Concurrence
Le langage Go offre un support natif pour la concurrence, ce qui est au cœur de ce langage. Sa courbe d'apprentissage est relativement faible, permettant aux développeurs de créer des applications concurrentes performantes sans avoir à se soucier des implémentations de bas niveau.
Goroutines
Une goroutine (coroutine) est un thread léger, ou thread en espace utilisateur, qui n'est pas directement orchestré par le système d'exploitation mais par le planificateur d'exécution de Go lui-même. Ainsi, la commutation de contexte a un coût très faible, ce qui explique en partie les bonnes performances de la concurrence en Go. Le concept de goroutine n'a pas été introduit par Go, et Go n'est pas le premier langage à les supporter. Cependant, Go est le premier langage à rendre la concurrence et les goroutines aussi simples et élégantes.
En Go, créer une goroutine est très simple : il suffit du mot-clé go, suivi d'un appel de fonction. Exemple :
TIP
Les fonctions intégrées avec valeur de retour ne peuvent pas suivre le mot-clé go, comme dans l'exemple erroné ci-dessous :
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}Ces trois façons de démarrer une goroutine sont valides. Cependant, dans la plupart des cas, cet exemple n'affichera rien, car les goroutines s'exécutent de manière concurrente et le système a besoin de temps pour les créer. Pendant ce temps, la goroutine principale se termine, et lorsque le thread principal se termine, toutes les goroutines enfants se terminent également. De plus, l'ordre d'exécution des goroutines est indéterminé et imprévisible. Exemple :
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}Cet exemple démarre des goroutines dans une boucle. Il est impossible de prédire avec précision ce qui sera affiché. Il est possible que les goroutines enfants n'aient pas commencé à s'exécuter avant que la goroutine principale ne se termine :
start
endOu seulement une partie des goroutines enfants s'exécutent avec succès avant que la goroutine principale ne se termine :
start
0
1
5
3
4
6
7
endLa solution la plus simple consiste à faire attendre la goroutine principale pendant un moment, en utilisant la fonction Sleep du paquet time, qui permet de suspendre l'exécution de la goroutine actuelle pendant une durée donnée :
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// Pause de 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}En réexécutant, on obtient :
start
0
1
5
2
3
4
6
8
9
7
endTous les chiffres sont affichés complètement, sans omission, mais l'ordre est toujours mélangé. Faisons attendre chaque itération un peu :
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}La sortie est maintenant dans l'ordre normal :
start
0
1
2
3
4
5
6
7
8
9
endLes résultats de l'exemple ci-dessus sont parfaits, mais le problème de la concurrence est-il résolu ? Non, pas du tout. Pour un programme concurrent, il y a beaucoup de facteurs incontrôlables : le moment d'exécution, l'ordre, le temps d'exécution, etc. Si le travail de la goroutine enfant dans la boucle n'est pas une simple impression de chiffre, mais une tâche énorme et complexe avec un temps d'exécution incertain, les problèmes précédents réapparaîtront. Exemple :
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// Simulation d'un temps d'exécution aléatoire
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}La sortie de ce code reste incertaine. Voici l'un des scénarios possibles :
start
0
3
4
endAinsi, time.Sleep n'est pas une bonne solution. Heureusement, Go fournit de nombreux moyens de contrôle de la concurrence. Les trois méthodes courantes sont :
channel: canalWaitGroup: sémaphoreContext: contexte
Chacune a ses cas d'usage. WaitGroup permet de contrôler dynamiquement un ensemble de goroutines en nombre spécifié. Context est plus adapté aux goroutines imbriquées profondément. Les canaux sont plus adaptés à la communication entre goroutines. Pour le contrôle traditionnel par verrou, Go fournit également :
Mutex: verrou d'exclusion mutuelleRWMutex: verrou de lecture/écriture
Canaux (Channels)
channel, traduit par canal. Voici comment Go décrit son rôle :
Do not communicate by sharing memory; instead, share memory by communicating.
C'est-à-dire partager la mémoire en communiquant via des messages. channel est conçu pour cela : c'est une solution de communication entre goroutines, qui peut également être utilisée pour le contrôle de la concurrence. Commençons par la syntaxe de base de channel. En Go, le mot-clé chan représente le type de canal, et il faut également déclarer le type de données stockées. Exemple d'un canal ordinaire :
var ch chan intCeci est une déclaration de canal. À ce stade, le canal n'est pas initialisé et sa valeur est nil, il ne peut pas être utilisé directement.
Création
Il n'existe qu'une seule façon de créer un canal : utiliser la fonction intégrée make. Pour les canaux, make accepte deux paramètres : le type de canal et, en option, la taille du tampon. Exemples :
intCh := make(chan int)
// Canal avec tampon de taille 1
strCh := make(chan string, 1)Après avoir utilisé un canal, il faut le fermer avec la fonction intégrée close :
func close(c chan<- Type)Exemple de fermeture d'un canal :
func main() {
intCh := make(chan int)
// faire quelque chose
close(intCh)
}Parfois, il est préférable d'utiliser defer pour fermer un canal.
Lecture et écriture
Pour un canal, Go utilise deux opérateurs imagés pour les opérations de lecture et d'écriture :
ch <- : écrire des données dans un canal
<- ch : lire des données d'un canal
<- représente visuellement le flux de données. Exemple de lecture/écriture sur un canal de type int :
func main() {
// Sans tampon, cela provoquerait un interblocage
intCh := make(chan int, 1)
defer close(intCh)
// Écrire des données
intCh <- 114514
// Lire des données
fmt.Println(<-intCh)
}L'exemple ci-dessus crée un canal de type int avec un tampon de taille 1, y écrit la donnée 114514, puis lit et affiche la donnée, et enfin ferme le canal. Pour l'opération de lecture, il y a une deuxième valeur de retour, un booléen indiquant si la lecture a réussi :
ints, ok := <-intChLe flux de données dans un canal fonctionne comme une file d'attente, c'est-à-dire FIFO (First In, First Out). Les opérations sur un canal sont synchrones : à un moment donné, une seule goroutine peut écrire des données, et une seule goroutine peut lire des données du canal.
