gmp
One of the biggest features of Go language is its native support for concurrency. With just a single keyword, you can start a coroutine, as shown in the example below.
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Go language's coroutines are so simple to use, requiring almost no extra work from developers, which is one of the reasons for its popularity. However, behind this simplicity lies a non-trivial concurrent scheduler supporting everything. Its name, I believe, many of you have heard of to some extent. Because its main participants are G (coroutine), M (system thread), and P (processor), it's also known as the GMP scheduler. The GMP scheduler's design influences the entire Go runtime design, including GC and network poller. It can be said to be the most core part of the entire language. Having some understanding of it may be helpful in future work.
History
Go language's concurrent scheduling model is not entirely original. It absorbed lessons and experiences from predecessors, evolving and improving to its current state. The languages it drew inspiration from include:
- Occam - 1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
The most significant influence was from Hoare's 1978 paper on CSP (Communicating Sequential Processes). The paper's fundamental idea is that processes exchange data through communication. All the programming languages mentioned above were influenced by CSP ideas. Erlang is the most typical message-oriented programming language, and the famous open-source message queue middleware RabbitMQ is written in Erlang. Today, with the development of computers and the internet, concurrency support has almost become a standard feature of modern languages. Go language, combining CSP ideas, was born accordingly.
Scheduling Model
First, let's briefly introduce the three components of GMP:
- G, Goroutine: Refers to coroutines in Go language
- M, Machine: Refers to system threads or worker threads, scheduled by the operating system
- P, Processor: Not referring to CPU processors, but an abstract concept by Go, referring to processors working on system threads, used to schedule coroutines on each system thread.
Coroutines are a more lightweight form of threads, with smaller scale and requiring fewer resources. Creation, destruction, and scheduling timing are all handled by the Go runtime, not the operating system, so their management cost is much lower than threads. However, coroutines depend on threads. Coroutines' execution time slices come from threads, and threads' time slices come from the operating system. Switching between different threads has a certain cost. How to make good use of threads' time slices for coroutines is the key to design.
1:N
The best way to solve a problem is to ignore it. Since thread switching has a cost, just don't switch. Allocate all coroutines to a single kernel thread, so only coroutine switching is involved.
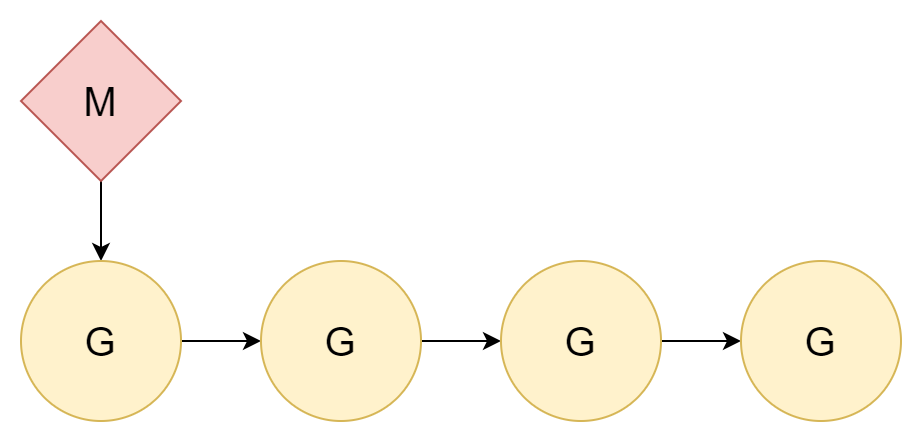
The relationship between threads and coroutines is 1:N. This approach has a very obvious disadvantage: today's computers are almost all multi-core CPUs, and such allocation cannot fully utilize multi-core CPU performance.
N:N
Another approach: one thread corresponds to one coroutine, and one coroutine can enjoy all of that thread's time slices. Multiple threads can also utilize multi-core CPU performance. However, thread creation and switching costs are relatively high. If it's a one-to-one relationship, it doesn't take good advantage of the lightweight nature of coroutines.
