slice
TIP
Reading this article requires knowledge of the unsafe standard library.
Slice should be the most commonly used data structure in Go language, without exception (actually there aren't many built-in data structures), and it can be seen everywhere. About its basic usage has been described in the language introduction, let's take a look at what it looks like internally and how it works internally.
Structure
Regarding the implementation of slices, the source code is located in the runtime/slice.go file. At runtime, a slice exists as a struct, with type runtime.slice, as shown below.
type slice struct {
array unsafe.Pointer
len int
cap int
}This struct has only three fields:
array: pointer to the underlying arraylen: length of the slice, referring to the number of elements already in the arraycap: capacity of the slice, referring to the total number of elements the array can hold
From the above information, we can see that the underlying implementation of slices still depends on arrays. Usually, it's just a struct that holds a reference to the array and records of capacity and length. This makes passing slices very low-cost, only copying references to data without copying all data, and when using len and cap to get the length and capacity of a slice, it's equivalent to getting their field values without traversing the array.
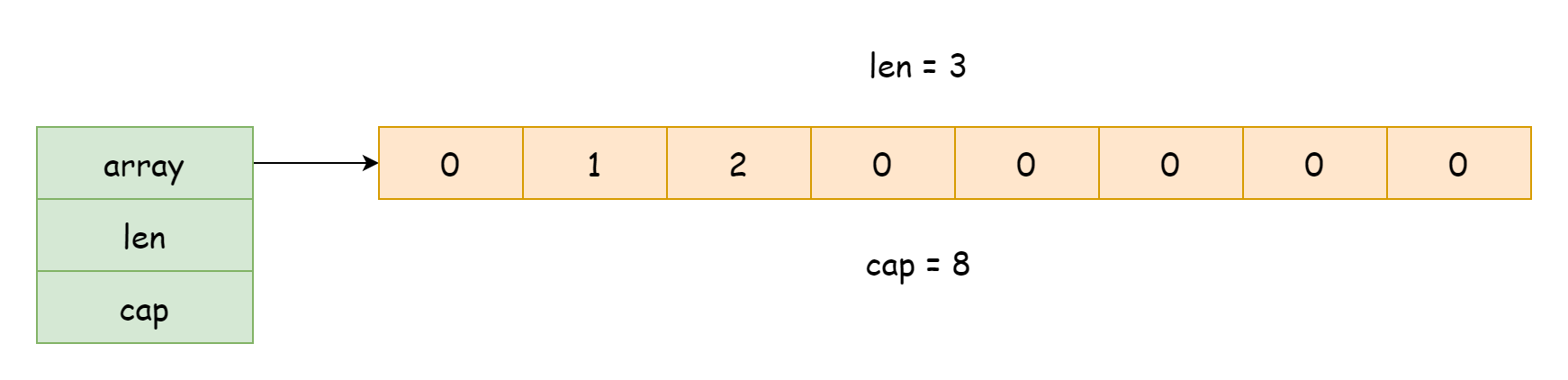
However, this also brings some not-so-obvious problems. Consider the following example:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]In the above code, s1 creates a new slice through slicing, but it and the source slice both reference the same underlying array. Modifying data in s1 also causes s to change. Therefore, when copying slices, the copy function should be used, which creates a slice that is completely independent from the original. Let's look at another example:
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Again using slicing to copy slices, but this time it won't affect the source slice. Initially, s1 and s did point to the same array, but subsequently too many elements were added to s1, exceeding the capacity of the array, so a larger new array was allocated to hold elements. Therefore, finally they point to different arrays. Think there's no problem now? Let's look at another example:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Clearly elements were added, but what's printed is an empty slice. Actually, data was indeed added to the slice, just written to the underlying array. In Go, function parameters are passed by value, so parameter s is actually a copy of the source slice struct. The append operation returns a slice struct with updated length after adding elements, but it's assigned to parameter s, not the source slice s, so the two are actually not related.
