gc
Garbage collection's job is to release memory of objects that are no longer in use and free up space for other objects. This simple description is implemented in a remarkably complex way. Garbage collection has a development history spanning decades. As early as the 1960s, the Lisp language first adopted garbage collection mechanisms. Python and Objective-C, which we're familiar with, primarily use reference counting for their GC mechanisms, while Java and C# use generational collection.
Today, garbage collection algorithms can be broadly categorized into the following types:
- Reference Counting: Each object tracks how many times it's referenced. When the count reaches 0, it's recycled.
- Mark-Sweep: Active objects are marked, and unmarked objects are collected.
- Copying Algorithm: Active objects are copied to new memory, and all objects in old memory are collected to free up space.
- Mark-Compact: An upgrade to mark-sweep that moves active objects to the head of the heap for easier management.
From an application perspective, they can be categorized as:
- Global Collection: Collects all garbage in one pass
- Generational Collection: Objects are divided into generations based on their lifetime, with different collection algorithms for each
- Incremental Collection: Only performs partial garbage collection each time
TIP
Visit The Journey of Go's Garbage Collector to read the original English article and learn more about Go's garbage collection history.
When Go was first released, its garbage collection mechanism was very primitive, with only a simple mark-sweep algorithm. The STW (Stop The World, referring to pausing the entire program for garbage collection) caused by garbage collection could last several seconds or even longer. Realizing this problem, the Go team began to improve the garbage collection algorithm. Between Go 1.0 and Go 1.8 versions, they tried many approaches:
- Read Barrier Concurrent Copying GC: This approach was abandoned due to high uncertainty in read barrier overhead.
- Request-Oriented Collector (ROC): Required write barriers to be enabled at all times, slowing down execution and increasing compilation time.
- Generational Collection: Generational collection wasn't efficient in Go because Go's compiler tends to allocate new objects on the stack, and long-lived objects on the heap, so most新生代 objects would be directly recycled by the stack.
- Card Marking Without Write Barriers: Replaced write barrier costs with hash scattering costs, requiring hardware support.
Ultimately, the Go team chose the combination of tri-color concurrent marking with write barriers, continuously improving and optimizing it in subsequent versions. This approach continues to this day. The following set of graphs shows GC latency changes from Go 1.4 to Go 1.9.
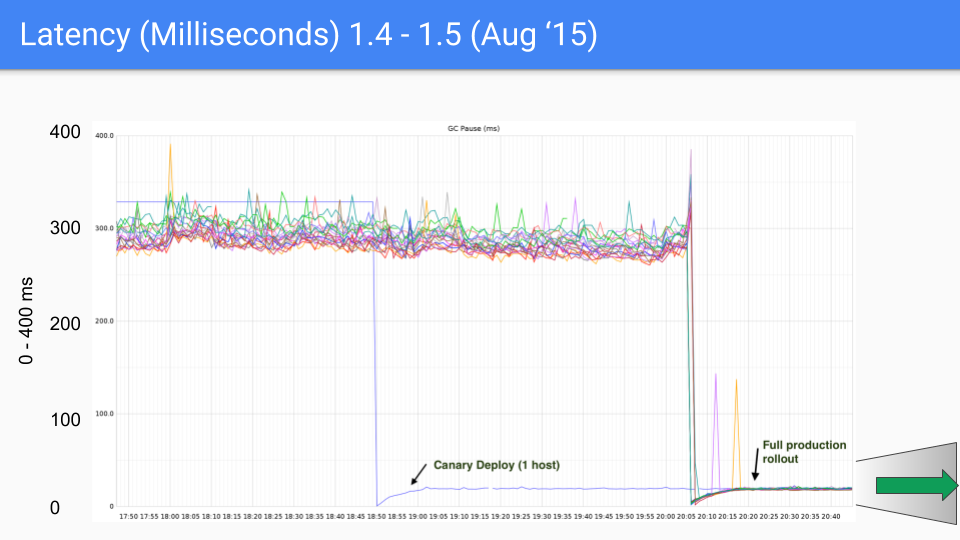
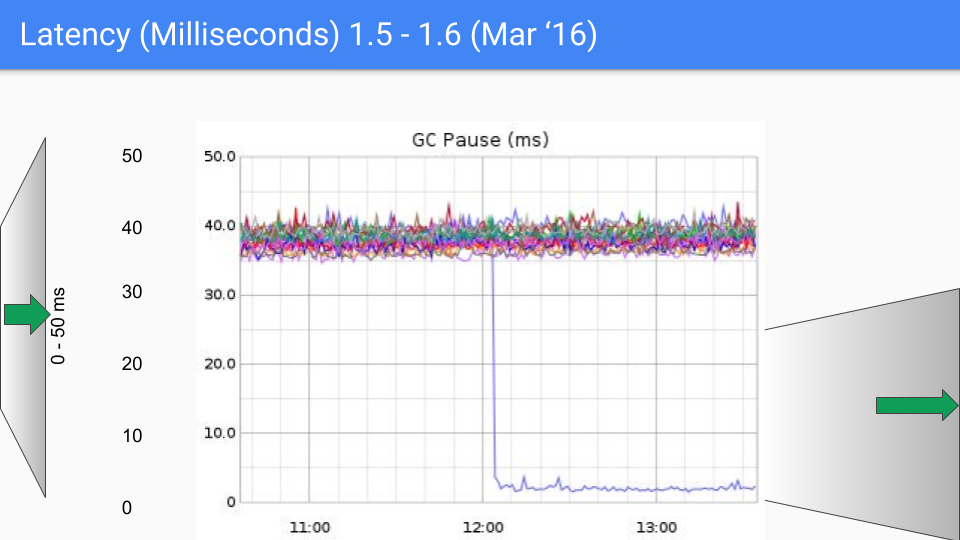
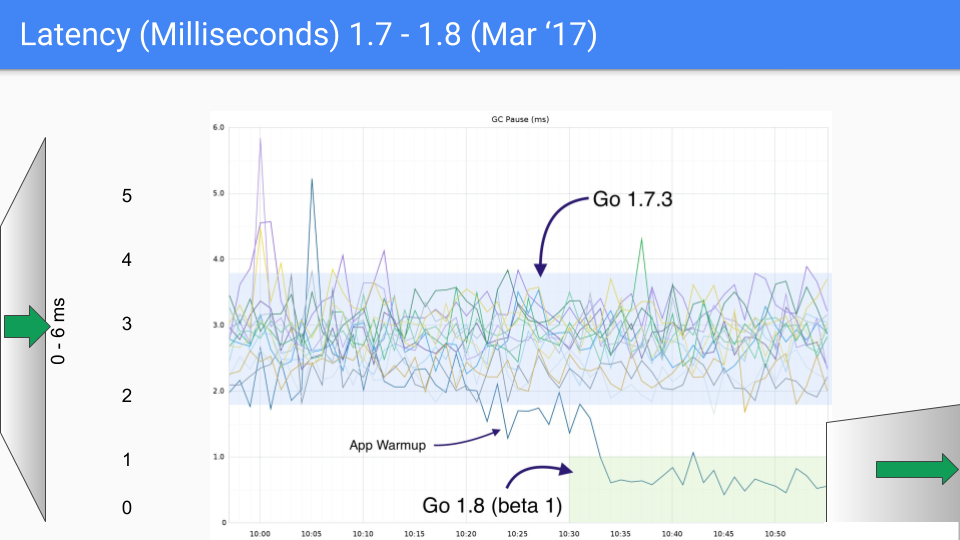
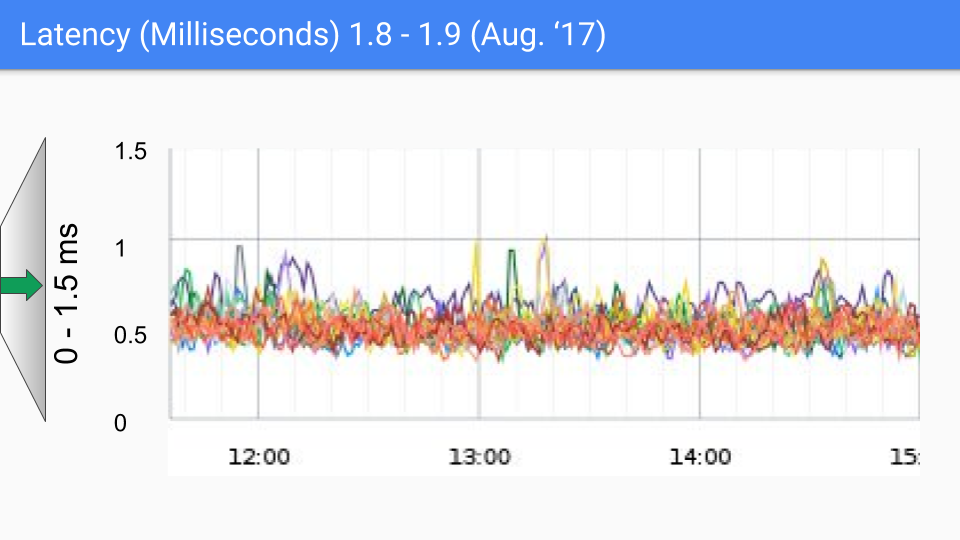
At the time of writing this article, Go's latest version is approaching Go 1.23. For today's Go, GC performance is no longer a concern. GC latency is now mostly below 100 microseconds, meeting the needs of most business scenarios.
Overall, garbage collection in Go can be divided into the following stages:
- Scan Phase: Collect root objects from the stack and global variables
- Mark Phase: Color the objects
- Mark Termination Phase: Handle cleanup work, close barriers
- Sweep Phase: Release and recycle garbage object memory
Concepts
The following concepts may appear in official documentation and articles, with brief explanations below:
- Mutator: A technical term referring to user programs. In Go, this refers to user code.
- Collector: Refers to the program responsible for garbage collection. In Go, this is the runtime.
- Finalizer: Code responsible for recycling and cleaning up object memory after mark-sweep work is completed.
- Controller: Refers to the
runtime.gcControllerglobal variable, whose type isgcControllerState. It implements the pacing algorithm and is responsible for determining when to perform garbage collection and how much work to execute. - Limiter: Refers to
runtime.gcCPULimiter, which prevents excessive CPU usage during garbage collection from affecting user programs.
Trigger
func gcStart(trigger gcTrigger)Garbage collection is initiated by the runtime.gcStart function, which only accepts the runtime.gcTrigger structure as a parameter, containing the GC trigger reason, current time, and which round of GC this is.
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: current time
n uint32 // gcTriggerCycle: cycle number to start
}Where gcTriggerKind has the following optional values:
const (
// gcTriggerHeap indicates that a cycle should be started when
// the heap size reaches the trigger heap size computed by the
// controller.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime indicates that a cycle should be started when
// it's been more than forcegcperiod nanoseconds since the
// previous GC cycle.
gcTriggerTime
// gcTriggerCycle indicates that a cycle should be started if
// we have not yet started cycle number gcTrigger.n (relative
// to work.cycles).
gcTriggerCycle
)In summary, there are three trigger times for garbage collection:
When creating new objects: When allocating memory by calling
runtime.mallocgc, if it's detected that heap memory has reached the threshold (generally twice the size at the previous GC, this value is also adjusted by the pacing algorithm), garbage collection is initiated.gofunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }Scheduled forced trigger: Go starts a separate goroutine at runtime to run the
runtime.forcegchelperfunction. If garbage collection hasn't been performed for a long time, it will forcibly start GC. This time is determined by theruntime.forcegcperiodconstant, which is 2 minutes. Additionally, the system monitoring goroutine also periodically checks whether forced GC is needed.gofunc forcegchelper() { for { ... gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) ... } }gofunc sysmon() { ... for { ... // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } } }Manual trigger: Through the
runtime.GCfunction, users can manually trigger garbage collection.gofunc GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
TIP
If interested, you can read Go Gc Pacer Re-Design in English, which explains the design philosophy and improvements of the pacing algorithm for triggering GC. Due to its complex content involving many mathematical formulas, it's not elaborated in the main text.
Mark
Today, Go's GC algorithm is still mark-then-sweep, but its implementation is no longer as simple as before.
Mark-Sweep
Let's start with the simplest mark-sweep algorithm. In memory, the reference relationships between objects form a graph. Garbage collection works on this graph, divided into two phases:
- Mark Phase: Starting from root nodes (root nodes are usually variables on the stack, global variables, and other active objects), traverse each reachable node one by one and mark them as active objects until all reachable nodes are traversed.
- Sweep Phase: Traverse all objects in the heap, recycle unmarked objects, and release or reuse their memory space.