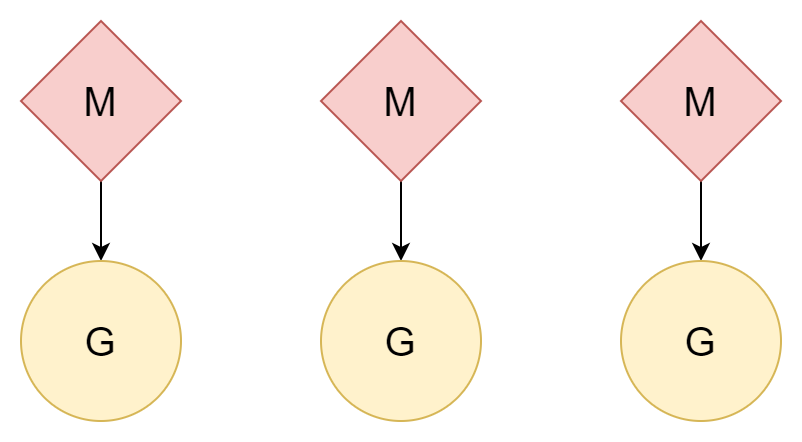
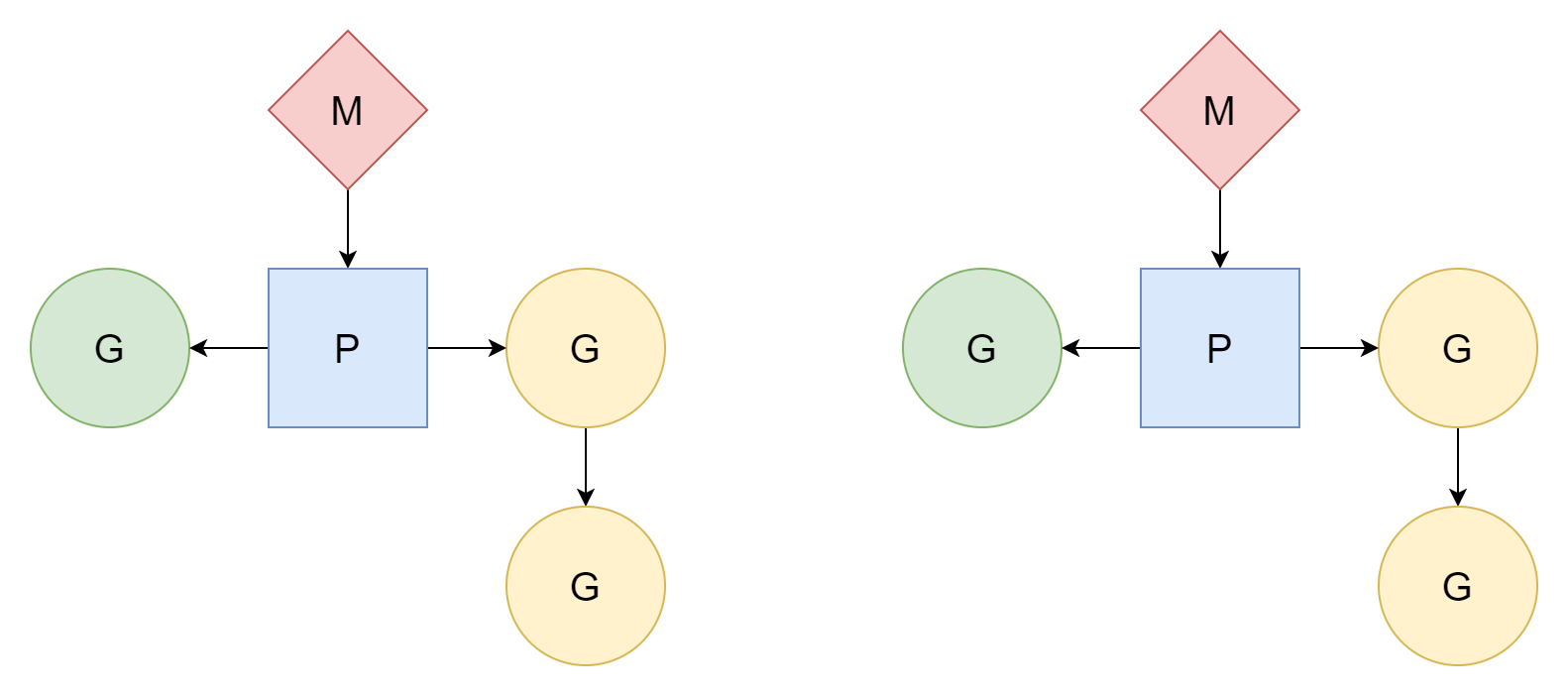
M:N
M threads correspond to N coroutines, where M is less than N. Multiple threads correspond to multiple coroutines, with each thread corresponding to several coroutines. Processor P is responsible for scheduling how coroutines G use threads' time slices. This method is relatively better and is the scheduling model that Go has used to this day.
M can only execute tasks after associating with processor P. Go creates GOMAXPROCS processors, so the actual number of threads available for executing tasks is GOMAXPROCS. Its default value is the number of CPU logical cores on the current machine, but we can also manually set its value.
- Modify through code
runtime.GOMAXPROCS(N), and it can be dynamically adjusted at runtime. Calling it causes immediate STW. - Set environment variable
export GOMAXPROCS=N, static.
In actual situations, the number of M is greater than the number of P, because at runtime they need to handle other tasks, such as some system calls. The maximum value is 10000.
GMP, these three participants, and the scheduler itself have their corresponding type representations at runtime. They are all located in the runtime/runtime2.go file. Below is a brief introduction to their structures to facilitate understanding later.
G
G's representation at runtime is the runtime.g structure, which is the most basic scheduling unit in the scheduling model. Its structure is as follows (many fields are omitted for easier understanding).
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}The first field is the start and end memory addresses of the stack belonging to this coroutine:
type stack struct {
lo uintptr
hi uintptr
}_panic and _defer are pointers pointing to the panic stack and defer stack respectively:
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm is the coroutine currently executing on this g:
m *m // current m; offset known to arm liblinkpreempt indicates whether the current coroutine needs to be preempted, equivalent to g.stackguard0 = stackpreempt:
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus is used to store the coroutine G's status value, with the following optional values:
| Name | Description |
|---|---|
_Gidle | Just allocated and not yet initialized |
_Grunnable | Indicates the current coroutine can run, located in the waiting queue |
_Grunning | Indicates the current coroutine is executing user code |
_Gsyscall | Assigned an M for executing system calls |
_Gwaiting | Coroutine blocked, reason for blocking see below |
_Gdead | Indicates the current coroutine is not in use, may have just exited or just initialized |
_Gcopystack | Indicates coroutine stack is moving, during this period no user code is executed, nor is it in the waiting queue |
_Gpreempted | Blocked itself enters preemption, waiting to be awakened by the preemptor |
_Gscan | GC is scanning coroutine stack space, can coexist with other states |
sched is used to store coroutine context information to restore the coroutine's execution state. You can see it stores sp, pc, ret pointers.
