slice
TIP
본 문서를 읽으려면 unsafe 표준 라이브러리에 대한 지식이 필요합니다.
슬라이스는 Go 언어에서 가장 흔히 사용되는 데이터 구조입니다. 실제로 내장된 데이터 구조도 몇 개 없으며, 어디에서나 볼 수 있습니다. 기본 사용법은 언어 입문에서 이미 설명했으므로, 여기서는 내부 구조와 작동 방식을 살펴보겠습니다.
구조
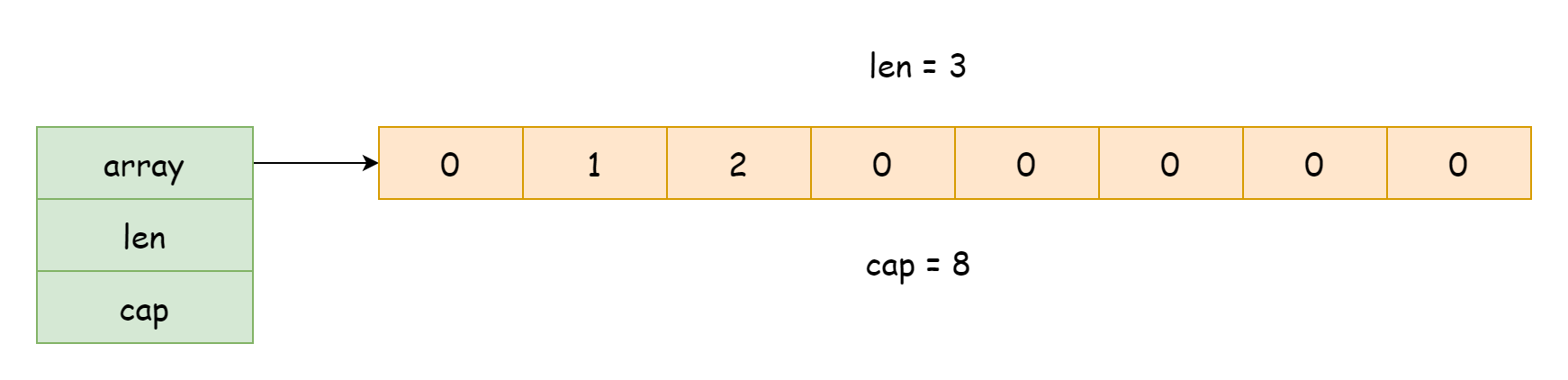
슬라이스 구현과 관련하여 소스 코드는 runtime/slice.go 파일에 위치합니다. 런타임에서 슬라이스는 구조체 형태로 존재하며, 유형은 runtime.slice 입니다.
type slice struct {
array unsafe.Pointer
len int
cap int
}이 구조체는 세 개의 필드만 가집니다.
array, 하부 배열을 가리키는 포인터len, 슬라이스 길이, 배열의 기존 요소 수cap, 슬라이스 용량, 배열이 수용할 수 있는 요소 총수
위 정보에서 알 수 있듯이, 슬라이스의 하부 구현은 여전히 배열에 의존하며, 평소에는 구조체일 뿐이며 배열에 대한 참조와 용량 및 길이 기록만 보유합니다. 이렇게 하면 슬라이스를 전달하는 비용이 매우 낮아지며, 데이터 참조만 복사되고 모든 데이터를 복사할 필요가 없습니다. 또한 len 과 cap 을 사용하여 슬라이스 길이와 용량을获取할 때 필드 값을获取하는 것과 같아 배열을 순회할 필요가 없습니다.
하지만 이는 몇 가지 발견하기 어려운 문제를 가져옵니다. 아래 예시를 보십시오.
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]위 코드에서 s1 은 슬라이스 방식으로 새 슬라이스를 생성했지만, 소스 슬라이스와 동일한 하부 배열을 참조합니다. s1 의 데이터를 수정하면 s 도 변경됩니다. 따라서 슬라이스를 복사할 때는 copy 함수를 사용해야 하며, 이 함수로 복사된 슬라이스는 원본과 무관합니다. 또 다른 예시를 보십시오.
