gmp
go 语言最大的特点之一就是它对于并发的天然支持,仅需一个关键字就可以开启一个协程,就像下面例子所演示的一样。
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}go 语言的协程使用起来如此的简单,对于开发者来说几乎不需要做什么额外的工作,这也是它受欢迎的原因之一。不过在简单的背后,是一个并不简单的并发调度器在支撑着这一切,它的名字相信各位或多或少都应该听说过,因为其主要参与者分别由 G(协程),M(系统线程),P(处理器)这三个成员组成,所以也被称为 GMP 调度器。GMP 调度器的设计影响着整个 go 语言运行时的设计,GC,网络轮询器,可以说它就是整个语言最核心的一块,如果对它能够有一定的了解,在日后的工作中说不定会有些许帮助。
历史
Go 语言的并发调度模型并发不是完全原创的,它吸收了很多前人的经验和教训,经过不断发展和改进才有了现在的样子。它借鉴过的语言有下面这些:
- Occam -1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
影响最为巨大的还是霍尔在 1978 年发表了一篇关于 CSP(Communicate Sequential Process)的论文,该论文的基本思想是进程与进程之间通过通信来进行数据的交换。在上面的几门编程语言中无一不受到了 CSP 思想的影响,Erlang 就是最为典型的一个面向消息的编程语言,著名开源消息队列中间件 RabbitMQ 就是采用 Erlang 编写的。到了现如今,随着的计算机和互联网的发展,并发支持几乎已经成为了一个现代语言的标配,结合了 CSP 思想的 go 语言便应运而生。
调度模型
首先来简单的介绍下 GMP 成的三个成员
- G,Goroutine,指的是 go 语言中的协程
- M,Machine,指是系统线程或者叫工作线程(worker thread),由操作系统来负责调度
- P,Processor,并非指 CPU 处理器,是 go 自己抽象的一个概念,指的是工作在系统线程上的处理器,通过它来调度每一个系统线程上的协程。
协程就是一种更加轻量的线程,规模更小,所需的资源也会更少,创建和销毁和调度的时机都是由 go 语言运行时来完成,而并非操作系统,所以它的管理成本要比线程低很多。不过协程也是依附于线程的,协程执行所需的时间片来自于线程,线程所需的时间片来自于操作系统,而不同的线程间的切换是有一定成本的,如何让协程利用好线程的时间片就是设计的关键所在。
1:N
解决问题的最好办法就是忽略这个问题,既然线程切换是有成本的,那直接不切换就行了。将所有的协程都分配到一个内核线程上,这样就只涉及到了协程间的切换。
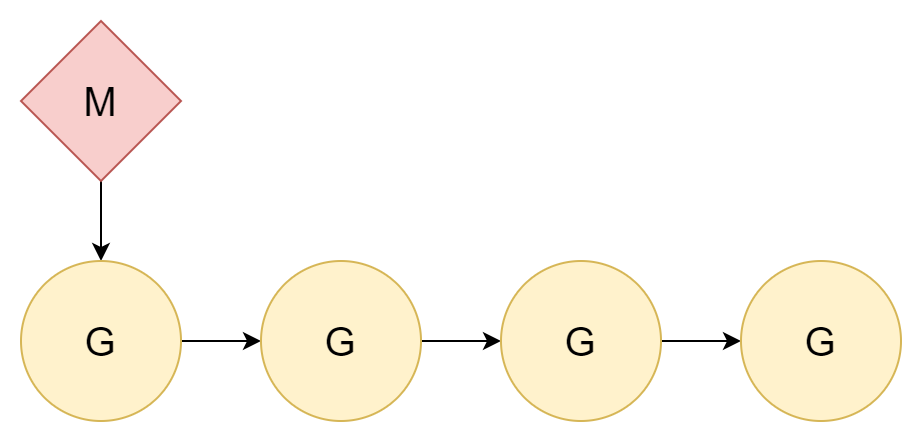
线程与协程间的关系是1:N,这样做有一个非常明显的缺点,当今时代的计算机几乎都是多核 CPU,这样的分配无法利用充分利用多核 CPU 的性能。
N:N
另一种方法,一个线程对应一个协程,一个协程可以享受该线程的所有时间片,多个线程也可以利用好多核 CPU 的性能。但是,线程的创建和切换成本是比较高的,如果是一比一的关系,反而没有利用好协程的轻量这一优势。
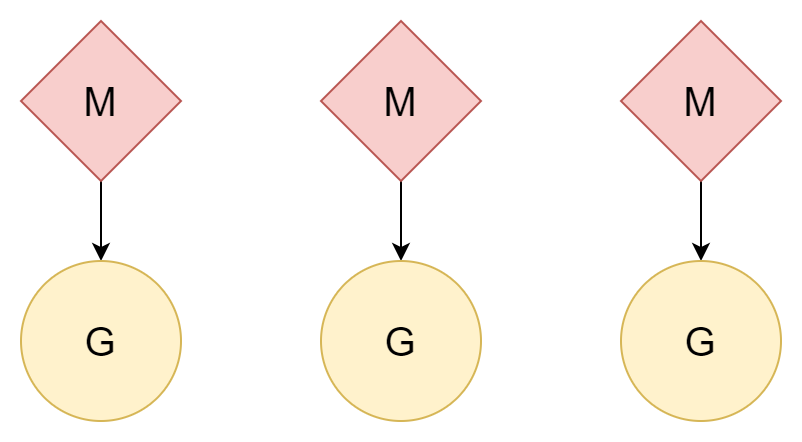
M:N
M 个线程对应 N 个协程,且 M 小于 N。多个线程对应多个协程,每一个线程都会对应若干个协程,由处理器 P 来负责调度协程 G 如何使用线程的时间片。这种方法是相对而言比较好的一种,也是 Go 一直沿用至今的调度模型。
M 只有与处理器 P 关联后才能执行任务,go 会创建GOMAXPROCS个处理器,所以真正能够用于执行任务的线程数量就是GOMAXPROCS个,它的默认值是当前机器上的 CPU 逻辑核数,我们也可以手动去设置它的值。
通过代码修改
runtime.GOMAXPROCS(N),并且可以在运行时动态调整,调用后直接 STW。设置环境变量
export GOMAXPROCS=N,静态。
在实际情况下,M 的数量会大于 P 的数量,因为在运行时会需要它们去处理其它的任务,比如一些系统调用,最大值是 10000。
GMP 这三个参与者以及调度器本身在运行时都有其对应的类型表示,它们都位于runtime/runtime2.go文件中,下面会对其结构进行简单的介绍,方便在后面进行理解。
G
G 在运行时的表现类型是runtime.g结构体,是调度模型中最基本的调度单元,其结构如下所示,为了方便理解,删去了不少的字段。
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}第一个字段就是属于该协程的栈的内存起始地址和结束地址
type stack struct {
lo uintptr
hi uintptr
}_panic和_defer是分别指向panic栈和defer栈的指针
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm正在执行当前 g 的协程