During the collection process, the object graph structure cannot be changed, so the entire program must be stopped, which is STW. Only after collection is complete can it continue running. The disadvantage of this algorithm is that it takes a long time, which significantly affects program execution efficiency. This was the mark algorithm used in early versions of Go, and its disadvantages are obvious:
- It produces memory fragments (due to Go's TCMalloc-style memory management, the impact of fragmentation is not significant)
- During the mark phase, all objects in the heap are scanned
- It causes STW, pausing the entire program, and the time is not short
Tri-color Marking
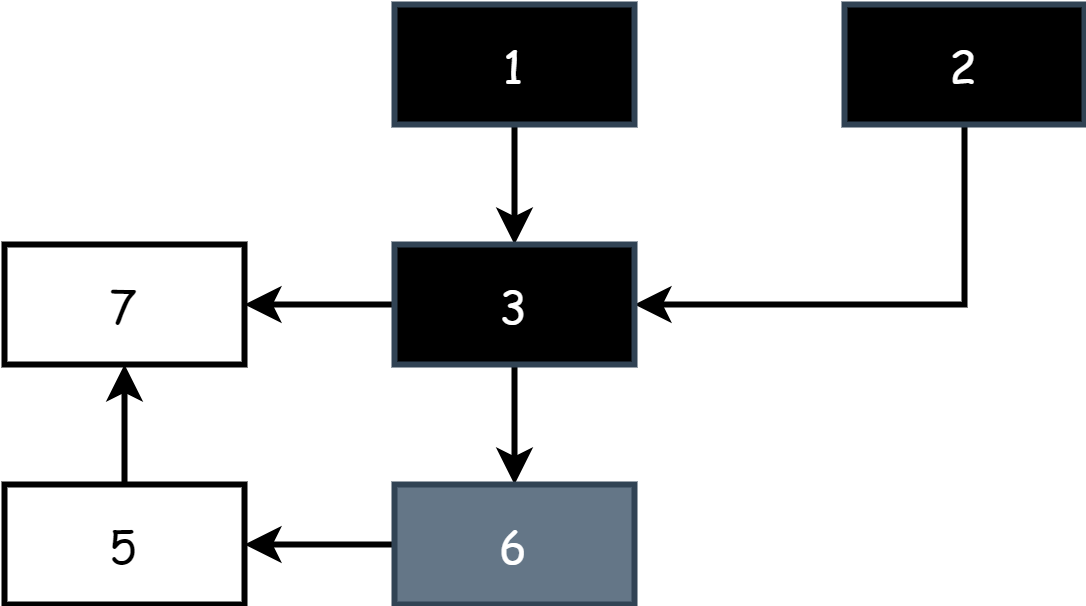
To improve efficiency, Go adopted the classic tri-color marking algorithm. The so-called tri-color refers to black, gray, and white:
- Black: The object has been visited during marking, and all objects it directly references have also been visited, indicating active objects.
- Gray: The object has been visited during marking, but the objects it directly references have not all been visited. When all are visited, it turns black, indicating active objects.
- White: The object has never been visited during marking. After being visited, it turns gray, indicating it may be a garbage object.
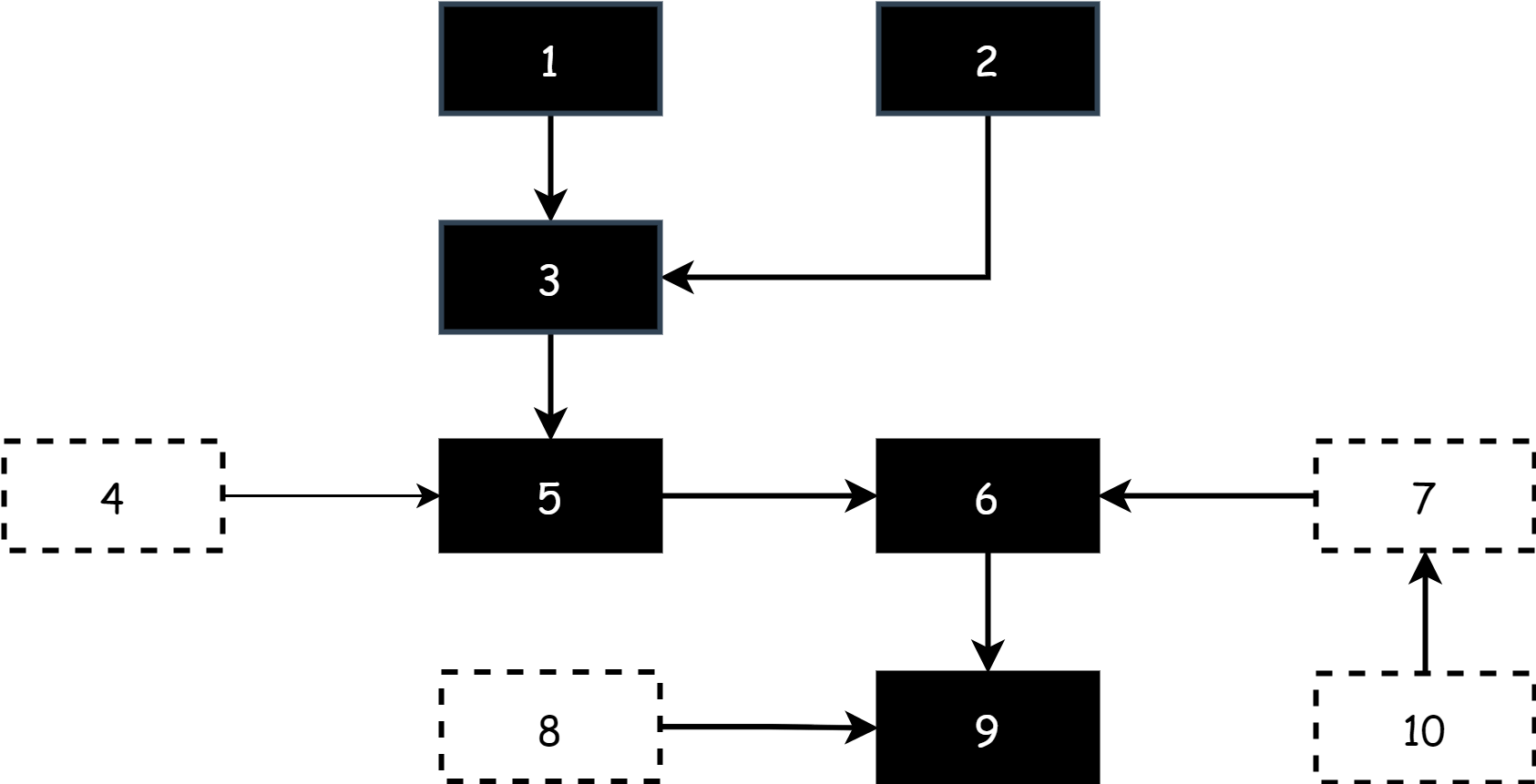
At the start of tri-color marking work, there are only gray and white objects on the field. All root objects are gray, and other objects are white, as shown below.
