Protobuf
Sito ufficiale: Protocol Buffers | Google Developers
Introduzione
Tutorial ufficiale: Protocol Buffer Basics: Go | Protocol Buffers | Google Developers
Protocol Buffers è un meccanismo di serializzazione di dati strutturati estensibile, indipendente dal linguaggio e dal protocollo, open source da Google nel 2008. È più veloce durante l'unpacking e packing, utilizzato principalmente nelle comunicazioni RPC. Può definire il modo strutturato dei dati, quindi utilizzare codice sorgente generato appositamente per scrivere e leggere facilmente dati strutturati da e verso vari flussi di dati, utilizzabile con vari linguaggi. Di seguito, Protocol Buffers sarà denominato protobuf.
protobuf è abbastanza popolare, specialmente nell'ambito Go, dove gRPC lo utilizza come meccanismo di serializzazione per il trasporto del protocollo.
Sintassi
Prima, diamo un'occhiata a un esempio per vedere come appare approssimativamente un file protobuf. Nel complesso, la sua sintassi è molto semplice e si può imparare in una decina di minuti. Di seguito è riportato un esempio di un file chiamato search.proto. L'estensione del file protobuf è .proto:
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
}
message SearchResult {
string data = 1;
}
service SearchService {
rpc Search(SearchRequest) returns(SearchResult);
}- La prima riga
syntax = "proto3";indica l'uso della sintassiproto3, che è la sintassi predefinita. messageè dichiarato in modo simile a una struct ed è la struttura di base diproto.SearchRequestdefinisce tre campi, ogni campo ha un nome e un tipo.servicedefinisce un servizio, un servizio contiene uno o più interfacce rpc.- Le interfacce rpc devono avere esattamente un parametro e un valore di ritorno, i loro tipi devono essere
message, non possono essere tipi di base.
Inoltre, è importante notare che ogni riga in un file proto deve terminare con un punto e virgola.
Commenti
Lo stile dei commenti è esattamente lo stesso di Go:
syntax = "proto3";
/* Commento
* Commento */
message SearchRequest {
string query = 1; //Commento
string number = 2;
}Tipi
I modificatori di tipo possono apparire solo nei message, non possono apparire da soli.
Tipi di Base
| Tipo Proto | Tipo Go |
|---|---|
| double | float64 |
| float | float32 |
| int32 | int32 |
| int64 | int64 |
| uint32 | uint32 |
| uint64 | uint64 |
| sint32 | int32 |
| sint64 | int64 |
| fixed32 | uint32 |
| fixed64 | uint64 |
| sfixed32 | int32 |
| sfixed64 | int64 |
| bool | bool |
| string | string |
| bytes | []byte |
Array
Aggiungere il modificatore repeated prima di un tipo di base indica che si tratta di un tipo array, corrispondente alle slice in Go:
message Company {
repeated string employee = 1;
}Map
Il tipo map in protobuf è definito nel seguente formato:
map<key_type, value_type> map_field = N;key_type deve essere numerico o stringa, value_type non ha limiti di tipo. Ecco un esempio:
message Person {
map<string, int64> cards = 1;
}Campi
In realtà, proto non è un tipo tradizionale chiave-valore. Nel file proto dichiarato non appariranno dati specifici. Dopo ogni = del campo dovrebbe esserci un numero unico nel message corrente. Questi numeri vengono utilizzati per identificare e definire questi campi nel corpo del messaggio binario. I numeri partono da 1, i numeri da 1 a 15 occupano 1 byte, da 16 a 2047 occupano due byte, quindi è meglio assegnare i numeri da 1 a 15 ai campi che appaiono più frequentemente per risparmiare spazio, e dovrebbe essere lasciato dello spazio per i campi che potrebbero apparire frequentemente in seguito.
