CGO
Poiché Go richiede la GC (Garbage Collection), per alcuni scenari che richiedono prestazioni più elevate, Go potrebbe non essere adatto. Il C, come tradizionale linguaggio di programmazione di sistema, ha prestazioni eccellenti, e cgo può collegare i due, consentendo chiamate reciproche. Go può chiamare C per affidare compiti sensibili alle prestazioni a C, mentre Go gestisce la logica di alto livello. CGO supporta anche le chiamate da C a Go, ma questo scenario è meno comune e generalmente non raccomandato.
TIP
Il codice dimostrato nell'articolo è stato testato su Windows 10, utilizzando gitbash come terminale. Si consiglia agli utenti Windows di installare mingw in anticipo.
Per CGO, c'è una breve introduzione ufficiale: C? Go? Cgo! - The Go Programming Language. Per una spiegazione più dettagliata, è possibile consultare cmd/cgo/doc.go nella libreria standard, oppure la documentazione cgo command - cmd/cgo - Go Packages. Entrambi contengono le stesse informazioni.
Chiamate di Codice
Vediamo un esempio:
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}Per utilizzare la funzionalità cgo, basta usare l'istruzione di importazione import "C". È importante notare che C deve essere in maiuscolo e il nome di importazione non può essere sovrascritto. Inoltre, è necessario assicurarsi che la variabile d'ambiente CGO_ENABLED sia impostata su 1. Per impostazione predefinita, questa variabile d'ambiente è abilitata.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1Oltre a ciò, è necessario assicurarsi di avere una toolchain di compilazione C/C++ locale, ovvero gcc. Su Windows, si tratta di mingw, per garantire che il programma possa essere compilato correttamente. Eseguire il seguente comando per compilare. Con cgo abilitato, il tempo di compilazione sarà più lungo rispetto al Go puro.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!Un altro punto importante è che, con cgo abilitato, non sarà possibile supportare la cross-compilazione.
Incorporare Codice C in Go
CGO supporta l'inserimento diretto del codice C nei file sorgente Go per la chiamata diretta. Vediamo l'esempio seguente, che definisce una funzione chiamata printSum, poi la chiama nella funzione main di Go.
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}Output:
c:1+2=3Questo approccio è adatto per scenari semplici. Se il codice C è molto esteso e si mescola con il codice Go, riducendo la leggibilità, non è consigliabile utilizzarlo.
Gestione degli Errori
In Go, la gestione degli errori avviene tramite valori di ritorno, ma il linguaggio C non supporta valori di ritorno multipli. Per questo, si può utilizzare errno in C, che indica che si è verificato un errore durante la chiamata della funzione. CGO gestisce questa situazione, consentendo di gestire gli errori nelle chiamate alle funzioni C in modo simile a Go. Per utilizzare errno, è necessario prima includere errno.h. Vediamo un esempio:
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}Output:
syscall.Errno
The device does not recognize the command.Come si può vedere, il tipo di errore è syscall.Errno. In errno.h sono definiti molti altri codici di errore, che si possono esplorare autonomamente.
Importare File C in Go
Importando file C, si può risolvere facilmente il problema sopra menzionato. Innanzitutto, creare un file header sum.h con il seguente contenuto:
int sum(int a, int b);Poi creare sum.c per implementare la funzione:
#include "sum.h"
int sum(int a, int b) {
return a + b;
}Quindi importare il file header in main.go:
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}Ora, per compilare, è necessario specificare la cartella corrente, altrimenti il file C non verrà trovato:
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3Nel codice, res è una variabile Go, mentre C.sum è una funzione C. Il suo valore di ritorno è int in C, non int in Go. La ragione per cui la chiamata ha successo è che cgo esegue la conversione dei tipi.
Chiamate da C a Go
Per chiamata da C a Go si intende la chiamata da parte del codice C in cgo a funzioni Go, non la chiamata da parte di programmi C nativi a Go. La catena di chiamata è: go-cgo-c->cgo->go. Go chiama C per sfruttare l'ecosistema e le prestazioni di C. Quasi non esiste la necessità di chiamare Go da programmi C nativi; se necessario, si consiglia di utilizzare la comunicazione di rete.
