gc
가비지 컬렉션은 더 이상 사용되지 않는 객체 메모리를 해제하여 다른 객체에 공간을 할당하는 작업입니다. 이렇게 간단한 설명이지만 구현은 매우 복잡합니다. 가비지 컬렉션의 발전 역사는 수십 년이 되었으며, 가장 일찍 1960 년대 Lisp 언어에서 최초로 가비지 컬렉션 메커니즘을 채택했습니다. 우리가 잘 아는 Python, Objective-C 의 주요 GC 메커니즘은 참조 카운팅이며, Java, C#은 세대별 컬렉션을 사용합니다. 오늘날 가비지 컬렉션은 컬렉션 알고리즘에 따라 대략 다음 몇 가지로 나눌 수 있습니다:
- 참조 카운팅: 각 객체가自身을 몇 번 참조하는지 기록하고, 카운트가 0 이 되면 회수합니다.
- 마크 앤드 스위프: 활성 객체를 마킹하고 마킹되지 않은 객체를 회수합니다.
- 복사 알고리즘: 활성 객체를 새로운 메모리에 복사하고 구 메모리의 모든 객체를 모두 회수하여 가비지 컬렉션 목적을 달성합니다.
- 마크 앤드 컴팩트: 마크 앤드 스위프의 업그레이드 버전으로, 회수 시 활성 객체를 힙의 헤드로 이동하여 관리하기 쉽게 합니다.
적용 방식에 따라 다음 몇 가지로 나눌 수 있습니다:
- 전역 컬렉션: 한 번에 모든 가비지를 직접 컬렉션합니다.
- 세대별 컬렉션: 객체의 생존 시간에 따라 다른 세대로 나누고 다른 컬렉션 알고리즘을 채택합니다.
- 증분 컬렉션: 매번 국소적인 가비지 컬렉션만 수행합니다.
TIP
The Journey of Go's Garbage Collector 에서 Go 가비지 컬렉션의 역사에 대한 영어 원문을 읽어보세요.
처음 출시되었을 때 Go 의 가비지 컬렉션 메커니즘은 매우 단순했으며 간단한 마크 앤드 스위프 알고리즘만 있었습니다. 가비지 컬렉션으로 인한 STW(Stop The World, 가비지 컬렉션으로 인해 전체 프로그램을 일시 중지하는 것) 는 몇 초 또는 그 이상 지속되었습니다. 이 문제를 인식한 Go 팀은 가비지 컬렉션 알고리즘 개선을 시작했으며, go1.0 에서 go1.8 버전 사이에 많은 시도를 했습니다.
- 읽기 배리어 동시성 복사 GC: 읽기 배리어의 오버헤드에는 많은 불확실성이 있어 이 방안은 취소되었습니다.
- 요청 지향 컬렉터 (ROC): 항상 쓰기 배리어를 활성화해야 하여 실행 속도가 느려지고 컴파일 시간이 늘어났습니다.
- 세대별 컬렉션: Go 에서의 세대별 컬렉션 효율은 높지 않았습니다. Go 컴파일러는 새 객체를 스택에 할당하고 장기 생존 객체를 힙에 할당하는 경향이 있어 신생대 객체 대부분은 스택에서 직접 회수되었습니다.
- 쓰기 배리어 없는 카드 마킹: 해시 산출 비용으로 쓰기 배리어 비용을 대체하며 하드웨어 지원이 필요합니다.
최종적으로 Go 팀은 3 색 동시성 마킹 + 쓰기 배리어 조합을 선택했고 이후 버전에서 지속적으로 개선 및 최적화했으며, 이 방식은 현재까지도 사용되고 있습니다. 아래 그림들은 go1.4 에서 go1.9 까지의 GC 지연 시간 변화를 보여줍니다.
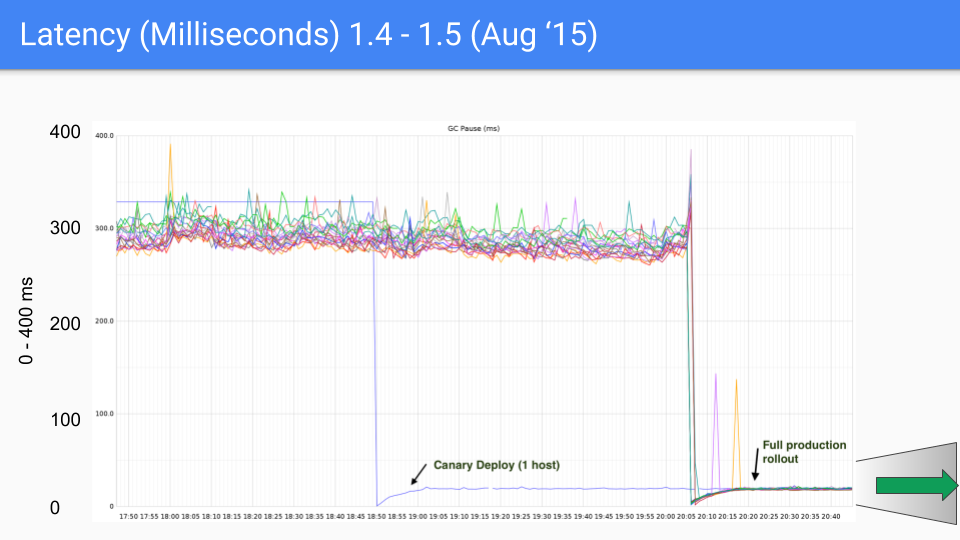
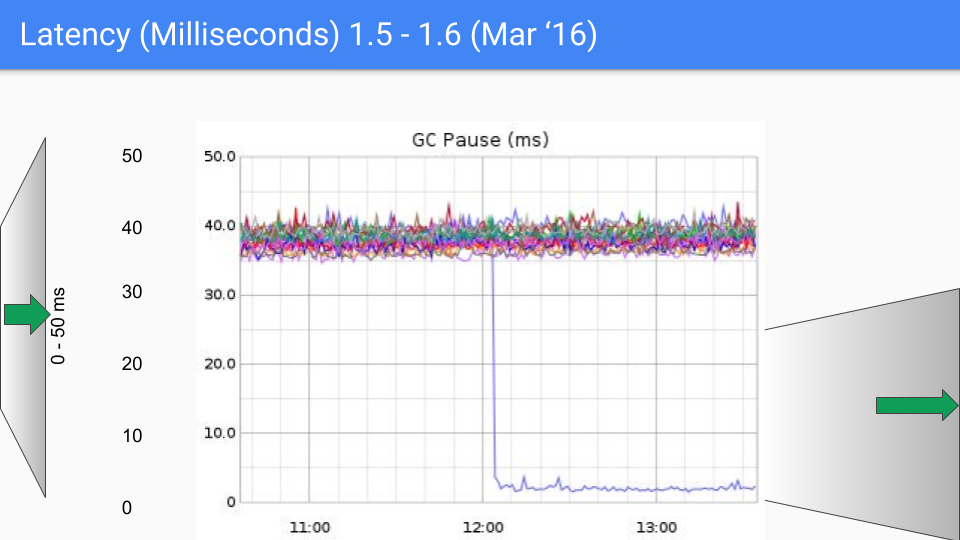
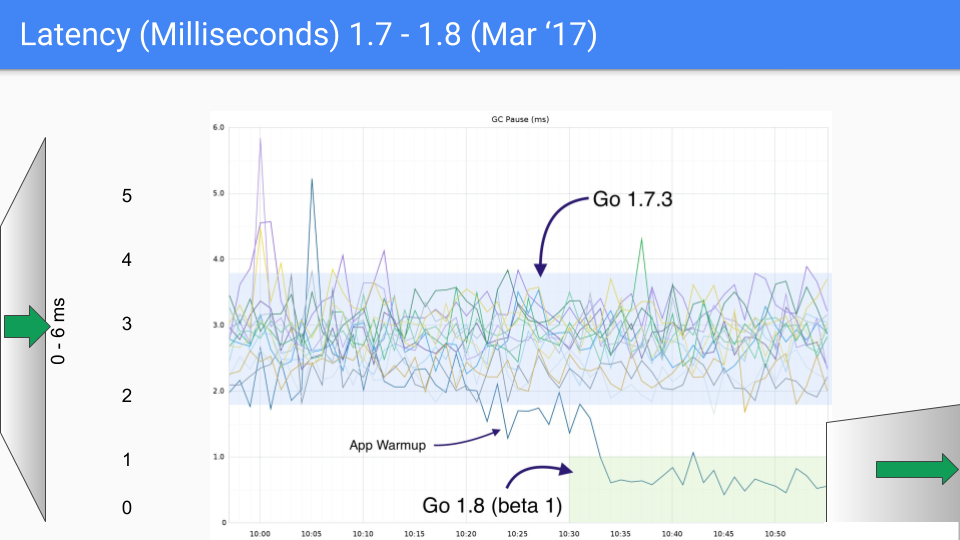
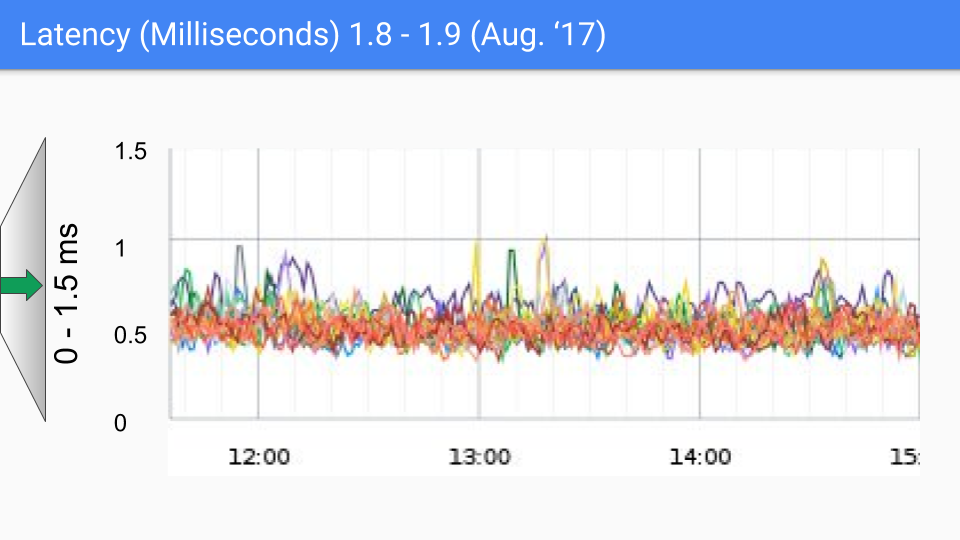
이 글을 작성할 당시 Go 의 최신 버전은 곧 go1.23 이 될 예정이며, 오늘날 Go 에게 GC 성능은 이미 문제가 되지 않습니다. 현재 GC 지연 시간은 대부분의 경우 100 마이크로초 이하로, 대부분의 비즈니스 시나리오 요구를 충족합니다.
전반적으로 Go 의 가비지 컬렉션은 다음 몇 가지 단계로 나눌 수 있습니다:
- 스캔 단계: 스택과 전역 변수에서 루트 객체를 수집합니다.
- 마킹 단계: 객체에 색상을 칠합니다.
- 마킹 종료 단계: 마무리 작업을 처리하고 배리어를 닫습니다.
- 컬렉션 단계: 가비지 객체의 메모리를 해제하고 회수합니다.
개념
공식 문서와 아티클에서 다음 몇 가지 개념이 나타날 수 있으며, 아래에 간단히 설명합니다.
- 뮤테이터 (mutator): 용어화된 표현으로 사용자 프로그램을 지칭하며, Go 에서는 사용자 코드를 의미합니다.
- 컬렉터 (collector): 가비지 컬렉션을 담당하는 프로그램을 지칭하며, Go 에서는 런타임이 가비지 컬렉션을 담당합니다.
- 파이널라이저 (finalizer): 마킹 스캔 작업 완료 후 객체 메모리 회수 및 정리를 담당하는 코드를 의미합니다.
