string
string 은 Go 에서 매우 흔한 기본 데이터 유형이며, Go 언어에서 처음 접한 데이터 유형이기도 합니다.
package main
import "fmt"
func main() {
fmt.Println("hello,world!")
}대부분의 사람이 Go 를 처음 접할 때 이 코드를 입력해 보았을 것입니다. builtin/builtin.go 에는 string 에 대한 간단한 설명이 있습니다.
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string위 문장에서 다음 정보를 얻을 수 있습니다.
string은 8 비트 바이트의 집합string유형은 일반적으로UTF-8인코딩string은 비어 있을 수 있지만nil은 아님string은 불변
이러한 특징은 Go 를 자주 사용하는 사람이라면 이미 잘 알고 있을 것입니다. 아래에서는 조금 다른 내용을 살펴보겠습니다.
구조
Go 에서 문자열은 런타임에 runtime.stringStruct 구조체로 표현되지만, 외부에 노출되지 않습니다. 대신 reflect.StringHeader 를 사용할 수 있습니다.
TIP
StringHeader 는 버전 go.1.21 에서 폐기되었지만, 매우 직관적이므로 아래 내용에서는 여전히 이를 사용하여 설명합니다. 이해에는 지장이 없으며, 자세한 내용은 Issues · golang/go (github.com) 를 참조하십시오.
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
// reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}필드 설명은 다음과 같습니다.
Data, 문자열 메모리 시작 주소를 가리키는 포인터Len, 문자열의 바이트 수
다음은 unsafe 포인터를 사용하여 문자열 주소에 액세스하는 예시입니다.
func main() {
str := "hello,world!"
h := *((*reflect.StringHeader)(unsafe.Pointer(&str)))
for i := 0; i < h.Len; i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(unsafe.Pointer(h.Data), uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}하지만 Go 는 이제 unsafe.StringData 를 사용하는 것을 권장합니다.
func main() {
str := "hello,world!"
ptr := unsafe.Pointer(unsafe.StringData(str))
for i := 0; i < len(str); i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(ptr, uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}두 출력은 모두 동일합니다.
h e l l o , w o r l d !
문자열은 본질적으로 연속된 메모리 주소이며, 각 주소에는 바이트가 저장됩니다. 다시 말해 바이트 배열이며, len 함수를 통해 가져온 결과는 문자 수가 아닌 바이트 수입니다. 문자열의 문자가 ASCII 문자가 아닐 때 특히 그렇습니다.
string 자체는 실제 데이터를 가리키는 포인터만 차지하므로 문자열 전달 비용이 매우 낮습니다. 개인적으로 생각하기에, 메모리 참조만 보유하므로 임의로 수정할 수 있다면 원래 참조가 여전히 원하는 데이터인지 알기 어렵습니다 (리플렉션이나 unsafe 패키지 사용 필요). 또 다른 장점은 기본적으로 동시성 안전이라는 점이며, 어떤 사람도 일반적인 상황에서는 수정할 수 없습니다.
연결
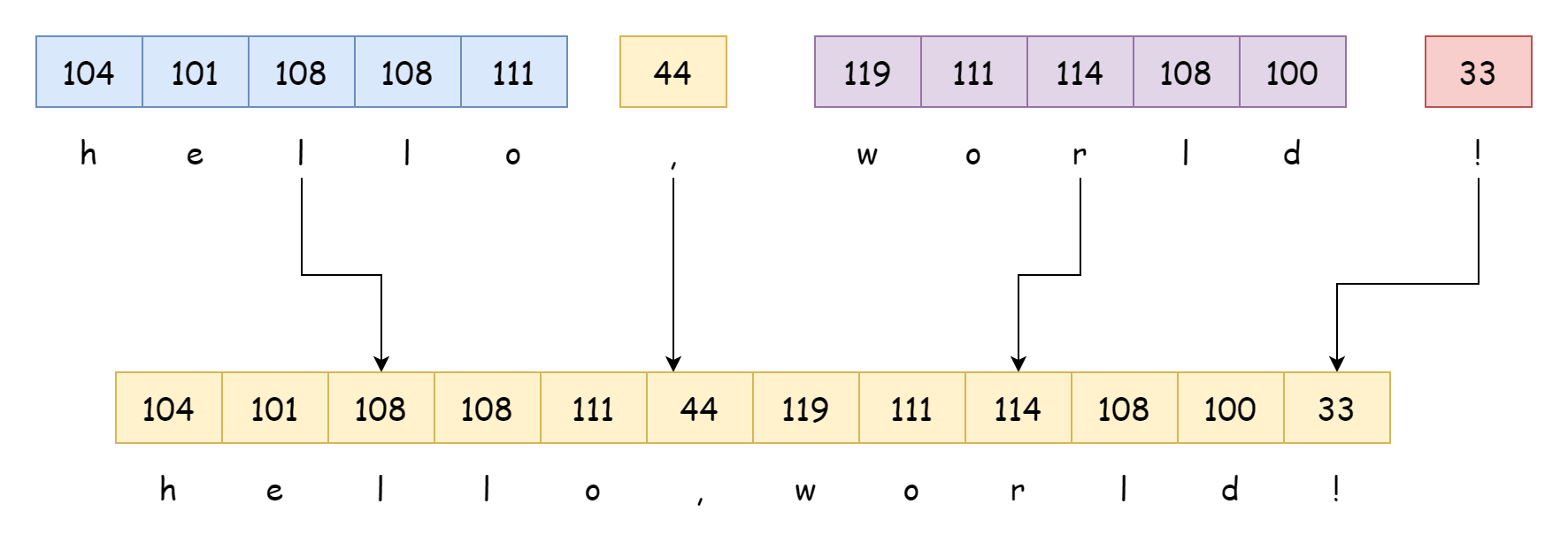
문자열 연결 문법은 다음과 같으며, 직접 + 연산자를 사용하여 연결합니다.
