CGO
เนื่องจาก Go ต้องการ GC สำหรับบางสถานการณ์ที่ต้องการประสิทธิภาพสูงกว่า Go อาจไม่เหมาะสม C เป็นภาษาโปรแกรมระบบดั้งเดิมที่มีประสิทธิภาพยอดเยี่ยม และ cgo สามารถเชื่อมโยงทั้งสองเข้าด้วยกัน ทำให้ Go เรียกใช้ C ได้ โดยมอบหมายงานที่อ่อนไหวต่อประสิทธิภาพให้ C ดำเนินการ ส่วน Go รับผิดชอบการจัดการตรรกะระดับสูง cgo ยังรองรับการเรียก Go จาก C แต่สถานการณ์นี้พบไม่บ่อยและไม่แนะนำให้ทำเช่นนั้น
TIP
โค้ดในบทความนี้ทดสอบบนสภาพแวดล้อม Windows 10 โดยใช้ gitbash สำหรับผู้ใช้ Windows แนะนำให้ติดตั้ง mingw ล่วงหน้า
เกี่ยวกับ cgo มีคำอธิบายเบื้องต้นจากทางการที่ C? Go? Cgo! - The Go Programming Language หากต้องการคำอธิบายที่ละเอียดมากขึ้น สามารถดูได้ที่ cmd/cgo/doc.go ในไลบรารีมาตรฐาน หรือดูเอกสารที่ cgo command - cmd/cgo - Go Packages ซึ่งทั้งสองมีเนื้อหาเหมือนกัน
การเรียกใช้โค้ด
ดูตัวอย่างด้านล่าง
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}หากต้องการใช้คุณสมบัติ cgo สามารถเปิดใช้งานได้ผ่านคำสั่งนำเข้า import "C" โปรดทราบว่า C ต้องเป็นตัวพิมพ์ใหญ่เท่านั้น และไม่สามารถเปลี่ยนชื่อการนำเข้าได้ ต้องตรวจสอบว่าตัวแปรสภาพแวดล้อม CGO_ENABLED ถูกตั้งค่าเป็น 1 โดยค่าเริ่มต้นตัวแปรสภาพแวดล้อมนี้จะถูกเปิดใช้งาน
$ go env | grep CGO
$ go env -w CGO_ENABLED=1นอกจากนี้ ยังต้องตรวจสอบว่ามีเครื่องมือสร้าง C/C++ ในเครื่อง ซึ่งก็คือ gcc ในแพลตฟอร์ม windows ก็คือ mingw เพื่อให้แน่ใจว่าโปรแกรมสามารถคอมไพล์ได้สำเร็จ ดำเนินการคำสั่งต่อไปนี้เพื่อคอมไพล์ หลังจากเปิด cgo เวลาในการคอมไพล์จะนานกว่า go ล้วน
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!อีกประการหนึ่งที่ควรทราบคือ หลังจากเปิด cgo จะไม่รองรับการครอสคอมไพล์
go ฝังโค้ด c
cgo รองรับ การเขียนโค้ด c ในไฟล์ซอร์ส go โดยตรง แล้วเรียกใช้ ดูตัวอย่างด้านล่าง ตัวอย่างนี้เขียนฟังก์ชันชื่อ printSum แล้วเรียกใช้ในฟังก์ชัน main ของ go
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}ผลลัพธ์
c:1+2=3วิธีนี้เหมาะสำหรับสถานการณ์ง่ายๆ หากโค้ด c มีจำนวนมาก และผสมกับโค้ด go จะทำให้อ่านยาก ไม่แนะนำให้ทำเช่นนั้น
การจัดการข้อผิดพลาด
