slice
TIP
การอ่านบทความนี้ต้องการความรู้จากไลบรารีมาตรฐาน unsafe
Slice น่าจะเป็นโครงสร้างข้อมูลที่ใช้บ่อยที่สุดในภาษา Go ไม่มีอันอื่นแล้ว (ที่จริงโครงสร้างข้อมูลที่สร้างไว้ก็มีไม่มาก) เกือบทุกที่สามารถเห็นมันได้ เกี่ยวกับวิธีการใช้งานพื้นฐานได้กล่าวไว้ในบทเรียนภาษาแล้ว ด้านล่างจะดูว่าภายในเป็นอย่างไร และทำงานอย่างไร
โครงสร้าง
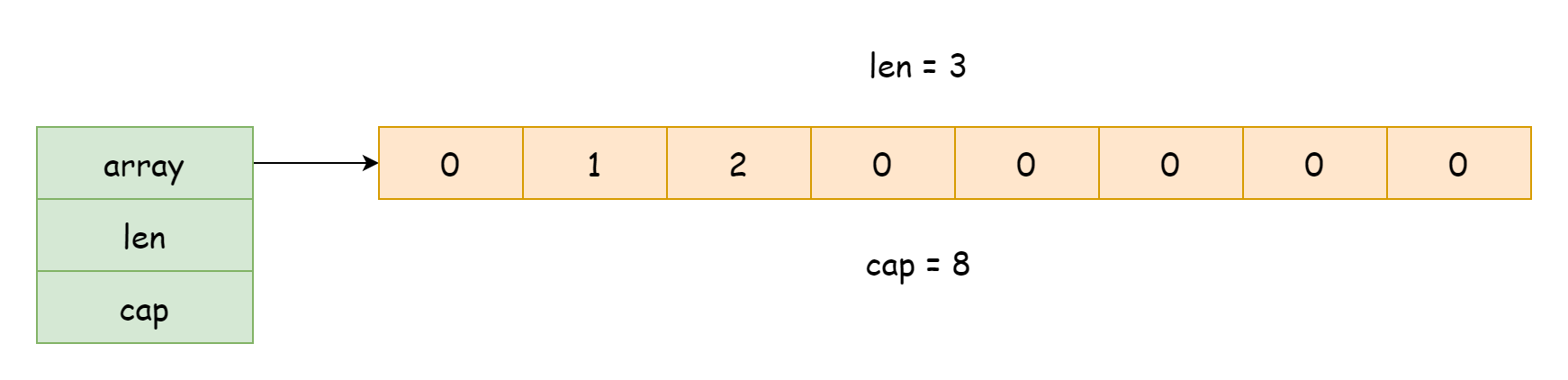
เกี่ยวกับการใช้งาน slice ซอร์สโค้ดอยู่ในไฟล์ runtime/slice.go ในขณะทำงาน slice มีอยู่ในรูปแบบของโครงสร้าง ประเภทคือ runtime.slice ดังนี้
type slice struct {
array unsafe.Pointer
len int
cap int
}โครงสร้างนี้มีเพียงสามฟิลด์
arrayตัวชี้ไปยังอาร์เรย์ระดับล่างlenความยาวของ slice หมายถึงจำนวนองค์ประกอบที่มีในอาร์เรย์capความจุของ slice หมายถึงจำนวนองค์ประกอบทั้งหมดที่อาร์เรย์สามารถเก็บได้
จากข้อมูลข้างต้นทราบว่า การใช้งานระดับล่างของ slice ยังคงขึ้นอยู่กับอาร์เรย์ ในปกติมันเป็นเพียงโครงสร้าง ถือการอ้างอิงไปยังอาร์เรย์ และบันทึกความจุและความยาว เช่นนี้ต้นทุนการส่ง slice จะต่ำมาก เพียงคัดลอกการอ้างอิงของข้อมูล ไม่ต้องคัดลอกข้อมูลทั้งหมด และเมื่อใช้ len และ cap เพื่อเข้าถึงความยาวและความจุของ slice ก็เท่ากับเข้าถึงค่าฟิลด์ ไม่ต้อง遍历อาร์เรย์
แต่นี่ก็นำมาซึ่งปัญหาที่ค้นพบได้ยาก ดูตัวอย่างด้านล่าง
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]ในโค้ดข้างต้น s1 สร้าง slice ใหม่ผ่านการตัดแต่ง แต่มันและ slice ต้นทางอ้างอิงไปยังอาร์เรย์ระดับล่างเดียวกัน การแก้ไขข้อมูลใน s1 ก็ทำให้ s เปลี่ยนแปลงด้วย ดังนั้นเมื่อคัดลอก slice ควรใช้ฟังก์ชัน copy ซึ่ง slice ที่คัดลอกไม่เกี่ยวข้องกันเลย ดูตัวอย่างอีกอัน
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]ยังคงใช้การตัดแต่งเพื่อคัดลอก slice แต่ครั้งนี้ไม่ส่งผลกระทบต่อ slice ต้นทาง ตอนแรก s1 และ s ชี้ไปยังอาร์เรย์เดียวกันจริง แต่ต่อมาเพิ่มองค์ประกอบมากเกินไปให้ s1 เกินจำนวนที่อาร์เรย์สามารถเก็บได้ จึงจัดสรรอาร์เรย์ใหม่ที่ใหญ่กว่าเพื่อเก็บองค์ประกอบ ดังนั้นสุดท้ายทั้งสองชี้ไปยังอาร์เรย์คนละอันแล้ว คิดว่าไม่มีปัญหาแล้วหรือ ก็ดูตัวอย่างอีกอัน
