Concorrenza
Il supporto di Go per la concorrenza è naturale, è il cuore di questo linguaggio. La difficoltà di apprendimento è relativamente bassa e gli sviluppatori possono creare applicazioni concorrenti di alto livello senza dover prestare troppa attenzione ai dettagli implementativi, migliorando il limite inferiore degli sviluppatori.
Goroutine
La goroutine (coroutine) è un thread leggero, o thread a livello utente, non direttamente schedulato dal sistema operativo, ma gestito dallo scheduler del linguaggio Go stesso durante l'esecuzione. Pertanto, il sovraccarico del cambio di contesto è molto piccolo, ed è uno dei motivi per cui le prestazioni concorrenti di Go sono eccellenti. Il concetto di coroutine non è stato introdotto per la prima volta da Go, e Go non è stato il primo linguaggio a supportare le coroutine, ma Go è il primo linguaggio in grado di combinare coroutine e supporto concorrente in modo semplice ed elegante.
In Go, creare una goroutine è molto semplice. Basta la parola chiave go per avviare rapidamente una goroutine. La parola chiave go deve essere seguita da una chiamata di funzione. Ecco un esempio:
TIP
Le funzioni built-in con valori di ritorno non sono consentite dopo la parola chiave go, come mostrato nell'esempio errato seguente:
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}Tutti e tre i modi per avviare una goroutine sono validi, ma in realtà, dopo l'esecuzione di questo esempio, nella maggior parte dei casi non verrà stampato nulla. Le goroutine vengono eseguite concorrentemente e il sistema richiede tempo per crearle. Prima che ciò accada, la goroutine principale si è già conclusa. Una volta che il thread principale termina, anche le goroutine secondarie terminano. Inoltre, l'ordine di esecuzione delle goroutine è incerto e imprevedibile. Ad esempio:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}Questo è un esempio di avvio di goroutine in un ciclo. Non è mai possibile prevedere con precisione cosa stamperà. Potrebbe essere che le goroutine secondarie non abbiano ancora iniziato a eseguire quando la goroutine principale termina, come segue:
start
endOppure solo alcune goroutine secondarie riescono a eseguire prima che la goroutine principale termini:
start
0
1
5
3
4
6
7
endIl metodo più semplice è far attendere la goroutine principale per un po', utilizzando la funzione Sleep del pacchetto time, che può sospendere la goroutine corrente per un periodo di tempo. Ecco un esempio:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// Sospende per 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}Eseguendo nuovamente, l'output è il seguente. Come si può vedere, tutti i numeri sono stati stampati completamente, senza omissioni:
start
0
1
5
2
3
4
6
8
9
7
endMa l'ordine è ancora confuso, quindi facciamo attendere ogni iterazione per un po'. Ecco un esempio:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}Ora l'output è nell'ordine corretto:
start
0
1
2
3
4
5
6
7
8
9
endI risultati dell'esempio sopra sono perfetti, ma il problema della concorrenza è stato risolto? No, per niente. Per i programmi concorrenti, ci sono molti fattori incontrollabili, come il timing di esecuzione, l'ordine, il tempo di esecuzione, ecc. Se il lavoro della goroutine secondaria nel ciclo non è solo un semplice output di numeri, ma un compito enorme e complesso, con tempo incerto, il problema si ripresenterà. Ad esempio, il codice seguente:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// Simula un tempo di esecuzione casuale
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}L'output di questo codice è ancora incerto. Ecco una delle possibili situazioni:
start
0
3
4
endQuindi time.Sleep non è una buona soluzione. Fortunatamente, Go fornisce molti strumenti di controllo della concorrenza. I tre metodi di controllo della concorrenza più comuni sono:
channel: pipelineWaitGroup: semaforoContext: contesto
I tre metodi hanno diversi scenari di applicazione. WaitGroup può controllare dinamicamente un gruppo di goroutine con un numero specificato, Context è più adatto per situazioni con livelli più profondi di goroutine annidate, e le pipeline sono più adatte per la comunicazione tra goroutine. Per il controllo tradizionale con lock, Go fornisce anche supporto:
Mutex: lock mutexRWMutex: lock di lettura-scrittura
Pipeline
channel, tradotto come pipeline, Go spiega il ruolo della pipeline come segue:
Do not communicate by sharing memory; instead, share memory by communicating.
Ovvero condividere la memoria tramite messaggi. channel è nato per questo scopo. È una soluzione per la comunicazione tra goroutine e può anche essere utilizzato per il controllo della concorrenza. Innanzitutto, conosciamo la sintassi di base di channel. In Go, la parola chiave chan rappresenta il tipo pipeline, e deve anche essere dichiarato il tipo di archiviazione della pipeline per specificare quale tipo di dati memorizza. L'esempio seguente mostra l'aspetto di una pipeline ordinaria:
var ch chan intQuesta è una dichiarazione di pipeline. A questo punto, la pipeline non è stata inizializzata e il suo valore è nil, quindi non può essere utilizzata direttamente.
Creazione
Quando si crea una pipeline, c'è uno e un solo metodo, ovvero utilizzare la funzione built-in make. Per le pipeline, la funzione make accetta due parametri: il primo è il tipo di pipeline e il secondo è un parametro opzionale per la dimensione del buffer della pipeline. Ecco un esempio:
intCh := make(chan int)
// Pipeline con dimensione buffer 1
strCh := make(chan string, 1)Dopo aver utilizzato una pipeline, è importante chiuderla. Utilizzare la funzione built-in close per chiudere una pipeline. La firma della funzione è la seguente:
func close(c chan<- Type)Ecco un esempio di chiusura di una pipeline:
func main() {
intCh := make(chan int)
// esegue qualcosa
close(intCh)
}A volte è meglio chiudere una pipeline utilizzando defer.
Lettura e Scrittura
Per una pipeline, Go utilizza due operatori molto descrittivi per rappresentare le operazioni di lettura e scrittura:
ch <-: indica la scrittura di dati in una pipeline
<- ch: indica la lettura di dati da una pipeline
<- descrive vividamente la direzione del flusso dei dati. Ecco un esempio di lettura e scrittura di una pipeline di tipo int:
func main() {
// Se non c'è buffer causerà deadlock
intCh := make(chan int, 1)
defer close(intCh)
// Scrive dati
intCh <- 114514
// Legge dati
fmt.Println(<-intCh)
}Nell'esempio sopra è stata creata una pipeline di tipo int con dimensione buffer 1, vi vengono scritti i dati 114514, poi letti e stampati, infine la pipeline viene chiusa. Per l'operazione di lettura, c'è un secondo valore di ritorno, un valore booleano che indica se la lettura dei dati è riuscita:
ints, ok := <-intChIl flusso dei dati in una pipeline funziona come una coda, ovvero First In First Out (FIFO). Le operazioni delle goroutine su una pipeline sono sincrone. In un dato momento, solo una goroutine può scrivere dati nella pipeline e solo una goroutine può leggere i dati dalla pipeline.