I campi in un message dovrebbero seguire le seguenti regole:
singular: Per impostazione predefinita è questo tipo di campo. In unmessageben strutturato, può esserci solo 0 o 1 di questo campo, ovvero non può esistere lo stesso campo ripetutamente. La seguente dichiarazione causerà un errore:protobufsyntax = "proto3"; message SearchRequest { string query = 1; string number = 2; string number = 3; // Campo duplicato }optional: Simile asingular, ma può verificare esplicitamente se il valore del campo è stato impostato. Potrebbero esserci le seguenti due situazioni:set: Verrà serializzatounset: Non verrà serializzato
repeated: Questo tipo di campo può apparire 0 o più volte. I valori duplicati verranno mantenuti in ordine (in sostanza è un array, può consentire la comparsa ripetuta di valori dello stesso tipo e li mantiene nell'ordine in cui appaiono, è un indice).map: Campo di tipo chiave-valore, dichiarato come segue:protobufmap<string,int32> config = 3;
Campi Riservati
La parola chiave reserve può dichiarare campi riservati. Dopo aver dichiarato i numeri dei campi riservati, non potranno più essere utilizzati come numeri e nomi di altri campi e si verificherà un errore durante la compilazione. La risposta ufficiale di Google è: se un file proto rimuove alcuni numeri in una nuova versione, in futuro altri utenti potrebbero riutilizzare questi numeri eliminati, ma se si torna alla versione precedente dei numeri, causerà un'errata corrispondenza tra i campi e i numeri, generando errori. I campi riservati possono svolgere un ruolo di promemoria durante la compilazione, ricordando che non è possibile utilizzare questo campo riservato, altrimenti la compilazione non passerà.
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
reserved "a"; // Dichiara un campo con nome specifico come campo riservato
reserved 1 to 2; // Dichiara una sequenza di numeri come campo riservato
reserved 3,4; // Dichiara
}In questo modo, questo file non passerà la compilazione.
Campi Deprecati
Se un campo è deprecato, può essere scritto come segue:
message Body {
string name = 1 [deprecated = true];
}Enumerazioni
È possibile dichiarare costanti enum e utilizzarle come tipo di campo. È importante notare che il primo elemento di un'enum deve essere zero, poiché il valore predefinito dell'enum è il primo elemento.
syntax = "proto3";
enum Type {
GET = 0;
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}Quando ci sono elementi enum con lo stesso valore all'interno di un'enum, è possibile utilizzare gli alias enum:
syntax = "proto3";
enum Type {
option allow_alias = true; // È necessario abilitare la configurazione per consentire l'uso di alias
GET = 0;
GET_ALIAS = 0; // Alias dell'elemento enum GET
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}Message Nidificati
message Outer { // Livello 0
message MiddleAA { // Livello 1
message Inner { // Livello 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Livello 1
message Inner { // Livello 2
int32 ival = 1;
bool booly = 2;
}
}
}Un message può nidificare la dichiarazione di un message, proprio come nidificare le struct.
Package
È possibile aggiungere un modificatore di package opzionale ai file protobuf per prevenire conflitti di nomi tra tipi di messaggi di protocollo.
package foo.bar;
message Open { ... }Quindi, è possibile utilizzare il nome del package quando si definiscono i campi nei tipi di messaggio:
message Foo {
...
foo.bar.Open open = 1;
...
}Import
L'importazione consente a più file protobuf di condividere definizioni. La sua sintassi è la seguente e non è possibile omettere l'estensione del file durante l'importazione:
import "a/b/c.proto";Durante l'importazione, vengono utilizzati percorsi relativi. Questo percorso relativo non si riferisce al percorso relativo tra il file che importa e il file importato, ma dipende dal percorso di scansione specificato quando il compilatore protoc genera il codice. Supponiamo di avere la seguente struttura di file:
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.protoSe dobbiamo solo generare il codice della directory player e specifichiamo solo la directory player nel percorso di scansione, allora le importazioni reciproche tra health.proto e player.proto possono scrivere direttamente il nome del file singolo, ad esempio player.proto importa health.proto:
import "health.proto";Se a questo punto player.proto importa common.proto o file nella directory monster, la compilazione fallirà, quindi la seguente scrittura è completamente errata, perché il compilatore non può trovare questi file:
import "../common.proto"; // Scrittura errataTIP
Tra l'altro, i simboli .. e . non sono consentiti nei percorsi di importazione.