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]역시 슬라이스 방식으로 복사했지만, 이번에는 소스 슬라이스에 영향을 미치지 않습니다. 처음에는 s1 과 s 가 실제로 동일한 배열을 가리켰지만, 이후 s1 에 너무 많은 요소가 추가되어 배열이 수용할 수 있는 양을 초과했으므로 더 큰 새 배열을 할당하여 요소를 저장했습니다. 따라서 마지막으로 두 개가 가리키는 배열이 달라졌습니다. 문제가 없다고 생각하시나요? 그러면 또 다른 예시를 보십시오.
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]요소를 추가했지만 빈 슬라이스가 출력됩니다. 실제로 데이터는 슬라이스에 추가되었지만 하부 배열에 기록되었습니다. Go 에서 함수 매개변수는 값 전달이므로 매개변수 s 는 소스 슬라이스 구조체의 사본이며, append 작업은 요소를 추가한 후 길이가 업데이트된 슬라이스 구조체를 반환하지만, 이는 소스 슬라이스 s 가 아닌 매개변수 s 에 할당되므로 둘 사이에는 연관이 없습니다.
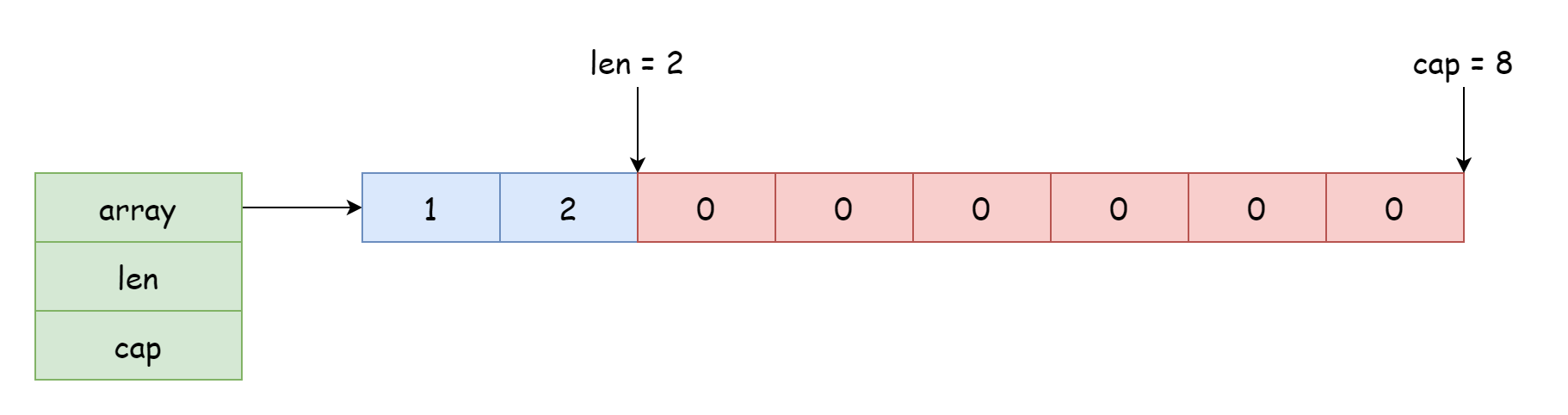
슬라이스가 액세스하고 수정할 수 있는 시작 위치는 배열 참조 위치에 따라 결정되며, 오프셋은 구조체에 기록된 길이에 따라 결정됩니다. 구조체의 포인터는 배열 시작뿐만 아니라 배열 중간도 가리킬 수 있습니다. 아래 그림과 같습니다.
