CGO
由於 go 需要 GC,對於一些性能要求更高的場景,go 可能不太適合處理,c 作為傳統的系統編程語言性能是非常優秀的,而 cgo 可以將兩者聯系起來,相互調用,讓 go 調用 c,將性能敏感的任務交給 c 去完成,go 負責處理上層邏輯,cgo 同樣支持 c 調用 go,不過這種場景比較少見,也不太建議這麼做。
TIP
文中代碼演示的環境是 win10,命令行用的是gitbash,windows 用戶建議提前安裝好 mingw。
關於 cgo,官方有一個簡單的介紹:C? Go? Cgo! - The Go Programming Language,如果想要更詳細的介紹,可以在標准庫cmd/cgo/doc.go中獲取更加詳細的信息,或者也可以直接看文檔cgo command - cmd/cgo - Go Packages,兩者內容是完全一樣的。
代碼調用
看下面一個例子
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}想要使用 cgo 特性,通過導入語句import "C"即可開啟,需要注意的是C必須是大寫字母,且導入名稱無法被重寫,同時需要確保環境變量CGO_ENABLED是否設置為1,在默認情況下該環境變量是默認啟用的。
$ go env | grep CGO
$ go env -w CGO_ENABLED=1除此之外,還需要確保本地擁有C/C++的構建工具鏈,也就是gcc,在 windows 平台就是mingw,這樣才能確保程序正常通過編譯。執行如下命令進行編譯,開啟了 cgo 以後編譯時間是要比純 go 要更久的。
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!另外要注意的一個點就是,開啟 cgo 以後,將無法支持交叉編譯。
go 嵌入 c 代碼
cgo 支持直接把 c 代碼寫在 go 源文件中,然後直接調用,看下面的例子,例子中編寫了一個名為printSum的函數,然後在 go 中的main函數進行調用。
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}輸出
c:1+2=3這適用於簡單的場景,如果 c 代碼非常多,跟 go 代碼糅雜在一起十分降低可讀性,就不太適合這麼做。
錯誤處理
在 go 語言中錯誤處理以返回值的形式返回,但 c 語言不允許有多返回值,為此可以使用 c 中的errno,表示在函數調用期間發生了錯誤,cgo 對此做了兼容,在調用 c 函數時可以像 go 一樣用返回值來處理錯誤。要使用errno,首先引入errno.h,看下面的一個例子
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}輸出
syscall.Errno
The device does not recognize the command.可以看到它的錯誤類型是syscall.Errno,errno.h中還定義了其它很多錯誤代碼,可以自己去了解。
go 引入 c 文件
通過引入 c 文件,就可以很好的解決上述的問題,首先創建一個頭文件sum.h,內容如下
int sum(int a, int b);然後再創建sum.c,編寫具體的函數
#include "sum.h"
int sum(int a, int b) {
return a + b;
}然後在main.go中導入頭文件
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}現在進行編譯的話,必須要指定當前文件夾,否則找不到 c 文件,如下
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3代碼中res是 go 中的一個變量,C.sum是 c 語言中的函數,它的返回值是 c 語言中的int而非 go 中的int,之所以能成功調用,是因為 cgo 從中做了類型轉換。
c 調用 go
