CGO
Go 는 GC 가 필요하기 때문에 일부 성능 요구가 더 높은 시나리오에서는 Go 가 적합하지 않을 수 있습니다. C 는 전통적인 시스템 프로그래밍 언어로 성능이 매우 우수하며, CGO 는 두 가지를 연결하여 상호 호출을 가능하게 합니다. Go 가 C 를 호출하여 성능에 민감한 작업을 C 에게 맡기고 Go 는 상위 로직을 처리합니다. CGO 는 C 가 Go 를 호출하는 것도 지원하지만 이러한 시나리오는 드물며 권장하지도 않습니다.
TIP
문서의 코드 데모 환경은 Win10 이며, 명령줄은 gitbash를 사용합니다. Windows 사용자는 미리 mingw 를 설치하는 것이 좋습니다.
CGO 에 대한 공식적인 간단한 소개는 다음과 같습니다: C? Go? Cgo! - The Go Programming Language. 더 자세한 소개가 필요하시면 표준 라이브러리 cmd/cgo/doc.go에서 자세한 정보를 확인하거나 cgo command - cmd/cgo - Go Packages 문서를 직접 참조할 수 있습니다. 두 문서의 내용은 완전히 동일합니다.
코드 호출
다음 예제를 살펴보겠습니다.
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}CGO 기능을 사용하려면 import "C" 문으로 활성화할 수 있습니다. C는 반드시 대문자여야 하며导入 이름은 재정의할 수 없습니다. 또한 환경 변수 CGO_ENABLED가 1로 설정되어 있는지 확인해야 합니다. 기본적으로 이 환경 변수는 기본적으로 활성화되어 있습니다.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1그 외에도 로컬에 C/C++ 빌드 도구 체인인 gcc가 있어야 합니다. Windows 플랫폼에서는 mingw가 있어야 프로그램이 정상적으로 컴파일될 수 있습니다. 다음 명령을 실행하여 컴파일합니다. CGO 를 활성화하면 순수 Go 보다 컴파일 시간이 더 오래 걸립니다.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!또한 주의할 점은 CGO 를 활성화하면 교차 컴파일을 사용할 수 없게 됩니다.
Go 에 C 코드 임베딩
CGO 를 사용하면 C 코드를 Go 소스 파일에 직접 작성하고 호출할 수 있습니다. 다음 예제에서는 printSum이라는 함수를 작성한 후 Go 의 main 함수에서 호출합니다.
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}출력
c:1+2=3이는 간단한 시나리오에 적합합니다. C 코드가 매우 많고 Go 코드와 섞여 가독성이 떨어지는 경우에는 적합하지 않습니다.
에러 처리
Go 언어에서 에러 처리는 반환 값으로 반환되지만 C 언어는 다중 반환 값을 허용하지 않습니다. 이를 위해 C 의 errno를 사용하여 함수 호출 중 발생한 에러를 나타낼 수 있습니다. CGO 는 이를 호환하도록 처리되어 C 함수 호출 시 Go 와 마찬가지로 반환 값으로 에러를 처리할 수 있습니다. errno를 사용하려면 먼저 errno.h를 포함해야 합니다. 다음 예제를 살펴보겠습니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}출력
syscall.Errno
The device does not recognize the command.에러 타입이 syscall.Errno임을 확인할 수 있습니다. errno.h에는 다른 많은 에러 코드도 정의되어 있으니 직접 확인해 보시기 바랍니다.
Go 에서 C 파일 포함
C 파일을 포함하면上述의 문제를 잘 해결할 수 있습니다. 먼저 헤더 파일 sum.h를 생성합니다. 내용은 다음과 같습니다.
int sum(int a, int b);그런 다음 sum.c를 생성하여 구체적인 함수를 작성합니다.
#include "sum.h"
int sum(int a, int b) {
return a + b;
}그런 다음 main.go에서 헤더 파일을 포함합니다.
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}이제 컴파일하려면 반드시 현재 폴더를 지정해야 합니다. 그렇지 않으면 C 파일을 찾을 수 없습니다.