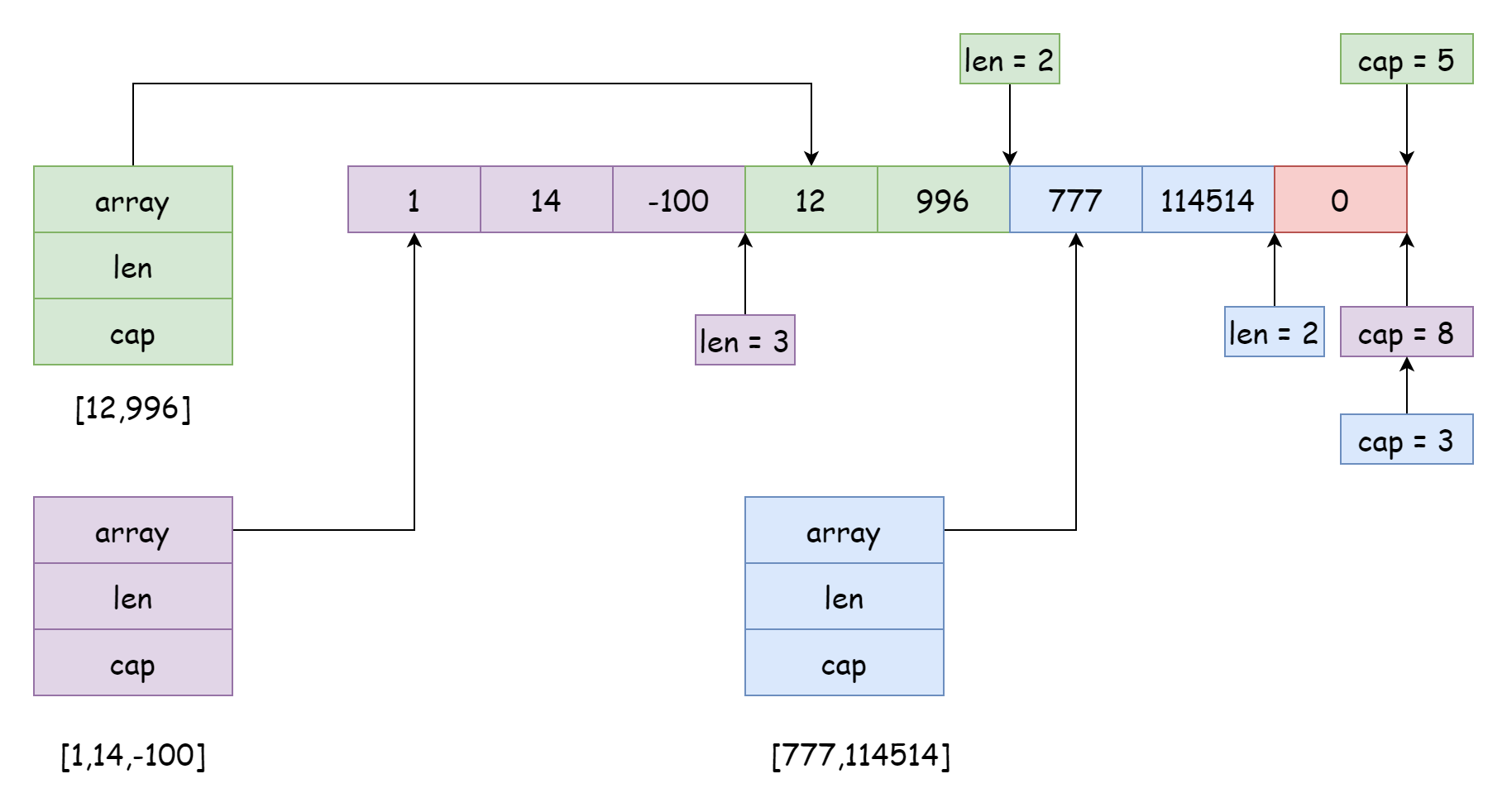
하나의 하부 배열은 여러 슬라이스에 의해 참조될 수 있으며, 참조 위치와 범위는 다를 수 있습니다. 위 그림과 같으며, 이러한 상황은 일반적으로 슬라이스를 분할할 때 발생합니다. 아래 코드와 같습니다.
