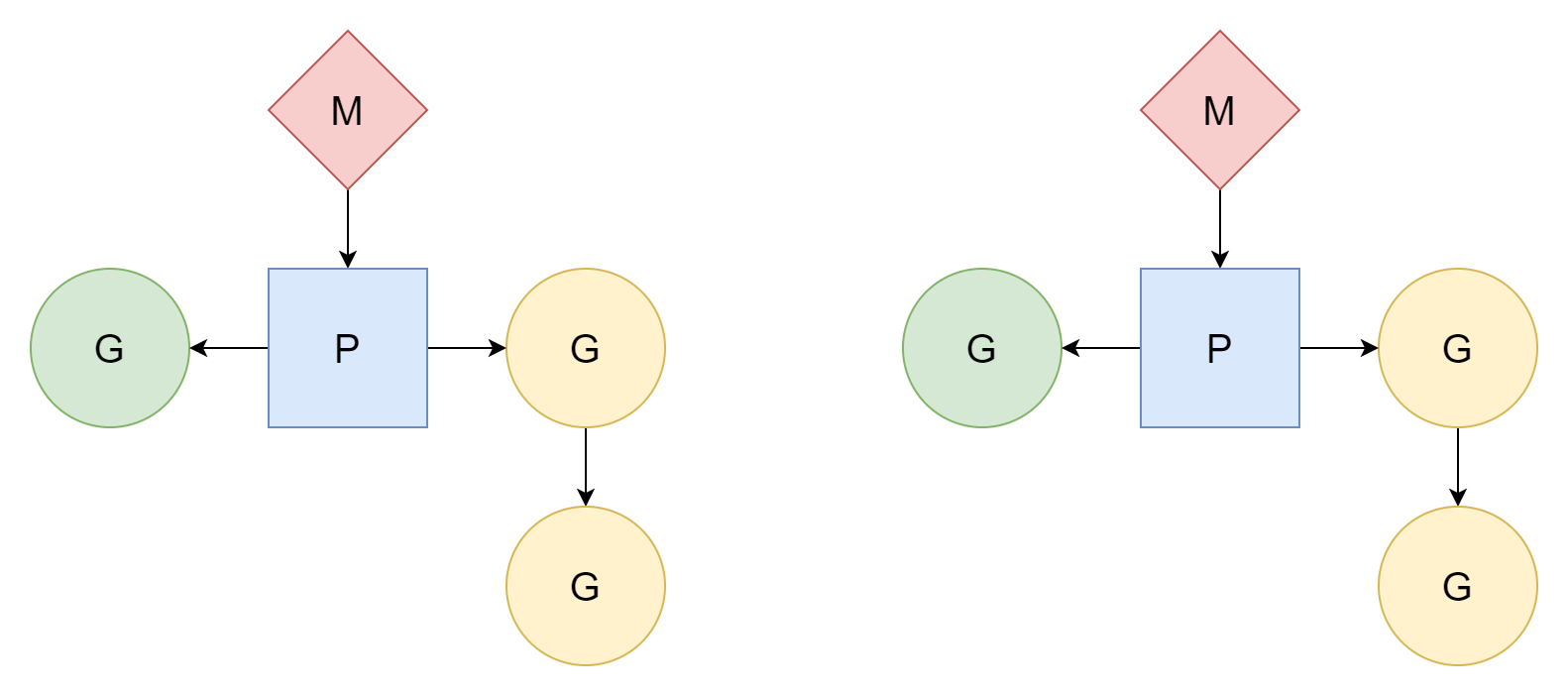
GMP の 3 つの参加者とスケジューラ自体は実行時にそれぞれ対応する型表現を持ち、それらはすべて runtime/runtime2.go ファイルに位置しています。後で理解しやすくするために、その構造を簡単に紹介します。
G
G は実行時に runtime.g 構造体で表現され、スケジューリングモデルの基本的なスケジューリングユニットです。その構造は以下の通りです。理解しやすくするために、多くのフィールドを削除しています。
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}最初のフィールドはコルーチンのスタックのメモリ開始アドレスと終了アドレスです。
type stack struct {
lo uintptr
hi uintptr
}_panic と _defer はそれぞれ panic スタックと defer スタックを指すポインタです。
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm は現在 g のコルーチンを実行しています。
m *m // current m; offset known to arm liblinkpreempt は現在のコルーチンがプリエンプトされる必要があるかどうかを示し、g.stackguard0 = stackpreempt と等価です。
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus はコルーチン G の状態値を格納するために使用され、以下のオプション値があります。
| 名称 | 説明 |
|---|---|
| _Gidle | 割り当てられたばかりで、初期化されていません |
| _Grunnable | 現在のコルーチンが実行可能で、待機キューに位置しています |
| _Grunning | 現在のコルーチンがユーザーコードを実行しています |
| _Gsyscall | M が割り当てられ、システムコールを実行します |
| _Gwaiting | コルーチンがブロックされています。ブロックの理由は後述します |
| _Gdead | 現在のコルーチンが使用されていません。終了したばかりか、初期化されたばかりです |
| _Gcopystack | コルーチンスタックが移動中です。この期間中ユーザーコードを実行せず、待機キューにも位置していません |
| _Gpreempted | 自身をブロックしてプリエンプトに入り、プリエンプト側によってウェイクアップされるのを待っています |
| _Gscan | GC がコルーチンスタック空間をスキャンしています。他の状態と共存できます |
sched はコルーチンのコンテキスト情報を格納し、コルーチンの実行現場を回復するために使用されます。sp、pc、ret ポインタが格納されていることがわかります。
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting は現在のコルーチンが待機しているコルーチンを示し、waitsince はコルーチンがブロックされた時刻を記録し、waitreason はコルーチンがブロックされた理由を示します。オプション値は以下の通りです。
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid と parentGoid は現在のコルーチンと親コルーチンの一意の識別子を示し、startpc は現在のコルーチンのエントリー関数のアドレスを示します。
M
M は実行時に runtime.m 構造体で表現され、ワーカースレッドの抽象化です。
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}同様に、M 内部のフィールドも多数ありますが、ここでは理解のために一部のフィールドのみを紹介します。
id、M の一意の識別子g0、スケジューリングスタックを持つコルーチンcurg、ワーカースレッド上で実行中のユーザーコルーチンgsignal、スレッド信号を処理するコルーチンgoSigStack、Go によって割り当てられた信号処理用スタック空間p、プロセッサ P のアドレス、oldpはシステムコール実行前の P を指し、nextpは新しく割り当てられた P を指しますmallocing、現在新しいメモリスペースを割り当てているかどうかを示しますthrowing、M で発生したエラータイプを示しますpreemptoff、プリエンプト識別子で、空文字列の場合現在実行中のコルーチンはプリエンプト可能ですlocks、現在 M の「ロック」数を示し、0 でない場合プリエンプトを禁止しますdying、M が回復不可能なpanicを発生したことを示し、[0,3]の 4 つのオプション値があり、低から高へ深刻度を示します。spinning、M がアイドル状態にあり、いつでも使用可能であることを示します。tls、スレッドローカルストレージ
P
P は実行時に runtime.p で表現され、M と G の間の作業をスケジューリングする責任を負います。その構造は以下の通りです。
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status は P の状態を示し、以下のオプション値があります。
| 値 | 説明 |
|---|---|
| _Pidle | P はアイドル状態にあり、スケジューラによって M を割り当てられる可能性があります。または他の状態間を遷移しているだけです |
| _Prunning | P は M に関連付けられ、ユーザーコードを実行しています |
| _Psyscall | P に関連付けられた M がシステムコールを実行していることを示します。この期間中 P は他の M によってプリエンプトされる可能性があります |