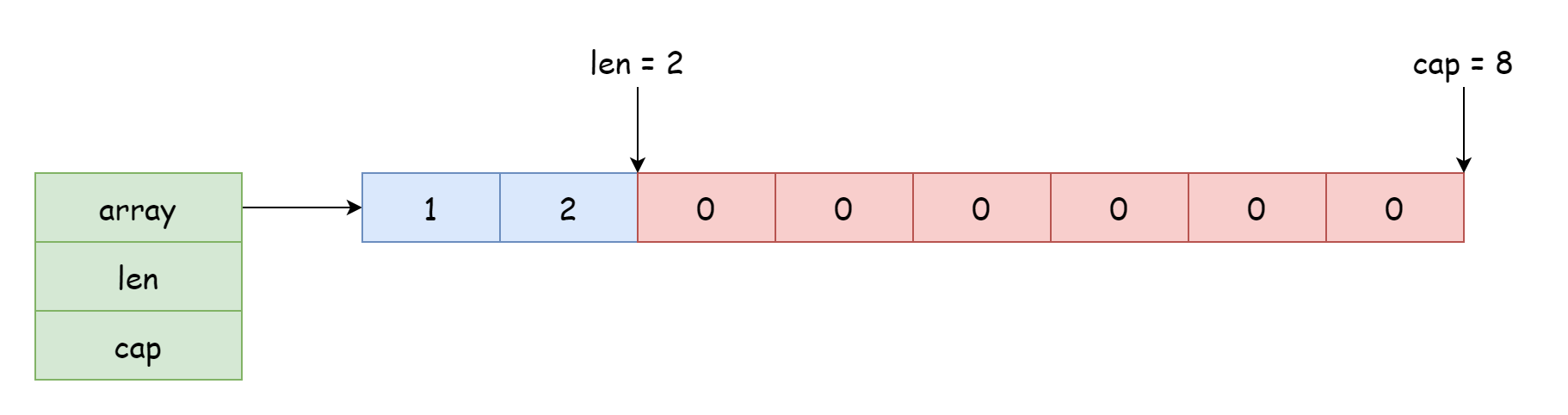
For a slice, the starting position it can access and modify depends on the reference position to the array, with offset determined by the length recorded in the struct. The pointer in the struct can point not only to the beginning but also to the middle of the array, as shown in the figure below.
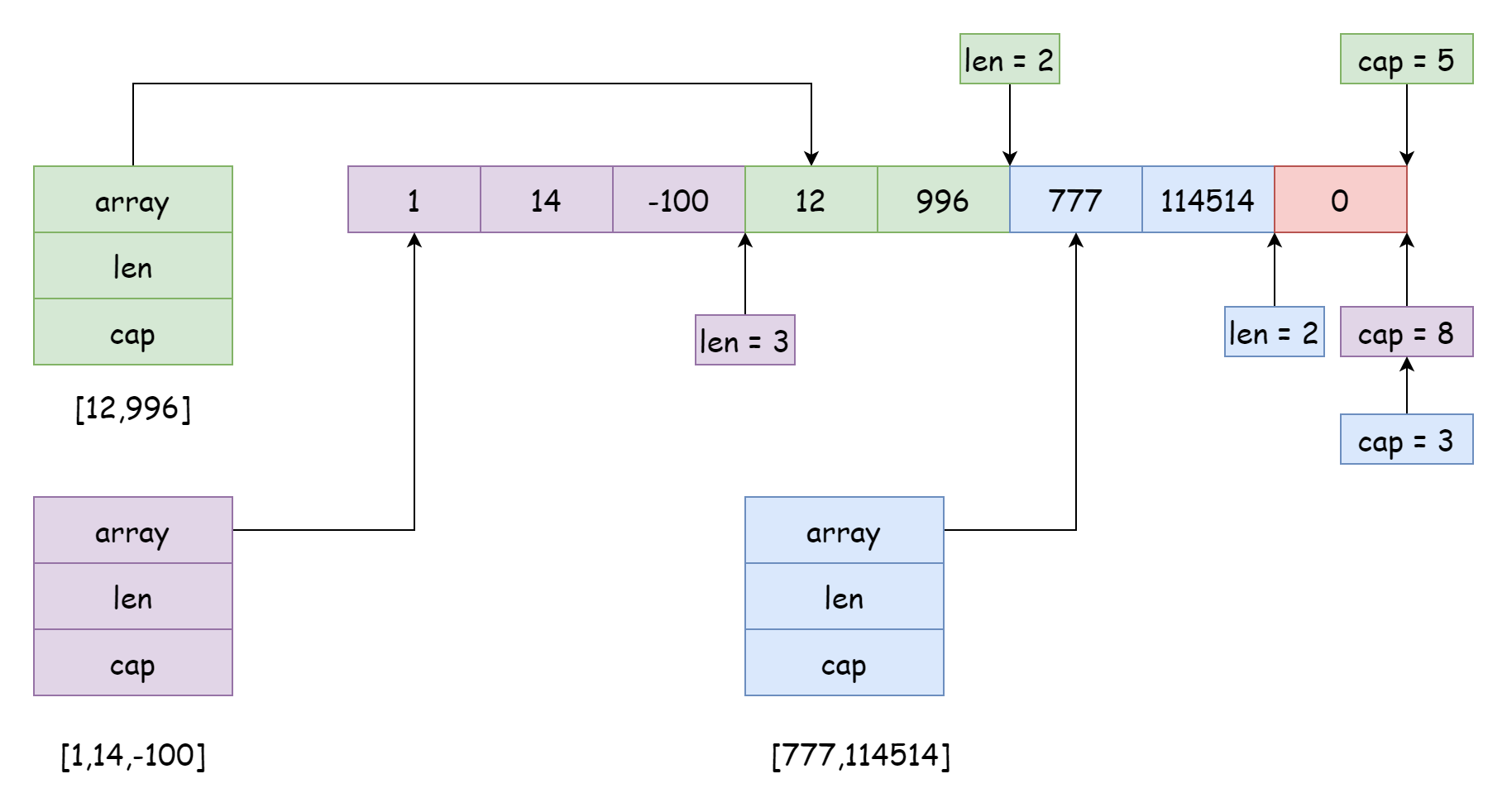
A single underlying array can be referenced by many slices, with different reference positions and ranges, as shown in the figure above. This situation usually occurs when slicing slices, similar to the following code:
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]When slicing, the capacity of the new slice equals the array length minus the starting position referenced by the new slice. For example, the capacity of the new slice created by s[4:6] is 6 = 10 - 4. Of course, the range referenced by slices doesn't necessarily have to be adjacent; they can also be interleaved. However, this can cause significant trouble, where data of the current slice might be modified by another slice without your knowledge. For example, in the purple slice in the figure above, if append is used to add elements later, it might overwrite the data of the green slice and blue slice. To avoid this situation, Go allows setting the capacity range when slicing, with the following syntax:
s4 = s[4:6:6]In this case, its capacity is limited to 2, so adding elements will trigger expansion. After expansion, it becomes a new array, unrelated to the source array, so there won't be any impact. Think this is the end of slice problems? Actually not. Let's look at another example:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// Number of elements to add is just greater than capacity
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]The code is no different from the previous example, just modified the input parameters to make the number of elements to add just greater than the slice capacity. This triggers expansion when adding, so data is not only not added to the source slice s, but even the underlying array it points to is not written. We can verify this with unsafe pointers, as shown below:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// Number of elements to add is just greater than capacity
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,As you can see, the underlying array of the source slice is empty, nothing at all, and all data is written to the new array. But it has nothing to do with the source slice, because even though append returns a new reference, only the value of formal parameter s is modified, which doesn't affect the source slice s. Slices as structs can indeed make them very lightweight, but the problems above are equally non-negligible, especially in actual code where these problems are usually hidden very deeply and difficult to discover.