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]분할 시 생성된 새 슬라이스의 용량은 배열 길이에서 새 슬라이스 참조 시작 위치를 뺀 값과 같습니다. 예를 들어 s[4:6] 로 생성된 새 슬라이스의 용량은 6 = 10 - 4 입니다. 물론 슬라이스 참조 범위가 반드시 인접할 필요는 없으며 서로 교차할 수도 있지만, 이는 매우 큰 문제를 발생시킵니다. 현재 슬라이스의 데이터가 다른 슬라이스에 의해 수정될 수 있기 때문입니다. 위 그림의 보라색 슬라이스와 같으며, 이후 append 을 사용하여 요소를 추가하면 녹색 슬라이스와 파란색 슬라이스의 데이터를 덮어쓸 수 있습니다. 이러한 상황을 피하기 위해 Go 는 분할 시 용량 범위를 설정할 수 있으며, 문법은 다음과 같습니다.
s4 = s[4:6:6]이 경우 용량이 2 로 제한되므로 요소를 추가하면 확장이 트리거되며, 확장 후에는 새 배열이 되어 소스 배열과 무관해지므로 영향이 없습니다. 슬라이스에 대한 문제가 여기서 끝났다고 생각하시나요? 그렇지 않습니다. 또 다른 예시를 보십시오.
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// 추가할 요소 수가 용량보다 약간 많음
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]코드는 이전 예시와 동일하며, 입력 매개변수만 수정하여 추가할 요소 수가 슬라이스 용량보다 약간 많도록 했습니다. 이렇게 하면 추가 시 확장이 트리거되므로 데이터는 소스 슬라이스 s 에 추가되지 않았을 뿐만 아니라 하부 배열에도 기록되지 않았습니다. unsafe 포인터를 통해 확인할 수 있습니다. 코드는 다음과 같습니다.
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// 추가할 요소 수가 용량보다 약간 많음
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,소스 슬라이스의 하부 배열이 비어 있으며 데이터가 모두 새 배열에 기록되었음을 알 수 있습니다. 하지만 소스 슬라이스와는 무관합니다. append 이 새 참조를 반환하더라도 수정되는 것은 형식 매개변수 s 의 값일 뿐이므로 소스 슬라이스 s 에는 영향을 미치지 않습니다. 슬라이스가 구조체로서 매우 가볍게 만들 수 있지만, 위의 문제도 간과할 수 없습니다. 특히 실제 코드에서는 이러한 문제가 일반적으로 매우 깊숙이 숨겨져 있어 발견하기 어렵습니다.
생성
런타임에서 make 함수를 사용하여 슬라이스를 생성하는 작업은 runtime.makeslice 에 의해 완료됩니다. 로직은 매우 간단하며, 함수 시그니처는 다음과 같습니다.
func makeslice(et *_type, len, cap int) unsafe.Pointer세 개의 매개변수를 받습니다: 요소 유형, 길이, 용량. 완료 후 하부 배열을 가리키는 포인터를 반환합니다. 코드는 다음과 같습니다.
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 필요한 총 메모리 계산, 너무 크면 수치 오버플로우 발생
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 문제 없으면 메모리 할당
return mallocgc(mem, et, true)
}로직이 매우 간단하며, 총 두 가지만 수행합니다.
- 필요한 메모리 계산
- 메모리 공간 할당
조건 검사가 실패하면 직접 panic 합니다.
- 메모리 계산 시 수치 오버플로우
- 계산 결과가 할당 가능한 최대 메모리 초과
- 길이와 용량이 불법
계산된 메모리가 32KB 보다 크면 힙에 할당되며, 완료 후 하부 배열을 가리키는 포인터를 반환합니다. runtime.slice 구조체 구축 작업은 makeslice 함수가 완료하지 않습니다. 실제로 구조체 구축 작업은 컴파일 기간에 완료되며, 런타임의 makeslice 함수는 메모리 할당만 담당합니다. 아래 코드와 같습니다.
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = cap관심 있다면 생성된 중간 코드를 확인할 수 있으며, 이와 유사합니다.
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8배열을 사용하여 슬라이스를 생성하는 경우, 아래 코드와 같습니다.
var arr [5]int
s := arr[:]이 과정은 아래 코드와 유사합니다.