| _Pgcstop | P が GC によって停止されたことを示します |
| _Pdead | P の大部分のリソースが剥奪され、もはや使用されません |
以下のいくつかのフィールドは P の runq ローカルキューを記録しています。ローカルキューの最大数は 256 で、この数を超えると G はグローバルキューに配置されます。
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext は次の使用可能な G を示します。
runnext guintptr他のいくつかのフィールドの説明は以下の通りです。
id、P の一意の識別子schedtick、コルーチンスケジューリング回数の増加に伴って増加します。runtime.execute関数で確認できます。syscalltick、システムコール回数の増加に伴って増加しますsysmontick、最後にシステム監視によって観察された情報を記録しますm、P に関連付けられた MgFree、アイドル状態の G リストpreempt、P が再度スケジューリングに入るべきかどうかを示します
グローバルキューの情報は runtime.schedt 構造体に格納され、スケジューラの実行時の表現形式です。以下の通りです。
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}初期化
スケジューラの初期化は Go プログラムのブート段階に位置し、Go プログラムをガイドする責任を負うのは runtime.rt0_go 関数です。これはアセンブリによって実装され、runtime/asm_*.s ファイルに位置しています。一部のコードは以下の通りです。
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RET以下の 2 行で runtime·osinit と runtime·schedinit の呼び出しを確認できます。
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)前者はオペレーティングシステム関連の作業を初期化する責任を負い、後者はスケジューラの初期化、つまり runtime·schedinit 関数を担当します。これはプログラム起動時にスケジューラ実行に必要なリソースを初期化する責任を負います。以下は簡略化後のコードです。
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}runtime.getg 関数はアセンブリによって実装され、その機能は現在のコルーチンの実行時表現、つまり runtime.g 構造体のポインタを取得することです。sched.maxmcount = 10000 によって、スケジューラ初期化時に M の最大数が 10000 に設定されていることがわかります。この値は固定で変更できません。その後ヒープスタックを初期化し、その後 runtime.mcommoninit 関数によって M を初期化します。その関数実装は以下の通りです。
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}この関数は M を事前初期化し、主に以下の作業を行います。
- M の id を割り当てます
- スレッド信号を処理するために G を個別に割り当てます。
runtime.mpreinit関数によって完了します - それをグローバル M リンクドリスト
runtime.allmのヘッダーノードにします
次に P を初期化します。その数はデフォルトで CPU の論理コア数で、次に環境変数の値です。
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}最後に runtime.procresize 関数が P の初期化を担当し、传入された数に基づいてすべての P を格納するグローバルスライス runtime.allp を変更します。まず数値サイズに基づいて拡張が必要かどうかを判断します。
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}その後各 P を初期化します。
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}現在のコルーチンが使用している P が破棄される必要がある場合、それを allp[0] に置き換え、runtime.acquirep 関数によって M と新しい P の関連付けを完了します。
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}その後不要な P を破棄します。破棄時には P のすべてのリソースを解放し、ローカルキュー内のすべての G をグローバルキューに配置し、破棄完了後に allp をスライスします。
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}最後にアイドル状態の P をリンクドリストにリンクし、最終的にリンクドリストのヘッダーノードを返します。
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsその後、スケジューラ初期化完了後、runtime.worldStarted によってすべての P を実行再開します。
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)その後 runtime.newproc 関数を通じて新しいコルーチンを作成して Go プログラムを起動し、その後 runtime.mstart を呼び出してスケジューラの実行を正式に開始します。これもアセンブリによって実装され、内部では runtime.mstart0 関数を呼び出して作成を行います。その関数の一部コードは以下の通りです。