CGO supporta l'esportazione di funzioni Go per essere chiamate da C. Per esportare una funzione Go, è necessario aggiungere il commento //export func_name sopra la firma della funzione. I parametri e il valore di ritorno devono essere tipi supportati da cgo. Ecco un esempio:
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Riscrivere il file sum.c come segue:
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}Modificare anche il file header sum.h:
void do_sum();Poi esportare la funzione in Go:
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Ora la funzione sum utilizzata in C è effettivamente fornita da Go. L'output è:
20Il punto chiave è l'importazione di _cgo_export.h nel file sum.c, che contiene tutte le tipologie esportate da Go. Senza questa importazione, non è possibile utilizzare le funzioni esportate da Go. Un altro punto importante è che _cgo_export.h non può essere importato nei file Go, poiché la generazione di questo file header richiede che tutti i file sorgente Go possano essere compilati. Pertanto, la seguente scrittura è errata:
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Il compilatore segnalerà che il file header non esiste:
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.Se una funzione Go ha più valori di ritorno, la chiamata da C restituirà una struttura.
A proposito, possiamo passare puntatori Go a C tramite i parametri delle funzioni C. Durante la chiamata della funzione C, cgo cercherà di garantire la sicurezza della memoria. Tuttavia, il valore di ritorno di una funzione Go esportata non può essere un puntatore, poiché in questo caso cgo non può determinare se è referenziato e non può fissare la memoria. Se la memoria restituita viene referenziata e poi deallocata da GC in Go o si sposta, il puntatore diventerà non valido, come mostrato di seguito:
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}La scrittura sopra non è consentita dalla compilazione per impostazione predefinita. Se si desidera disabilitare questo controllo, è possibile impostare come segue:
GODEBUG=cgocheck=0Ci sono due livelli di controllo. Più alto è il livello, maggiore è il sovraccarico runtime. Per maggiori dettagli, consultare cgo command - passing_pointer.
Conversione dei Tipi
CGO esegue una mappatura dei tipi tra C e Go per facilitare le chiamate runtime. Per i tipi in C, dopo aver importato import "C" in Go, nella maggior parte dei casi è possibile accedervi direttamente tramite:
C.typenameAd esempio:
C.int(1)
C.char('a')Tuttavia, i tipi in C possono essere composti da più parole chiave, ad esempio:
unsigned charIn questo caso, non è possibile accedervi direttamente. Si può utilizzare la parola chiave typedef in C per creare un alias per il tipo, equivalente agli alias di tipo in Go. Ad esempio:
typedef unsigned char byte;In questo modo, è possibile accedere al tipo unsigned char tramite C.byte. Ecco un esempio:
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}Output:
a
b
cNella maggior parte dei casi, cgo ha già definito alias per i tipi comuni (come i tipi di base). È anche possibile definirne di propri secondo il metodo sopra, senza conflitti.
char
Il tipo char in C corrisponde al tipo int8 in Go, mentre unsigned char corrisponde a uint8, ovvero il tipo byte in Go.
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}Output:
type: main._Ctype_char, val: 99Se si passa C.char(math.MaxInt8 + 1) come parametro a set, la compilazione fallirà con il seguente errore:
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charStringhe
CGO fornisce alcune pseudo-funzioni per passare stringhe e slice di byte tra C e Go. Queste funzioni in realtà non esistono e non è possibile trovarne le definizioni, proprio come import "C", il pacchetto C non esiste. Sono state create per facilitare l'uso degli sviluppatori e, dopo la compilazione, verranno convertite in altre operazioni.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteLa stringa in Go è essenzialmente una struttura che contiene un riferimento a un array sottostante. Quando si passa a una funzione C, è necessario utilizzare C.CString() per creare una "stringa" in C usando malloc, allocando spazio di memoria e restituendo un puntatore C. Poiché in C non esiste il tipo stringa, si usa solitamente char* per rappresentare una stringa, ovvero un puntatore a un array di caratteri. Ricordarsi di liberare la memoria con free dopo l'uso.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}Può anche essere un tipo array char, entrambi sono essenzialmente puntatori all'elemento iniziale.