Senza Buffer
Per le pipeline senza buffer, poiché la capacità del buffer è 0, non possono memorizzare temporaneamente alcun dato. Poiché le pipeline senza buffer non possono memorizzare dati, quando si scrivono dati deve esserci immediatamente un'altra goroutine che legge i dati, altrimenti si bloccherà in attesa. Lo stesso vale per la lettura dei dati. Questo spiega perché il codice seguente, che sembra normale, causerà un deadlock:
func main() {
// Crea una pipeline senza buffer
ch := make(chan int)
defer close(ch)
// Scrive dati
ch <- 123
// Legge dati
n := <-ch
fmt.Println(n)
}Le pipeline senza buffer non dovrebbero essere utilizzate in modo sincrono. La soluzione corretta è avviare una nuova goroutine per inviare dati, come nell'esempio seguente:
func main() {
// Crea una pipeline senza buffer
ch := make(chan int)
defer close(ch)
go func() {
// Scrive dati
ch <- 123
}()
// Legge dati
n := <-ch
fmt.Println(n)
}Con Buffer
Quando una pipeline ha un buffer, è come una coda bloccante. Leggere da una pipeline vuota o scrivere in una pipeline piena causerà il blocco. Le pipeline senza buffer devono avere un ricevitore immediato quando si inviano dati, altrimenti si bloccheranno indefinitamente. Per le pipeline con buffer, non è necessario. Quando si scrivono dati in una pipeline con buffer, i dati vengono prima inseriti nel buffer. Solo quando il buffer è pieno, la goroutine si bloccherà in attesa che un'altra goroutine legga i dati dalla pipeline. Allo stesso modo, quando si legge da una pipeline con buffer, i dati vengono prima letti dal buffer. Solo quando il buffer è vuoto, la goroutine si bloccherà in attesa che un'altra goroutine scriva i dati nella pipeline. Pertanto, l'esempio di deadlock nelle pipeline senza buffer può essere eseguito senza problemi qui:
func main() {
// Crea una pipeline con buffer
ch := make(chan int, 1)
defer close(ch)
// Scrive dati
ch <- 123
// Legge dati
n := <-ch
fmt.Println(n)
}Anche se può essere eseguito senza problemi, questo modo di lettura e scrittura sincrona è molto pericoloso. Una volta che il buffer della pipeline è vuoto o pieno, si bloccherà indefinitamente, poiché non ci sono altre goroutine che scrivono o leggono i dati dalla pipeline. Vediamo l'esempio seguente:
func main() {
// Crea una pipeline con buffer
ch := make(chan int, 5)
// Crea due pipeline senza buffer
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// Responsabile della scrittura
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("Scrittura", i)
}
chW <- struct{}{}
}()
// Responsabile della lettura
go func() {
for i := 0; i < 10; i++ {
// Ogni lettura richiede 1 millisecondo
time.Sleep(time.Millisecond)
fmt.Println("Lettura", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("Scrittura completata", <-chW)
fmt.Println("Lettura completata", <-chR)
}Qui sono state create 3 pipeline: una pipeline con buffer per la comunicazione tra goroutine e due pipeline senza buffer per sincronizzare l'ordine di esecuzione delle goroutine padre e figlio. La goroutine responsabile della lettura attende 1 millisecondo prima di ogni lettura, mentre la goroutine responsabile della scrittura può scrivere al massimo 5 dati in una volta, poiché la dimensione massima del buffer della pipeline è 5. Senza goroutine che leggono, deve bloccarsi in attesa. Quindi l'output di questo esempio è il seguente:
Scrittura 0
Scrittura 1
Scrittura 2
Scrittura 3
Scrittura 4 // Ha scritto 5 dati, il buffer è pieno, aspetta che altre goroutine leggano
Lettura 0
Scrittura 5 // Legge uno, scrive uno
Lettura 1
Scrittura 6
Lettura 2
Scrittura 7
Lettura 3
Scrittura 8
Scrittura 9
Lettura 4
Scrittura completata {} // Tutti i dati sono stati inviati, la goroutine di scrittura termina
Lettura 5
Lettura 6
Lettura 7
Lettura 8
Lettura 9
Lettura completata {} // Tutti i dati sono stati letti, la goroutine di lettura terminaCome si può vedere, la goroutine responsabile della scrittura ha inviato 5 dati all'inizio. Dopo che il buffer è stato pieno, ha iniziato a bloccarsi in attesa che la goroutine di lettura leggesse. Successivamente, ogni volta che la goroutine di lettura legge un dato ogni 1 millisecondo e c'è spazio nel buffer, la goroutine di scrittura scrive un dato, fino a quando tutti i dati sono stati inviati e la goroutine di scrittura termina. Poi, quando la goroutine di lettura ha letto tutti i dati nel buffer, anche la goroutine di lettura termina e infine la goroutine principale termina.
TIP
Utilizzando la funzione built-in len è possibile accedere al numero di dati nel buffer della pipeline, e con cap è possibile accedere alla dimensione del buffer della pipeline.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}Output:
3 5Utilizzando le condizioni di blocco delle pipeline, è facile scrivere un esempio in cui la goroutine principale attende il completamento delle goroutine secondarie:
func main() {
// Crea una pipeline senza buffer
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// Scrive
ch <- struct{}{}
}()
// Attende in blocco la lettura
<-ch
fmt.Println(1)
}Output:
2
1Utilizzando le pipeline con buffer, è anche possibile implementare un semplice lock mutex. Vediamo l'esempio seguente:
var count = 0
// Pipeline con dimensione buffer 1
var lock = make(chan struct{}, 1)
func Add() {
// Acquisisce il lock
lock <- struct{}{}
fmt.Println("Conteggio corrente", count, "esegue addizione")
count += 1
// Rilascia il lock
<-lock
}
func Sub() {
// Acquisisce il lock
lock <- struct{}{}
fmt.Println("Conteggio corrente", count, "esegue sottrazione")
count -= 1
// Rilascia il lock
<-lock
}Poiché la dimensione del buffer della pipeline è 1, può esserci al massimo un dato nel buffer. Le funzioni Add e Sub tenteranno di inviare dati alla pipeline prima di ogni operazione. Poiché la dimensione del buffer è 1, se un'altra goroutine ha già scritto dati e il buffer è pieno, la goroutine corrente dovrà bloccarsi in attesa fino a quando non si libera uno spazio nel buffer. In questo modo, in un dato momento, al massimo una goroutine può modificare la variabile count, implementando così un semplice lock mutex.
Punti di Attenzione
Di seguito sono riportati alcuni riepiloghi. Le seguenti situazioni, se utilizzate in modo improprio, possono causare il blocco delle pipeline:
Lettura e Scrittura di Pipeline Senza Buffer
Quando si eseguono operazioni di lettura e scrittura sincrone su una pipeline senza buffer, la goroutine corrente si bloccherà:
func main() {
// Crea una pipeline senza buffer
intCh := make(chan int)
defer close(intCh)
// Invia dati
intCh <- 1
// Legge dati
ints, ok := <-intCh
fmt.Println(ints, ok)
}Lettura di una Pipeline con Buffer Vuoto
Quando si legge da una pipeline con buffer vuoto, la goroutine corrente si bloccherà:
func main() {
// Crea una pipeline con buffer
intCh := make(chan int, 1)
defer close(intCh)
// Il buffer è vuoto, blocca in attesa che altre goroutine scrivano dati
ints, ok := <-intCh
fmt.Println(ints, ok)
}Scrittura in una Pipeline con Buffer Pieno
Quando il buffer della pipeline è pieno, scrivere dati causerà il blocco della goroutine corrente:
func main() {
// Crea una pipeline con buffer
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// Pieno, blocca in attesa che altre goroutine leggano dati
intCh <- 1
}Pipeline è nil
Quando la pipeline è nil, qualsiasi operazione di lettura o scrittura causerà il blocco della goroutine corrente:
func main() {
var intCh chan int
// Scrittura
intCh <- 1
}func main() {
var intCh chan int
// Lettura
fmt.Println(<-intCh)
}Le condizioni di blocco delle pipeline devono essere ben comprese e familiarizzate. Nella maggior parte dei casi, questi problemi sono nascosti in modo molto sottile e non sono intuitivi come negli esempi.