m *m // current m; offset known to arm liblinkpreempt表示当前协程是否需要被抢占,等价于g.stackguard0 = stackpreempt
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus用于存储协程 G 的状态值,它有以下可选的值
| 名称 | 描述 |
|---|---|
| _Gidle | 刚被分配,且未被初始化 |
| _Grunnable | 表示当前协程可以运行,位于等待队列中 |
| _Grunning | 表示当前协程正在执行用户代码 |
| _Gsyscall | 被分配了一个 M,用于执行系统调用, |
| _Gwaiting | 协程阻塞,阻塞的原因见下文 |
| _Gdead | 表示当前协程未被使用,可能刚刚退出,也可能刚刚初始化 |
| _Gcopystack | 表示协程栈正在移动,在此期间不执行用户代码,也不位于等待队列中 |
| _Gpreempted | 阻塞自身进入抢占,等待被抢占方唤醒 |
| _Gscan | GC 正在扫描协程栈空间,可以其它状态共存 |
sched用于存储协程上下文信息用于恢复协程的执行现场,可以看到里面存储着sp,pc,ret指针。
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting 表示当前协程正在等待的协程,waitsince记录了协程发生阻塞的时刻,waitreason表示协程阻塞的原因,可选的值如下。
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid和parentGoid表示当前协程和父协程的唯一标识,startpc表示当前协程入口函数的地址。
M
M在运行时表现为runtime.m结构体,是对工作线程的抽象
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}同样的,M 内部的字段也有很多,这里仅介绍部分字段方便理解。
id,M 的唯一标识符g0,拥有调度栈的协程curg,正在工作线程上运行的用户协程gsignal,负责处理线程信号的协程goSigStack,go 分配的用于信号处理的栈空间p,处理器 P 的地址,oldp指向在执行系统调用前的 P,nextp指向新分配的 Pmallocing,用于表示当前是否正在分配新的内存空间throwing,表示当 M 发生的错误类型preemptoff,抢占标识符,当它为空串时表示当前正在运行的协程可以被抢占locks,表示当前 M"锁"的数量,不为 0 时禁止抢占dying,表示 M 发生了无法挽回的panic,有[0,3]四个可选值,从低到高表示严重程度。spinning,表示 M 正处于空闲状态,并且随时可用。tls,线程本地存储
P
P 在运行时由runtime.p表示,负责调度 M 与 G 之间的工作,其结构如下所示
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status表示 P 的状态,有以下几个可选值
| 值 | 描述 |
|---|---|
| _Pidle | P 位于空闲状态,可以被调度器分配 M,也有可能只是在其它状态间转换 |
| _Prunning | P 与 M 关联,并且正在执行用户代码 |
| _Psyscall | 表示与 P 关联的 M 正在进行系统调用,在此期间 P 可能会被其它的 M 抢占 |
| _Pgcstop | 表示 P 因 GC 而停止 |
| _Pdead | P 的大部分资源都被剥夺,将不再会被使用 |
下面几个字段记录了 P 中的runq本地队列,可以看到本地队列的最大数量是 256,超过此数量后 G 会被放到全局队列中去。
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext表示下一个可用的 G
runnext guintptr其它的几个字段释义如下
id,P 的唯一标识符schedtick,随着协程调度次数的增加而增加,在runtime.execute函数中可见。syscalltick,随着系统调用的次数增加而增加sysmontick,记录了上一次被系统监控观察的信息m,与 P 关联的 MgFree,空闲的 G 列表preempt,表示 P 应该再次进入调度
全局队列的信息则存放在runtime.schedt结构体中,是调度器在运行时的表示形式,如下。
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}初始化
调度器的初始化位于 go 程序的引导阶段,负责引导 go 程序的就是runtime.rt0_go函数,它由汇编实现位于文件runtime/asm_*.s中,部分代码如下
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RET可以通过下面两行可以看到对runtime·osinit和runtime·schedinit的调用。