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting indicates the coroutine that the current coroutine is waiting for, waitsince records the time when the coroutine was blocked, and waitreason indicates the reason for coroutine blocking, with optional values as follows.
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid and parentGoid represent the unique identifiers of the current coroutine and parent coroutine, and startpc represents the address of the current coroutine's entry function.
M
M is represented at runtime as the runtime.m structure, which is an abstraction of worker threads:
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}Similarly, M has many internal fields. Here only some fields are introduced for easier understanding.
id: M's unique identifierg0: Coroutine with scheduling stackcurg: User coroutine running on the worker threadgsignal: Coroutine responsible for handling thread signalsgoSigStack: Stack space allocated by Go for signal handlingp: Address of processor P,oldppoints to P before executing system call,nextppoints to newly allocated Pmallocing: Indicates whether currently allocating new memory spacethrowing: Indicates the error type when M occurspreemptoff: Preemption identifier, when it's an empty string it indicates the currently running coroutine can be preemptedlocks: Indicates the current M's "lock" count, preemption is prohibited when not 0dying: Indicates M has encountered an unrecoverablepanic, has[0,3]four optional values, from low to high indicating severity.spinning: Indicates M is in idle state and随时 available.tls: Thread local storage
P
P is represented at runtime as runtime.p, responsible for scheduling work between M and G. Its structure is as follows:
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status indicates P's state, with the following optional values:
| Value | Description |
|---|---|
_Pidle | P is in idle state, can be assigned M by scheduler, or may just be transitioning between other states |
_Prunning | P is associated with M and is executing user code |
_Psyscall | Indicates M associated with P is performing system call, during this period P may be preempted by other M |
_Pgcstop | Indicates P is stopped due to GC |
_Pdead | Most resources of P are stripped, will no longer be used |
The following fields record P's runq local queue. You can see the local queue's maximum size is 256. Beyond this number, G will be placed in the global queue.
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext indicates the next available G:
runnext guintptrOther fields are explained as follows:
id: P's unique identifierschedtick: Increments with each coroutine scheduling, visible inruntime.executefunction.syscalltick: Increments with each system callsysmontick: Records information last observed by system monitorm: M associated with PgFree: List of idle Gpreempt: Indicates P should enter scheduling again
Global queue information is stored in the runtime.schedt structure, which is the scheduler's representation at runtime, as follows.
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}Initialization
Scheduler initialization is located in the bootstrap phase of Go programs. The function responsible for bootstrapping the Go program is runtime.rt0_go, implemented in assembly and located in the runtime/asm_*.s file. Part of the code is as follows:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RETYou can see calls to runtime·osinit and runtime·schedinit from the following two lines.
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)The former is responsible for initializing operating system related work, and the latter is responsible for scheduler initialization, which is the runtime·schedinit function. It's responsible for initializing resources needed for scheduler operation when the program starts. Below is simplified code.
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}The runtime.getg function is implemented in assembly. Its function is to get the runtime representation of the current coroutine, which is a pointer to the runtime.g structure. Through sched.maxmcount = 10000, you can see that the maximum number of M is set to 10000 when the scheduler is initialized. This value is fixed and cannot be modified. After that, it initializes the heap stack, then uses the runtime.mcommoninit function to initialize M. Its function implementation is as follows:
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}This function pre-initializes M, mainly doing the following work:
- Allocate M's id
- Allocate a separate G for handling thread signals, completed by
runtime.mpreinitfunction - Add it as the head node of the global M linked list
runtime.allm
Next, initialize P. Its quantity defaults to the number of CPU logical cores, followed by the environment variable value.
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}Finally, the runtime.procresize function is responsible for initializing P. It modifies the global slice runtime.allp that stores all P based on the passed quantity. First, it determines whether to expand capacity based on the quantity size.
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}Then initialize each P:
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}If the P currently used by the current coroutine needs to be destroyed, it's replaced with allp[0], and the runtime.acquirep function completes the association between M and the new P.
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}Then destroy P that are no longer needed. During destruction, all resources of P are released, all G in its local queue are placed in the global queue, and after destruction, allp is sliced.
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}Finally, link idle P into a linked list and ultimately return the head node of the list:
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsAfter that, the scheduler is initialized, and runtime.worldStarted restores all P to running.
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)Then a new coroutine is created through the runtime.newproc function to start the Go program, followed by calling runtime.mstart to officially start the scheduler's operation. It's also implemented in assembly, and internally calls the runtime.mstart0 function for creation. Part of the function's code is as follows:
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()At this point, M only has one coroutine g0, which uses the thread's system stack, not a separately allocated stack space. The mstart0 function first initializes G's stack boundary, then hands over to mstart1 to complete the remaining initialization work.
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()Before starting, it first records the current execution context, because after successful initialization, it will enter the scheduling loop and never return. Other calls can reuse the execution context to return from mstart1 function to achieve the purpose of exiting the thread. After recording, the runtime.asminit and runtime.minit two functions are responsible for initializing the system stack, then the runtime.mstartm0 function sets up callbacks for handling signals. After executing the callback function m.mstartfn, the runtime.acquirep function associates M with the previously created P, and finally enters the scheduling loop.
The runtime.schedule called here is the first scheduling loop of the entire Go runtime, representing the scheduler officially starting work.
Threads
In the scheduler, G needs to rely on P to execute user code, and P needs to be associated with an M to work properly. M refers to system threads.
Creation
M creation is completed by the runtime.newm function, which accepts a function, P, and id as parameters. The function as a parameter cannot be a closure.
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}Before starting, newm first calls the runtime.allocm function to create the thread's runtime representation, which is M. During the process, it uses the runtime.mcommoninit function to initialize M's stack boundary.
