map
Unlike other languages, Go provides map support through the map keyword rather than encapsulating it as a standard library. A map is a widely used data structure with many implementation methods at the底层 level. The two most common methods are red-black trees and hash tables. Go uses the hash table implementation.
TIP
The map implementation involves a large number of pointer movement operations, so reading this article requires knowledge of the unsafe standard library.
Internal Structure
The runtime.hmap struct represents a map in Go. Like slices, the internal implementation of map is also a struct.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
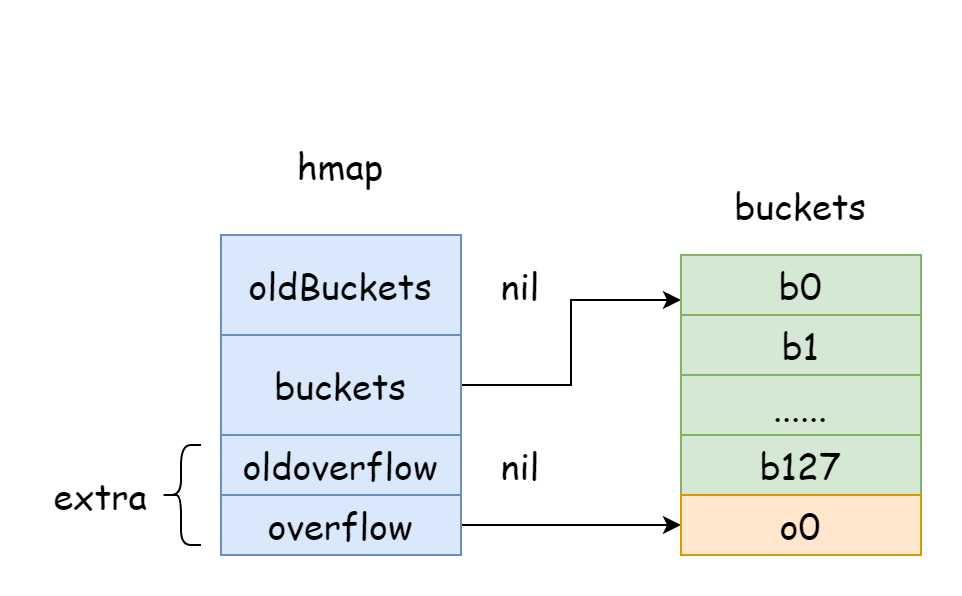
extra *mapextra // optional fields
}The English comments explain very clearly. Below are some simple explanations for the more important fields:
count: represents the number of elements in hmap, equivalent tolen(map).flags: hmap flags indicating what state the hmap is in, with the following possibilities:goconst ( iterator = 1 // Iterator is using buckets oldIterator = 2 // Iterator is using old buckets hashWriting = 4 // A goroutine is writing to hmap sameSizeGrow = 8 // Growing with equal size )B: the number of hash buckets in hmap is1 << B.noverflow: approximate number of overflow buckets in hmap.hash0: hash seed, specified when hmap is created, used to calculate hash values.buckets: pointer to the hash bucket array.oldbuckets: pointer to the hash bucket array before hmap expansion.extra: stores overflow buckets of hmap. Overflow buckets are new buckets created when the current bucket is full to store elements.
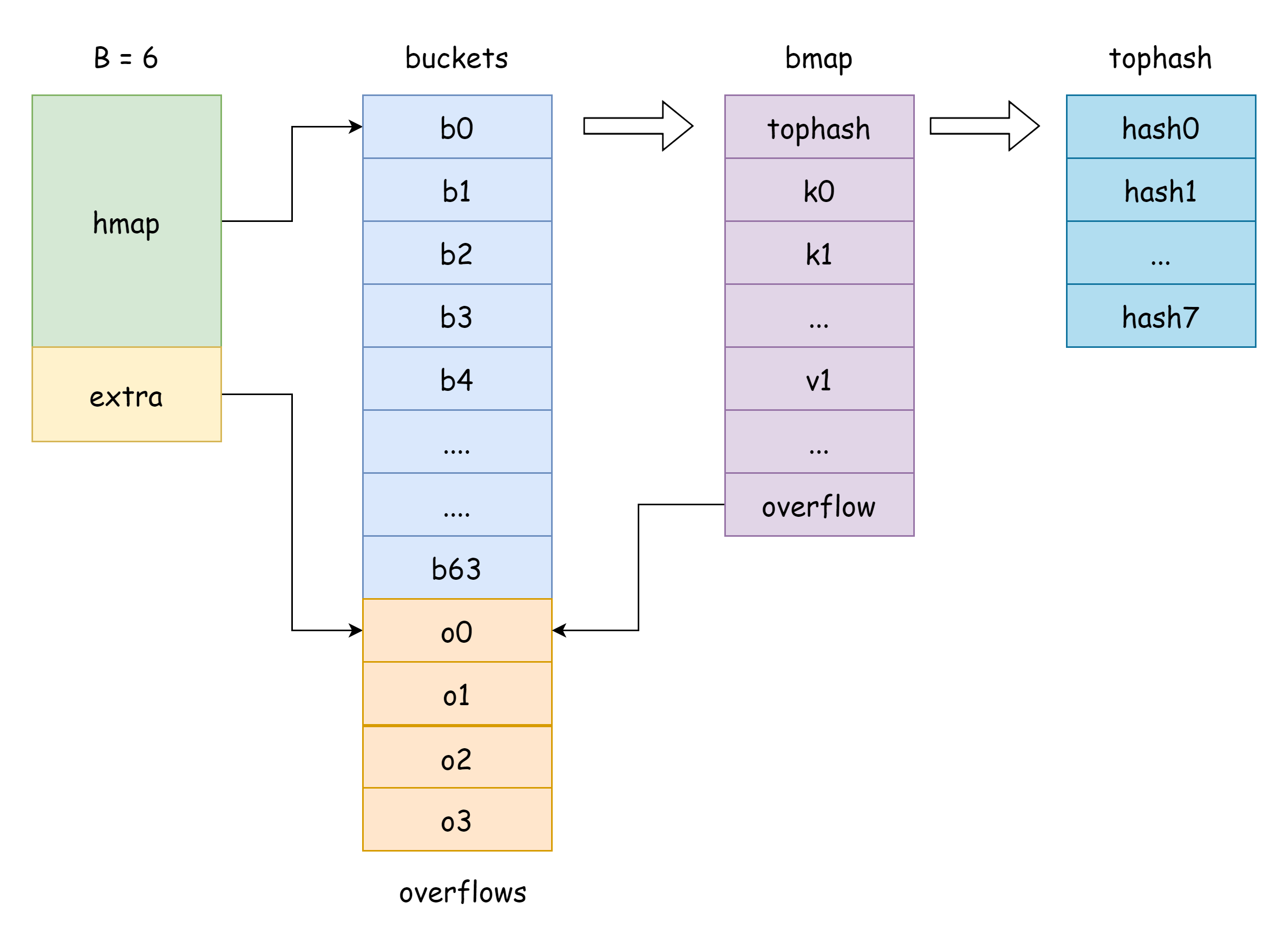
The buckets in hmap is a bucket slice pointer, corresponding to the runtime.bmap struct in Go:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}As you can see, it only has a tophash field, which stores the high 8 bits of each key. However, bmap actually has more fields than these. This is because map can store various types of key-value pairs, so memory space needs to be derived based on types during compilation. The MapBucketType function in cmd/compile/internal/reflectdata/reflect.go constructs bmap during compilation, performing a series of checks, such as whether the key type is comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeSo actually, the bmap structure is as follows, but these fields are invisible to us. Go accesses them through moving unsafe pointers in actual operations:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Some explanations are as follows:
