string
string เป็นหนึ่งในประเภทข้อมูลพื้นฐานที่พบได้บ่อยมากใน Go และเป็นประเภทข้อมูลแรกที่ฉันได้สัมผัสในภาษา Go
package main
import "fmt"
func main() {
fmt.Println("hello,world!")
}เชื่อว่าโค้ดนี้คนส่วนใหญ่เคยพิมพ์เมื่อเริ่มเรียนรู้ Go ใน builtin/builtin.go มีคำอธิบายสั้นๆ เกี่ยวกับ string
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string stringจากข้อความข้างต้นได้ข้อมูลดังนี้
stringคือเซตของไบต์ 8 บิตประเภท
stringมักเป็นการเข้ารหัสUTF-8stringสามารถเป็นค่าว่างได้ แต่ไม่ใช่nilstringไม่สามารถเปลี่ยนแปลงได้
คุณสมบัติเหล่านี้คนที่ใช้ Go บ่อยๆ ควรรู้ดีอยู่แล้ว ต่อไปมาดูสิ่งที่แตกต่างบ้าง
โครงสร้าง
ใน Go สตริงแสดงด้วยโครงสร้าง runtime.stringStruct ในขณะทำงาน แต่ไม่ได้เปิดเผยออกมา แทนที่ด้วย reflect.StringHeader
TIP
แม้ว่า StringHeader จะถูกเลิกใช้แล้วในเวอร์ชัน go.1.21 แต่มันก็เข้าใจง่าย เนื้อหาด้านล่างยังคงใช้มันเพื่ออธิบาย ไม่กระทบต่อความเข้าใจ รายละเอียดดูที่ Issues · golang/go (github.com)
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
// reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}ฟิลด์มีความหมายดังนี้
Dataเป็นตัวชี้ไปยังที่อยู่เริ่มต้นของหน่วยความจำสตริงLenจำนวนไบต์ของสตริง
ด้านล่างเป็นตัวอย่างการเข้าถึงที่อยู่สตริงผ่านตัวชี้ unsafe
func main() {
str := "hello,world!"
h := *((*reflect.StringHeader)(unsafe.Pointer(&str)))
for i := 0; i < h.Len; i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(unsafe.Pointer(h.Data), uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}แต่ตอนนี้ Go แนะนำให้ใช้ unsafe.StringData แทน
func main() {
str := "hello,world!"
ptr := unsafe.Pointer(unsafe.StringData(str))
for i := 0; i < len(str); i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(ptr, uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}ทั้งสองให้ผลลัพธ์เหมือนกัน
h e l l o , w o r l d !
โดยพื้นฐานแล้วสตริงคือที่อยู่หน่วยความจำที่ต่อเนื่องกัน แต่ละที่อยู่เก็บหนึ่งไบต์ กล่าวอีกนัยหนึ่งคืออาร์เรย์ของไบต์ ผลลัพธ์ที่ได้จากฟังก์ชัน len คือจำนวนไบต์ ไม่ใช่จำนวนอักขระในสตริง โดยเฉพาะเมื่ออักขระในสตริงเป็นอักขระที่ไม่ใช่ ASCII
string เองใช้หน่วยความจำน้อยมาก คือตัวชี้ไปยังข้อมูลจริง ทำให้ต้นทุนการส่งผ่านสตริงต่ำมาก ตามความเห็นส่วนตัว เนื่องจากถือการอ้างอิงหน่วยความจำเพียงอย่างเดียว หากสามารถแก้ไขได้อย่างอิสระ จะยากที่จะรู้ว่าข้อมูลที่ชี้ไปยังเดิมยังคงเป็นข้อมูลที่ต้องการหรือไม่ (ต้องใช้ reflection หรือแพ็กเกจ unsafe) เว้นแต่ผู้ใช้ข้อมูลเก่าจะไม่ต้องการสตริงนี้อีกหลังจากใช้งาน ข้อดีอีกอย่างคือปลอดภัยต่อการทำงานพร้อมกันโดยธรรมชาติ ไม่มีใครสามารถแก้ไขได้ในสถานการณ์ปกติ
การต่อกัน
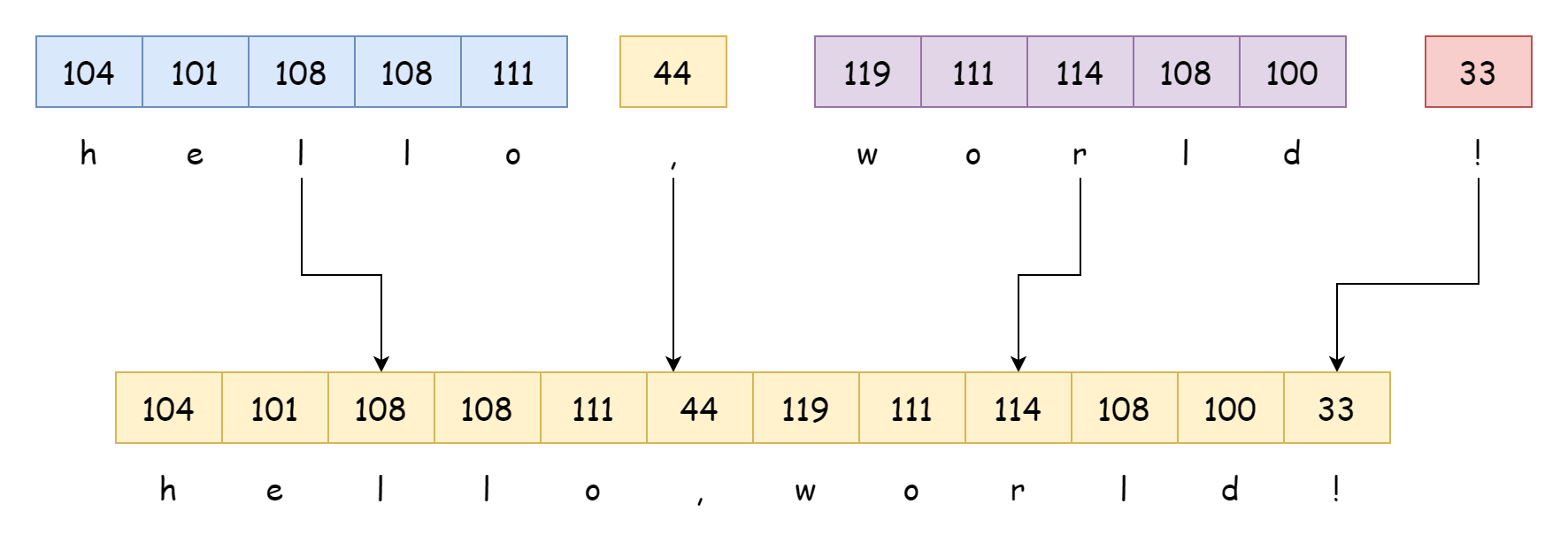