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}Then runtime.newm1 calls the runtime.newosproc function to complete the actual system thread creation.
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}The implementation of runtime.newosproc varies depending on the operating system. How exactly it's created is not our concern; it's handled by the operating system. Then runtime.mstart is used to start M's work.
Exit
runtime.gogo(&mp.g0.sched)As mentioned during initialization, when calling the mstart1 function, the execution context is saved in the sched field of g0. Passing this field to the runtime.gogo function (implemented in assembly) allows the thread to jump to the execution context and continue execution. When saving, getcallerpc() was used, so when restoring the context, it returns to the mstart0 function.
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)After the execution context is restored, following the execution order, it enters the mexit function to exit the thread.
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)It mainly does the following things:
- Call
runtime.unminitto undoruntime.minit's work - Remove this M from the global variable
allm - Set the scheduler's
freemto point to the current M - Use
runtime.releasepto unbind P from the current M, and useruntime.handoffpto bind P with other M to continue working - Use
runtime.destroyto destroy M's resources - Finally, the operating system exits the thread
At this point, M has successfully exited.
Pause
When M needs to be paused due to scheduler scheduling, GC, system calls, or other reasons, the runtime.stopm function is called to pause the thread. Below is simplified code.
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}It first puts M into the global idle M list, then uses mPark() to block the current thread at notesleep(&gp.m.park). When awakened, this function returns.
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}After being awakened, M will look for a P to bind to and continue executing tasks.
Coroutines
The lifecycle of a coroutine corresponds exactly to the several states of a coroutine. Understanding the coroutine lifecycle is very helpful for understanding the scheduler, after all, the entire scheduler is designed around coroutines. The entire coroutine lifecycle is as shown in the figure below.
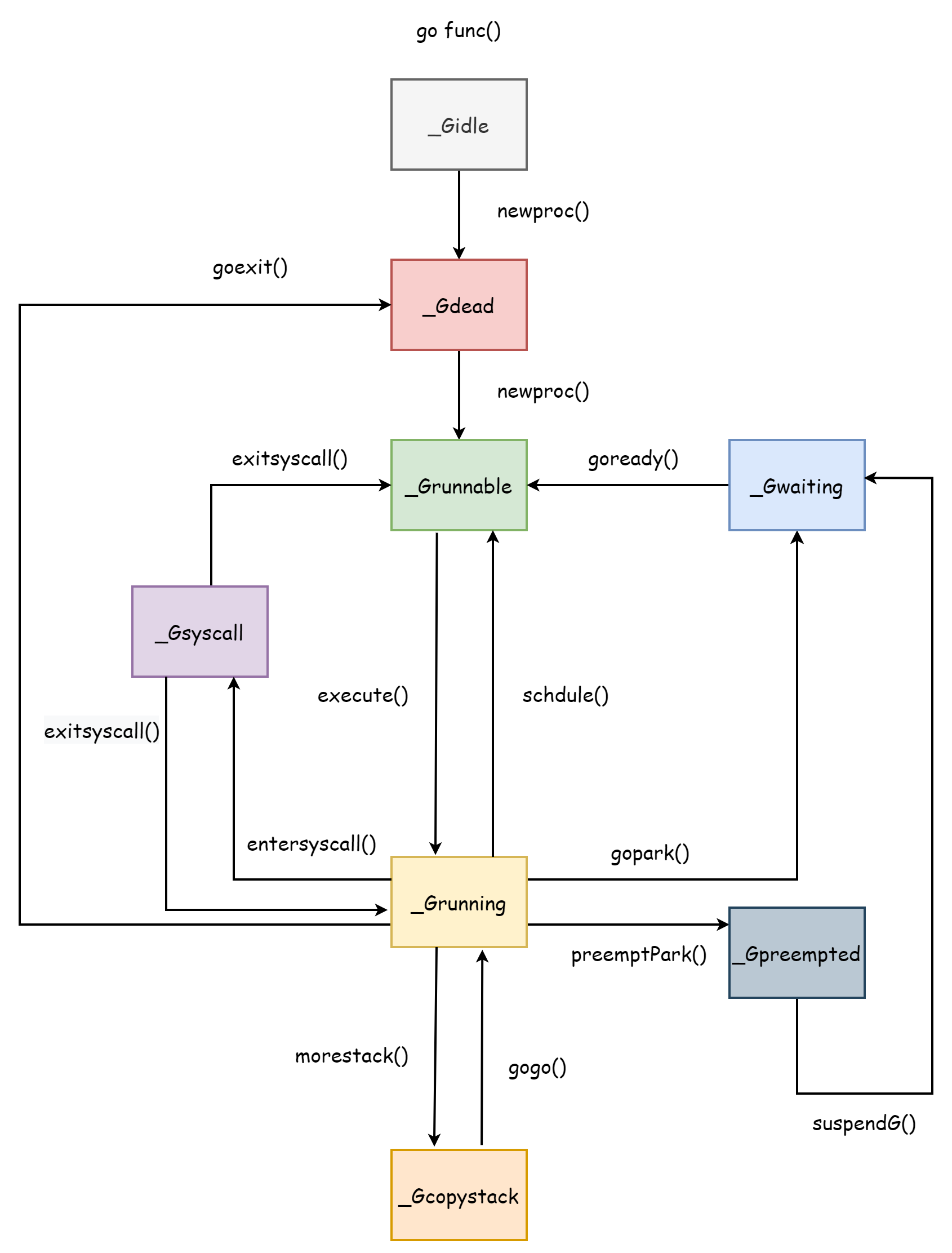
_Gcopystack is the state when the coroutine stack is expanding, which will be explained in the Coroutine Stack section.
