Concurrencia
El soporte de Go para la concurrencia es natural, este es el núcleo del lenguaje. La dificultad para aprenderlo es relativamente baja, y los desarrolladores pueden crear aplicaciones concurrentes bastante buenas sin necesidad de preocuparse demasiado por la implementación subyacente, lo que mejora el nivel mínimo de los desarrolladores.
Goroutines
Una goroutine (corrutina) es un hilo ligero, o dicho de otra manera, un hilo en espacio de usuario que no es programado directamente por el sistema operativo, sino por el planificador del propio lenguaje Go en tiempo de ejecución. Por lo tanto, la sobrecarga del cambio de contexto es muy pequeña, esta es una de las razones por las que el rendimiento de concurrencia de Go es muy bueno. El concepto de goroutine no fue introducido por primera vez por Go, y Go no fue el primer lenguaje en soportar goroutines, pero Go es el primer lenguaje que puede soportar goroutines y concurrencia de manera simple y elegante.
En Go, crear una goroutine es muy simple, solo se necesita la palabra clave go para iniciar rápidamente una goroutine. La palabra clave go debe ir seguida de una llamada a función. Un ejemplo es el siguiente:
TIP
Las funciones incorporadas con valor de retorno no pueden seguir a la palabra clave go, como se muestra en el siguiente ejemplo erróneo:
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}Las tres formas anteriores de iniciar goroutines son válidas, pero en realidad, después de ejecutar este ejemplo, en la mayoría de los casos no se mostrará nada. Las goroutines se ejecutan concurrentemente, y el sistema necesita tiempo para crearlas. Antes de eso, la goroutine principal ya ha terminado de ejecutarse. Una vez que el hilo principal sale, las otras goroutines secundarias también salen naturalmente. Además, el orden de ejecución de las goroutines es incierto e impredecible. Por ejemplo:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}Este es un ejemplo de iniciar goroutines en un bucle, nunca se puede predecir con precisión qué mostrará. Puede que las goroutines secundarias no hayan comenzado a ejecutarse cuando la goroutine principal ya ha terminado, como se muestra a continuación:
start
endO solo algunas de las goroutines secundarias se ejecutan con éxito antes de que la goroutine principal salga, como se muestra a continuación:
start
0
1
5
3
4
6
7
endLa forma más simple es hacer que la goroutine principal espere un poco, usando la función Sleep del paquete time, que puede pausar la goroutine actual por un período de tiempo. Un ejemplo es el siguiente:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// Pausar 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}Al ejecutar nuevamente, la salida es la siguiente, se puede ver que todos los números se muestran completamente, sin omisiones:
start
0
1
5
2
3
4
6
8
9
7
endPero el orden todavía está desordenado, por lo que hacemos que cada iteración espere un poco. Un ejemplo es el siguiente:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}Ahora la salida está en el orden normal:
start
0
1
2
3
4
5
6
7
8
9
endLa salida del ejemplo anterior es perfecta, ¿pero se ha resuelto el problema de la concurrencia? No, en absoluto. Para los programas concurrentes, hay muchos factores incontrolables: el momento de ejecución, el orden, el tiempo de ejecución, etc. Si el trabajo de la goroutine en el bucle no es solo mostrar un número simple, sino una tarea enorme y compleja con tiempo incierto, el problema anterior se reproducirá. Por ejemplo, el siguiente código:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// Simular tiempo de ejecución aleatorio
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}La salida de este código sigue siendo incierta, esta es una de las posibles situaciones:
start
0
3
4
endPor lo tanto, time.Sleep no es una buena solución. Afortunadamente, Go proporciona muchos medios de control de concurrencia. Hay tres métodos de control de concurrencia comúnmente utilizados:
channel: canalWaitGroup: semáforoContext: contexto
Los tres métodos tienen diferentes situaciones de aplicación. WaitGroup puede controlar dinámicamente un conjunto de un número especificado de goroutines, Context es más adecuado para situaciones donde las goroutines anidadas tienen niveles más profundos, y los canales son más adecuados para la comunicación entre goroutines. Para el control de bloqueo más tradicional, Go también proporciona soporte:
Mutex: mutexRWMutex: mutex de lectura/escritura
Canales
channel, traducido como canal, Go explica el papel del canal de la siguiente manera:
Do not communicate by sharing memory; instead, share memory by communicating.
Es decir, compartir memoria mediante mensajes. channel existe para esto, es una solución para la comunicación entre goroutines y también se puede usar para el control de concurrencia. Primero, conozcamos la sintaxis básica de channel. En Go, la palabra clave chan representa el tipo de canal, y también se debe declarar el tipo de almacenamiento del canal para especificar qué tipo de datos almacena. El siguiente ejemplo es la apariencia de un canal ordinario:
var ch chan intEsta es una declaración de canal, en este momento el canal no está inicializado, su valor es nil y no se puede usar directamente.
Creación
Al crear un canal, hay una y solo una forma, que es usar la función incorporada make. Para los canales, la función make recibe dos parámetros: el primero es el tipo de canal y el segundo es un parámetro opcional para el tamaño del búfer del canal. Un ejemplo es el siguiente:
intCh := make(chan int)
// Canal con tamaño de búfer 1
strCh := make(chan string, 1)Después de usar un canal, debes recordar cerrarlo. Usa la función incorporada close para cerrar un canal. La firma de la función es la siguiente:
func close(c chan<- Type)Un ejemplo de cerrar un canal es el siguiente:
func main() {
intCh := make(chan int)
// do something
close(intCh)
}A veces es mejor usar defer para cerrar el canal.
Lectura y escritura
Para un canal, Go usa dos operadores muy visuales para representar las operaciones de lectura y escritura:
ch <-: representa escribir datos en un canal
<- ch: representa leer datos de un canal
<- representa vívidamente la dirección del flujo de datos. Veamos un ejemplo de lectura y escritura de un canal de tipo int:
func main() {
// Si no hay búfer causará deadlock
intCh := make(chan int, 1)
defer close(intCh)
// Escribir datos
intCh <- 114514
// Leer datos
fmt.Println(<-intCh)
}En el ejemplo anterior, se crea un canal de tipo int con un tamaño de búfer de 1, se le escriben los datos 114514, luego se leen los datos y se muestran, y finalmente se cierra el canal. Para la operación de lectura, hay un segundo valor de retorno, un valor booleano que indica si la lectura de datos fue exitosa:
ints, ok := <-intChEl flujo de datos en el canal es como una cola, es decir, primero en entrar, primero en salir (FIFO). La operación de las goroutines en el canal es síncrona. En un momento dado, solo una goroutine puede escribir datos en él, y solo una goroutine puede leer datos del canal.