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo 는 해당 배열을 슬라이스의 하부 배열로 직접 사용하므로, 슬라이스中的数据를 수정하면 배열의 데이터에도 영향을 미칩니다. 배열을 사용하여 슬라이스를 생성할 때 길이는 high-low 와 같고, 용량은 max-low 와 같습니다. 여기서 max 는 기본적으로 배열 길이이며, 분할 시 수동으로 용량을 지정할 수도 있습니다. 예를 들어
var arr [5]int
s := arr[2:3:4]
액세스
슬라이스 액세스는 배열과 마찬가지로 인덱스를 사용합니다.
elem := s[i]슬라이스 액세스 작업은 컴파일 기간에 이미 완료되며, 중간 코드를 생성하여 액세스합니다. 최종 생성된 코드는 아래 의사코드와 같이 이해할 수 있습니다.
p := s.ptr
e := *(p + sizeof(elem(s)) * i)실제로는 포인터 이동 작업을 통해 해당 인덱스 요소에 액세스합니다. cmd/compile/internal/ssagen.exprCheckPtr 함수의 다음 부분 코드에 해당합니다.
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// 오프셋 포인터
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)len 과 cap 함수를 사용하여 슬라이스 길이와 용량에 액세스할 때도 마찬가지이며, 역시 cmd/compile/internal/ssagen.exprCheckPtr 함수의 부분 코드에 해당합니다.
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))실제 생성된 코드에서는 포인터를 이동하여 슬라이스 구조체의 len 필드에 액세스합니다. 아래 의사코드와 같이 이해할 수 있습니다.
p := &s
len := *(p + 8)
cap := *(p + 16)지금 아래 코드와 같다면
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}그렇다면 생성 중인 어떤 단계의 중간 코드는 대체로 다음과 같을 것입니다.
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9위에서 대략 알 수 있듯이, 하나는 8 을 더하고 하나는 16 을 더하므로 포인터 오프셋을 통해 슬라이스 필드에 액세스합니다.
컴파일 기간에 길이와 용량을 추론할 수 있으면 런타임에 포인터를 오프셋하여 값을 가져올 필요가 없습니다. 아래 상황과 같이 포인터를 이동할 필요가 없습니다.
s := make([]int, 10, 20)
l := len(s)
c := cap(s)변수 l 과 c 의 값은 직접 10 과 20 으로 대체됩니다.
쓰기
수정
s := make([]int, 10)
s[0] = 100인덱스를 통해 슬라이스 값을 수정할 때, 컴파일 기간에 OpStore 작업을 통해 아래 의사코드와 유사한 코드를 생성합니다.
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = val생성 중인 어떤 단계의 중간 코드는 대체로 다음과 같을 것입니다.
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:코드에서 슬라이스 길이에 액세스하여 인덱스가 합법적인지 확인한 후, 포인터를 이동하여 요소를 저장합니다.
추가
append 함수를 통해 슬라이스에 요소를 추가할 수 있습니다.
var s []int
s = append(s, 1, 2, 3)요소를 추가한 후 새 슬라이스 구조체를 반환합니다. 확장하지 않으면 소스 슬라이스 대비 길이만 업데이트되며, 확장하면 새 배열을 가리킵니다. append 사용 문제는 구조 부분에서 이미 자세히 설명했으므로 여기서는 더 이상 설명하지 않으며, 아래에서는 append 가 어떻게 작동하는지 살펴보겠습니다.
런타임에는 runtime.appendslice 와 같은 함수가 없으며, 요소 추가 작업은 실제로 컴파일 기간에 이미 처리됩니다. append 함수는 해당 중간 코드로展开되며, 판단 코드는 cmd/compile/internal/walk/assign.go walkassign 함수의 다음 부분에 있습니다.
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}세 가지 상황으로 나뉩니다.
- 여러 요소 추가
- 슬라이스 추가
- 임시 생성된 슬라이스 추가
아래에서는 생성된 코드가 어떻게 생겼는지 설명하여 append 가 실제로 어떻게 작동하는지 이해할 수 있도록 하겠습니다. 코드 생성 과정에 관심이 있다면 직접 알아볼 수 있습니다.
요소 추가
s = append(s, x, y, z)유한한 수의 요소만 추가하는 경우, walkAppend 함수에 의해 아래 코드로展开됩니다.