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)前者负责初始化操作系统相关的工作,后者负责调度器的初始化,也就是runtime·schedinit函数。它会在程序启动时负责初始化调度器运行所需的资源,下面是简化后的代码。
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}runtime.getg函数由汇编实现,它的功能是获取到当前协程的运行时表示,也就是runtime.g结构体的指针。通过sched.maxmcount = 10000可以看到,在调度器初始化的时候就设置了 M 的最大数量为 10000,这个值是固定的且没法修改。再之后就是初始化堆栈,然后才是runtime.mcommoninit函数来初始化 M,其函数实现如下
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}该函数对 M 进行预初始化,主要做了以下工作
- 分配 M 的 id
- 单独分配一个 G 用来处理线程信号,由
runtime.mpreinit函数完成 - 将其作为全局 M 链表
runtime.allm的头结点
接下来初始化 P,其数量默认是 CPU 的逻辑核数,其次是环境变量的值。
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}最后由runtime.procresize函数来负责初始化 P,它会根据传入的数量来修改runtime.allp这个存放所有 P 的全局切片。首先根据数量大小判断是否需要扩容
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}然后再初始化每一个 P
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}如果当前协程正在使用的 P 需要被销毁,则将其替换为allp[0],由runtime.acquirep函数来完成 M 与新 P 的关联。
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}随后销毁不再需要的 P,在销毁时会释放 P 的所有资源,将其本地队列中所有的 G 放入全局队列中,销毁完毕然后对allp进行切片。
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}最后将空闲的 P 链接成一个链表,并最终返回链表的头结点
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePs再之后,调度器初始化完毕,由runtime.worldStarted将所有的 P 恢复运行。
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)然后会通过runtime.newproc函数创建一个新的协程来启动 go 程序,随后调用runtime.mstart来正式启动调度器的运行,它同样是由汇编实现,其内部会调用runtime.mstart0函数进行创建,该函数部分代码如下
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()此时的 M 只有拥有一个协程g0,该协程使用线程的系统栈,并非单独分配的栈空间。mstart0函数会先初始化 G 的栈边界,然后交给mstart1去完成剩下的初始化工作。
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()在开始之前,首先会记录当前的执行现场,因为初始化成功之后就会进入调度循环并且永远也不会返回,其它的调用可以复用执行现场从mstart1函数返回达到退出线程的目的。记录完毕后,由runtime.asminit和runtime.minit两个函数负责初始化系统栈,然后由runtime.mstartm0函数设置用于处理信号的回调。执行回调函数m.mstartfn后 ,runtime.acquirep函数将 M 与先前创建好的 P 进行关联,最后进入调度循环。
这里调用的runtime.schudule是整个 go 运行时的第一轮调度循环,代表着调度器正式开始工作。
线程
在调度器中,G 想要执行用户代码要依靠 P,而 P 要正常工作必须要与一个 M 关联,M 指的就是系统线程。
创建
M 的创建是由函数runtime.newm完成的,它接受一个函数和 P 以及 id 作为参数,作为参数的函数不能闭包。
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}在开始前,newm会先调用runtime.allocm函数来创建线程的运行时表示也就是 M,在过程中会使用runtime.mcommoninit函数来初始化 M 的栈边界。