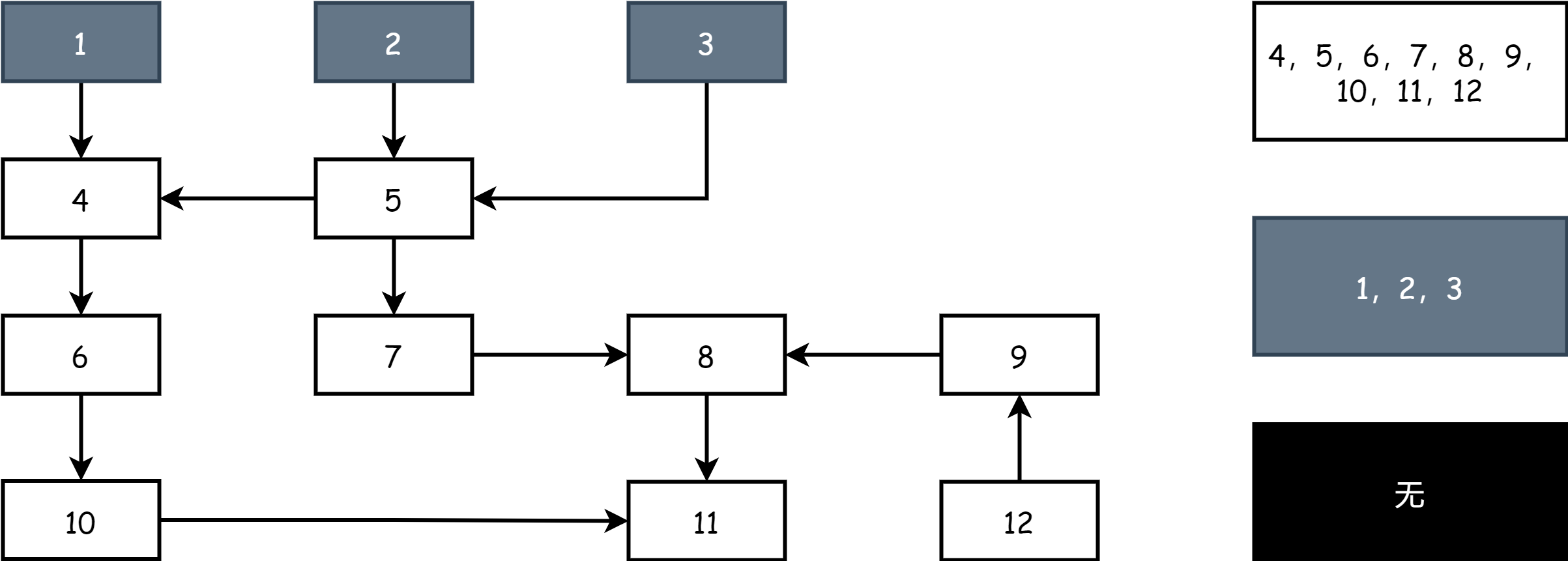
At the start of each marking round, start from gray objects, mark gray objects as black to indicate they are active objects, then mark all objects directly referenced by black objects as gray. The rest remain white. At this point, there are black, gray, and white objects on the field.
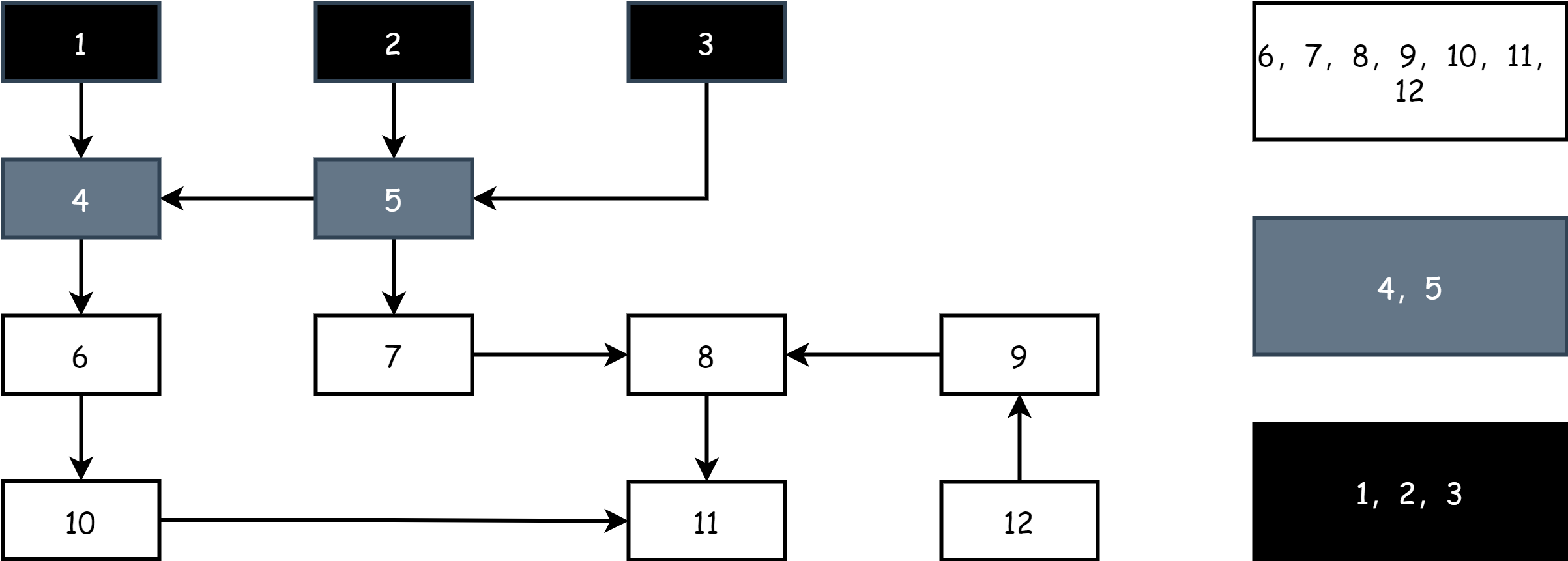
Continuously repeat the above steps until only black and white objects remain on the field. When the gray object set is empty, it indicates marking is complete, as shown below.