ในภาษา go การจัดการข้อผิดพลาดจะส่งคืนผ่านค่าส่งกลับ แต่ภาษา c ไม่อนุญาตให้มีค่าส่งกลับหลายค่า จึงสามารถใช้ errno ใน c เพื่อระบุว่าเกิดข้อผิดพลาดระหว่างการเรียกฟังก์ชัน cgo ได้รองรับส่วนนี้ เมื่อเรียกฟังก์ชัน c สามารถจัดการข้อผิดพลาดด้วยค่าส่งกลับเหมือนใน go ได้ หากต้องการใช้ errno ต้องนำเข้า errno.h ก่อน ดูตัวอย่างด้านล่าง
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}ผลลัพธ์
syscall.Errno
The device does not recognize the command.จะเห็นว่าประเภทข้อผิดพลาดคือ syscall.Errno ใน errno.h ยังกำหนดรหัสข้อผิดพลาดอื่นๆ อีกมากมาย สามารถศึกษาเพิ่มเติมได้
go นำเข้าไฟล์ c
ผ่านการนำเข้าไฟล์ c สามารถแก้ปัญหาข้างต้นได้ดี ก่อนอื่นสร้างไฟล์เฮดเดอร์ sum.h เนื้อหาดังนี้
int sum(int a, int b);จากนั้นสร้าง sum.c เขียนฟังก์ชันจริง
#include "sum.h"
int sum(int a, int b) {
return a + b;
}จากนั้นนำเข้าไฟล์เฮดเดอร์ใน main.go
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}หากต้องการคอมไพล์ตอนนี้ ต้องระบุโฟลเดอร์ปัจจุบัน มิฉะนั้นจะหาไฟล์ c ไม่พบ ดังต่อไปนี้
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3ในโค้ด res เป็นตัวแปรใน go C.sum เป็นฟังก์ชันในภาษา c ค่าส่งกลับเป็น int ในภาษา c ไม่ใช่ int ใน go ที่สามารถเรียกใช้สำเร็จได้เพราะ cgo ทำการแปลงประเภทให้
c เรียก go
c เรียก go หมายถึง c เรียก go ใน cgo ไม่ใช่โปรแกรม c ดั้งเดิมเรียก go เป็นโซ่การเรียก go-cgo-c->cgo->go การที่ go เรียก c ก็เพื่อใช้ระบบนิเวศและประสิทธิภาพของ c แทบไม่มีความต้องการให้โปรแกรม c ดั้งเดิมเรียก go หากมีก็แนะนำให้ใช้การสื่อสารผ่านเครือข่ายแทน
cgo รองรับ การส่งออกฟังก์ชัน go ให้ c เรียก หากต้องการส่งออกฟังก์ชัน go ต้องเพิ่มคำอธิบาย //export func_name เหนือลายเซ็นฟังก์ชัน และพารามิเตอร์กับค่าส่งกลับต้องเป็นประเภทที่ cgo รองรับ ตัวอย่างดังนี้
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}แก้ไขไฟล์ sum.c ข้างต้นเป็นเนื้อหาดังนี้
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}พร้อมกันนี้แก้ไขไฟล์เฮดเดอร์ sum.h
void do_sum();จากนั้นส่งออกฟังก์ชันใน go
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}ตอนนี้ฟังก์ชัน sum ที่ใช้ใน c จริงๆ แล้วมาจาก go ผลลัพธ์การส่งออกดังนี้
