slice
TIP
Leer este artículo requiere conocimiento de la biblioteca estándar unsafe.
El slice es probablemente la estructura de datos más utilizada en Go, sin excepción (de hecho, no hay muchas estructuras de datos incorporadas), se puede ver en casi todas partes. Su uso básico se ha descrito en la introducción al lenguaje. A continuación veremos cómo es internamente y cómo funciona.
Estructura
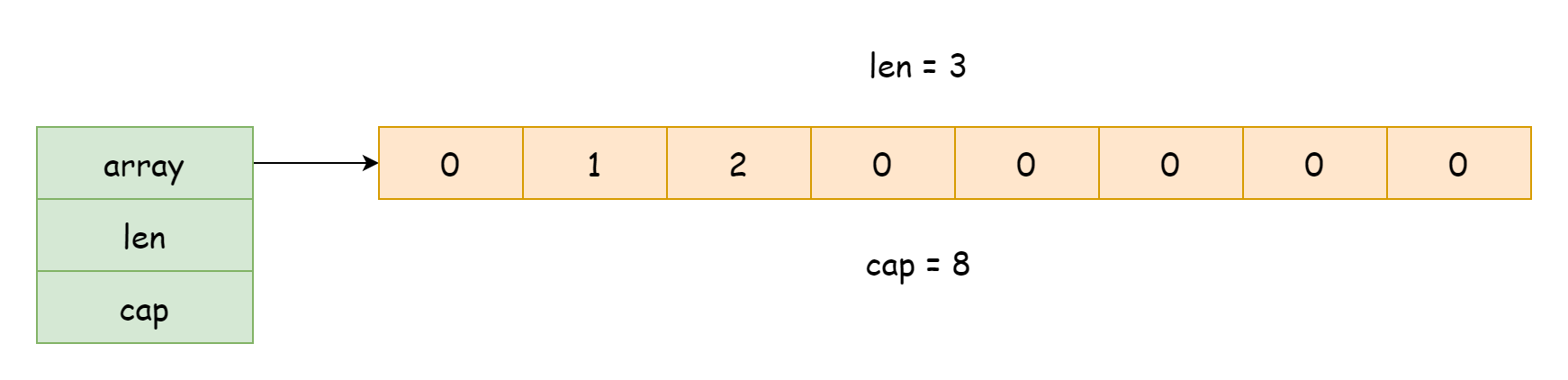
La implementación del slice se encuentra en el archivo runtime/slice.go. En tiempo de ejecución, un slice existe como una estructura de tipo runtime.slice, como se muestra a continuación.
type slice struct {
array unsafe.Pointer
len int
cap int
}Esta estructura tiene solo tres campos:
array: puntero al array subyacentelen: longitud del slice, se refiere al número de elementos existentes en el arraycap: capacidad del slice, se refiere al número total de elementos que el array puede contener
De lo anterior se deduce que la implementación subyacente del slice depende del array. Normalmente es solo una estructura que mantiene una referencia al array, junto con registros de capacidad y longitud. Esto hace que pasar un slice tenga un costo muy bajo, solo se copia la referencia a los datos, no todos los datos. Además, al usar len y cap para obtener la longitud y capacidad del slice, es equivalente a obtener los valores de sus campos, sin necesidad de iterar sobre el array.
Sin embargo, esto también trae algunos problemas no fáciles de descubrir. Veamos el siguiente ejemplo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]En el código anterior, s1 crea un nuevo slice mediante slicing, pero tanto el nuevo slice como el slice original hacen referencia al mismo array subyacente. Modificar los datos en s1 también causa cambios en s. Por lo tanto, al copiar un slice se debe usar la función copy, que crea un slice independiente. Veamos otro ejemplo:
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Nuevamente se usa slicing para copiar el slice, pero esta vez no afecta al slice original. Inicialmente s1 y s apuntaban al mismo array, pero luego se agregaron demasiados elementos a s1 superando la capacidad del array, por lo que se asignó un nuevo array más grande para contener los elementos. Así que finalmente ambos apuntan a arrays diferentes. ¿Piensa que ya no hay problemas? Veamos otro ejemplo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Aunque se agregaron elementos, se imprime un slice vacío. En realidad, los datos sí se agregaron al slice, pero se escribieron en el array subyacente. En Go, los parámetros de función se pasan por valor, por lo que el parámetro s es una copia de la estructura del slice original. La operación append devuelve un nuevo slice con longitud actualizada después de agregar elementos, pero se asigna al parámetro s, no al slice original, por lo que ambos no están realmente relacionados.