tophash: stores the high 8 bits of each key. For a tophash element, there are the following special values:goconst ( emptyRest = 0 // Current element is empty, and no more available keys follow emptyOne = 1 // Current element is empty, but there are available keys following evacuatedX = 2 // Appears during expansion, only in oldbuckets, indicates element was moved to upper half of new bucket array evacuatedY = 3 // Appears during expansion, only in oldbuckets, indicates element was moved to lower half of new bucket array evacuatedEmpty = 4 // Appears during expansion, element itself is empty, marked during relocation minTopHash = 5 // Minimum tophash value for a normal key-value )If
tophash[i]is greater thanminTopHash, it indicates that a normal key-value exists at the corresponding index.keys: array storing keys of specified type.elems: array storing values of specified type.overflow: pointer to overflow bucket.
Since key-values cannot be directly accessed through struct fields, Go declares a constant dataoffset in advance, representing the memory offset of data in bmap:
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Actually, key-values are stored in a contiguous memory address, similar to the following structure. This is done to avoid memory space waste due to memory alignment:
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...So for a bmap, after moving the pointer by dataoffset, moving i*sizeof(keyType) gives the address of the i-th key:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Getting the address of the i-th value works the same way:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))The buckets pointer in hmap points to the first hash bucket address. To get the address of the i-th hash bucket, the offset is i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))These operations will appear very frequently in subsequent content.
Hash
Collision
In hmap, there's a field extra specifically for storing overflow bucket information. It points to a slice storing overflow buckets, with the following structure:
type mapextra struct {
// Pointer slice for overflow buckets
overflow *[]*bmap
// Pointer slice for old overflow buckets before expansion
oldoverflow *[]*bmap
// Pointer to next free overflow bucket
nextOverflow *bmap
}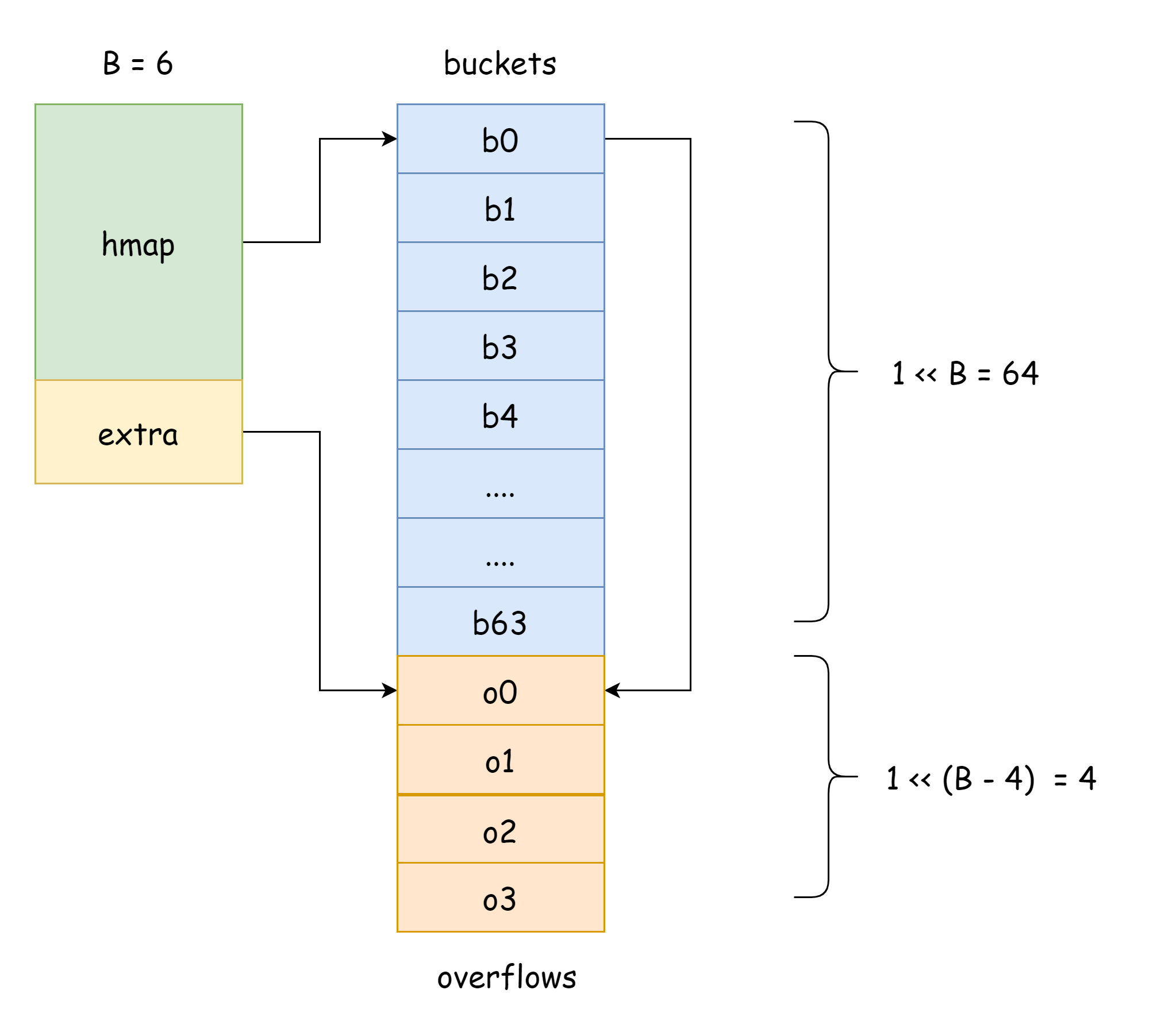
TIP
In the figure above, the blue part is the hash bucket array, and the orange part is the overflow hash bucket array. Overflow buckets are collectively referred to as overflow buckets below.
