CGO
Since Go requires GC, for some scenarios with higher performance requirements, Go may not be very suitable for handling them. C, as a traditional system programming language, has excellent performance, and cgo can connect the two, allowing mutual calls. Go can call C to hand over performance-sensitive tasks to C, while Go handles upper-level logic. cgo also supports C calling Go, but this scenario is relatively rare and not recommended.
TIP
The code demonstrations in this article are in a win10 environment, using gitbash for the command line. Windows users are advised to install mingw in advance.
Regarding cgo, the official documentation has a simple introduction: C? Go? Cgo! - The Go Programming Language. If you want a more detailed introduction, you can get more detailed information in the standard library cmd/cgo/doc.go, or you can directly read the documentation cgo command - cmd/cgo - Go Packages. The content of both is exactly the same.
Code Calling
Take a look at the following example
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}To use cgo features, simply enable it through the import statement import "C". Note that C must be an uppercase letter, and the import name cannot be rewritten. Also, make sure the environment variable CGO_ENABLED is set to 1. By default, this environment variable is enabled.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1Additionally, you need to ensure that the local environment has a C/C++ build toolchain, which is gcc. On the Windows platform, this is mingw, to ensure the program compiles normally. Execute the following command to compile. After enabling cgo, compilation time will be longer than pure Go.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!Another point to note is that after enabling cgo, cross-compilation is no longer supported.
Go Embedding C Code
cgo supports writing C code directly in Go source files and then calling it directly. Take a look at the following example, which defines a function named printSum, and then calls it in the main function in Go.
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}Output
c:1+2=3This is suitable for simple scenarios. If there is a lot of C code, mixing it with Go code significantly reduces readability, so this approach is not recommended.
Error Handling
In Go language, error handling is returned in the form of return values, but C language does not allow multiple return values. For this purpose, you can use errno in C, which indicates that an error occurred during the function call. cgo is compatible with this, allowing error handling in Go style with return values when calling C functions. To use errno, first include errno.h. Take a look at the following example
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}Output
syscall.Errno
The device does not recognize the command.You can see that its error type is syscall.Errno. errno.h also defines many other error codes, which you can explore on your own.
Go Importing C Files
By importing C files, the aforementioned problem can be solved. First, create a header file sum.h with the following content
int sum(int a, int b);Then create sum.c and write the specific function
#include "sum.h"
int sum(int a, int b) {
return a + b;
}Then import the header file in main.go
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}Now when compiling, you must specify the current folder, otherwise the C file won't be found, as shown below
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3In the code, res is a Go variable, and C.sum is a C language function. Its return value is C language int, not Go int. The reason it can be called successfully is because cgo performs type conversion in between.
C Calling Go
C calling Go refers to C calling Go in cgo, not native C programs calling Go. They form a call chain like go-cgo-c->cgo->go. Go calling C is to leverage C's ecosystem and performance. There's almost no need for native C programs to call Go. If there is such a need, it's recommended to use network communication instead.
cgo supports exporting Go functions for C to call. To export a Go function, add the //export func_name comment above the function signature, and both its parameters and return values must be types supported by cgo. An example is as follows
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Rewrite the previous sum.c file with the following content
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}Also modify the header file sum.h
void do_sum();Then export the function in Go
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Now the sum function used in C is actually provided by Go. The output is as follows
20The key point is the _cgo_export.h imported in the sum.c file. It contains information about all types exported by Go. If you don't import it, you won't be able to use the functions exported by Go. Another point to note is that _cgo_export.h cannot be imported in Go files because the prerequisite for generating this header file is that all Go source files can compile successfully. Therefore, the following approach is incorrect
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}The compiler will indicate that the header file doesn't exist
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.If a Go function has multiple return values, C will return a struct when calling it.
By the way, we can pass Go pointers to C through C function parameters. During the C function call, cgo will try to ensure memory safety. However, exported Go function return values cannot contain pointers because in this case, cgo cannot determine whether they are being referenced, nor can it fix the memory. If the returned memory is referenced and then garbage collected in Go or shifted, it will cause pointer out-of-bounds, as shown below.