Le seguenti situazioni possono anche causare panic:
Chiusura di una Pipeline nil
Quando la pipeline è nil, l'uso della funzione close per chiuderla causerà un panic:
func main() {
var intCh chan int
close(intCh)
}Scrittura in una Pipeline Chiusa
Scrivere dati in una pipeline già chiusa causerà un panic:
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}Chiusura di una Pipeline Già Chiusa
In alcune situazioni, la pipeline può essere passata attraverso più livelli e il chiamante potrebbe non sapere chi dovrebbe chiudere la pipeline. In questo caso, potrebbe verificarsi la chiusura di una pipeline già chiusa, causando un panic:
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Può solo inviare dati alla pipeline
ch <- 1
close(ch)
}Pipeline Unidirezionali
Una pipeline bidirezionale è una pipeline che può sia scrivere che leggere, ovvero può essere operata su entrambi i lati della pipeline. Una pipeline unidirezionale è una pipeline di sola lettura o di sola scrittura, ovvero può essere operata solo su un lato della pipeline. Creare manualmente una pipeline di sola lettura o di sola scrittura non ha molto senso, poiché non poter leggere o scrivere alla pipeline ne perde lo scopo. Le pipeline unidirezionali sono solitamente utilizzate per limitare il comportamento della pipeline e generalmente appaiono nei parametri e nei valori di ritorno delle funzioni. Ad esempio, la firma della funzione built-in close utilizzata per chiudere le pipeline utilizza una pipeline unidirezionale:
func close(c chan<- Type)Oppure la funzione After del pacchetto time comunemente utilizzata:
func After(d Duration) <-chan TimeIl parametro formale della funzione close è una pipeline di sola scrittura, e il valore di ritorno della funzione After è una pipeline di sola lettura. Quindi la sintassi delle pipeline unidirezionali è la seguente:
- Il simbolo freccia
<-è davanti, è una pipeline di sola lettura, come<-chan int - Il simbolo freccia
<-è dietro, è una pipeline di sola scrittura, comechan<- string
Quando si tenta di scrivere dati in una pipeline di sola lettura, la compilazione non riuscirà:
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}L'errore è il seguente, molto chiaro:
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)Lo stesso vale per la lettura di una pipeline di sola scrittura.
Una pipeline bidirezionale può essere convertita in una pipeline unidirezionale, ma non il contrario. Di solito, quando si passa una pipeline bidirezionale a una goroutine o funzione e non si desidera che legga/invii dati, è possibile utilizzare una pipeline unidirezionale per limitare il comportamento dell'altra parte:
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Può solo inviare dati alla pipeline
ch <- 1
}Lo stesso vale per le pipeline di sola lettura:
TIP
chan è un tipo di riferimento. Anche se Go passa i parametri per valore, il riferimento rimane lo stesso. Questo verrà spiegato nei principi delle pipeline successive.
for range
Utilizzando l'istruzione for range, è possibile iterare e leggere i dati da una pipeline con buffer, come nell'esempio seguente:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}Di solito, quando si utilizza for range per iterare su altre strutture dati iterabili, ci sono due valori di ritorno: il primo è l'indice e il secondo è il valore dell'elemento. Ma per le pipeline, c'è uno e un solo valore di ritorno. for range continuerà a leggere gli elementi dalla pipeline. Quando il buffer della pipeline è vuoto o senza buffer, si bloccherà in attesa fino a quando un'altra goroutine scriverà dati nella pipeline per continuare a leggere. Quindi l'output è il seguente:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!Come si può vedere, il codice sopra ha causato un deadlock, poiché la goroutine secondaria ha terminato l'esecuzione, mentre la goroutine principale è ancora in attesa che altre goroutine scrivano dati nella pipeline. Quindi la pipeline dovrebbe essere chiusa dopo aver finito di scrivere i dati. Modificare il codice come segue:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// Chiude la pipeline
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}Chiudendo la pipeline dopo la scrittura, il codice sopra non causerà più un deadlock. Come menzionato in precedenza, la lettura di una pipeline ha due valori di ritorno. Quando for range non riesce a leggere i dati con successo, esce dal ciclo. Il secondo valore di ritorno indica se i dati sono stati letti con successo, non se la pipeline è stata chiusa. Anche se la pipeline è stata chiusa, per le pipeline con buffer, è ancora possibile leggere i dati e il secondo valore di ritorno è ancora true. Vediamo un esempio:
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// Chiude la pipeline
close(ch)
// Legge di nuovo i dati
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}Risultato:
0 true
1 true
2 true
3 true
4 true
0 falsePoiché la pipeline è stata chiusa, anche se il buffer è vuoto, leggere di nuovo i dati non causerà il blocco della goroutine corrente. Come si può vedere, alla sesta iterazione, il valore letto è zero e ok è false.
TIP
Per quanto riguarda il momento di chiudere la pipeline, dovrebbe essere chiusa dal lato che invia i dati alla pipeline, non dal lato che riceve i dati. Nella maggior parte dei casi, il lato che riceve i dati sa solo ricevere i dati e non sa quando chiudere la pipeline.
WaitGroup
sync.WaitGroup è una struttura fornita dal pacchetto sync. WaitGroup significa attesa di esecuzione. Utilizzandolo, è possibile implementare facilmente l'attesa di un gruppo di goroutine. Questa struttura espone solo tre metodi:
Il metodo Add viene utilizzato per specificare il numero di goroutine da attendere:
func (wg *WaitGroup) Add(delta int)Il metodo Done indica che la goroutine corrente ha terminato l'esecuzione:
func (wg *WaitGroup) Done()Il metodo Wait attende la fine delle goroutine secondarie, altrimenti si blocca:
func (wg *WaitGroup) Wait()WaitGroup è molto semplice da usare, è pronto all'uso. La sua implementazione interna è un contatore + semaforo. All'inizio del programma, viene chiamato Add per inizializzare il conteggio. Ogni volta che una goroutine termina, viene chiamato Done e il conteggio diminuisce di 1, fino a quando non diventa 0. Durante questo periodo, la goroutine principale che chiama Wait rimarrà bloccata fino a quando tutti i conteggi non saranno ridotti a 0, quindi verrà risvegliata. Vediamo un semplice esempio di utilizzo:
func main() {
var wait sync.WaitGroup
// Specifica il numero di goroutine secondarie
wait.Add(1)
go func() {
fmt.Println(1)
// Esecuzione completata
wait.Done()
}()
// Attende la goroutine secondaria
wait.Wait()
fmt.Println(2)
}Questo codice stamperà sempre prima 1 e poi 2. La goroutine principale attende che la goroutine secondaria termini prima di uscire:
1
2Per l'esempio iniziale presentato nella sezione sulle goroutine, è possibile apportare le seguenti modifiche:
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// Conta 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// Conta 1 nel ciclo
wait.Add(1)
go func() {
fmt.Println(i)
// Diminuisce di 1 entrambi i conteggi
wait.Done()
mainWait.Done()
}()
// Attende che la goroutine del ciclo corrente termini
wait.Wait()
}
// Attende che tutte le goroutine terminino
mainWait.Wait()
fmt.Println("end")
}Qui viene utilizzato sync.WaitGroup al posto di time.Sleep. L'ordine di esecuzione delle goroutine concorrenti è più controllabile. Indipendentemente da quante volte viene eseguito, l'output è il seguente:
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup è solitamente adatto quando è necessario regolare dinamicamente il numero di goroutine, ad esempio quando si conosce in anticipo il numero di goroutine o quando è necessario regolare dinamicamente durante l'esecuzione. Il valore di WaitGroup non dovrebbe essere copiato e il valore copiato non dovrebbe essere continuato a utilizzare, specialmente quando viene passato come parametro di funzione. Dovrebbe essere passato un puntatore invece di un valore. Se si utilizza un valore copiato, il conteggio non può essere applicato al vero WaitGroup, il che potrebbe causare il blocco continuo della goroutine principale in attesa e il programma non potrà essere eseguito normalmente. Ad esempio, il codice seguente:
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}L'errore indica che tutte le goroutine sono uscite, ma la goroutine principale è ancora in attesa, formando un deadlock. Questo perché la chiamata a Done all'interno della funzione hello su un parametro formale WaitGroup non ha effetto sul mainWait originale. Quindi dovrebbe essere utilizzato un puntatore per il passaggio:
hello
fatal error: all goroutines are asleep - deadlock!TIP
Quando il conteggio diventa negativo o il numero di conteggi è maggiore del numero di goroutine secondarie, verrà generato un panic.