The above figure shows the general structure of hmap. buckets points to the hash bucket array, extra points to the overflow bucket array, bucket bucket0 points to overflow bucket overflow0. Two different types of buckets are stored in two slices, and memory for both types of buckets is contiguous. When two keys are assigned to the same bucket after hashing, this is a hash collision. Go resolves hash collisions using chaining. When the number of colliding keys exceeds bucket capacity (usually 8, depending on internal/abi.MapBucketCount), a new bucket is created to store these keys. This new bucket is called an overflow bucket, meaning the original bucket is full and elements overflow into this new bucket. After creation, the hash bucket has a pointer pointing to the new overflow bucket. Connecting these bucket pointers forms a bmap linked list.
For chaining, the load factor is used to measure hash table collisions, with the following formula:
loadfactor := len(elems) / len(buckets)When the load factor is larger, it means more hash collisions, i.e., more overflow buckets. When reading/writing the hash table, you need to traverse more overflow bucket linked lists to find the specified location, resulting in poorer performance. To improve this situation, the number of buckets should be increased, i.e., expansion. For hmap, two conditions trigger expansion:
- Load factor exceeds threshold
bucketCnt*13/16, which is at least 6.5. - Too many overflow buckets
When the load factor is smaller, it means hmap has low memory utilization and occupies more memory. The function Go uses to calculate load factor is runtime.overLoadFactor:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Where loadFactorNum and loadFactorDen are constants, and bucketshift calculates 1 << B. Given:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenSimplifying gives:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Where (bucketCnt * 13 / 16) equals 6.5, and 1 << B is the number of hash buckets. So this function calculates whether element count divided by bucket count is greater than load factor 6.5.
Calculation
Go's internal hash calculation function is located in runtime/alg.go as f32hash:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}As you can see, map hash calculation is not type-based but memory-based, eventually going to the memhash function, which is implemented in assembly with logic in runtime/asm*.s. Memory-based hash values should not be persisted because they should only be used at runtime; it's impossible to guarantee identical memory distribution in every run.
There's also a function named typehash in this file that calculates hash values based on different types, but map doesn't use this function for hashing:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrThis implementation is slower than the one above but more general, mainly used for reflection and compile-time function generation, such as:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Creation
Map initialization has two methods, as described in the language introduction: one uses the map keyword directly, and the other uses the make function. Regardless of the initialization method, both are ultimately created by runtime.makemap. The function signature is:
func makemap(t *maptype, hint int, h *hmap) *hmapParameters:
t: refers to map type; different types require different memory usage.hint: refers to the second parameter ofmakefunction, the expected capacity of map elements.h: refers tohmappointer, can benil.
Return value is the initialized hmap pointer. During initialization, this function has several main tasks. First, it calculates whether expected allocated memory will exceed maximum allocated memory:
// Multiply expected capacity by bucket type memory size
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Numeric overflow or exceeds maximum allocatable memory
if overflow || mem > maxAlloc {
hint = 0
}As mentioned in the internal structure section, hmap consists of buckets. In the lowest memory utilization case, one bucket has only one element, occupying the most memory. So expected maximum memory usage is element count multiplied by corresponding type memory size. When calculation result overflows or exceeds maximum allocatable memory, set hint to 0 because hint is needed later to calculate bucket array capacity.
Second step initializes hmap and calculates a random hash seed:
// Initialize
if h == nil {
h = new(hmap)
}
// Get a random hash seed
h.hash0 = fastrand()Then calculate hash bucket capacity based on hint value:
B := uint8(0)
// Keep looping until hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Assign to hmap
h.B = BBy continuously looping to find the first B value satisfying (hint / 1 << B) < 6.5, assign it to hmap. After knowing hash bucket capacity, finally allocate memory for hash buckets:
if h.B != 0 {
var nextOverflow *bmap
// Allocated hash buckets and pre-allocated free overflow buckets
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// If pre-allocated free overflow buckets, point to them
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}The makeBucketArray function allocates corresponding memory size for hash buckets based on B value and pre-allocates free overflow buckets. When B is less than 4, no overflow buckets are created. If greater than 4, 2^B-4 overflow buckets are created. Corresponding to the following code in runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// Won't create overflow buckets if less than 4
if b >= 4 {
// Expected bucket count plus 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Memory required for overflow buckets
sz := t.Bucket.Size_ * nbuckets
// Round up memory space
up := roundupsize(sz)
if up != sz {
// If not equal, recalculate using up
nbuckets = up / t.Bucket.Size_
}
}base refers to expected bucket count, nbuckets refers to actual allocated bucket count, which includes overflow bucket count.
if base != nbuckets {
// First available overflow bucket
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// To reduce overflow bucket tracking overhead, point last available overflow bucket's overflow pointer to hash bucket head
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// Last overflow bucket points to hash bucket
last.setoverflow(t, (*bmap)(buckets))
}When they're not equal, it means extra overflow buckets were allocated. nextoverflow pointer points to the first available overflow bucket. As you can see, hash buckets and overflow buckets are actually in the same contiguous memory, which is why hash bucket array and overflow bucket array are adjacent in the diagram.