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}再之后由runtime.newm1调用runtime.newosproc函数来完成真正的系统线程的创建。
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}runtim.newosproc的实现会根据操作系统的不同而不同,具体怎么创建就不是我们要关心的事了,由操作系统负责,然后由runtime.mstart来启动 M 的工作。
退出
runtime.gogo(&mp.g0.sched)在初始的时候提到过,在调用mstart1函数时将执行现场保存在了 g0的sched字段中,将该字段传给runtime.gogo函数(汇编实现)就可以让线程跳到执行现场继续执行,在保存的时候用的是getcallerpc(),所以恢复现场的时候是回到了mstar0函数。
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)执行现场恢复后,按照执行顺序就会进入mexit函数来退出线程。
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)它总共做了以下几个主要的事情
- 调用
runtime.uminit来撤销runtime.minit的工作 - 从全局变量
allm中删除该 M - 将调度器的
freem指向当前 M - 由
runtime.releasep将 P 与当前 M 解绑,并由runtime.handoffp让 P 跟其它的 M 绑定以继续工作 - 由
runtime.destroy负责销毁 M 的资源 - 最后由操作系统来退出线程
到此 M 就成功退出了。
暂停
当因为调度器调度,GC,系统调用等原因需要暂停 M 时,就会调用runtime.stopm函数来暂停线程,下面是简化后的代码。
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}它首先会将 M 放入全局的空闲 M 列表中,然后由mPark()将当前线程阻塞在notesleep(&gp.m.park)这里,当被唤醒过后该函数就会返回
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}唤醒后的 M 会去寻找一个 P 进行绑定从而继续执行任务。
协程
协程的生命周期刚好对应着协程的几个状态,了解协程的生命周期对了解调度器会很有帮助,毕竟整个调度器就是围绕着协程来设计的,整个协程的生命周期就如下图所示。
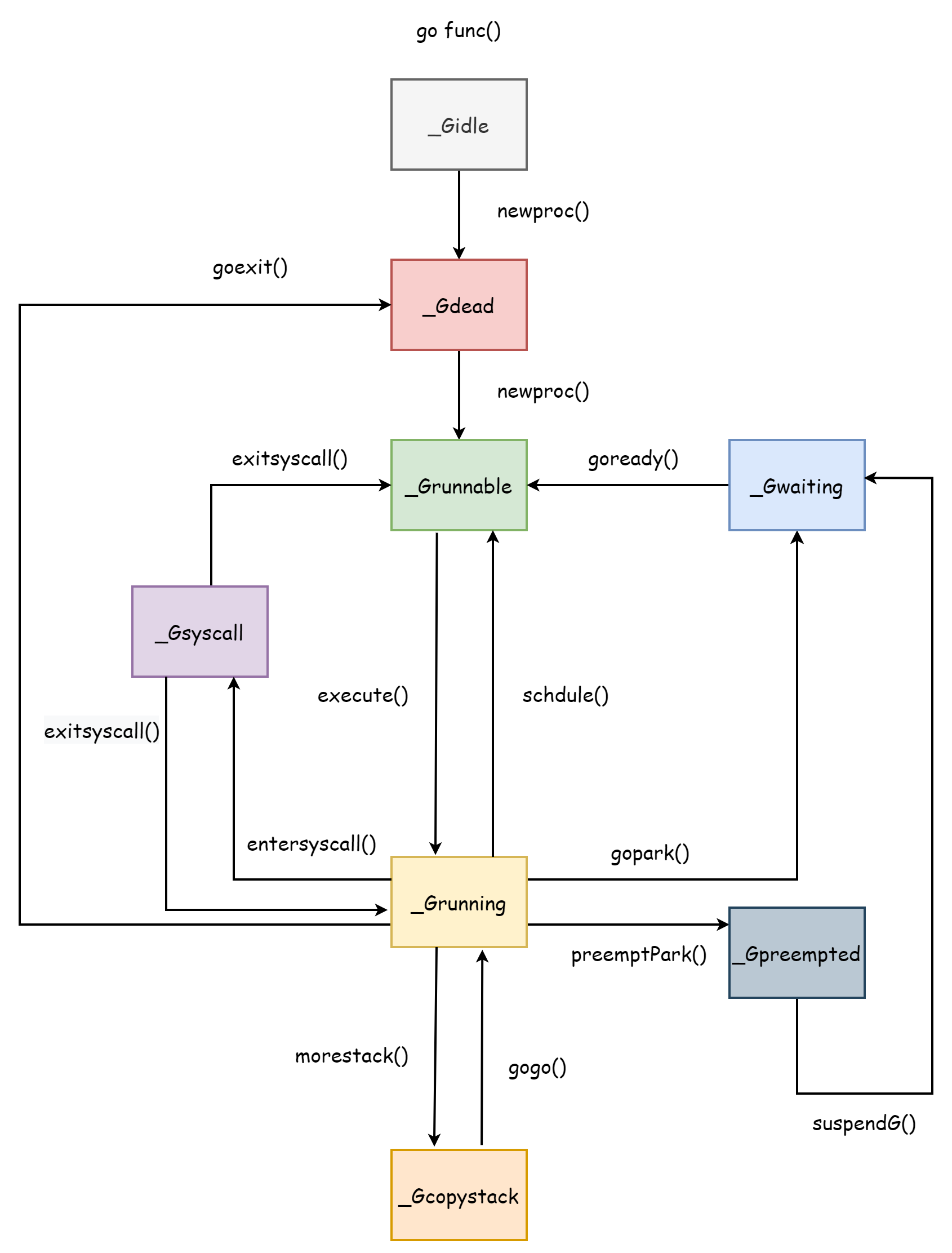
_Gcopystack是协程栈扩张时具有的状态,在协程栈部分进行讲解。
创建
协程的创建从语法层面上来讲只需要一个go关键字加一个函数。
go doSomething()编译后会变成runtime.newproc函数的调用
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}由runtime.newproc1来完成实际的创建,在创建时首先会锁住 M,禁止抢占,然后会去 P 的本地gfree列表中寻找空闲的 G 来重复利用,如果找不到就由runtime.malg 创建一个新的 G,并为其分配 2kb 的栈空间。此时 G 的状态为_Gdead。
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}在 go1.18 及以后,参数的拷贝不再由newproc1函数完成,在这之前,会使用runtime.memmove来拷贝函数的参数。现在的话只是负责重置协程的栈空间,将runtime.goexit作为栈底由它来进行协程的退出处理,然后设置入口函数的 PCnewg.startpc = fn.fn表示从这里开始执行,设置完成后,此时 G 的状态为_Grunnable。
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)最后设置 G 的唯一标识符,然后释放 M,返回创建的协程 G。
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newg协程创建完毕后,会由runtime.runqput函数尝试将其放入 P 的本地队列中,如果放不下就放到全局队列中。在协程创建的整个过程中,其状态变化首先是由_Gidle变为_Gdead,设置好入口函数后由_Gdead变为_Grunnable。
退出
在创建的时候 go 就已经将runtime.goexit函数作为协程的栈底,那么当协程执行完毕后最终就会走入该函数,经过调用链goexit->goexit1->goexit0,最终由runtime.goexit0来负责协程的退出工作。
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}该函数主要做了下面几个事情
- 设置状态为
_Gdead - 重置字段值
dropg()切断 M 与 G 之间的关联gfput(pp, gp)将当前 G 放入 P 的本地空闲列表中schedule()进行新一轮调度,将 M 的执行权让给其它的 G