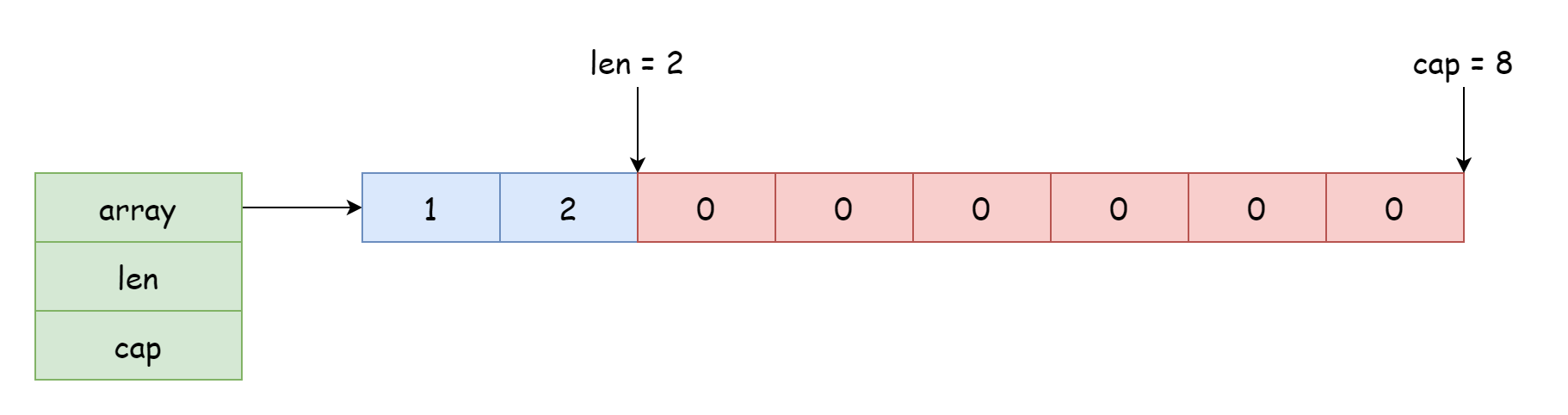
Para un slice, la posición de inicio que puede acceder y modificar depende de la posición de referencia al array. El desplazamiento depende de la longitud registrada en la estructura. El puntero en la estructura puede apuntar al inicio del array o al medio, como se muestra en la siguiente imagen.
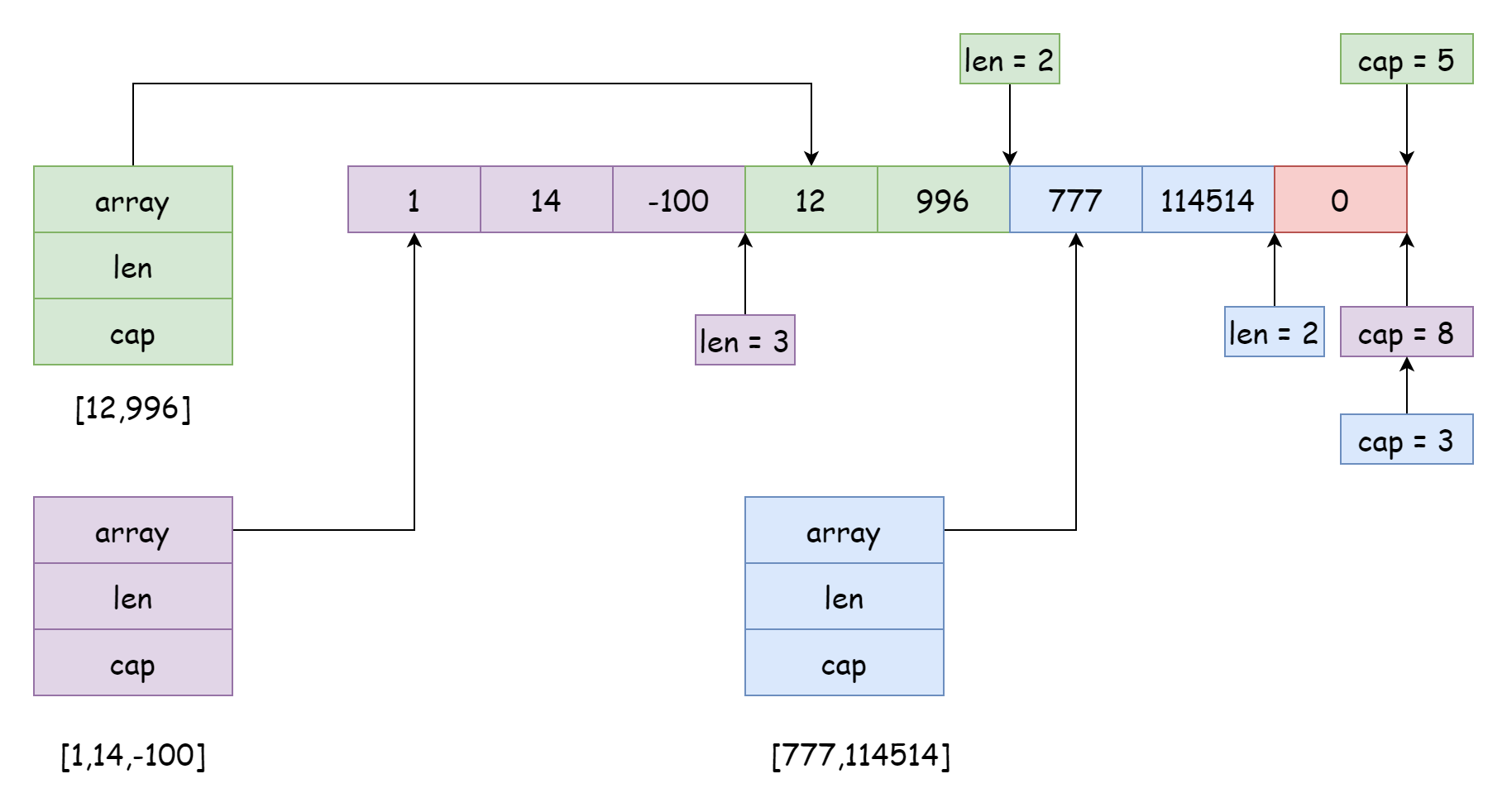
Un array subyacente puede ser referenciado por muchos slices, y las posiciones y rangos de referencia pueden ser diferentes, como se muestra arriba. Esta situación generalmente ocurre cuando se corta un slice, similar al siguiente código:
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]Al cortar, la capacidad del nuevo slice es igual a la longitud del array menos la posición de inicio del nuevo slice. Por ejemplo, la capacidad del nuevo slice generado por s[4:6] es 6 = 10 - 4. Por supuesto, el rango de referencia del slice no tiene que ser adyacente, también puede estar entrelazado, pero esto puede causar grandes problemas. Los datos del slice actual pueden ser modificados por otro slice sin conocimiento, como el slice morado en la imagen anterior. Si se usa append para agregar elementos posteriormente, podría sobrescribir los datos del slice verde y el slice azul. Para evitar esta situación, Go permite establecer el rango de capacidad al cortar, con la siguiente sintaxis:
s4 = s[4:6:6]En este caso, su capacidad se limita a 2, por lo que agregar elementos desencadenará una expansión. Después de la expansión, será un nuevo array, sin relación con el array original, por lo que no habrá efectos. ¿Piensa que los problemas del slice terminan aquí? En realidad no. Veamos otro ejemplo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// La cantidad de elementos a agregar es ligeramente mayor que la capacidad
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]El código es igual que el ejemplo anterior, solo se modificaron los parámetros de entrada para que la cantidad de elementos a agregar sea ligeramente mayor que la capacidad del slice. De esta manera, se desencadenará una expansión al agregar. Como resultado, los datos no solo no se agregan al slice original s, sino que ni siquiera se escriben en el array subyacente. Podemos confirmar esto usando punteros unsafe, como se muestra a continuación:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// La cantidad de elementos a agregar es ligeramente mayor que la capacidad
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,Como se puede ver, el array subyacente del slice original está vacío, sin nada. Todos los datos se escribieron en el nuevo array. Pero esto no tiene relación con el slice original, porque incluso si append devuelve una nueva referencia, solo modifica el valor del parámetro formal s, sin afectar al slice original s. Que el slice sea una estructura ligera es ciertamente ventajoso, pero los problemas anteriores no deben ignorarse, especialmente en código real donde estos problemas suelen estar muy ocultos y son difíciles de detectar.