Sans tampon
Pour un canal sans tampon, la capacité du tampon est de 0, donc aucune donnée n'est temporairement stockée. Comme un canal sans tampon ne peut pas stocker de données, lors de l'écriture, une autre goroutine doit immédiatement lire les données, sinon elle sera bloquée. Il en va de même pour la lecture. Cela explique pourquoi le code ci-dessous, qui semble normal, provoque un interblocage :
func main() {
// Créer un canal sans tampon
ch := make(chan int)
defer close(ch)
// Écrire des données
ch <- 123
// Lire des données
n := <-ch
fmt.Println(n)
}Un canal sans tampon ne doit pas être utilisé de manière synchrone. Il faut démarrer une nouvelle goroutine pour envoyer des données :
func main() {
// Créer un canal sans tampon
ch := make(chan int)
defer close(ch)
go func() {
// Écrire des données
ch <- 123
}()
// Lire des données
n := <-ch
fmt.Println(n)
}Avec tampon
Lorsqu'un canal a un tampon, il fonctionne comme une file d'attente bloquante. Lire un canal vide ou écrire dans un canal plein provoquera un blocage. Pour un canal sans tampon, l'envoi de données nécessite une réception immédiate, sinon il restera bloqué. Pour un canal avec tampon, les données sont d'abord placées dans le tampon. Ce n'est que lorsque le tampon est plein que la goroutine sera bloquée en attendant qu'une autre goroutine lise les données. De même, lors de la lecture d'un canal avec tampon, les données sont d'abord lues depuis le tampon. Ce n'est que lorsque le tampon est vide que la goroutine sera bloquée en attendant qu'une autre goroutine écrive des données. Ainsi, l'exemple qui provoquerait un interblocage avec un canal sans tampon fonctionne ici :
func main() {
// Créer un canal avec tampon
ch := make(chan int, 1)
defer close(ch)
// Écrire des données
ch <- 123
// Lire des données
n := <-ch
fmt.Println(n)
}Bien que cela fonctionne, cette manière synchrone de lecture/écriture est dangereuse. Une fois le tampon vide ou plein, le canal restera bloqué indéfiniment car aucune autre goroutine n'écrit ou ne lit. Voici un exemple :
func main() {
// Créer un canal avec tampon
ch := make(chan int, 5)
// Créer deux canaux sans tampon
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// Responsable de l'écriture
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("écriture", i)
}
chW <- struct{}{}
}()
// Responsable de la lecture
go func() {
for i := 0; i < 10; i++ {
// Chaque lecture prend 1 milliseconde
time.Sleep(time.Millisecond)
fmt.Println("lecture", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("écriture terminée", <-chW)
fmt.Println("lecture terminée", <-chR)
}Trois canaux sont créés : un canal avec tampon pour la communication entre goroutines, et deux canaux sans tampon pour synchroniser l'ordre d'exécution des goroutines parent et enfant. La goroutine de lecture attend 1 milliseconde avant chaque lecture. La goroutine d'écriture ne peut écrire que 5 données au maximum d'un coup, car le tampon du canal a une taille maximale de 5. Avant qu'une goroutine ne vienne lire, elle doit attendre bloquée. La sortie de cet exemple est :
écriture 0
écriture 1
écriture 2
écriture 3
écriture 4 // 5 écrits d'un coup, tampon plein, attendre la lecture
lecture 0
écriture 5 // une lecture, une écriture
lecture 1
écriture 6
lecture 2
écriture 7
lecture 3
écriture 8
écriture 9
lecture 4
écriture terminée {} // toutes les données envoyées, goroutine d'écriture terminée
lecture 5
lecture 6
lecture 7
lecture 8
lecture 9
lecture terminée {} // toutes les données lues, goroutine de lecture terminéeOn peut voir que la goroutine d'écriture envoie d'abord 5 données d'un coup. Une fois le tampon plein, elle attend bloquée que la goroutine de lecture lise. Ensuite, chaque fois que la goroutine de lecture lit une donnée toutes les 1 millisecondes et libère de l'espace dans le tampon, la goroutine d'écriture écrit une donnée, jusqu'à ce que toutes les données soient envoyées et que la goroutine d'écriture se termine. Ensuite, lorsque la goroutine de lecture a lu toutes les données du tampon, elle se termine également, et enfin la goroutine principale se termine.
TIP
La fonction intégrée len permet d'accéder au nombre de données dans le tampon du canal, et cap permet d'accéder à la taille du tampon.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}Sortie :
3 5En utilisant les conditions de blocage d'un canal, on peut facilement écrire un exemple où la goroutine principale attend la fin des goroutines enfants :
func main() {
// Créer un canal sans tampon
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// Écrire
ch <- struct{}{}
}()
// Attendre bloqué la lecture
<-ch
fmt.Println(1)
}Sortie :
2
1On peut également implémenter un simple verrou d'exclusion mutuelle avec un canal avec tampon :
var count = 0
// Canal avec tampon de taille 1
var lock = make(chan struct{}, 1)
func Add() {
// Verrouiller
lock <- struct{}{}
fmt.Println("comptage actuel", count, "exécution de l'addition")
count += 1
// Déverrouiller
<-lock
}
func Sub() {
// Verrouiller
lock <- struct{}{}
fmt.Println("comptage actuel", count, "exécution de la soustraction")
count -= 1
// Déverrouiller
<-lock
}Comme la taille du tampon du canal est 1, une seule donnée au maximum peut être stockée dans le tampon. Les fonctions Add et Sub tentent d'envoyer des données dans le canal avant chaque opération. Comme la taille du tampon est 1, si une autre goroutine a déjà écrit des données et que le tampon est plein, la goroutine actuelle doit attendre bloquée jusqu'à ce qu'une place se libère dans le tampon. Ainsi, à un moment donné, une seule goroutine au maximum peut modifier la variable count, ce qui implémente un simple verrou d'exclusion mutuelle.
Points d'attention
Voici un résumé des situations qui peuvent provoquer un blocage d'un canal :
Lecture/écriture d'un canal sans tampon
Une opération synchrone de lecture ou d'écriture sur un canal sans tampon bloquera la goroutine :
func main() {
// Créer un canal sans tampon
intCh := make(chan int)
defer close(intCh)
// Envoyer des données
intCh <- 1
// Lire des données
ints, ok := <-intCh
fmt.Println(ints, ok)
}Lecture d'un canal avec tampon vide
Lire un canal dont le tampon est vide bloquera la goroutine :
func main() {
// Créer un canal avec tampon
intCh := make(chan int, 1)
defer close(intCh)
// Tampon vide, bloqué en attendant qu'une autre goroutine écrive
ints, ok := <-intCh
fmt.Println(ints, ok)
}Écriture dans un canal avec tampon plein
Écrire dans un canal dont le tampon est plein bloquera la goroutine :
func main() {
// Créer un canal avec tampon
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// Plein, bloqué en attendant qu'une autre goroutine lise
intCh <- 1
}Canal nil
Lorsqu'un canal est nil, toute lecture ou écriture bloquera la goroutine :
func main() {
var intCh chan int
// Écrire
intCh <- 1
}func main() {
var intCh chan int
// Lire
fmt.Println(<-intCh)
}Les conditions de blocage d'un canal doivent être bien maîtrisées et connues. Dans la plupart des cas, ces problèmes sont bien cachés et ne sont pas aussi évidents que dans les exemples.