Supponiamo che durante la compilazione venga specificato pb_learn come percorso di scansione, allora è possibile importare file di altre directory tramite percorsi relativi. Il percorso effettivo di importazione è l'indirizzo relativo dell'indirizzo assoluto del file rispetto a pb_learn. Ecco un esempio di player.proto che importa altri file:
import "common.proto";
import "monster/monster.proto";
import "player/health.proto";Anche health.proto che si trova nella stessa directory deve utilizzare il percorso relativo. Quindi in un progetto, generalmente creiamo una cartella separata per archiviare tutti i file protobuf e specifichiamo il percorso di scansione durante la compilazione. Tutte le operazioni di importazione in quella directory sono basate sul suo percorso relativo.
TIP
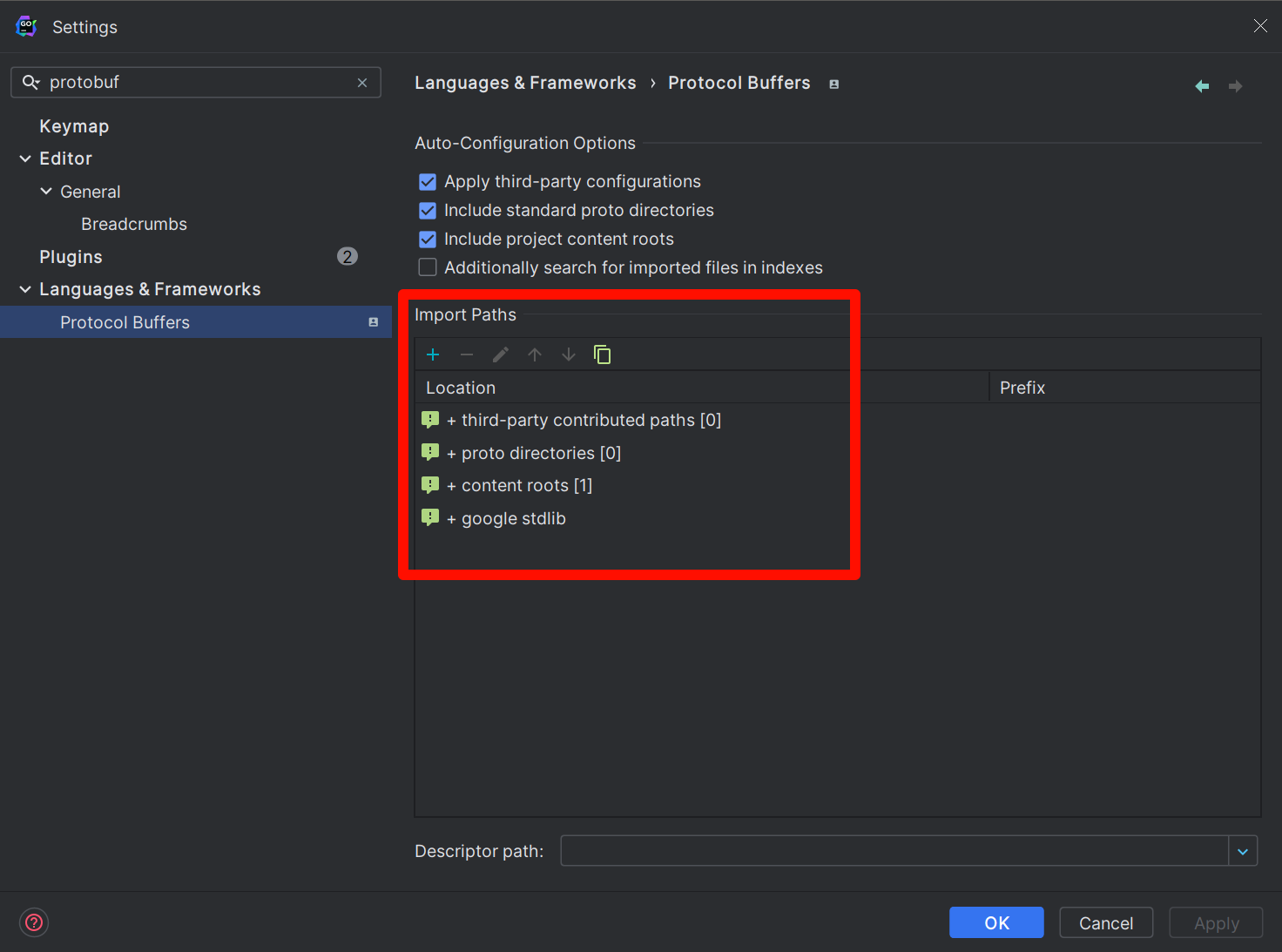
Se si utilizza l'editor GoLand, per le directory protobuf create autonomamente, non è possibile analizzarle per impostazione predefinita, il che causerà evidenziazioni rosse. Per far riconoscere GoLand, è necessario impostare manualmente il percorso di scansione. Il principio è esattamente lo stesso di quanto spiegato sopra. Il metodo di impostazione è il seguente: aprire le seguenti impostazioni
File | Settings | Languages & Frameworks | Protocol BuffersAggiungere manualmente il percorso di scansione in Import Paths. Questo percorso di scansione dovrebbe essere coerente con il percorso specificato durante la compilazione.