Sin búfer
Para un canal sin búfer, debido a que la capacidad del búfer es 0, no almacena temporalmente ningún dato. Debido a que un canal sin búfer no puede almacenar datos, al escribir datos en el canal, debe haber otra goroutine que lea los datos inmediatamente, de lo contrario, se bloqueará y esperará. Lo mismo ocurre al leer datos, lo que explica por qué el siguiente código que parece normal causará un deadlock:
func main() {
// Crear canal sin búfer
ch := make(chan int)
defer close(ch)
// Escribir datos
ch <- 123
// Leer datos
n := <-ch
fmt.Println(n)
}Un canal sin búfer no debe usarse de forma síncrona. Lo correcto es iniciar una nueva goroutine para enviar datos, como en el siguiente ejemplo:
func main() {
// Crear canal sin búfer
ch := make(chan int)
defer close(ch)
go func() {
// Escribir datos
ch <- 123
}()
// Leer datos
n := <-ch
fmt.Println(n)
}Con búfer
Cuando un canal tiene un búfer, es como una cola bloqueante. Leer un canal vacío y escribir en un canal lleno causarán bloqueo. Al enviar datos a un canal sin búfer, debe haber alguien que lo reciba inmediatamente, de lo contrario, se bloqueará para siempre. Para un canal con búfer no es necesario hacerlo así. Al escribir datos en un canal con búfer, los datos se colocan primero en el búfer. Solo cuando el búfer está lleno, se bloqueará y esperará a que una goroutine lea los datos del canal. De la misma manera, al leer un canal con búfer, los datos se leen primero del búfer. Hasta que el búfer no tenga datos, se bloqueará y esperará a que una goroutine escriba datos en el canal. Por lo tanto, el ejemplo que causaría deadlock en un canal sin búfer puede ejecutarse sin problemas aquí:
func main() {
// Crear canal con búfer
ch := make(chan int, 1)
defer close(ch)
// Escribir datos
ch <- 123
// Leer datos
n := <-ch
fmt.Println(n)
}Aunque puede ejecutarse sin problemas, esta forma de lectura/escritura síncrona es muy peligrosa. Una vez que el búfer del canal está vacío o lleno, se bloqueará para siempre porque no hay otras goroutines que escriban o lean datos del canal. Veamos el siguiente ejemplo:
func main() {
// Crear canal con búfer
ch := make(chan int, 5)
// Crear dos canales sin búfer
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// Responsable de escribir
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("写入", i)
}
chW <- struct{}{}
}()
// Responsable de leer
go func() {
for i := 0; i < 10; i++ {
// Cada lectura de datos toma 1 milisegundo
time.Sleep(time.Millisecond)
fmt.Println("读取", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("写入完毕", <-chW)
fmt.Println("读取完毕", <-chR)
}Aquí se crean un total de 3 canales: un canal con búfer para la comunicación entre goroutines y dos canales sin búfer para sincronizar el orden de ejecución de las goroutines padre e hijo. La goroutine responsable de leer espera 1 milisegundo antes de cada lectura, y la goroutine responsable de escribir puede escribir como máximo 5 datos de una vez porque el búfer del canal tiene un máximo de 5. Antes de que haya una goroutine que lea, solo puede bloquearse y esperar. Por lo tanto, la salida del ejemplo es la siguiente:
写入 0
写入 1
写入 2
写入 3
写入 4 // Escribe 5 de una vez, el búfer está lleno, espera a que otras goroutines lean
读取 0
写入 5 // Lee uno, escribe uno
读取 1
写入 6
读取 2
写入 7
读取 3
写入 8
写入 9
读取 4
写入完毕 {} // Todos los datos se han enviado, la goroutine de escritura termina
读取 5
读取 6
读取 7
读取 8
读取 9
读取完毕 {} // Todos los datos se han leído, la goroutine de lectura terminaSe puede ver que la goroutine responsable de escribir envía 5 datos de una vez al principio. Después de que el búfer está lleno, comienza a bloquearse y esperar a que la goroutine de lectura lea. Luego, cada vez que la goroutine de lectura lee un dato cada 1 milisegundo y hay espacio en el búfer, la goroutine de escritura escribe un dato, hasta que todos los datos se envían y la goroutine de escritura termina. Luego, cuando la goroutine de lectura lee todos los datos del búfer, la goroutine de lectura también termina, y finalmente la goroutine principal sale.
TIP
Puedes acceder al número de datos en el búfer del canal mediante la función incorporada len, y puedes acceder al tamaño del búfer del canal mediante cap.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}Salida:
3 5Usando las condiciones de bloqueo del canal, puedes escribir fácilmente un ejemplo donde la goroutine principal espera a que las goroutines secundarias terminen de ejecutarse:
func main() {
// Crear un canal sin búfer
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// Escribir
ch <- struct{}{}
}()
// Bloquear y esperar lectura
<-ch
fmt.Println(1)
}Salida:
2
1También puedes implementar un mutex simple usando un canal con búfer. Veamos el siguiente ejemplo:
var count = 0
// Canal con tamaño de búfer 1
var lock = make(chan struct{}, 1)
func Add() {
// Bloquear
lock <- struct{}{}
fmt.Println("当前计数为", count, "执行加法")
count += 1
// Desbloquear
<-lock
}
func Sub() {
// Bloquear
lock <- struct{}{}
fmt.Println("当前计数为", count, "执行减法")
count -= 1
// Desbloquear
<-lock
}Debido a que el tamaño del búfer del canal es 1, como máximo solo hay un dato almacenado en el búfer. Las funciones Add y Sub intentan enviar datos al canal antes de cada operación. Debido a que el tamaño del búfer es 1, si otra goroutine ya ha escrito datos y el búfer está lleno, la goroutine actual debe bloquearse y esperar hasta que haya espacio en el búfer. De esta manera, en un momento dado, como máximo solo una goroutine puede modificar la variable count, logrando así un mutex simple.
Puntos a tener en cuenta
A continuación hay un resumen de varias situaciones que pueden causar bloqueo del canal si se usan incorrectamente:
Lectura/escritura de canal sin búfer
Cuando se realizan operaciones de lectura/escritura síncronas directamente en un canal sin búfer, causará que la goroutine se bloquee:
func main() {
// Crear un canal sin búfer
intCh := make(chan int)
defer close(intCh)
// Enviar datos
intCh <- 1
// Leer datos
ints, ok := <-intCh
fmt.Println(ints, ok)
}Leer un canal con búfer vacío
Cuando se lee un canal con el búfer vacío, causará que la goroutine se bloquee:
func main() {
// Crear un canal con búfer
intCh := make(chan int, 1)
defer close(intCh)
// El búfer está vacío, bloquear y esperar a que otras goroutines escriban datos
ints, ok := <-intCh
fmt.Println(ints, ok)
}Escribir en un canal con búfer lleno
Cuando el búfer del canal está lleno, escribir datos causará que la goroutine se bloquee:
func main() {
// Crear un canal con búfer
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// Lleno, bloquear y esperar a que otras goroutines lean datos
intCh <- 1
}Canal es nil
Cuando el canal es nil, cualquier lectura o escritura causará que la goroutine actual se bloquee:
func main() {
var intCh chan int
// Escribir
intCh <- 1
}func main() {
var intCh chan int
// Leer
fmt.Println(<-intCh)
}Las condiciones de bloqueo del canal deben dominarse y familiarizarse bien. En la mayoría de los casos, estos problemas están muy ocultos y no son tan intuitivos como en los ejemplos.