Les situations suivantes provoqueront également un panic :
Fermeture d'un canal nil
Fermer un canal nil avec la fonction close provoquera un panic :
func main() {
var intCh chan int
close(intCh)
}Écriture dans un canal fermé
Écrire dans un canal déjà fermé provoquera un panic :
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}Fermeture d'un canal déjà fermé
Dans certaines situations, un canal peut être transmis à travers plusieurs couches, et l'appelant peut ne pas savoir qui doit fermer le canal. Ainsi, fermer un canal déjà fermé provoquera un panic :
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Peut seulement envoyer des données au canal
ch <- 1
close(ch)
}Canaux unidirectionnels
Un canal bidirectionnel peut à la fois écrire et lire, c'est-à-dire qu'on peut opérer des deux côtés du canal. Un canal unidirectionnel est soit en lecture seule, soit en écriture seule, c'est-à-dire qu'on ne peut opérer que d'un seul côté du canal. Créer manuellement un canal en lecture seule ou en écriture seule n'a pas beaucoup de sens, car ne pas pouvoir lire ou écrire dans un canal lui enlève son utilité. Les canaux unidirectionnels sont généralement utilisés pour restreindre le comportement d'un canal, et apparaissent souvent dans les paramètres et valeurs de retour de fonctions. Par exemple, la signature de la fonction intégrée close utilise un canal unidirectionnel :
func close(c chan<- Type)Ou la fonction After du paquet time :
func After(d Duration) <-chan TimeLe paramètre de la fonction close est un canal en écriture seule, et la valeur de retour de la fonction After est un canal en lecture seule. La syntaxe des canaux unidirectionnels est :
- Le symbole
<-devant : canal en lecture seule, comme<-chan int - Le symbole
<-derrière : canal en écriture seule, commechan<- string
Tenter d'écrire dans un canal en lecture seule ne passera pas la compilation :
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}L'erreur est claire :
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)Il en va de même pour la lecture d'un canal en écriture seule.
Un canal bidirectionnel peut être converti en canal unidirectionnel, mais pas l'inverse. En général, lorsqu'on passe un canal bidirectionnel à une goroutine ou une fonction et qu'on ne souhaite pas qu'elle lise/envoie des données, on peut utiliser un canal unidirectionnel pour restreindre le comportement de l'autre partie :
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Peut seulement envoyer des données au canal
ch <- 1
}Il en va de même pour les canaux en lecture seule.
TIP
chan est un type de référence. Même si les paramètres de fonction en Go sont passés par valeur, la référence reste la même, ce qui sera expliqué dans la section sur les principes des canaux.
for range
Avec l'instruction for range, on peut parcourir et lire les données d'un canal avec tampon :
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}En général, for range parcourt d'autres structures de données itérables avec deux valeurs de retour : la première est l'index, la seconde est la valeur de l'élément. Mais pour un canal, il n'y a qu'une seule valeur de retour. for range lit continuellement les éléments du canal. Lorsque le tampon du canal est vide ou sans tampon, il attend bloqué jusqu'à ce qu'une autre goroutine écrive des données dans le canal pour continuer la lecture. La sortie est donc :
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!On peut voir que le code ci-dessus a provoqué un interblocage, car la goroutine enfant s'est terminée, tandis que la goroutine principale attend toujours bloquée qu'une autre goroutine écrive des données dans le canal. Il faut donc fermer le canal après avoir fini d'écrire. Modifions le code comme suit :
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// Fermer le canal
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}Fermer le canal après l'écriture évite l'interblocage. Comme mentionné précédemment, la lecture d'un canal a deux valeurs de retour. Lors du parcours d'un canal avec for range, lorsque la lecture échoue, la boucle se termine. La deuxième valeur de retour indique si la lecture a réussi, et non si le canal est fermé. Même si le canal est fermé, pour un canal avec tampon, on peut toujours lire des données, et la deuxième valeur de retour reste true. Voici un exemple :
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// Fermer le canal
close(ch)
// Lire à nouveau
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}Résultat :
0 true
1 true
2 true
3 true
4 true
0 falseComme le canal est fermé, même si le tampon est vide, lire à nouveau ne bloquera pas la goroutine. On peut voir qu'à la sixième itération, la valeur lue est la valeur zéro et ok est false.
TIP
Concernant le moment de fermer un canal, il est préférable de le fermer du côté qui envoie les données, et non du côté qui reçoit, car dans la plupart cas, le récepteur sait seulement recevoir des données et ne sait pas quand fermer le canal.
WaitGroup
sync.WaitGroup est une structure fournie par le paquet sync. WaitGroup signifie attendre l'exécution, et permet facilement d'attendre un ensemble de goroutines. Cette structure expose seulement trois méthodes :
La méthode Add indique le nombre de goroutines à attendre :
func (wg *WaitGroup) Add(delta int)La méthode Done indique que la goroutine actuelle a terminé :
func (wg *WaitGroup) Done()La méthode Wait attend la fin des goroutines enfants, sinon elle bloque :
func (wg *WaitGroup) Wait()WaitGroup est très simple à utiliser, prêt à l'emploi. Son implémentation interne est un compteur + sémaphore. Au début du programme, on appelle Add pour initialiser le compteur. Chaque fois qu'une goroutine termine, on appelle Done, et le compteur est décrémenté de 1 jusqu'à 0. Pendant ce temps, la goroutine principale qui appelle Wait reste bloquée jusqu'à ce que tout le compteur soit à 0, puis est réveillée. Voici un exemple simple :
func main() {
var wait sync.WaitGroup
// Spécifier le nombre de goroutines enfants
wait.Add(1)
go func() {
fmt.Println(1)
// Terminé
wait.Done()
}()
// Attendre la goroutine enfant
wait.Wait()
fmt.Println(2)
}Ce code affiche toujours 1 puis 2. La goroutine principale attend que la goroutine enfant se termine avant de se terminer.
1
2Pour l'exemple initial de la section sur les goroutines, on peut le modifier comme suit :
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// Compteur à 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// Compteur à 1 dans la boucle
wait.Add(1)
go func() {
fmt.Println(i)
// Décrémenter les deux compteurs
wait.Done()
mainWait.Done()
}()
// Attendre que la goroutine de la boucle actuelle se termine
wait.Wait()
}
// Attendre que toutes les goroutines se terminent
mainWait.Wait()
fmt.Println("end")
}Ici, sync.WaitGroup remplace time.Sleep. L'ordre d'exécution concurrente des goroutines est plus contrôlable. Peu importe le nombre d'exécutions, la sortie est :
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup est généralement adapté lorsque le nombre de goroutines peut être ajusté dynamiquement, par exemple lorsqu'on connaît à l'avance le nombre de goroutines, ou lorsqu'on doit l'ajuster dynamiquement pendant l'exécution. La valeur de WaitGroup ne doit pas être copiée, et la valeur copiée ne doit pas être réutilisée, surtout lorsqu'elle est passée comme paramètre de fonction : il faut passer un pointeur et non une valeur. Si on utilise une valeur copiée, le compteur n'affectera pas le vrai WaitGroup, ce qui peut bloquer indéfiniment la goroutine principale et empêcher le programme de fonctionner correctement. Exemple :
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}L'erreur indique que toutes les goroutines se sont terminées, mais la goroutine principale attend toujours, ce qui forme un interblocage, car l'appel à Done dans la fonction hello sur le paramètre WaitGroup n'affecte pas le mainWait original. Il faut donc utiliser un pointeur pour le passage.
hello
fatal error: all goroutines are asleep - deadlock!TIP
Lorsque le compteur devient négatif, ou que le nombre de comptages est supérieur au nombre de goroutines enfants, un panic sera déclenché.
