병발성
Go 언어의 병발성 지원은 순수하게 네이티브합니다. 이는 이 언어의 핵심으로, 습득 난이도가 상대적으로 낮아 개발자가底层 구현을 크게 신경 쓰지 않아도 상당히 훌륭한 병발성 애플리케이션을 만들 수 있어 개발자의 하한선을 높여줍니다.
루틴
루틴 (coroutine) 은 경량 스레드 또는 사용자 수준 스레드로, 운영체제에 의해 직접 스케줄링되지 않고 Go 언어 자체의 스케줄러에 의해 런타임 시 스케줄링됩니다. 따라서 컨텍스트 전환 오버헤드가 매우 작으며, 이것이 Go 의 병발성 성능이 좋은 이유 중 하나입니다. 루틴이라는 개념은 Go 가 처음 제안한 것은 아니며 Go 가 루틴을 지원하는 첫 번째 언어도 아니지만, Go 는 루틴과 병발성을 매우 간결하고 우아하게 지원할 수 있는 첫 번째 언어입니다.
Go 에서 루틴을 생성하는 것은 매우 간단하며 go 키워드 하나만으로 함수 호출을 빠르게 루틴으로 시작할 수 있습니다. go 키워드 뒤에는 반드시 함수 호출이 와야 합니다. 예제는 다음과 같습니다.
TIP
반환 값이 있는 내장 함수는 go 키워드 뒤에 올 수 없습니다. 예를 들어 다음과 같은 잘못된 예제가 있습니다.
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}위의 세 가지 루틴 시작 방식은 모두 가능하지만, 실제로 이 예제를 실행하면 대부분의 경우 아무것도 출력되지 않습니다. 루틴은 병렬로 실행되며, 시스템이 루틴을 생성하는 데 시간이 걸리고 그 전에 메인 루틴이 이미 실행을 완료합니다. 메인 스레드가 종료되면 다른 서브 루틴도 자연스럽게 종료됩니다. 또한 루틴의 실행 순서도 불확실하고 예측할 수 없습니다. 예를 들어 다음 예제를 살펴보겠습니다.
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}이는 루프 내에서 루틴을 시작하는 예제로, 정확히 무엇을 출력할지 예측할 수 없습니다. 서브 루틴이 시작되기 전에 메인 루틴이 이미 종료될 수 있습니다. 상황은 다음과 같습니다.
start
end또는 서브 루틴 중 일부만 메인 루틴이 종료되기 전에 성공적으로 실행될 수 있습니다. 상황은 다음과 같습니다.
start
0
1
5
3
4
6
7
end가장 간단한 방법은 메인 루틴이 잠시 기다리는 것이며, time 패키지의 Sleep 함수를 사용하여 현재 루틴을 일정 시간 동안 일시 중지할 수 있습니다. 예제는 다음과 같습니다.
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// 1ms 일시 중지
time.Sleep(time.Millisecond)
fmt.Println("end")
}다시 실행하면 다음과 같이 출력되며, 모든 숫자가 누락 없이 완전히 출력된 것을 볼 수 있습니다.
start
0
1
5
2
3
4
6
8
9
7
end하지만 순서는 여전히 뒤섞여 있으므로, 매번 루프에서 조금씩 기다리도록 합니다. 예제는 다음과 같습니다.
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}이제 출력은 정상적인 순서가 되었습니다.
start
0
1
2
3
4
5
6
7
8
9
end위의 예제 결과는 완벽해 보이지만, 병발성 문제가 해결된 것일까요? 아닙니다. 전혀 해결되지 않았습니다. 병발성 프로그램의 경우 제어할 수 없는 요소가 매우 많으며, 실행 시기, 선후 순서, 실행 과정의 소요 시간 등이 모두 변수입니다. 만약 루프 내 서브 루틴의 작업이 단순한 숫자 출력이 아니라 매우 거대하고 복잡한 작업이라면, 소요 시간은 불확실하며 이전 문제가 다시 발생할 것입니다. 예를 들어 다음 코드를 살펴보겠습니다.
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// 무작위 소요 시간 시뮬레이션
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}이 코드의 출력은 여전히 불확실하며, 다음은 가능한 상황 중 하나입니다.
start
0
3
4
end따라서 time.Sleep 은 좋은 해결 방법이 아닙니다. 다행히 Go 는 많은 병발성 제어 수단을 제공합니다. 일반적으로 사용되는 병발성 제어 방법은 세 가지가 있습니다.
channel: 파이프WaitGroup: 세마포어Context: 컨텍스트
세 방법은 각기 다른 적용 상황이 있습니다. WaitGroup 은 동적으로 지정된 수량의 루틴을 제어할 수 있으며, Context 는 자손 루틴 중첩 계층이 더 깊은 상황에 더 적합하고, 파이프는 루틴 간 통신에 더 적합합니다. 더 전통적인 잠금 제어에 대해 Go 도 이를 지원합니다.
Mutex: 상호 배타적 잠금RWMutex: 읽기/쓰기 상호 배타적 잠금
파이프
channel 은 파이프를 의미하며, Go 는 파이프의 작용을 다음과 같이 설명합니다.
Do not communicate by sharing memory; instead, share memory by communicating.
즉, 메시지를 통해 메모리를 공유하며, channel 은 이를 위해 존재합니다. 이는 루틴 간 통신을 위한 솔루션이며 동시에 병발성 제어에도 사용할 수 있습니다. 먼저 channel 의 기본 문법을 알아보겠습니다. Go 에서 chan 키워드는 파이프 타입을 나타내며, 동시에 파이프의 저장 타입을 선언하여 저장하는 데이터의 타입을 지정해야 합니다. 아래 예제는 일반 파이프의 모습입니다.
var ch chan int이는 파이프 선언문으로, 이때 파이프는 아직 초기화되지 않았으며 값은 nil 이므로直接使用할 수 없습니다.
생성
파이프를 생성할 때는 한 가지 방법만 있으며, 바로 내장 함수 make 를 사용하는 것입니다. 파이프의 경우 make 함수는 두 개의 매개변수를 받습니다. 첫 번째는 파이프 타입이고, 두 번째는 선택적 매개변수로 파이프의 버퍼 크기입니다. 예제는 다음과 같습니다.
intCh := make(chan int)
// 버퍼 크기가 1 인 파이프
strCh := make(chan string, 1)파이프 사용이 끝나면 반드시 해당 파이프를 닫아야 합니다. 내장 함수 close 를 사용하여 파이프를 닫습니다. 해당 함수 시그니처는 다음과 같습니다.
func close(c chan<- Type)파이프를 닫는 예제는 다음과 같습니다.
func main() {
intCh := make(chan int)
// do something
close(intCh)
}어떤 때는 defer 를 사용하여 파이프를 닫는 것이 더 나을 수 있습니다.
읽기/쓰기
파이프에 대해 Go 는 읽기/쓰기 작업을 나타내기 위해 두 가지 매우 직관적인 연산자를 사용합니다.
ch <-: 파이프에 데이터 쓰기
<- ch: 파이프에서 데이터 읽기
<- 는 데이터의 흐름 방향을 매우 생동감 있게 나타냅니다. int 타입 파이프의 읽기/쓰기 예제를 살펴보겠습니다.
func main() {
// 버퍼가 없으면 데드락이 발생합니다
intCh := make(chan int, 1)
defer close(intCh)
// 데이터 쓰기
intCh <- 114514
// 데이터 읽기
fmt.Println(<-intCh)
}위의 예제에서는 버퍼 크기가 1 인 int 형 파이프를 생성하고, 데이터 114514 를 쓴 다음, 데이터를 읽고 출력한 후, 해당 파이프를 닫습니다. 읽기 작업의 경우 두 번째 반환 값인 불리언 타입 값이 있어 데이터 읽기 성공 여부를 나타냅니다.
ints, ok := <-intCh파이프 내 데이터 흐름 방식은 큐와 같으며, 즉 선입선출 (FIFO) 입니다. 루틴의 파이프 작업은 동기적이며, 특정 시점에는 하나의 루틴만 파이프에 데이터를 쓸 수 있고, 동시에 하나의 루틴만 파이프에서 데이터를 읽을 수 있습니다.