20จุดสำคัญอยู่ที่การนำเข้า _cgo_export.h ในไฟล์ sum.c ซึ่งมีข้อมูลเกี่ยวกับประเภทที่ go ส่งออกทั้งหมด หากไม่นำเข้าจะไม่สามารถใช้ฟังก์ชันที่ go ส่งออกได้ อีกประการที่ควรทราบคือ _cgo_export.h ไม่สามารถนำเข้าในไฟล์ go ได้ เพราะเงื่อนไขเบื้องต้นในการสร้างไฟล์เฮดเดอร์นี้คือไฟล์ซอร์ส go ทั้งหมดต้องสามารถคอมไพล์ได้ ดังนั้นการเขียนแบบนี้จึงผิด
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}คอมไพเลอร์จะแจ้งเตือนว่าไฟล์เฮดเดอร์ไม่มีอยู่
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.หากฟังก์ชัน go มีค่าส่งกลับหลายค่า c จะส่งคืนสตรักต์เมื่อเรียก
นอกจากนี้ เรายังสามารถส่งพอยน์เตอร์ go ผ่านพารามิเตอร์ฟังก์ชัน c ให้ c ได้ ในช่วงที่เรียกฟังก์ชัน c cgo จะพยายามรับประกันความปลอดภัยของหน่วยความจำ แต่ค่าส่งกลับของฟังก์ชัน go ที่ส่งออกไม่สามารถมีพอยน์เตอร์ได้ เพราะในกรณีนี้ cgo ไม่สามารถตัดสินได้ว่าถูกอ้างอิงหรือไม่ และไม่สะดวกในการตรึงหน่วยความจำ หากหน่วยความจำที่ส่งกลับถูกอ้างอิง แล้วใน go หน่วยความจำนี้ถูก GC หรือเกิดการเลื่อนตำแหน่ง จะทำให้พอยน์เตอร์เกินขอบเขต ดังแสดงด้านล่าง
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}การเขียนข้างต้นโดยค่าเริ่มต้นจะไม่อนุญาตให้คอมไพล์ผ่าน หากต้องการปิดการตรวจสอบนี้ สามารถตั้งค่าดังนี้
GODEBUG=cgocheck=0มีสองระดับการตรวจสอบ สามารถตั้งค่าเป็น 1, 2 ยิ่งระดับสูงการตรวจสอบจะทำให้เกิดโอเวอร์เฮดขณะรันไทม์มากขึ้น สามารถไปดูรายละเอียดได้ที่ cgo command - passing_pointer
การแปลงประเภท
cgo ทำการแมปประเภทระหว่าง c กับ go เพื่อความสะดวกในการเรียกใช้ขณะรันไทม์ สำหรับประเภทใน c หลังจากนำเข้า import "C" ใน go ส่วนใหญ่สามารถเข้าถึงได้โดยตรงผ่าน
C.typenameเช่น
C.int(1)
C.char('a')แต่ประเภทภาษา c สามารถประกอบด้วยคำสำคัญหลายคำ เช่น
unsigned charในกรณีนี้ไม่สามารถเข้าถึงได้โดยตรง แต่สามารถใช้คำสำคัญ typedef ใน c เพื่อตั้งชื่อประเภทได้ ซึ่งมีฟังก์ชันเหมือนกับชื่อประเภทใน go ดังนี้
typedef unsigned char byte;ด้วยวิธีนี้ สามารถเข้าถึงประเภท unsigned char ผ่าน C.byte ได้ ตัวอย่างดังนี้
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}ผลลัพธ์
a
b
cในกรณีส่วนใหญ่ cgo ได้ตั้งชื่อประเภทที่ใช้บ่อย (เช่น ประเภทพื้นฐาน) ไว้แล้ว หรือสามารถกำหนดเองตามวิธีข้างต้นได้ ไม่ขัดแย้งกัน
char
char ใน c สอดคล้องกับประเภท int8 ใน go unsigned char สอดคล้องกับ uint8 ใน go ซึ่งก็คือประเภท byte