Access
As mentioned in the syntax introduction, there are three ways to access a map:
# Access value directly
val := dict[key]
# Access value and whether key exists
val, exist := dict[key]
# Iterate over map
for key, val := range dict{
}These three ways use different functions, with for range map iteration being the most complex.
Key-Value
For the first two methods, they correspond to two functions: runtime.mapaccess1 and runtime.mapaccess2:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)The key is a pointer to the map key being accessed, and the return is also a pointer. During access, first calculate the key's hash value to locate which hash bucket the key is in:
// Boundary handling
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Prevent concurrent read/write
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Use specified type hasher to calculate hash
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Locate key's hash bucket by moving pointer
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))At the start of access, handle boundary cases and prevent concurrent map read/write. When map is in concurrent read/write state, panic occurs. Then calculate hash value. The bucketMask function calculates (1 << B) - 1, so hash & m equals hash & (1 << B) - 1, which is binary modulo operation, equivalent to hash % (1 << B). Using bitwise operations is faster. The last three lines calculate the hash value modulo current map bucket count to get hash bucket number, then move pointer based on number to get key's hash bucket pointer.
After knowing which hash bucket the key is in, you can start searching:
// Get high 8 bits of hash value
top := tophash(hash)
bucketloop:
// Traverse bmap linked list
for ; b != nil; b = b.overflow(t) {
// Elements in bmap
for i := uintptr(0); i < bucketCnt; i++ {
// Compare calculated top with tophash elements
if b.tophash[i] != top {
// Following are all empty, nothing left.
if b.tophash[i] == emptyRest {
break bucketloop
}
// Continue traversing overflow buckets if not equal
continue
}
// Move pointer to get key at corresponding index
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Handle pointer
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Compare if two keys are equal
if t.Key.Equal(key, k) {
// If equal, move pointer to return element at k's index
// This line shows key-value memory addresses are contiguous
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Not found, return zero value.
return unsafe.Pointer(&zeroVal[0])When locating hash bucket, positioning is done via modulo, so which hash bucket the key is in depends on the low bits of hash value. How many low bits depend on B's size. After finding the hash bucket, tophash stores the high 8 bits of hash value. Since low bits modulo values are the same, there's no need to compare keys one by one; comparing high 8 bits of hash value is sufficient. If high 8 bits are equal, then compare keys. If keys are also equal, element is found. If not equal, continue traversing tophash array. If still not found, continue traversing overflow bucket bmap linked list until bmap's tophash[i] is emptyRest, then exit loop and return zero value for corresponding type.
The mapaccess2 function logic is completely consistent with mapaccess1, just with an additional boolean return value indicating whether element exists.
Iteration
Map iteration syntax is as follows:
for key, val := range dict {
// do somthing...
}During actual iteration, Go uses the hiter struct to store iteration information. hiter is short for hmap iterator, meaning hash table iterator:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Below are simple explanations for some fields:
key,elem: key-value obtained duringfor rangeiterationbuckets: specified during iterator initialization, points to hash bucket headbptr: bmap currently being traversedstartBucket: starting bucket index when iteration beginsoffset: intra-bucket offset, range[0, bucketCnt-1]B: hmap's B valuei: intra-bucket element indexwrapped: whether wrapped from hash bucket array end back to head
Before iteration begins, Go initializes the iterator through runtime.mapiterinit function, then iterates over map through runtime.mapinternext function. Both need to use hiter struct:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)For iterator initialization, first get a snapshot of current map state:
it.t = t
it.h = h
// Record snapshot of hmap current state, only need to save B value.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}During subsequent iteration, what's actually traversed is a snapshot of map, not the actual map. So elements and buckets added during traversal won't be traversed. Concurrent traversal and writing may trigger fatal:
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Second step determines two starting positions for traversal: first is starting bucket position, second is starting position within bucket. Both are randomly selected:
// r is a random number
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) gets starting bucket position
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 gets starting element position within bucket
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Record current bucket index being traversed
it.bucket = it.startBucketGet a random number through fastrand() or fastrand64(), then use two modulo operations to get bucket starting position and intra-bucket starting position.
TIP
Although map doesn't allow concurrent read/write, it does allow concurrent traversal.
Next, iteration actually begins. How to traverse buckets and exit strategy correspond to the following code:
// hmap
h := it.h
// maptype
t := it.t
// Bucket position to traverse
bucket := it.bucket
// bmap being traversed
b := it.bptr
// Intra-bucket index i
i := it.i
next:
if b == nil {
// If current bucket position equals starting position, means went full circle, already traversed what follows
// Iteration complete, can exit
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Move bucket index forward
bucket++
// bucket == 1 << B, reached end of hash bucket array
if bucket == bucketShift(it.B) {
// Start from beginning
bucket = 0
it.wrapped = true
}
i = 0
}Hash bucket starting position is randomly selected. During traversal, iterate from starting position toward bucket slice end one by one. When reaching 1 << B, then start from beginning. When returning to starting position again, it means traversal is complete, then exit. The above code describes how to traverse buckets in map. The following code describes how to traverse within a bucket:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Skip if current element is empty
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Move pointer to get key
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Move pointer to get value
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Handle equal-size expansion case. When key-value has been evacuated to other positions, need to re-find key-value.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// If not found, look in overflow bucket
b = b.overflow(t)
i = 0
goto nextTIP
In the expansion judgment condition above, one expression may cause confusion:
t.Key.Equal(k, k)The reason for checking whether k equals itself is to filter out Nan key cases. If an element's key is Nan, then accessing that element normally becomes impossible. Whether iterating, directly accessing, or deleting cannot proceed normally because Nan != Nan is always true, so this key can never be found.
First, use i and offset values with modulo operation to get intra-bucket index to traverse. Get key-value by moving pointer. Since during map traversal, other write operations may trigger map expansion, actual key-value may no longer be in original position. In this case, need to use mapaccessK function to re-get actual key-value. Function signature:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Its functionality is completely consistent with mapaccess1, except mapaccessK returns both key and value. After finally getting key-value, assign it to iterator's key and elem, then update iterator index. This completes one iteration, and code execution returns to for range code block. If not found within bucket, look in overflow bucket and repeat above steps until overflow bucket linked list traversal is complete, then continue iterating next hash bucket.