Any
Il tipo Any consente di utilizzare i messaggi come tipi incorporati senza bisogno delle loro definizioni proto. Possiamo importare direttamente i tipi definiti da Google, che sono inclusi automaticamente e non richiedono scrittura manuale:
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}Google ha anche predefinito molti altri tipi. Consultare protobuf/ptypes at master · golang/protobuf (github.com) per ulteriori informazioni, principalmente tra cui:
- Wrapper per tipi di base
- Tipo di tempo
- Tipo Duration
Le definizioni protobuf corrispondenti dovrebbero trovarsi nella directory include del compilatore protoc.
OneOf
La spiegazione della documentazione ufficiale è troppo prolissa. In parole semplici, indica che un campo può avere più tipi possibili durante la trasmissione, ma alla fine verrà utilizzato solo un tipo. All'interno non possono apparire campi modificati con repeated, proprio come l'union nel linguaggio C:
message Stock {
// Dati specifici per Stock
}
message Currency {
// Dati specifici per Currency
}
message ChangeNotification {
int32 id = 1;
oneof instrument {
Stock stock = 2;
Currency currency = 3;
}
}Service
La parola chiave service può definire un servizio RPC. Un servizio RPC contiene diverse interfacce rpc, che si dividono in interfacce unarie e interfacce stream:
message Body {
string name = 1;
}
service ExampleService {
rpc DoSomething(Body) returns(Body);
}Le interfacce stream si dividono in stream unidirezionali e bidirezionali, generalmente modificate con la parola chiave stream. Ecco un esempio:
message Body {
string name = 1;
}
service ExampleService {
// Stream lato client
rpc DoSomething(stream Body) returns(Body);
// Stream lato server
rpc DoSomething1(Body) returns(stream Body);
// Stream bidirezionale
rpc DoSomething2(stream Body) returns(stream Body);
}Il cosiddetto stream significa inviare dati reciprocamente a lungo termine in una connessione, non più come una semplice domanda e risposta come nelle interfacce unarie.
Empty
Empty è in realtà un message vuoto, corrispondente a una struct vuota in Go. Viene raramente utilizzato per modificare i campi, principalmente per indicare che un'interfaccia rpc non richiede parametri o non ha valore di ritorno:
syntax = "proto3";
import "google/protobuf/empty.proto";
service EmptyService {
rpc Do(google.protobuf.Empty) returns(google.protobuf.Empty);
}Option
Option viene generalmente utilizzato per controllare alcuni comportamenti di protobuf. Ad esempio, per controllare il package generato dal codice sorgente del linguaggio Go, è possibile dichiarare come segue:
option go_package = "github/jack/sample/pb_learn;pb_learn"Quello prima del punto e virgola è il percorso di importazione per altri file sorgente dopo la generazione del codice, quello dopo il punto e virgola è il nome del package del file generato corrispondente.