Creation
At runtime, the work of creating slices using the make function is done by runtime.makeslice. Its logic is quite simple, and the function signature is as follows:
func makeslice(et *_type, len, cap int) unsafe.PointerIt receives three parameters: element type, length, capacity, and returns a pointer to the underlying array after completion. Its code is as follows:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Calculate total memory needed, if too large will cause overflow
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Allocate memory if everything is fine
return mallocgc(mem, et, true)
}As you can see, the logic is very simple, doing only two things in total:
- Calculate required memory
- Allocate memory space
If condition checks fail, it will directly panic:
- Memory calculation overflows
- Calculation result is greater than maximum allocatable memory
- Length and capacity are invalid
If the calculated memory is greater than 32KB, it will be allocated on the heap. After that, it returns a pointer to the underlying array. The work of building the runtime.slice struct is not done by the makeslice function. Actually, building the struct is done during compilation. The runtime makeslice function is only responsible for allocating memory, similar to the following code:
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capIf you're interested, you can look at the generated intermediate code, which is similar to this:
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8If using an array to create a slice, like the following:
var arr [5]int
s := arr[:]This process is similar to the following code:
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo directly uses the array as the underlying array of the slice, so modifying data in the slice will also affect the array's data. When creating a slice using an array, the length equals high-low, and capacity equals max-low, where max defaults to array length, or you can manually specify capacity when slicing, for example:
var arr [5]int
s := arr[2:3:4]
Access
Accessing a slice is done using array subscript indexing:
elem := s[i]Slice access operations are completed during compilation, generating intermediate code to access. The final generated code can be understood as the following pseudocode:
p := s.ptr
e := *(p + sizeof(elem(s)) * i)Actually, it accesses elements at corresponding indices through pointer operations, corresponding to the following part of the cmd/compile/internal/ssagen.exprCheckPtr function:
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Offset pointer
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)When accessing slice length and capacity using len and cap functions, the same principle applies, also corresponding to part of the cmd/compile/internal/ssagen.exprCheckPtr function:
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))In the actual generated code, it accesses the len field in the slice struct by moving the pointer, which can be understood as the following pseudocode:
p := &s
len := *(p + 8)
cap := *(p + 16)Suppose we have the following code:
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}Then the intermediate code at some stage of generation will most likely look like this:
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9From above, we can see one adds 8, one adds 16, obviously accessing slice fields through pointer offset.
If the length and capacity can be inferred during compilation, there's no need to offset pointers at runtime to get values. For example, the following case doesn't need pointer movement:
s := make([]int, 10, 20)
l := len(s)
c := cap(s)The values of variables l and c will be directly replaced with 10 and 20.
Write
Modification
s := make([]int, 10)
s[0] = 100When modifying slice values through index subscripts, during compilation, OpStore operation generates pseudocode similar to the following:
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valAt some stage of generation, the intermediate code will most likely look like this:
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:As you can see, the code accesses slice length to check if the index is valid, and finally stores elements by moving the pointer.
Append
Elements can be added to a slice using the append function:
var s []int
s = append(s, 1, 2, 3)After adding elements, it returns a new slice struct. If no expansion occurred, compared to the source slice, only the length is updated; otherwise, it will point to a new array. Regarding append usage problems, this has been explained in detail in the Structure section, so no further elaboration here. Below, we'll focus on how append works.
At runtime, there is no function like runtime.appendslice corresponding to it. The work of adding elements is actually done during compilation. The append function is expanded into corresponding intermediate code. The judgment code is in the cmd/compile/internal/walk/assign.go walkassign function:
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}As you can see, it's divided into three cases:
- Add several elements
- Add a slice
- Add a temporarily created slice
Below we'll explain what the generated code looks like, so you understand how append actually works. If you're interested in the code generation process, you can learn about it yourself.
Adding Elements
s = append(s, x, y, z)If only adding a finite number of elements, it will be expanded by the walkAppend function into the following code:
// Number of elements to add
const argc = len(args) - 1
newLen := s.len + argc
// Whether expansion is needed
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zFirst calculate the number of elements to add, then determine if expansion is needed, and finally assign values one by one.
Adding Slice
s = append(s, s1...)If directly adding a slice, it will be expanded by the appendSlice function into the following code:
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Same as before, calculate new length, determine if expansion is needed. The difference is that Go doesn't add elements from the source slice one by one, but chooses to directly copy memory.
Adding Temporary Slice
s = append(s, make([]T, l2)...)If adding a temporarily created slice, it will be expanded by the extendslice function into the following code:
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)For temporarily added slices, Go gets the length of the temporary slice. If the current slice's capacity is insufficient to accommodate it, it will attempt to expand. After that, it also clears the corresponding part of memory.
Expansion
From the structure section, we know that the underlying layer of slices is still an array. Arrays are data structures with fixed length, but slice length is variable. When array capacity is insufficient, the slice will apply for a larger memory space to store data, which is a new array, then copy the old data over, and the slice's reference will point to the new array. This process is called expansion. The work of expansion is done at runtime by the runtime.growslice function, with the following function signature:
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceSimple parameter explanation:
oldPtr: pointer to the old arraynewLen: length of the new array,newLen = oldLen + numoldCap: capacity of the old slice, which equals the length of the old arrayet: element type
Its return value returns a new slice, which has nothing to do with the original slice. The only thing they have in common is that the saved data is the same.
var s []int
s = append(s, elems...)When using append to add elements, it requires its return value to overwrite the original slice. If expansion occurred, what's returned is a new slice.