- 컨트롤러:
runtime.gcController전역 변수를 지칭하며, 유형은gcControllerState로, 스텝 조정 알고리즘을 구현하여 가비지 컬렉션 시기와 작업량을 확인하는 역할을 합니다. - 리미터:
runtime.gcCPULimiter를 지칭하며, 가비지 컬렉션 시 CPU 점유율이 너무 높아 사용자 프로그램에 영향을 미치는 것을 방지합니다.
트리거
func gcStart(trigger gcTrigger)가비지 컬렉션은 runtime.gcStart 함수에 의해 시작되며, 이 함수는 runtime.gcTrigger 구조체 매개변수만 받습니다. 여기에는 GC 트리거 원인, 현재 시간, 그리고 몇 번째 GC 라운드가 포함됩니다.
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: 현재 시간
n uint32 // gcTriggerCycle: 시작할 라운드 번호
}그중 gcTriggerKind에는 다음 몇 가지 선택 값이 있습니다.
const (
// gcTriggerHeap 은 힙 크기가 컨트롤러에 의해 계산된
// 트리거 힙 크기에 도달했을 때 라운드를 시작해야 함을 나타냅니다.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime 은 이전 GC 라운드 이후로
// forcegcperiod 나노초보다 더 지났을 때
// 라운드를 시작해야 함을 나타냅니다.
gcTriggerTime
// gcTriggerCycle 은 아직 라운드 번호 gcTrigger.n 을
// 시작하지 않았을 때 (work.cycles 기준) 라운드를
// 시작해야 함을 나타냅니다.
gcTriggerCycle
)전반적으로 가비지 컬렉션 트리거 시점은 세 가지가 있습니다.
새 객체 생성 시:
runtime.mallocgc를 호출하여 메모리를 할당할 때, 힙 메모리가 임계값 (일반적으로 이전 GC 의 두 배이며, 이 값은 스텝 조정 알고리즘에 의해 조정됨) 에 도달하면 가비지 컬렉션을 시작합니다.gofunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }
-定时强制触发:Go 在运行时会启动一个单独的协程来运行 runtime.forcegchelper 函数,如果长时间没有进行垃圾回收,它便会强制开启 GC,这个时间由 runtime.forcegcperiod 常量决定,其值为 2 分钟,同时在系统监控协程中也会定时检查是否需要强制 GC
func forcegchelper() {
for {
...
gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()})
...
}
}func sysmon() {
...
for {
...
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() {
lock(&forcegc.lock)
forcegc.idle.Store(false)
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
}
}수동 트리거:
runtime.GC함수를 통해 사용자가 수동으로 가비지 컬렉션을 트리거할 수 있습니다.gofunc GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
TIP
관심 있는 분들은 Go Gc Pacer Re-Design 에서 GC 트리거 스텝 조정 알고리즘 (pacing algorithm) 의 설계 이념과 개선에 대한 영어 원문을 읽어보시기 바랍니다. 내용이 매우 복잡하고 많은 수학 공식이 포함되어 있어 본문에서는 자세히 설명하지 않습니다.
마킹
현재 Go 의 GC 알고리즘은 여전히 먼저 마킹한 후 스윕하는 단계이지만, 구현은 이전처럼 단순하지 않습니다.
마크 앤드 스위프
가장 간단한 마크 앤드 스위프 알고리즘부터 시작하겠습니다. 메모리에서 객체 간의 참조 관계는 그래프를 구성하며, 가비지 컬렉션 작업은 이 그래프에서 수행됩니다. 작업은 두 단계로 나뉩니다:
- 마킹 단계: 루트 노드 (루트 노드는 일반적으로 스택의 변수, 전역 변수 등 활성 객체) 에서 시작하여 도달 가능한 모든 노드를 하나씩 순회하며 활성 객체로 마킹합니다. 도달 가능한 모든 노드를 순회할 때까지 계속합니다.
- 스윕 단계: 힙의 모든 객체를 순회하며 마킹되지 않은 객체를 회수하고 메모리 공간을 해제하거나 재사용합니다.