退出后,协程的状态由_Grunning变化为_Gdead,在以后新建协程时仍有可能被重复利用。
系统调用
当协程 G 在执行用户代码时如果进行了系统调用,触发系统调用的方法有两种
syscall标准库的系统调用- cgo 调用
因为系统调用会阻塞工作线程,所以在此之前需要进行准备工作,由runtime.entersyscall函数完成这一过程,但前者也只是对runtime.reentersyscall函数的一个简单调用,实际的工作是由后者来完成的。首先会锁住当前的 M,在进行准备期间 G 禁止被抢占,也禁止栈扩张,设置gp.stackguard0 = stackPreempt表示在准备工作完成后将 P 的执行权将被其它的 G 抢占,然后保留协程的执行现场,方便系统调用返回后恢复。
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pc再之后,因为了防止长时间阻塞而影响其它 G 的执行,M 与 P 会解绑,解绑后的 M 和 G 会因执行系统调用而阻塞,而 P 在解绑以后可能会与其它空闲的 M 绑定从而让 P 本地队列中其它的 G 能够继续工作。
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--在准备工作完成后,释放 M 的锁,在此期间 G 的状态由_Grunning变为_Gsyscall,P 的状态变为_Psyscall。
当系统调用返回后,线程 M 不再阻塞,对应的 G 也需要再次被调度来执行用户代码,由runtime.exitsyscall函数来完成这个善后的工作。首先锁住当前的 M,获取旧 P 的引用。
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0此时分为两种情况来处理,第一种情况是是否有 P 可以直接使用,runtime.exitsyscallfast函数会判断原来的 P 是否可用,即 P 的状态是否为_Psyscall,否则的话就会去找空闲的 P。
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}如果成功找到了可用的 P,M 会与 P 进行绑定,G 由_Gsyscall状态切换为_Grunning状态,然后通过runtime.GoschedG 主动让出执行权,P 进入调度循环寻找其它可用的 G。
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}假如没有找到的话,M 会与 G 解绑,G 由_Gsyscall切换为_Grunnable状态,然后再次尝试是否能找到空闲的 P,如果没有找到就直接将 G 放入全局队列中,然后进入新一轮调度循环,旧 M 由runtime.stopm进入空闲状态,等待日后的新任务。如果 P 找到了的话,旧 M 和 G 与新的 P 进行关联,然后继续执行用户代码,状态由_Grunnable变为_Grunning。
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}在退出系统调用后,G 的状态最终有两种结果,一种是等待被调度的_Grunnable,一种是继续运行的_Grunning。
挂起
当前协程因为一些原因挂起的时候,状态会由_Grunnable变为_Gwaiting,挂起的原因有很多,可以是因为通道阻塞,select,锁或者是time.sleep,更多原因见G 结构。拿time.Sleep举例,它实际上是链接到了runtime.timesleep,后者的代码如下。
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}可以看出,它通过getg获取当前的协程,再通过runtime.gopark使得当前的协程挂起。runtime.gopark会更新 G 和 M 的阻塞原因,释放 M 的锁
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)然后切换到系统栈上由runtime.park_m来将 G 的状态切换为_Gwaiting,然后切断 M 与 G 之间的关联并进入新的调度循环从而将执行权让给其它的 G。挂起后,G 即不执行用户代码,也不在本地队列中,只是保持着对 M 和 P 的引用。
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()在runtime.timesleep函数中有这么一行代码,指定了t.f的值
t.f = goroutineReady这个runtime.goroutineReady函数的作用就是用于唤醒挂起的协程,它会调用runtime.ready函数来唤醒协程
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)唤醒后,将 G 的状态切换为_Grunnable,然后将 G 放入 P 的本地队列中等待日后被调度。