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3코드에서 res는 Go 의 변수이고 C.sum은 C 언어의 함수입니다. 그 반환 값은 C 언어의 int이지 Go 의 int가 아닙니다. 성공적으로 호출할 수 있는 이유는 CGO 가 중간에서 타입 변환을 수행했기 때문입니다.
C 에서 Go 호출
C 에서 Go 를 호출한다는 것은 CGO 에서 C 가 Go 를 호출하는 것을 의미하며 네이티브 C 프로그램이 Go 를 호출하는 것이 아닙니다. 호출 체인은 go-cgo-c->cgo->go와 같습니다. Go 가 C 를 호출하는 것은 C 의 생태계와 성능을 활용하기 위한 것이며 네이티브 C 프로그램이 Go 를 호출하는 요구사항은 거의 없습니다. 만약 있다면 네트워크 통신으로 대체하는 것을 권장합니다.
CGO 는 C 가 호출할 수 있도록 Go 함수를 내보낼 수 있습니다. Go 함수를 내보내려면 함수 시그니처 위에 //export func_name 주석을 추가해야 하며 매개변수와 반환 값은 모두 CGO 가 지원하는 타입이어야 합니다. 예제는 다음과 같습니다.
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}앞서 작성한 sum.c 파일을 다음과 같이 수정합니다.
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}동시에 헤더 파일 sum.h를 수정합니다.
void do_sum();그런 다음 Go 에서 함수를 내보냅니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}이제 C 에서 사용하는 sum 함수는 실제로 Go 가 제공하는 것이며 출력 결과는 다음과 같습니다.
20핵심은 sum.c 파일에서 포함하는 _cgo_export.h에 있으며 이는 모든 Go 가 내보낸 타입에 대한 정보를 포함합니다. 이를 포함하지 않으면 Go 가 내보낸 함수를 사용할 수 없습니다. 또 다른 주의할 점은 _cgo_export.h를 Go 파일에서 포함할 수 없다는 것입니다. 해당 헤더 파일이 생성되기 위한 전제 조건은 모든 Go 소스 파일이 컴파일을 통과할 수 있어야 하기 때문입니다. 따라서 다음과 같은 작성 방식은 잘못되었습니다.
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}컴파일러는 헤더 파일이 존재하지 않는다고 표시합니다.
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.만약 Go 함수가 여러 개의 반환 값을 가진다면 C 에서 호출할 때 구조체를 반환합니다.
덧붙여 Go 포인터를 C 함수 매개변수를 통해 C 에게 전달할 수 있습니다. C 함수 호출 기간 동안 CGO 는 메모리 안전을 최대한 보장합니다. 하지만 내보낸 Go 함수의 반환 값은 포인터를 포함할 수 없습니다. 이러한 경우 CGO 는 그것이 참조되는지 여부를 판단할 수 없고 메모리를 고정하기도 어렵기 때문입니다. 만약 반환된 메모리가 참조된 후 Go 에서 해당 메모리가 GC 되거나 오프셋이 발생하면 포인터가 범위를 벗어나게 됩니다. 다음과 같습니다.
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}위의 작성 방식은 기본적으로 컴파일을 통과할 수 없습니다. 이 검사를 비활성화하려면 다음과 같이 설정할 수 있습니다.
GODEBUG=cgocheck=0이는 두 가지 검사 레벨이 있으며 1, 2로 설정할 수 있습니다. 레벨이 높을수록 런타임 오버헤드가 커집니다. 자세한 내용은 cgo command - passing_pointer에서 확인할 수 있습니다.
타입 변환
CGO 는 C 와 Go 간의 타입 매핑을 제공하여 런타임 호출을 용이하게 합니다. C 의 타입은 Go 에서 import "C"를 포함하면 대부분의 경우
C.typename이 방식으로 직접 접근할 수 있습니다. 예를 들어
C.int(1)
C.char('a')하지만 C 언어 타입은 여러 키워드로 구성될 수 있습니다. 예를 들어
unsigned char이러한 경우에는 직접 접근할 수 없지만 C 의 typedef 키워드를 사용하여 타입에 별칭을 부여할 수 있습니다. 이는 Go 의 타입 별칭과 동일합니다. 다음과 같습니다.
typedef unsigned char byte;이제 C.byte로 unsigned char 타입에 접근할 수 있습니다. 예제는 다음과 같습니다.