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()此时 M には 1 つのコルーチン g0 のみがあり、このコルーチンはスレッドのシステムスタックを使用し、個別に割り当てられたスタックスペースではありません。mstart0 関数はまず G のスタック境界を初期化し、その後 mstart1 に残りの初期化作業を完了させます。
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()開始前に、まず現在の実行現場を記録します。初期化成功後はスケジューリングループに入り、二度と戻らないため、他の呼び出しは実行現場を復元して mstart1 関数から戻り、スレッドを終了する目的を達成できます。記録完了後、runtime.asminit と runtime.minit の 2 つの関数によってシステムスタックを初期化し、その後 runtime.mstartm0 関数によって信号を処理するためのコールバックを設定します。コールバック関数 m.mstartfn を実行後、runtime.acquirep 関数によって M と以前作成された P を関連付け、最後にスケジューリングループに入ります。
ここで呼び出される runtime.schedule は Go ランタイムの最初のスケジューリングループで、スケジューラが正式に作業を開始することを表します。
スレッド
スケジューラにおいて、G がユーザーコードを実行するには P に依存し、P が正常に動作するには M に関連付けられる必要があります。M はシステムスレッドを指します。
作成
M の作成は runtime.newm 関数によって完了され、関数と P および id をパラメータとして受け取ります。パラメータとしての関数はクロージャにできません。
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}開始前に、newm はまず runtime.allocm 関数を呼び出してスレッドの実行時表現である M を作成します。このプロセスでは runtime.mcommoninit 関数を使用して M のスタック境界を初期化します。
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}その後 runtime.newm1 が runtime.newosproc 関数を呼び出して実際のシステムスレッドの作成を完了します。
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}runtime.newosproc の実装はオペレーティングシステムによって異なります。どのように作成するかは私たちが関心を持つことではなく、オペレーティングシステムが担当し、その後 runtime.mstart によって M の作業を開始します。
終了
runtime.gogo(&mp.g0.sched)初期化のときに述べたように、mstart1 関数を呼び出す際に実行現場を g0 の sched フィールドに保存しました。このフィールドを runtime.gogo 関数(アセンブリ実装)に渡すと、スレッドが実行現場にジャンプして続行できます。保存する際には getcallerpc() を使用したため、実行現場を復元する際には mstart0 関数に戻ります。
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)実行現場が復元されると、実行順序に従って mexit 関数に入り、スレッドを終了します。
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)これは主に以下のいくつかのことを行います。
runtime.unminitを呼び出してruntime.minitの作業を取り消します- グローバル変数
allmからこの M を削除します - スケジューラの
freemを現在の M に向けます runtime.releasepによって P と現在の M のバインドを解除し、runtime.handoffpによって P が他の M とバインドして作業を継続できるようにしますruntime.destroyによって M のリソースを破棄します- 最後にオペレーティングシステムによってスレッドを終了します
これで M は正常に終了します。
一時停止
スケジューラスケジューリング、GC、システムコールなどの理由で M を一時停止する必要がある場合、runtime.stopm 関数を呼び出してスレッドを一時停止します。以下は簡略化後のコードです。
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}まず M をグローバルアイドル M リストに配置し、その後 mPark() によって現在のスレッドを notesleep(&gp.m.park) ここでブロックします。ウェイクアップされるとこの関数は戻ります。
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}ウェイクアップ後の M は P を見つけてバインドし、タスクの実行を継続します。
コルーチン
コルーチンのライフサイクルはちょうどコルーチンのいくつかの状態に対応しており、コルーチンのライフサイクルを理解することはスケジューラを理解するのに役立ちます。スケジューラ全体はコルーチンを中心に設計されているため、コルーチンのライフサイクル全体は以下の図の通りです。
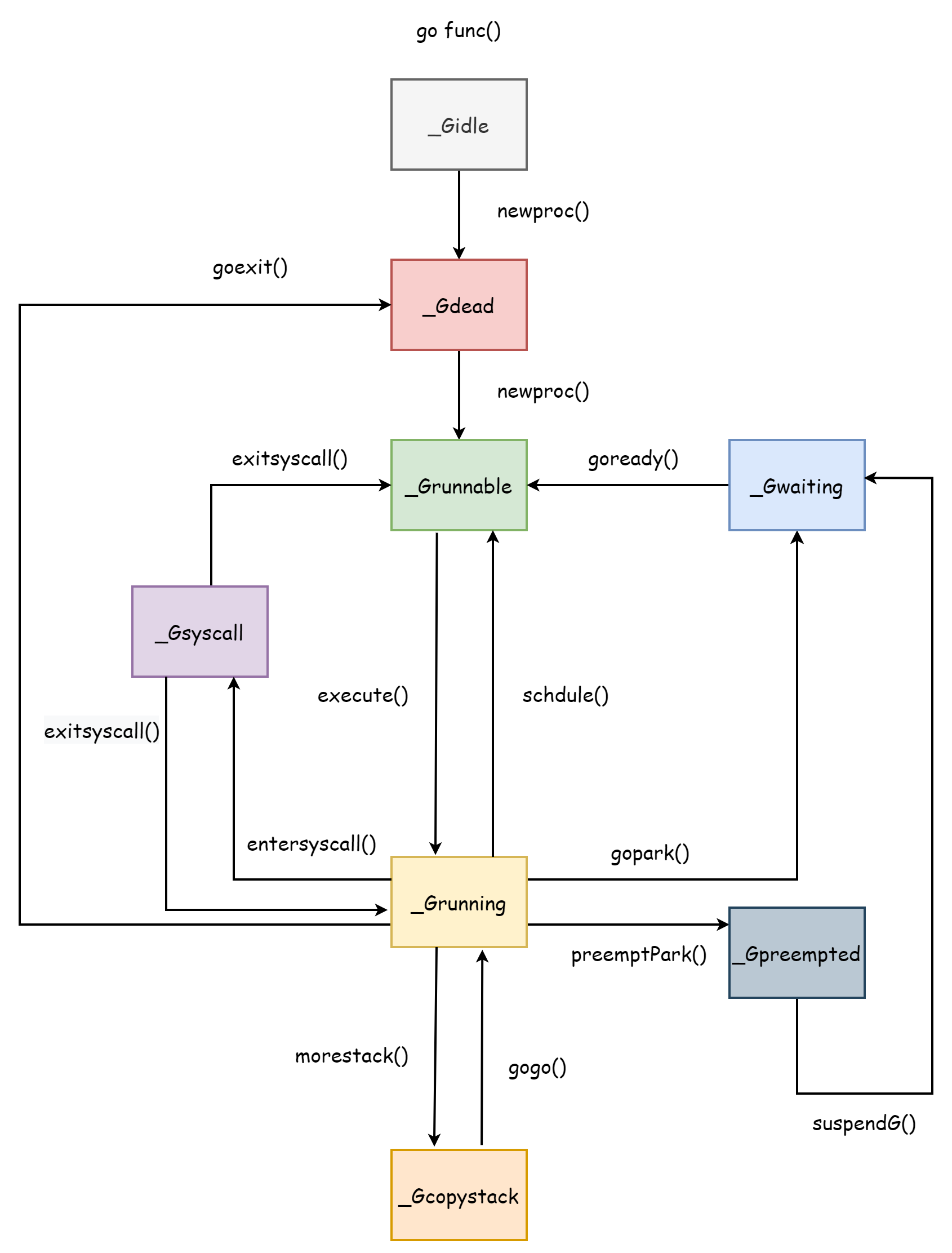
_Gcopystack はコルーチンスタック拡張時に持つ状態で、コルーチンスタック 部分で説明します。