协程栈
go 语言中的协程是典型的有栈协程,每开启一个协程都会为其在堆上分配一个独立的栈空间,并且它会随着使用量的变化而增长或缩小。在调度器初始化的时候,runtime.stackinit函数负责来初始化全局的栈空间缓存stackpool和stackLarge。
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}除此之外,每一个 P 都有一个自己独立的栈空间缓存mcache
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}线程缓存mcache是每一个线程独立的且不是分配在堆内存上,访问的时候不需要加锁,这三个栈缓存在后续分配空间的时候都会用到。
分配
在新建协程时,如果没有可重复利用的协程,就会选择为其分配一个新的栈空间,它的大小默认为 2KB。
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}负责分配栈空间的函数就是runtime.stackalloc
func stackalloc(n uint32) stack根据申请的栈内存大小是否小于 32KB 分为两种情况,32KB 同时也是 go 中判断是小对象还是大对象的标准。倘若小于这个值就会从stackpool缓存中去获取,当 M 与 P 绑定且 M 不允许被抢占时,就会去本地的线程缓存中获取。
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}倘若大于 32KB,就会去stackLarge缓存中获取,如果还不够的话就直接在堆上分配内存。
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}完事后返回栈空间的低地址和高地址
return stack{uintptr(v), uintptr(v) + uintptr(n)}扩容
默认的协程栈大小为 2KB,足够轻量,所以创建一个协程的成本非常低,但这不一定够用,当栈空间不够用的时候就需要扩容。编译器会在函数的开头插入runtime.morestack函数来检查当前协程是否需要进行栈扩容,如果需要的话就调用runtime.newstack来完成真正的扩容操作。
TIP
由于morestack几乎会在所有函数的开头都被插入,所以栈扩容检查的时机也是一个协程抢占点。
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)可以看到,计算后的栈空间容量是原来的两倍,由runtime.copystack函数来完成栈拷贝的工作,在拷贝前 G 的状态由_Grunning切换为_Gcopystack。
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}该函数总共做了以下几个工作
- 分配新的栈空间
- 将旧栈内存通过
runtime.memmove直接复制到新的栈空间中, - 调整包含栈指针的结构,比如 defer,panic 等
- 更新 G 的栈空间字段
- 通过
runtime.adjustframe调整指向旧栈内存的指针 - 释放旧栈的内存
完成后,G 的状态由_Gcopystack切换为_Grunning,并由runtime.gogo函数让 G 继续执行用户代码。正是因为协程栈扩容的存在,所以 go 中的内存是不稳定的。
收缩
当 G 的状态为_Grunnable,_Gsyscall,_Gwaiting时,GC 会扫描协程栈的内存空间。
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}实际的栈收缩工作由runtime.shrinkstack来完成。
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}当使用的栈空间不足原有的 1/4 时,就会通过runtime.copystack将其缩小为原来的 1/2,后面的工作跟之前就没什么两样了。
分段栈
从copystack的过程可以看到,它会将旧栈内存拷贝到一个更大的栈空间上,不管是原来的栈还是新的栈它们的内存地址都是连续的。而在远古时期的 go 语言中,栈扩容时做法和现在不一样,那会觉得内存拷贝太消耗性能了,采用的是分段栈的思路,如果栈空间内存不够用了,就再申请一片新的栈空间,原有的栈空间内存不会释放也不会被拷贝,彼此之前通过指针链接起来,形成了一个栈链表,这也就是分段栈的由来,就如下图所示
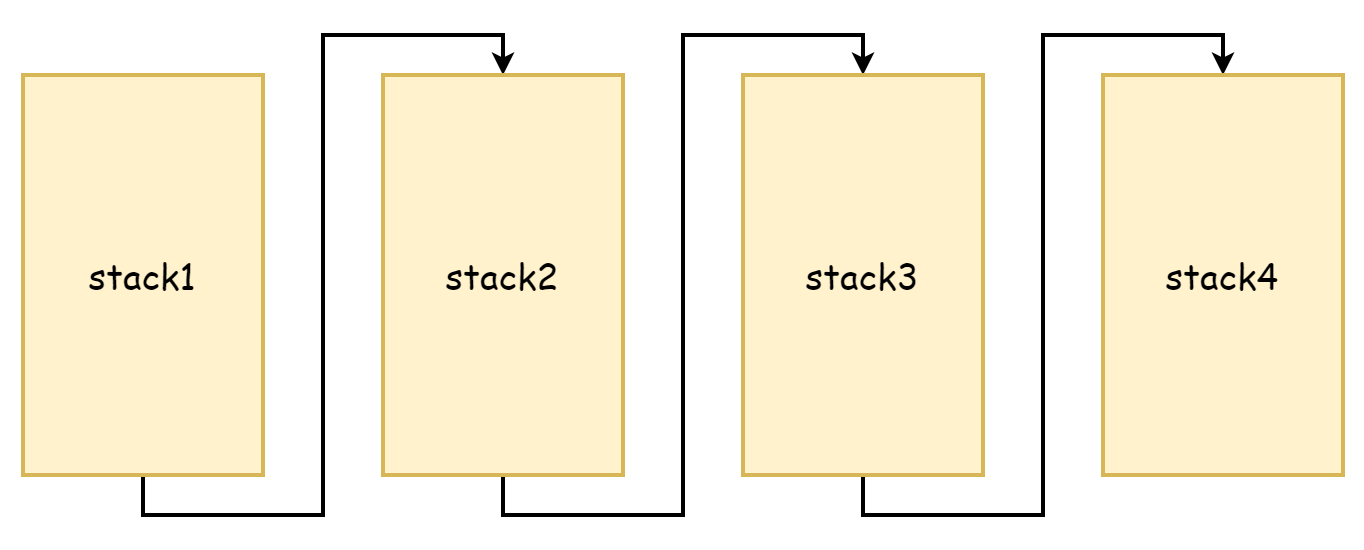
这样做的好处在于不用拷贝原有的栈,但缺点也十分的明显,就是会十分频繁的触发栈扩容和缩容。当栈空间的空闲内存所剩无几时,新的函数调用会触发栈的扩容,当这些函数返回时,不再需要新的栈空间了后就又会触发缩容,假如这些函数调用的频率非常高,那么就会非常频繁的触发扩容和缩容,这种操作所造成的性能损耗是非常大的。