버퍼 없음
버퍼가 없는 파이프의 경우 버퍼 용량이 0 이므로 데이터를 임시로 저장할 수 없습니다. 버퍼가 없는 파이프는 데이터를 저장할 수 없으므로, 데이터를 쓸 때는 즉시 다른 루틴이 데이터를 읽어야 하며, 그렇지 않으면 블로킹되어 대기합니다. 데이터를 읽을 때도 마찬가지이며, 이것이 아래看起来很正常的 코드가 데드락을 발생시키는 이유입니다.
func main() {
// 버퍼 없는 파이프 생성
ch := make(chan int)
defer close(ch)
// 데이터 쓰기
ch <- 123
// 데이터 읽기
n := <-ch
fmt.Println(n)
}버퍼가 없는 파이프는 동기적으로 사용해서는 안 되며, 올바르게 말하면 데이터를 보내기 위해 새로운 루틴을 시작해야 합니다. 다음 예제와 같습니다.
func main() {
// 버퍼 없는 파이프 생성
ch := make(chan int)
defer close(ch)
go func() {
// 데이터 쓰기
ch <- 123
}()
// 데이터 읽기
n := <-ch
fmt.Println(n)
}버퍼 있음
파이프에 버퍼가 있으면 블로킹 큐와 같습니다. 빈 파이프를 읽거나 가득 찬 파이프에 쓰면 블로킹됩니다. 버퍼가 없는 파이프는 데이터를 보낼 때 즉시 수신해야 하며, 그렇지 않으면 계속 블로킹됩니다. 버퍼가 있는 파이프의 경우 그럴 필요가 없습니다. 버퍼가 있는 파이프에 데이터를 쓸 때는 먼저 데이터를 버퍼에 넣고, 버퍼 용량이 가득 차야만 루틴이 파이프에서 데이터를 읽을 때까지 블로킹되어 대기합니다. 마찬가지로, 버퍼가 있는 파이프를 읽을 때는 먼저 버퍼에서 데이터를 읽고, 버퍼에 데이터가 없을 때까지 읽은 후에야 루틴이 파이프에 데이터를 쓸 때까지 블로킹되어 대기합니다. 따라서, 버퍼가 없는 파이프에서 데드락을 발생시키는 예제가 여기서는 원활하게 실행됩니다.
func main() {
// 버퍼 있는 파이프 생성
ch := make(chan int, 1)
defer close(ch)
// 데이터 쓰기
ch <- 123
// 데이터 읽기
n := <-ch
fmt.Println(n)
}원활하게 실행되지만, 이러한 동기식 읽기/쓰기 방식은 매우 위험합니다. 파이프 버퍼가 비거나 가득 차면, 파이프에 데이터를 쓰거나 읽을 다른 루틴이 없으므로 계속 블로킹됩니다. 다음 예제를 살펴보겠습니다.
func main() {
// 버퍼 있는 파이프 생성
ch := make(chan int, 5)
// 버퍼 없는 파이프 2 개 생성
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// 쓰기 담당
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("쓰기", i)
}
chW <- struct{}{}
}()
// 읽기 담당
go func() {
for i := 0; i < 10; i++ {
// 데이터 읽을 때마다 1ms 소요
time.Sleep(time.Millisecond)
fmt.Println("읽기", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("쓰기 완료", <-chW)
fmt.Println("읽기 완료", <-chR)
}여기서 총 3 개의 파이프를 생성했습니다. 하나는 버퍼가 있는 파이프이며 루틴 간 통신에 사용되고, 두 개는 버퍼가 없는 파이프이며 부모 - 자식 루틴의 실행 순서를 동기화하는 데 사용됩니다. 읽기 담당 루틴은 데이터를 읽기 전에 1ms 를 대기하고, 쓰기 담당 루틴은 한 번에 최대 5 개의 데이터만 쓸 수 있습니다. 파이프 버퍼의 최대 크기가 5 이므로, 다른 루틴이 읽기 전에는 블로킹되어 대기해야 합니다. 따라서 이 예제의 출력은 다음과 같습니다.
쓰기 0
쓰기 1
쓰기 2
쓰기 3
쓰기 4 // 5 개를 한 번에 썼고, 버퍼가 가득 차서 다른 루틴이 읽을 때까지 대기
읽기 0
쓰기 5 // 하나 읽고, 하나 씀
읽기 1
쓰기 6
읽기 2
쓰기 7
읽기 3
쓰기 8
쓰기 9
읽기 4
쓰기 완료 {} // 모든 데이터 전송 완료, 쓰기 루틴 실행 완료
읽기 5
읽기 6
읽기 7
읽기 8
읽기 9
읽기 완료 {} // 모든 데이터 읽기 완료, 읽기 루틴 실행 완료쓰기 담당 루틴이 처음에 5 개의 데이터를 한 번에 보낸 것을 볼 수 있으며, 버퍼가 가득 찬 후 읽기 루틴이 읽을 때까지 블로킹되어 대기합니다. 이후 읽기 루틴이 1ms 마다 하나의 데이터를 읽으면 버퍼에 여유 공간이 생기고, 쓰기 루틴은 하나의 데이터를 씁니다. 모든 데이터가 전송될 때까지 계속되며, 쓰기 루틴 실행이 종료된 후, 읽기 루틴이 버퍼의 모든 데이터를 읽으면 읽기 루틴도 실행이 종료되고, 마지막으로 메인 루틴이 종료됩니다.
TIP
내장 함수 len 을 사용하면 파이프 버퍼의 데이터 개수를 확인할 수 있고, cap 을 사용하면 파이프 버퍼의 크기를 확인할 수 있습니다.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}출력
3 5파이프의 블로킹 조건을 이용하여 메인 루틴이 서브 루틴 실행이 완료될 때까지 대기하는 예제를 쉽게 작성할 수 있습니다.
func main() {
// 버퍼 없는 파이프 생성
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// 쓰기
ch <- struct{}{}
}()
// 블로킹 대기 읽기
<-ch
fmt.Println(1)
}출력
2
1버퍼가 있는 파이프를 사용하여 간단한 상호 배타적 잠금을 구현할 수도 있습니다. 다음 예제를 살펴보겠습니다.
var count = 0
// 버퍼 크기가 1 인 파이프
var lock = make(chan struct{}, 1)
func Add() {
// 잠금
lock <- struct{}{}
fmt.Println("현재 카운트", count, "덧셈 실행")
count += 1
// 잠금 해제
<-lock
}
func Sub() {
// 잠금
lock <- struct{}{}
fmt.Println("현재 카운트", count, "뺄셈 실행")
count -= 1
// 잠금 해제
<-lock
}파이프의 버퍼 크기가 1 이므로 버퍼에 최대 하나의 데이터만 저장할 수 있습니다. Add 와 Sub 함수는 각 작업 전에 파이프에 데이터를 보내려고 시도합니다. 버퍼 크기가 1 이므로, 다른 루틴이 이미 데이터를 썼다면 버퍼가 가득 차서 현재 루틴은 버퍼에 여유 공간이 생길 때까지 블로킹되어 대기해야 합니다. 이렇게 하면 특정 시점에 최대 하나의 루틴만 변수 count 를 수정할 수 있어 간단한 상호 배타적 잠금을 구현할 수 있습니다.
주의점
다음은 요약입니다. 파이프 사용이 적절하지 않으면 파이프가 블로킹될 수 있는 몇 가지 상황이 있습니다.
버퍼 없는 파이프 읽기/쓰기
버퍼 없는 파이프에 동기식 읽기/쓰기 작업을 직접 수행하면 해당 루틴이 블로킹됩니다.
func main() {
// 버퍼 없는 파이프 생성
intCh := make(chan int)
defer close(intCh)
// 데이터 보내기
intCh <- 1
// 데이터 읽기
ints, ok := <-intCh
fmt.Println(ints, ok)
}빈 버퍼 파이프 읽기
버퍼가 빈 파이프를 읽으면 해당 루틴이 블로킹됩니다.
func main() {
// 버퍼 있는 파이프 생성
intCh := make(chan int, 1)
defer close(intCh)
// 버퍼가 비었음, 다른 루틴이 데이터를 쓸 때까지 블로킹 대기
ints, ok := <-intCh
fmt.Println(ints, ok)
}가득 찬 버퍼 파이프 쓰기
파이프 버퍼가 가득 찬 경우, 데이터를 쓰면 해당 루틴이 블로킹됩니다.
func main() {
// 버퍼 있는 파이프 생성
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// 가득 참, 다른 루틴이 데이터를 읽을 때까지 블로킹 대기
intCh <- 1
}파이프가 nil
파이프가 nil일 때, 어떻게 읽기/쓰기를 해도 현재 루틴이 블로킹됩니다.
func main() {
var intCh chan int
// 쓰기
intCh <- 1
}func main() {
var intCh chan int
// 읽기
fmt.Println(<-intCh)
}파이프 블로킹 조건을 잘 숙지하고 익숙해져야 합니다. 대부분의 경우 이러한 문제들은 예제처럼 직관적이지 않고 매우 숨겨져 있습니다.