Context
Context, tradotto come contesto, è una soluzione di controllo della concorrenza fornita da Go. Rispetto alle pipeline e a WaitGroup, può controllare meglio le goroutine discendenti e le goroutine con livelli più profondi. Context è di per sé un'interfaccia. Finché un'interfaccia viene implementata, può essere chiamata contesto, come gin.Context nel famoso framework Web Gin. La libreria standard context fornisce anche alcune implementazioni,分别是:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
Vediamo prima la definizione dell'interfaccia Context, quindi comprendiamo la sua implementazione specifica:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
Questo metodo ha due valori di ritorno. deadline è l'ora di scadenza, ovvero il momento in cui il contesto dovrebbe essere cancellato. Il secondo valore indica se è stato impostato un deadline. Se non è stato impostato, è sempre false:
Deadline() (deadline time.Time, ok bool)Done
Il suo valore di ritorno è una pipeline di sola lettura di tipo struct vuoto. Questa pipeline serve solo come notifica e non trasmette alcun dato. Quando il lavoro svolto dal contesto dovrebbe essere cancellato, questo canale verrà chiuso. Per alcuni contesti che non supportano la cancellazione, potrebbe restituire nil:
Done() <-chan struct{}Err
Questo metodo restituisce un error per indicare il motivo della chiusura del contesto. Quando la pipeline Done non è chiusa, restituisce nil. Dopo la chiusura, restituirà un err per spiegare perché è stato chiuso:
Err() errorValue
Questo metodo restituisce il valore corrispondente alla chiave. Se la key non esiste o il metodo non è supportato, restituirà nil:
Value(key any) anyemptyCtx
Come suggerisce il nome, emptyCtx è un contesto vuoto. Tutte le implementazioni nel pacchetto context non sono esposte esternamente, ma vengono fornite funzioni corrispondenti per creare contesti. emptyCtx può essere creato tramite context.Background e context.TODO. Le due funzioni sono le seguenti:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}Come si può vedere, restituiscono solo un puntatore emptyCtx. Il tipo sottostante di emptyCtx è in realtà un int. Il motivo per cui non viene utilizzato uno struct vuoto è che le istanze di emptyCtx devono avere indirizzi di memoria diversi. Non può essere cancellato, non ha deadline e non può assumere valori. I metodi implementati restituiscono tutti valori zero:
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx è solitamente utilizzato come contesto di livello superiore e viene passato come contesto padre quando si creano gli altri tre tipi di contesti. Le relazioni tra le varie implementazioni nel pacchetto context sono mostrate nella figura seguente:
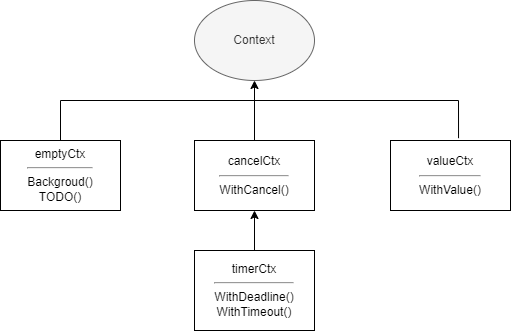
valueCtx
L'implementazione di valueCtx è relativamente semplice. Contiene solo una coppia chiave-valore e un campo incorporato di tipo Context:
type valueCtx struct {
Context
key, val any
}Implementa solo il metodo Value, e la logica è molto semplice: se non viene trovato nel contesto corrente, cerca nel contesto padre:
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}Vediamo un semplice caso di utilizzo di valueCtx:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// Passa il contesto
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// Crea un timer
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // Non verrà mai eseguito
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx è spesso utilizzato per trasmettere dati in goroutine a più livelli. Non può essere cancellato, quindi ctx.Done restituirà sempre nil e select ignorerà le pipeline nil. L'output finale è il seguente:
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
Sia cancelCtx che timerCtx implementano l'interfaccia canceler. Il tipo di interfaccia è il seguente:
type canceler interface {
// removeFromParent indica se rimuovere se stessi dal contesto padre
// err indica il motivo della cancellazione
cancel(removeFromParent bool, err error)
// Done restituisce una pipeline per notificare il motivo della cancellazione
Done() <-chan struct{}
}Il metodo cancel non è esposto esternamente. Viene incapsulato come valore di ritorno per chiamate esterne tramite chiusura durante la creazione del contesto, come mostrato nel codice sorgente di context.WithCancel:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// Tenta di aggiungere se stesso ai children del padre
propagateCancel(parent, &c)
// Restituisce context e una funzione
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx significa contesto cancellabile. Durante la creazione, se il padre implementa canceler, aggiungerà se stesso ai children del padre, altrimenti continuerà a cercare verso l'alto. Se nessun padre implementa canceler, avvierà una goroutine per attendere la cancellazione del padre, quindi quando il padre termina, cancellerà il contesto corrente. Quando viene chiamata cancelFunc, il canale Done verrà chiuso e qualsiasi figlio di questo contesto verrà cancellato di conseguenza. Infine, rimuoverà se stesso dal padre. Ecco un semplice esempio:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// Restituisce un cancelCtx e una funzione cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("In attesa della cancellazione...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}L'output è il seguente:
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
context canceledVediamo un altro esempio con livelli di annidamento più profondi:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("Elaborazione richiesta http...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth padre cancellato", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail padre cancellato", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}Nell'esempio sono stati creati 3 cancelCtx. Anche se il cancelCtx padre cancellerà i suoi contesti figli contemporaneamente alla propria cancellazione, per sicurezza, se viene creato un cancelCtx, la funzione cancel dovrebbe essere chiamata dopo il completamento del processo corrispondente. L'output è il seguente:
Elaborazione richiesta http...
auth...
mail...
mail...
auth...
Elaborazione richiesta http...
auth...
mail...
Elaborazione richiesta http...
Elaborazione richiesta http...
auth...
mail...
auth...
Elaborazione richiesta http...
mail...
context canceled
auth padre cancellato context canceled
mail padre cancellato context canceledtimerCtx
timerCtx aggiunge un meccanismo di timeout sulla base di cancelCtx. Il pacchetto context fornisce due funzioni di creazione,分别是 WithDeadline e WithTimeout. Entrambe le funzioni sono simili. La prima specifica un'ora di scadenza concreta, ad esempio un'ora specifica 2023/3/20 16:32:00. La seconda specifica un intervallo di tempo di scadenza, ad esempio tra 5 minuti. Le firme delle due funzioni sono le seguenti:
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx cancellerà automaticamente il contesto corrente alla scadenza del tempo. Oltre a chiudere il timer aggiuntivo, il processo di cancellazione è fondamentalmente coerente con cancelCtx. Ecco un semplice esempio di utilizzo di timerCtx:
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("Contesto cancellato", ctx.Err())
return
default:
fmt.Println("In attesa della cancellazione...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}Anche se il contesto scade automaticamente, per sicurezza, dopo il completamento del processo correlato, è meglio cancellare manualmente il contesto. L'output è il seguente:
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
In attesa della cancellazione...