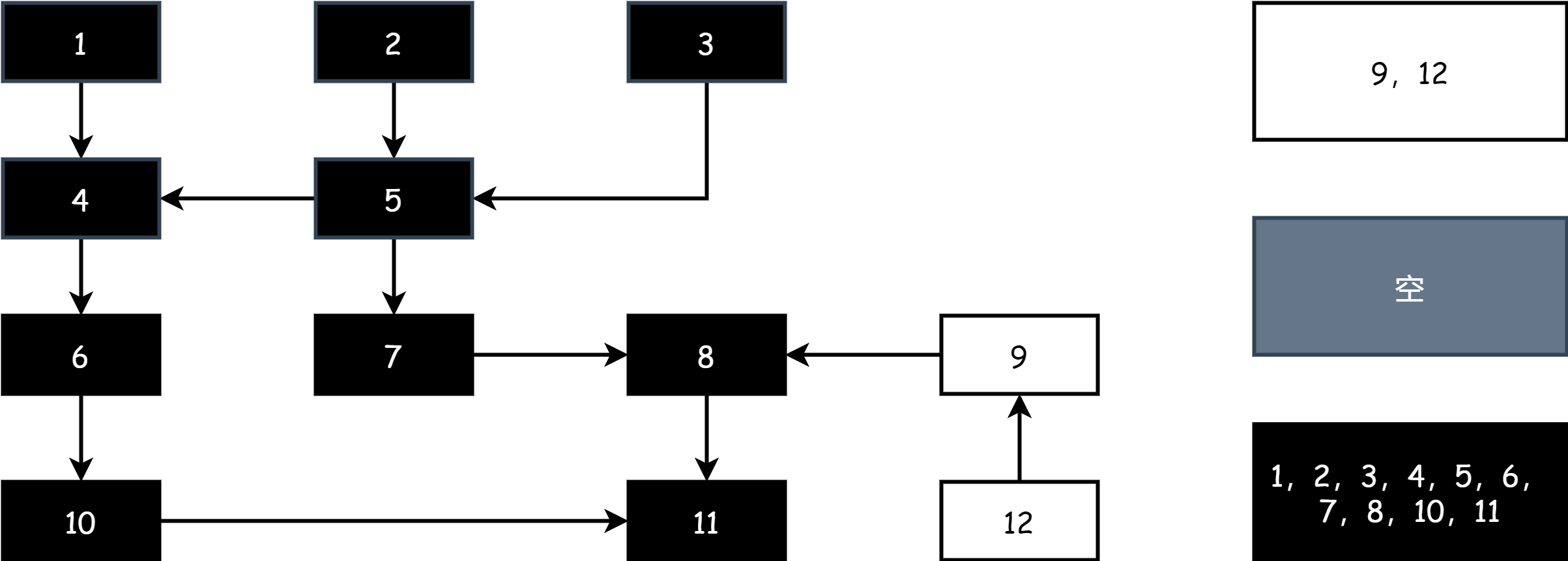
After marking is complete, in the sweep phase, simply release the memory of objects in the white set.
Invariance
The tri-color marking algorithm itself cannot perform concurrent marking (referring to the program running while marking). If the object graph structure changes during marking, this could lead to two situations:
- Over-marking: After an object is marked as black, the user program deletes all references to that object. Then it should be a white object and needs to be collected.
- Under-marking: After an object is marked as white, other objects in the user program reference that object. Then it should be a black object and should not be collected.
The first situation is acceptable because uncollected objects can be handled in the next round of collection. But the second situation is unacceptable. Releasing the memory of an object that's in use would cause serious program errors, which must be avoided.
The concept of tri-color invariance comes from Pekka P. Pirinen's 1998 paper "Barrier Techniques for Incremental Tracing". It refers to two invariants of object colors during concurrent marking:
- Strong Tri-color Invariance: Black objects cannot directly reference white objects.
- Weak Tri-color Invariance: When a black object directly references a white object, there must be another gray object that can directly or indirectly reach that white object, called being protected by the gray object.
For strong tri-color invariance, it's known that black object 3 is an already visited object, and its child objects have also been visited and marked as gray objects. If at this point the user program concurrently adds a new reference to white object 7 for black object 3, normally white object 7 should be marked as gray. But since black object 3 has already been visited, object 7 won't be visited, so it always remains a white object and is eventually incorrectly cleaned up.

For weak tri-color invariance, it's actually similar to strong tri-color invariance. Because gray objects can directly or indirectly reach the white object, during subsequent marking it will eventually be marked as a gray object, thus avoiding being incorrectly collected.
Through invariance, it can be ensured that no objects are incorrectly collected during marking, thus guaranteeing the correctness of marking work under concurrent conditions. This allows tri-color marking to work concurrently, significantly improving marking efficiency compared to the mark-sweep algorithm. The key to ensuring tri-color invariance under concurrent conditions lies in barrier technology.
Marking Work
During the GC scan phase, there's a global variable runtime.gcphase used to indicate GC status, with the following optional values:
_GCoff: Marking work has not started_GCmark: Marking work has started_GCmarktermination: Marking work is about to terminate
When marking work starts, runtime.gcphase status is _GCmark. The marking work is executed by the runtime.gcDrain function, where the runtime.gcWork parameter is a buffer pool storing object pointers to be tracked.
func gcDrain(gcw *gcWork, flags gcDrainFlags)During work, it attempts to get trackable pointers from the buffer pool. If there are any, it calls the runtime.scanobject function to continue the scan task. Its role is to continuously scan objects in the buffer, marking them black.
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
scanobject(b, gcw)Marking work only stops when P is preempted or STW is about to occur.
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork is a queue using the producer/consumer model. The queue is responsible for storing gray objects to be scanned. Each processor P has such a queue locally, corresponding to the runtime.p.gcw field.
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}The runitme.scanobject function continuously marks reachable white objects as gray during scanning, then puts them into the local queue via gcw.put. Meanwhile, the gcDrain function continuously tries to get gray objects via gcw.tryget to continue scanning. The marking and scanning process is incremental and doesn't need to complete all marking work at once. When marking tasks are preempted for some reason, they are interrupted. When resumed, they can continue the marking work based on the remaining gray objects in the queue.
Background Marking
Marking work is not executed immediately when GC starts. When GC is first triggered, Go creates as many marking tasks as the current total number of processor P's. They are added to the global task queue and then enter sleep until awakened during the mark phase. At runtime, task distribution is performed by runtime.gcBgMarkStartWorkers. The marking task actually refers to the runtime.gcBgMarkWorker function, where gcBgMarkWorkerCount and gomaxprocs are two runtime global variables representing the current number of workers and the number of processor P's respectively.