c 調用 go,指的是在 cgo 中 c 調用 go,而非原生的 c 程序調用 go,它們是這樣一個調用鏈go-cgo-c->cgo->go。go 調用 c 是為了利用 c 的生態和性能,幾乎沒有原生的 c 程序調用 go 這種需求,如果有的話也建議通過網絡通信來代替。
cgo 支持導出 go 函數讓 c 調用,如果要導出 go 函數,需在函數簽名上方加上//export func_name注釋,並且其參數和返回值都得是 cgo 支持的類型,例子如下
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}改寫剛剛的sum.c文件為如下內容
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}同時修改頭文件sum.h
void do_sum();然後在 go 中導出函數
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}現在 c 中使用的sum函數實際上是 go 提供的,輸出結果如下
20關鍵點在於sum.c文件中導入的_cgo_export.h,它包含了有關所有 go 導出的類型,如果不導入的話就無法使用 go 導出的函數。另一個注意點是_cgo_export.h不能在 go 文件導入,因為該頭文件生成的前提是所有 go 源文件能夠通過編譯。因此下面這種寫法是錯誤的
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}編譯器會提示頭文件不存在
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.倘若 go 函數具有多個返回值,那麼 c 調用時將返回一個結構體。
順帶一提,我們可以把 go 指針通過 c 函數參數傳遞給 c,在 c 函數調用期間 cgo 會盡量保證內存安全,但是導出的 go 函數返回值不能帶指針,因為在這種情況下 cgo 沒法判斷其是否被引用,也不好固定內存,如果返回的內存被引用了,然後在 go 中這段內存被 GC 掉了或者發生偏移,將導致指針越界,如下所示。
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}上面的寫法默認是不允許通過編譯的,如果想要關閉這個檢查,可以如下設置。
GODEBUG=cgocheck=0它有兩種檢查級別,可以設為1,2,級別越高檢查造成運行時開銷越大,可以 前往cgo command - passing_pointer了解細節。
類型轉換
cgo 對 c 與 go 之間的類型做了一個映射,方便它們在運行時調用。對於 c 中的類型,在 go 中導入import "C"之後,大部分情況下可以通過
C.typename這種方式來直接訪問,比如
C.int(1)
C.char('a')但 c 語言類型可以由多個關鍵字組成,比如
unsigned char這種情況就沒法直接訪問了,不過可以使用 c 中的typedef關鍵字來給類型取個別名,其功能等同於 go 中的類型別名。如下
typedef unsigned char byte;這樣一來,就可以通過C.byte來訪問類型unsigned char了。例子如下
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}輸出
a
b
c大部分情況下,cgo 給常用類型(基本類型之類的)已經取好了別名,也可以根據上述的方法自己定義,不會沖突。
char
c 中的char對應 go 中的int8類型,unsigned char對應 go 中的uint8也就是byte類型。
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}輸出
type: main._Ctype_char, val: 99如果將set的參數換成C.char(math.MaxInt8 + 1),那麼編譯就會失敗,並提示如下錯誤
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_char字符串