다음과 같은 몇 가지 상황은 panic 을 유발합니다.
nil 파이프 닫기
파이프가 nil일 때, close 함수로 닫으면 panic 이 발생합니다.
func main() {
var intCh chan int
close(intCh)
}닫힌 파이프에 쓰기
닫힌 파이프에 데이터를 쓰면 panic 이 발생합니다.
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}닫힌 파이프 다시 닫기
어떤 상황에서는 파이프가 여러 계층을 거쳐 전달되어 호출자가 누구에게 파이프를 닫아야 하는지 모를 수 있습니다. 이렇게 하면 이미 닫힌 파이프를 다시 닫으려고 하여 panic 이 발생합니다.
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// 파이프에만 데이터 보낼 수 있음
ch <- 1
close(ch)
}단방향 파이프
양방향 파이프는 쓰기와 읽기가 모두 가능한 파이프를 의미하며, 파이프 양쪽에서 작업할 수 있습니다. 단방향 파이프는 읽기 전용 또는 쓰기 전용 파이프를 의미하며, 파이프의 한쪽에서만 작업할 수 있습니다. 수동으로 생성한 읽기 전용 또는 쓰기 전용 파이프는 큰 의미가 없습니다. 파이프의 읽기/쓰기를 할 수 없으면 존재 이유가 없어지기 때문입니다. 단방향 파이프는 일반적으로 파이프의 동작을 제한하는 데 사용되며, 일반적으로 함수의 형식 매개변수와 반환 값에서 나타납니다. 예를 들어, 파이프를 닫는 내장 함수 close 의 함수 시그니처는 단방향 파이프를 사용합니다.
func close(c chan<- Type)또는 일반적으로 사용되는 time 패키지의 After 함수를 예로 들 수 있습니다.
func After(d Duration) <-chan Timeclose 함수의 형식 매개변수는 쓰기 전용 파이프이고, After 함수의 반환 값은 읽기 전용 파이프입니다. 따라서 단방향 파이프의 문법은 다음과 같습니다.
- 화살표 기호
<-가 앞에 있으면 읽기 전용 파이프입니다. 예:<-chan int - 화살표 기호
<-가 뒤에 있으면 쓰기 전용 파이프입니다. 예:chan<- string
읽기 전용 파이프에 데이터를 쓰려고 하면 컴파일이 통과되지 않습니다.
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}에러는 다음과 같이 매우 명확합니다.
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)쓰기 전용 파이프에서 데이터를 읽는 것도 마찬가지입니다.
양방향 파이프는 단방향 파이프를 변환할 수 있지만, 그 반대는 불가능합니다. 일반적으로 양방향 파이프를 어떤 루틴이나 함수에 전달할 때 읽기/쓰기를 원하지 않는 경우, 단방향 파이프를 사용하여 상대방의 동작을 제한할 수 있습니다.
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// 파이프에만 데이터 보낼 수 있음
ch <- 1
}읽기 전용 파이프도 같은 이치입니다.
TIP
chan 은 참조 타입입니다. Go 의 함수 매개변수가 값 전달이지만, 참조는 여전히 동일합니다. 이는 이후 파이프 원리에서 설명합니다.
for range
for range 문을 사용하면 버퍼 파이프의 데이터를 순회하며 읽을 수 있습니다. 다음 예제와 같습니다.
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}일반적으로 for range 는 다른 반복 가능한 데이터 구조를 순회할 때 두 개의 반환 값이 있습니다. 첫 번째는 인덱스이고, 두 번째는 요소 값입니다. 하지만 파이프의 경우 반환 값이 하나뿐입니다. for range 는 파이프의 요소를 계속 읽으며, 파이프 버퍼가 비거나 버퍼가 없을 때는 블로킹되어 대기하다가, 다른 루틴이 파이프에 데이터를 써야만 계속 데이터를 읽습니다. 따라서 출력은 다음과 같습니다.
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!위의 코드가 데드락을 발생시킨 것을 볼 수 있습니다. 서브 루틴이 이미 실행을 완료했지만, 메인 루틴은 다른 루틴이 파이프에 데이터를 쓸 때까지 블로킹되어 대기하고 있기 때문입니다. 따라서 파이프에 데이터 쓰기를 완료한 후 파이프를 닫아야 합니다. 다음과 같이 코드를 수정합니다.
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// 파이프 닫기
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}쓰기를 완료한 후 파이프를 닫으면, 위의 코드는 더 이상 데드락을 발생시키지 않습니다. 앞서 파이프 읽기에는 두 개의 반환 값이 있다고 언급했습니다. for range 는 파이프를 순회할 때, 데이터를 성공적으로 읽을 수 없으면 루프를 종료합니다. 두 번째 반환 값은 데이터를 성공적으로 읽을 수 있는지 여부를 나타내며, 파이프가 닫혔는지 여부가 아닙니다. 파이프가 닫힌 후에도 버퍼가 있는 파이프의 경우 여전히 데이터를 읽을 수 있으며, 두 번째 반환 값은 여전히 true 입니다. 다음 예제를 살펴보겠습니다.
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// 파이프 닫기
close(ch)
// 데이터 다시 읽기
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}출력 결과
0 true
1 true
2 true
3 true
4 true
0 false파이프가 닫혔으므로, 버퍼가 비어 있어도 다시 데이터를 읽어도 현재 루틴이 블로킹되지 않습니다. 여섯 번째 순회 시 읽은 값은 제로 값이며, ok 는 false 인 것을 볼 수 있습니다.
TIP
파이프를 닫는 시기는 가능한 한 파이프에 데이터를 보내는 쪽에서 닫아야 하며, 수신 쪽에서 파이프를 닫아서는 안 됩니다. 대부분의 경우 수신 쪽은 데이터만 받을 뿐, 언제 파이프를 닫아야 하는지 알지 못하기 때문입니다.
WaitGroup
sync.WaitGroup 은 sync 패키지에서 제공하는 구조체로, WaitGroup 은 대기 실행을 의미하며, 이를 사용하면 한 세트의 루틴을 기다리는 효과를 쉽게 구현할 수 있습니다. 해당 구조체는 세 가지 메서드만 외부에 노출합니다.
Add 메서드는 기다릴 루틴의 수를 지정하는 데 사용합니다.
func (wg *WaitGroup) Add(delta int)Done 메서드는 현재 루틴이 실행을 완료했음을 나타냅니다.
func (wg *WaitGroup) Done()Wait 메서드는 서브 루틴이 종료될 때까지 대기하며, 그렇지 않으면 블로킹됩니다.
func (wg *WaitGroup) Wait()WaitGroup 사용은 매우 간단하며, 바로 사용할 수 있습니다. 내부 구현은 카운터 + 세마포어로, 프로그램 시작 시 Add 를 호출하여 카운트를 초기화하고, 루틴이 실행을 완료할 때마다 Done 을 호출하면 카운트가 1 감소하며, 0 이 될 때까지 감소합니다. 이 기간 동안 메인 루틴이 Wait 을 호출하면 모든 카운트가 0 이 될 때까지 블로킹되었다가 깨어납니다. 간단한 사용 예제를 살펴보겠습니다.
func main() {
var wait sync.WaitGroup
// 서브 루틴 수 지정
wait.Add(1)
go func() {
fmt.Println(1)
// 실행 완료
wait.Done()
}()
// 서브 루틴 대기
wait.Wait()
fmt.Println(2)
}이 코드는 항상 1 을 출력한 후 2 를 출력하며, 메인 루틴은 서브 루틴이 실행을 완료한 후 종료됩니다.
1
2루틴 소개에서 가장 처음 나온 예제를 다음과 같이 수정할 수 있습니다.
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// 카운트 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// 루프 내에서 카운트 1
wait.Add(1)
go func() {
fmt.Println(i)
// 두 카운트 -1
wait.Done()
mainWait.Done()
}()
// 현재 루프의 루틴 실행 완료 대기
wait.Wait()
}
// 모든 루틴 실행 완료 대기
mainWait.Wait()
fmt.Println("end")
}여기서는 time.Sleep 대신 sync.WaitGroup 을 사용했으며, 루틴 병렬 실행의 순서를 더 잘 제어할 수 있습니다. 몇 번을 실행해도 출력은 다음과 같습니다.