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}ผลลัพธ์
type: main._Ctype_char, val: 99หากเปลี่ยนพารามิเตอร์ของ set เป็น C.char(math.MaxInt8 + 1) การคอมไพล์จะล้มเหลว และแสดงข้อผิดพลาดดังนี้
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charสตริง
cgo มีฟังก์ชันเทียมสำหรับส่งสตริงและสไลซ์ไบต์ระหว่าง c และ go ฟังก์ชันเหล่านี้ไม่มีอยู่จริง คุณไม่สามารถหาคำจำกัดความของมันได้ เช่นเดียวกับ import "C" แพ็กเกจ C ก็ไม่มีอยู่จริงเช่นกัน เพียงเพื่อความสะดวกสำหรับผู้พัฒนา หลังจากคอมไพล์แล้วจะถูกแปลงเป็นการดำเนินการอื่นๆ
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteสตริงใน go โดยพื้นฐานแล้วเป็นสตรักต์ที่มีการอ้างอิงไปยังอาร์เรย์พื้นฐาน เมื่อส่งให้ฟังก์ชัน c ต้องใช้ C.CString() เพื่อสร้าง "สตริง" ใน c โดยใช้ malloc จัดสรรพื้นที่หน่วยความจำ แล้วส่งคืนพอยน์เตอร์ c เนื่องจาก c ไม่มีประเภทสตริง โดยปกติจะใช้ char* เพื่อแสดงสตริง ซึ่งก็คือพอยน์เตอร์ของอาร์เรย์ตัวอักษร อย่าลืมใช้ free เพื่อปลดปล่อยหน่วยความจำหลังจากใช้งานเสร็จ
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}หรืออาจเป็นประเภทอาร์เรย์ char ทั้งสองอย่างเหมือนกัน คือเป็นพอยน์เตอร์ที่ชี้ไปยังองค์ประกอบส่วนหัว
void printfGoString(char s[]) {
puts(s);
}สามารถส่งสไลซ์ไบต์ได้ เนื่องจาก C.CBytes() จะส่งคืน unsafe.Pointer ต้องแปลงเป็นประเภท *C.char ก่อนส่งให้ฟังก์ชัน c
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}ผลลัพธ์ของตัวอย่างข้างต้นเหมือนกันทั้งหมด
this is a go stringวิธีการส่งสตริงเหล่านี้เกี่ยวข้องกับการคัดลอกหน่วยความจำหนึ่งครั้ง หลังจากส่งแล้วจริงๆ แล้วจะมีสำเนาหนึ่งชุดในหน่วยความจำ c และอีกชุดในหน่วยความจำ go การทำเช่นนี้ปลอดภัยกว่า อย่างไรก็ตาม เรายังสามารถส่งพอยน์เตอร์ให้ฟังก์ชัน c โดยตรง หรือแก้ไขสตริง go ใน c ได้ ดูตัวอย่างด้านล่าง
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}ผลลัพธ์
this is a go stringตัวอย่างนี้ใช้ unsafe.SliceData เพื่อรับพอยน์เตอร์ของอาร์เรย์พื้นฐานของสตริงโดยตรง แล้วแปลงเป็นพอยน์เตอร์ c ก่อนส่งให้ฟังก์ชัน c หน่วยความจำของสตริงนี้ถูกจัดการโดย go จึงไม่จำเป็นต้อง free อีกต่อไป ข้อดีของการทำเช่นนี้คือกระบวนการส่งผ่านไม่ต้องคัดลอกอีกต่อไป แต่มีความเสี่ยงบางอย่าง ตัวอย่างด้านล่างแสดงให้เห็นการแก้ไขสตริง go ใน c