cgo 提供了一些偽函數用於在 c 和 go 之間傳遞字符串和字節切片,這些函數實際上並不存在,你也沒法找到它們的定義,就跟import "C"一樣,C這個包也是不存在的,只是為了方便開發者使用,在編譯後它們會被轉換成其它的操作。
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []bytego 中的字符串本質上是一個結構體,裡面持有著一個底層數組的引用,在傳遞給 c 函數時,需要使用C.CString()在 c 中使用malloc創建一個「字符串」,為其分配內存空間,然後返回一個 c 指針,因為 c 中沒有字符串這個類型,通常會使用char*來表示字符串,也就是一個字符數組的指針,使用完畢後記得使用free釋放內存。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}也可以是char數組類型,兩者其實都一樣,都是指向頭部元素的指針。
void printfGoString(char s[]) {
puts(s);
}也可以傳遞字節切片,由於C.CBytes()會返回一個unsafe.Pointer,在傳遞給 c 函數之前要將其轉換為*C.char類型。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}上面的例子輸出都是一樣的
this is a go string上述這幾種字符串傳遞方法涉及到了一次內存拷貝,在傳遞過後實際上是在 c 內存和 go 內存中各自保存了一份,這樣做會更安全。話雖如此,我們依然可以直接傳遞指針給 c 函數,也可以在 c 中直接修改 go 中的字符串,看下面的例子
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}輸出
this is a go string例子通過unsafe.SliceData直接獲取了字符串底層數組的指針,並將其轉換為了 c 指針後傳遞給 c 函數,該字符串的內存是由 go 進行管理的,自然也就不再需要 free,這樣做的好處就是傳遞的過程不再需要拷貝,但有一定的風險。下面的例子演示了在 c 中修改 go 中的字符串
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}輸出
this is a go string
this is c go string
this is c go string整數
go 與 c 之間的整數映射關系如下表所示,關於整數的類型映射還在可以在標准庫cmd/cgo/gcc.go看到一些相關信息。
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
示例代碼如下
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}cgo 同時也對<stdint.h>的整數類型提供了支持,這裡的類型內存大小更為清晰明確,而且其命名風格也與 go 非常相似。
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
在使用 cgo 時,建議使用<stdint.h>中的整數類型。
浮點數
go 與 c 的浮點數類型映射如下
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
代碼示例如下
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}切片
切片的情況的實際上跟上面講到的字符串差不多,不過區別在於 cgo 沒有提供偽函數來對切片進行拷貝,想讓 c 訪問到 go 中的切片就只能把切片的指針傳過去。看下面的一個例子
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}輸出
0 1 2 3 4 5 6 7 8 9這裡將切片的底層數組的指針傳遞給了 c 函數,由於該數組的內存是由 go 管理,不建議 c 長期持有其指針引用。反過來,將 c 的數組作為 go 切片的底層數組的例子如下