void printfGoString(char s[]) {
puts(s);
}È anche possibile passare slice di byte. Poiché C.CBytes() restituisce un unsafe.Pointer, è necessario convertirlo in *C.char prima di passarlo alla funzione C.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}L'output degli esempi sopra è lo stesso:
this is a go stringQuesti metodi di passaggio delle stringhe comportano una copia di memoria. Dopo il passaggio, esistono due copie separate nella memoria C e Go, rendendo l'operazione più sicura. Detto questo, è comunque possibile passare direttamente puntatori a funzioni C e modificare le stringhe Go in C. Vediamo un esempio:
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}Output:
this is a go stringL'esempio ottiene direttamente il puntatore all'array sottostante della stringa tramite unsafe.SliceData, lo converte in un puntatore C e lo passa alla funzione C. La memoria della stringa è gestita da Go, quindi non è necessario liberarla. Il vantaggio è che non è necessaria una copia durante il passaggio, ma c'è un certo rischio. L'esempio seguente dimostra la modifica di una stringa Go in C:
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}Output:
this is a go string
this is c go string
this is c go stringInteri
La mappatura tra interi Go e C è mostrata nella tabella seguente. Per ulteriori informazioni sulla mappatura dei tipi interi, consultare la libreria standard cmd/cgo/gcc.go.
| go | c | cgo |
|---|---|---|
| int8 | signed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
Esempio di codice:
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO supporta anche i tipi interi di <stdint.h>, che hanno dimensioni di memoria più chiare e uno stile di denominazione simile a Go.
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
Si consiglia di utilizzare i tipi interi di <stdint.h> quando si usa cgo.
Numeri in Virgola Mobile
La mappatura tra i tipi floating-point Go e C è la seguente:
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
Esempio di codice:
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}Slice
Le slice sono simili alle stringhe discusse sopra, ma cgo non fornisce pseudo-funzioni per copiare le slice. Per consentire a C di accedere alle slice Go, è necessario passare il puntatore della slice. Vediamo un esempio:
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}Output:
0 1 2 3 4 5 6 7 8 9Qui il puntatore all'array sottostante della slice viene passato alla funzione C. Poiché la memoria dell'array è gestita da Go, non è consigliabile che C mantenga a lungo un riferimento al puntatore. Al contrario, ecco un esempio in cui l'array C viene utilizzato come array sottostante per una slice Go:
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}Output:
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7La funzione unsafe.Slice converte un puntatore a un array in una slice. Per intuizione, un array in C è un puntatore all'elemento iniziale, quindi si potrebbe pensare di usarlo così:
goslice := unsafe.Slice(&C.s, l)Come si può vedere dall'output, facendo così, tranne il primo elemento, tutto il resto della memoria va fuori limite.
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]Anche se un array in C è solo un puntatore iniziale, dopo essere stato avvolto da cgo diventa un array Go con il proprio indirizzo. Pertanto, si dovrebbe prendere l'indirizzo dell'elemento iniziale dell'array.
goslice := unsafe.Slice(&C.s[0], l)Strutture
È possibile accedere alle strutture C utilizzando il prefisso C.struct_ seguito dal nome della struttura. Le strutture C non possono essere incorporate come strutture anonime nelle strutture Go. Ecco un semplice esempio di struttura C:
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}Output:
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}Se alcuni membri della struttura C contengono bit-field, cgo ignorerà tali membri. Ad esempio, modificando person come segue:
struct person {
int32_t age: 1;
char* name;
};Eseguendo nuovamente si otterrà un errore:
p.age undefined (type _Ctype_struct_person has no field or method age)Le regole di allineamento della memoria per i campi delle strutture in C e Go non sono le stesse. Con cgo abilitato, nella maggior parte dei casi sarà il C a dominare.