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}ผลลัพธ์
this is a go string
this is c go string
this is c go stringจำนวนเต็ม
ความสัมพันธ์การแมปประเภทจำนวนเต็มระหว่าง go กับ c แสดงในตารางด้านล่าง เกี่ยวกับประเภทการแมปจำนวนเต็มสามารถดูข้อมูลเพิ่มเติมได้ในไลบรารีมาตรฐาน cmd/cgo/gcc.go
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
ตัวอย่างโค้ดดังนี้
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}cgo ยังรองรับประเภทจำนวนเต็มใน <stdint.h> ประเภทที่นี่มีขนาดหน่วยความจำชัดเจนกว่า และสไตล์การตั้งชื่อคล้ายกับ go มาก
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
เมื่อใช้ cgo แนะนำให้ใช้ประเภทจำนวนเต็มใน <stdint.h>
จำนวนทศนิยม
การแมปประเภทจำนวนทศนิยมระหว่าง go กับ c มีดังนี้
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
ตัวอย่างโค้ดดังนี้
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}สไลซ์
สถานการณ์ของสไลซ์จริงๆ แล้วคล้ายกับสตริงที่กล่าวมาข้างต้น แต่ความแตกต่างคือ cgo ไม่มีฟังก์ชันเทียมสำหรับการคัดลอกสไลซ์ หากต้องการให้ c เข้าถึงสไลซ์ใน go ได้ ต้องส่งพอยน์เตอร์ของสไลซ์เท่านั้น ดูตัวอย่างด้านล่าง
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}ผลลัพธ์
0 1 2 3 4 5 6 7 8 9ที่นี่ส่งพอยน์เตอร์ของอาร์เรย์พื้นฐานของสไลซ์ให้ฟังก์ชัน c เนื่องจากหน่วยความจำของอาร์เรย์นี้ถูกจัดการโดย go ไม่แนะนำให้ c ถือการอ้างอิงพอยน์เตอร์เป็นเวลานาน ในทางกลับกัน ตัวอย่างของการใช้อาร์เรย์ c เป็นอาร์เรย์พื้นฐานของสไลซ์ go มีดังนี้
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}ผลลัพธ์
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7ผ่านฟังก์ชัน unsafe.Slice สามารถแปลงพอยน์เตอร์อาร์เรย์เป็นสไลซ์ ตามสัญชาตญาณแล้ว อาร์เรย์ใน c คือพอยน์เตอร์ที่ชี้ไปยังองค์ประกอบแรก ตามเหตุผลแล้วควรใช้เช่นนี้
goslice := unsafe.Slice(&C.s, l)จากการส่งออกจะเห็นว่า หากทำเช่นนี้ นอกจากองค์ประกอบแรกแล้ว หน่วยความจำที่เหลือจะเกินขอบเขตทั้งหมด
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]แม้อาร์เรย์ใน c จะเป็นเพียงพอยน์เตอร์ส่วนหัว แต่หลังจากถูกห่อหุ้มโดย cgo ก็กลายเป็นอาร์เรย์ go มีที่อยู่ของตัวเอง ดังนั้นควรอ้างอิงที่อยู่ขององค์ประกอบส่วนหัวของอาร์เรย์