// 추가할 요소 수
const argc = len(args) - 1
newLen := s.len + argc
// 확장 필요 여부
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = z먼저 추가할 요소 수를 계산한 후 확장 필요 여부를 판단하고, 마지막으로 하나씩 할당합니다.
슬라이스 추가
s = append(s, s1...)슬라이스를 직접 추가하는 경우, appendSlice 함수에 의해 아래 코드로展开됩니다.
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))여전히 이전과 같이 새 길이를 계산하고 확장 필요 여부를 판단하지만, Go 는 소스 슬라이스의 요소를 하나씩 추가하지 않고 직접 메모리를 복사합니다.
임시 슬라이스 추가
s = append(s, make([]T, l2)...)임시 생성된 슬라이스를 추가하는 경우, extendslice 함수에 의해 아래 코드로展开됩니다.
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)임시 추가된 슬라이스의 경우, Go 는 임시 슬라이스의 길이를 가져와 현재 슬라이스의 용량이 수용하기에 충분하지 않으면 확장을 시도한 후 해당 부분의 메모리를 지웁니다.
확장
구조 부분에서 알 수 있듯이, 슬라이스의 하부는 여전히 배열이며, 배열은 길이가 고정된 데이터 구조이지만 슬라이스 길이는 가변적입니다. 슬라이스는 배열 용량이 부족할 때 더 큰 메모리 공간을 신청하여 데이터를 저장합니다. 즉, 새 배열을 만들고, 이전 데이터를 복사한 후 슬라이스 참조가 새 배열을 가리키도록 합니다. 이 과정을 확장이라고 합니다. 확장 작업은 런타임에서 runtime.growslice 함수에 의해 완료되며, 함수 시그니처는 다음과 같습니다.
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice매개변수 간단히 설명
oldPtr, 이전 배열을 가리키는 포인터newLen, 새 배열 길이,newLen = oldLen + numoldCap, 이전 슬라이스 용량, 이전 배열 길이와 같음et, 요소 유형
반환 값은 새 슬라이스를 반환하며, 새 슬라이스는 이전 슬라이스와 무관하며, 유일한 공통점은 저장된 데이터가 같다는 것입니다.
var s []int
s = append(s, elems...)append 을 사용하여 요소를 추가할 때 반환 값을 원래 슬라이스에 덮어쓰도록 요구합니다. 확장이 발생하면 새 슬라이스를 반환합니다.
확장 시 먼저 새 길이와 용량을 결정해야 하며, 아래 코드에 해당합니다.
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// 두 배 용량
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// 수치 오버플로우
if newcap <= 0 {
newcap = newLen
}
}
}위 코드에서 알 수 있듯이, 용량이 256 보다 작은 슬라이스는 용량이 두 배로 증가하며, 용량이 256 이상인 슬라이스는 최소한 원래 용량의 1.25 배가 됩니다. 슬라이스가 작을 때는 매번 직접 두 배로 증가하여 빈번한 확장을 피할 수 있으며, 슬라이스가 클 때는 확장 배율이 줄어들어 너무 많은 메모리를 신청하여 낭비하는 것을 피할 수 있습니다.
새 길이와 용량을 얻은 후所需 메모리를 계산하며, 아래 코드에 해당합니다.
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// 최종 용량
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}메모리 계산 공식은 mem = cap * sizeof(et) 입니다. 메모리 정렬을 용이하게 하기 위해 과정에서 계산된 메모리를 2 의 정수 제곱으로 올림하며, 새 용량을 다시 계산합니다. 새 용량이 너무 커서 계산 시 수치 오버플로우가 발생하거나 새 메모리가 할당 가능한 최대 메모리를 초과하면 panic 합니다.
var p unsafe.Pointer
// 메모리 할당
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}所需 결과를 계산한 후 지정된 크기의 메모리를 할당하고, newLen 에서 newCap 까지의 메모리를 지운 후 이전 배열의 데이터를 새 슬라이스에 복사하고, 마지막으로 슬라이스 구조체를 구축합니다.