Creation
From a syntax perspective, coroutine creation only requires a go keyword plus a function.
go doSomething()After compilation, it becomes a call to runtime.newproc function:
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}The actual creation is completed by runtime.newproc1. During creation, it first locks M, prohibits preemption, then looks for idle G in P's local gfree list to reuse. If not found, it creates a new G using runtime.malg and allocates 2kb of stack space. At this point, G's status is _Gdead.
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}In Go 1.18 and later, parameter copying is no longer completed by the newproc1 function. Before this, runtime.memmove was used to copy function parameters. Now it's only responsible for resetting the coroutine's stack space, using runtime.goexit as the stack bottom for coroutine exit handling, then setting the entry function's PC newg.startpc = fn.fn to indicate execution starts from here. After setting is complete, G's status is _Grunnable.
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)Finally, set G's unique identifier, then release M and return the created coroutine G.
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgAfter the coroutine is created, the runtime.runqput function attempts to put it into P's local queue. If it doesn't fit, it's placed in the global queue. During the entire coroutine creation process, its status changes first from _Gidle to _Gdead, and after setting the entry function, from _Gdead to _Grunnable.
Exit
During creation, Go has already set the runtime.goexit function as the coroutine's stack bottom. So when the coroutine execution is complete, it will eventually enter this function. Through the call chain goexit->goexit1->goexit0, the runtime.goexit0 function is ultimately responsible for coroutine exit work.
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}This function mainly does the following things:
- Set status to
_Gdead - Reset field values
dropg()cuts the association between M and Ggfput(pp, gp)puts the current G into P's local idle listschedule()performs a new round of scheduling, yielding M's execution rights to other G
After exiting, the coroutine's status changes from _Grunning to _Gdead, and it may still be reused when creating new coroutines in the future.
System Calls
When coroutine G is executing user code, if it performs a system call, there are two ways to trigger a system call:
- System calls from the
syscallstandard library - cgo calls
Because system calls block worker threads, preparation work needs to be done beforehand, completed by the runtime.entersyscall function. However, the former is just a simple call to the runtime.reentersyscall function, and the actual work is completed by the latter. First, it locks the current M. During preparation, G is prohibited from being preempted and stack expansion is prohibited. Setting gp.stackguard0 = stackPreempt indicates that after preparation is complete, P's execution rights will be preempted by other G. Then it saves the coroutine's execution context for recovery after the system call returns.
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcAfter that, to prevent long-term blocking from affecting the execution of other G, M and P will unbind. After unbinding, M and G will block due to executing system calls, while P, after unbinding, may bind with other idle M so that other G in P's local queue can continue working.
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--After preparation is complete, release M's lock. During this period, G's status changes from _Grunning to _Gsyscall, and P's status becomes _Psyscall.
When the system call returns, thread M is no longer blocked, and the corresponding G also needs to be scheduled again to execute user code, completed by the runtime.exitsyscall function. First, lock the current M and get a reference to the old P.
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0At this point, there are two cases to handle. The first case is whether there's a P available for direct use. The runtime.exitsyscallfast function will determine if the original P is available, i.e., whether P's status is _Psyscall. Otherwise, it will look for an idle P.
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}If a usable P is successfully found, M will bind with P, G will switch from _Gsyscall status to _Grunning status, and then through runtime.Gosched, G will voluntarily yield execution rights, and P will enter the scheduling loop to look for other available G.
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}If not found, M will unbind with G, G will switch from _Gsyscall to _Grunnable status, then try again to find an idle P. If not found, directly put G into the global queue, then enter a new scheduling loop. The old M enters idle state through runtime.stopm, waiting for new tasks in the future. If P is found, the old M and G associate with the new P, then continue executing user code, with status changing from _Grunnable to _Grunning.
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}After exiting the system call, G's status ultimately has two results: one is _Grunnable waiting to be scheduled, and the other is _Grunning continuing to run.
Suspension
When the current coroutine is suspended for some reason, its status changes from _Grunnable to _Gwaiting. There are many reasons for suspension, such as channel blocking, select, locks, or time.sleep. For more reasons, see G Structure. Taking time.Sleep as an example, it actually links to runtime.timesleep. The latter's code is as follows.
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}As you can see, it gets the current coroutine through getg, then makes the current coroutine suspend through runtime.gopark. runtime.gopark updates G and M's blocking reason, releases M's lock.
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)Then switch to the system stack and use runtime.park_m to switch G's status to _Gwaiting, then cut the association between M and G and enter a new scheduling loop to yield execution rights to other G. After suspension, G neither executes user code nor is in the local queue, just maintaining references to M and P.
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()In the runtime.timesleep function, there's this line of code specifying the value of t.f:
t.f = goroutineReadyThis runtime.goroutineReady function is used to wake up suspended coroutines. It calls the runtime.ready function to wake up the coroutine.
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)After waking up, switch G's status to _Grunnable, then put G into P's local queue to wait for future scheduling.
Coroutine Stack
Coroutines in Go language are a typical stack-based coroutine. Each coroutine is allocated an independent stack space on the heap, and it grows or shrinks with usage changes. During scheduler initialization, the runtime.stackinit function is responsible for initializing the global stack space cache stackpool and stackLarge.
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}In addition, each P has its own independent stack space cache mcache:
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}Thread cache mcache is independent for each thread and not allocated on heap memory. No locking is needed when accessing. These three stack caches will be used in subsequent space allocation.
Allocation
When creating a coroutine, if there's no reusable coroutine, a new stack space will be allocated for it. Its default size is 2KB.