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]明明已经添加了元素,但是打印出来的确是空切片,实际上数据确实是已经添加到了切片中,只不过是写入到了底层数组。go 中的函数参数是传值传递,所以参数 s 实际上源切片结构体的一个拷贝,而 append 操作在添加元素后会返回一个更新了长度的切片结构体,只不过赋值的是参数 s 而非源切片 s,两者并其实没有什么联系。
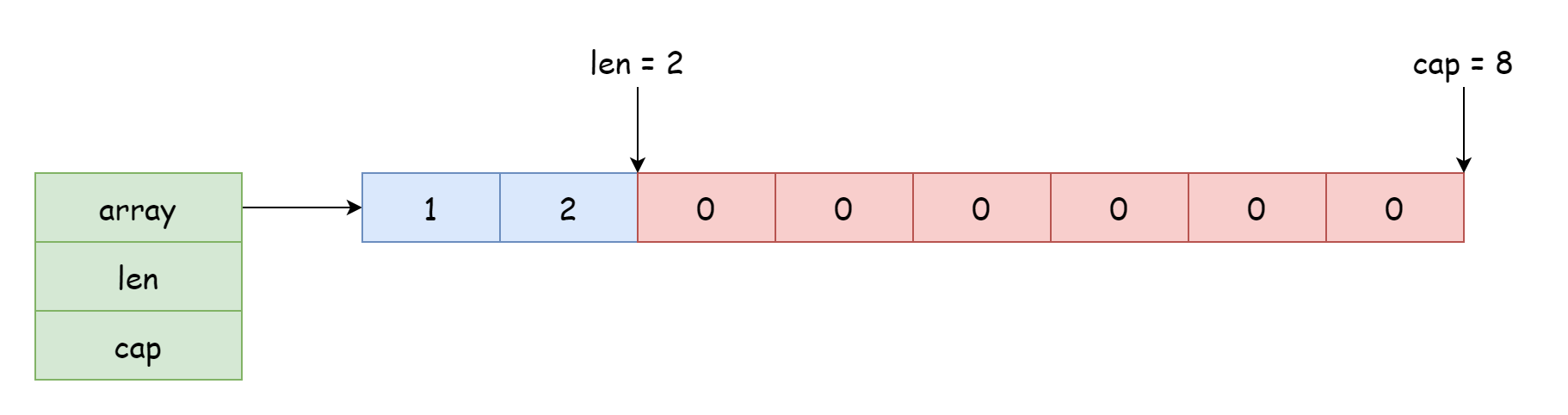
สำหรับ slice แล้ว ตำแหน่งเริ่มต้นที่สามารถเข้าถึงและแก้ไขได้ขึ้นอยู่กับตำแหน่งการอ้างอิงไปยังอาร์เรย์ ค่าออฟเซ็ตขึ้นอยู่กับความยาวที่บันทึกในโครงสร้าง ตัวชี้ในโครงสร้างนอกจากสามารถชี้ไปยังจุดเริ่มต้นของอาร์เรย์แล้ว ยังสามารถชี้ไปยังกลางอาร์เรย์ได้ เช่นเดียวกับภาพด้านล่าง
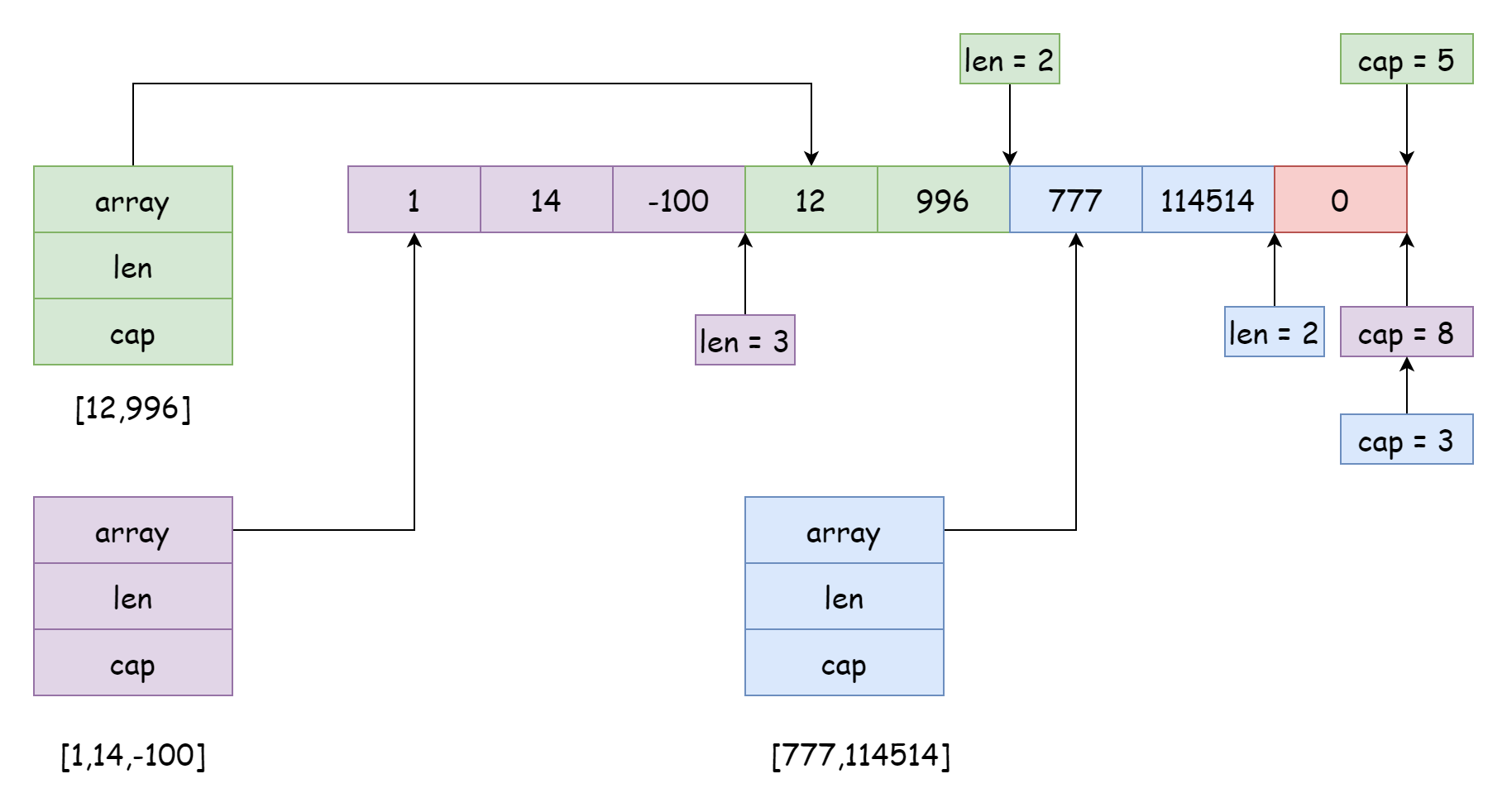
อาร์เรย์ระดับล่างหนึ่งอันสามารถถูก slice หลายอันอ้างอิงได้ และตำแหน่งและขอบเขตที่อ้างอิงสามารถแตกต่างกันได้ เช่นเดียวกับภาพด้านบน สถานการณ์นี้มักเกิดขึ้นเมื่อตัด slice เช่นโค้ดด้านล่าง
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]เมื่อตัดแต่ง ความจุของ slice ใหม่ที่สร้างเท่ากับควาามยาวของอาร์เรย์ลบด้วยตำแหน่งเริ่มต้นที่ slice ใหม่อ้างอิง เช่น s[4:6] สร้าง slice ใหม่มีความจุ 6 = 10 - 4 แน่นอน ขอบเขตที่ slice อ้างอิงไม่จำเป็นต้องติดกันเสมอไป สามารถสลับกันได้ แต่นี่จะสร้างปัญหาใหญ่มาก อาจทำให้ข้อมูลของ slice ปัจจุบันถูกแก้ไขโดย slice อื่นโดยไม่รู้ตัว เช่น slice สีม่วงในภาพด้านบน หากใช้ append เพิ่มองค์ประกอบในกระบวนการต่อมา ก็อาจทับข้อมูลของ slice สีเขียวและ slice สีน้ำเงิน เพื่อหลีกเลี่ยงสถานการณ์นี้ Go อนุญาตให้ตั้งค่าความจุเมื่อตัดแต่ง ไวยากรณ์ดังนี้
s4 = s[4:6:6]ในกรณีนี้ ความจุถูกจำกัดไว้ที่ 2 ดังนั้นการเพิ่มองค์ประกอบจะทำให้เกิดการขยายความจุ หลังจากขยายความจุก็เป็นอาร์เรย์ใหม่แล้ว ไม่เกี่ยวข้องกับอาร์เรย์ต้นทาง ก็จะไม่ส่งผลกระทบ คิดว่าปัญหาเกี่ยวกับ slice จบแค่นี้หรือ ยังไม่หมด ดูตัวอย่างอีกอัน