Union
È possibile accedere alle union C utilizzando C.union_ seguito dal nome. Poiché Go non supporta le union, esse esistono come array di byte in Go. Ecco un semplice esempio:
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}Output:
[4]uint8 [0 0 0 0]È possibile accedere e modificare utilizzando unsafe.Pointer:
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}Output:
0
1024
[0 4 0 0]Enum
È possibile accedere agli enum C utilizzando il prefisso C.enum_ seguito dal nome del tipo enum. Ecco un semplice esempio:
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}Output:
0 alive
1 deadPuntatori
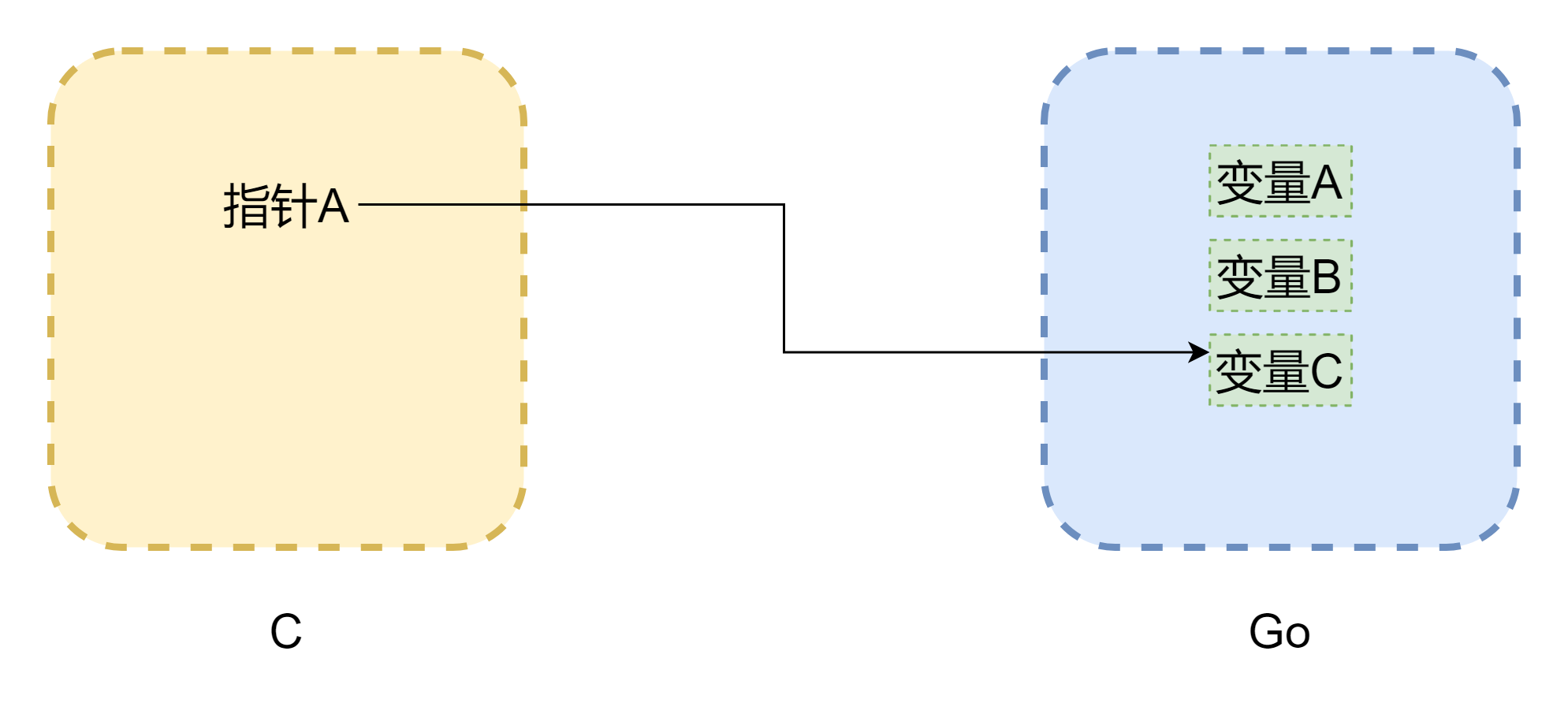
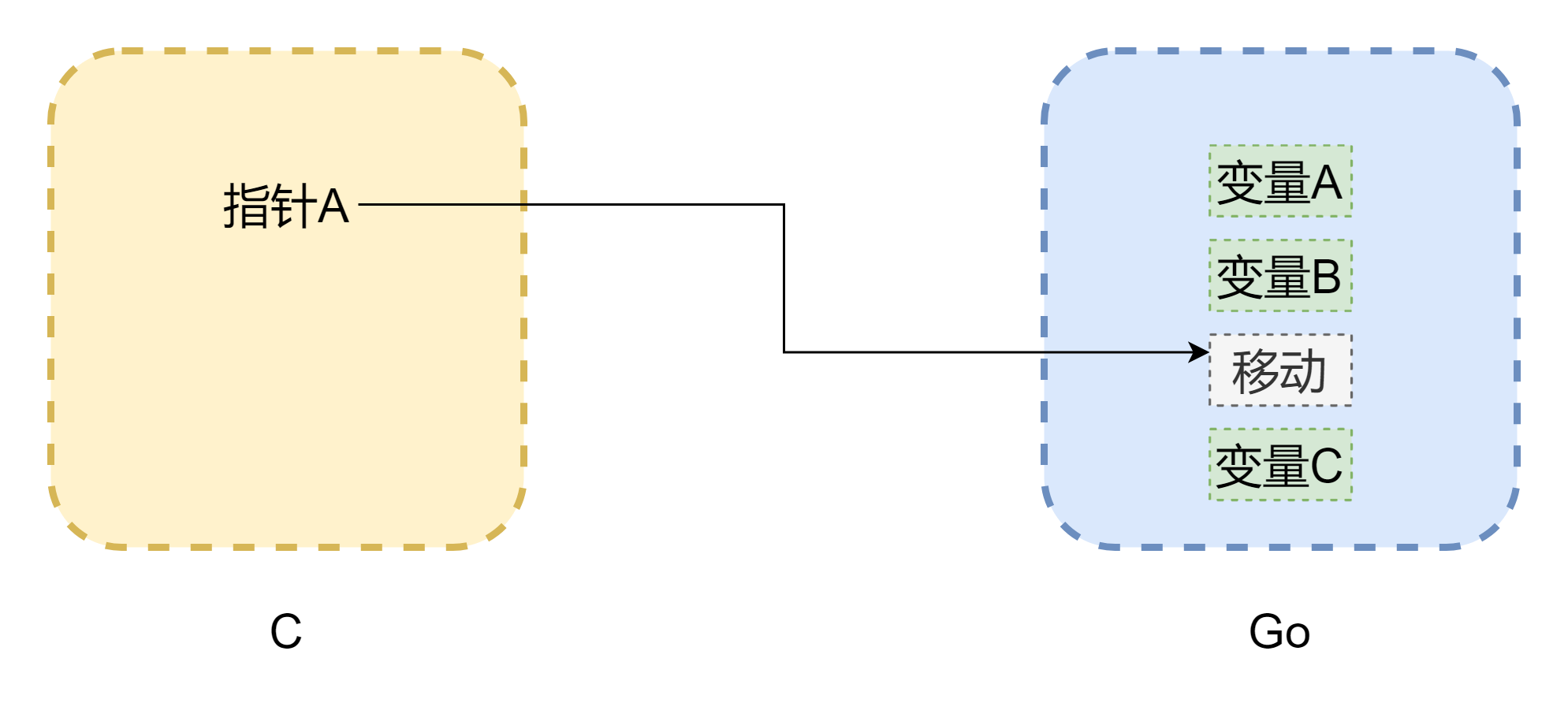
Quando si parla di puntatori, non si può evitare di parlare di memoria. Il problema principale nelle chiamate reciproche tra cgo è che i modelli di memoria dei due linguaggi non sono gli stessi. La memoria in C è completamente gestita manualmente dallo sviluppatore, utilizzando malloc() per allocare memoria e free() per liberarla. Se non viene liberata manualmente, non verrà mai liberata automaticamente, quindi la gestione della memoria in C è molto stabile. Go, invece, ha la GC e lo spazio stack delle Goroutine può essere regolato dinamicamente. Quando lo stack non è sufficiente, crescerà, il che può causare cambiamenti negli indirizzi di memoria. Come mostrato nella figura sopra (il disegno non è rigoroso), il puntatore potrebbe diventare un dangling pointer comune in C. Anche se cgo può evitare lo spostamento della memoria nella maggior parte dei casi (grazie a runtime.Pinner per fissare la memoria), Go non consiglia di mantenere riferimenti a lungo termine alla memoria Go in C. Al contrario, se Go mantiene puntatori alla memoria C, è relativamente sicuro, a meno che non si chiami manualmente C.free(), quella memoria non verrà liberata automaticamente.
Se si desidera passare puntatori tra C e Go, è necessario prima convertirli in unsafe.Pointer, quindi nel tipo di puntatore corrispondente, proprio come void* in C. Vediamo due esempi. Il primo è un esempio in cui un puntatore C referencia una variabile Go, modificandola anche.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}Output:
1
3
3Il secondo esempio mostra un puntatore Go che referencia una variabile C e la modifica.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}Output:
10
11A proposito, cgo non supporta i puntatori a funzione in C.