Las siguientes situaciones también causarán panic:
Cerrar un canal nil
Cuando el canal es nil, usar la función close para cerrarlo causará panic:
func main() {
var intCh chan int
close(intCh)
}Escribir en un canal cerrado
Escribir datos en un canal cerrado causará panic:
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}Cerrar un canal ya cerrado
En algunas situaciones, el canal puede pasar a través de múltiples capas, y el llamador puede no saber quién debe cerrar el canal. En este caso, puede ocurrir que se intente cerrar un canal ya cerrado, lo que causará panic:
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Solo puede enviar datos al canal
ch <- 1
close(ch)
}Canales unidireccionales
Un canal bidireccional es aquel que puede tanto escribir como leer, es decir, se puede operar en ambos lados del canal. Un canal unidireccional es aquel que solo lee o solo escribe, es decir, solo se puede operar en un lado del canal. Crear manualmente un canal de solo lectura o solo escritura no tiene mucho sentido, porque no poder leer o escribir en el canal pierde su propósito. Los canales unidireccionales se usan generalmente para restringir el comportamiento del canal, y generalmente aparecen en los parámetros y valores de retorno de las funciones. Por ejemplo, la firma de la función close incorporada que se usa para cerrar un canal usa un canal unidireccional:
func close(c chan<- Type)O la función After del paquete time que se usa comúnmente:
func After(d Duration) <-chan TimeEl parámetro de la función close es un canal de solo escritura, y el valor de retorno de la función After es un canal de solo lectura. Por lo tanto, la sintaxis de los canales unidireccionales es la siguiente:
- El símbolo de flecha
<-al principio es un canal de solo lectura, como<-chan int - El símbolo de flecha
<-al final es un canal de solo escritura, comochan<- string
Cuando intentas escribir datos en un canal de solo lectura, no podrá compilarse:
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}El error es el siguiente, el significado es muy claro:
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)Lo mismo ocurre al leer datos de un canal de solo escritura.
Un canal bidireccional se puede convertir en un canal unidireccional, pero no al revés. Normalmente, cuando pasas un canal bidireccional a una goroutine o función y no quieres que lea/envíe datos, puedes usar un canal unidireccional para restringir el comportamiento de la otra parte:
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Solo puede enviar datos al canal
ch <- 1
}Lo mismo ocurre con los canales de solo lectura.
TIP
chan es un tipo de referencia. Aunque los parámetros de función de Go son por valor, la referencia sigue siendo la misma. Esto se explicará más adelante en el principio del canal.
for range
Usando la declaración for range, puedes iterar y leer datos de un canal con búfer, como en el siguiente ejemplo:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}Normalmente, cuando for range itera sobre otras estructuras de datos iterables, hay dos valores de retorno: el primero es el índice y el segundo es el valor del elemento. Pero para un canal, solo hay un valor de retorno. for range leerá continuamente los elementos del canal. Cuando el búfer del canal está vacío o no hay búfer, se bloqueará y esperará hasta que otra goroutine escriba datos en el canal para continuar leyendo. Por lo tanto, la salida es la siguiente:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!Se puede ver que el código anterior causó un deadlock porque la goroutine secundaria ya ha terminado de ejecutarse, y la goroutine principal todavía está bloqueada esperando que otras goroutines escriban datos en el canal. Por lo tanto, el canal debe cerrarse después de terminar de escribir. Modifica el código de la siguiente manera:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// Cerrar canal
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}Cerrar el canal después de escribir evita que el código anterior cause un deadlock. Como se mencionó anteriormente, leer un canal tiene dos valores de retorno. Cuando for range itera sobre un canal y no puede leer datos con éxito, saldrá del bucle. El segundo valor de retorno indica si se pudo leer datos con éxito, no si el canal está cerrado. Incluso si el canal está cerrado, para un canal con búfer, todavía se pueden leer datos, y el segundo valor de retorno sigue siendo true. Veamos el siguiente ejemplo:
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// Cerrar canal
close(ch)
// Leer datos nuevamente
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}Resultado de la salida:
0 true
1 true
2 true
3 true
4 true
0 falseDado que el canal ya está cerrado, incluso si el búfer está vacío, leer datos nuevamente no causará que la goroutine actual se bloquee. Se puede ver que en la sexta iteración, se lee el valor cero y ok es false.
TIP
En cuanto al momento de cerrar el canal, debes intentar cerrar el canal en el lado que envía datos al canal, no en el lado que recibe datos. Porque en la mayoría de los casos, el lado que recibe datos solo sabe recibir datos y no sabe cuándo cerrar el canal.
WaitGroup
sync.WaitGroup es una estructura proporcionada por el paquete sync. WaitGroup significa esperar ejecución, y se puede usar para implementar fácilmente el efecto de esperar un conjunto de goroutines. Esta estructura solo expone tres métodos al exterior.
El método Add se usa para especificar el número de goroutines a esperar:
func (wg *WaitGroup) Add(delta int)El método Done indica que la goroutine actual ha terminado de ejecutarse:
func (wg *WaitGroup) Done()El método Wait espera a que las goroutines secundarias terminen, de lo contrario se bloquea:
func (wg *WaitGroup) Wait()WaitGroup es muy simple de usar, es listo para usar. Su implementación interna es un contador + semáforo. Al iniciar el programa, se llama a Add para inicializar el conteo. Cada vez que una goroutine termina de ejecutarse, se llama a Done, y el conteo disminuye en 1 hasta que llega a 0. Durante este período, la goroutine principal que llama a Wait se bloqueará hasta que todo el conteo disminuya a 0, y luego se despertará. Veamos un ejemplo de uso simple:
func main() {
var wait sync.WaitGroup
// Especificar el número de goroutines secundarias
wait.Add(1)
go func() {
fmt.Println(1)
// Ejecución terminada
wait.Done()
}()
// Esperar goroutine secundaria
wait.Wait()
fmt.Println(2)
}Este código siempre muestra 1 primero y luego 2. La goroutine principal esperará a que la goroutine secundaria termine de ejecutarse antes de salir.
1
2Para el primer ejemplo en la introducción de goroutines, se pueden hacer las siguientes modificaciones:
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// Contar 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// Contar 1 dentro del bucle
wait.Add(1)
go func() {
fmt.Println(i)
// Dos conteos -1
wait.Done()
mainWait.Done()
}()
// Esperar a que la goroutine del bucle actual termine
wait.Wait()
}
// Esperar a que todas las goroutines terminen
mainWait.Wait()
fmt.Println("end")
}Aquí se usa sync.WaitGroup en lugar del time.Sleep original. El orden de ejecución concurrente de las goroutines es más controlable. No importa cuántas veces se ejecute, la salida es la siguiente:
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup es generalmente adecuado cuando se puede ajustar dinámicamente el número de goroutines, por ejemplo, cuando se conoce de antemano el número de goroutines o cuando se necesita ajustar dinámicamente durante la ejecución. El valor de WaitGroup no debe copiarse, y el valor copiado no debe continuar usándose. Especialmente cuando se pasa como parámetro de función, se debe pasar un puntero en lugar de un valor. Si se usa el valor copiado, el conteo no puede afectar al WaitGroup real, lo que puede hacer que la goroutine principal se bloquee y espere para siempre, y el programa no podrá ejecutarse normalmente. Por ejemplo, el siguiente código:
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}El error indica que todas las goroutines han salido, pero la goroutine principal todavía está esperando, lo que forma un deadlock. Porque la llamada a Done dentro de la función hello en un parámetro WaitGroup no afecta al mainWait original. Por lo tanto, se debe usar un puntero para pasar:
hello
fatal error: all goroutines are asleep - deadlock!TIP
Cuando el conteo se vuelve negativo o el número de conteo es mayor que el número de goroutines secundarias, se producirá un panic.