作成
コルーチンの作成は構文レベルでは go キーワードと関数只需要です。
go doSomething()コンパイル後には runtime.newproc 関数の呼び出しになります。
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1 によって実際の作成を完了します。作成時にはまず M をロックし、プリエンプトを禁止し、その後 P のローカル gfree リストからアイドル状態の G を探して再利用します。見つからない場合は runtime.malg によって新しい G を作成し、2kb のスタックスペースを割り当てます。此时 G の状態は _Gdead です。
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}Go 1.18 以降、パラメータのコピーは newproc1 関数によって完了されません。それ以前は、runtime.memmove を使用して関数のパラメータをコピーしていました。現在ではコルーチンのスタックスペースをリセットする責任のみを負い、runtime.goexit をスタックボトムとしてコルーチンの終了処理を行い、その後エントリー関数の PC newg.startpc = fn.fn を設定してここから実行することを示します。設定完了後、此时 G の状態は _Grunnable です。
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)最後に G の一意の識別子を設定し、その後 M を解放して作成されたコルーチン G を返します。
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgコルーチン作成完了後、runtime.runqput 関数によって P のローカルキューに配置しようとします。配置できない場合はグローバルキューに配置します。コルーチン作成の全プロセス中、その状態変化はまず _Gidle から _Gdead に変化し、エントリー関数設定後に _Gdead から _Grunnable に変化します。
終了
作成時に Go はすでに runtime.goexit 関数をコルーチンのスタックボトムとして設定しているため、コルーチン実行完了後最終的にこの関数に入ります。呼び出しチェーン goexit->goexit1->goexit0 を経て、最終的に runtime.goexit0 によってコルーチンの終了作業を担当します。
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}この関数は主に以下のいくつかのことを行います。
- 状態を
_Gdeadに設定します - フィールド値をリセットします
dropg()は M と G の間の関連付けを切断しますgfput(pp, gp)は現在の G を P のローカルアイドルリストに配置しますschedule()は新しいラウンドのスケジューリングを行い、M の実行権を他の G に譲ります
終了後、コルーチンの状態は _Grunning から _Gdead に変化し、今後コルーチン作成時に再利用される可能性があります。
システムコール
コルーチン G がユーザーコードを実行中にシステムコールを行った場合、システムコールをトリガーする方法は 2 つあります。
syscall標準ライブラリのシステムコール- cgo コール
システムコールはワーカースレッドをブロックするため、その前に準備作業が必要です。runtime.entersyscall 関数がこのプロセスを完了する責任を負いますが、前者も runtime.reentersyscall 関数のシンプルな呼び出しに過ぎず、実際の作業は後者によって完了されます。まず現在の M をロックし、準備期間中 G はプリエンプトを禁止され、スタック拡張も禁止されます。gp.stackguard0 = stackPreempt を設定して、準備完了後に P の実行権が他の G によってプリエンプトされることを示し、その後コルーチンの実行現場を保存して、システムコール戻り後に回復しやすくします。
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcその後、長時間ブロックして他の G の実行に影響を与えるのを防ぐために、M と P はバインドを解除されます。バインド解除後の M と G はシステムコール実行のためにブロックされ、P はバインド解除後に他のアイドル M とバインドして P ローカルキュー内の他の G が作業を継続できるようにします。
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--準備完了後、M のロックを解放します。この期間中 G の状態は _Grunning から _Gsyscall に変化し、P の状態は _Psyscall に変化します。
システムコールが戻ると、スレッド M はブロックされなくなり、対応する G も再度スケジューリングされてユーザーコードを実行する必要があります。runtime.exitsyscall 関数がこの後処理作業を完了する責任を負います。まず現在の M をロックし、旧 P の参照を取得します。
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0此时 2 つの状況に分けて処理します。1 つ目は直接使用可能な P があるかどうかです。runtime.exitsyscallfast 関数は元の P が使用可能かどうかを判断します。つまり P の状態が _Psyscall かどうかで、そうでない場合はアイドル P を探します。