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// จำนวนองค์ประกอบที่เพิ่มมากกว่าความจุพอดี
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]โค้ดไม่ต่างจากตัวอย่างก่อนหน้า เพียงแก้ไขพารามิเตอร์อินพุต ให้จำนวนองค์ประกอบที่เพิ่มมากกว่าความจุของ slice พอดี เช่นนี้จะทำให้เกิดการขยายความจุเมื่อเพิ่ม เช่นนี้ข้อมูลไม่เพียงไม่ถูกเพิ่มไปยัง slice ต้นทาง s แม้แต่อาร์เรย์ระดับล่างที่ชี้ไปยังก็ไม่ได้ถูกเขียนข้อมูล เราสามารถยืนยันด้วยตัวชี้ unsafe ได้ ดังนี้
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// จำนวนองค์ประกอบที่เพิ่มมากกว่าความจุพอดี
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,จะเห็นว่าอาร์เรย์ระดับล่างของ slice ต้นทางว่างเปล่า ไม่มีอะไรเลย ข้อมูลถูกเขียนไปยังอาร์เรย์ใหม่ทั้งหมด แต่ไม่เกี่ยวข้องกับ slice ต้นทาง เพราะแม้ว่า append จะส่งคืนการอ้างอิงใหม่ แต่ที่แก้ไขคือค่าของพารามิเตอร์ s เท่านั้น ไม่ส่งผลกระทบต่อ slice ต้นทาง s Slice ในฐานะโครงสร้างทำให้มันเบามาก แต่ปัญหาข้างต้นก็ไม่ควรมองข้าม โดยเฉพาะในโค้ดจริงปัญหาเหล่านี้มักซ่อนลึก ค้นพบได้ยาก
การสร้าง
ในขณะทำงาน การใช้ฟังก์ชัน make สร้าง slice ดำเนินการโดย runtime.makeslice ตรรกะค่อนข้างง่าย ลายเซ็นฟังก์ชันดังนี้
func makeslice(et *_type, len, cap int) unsafe.Pointerรับพารามิเตอร์สามตัว ประเภทองค์ประกอบ ความยาว ความจุ เสร็จแล้วส่งคืนตัวชี้ไปยังอาร์เรย์ระดับล่าง โค้ดดังนี้
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// คำนวณหน่วยความจำที่ต้องการ หากใหญ่เกินไปจะทำให้เกิด overflow
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// หากไม่มีปัญหาก็จัดสรรหน่วยความจำ
return mallocgc(mem, et, true)
}จะเห็นว่าตรรกะง่ายมาก ทำเพียงสองอย่าง
- คำนวณหน่วยความจำที่ต้องการ
- จัดสรรพื้นที่หน่วยความจำ
หากการตรวจสอบเงื่อนไขล้มเหลว จะ panic ทันที
- คำนวณหน่วยความจำแล้ว overflow