Context
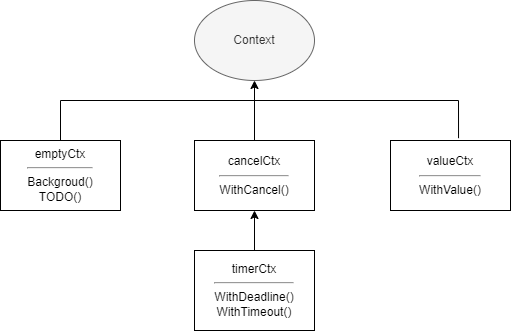
Context, traducido como contexto, es una solución de control de concurrencia proporcionada por Go. En comparación con los canales y WaitGroup, puede controlar mejor las goroutines descendientes y las goroutines de niveles más profundos. Context en sí es una interfaz. Cualquier cosa que implemente esta interfaz se puede llamar contexto, como gin.Context en el famoso framework web Gin. La biblioteca estándar context también proporciona varias implementaciones, que son:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
Primero veamos la definición de la interfaz Context, luego conozcamos su implementación específica.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
Este método tiene dos valores de retorno. deadline es la hora límite, es decir, el momento en que el contexto debe cancelarse. El segundo valor es si se ha establecido deadline. Si no se ha establecido, siempre es false.
Deadline() (deadline time.Time, ok bool)Done
Su valor de retorno es un canal de solo lectura de tipo estructura vacía. Este canal solo sirve como notificación y no transmite ningún dato. Cuando el trabajo realizado por el contexto debe cancelarse, este canal se cerrará. Para algunos contextos que no admiten cancelación, puede devolver nil.
Done() <-chan struct{}Err
Este método devuelve un error que indica la razón del cierre del contexto. Cuando el canal Done no está cerrado, devuelve nil. Si se ha cerrado, devolverá un err para explicar por qué se cerró.
Err() errorValue
Este método devuelve el valor correspondiente a la clave. Si key no existe o no se admite este método, devolverá nil.
Value(key any) anyemptyCtx
Como su nombre indica, emptyCtx es un contexto vacío. Todas las implementaciones del paquete context no se exponen al exterior, pero se proporcionan funciones correspondientes para crear contextos. emptyCtx se puede crear a través de context.Background y context.TODO. Las dos funciones son las siguientes:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}Se puede ver que solo devuelven un puntero emptyCtx. El tipo subyacente de emptyCtx es en realidad un int. La razón por la que no se usa una estructura vacía es porque las instancias de emptyCtx deben tener diferentes direcciones de memoria. No se puede cancelar, no tiene deadline y no se puede obtener un valor. Los métodos implementados devuelven valores cero.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx generalmente se usa como el contexto de nivel superior y se pasa como contexto padre al crear los otros tres tipos de contextos. La relación entre las implementaciones en el paquete context se muestra en la siguiente figura:
valueCtx
La implementación de valueCtx es relativamente simple. Solo contiene un par clave-valor y un campo incrustado de tipo Context.
type valueCtx struct {
Context
key, val any
}Solo implementa el método Value, y la lógica es muy simple: si no se encuentra en el contexto actual, busca en el contexto padre.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}A continuación, veamos un caso de uso simple de valueCtx:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// Pasar contexto
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// Crear nuevo temporizador
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // Nunca se ejecutará
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx se usa a menudo para pasar datos en goroutines multinivel. No se puede cancelar, por lo que ctx.Done siempre devolverá nil, y select ignorará el canal nil. La salida final es la siguiente:
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
Tanto cancelCtx como timerCtx implementan la interfaz canceler. El tipo de interfaz es el siguiente:
type canceler interface {
// removeFromParent indica si se debe eliminar del contexto padre
// err indica la razón de la cancelación
cancel(removeFromParent bool, err error)
// Done devuelve un canal para notificar la razón de la cancelación
Done() <-chan struct{}
}El método cancel no se expone al exterior. Al crear un contexto, se empaqueta en el valor de retorno mediante un cierre para que sea llamado desde el exterior, como se muestra en el código fuente de context.WithCancel:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// Intentar agregarse a los children del padre
propagateCancel(parent, &c)
// Devolver context y una función
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx, traducido como contexto cancelable. Al crearlo, si el padre implementa canceler, se agregará a los children del padre; de lo contrario, buscará hacia arriba. Si ningún padre implementa canceler, iniciará una goroutine para esperar a que el padre se cancele, y luego cancelará el contexto actual cuando el padre termine. Cuando se llama a cancelFunc, el canal Done se cerrará, y cualquier hijo de este contexto también se cancelará. Finalmente, se eliminará del padre. A continuación se muestra un ejemplo simple:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// Devuelve un cancelCtx y una función cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}La salida es la siguiente:
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
context canceledA continuación, otro ejemplo con un nivel de anidamiento más profundo:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("正在处理 http 请求...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth 父级取消", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail 父级取消", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}En el ejemplo se crean 3 cancelCtx. Aunque el cancelCtx padre cancelará sus contextos hijos al mismo tiempo que se cancela, por seguridad, si se crea un cancelCtx, se debe llamar a la función cancel después de que el proceso correspondiente termine. La salida es la siguiente:
正在处理 http 请求...
auth...
mail...
mail...
auth...
正在处理 http 请求...
auth...
mail...
正在处理 http 请求...
正在处理 http 请求...
auth...
mail...
auth...
正在处理 http 请求...
mail...
context canceled
auth 父级取消 context canceled
mail 父级取消 context canceledtimerCtx
timerCtx agrega un mecanismo de tiempo de espera sobre la base de cancelCtx. El paquete context proporciona dos funciones de creación: WithDeadline y WithTimeout. Ambas funciones son similares. La primera especifica un tiempo de espera específico, como una hora específica 2023/3/20 16:32:00. La segunda especifica un intervalo de tiempo de espera, como 5 minutos después. Las firmas de las dos funciones son las siguientes:
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx cancelará automáticamente el contexto actual cuando expire el tiempo. El proceso de cancelación es básicamente el mismo que cancelCtx, excepto que debe cerrar adicionalmente el timer. A continuación se muestra un ejemplo de uso simple de timerCtx:
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("上下文取消", ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}Aunque el contexto se cancelará automáticamente cuando expire, por seguridad, es mejor cancelar manualmente el contexto después de que el proceso relacionado termine. La salida es la siguiente:
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
上下文取消 context deadline exceededWithTimeout es en realidad muy similar a WithDeadline. Su implementación es solo una ligera encapsulación y llama a WithDeadline. El uso es el mismo que el ejemplo anterior de WithDeadline, como se muestra a continuación:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
Al igual que la asignación de memoria sin recuperación causará una fuga de memoria, el contexto también es un recurso. Si se crea pero nunca se cancela, también causará una fuga de contexto. Por lo tanto, es mejor evitar esta situación.