Modification
Map modification syntax is as follows:
dict[key] = valIn Go, map modification operations are completed by runtime.mapassign function:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerIts access process logic is the same as mapaccess1, but when key doesn't exist, a position is allocated for it. If it exists, it's updated. Finally, element pointer is returned. At the beginning, some preparation work is needed:
// Writing to nil map is not allowed
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Concurrent writes are prohibited
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Calculate key hash value
hash := t.Hasher(key, uintptr(h.hash0))
// Modify hmap state
h.flags ^= hashWriting
// Initialize hash bucket
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}The above code does the following:
- hmap state check
- Calculate key hash value
- Check if hash bucket needs initialization
Then use hash value modulo operation to get hash bucket position and key's tophash:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Move pointer to get bmap at specified position
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Calculate tophash
top := tophash(hash)Now bucket position, bmap, and tophash are determined, so element search can begin:
// tophash to insert
var inserti *uint8
// key value pointer to insert
var insertk unsafe.Pointer
// value value pointer to insert
var elem unsafe.Pointer
bucketloop:
for {
// Traverse tophash array in bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash not equal
if b.tophash[i] != top {
// If current bucket index is empty and no element inserted yet, select this position for insertion
if isEmpty(b.tophash[i]) && inserti == nil {
// Found a suitable position to allocate for key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Exit loop after traversal complete
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// If tophash is equal, key may already exist
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Check if keys are equal
if !t.Key.Equal(key, k) {
continue
}
// If key value needs updating, copy key memory directly to k position
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Got element pointer
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Update complete, return element pointer
goto done
}
// Reached here means key not found, traverse overflow bucket linked list to continue searching
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Reached here means key doesn't exist in map, but may have found a suitable position for key, or may not have
// Didn't find a suitable position to allocate for key
if inserti == nil {
// Current hash bucket and its overflow bucket are full, allocate a new overflow bucket
newb := h.newoverflow(t, b)
// Allocate a position for key in overflow bucket
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// If storing key pointer
if t.IndirectKey() {
// Allocate new memory, returns unsafe pointer
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Assign to insertk for later key memory copy
insertk = kmem
}
// If storing element pointer
if t.IndirectElem() {
// Allocate memory
vmem := newobject(t.Elem)
// Make pointer point to vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Copy key memory directly to insertk position
typedmemmove(t.Key, insertk, key)
*inserti = top
// Increment count
h.count++
done:
// Reached here means modification process is complete
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Return element pointer
return elemIn the large code block above, first enter for loop to try searching in hash bucket and overflow bucket. Search logic is completely consistent with mapaccess. At this point, there are three possibilities:
- First, found existing key in map, directly jump to
doneblock, return element pointer - Second, found a position in map to allocate for key, copy key to specified position, and return element pointer
- Third, all buckets searched, no position found in map to allocate for key, create a new overflow bucket, assign key to bucket, then copy key to specified position, and return element pointer
After finally getting element pointer, assignment can be done. However, this operation is not completed by mapassign function; it only returns element pointer. Assignment operation is inserted during compilation, invisible in source code but visible in compiled code. Suppose we have the following code:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Get assembly code with following command:
go tool compile -S -N -l main.goKey parts are here:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)As you can see, runtime.mapassign_faststr is called. LEAQ go:string."world"(SB), CX stores string address in CX, and MOVQ CX, (AX) stores it in AX, thus completing element assignment.
Deletion
In Go, to delete a map element, you can only use the built-in function delete:
delete(dict, "abc")Internally, it calls runtime.mapdelete function:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)It deletes the element with specified key in map. Regardless of whether element exists in map, it won't react. Function preparation logic at the beginning is similar:
- hmap state check
- Calculate key hash value
- Locate hash bucket
- Calculate tophash
There's much repetitive content, so no further elaboration. Here we only focus on deletion logic:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Exit loop if not found
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Move pointer to find key position
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Delete key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Move pointer to find element position
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Delete element
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Decrement count
h.count--
// Reset hash seed to reduce collision probability
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}As you can see from the above code, search logic is almost completely consistent with previous operations. Find element, then delete, hmap recorded count decrements by one. When count becomes 0, reset hash seed.
Another point to note is that after deleting element, current index's tophash state needs to be modified:
// Mark current tophash as empty
b.tophash[i] = emptyOne
// If at end of tophash
if i == bucketCnt-1 {
// If overflow bucket not empty and has elements, current element is not the last one
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Adjacent element not empty
if b.tophash[i+1] != emptyRest {
goto notLast
}
}If element is indeed the last element, some桶's tophash array values in bucket linked list need to be corrected. Otherwise, subsequent traversal won't be able to exit at correct position. When creating overflow buckets in map, to reduce overflow bucket tracking overhead, last overflow bucket's overflow pointer points to head hash bucket, so it's actually a singly linked circular list. The "head" of the list is the hash bucket. Here b is the b after search, very likely a certain overflow bucket in the middle of the list. Traverse the circular linked list in reverse order to find the last existing element. Although code writes forward traversal, since list is a ring, it keeps traversing forward until before the current overflow bucket. From the result perspective, it is indeed reverse. Then traverse tophash array in bucket in reverse order, updating elements with emptyOne status to emptyRest, until finding the last existing element. To avoid infinite loop in ring, when returning to the initial bucket, i.e., bOrig, it means no more available elements in list, so exit loop:
// Reached here means no elements follow current element
// Continuously traverse bmap linked list in reverse order, traverse tophash in bucket in reverse order
// Update elements with emptyOne status to emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Find previous bmap in current bmap linked list
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Clear
In go1.21 version, built-in function clear was added to clear all elements in map:
clear(dict)Internally, it calls runtime.mapclear function, responsible for deleting all elements in map:
func mapclear(t *maptype, h *hmap)This function's logic is not complex. First, mark entire map as empty:
// Traverse every bucket and overflow bucket, set all tophash elements to emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))The above code traverses every bucket and sets all elements in bucket's tophash array to emptyRest, marking map as empty. This prevents iterator from continuing iteration, then clear map:
// Reset hash seed
h.hash0 = fastrand()
// Reset extra struct
if h.extra != nil {
*h.extra = mapextra{}
}
// This operation clears original buckets memory and reallocates new buckets
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Allocate new free overflow buckets
h.extra.nextOverflow = nextOverflow
}Clear previous bucket memory through makeBucketArray, then allocate new ones. This completes bucket clearing. Additionally, there are some details like setting count to 0 and other operations not elaborated.