goslice := unsafe.Slice(&C.s[0], l)สตรักต์
ผ่านคำนำหน้า C.struct_ บวกกับชื่อสตรักต์ สามารถเข้าถึงสตรักต์ c ได้ สตรักต์ c ไม่สามารถฝังเป็นสตรักต์ไม่ระบุชื่อใน go ได้ ด้านล่างนี้เป็นตัวอย่างสตรักต์ c อย่างง่าย
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}ผลลัพธ์
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}หากสมาชิกบางตัวของสตรักต์ c มี bit-field cgo จะละเว้นสมาชิกสตรักต์ประเภทนี้ เช่น การแก้ไข person เป็นแบบนี้
struct person {
int32_t age: 1;
char* name;
};ดำเนินการอีกครั้งจะเกิดข้อผิดพลาด
p.age undefined (type _Ctype_struct_person has no field or method age)กฎการจัดตำแหน่งหน่วยความจำของฟิลด์สตรักต์ระหว่าง c และ go ไม่เหมือนกัน หากเปิด cgo ในกรณีส่วนใหญ่จะให้ c เป็นหลัก
ยูเนียน
ผ่าน C.union_ บวกกับชื่อสามารถเข้าถึงยูเนียนใน c ได้ เนื่องจาก go ไม่รองรับยูเนียน พวกมันจะมีอยู่ใน go ในรูปแบบของอาร์เรย์ไบต์ ด้านล่างนี้เป็นตัวอย่างง่ายๆ
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}ผลลัพธ์
[4]uint8 [0 0 0 0]ผ่าน unsafe.Pointer สามารถเข้าถึงและแก้ไขได้
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}ผลลัพธ์
0
1024
[0 4 0 0]อีเนียม
ผ่านคำนำหน้า C.enum_ บวกกับชื่อประเภทอีเนียมสามารถเข้าถึงประเภทอีเนียมใน c ได้ ด้านล่างนี้เป็นตัวอย่างง่ายๆ
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}ผลลัพธ์
0 alive
1 deadพอยน์เตอร์
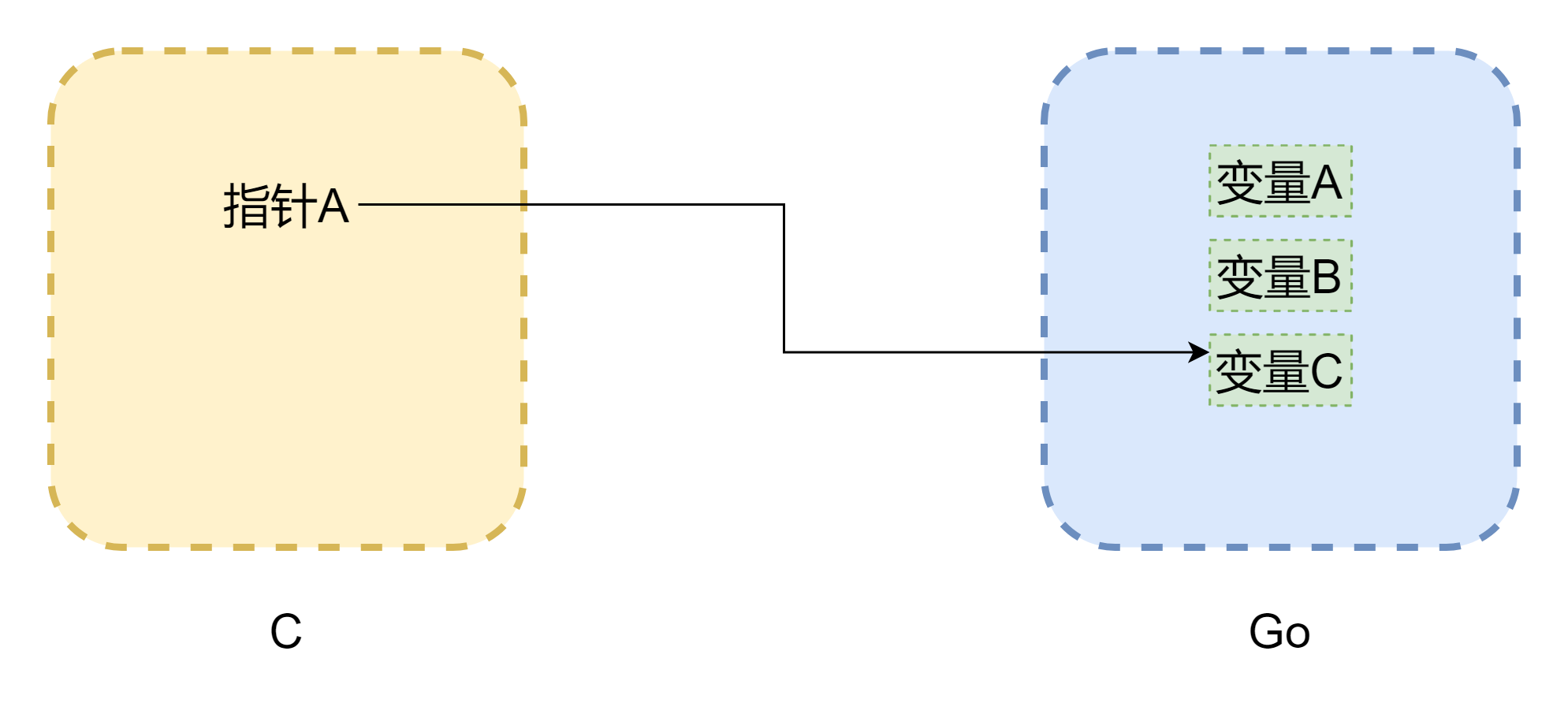
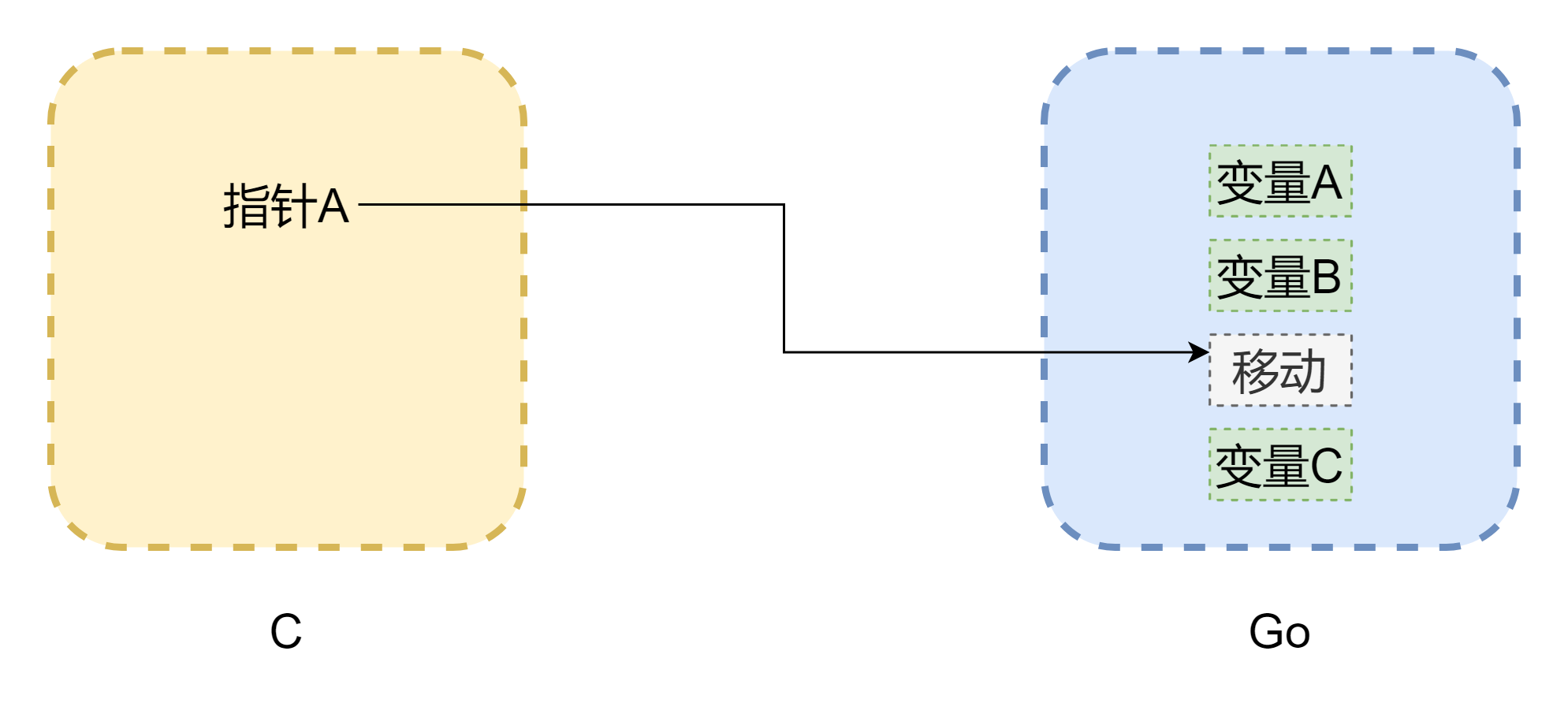
เมื่อพูดถึงพอยน์เตอร์ต้องพูดถึงหน่วยความจำ ปัญหาที่ใหญ่ที่สุดของการเรียกใช้ระหว่าง cgo คือโมเดลหน่วยความจำของทั้งสองภาษาไม่เหมือนกัน หน่วยความจำของภาษา c ถูกจัดการโดยผู้พัฒนาอย่างสมบูรณ์ ใช้ malloc() จัดสรรหน่วยความจำ free() ปลดปล่อยหน่วยความจำ หากไม่ปลดปล่อยด้วยตนเอง มันจะไม่ปลดปล่อยเองอย่างแน่นอน ดังนั้นการจัดการหน่วยความจำของ c จึงมีความเสถียรมาก แต่ go แตกต่างออกไป มันมี GC และพื้นที่สแต็กของ Goroutine จะถูกปรับแบบไดนามิก เมื่อพื้นที่สแต็กไม่เพียงพอจะเพิ่มขึ้น ดังนั้นที่อยู่หน่วยความจำอาจเปลี่ยนแปลงไป เหมือนกับในรูปด้านบน (รูปวาดไม่เข้มงวดมากนัก) พอยน์เตอร์อาจกลายเป็นพอยน์เตอร์ลอยที่พบได้บ่อยใน