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}출력
a
b
c대부분의 경우 CGO 는 일반 타입 (기본 타입 등) 에 이미 별칭을 부여했으며 위의 방법에 따라 직접 정의할 수도 있고 충돌하지 않습니다.
char
C 의 char는 Go 의 int8 타입에 해당하며 unsigned char는 Go 의 uint8인 byte 타입에 해당합니다.
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}출력
type: main._Ctype_char, val: 99만약 set 의 매개변수를 C.char(math.MaxInt8 + 1)로 변경하면 컴파일이 실패하고 다음과 같은 에러가 표시됩니다.
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_char문자열
CGO 는 C 와 Go 간에 문자열과 바이트 슬라이스를 전달하기 위해 일부 의사 함수를 제공합니다. 이러한 함수는 실제로 존재하지 않으며 정의를 찾을 수 없습니다. import "C"와 마찬가지로 C 패키지도 존재하지 않지만 개발자가 사용하기 편리하도록 컴파일 후 다른 작업으로 변환됩니다.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteGo 의 문자열 본질적으로 구조체로 내부에底层 배열의 참조를保持합니다. C 함수에 전달할 때는 C.CString()을 사용하여 C 에서 malloc으로 "문자열"을 생성하고 메모리 공간을 할당한 후 C 포인터를 반환합니다. C 에는 문자열 타입이 없으므로 일반적으로 char*로 문자열을 나타내며 이는 문자 배열의 포인터입니다. 사용이 끝나면 반드시 free로 메모리를 해제해야 합니다.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}char 배열 타입일 수도 있으며 둘 다 실제로 동일하게 헤드 요소의 포인터를 가리킵니다.
void printfGoString(char s[]) {
puts(s);
}바이트 슬라이스도 전달할 수 있습니다. C.CBytes()는 unsafe.Pointer를 반환하므로 C 함수에 전달하기 전에 *C.char 타입으로 변환해야 합니다.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}위의 예제 출력은 모두 동일합니다.
this is a go string上述의 몇 가지 문자열 전달 방법은 메모리 복사를 한 번 거치며 전달 후 실제로 C 메모리와 Go 메모리에 각각 사본이 보관됩니다. 이렇게 하는 것이 더 안전합니다. 그렇지만 우리는 여전히 포인터를 직접 C 함수에 전달할 수 있으며 C 에서 Go 의 문자열을 직접 수정할 수도 있습니다. 다음 예제를 살펴보겠습니다.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}출력
this is a go string예제에서는 unsafe.SliceData를 사용하여 문자열의底层 배열 포인터를 직접 가져와 C 포인터로 변환한 후 C 함수에 전달합니다. 해당 문자열의 메모리는 Go 가 관리하므로 더 이상 free 가 필요하지 않습니다. 이렇게 하는 장점은 전달 과정에서 복사가 필요하지 않지만 일정한 위험이 있습니다. 다음 예제는 C 에서 Go 의 문자열을 수정하는 것을 보여줍니다.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}출력
this is a go string
this is c go string
this is c go string정수
Go 와 C 간의 정수 매핑 관계는 다음 표와 같습니다. 정수 타입 매핑에 대한 자세한 정보는 표준 라이브러리 cmd/cgo/gcc.go에서 확인할 수 있습니다.
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
예제 코드는 다음과 같습니다.
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO 는 <stdint.h>의 정수 타입도 지원합니다. 여기의 타입 메모리 크기가 더 명확하고 명명 스타일도 Go 와 매우 유사합니다.
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
CGO 사용 시 <stdint.h>의 정수 타입을 사용하는 것이 좋습니다.
부동소수점
Go 와 C 의 부동소수점 타입 매핑은 다음과 같습니다.
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
코드 예제는 다음과 같습니다.
