التزامن
دعم لغة Go للتزامن طبيعي بالكامل، وهذا هو جوهر هذه اللغة، حيث أن صعوبة البدء بها صغيرة نسبيًا، ولا يحتاج المطورون للتركيز كثيرًا على التنفيذ الأساسي لإنشاء تطبيق تزامني جيد جدًا، مما يرفع الحد الأدنى للمطورين.
الكوروتين
الكوروتين (coroutine) هو خيط خفيف الوزن، أو يمكن القول إنه خيط في وضع المستخدم، لا يتم جدولته مباشرة من قبل نظام التشغيل، بل يتم جدولته في وقت التشغيل بواسطة مجدول Go نفسه، لذا فإن تكلفة تبديل السياق صغيرة جدًا، وهذا أحد الأسباب التي تجعل أداء التزامن في Go جيدًا جدًا. مفهوم الكوروتين لم تكن Go أول من اقترحه، وGo ليست أول لغة تدعم الكوروتين، لكن Go هي أول لغة يمكنها دعم الكوروتين والتزامن بشكل بسيط وأنيق للغاية.
في Go، إنشاء كوروتين بسيط جدًا، كل ما تحتاجه هو كلمة مفتاحية go واحدة لبدء كوروتين بسرعة، ويجب أن يتبع كلمة go استدعاء دالة. المثال التالي:
TIP
الدوال المدمجة التي لها قيمة إرجاع لا يُسمح لها باتباع كلمة go المفتاحية، مثل المثال الخاطئ التالي
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}الطرق الثلاث أعلاه لبدء الكوروتين صحيحة جميعها، لكن في الواقع هذا المثال في معظم الحالات لن يُخرج أي شيء بعد التنفيذ، الكوروتينات تتنافس في التنفيذ، ويحتاج النظام وقتًا لإنشاء الكوروتين، وقبل ذلك، يكون الكوروتين الرئيسي قد انتهى بالفعل، وبمجرد خروج الخيط الرئيسي، تخرج الكوروتينات الفرعية الأخرى بشكل طبيعي. أيضًا ترتيب تنفيذ الكوروتينات غير مؤكد ولا يمكن التنبؤ به، مثل المثال التالي:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}هذا مثال على بدء الكوروتينات في حلقة، لا يمكن أبدًا التنبؤ بدقة بما ستخرجه. ربما لم تبدأ الكوروتينات الفرعية في العمل بعد، والكوروتين الرئيسي قد انتهى بالفعل، والحالة كالتالي:
start
endأو ربما نجحت بعض الكوروتينات الفرعية فقط في العمل قبل خروج الكوروتين الرئيسي، والحالة كالتالي:
start
0
1
5
3
4
6
7
endأبسط طريقة هي جعل الكوروتين الرئيسي ينتظر قليلًا، وذلك باستخدام دالة Sleep من حزمة time، والتي يمكنها إيقاف الكوروتين الحالي لفترة من الوقت، المثال التالي:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// إيقاف 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}عند التنفيذ مرة أخرى يكون الإخراج كالتالي، يمكن رؤية أن جميع الأرقام قد أُخرجت بالكامل بدون نقص:
start
0
1
5
2
3
4
6
8
9
7
endلكن الترتيب لا يزال فوضويًا، لذلك نجعل كل دورة تنتظر قليلًا. المثال التالي:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}الإخراج الآن أصبح بالترتيب الصحيح:
start
0
1
2
3
4
5
6
7
8
9
endفي المثال أعلاه، نتيجة الإخراج مثالية، إذن هل حُلت مشكلة التزامن؟ لا، على الإطلاق. بالنسبة للبرامج التزامنية، هناك عوامل غير قابلة للسيطرة كثيرة جدًا، توقيت التنفيذ، الترتيب، الوقت المستغرق في عملية التنفيذ، وغيرها. إذا كان عمل الكوروتين الفرعي في الحلقة ليس مجرد إخراج أرقام بسيط، بل مهمة ضخمة ومعقدة جدًا، والوقت المستغرق غير مؤكد، فستظل المشكلة السابقة تظهر. مثل الكود التالي:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// محاكاة وقت عشوائي
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}إخراج هذا الكود لا يزال غير مؤكد، وفيما يلي إحدى الحالات المحتملة:
start
0
3
4
endلذلك time.Sleep ليست حلاً جيدًا، ولحسن الحظ توفر Go وسائل كثيرة للتحكم في التزامن، وطرق التحكم في التزامن الشائعة هي ثلاث:
channel: الأنبوبWaitGroup: الإشارةContext: السياق
الطرق الثلاث لها حالات استخدام مختلفة، WaitGroup يمكنه التحكم ديناميكيًا في مجموعة من الكوروتينات بعدد محدد، Context أكثر ملاءمة للحالات التي يكون فيها تداخل مستويات الكوروتينات الفرعية والذرية أعمق، والأنابيب أكثر ملاءمة للتواصل بين الكوروتينات. بالنسبة للتحكم بالأقفال التقليدي، توفر Go دعمًا له أيضًا:
Mutex: القفل المتبادلRWMutex: قفل القراءة والكتابة المتبادل
الأنابيب
channel،تُرجمت كأنبوب، تشرح Go دور الأنبوب كالتالي:
Do not communicate by sharing memory; instead, share memory by communicating.