Creación
En tiempo de ejecución, la creación de un slice mediante la función make es realizada por runtime.makeslice. Su lógica es bastante simple, la signatura de la función es:
func makeslice(et *_type, len, cap int) unsafe.PointerRecibe tres parámetros: tipo de elemento, longitud y capacidad. Después de completar, devuelve un puntero al array subyacente. El código es el siguiente:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Calcular la memoria total necesaria, si es demasiado grande puede causar desbordamiento numérico
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Si todo está bien, asignar memoria
return mallocgc(mem, et, true)
}Como se puede ver, la lógica es muy simple, solo hace dos cosas:
- Calcular la memoria necesaria
- Asignar espacio de memoria
Si la verificación de condiciones falla, se produce un panic:
- Desbordamiento numérico al calcular la memoria
- El resultado calculado excede la memoria máxima asignable
- Longitud y capacidad inválidas
Si la memoria calculada es mayor que 32KB, se asignará en el heap. Después de esto, se devuelve un puntero al array subyacente. La construcción de la estructura runtime.slice no es realizada por la función makeslice. En realidad, la construcción de la estructura se completa durante la compilación. La función makeslice en tiempo de ejecución solo es responsable de asignar memoria, similar al siguiente código:
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capSi está interesado, puede ver el código intermedio generado, que es similar a esto:
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8Si se usa un array para crear un slice, como en el siguiente caso:
var arr [5]int
s := arr[:]Este proceso es similar al siguiente código:
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo usa directamente el array como el array subyacente del slice, por lo que modificar los datos del slice también afectará los datos del array. Al crear un slice desde un array, la longitud es igual a high-low, y la capacidad es igual a max-low, donde max por defecto es la longitud del array, o también se puede especificar manualmente la capacidad al cortar, por ejemplo:
var arr [5]int
s := arr[2:3:4]
Acceso
Se accede al slice usando indexación por subíndice, igual que con los arrays:
elem := s[i]La operación de acceso al slice se completa durante la compilación, generando código intermedio para acceder. El código final generado se puede entender como el siguiente pseudocódigo:
p := s.ptr
e := *(p + sizeof(elem(s)) * i)En realidad, se accede al elemento del subíndice correspondiente mediante operación de desplazamiento de puntero. Esto corresponde a la siguiente parte del código en la función cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Desplazar puntero
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)Al acceder a la longitud y capacidad del slice mediante las funciones len y cap, es lo mismo. También corresponde a parte del código en la función cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))En el código realmente generado, se accede al campo len de la estructura del slice moviendo el puntero. Se puede entender como el siguiente pseudocódigo:
p := &s
len := *(p + 8)
cap := *(p + 16)Supongamos que tenemos el siguiente código:
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}Entonces el código intermedio en alguna etapa de generación probablemente se vea así:
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9De lo anterior se puede ver que uno suma 8 y el otro suma 16, claramente se accede a los campos del slice mediante desplazamiento de puntero.
Si se puede inferir la longitud y capacidad durante la compilación, no se necesitará desplazar el puntero en tiempo de ejecución para obtener el valor. Por ejemplo, en la siguiente situación no es necesario mover el puntero:
s := make([]int, 10, 20)
l := len(s)
c := cap(s)Los valores de las variables l y c se reemplazan directamente por 10 y 20.
Escritura
Modificación
s := make([]int, 10)
s[0] = 100Al modificar el valor de un slice mediante indexación por subíndice, durante la compilación se genera pseudocódigo similar al siguiente mediante la operación OpStore:
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valEl código intermedio en alguna etapa de generación probablemente se vea así:
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:Como se puede ver, el código accede a la longitud del slice para verificar si el subíndice es válido, y finalmente almacena el elemento moviendo el puntero.
Adición
Se pueden agregar elementos a un slice mediante la función append:
var s []int
s = append(s, 1, 2, 3)Después de agregar elementos, devuelve una nueva estructura de slice. Si no hay expansión, solo se actualiza la longitud en comparación con el slice original; de lo contrario, apuntará a un nuevo array. Los problemas de uso de append se han explicado en detalle en la sección Estructura, por lo que no se repetirá aquí. A continuación nos centraremos en cómo funciona append.