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup 은 일반적으로 루틴 수를 동적으로 조정할 수 있을 때 적합합니다. 예를 들어, 루틴 수를 미리 알거나, 실행 과정에서 동적으로 조정해야 할 때입니다. WaitGroup 의 값은 복사해서는 안 되며, 복사된 값도 계속 사용해서는 안 됩니다. 특히 함수 매개변수로 전달할 때는 값이 아닌 포인터를 전달해야 합니다. 복사된 값을 사용하면 카운트가 실제 WaitGroup 에 적용되지 않아 메인 루틴이 계속 블로킹되어 대기하게 되고, 프로그램이 정상적으로 실행되지 않을 수 있습니다. 예를 들어 다음 코드와 같습니다.
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}에러는 모든 루틴이 종료되었지만 메인 루틴이 여전히 대기 중이므로 데드락이 형성되었습니다. hello 함수 내부에서 형식 매개변수 WaitGroup 에 Done 을 호출해도 원래의 mainWait 에 적용되지 않기 때문입니다. 따라서 포인터를 사용하여 전달해야 합니다.
hello
fatal error: all goroutines are asleep - deadlock!TIP
카운트가 음수가 되거나, 카운트 수가 서브 루틴 수보다 크면 panic 이 발생합니다.
Context
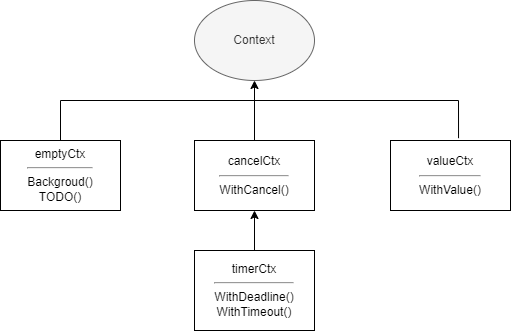
Context 는 컨텍스트로 번역되며, Go 에서 제공하는 병발성 제어 솔루션입니다. 파이프와 WaitGroup 에 비해 자손 루틴과 계층이 더 깊은 루틴을 더 잘 제어할 수 있습니다. Context 자체는 인터페이스이며, 이 인터페이스를 구현한 것은 모두 컨텍스트라고 할 수 있습니다. 예를 들어 유명한 Web 프레임워크 Gin 의 gin.Context 가 있습니다. context 표준 라이브러리도 몇 가지 구현을 제공합니다.
emptyCtxcancelCtxtimerCtxvalueCtx
Context
먼저 Context 인터페이스의 정의를 살펴보고, 구체적인 구현을 알아보겠습니다.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
이 메서드는 두 개의 반환 값을 가집니다. deadline 은 마감 시간, 즉 컨텍스트가 취소되어야 하는 시간입니다. 두 번째 값은 deadline 을 설정했는지 여부이며, 설정하지 않으면 항상 false 입니다.
Deadline() (deadline time.Time, ok bool)Done
반환 값은 빈 구조체 타입의 읽기 전용 파이프입니다. 해당 파이프는 알림 역할만 하며, 어떤 데이터도 전달하지 않습니다. 컨텍스트가 수행한 작업을 취소해야 할 때, 해당 채널이 닫힙니다. 취소를 지원하지 않는 일부 컨텍스트의 경우 nil 을 반환할 수 있습니다.
Done() <-chan struct{}Err
이 메서드는 error 를 반환하며, 컨텍스트가 닫힌 이유를 나타내는 데 사용합니다. Done 파이프가 닫히지 않았을 때는 nil 을 반환하며, 닫힌 후에는 err 를 반환하여 왜 닫혔는지 설명합니다.
Err() errorValue
이 메서드는 해당 키의 값을 반환합니다. key 가 존재하지 않거나, 해당 메서드를 지원하지 않으면 nil 을 반환합니다.
Value(key any) anyemptyCtx
이름에서 알 수 있듯이, emptyCtx 는 빈 컨텍스트입니다. context 패키지의 모든 구현은 외부에 노출되지 않지만, 컨텍스트를 생성하는 함수를 제공합니다. emptyCtx 는 context.Background 와 context.TODO 를 통해 생성할 수 있습니다. 두 함수는 다음과 같습니다.
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}단순히 emptyCtx 포인터를 반환하는 것을 볼 수 있습니다. emptyCtx 의底层 타입은 실제로 int입니다. 빈 구조체를 사용하지 않는 이유는 emptyCtx 의 인스턴스는 서로 다른 메모리 주소를 가져야 하기 때문입니다. 이는 취소할 수 없으며, deadline 이 없고, 값을 가져올 수도 없습니다. 구현된 메서드는 모두 제로 값을 반환합니다.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx 는 일반적으로 최상위 컨텍스트로 사용되며, 다른 세 가지 컨텍스트를 생성할 때 부모 컨텍스트로 전달됩니다. context 패키지의 각 구현 관계는 아래 그림과 같습니다.
valueCtx
valueCtx 구현은 비교적 간단하며, 내부에 한 쌍의 키 - 값 쌍과 Context 타입의 임베딩된 필드만 포함합니다.
type valueCtx struct {
Context
key, val any
}자체는 Value 메서드만 구현했으며, 로직도 매우 간단합니다. 현재 컨텍스트에서 찾을 수 없으면 부모 컨텍스트에서 찾습니다.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}다음은 valueCtx 의 간단한 사용 사례입니다.
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// 컨텍스트 전달
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// 새 타이머 생성
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // 영원히 실행되지 않음
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx 는 다단계 루틴에서 일부 데이터를 전달하는 데 주로 사용되며, 취소할 수 없으므로 ctx.Done 은 항상 nil 을 반환하며, select 는 nil 파이프를 무시합니다. 마지막 출력은 다음과 같습니다.
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx 와 timerCtx 는 모두 canceler 인터페이스를 구현했습니다. 인터페이스 타입은 다음과 같습니다.
type canceler interface {
// removeFromParent 는 부모 컨텍스트에서 자신을 삭제할지 여부를 나타냄
// err 는 취소 이유를 나타냄
cancel(removeFromParent bool, err error)
// Done 은 취소 이유를 알리는 파이프를 반환
Done() <-chan struct{}
}cancel 메서드는 외부에 노출되지 않으며, 컨텍스트 생성 시 클로저를 통해 반환 값으로 포장하여 외부에서 호출할 수 있도록 합니다. context.WithCancel 소스 코드에 표시된 것과 같습니다.
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// 자신을 부모의 children 에 추가 시도
propagateCancel(parent, &c)
// context 와 함수 반환
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx 는 취소 가능한 컨텍스트로 번역됩니다. 생성 시, 부모가 canceler 를 구현하면 자신을 부모의 children 에 추가하고, 그렇지 않으면 계속 위로 찾아갑니다. 모든 부모가 canceler 를 구현하지 않으면, 부모가 취소될 때까지 대기하는 루틴을 시작하고, 부모가 종료될 때 현재 컨텍스트를 취소합니다. cancelFunc 를 호출하면 Done 채널이 닫히며, 해당 컨텍스트의 모든 자식도 함께 취소되고, 마지막으로 자신을 부모에서 삭제합니다. 다음은 간단한 예제입니다.
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// cancelCtx 와 cancel 함수 반환
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("취소 대기 중...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}출력은 다음과 같습니다.
취소 대기 중...
취소 대기 중...
취소 대기 중...
취소 대기 중...
취소 대기 중...
context canceled계층 중첩이 더 깊은 예제를 하나 더 살펴보겠습니다.