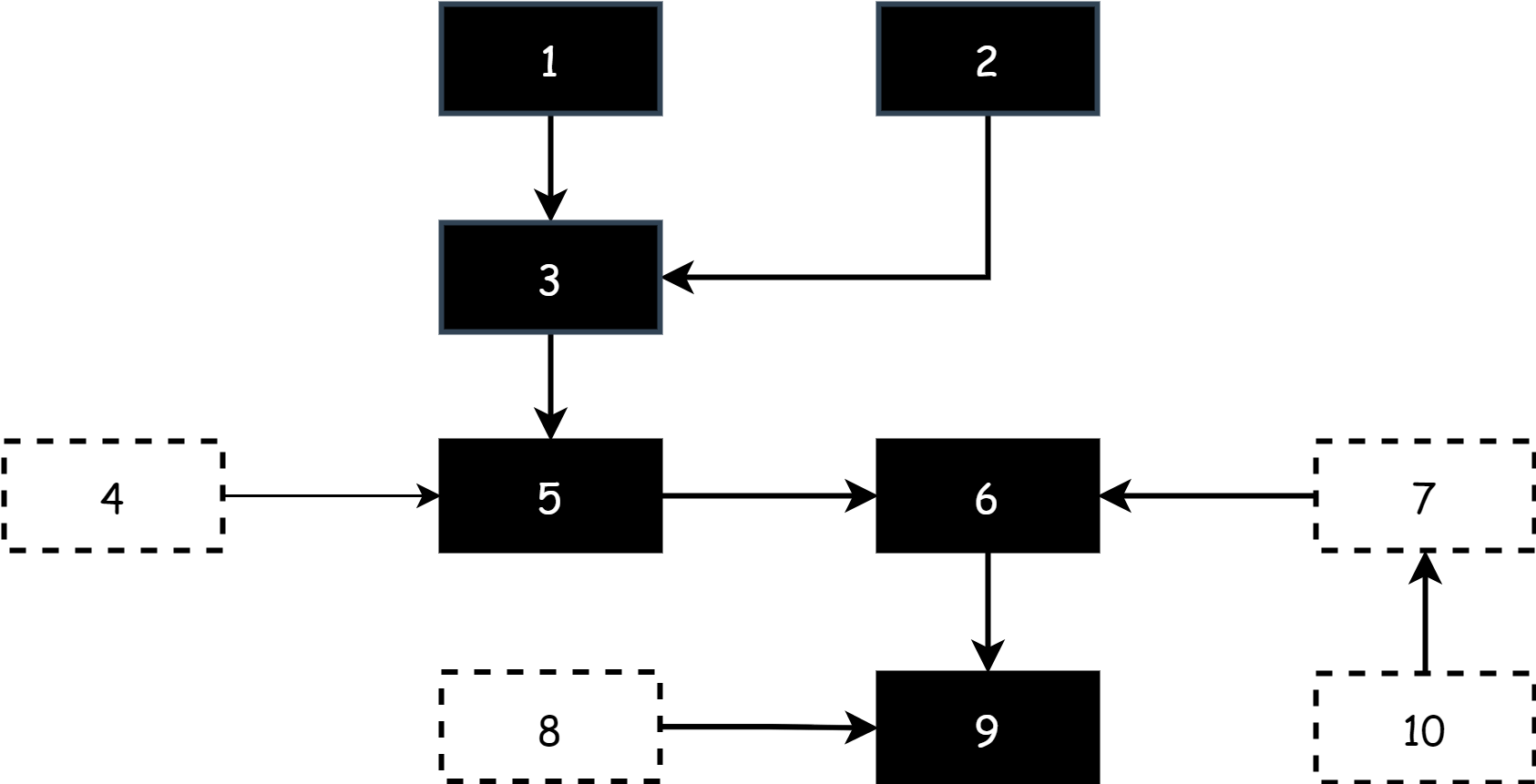
회수 과정에서 객체 그래프 구조는 변경될 수 없으므로 전체 프로그램을 중지해야 합니다. 이것이 STW 입니다. 회수가 완료된 후에야 계속 실행할 수 있습니다. 이 알고리즘의 단점은 시간이 오래 걸려 프로그램 실행 효율에 큰 영향을 미친다는 점입니다. 이는 초기 버전 Go 에서 사용한 마킹 알고리즘이며 단점이 비교적 명확합니다.
- 메모리 단편화가 발생합니다 (Go 의 TCMalloc 스타일 메모리 관리 방식으로 인해 단편화 문제의 영향은 크지 않습니다).
- 마킹 단계에서 힙의 모든 객체를 스캔합니다.
- STW 를 유발하여 전체 프로그램을 일시 중지하며 시간이 짧지 않습니다.
3 색 마킹
효율성을 개선하기 위해 Go 는 고전적인 3 색 마킹 알고리즘을 채택했습니다.所谓 3 색이란 흑, 회, 백 3 색을 의미합니다:
- 흑색: 마킹 과정에서 객체가 이미 방문되었으며, 직접 참조하는 객체도 모두 방문되어 활성 객체임을 나타냅니다.
- 회색: 마킹 과정에서 객체가 이미 방문되었지만, 직접 참조하는 객체는 모두 방문되지 않았습니다. 모두 방문되면 흑색으로 변하며 활성 객체임을 나타냅니다.
- 백색: 마킹 과정에서 한 번도 방문되지 않았으며, 방문 후 회색으로 변하며 가비지 객체일 수 있음을 나타냅니다.
3 색 마킹 작업 시작 시에는 회색과 백색 객체만 있으며, 모든 루트 객체는 회색이고 다른 객체는 백색입니다. 아래 그림과 같습니다.
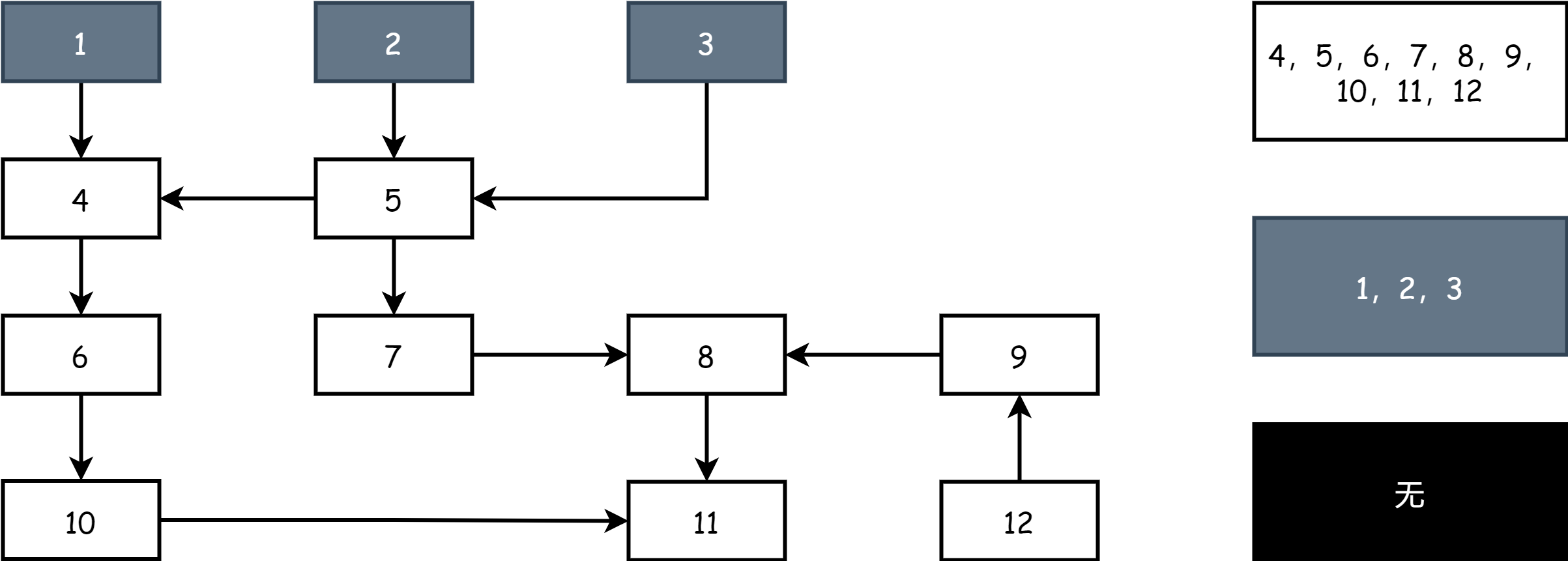
매 라운드 마킹 시작 시 먼저 회색 객체부터 시작하여 회색 객체를 흑색으로 마킹하여 활성 객체임을 나타낸 후, 흑색 객체가 직접 참조하는 모든 객체를 회색으로 마킹합니다. 나머지는 백색이며, 이때 필드에는 흑, 백, 회 3 색이 있게 됩니다.