所以在 go1.4 之后换成了连续栈,连续栈因为分配了一个容量更大的栈空间,不会出现已使用内存达到临界值时因函数调用而频繁的触发扩缩容这种情况,并且由于内存地址是连续的,根据缓存的空间局部性原理而言,连续栈对 CPU 缓存也更加友好。
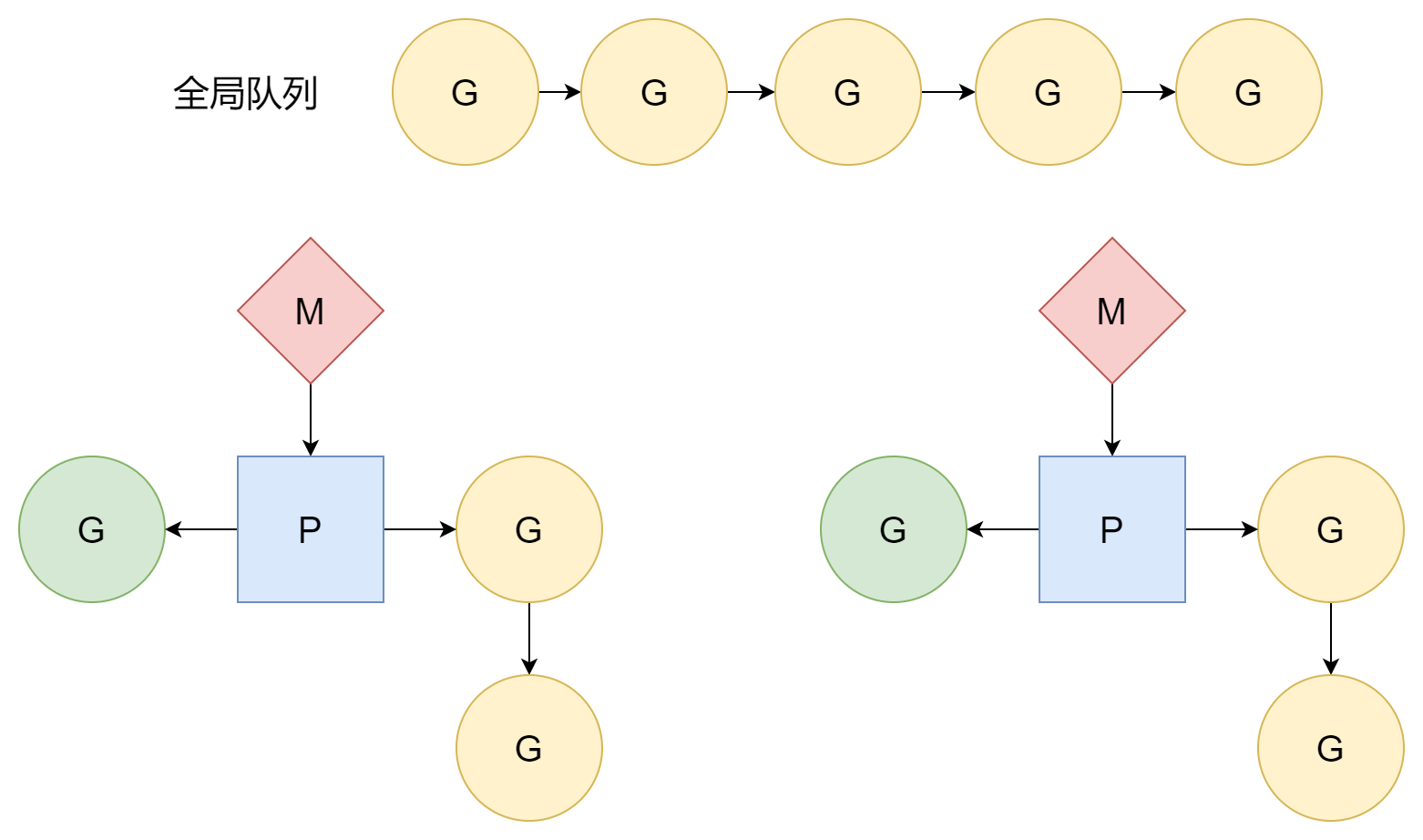
调度循环
在调度器初始化部分提到过,在runtime.mstart1函数中,M 与 P 成功关联后就会进入第一个runtime.schedule调度循环正式开始调度 G 以执行用户代码。在调度循环中,这一部分就主要是 P 在发挥作用。M 对应着系统线程,G 对应着入口函数也就是用户代码,但 P 并不像 M 和 G 一样有着对应的实体,它只是一个抽象的概念,作为中间人处理着 M 和 G 之间的关系。
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}上面的代码经过简化,删去了许多条件判断,最核心的点只有两个runtime.findRunnable和runtime.execute,前者负责找到一个 G,并且一定会返回一个可用的 G,后者负责让 G 继续执行用户代码。
对于findRunnable函数而言,第一个 G 来源就是 P 的本地队列
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}如果本地队列没有 G,那么就尝试从全局队列中获取
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}如果本地和全局队列中都没有找到,就会尝试从网络轮询器中获取
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}倘若还找不到,最终就会从其它的 P 去偷取它本地队列中的 G。在创建协程的时候提到过,P 的本地队列中的 G 一大来源是当前协程派生的子协程,然而并非所有的协程都会创建子协程,这样就可能会出现一部分 P 非常忙碌,另一部分 P 是空闲的,这会导致一种情况,有的 G 因为一直在等待而迟迟无法被运行,而另一边的 P 十分清闲,什么事也没有。为了能够压榨所有的 P,让它们发挥最大的工作效率,当 P 找不到 G 的时候,就会去其它 P 的本地队列中“偷取”能够执行的 G,这样一来,每一个 P 都能拥有较为均匀的 G 队列,就很少会出现 P 与 P 之间隔岸观火的情况了。
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork会随机选一个 P 来进行偷取,真正的偷取工作由runtime.runqgrab函数来完成,它会尝试偷取该 P 本地队列一半的 G。
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}整个偷取工作会进行四次,如果四次后也偷不到 G 那么就返回。如果最终无法找到,当前 M 会被runtime.stopm给暂停,直到被唤醒后继续重复上面的步骤。当找到并返回了一个 G 后,就将其交给runtime.execute来运行 G。
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)首先更新 M 的curg,然后更新 G 的状态为_Grunning,最后交给runtime.gogo来恢复 G 的运行。
总的的来说,在调度循环中 G 的来源根据优先级来分有四个
- P 的本地队列
- 全局队列
- 网络轮询器
- 从其它 P 的本地队列偷
runtime.execute在执行过后并不会返回,刚获取的 G 也不会永远执行下去,在某一个时机触发调度以后,它的执行权会被剥夺,然后进入新一轮调度循环,将执行权让给其它的 G。
调度策略
不同的 G 执行用户代码的时长可能不同,部分 G 可能会耗时很长,部分 G 耗时很短,执行时机长的 G 可能会导致其它的 G 迟迟无法得到执行,所以交替执行 G 才是正确的方式,在操作系统中这种工作方式被称之为并发。
协作式调度
协作式调度的基本思路是,让 G 自行将执行权让给其它的 G,主要有两种方法。
第一种方法就是在用户代码中主动让权,go 提供了runtime.Gosched()函数,使用者可以自己决定在何时让出执行权,不过在很多时候调度器内部的工作细节都使用者来说都是一个黑盒,很难去判断到底什么时候该主动让权,对使用者的要求比较高,并且 go 的调度器力求对使用者屏蔽大部分细节,追求更简单的使用方法,在这种情况下让使用者也参与到调度工作中并非是什么好事。
第二种方法是抢占标记,虽然它的名字有抢占的字眼,但它本质上还是协作式调度策略。思路就是在函数的头部插入抢占检测代码runtime.morestack(),插入的过程在编译期完成,前面提到过它原本是用于进行栈扩容检测的函数,因为其检测点是每一个函数的调用,这同样是一个进行抢占检测的良好时机。runtime.newstack函数上半部分都是在进行抢占检测,下半部分则在进行栈扩容检测,前面为了避免干扰就将这部分省掉了,现在就来看看这部分干了什么。首先会根据gp.stackguard0进行抢占判断,如果不需要的话就继续执行用户代码。