أي مشاركة الذاكرة من خلال الرسائل، وُلد channel لهذا الغرض، وهو حل للتواصل بين الكوروتينات، ويمكن استخدامه أيضًا للتحكم في التزامن، فلنبدأ بتعلم الصيغة الأساسية للـ channel. في Go يتم استخدام الكلمة المفتاحية chan لتمثيل نوع الأنبوب، ويجب أيضًا الإعلان عن نوع التخزين للأنبوب، لتحديد نوع البيانات المخزنة فيه، والمثال التالي يظهر شكل الأنبوب العادي.
var ch chan intهذا عبارة عن إعلان أنبوب، في هذه اللحظة لم يتم تهيئة الأنبوب بعد، وقيمته nil، ولا يمكن استخدامه مباشرة.
الإنشاء
عند إنشاء أنبوب، هناك طريقة واحدة فقط، وهي استخدام الدالة المدمجة make، بالنسبة للأنبوب، تأخذ دالة make وسيطين، الأول هو نوع الأنبوب، والثاني هو وسيط اختياري وهو حجم المخزن المؤقت للأنبوب. المثال التالي:
intCh := make(chan int)
// أنبوب بحجم مخزن مؤقت 1
strCh := make(chan string, 1)بعد الانتهاء من استخدام الأنبوب يجب تذكر إغلاقه، واستخدام الدالة المدمجة close لإغلاق الأنبوب، وتوقيع هذه الدالة كالتالي.
func close(c chan<- Type)مثال على إغلاق الأنبوب:
func main() {
intCh := make(chan int)
// do something
close(intCh)
}في بعض الأحيان قد يكون استخدام defer لإغلاق الأنبوب أفضل.
القراءة والكتابة
بالنسبة للأنبوب، استخدمت Go عاملين تشغيليين بصريين للغاية للتعبير عن عمليات القراءة والكتابة:
ch <-: تعني كتابة البيانات إلى أنبوب
<- ch: تعني قراءة البيانات من أنبوب
<- تعبر بشكل حيوي عن اتجاه تدفق البيانات، لنرى مثالًا على القراءة والكتابة لأنبوب من نوع int:
func main() {
// إذا لم يكن هناك مخزن مؤقت فسيؤدي ذلك إلى طريق مسدود
intCh := make(chan int, 1)
defer close(intCh)
// كتابة البيانات
intCh <- 114514
// قراءة البيانات
fmt.Println(<-intCh)
}في المثال أعلاه تم إنشاء أنبوب من نوع int بحجم مخزن مؤقت 1، وكُتبت إليه البيانات 114514، ثم قُرأت البيانات وأُخرجت، وأخيرًا أُغلق الأنبوب. بالنسبة لعملية القراءة، هناك قيمة إرجاع ثانية، وهي قيمة من نوع منطقي، تُستخدم للإشارة إلى ما إذا كانت قراءة البيانات قد نجحت:
ints, ok := <-intChطريقة تدفق البيانات في الأنبوب تشبه قائمة الانتظار، أي من يدخل أولًا يخرج أولًا (FIFO)، وعملية الكوروتين على الأنبوب متزامنة، في لحظة معينة، كوروتين واحد فقط يمكنه كتابة البيانات إليه، وكوروتين واحد فقط يمكنه قراءة البيانات من الأنبوب.