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}輸出
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7通過unsafe.Slice函數可以將數組指針轉換為切片,按照直覺來說,c 中的數組就是一個指向頭部元素的指針,按照常理來說應該這樣使用
goslice := unsafe.Slice(&C.s, l)通過輸出可以看到,如果這樣做的話,除了第一個元素,剩下的內存全都越界了。
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]即便 c 中的數組只是一個頭指針,經過 cgo 包裹了一下就成了 go 數組,有了自己的地址,所以應該對數組頭部元素取址。
goslice := unsafe.Slice(&C.s[0], l)結構體
通過C.struct_前綴加上結構體名稱,就可以訪問 c 結構體,c 結構體無法被當作匿名結構體嵌入 go 結構體。下面是一個簡單的 c 結構體的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}輸出
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}如果 c 結構體的某些成員包含bit-field,cgo 就會忽略這類結構體成員,比如將person修改為下面這種
struct person {
int32_t age: 1;
char* name;
};再次執行就會報錯
p.age undefined (type _Ctype_struct_person has no field or method age)c 和 go 的結構體字段的內存對齊規則並不相同,如果開啟了 cgo,大部分情況下會以 c 為主導。
聯合體
使用C.union_加上名稱就可以訪問 c 中的聯合體,由於 go 並不支持聯合體,它們在 go 中會以字節數組的形式存在。下面是一個簡單的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}輸出
[4]uint8 [0 0 0 0]通過unsafe.Pointer可以進行訪問和修改
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}輸出
0
1024
[0 4 0 0]枚舉
通過前綴C.enum_加上枚舉類型名就可以訪問 c 中的枚舉類型。下面是一個簡單的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}輸出
0 alive
1 dead指針
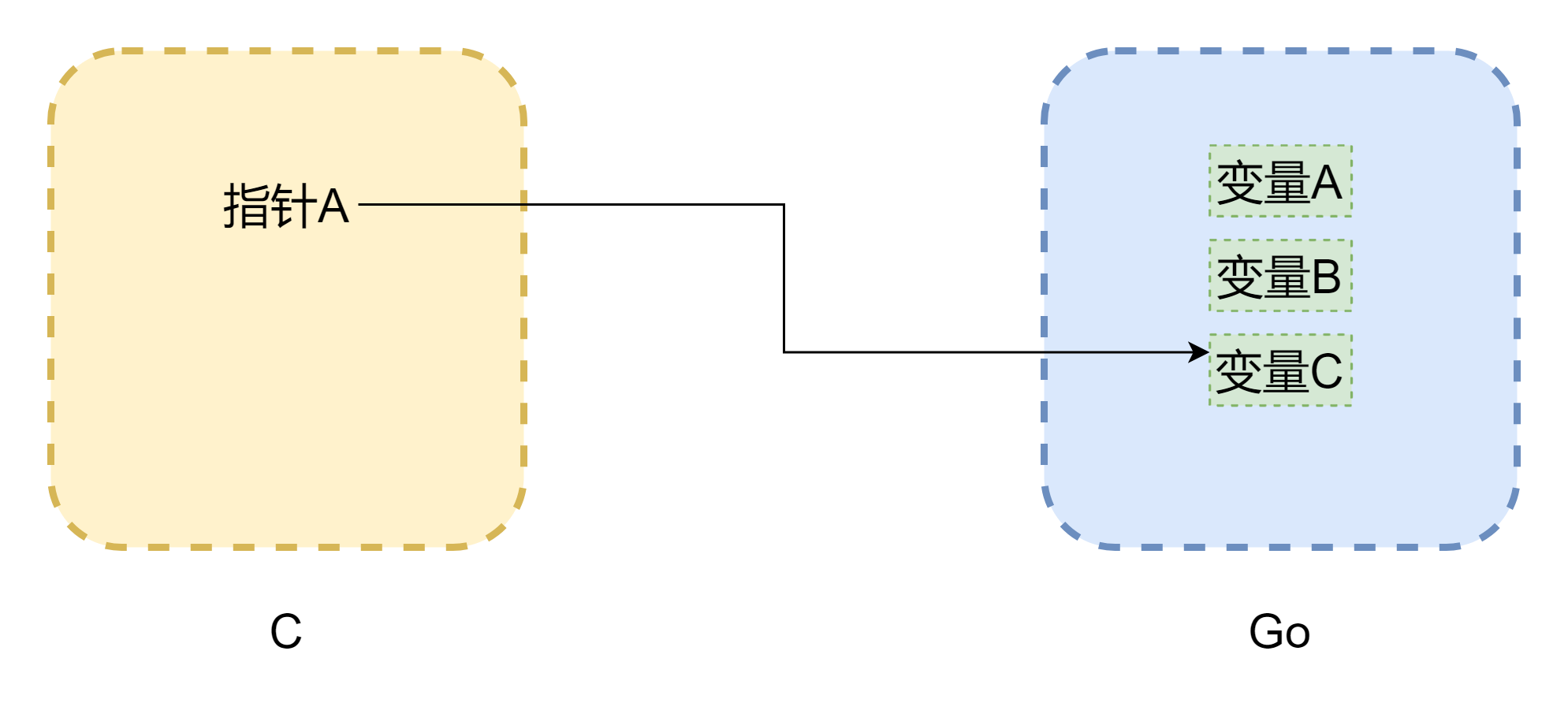
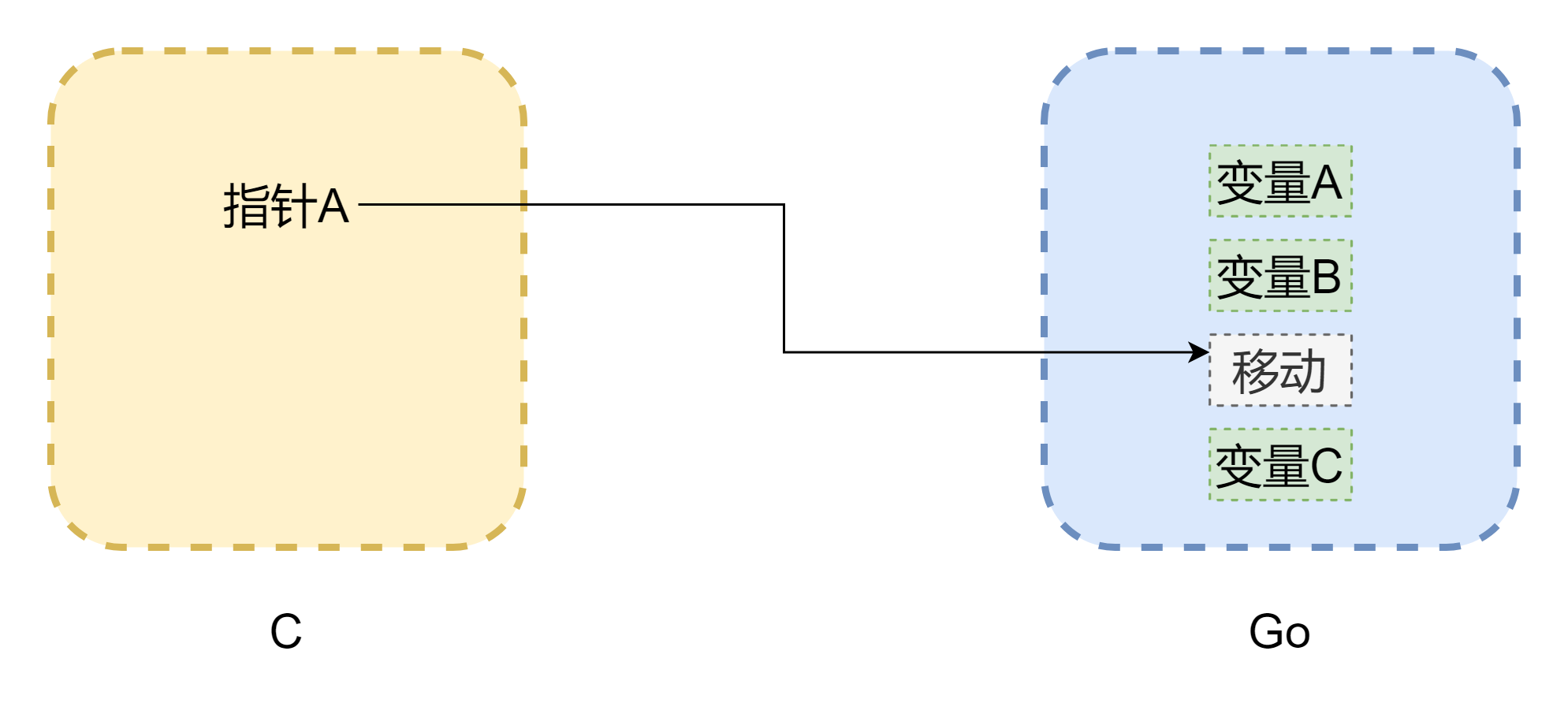
談到了指針避不開內存,cgo 之間相互調用最大的問題就是兩門語言的內存模型並不相同,c 語言的內存完全是由開發者手動管理,用malloc()分配內存,free()釋放內存,如果不去手動釋放,它是絕對不會自己釋放掉的,所以 c 的內存管理是非常穩定的。而 go 就不一樣了,它帶有 GC,並且 Goroutine 的棧空間是會動態調整的,當棧空間不足時會進行增長,那麼這樣一來,內存地址就可能發生了變化,跟上圖一樣(圖畫的並不嚴謹),指針可能就成了 c 中常見的懸掛指針。即便 cgo 在大多數情況可以避免內存移動(由runtime.Pinner來固定內存),但 go 官方也不建議在 c 中長期引用 go 的內存。但是反過來,go 中的指針引用 c 中的內存的話,是比較安全的,除非手動調用C.free(),否則這塊內存是不會被自動釋放掉的。
如果要在 c 和 go 之間傳遞指針,就需要先將其轉為unsafe.Pointer,然後再轉換成對應的指針類型,就跟 c 中的void*一樣。看兩個例子,第一個是 c 指針引用 go 變量的例子,而且還對變量做了修改。