Context
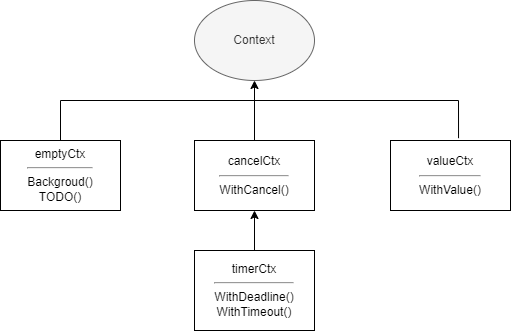
Context, traduit par contexte, est une solution de contrôle de la concurrence fournie par Go. Comparé aux canaux et WaitGroup, il permet de mieux contrôler les goroutines enfants et les goroutines à niveaux plus profonds. Context est lui-même une interface, et tout ce qui implémente cette interface peut être appelé contexte, comme gin.Context dans le célèbre framework Web Gin. La bibliothèque standard context fournit plusieurs implémentations :
emptyCtxcancelCtxtimerCtxvalueCtx
Context
Commençons par la définition de l'interface Context, puis découvrons ses implémentations concrètes.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
Cette méthode a deux valeurs de retour : deadline est l'heure limite, c'est-à-dire le moment où le contexte doit être annulé. La deuxième valeur indique si deadline est défini ; si non défini, elle est toujours false.
Deadline() (deadline time.Time, ok bool)Done
La valeur de retour est un canal en lecture seule de type structure vide. Ce canal sert uniquement à notifier et ne transmet aucune donnée. Lorsque le travail du contexte doit être annulé, ce canal est fermé. Pour certains contextes qui ne supportent pas l'annulation, cela peut retourner nil.
Done() <-chan struct{}Err
Cette méthode retourne une error, indiquant la raison de la fermeture du contexte. Lorsque le canal Done n'est pas fermé, retourne nil. Après fermeture, retourne une err expliquant pourquoi il a été fermé.
Err() errorValue
Cette méthode retourne la valeur correspondant à la clé. Si key n'existe pas, ou si la méthode n'est pas supportée, retourne nil.
Value(key any) anyemptyCtx
Comme son nom l'indique, emptyCtx est un contexte vide. Toutes les implémentations du paquet context ne sont pas exposées, mais des fonctions correspondantes sont fournies pour créer des contextes. emptyCtx peut être créé via context.Background et context.TODO. Les deux fonctions sont :
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}On voit qu'elles retournent simplement un pointeur emptyCtx. Le type sous-jacent de emptyCtx est en fait un int. La raison de ne pas utiliser une structure vide est que les instances de emptyCtx doivent avoir des adresses mémoire différentes. Il ne peut pas être annulé, n'a pas de deadline, et ne peut pas prendre de valeur ; les méthodes implémentées retournent toutes des valeurs zéro.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx est généralement utilisé comme contexte de niveau supérieur, passé comme contexte parent lors de la création des trois autres types de contextes. Les relations entre les implémentations du paquet context sont illustrées ci-dessous :
valueCtx
L'implémentation de valueCtx est simple : elle contient seulement une paire clé-valeur et un champ intégré de type Context.
type valueCtx struct {
Context
key, val any
}Elle implémente seulement la méthode Value, et la logique est simple : si le contexte actuel ne trouve pas, il cherche dans le contexte parent.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}Voici un exemple simple d'utilisation de valueCtx :
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// Passer le contexte
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// Créer un minuteur
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // Ne sera jamais exécuté
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx est souvent utilisé pour transmettre des données dans des goroutines à plusieurs niveaux. Il ne peut pas être annulé, donc ctx.Done retournera toujours nil, et select ignorera le canal nil. La sortie finale est :
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx et timerCtx implémentent tous deux l'interface canceler, de type :
type canceler interface {
// removeFromParent indique s'il faut se supprimer du contexte parent
// err indique la raison de l'annulation
cancel(removeFromParent bool, err error)
// Done retourne un canal pour notifier la raison de l'annulation
Done() <-chan struct{}
}La méthode cancel n'est pas exposée. Lors de la création du contexte, elle est encapsulée dans une fermeture pour être retournée comme valeur de retour, comme dans le code source de context.WithCancel :
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// Essayer de s'ajouter aux children du parent
propagateCancel(parent, &c)
// Retourner context et une fonction
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx, traduit par contexte annulable. Lors de la création, si le parent implémente canceler, il s'ajoute aux children du parent, sinon il remonte vers le haut. Si aucun parent n'implémente canceler, une goroutine est démarrée pour attendre l'annulation du parent, puis annule le contexte actuel lorsque le parent se termine. Lorsque cancelFunc est appelé, le canal Done est fermé, et tous les enfants de ce contexte sont également annulés. Enfin, il se supprime du parent. Voici un exemple simple :
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// Retourne un cancelCtx et une fonction cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("en attente d'annulation...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}Sortie :
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
context canceledVoici un exemple avec un niveau d'imbrication plus profond :
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("traitement de la requête http...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth annulation parent", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail annulation parent", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}Dans cet exemple, 3 cancelCtx sont créés. Bien que le cancelCtx parent annule ses contextes enfants lors de son annulation, par précaution, si un cancelCtx est créé, il faut appeler la fonction cancel après la fin du processus correspondant. Sortie :
traitement de la requête http...
auth...
mail...
mail...
auth...
traitement de la requête http...
auth...
mail...
traitement de la requête http...
traitement de la requête http...
auth...
mail...
auth...
traitement de la requête http...
mail...
context canceled
auth annulation parent context canceled
mail annulation parent context canceledtimerCtx
timerCtx ajoute un mécanisme de délai d'attente sur la base de cancelCtx. Le paquet context fournit deux fonctions de création : WithDeadline et WithTimeout. Les deux sont similaires : le premier spécifie une heure limite concrète, par exemple 2023/3/20 16:32:00, le second spécifie un intervalle de temps de délai, par exemple 5 minutes plus tard. Les signatures des deux fonctions sont :
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx annule automatiquement le contexte actuel lorsque le temps expire. Le processus d'annulation est基本与 cancelCtx 一致,除了需要额外关闭 timer。Voici un exemple simple d'utilisation de timerCtx :
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("contexte annulé", ctx.Err())
return
default:
fmt.Println("en attente d'annulation...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}Bien que le contexte soit automatiquement annulé à l'échéance, par précaution, il est préférable d'annuler manuellement le contexte après la fin des processus concernés. Sortie :
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
en attente d'annulation...
contexte annulé context deadline exceededWithTimeout est en fait très similaire à WithDeadline. Son implémentation est simplement un léger encapsulage qui appelle WithDeadline, et l'usage est le même que dans l'exemple ci-dessus avec WithDeadline :
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
Tout comme l'allocation de mémoire sans libération provoque une fuite de mémoire, le contexte est aussi une ressource. S'il est créé mais jamais annulé, cela provoquera une fuite de contexte. Il est donc préférable d'éviter cette situation.