Select
select en el sistema Linux es una solución de multiplexación de E/S. De manera similar, en Go, select es una estructura de control de multiplexación de canales. ¿Qué es la multiplexación? Simplemente, en una palabra: en un momento dado, monitorear simultáneamente si múltiples elementos están disponibles. Lo que se puede monitorear pueden ser solicitudes de red, E/S de archivos, etc. En Go, los elementos que select monitorea son canales, y solo pueden ser canales. La sintaxis de select es similar a la declaración switch. A continuación, veamos cómo es una declaración select:
func main() {
// Crear tres canales
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("所有管道都不可用")
}
}Uso
Al igual que switch, select se compone de múltiples case y un default. La rama default se puede omitir. Cada case solo puede operar un canal y solo puede realizar una operación: leer o escribir. Cuando hay múltiples case disponibles, select elegirá pseudoaleatoriamente un case para ejecutar. Si todos los case no están disponibles, se ejecutará la rama default. Si no hay rama default, se bloqueará y esperará hasta que al menos un case esté disponible. Dado que en el ejemplo anterior no se escriben datos en los canales, naturalmente todos los case no están disponibles, por lo que la salida final es el resultado de la ejecución de la rama default. Después de modificarlo ligeramente, es el siguiente:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// Iniciar una nueva goroutine
go func() {
// Escribir datos en el canal A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}El ejemplo anterior inicia una nueva goroutine para escribir datos en el canal A. select no tiene rama predeterminada, por lo que se bloqueará y esperará hasta que haya un case disponible. Cuando el canal A está disponible, después de ejecutar la rama correspondiente, la goroutine principal sale directamente. Para monitorear continuamente los canales, se puede usar junto con un bucle for, como se muestra a continuación:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// Bucle for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Esto确实 usa los tres canales, pero el bucle infinito + select causará que la goroutine principal se bloquee permanentemente. Por lo tanto, se puede poner en una nueva goroutine y agregar algo de otra lógica:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // Establecer tiempo de espera de 1 segundo
break Loop // Salir del bucle
}
}
l <- struct{}{} // Decirle a la goroutine principal que puede salir
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}En el ejemplo anterior, se usa un bucle for junto con select para monitorear continuamente si los tres canales están disponibles. El cuarto case es un canal de tiempo de espera. Después del tiempo de espera, saldrá del bucle y terminará la goroutine secundaria. La salida final es la siguiente:
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueTiempo de espera
El ejemplo anterior usa la función time.After, cuyo valor de retorno es un canal de solo lectura. Esta función se usa junto con select para implementar muy fácilmente un mecanismo de tiempo de espera. Un ejemplo es el siguiente:
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("超时")
}
}Bloqueo permanente
Cuando la declaración select no tiene nada, se bloqueará permanentemente. Por ejemplo:
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end nunca se mostrará, y la goroutine principal se bloqueará para siempre. Esta situación generalmente tiene un propósito especial.
TIP
Si operas en un canal con valor nil en el case de select, no causará bloqueo. Este case se ignorará y nunca se ejecutará. Por ejemplo, el siguiente código, no importa cuántas veces se ejecute, solo mostrará timeout:
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}No bloqueo
Usando la rama default de select junto con canales, podemos implementar operaciones de envío/recepción no bloqueantes, como se muestra a continuación:
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}De la misma manera, también se puede implementar un juicio no bloqueante de si un context ha terminado:
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}Bloqueos
Primero veamos un ejemplo:
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Simular tiempo de acceso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// Acceder a datos
temp := *data
// Simular tiempo de cálculo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// Modificar datos
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最终结果", count)
}Para el ejemplo anterior, se inician diez goroutines para realizar una operación +1 en count, y se usa time.Sleep para simular diferentes tiempos de ejecución. Según la intuición, 10 goroutines ejecutan 10 operaciones +1, el resultado final debe ser 10. El resultado correcto es efectivamente 10, pero la realidad no es así. El resultado de la ejecución del ejemplo anterior es el siguiente:
1
2
3
3
2
2
3
3
3
4
最终结果 4Se puede ver que el resultado final es 4, y esto es solo una de las muchas posibilidades. Debido a que el tiempo de acceso y cálculo de cada goroutine es diferente, la goroutine A tarda 500 milisegundos en acceder a los datos, y el valor de count accedido es 1. Luego tarda 400 milisegundos en calcular, pero durante estos 400 milisegundos, la goroutine B ya ha completado el acceso y cálculo y ha actualizado exitosamente el valor de count. Después de que la goroutine A termina de calcular, el valor al que accedió inicialmente ya está obsoleto, pero la goroutine A no lo sabe y todavía suma uno al valor al que accedió inicialmente y lo asigna a count. De esta manera, el resultado de la ejecución de la goroutine B se sobrescribe. Cuando múltiples goroutines leen y acceden a un dato compartido, especialmente ocurrirá este problema. Para esto, se necesitan bloqueos.
Mutex y RWMutex en el paquete sync de Go proporcionan dos implementaciones: mutex y mutex de lectura/escritura, y proporcionan una API muy simple y fácil de usar. Solo se necesita Lock() para bloquear y Unlock() para desbloquear. Cabe señalar que los bloqueos proporcionados por Go son bloqueos no recursivos, es decir, bloqueos no reentrantes. Por lo tanto, bloquear o desbloquear repetidamente causará fatal. El significado del bloqueo es proteger invariantes. Bloquear es esperar que los datos no sean modificados por otras goroutines, como se muestra a continuación:
func DoSomething() {
Lock()
// Durante este proceso, los datos no serán modificados por otras goroutines
Unlock()
}Si fuera un bloqueo recursivo, podría ocurrir la siguiente situación:
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}La función DoSomething obviamente no sabe qué puede hacer la función DoOther con los datos, modificando así los datos, como iniciar algunas goroutines secundarias que destruyen los invariantes. Esto no es factible en Go. Una vez que se bloquea, se debe garantizar la invariabilidad de los invariantes. En este momento, bloquear o desbloquear repetidamente causará un deadlock. Por lo tanto, al escribir código, se debe evitar la situación anterior. Cuando sea necesario, usa inmediatamente la declaración defer para desbloquear al mismo tiempo que bloqueas.