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}The above approach is not allowed to compile by default. If you want to disable this check, you can set it as follows.
GODEBUG=cgocheck=0It has two check levels, which can be set to 1 or 2. The higher the level, the greater the runtime overhead. You can visit cgo command - passing_pointer for details.
Type Conversion
cgo provides a mapping between C and Go types to facilitate runtime calls. For C types, after importing import "C" in Go, most can be accessed directly through
C.typenameFor example
C.int(1)
C.char('a')But C language types can consist of multiple keywords, such as
unsigned charIn this case, they cannot be accessed directly. However, you can use the typedef keyword in C to give a type an alias, which functions the same as type aliases in Go. As follows
typedef unsigned char byte;This way, you can access the type unsigned char through C.byte. An example is as follows
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}Output
a
b
cIn most cases, cgo has already provided aliases for commonly used types (such as basic types). You can also define them yourself using the method above, which won't cause conflicts.
char
The char in C corresponds to the int8 type in Go, and unsigned char corresponds to the uint8 type, which is byte in Go.
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}Output
type: main._Ctype_char, val: 99If you change the argument of set to C.char(math.MaxInt8 + 1), the compilation will fail with the following error
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charStrings
cgo provides some pseudo-functions for passing strings and byte slices between C and Go. These functions don't actually exist, and you can't find their definitions. Just like import "C", the C package doesn't exist either. They are designed for developer convenience and will be converted to other operations after compilation.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteA string in Go is essentially a struct that holds a reference to an underlying array. When passing it to a C function, you need to use C.CString() to create a "string" in C using malloc, allocate memory space for it, and return a C pointer. Since C doesn't have a string type, char* is typically used to represent strings, which is a pointer to a character array. Remember to use free to release the memory after use.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}It can also be a char array type. Both are essentially the same - a pointer to the head element.
void printfGoString(char s[]) {
puts(s);
}You can also pass byte slices. Since C.CBytes() returns an unsafe.Pointer, you need to convert it to *C.char type before passing it to a C function.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}The output of the above examples is the same
this is a go stringThese string passing methods involve a memory copy. After passing, there's actually a copy in both C memory and Go memory, which is safer. That said, we can still pass pointers directly to C functions and modify Go strings directly in C. Take a look at the following example
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}Output
this is a go stringThe example uses unsafe.SliceData to directly get the pointer to the underlying array of the string, converts it to a C pointer, and passes it to the C function. The string's memory is managed by Go, so there's no need to free it. The advantage is that no copying is needed during the passing process, but there's some risk. The following example demonstrates modifying a Go string in C
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}Output
this is a go string
this is c go string
this is c go stringIntegers
The mapping relationship between Go and C integers is shown in the table below. More information about integer type mapping can also be found in the standard library cmd/cgo/gcc.go.
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
Example code is as follows
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}cgo also provides support for integer types in <stdint.h>. The memory sizes of these types are clearer and more explicit, and their naming style is very similar to Go.
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
When using cgo, it's recommended to use integer types from <stdint.h>.
Floating Point Numbers
The mapping of floating point types between Go and C is as follows
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
Example code is as follows
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}Slices
The situation with slices is similar to strings discussed above. The difference is that cgo doesn't provide pseudo-functions to copy slices. To let C access Go slices, you can only pass the slice pointer. Take a look at the following example
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}Output
0 1 2 3 4 5 6 7 8 9Here, the pointer to the slice's underlying array is passed to the C function. Since the array's memory is managed by Go, it's not recommended for C to hold the pointer reference for a long time. Conversely, an example of using a C array as the underlying array for a Go slice is as follows
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}Output
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7The unsafe.Slice function can convert an array pointer to a slice. Intuitively, a C array is just a pointer to the head element. Conventionally, it should be used like this
goslice := unsafe.Slice(&C.s, l)From the output, you can see that if you do this, except for the first element, all the remaining memory is out of bounds.