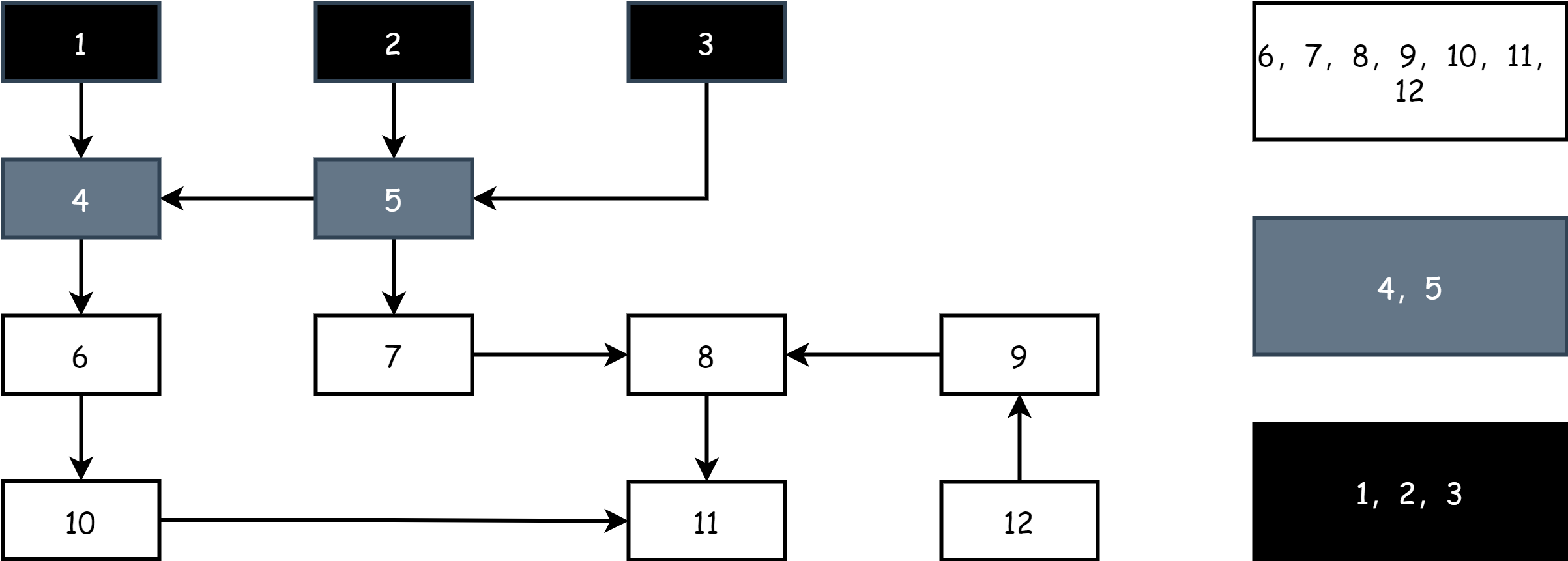
위 단계를 반복하여 필드에 흑색과 백색 객체만 남을 때까지 계속합니다. 회색 객체 집합이 비어지면 마킹이 종료되었음을 나타냅니다. 아래 그림과 같습니다.
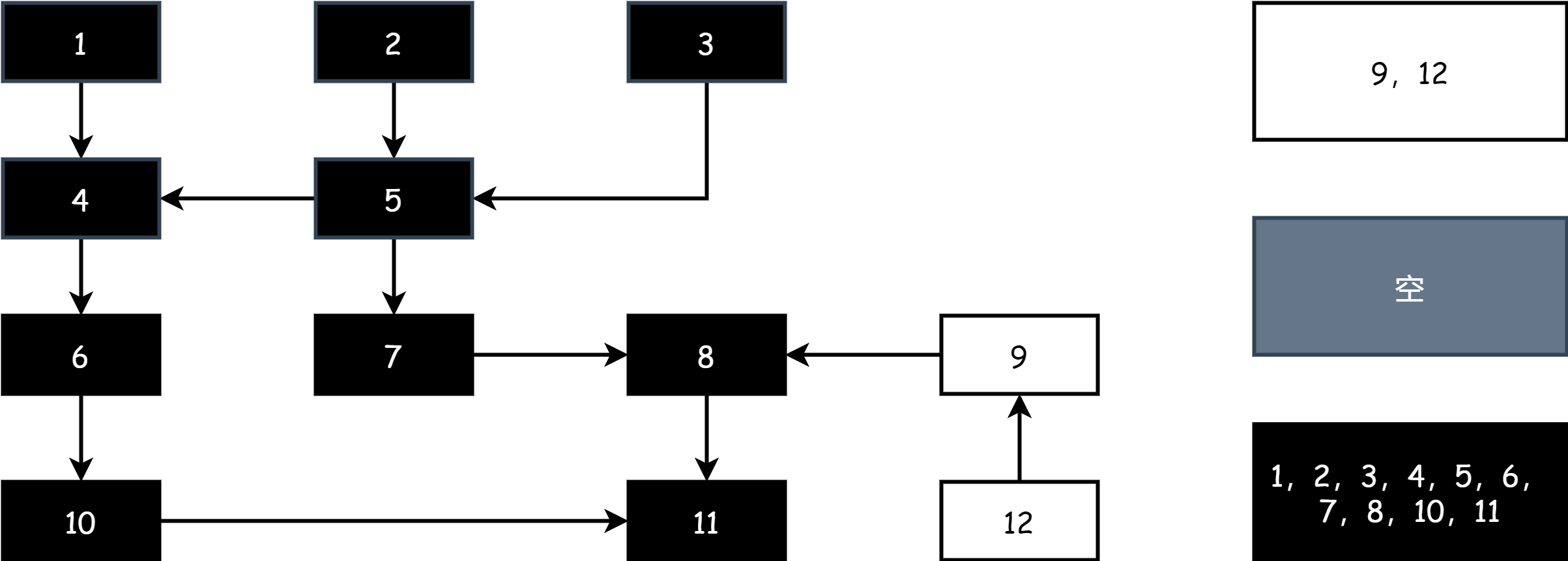
마킹이 종료되면 스윕 단계에서 백색 집합의 객체 메모리만 해제하면 됩니다.
불변성
3 색 마킹법 자체는 동시성 마킹 (프로그램이 실행되면서 마킹하는 것) 을 수행할 수 없습니다. 마킹 중 객체 그래프 구조가 변경되면 다음 두 가지 상황이 발생할 수 있습니다.
- 과다 마킹: 객체가 흑색으로 마킹된 후 사용자 프로그램이 해당 객체에 대한 모든 참조를 삭제하면, 이 객체는 백색이어야 하며 제거되어야 합니다.
- 누락 마킹: 객체가 백색으로 마킹된 후 사용자 프로그램의 다른 객체가 해당 객체를 참조하면, 이 객체는 흑색이어야 하며 제거되지 않아야 합니다.
첫 번째 상황은 수용할 수 있습니다. 제거되지 않은 객체는 다음 라운드에서 처리될 수 있기 때문입니다. 하지만 두 번째 상황은 수용할 수 없습니다. 사용 중인 객체 메모리가 잘못 해제되면 심각한 프로그램 오류가 발생하므로 반드시 방지해야 합니다.
3 색 불변성 개념은 Pekka P. Pirinen 이 1998 년 발표한 논문 《Barrier techniques for incremental tracing》 에서 나왔습니다. 이는 동시성 마킹 시 객체 색상의 두 가지 불변성을 의미합니다:
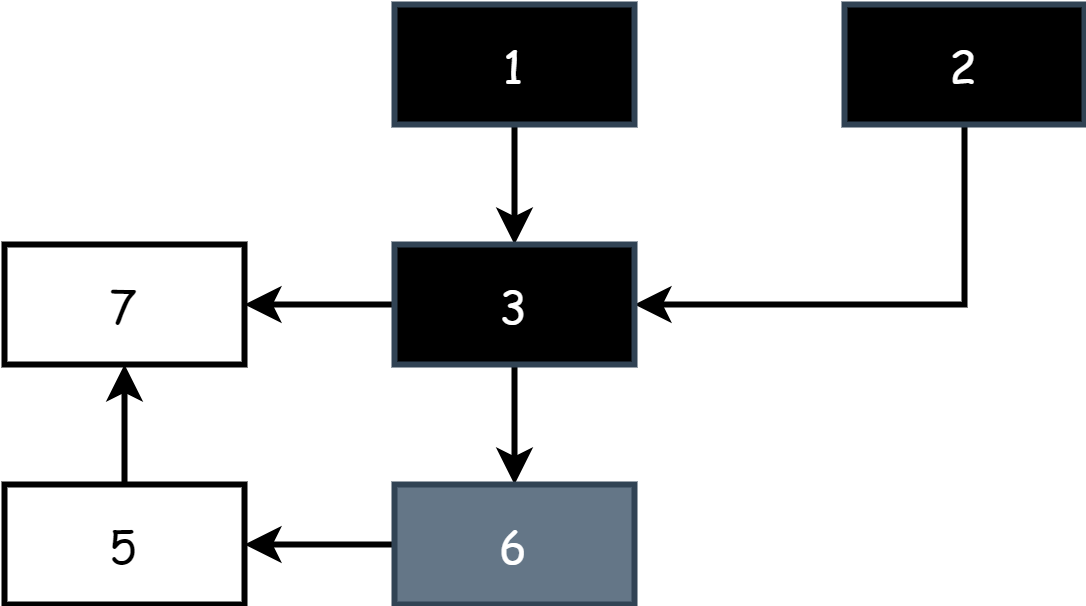
강 3 색 불변성: 흑색 객체는 백색 객체를 직접 참조할 수 없습니다.