- ผลลัพธ์คำนวณมากกว่าหน่วยความจำสูงสุดที่จัดสรรได้
- ความยาวและความจุไม่ถูกต้อง
หากหน่วยความจำที่คำนวณได้มากกว่า 32KB จะจัดสรรไปยัง heap เสร็จแล้วจะส่งคืนตัวชี้ไปยังอาร์เรย์ระดับล่าง การสร้างโครงสร้าง runtime.slice ไม่เสร็จโดยฟังก์ชัน makeslice ที่จริง การสร้างโครงสร้างเสร็จในช่วงคอมไพล์ ฟังก์ชัน makeslice ในขณะทำงานรับผิดชอบเพียงจัดสรรหน่วยความจำ เช่นโค้ดด้านล่าง
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capหากสนใจสามารถไปดูโค้ดกลางที่สร้าง คล้ายกับด้านล่าง
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8หากใช้อาร์เรย์สร้าง slice เช่นด้านล่าง
var arr [5]int
s := arr[:]กระบวนการนี้คล้ายกับโค้ดด้านล่าง
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo จะใช้อาร์เรย์นั้นเป็นอาร์เรย์ระดับล่างของ slice โดยตรง ดังนั้นการแก้ไขข้อมูลใน slice ก็ส่งผลกระทบต่อข้อมูลของอาร์เรย์ด้วย เมื่อใช้อาร์เรย์สร้าง slice ความยาวเท่ากับ high-low ความจุเท่ากับ max-low โดย max เป็นความยาวของอาร์เรย์โดยค่าเริ่มต้น หรือสามารถระบุความจุเมื่อตัดแต่งได้ เช่น
var arr [5]int
s := arr[2:3:4]
การเข้าถึง
การเข้าถึง slice ใช้อินเด็กซ์เหมือนการเข้าถึงอาร์เรย์
elem := s[i]การเข้าถึง slice เสร็จในช่วงคอมไพล์ โดยสร้างโค้ดกลางเพื่อเข้าถึง โค้ดที่สร้างสุดท้ายสามารถเข้าใจเป็นโค้ดจำลองด้านล่าง
p := s.ptr
e := *(p + sizeof(elem(s)) * i)ที่จริงคือการเข้าถึงองค์ประกอบของอินเด็กซ์ที่ตรงกันผ่านการย้ายตัวชี้ ตรงกับฟังก์ชัน cmd/compile/internal/ssagen.exprCheckPtr ในโค้ดบางส่วนดังนี้
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// ย้ายตัวชี้
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)เมื่อใช้ฟังก์ชัน len และ cap เพื่อเข้าถึงความยาวและความจุของ slice ก็เช่นเดียวกัน ตรงกับฟังก์ชัน cmd/compile/internal/ssagen.exprCheckPtr ในโค้ดบางส่วนดังนี้