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has
// a background GC G.
//
// Worker Gs don't exit if gomaxprocs is reduced. If it is raised
// again, we can reuse the old workers; no need to create new workers.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// The worker is now guaranteed to be added to the pool before
// its P's next findRunnableGCWorker.
gcBgMarkWorkerCount++
}
}After the worker starts, it creates a runtime.gcBgMarkWorkerNode structure, adds it to the global worker pool runitme.gcBgMarkWorkerPool, then calls the runtime.gopark function to put the goroutine to sleep.
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// Go to sleep until woken by
// gcController.findRunnableGCWorker.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// Release this G to the pool.
gcBgMarkWorkerPool.push(&node.node)
// Note that at this point, the G may immediately be
// rescheduled and may be running.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}There are two situations that can wake up workers:
- During the mark phase, the scheduling loop wakes up sleeping workers through the
runtime.runtime.gcController.findRunnableGCWorkerfunction. - During the mark phase, if processor P is currently in an idle state, the scheduling loop tries to directly get available workers from the global worker pool
gcBgMarkWorkerPool.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// Try to schedule a GC worker.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}Processor P has a field in its structure gcMarkWorkerMode to indicate the execution mode of marking tasks, with the following optional values:
gcMarkWorkerNotWorker: Indicates the current processor P is not executing marking tasks.gcMarkWorkerDedicatedMode: Indicates the current processor P is dedicated to executing marking tasks and won't be preempted during this period.gcMarkWorkerFractionalMode: Indicates the current processor is executing marking tasks because GC utilization doesn't meet the standard (25% is the standard). Execution can be preempted during this period. Assuming the current number of processor P's is 5, according to the calculation formula, one processor P dedicated to marking tasks is needed. Utilization only reached 20%, and the remaining 5% utilization requires opening aFractionalModeprocessor P to make up. The specific calculation code is as follows:gofunc (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // Too many dedicated workers. dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode: Indicates the current processor is executing marking tasks because it's idle. Execution can be preempted during this period.
The Go team doesn't want GC to occupy too much performance, thus affecting the normal operation of user programs. By performing marking work according to these different modes, GC can be completed without wasting performance or affecting user programs. It's worth noting that the basic allocation unit of marking tasks is processor P, so marking work is performed concurrently. Multiple marking tasks and user programs execute concurrently without affecting each other.
Mark Assist
Goroutine G has a field gcAssistBytes at runtime, here referred to as GC assist credits. During GC marking state, when a goroutine attempts to allocate a certain size of memory, it's deducted credits equal to the size of the allocated memory. If the credits are negative at this point, the goroutine must assist in completing a quantitative amount of GC scan tasks to repay the credits. When credits are positive, the goroutine doesn't need to complete assist marking tasks.
The function for deducting credits is runtime.deductAssistCredit, which is called before the runtime.mallocgc function allocates memory.
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
return assistG
}However, when a goroutine completes a quantitative amount of assist scan work, it repays quantitative credits to the current goroutine. The function actually responsible for assist marking is runtime.gcDrainN.
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// Work completed
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}Since scanning is concurrent, only part of the recorded work is from the current goroutine. The remaining work is repaid to other goroutines one by one according to the order of the assist queue. If there's still remaining, it's added to the global credits gcController.assistBytesPerWork.
func gcFlushBgCredit(scanWork int64) {
// If queue is empty, directly add to global credits
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// Still remaining
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}Correspondingly, when too many credits need to be repaid (allocating too much memory), global credits can also be used to offset part of one's own debt.
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// Use global credits as collateral
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}Mark assist is a balancing measure under high-load conditions. The speed at which user programs allocate memory is far higher than the marking speed. For every byte of memory allocated, a corresponding amount of marking work is performed.
Mark Termination
When all reachable gray objects have been colored black, the state transitions from _GCmark to _GCmarktermination. This process is completed by the runtime.gcMarkDone function. At the start, it checks whether there are still tasks to execute.
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// Execute all marking operations intercepted by write barriers in batch
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}After there are no global tasks and local tasks to execute, call runtime.stopTheWorldWithSema for STW, then do some cleanup work.
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Notify the CPU limiter that GC assists will now cease.
gcCPULimiter.startGCTransition(false, now)
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Perform mark termination. This will restart the world.
gcMarkTermination(stw)First, set runtime.BlackenEnabled to 0, indicating that marking work has ended. Notify the limiter that mark assist has ended, close memory barriers, wake up all goroutines sleeping due to assist marking, then re-awaken all user goroutines. Also collect various data from this round of scan work to adjust the pacing algorithm for the next round of scanning. After cleanup work is completed, call the runtime.gcSweep function to clean up garbage objects, then call runtime.startTheWorldWithSema to resume program operation.
Barriers
The role of memory barriers can be understood as hooking object assignment behavior, performing specified operations before assignment. This hook code is usually inserted into code by the compiler during compilation. As mentioned earlier, adding and deleting object references during tri-color marking in concurrent conditions both cause problems. Since both are write operations (deletion is assigning null value), the barriers intercepting them are collectively called write barriers. But barrier mechanisms are not without cost. Intercepting memory write operations causes additional overhead, so barrier mechanisms only take effect on the heap. Considering implementation complexity and performance overhead, they don't take effect on stacks and registers.
TIP
To learn more about Go's application details of barrier technology, visit Eliminate STW stack rescan to read the original English article. This article references a lot of content from it.
Insertion Write Barrier
The insertion write barrier was proposed by Dijkstra. It satisfies strong tri-color invariance. When a black object adds a new white object reference, the insertion write barrier intercepts this operation and marks the white object as gray. This avoids black objects directly referencing white objects, ensuring strong tri-color invariance. This is quite easy to understand.

As mentioned earlier, write barriers are not applied to stacks. If the reference relationship of stack objects changes during concurrent marking, such as a black object in the stack referencing a white object in the heap, to ensure the correctness of stack objects, all objects in the stack can only be marked as gray objects again after marking is complete, then rescanned. This means one round of marking needs to scan the stack space twice, and the second scan requires STW. If hundreds or thousands of goroutine stacks exist simultaneously in the program, the time consumption of this scanning process cannot be ignored. According to official statistics, the rescan time consumption is around 10-100 milliseconds.
Advantages: STW is not required during scanning.
Disadvantages: Requires a second scan of stack space to ensure correctness, requires STW.