Librerie di Collegamento
Il linguaggio C non ha una gestione delle dipendenze come Go. Per utilizzare direttamente le librerie scritte da altri, oltre a ottenere il codice sorgente, c'è un altro metodo: le librerie di collegamento statico e dinamico. CGO supporta anche questi, permettendoci di importare librerie scritte da altri nei programmi Go senza bisogno del codice sorgente.
Libreria di Collegamento Dinamico
Una libreria di collegamento dinamico non può essere eseguita autonomamente. Durante l'esecuzione, viene caricata in memoria insieme al file eseguibile. Di seguito viene dimostrata la creazione di una semplice libreria di collegamento dinamico e la sua chiamata tramite cgo. Innanzitutto, preparare un file lib/sum.c con il seguente contenuto:
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}Creare il file header lib/sum.h:
#include <stdint.h>
int sum(int32_t a, int32_t b);Successivamente, utilizzare gcc per creare la libreria di collegamento dinamico. Prima compilare per generare il file oggetto:
$ cd lib
$ gcc -c sum.c -o sum.oPoi creare la libreria di collegamento dinamico:
$ gcc -shared -o libsum.dll sum.oDopo averla creata, importare il file header sum.h nel codice Go e indicare a cgo dove trovare la libreria tramite macro:
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Iindica il percorso relativo per cercare i file header-Lindica il percorso di ricerca della libreria,${SRCDIR}rappresenta il percorso assoluto della cartella corrente-lindica il nome del file della libreria, sum corrisponde asum.dll
CFLAGS e LDFLAGS sono entrambe opzioni di compilazione gcc. Per motivi di sicurezza, cgo ha disabilitato alcuni parametri. Per maggiori dettagli, consultare cgo command.
Posizionare la libreria dinamica nella stessa directory dell'eseguibile:
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goInfine, compilare ed eseguire il programma Go:
$ go build main.go && ./main.exe
3La chiamata alla libreria di collegamento dinamico è riuscita.
Libreria di Collegamento Statico
A differenza della libreria di collegamento dinamico, quando si importa una libreria di collegamento statico tramite cgo, questa verrà collegata con il file oggetto Go per formare un file eseguibile finale. Prendiamo ancora sum.c come esempio. Prima compilare il file sorgente in un file oggetto:
$ gcc -o sum.o -c sum.cPoi impacchettare il file oggetto in una libreria di collegamento statico (deve iniziare con il prefisso lib, altrimenti non verrà trovata):
$ ar rcs libsum.a sum.oContenuto del file Go:
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}Compilare:
$ go build && ./main.exe
3La chiamata alla libreria di collegamento statico è riuscita.
Conclusione
Sebbene l'obiettivo di utilizzare cgo sia migliorare le prestazioni, il passaggio tra C e Go comporta anche una certa perdita di prestazioni. Per compiti molto semplici, l'efficienza di cgo non è migliore di quella del Go puro. Vediamo un esempio:
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}Questo è un test molto semplice. Sono state scritte funzioni di somma di due numeri in C e Go, ciascuna eseguita 1 milione di volte per calcolare il tempo medio. I risultati del test sono:
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opCome si può vedere dai risultati, il tempo medio di cgo è oltre venti volte superiore a quello del Go puro. Se il compito non è una semplice somma di due numeri ma un'operazione più dispendiosa in termini di tempo, il vantaggio di cgo sarebbe maggiore. Oltre a ciò, l'uso di cgo presenta i seguenti svantaggi:
- Molti strumenti della toolchain Go non possono essere utilizzati, come gotest e pprof. L'esempio di test sopra non può utilizzare gotest, quindi è necessario scriverlo manualmente.
- La velocità di compilazione rallenta e non è più possibile utilizzare la cross-compilazione integrata.
- Problemi di sicurezza della memoria.
- Problemi di dipendenze. Se altri utilizzano la tua libreria, dovranno anche abilitare cgo.
Prima di introdurre cgo in un progetto, è necessario valutare attentamente. Per compiti molto complessi, l'uso di cgo può effettivamente portare vantaggi, ma per compiti semplici, è meglio attenersi a Go.