Select
select dans le système Linux est une solution de multiplexage d'E/S. De même, en Go, select est une structure de contrôle de multiplexage de canaux. Qu'est-ce que le multiplexage ? En une phrase : à un moment donné, surveiller simultanément si plusieurs éléments sont disponibles. Les éléments surveillés peuvent être des requêtes réseau, des E/S de fichiers, etc. Dans select en Go, les éléments surveillés sont des canaux, et seulement des canaux. La syntaxe de select est similaire à l'instruction switch. Voici à quoi ressemble une instruction select :
func main() {
// Créer trois canaux
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("tous les canaux sont indisponibles")
}
}Utilisation
Comme switch, select est composé de plusieurs case et d'un default. La branche default peut être omise. Chaque case ne peut opérer qu'un seul canal, et ne peut effectuer qu'une seule opération : soit lecture, soit écriture. Lorsque plusieurs case sont disponibles, select en choisit un de manière pseudo-aléatoire pour l'exécuter. Si tous les case sont indisponibles, la branche default est exécutée. S'il n'y a pas de branche default, select attend bloqué jusqu'à ce qu'au moins un case soit disponible. Comme dans l'exemple ci-dessus aucune donnée n'est écrite dans les canaux, naturellement tous les case sont indisponibles, donc la sortie finale est le résultat de l'exécution de la branche default. Modifions légèrement :
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// Démarrer une nouvelle goroutine
go func() {
// Écrire des données dans le canal A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}L'exemple ci-dessus démarre une nouvelle goroutine pour écrire des données dans le canal A. select n'ayant pas de branche par défaut, il attend bloqué jusqu'à ce qu'un case soit disponible. Lorsque le canal A est disponible, après l'exécution de la branche correspondante, la goroutine principale se termine directement. Pour surveiller continuellement les canaux, on peut l'utiliser avec une boucle for :
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// boucle for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Cela permet effectivement d'utiliser les trois canaux, mais la boucle infinie + select provoquera un blocage permanent de la goroutine principale. On peut donc la placer dans une nouvelle goroutine et ajouter d'autres logiques :
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // Définir un délai d'attente de 1 seconde
break Loop // Quitter la boucle
}
}
l <- struct{}{} // Indiquer à la goroutine principale qu'elle peut se terminer
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Dans l'exemple ci-dessus, la boucle for配合 select surveille continuellement si les trois canaux sont disponibles, et le quatrième case est un canal de délai d'attente. Après le délai, la boucle se termine et la goroutine enfant se termine. La sortie finale est :
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueDélai d'attente
L'exemple précédent utilise la fonction time.After, dont la valeur de retour est un canal en lecture seule. Cette fonction配合 select permet d'implémenter très simplement un mécanisme de délai d'attente :
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("délai d'attente dépassé")
}
}Blocage permanent
Lorsqu'une instruction select ne contient rien, elle bloque永久ement :
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end ne sera jamais affiché, la goroutine principale restera bloquée. Cette situation a généralement un usage spécial.
TIP
Dans un case de select, opérer sur un canal de valeur nil ne provoque pas de blocage, ce case est ignoré et ne sera jamais exécuté. Par exemple, le code ci-dessous affichera toujours timeout peu importe le nombre d'exécutions :
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}Non-bloquant
En utilisant la branche default de select配合 les canaux, on peut implémenter des opérations d'envoi/réception non bloquantes :
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}De même, on peut implémenter une vérification non bloquante pour savoir si un context est terminé :
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}Verrous
Voici d'abord un exemple :
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Simulation d'un temps d'accès
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// Accéder aux données
temp := *data
// Simulation d'un temps de calcul
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// Modifier les données
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("résultat final", count)
}Dans l'exemple ci-dessus, dix goroutines sont démarrées pour effectuer une opération +1 sur count, et time.Sleep est utilisé pour simuler différents temps d'exécution. Selon l'intuition, 10 goroutines exécutant 10 opérations +1, le résultat final devrait être 10, et le résultat correct est effectivement 10, mais ce n'est pas le cas. Le résultat de l'exemple ci-dessus est :
1
2
3
3
2
2
3
3
3
4
résultat final 4On peut voir que le résultat final est 4, et ce n'est que l'un des nombreux résultats possibles. Comme le temps d'accès et de calcul de chaque goroutine est différent, la goroutine A accède aux données en 500 millisecondes, et à ce moment la valeur de count est 1. Ensuite, elle passe 400 millisecondes à calculer, mais pendant ces 400 millisecondes, la goroutine B a déjà terminé l'accès et le calcul et a réussi à mettre à jour la valeur de count. Après que la goroutine A a terminé le calcul, la valeur à laquelle elle a accédé initialement est obsolète, mais la goroutine A ne le sait pas, et ajoute toujours un à la valeur à laquelle elle a accédé initialement, et l'assigne à count. Ainsi, le résultat d'exécution de la goroutine B est écrasé. Lorsque plusieurs goroutines lisent et accèdent à une donnée partagée, ce genre de problème se produit particulièrement, et pour cela il faut utiliser des verrous.
Dans Go, Mutex et RWMutex du paquet sync fournissent deux implémentations : verrou d'exclusion mutuelle et verrou de lecture/écriture, et fournissent une API très simple et facile à utiliser. Pour verrouiller, il suffit de Lock(), et pour déverrouiller, il suffit de Unlock(). Il faut noter que les verrous fournis par Go sont des verrous non récursifs, c'est-à-dire des verrous non réentrants, donc verrouiller ou déverrouiller à plusieurs reprises provoquera un fatal. Le sens d'un verrou est de protéger les invariants : verrouiller signifie qu'on souhaite que les données ne soient pas modifiées par d'autres goroutines :
func DoSomething() {
Lock()
// Pendant ce processus, les données ne seront pas modifiées par d'autres goroutines
Unlock()
}S'il s'agissait d'un verrou récursif, la situation suivante pourrait se produire :
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// faire autre chose
Unlock()
}La fonction DoSomething ne sait évidemment pas ce que la fonction DoOther pourrait faire aux données, et ainsi modifier les données, par exemple en démarrant quelques goroutines enfants qui brisent l'invariant. Cela ne fonctionne pas en Go : une fois verrouillé, il faut garantir l'invariabilité de l'invariant. À ce moment, verrouiller ou déverrouiller à plusieurs reprises provoquera un interblocage. Il faut donc éviter la situation ci-dessus lors de l'écriture du code, et si nécessaire, utiliser immédiatement l'instruction defer pour déverrouiller en même temps que le verrouillage.