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}The function responsible for allocating stack space is runtime.stackalloc:
func stackalloc(n uint32) stackThere are two cases based on whether the requested stack memory size is less than 32KB. 32KB is also Go's standard for judging whether an object is small or large. If it's less than this value, it will be obtained from the stackpool cache. When M is bound with P and M is not allowed to be preempted, it will be obtained from the local thread cache.
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}If it's greater than 32KB, it will be obtained from the stackLarge cache. If that's still not enough, memory is directly allocated on the heap.
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}After completion, return the low and high addresses of the stack space:
return stack{uintptr(v), uintptr(v) + uintptr(n)}Expansion
The default coroutine stack size is 2KB, which is lightweight enough, so the cost of creating a coroutine is very low. But this may not be enough. When the stack space is not enough, it needs to expand. The compiler inserts the runtime.morestack function at the beginning of functions to check if the current coroutine needs stack expansion. If needed, it calls runtime.newstack to complete the actual expansion operation.
TIP
Since morestack is inserted at the beginning of almost all functions, the stack expansion check timing is also a coroutine preemption point.
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)As you can see, the calculated stack space capacity is twice the original. The runtime.copystack function completes the stack copy work. Before copying, G's status switches from _Grunning to _Gcopystack.
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}This function does the following work:
- Allocate new stack space
- Directly copy old stack memory to the new stack space through
runtime.memmove - Adjust structures containing stack pointers, such as defer, panic, etc.
- Update G's stack space field
- Adjust pointers pointing to old stack memory through
runtime.adjustframe - Release old stack memory
After completion, G's status switches from _Gcopystack to _Grunning, and the runtime.gogo function lets G continue executing user code. It's precisely because of coroutine stack expansion that memory in Go is unstable.
Contraction
When G's status is _Grunnable, _Gsyscall, or _Gwaiting, GC scans the coroutine stack's memory space.
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}The actual stack contraction work is completed by runtime.shrinkstack.
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}When the used stack space is less than 1/4 of the original, it uses runtime.copystack to shrink it to 1/2 of the original. The remaining work is the same as before.
Segmented Stack
From the copystack process, you can see that it copies old stack memory to a larger stack space. Both the original stack and the new stack have continuous memory addresses. In ancient Go language, stack expansion was done differently. At that time, it was thought that memory copying was too performance-consuming, so segmented stack approach was adopted. If stack space memory was not enough, a new stack space was applied for. The original stack space memory was not released or copied, and they were linked together through pointers, forming a stack linked list. This is the origin of segmented stacks, as shown in the figure below.
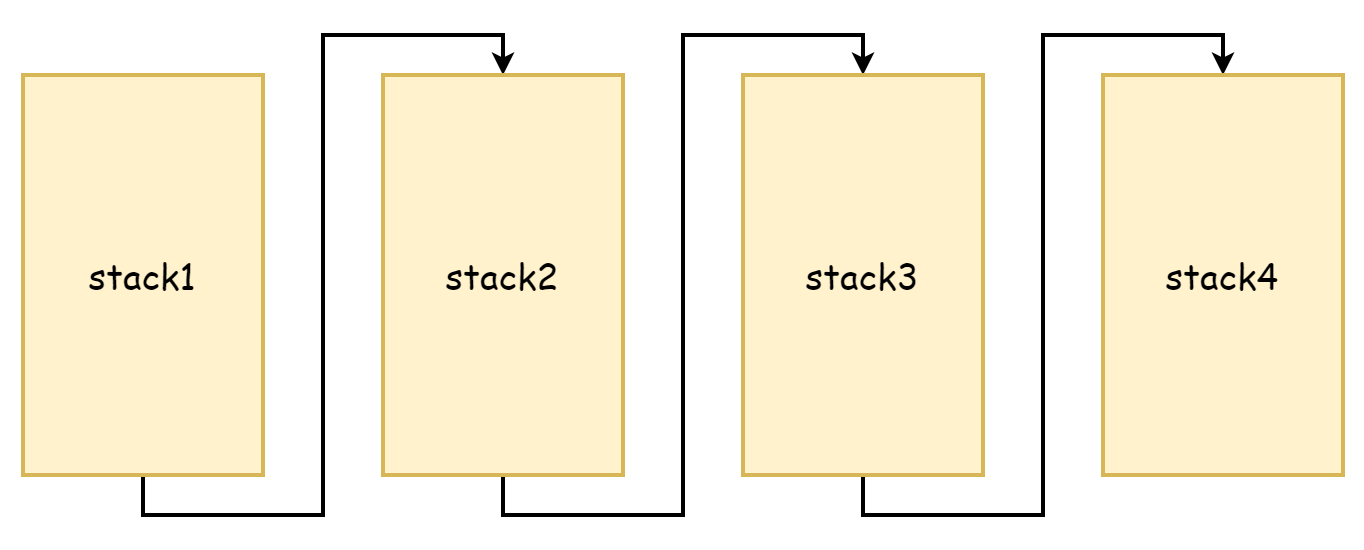
The advantage of this approach is that it doesn't need to copy the original stack, but the disadvantages are also very obvious: it triggers stack expansion and contraction very frequently. When stack space idle memory is running low, new function calls trigger stack expansion. When these functions return and the new stack space is no longer needed, it triggers contraction again. If these function calls are very frequent, the performance loss caused by such operations is very significant.
So after Go 1.4, it switched to continuous stacks. Continuous stacks allocate a larger capacity stack space, so when used memory reaches a critical value, it doesn't frequently trigger expansion/contraction due to function calls. And because memory addresses are continuous, according to cache spatial locality principle, continuous stacks are also more CPU cache friendly.