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]Even though a C array is just a head pointer, after being wrapped by cgo, it becomes a Go array with its own address. Therefore, you should take the address of the array's head element.
goslice := unsafe.Slice(&C.s[0], l)Structs
By using the C.struct_ prefix followed by the struct name, you can access C structs. C structs cannot be embedded in Go structs as anonymous structs. Here's a simple example of a C struct
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}Output
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}If certain members of a C struct contain bit-field, cgo will ignore those struct members. For example, modifying person to the following
struct person {
int32_t age: 1;
char* name;
};Executing again will result in an error
p.age undefined (type _Ctype_struct_person has no field or method age)The memory alignment rules for C and Go struct fields are different. If cgo is enabled, in most cases C will be the dominant factor.
Unions
Using C.union_ followed by the name, you can access unions in C. Since Go doesn't support unions, they exist as byte arrays in Go. Here's a simple example
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}Output
[4]uint8 [0 0 0 0]You can access and modify it through unsafe.Pointer
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}Output
0
1024
[0 4 0 0]Enums
By using the prefix C.enum_ followed by the enum type name, you can access enum types in C. Here's a simple example
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}Output
0 alive
1 deadPointers
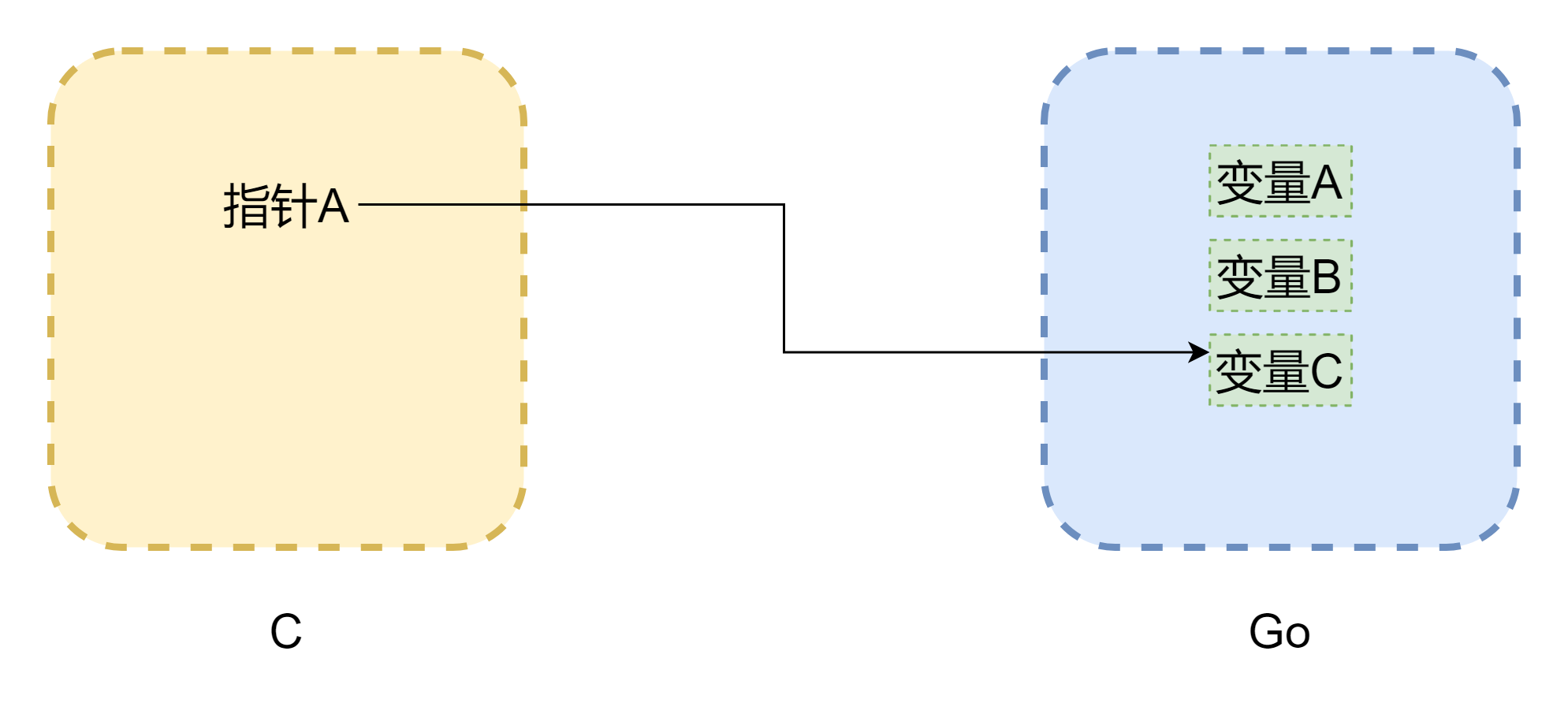
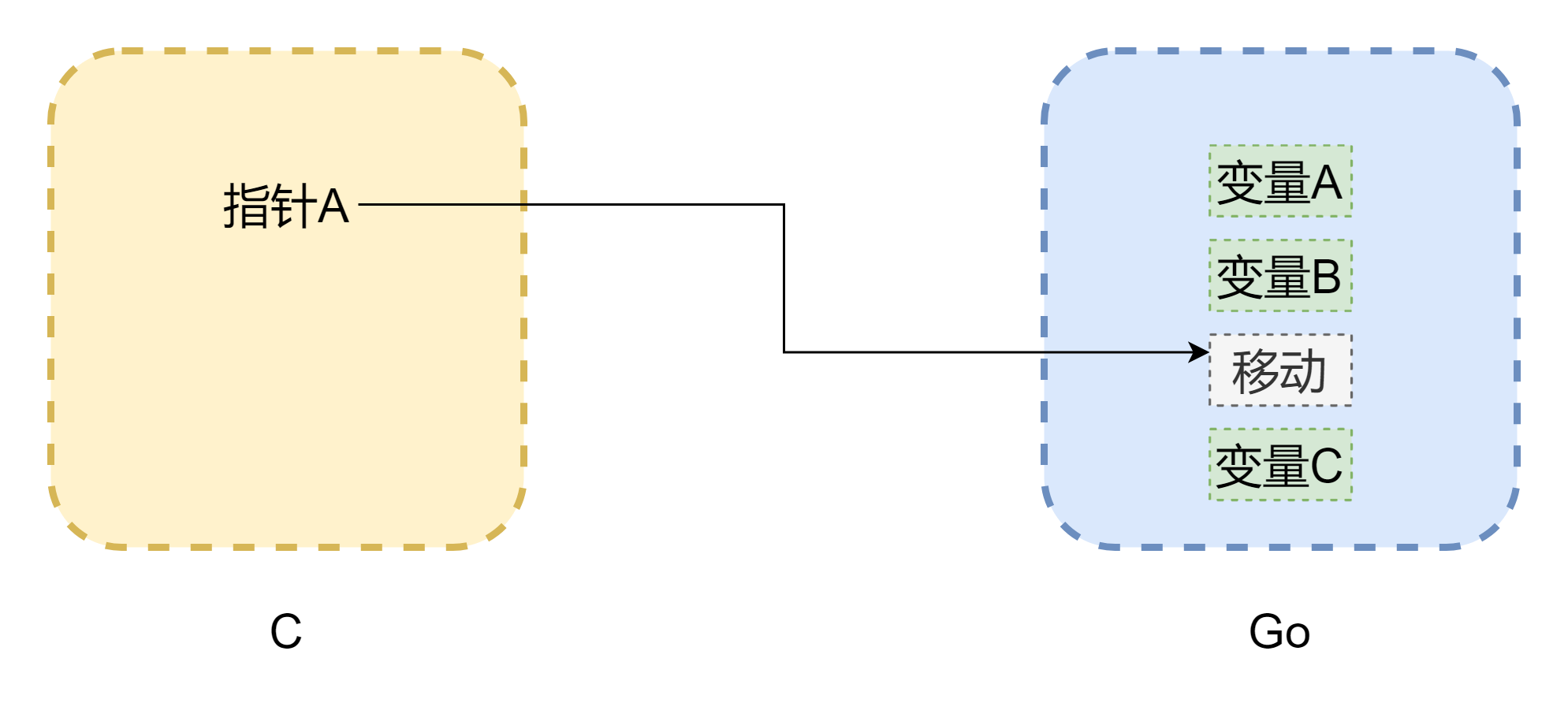
When discussing pointers, we can't avoid memory. The biggest problem with mutual calls between cgo is that the memory models of the two languages are different. C language memory is completely manually managed by developers - using malloc() to allocate memory and free() to release memory. If not manually released, it will never be released automatically, so C's memory management is very stable. Go is different - it has GC, and Goroutine's stack space is dynamically adjusted. When stack space is insufficient, it will grow, which means memory addresses may change. As shown in the figure above (the figure is not strictly accurate), pointers may become dangling pointers common in C. Even though cgo can avoid memory movement in most cases (memory is pinned by runtime.Pinner), Go officials also don't recommend long-term references to Go memory in C. However, the reverse is safer - if Go pointers reference C memory, it's relatively safe unless you manually call C.free(), otherwise this memory won't be automatically released.