복사
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)copy 함수를 사용하여 슬라이스를 복사할 때, cmd/compile/internal/walk.walkcopy 에 의해 컴파일 기간에 생성된 코드가 어떤 방식으로 복사할지 결정합니다. 런타임에서 호출하면 runtime.slicecopy 함수를 사용하게 되며, 이 함수는 슬라이스 복사를 담당하며, 함수 시그니처는 다음과 같습니다.
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int소스 슬라이스와 대상 슬라이스의 포인터와 길이, 그리고 복사할 길이 width 를 받습니다. 이 함수의 로직은 매우 간단하며, 다음과 같습니다.
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// 복사할 바이트 수 계산
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}width 의 값은 두 슬라이스 길이의 최솟값에 따라 결정됩니다. 슬라이스를 복사할 때 요소를 하나씩 순회하여 복사하지 않고, 하부 배열의 메모리를 통째로 복사한다는 것을 알 수 있습니다. 슬라이스가 클 때 메모리 복사로 인한 성능 영향은 적지 않습니다.
런타임에서 호출하지 않으면 아래 형태의 코드로展开됩니다.
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}두 방식의 원리는 동일하며, 모두 메모리 복사 방식을 통해 슬라이스를 복사합니다. memmove 함수는 어셈블리로 구현되었으며, 관심이 있다면 runtime/memmove_amd64.s 에서 세부 사항을 확인할 수 있습니다.
지우기
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}버전 go1.21 에서 내장 함수 clear 함수가 새로 추가되어 슬라이스 내용을 지우거나 모든 요소를 제로 값으로 설정하는 데 사용할 수 있습니다. clear 함수가 슬라이스에 작용할 때, 컴파일러는 컴파일 기간에 cmd/compile/internal/walk.arrayClear 함수에 의해 아래 형태로展开됩니다.
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}먼저 슬라이스 길이가 0 인지 판단한 후 지울 바이트 수를 계산하고, 요소가 포인터인지에 따라 두 가지 경우로 나누어 처리하지만, 최종적으로 memclrNoHeapPointers 함수를 사용하게 됩니다. 시그니처는 다음과 같습니다.
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)두 개의 매개변수를 받으며, 하나는 시작 주소를 가리키는 값이고, 다른 하나는 오프셋, 즉 지울 바이트 수입니다. 메모리 시작 주소는 슬라이스가 보유한 참조 주소이며, 오프셋 n = sizeof(et) * len 입니다. 이 함수는 어셈블리로 구현되었으며, 관심이 있다면 runtime/memclr_amd64.s 에서 세부 사항을 확인할 수 있습니다.
值得一提的是,如果源代码中尝试使用遍历来清空数组,例如这种
for i := range s {
s[i] = ZERO_val
}在没有 clear 函数之前,通常都是这样来清空切片。在编译时,现在这段代码会被 cmd/compile/internal/walk.arrayRangeClear 函数优化成这种形式
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// 停止循环
i = len(s) - 1
}
}逻辑还是跟上面的一模一样,其中多了一行 i = len(s)-1,其作用是为了在内存清除以后停止循环。
遍历
for i, e := range s {
fmt.Println(i, e)
}在使用 for range 遍历切片时,会由 cmd/compile/internal/walk/range.go 中的 walkRange 函数展开成如下形式
// 拷贝结构体
hs := s
// 获取底层数组指针
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}可以看到的是,for range 的实现依旧是通过移动指针来遍历元素的。为了避免在遍历时切片被更新,事先拷贝了一份结构体 hs,为了避免遍历结束后指针指向越界的内存,hu 使用的 uinptr 类型来存放地址,在需要访问元素的时候才转换成 unsafe.Pointer。
变量 v2 也就是 for range 中的 e,在整个遍历过程中从始至终都是一个变量,它只会被覆盖,不会重新创建。这一点引发了困扰 go 开发者十年的循环变量问题,到了版本 go.1.21 官方才终于决定要打算解决,预计在后面版本的更新中,v2 的创建方式可能会变成下面这样。
v2 := *hp构造中间代码过程这里省略了,这并不属于切片范围的知识,感兴趣可以自己去了解下。