Expansion
In all previous operations, to focus more on the logic itself, much expansion-related content was shielded, making it simpler. Expansion logic is actually quite complex, placed last to avoid interference. Now let's see how Go expands maps. As mentioned earlier, expansion is triggered by two conditions:
- Load factor exceeds 6.5
- Too many overflow buckets
The function to check if load factor exceeds threshold is runtime.overLoadFactor, explained in the hash collision section. The function to check if overflow bucket count is too many is runtime.tooManyOverflowBuckets, which works simply:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}The above code can be simplified to the following expression, immediately understandable:
overflow >= 1 << (min(15,B) % 16)Here, Go's definition of "too many" is: overflow bucket count is about the same as hash bucket count. If threshold is too low, extra work is done. If threshold is too high, expansion consumes大量 memory. Expansion may be triggered during modification and deletion. Code to check if expansion is needed:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}As you can see, these three conditions restrict:
- Cannot be expanding currently
- Load factor less than 6.5
- Overflow bucket count cannot be too many
The function responsible for expansion is naturally runtime.hashGrow:
func hashGrow(t *maptype, h *hmap)Actually, expansion has different types based on different triggering conditions:
- Incremental expansion
- Equal-size expansion
Incremental Expansion
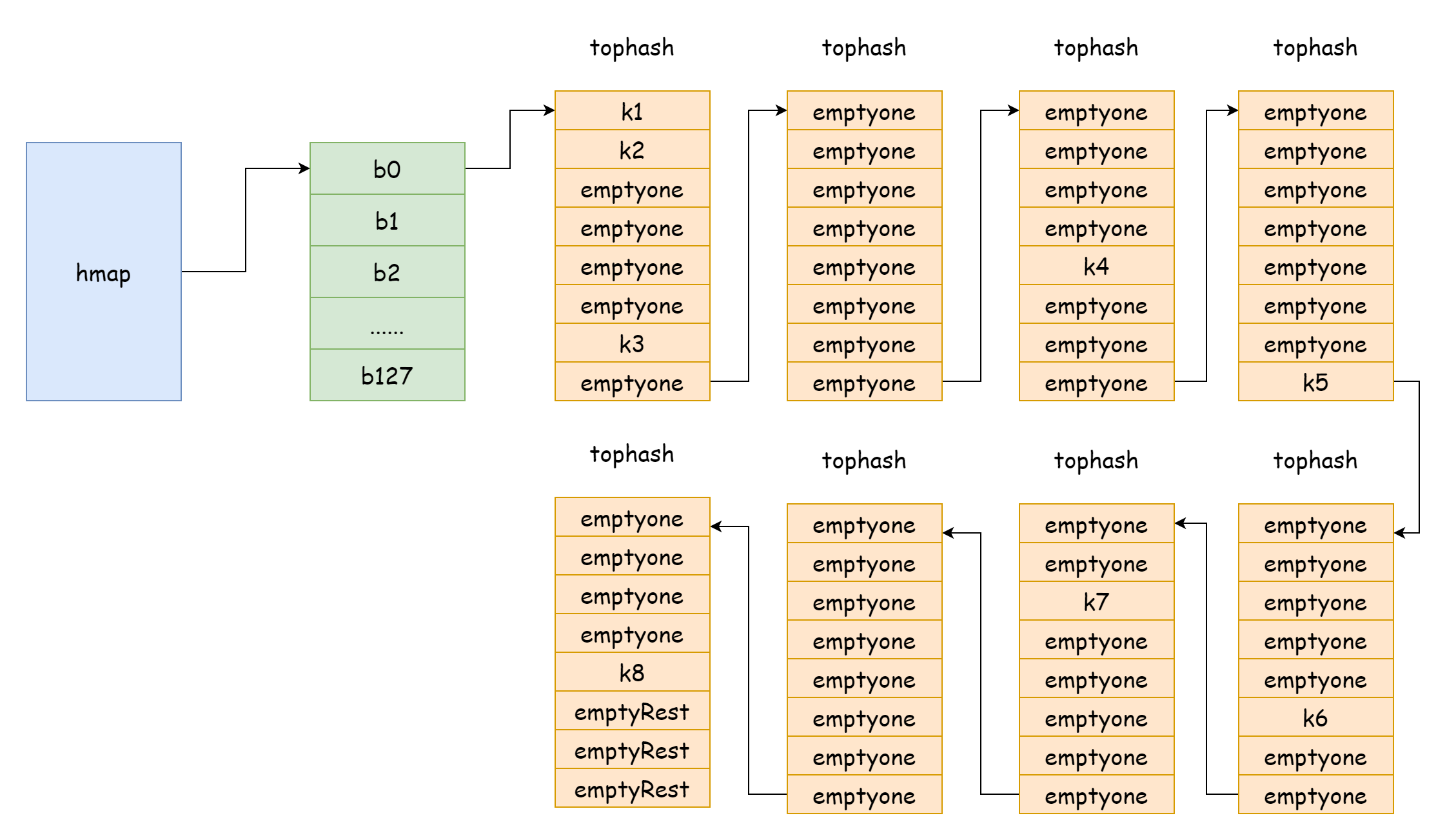
When load factor is too large, i.e., element count is much larger than hash bucket count, when hash collisions are severe, many overflow bucket linked lists form. This causes map read/write performance to decline because more overflow bucket linked lists need to be traversed to find an element. Traversal time complexity is O(n). Hash table lookup time complexity mainly depends on hash calculation time and traversal time. When traversal time is much less than hash calculation time, lookup time complexity can be considered O(1). If hash collisions are frequent and too many keys are assigned to the same hash bucket, overflow bucket linked list becomes too long, increasing traversal time, which increases lookup time. Since add/delete/modify operations all need to perform lookup first, this causes entire map performance to seriously decline.