Contesto cancellato context deadline exceededWithTimeout è in realtà molto simile a WithDeadline. La sua implementazione è solo un leggero incapsulamento e chiama WithDeadline. L'uso è lo stesso dell'esempio WithDeadline sopra:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
Proprio come l'allocazione della memoria senza recupero causerà una perdita di memoria, il contesto è anche una risorsa. Se viene creato ma non viene mai cancellato, causerà una perdita di contesto. Quindi è meglio evitare questa situazione.
Select
select nei sistemi Linux è una soluzione di I/O multiplexing. Allo stesso modo, in Go, select è una struttura di controllo di multiplexing delle pipeline. Cos'è il multiplexing? In breve, in un dato momento, monitora simultaneamente se più elementi sono disponibili. Gli elementi monitorati possono essere richieste di rete, I/O di file, ecc. In Go, gli elementi monitorati da select sono le pipeline e solo le pipeline. La sintassi di select è simile all'istruzione switch. Vediamo come appare un'istruzione select:
func main() {
// Crea tre pipeline
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("Tutte le pipeline non sono disponibili")
}
}Utilizzo
Simile a switch, select è composto da più case e un default. Il ramo default può essere omesso. Ogni case può operare solo su una pipeline e può eseguire solo un'operazione, o lettura o scrittura. Quando più case sono disponibili, select ne sceglierà uno in modo pseudo-casuale da eseguire. Se tutti i case non sono disponibili, verrà eseguito il ramo default. Se non c'è un ramo default, si bloccherà in attesa fino a quando almeno un case è disponibile. Poiché nell'esempio sopra non vengono scritti dati nelle pipeline, naturalmente tutti i case non sono disponibili, quindi l'output finale è il risultato dell'esecuzione del ramo default. Dopo una leggera modifica:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// Avvia una nuova goroutine
go func() {
// Scrive dati nella pipeline A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}L'esempio sopra avvia una nuova goroutine per scrivere dati nella pipeline A. Poiché select non ha un ramo predefinito, rimarrà bloccato in attesa fino a quando un case è disponibile. Quando la pipeline A è disponibile, dopo aver eseguito il ramo corrispondente, la goroutine principale esce direttamente. Per monitorare continuamente le pipeline, è possibile utilizzarlo con un ciclo for, come segue:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// Ciclo for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Questo utilizza effettivamente tutte e tre le pipeline, ma il ciclo infinito + select causerà il blocco permanente della goroutine principale. Quindi è possibile metterlo in una nuova goroutine e aggiungere altra logica:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // Imposta un timeout di 1 secondo
break Loop // Esce dal ciclo
}
}
l <- struct{}{} // Dice alla goroutine principale che può uscire
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Nell'esempio sopra, viene utilizzato un ciclo for con select per monitorare continuamente se le tre pipeline sono disponibili. Il quarto case è una pipeline di timeout. Dopo il timeout, uscirà dal ciclo e terminerà la goroutine secondaria. L'output finale è il seguente:
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueTimeout
L'esempio precedente ha utilizzato la funzione time.After, il cui valore di ritorno è una pipeline di sola lettura. Questa funzione, utilizzata con select, può implementare molto semplicemente un meccanismo di timeout. Ecco un esempio:
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("Timeout")
}
}Blocco Permanente
Quando l'istruzione select non contiene nulla, si bloccherà permanentemente. Ad esempio:
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end non verrà mai stampato e la goroutine principale rimarrà bloccata. Questa situazione ha generalmente uno scopo speciale.
TIP
Se si opera su una pipeline con valore nil nel case di select, non causerà il blocco e quel case verrà ignorato e non verrà mai eseguito. Ad esempio, il codice seguente stamperà sempre timeout indipendentemente da quante volte viene eseguito:
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}Non Bloccante
Utilizzando il ramo default di select con le pipeline, è possibile implementare operazioni di invio e ricezione non bloccanti, come mostrato di seguito:
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}Allo stesso modo, è anche possibile implementare un判断 non bloccante se un context è terminato:
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}Lock
Vediamo prima un esempio:
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Simula il tempo di accesso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// Accede ai dati
temp := *data
// Simula il tempo di calcolo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// Modifica i dati
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("Risultato finale", count)
}Per l'esempio sopra, vengono avviate dieci goroutine per eseguire un'operazione +1 su count e viene utilizzato time.Sleep per simulare diversi tempi di esecuzione. Secondo l'intuizione, 10 goroutine che eseguono 10 operazioni +1, il risultato finale dovrebbe essere 10. Il risultato corretto è effettivamente 10, ma la realtà non è così. Il risultato dell'esecuzione dell'esempio sopra è il seguente:
1
2
3
3
2
2
3
3
3
4
Risultato finale 4Come si può vedere, il risultato finale è 4, e questo è solo uno dei molti possibili risultati. Poiché il tempo di accesso e calcolo di ogni goroutine è diverso, la goroutine A impiega 500 millisecondi per accedere ai dati, e il valore di count accesso è 1. Poi impiega altri 400 millisecondi per il calcolo, ma durante questi 400 millisecondi, la goroutine B ha già completato l'accesso e il calcolo e ha aggiornato con successo il valore di count. Dopo che la goroutine A ha completato il calcolo, il valore accesso inizialmente dalla goroutine A è obsoleto, ma la goroutine A non lo sa e aggiunge comunque uno al valore accesso inizialmente, assegnandolo a count. In questo modo, il risultato dell'esecuzione della goroutine B viene sovrascritto. Quando più goroutine leggono e accedono a un dato condiviso, questo tipo di problema si verifica spesso. Per questo è necessario utilizzare i lock.
In Go, Mutex e RWMutex nel pacchetto sync forniscono due implementazioni: lock mutex e lock di lettura-scrittura, e forniscono API molto semplici e facili da usare. Per acquisire il lock basta Lock(), e per rilasciare il lock basta Unlock(). È importante notare che i lock forniti da Go sono lock non ricorsivi, ovvero lock non rientranti. Quindi acquisire o rilasciare ripetutamente il lock causerà un fatal. Il significato del lock è proteggere gli invarianti. Acquisire il lock significa sperare che i dati non vengano modificati da altre goroutine, come segue:
func DoSomething() {
Lock()
// Durante questo processo, i dati non possono essere modificati da altre goroutine
Unlock()
}Se fosse un lock ricorsivo, potrebbe verificarsi la seguente situazione:
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// esegue altro
Unlock()
}La funzione DoSomething ovviamente non sa cosa potrebbe fare la funzione DoOther ai dati, modificandoli, ad esempio avviando alcune goroutine secondarie che distruggono gli invarianti. Questo non è ammissibile in Go. Una volta acquisito il lock, deve essere garantita l'invarianza degli invarianti. In questo momento, acquisire o rilasciare ripetutamente il lock causerà un deadlock. Quindi, quando si scrive il codice, si dovrebbe evitare la situazione sopra. Quando necessario, utilizzare immediatamente l'istruzione defer per rilasciare il lock mentre lo si acquisisce.