Verrou d'exclusion mutuelle
sync.Mutex est l'implémentation de verrou d'exclusion mutuelle fournie par Go, qui implémente l'interface sync.Locker :
type Locker interface {
// Verrouiller
Lock()
// Déverrouiller
Unlock()
}L'utilisation d'un verrou d'exclusion mutuelle peut parfaitement résoudre le problème ci-dessus :
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Verrouiller
lock.Lock()
// Simulation d'un temps d'accès
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Accéder aux données
temp := *data
// Simulation d'un temps de calcul
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// Modifier les données
*data = temp + ans
// Déverrouiller
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("résultat final", count)
}Chaque goroutine, avant d'accéder aux données, verrouille d'abord, et déverrouille après la mise à jour. Les autres goroutines qui veulent accéder doivent d'abord obtenir le verrou, sinon elles attendent bloquées. Ainsi, le problème ci-dessus n'existe plus, et la sortie est :
1
2
3
4
5
6
7
8
9
10
résultat final 10Verrou de lecture/écriture
Le verrou d'exclusion mutuelle convient aux situations où la fréquence des opérations de lecture et d'écriture est à peu près la même. Pour certaines données avec beaucoup de lectures et peu d'écritures, l'utilisation d'un verrou d'exclusion mutuelle provoquerait une compétition inutile de verrous par de nombreuses goroutines, ce qui consommerait beaucoup de ressources système. À ce moment, il faut utiliser un verrou de lecture/écriture, c'est-à-dire un verrou d'exclusion mutuelle de lecture/écriture. Pour une goroutine :
- Si elle obtient un verrou de lecture, les autres goroutines seront bloquées lors d'opérations d'écriture, mais ne seront pas bloquées lors d'opérations de lecture
- Si elle obtient un verrou d'écriture, les autres goroutines seront bloquées lors d'opérations d'écriture et lors d'opérations de lecture
L'implémentation du verrou de lecture/écriture en Go est sync.RWMutex, qui implémente également l'interface Locker, mais fournit plus de méthodes disponibles :
// Verrouiller en lecture
func (rw *RWMutex) RLock()
// Essayer de verrouiller en lecture
func (rw *RWMutex) TryRLock() bool
// Déverrouiller en lecture
func (rw *RWMutex) RUnlock()
// Verrouiller en écriture
func (rw *RWMutex) Lock()
// Essayer de verrouiller en écriture
func (rw *RWMutex) TryLock() bool
// Déverrouiller en écriture
func (rw *RWMutex) Unlock()Les deux opérations de verrouillage par essai TryRLock et TryLock sont non bloquantes : si le verrouillage réussit, elles retournent true ; si le verrou ne peut pas être obtenu, elles ne bloquent pas mais retournent false. L'implémentation interne du verrou de lecture/écriture est toujours un verrou d'exclusion mutuelle : ce n'est pas parce qu'il y a un verrou de lecture et un verrou d'écriture qu'il y a deux verrous ; il n'y a toujours qu'un seul verrou. Voici un exemple d'utilisation d'un verrou de lecture/écriture :
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// Plus de lectures que d'écritures
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Attendre la fin des goroutines enfants
wait.Wait()
fmt.Println("résultat final", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("verrou de lecture obtenu")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("verrou de lecture libéré", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("verrou d'écriture obtenu")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("verrou d'écriture libéré", *i)
rw.Unlock()
wait.Done()
}Cet exemple démarre 3 goroutines d'écriture et 7 goroutines de lecture. Lors de la lecture des données, elles obtiennent d'abord un verrou de lecture. Les goroutines de lecture peuvent normalement obtenir le verrou de lecture, mais bloqueront les goroutines d'écriture. Lors de l'obtention du verrou d'écriture, les goroutines de lecture et d'écriture seront toutes deux bloquées jusqu'à la libération du verrou d'écriture. Ainsi, l'exclusion mutuelle entre les goroutines de lecture et d'écriture est réalisée, garantissant l'exactitude des données. La sortie de l'exemple est :
verrou de lecture obtenu
verrou de lecture obtenu
verrou de lecture obtenu
verrou de lecture obtenu
libération du verrou de lecture 0
libération du verrou de lecture 0
libération du verrou de lecture 0
libération du verrou de lecture 0
verrou d'écriture obtenu
libération du verrou d'écriture 1
verrou de lecture obtenu
verrou de lecture obtenu
verrou de lecture obtenu
libération du verrou de lecture 1
libération du verrou de lecture 1
libération du verrou de lecture 1
verrou d'écriture obtenu
libération du verrou d'écriture 2
verrou d'écriture obtenu
libération du verrou d'écriture 3
résultat final 3TIP
Pour un verrou, il ne faut pas le passer et le stocker comme valeur, il faut utiliser un pointeur.
Variable de condition
Une variable de condition apparaît et est utilisée avec un verrou d'exclusion mutuelle, donc certaines personnes pourraient l'appeler à tort verrou de condition, mais ce n'est pas un verrou : c'est un mécanisme de communication. Go fournit une implémentation avec sync.Cond, et la signature de la fonction de création d'une variable de condition est :
func NewCond(l Locker) *CondOn peut voir que la création d'une variable de condition nécessite d'abord de créer un verrou. sync.Cond fournit les méthodes suivantes :
// Attendre bloqué que la condition soit satisfaite, jusqu'à être réveillé
func (c *Cond) Wait()
// Réveiller une goroutine bloquée par la condition
func (c *Cond) Signal()
// Réveiller toutes les goroutines bloquées par la condition
func (c *Cond) Broadcast()L'utilisation d'une variable de condition est très simple. Modifions légèrement l'exemple de verrou de lecture/écriture ci-dessus :
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// Variable de condition
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// Plus de lectures que d'écritures
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Attendre la fin des goroutines enfants
wait.Wait()
fmt.Println("résultat final", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("verrou de lecture obtenu")
// Si la condition n'est pas satisfaite, attendre bloqué
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("verrou de lecture libéré", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("verrou d'écriture obtenu")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("verrou d'écriture libéré", *i)
rw.Unlock()
// Réveiller toutes les goroutines bloquées par la variable de condition
cond.Broadcast()
wait.Done()
}Lors de la création de la variable de condition, comme ici la variable de condition agit sur les goroutines de lecture, le verrou de lecture est passé comme verrou d'exclusion mutuelle. Si le verrou de lecture/écriture était passé directement, cela provoquerait un problème de déverrouillage répété pour les goroutines d'écriture. Ici, sync.rlocker est passé, obtenu via la méthode RWMutex.RLocker :
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }On peut voir que rlocker encapsule simplement l'opération de verrou de lecture du verrou de lecture/écriture : c'est en fait la même référence, toujours le même verrou. Lors de la lecture des données par les goroutines de lecture, si la valeur est inférieure à 3, elles attendront bloquées jusqu'à ce que la valeur soit supérieure à 3. Les goroutines d'écriture, après la mise à jour des données, tenteront de réveiller toutes les goroutines bloquées par la variable de condition. La sortie finale est :
verrou de lecture obtenu
verrou de lecture obtenu
verrou de lecture obtenu
verrou de lecture obtenu
verrou d'écriture obtenu
libération du verrou d'écriture 1
verrou de lecture obtenu
verrou d'écriture obtenu
libération du verrou d'écriture 2
verrou de lecture obtenu
verrou de lecture obtenu
verrou d'écriture obtenu
libération du verrou d'écriture 3 // La troisième goroutine d'écriture est terminée
libération du verrou de lecture 3
libération du verrou de lecture 3
libération du verrou de lecture 3
libération du verrou de lecture 3
libération du verrou de lecture 3
libération du verrou de lecture 3
libération du verrou de lecture 3
résultat final 3On peut voir dans le résultat que lorsque la troisième goroutine d'écriture a terminé la mise à jour des données, les sept goroutines de lecture bloquées par la variable de condition ont repris leur exécution.
TIP
Pour une variable de condition, il faut utiliser for et non if. Il faut utiliser une boucle pour vérifier si la condition est satisfaite, car lorsqu'une goroutine est réveillée, on ne peut pas garantir que la condition actuelle est déjà satisfaite.
for !condition {
cond.Wait()
}sync
Une grande partie des outils de concurrence en Go sont fournis par la bibliothèque standard sync. Nous avons déjà présenté sync.WaitGroup, sync.Locker, etc. En plus de cela, le paquet sync fournit d'autres outils utilisables.