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}使用可能な P を見つけた場合、M は P とバインドされ、G は _Gsyscall 状態から _Grunning 状態に切り替わり、その後 runtime.Gosched によって G が積極的に実行権を譲り、P はスケジューリングループに入って他の使用可能な G を探します。
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}見つからない場合、M は G とバインドを解除され、G は _Gsyscall から _Grunnable 状態に切り替わり、その後再度アイドル P を見つけられるかどうかを試みます。見つからない場合は直接 G をグローバルキューに配置し、その後新しいスケジューリングループに入ります。旧 M は runtime.stopm によってアイドル状態になり、日後の新タスクを待機します。P を見つけた場合、旧 M と G は新しい P と関連付けられ、その後ユーザーコードの実行を継続し、状態は _Grunnable から _Grunning に変化します。
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}システムコール終了後、G の状態には 2 つの結果があります。1 つはスケジューリング待ちの _Grunnable、もう 1 つは実行を継続する _Grunning です。
サスペンド
現在のコルーチンが何らかの理由でサスペンドする場合、状態は _Grunnable から _Gwaiting に変化します。サスペンドの理由は多数あり、チャネルブロッキング、select、ロック、または time.sleep などが考えられます。詳細な理由は G 構造 を参照してください。time.Sleep を例に取ると、実際には runtime.timesleep にリンクされています。後者のコードは以下の通りです。
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}getg を通じて現在のコルーチンを取得し、その後 runtime.gopark によって現在のコルーチンをサスペンドすることがわかります。runtime.gopark は G と M のブロッキング理由を更新し、M のロックを解放します。
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)その後システムスタックに切り替えて runtime.park_m によって G の状態を _Gwaiting に切り替え、その後 M と G の間の関連付けを切断して新しいスケジューリングループに入り、実行権を他の G に譲ります。サスペンド後、G はユーザーコードを実行せず、ローカルキューにも位置していませんが、M と P への参照を保持しています。
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()runtime.timesleep 関数にはこのような 1 行のコードがあります。
t.f = goroutineReadyこの runtime.goroutineReady 関数はサスペンドされたコルーチンをウェイクアップするために使用され、runtime.ready 関数を呼び出してコルーチンをウェイクアップします。
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)ウェイクアップ後、G の状態を _Grunnable に切り替え、その後 G を P のローカルキューに配置して日後スケジューリングを待機します。
コルーチンスタック
Go 言語のコルーチンは典型的なスタックコルーチンで、コルーチンを開始するたびにヒープ上に独立したスタックスペースを割り当てます。使用量の変化に応じて成長または縮小します。スケジューラ初期化時、runtime.stackinit 関数がグローバルスタックスペースキャッシュ stackpool と stackLarge を初期化する責任を負います。
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}これに加えて、各 P には独自の独立したスタックスペースキャッシュ mcache があります。
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}スレッドキャッシュ mcache は各スレッド独立で、ヒープメモリ上に割り当てられていません。アクセス時にロックをかける必要はありません。これら 3 つのスタックキャッシュは後続のスペース割り当て時に使用されます。
割り当て
コルーチン作成時、再利用可能なコルーチンがない場合、新しいスタックスペースを割り当てます。デフォルトサイズは 2KB です。
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}スタックスペースを割り当てる責任を負う関数は runtime.stackalloc です。
func stackalloc(n uint32) stack申請されたスタックメモリサイズが 32KB よりも小さいかどうかによって 2 つの状況に分かれます。32KB は Go において小オブジェクトか大オブジェクトかを判断する基準でもあります。この値より小さい場合は stackpool キャッシュから取得します。M と P がバインドされ、M がプリエンプトを禁止されている場合、ローカルスレッドキャッシュから取得します。
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}32KB より大きい場合は stackLarge キャッシュから取得し、それでも足りない場合は直接ヒープ上にメモリを割り当てます。