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}슬라이스
슬라이스 상황은 실제로 위에서 설명한 문자열과 비슷하지만 CGO 가 슬라이스 복사를 위한 의사 함수를 제공하지 않는다는 점이 다릅니다. C 가 Go 의 슬라이스에 접근하려면 포인터를 전달해야 합니다. 다음 예제를 살펴보겠습니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}출력
0 1 2 3 4 5 6 7 8 9여기서는 슬라이스의底层 배열 포인터를 C 함수에 전달했습니다. 해당 배열의 메모리는 Go 가 관리하므로 C 가 장기적으로 포인터 참조를 보유하는 것은 권장하지 않습니다. 반대로 C 의 배열을 Go 슬라이스의底层 배열로 사용하는 예제는 다음과 같습니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}출력
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7unsafe.Slice 함수를 사용하여 배열 포인터를 슬라이스로 변환할 수 있습니다. 직관적으로 생각하면 C 의 배열은 헤드 요소의 포인터이므로 다음과 같이 사용해야 할 것 같습니다.
goslice := unsafe.Slice(&C.s, l)출력을 보면 이렇게 하면 첫 번째 요소를 제외하고 나머지 메모리는 모두 범위를 벗어납니다.
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]C 의 배열이 헤드 포인터일 뿐이지만 CGO 로 감싸면 Go 배열이 되어 자신의 주소를 갖게 되므로 배열의 헤드 요소에 대해 주소를 취해야 합니다.
goslice := unsafe.Slice(&C.s[0], l)구조체
C.struct_ 접두사에 구조체 이름을 추가하면 C 구조체에 접근할 수 있습니다. C 구조체는 Go 구조체에 익명 구조체로 임베딩할 수 없습니다. 다음은 간단한 C 구조체 예제입니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}출력