Once
Lors de l'utilisation de certaines structures de données, si ces structures sont trop volumineuses, on peut envisager un chargement paresseux, c'est-à-dire initialiser la structure de données seulement lorsqu'on en a vraiment besoin. Exemple :
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// Initialiser seulement lorsqu'on utilise vraiment le slice
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}Le problème est que s'il n'y a qu'une seule goroutine qui l'utilise, il n'y a aucun problème, mais si plusieurs goroutines y accèdent, des problèmes peuvent survenir. Par exemple, les goroutines A et B appellent simultanément la méthode Add. A s'exécute un peu plus vite, a déjà terminé l'initialisation et a ajouté les données avec succès. Ensuite, la goroutine B initialise à nouveau, écrasant ainsi les données ajoutées par la goroutine A. C'est le problème.
C'est le problème que sync.Once résout. Comme son nom l'indique, Once signifie une fois. sync.Once garantit qu'une opération spécifiée ne sera exécutée qu'une seule fois dans des conditions concurrentes. Son utilisation est très simple : il expose seulement une méthode Do, de signature :
func (o *Once) Do(f func())Lors de l'utilisation, il suffit de passer l'opération d'initialisation à la méthode Do :
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// Initialiser seulement lorsqu'on utilise vraiment le slice
m.o.Do(func() {
fmt.Println("initialisation")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}Sortie :
initialisation
4On peut voir dans le résultat que toutes les données sont ajoutées normalement au slice, et l'opération d'initialisation n'est exécutée qu'une seule fois. En fait, l'implémentation de sync.Once est très simple : sans les commentaires, la logique réelle du code ne fait que 16 lignes. Son principe est verrou + opération atomique. Code source :
type Once struct {
// Utilisé pour juger si l'opération a déjà été exécutée
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Chargement atomique des données
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// Verrouiller
o.m.Lock()
// Déverrouiller
defer o.m.Unlock()
// Juger si exécuté
if o.done == 0 {
// Modifier done après exécution
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
L'objectif de conception de sync.Pool est de stocker des objets temporaires pour une réutilisation ultérieure. C'est un pool d'objets temporaire sûr pour la concurrence. Les objets temporairement inutilisés sont placés dans le pool, et lors d'une utilisation ultérieure, ils peuvent être réutilisés sans avoir à créer d'objets supplémentaires, réduisant ainsi la fréquence d'allocation et de libération de mémoire, et surtout réduisant la pression sur le GC. sync.Pool n'a que deux méthodes :
// Demander un objet
func (p *Pool) Get() any
// Placer un objet
func (p *Pool) Put(x any)Et sync.Pool a un champ New exposé, utilisé pour initialiser un objet lorsque le pool ne peut pas en obtenir :
New func() anyVoici un exemple :
var wait sync.WaitGroup
// Pool d'objets temporaires
var pool sync.Pool
// Utilisé pour compter combien d'objets ont été créés au total
var numOfObject atomic.Int64
// BigMemData Supposons que c'est une structure qui occupe beaucoup de mémoire
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"grande mémoire"}
}
wait.Add(1000)
// Démarrer 1000 goroutines ici
for i := 0; i < 1000; i++ {
go func() {
// Demander un objet
val := pool.Get()
// Utiliser l'objet
_ = val.(BigMemData)
// Libérer l'objet après utilisation
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}Dans l'exemple, 1000 goroutines sont démarrées pour demander et libérer continuellement des objets dans le pool. Si le pool d'objets n'est pas utilisé, alors les 1000 goroutines doivent chacune instancier un objet, et ces 1000 objets instanciés doivent être libérés par le GC après utilisation. S'il y a des centaines de milliers de goroutines ou si le coût de création de l'objet est très élevé, dans ce cas, cela occuperait beaucoup de mémoire et exercerait une très grande pression sur le GC. Après l'adoption du pool d'objets, les objets peuvent être réutilisés pour réduire la fréquence d'instanciation. Par exemple, la sortie de l'exemple ci-dessus pourrait être :
5Même avec 1000 goroutines démarrées, seulement 5 objets ont été créés pendant tout le processus. Sans le pool d'objets, les 1000 goroutines créeraient 1000 objets. L'amélioration apportée par cette optimisation est évidente, surtout lorsque le volume de concurrence est très élevé et que le coût d'instanciation des objets est particulièrement élevé.
Lors de l'utilisation de sync.Pool, il faut noter plusieurs points :
- Objets temporaires :
sync.Poolconvient seulement pour stocker des objets temporaires. Les objets dans le pool peuvent être supprimés par le GC sans aucune notification, il n'est donc pas recommandé de stocker des connexions réseau, des connexions de base de données, etc. danssync.Pool. - Imprévisible : Lors de la demande d'un objet dans
sync.Pool, on ne peut pas prédire si cet objet est nouvellement créé ou réutilisé, et on ne peut pas savoir combien d'objets il y a dans le pool. - Sûr pour la concurrence : Le gouvernement garantit que
sync.Poolest toujours sûr pour la concurrence, mais ne garantit pas que la fonctionNewutilisée pour créer des objets soit sûre pour la concurrence. La fonctionNewest passée par l'utilisateur, donc la sécurité de concurrence de la fonctionNewdoit être maintenue par l'utilisateur lui-même. C'est pourquoi dans l'exemple ci-dessus, le comptage d'objets utilise une valeur atomique.
TIP
Enfin, il faut noter que lorsqu'on a fini d'utiliser un objet, il faut absolument le libérer dans le pool. Si on ne le libère pas après utilisation, l'utilisation du pool d'objets sera inutile.
La bibliothèque standard fmt fournit un exemple d'utilisation de pool d'objets dans la fonction fmt.Fprintf :
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// Demander un tampon d'impression
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// Libérer après utilisation
p.free()
return
}Les implémentations de la fonction newPrinter et de la méthode free sont :
func newPrinter() *pp {
// Un objet demandé au pool d'objets
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// Pour que la taille du tampon dans le pool d'objets soit à peu près la même afin de mieux contrôler élastiquement la taille du tampon
// Les tampons trop grands ne sont pas remis dans le pool d'objets
if cap(p.buf) > 64<<10 {
return
}
// Réinitialiser les champs puis libérer l'objet dans le pool
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map est une implémentation de Map sûre pour la concurrence fournie officiellement. Prêt à l'emploi, très simple à utiliser. Voici les méthodes exposées par cette structure :
// Lire une valeur selon une clé, la valeur de retour retourne la valeur correspondante et si cette valeur existe
func (m *Map) Load(key any) (value any, ok bool)
// Stocker une paire clé-valeur
func (m *Map) Store(key, value any)
// Supprimer une paire clé-valeur
func (m *Map) Delete(key any)
// Si la clé existe déjà, retourne la valeur originale, sinon stocke la nouvelle valeur et la retourne. Lorsque la valeur est lue avec succès, loaded est true, sinon false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// Supprimer une paire clé-valeur, et retourne sa valeur originale. loaded dépend de si la clé existe
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Parcourir le Map, lorsque f() retourne false, le parcours s'arrête
func (m *Map) Range(f func(key, value any) bool)Voici un exemple simple démontrant l'utilisation de base de sync.Map :
func main() {
var syncMap sync.Map
// Stocker des données
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// Lire des données
fmt.Println(syncMap.Load("a"))
// Lire et supprimer
fmt.Println(syncMap.LoadAndDelete("a"))
// Lire ou stocker
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// Parcourir le map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Sortie :
a true
a true
hello world false
a hello world
b goodbye worldVoici maintenant un exemple d'utilisation concurrente d'un map :
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}Dans l'exemple ci-dessus, un map ordinaire est utilisé, avec 10 goroutines qui stockent continuellement des données. Cela déclenchera très probablement un fatal, le résultat sera probablement :
fatal error: concurrent map writesL'utilisation de sync.Map peut éviter ce problème :
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Sortie :
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4Pour la sécurité de la concurrence, il faut certainement faire certains sacrifices. Les performances de sync.Map sont environ 10 à 100 fois inférieures à celles d'un map.