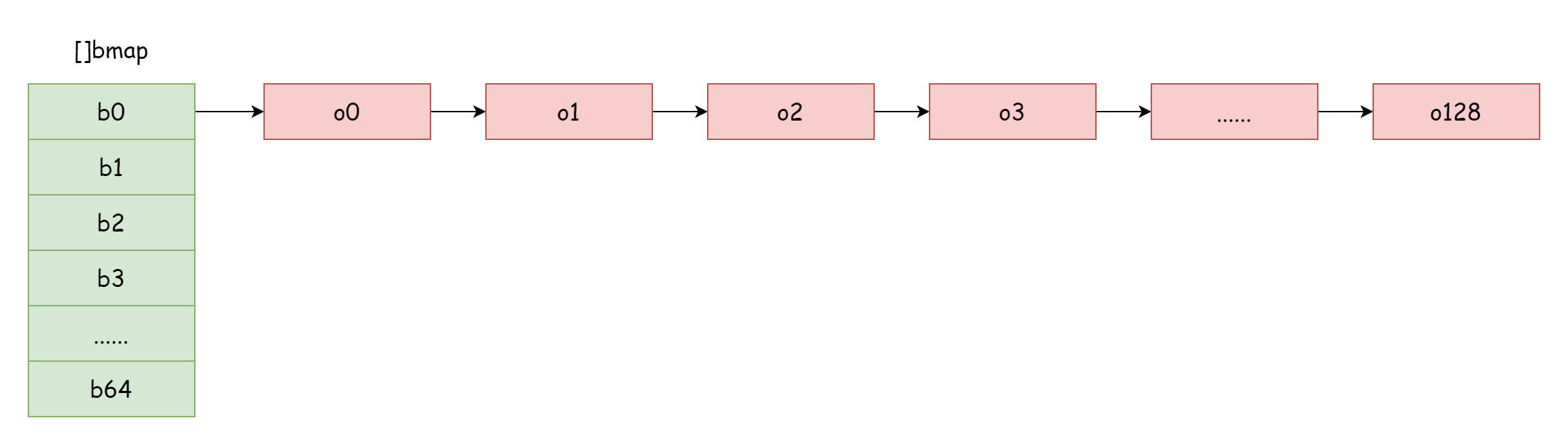
In such extreme cases as shown in the figure, lookup time complexity is basically no different from O(n). To address this, the solution is to add more hash buckets to avoid forming overly long overflow bucket linked lists. This method is also called incremental expansion.
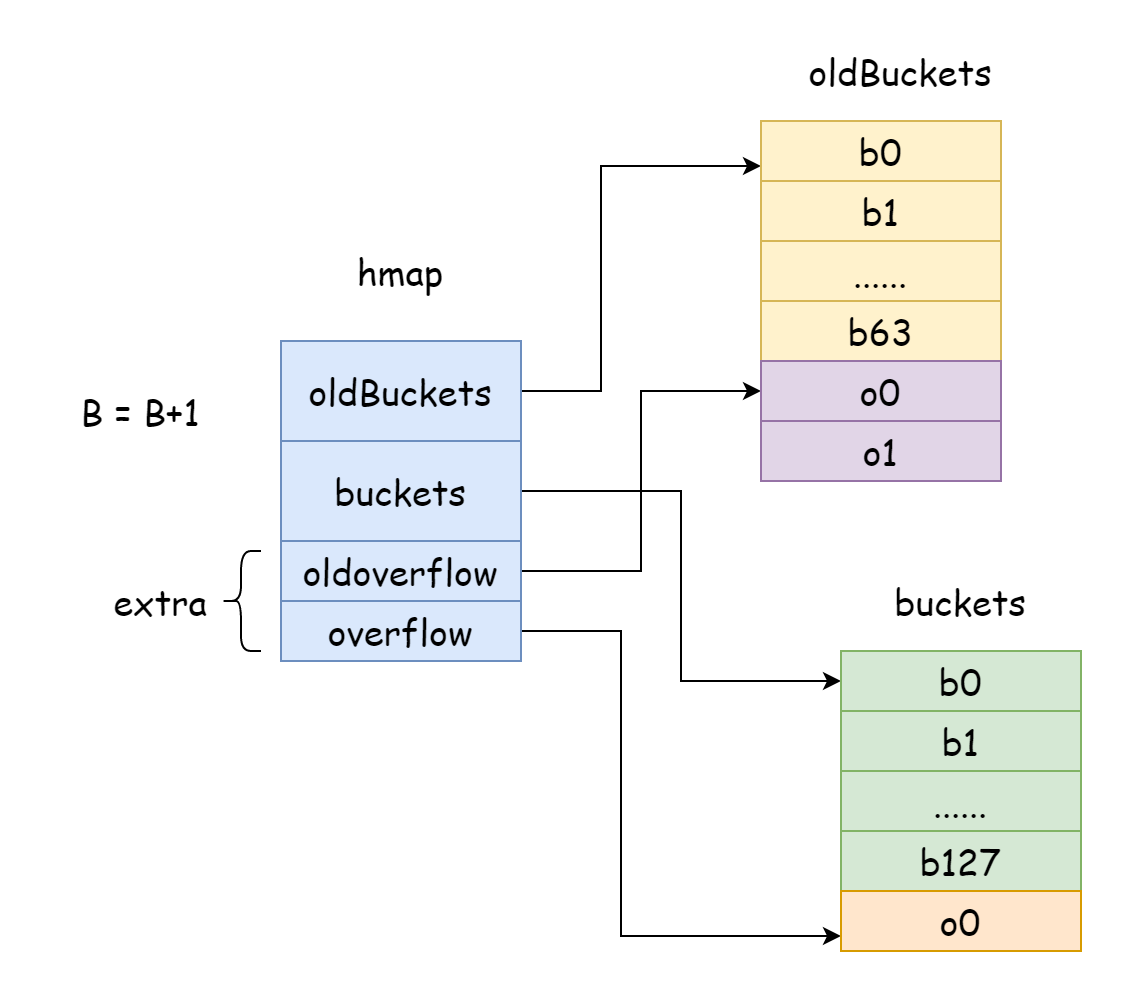
In Go, incremental expansion adds one to B each time, meaning hash bucket scale doubles each time. After expansion, old data needs to be relocated to new map. If map element count is in tens or hundreds of millions, relocating all at once would take too long. So Go adopts gradual relocation strategy. For this, Go makes hmap's oldBuckets point to original hash bucket array, indicating this is old data. Then create larger capacity hash bucket array, making hmap's buckets point to new hash bucket array. During each modification and deletion, relocate some elements from old bucket to new bucket until relocation is complete, then old bucket memory is released.