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}만약 C 구조체의 일부 멤버에 bit-field가 포함되어 있으면 CGO 는 해당 구조체 멤버를 무시합니다. 예를 들어 person을 다음과 같이 수정하면
struct person {
int32_t age: 1;
char* name;
};다시 실행하면 에러가 발생합니다.
p.age undefined (type _Ctype_struct_person has no field or method age)C 와 Go 의 구조체 필드 메모리 정렬 규칙이 동일하지 않습니다. CGO 를 활성화하면 대부분의 경우 C 가 주도권을 갖습니다.
유니온
C.union_에 이름을 추가하면 C 의 유니온에 접근할 수 있습니다. Go 는 유니온을 지원하지 않으므로 Go 에서는 바이트 배열 형태로 존재합니다. 다음은 간단한 예제입니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}출력
[4]uint8 [0 0 0 0]unsafe.Pointer를 사용하여 접근하고 수정할 수 있습니다.
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}출력
0
1024
[0 4 0 0]열거형
C.enum_ 접두사에 열거형 타입 이름을 추가하면 C 의 열거형 타입에 접근할 수 있습니다. 다음은 간단한 예제입니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}출력
0 alive
1 dead포인터
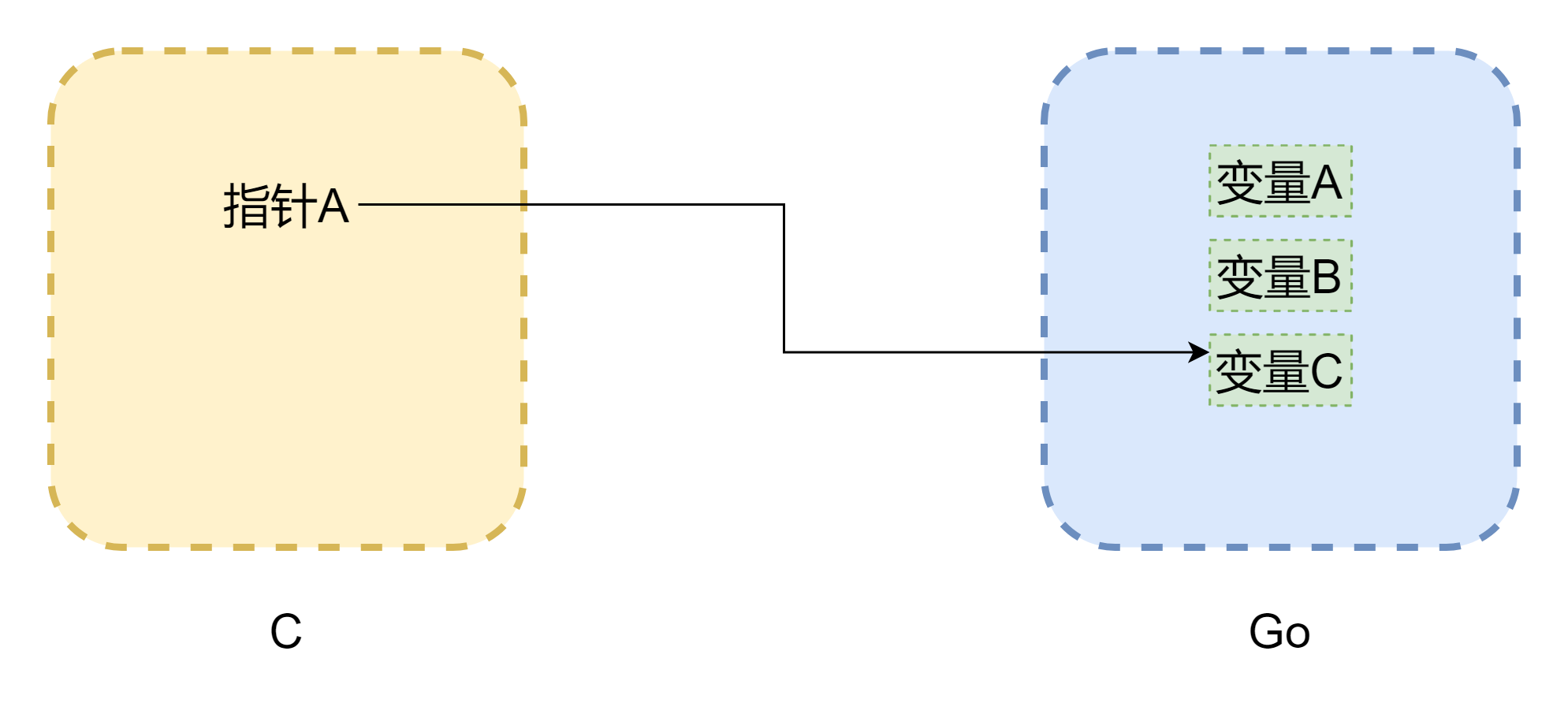
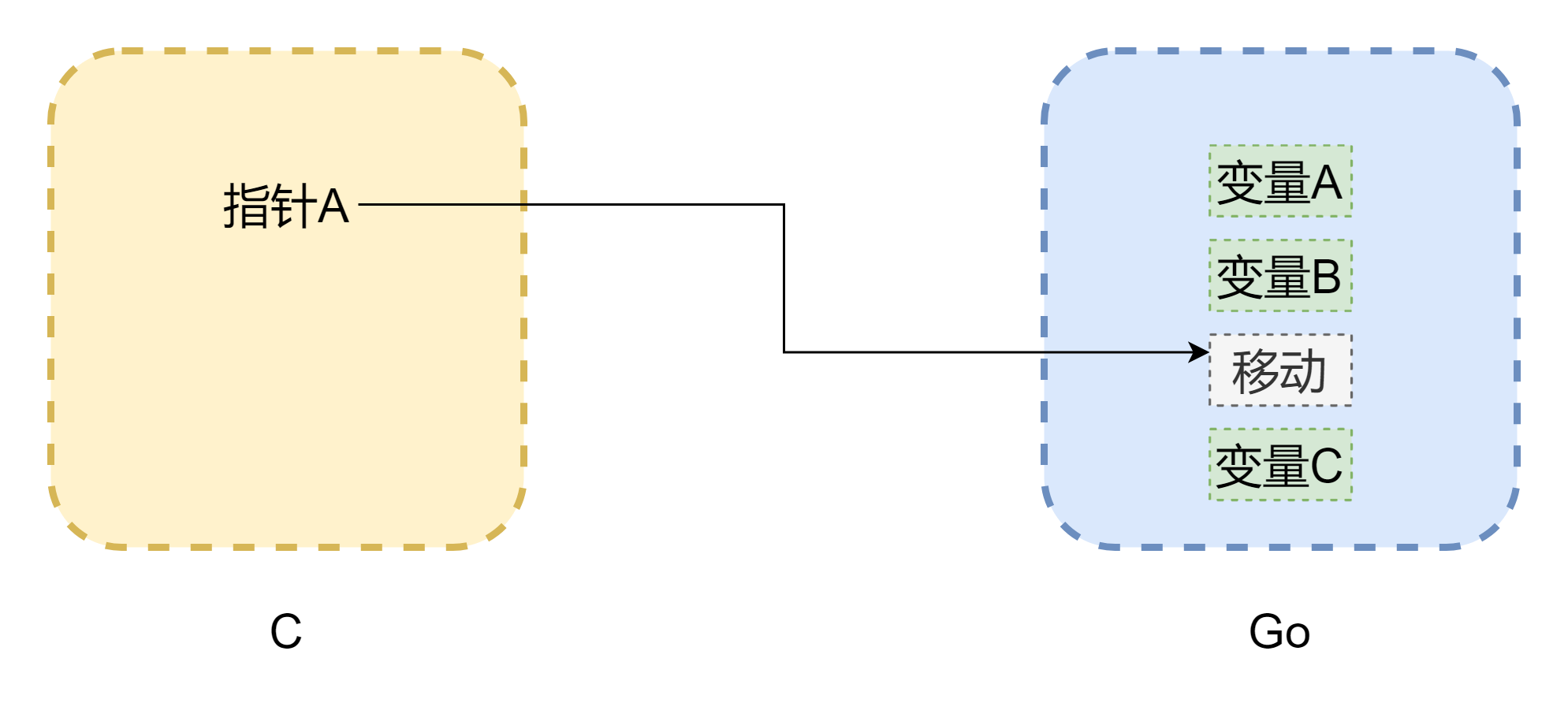