Può fare alcune ottimizzazioni. Ci sono i seguenti valori disponibili e non può essere dichiarato ripetutamente:
SPEED: Ottimizzazione più alta, volume di codice generato più grande, questo è il predefinito.CODE_SIZE: Riduce il volume di codice generato, ma dipenderà dalla riflessione per la serializzazione.LITE_RUNTIME: Volume di codice minimo, ma mancherà alcune funzionalità.
Ecco un caso d'uso:
option optimize_for = SPEED;Oltre a questo, option può anche aggiungere alcune metainformazioni a message ed enum. Utilizzando la riflessione è possibile ottenere queste informazioni, il che è particolarmente utile durante la validazione dei parametri.
Compilazione
La compilazione è la generazione del codice. Sopra è stato definito solo il file protobuf. Durante l'uso effettivo, è necessario convertirlo in codice sorgente di un linguaggio specifico per poterlo utilizzare. Completiamo questo compito tramite il compilatore protoc, che supporta più linguaggi.
Installazione
Per scaricare il compilatore, andare su protocolbuffers/protobuf: Protocol Buffers - Google's data interchange format (github.com) per scaricare l'ultima versione di Release, generalmente è un file compresso:
protoc-25.1-win64
│ readme.txt
│
├─bin
│ protoc.exe
│
└─include
└─google
└─protobuf
│ any.proto
│ api.proto
│ descriptor.proto
│ duration.proto
│ empty.proto
│ field_mask.proto
│ source_context.proto
│ struct.proto
│ timestamp.proto
│ type.proto
│ wrappers.proto
│
└─compiler
plugin.protoDopo il download, aggiungere la directory bin alle variabili d'ambiente per poter utilizzare il comando protoc. Dopo il completamento, verificare la versione. Se l'output è normale, l'installazione è riuscita:
$ protoc --version
libprotoc 25.1Il compilatore scaricato non supporta il linguaggio Go per impostazione predefinita, poiché la generazione del codice del linguaggio Go è un file eseguibile separato, mentre gli altri linguaggi sono tutti insieme. Quindi installare il plugin del linguaggio Go per tradurre le definizioni protobuf in codice sorgente del linguaggio Go:
$ go install google.golang.org/protobuf/cmd/protoc-gen-go@latestSe è necessario generare anche codice di servizio gRPC, installare il seguente plugin:
$ go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latestDopo l'installazione, verificare la versione:
$ protoc-gen-go-grpc --version
protoc-gen-go-grpc 1.3.0
$ protoc-gen-go --version
protoc-gen-go.exe v1.31.0Questi plugin sono anche file binari separati, ma possono essere chiamati solo tramite protoc e non possono essere eseguiti separatamente:
(this program should be run by protoc, not directly)Oltre a questi, ci sono molti altri plugin, come plugin per generare documentazione di interfaccia openapi, ecc. Se interessati, è possibile cercarli autonomamente.
Generazione
Prendiamo ancora l'esempio precedente, la struttura è la seguente:
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.protoPer la generazione del codice, è necessario specificare tre parametri in totale:
- Percorso di scansione: indica al compilatore dove cercare i file
protobufe come analizzare i percorsi di importazione. - Percorso di generazione: dove vengono posizionati i file dopo la compilazione.
- File di destinazione: specifica quali file di destinazione devono essere compilati.
Prima di iniziare, assicurarsi che go_package nei file protobuf sia impostato correttamente. Tramite protoc -h è possibile visualizzare i parametri supportati. I più comuni sono -I o --proto_path, che possono essere utilizzati più volte per specificare più percorsi di scansione, ad esempio:
$ protoc --proto_path=./pb_learn --proto_path=./third_partySpecificare solo il percorso di scansione non è sufficiente. È anche necessario specificare il percorso di generazione e i file protobuf di destinazione. Qui si generano file go, quindi si utilizza il parametro --go_out, supportato dal plugin protoc-gen-go scaricato in precedenza:
$ cd pb_learn
$ protoc --proto_path=. --go_out=. common.proto
$ ls
common.pb.go common.proto monster/ player/Il parametro --go_out specifica il percorso di generazione. . indica il percorso corrente. common.proto è il file da compilare. Se si desidera generare codice grpc (a condizione che sia installato il plugin grpc), è possibile aggiungere il parametro --go-grpc_out (se non è definito service nel file protobuf, non verrà generato il file corrispondente):
$ protoc --proto_path=. --go_out=. --go-grpc_out=. common.proto
$ ls
common.pb.go common.proto common_grpc.pb.go monster/ player/common.pb.go è la definizione di tipo protobuf generata. common_grpc.pb.go è il codice gRPC generato, che si basa sul primo. Se non viene generata la definizione del linguaggio corrispondente, non è possibile generare codice gRPC.