En tiempo de ejecución, no hay una función como runtime.appendslice correspondiente. El trabajo de agregar elementos se realiza durante la compilación. La función append se expande al código intermedio correspondiente. El código de decisión se encuentra en la función cmd/compile/internal/walk/assign.go walkassign:
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}Como se puede ver, se divide en tres casos:
- Agregar varios elementos
- Agregar un slice
- Agregar un slice creado temporalmente
A continuación se explicará cómo se ve el código generado, para entender cómo funciona realmente append. Si está interesado en el proceso de generación de código, puede investigarlo por su cuenta.
Agregar elementos
s = append(s, x, y, z)Si solo se agregan un número limitado de elementos, la función walkAppend lo expande al siguiente código:
// Cantidad de elementos a agregar
const argc = len(args) - 1
newLen := s.len + argc
// ¿Se necesita expansión?
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zPrimero calcula la cantidad de elementos a agregar, luego determina si se necesita expansión, y finalmente asigna valores uno por uno.
Agregar slice
s = append(s, s1...)Si se agrega directamente un slice, la función appendSlice lo expande al siguiente código:
newLen := s.len + s1.len
// Comparar como uint para que growslice pueda hacer panic en caso de desbordamiento.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Igual que antes, calcula la nueva longitud, determina si se necesita expansión. La diferencia es que Go no agrega los elementos del slice original uno por uno, sino que elige copiar directamente la memoria.
Agregar slice temporal
s = append(s, make([]T, l2)...)Si se agrega un slice creado temporalmente, la función extendslice lo expande al siguiente código:
if l2 >= 0 {
// Bloque if vacío aquí para SetLikely(true) más significativo
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// Limpiar la porción nueva del array subyacente.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)Para un slice agregado temporalmente, Go obtiene la longitud del slice temporal. Si la capacidad del slice actual es insuficiente para contenerlo, intentará expandirse. Después de esto, también limpiará la parte correspondiente de la memoria.
Expansión
Por el contenido de la sección de estructura, se sabe que la implementación subyacente de un slice es aún un array. El array es una estructura de datos de longitud fija, pero la longitud del slice es variable. Cuando la capacidad del array es insuficiente, el slice solicitará un área de memoria más grande para almacenar datos, es decir, un nuevo array, luego copiará los datos antiguos al nuevo, y la referencia del slice apuntará al nuevo array. Este proceso se llama expansión. El trabajo de expansión se completa en tiempo de ejecución por la función runtime.growslice, cuya signatura es:
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceExplicación simple de los parámetros:
oldPtr: puntero al array antiguonewLen: longitud del nuevo array,newLen = oldLen + numoldCap: capacidad del slice antiguo, igual a la longitud del array antiguoet: tipo de elemento
Su valor de retorno es un nuevo slice, que no tiene relación con el slice original. El único punto en común es que los datos guardados son los mismos.
var s []int
s = append(s, elems...)Al usar append para agregar elementos, se requiere que su valor de retorno sobrescriba el slice original. Si ocurre una expansión, se devuelve un nuevo slice.
Al expandir, primero se debe determinar la nueva longitud y capacidad, correspondiente al siguiente código:
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Doble capacidad
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Desbordamiento numérico
if newcap <= 0 {
newcap = newLen
}
}
}Por el código anterior, para slices con capacidad menor a 256, la capacidad se duplica. Para slices con capacidad mayor o igual a 256, será al menos 1.25 veces la capacidad original. Cuando el slice es pequeño, aumentar directamente el doble cada vez puede evitar expansiones frecuentes. Cuando el slice es grande, la tasa de expansión se reduce para evitar solicitar demasiada memoria y causar desperdicio.
Después de obtener la nueva longitud y capacidad, se calcula la memoria necesaria, correspondiente al siguiente código:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Capacidad final
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}La fórmula de cálculo de memoria es mem = cap * sizeof(et). Para facilitar la alineación de memoria, durante el proceso se redondea la memoria calculada hacia arriba a una potencia entera de 2, y se calcula nuevamente la nueva capacidad. Si la nueva capacidad es demasiado grande y causa desbordamiento numérico, o si la nueva memoria excede la memoria máxima asignable, se producirá un panic.
var p unsafe.Pointer
// Asignar memoria
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}Después de calcular los resultados necesarios, se asigna memoria del tamaño especificado, luego se limpia la memoria en el rango de newLen a newCap, se copian los datos del array antiguo al nuevo slice, y finalmente se construye la estructura del slice.