포인터를 논할 때 메모리를 피할 수 없습니다. CGO 간 상호 호출의 가장 큰 문제는 두 언어의 메모리 모델이 다르다는 것입니다. C 언어의 메모리는 전적으로 개발자가 수동으로 관리하며 malloc()으로 메모리를 할당하고 free()로 메모리를 해제합니다. 수동으로 해제하지 않으면 절대 자동으로 해제되지 않으므로 C 의 메모리 관리는 매우 안정적입니다. 반면 Go 는 GC 가 있으며 Goroutine 의 스택 공간은 동적으로 조정됩니다. 스택 공간이 부족하면 증가하므로 메모리 주소가 변경될 수 있습니다. 위의 그림과 같이 (그림은 엄밀하지는 않습니다) 포인터가 C 에서 흔한 댕글링 포인터가 될 수 있습니다. CGO 가 대부분의 경우 메모리 이동을 방지할 수 있지만 (runtime.Pinner로 메모리를 고정) Go 공식은 C 에서 Go 메모리를 장기적으로 참조하는 것을 권장하지 않습니다. 반대로 Go 의 포인터가 C 의 메모리를 참조하는 것은 비교적 안전하며 수동으로 C.free()를 호출하지 않는 한 해당 메모리는 자동으로 해제되지 않습니다.
C 와 Go 간에 포인터를 전달하려면 먼저 unsafe.Pointer로 변환한 후 해당 포인터 타입으로 변환해야 합니다. C 의 void*와 같습니다. 두 가지 예제를 살펴보겠습니다. 첫 번째는 C 포인터가 Go 변수를 참조하는 예제이며 변수를 수정하기도 합니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}출력
1
3
3두 번째는 Go 포인터가 C 변수를 참조하고 수정하는 예제입니다.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}출력
10
11덧붙여 CGO 는 C 의 함수 포인터를 지원하지 않습니다.
링크 라이브러리
C 언어에는 Go 와 같은 의존성 관리가 없습니다. 다른 사람이 작성한 라이브러리를直接使用하려면 소스 코드를 가져오는 것 외에 정적 링크 라이브러리와 동적 링크 라이브러리라는 방법이 있습니다. CGO 도 이를 지원하며 이를 통해 Go 프로그램에서 다른 사람이 작성한 라이브러리를 소스 코드 없이도 포함할 수 있습니다.