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}当g.stackguard0 == stackPreempt时,由runtime.canPreemptM()函数来判断协程条件是否需要被抢占,代码如下,
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}可以看到能够被抢占需要满足四个条件
- M 没有被锁住
- 没有正在分配内存
- 没有禁用抢占
- P 处于
_Prunning状态
而在以下两种种情况会将g.stackguard0设置为stackPreempt
- 需要进行垃圾回收时
- 发生系统调用时
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}最后就会走到runtime.gopreempt_m()主动让出当前协程的执行权。首先切断 M 与 G 之间的联系,状态变为_Grunnbale,然后将 G 放入全局队列中,最后进入调度循环将执行权让给其它的 G。
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()这样一来,所有的协程在进行函数调用时都可能会进入该函数进行抢占检测,这种策略得依赖函数调用这一时机才能触发抢占并且主动让权。在 1.14 之前,go 一直都是沿用的这种调度策略,但这样会有一个问题,如果没有函数调用,就没法检测了,比如下面这段经典代码,应该在很多教程中都有出现
func main() {
// 限制P的数量只能为1
runtime.GOMAXPROCS(1)
// 协程1
go func() {
for {
// 该协程不停的空转
}
}()
// 进入系统调用,主协程让权给其它协程
time.Sleep(time.Millisecond)
println("exit")
}代码中创建了一个空转的协程 1,然后主协程因为系统调用主动让权,此时协程 1 正在被调度,但因为它根本就不调用函数,也就没法进行抢占检测,由于 P 只有一个,没有其它空闲的 P,这样会导致主协程永远无法被调度,exit也就永远无法输出,不过这种问题也仅限于 go1.14 之前。
抢占式调度
官方在 go1.14 加入了基于信号的抢占式调度策略,这是一种异步抢占策略,通过异步线程发送信号的方式来进行抢占线程,基于信号的抢占式调度目前只有有两个入口,分别是系统监控和 GC。
在系统监控的循环中,会遍历每一个 P,如果 P 正在调度的 G 执行时间超过了 10ms,就会强制触发抢占。这部分工作由runtime.retake函数完成,下面是简化的后代码。
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}当需要进行垃圾回收时,如果 G 是状态是_Grunning,也就是还在运行,同样也会触发抢占。
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}两个抢占入口最后都会进入runtime.preemptM函数中,由它来完成抢占信号的发送。当信号成功发送后,在runtime.mstart时通过runtime.initsig注册的信号处理器回调函数runtime.sighandler就会派上用场,如果检测到发送的是抢占信号,就会开始抢占。
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt会修改目标协程的上下文,注入调用runtime.asyncPreempt。
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...这样一来当重新切换回用户代码的时候,目标协程就会走到runtime.asyncPreempt函数,在该函数中涉及到runtime.asyncPreempt2的调用。
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RET它会让当前协程停止工作并进行一轮新的调度循环从而将执行权让给其它协程。
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}这一过程过程都发生在runtime.asyncPreempt函数中,它由汇编实现(位于runtime/preempt_*.s中)并且会在调度完成后恢复先前被修改的协程上下文,以便让该协程在日后能够正常恢复。在采用异步抢占策略以后,之前的例子就不再会永久阻塞主协程了,当空转协程运行一定时间后就会被强制执行调度循环,从而将执行权让给了主协程,最终让程序能够正常结束。
小结
总的来说,触发调度的时机有以下几个:
- 函数调用
- 系统调用
- 系统监控
- 垃圾回收,垃圾回收对于执行时间过长的协程也会进行抢占
- 协程因管道,锁等原因而挂起
调度策略主要就是两大类,协作式和抢占式,协作式是主动让出执行权,抢占式是异步抢占执行权,两者共存才形成了如今的调度器。