Atomiques
En informatique, une opération atomique ou primitive désigne généralement des opérations qui ne peuvent pas être décomposées en opérations plus fines. Comme ces opérations ne peuvent pas être décomposées en étapes plus petites, elles ne peuvent pas être interrompues par d'autres goroutines avant d'être terminées. Ainsi, le résultat de l'exécution est soit un succès, soit un échec, sans troisième situation. S'il y a d'autres situations, alors ce n'est pas une opération atomique. Exemple :
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}Le code ci-dessus est une simple branche de jugement. Bien que le code soit très court, ce n'est pas non plus une opération atomique. Les véritables opérations atomiques sont supportées au niveau des instructions matérielles.
Types
Heureusement, dans la plupart des cas, il n'est pas nécessaire d'écrire soi-même de l'assembleur. Le paquet sync/atomic de la bibliothèque standard Go fournit déjà des API liées aux opérations atomiques, et fournit les types suivants pour effectuer des opérations atomiques :
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}Parmi eux, le type atomique Pointer supporte les génériques, et le type Value supporte le stockage de n'importe quel type. En plus de cela, de nombreuses fonctions sont fournies pour faciliter les opérations. Comme la granularité des opérations atomiques est trop fine, dans la plupart des cas, il est plus adapté de traiter ces types de données de base.
TIP
Les opérations atomiques du paquet atomic n'ont que des signatures de fonctions, pas d'implémentations concrètes. Les implémentations concrètes sont écrites en assembleur plan9.
Utilisation
Chaque type atomique fournit les trois méthodes suivantes :
Load(): obtenir atomiquement la valeurSwap(newVal type) (old type): échanger atomiquement la valeur, et retourner l'ancienne valeurStore(val type): stocker atomiquement la valeur
Différents types peuvent avoir d'autres méthodes supplémentaires. Par exemple, les types entiers fournissent tous la méthode Add pour réaliser des opérations d'addition/soustraction atomiques. Voici un exemple avec un type int64 :
func main() {
var aint64 atomic.Uint64
// Stocker une valeur
aint64.Store(64)
// Échanger une valeur
aint64.Swap(128)
// Ajouter
aint64.Add(112)
// Charger une valeur
fmt.Println(aint64.Load())
}Ou on peut utiliser directement les fonctions :
func main() {
var aint64 int64
// Stocker une valeur
atomic.StoreInt64(&aint64, 64)
// Échanger une valeur
atomic.SwapInt64(&aint64, 128)
// Ajouter
atomic.AddInt64(&aint64, 112)
// Charger
fmt.Println(atomic.LoadInt64(&aint64))
}L'utilisation des autres types est très similaire. La sortie finale est :
240CAS
Le paquet atomic fournit également l'opération CompareAndSwap, c'est-à-dire CAS. C'est le cœur de l'implémentation des verrous optimistes et des structures de données sans verrou. Le verrou optimiste n'est pas lui-même un verrou : c'est une méthode de contrôle de la concurrence sans verrou dans des conditions concurrentes. Avant de modifier des données, le thread/goroutine ne verrouille pas d'abord, mais lit d'abord les données, effectue le calcul, puis lors de la soumission de la modification, utilise CAS pour juger si d'autres threads ont modifié ces données pendant cette période. Si non (la valeur est toujours égale à la valeur lue précédemment), la modification réussit ; sinon, échec et nouvelle tentative. C'est pourquoi on l'appelle verrou optimiste : il suppose toujours de manière optimiste que les données partagées ne seront pas modifiées, et n'exécute l'opération correspondante que lorsqu'il découvre que les données n'ont pas été modifiées. Le mutex que nous avons vu précédemment est un verrou pessimiste : le mutex suppose toujours de manière pessimiste que les données partagées seront certainement modifiées, donc il verrouille lors de l'opération, et déverrouille après l'opération. Comme la concurrence implémentée sans verrou a une sécurité et une efficacité plus élevées que les verrous, de nombreuses structures de données sûres pour la concurrence utilisent CAS pour leur implémentation. Cependant, l'efficacité réelle dépend du scénario d'utilisation concret. Voici un exemple :
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}C'est un exemple utilisant un verrou d'exclusion mutuelle. Chaque fois avant d'ajouter un nombre, on verrouille d'abord, et après l'exécution, on déverrouille. Pendant le processus, cela provoquera le blocage d'autres goroutines. Ensuite, utilisons CAS pour le transformer :
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}Pour CAS, il y a trois paramètres : valeur en mémoire, valeur attendue, nouvelle valeur. Lors de l'exécution, CAS compare la valeur attendue avec la valeur actuelle en mémoire. Si la valeur en mémoire est identique à la valeur attendue, l'opération suivante est exécutée, sinon rien n'est fait. Pour les opérations atomiques du paquet atomic de Go, les fonctions liées à CAS nécessitent de passer une adresse, une valeur attendue, une nouvelle valeur, et retournent une valeur booléenne indiquant si le remplacement a réussi. Par exemple, la signature de la fonction d'opération CAS de type int64 est :
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)Dans l'exemple CAS, on obtient d'abord la valeur attendue via LoadInt64, puis on utilise CompareAndSwapInt64 pour comparer et échanger. Si cela ne réussit pas, on boucle continuellement jusqu'à succès. Cette opération sans verrou ne provoque pas le blocage des goroutines, mais la boucle continue représente toujours une charge non négligeable pour le CPU. Ainsi, dans certaines implémentations, après un certain nombre d'échecs, on peut abandonner l'opération. Mais pour l'opération ci-dessus, qui n'est qu'une simple addition de nombres, les opérations impliquées ne sont pas complexes, donc on peut tout à fait envisager une implémentation sans verrou.
TIP
Dans la plupart des cas, simplement comparer des valeurs ne peut pas assurer la sécurité de la concurrence. Par exemple, le problème ABA causé par CAS nécessite d'ajouter un version supplémentaire pour résoudre le problème.
Value
La structure atomic.Value peut stocker des valeurs de n'importe quel type :
type Value struct {
// type any
v any
}Bien qu'elle puisse stocker n'importe quel type, elle ne peut pas stocker nil, et les types des valeurs stockées avant et après doivent être cohérents. Les deux exemples ci-dessous ne passeront pas la compilation :
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into ValueEn dehors de cela, son utilisation n'est pas très différente des autres types atomiques. Il faut noter que tous les types atomiques ne doivent pas copier des valeurs, mais utiliser leurs pointeurs.