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))ในโค้ดที่สร้างจริง การเข้าถึงฟิลด์ len ในโครงสร้าง slice ผ่านการย้ายตัวชี้ สามารถเข้าใจเป็นโค้ดจำลองด้านล่าง
p := &s
len := *(p + 8)
cap := *(p + 16)สมมติว่ามีโค้ดดังนี้
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}那么在生成中的某个阶段的中间代码大概率长这样
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9จากข้างต้นจะเห็นว่า บวก 8 อันหนึ่ง บวก 16 อันหนึ่ง ชัดเจนว่าเข้าถึงฟิลด์ slice ผ่านการย้ายตัวชี้
หากสามารถอนุมานความยาวและความจุในช่วงคอมไพล์ได้ ก็ไม่จำเป็นต้องย้ายตัวชี้เพื่อรับค่าในขณะทำงาน เช่นสถานการณ์ด้านล่างไม่จำเป็นต้องย้ายตัวชี้
s := make([]int, 10, 20)
l := len(s)
c := cap(s)ค่าของตัวแปร l และ c จะถูกแทนที่ด้วย 10 และ 20 โดยตรง
การเขียน
การแก้ไข
s := make([]int, 10)
s[0] = 100当通过索引下标修改切片的值时,在编译期间会通过 OpStore操作生成类似如下的伪代码
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = val在生成中的某个阶段的中间代码大概率长这样
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:可以看到代码访问切片长度以检查下标是否合法,最后通过移动指针来存储元素。
การเพิ่ม
通过 append函数可以向切片添加元素
var s []int
s = append(s, 1, 2, 3)添加元素后,它会返回一个新的切片结构体,如果没有扩容的话相较于源切片只是更新了长度,否则会的话会指向一个新的数组。有关于 append 的使用问题在 结构 这部分已经讲的很详细了,不再过多阐述,下面会关注于 append 是如何工作的。
在运行时,并没有类似 runtime.appendslice这样的函数与之对应,添加元素的工作实际上在编译期就已经做好了,append 函数会被展开对应的中间代码,判断的代码在cmd/compile/internal/walk/assign.go walkassign 函数中,
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}可以看到分成三种情况
- 添加若干个元素
- 添加一个切片
- 添加一个临时创建的切片
下面会讲一讲生成的代码长什么样,这样明白 append 实际上是怎么工作的,代码生成的过程如果感兴趣可以自己去了解下。
添加元素
s = append(s, x, y, z)如果只是添加有限个元素,会由 walkAppend 函数展开成以下代码
// 待添加元素数量
const argc = len(args) - 1
newLen := s.len + argc
// 是否需要扩容
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = z首先计算出待添加元素数量,然后判断是否需要扩容,最后再一个个赋值。
添加切片
s = append(s, s1...)如果是直接添加一个切片,会由 appendSlice 函数展开成以下代码
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))还是跟之前一样,计算新长度,判断是否需要扩容,不同的是 go 并不会一个个去添加源切片的元素,而是选择直接复制内存。