Scheduling Loop
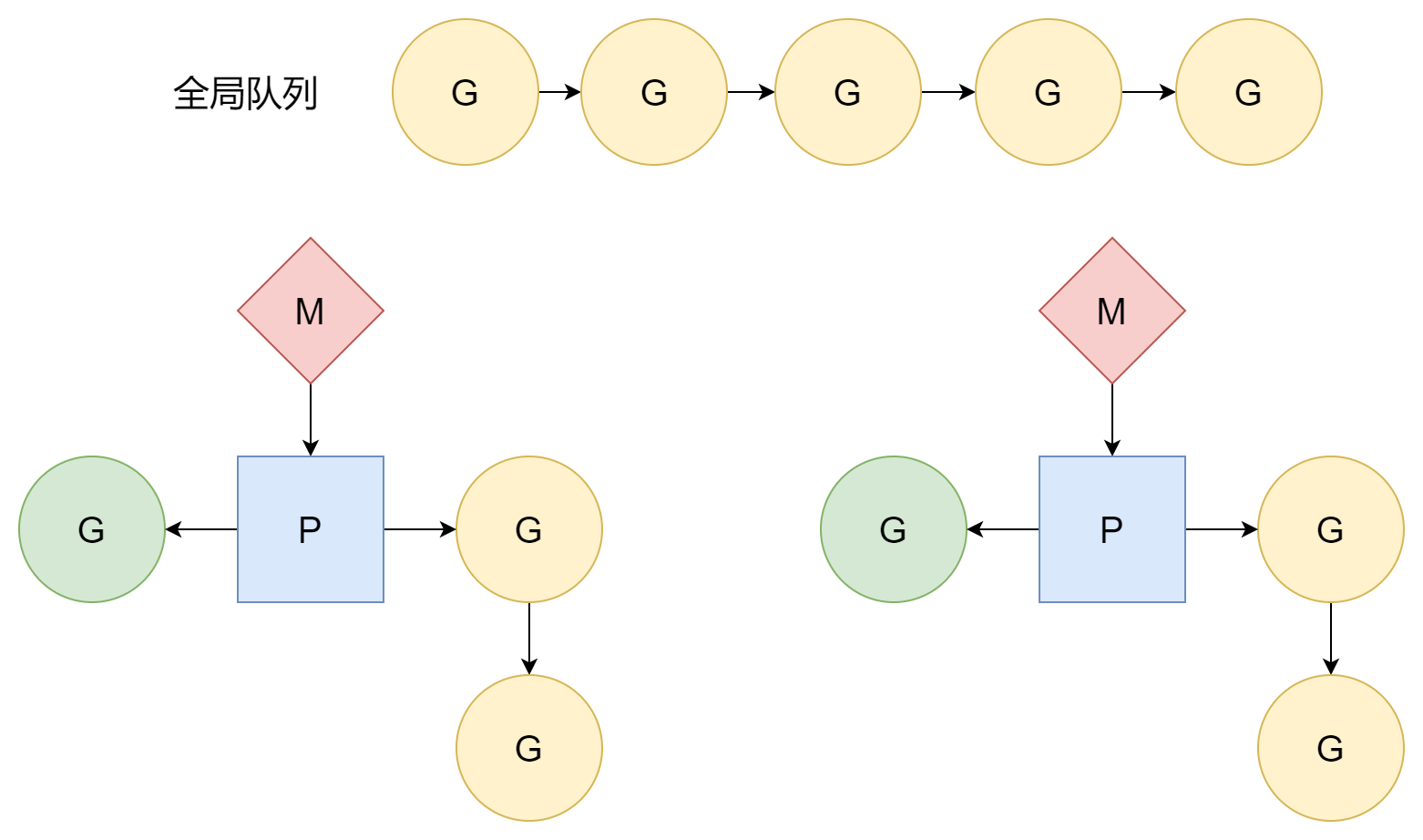
As mentioned in the scheduler initialization section, in the runtime.mstart1 function, after M and P are successfully associated, it enters the first runtime.schedule scheduling loop, officially starting to schedule G to execute user code. In the scheduling loop, this part is mainly where P plays a role. M corresponds to system threads, G corresponds to entry functions (i.e., user code), but P is not like M and G which have corresponding entities. It's just an abstract concept, acting as an intermediary handling the relationship between M and G.
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}The above code is simplified, with many conditional judgments removed. The most core points are only two: runtime.findRunnable and runtime.execute. The former is responsible for finding a G and will definitely return an available G, while the latter is responsible for letting G continue executing user code.
For the findRunnable function, the first G source is P's local queue:
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}If there's no G in the local queue, then try to get from the global queue:
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}If not found in local and global queues, try to get from the network poller:
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}If still not found, ultimately it will steal G from other P's local queues. As mentioned during coroutine creation, one major source of G in P's local queue is sub-coroutines spawned by the current coroutine. However, not all coroutines will create sub-coroutines, so it's possible that some P are very busy while other P are idle. This could lead to a situation where some G are waiting and cannot be run for a long time, while on the other side P are very idle with nothing to do. In order to squeeze all P to maximize their work efficiency, when P cannot find G, it will "steal" executable G from other P's local queues. This way, each P can have a relatively uniform G queue, and it's less likely to have a situation where P watch each other from across the river.
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork will randomly select a P to steal from. The actual stealing work is completed by the runtime.runqgrab function, which attempts to steal half of the G from that P's local queue.
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}The entire stealing work is performed four times. If after four times no G is stolen, it returns. If ultimately unable to find, the current M is paused by runtime.stopm until awakened to continue repeating the above steps. When a G is found and returned, it's handed over to runtime.execute to run G.