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("http 요청 처리 중...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth 부모 취소", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail 부모 취소", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}예제에서는 3 개의 cancelCtx 를 생성했습니다. 부모 cancelCtx 가 취소될 때 자식 컨텍스트도 취소되지만, 안전하게 위해 cancelCtx 를 생성한 경우, 해당 프로세스가 종료된 후 cancel 함수를 호출해야 합니다. 출력은 다음과 같습니다.
http 요청 처리 중...
auth...
mail...
mail...
auth...
http 요청 처리 중...
auth...
mail...
http 요청 처리 중...
http 요청 처리 중...
auth...
mail...
auth...
http 요청 처리 중...
mail...
context canceled
auth 부모 취소 context canceled
mail 부모 취소 context canceledtimerCtx
timerCtx 는 cancelCtx 에 타임아웃 메커니즘을 추가한 것입니다. context 패키지에는 두 가지 생성 함수가 있습니다. WithDeadline 과 WithTimeout 입니다. 두 함수는 기능이 비슷하며, 전자는 구체적인超时 시간을 지정합니다. 예를 들어 구체적인 시간 2023/3/20 16:32:00을 지정하고, 후자는超时 시간 간격을 지정합니다. 예를 들어 5 분 후입니다. 두 함수의 시그니처는 다음과 같습니다.
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx 는 시간이 만료되면 자동으로 현재 컨텍스트를 취소합니다. 취소 프로세스는 timer 를 추가로 닫는 것 외에는 기본적으로 cancelCtx 와 일치합니다. 다음은 간단한 timerCtx 사용 예제입니다.
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("컨텍스트 취소", ctx.Err())
return
default:
fmt.Println("취소 대기 중...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}컨텍스트가 만료되면 자동으로 취소되지만, 안전하게 위해 관련 프로세스가 종료된 후 수동으로 컨텍스트를 취소하는 것이 좋습니다. 출력은 다음과 같습니다.
취소 대기 중...
취소 대기 중...
취소 대기 중...
취소 대기 중...
취소 대기 중...
컨텍스트 취소 context deadline exceededWithTimeout 는 실제로 WithDeadline 와 매우 유사하며, 구현도 약간 포장하여 WithDeadline 를 호출하는 것뿐입니다. 위 예제의 WithDeadline 사용법과 동일합니다.
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
메모리 할당 후 회수하지 않으면 메모리 누수가 발생하는 것과 마찬가지로, 컨텍스트도 일종의 리소스입니다. 생성했지만 취소하지 않으면 컨텍스트 누수가 발생하므로 이러한 상황을 피하는 것이 좋습니다.
Select
select 는 Linux 시스템에서 IO 멀티플렉싱 솔루션입니다. 비슷하게, Go 에서 select 는 파이프 멀티플렉싱 제어 구조입니다. 멀티플렉싱이 무엇인지 간단히 한 마디로 요약하면: 특정 시점에 여러 요소가 사용 가능한지 동시에 모니터링하며, 모니터링할 요소는 네트워크 요청, 파일 IO 등이 될 수 있습니다. Go 에서 select 가 모니터링하는 요소는 파이프이며, 파이프만 가능합니다. select 의 문법은 switch 문과 유사합니다. select 문이 어떻게 생겼는지 살펴보겠습니다.
func main() {
// 파이프 3 개 생성
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("모든 파이프 사용 불가")
}
}사용
switch 와 마찬가지로, select 는 여러 개의 case 와 하나의 default 로 구성되며, default 분기는 생략할 수 있습니다. 각 case 는 하나의 파이프만 작업할 수 있으며, 한 가지 작업만 수행할 수 있습니다. 읽기 또는 쓰기 중 하나입니다. 여러 case 가 사용 가능할 때, select 는 의사 무작위로 하나의 case 를 선택하여 실행합니다. 모든 case 가 사용 불가능하면 default 분기를 실행하며, default 분기가 없으면 최소한 하나의 case 가 사용 가능해질 때까지 블로킹되어 대기합니다. 위 예제에서는 파이프에 데이터를 쓰지 않았으므로 자연스럽게 모든 case 가 사용 불가능하여 최종 출력은 default 분기의 실행 결과가 됩니다. 약간 수정하면 다음과 같습니다.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// 새 루틴 시작
go func() {
// A 파이프에 데이터 쓰기
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}위 예제에서는 새 루틴을 시작하여 파이프 A 에 데이터를 씁니다. select 에는 기본 분기가 없으므로 case 가 사용 가능해질 때까지 블로킹되어 대기합니다. 파이프 A 가 사용 가능해지면 해당 분기를 실행한 후 메인 루틴이 바로 종료됩니다. 파이프를 계속 모니터링하려면 for 루프와 함께 사용하면 됩니다. 다음과 같습니다.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// for 루프
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}이렇게 하면 세 파이프 모두 사용할 수 있지만, 무한 루프 + select 는 메인 루틴을 영구적으로 블로킹하므로, 새 루틴에 배치하고 다른 로직을 추가할 수 있습니다.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // 1 초超时 시간 설정
break Loop // 루프 종료
}
}
l <- struct{}{} // 메인 루틴에 종료 가능하다고 알림
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}위 예제에서는 for 루프와 select 를 사용하여 세 파이프가 사용 가능한지 계속 모니터링하며, 네 번째 case 는超时 파이프입니다.超时 후 루프를 종료하고 서브 루틴을 종료합니다. 최종 출력은 다음과 같습니다.
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 true超时
이전 예제에서는 time.After 함수를 사용했습니다. 반환 값은 읽기 전용 파이프이며, 해당 함수와 select 를 함께 사용하면 매우 간단하게超时 메커니즘을 구현할 수 있습니다. 예제는 다음과 같습니다.
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("超时")
}
}영구 블로킹
select 문에 아무것도 없으면 영구적으로 블로킹됩니다. 예를 들어
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end 는 영원히 출력되지 않으며, 메인 루틴은 계속 블로킹됩니다. 이러한 상황은 일반적으로 특별한 용도가 있습니다.
TIP
select 의 case 에서 값이 nil 인 파이프를 작업하면 블로킹되지 않으며, 해당 case 는 무시되어 영원히 실행되지 않습니다. 다음 코드는 몇 번을 실행해도 timeout 만 출력합니다.
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}논블로킹
select 의 default 분기와 파이프를 함께 사용하면 논블로킹 송수신 작업을 구현할 수 있습니다. 다음과 같습니다.
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}마찬가지로, context 가 종료되었는지 논블로킹으로 판단할 수도 있습니다.
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}잠금
먼저 다음 예제를 살펴보겠습니다.
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
//访问耗时 시뮬레이션
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// 데이터访问
temp := *data
// 계산耗时 시뮬레이션
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// 데이터 수정
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("최종 결과", count)
}위의 예제에서는 count 에 +1 작업을 수행하는 10 개의 루틴을 시작했으며, time.Sleep 을 사용하여 서로 다른耗时를 시뮬레이션했습니다. 직관적으로 말하면, 10 개의 루틴이 10 개의 +1 작업을 수행하므로 최종 결과는 반드시 10 이어야 합니다. 올바른 결과도 실제로 10 이지만, 사실은 그렇지 않습니다. 위의 예제 실행 결과는 다음과 같습니다.
1
2
3
3
2
2
3
3
3
4
최종 결과 4최종 결과가 4 인 것을 볼 수 있으며, 이는 많은 가능한 결과 중 하나일 뿐입니다. 각 루틴의访问 및 계산에 필요한 시간이 다르기 때문에, A 루틴이 데이터访问에 500ms 가 소요되며, 이때访问한 count 값은 1 입니다. 이후 400ms 를 계산에 소요하지만, 이 400ms 동안 B 루틴이 이미访问 및 계산을 완료하고 count 값을 성공적으로 업데이트했습니다. A 루틴은 계산 완료 후, 처음访问한 값이 이미 오래되었지만, 이를 알지 못하고, 원래访问한 값에 1 을 더하여 count 에 할당합니다. 이렇게 되면 B 루틴의 실행 결과가 덮어쓰여집니다. 여러 루틴이 공유 데이터를 읽고访问할 때, 특히 이러한 문제가 발생합니다. 이를 위해 잠금이 필요합니다.
Go 에서 sync 패키지의 Mutex 와 RWMutex 는 상호 배타적 잠금과 읽기/쓰기 잠금 두 가지 구현을 제공하며, 매우 간단하고 사용하기 쉬운 API 를 제공합니다. 잠금은 Lock() 만 필요하며, 잠금 해제 또한 Unlock() 만 필요합니다. 주의할 점은 Go 가 제공하는 잠금은 비재귀적 잠금, 즉 비재진입 잠금이라는 것입니다. 따라서 잠금을 반복하거나 잠금 해제를 반복하면 fatal 이 발생합니다. 잠금의 의미는 불변량을 보호하는 데 있으며, 잠금을 걸면 데이터가 다른 루틴에 의해 수정되지 않기를 바랍니다. 다음과 같습니다.
func DoSomething() {
Lock()
// 이 과정에서 데이터는 다른 루틴에 의해 수정되지 않음
Unlock()
}만약 재귀적 잠금이라면, 다음과 같은 상황이 발생할 수 있습니다.