添加临时切片
s = append(s, make([]T, l2)...)如果是添加一个临时创建的切片,会由 extendslice 函数展开成以下代码
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)对于临时添加的切片,go 会获取临时切片的长度,如果当前切片的容量不足以足以容纳,就会尝试扩容,完事后还会清除对应部分的内存。
扩容
由结构部分的内容可以得知,切片的底层依旧是一个数组,数组是一个长度固定的数据结构,但切片长度是可变的。切片在数组容量不足时,会申请一片更大的内存空间来存放数据,也就是一个新的数组,再将旧数据拷贝过去,然后切片的引用就会指向新数组,这个过程就被称为扩容。扩容的工作在运行时由 runtime.growslice 函数来完成,其函数签名如下
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice参数的简单解释
oldPtr,指向旧数组的指针newLen,新数组的长度,newLen = oldLen + numoldCap,旧切片的容量,也就等于旧数组的长度et,元素类型
它的返回值返回了一个新的切片,新切片跟原来的切片毫不相干,唯一共同点就是保存的数据是一样的。
var s []int
s = append(s, elems...)在使用 append 添加元素时,会要求将其返回值覆盖原切片,如果发生了扩容的话,返回的就是一个新切片了。
在扩容时,首先需要确定新的长度和容量,对应下面的代码
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// 双倍容量
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// 数值溢出了
if newcap <= 0 {
newcap = newLen
}
}
}由上面的代码可知,对于容量小于 256 的切片,容量增长一倍,而容量大于等于 256 的切片,则至少会是原容量的 1.25 倍,当前切片较小时,每次都直接增大一倍,可以避免频繁的扩容,当切片较大时,扩容的倍率就会减小,避免申请过多的内存而造成浪费。
得到新长度和容量后,再计算所需内存,对应如下代码
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// 最终的容量
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}内存计算公式就是 mem = cap * sizeof(et),为了方便内存对齐,过程中会将计算得到的内存向上取整为 2 的整数次方,并再次计算新容量。如果说新容量太大导致计算时数值溢出,或者说新内存超过了可以分配的最大内存,就会 panic。
var p unsafe.Pointer
// 分配内存
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}计算出所需结果后,就分配指定大小的内存,再将 newLen到newCap 这个区间的内存清空,然后将旧数组的数据拷贝到新切片中,最后构建切片结构体。
拷贝
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)当使用 copy 函数拷贝切片时,会由 cmd/compile/internal/walk.walkcopy 在编译期间生成的代码决定以何种方式拷贝,如果是在运行时调用,就会用到函数 runtime.slicecopy,该函数负责拷贝切片,函数签名如下
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int它接收源切片和目的切片的指针和长度,以及要拷贝的长度 width。这个函数的逻辑十分简单,如下所示