Mutex
sync.Mutex es la implementación de mutex proporcionada por Go. Implementa la interfaz sync.Locker:
type Locker interface {
// Bloquear
Lock()
// Desbloquear
Unlock()
}Usar un mutex puede resolver perfectamente el problema anterior. Un ejemplo es el siguiente:
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Bloquear
lock.Lock()
// Simular tiempo de acceso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Acceder a datos
temp := *data
// Simular tiempo de cálculo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// Modificar datos
*data = temp + ans
// Desbloquear
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最终结果", count)
}Cada goroutine, antes de acceder a los datos, primero bloquea. Después de actualizar, desbloquea. Otras goroutines que quieran acceder deben obtener primero el bloqueo; de lo contrario, se bloquearán y esperarán. De esta manera, no existe el problema anterior, por lo que la salida es la siguiente:
1
2
3
4
5
6
7
8
9
10
最终结果 10Mutex de lectura/escritura
El mutex es adecuado para situaciones donde la frecuencia de operaciones de lectura y escritura es similar. Para algunos datos con más lecturas y menos escrituras, si se usa un mutex, causará una gran cantidad de competencia innecesaria por el bloqueo de las goroutines, lo que consumirá muchos recursos del sistema. En este momento, se necesita un mutex de lectura/escritura. Para una goroutine:
- Si obtiene un bloqueo de lectura, otras goroutines se bloquearán al realizar operaciones de escritura, pero no se bloquearán al realizar operaciones de lectura.
- Si obtiene un bloqueo de escritura, otras goroutines se bloquearán al realizar operaciones de escritura y también se bloquearán al realizar operaciones de lectura.
La implementación del mutex de lectura/escritura en Go es sync.RWMutex. También implementa la interfaz Locker, pero proporciona más métodos disponibles, como se muestra a continuación:
// Bloquear lectura
func (rw *RWMutex) RLock()
// Intentar bloquear lectura
func (rw *RWMutex) TryRLock() bool
// Desbloquear lectura
func (rw *RWMutex) RUnlock()
// Bloquear escritura
func (rw *RWMutex) Lock()
// Intentar bloquear escritura
func (rw *RWMutex) TryLock() bool
// Desbloquear escritura
func (rw *RWMutex) Unlock()Las dos operaciones de intento de bloqueo TryRLock y TryLock son no bloqueantes. Si el bloqueo se realiza con éxito, devolverá true. Si no se puede obtener el bloqueo, no se bloqueará, sino que devolverá false. La implementación interna del mutex de lectura/escritura sigue siendo un mutex. No es que haya dos bloqueos porque se dividen en bloqueo de lectura y bloqueo de escritura. Siempre solo hay un bloqueo. A continuación, veamos un caso de uso de mutex de lectura/escritura:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// Más lecturas, menos escrituras
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Esperar a que las goroutines secundarias terminen
wait.Wait()
fmt.Println("最终结果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到读锁")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("释放读锁", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到写锁")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("释放写锁", *i)
rw.Unlock()
wait.Done()
}Este ejemplo inicia 3 goroutines de escritura y 7 goroutines de lectura. Al leer datos, todas obtendrán primero un bloqueo de lectura. Las goroutines de lectura pueden obtener normalmente el bloqueo de lectura, pero bloquearán las goroutines de escritura. Al obtener un bloqueo de escritura, bloqueará tanto las goroutines de lectura como de escritura hasta que se libere el bloqueo de escritura. De esta manera, se logra la exclusión mutua entre las goroutines de lectura y escritura, garantizando la corrección de los datos. La salida del ejemplo es la siguiente:
拿到读锁
拿到读锁
拿到读锁
拿到读锁
释放读锁 0
释放读锁 0
释放读锁 0
释放读锁 0
拿到写锁
释放写锁 1
拿到读锁
拿到读锁
拿到读锁
释放读锁 1
释放读锁 1
释放读锁 1
拿到写锁
释放写锁 2
拿到写锁
释放写锁 3
最终结果 3TIP
Para los bloqueos, no se deben pasar y almacenar como valores. Se deben usar punteros.
Variables de condición
Las variables de condición aparecen y se usan junto con los mutex, por lo que algunas personas pueden llamarlas erróneamente bloqueos de condición, pero no son bloqueos. Son un mecanismo de comunicación. sync.Cond en Go proporciona una implementación para esto. La firma de la función para crear una variable de condición es la siguiente:
func NewCond(l Locker) *CondSe puede ver que la premisa para crear una variable de condición es necesitar crear un bloqueo. sync.Cond proporciona los siguientes métodos para usar:
// Bloquear y esperar a que la condición se cumpla, hasta ser despertado
func (c *Cond) Wait()
// Despertar una goroutine bloqueada por la condición
func (c *Cond) Signal()
// Despertar todas las goroutines bloqueadas por la condición
func (c *Cond) Broadcast()Las variables de condición son muy simples de usar. Modifica ligeramente el ejemplo del mutex de lectura/escritura anterior:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// Variable de condición
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// Más lecturas, menos escrituras
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Esperar a que las goroutines secundarias terminen
wait.Wait()
fmt.Println("最终结果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到读锁")
// Bloquear continuamente si la condición no se cumple
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("释放读锁", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到写锁")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("释放写锁", *i)
rw.Unlock()
// Despertar todas las goroutines bloqueadas por la variable de condición
cond.Broadcast()
wait.Done()
}Al crear la variable de condición, dado que aquí la variable de condición actúa sobre las goroutines de lectura, se pasa el bloqueo de lectura como mutex. Si se pasa directamente el mutex de lectura/escritura, causará un problema de desbloqueo repetido de las goroutines de escritura. Aquí se pasa sync.rlocker, obtenido a través del método RWMutex.RLocker:
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }Se puede ver que rlocker solo encapsula la operación de bloqueo de lectura del mutex de lectura/escritura. En realidad, es la misma referencia, sigue siendo el mismo bloqueo. Cuando las goroutines de lectura leen datos, si es menor que 3, se bloquearán y esperarán continuamente hasta que los datos sean mayores que 3. Las goroutines de escritura, después de actualizar los datos, intentarán despertar todas las goroutines bloqueadas por la variable de condición. Por lo tanto, la salida final es la siguiente:
拿到读锁
拿到读锁
拿到读锁
拿到读锁
拿到写锁
释放写锁 1
拿到读锁
拿到写锁
释放写锁 2
拿到读锁
拿到读锁
拿到写锁
释放写锁 3 // La tercera goroutine de escritura termina
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
最终结果 3Del resultado se puede ver que cuando la tercera goroutine de escritura termina de actualizar los datos, las siete goroutines de lectura bloqueadas por la variable de condición se reanudan.
TIP
Para las variables de condición, se debe usar for en lugar de if. Se debe usar un bucle para juzgar si la condición se cumple, porque cuando una goroutine es despertada, no se puede garantizar que la condición actual ya se haya cumplido.
for !condition {
cond.Wait()
}sync
Una gran parte de las herramientas relacionadas con la concurrencia en Go son proporcionadas por la biblioteca estándar sync. Anteriormente ya se introdujeron sync.WaitGroup, sync.Locker, etc. Además, el paquete sync tiene algunas otras herramientas que se pueden usar.