func hashGrow(t *maptype, h *hmap) {
// Difference
bigger := uint8(1)
// Old buckets
oldbuckets := h.buckets
// New hash buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Overflow buckets also need to specify old and new buckets
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}The above code creates new hash buckets with double capacity, then specifies references to old and new hash buckets, and old and new overflow buckets. Actual relocation work is not completed by hashGrow function; it only specifies old and new buckets and updates some hmap states. This work is actually completed by runtime.growWork function:
func growWork(t *maptype, h *hmap, bucket uintptr)It's called in mapassign and mapdelete functions in the following form. Its role is to perform partial relocation if current map is expanding:
if h.growing() {
growWork(t, h, bucket)
}During modification and deletion, need to check if currently expanding, mainly done by hmap.growing method. Content is simple: check if oldbuckets is not empty:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Let's see what growWork function does:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}The bucket&h.oldbucketmask() operation calculates old bucket position, ensuring the bucket to relocate is the old bucket of current bucket. From the function, you can see the function actually responsible for relocation is runtime.evacuate. It uses evaDst struct to represent relocation destination, mainly for iterating new buckets during relocation:
type evacDst struct {
b *bmap // New bucket at relocation destination
i int // Intra-bucket index
k unsafe.Pointer // Pointer to new key destination
e unsafe.Pointer // Pointer to new value destination
}Before relocation begins, Go allocates two evacDst structs: one points to upper half of new hash bucket, another points to lower half of new hash bucket:
// Locate specified hash bucket in old buckets
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Old bucket length = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Points to upper half of new bucket
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// Check if equal-size expansion
if !h.sameSizeGrow() {
y := &xy[1]
// Points to lower half of new bucket
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Old bucket relocation destinations are two new buckets. After relocation, part of data in bucket will be in upper half, another part in lower half. This is done to make expanded data more evenly distributed. The more evenly distributed, the better map lookup performance. How Go relocates data to two new buckets corresponds to the following code:
// Traverse overflow bucket linked list
for ; b != nil; b = b.overflow(t) {
// Get first key-value pair in each bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Traverse every key-value pair in bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Skip if empty
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// New hash bucket shouldn't be in relocation state
// Otherwise something is wrong
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// This variable determines whether current key-value pair is relocated to upper or lower half
// Its value can only be 0 or 1
var useY uint8
if !h.sameSizeGrow() {
// Recalculate hash value
hash := t.Hasher(k2, uintptr(h.hash0))
// Handle k2 != k2 special case
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Check constant values
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Update old bucket tophash, indicating current element has been relocated
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// Specify relocation destination
dst := &xy[useY] // evacuation destination
// If new bucket capacity is insufficient, create an overflow bucket
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// Copy key
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// Copy value
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Move new bucket destination pointer forward, preparing for next key-value
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}From the above code, Go traverses every element in every bucket in old bucket linked list, moving data to new bucket. Whether data goes to upper or lower half depends on recalculated hash value:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}After relocation, current element's tophash is set to evacuatedX or evacuatedY. If trying to lookup data during expansion, this status indicates data has been relocated, so you know to look for corresponding data in new bucket. This logic corresponds to the following code in runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// If old bucket has been relocated, don't look there
if !evacuated(oldb) {
b = oldb
}
}When accessing element, if currently in expansion state, first try to look in old bucket. If old bucket has been relocated, don't look in old bucket. Back to relocation, destination has been determined. Next is to copy data to new bucket, then make evacDst struct point to next destination:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}This continues until current bucket is fully relocated. Then Go clears all old bucket key-value data memory, leaving only hash bucket tophash array (left because tophash array is needed later to judge relocation status). Overflow bucket memory in old bucket is no longer referenced and will be GC recycled. hmap has a field nevacuate to record relocation progress. After relocating an old hash bucket, it increments by one. When its value equals old bucket count, it means entire map expansion is complete. Next, runtime.advanceEvacuationMark function performs expansion wrap-up:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}It counts relocated quantity and confirms whether it equals old bucket count. If equal, clear all references to old buckets and old overflow buckets.至此 expansion is complete.
In growWork function, evacuate function is called twice in total. First time relocates old bucket of currently accessed bucket. Second time relocates old bucket pointed by h.nevacuate. Two buckets are relocated in total, meaning during gradual relocation, two buckets are relocated each time.
Equal-Size Expansion
As mentioned earlier, equal-size expansion is triggered when overflow bucket count is too many. Suppose map first adds大量 elements, then deletes大量 elements. Many buckets may be empty, some buckets may have many elements, data distribution is very uneven, and quite a few overflow buckets are empty, occupying considerable memory. To solve such problems, need to create a new map with equal capacity, reallocate hash buckets. This process is called equal-size expansion. So it's actually not an expansion operation, but redistributing all elements to make data distribution more even. Equal-size expansion logic is combined into incremental expansion operation, with new and old map capacities completely equal.
In hashGrow function, if load factor hasn't exceeded threshold, equal-size expansion is performed. Go updates h.flags status to sameSizeGrow, h.B won't increment by one, so newly created hash bucket capacity won't change:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)In evacuate function, when initially creating eavcDst struct, if equal-size expansion, only one struct pointing to new bucket is created:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}And during element relocation, equal-size expansion doesn't recalculate hash value, nor has upper/lower half selection:
if !h.sameSizeGrow() {
// Recalculate hash value
hash := t.Hasher(k2, uintptr(h.hash0))
// Handle k2 != k2 special case
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Except for these, other logic is completely consistent with incremental expansion. After equal-size expansion and hash bucket reallocation, overflow bucket count decreases. Old overflow buckets are all GC recycled.