Copia
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)Al usar la función copy para copiar un slice, cmd/compile/internal/walk.walkcopy determina durante la compilación cómo se copiará. Si se llama en tiempo de ejecución, se usará la función runtime.slicecopy, que es responsable de copiar slices. La signatura de la función es:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intRecibe los punteros y longitudes del slice de origen y destino, así como la longitud a copiar width. La lógica de esta función es muy simple, como se muestra a continuación:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Calcular el número de bytes a copiar
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}El valor de width depende del mínimo de las longitudes de los dos slices. Como se puede ver, al copiar un slice no se iteran los elementos uno por uno para copiar, sino que se elige copiar directamente toda la memoria del array subyacente. Cuando el slice es grande, el impacto en el rendimiento de copiar memoria no es pequeño.
Si no se llama en tiempo de ejecución, se expande al siguiente código:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Ambas formas tienen el mismo principio, ambas copian el slice copiando memoria. La función memmove está implementada en ensamblador. Si está interesado, puede ver los detalles en runtime/memmove_amd64.s.
Limpieza
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}En la versión go1.21, se agregó la función incorporada clear que se puede usar para vaciar el contenido de un slice, o más precisamente, establecer todos los elementos en su valor cero. Cuando la función clear actúa sobre un slice, el compilador la expande durante la compilación mediante la función cmd/compile/internal/walk.arrayClear a la siguiente forma:
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}Primero se determina si la longitud del slice es 0, luego se calcula el número de bytes a limpiar, y se divide en dos casos según si el elemento es un puntero o no. Pero finalmente se usará la función memclrNoHeapPointers, cuya signatura es:
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)Recibe dos parámetros: uno es el puntero a la dirección de inicio, y el otro es el desplazamiento, es decir, el número de bytes a limpiar. La dirección de inicio de la memoria es la dirección de la referencia que mantiene el slice, y el desplazamiento n = sizeof(et) * len. Esta función está implementada en ensamblador. Si está interesado, puede ver los detalles en runtime/memclr_amd64.s.
Vale la pena mencionar que si en el código fuente se intenta usar un bucle para vaciar el array, por ejemplo:
for i := range s {
s[i] = ZERO_val
}Antes de que existiera la función clear, normalmente se vaciaba el slice de esta manera. Durante la compilación, ahora este código es optimizado por la función cmd/compile/internal/walk.arrayRangeClear a la siguiente forma:
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Detener el bucle
i = len(s) - 1
}
}La lógica es exactamente la misma que la anterior, con una línea adicional i = len(s)-1, cuyo propósito es detener el bucle después de limpiar la memoria.
Iteración
for i, e := range s {
fmt.Println(i, e)
}Al usar for range para iterar sobre un slice, la función walkRange en cmd/compile/internal/walk/range.go lo expande a la siguiente forma:
// Copiar estructura
hs := s
// Obtener puntero al array subyacente
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}Como se puede ver, la implementación de for range aún itera sobre los elementos moviendo el puntero. Para evitar que el slice se actualice durante la iteración, se copia previamente la estructura hs. Para evitar que el puntero apunte a memoria fuera de límites después de la iteración, hu usa el tipo uintptr para almacenar la dirección, y solo se convierte a unsafe.Pointer cuando se necesita acceder al elemento.
La variable v2, es decir, e en for range, es siempre la misma variable durante todo el proceso de iteración. Solo se sobrescribe, no se vuelve a crear. Esto provocó el problema de variables de bucle que confundió a los desarrolladores de Go durante diez años. En la versión go1.21, el equipo oficial finalmente decidió resolverlo. Se espera que en actualizaciones de versiones posteriores, la creación de v2 pueda cambiar a la siguiente forma:
v2 := *hpEl proceso de construcción del código intermedio se omite aquí, ya que no pertenece al conocimiento del ámbito de los slices. Si está interesado, puede investigarlo por su cuenta.