If you want to pass pointers between C and Go, you need to first convert them to unsafe.Pointer, and then convert to the corresponding pointer type, just like void* in C. Let's look at two examples. The first is a C pointer referencing a Go variable, and even modifying the variable.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}Output
1
3
3The second is a Go pointer referencing a C variable and modifying it.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}Output
10
11By the way, cgo doesn't support function pointers in C.
Linking Libraries
C language doesn't have dependency management like Go. To use libraries written by others directly, besides getting the source code directly, there's also the option of static and dynamic linking libraries. cgo also supports these. Thanks to this, we can import libraries written by others in Go programs without needing the source code.
Dynamic Linking Library
Dynamic linking libraries cannot run independently. They are loaded into memory together with the executable file at runtime. Below demonstrates making a simple dynamic linking library and calling it with cgo. First, prepare a lib/sum.c file with the following content
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}Write the header file lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);Next, use gcc to make a dynamic linking library. First, compile to generate the object file
$ cd lib
$ gcc -c sum.c -o sum.oThen make the dynamic linking library
$ gcc -shared -o libsum.dll sum.oAfter making it, import the sum.h header file in Go code, and also need to tell cgo through macros where to find the library file
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Irefers to the relative path for searching header files-Lrefers to the library search path,${SRCDIR}represents the absolute path of the current path because its parameter must be an absolute path-lrefers to the library file name, sum issum.dll.
CFFLAGS and LDFLAGS are both gcc compilation options. For security reasons, cgo disables some parameters. Visit cgo command for details.
Put the dynamic library in the same directory as the exe
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goFinally, compile the Go program and execute
$ go build main.go && ./main.exe
3The dynamic linking library call is successful.
Static Linking Library
Unlike dynamic linking libraries, when importing static linking libraries with cgo, they will be linked with Go object files into a single executable file. Let's use sum.c as an example again. First, compile the source file into an object file
$ gcc -o sum.o -c sum.cThen package the object file into a static linking library (must start with lib prefix, otherwise it won't be found)
$ ar rcs libsum.a sum.oGo file content
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}Compile
$ go build && ./main.exe
3The static linking library call is successful.
Final Words
Although the purpose of using cgo is for performance, switching between C and Go also causes significant performance loss. For some very simple tasks, cgo's efficiency is not as good as pure Go. Let's look at an example
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}This is a very simple test. A function that sums two numbers is written in both C and Go, then each is run 1 million times to calculate the average execution time. The test results are as follows
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opFrom the results, you can see that cgo's average execution time is more than twenty times that of pure Go. If the task being executed is not just simple addition but a more time-consuming task, cgo's advantage would be greater. Besides, using cgo has the following disadvantages
- Many Go toolchains will not be usable, such as gotest, pprof. The test example above cannot use gotest and must be handwritten.
- Compilation becomes slower, and built-in cross-compilation is no longer available
- Memory safety issues
- Dependency issues - if others use your library, they also need to enable cgo.
Before considering thoroughly, don't introduce cgo into your project. For some very complex tasks, using cgo can indeed bring benefits. But if it's just simple tasks, it's better to stick with Go.