Once
Al usar algunas estructuras de datos, si estas estructuras de datos son demasiado grandes, se puede considerar usar carga diferida, es decir, inicializar la estructura de datos solo cuando realmente se vaya a usar. Como en el siguiente ejemplo:
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// Solo se considera inicializar cuando realmente se usa el slice
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}Entonces surge el problema. Si solo hay una goroutine que lo usa, definitivamente no hay problema. Pero si hay múltiples goroutines que acceden, puede haber problemas. Por ejemplo, las goroutines A y B llaman al método Add al mismo tiempo. A se ejecuta un poco más rápido, ya ha inicializado y ha agregado datos exitosamente. Luego la goroutine B inicializa nuevamente, lo que sobrescribe directamente los datos agregados por la goroutine A. Este es el problema.
Este es el problema que sync.Once resuelve. Como su nombre indica, Once significa una vez. sync.Once garantiza que una operación especificada se ejecutará solo una vez bajo condiciones concurrentes. Su uso es muy simple, solo expone un método Do al exterior. La firma es la siguiente:
func (o *Once) Do(f func())Al usarlo, solo necesitas pasar la operación de inicialización al método Do, como se muestra a continuación:
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// Solo se considera inicializar cuando realmente se usa el slice
m.o.Do(func() {
fmt.Println("初始化")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}La salida es la siguiente:
初始化
4Del resultado de la salida se puede ver que todos los datos se agregan normalmente al slice, y la operación de inicialización se ejecuta solo una vez. De hecho, la implementación de sync.Once es bastante simple. Eliminando los comentarios, la lógica del código real tiene solo 16 líneas. Su principio es bloqueo + operación atómica. El código fuente es el siguiente:
type Once struct {
// Usado para juzgar si la operación ya se ejecutó
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Carga atómica de datos
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// Bloquear
o.m.Lock()
// Desbloquear
defer o.m.Unlock()
// Juzgar si se ejecutó
if o.done == 0 {
// Modificar done después de ejecutar
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
El propósito de diseño de sync.Pool es almacenar objetos temporales para su reutilización posterior. Es un pool de objetos temporal concurrentemente seguro. Los objetos que no se usan temporalmente se ponen en el pool, y en el uso posterior no es necesario crear objetos adicionales, se pueden reutilizar directamente, reduciendo la frecuencia de asignación y liberación de memoria. Lo más importante es reducir la presión en GC. sync.Pool tiene solo dos métodos en total, como se muestra a continuación:
// Solicitar un objeto
func (p *Pool) Get() any
// Poner un objeto
func (p *Pool) Put(x any)Y sync.Pool tiene un campo New expuesto al exterior, usado para inicializar un objeto cuando el pool de objetos no puede solicitar un objeto:
New func() anyA continuación se demuestra con un ejemplo:
var wait sync.WaitGroup
// Pool de objetos temporales
var pool sync.Pool
// Usado para contar cuántos objetos se crearon en total durante el proceso
var numOfObject atomic.Int64
// BigMemData Supongamos que esta es una estructura que ocupa mucha memoria
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"大内存"}
}
wait.Add(1000)
// Aquí se inician 1000 goroutines
for i := 0; i < 1000; i++ {
go func() {
// Solicitar objeto
val := pool.Get()
// Usar objeto
_ = val.(BigMemData)
// Liberar objeto después de usar
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}En el ejemplo se inician 1000 goroutines que solicitan y liberan objetos continuamente en el pool. Si no se usa un pool de objetos, entonces las 1000 goroutines necesitan instanciar objetos各自, y estos 1000 objetos instanciados necesitan ser liberados por GC después de usar. Si hay cientos de miles de goroutines o el costo de crear el objeto es muy alto, en este caso ocupará mucha memoria y traerá mucha presión a GC. Después de usar un pool de objetos, se pueden reutilizar objetos para reducir la frecuencia de instanciación. Por ejemplo, la salida del ejemplo anterior puede ser la siguiente:
5Aunque se inician 1000 goroutines, solo se crean 5 objetos en todo el proceso. Si no se usa un pool de objetos, las 1000 goroutines crearán 1000 objetos. La mejora que trae esta optimización es obvia, especialmente cuando el volumen de concurrencia es particularmente grande y el costo de instanciar objetos es particularmente alto, se puede reflejar mejor la ventaja.
Al usar sync.Pool, se deben prestar atención a varios puntos:
- Objetos temporales:
sync.Poolsolo es adecuado para almacenar objetos temporales. Los objetos en el pool pueden ser eliminados por GC sin ninguna notificación, por lo que no se recomienda almacenar conexiones de red, conexiones de base de datos, etc. ensync.Pool. - Impredecible:
sync.Poolno puede predecir si un objeto es nuevo o reutilizado al solicitar un objeto, y tampoco puede saber cuántos objetos hay en el pool. - Seguridad concurrente: El oficial garantiza que
sync.Pooles definitivamente concurrentemente seguro, pero no garantiza que la funciónNewusada para crear objetos sea concurrentemente segura. La funciónNewes pasada por el usuario, por lo que la seguridad concurrente de la funciónNewdebe ser mantenida por el usuario mismo. Esta es también la razón por la que el conteo de objetos en el ejemplo anterior usa un valor atómico.
TIP
Finalmente, se debe prestar atención a que, después de usar el objeto, se debe liberar de vuelta al pool. Si se usa y no se libera, el uso del pool de objetos no tendrá sentido.
La biblioteca estándar fmt tiene un caso de uso de pool de objetos en la función fmt.Fprintf:
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// Solicitar un búfer de impresión
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// Liberar después de usar
p.free()
return
}Donde la implementación de la función newPrinter y el método free es la siguiente:
func newPrinter() *pp {
// Un objeto solicitado del pool de objetos
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// Para que el tamaño del búfer en el pool de objetos sea aproximadamente el mismo para controlar mejor el tamaño del búfer de manera elástica
// Los búferes demasiado grandes no se devuelven al pool de objetos
if cap(p.buf) > 64<<10 {
return
}
// Liberar objeto al pool después de restablecer campos
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map es una implementación de Map concurrentemente segura proporcionada oficialmente. Es listo para usar y muy simple de usar. A continuación se muestran los métodos expuestos por esta estructura:
// Leer un valor según una clave, el valor de retorno devolverá el valor correspondiente y si el valor existe
func (m *Map) Load(key any) (value any, ok bool)
// Almacenar un par clave-valor
func (m *Map) Store(key, value any)
// Eliminar un par clave-valor
func (m *Map) Delete(key any)
// Si la clave ya existe, devolver el valor original; de lo contrario, almacenar el nuevo valor y devolverlo. Cuando se lee el valor con éxito, loaded es true; de lo contrario, es false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// Eliminar un par clave-valor y devolver su valor original. El valor de loaded depende de si la clave existe
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Iterar sobre Map, cuando f() devuelve false, se detendrá la iteración
func (m *Map) Range(f func(key, value any) bool)A continuación se usa un ejemplo simple para demostrar el uso básico de sync.Map:
func main() {
var syncMap sync.Map
// Almacenar datos
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// Leer datos
fmt.Println(syncMap.Load("a"))
// Leer y eliminar
fmt.Println(syncMap.LoadAndDelete("a"))
// Leer o almacenar
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// Iterar sobre map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Salida:
a true
a true
hello world false
a hello world
b goodbye worldA continuación, veamos un ejemplo de uso concurrente de map:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}En el ejemplo anterior se usa un map ordinario, se inician 10 goroutines que almacenan datos continuamente. Obviamente, esto probablemente desencadenará un fatal, y el resultado probablemente será el siguiente:
fatal error: concurrent map writesUsar sync.Map puede evitar este problema:
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}La salida es la siguiente:
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4Para la seguridad concurrente, definitivamente se deben hacer ciertos sacrificios. El rendimiento de sync.Map es de 10 a 100 veces menor que el de map.