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}完了後、スタックスペースの低アドレスと高アドレスを返します。
return stack{uintptr(v), uintptr(v) + uintptr(n)}拡張
デフォルトのコルーチンスタックサイズは 2KB で、十分に軽量であるため、コルーチンを作成するコストは非常に低くなりますが、必ずしも十分とは限りません。スタックスペースが不足する場合、拡張が必要です。コンパイラは関数の先頭に runtime.morestack 関数を挿入して現在のコルーチンがスタック拡張が必要かどうかをチェックします。必要な場合は runtime.newstack を呼び出して実際の拡張作業を完了します。
TIP
morestack はほぼすべての関数の先頭に挿入されるため、スタック拡張チェックのタイミングもコルーチンプリエンプトポイントの 1 つです。
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)計算後のスタックスペース容量は元の 2 倍で、runtime.copystack 関数がスタックコピー作業を完了する責任を負います。コピー前に G の状態は _Grunning から _Gcopystack に切り替わります。
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}この関数は主に以下のいくつかの作業を行います。
- 新しいスタックスペースを割り当てます
- 旧スタックメモリを
runtime.memmoveを通じて直接新しいスタックスペースにコピーします - defer、panic などスタックポインタを含む構造を調整します
- G のスタックスペースフィールドを更新します
runtime.adjustframeを通じて旧スタックメモリを指すポインタを調整します- 旧スタックのメモリを解放します
完了後、G の状態は _Gcopystack から _Grunning に切り替わり、runtime.gogo 関数によって G がユーザーコードの実行を継続します。コルーチンスタック拡張が存在するため、Go におけるメモリは不安定です。
縮小
G の状態が _Grunnable、_Gsyscall、_Gwaiting の場合、GC はコルーチンスタックのメモリスペースをスキャンします。
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}実際のスタック縮小作業は runtime.shrinkstack によって完了されます。
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}使用されているスタックスペースが元の 1/4 未満の場合、runtime.copystack を通じて元の 1/2 に縮小します。後続の作業は以前と同じです。
セグメントスタック
copystack のプロセスから見ると、旧スタックメモリをより大きなスタックスペースにコピーします。元のスタックも新しいスタックもメモリアドレスは連続です。远古時代の Go 言語では、スタック拡張時の做法は現在とは異なり、メモリコピーはパフォーマンスを消費しすぎると考え、セグメントスタックの思路を採用していました。スタックスペースメモリが不足した場合、新しいスタックスペースを申請し、既存のスタックスペースメモリは解放されず、コピーもされず、互いにポインタでリンクされ、スタックリンクドリストを形成します。これがセグメントスタックの由来で、以下の図の通りです。
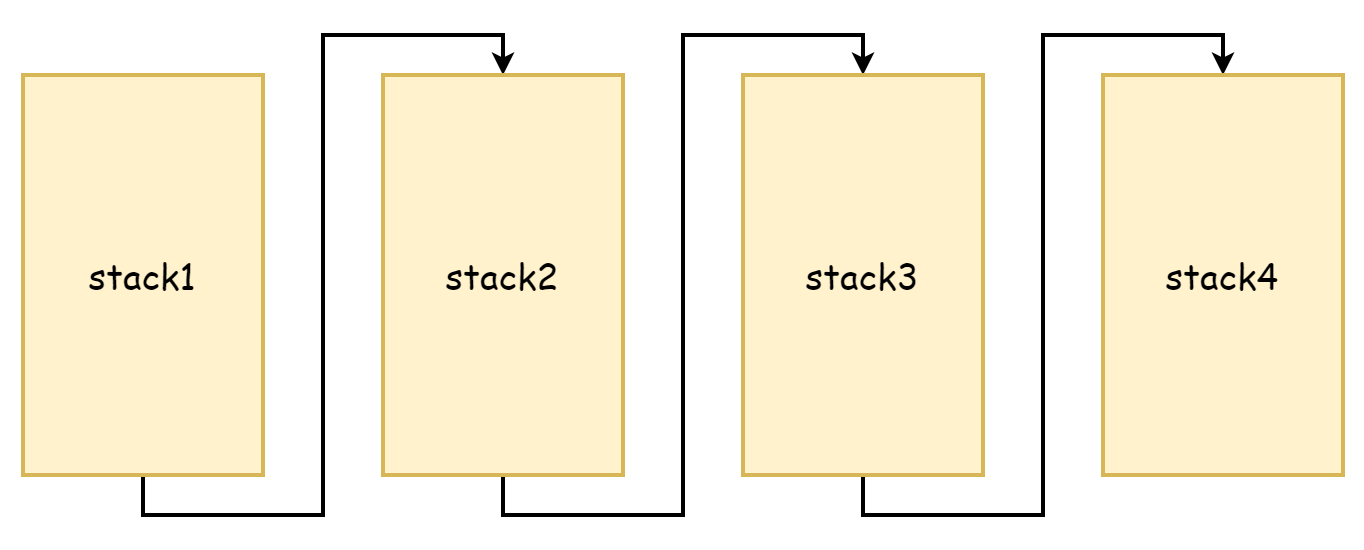
これの利点は既存のスタックをコピーする必要がないことですが、欠点も非常に明確で、スタック拡張と縮小を非常に頻繁にトリガーすることです。スタックスペースのアイドルメモリが残りわずかになった場合、新しい関数呼び出しはスタック拡張をトリガーします。これらの関数が戻ると、新しいスタックスペースが不要になったため、再び縮小をトリガーします。これらの関数呼び出しの頻度が非常に高い場合、拡張と縮小を非常に頻繁にトリガーし、この操作によるパフォーマンスの損失は非常に大きくなります。
そのため Go 1.4 以降は連続スタックに変更されました。連続スタックは容量がより大きなスタックスペースを割り当てるため、使用済みメモリが臨界値に達した際に関数呼び出しによって頻繁に拡張縮小をトリガーする状況は発生せず、メモリアドレスが連続しているため、キャッシュの空間局所性原理に基づき、連続スタックは CPU キャッシュにもより友好的です。
スケジューリングループ
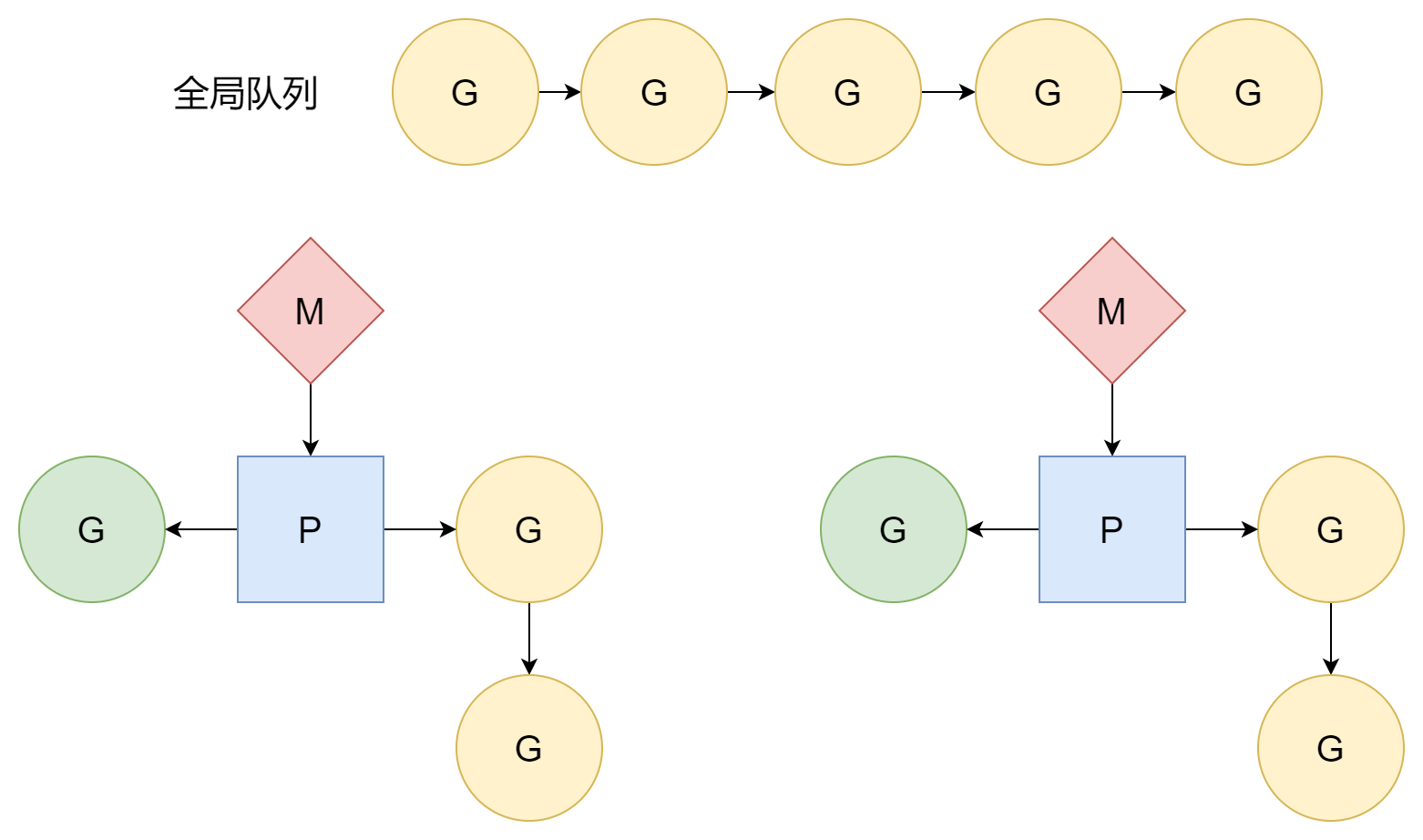
スケジューラ初期化部分で述べたように、runtime.mstart1 関数で M と P が正常に関連付けられた後、最初の runtime.schedule スケジューリングループに入り、正式に G をスケジューリングしてユーザーコードを実行します。スケジューリングループ中、この部分は主に P が役割を果たしています。M はシステムスレッドに対応し、G はエントリー関数つまりユーザーコードに対応しますが、P は M や G のような実体を持つわけではなく、抽象的な概念で、中間人として M と G の間の関係を処理しています。
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}上記のコードは簡略化され、多くの条件判断が削除されています。最も核心的な点は 2 つのみで、runtime.findRunnable と runtime.execute です。前者は G を見つける責任を負い、必ず使用可能な G を返します。後者は G がユーザーコードの実行を継続する責任を負います。
findRunnable 関数にとって、最初の G ソースは P のローカルキューです。