ไวยากรณ์การต่อสตริงแสดงด้านล่าง ใช้ตัวดำเนินการ + เพื่อต่อกันโดยตรง
var (
hello = "hello"
dot = ","
world = "world"
last = "!"
)
str := hello + dot + world + lastการต่อกันดำเนินการโดยฟังก์ชัน runtime.concatstrings ในขณะทำงาน หากเป็นสตริงตัวอักษรแบบนี้ คอมไพเลอร์จะอนุมานผลลัพธ์ได้โดยตรง
str := "hello" + "," + "world" + "!"
_ = strเมื่อส่งออกโค้ดแอสเซมบลีจะทราบผลลัพธ์ บางส่วนแสดงดังนี้
LEAQ go:string."hello,world!"(SB), AX
MOVQ AX, main.str(SP)เห็นได้ชัดว่าคอมไพเลอร์ถือว่าเป็นสตริงเดียวเต็มรูปแบบ ค่าของมันถูกกำหนดในช่วงคอมไพล์แล้ว ไม่ได้ถูกต่อโดย runtime.concatstrings ในขณะทำงาน มีเพียงการต่อตัวแปรสตริงเท่านั้นที่จะเสร็จในขณะทำงาน ลายเซ็นฟังก์ชันดังนี้ รับอาร์เรย์ไบต์และสไลซ์สตริง
func concatstrings(buf *tmpBuf, a []string) stringเมื่อตัวแปรสตริงที่ต่อกันน้อยกว่า 5 จะใช้ฟังก์ชันด้านล่างแทน (คาดเดาส่วนตัว: จากการส่งพารามิเตอร์และตัวแปรไม่ระบุชื่อ ทั้งหมดอยู่บนสแต็ก ดีกว่าสไลซ์ที่สร้างในขณะทำงานสำหรับ GC?) แม้สุดท้ายจะเสร็จโดย concatstrings
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}มาดูว่าฟังก์ชัน concatstrings ทำอะไรข้างใน
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
// ข้ามหากความยาวเป็น 0
if n == 0 {
continue
}
// คำนวณตัวเลข overflow
if l+n < l {
throw("string concatenation too long")
}
l += n
// นับจำนวน
count++
idx = i
}
// ไม่มีสตริงก็คืนค่าว่าง
if count == 0 {
return ""
}
// หากมีเพียงสตริงเดียวก็คืนค่าโดยตรง
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
// เปิดหน่วยความจำสำหรับสตริงใหม่
s, b := rawstringtmp(buf, l)
for _, x := range a {
// คัดลอก
copy(b, x)
// ตัด
b = b[len(x):]
}
return s
}อย่างแรกที่ทำคือนับความยาวรวมและจำนวนของสตริงที่จะต่อ จากนั้นจัดสรรหน่วยความจำตามความยาวรวม ฟังก์ชัน rawstringtmp จะคืนค่าสตริง s และสไลซ์ไบต์ b แม้ความยาวจะกำหนดไว้แต่ไม่มีเนื้อหาใดๆ เพราะโดยพื้นฐานแล้วเป็นตัวชี้ไปยังที่อยู่หน่วยความจำใหม่ทั้งสอง โค้ดจัดสรรหน่วยความจำดังนี้
func rawstring(size int) (s string, b []byte) {
// ไม่ได้ระบุประเภท
p := mallocgc(uintptr(size), nil, false)
// แม้จัดสรรหน่วยความจำแล้วแต่ข้างบนไม่มีอะไร
return unsafe.String((*byte)(p), size), unsafe.Slice((*byte)(p), size)
}สตริง s ที่คืนมาเพื่อความสะดวกในการแสดง สไลซ์ไบต์ b เพื่อความสะดวกในการแก้ไขสตริง ทั้งสองชี้ไปยังที่อยู่หน่วยความจำเดียวกัน
for _, x := range a {
// คัดลอก
copy(b, x)
// ตัด
b = b[len(x):]
}ฟังก์ชัน copy เรียกใช้ runtime.slicecopy ในขณะทำงาน ซึ่งทำงานคัดลอกหน่วยความจำจาก src ไปยังที่อยู่ dst โดยตรง เมื่อคัดลอกสตริงทั้งหมดเสร็จสิ้น กระบวนการต่อกันก็เสร็จสิ้น หากสตริงที่คัดลอกมีขนาดใหญ่มาก กระบวนการนี้จะใช้ประสิทธิภาพมาก