var (
hello = "hello"
dot = ","
world = "world"
last = "!"
)
str := hello + dot + world + last런타임에서 연결 작업은 runtime.concatstrings 함수에 의해 완료됩니다. 아래 코드와 같은 리터럴 연결인 경우, 컴파일러는 직접 결과를 추론합니다.
str := "hello" + "," + "world" + "!"
_ = str어셈블리 코드를 출력하면 결과를 알 수 있으며, 일부는 다음과 같습니다.
LEAQ go:string."hello,world!"(SB), AX
MOVQ AX, main.str(SP)컴파일러가 이를 완전한 문자열로 간주하며, 값은 컴파일 기간에 이미 결정되므로 런타임에 runtime.concatstrings 에 의해 연결되지 않습니다. 문자열 변수를 연결할 때만 런타임에 완료되며, 함수 시그니처는 다음과 같으며 바이트 배열과 문자열 슬라이스를 받습니다.
func concatstrings(buf *tmpBuf, a []string) string연결할 문자열 변수가 5 개 미만일 때는 아래 함수로 대체됩니다 (개인 추측: 매개변수와 익명 변수 전달은 모두 스택에 존재하므로 런타임에 생성된 슬라이스보다 GC 에 더 좋음?). 마지막은 concatstrings 함수가 연결을 완료합니다.
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}아래에서는 concatstrings 함수 내부에서 무엇을 하는지 살펴보겠습니다.
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
// 길이가 0 이면 건너뜀
if n == 0 {
continue
}
// 수치 계산 오버플로우
if l+n < l {
throw("string concatenation too long")
}
l += n
// 카운트
count++
idx = i
}
// 문자열이 없으면 빈 문자열 반환
if count == 0 {
return ""
}
// 문자열이 하나만 있으면 직접 반환
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
// 새 문자열을 위한 메모리 할당
s, b := rawstringtmp(buf, l)
for _, x := range a {
// 복사
copy(b, x)
// 자르기
b = b[len(x):]
}
return s
}먼저 수행하는 작업은 연결할 문자열의 총 길이와 수를 통계한 후 총 길이에 따라 메모리를 할당합니다. rawstringtmp 함수는 문자열 s 와 바이트 슬라이스 b 를 반환하며, 길이는 확정되지만 내용은 없습니다. 이들은 본질적으로 새 메모리 주소를 가리키는 두 개의 포인터이기 때문입니다. 메모리 할당 코드는 다음과 같습니다.
func rawstring(size int) (s string, b []byte) {
// 유형 지정 안 함
p := mallocgc(uintptr(size), nil, false)
// 메모리 할당했지만 내용은 없음
return unsafe.String((*byte)(p), size), unsafe.Slice((*byte)(p), size)
}반환된 문자열 s 는 표현을 위한 것이며, 바이트 슬라이스 b 는 문자열 수정을 위한 것입니다. 둘은 모두 동일한 메모리 주소를 가리킵니다.
for _, x := range a {
// 복사
copy(b, x)
// 자르기
b = b[len(x):]
}copy 함수는 런타임에 runtime.slicecopy 를 호출하며, src 의 메모리를 dst 주소로 직접 복사합니다. 모든 문자열 복사完毕后 연결 과정이 끝납니다. 복사하는 문자열이 매우 크면 이 과정은 상당한 성능 소모가 발생합니다.