Atómicos
En la ciencia de la computación, los átomos u operaciones primitivas se usan generalmente para describir algunas operaciones que no se pueden refinar y dividir más. Debido a que estas operaciones no se pueden refinar en pasos más pequeños, no serán interrumpidas por ninguna otra goroutine antes de que se completen. Por lo tanto, el resultado de la ejecución es éxito o fracaso, no hay una tercera situación. Si aparece otra situación, entonces no es una operación atómica. Por ejemplo, el siguiente código:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}El código anterior es una rama de juicio simple. Aunque hay muy poco código, tampoco es una operación atómica. Las verdaderas operaciones atómicas son soportadas por el nivel de instrucciones de hardware.
Tipos
Afortunadamente, en la mayoría de los casos no es necesario escribir ensamblador uno mismo. El paquete sync/atomic de la biblioteca estándar de Go ya ha proporcionado API relacionadas con operaciones atómicas. Proporciona los siguientes tipos para realizar operaciones atómicas:
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}Donde el tipo atómico Pointer soporta genéricos, y el tipo Value soporta almacenar cualquier tipo. Además, proporciona muchas funciones para facilitar las operaciones. Debido a que la granularidad de las operaciones atómicas es demasiado fina, en la mayoría de los casos, es más adecuado manejar estos tipos de datos básicos.
TIP
Las operaciones atómicas en el paquete atomic solo tienen firmas de funciones, no tienen implementaciones específicas. Las implementaciones específicas están escritas en ensamblador plan9.
Uso
Cada tipo atómico proporcionará los siguientes tres métodos:
Load(): obtener el valor atómicamenteSwap(newVal type) (old type): intercambiar el valor atómicamente y devolver el valor antiguoStore(val type): almacenar el valor atómicamente
Diferentes tipos pueden tener otros métodos adicionales. Por ejemplo, los tipos enteros proporcionarán el método Add para implementar operaciones de suma y resta atómicas. A continuación se demuestra con un tipo int64:
func main() {
var aint64 atomic.Uint64
// Almacenar valor
aint64.Store(64)
// Intercambiar valor
aint64.Swap(128)
// Aumentar
aint64.Add(112)
// Cargar valor
fmt.Println(aint64.Load())
}O también se pueden usar funciones directamente:
func main() {
var aint64 int64
// Almacenar valor
atomic.StoreInt64(&aint64, 64)
// Intercambiar valor
atomic.SwapInt64(&aint64, 128)
// Aumentar
atomic.AddInt64(&aint64, 112)
// Cargar
fmt.Println(atomic.LoadInt64(&aint64))
}El uso de otros tipos es muy similar. La salida final es:
240CAS
El paquete atomic también proporciona la operación CompareAndSwap, es decir, CAS. Es el núcleo de la implementación de bloqueos optimistas y estructuras de datos sin bloqueo. El bloqueo optimista en sí no es un bloqueo, es una forma de control de concurrencia sin bloqueo bajo condiciones concurrentes: los hilos/goroutines no bloquearán primero antes de modificar los datos, sino que primero leerán los datos, realizarán cálculos, y luego al enviar la modificación usarán CAS para juzgar si otros hilos han modificado los datos durante este período. Si no (el valor sigue siendo igual al valor leído anteriormente), la modificación es exitosa; de lo contrario, falla y reintenta. Por lo tanto, se llama bloqueo optimista porque siempre asume optimistamente que los datos compartidos no serán modificados, y solo ejecutará la operación correspondiente cuando descubra que los datos no han sido modificados. El mutex aprendido anteriormente es un bloqueo pesimista. El mutex siempre asume pesimistamente que los datos compartidos serán modificados, por lo que bloqueará al operar y desbloqueará después de completar la operación. Debido a que la concurrencia implementada sin bloqueo tiene mayor seguridad y eficiencia en relación con los bloqueos, muchas estructuras de datos concurrentemente seguras usan CAS para implementar. Sin embargo, la eficiencia real debe combinarse con el escenario de uso específico. Veamos el siguiente ejemplo:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}Este es un ejemplo que usa un mutex. Cada vez que se aumenta un número, primero se bloquea. Después de ejecutar, se desbloquea. El proceso causará que otras goroutines se bloqueen. A continuación, se usa CAS para transformar:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}Para CAS, hay tres parámetros: valor en memoria, valor esperado y nuevo valor. Al ejecutar, CAS comparará el valor esperado con el valor en memoria actual. Si el valor en memoria es el mismo que el valor esperado, ejecutará la operación posterior; de lo contrario, no hará nada. Para las operaciones atómicas en el paquete atomic de Go, las funciones relacionadas con CAS necesitan pasar la dirección, el valor esperado y el nuevo valor, y devolverán un valor booleano que indica si la sustitución fue exitosa. Por ejemplo, la firma de la función de operación CAS de tipo int64 es la siguiente:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)En el ejemplo de CAS, primero se obtiene el valor esperado a través de LoadInt64, luego se usa CompareAndSwapInt64 para comparar e intercambiar. Si no tiene éxito, se循环 continuamente hasta que tenga éxito. Esta operación sin bloqueo no causará que las goroutines se bloqueen, pero el循环 continuo sigue siendo una gran sobrecarga para la CPU. Por lo tanto, en algunas implementaciones, se puede abandonar la operación después de fallar un cierto número de veces. Pero para la operación anterior, solo es una suma simple de números, las operaciones involucradas no son complejas, por lo que se puede considerar completamente una implementación sin bloqueo.
TIP
En la mayoría de los casos, solo comparar valores no puede lograr seguridad concurrente. Por ejemplo, el problema ABA causado por CAS requiere usar version adicional para resolver el problema.
Value
La estructura atomic.Value puede almacenar valores de cualquier tipo. La estructura es la siguiente:
type Value struct {
// Tipo any
v any
}Aunque puede almacenar cualquier tipo, no puede almacenar nil, y los tipos de valores almacenados antes y después deben ser consistentes. Los dos ejemplos siguientes no pueden compilarse:
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into ValueAdemás, su uso no es muy diferente de otros tipos atómicos. Y se debe prestar atención a que todos los tipos atómicos no deben copiar valores, sino que deben usar sus punteros.