การแปลง
ที่กล่าวมาข้างต้น สตริงไม่สามารถแก้ไขได้ หากลองแก้ไขจะไม่สามารถคอมไพล์ผ่าน Go จะแจ้งข้อผิดพลาดดังนี้
str := "hello" + "," + "world" + "!"
str[0] = '1'cannot assign to string (neither addressable nor a map index expression)หากต้องการแก้ไขสตริง ต้องแปลงเป็นสไลซ์ไบต์ []byte ก่อน ใช้งานง่ายมาก
bs := []byte(str)ภายในเรียกฟังก์ชัน runtime.stringtoslicebyte ซึ่งมีตรรกะง่ายมาก โค้ดดังนี้
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}หากความยาวสตริงน้อยกว่าความยาวบัฟเฟอร์ก็คืนค่าสไลซ์ไบต์ของบัฟเฟอร์โดยตรง เช่นนี้สามารถประหยัดหน่วยความจำเมื่อแปลงสตริงขนาดเล็ก มิฉะนั้นจะเปิดหน่วยความจำใหม่เท่ากับความยาวสตริง แล้วคัดลอกสตริงไปยังที่อยู่หน่วยความจำใหม่ ฟังก์ชัน rawbyteslice(len(s)) ทำหน้าที่คล้ายกับฟังก์ชัน rawstring ก่อนหน้า คือจัดสรรหน่วยความจำ
ในทำนองเดียวกัน สไลซ์ไบต์สามารถแปลงเป็นสตริงได้ง่ายในไวยากรณ์
str := string([]byte{'h','e','l','l','o'})ภายในเรียกฟังก์ชัน runtime.slicebytetostring ซึ่งเข้าใจง่าย โค้ดดังนี้
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string {
if n == 0 {
return ""
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if goarch.BigEndian {
p = add(p, 7)
}
return unsafe.String((*byte)(p), 1)
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return unsafe.String((*byte)(p), n)
}อย่างแรกจัดการกรณีพิเศษที่ความยาวสไลซ์เป็น 0 และ 1 ในกรณีนี้ไม่ต้องคัดลอกหน่วยความจำ จากนั้นหากความยาวน้อยกว่าความยาวบัฟเฟอร์ก็ใช้หน่วยความจำบัฟเฟอร์ มิฉะนั้นเปิดหน่วยความจำใหม่ สุดท้ายใช้ฟังก์ชัน memmove คัดลอกหน่วยความจำโดยตรง หน่วยความจำที่คัดลอกแล้วไม่มีความสัมพันธ์กับหน่วยความจำต้นทาง จึงสามารถแก้ไขได้อย่างอิสระ
ควรสังเกตว่าการแปลงทั้งสองวิธีข้างต้นต้องการคัดลอกหน่วยความจำ หากหน่วยความจำที่จะคัดลอกมีขนาดใหญ่มาก จะใช้ประสิทธิภาพมาก เมื่ออัปเดตเป็น go1.20 แพ็กเกจ unsafe อัปเดตฟังก์ชันต่อไปนี้
// ส่งตัวชี้ประเภทไปยังที่อยู่หน่วยความจำและความยาวข้อมูล คืนค่ารูปแบบสไลซ์
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
// ส่งสไลซ์ ได้ตัวชี้ไปยังอาร์เรย์ระดับล่าง
func SliceData(slice []ArbitraryType) *ArbitraryType
// ตามที่อยู่และความยาวที่ส่ง คืนค่าสตริง
func String(ptr *byte, len IntegerType) string
// ส่งสตริง คืนค่าที่อยู่เริ่มต้น แต่ไบต์ที่คืนมาไม่สามารถแก้ไขได้
func StringData(str string) *byteโดยเฉพาะฟังก์ชัน String และ StringData ไม่เกี่ยวข้องกับการคัดลอกหน่วยความจำ ก็สามารถแปลงได้ แต่ควรสังเกตว่า การใช้พวกมันต้องมีเงื่อนไขว่าข้อมูลเป็นแบบอ่านอย่างเดียว ไม่มีการแก้ไขในภายหลัง มิฉะนั้นสตริงจะเปลี่ยนแปลง ดูตัวอย่างด้านล่าง
func main() {
bs := []byte("hello,world!")