Lock Mutex
sync.Mutex è l'implementazione del lock mutex fornita da Go. Implementa l'interfaccia sync.Locker:
type Locker interface {
// Acquisisce il lock
Lock()
// Rilascia il lock
Unlock()
}Utilizzando il lock mutex, è possibile risolvere perfettamente il problema sopra. Ecco un esempio:
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Acquisisce il lock
lock.Lock()
// Simula il tempo di accesso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Accede ai dati
temp := *data
// Simula il tempo di calcolo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// Modifica i dati
*data = temp + ans
// Rilascia il lock
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("Risultato finale", count)
}Ogni goroutine, prima di accedere ai dati, acquisisce prima il lock e, dopo aver aggiornato, rilascia il lock. Altre goroutine che vogliono accedere devono prima ottenere il lock, altrimenti si bloccano in attesa. In questo modo, non esiste il problema sopra, quindi l'output è il seguente:
1
2
3
4
5
6
7
8
9
10
Risultato finale 10Lock di Lettura-Scrittura
Il lock mutex è adatto per situazioni in cui la frequenza delle operazioni di lettura e scrittura è simile. Per alcuni dati con molte letture e poche scritture, se si utilizza un lock mutex, causerà una grande quantità di competizione non necessaria per il lock da parte delle goroutine, il che consumerà molte risorse di sistema. In questo momento, è necessario utilizzare il lock di lettura-scrittura, ovvero il lock mutex di lettura-scrittura. Per una goroutine:
- Se acquisisce il lock di lettura, altre goroutine che eseguono operazioni di scrittura si bloccheranno, mentre altre goroutine che eseguono operazioni di lettura non si bloccheranno
- Se acquisisce il lock di scrittura, altre goroutine che eseguono operazioni di scrittura si bloccheranno e altre goroutine che eseguono operazioni di lettura si bloccheranno
L'implementazione del lock mutex di lettura-scrittura in Go è sync.RWMutex, che implementa anche l'interfaccia Locker, ma fornisce più metodi disponibili, come segue:
// Acquisisce il lock di lettura
func (rw *RWMutex) RLock()
// Tenta di acquisire il lock di lettura
func (rw *RWMutex) TryRLock() bool
// Rilascia il lock di lettura
func (rw *RWMutex) RUnlock()
// Acquisisce il lock di scrittura
func (rw *RWMutex) Lock()
// Tenta di acquisire il lock di scrittura
func (rw *RWMutex) TryLock() bool
// Rilascia il lock di scrittura
func (rw *RWMutex) Unlock()Le due operazioni di tentativo di acquisizione del lock TryRLock e TryLock sono non bloccanti. Se l'acquisizione del lock ha successo, restituiscono true. Se non è possibile ottenere il lock, non si bloccano ma restituiscono false. L'implementazione interna del lock mutex di lettura-scrittura è ancora un lock mutex. Non è che ci siano due lock solo perché ci sono lock di lettura e scrittura. C'è sempre e solo un lock. Vediamo un caso di utilizzo del lock mutex di lettura-scrittura:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// Molte letture, poche scritture
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Attende la fine delle goroutine secondarie
wait.Wait()
fmt.Println("Risultato finale", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("Ottiene lock di lettura")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("Rilascia lock di lettura", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("Ottiene lock di scrittura")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("Rilascia lock di scrittura", *i)
rw.Unlock()
wait.Done()
}Questo esempio avvia 3 goroutine di scrittura e 7 goroutine di lettura. Quando leggono i dati, acquisiscono prima il lock di lettura. Le goroutine di lettura possono ottenere normalmente il lock di lettura, ma bloccheranno le goroutine di scrittura. Quando acquisiscono il lock di scrittura, bloccheranno sia le goroutine di lettura che di scrittura fino a quando non viene rilasciato il lock di scrittura. In questo modo, si realizza l'esclusione reciproca tra goroutine di lettura e scrittura, garantendo la correttezza dei dati. L'output dell'esempio è il seguente:
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di lettura
Rilascia lock di lettura 0
Rilascia lock di lettura 0
Rilascia lock di lettura 0
Rilascia lock di lettura 0
Ottiene lock di scrittura
Rilascia lock di scrittura 1
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di lettura
Rilascia lock di lettura 1
Rilascia lock di lettura 1
Rilascia lock di lettura 1
Ottiene lock di scrittura
Rilascia lock di scrittura 2
Ottiene lock di scrittura
Rilascia lock di scrittura 3
Risultato finale 3TIP
Per i lock, non dovrebbero essere passati e archiviati come valori. Dovrebbe essere utilizzato un puntatore.
Variabili di Condizione
Le variabili di condizione appaiono e vengono utilizzate insieme ai lock mutex, quindi alcune persone potrebbero erroneamente chiamarle lock di condizione, ma non sono lock. Sono un meccanismo di comunicazione. Go fornisce un'implementazione per sync.Cond, e la firma della funzione per creare una variabile di condizione è la seguente:
func NewCond(l Locker) *CondCome si può vedere, il prerequisito per creare una variabile di condizione è la creazione di un lock. sync.Cond fornisce i seguenti metodi per l'uso:
// Attende in blocco che la condizione sia soddisfatta, fino a quando non viene risvegliata
func (c *Cond) Wait()
// Risveglia una goroutine bloccata a causa della condizione
func (c *Cond) Signal()
// Risveglia tutte le goroutine bloccate a causa della condizione
func (c *Cond) Broadcast()Le variabili di condizione sono molto semplici da usare. Modificando leggermente l'esempio del lock mutex di lettura-scrittura sopra:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// Variabile di condizione
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// Molte letture, poche scritture
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Attende la fine delle goroutine secondarie
wait.Wait()
fmt.Println("Risultato finale", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("Ottiene lock di lettura")
// Se la condizione non è soddisfatta, continua a bloccarsi
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("Rilascia lock di lettura", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("Ottiene lock di scrittura")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("Rilascia lock di scrittura", *i)
rw.Unlock()
// Risveglia tutte le goroutine bloccate a causa della variabile di condizione
cond.Broadcast()
wait.Done()
}Quando si crea la variabile di condizione, poiché in questo caso la variabile di condizione agisce sulle goroutine di lettura, il lock di lettura viene passato come lock mutex. Se si passa direttamente il lock mutex di lettura-scrittura, causerà il problema del rilascio ripetuto del lock da parte delle goroutine di scrittura. Qui viene passato sync.rlocker, ottenuto tramite il metodo RWMutex.RLocker:
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }Come si può vedere, rlocker incapsula solo le operazioni di lock di lettura del lock mutex di lettura-scrittura. In realtà, è lo stesso riferimento, quindi è lo stesso lock. Quando le goroutine di lettura leggono i dati, se il valore è inferiore a 3, continueranno a bloccarsi in attesa fino a quando il dato non è maggiore di 3. Le goroutine di scrittura, dopo aver aggiornato i dati, tenteranno di risvegliare tutte le goroutine bloccate a causa della variabile di condizione. Quindi l'output finale è il seguente:
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di scrittura
Rilascia lock di scrittura 1
Ottiene lock di lettura
Ottiene lock di scrittura
Rilascia lock di scrittura 2
Ottiene lock di lettura
Ottiene lock di lettura
Ottiene lock di scrittura
Rilascia lock di scrittura 3 // La terza goroutine di scrittura termina
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Rilascia lock di lettura 3
Risultato finale 3Dal risultato, si può vedere che quando la terza goroutine di scrittura aggiorna i dati, le sette goroutine di lettura bloccate a causa della variabile di condizione riprendono l'esecuzione.
TIP
Per le variabili di condizione, dovrebbe essere utilizzato for invece di if. Dovrebbe essere utilizzato un ciclo per判断 se la condizione è soddisfatta, poiché quando una goroutine viene risvegliata, non è garantito che la condizione corrente sia già soddisfatta:
for !condition {
cond.Wait()
}sync
Una gran parte degli strumenti relativi alla concorrenza in Go sono forniti dalla libreria standard sync. Sopra sono stati presentati sync.WaitGroup, sync.Locker, ecc. Oltre a questi, il pacchetto sync fornisce anche altri strumenti utilizzabili.