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}DoSomething 함수는 분명히 DoOther 함수가 데이터에 무엇을 할지 알지 못하므로, 데이터를 수정하여 불변량을 파괴할 수 있습니다. 예를 들어 몇 개의 서브 루틴을 더 시작하는 것입니다. 이는 Go 에서 통하지 않습니다. 잠금을 건 후에는 반드시 불변량의 불변성을 보장해야 하며, 이때 잠금을 반복하거나 잠금 해제를 반복하면 데드락이 발생합니다. 따라서 코드를 작성할 때는 위의 상황을 피해야 하며, 필요할 때는 잠금을 걸면서 즉시 defer 문을 사용하여 잠금을 해제해야 합니다.
상호 배타적 잠금
sync.Mutex 는 Go 에서 제공하는 상호 배타적 잠금 구현으로, sync.Locker 인터페이스를 구현했습니다.
type Locker interface {
// 잠금
Lock()
// 잠금 해제
Unlock()
}상호 배타적 잠금을 사용하면 위의 문제를 매우 완벽하게 해결할 수 있습니다. 예제는 다음과 같습니다.
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// 잠금
lock.Lock()
//访问耗时 시뮬레이션
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// 데이터访问
temp := *data
// 계산耗时 시뮬레이션
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// 데이터 수정
*data = temp + ans
// 잠금 해제
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("최종 결과", count)
}각 루틴은 데이터를访问하기 전에 먼저 잠금을 걸고, 업데이트 완료 후 잠금을 해제합니다. 다른 루틴이访问하려면 먼저 잠금을 얻어야 하며, 그렇지 않으면 블로킹되어 대기합니다. 이렇게 하면 위의 문제가 더 이상 발생하지 않으므로 출력은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
최종 결과 10읽기/쓰기 잠금
상호 배타적 잠금은 읽기 작업과 쓰기 작업 빈도가 비슷한 상황에 적합합니다. 읽기가 많고 쓰기가 적은 데이터의 경우, 상호 배타적 잠금을 사용하면 많은 불필요한 루틴 경쟁이 발생하여 많은 시스템 리소스를 소모합니다. 이때 읽기/쓰기 잠금이 필요합니다. 즉, 읽기/쓰기 상호 배타적 잠금입니다. 하나의 루틴에 대해:
- 읽기 잠금을 얻으면, 다른 루틴이 쓰기 작업을 할 때는 블로킹되며, 다른 루틴이 읽기 작업을 할 때는 블로킹되지 않습니다.
- 쓰기 잠금을 얻으면, 다른 루틴이 쓰기 작업을 할 때는 블로킹되며, 다른 루틴이 읽기 작업을 할 때도 블로킹됩니다.
Go 에서 읽기/쓰기 상호 배타적 잠금 구현은 sync.RWMutex 입니다. 이 또한 Locker 인터페이스를 구현했지만, 더 많은 사용 가능한 메서드를 제공합니다.
// 읽기 잠금
func (rw *RWMutex) RLock()
// 읽기 잠금 시도
func (rw *RWMutex) TryRLock() bool
// 읽기 잠금 해제
func (rw *RWMutex) RUnlock()
// 쓰기 잠금
func (rw *RWMutex) Lock()
// 쓰기 잠금 시도
func (rw *RWMutex) TryLock() bool
// 쓰기 잠금 해제
func (rw *RWMutex) Unlock()TryRlock 와 TryLock 두 가지 잠금 시도 작업은 논블로킹 방식입니다. 잠금 성공 시 true 를 반환하며, 잠금을 얻을 수 없을 때는 블로킹되지 않고 false 를 반환합니다. 읽기/쓰기 상호 배타적 잠금의 내부 구현은 여전히 상호 배타적 잠금이며, 읽기 잠금과 쓰기 잠금이 있다고 해서 두 개의 잠금이 있는 것은 아닙니다. 처음부터 끝까지 하나의 잠금만 있습니다. 읽기/쓰기 상호 배타적 잠금 사용 사례를 살펴보겠습니다.
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// 읽기 많고 쓰기 적음
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// 서브 루틴 종료 대기
wait.Wait()
fmt.Println("최종 결과", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("읽기 잠금 획득")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("읽기 잠금 해제", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("쓰기 잠금 획득")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("쓰기 잠금 해제", *i)
rw.Unlock()
wait.Done()
}이 예제에서는 3 개의 쓰기 루틴과 7 개의 읽기 루틴을 시작했습니다. 데이터를 읽을 때는 모두 먼저 읽기 잠금을 얻으며, 읽기 루틴은 정상적으로 읽기 잠금을 얻을 수 있지만, 쓰기 루틴은 블로킹됩니다. 쓰기 잠금을 얻을 때는 읽기 루틴과 쓰기 루틴 모두 블로킹되며, 쓰기 잠금이 해제될 때까지 대기합니다. 이렇게 하면 읽기 루틴과 쓰기 루틴이 상호 배타적이며, 데이터의 정확성을 보장합니다. 예제 출력은 다음과 같습니다.
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 해제 0
읽기 잠금 해제 0
읽기 잠금 해제 0
읽기 잠금 해제 0
쓰기 잠금 획득
쓰기 잠금 해제 1
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 해제 1
읽기 잠금 해제 1
읽기 잠금 해제 1
쓰기 잠금 획득
쓰기 잠금 해제 2
쓰기 잠금 획득
쓰기 잠금 해제 3
최종 결과 3TIP
잠금의 경우, 값으로 전달하고 저장해서는 안 되며, 포인터를 사용해야 합니다.
조건 변수
조건 변수는 상호 배타적 잠금과 함께 나타나고 사용되므로, 일부 사람들은 조건 잠금이라고 오해할 수 있지만, 이는 잠금이 아니며, 일종의 통신 메커니즘입니다. Go 의 sync.Cond 는 이에 대한 구현을 제공하며, 조건 변수를 생성하는 함수 시그니처는 다음과 같습니다.
func NewCond(l Locker) *Cond조건 변수를 생성하려면 먼저 잠금을 생성해야 합니다. sync.Cond 는 다음과 같은 메서드를 제공합니다.
// 조건이 유효해질 때까지 블로킹 대기, 깨어날 때까지
func (c *Cond) Wait()
// 조건으로 인해 블로킹된 하나의 루틴 깨우기
func (c *Cond) Signal()
// 조건으로 인해 블로킹된 모든 루틴 깨우기
func (c *Cond) Broadcast()조건 변수 사용은 매우 간단하며, 위의 읽기/쓰기 상호 배타적 잠금 예제를 약간 수정하면 됩니다.
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// 조건 변수
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// 읽기 많고 쓰기 적음
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// 서브 루틴 종료 대기
wait.Wait()
fmt.Println("최종 결과", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("읽기 잠금 획득")
// 조건이 만족되지 않으면 계속 블로킹
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("읽기 잠금 해제", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("쓰기 잠금 획득")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("쓰기 잠금 해제", *i)
rw.Unlock()
// 조건 변수로 인해 블로킹된 모든 루틴 깨우기
cond.Broadcast()
wait.Done()
}조건 변수를 생성할 때, 여기서 조건 변수는 읽기 루틴에 작용하므로, 읽기 잠금을 상호 배타적 잠금으로 전달합니다. 읽기/쓰기 상호 배타적 잠금을 직접 전달하면 쓰기 루틴이 잠금을 반복 해제하는 문제가 발생합니다. 여기서 전달하는 것은 sync.rlocker 로, RWMutex.RLocker 메서드를 통해 얻습니다.
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }rlocker 는 읽기/쓰기 상호 배타적 잠금의 읽기 잠금 작업을 포장한 것뿐이며, 실제로는 동일한 참조이며, 동일한 잠금입니다. 읽기 루틴이 데이터를 읽을 때, 3 보다 작으면 계속 블로킹되어 대기하며, 데이터가 3 보다 커질 때까지 대기합니다. 쓰기 루틴은 데이터 업데이트 후 조건 변수로 인해 블로킹된 모든 루틴을 깨우려고 시도합니다. 따라서 마지막 출력은 다음과 같습니다.