Deletion Write Barrier
The deletion write barrier was proposed by Yuasa, also known as snapshot-at-the-beginning barrier. This method requires STW at the start to snapshot record root objects, and marks all root objects black and all first-level child objects gray. This way, the rest of the white child objects are under the protection of gray objects. The Go team didn't directly apply the deletion write barrier but chose to mix it with the insertion write barrier. So for ease of understanding later, it still needs to be explained here. The rule for the deletion write barrier to ensure correctness under concurrent conditions is: when deleting a reference to a white object from a gray or white object, the white object is directly marked as gray.
Interpret in two situations:
- Deleting a gray object's reference to a white object: Since it's unknown whether the white object's downstream is referenced by a black object, this action may cut off the gray object's protection of the white object.
- Deleting a white object's reference to a white object: Since it's unknown whether the white object's upstream is protected by gray and whether the downstream is referenced by black, this action may also cut off gray's protection of white.
In either situation, the deletion write barrier marks the referenced white object as gray. This satisfies weak tri-color invariance. This is a conservative approach because the upstream and downstream situations are unknown. Marking it as gray means it's no longer treated as a garbage object. Even if deleting the reference causes the object to become unreachable (i.e., become a garbage object), it's still marked as gray. It will be released in the next round of scanning, which is better than memory errors caused by objects being incorrectly collected.

Advantages: Since stack objects are all black, there's no need for a second scan of stack space.
Disadvantages: STW is required at the start of scanning to snapshot record root objects in stack space.
Hybrid Write Barrier
Go 1.8 version introduced a new barrier mechanism: hybrid write barrier, a mix of insertion write barrier and deletion write barrier, combining the advantages of both:
- Insertion write barrier doesn't require STW for snapshot at start.
- Deletion write barrier doesn't require STW for second scan of stack space.
Below is the pseudocode given by officials:
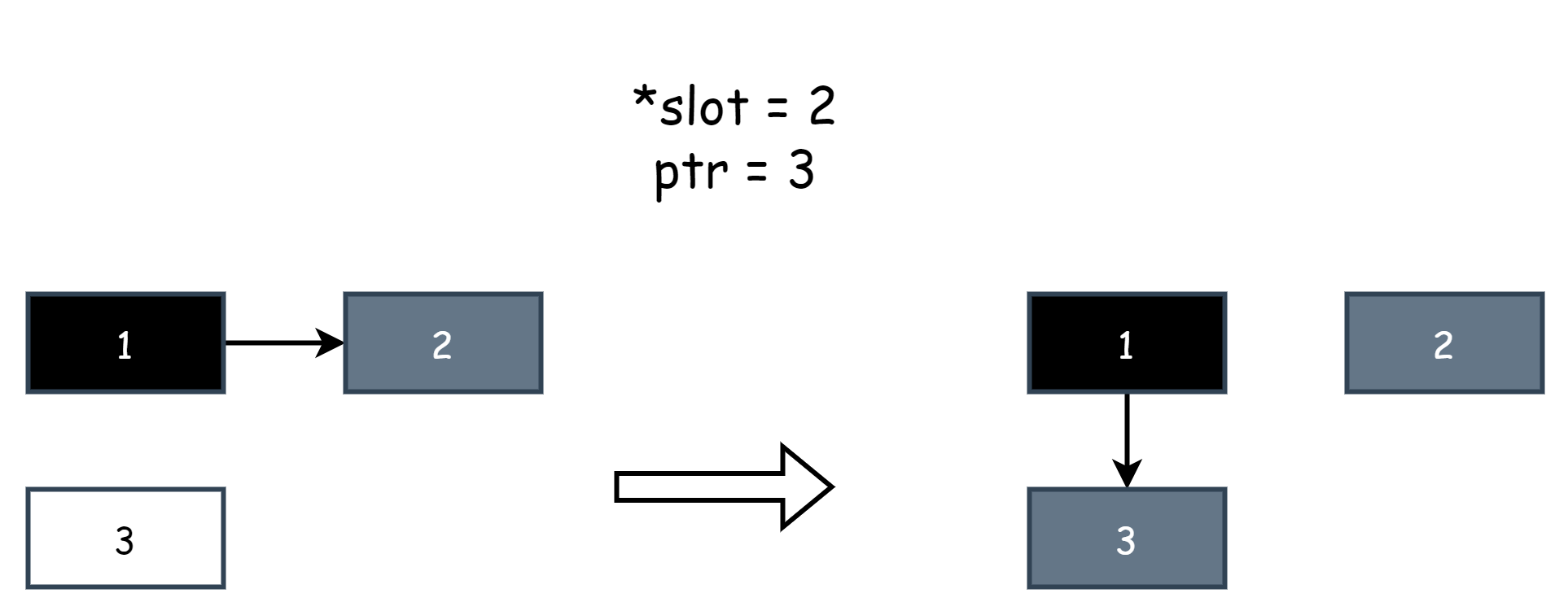
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptrSimply explain some concepts inside: slot is a pointer representing a reference to other objects, *slot is the original object, ptr is the new object, *slot=ptr is an assignment operation, equivalent to modifying the object's reference. Assigning null is deleting the reference. shade() means marking an object as gray. shade(*slot) means marking the original object as gray, and shade(ptr) means marking the new object as gray. Below is an example diagram. Assuming object 1 originally references object 2, then the user program modifies the reference to let object 1 reference object 3. The hybrid write barrier captures this behavior, where *slot represents object 2 and ptr represents object 1.
Officials summarized the effect of the above pseudocode in one sentence:
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
Translated, when the hybrid write barrier intercepts a write operation, it marks the original object as gray. If the current goroutine's stack hasn't been scanned yet, it also marks the new object as gray.