약 3 색 불변성: 흑색 객체가 백색 객체를 직접 참조할 때, 다른 회색 객체가 해당 백색 객체를 직접 또는 간접적으로 방문할 수 있어야 합니다. 이를 회색 객체의 보호를 받는다고 합니다.
강 3 색 불변성의 경우, 흑색 객체 3 이 이미 방문된 객체이며 하위 객체도 모두 방문되어 회색으로 마킹된 것으로 알려져 있습니다. 이때 사용자 프로그램이 병렬적으로 흑색 객체 3 에 백색 객체 7 의 새 참조를 추가하면, 정상적으로 백색 객체 7 은 회색으로 마킹되어야 하지만 흑색 객체 3 이 이미 방문되었기 때문에 객체 7 은 방문되지 않아 항상 백색 객체로 남고 최종적으로 잘못 제거됩니다.

약 3 색 불변성의 경우, 강 3 색 불변성과 동일합니다. 회색 객체가 해당 백색 객체를 직접 또는 간접적으로 방문할 수 있기 때문에 후속 마킹 과정에서 최종적으로 회색 객체로 마킹되어 잘못 제거되는 것을 방지할 수 있습니다.
불변성을 통해 마킹 과정에서 객체가 잘못 제거되지 않도록 보장할 수 있으며, 이는 동시성 조건에서 마킹 작업의 정확성을 보장하여 3 색 마킹이 동시성으로 작동할 수 있게 합니다. 이렇게 하면 마킹 효율이 마크 앤드 스위프 알고리즘에 비해 상당히 향상됩니다. 동시성 조건에서 3 색 불변성을 보장하는 핵심은 배리어 기술에 있습니다.
마킹 작업
GC 스캔 단계에서 runtime.gcphase라는 전역 변수가 GC 상태를 나타내는 데 사용됩니다. 다음 선택 값이 있습니다:
_GCoff: 마킹 작업이 시작되지 않음_GCmark: 마킹 작업이 시작됨_GCmarktermination: 마킹 작업이 곧 종료됨
마킹 작업이 시작되면 runtime.gcphase 상태는 _GCmark가 되며, 마킹 작업은 runtime.gcDrain 함수에 의해 실행됩니다. 여기서 runtime.gcWork 매개변수는 추적할 객체 포인터를 저장하는 버퍼 풀입니다.
func gcDrain(gcw *gcWork, flags gcDrainFlags)작업 시 버퍼 풀에서 추적 가능한 포인터를 가져오려고 시도하며, 있으면 runtime.scanobject 함수를 호출하여 스캔 작업을 계속 실행합니다. 이 함수의 역할은 버퍼의 객체를 계속 스캔하여 흑색으로 염색하는 것입니다.
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 쓰기 배리어 버퍼 플러시
// 더 많은 작업을 생성할 수 있음
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// 작업을 가져올 수 없음
break
}
scanobject(b, gcw)P 가 선점되거나 STW 가 발생해야만 스캔 작업이 중지됩니다.
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork 는 생산자/소비자 모델을 채택한 큐이며, 이 큐는 스캔할 회색 객체를 저장합니다. 각 프로세서 P 로컬에도 이러한 큐가 있으며, runtime.p.gcw 필드에 해당합니다.
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}runitme.scanobject 함수는 스캔 시 도달 가능한 백색 객체를 계속 회색으로 마킹한 후 gcw.put 을 호출하여 로컬 큐에 넣습니다. 동시에 gcDrain 함수도 gcw.tryget 을 통해 회색 객체를 가져와 스캔을 계속합니다. 마킹 스캔 과정은 증분식이며 한 번에 모든 마킹 작업을 완료할 필요가 없습니다. 마킹 작업이 어떤 이유로 선점되면 중단되며, 복구 후 큐에 남은 회색 객체에 따라 마킹 작업을 계속 완료할 수 있습니다.
백그라운드 마킹
마킹 작업은 GC 시작 시 즉시 실행되지 않습니다. GC 를 트리거할 때 Go 는 현재 프로세서 P 의 총 수와 동일한 수의 마킹 작업을 생성하며, 이들은 전역 작업 큐에 추가된 후 마킹 단계에서 깨어날 때까지 대기합니다. 런타임에서는 runtime.gcBgMarkStartWorkers 에 의해 작업이 할당되며, 마킹 작업은 실제로 runtime.gcBgMarkWorker 함수를 의미합니다. 여기서 gcBgMarkWorkerCount 와 gomaxprocs 두 런타임 전역 변수는 각각 현재 worker 수와 프로세서 P 수를 나타냅니다.
func gcBgMarkStartWorkers() {
// 백그라운드 마킹은 P 별 G 에 의해 수행됩니다. 각 P 에
// 백그라운드 GC G 가 있는지 확인합니다.
//
// Worker G 는 gomaxprocs 가 감소해도 종료되지 않습니다. 다시
// 증가하면 이전 worker 를 재사용할 수 있습니다. 새 worker 를
// 생성할 필요가 없습니다.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// worker 는 이제 P 의 다음 findRunnableGCWorker 전에
// 풀에 추가되는 것이 보장됩니다.
gcBgMarkWorkerCount++
}
}worker 가 시작된 후 runtime.gcBgMarkWorkerNode 구조체를 생성하여 전역 worker 풀 runitme.gcBgMarkWorkerPool 에 추가한 후 runtime.gopark 함수를 호출하여 고루틴을 대기 상태로 만듭니다.
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// gcController.findRunnableGCWorker 에 의해
// 깨어날 때까지 대기합니다.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// 이 G 를 풀에 릴리스합니다.
gcBgMarkWorkerPool.push(&node.node)
// 이 시점에서 G 는 즉시
// 재스케줄링될 수 있으며 실행 중일 수 있습니다.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}worker 를 깨울 수 있는 두 가지 상황이 있습니다:
- 마킹 단계일 때, 스케줄링 루프는
runtime.runtime.gcController.findRunnableGCWorker함수를 통해 대기 중인 worker 를 깨웁니다. - 마킹 단계일 때, 프로세서 P 가 현재 유휴 상태이면, 스케줄링 루프는 전역 worker 풀
gcBgMarkWorkerPool에서 사용 가능한 worker 를 가져오려고 시도합니다.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// GC worker 를 스케줄링하려고 시도합니다.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// 할 일이 없습니다.
//
// GC 마킹 단계에 있으면 객체를 안전하게 스캔하고 흑색으로
// 만들 수 있으며 할 일이 있으면 유휴 시간 마킹을 실행하여
// P 를 포기하지 않습니다.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}프로세서 P 구조체에는 gcMarkWorkerMode라는 필드가 있어 마킹 작업의 실행 모드를 나타냅니다. 다음 선택 값이 있습니다:
gcMarkWorkerNotWorker: 현재 프로세서 P 가 마킹 작업을 실행하고 있지 않음을 나타냅니다.gcMarkWorkerDedicatedMode: 현재 프로세서 P 가 전적으로 마킹 작업에 사용되며 기간 중 선점되지 않음을 나타냅니다.gcMarkWorkerFractionalMode: 현재 프로세서가 GC 활용률이 기준에 미달 (25%达标) 하여 마킹 작업을 실행하며, 실행 중 선점될 수 있습니다. 현재 프로세서 P 수가 5 라고 가정하면, 계산식에 따라 전적으로 마킹 작업에 사용되는 프로세서 P 가 하나 필요하며 활용률은 20% 만 달성되었습니다. 나머지 5% 활용률을 보완하기 위해FractionalMode프로세서 P 를 하나 더开启해야 합니다. 구체적인 계산 코드는 아래와 같습니다.gofunc (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // 너무 많은 전용 worker dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode: 현재 프로세서가 유휴 상태여서 마킹 작업을 실행하며, 실행 중 선점될 수 있습니다.