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 획득
읽기 잠금 획득
쓰기 잠금 획득
쓰기 잠금 해제 1
읽기 잠금 획득
쓰기 잠금 획득
쓰기 잠금 해제 2
읽기 잠금 획득
읽기 잠금 획득
쓰기 잠금 획득
쓰기 잠금 해제 3 // 세 번째 쓰기 루틴 실행 완료
읽기 잠금 해제 3
읽기 잠금 해제 3
읽기 잠금 해제 3
읽기 잠금 해제 3
읽기 잠금 해제 3
읽기 잠금 해제 3
읽기 잠금 해제 3
최종 결과 3결과에서 볼 수 있듯이, 세 번째 쓰기 루틴이 데이터 업데이트를 완료한 후, 조건 변수로 인해 블로킹된 7 개의 읽기 루틴이 모두 실행을 재개했습니다.
TIP
조건 변수의 경우, if 대신 for 를 사용해야 하며, 조건이 만족되는지 루프로 판단해야 합니다. 루틴이 깨어났을 때 현재 조건이 이미 만족되었는지 보장할 수 없기 때문입니다.
for !condition {
cond.Wait()
}sync
Go 에서 많은 병발성 관련 도구는 sync 표준 라이브러리에서 제공합니다. 위에서 이미 sync.WaitGroup, sync.Locker 등을 소개했습니다. 그 외에도, sync 패키지에는 사용할 수 있는 다른 도구도 있습니다.
Once
데이터 구조를 사용할 때, 데이터 구조가 너무 방대하면, 실제로 사용할 때만 해당 데이터 구조를 초기화하는 지연 로딩 방식을 고려할 수 있습니다. 다음 예제와 같습니다.
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// 실제로 슬라이스를 사용할 때만 초기화 고려
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}문제가 발생합니다. 하나의 루틴만 사용하면 아무런 문제가 없지만, 여러 루틴이访问하면 문제가 발생할 수 있습니다. 예를 들어 루틴 A 와 B 가 동시에 Add 메서드를 호출하면, A 가 약간 더 빠르게 실행되어 초기화를 완료하고, 데이터를 성공적으로 추가한 후, 루틴 B 가 다시 초기화하면, 루틴 A 가 추가한 데이터를 직접 덮어쓰게 됩니다. 이것이 문제입니다.
이것이 sync.Once 가 해결하려는 문제입니다. 이름에서 알 수 있듯이, Once 는 한 번을 의미하며, sync.Once 는 병발성 조건에서 지정된 작업이 한 번만 실행되도록 보장합니다. 사용은 매우 간단하며, Do 메서드 하나만 외부에 노출합니다. 시그니처는 다음과 같습니다.
func (o *Once) Do(f func())사용할 때는 초기화 작업만 Do 메서드에 전달하면 됩니다. 다음과 같습니다.
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// 실제로 슬라이스를 사용할 때만 초기화 고려
m.o.Do(func() {
fmt.Println("초기화")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}출력은 다음과 같습니다.
초기화
4출력 결과에서 볼 수 있듯이, 모든 데이터가 정상적으로 슬라이스에 추가되며, 초기화 작업은 한 번만 실행되었습니다. 실제로 sync.Once 의 구현은 매우 간단하며, 주석을 제거하면 실제 코드 로직은 16 줄뿐입니다. 원리는 잠금 + 원자 조작입니다. 소스 코드는 다음과 같습니다.
type Once struct {
// 작업이 이미 실행되었는지 판단
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// 원자적으로 데이터 로드
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// 잠금
o.m.Lock()
// 잠금 해제
defer o.m.Unlock()
// 실행 여부 판단
if o.done == 0 {
// 실행 완료 후 done 수정
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
sync.Pool 의 설계 목적은 임시 객체를 저장하여 나중에 재사용하는 것으로, 임시 병발성 안전 객체 풀입니다. 잠시 사용하지 않는 객체를 풀에 넣고, 이후 사용 시 추가적으로 객체를 생성하지 않고 바로 재사용할 수 있어, 메모리 할당 및 해제 빈도를 줄이며, 가장 중요한 점은 GC 압력을 낮춥니다. sync.Pool 은 두 가지 메서드만 있습니다.
// 객체 신청
func (p *Pool) Get() any
// 객체 넣기
func (p *Pool) Put(x any)그리고 sync.Pool 에는 외부에 노출된 New 필드가 있어, 객체 풀에서 객체를 신청할 수 없을 때 객체를 초기화하는 데 사용합니다.
New func() any다음은 예제로 데모합니다.
var wait sync.WaitGroup
// 임시 객체 풀
var pool sync.Pool
// 과정에서 총 몇 개의 객체가 생성되었는지 카운트
var numOfObject atomic.Int64
// BigMemData 메모리를 많이 차지하는 구조체라고 가정
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"대용량 메모리"}
}
wait.Add(1000)
// 여기서 1000 개의 루틴 시작
for i := 0; i < 1000; i++ {
go func() {
// 객체 신청
val := pool.Get()
// 객체 사용
_ = val.(BigMemData)
// 사용 완료 후 객체 반환
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}예제에서는 1000 개의 루틴을 시작하여 풀에서 객체를 계속 신청하고 해제합니다. 객체 풀을 사용하지 않으면, 1000 개의 루틴이 각각 객체를 인스턴스화해야 하며, 이 1000 개의 인스턴스화된 객체는 사용 완료 후 GC 가 메모리를 해제해야 합니다. 수십만 개의 루틴이 있거나 객체 생성 비용이 매우 비싼 경우, 이 경우 많은 메모리를 차지하고 GC 에 매우 큰 압력을 줍니다. 객체 풀을 사용하면 객체를 재사용하여 인스턴스화 빈도를 줄일 수 있습니다. 위의 예제 출력은 다음과 같을 수 있습니다.
51000 개의 루틴을 시작했지만, 전체 과정에서 5 개의 객체만 생성되었습니다. 객체 풀을 사용하지 않으면 1000 개의 루틴이 1000 개의 객체를 생성하며, 이러한 최적화로 인한 향상은 분명합니다. 특히 병발성 양이 매우 크고 객체 인스턴스화 비용이 매우 높을 때 장점이 더 두드러집니다.
sync.Pool 사용 시 몇 가지 주의점이 있습니다.
- 임시 객체:
sync.Pool은 임시 객체만 저장하는 데 적합합니다. 풀의 객체는 아무런 알림 없이 GC 에 의해 제거될 수 있으므로, 네트워크 연결, 데이터베이스 연결 등을sync.Pool에 저장하는 것은 권장하지 않습니다. - 예측 불가:
sync.Pool은 객체를 신청할 때, 이 객체가 새로 생성된 것인지 재사용된 것인지 예측할 수 없으며, 풀에 몇 개의 객체가 있는지도 알 수 없습니다. - 병발성 안전: 공식은
sync.Pool이 반드시 병발성 안전임을 보장하지만, 객체를 생성하는New함수가 병발성 안전임을 보장하지는 않습니다.New함수는 사용자가 전달하므로,New함수의 병발성 안전성은 사용자가 직접 유지해야 합니다. 이것이 위 예제에서 객체 카운트에 원자 값을 사용하는 이유입니다.
TIP
마지막으로 주의할 점은, 객체 사용 완료 후 반드시 풀에 반환해야 합니다. 사용한 후 반환하지 않으면 객체 풀 사용이 무의미해집니다.
표준 라이브러리 fmt 패키지에는 객체 풀 사용 사례가 있습니다. fmt.Fprintf 함수에서
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// 프린트 버퍼 신청
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// 사용 완료 후 해제
p.free()
return
}그중 newPrinter 함수와 free 메서드 구현은 다음과 같습니다.
func newPrinter() *pp {
// 객체 풀에서 객체 신청
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// 객체 풀의 버퍼 크기를 대략적으로 동일하게 유지하여 버퍼 크기를 더 잘 탄력적으로 제어
// 너무 큰 버퍼는 객체 풀에 반환하지 않음
if cap(p.buf) > 64<<10 {
return
}
// 필드 리셋 후 객체를 풀에 반환
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map 는 공식에서 제공하는 병발성 안전 Map 구현으로, 바로 사용할 수 있으며, 사용은 매우 간단합니다. 다음은 해당 구조체가 외부에 노출하는 메서드입니다.