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// 计算要复制的字节数
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}width 的取值,取决于两个切片的长度最小值。可以看到的是,在复制切片的时候并不是一个个遍历元素去复制的,而是选择了直接把底层数组的内存整块复制过去,当切片很大时拷贝内存带来性能的影响并不小。
倘若不是在运行时调用,就会展开成如下形式的代码
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}两种方式的原理都是一样的,都是通过拷贝内存的方式拷贝切片。memmove 函数是由汇编实现的,感兴趣可以去 runtime/memmove_amd64.s 浏览细节。
清空
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}在版本 go1.21 中,新增了内置函数 clear 函数可以用于清空切片的内容,或者说是将所有元素都置为零值。当 clear 函数作用于切片时,编译器会在编译期间由 cmd/compile/internal/walk.arrayClear 函数展开成下面这种形式
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}首先判断切片长度是否为 0,然后计算需要清理的字节数,再根据元素是否是指针分成两种情况来处理,但最终都会用到 memclrNoHeapPointers 函数,其签名如下。
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)它接收两个参数,一个是指向起始地址的真,另一个就是偏移量,也就是要清理的字节数。内存起始地址为切片所持有的引用的地址,偏移量 n = sizeof(et) * len,该函数是由汇编实现,感兴趣可以去 runtime/memclr_amd64.s 查看细节。
值得一提的是,如果源代码中尝试使用遍历来清空数组,例如这种
for i := range s {
s[i] = ZERO_val
}在没有 clear 函数之前,通常都是这样来清空切片。在编译时,现在这段代码会被 cmd/compile/internal/walk.arrayRangeClear 函数优化成这种形式
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// 停止循环
i = len(s) - 1
}
}逻辑还是跟上面的一模一样,其中多了一行i = len(s)-1,其作用是为了在内存清除以后停止循环。
遍历
for i, e := range s {
fmt.Println(i, e)
}在使用 for range 遍历切片时,会由 cmd/compile/internal/walk/range.go中的walkRange 函数展开成如下形式
// 拷贝结构体
hs := s
// 获取底层数组指针
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}可以看到的是,for range 的实现依旧是通过移动指针来遍历元素的。为了避免在遍历时切片被更新,事先拷贝了一份结构体 hs,为了避免遍历结束后指针指向越界的内存,hu 使用的 uinptr 类型来存放地址,在需要访问元素的时候才转换成unsafe.Pointer。
变量 v2也就是for range 中的e,在整个遍历过程中从始至终都是一个变量,它只会被覆盖,不会重新创建。这一点引发了困扰 go 开发者十年的循环变量问题,到了版本go.1.21 官方才终于决定要打算解决,预计在后面版本的更新中,v2 的创建方式可能会变成下面这样。
v2 := *hp构造中间代码过程这里省略了,这并不属于切片范围的知识,感兴趣可以自己去了解下。