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}ローカルキューに G がない場合、グローバルキューから取得しようとします。
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}ローカルとグローバルキューの両方で見つからない場合、ネットワークポーラーから取得しようとします。
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}それでも見つからない場合、最終的に他の P からそのローカルキュー内の G を「盗む」ことになります。コルーチン作成時に述べたように、P のローカルキュー内の G の主なソースは現在のコルーチンから派生した子コルーチンですが、すべてのコルーチンが子コルーチンを作成するわけではありません。このため、一部の P は非常に忙しく、別の一部の P はアイドル状態という状況が発生する可能性があります。これにより、一部の G は待機し続けて実行されず、另一方の P は非常に暇で何もできないという状況が発生します。すべての P を絞り出して最大の作業効率を発揮させるために、P が G を見つけられない場合、他の P のローカルキューから実行可能な G を「盗み」に行きます。これにより、各 P は比較的均等な G キューを持つことができ、P と P の間で傍観する状況はほとんど発生しません。
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork はランダムに P を選んで盗みに行きます。実際の盗み作業は runtime.runqgrab 関数によって完了され、その P のローカルキューの半分の G を盗もうとします。
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}盗み作業は 4 回行われ、4 回後も G を盗めない場合は戻ります。最終的に見つからない場合、現在の M は runtime.stopm によって一時停止され、ウェイクアップ後に上記のステップを継続して繰り返します。G を見つけて返した後、runtime.execute に渡して G を実行します。
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)まず M の curg を更新し、その後 G の状態を _Grunning に更新し、最後に runtime.gogo に渡して G の実行を回復します。
総じて、スケジューリングループ中の G のソースは優先度に基づいて 4 つに分かれます。
- P のローカルキュー
- グローバルキュー
- ネットワークポーラー
- 他の P のローカルキューから盗む
runtime.execute は実行後は戻らず、取得した G も永遠に実行し続けるわけではありません。あるタイミングでスケジューリングがトリガーされると、その実行権は剥奪され、新しいスケジューリングループに入り、実行権を他の G に譲ります。
スケジューリング戦略
異なる G がユーザーコードを実行する時間は異なる可能性があります。一部の G は非常に時間がかかり、一部の G は非常に短時間です。実行時間が長い G は他の G が実行できない原因となる可能性があるため、G を交互に実行することが正しい方法です。オペレーティングシステムではこの作業方式を並行と呼びます。
協調スケジューリング
協調スケジューリングの基本的な考え方は、G 自身が実行権を他の G に譲ることです。主に 2 つの方法があります。
1 つ目の方法はユーザーコード内で積極的に権限を譲ることです。Go は runtime.Gosched() 関数を提供しており、使用者はいつ実行権を譲るかを自分で決定できます。しかし多くの場合、スケジューラ内部の作業詳細は使用者にとってブラックボックスであり、いつ積極的に権限を譲るべきかを判断するのは難しく、使用者への要求が比較的高くなります。また Go のスケジューラは使用者に対して大部分の詳細を隠蔽し、よりシンプルな使用方法を追求しているため、この状況で使用者もスケジューリング作業に参加させることは良いことではありません。
2 つ目の方法はプリエンプトマークです。名前にはプリエンプトという文字がありますが、本質的には協調スケジューリング戦略です。思路は関数のヘッダーにプリエンプト検出コード runtime.morestack() を挿入することで、挿入プロセスはコンパイル期間中に完了します。前述したように、これは元々スタック拡張検出用の関数で、その検出ポイントはすべての関数呼び出しです。これもプリエンプト検出の良好なタイミングです。runtime.newstack 関数の上半分はすべてプリエンプト検出を行っており、下半分はスタック拡張検出を行っています。前述で干渉を避けるためにこの部分を省略しましたが、今からこの部分が何を行うかを見てみましょう。まず gp.stackguard0 に基づいてプリエンプト判断を行い、必要ない場合はユーザーコードの実行を継続します。
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}g.stackguard0 == stackPreempt の場合、runtime.canPreemptM() 関数によってコルーチン条件がプリエンプトされる必要があるかどうかを判断します。コードは以下の通りです。
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}プリエンプト可能になるには 4 つの条件を満たす必要があります。
- M がロックされていない
- メモリ割り当て中ではない
- プリエンプトが禁止されていない
- P が
_Prunning状態にある