// key 로 값 읽기, 반환 값은 해당 값과 값 존재 여부
func (m *Map) Load(key any) (value any, ok bool)
// 키 - 값 쌍 저장
func (m *Map) Store(key, value any)
// 키 - 값 쌍 삭제
func (m *Map) Delete(key any)
// key 가 이미 존재하면 기존 값 반환, 그렇지 않으면 새 값 저장 후 반환, 값 성공 읽기 시 loaded 는 true, 그렇지 않으면 false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// 키 - 값 쌍 삭제 후 기존 값 반환, loaded 는 key 존재 여부에 따라 결정
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Map 순회, f() 가 false 를 반환하면 순회 중지
func (m *Map) Range(f func(key, value any) bool)다음은 간단한 예제로 sync.Map 의 기본 사용을 데모합니다.
func main() {
var syncMap sync.Map
// 데이터 저장
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// 데이터 읽기
fmt.Println(syncMap.Load("a"))
// 읽기 및 삭제
fmt.Println(syncMap.LoadAndDelete("a"))
// 읽기 또는 저장
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// map 순회
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}출력
a true
a true
hello world false
a hello world
b goodbye world다음은 map 을 병발성으로 사용하는 예제를 살펴보겠습니다.
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}위 예제에서는 일반 map 을 사용했으며, 10 개의 루틴을 시작하여 계속 데이터를 저장합니다. 분명히 이는 fatal 을 트리거할 가능성이 높으며, 결과는 대체로 다음과 같습니다.
fatal error: concurrent map writessync.Map 을 사용하면 이 문제를 피할 수 있습니다.
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}출력은 다음과 같습니다.
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4병발성 안전을 위해 일정 희생을 해야 하며, sync.Map 의 성능은 map 보다 10-100 배 정도 낮습니다.
원자
컴퓨터 과학에서 원자 또는 프라임 조작은 일반적으로 더 이상 세분화할 수 없는 조작을 나타내는 데 사용됩니다. 이러한 조작은 더 작은 단계로 세분화할 수 없으며, 실행 완료 전에는 다른 어떤 루틴에도 중단되지 않으므로, 실행 결과는 성공하거나 실패하거나, 세 번째 상황은 없습니다. 다른 상황이 나타나면, 그것은 원자 조작이 아닙니다. 다음 코드와 같습니다.
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}위의 코드는 간단한 판단 분기이며, 코드가 적지만 원자 조작은 아닙니다. 진정한 원자 조작은 하드웨어 명령어 수준에서 지원됩니다.
타입
대부분의 경우 어셈블리를 직접 작성할 필요가 없으며, Go 표준 라이브러리 sync/atomic 패키지에는 원자 조작 관련 API 가 제공되어 있으며, 다음과 같은 몇 가지 타입을 제공하여 원자 조작을 수행합니다.
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}그중 Pointer 원자 타입은 제네릭을 지원하며, Value 타입은 모든 타입을 저장할 수 있습니다. 그 외에도, 조작을 편리하게 하는 많은 함수가 제공됩니다. 원자 조작의 입자가 너무 세밀하여, 대부분의 경우 이러한 기본 데이터 타입을 처리하는 데 더 적합합니다.
TIP
atomic 패키지의 원자 조작은 함수 시그니처만 있으며, 구체적인 구현은 plan9 어셈블리로 작성되었습니다.
사용
각 원자 타입은 다음 세 가지 메서드를 제공합니다.
Load(): 원자적으로 값 가져오기Swap(newVal type) (old type): 원자적으로 값 교환 후 이전 값 반환Store(val type): 원자적으로 값 저장
다른 타입에는 다른 추가 메서드가 있을 수 있습니다. 예를 들어 정수 타입에는 원자 덧셈/뺄셈 조작을 구현하는 Add 메서드가 모두 제공됩니다. 다음은 int64 타입 데모 예제입니다.
func main() {
var aint64 atomic.Uint64
// 값 저장
aint64.Store(64)
// 값 교환
aint64.Swap(128)
// 증가
aint64.Add(112)
// 값 로드
fmt.Println(aint64.Load())
}또는 함수를直接使用할 수도 있습니다.
func main() {
var aint64 int64
// 값 저장
atomic.StoreInt64(&aint64, 64)
// 값 교환
atomic.SwapInt64(&aint64, 128)
// 증가
atomic.AddInt64(&aint64, 112)
// 로드
fmt.Println(atomic.LoadInt64(&aint64))
}다른 타입 사용도 매우 유사하며, 최종 출력은 다음과 같습니다.
240CAS
atomic 패키지는 CompareAndSwap 조작, 즉 CAS 를 제공합니다. 이는 낙관적 잠금과 무잠금 데이터 구조 구현의 핵심입니다. 낙관적 잠금 자체는 잠금이 아니며, 병발성 조건에서 무잠금 병발성 제어 방식입니다: 스레드/루틴은 데이터를 수정하기 전에 먼저 잠금을 걸지 않고, 먼저 데이터를 읽고, 계산을 수행한 후, 수정 제출 시 CAS 를 사용하여 해당 기간 동안 다른 스레드가 데이터를 수정했는지 판단합니다. 수정하지 않았다면 (값이 이전에 읽은 값과 동일하면), 수정 성공; 그렇지 않으면 실패하고 재시도합니다. 따라서 낙관적 잠금이라고 불리는 이유는 공유 데이터가 수정되지 않을 것이라고 항상 낙관적으로 가정하며, 데이터가 수정되지 않았을 때만 해당 작업을 실행하기 때문입니다. 앞서 알아본 상호 배타량은 비관적 잠금입니다. 상호 배타량은 항상 공유 데이터가 수정될 것이라고 비관적으로 생각하므로, 작업 시 잠금을 걸고, 작업 완료 후 잠금을 해제합니다. 무잠금 구현 병발성의 안전성과 효율성은 잠금에 비해 더 높으며, 많은 병발성 안전 데이터 구조는 CAS 를 사용하여 구현합니다. 하지만 진정한 효율성은 구체적인 사용 상황에 따라 결합해야 합니다. 다음 예제를 살펴보겠습니다.
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}이는 상호 배타적 잠금을 사용한 예제로, 매번 숫자를 증가시키기 전에 먼저 잠금을 걸고, 실행 완료 후 잠금을 해제하며, 과정에서 다른 루틴이 블로킹됩니다. 다음으로 CAS 를 사용하여 개선해 보겠습니다.
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}CAS 의 경우, 세 개의 매개변수가 있습니다. 메모리 값, 기대 값, 새 값입니다. 실행 시, CAS 는 기대 값과 현재 메모리 값을 비교하며, 메모리 값이 기대 값과 동일하면 후속 작업을 실행하고, 그렇지 않으면 아무것도 하지 않습니다. Go 의 atomic 패키지 원자 조작의 경우, CAS 관련 함수는 주소, 기대 값, 새 값을 전달해야 하며, 성공적으로 교체되었는지 여부를 나타내는 불리언 값을 반환합니다. 예를 들어 int64 타입의 CAS 조작 함수 시그니처는 다음과 같습니다.
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)CAS 예제에서는, 먼저 LoadInt64 를 사용하여 기대 값을 가져온 후, CompareAndSwapInt64 를 사용하여 비교 교환을 수행하며, 성공하지 못하면 계속 루프하여 성공할 때까지 합니다. 이러한 무잠금 조작은 루틴이 블로킹되지 않지만, 계속 루프하는 것은 CPU 에게 작은 부담이 아닙니다. 따라서 일부 구현에서는 실패가 일정 횟수에 도달하면 작업을 포기할 수 있습니다. 하지만 위의 조작의 경우, 단순히 숫자를 더하는 것뿐이며, 관련된 조작이 복잡하지 않으므로, 무잠금 구현을 고려할 수 있습니다.
TIP
대부분의 경우, 값만 비교하는 것으로는 병발성 안전을 달성할 수 없습니다. 예를 들어 CAS 로 인한 ABA 문제는 추가 version 을 사용하여 문제를 해결해야 합니다.
Value
atomic.Value 구조체는 모든 타입의 값을 저장할 수 있으며, 구조체는 다음과 같습니다.
type Value struct {
// any 타입
v any
}모든 타입을 저장할 수 있지만, nil 을 저장할 수 없으며, 전후 저장 값 타입은 일치해야 합니다. 다음 두 예제는 컴파일을 통과할 수 없습니다.
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into Value그 외에도, 사용은 다른 원자 타입과 큰 차이가 없으며, 주의할 점은 모든 원자 타입은 값을 복사해서는 안 되며, 포인터를 사용해야 합니다.