c แม้ cgo ในกรณีส่วนใหญ่สามารถหลีกเลี่ยงการย้ายหน่วยความจำ (ใช้ runtime.Pinner เพื่อตรึงหน่วยความจำ) แต่ go ทางการก็ไม่แนะนำให้引用หน่วยความจำ go ใน c เป็นเวลานาน แต่ในทางกลับกัน หากพอยน์เตอร์ใน go อ้างอิงหน่วยความจำใน c จะค่อนข้างปลอดภัย เว้นแต่จะเรียก C.free() ด้วยตนเอง มิฉะนั้นหน่วยความจำนี้จะไม่ถูกปลดปล่อยอัตโนมัติ
หากต้องการส่งพอยน์เตอร์ระหว่าง c และ go ต้องแปลงเป็น unsafe.Pointer ก่อน แล้วจึงแปลงเป็นประเภทพอยน์เตอร์ที่สอดคล้องกัน เหมือนกับ void* ใน c ดูสองตัวอย่าง ตัวอย่างแรกคือพอยน์เตอร์ c อ้างอิงตัวแปร go และยังแก้ไขตัวแปรด้วย
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}ผลลัพธ์
1
3
3ตัวอย่างที่สองคือพอยน์เตอร์ go อ้างอิงตัวแปร c และแก้ไขมัน
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}ผลลัพธ์
10
11เพิ่มเติม cgo ไม่รองรับพอยน์เตอร์ฟังก์ชันใน c
ไลบรารีลิงก์
ภาษา c ไม่มีการจัดการการพึ่งพาเหมือน go หากต้องการใช้ไลบรารีที่คนอื่นเขียนโดยตรง นอกจากการรับซอร์สโค้ดโดยตรงแล้ว ยังมีอีกวิธีคือไลบรารีลิงก์สแตติกและไลบรารีลิงก์ไดนามิก cgo ก็รองรับสิ่งเหล่านี้ ด้วยเหตุนี้ เราสามารถนำเข้าไลบรารีที่คนอื่นเขียนในโปรแกรม go ได้ โดยไม่ต้องมีซอร์สโค้ด
ไลบรารีลิงก์ไดนามิก
ไลบรารีลิงก์ไดนามิกไม่สามารถรันแยกได้ มันจะถูกโหลดเข้าสู่หน่วยความจำพร้อมกับไฟล์ที่รันได้ขณะรันไทม์ ด้านล่างนี้สาธิตการสร้างไลบรารีลิงก์ไดนามิกอย่างง่าย และใช้ cgo เรียกใช้ ก่อนอื่นเตรียมไฟล์ lib/sum.c เนื้อหาดังนี้
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}เขียนไฟล์เฮดเดอร์ lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);ต่อไปใช้ gcc เพื่อสร้างไลบรารีลิงก์ไดนามิก ก่อนอื่นคอมไพล์สร้างไฟล์ออบเจกต์
$ cd lib
$ gcc -c sum.c -o sum.oจากนั้นสร้างไลบรารีลิงก์ไดนามิก
$ gcc -shared -o libsum.dll sum.oหลังจากสร้างเสร็จ แล้วนำเข้าไฟล์เฮดเดอร์ sum.h ในโค้ด go และต้องบอก cgo ผ่านมาโครว่าต้องไปที่ไหนเพื่อค้นหาไฟล์ไลบรารี
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Iหมายถึงเส้นทางสัมพัทธ์สำหรับค้นหาไฟล์เฮดเดอร์-Lหมายถึงเส้นทางค้นหาไลบรารี${SRCDIR}หมายถึงเส้นทางสัมบูรณ์ของเส้นทางปัจจุบัน เพราะพารามิเตอร์ของมันต้องเป็นเส้นทางสัมบูรณ์-lหมายถึงชื่อไฟล์ไลบรารี sum คือsum.dll