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}輸出
1
3
3第二個是 go 指針引用 c 變量,並對其修改的例子。
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}輸出
10
11順帶一提,cgo 不支持 c 中的函數指針。
鏈接庫
c 語言並沒有像 go 這樣的依賴管理,想要直接使用別人寫好的庫除了直接獲取源代碼之外,還有個辦法就是靜態鏈接庫和動態鏈接庫,cgo 也支持這些,得益於此,我們就可以在 go 程序中導入別人寫好的庫,而不需要源代碼。
動態鏈接庫
動態鏈接庫無法單獨運行,它在運行時會與可執行文件一起加載到內存中,下面演示制作一個簡單的動態鏈接庫,並使用 cgo 進行調用。首先准備一個lib/sum.c文件,內容如下
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}編寫頭文件lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);接下來使用gcc來制作動態鏈接庫,首先編譯生成目標文件
$ cd lib
$ gcc -c sum.c -o sum.o然後制作動態鏈接庫
$ gcc -shared -o libsum.dll sum.o制作完成後,然後在 go 代碼中引入sum.h頭文件,並且還得通過宏告訴 cgo 去哪裡尋找庫文件
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -I指的是搜索頭文件的相對路徑,-L指的是庫搜索路徑,${SRCDIR}代指當前路徑的絕對路徑,因為它的參數必須是絕對路徑-l指的是庫文件的名稱,sum 就是sum.dll。
CFFLAGS和LDFLAGS這兩個都是 gcc 的編譯選項,出安全考慮,cgo 禁用了一些參數,前往cgo command了解細節。
把動態庫放到exe的同級目錄下
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.go最後編譯 go 程序並執行
$ go build main.go && ./main.exe
3到此動態鏈接庫調用成功。
靜態鏈接庫
不同於動態鏈接庫,使用 cgo 導入靜態鏈接庫時,它會與 go 的目標文件最終鏈接成一個可執行文件。還是拿sum.c舉例,先將源文件編譯成目標文件
$ gcc -o sum.o -c sum.c然後將目標文件打包成靜態鏈接庫(必須是lib前綴開頭,不然會找不到)
$ ar rcs libsum.a sum.ogo 文件內容
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}編譯
$ go build && ./main.exe
3到此,靜態鏈接庫調用成功。
最後
雖然使用 cgo 的出發點是為了性能,但在 c 與 go 之間切換也會不小的造成性能損失,對於一些十分簡單的任務,cgo 的效率並不如純 go。看一個例子
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}這是一個非常簡單的測試,分別用 c 和 go 編寫了一個兩數求和的函數,然後各自運行 100w 次,求其平均耗時,測試結果如下
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/op從結果可以看到,cgo 的平均耗時是純 go 的二十幾倍,倘若執行的不是單純的兩數相加,而是一個比較耗時的任務,cgo 的優勢會更大一些。除此之外,使用 cgo 還有以下缺點
- 許多 go 配套工具鏈將無法使用,比如 gotest,pprof,上面的測試例子就不能使用 gotest,只能自己手寫。
- 編譯速度變慢,自帶的交叉編譯也沒法用了
- 內存安全問題
- 依賴問題,如果別人用了你的庫,等於也要開啟 cgo。
在沒有考慮周全之前,不要在項目中引入 cgo,對於一些十分復雜的任務,使用 cgo 確實可以帶來好處,但如果只是一些簡單的任務,還是老老實實用 go 吧。