s := unsafe.String((*byte)(unsafe.SliceData(bs)), len(bs))
bs[0] = 'b'
fmt.Println(s)
}อย่างแรกใช้ SliceData เพื่อรับที่อยู่ของอาร์เรย์ระดับล่างของสไลซ์ไบต์ แล้วใช้ String เพื่อรับรูปแบบสตริง จากนั้นแก้ไขสไลซ์ไบต์โดยตรง สตริงก็เปลี่ยนแปลงด้วย ซึ่งขัดแย้งกับจุดประสงค์เดิมของสตริง ดูตัวอย่างอีกอัน
func main() {
str := "hello,world!"
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
// fatal
bytes[0] = 'b'
fmt.Println(str)
}หลังจากได้รับรูปแบบสไลซ์ของสตริงแล้ว หากลองแก้ไขสไลซ์ไบต์ จะ fatal โดยตรง ลองเปลี่ยนวิธีประกาศสตริงดูว่ามีความแตกต่างอย่างไร
func main() {
var str string
fmt.Scanln(&str)
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
bytes[0] = 'b'
fmt.Println(str)
}hello,world!
[104 101 108 108 111 44 119 111 114 108 100 33]
bello,world!จากผลลัพธ์จะเห็นว่าแก้ไขสำเร็จจริงๆ ที่ fatal ก่อนหน้านี้เพราะตัวแปร str เก็บสตริงตัวอักษร สตริงตัวอักษรเก็บในส่วนข้อมูลอ่านอย่างเดียว ไม่ใช่ heap หรือ stack从根本上ตัดความเป็นไปได้ที่สตริงที่ประกาศด้วยตัวอักษรจะถูกแก้ไขในภายหลัง สำหรับตัวแปรสตริงธรรมดา โดยพื้นฐานแล้วสามารถแก้ไขได้จริง แต่คอมไพเลอร์ไม่อนุญาต写法总之استفادهتابعهههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههههه......总之,使用 unsafe 函数来操作字符串转换并不安全,除非能保证永远不会对数据进行修改。
การ遍历
s := "hello world!"
for i, r := range s {
fmt.Println(i, r)
}เพื่อจัดการกับกรณีอักขระหลายไบต์ การ遍历สตริงมักใช้ลูป for range เมื่อใช้ for range遍历สตริง คอมไพเลอร์จะขยายเป็นโค้ดรูปแบบดังนี้ในช่วงคอมไพล์
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
// ตรวจสอบว่าเป็นอักขระไบต์เดียวหรือไม่
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
i, r = hv1t, hv2
// 循环体
}ในโค้ดที่ขยาย ลูป for range จะแทนที่ด้วยลูป for แบบคลาสสิก ในลูปจะตรวจสอบว่าไบต์ปัจจุบันเป็นอักขระไบต์เดียวหรือไม่ หากเป็นอักขระหลายไบต์จะเรียกฟังก์ชัน runtime.decoderune ในขณะทำงานเพื่อรับรหัสที่สมบูรณ์ จากนั้นกำหนดค่าให้ i, r หลังจากจัดการเสร็จแล้วก็ดำเนินการตามลูปที่กำหนดไว้ในซอร์สโค้ด
งานที่รับผิดชอบในการสร้างโค้ดกลางเสร็จโดยฟังก์ชัน walkRange ใน cmd/compile/internal/walk/range.go ซึ่งรับผิดชอบจัดการทุกประเภทที่สามารถ遍历ด้วย for range ได้ ที่นี่ไม่ขยายแล้ว หากสนใจสามารถ去了解ได้เอง