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)First update M's curg, then update G's status to _Grunning, and finally hand over to runtime.gogo to restore G's execution.
Overall, in the scheduling loop, G sources are divided into four levels according to priority:
- P's local queue
- Global queue
- Network poller
- Steal from other P's local queues
After runtime.execute executes, it doesn't return. The G just obtained won't execute forever either. At some point when scheduling is triggered, its execution rights will be deprived, then enter a new scheduling loop, yielding execution rights to other G.
Scheduling Strategy
Different G may have different execution times for user code. Some G may take a long time, while others take a short time. G with long execution times may cause other G to be unable to execute for a long time, so alternating execution of G is the correct way. This working method is called concurrency in operating systems.
Cooperative Scheduling
The basic idea of cooperative scheduling is to let G voluntarily yield execution rights to other G. There are mainly two methods.
The first method is to voluntarily yield in user code. Go provides the runtime.Gosched() function, allowing users to decide when to yield execution rights. However, in many cases, the internal working details of the scheduler are a black box to users, making it difficult to judge when to voluntarily yield. This requires higher demands on users. Moreover, Go's scheduler strives to shield most details from users and pursue simpler usage methods. In this case, involving users in scheduling work is not a good thing.
The second method is preemption marking. Although its name has the word "preemption", it's essentially still a cooperative scheduling strategy. The idea is to insert preemption detection code runtime.morestack() at the beginning of functions. The insertion process is completed during the compilation phase. As mentioned earlier, it was originally a function for stack expansion detection. Because its detection point is every function call, this is also a good timing for preemption detection. The upper part of the runtime.newstack function is all for preemption detection, while the lower part is for stack expansion detection. To avoid interference earlier, this part was omitted. Now let's see what this part does. First, it makes a preemption judgment based on gp.stackguard0. If preemption is not needed, it continues executing user code.
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}When g.stackguard0 == stackPreempt, the runtime.canPreemptM() function judges whether the coroutine conditions need to be preempted. The code is as follows:
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}As you can see, being preemptable requires meeting four conditions:
- M is not locked
- Not currently allocating memory
- Preemption is not disabled
- P is in
_Prunningstatus
In the following two situations, g.stackguard0 is set to stackPreempt:
- When garbage collection is needed
- When a system call occurs
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}Finally, it goes to runtime.gopreempt_m() to voluntarily yield the current coroutine's execution rights. First, cut the connection between M and G, status becomes _Grunnable, then put G into the global queue, and finally enter the scheduling loop to yield execution rights to other G.
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()This way, all coroutines may enter this function for preemption detection during function calls. This strategy relies on function call timing to trigger preemption and voluntarily yield. Before Go 1.14, Go always used this scheduling strategy. But this has a problem: if there's no function call, detection can't happen. For example, the following classic code, which should have appeared in many tutorials:
func main() {
// Limit P quantity to only 1
runtime.GOMAXPROCS(1)
// Coroutine 1
go func() {
for {
// This coroutine keeps spinning idle
}
}()
// Enter system call, main coroutine yields to other coroutines
time.Sleep(time.Millisecond)
println("exit")
}The code creates a spinning idle coroutine 1, then the main coroutine voluntarily yields due to system call. At this point, coroutine 1 is being scheduled, but because it doesn't call functions at all, it can't perform preemption detection. Since there's only one P and no other idle P, this causes the main coroutine to never be scheduled, and exit can never be output. However, this problem is limited to before Go 1.14.
Preemptive Scheduling
Officials added signal-based preemptive scheduling strategy in Go 1.14. This is an asynchronous preemption strategy that preempts threads by sending signals through asynchronous threads. Signal-based preemptive scheduling currently has two entry points: system monitoring and GC.
In the system monitoring loop, it traverses every P. If the G being scheduled by P executes for more than 10ms, it forcibly triggers preemption. This work is completed by the runtime.retake function. Below is simplified code.
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}When garbage collection is needed, if G's status is _Grunning, meaning it's still running, it will also trigger preemption.
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}Both preemption entry points ultimately enter the runtime.preemptM function, which completes the sending of preemption signals. When the signal is successfully sent, the signal handler callback function runtime.sighandler registered through runtime.initsig at runtime.mstart comes into play. If it detects that a preemption signal was sent, it starts preemption.
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt modifies the target coroutine's context and injects a call to runtime.asyncPreempt.
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...This way, when switching back to user code, the target coroutine will go to the runtime.asyncPreempt function, which involves a call to runtime.asyncPreempt2.
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RETIt makes the current coroutine stop working and perform a new round of scheduling loop to yield execution rights to other coroutines.
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}This entire process happens in the runtime.asyncPreempt function, which is implemented in assembly (located in runtime/preempt_*.s) and restores the previously modified coroutine context after scheduling is complete, so that the coroutine can normally recover in the future. After adopting the asynchronous preemption strategy, the previous example will no longer permanently block the main coroutine. When the spinning coroutine runs for a certain time, it will be forcibly executed in the scheduling loop, thereby yielding execution rights to the main coroutine, ultimately allowing the program to end normally.
Summary
Overall, the timing for triggering scheduling includes the following:
- Function calls
- System calls
- System monitoring
- Garbage collection (GC also preempts coroutines that have been executing for too long)
- Coroutine suspension due to channels, locks, or other reasons
Scheduling strategies are mainly two categories: cooperative and preemptive. Cooperative is voluntarily yielding execution rights, while preemptive is asynchronously seizing execution rights. Both coexist to form today's scheduler.