동적 링크 라이브러리
동적 링크 라이브러리는 단독으로 실행할 수 없으며 런타임 시 실행 파일과 함께 메모리에 로드됩니다. 아래에서는 간단한 동적 링크 라이브러리를 제작하고 CGO 를 사용하여 호출하는 방법을 보여줍니다. 먼저 lib/sum.c 파일을 준비합니다. 내용은 다음과 같습니다.
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}헤더 파일 lib/sum.h를 작성합니다.
#include <stdint.h>
int sum(int32_t a, int32_t b);다음으로 gcc를 사용하여 동적 링크 라이브러리를 제작합니다. 먼저 목표 파일을 생성합니다.
$ cd lib
$ gcc -c sum.c -o sum.o그런 다음 동적 링크 라이브러리를 제작합니다.
$ gcc -shared -o libsum.dll sum.o제작이 완료되면 Go 코드에서 sum.h 헤더 파일을 포함하고 CGO 에게 라이브러리 파일을 어디에서 찾을지 알려주는 매크로를 사용합니다.
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -I는 헤더 파일을 검색하는 상대 경로입니다.-L은 라이브러리 검색 경로이며${SRCDIR}는 현재 경로의 절대 경로를 나타냅니다. 매개변수는 반드시 절대 경로여야 합니다.-l은 라이브러리 파일의 이름이며 sum 은sum.dll을 의미합니다.
CFFLAGS와 LDFLAGS는 모두 gcc 의 컴파일 옵션이며 보안상의 이유로 CGO 는 일부 매개변수를 비활성화했습니다. 자세한 내용은 cgo command에서 확인할 수 있습니다.
동적 라이브러리를 exe와 동일한 디렉토리에 배치합니다.
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.go마지막으로 Go 프로그램을 컴파일하고 실행합니다.
$ go build main.go && ./main.exe
3이제 동적 링크 라이브러리 호출이 성공했습니다.
정적 링크 라이브러리
동적 링크 라이브러리와 달리 CGO 를 사용하여 정적 링크 라이브러리를 포함하면 Go 의 목표 파일과 최종적으로 링크되어 실행 파일을 생성합니다. 여전히 sum.c를 예로 들어 소스 파일을 목표 파일로 컴파일합니다.
$ gcc -o sum.o -c sum.c그런 다음 목표 파일을 정적 링크 라이브러리로 패키징합니다 (lib 접두사로 시작해야 하며 그렇지 않으면 찾을 수 없습니다).
$ ar rcs libsum.a sum.oGo 파일 내용
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}컴파일
$ go build && ./main.exe
3이제 정적 링크 라이브러리 호출이 성공했습니다.
마지막으로
CGO 사용의 출발점은 성능이지만 C 와 Go 간 전환은 성능 손실을 초래합니다. 매우 간단한 작업의 경우 CGO 의 효율성이 순수 Go 보다 낮습니다. 다음 예제를 살펴보겠습니다.
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}이는 매우 간단한 테스트로 C 와 Go 로 각각 두 수의 합을 구하는 함수를 작성하고 각각 100 만 번 실행하여 평균 소요 시간을 구합니다. 테스트 결과는 다음과 같습니다.
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/op결과에서 볼 수 있듯이 CGO 의 평균 소요 시간은 순수 Go 의 20 배 이상입니다. 만약 단순한 두 수의 덧셈이 아닌 시간이 더 소요되는 작업을 수행한다면 CGO 의 장점이 더 커질 것입니다. 그 외에도 CGO 사용에는 다음과 같은 단점이 있습니다.
- 많은 Go 도구 체인을 사용할 수 없게 됩니다. 예를 들어 gotest, pprof 등 위의 테스트 예제는 gotest 를 사용할 수 없어 직접 작성해야 합니다.
- 컴파일 속도가 느려지고 내장 교차 컴파일도 사용할 수 없게 됩니다.
- 메모리 안전 문제
- 의존성 문제 - 다른 사람이 라이브러리를 사용하면 CGO 를 활성화해야 합니다.
충분히 고려하지 않았다면 프로젝트에 CGO 를 도입하지 마십시오. 매우 복잡한 작업의 경우 CGO 를 사용하는 것이 이점이 있지만 간단한 작업의 경우老老实实 Go 를 사용하는 것이 좋습니다.