Once
Quando si utilizzano alcune strutture dati, se queste strutture dati sono troppo grandi, è possibile considerare l'utilizzo del caricamento lazy, ovvero inizializzare la struttura dati solo quando viene effettivamente utilizzata. Come nell'esempio seguente:
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// Quando viene effettivamente utilizzata la slice, viene inizializzata
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}Il problema è che se c'è solo una goroutine che la utilizza, non ci sono problemi, ma se ci sono più goroutine che accedono, potrebbero verificarsi problemi. Ad esempio, le goroutine A e B chiamano contemporaneamente il metodo Add. A esegue leggermente più velocemente, ha già completato l'inizializzazione e ha aggiunto con successo i dati. Poi la goroutine B inizializza di nuovo, sovrascrivendo direttamente i dati aggiunti dalla goroutine A. Questo è il problema.
Questo è il problema che sync.Once deve risolvere. Come suggerisce il nome, Once significa una volta. sync.Once garantisce che un'operazione specificata venga eseguita una sola volta in condizioni concorrenti. Il suo utilizzo è molto semplice. Espone solo un metodo Do, con la seguente firma:
func (o *Once) Do(f func())Durante l'uso, basta passare l'operazione di inizializzazione al metodo Do, come segue:
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// Quando viene effettivamente utilizzata la slice, viene inizializzata
m.o.Do(func() {
fmt.Println("Inizializzazione")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}L'output è il seguente:
Inizializzazione
4Dal risultato dell'output, si può vedere che tutti i dati vengono aggiunti normalmente alla slice e l'operazione di inizializzazione viene eseguita solo una volta. In realtà, l'implementazione di sync.Once è molto semplice. Rimuovendo i commenti, la logica del codice reale è di sole 16 righe. Il suo principio è lock + operazioni atomiche. Il codice sorgente è il seguente:
type Once struct {
// Utilizzato per判断 se l'operazione è stata eseguita
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Caricamento atomico dei dati
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// Acquisisce il lock
o.m.Lock()
// Rilascia il lock
defer o.m.Unlock()
//判断 se è stato eseguito
if o.done == 0 {
// Modifica done dopo l'esecuzione
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
Lo scopo di progettazione di sync.Pool è memorizzare oggetti temporanei per il riutilizzo successivo. È un pool di oggetti temporaneo sicuro per la concorrenza. Gli oggetti temporaneamente non utilizzati vengono inseriti nel pool e non è necessario creare oggetti extra per il riutilizzo successivo, riducendo la frequenza di allocazione e rilascio della memoria. Il punto più importante è ridurre la pressione sulla GC. sync.Pool ha solo due metodi, come segue:
// Richiede un oggetto
func (p *Pool) Get() any
// Inserisce un oggetto
func (p *Pool) Put(x any)Inoltre, sync.Pool ha un campo New esposto esternamente, utilizzato per inizializzare un oggetto quando il pool di oggetti non riesce a richiederne uno:
New func() anyDi seguito viene dimostrato con un esempio:
var wait sync.WaitGroup
// Pool di oggetti temporanei
var pool sync.Pool
// Utilizzato per contare quanti oggetti sono stati creati durante il processo
var numOfObject atomic.Int64
// BigMemData Supponiamo che questa sia una struttura che occupa molta memoria
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"Grande memoria"}
}
wait.Add(1000)
// Qui vengono avviate 1000 goroutine
for i := 0; i < 1000; i++ {
go func() {
// Richiede un oggetto
val := pool.Get()
// Utilizza l'oggetto
_ = val.(BigMemData)
// Rilascia l'oggetto dopo l'uso
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}Nell'esempio vengono avviate 1000 goroutine che richiedono e rilasciano continuamente oggetti dal pool. Se non viene utilizzato un pool di oggetti, allora le 1000 goroutine devono ciascuna istanziare un oggetto, e questi 1000 oggetti istanziati devono essere rilasciati dalla GC dopo l'uso. Se ci sono decine di migliaia di goroutine o se il costo di creazione dell'oggetto è molto elevato, in questo caso occuperà molta memoria e porterà una grande pressione alla GC. Dopo aver utilizzato un pool di oggetti, è possibile riutilizzare gli oggetti riducendo la frequenza di istanziazione. Ad esempio, l'output dell'esempio sopra potrebbe essere il seguente:
5Anche se sono state avviate 1000 goroutine, durante l'intero processo sono stati creati solo 5 oggetti. Se non viene utilizzato un pool di oggetti, le 1000 goroutine creerebbero 1000 oggetti. Il miglioramento portato da questa ottimizzazione è ovvio, specialmente quando il volume di concorrenza è particolarmente elevato e il costo di istanziazione degli oggetti è particolarmente elevato.
Quando si utilizza sync.Pool, è necessario prestare attenzione ad alcuni punti:
- Oggetti temporanei:
sync.Poolè adatto solo per memorizzare oggetti temporanei. Gli oggetti nel pool potrebbero essere rimossi dalla GC senza alcun avviso, quindi non è consigliabile inserire connessioni di rete, connessioni di database, ecc. insync.Pool. - Imprevedibile: quando si richiede un oggetto da
sync.Pool, non è possibile prevedere se l'oggetto è appena creato o riutilizzato, né è possibile sapere quanti oggetti ci sono nel pool. - Sicurezza per la concorrenza: il governo garantisce che
sync.Poolsia sicuramente sicuro per la concorrenza, ma non garantisce che la funzioneNewutilizzata per creare oggetti sia sicura per la concorrenza. La funzioneNewviene passata dall'utente, quindi la sicurezza per la concorrenza della funzioneNewdeve essere mantenuta dall'utente stesso. Questo è anche il motivo per cui nel conteggio degli oggetti nell'esempio sopra viene utilizzato un valore atomico.
TIP
Infine, è importante notare che dopo aver utilizzato un oggetto, deve essere rilasciato nel pool. Se non viene rilasciato, l'utilizzo del pool di oggetti sarà inutile.
La libreria standard fmt ha un caso di utilizzo del pool di oggetti nella funzione fmt.Fprintf:
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// Richiede un buffer di stampa
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// Rilascia dopo l'uso
p.free()
return
}Le implementazioni delle funzioni newPrinter e free sono le seguenti:
func newPrinter() *pp {
// Richiede un oggetto dal pool di oggetti
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// Per mantenere la dimensione del buffer nel pool di oggetti approssimativamente la stessa per un migliore controllo elastico del buffer
// I buffer troppo grandi non vengono restituiti al pool di oggetti
if cap(p.buf) > 64<<10 {
return
}
// Reimposta i campi e rilascia l'oggetto nel pool
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map è un'implementazione sicura per la concorrenza di Map fornita ufficialmente. È pronto all'uso e molto semplice da utilizzare. Di seguito sono riportati i metodi esposti da questa struttura:
// Legge un valore in base a una chiave. Il valore di ritorno restituisce il valore corrispondente e se il valore esiste
func (m *Map) Load(key any) (value any, ok bool)
// Memorizza una coppia chiave-valore
func (m *Map) Store(key, value any)
// Elimina una coppia chiave-valore
func (m *Map) Delete(key any)
// Se la chiave esiste già, restituisce il valore originale, altrimenti memorizza il nuovo valore e lo restituisce. Quando il valore viene letto con successo, loaded è true, altrimenti è false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// Elimina una coppia chiave-valore e restituisce il suo valore originale. Il valore di loaded dipende dall'esistenza della chiave
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Itera sulla Map. Quando f() restituisce false, si interrompe l'iterazione
func (m *Map) Range(f func(key, value any) bool)Di seguito viene utilizzato un semplice esempio per dimostrare l'uso di base di sync.Map:
func main() {
var syncMap sync.Map
// Memorizza dati
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// Legge dati
fmt.Println(syncMap.Load("a"))
// Legge ed elimina
fmt.Println(syncMap.LoadAndDelete("a"))
// Legge o memorizza
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// Itera sulla map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Output:
a true
a true
hello world false
a hello world
b goodbye worldOra vediamo un esempio di utilizzo concorrente di map:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}Nell'esempio sopra viene utilizzata una map ordinaria, avviando 10 goroutine che memorizzano continuamente dati. Ovviamente, questo potrebbe facilmente causare un fatal. Il risultato sarà probabilmente il seguente:
fatal error: concurrent map writesUtilizzando sync.Map è possibile evitare questo problema:
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Output:
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4Per la sicurezza della concorrenza, è necessario fare alcuni sacrifici. Le prestazioni di sync.Map sono circa 10-100 volte inferiori rispetto a map.