Go 팀은 GC 가 사용자 프로그램의 정상적인 실행에 영향을 미치지 않도록 GC 가 너무 많은 성능을 차지하지 않기를 원합니다. 이러한 다양한 모드를 통해 마킹 작업을 수행하면 성능을 낭비하지 않고 사용자 프로그램에 영향을 미치지 않으면서 GC 를 완료할 수 있습니다. 주목할 점은 마킹 작업의 기본 할당 단위가 프로세서 P 이므로 마킹 작업은 병렬로 수행되며, 여러 마킹 작업과 사용자 프로그램 간에 병렬로 실행되어 서로 영향을 미치지 않습니다.
마킹 보조
고루틴 G 는 런타임에 gcAssistBytes라는 필드를 가지고 있으며, 이를 GC 보조 점수라고 부릅니다. GC 마킹 상태일 때, 한 고루틴이若干 크기의 메모리를 할당하려고 시도하면 할당된 메모리 크기와 동일한 점수가 차감됩니다. 이때 점수가 음수이면 해당 고루틴은 정량의 GC 스캔 작업을 보조하여 점수를 상환해야 합니다. 점수가 양수이면 고루틴은 보조 마킹 작업을 완료할 필요가 없습니다.
점수를 차감하는 함수는 runtime.deductAssistCredit이며, runtime.mallocgc 함수에서 메모리를 할당하기 전에 호출됩니다.
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// 이 할당에 대해 현재 사용자 G 에게 청구합니다.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// 할당을 G 에게 청구합니다. 내부 단편화는
// mallocgc 끝에서 처리합니다.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// 이 G 는 빚이 있습니다. 할당 전에
// 이를 수정하기 위해 GC 를 보조합니다. 이는
// 선점 비활성화 전에 발생해야 합니다.
gcAssistAlloc(assistG)
}
}
return assistG
}그러나 고루틴이 정량의 보조 스캔 작업을 완료하면 정량의 점수를 현재 고루틴에 상환하며, 실제로 보조 마킹을 담당하는 함수는 runtime.gcDrainN입니다.
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// 작업 완료
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}스캔은 병렬로 수행되므로 기록된 작업량의 일부만 현재 고루틴의 것이며, 나머지 작업량은 보조 큐의 순서에 따라 다른 고루틴에 상환됩니다. 남은 것이 있으면 전역 점수 gcController.assistBytesPerWork 에 추가됩니다.
func gcFlushBgCredit(scanWork int64) {
// 큐가 비어 있으면 전역 점수에 직접 추가
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// 나머지
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}相应地,当需要偿还的积分过多时(申请的内存过大),也可以使用全局积分来抵消部分自己的借债
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// 전역 점수로 담보
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}마킹 보조는 고부하 상황에서 일종의 균형 수단입니다. 사용자 프로그램이 메모리를 할당하는 속도가 마킹 속도보다 훨씬 빠를 때, 할당된 만큼의 메모리에 대해 마킹 작업을 수행합니다.
마킹 종료
도달 가능한 모든 회색 객체가 흑색으로 염색되면 _GCmark 상태에서 _GCmarktermination 상태로 전환됩니다. 이 과정은 runtime.gcMarkDone 함수에 의해 완료됩니다. 시작 시 아직 실행할 작업이 있는지 확인합니다.
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// 쓰기 배리어에 의해 인터셉트된 모든 마킹 작업을 일괄 실행
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}전역 작업과 로컬 작업이 모두 없으면 runtime.stopTheWorldWithSema 를 호출하여 STW 를 수행한 후 마무리 작업을 합니다.
// 보조 및 백그라운드 worker 를 비활성화합니다.
// 차단된 보조를 깨우기 전에 이 작업을 수행해야 합니다.
atomic.Store(&gcBlackenEnabled, 0)
// CPU 리미터에 GC 보조가 이제 중지될 것임을 알립니다.
gcCPULimiter.startGCTransition(false, now)
// 차단된 모든 보조를 깨웁니다. 이는
// 월드를 다시 시작할 때 실행됩니다.
gcWakeAllAssists()
// STW 모드에서 사용자 고루틴을 다시 활성화합니다.
// 이는 월드를 시작한 후 실행됩니다.
schedEnableUser(true)
// endCycle 은 모든 gcWork 캐시 통계가
// 플러시되는 것에 의존합니다. 위의 종료 알고리즘은
// ragged 배리어 이후의 할당까지 이를 보장했습니다.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// 마킹 종료를 수행합니다. 이는
// 월드를 다시 시작합니다.
gcMarkTermination(stw)먼저 runtime.BlackenEnabled 를 0 으로 설정하여 마킹 작업이 종료되었음을 나타내고, 리미터에 마킹 보조가 종료되었음을 알리며, 메모리 배리어를 닫고, 보조 마킹으로 인해 대기 중인 모든 고루틴을 깨운 후 모든 사용자 고루틴을 다시 깨웁니다. 또한 다음 라운드 스캔을 위해 스텝 조정 알고리즘을 조정하기 위해 이번 라운드 스캔 작업의 다양한 데이터를 수집합니다. 마무리 작업이 완료되면 runtime.gcSweep 함수를 호출하여 가비지 객체를 정리한 후 runtime.startTheWorldWithSema 를 호출하여 프로그램을 다시 실행합니다.
배리어
메모리 배리어의 역할은 객체 할당 행위를 hook 하는 것으로 이해할 수 있으며, 할당 전에 지정된 작업을 수행합니다. 이러한 hook 코드는 일반적으로 컴파일 기간 중 컴파일러에 의해 코드에 삽입됩니다. 앞서 언급했듯이 3 색 마킹은 동시성 조건에서 객체 참조를 추가하고 삭제하면 문제가 발생합니다. 둘 다 쓰기 작업이므로 (삭제는 null 값을 할당하는 것) 이들을 인터셉트하는 배리어를 통칭하여 쓰기 배리어라고 합니다. 하지만 배리어 메커니즘은 비용이 없지 않으며, 메모리 쓰기 작업을 인터셉트하면 추가 오버헤드가 발생하므로 배리어 메커니즘은 힙에서만 유효하며, 구현 복잡도와 성능 손실을 고려하여 스택과 레지스터에는 적용되지 않습니다.
TIP
Go 의 배리어 기술 적용 세부 사항에 대해 더 알고 싶다면 Eliminate STW stack rescan 에서 영어 원문을 읽어보세요. 이 글은 많은 내용을 참고했습니다.
삽입 쓰기 배리어
삽입 쓰기 배리어는 Dijkstra 가 제안했으며 강 3 색 불변식을 만족합니다. 흑색 객체에 새 백색 객체 참조를 추가할 때 삽입 쓰기 배리어는 이 작업을 인터셉트하여 해당 백색 객체를 회색으로 마킹합니다. 이렇게 하면 흑색 객체가 백색 객체를 직접 참조하는 것을 방지하여 강 3 색 불변식을 보장합니다. 이는 매우 이해하기 쉽습니다.

앞서 언급했듯이 쓰기 배리어는 스택에 적용되지 않습니다. 병렬 마킹 과정에서 스택 객체의 참조 관계가 변경되면, 예를 들어 스택의 흑색 객체가 힙의 백색 객체를 참조하는 경우, 스택 객체의 정확성을 보장하기 위해 마킹 종료 후 스택의 모든 객체를 다시 회색 객체로 마킹한 후 다시 스캔해야 합니다. 즉, 한 라운드 마킹은 스택 공간을 두 번 스캔해야 하며, 두 번째 스캔 시 반드시 STW 가 필요합니다. 프로그램에 수백 수천 개의 고루틴 스택이 동시에 존재한다면, 이 스캔 과정의 소요 시간은 무시할 수 없습니다. 공식 통계 데이터에 따르면 재스캔 소요 시간은 대략 10-100 밀리초 정도입니다.
장점: 스캔 시 STW 가 필요하지 않습니다.
단점: 정확성을 보장하기 위해 스택 공간을 두 번 스캔해야 하며 STW 가 필요합니다.