CFFLAGS และ LDFLAGS ทั้งสองนี้เป็นตัวเลือกการคอมไพล์ของ gcc เนื่องจากความปลอดภัย cgo ได้ปิดใช้งานบางพารามิเตอร์ ไปดูรายละเอียดได้ที่ cgo command
นำไลบรารีไดนามิกไปไว้ในไดเรกทอรีเดียวกับ exe
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goสุดท้ายคอมไพล์โปรแกรม go และดำเนินการ
$ go build main.go && ./main.exe
3至此 ไลบรารีลิงก์ไดนามิกเรียกใช้สำเร็จ
ไลบรารีลิงก์สแตติก
ต่างจากไลบรารีลิงก์ไดนามิก เมื่อใช้ cgo นำเข้าไลบรารีลิงก์สแตติก มันจะลิงก์กับไฟล์เป้าหมายของ go ในที่สุดกลายเป็นไฟล์ที่รันได้ ยังใช้ sum.c เป็นตัวอย่าง ก่อนอื่นคอมไพล์ไฟล์ซอร์สเป็นไฟล์ออบเจกต์
$ gcc -o sum.o -c sum.cจากนั้นแพ็กไฟล์ออบเจกต์เป็นไลบรารีลิงก์สแตติก (ต้องขึ้นต้นด้วยคำนำหน้า lib ไม่เช่นนั้นจะหาไม่พบ)
$ ar rcs libsum.a sum.oเนื้อหาไฟล์ go
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}คอมไพล์
$ go build && ./main.exe
3至此 ไลบรารีลิงก์สแตติกเรียกใช้สำเร็จ
สรุป
แม้จุดเริ่มต้นของการใช้ cgo คือเพื่อประสิทธิภาพ แต่การสลับระหว่าง c กับ go ก็ทำให้เกิดการสูญเสียประสิทธิภาพไม่น้อย สำหรับงานที่ง่ายมากบางงาน ประสิทธิภาพของ cgo ไม่ดีเท่า go ล้วน ดูตัวอย่างหนึ่ง
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}นี่เป็นการทดสอบที่ง่ายมาก เขียนฟังก์ชันหาผลรวมของสองตัวเลขด้วย c และ go แยกกัน แล้วรันอย่างละ 100w ครั้ง หาเวลาเฉลี่ยที่ใช้ ผลการทดสอบมีดังนี้
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opจากผลลัพธ์จะเห็นว่า เวลาเฉลี่ยของ cgo มากกว่า go ล้วนยี่สิบกว่าเท่า หากสิ่งที่ดำเนินการไม่ใช่แค่การบวกสองตัวเลขธรรมดา แต่เป็นงานที่ใช้เวลาค่อนข้างมาก ข้อได้เปรียบของ cgo จะมากขึ้น นอกจากนั้น การใช้ cgo ยังมีข้อเสียต่อไปนี้
- เครื่องมือ go หลายอย่างจะไม่สามารถใช้ได้ เช่น gotest, pprof ตัวอย่างการทดสอบข้างต้นไม่สามารถใช้ gotest ได้ ต้องเขียนเอง
- ความเร็วในการคอมไพล์ช้าลง การครอสคอมไพล์ที่มาด้วยก็ไม่สามารถใช้ได้
- ปัญหาความปลอดภัยของหน่วยความจำ
- ปัญหาการพึ่งพา หากคนอื่นใช้ไลบรารีของคุณ เท่ากับต้องเปิด cgo ด้วย
ก่อนจะพิจารณาอย่างรอบคอบ อย่า引入 cgo ในโปรเจกต์ สำหรับงานที่ซับซ้อนมากบางงาน การใช้ cgo สามารถนำประโยชน์มาให้ได้จริงๆ แต่ถ้าเป็นงานง่ายๆ บางอย่าง ก็ใช้ go ต่อไปเถิด