以下の 2 つの状況で g.stackguard0 を stackPreempt に設定します。
- ガベージコレクションが必要な場合
- システムコールが発生する場合
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}最後に runtime.gopreempt_m() によって現在のコルーチンの実行権を積極的に譲ります。まず M と G の間の関連付けを切断し、状態を _Grunnable にし、その後 G をグローバルキューに配置し、最後にスケジューリングループに入って実行権を他の G に譲ります。
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()これにより、すべてのコルーチンは関数呼び出しを行う際にこの関数に入ってプリエンプト検出を行う可能性があります。この戦略は関数呼び出しというタイミングに依存してプリエンプトをトリガーし、積極的に権限を譲ります。1.14 之前、Go は一貫してこのスケジューリング戦略を使用していましたが、これには問題があります。関数呼び出しがない場合、検出できません。以下の古典的なコードは多くのチュートリアルで登場しているはずです。
func main() {
// P の数を 1 に制限
runtime.GOMAXPROCS(1)
// コルーチン 1
go func() {
for {
// このコルーチンは絶えず空転
}
}()
// システムコールに入り、メインコルーチンは他のコルーチンに権限を譲る
time.Sleep(time.Millisecond)
println("exit")
}コードは空転するコルーチン 1 を作成し、その後メインコルーチンはシステムコールによって積極的に権限を譲ります。此时 コルーチン 1 はスケジューリングされていますが、関数を呼び出さないため、プリエンプト検出を行えません。P が 1 つのみで、他のアイドル P がないため、メインコルーチンは永遠にスケジューリングされず、exit も永遠に出力されません。ただしこの問題は Go 1.14 之前に限定されます。
プリエンプティブスケジューリング
公式は Go 1.14 でシグナルベースのプリエンプティブスケジューリング戦略を追加しました。これは非同期プリエンプト戦略で、非同期スレッドがシグナルを送信してプリエンプトを行います。シグナルベースのプリエンプティブスケジューリングは現在 2 つのエントリポイントがあります。システム監視と GC です。
システム監視ループでは、すべての P を走査し、P がスケジューリングしている G の実行時間が 10ms を超えた場合、強制的にプリエンプトをトリガーします。この部分の作業は runtime.retake 関数によって完了されます。以下は簡略化後のコードです。
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}ガベージコレクションが必要な場合、G の状態が _Grunning、つまり実行中の場合、同様にプリエンプトがトリガーされます。
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}2 つのプリエンプトエントリポイントは最終的に runtime.preemptM 関数に入り、これによってプリエンプトシグナルの送信を完了します。シグナルが正常に送信されると、runtime.mstart 時に runtime.initsig によって登録されたシグナルプロセッサコールバック関数 runtime.sighandler が役立ちます。プリエンプトシグナルが送信されたことが検出されると、プリエンプトが開始されます。
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt はターゲットコルーチンのコンテキストを変更し、runtime.asyncPreempt 呼び出しを注入します。
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...これによりユーザーコードに再度切り替わると、ターゲットコルーチンは runtime.asyncPreempt 関数に入り、この関数では runtime.asyncPreempt2 の呼び出しが含まれます。
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RETこれにより現在のコルーチンは作業を停止し、新しいスケジューリングループを行って実行権を他のコルーチンに譲ります。
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}このプロセス全体は runtime.asyncPreempt 関数内で発生し、アセンブリによって実装され(runtime/preempt_*.s に位置)、スケジューリング完了後に以前変更されたコルーチンコンテキストを回復し、そのコルーチンが日後正常に回復できるようにします。非同期プリエンプト戦略を採用した後、以前の例はメインコルーチンを永久にブロックしなくなりました。空転コルーチンが一定時間実行されると、強制的にスケジューリングループが実行され、実行権をメインコルーチンに譲り、最終的にプログラムが正常に終了できるようになります。
まとめ
総じて、スケジューリングをトリガーするタイミングには以下があります。
- 関数呼び出し
- システムコール
- システム監視
- ガベージコレクション。実行時間が長すぎるコルーチンもプリエンプトされます
- コルーチンがパイプライン、ロックなどの理由でサスペンドする場合
スケジューリング戦略は主に 2 つのカテゴリーに分かれます。協調式とプリエンプティブ式です。協調式は積極的に実行権を譲り、プリエンプティブ式は非同期で実行権をプリエンプトします。両者が共存して現在のスケジューラを形成しています。