Atomico
Nell'informatica, le operazioni atomiche o primitive sono solitamente utilizzate per descrivere operazioni che non possono essere ulteriormente suddivise. Poiché queste operazioni non possono essere suddivise in passaggi più piccoli, non possono essere interrotte da altre goroutine prima del completamento dell'esecuzione. Quindi il risultato dell'esecuzione è o successo o fallimento, non c'è una terza situazione. Se si verificano altre situazioni, allora non è un'operazione atomica. Ad esempio, il codice seguente:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}Il codice sopra è un semplice ramo di判断. Anche se il codice è molto breve, non è un'operazione atomica. Le vere operazioni atomiche sono supportate a livello di istruzioni hardware.
Tipi
Fortunatamente, nella maggior parte dei casi non è necessario scrivere assembly da soli. Il pacchetto sync/atomic della libreria standard Go ha già fornito API relative alle operazioni atomiche. Fornisce i seguenti tipi per eseguire operazioni atomiche:
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}Tra questi, il tipo atomico Pointer supporta i generici e il tipo Value supporta la memorizzazione di qualsiasi tipo. Oltre a questi, fornisce anche molte funzioni per facilitare le operazioni. Poiché la granularità delle operazioni atomiche è troppo fine, nella maggior parte dei casi, è più adatto gestire questi tipi di dati di base.
TIP
Le operazioni atomiche nel pacchetto atomic hanno solo firme di funzioni, senza implementazioni specifiche. Le implementazioni specifiche sono scritte in assembly plan9.
Utilizzo
Ogni tipo atomico fornisce i seguenti tre metodi:
Load(): ottiene atomicamente il valoreSwap(newVal type) (old type): scambia atomicamente il valore e restituisce il vecchio valoreStore(val type): memorizza atomicamente il valore
Tipi diversi potrebbero avere altri metodi aggiuntivi. Ad esempio, i tipi interi forniscono tutti il metodo Add per eseguire operazioni di addizione e sottrazione atomiche. Di seguito viene utilizzato un esempio di tipo int64:
func main() {
var aint64 atomic.Uint64
// Memorizza un valore
aint64.Store(64)
// Scambia un valore
aint64.Swap(128)
// Aggiunge
aint64.Add(112)
// Carica un valore
fmt.Println(aint64.Load())
}Oppure è anche possibile utilizzare direttamente le funzioni:
func main() {
var aint64 int64
// Memorizza un valore
atomic.StoreInt64(&aint64, 64)
// Scambia un valore
atomic.SwapInt64(&aint64, 128)
// Aggiunge
atomic.AddInt64(&aint64, 112)
// Carica
fmt.Println(atomic.LoadInt64(&aint64))
}L'uso di altri tipi è molto simile. L'output finale è:
240CAS
Il pacchetto atomic fornisce anche l'operazione CompareAndSwap, ovvero CAS. È il nucleo dell'implementazione di lock ottimistici e strutture dati senza lock. Il lock ottimistico non è di per sé un lock, ma un modo di controllo della concorrenza senza lock in condizioni concorrenti: un thread/goroutine, prima di modificare i dati, non acquisisce prima un lock, ma legge prima i dati, esegue il calcolo, poi quando invia la modifica utilizza CAS per判断 se altri thread hanno modificato i dati durante questo periodo. Se no (il valore è ancora uguale al valore letto in precedenza), la modifica ha successo; altrimenti, fallisce e riprova. Quindi il motivo per cui è chiamato lock ottimistico è perché presume sempre ottimisticamente che i dati condivisi non verranno modificati e esegue l'operazione corrispondente solo quando scopre che i dati non sono stati modificati. Il lock mutex appreso in precedenza è un lock pessimistico. Il lock mutex presume sempre pessimisticamente che i dati condivisi verranno modificati, quindi acquisisce un lock durante l'operazione e rilascia il lock dopo il completamento dell'operazione. Poiché la concorrenza implementata senza lock ha una sicurezza ed efficienza superiori rispetto ai lock, molte strutture dati sicure per la concorrenza utilizzano CAS per l'implementazione. Tuttavia, l'efficienza reale deve essere combinata con scenari di utilizzo specifici. Vediamo un esempio:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}Questo è un esempio che utilizza un lock mutex. Ogni volta che si aggiunge un numero, si acquisisce prima un lock e, dopo l'esecuzione, si rilascia il lock. Durante il processo, altre goroutine si bloccheranno. Successivamente, utilizziamo CAS per trasformarlo:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}Per CAS, ci sono tre parametri: valore in memoria, valore atteso, nuovo valore. Durante l'esecuzione, CAS confronta il valore atteso con il valore in memoria corrente. Se il valore in memoria è uguale al valore atteso, esegue l'operazione successiva, altrimenti non fa nulla. Per le operazioni atomiche nel pacchetto atomic di Go, le funzioni relative a CAS richiedono l'indirizzo, il valore atteso e il nuovo valore, e restituiscono un valore booleano che indica se la sostituzione è riuscita. Ad esempio, la firma della funzione di operazione CAS per il tipo int64 è la seguente:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)Nell'esempio CAS, prima si ottiene il valore atteso tramite LoadInt64, poi si utilizza CompareAndSwapInt64 per confrontare e scambiare. Se non ha successo, si continua a ciclare fino a quando non ha successo. Questa operazione senza lock non causerà il blocco delle goroutine, ma il ciclo continuo è comunque un costo non indifferente per la CPU. Quindi in alcune implementazioni, se il fallimento raggiunge un certo numero di volte, si potrebbe rinunciare all'operazione. Ma per l'operazione sopra, che è solo una semplice addizione di numeri, le operazioni coinvolte non sono complesse, quindi si può sicuramente considerare un'implementazione senza lock.
TIP
Nella maggior parte dei casi, solo confrontare i valori non può garantire la sicurezza della concorrenza. Ad esempio, il problema ABA causato da CAS richiede l'aggiunta di un version extra per risolvere il problema.
Value
La struttura atomic.Value può memorizzare valori di qualsiasi tipo. La struttura è la seguente:
type Value struct {
// Tipo any
v any
}Anche se può memorizzare qualsiasi tipo, non può memorizzare nil e i valori memorizzati prima e dopo dovrebbero essere dello stesso tipo. I due esempi seguenti non possono passare la compilazione:
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into ValueOltre a questo, il suo utilizzo non è molto diverso dagli altri tipi atomici. È importante notare che tutti i tipi atomici non dovrebbero copiare i valori, ma dovrebbero utilizzare i loro puntatori.