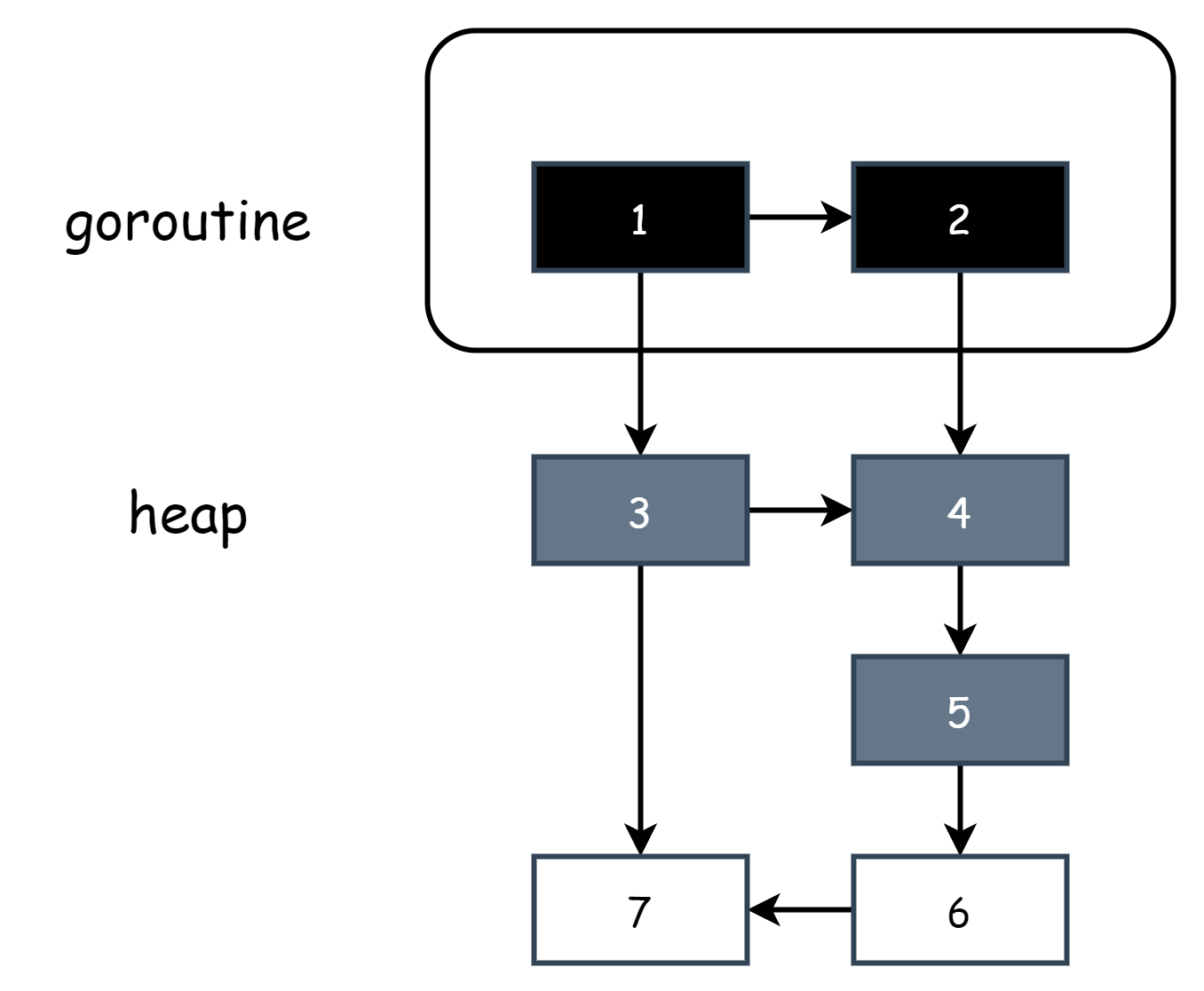
When marking work starts, the stack space needs to be scanned to collect root objects. At this time, they are directly marked all black. During this period, any newly created objects are also marked black to ensure all objects in the stack are black objects. So current stack is grey in the pseudocode means the current goroutine's stack hasn't been scanned yet. Therefore, goroutine stacks only have two states: either all black or all gray. During the process from all gray to all black, the current goroutine needs to be paused. So under the hybrid write barrier, there's still local STW. When the goroutine stack is all black, strong tri-color invariance must be satisfied at this point. Because after scanning, black objects in the stack only reference gray objects. There won't be a situation where black objects directly reference white objects. So at this point, insertion write barrier is not needed, corresponding to the pseudocode:
if current stack is grey:
shade(ptr)But deletion write barrier is still needed to satisfy weak tri-color invariance, which is:
shade(*slot)After scanning is complete, since objects in stack space are already all black, there's no need for a second scan of stack space, saving STW time.
At this point, which is after Go 1.8 version, Go has largely established the basic framework of garbage collection. Subsequent version optimizations related to garbage collection are also built on the foundation of the hybrid write barrier. Since most STW has been eliminated, the average latency of garbage collection has been reduced to the microsecond level.
Shading Cache
In the barrier mechanisms mentioned earlier, when intercepting write operations, object colors are marked immediately. After adopting the hybrid write barrier, since both the original object and new object need to be colored, the workload doubles, and the code inserted by the compiler also increases. To optimize, in Go 1.10 version, write barriers no longer immediately mark object colors when shading. Instead, the original object and new object are stored in a cache pool. After accumulating a certain quantity, batch marking is performed. This is more efficient.
The structure responsible for caching is runtime.wbBuf, which is actually an array with a size of 512.
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}Every P locally has such a cache:
type p struct {
...
wbBuf wbBuf
...
}During marking work, if there are no available gray objects in the gcw queue, objects in the cache are put into the local queue.
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush write barrier cache
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}Another situation is that when mark termination occurs, each P's local wbBuf is also checked for remaining gray objects:
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}Sweep
In garbage collection, the most important part is how to find garbage objects, which is the scan and mark work. After marking work is completed, the sweep work is relatively less complex. It only needs to recycle and release unmarked objects. This part of the code is mainly in the runtime/mgcsweep.go file. According to comments in the file, Go's sweep algorithms are divided into two types.
Object Sweep
Object sweep work is completed by runtime.sweepone during the mark termination phase. The process is asynchronous. During cleanup, it attempts to find unmarked objects in memory units and recycles them. If an entire memory unit is unmarked, then the entire unit is recycled.
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// Try to get recycler
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// Cleanup
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}For the object sweep algorithm, recycling an entire unit is relatively difficult, so there's a second sweep algorithm.
Unit Sweep
Unit sweep work is performed before memory allocation, completed by the runtime.mheap.reclaim method. It searches the heap for memory units where all objects are unmarked, then recycles the entire unit.
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}For memory units, there's a sweepgen field used to indicate their sweep status:
mspan.sweepgen == mheap.sweepgen - 2: The memory unit needs to be swept.mspan.sweepgen == mheap.sweepgen - 1: The memory unit is being swept.mspan.sweepgen == mheap.sweepgen: The memory unit has been swept and can be used normally.mspan.sweepgen == mheap.sweepgen + 1: The memory unit is in cache and needs to be swept.mspan.sweepgen == mheap.sweepgen + 3: The memory unit has been swept but is still in cache.
mheap.sweepgen increases with each GC round, and each time it increases by 2.