Se si desidera compilare tutti i file protobuf nella directory, è possibile utilizzare il carattere jolly *, ad esempio:
$ protoc --proto_path=. --go_out=. --go-grpc_out=. ./*.protoSe si desidera includere tutti i file, è possibile utilizzare il carattere jolly **, ad esempio ./**/*.proto:
$ protoc --proto_path=. --go_out=. --go-grpc_out=. ./**/*.protoTuttavia, questo metodo si applica solo alle shell che supportano questo carattere jolly. Ad esempio, in Windows, né cmd né powershell supportano questa scrittura:
D> protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./**/*.proto
Invalid file name pattern or missing input file "./**/*.proto"Fortunatamente, gitbash supporta molti comandi Linux e può anche far supportare questa sintassi a Windows. Per evitare di dover scrivere comandi ripetuti ogni volta, è possibile inserirli in un makefile:
.PHONY: all
proto_gen:
protoc --proto_path=. \
--go_out=paths=source_relative:. \
--go-grpc_out=paths=source_relative:. \
./**/*.proto ./*.protoSi può notare che è stato aggiunto paths=source_relative:.. Questo imposta la modalità del percorso di generazione del file. Ci sono le seguenti opzioni disponibili:
paths=import: Questo è il predefinito. I file verranno generati nella directory specificata daimport. Può anche essere un percorso di modulo. Ad esempio, se esiste un fileprotos/buzz.protoe si specificapaths=example.com/project/protos/fizz, alla fine verrà generatoexample.com/project/protos/fizz/buzz.pb.go.module=$PREFIX: Durante la generazione, verrà rimosso il prefisso del percorso. Nell'esempio sopra, se si specifica il prefissoexample.com/project, alla fine verrà generatoprotos/fizz/buzz.pb.go. Questa modalità è principalmente utilizzata per generare direttamente nel modulo (sembra che non ci sia molta differenza).paths=source_relative: I file generati manterranno la stessa struttura relativa dei fileprotobufnella directory specificata.
Dopo i due punti : viene specificato il percorso di generazione.
| common.proto
| common.pb.go
│
├─monster
│ monster.pb.go
│ monster.proto
│
└─player
health.pb.go
health.proto
health_grpc.pb.go
player.pb.go
player.protoRiflessione
È possibile estendere enum e message tramite options. Prima importare "google/protobuf/descriptor.proto":
import "google/protobuf/descriptor.proto";
extend google.protobuf.EnumValueOptions {
optional string string_name = 123456789;
}
enum Integer {
INT64 = 0[
(string_name) = "int_64"
];
}Questo equivale ad aggiungere una metainformazione a questo valore enum. Lo stesso vale per message:
import "google/protobuf/descriptor.proto";
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
message MyMessage {
option (my_option) = "Hello world!";
}Questo equivale a una riflessione relativa a protobuf. Dopo la generazione del codice, è possibile accedere tramite Descriptor:
func main() {
message := pb_learn.MyMessage{}
message.ProtoReflect().Descriptor().Options().ProtoReflect().Range(func(descriptor protoreflect.FieldDescriptor, value protoreflect.Value) bool {
fmt.Println(descriptor.FullName(), ":", value)
return true
})
}Output:
my_option:"Hello world!"Questo metodo può essere paragonato all'aggiunta di tag alle struct in Go, è quasi la stessa sensazione. Secondo questo metodo, è anche possibile implementare la funzionalità di validazione dei parametri. Basta scrivere le regole in options e utilizzare Descriptor per verificare.