삭제 쓰기 배리어
삭제 쓰기 배리어는 Yuasa 가 제안했으며, 스냅샷 기반 배리어라고도 합니다. 이 방식은 시작 시 루트 객체의 스냅샷을 기록하기 위해 STW 가 필요하며, 모든 루트 객체를 흑색으로, 모든 1 차 하위 객체를 회색으로 마킹합니다. 이렇게 하면 나머지 백색 하위 객체는 모두 회색 객체의 보호 아래 있게 됩니다. Go 팀은 삭제 쓰기 배리어를 직접 적용하지 않고 삽입 쓰기 배리어와 혼합하여 사용하기로 선택했습니다. 따라서 후속 이해를 돕기 위해 여기서 설명합니다. 삭제 쓰기 배리어는 병렬 조건에서 정확성을 보장하는 규칙은 다음과 같습니다: 회색 또는 백색 객체에서 백색 객체에 대한 참조를 삭제할 때 백색 객체를 직접 회색 객체로 마킹합니다.
두 가지 상황으로 나누어 해석합니다:
회색 객체에서 백색 객체에 대한 참조 삭제: 백색 객체 하류가 흑색 객체에 의해 참조되는지 알 수 없으므로, 이 조치는 회색 객체에서 백색 객체에 대한 보호를 차단할 수 있습니다.
백색 객체에서 백색 객체에 대한 참조 삭제: 백색 객체 상류가 회색 보호를 받는지, 하류가 흑색 객체에 의해 참조되는지 알 수 없으므로, 이 조치 또한 회색에서 백색 객체에 대한 보호를 차단할 수 있습니다.
어떤 상황이든 삭제 쓰기 배리어는 참조된 백색 객체를 회색으로 마킹합니다. 이렇게 하면 약 3 색 불변식을 만족할 수 있습니다. 이는 보수적인做法으로, 상류와 하류 상황이 알려지지 않았기 때문에 회색으로 마킹하는 것은 더 이상 가비지 객체로 간주하지 않는다는 뜻입니다. 참조 삭제 후 해당 객체가 도달 불가능해져 가비지 객체가 되더라도 여전히 회색으로 마킹되며, 다음 라운드 스캔에서 해제됩니다. 이는 객체가 잘못 제거되어 발생하는 메모리 오류보다 낫습니다.

장점: 스택 객체가 모두 흑색이므로 스택 공간을 두 번 스캔할 필요가 없습니다.
단점: 스캔 시작 시 스택 공간의 루트 객체에 대한 스냅샷을 기록하기 위해 STW 가 필요합니다.
혼합 쓰기 배리어
go1.8 버전은 새로운 배리어 메커니즘인 혼합 쓰기 배리어를 도입했습니다. 이는 삽입 쓰기 배리어와 삭제 쓰기 배리어의 혼합으로, 두 가지의 장점을 결합합니다:
- 삽입 쓰기 배리어는 시작 시 스냅샷을 기록하기 위해 STW 가 필요하지 않습니다.
- 삭제 쓰기 배리어는 스택 공간을 두 번 스캔하기 위해 STW 가 필요하지 않습니다.
아래는 공식에서 제공한 의사 코드입니다:
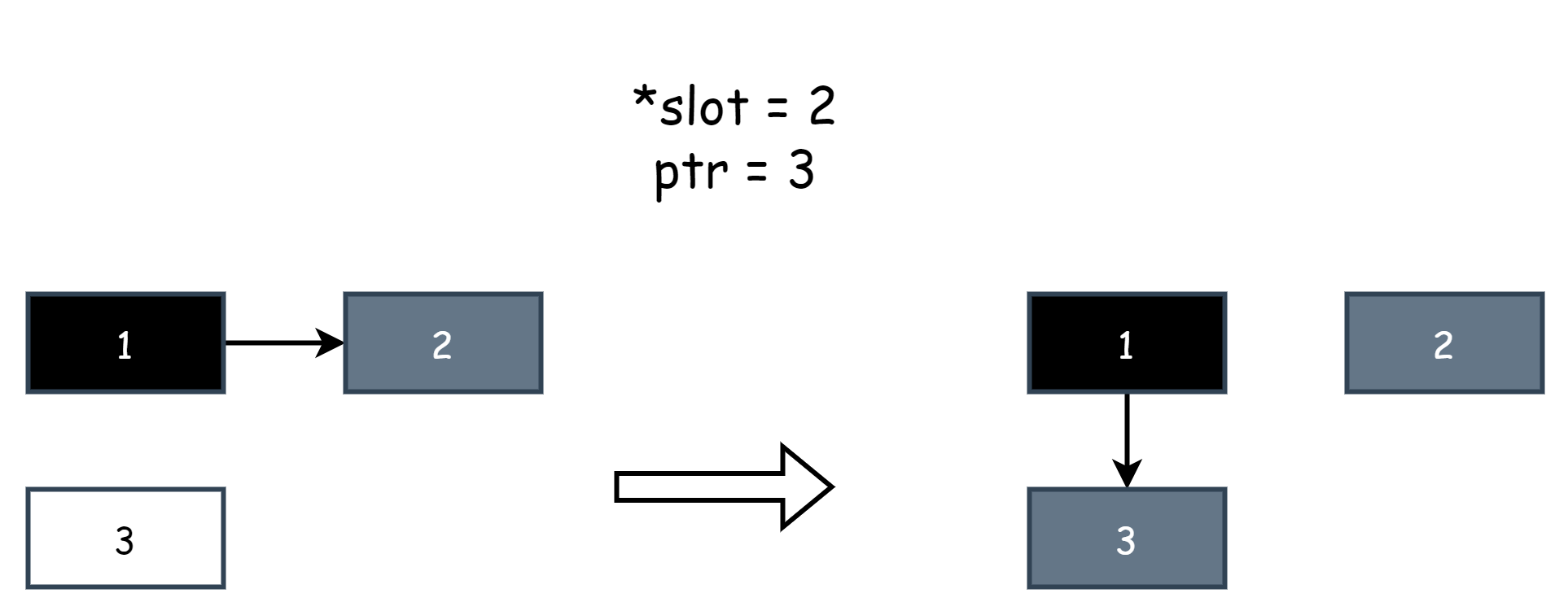
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr여기서 몇 가지 개념을 간단히 설명하면, slot은 다른 객체에 대한 참조를 나타내는 포인터이며, *slot은 원본 객체, ptr은 새 객체, *slot=ptr은 할당 작업으로 객체 참조를 수정하는 것이며, null 값을 할당하는 것은 참조를 삭제하는 것입니다. shade() 는 객체를 회색으로 마킹하는 것을 나타내며, shade(*slot) 은 원본 객체를 회색으로 마킹하고, shade(ptr) 은 새 객체를 회색으로 마킹합니다. 아래는 예시 그림으로, 객체 1 이 원래 객체 2 를 참조하다가 사용자 프로그램이 참조를 수정하여 객체 1 이 객체 3 을 참조하도록 변경했다고 가정합니다. 혼합 쓰기 배리어는 이 행위를 포착했으며, 여기서 *slot은 객체 2 를, ptr은 객체 1 을 나타냅니다.
공식은 위 의사 코드의 역할을 한 문장으로 요약했습니다.
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
번역하면, 혼합 쓰기 배리어가 쓰기 작업을 인터셉트했을 때 원본 객체를 회색으로 마킹하며, 현재 고루틴 스택이 아직 스캔되지 않았다면 새 객체도 회색으로 마킹합니다.