During expansion, first need to determine the new length and capacity, corresponding to the code below:
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Double capacity
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Numeric overflow
if newcap <= 0 {
newcap = newLen
}
}
}From the above code, for slices with capacity less than 256, capacity doubles. For slices with capacity greater than or equal to 256, it will be at least 1.25 times the original capacity. When the current slice is small, doubling each time can avoid frequent expansions. When the slice is large, the expansion rate decreases to avoid applying for too much memory and causing waste.
After getting the new length and capacity, calculate the required memory, corresponding to the following code:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Final capacity
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}The memory calculation formula is mem = cap * sizeof(et). For memory alignment convenience, the calculated memory is rounded up to an integer power of 2 during the process, and new capacity is calculated again. If the new capacity is too large causing overflow during calculation, or if new memory exceeds the maximum allocatable memory, it will panic.
var p unsafe.Pointer
// Allocate memory
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}After calculating the required results, allocate memory of the specified size, then clear the memory from newLen to newCap, copy the old array data to the new slice, and finally build the slice struct.
Copy
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)When using the copy function to copy slices, the code generated during compilation by cmd/compile/internal/walk.walkcopy determines how to copy. If called at runtime, it will use the function runtime.slicecopy, which is responsible for copying slices. The function signature is as follows:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intIt receives pointers and lengths of source and destination slices, as well as the length to copy width. This function's logic is very simple, as shown below:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Calculate number of bytes to copy
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}The value of width depends on the minimum length of the two slices. As you can see, when copying slices, it doesn't traverse elements one by one to copy, but directly copies the entire underlying array's memory. When the slice is large, the performance impact of copying memory is not small.
If not called at runtime, it will be expanded into code like the following:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Both methods work the same way, copying slices by copying memory. The memmove function is implemented in assembly. If interested, you can browse details at runtime/memmove_amd64.s.
Clear
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}In version go1.21, a new built-in function clear was added, which can be used to clear the contents of a slice, or rather, set all elements to zero values. When the clear function acts on a slice, the compiler expands it during compilation by the cmd/compile/internal/walk.arrayClear function into the following form:
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}First, it checks if the slice length is 0, then calculates the number of bytes to clear, and then handles two cases depending on whether the element is a pointer. But ultimately, it will use the memclrNoHeapPointers function, with the following signature:
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)It receives two parameters: one is a pointer to the starting address, and the other is the offset, which is the number of bytes to clear. The starting memory address is the address of the reference held by the slice, and offset n = sizeof(et) * len. This function is implemented in assembly. If interested, you can check details at runtime/memclr_amd64.s.
It's worth mentioning that if the source code attempts to use iteration to clear the array, for example:
for i := range s {
s[i] = ZERO_val
}Before the clear function, this was usually how slices were cleared. During compilation, this code is now optimized by the cmd/compile/internal/walk.arrayRangeClear function into the following form:
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Stop loop
i = len(s) - 1
}
}The logic is exactly the same as above, with an extra line i = len(s)-1, whose purpose is to stop the loop after memory is cleared.
Iteration
for i, e := range s {
fmt.Println(i, e)
}When using for range to iterate over a slice, it will be expanded by the walkRange function in cmd/compile/internal/walk/range.go into the following form:
// Copy struct
hs := s
// Get underlying array pointer
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}As you can see, the implementation of for range still iterates over elements by moving pointers. To avoid the slice being updated during iteration, a copy of the struct hs is made beforehand. To avoid the pointer pointing to out-of-bounds memory after iteration ends, hu uses uintptr type to store the address, and only converts to unsafe.Pointer when needing to access elements.
Variable v2, which is e in for range, is a single variable throughout the entire iteration process. It will only be overwritten, not recreated. This point triggered the loop variable problem that has plagued Go developers for a decade. It wasn't until version go1.21 that officials finally decided to solve it. It's expected that in future version updates, the creation method of v2 might become like this:
v2 := *hpThe process of generating intermediate code is omitted here, as this doesn't belong to slice-related knowledge. If interested, you can learn about it yourself.