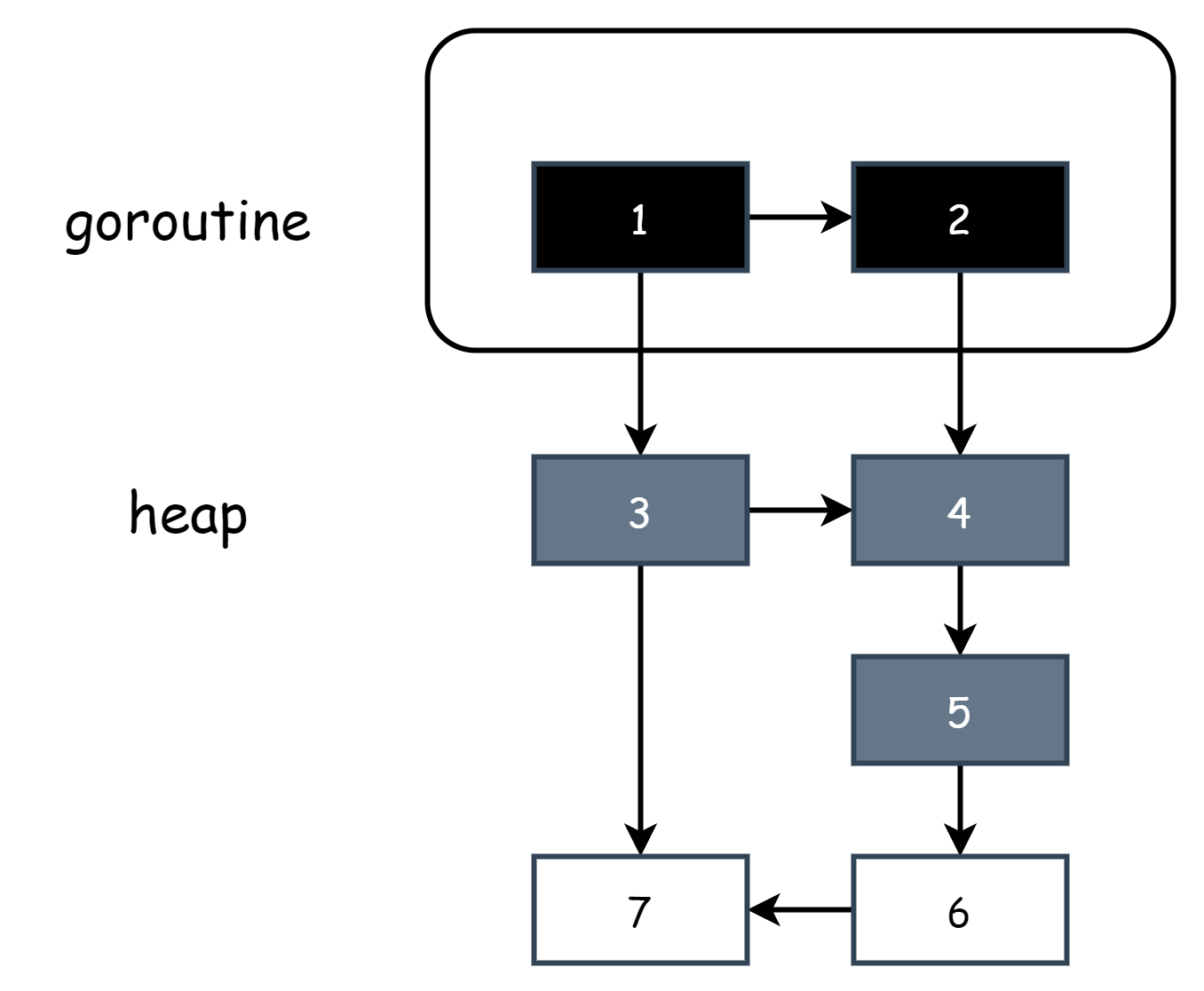
마킹 작업이 시작되면 스택 공간을 스캔하여 루트 객체를 수집합니다. 이때 모두 직접 흑색으로 마킹하며, 이 기간 중 새로 생성된 객체도 흑색으로 마킹하여 스택의 모든 객체가 흑색이 되도록 보장합니다. 따라서 의사 코드에서 current stack is grey는 현재 고루틴 스택이 아직 스캔되지 않았음을 나타냅니다. 따라서 고루틴 스택은 두 가지 상태만 있으며, 모두 흑색이거나 모두 회색입니다. 모두 회색에서 모두 흑색으로 변하는 과정에서 현재 고루틴을 일시 중지해야 하므로 혼합 쓰기 배리어 하에서도 국소적인 STW 가 있습니다. 고루틴 스택이 모두 흑색일 때는 반드시 강 3 색 불변식을 만족합니다. 스캔 후 스택의 흑색 객체는 회색 객체만 참조하며, 흑색 객체가 백색 객체를 직접 참조하는 상황은 없기 때문입니다. 따라서 이때 삽입 쓰기 배리어가 필요하지 않습니다. 의사 코드에 해당합니다.
if current stack is grey:
shade(ptr)하지만 여전히 약 3 색 불변식을 만족하기 위해 삭제 쓰기 배리어가 필요합니다. 즉,
shade(*slot)스캔이 완료되면 스택 공간의 객체가 이미 모두 흑색이므로 스택 공간을 다시 스캔할 필요가 없어 STW 시간을 절약할 수 있습니다.
이로써 go1.8 버전 이후 Go 는 대체로 가비지 컬렉션의 기본 프레임을 확립했습니다. 이후 버전의 가비지 컬렉션 최적화도 모두 혼합 쓰기 배리어를 기반으로 합니다. 이미 대부분의 STW 가 제거되었으므로 이때 가비지 컬렉션의 평균 지연 시간은 이미 마이크로초级别로 감소했습니다.
염색 캐시
앞서 언급한 배리어 메커니즘에서 쓰기 작업을 인터셉트할 때 즉시 객체 색상을 마킹했습니다. 혼합 쓰기 배리어를 채택한 후 원본 객체와 새 객체 모두를 마킹해야 하므로 작업량이 두 배가 되며, 컴파일러가 삽입하는 코드도 증가합니다. 최적화를 위해 go1.10 버전에서 쓰기 배리어는 염색 시 즉시 객체 색상을 마킹하지 않고 원본 객체와 새 객체를 캐시 풀에 저장합니다. 일정 수량이 쌓인 후 일괄 마킹합니다. 이렇게 하면 효율이 더 높아집니다.
캐시를 담당하는 구조는 runtime.wbBuf이며, 실제로는 크기가 512 인 배열입니다.
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}각 P 로컬에도 이러한 캐시가 있습니다.
type p struct {
...
wbBuf wbBuf
...
}마킹 작업이 진행 중일 때 gcw 큐에서 사용 가능한 회색 객체가 없으면 캐시의 객체를 로컬 큐에 넣습니다.
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 쓰기 배리어 캐시 플러시
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}또 다른 상황은 마킹 종료 시 각 P 로컬의 wbBuf에 남은 회색 객체가 있는지 확인하는 것입니다.
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}컬렉션
가비지 컬렉션에서 가장 중요한 부분은 어떻게 가비지 객체를 찾아내는지에 있으며, 이것이 스캔 마킹 작업입니다. 마킹 작업이 완료되면 컬렉션 작업은 상대적으로 복잡하지 않습니다. 마킹되지 않은 객체만 회수하여 해제하면 됩니다. 이 부분 코드는 주로 runtime/mgcsweep.go 파일에 있으며, 파일 주석에 따르면 Go 의 컬렉션 알고리즘은 두 가지로 나뉩니다.
객체 컬렉션
객체 컬렉션 작업은 마킹 종료 단계에서 runtime.sweepone 에 의해 완료되며, 과정은 비동기입니다. 정리 시 메모리单元에서 마킹되지 않은 객체를 찾아 회수합니다. 만약 전체 메모리单元이 마킹되지 않았다면 이单元 전체가 회수됩니다.
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// 컬렉터 획득 시도
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// 정리
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}객체 컬렉션 알고리즘의 경우 전체单元을 회수하는 것이 비교적 어렵기 때문에 두 번째 컬렉션 알고리즘이 있습니다.
###单元컬렉션
单元컬렉션 작업은 메모리 할당 전에 수행되며, runtime.mheap.reclaim 메서드에 의해 완료됩니다. 이 메서드는 힙에서 모든 객체가 마킹되지 않은 메모리单元을 찾아 전체单元을 회수합니다.
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}메모리单元에는 sweepgen 필드가 있어 컬렉션 상태를 나타냅니다.
mspan.sweepgen == mheap.sweepgen - 2: 이 메모리单元은 컬렉션이 필요합니다.mspan.sweepgen == mheap.sweepgen - 1: 이 메모리单元은 현재 컬렉션 중입니다.mspan.sweepgen == mheap.sweepgen: 이 메모리单元은 이미 컬렉션이 완료되어 정상적으로 사용할 수 있습니다.mspan.sweepgen == mheap.sweepgen + 1: 메모리单元은 캐시에 있으며 컬렉션이 필요합니다.mspan.sweepgen == mheap.sweepgen + 3: 메모리单元은 이미 컬렉션이 완료되었지만 여전히 캐시에 있습니다.
mheap.sweepgen 은 GC 라운드에 따라 증가하며, 매번 +2 됩니다.