أنبوب بدون مخزن مؤقت
بالنسبة للأنبوب بدون مخزن مؤقت، لأن سعة المخزن المؤقت تساوي 0، فلن يخزن أي بيانات مؤقتًا. ولأن الأنبوب بدون مخزن مؤقت لا يمكنه تخزين البيانات، عند كتابة البيانات إلى الأنبوب يجب أن يكون هناك كوروتين آخر يقرأ البيانات فورًا، وإلا سيحدث حظر وانتظار، ونفس الشيء عند قراءة البيانات، وهذا يفسر لماذا الكود التالي الذي يبدو طبيعيًا سيحدث فيه طريق مسدود.
func main() {
// إنشاء أنبوب بدون مخزن مؤقت
ch := make(chan int)
defer close(ch)
// كتابة البيانات
ch <- 123
// قراءة البيانات
n := <-ch
fmt.Println(n)
}الأنبوب بدون مخزن مؤقت لا يجب استخدامه بشكل متزامن، الصحيح هو فتح كوروتين جديد لإرسال البيانات، كما في المثال التالي:
func main() {
// إنشاء أنبوب بدون مخزن مؤقت
ch := make(chan int)
defer close(ch)
go func() {
// كتابة البيانات
ch <- 123
}()
// قراءة البيانات
n := <-ch
fmt.Println(n)
}أنبوب بمخزن مؤقت
عندما يكون للأنبوب مخزن مؤقت، يصبح مثل قائمة انتظار حظر، قراءة أنبوب فارغ والكتابة إلى أنبوب ممتلئ ستسبب حظرًا. الأنبوب بدون مخزن مؤقت عند إرسال البيانات، يجب أن يكون هناك مستقبل فورًا، وإلا سيظل محجوبًا. بالنسبة للأنبوب بمخزن مؤقت فلا حاجة لذلك، عند الكتابة إلى أنبوب بمخزن مؤقت، ستُوضع البيانات أولًا في المخزن المؤقت، وفقط عندما تمتلئ سعة المخزن المؤقت سيحدث حظر في انتظار كوروتين لقراءة البيانات من الأنبوب. وبالمثل، عند قراءة أنبوب بمخزن مؤقت، ستُقرأ البيانات أولًا من المخزن المؤقت، حتى إذا لم يتبق بيانات في المخزن المؤقت، سيحدث حظر في انتظار كوروتين لكتابة البيانات إلى الأنبوب. لذلك، مثال الطريق المسدود في الأنبوب بدون مخزن مؤقت يمكن تشغيله هنا بنجاح.
func main() {
// إنشاء أنبوب بمخزن مؤقت
ch := make(chan int, 1)
defer close(ch)
// كتابة البيانات
ch <- 123
// قراءة البيانات
n := <-ch
fmt.Println(n)
}رغم أنه يمكن تشغيله بنجاح، لكن طريقة القراءة والكتابة المتزامنة هذه خطيرة جدًا، بمجرد أن يصبح المخزن المؤقت للأنبوب فارغًا أو ممتلئًا، سيظل محجوبًا للأبد، لأنه لا يوجد كوروتين آخر لكتابة أو قراءة البيانات من الأنبوب. لنرى المثال التالي:
func main() {
// إنشاء أنبوب بمخزن مؤقت
ch := make(chan int, 5)
// إنشاء أنبوبين بدون مخزن مؤقت
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// مسؤول عن الكتابة
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("كتابة", i)
}
chW <- struct{}{}
}()
// مسؤول عن القراءة
go func() {
for i := 0; i < 10; i++ {
// كل قراءة تحتاج 1 ميلي ثانية
time.Sleep(time.Millisecond)
fmt.Println("قراءة", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("انتهت الكتابة", <-chW)
fmt.Println("انتهت القراءة", <-chR)
}هنا تم إنشاء 3 أنابيب إجمالًا، أنبوب واحد بمخزن مؤقت للتواصل بين الكوروتينات، وأنبوبان بدون مخزن مؤقت لمزامنة ترتيب تنفيذ الكوروتينات الفرعية والأب. الكوروتين المسؤول عن القراءة ينتظر 1 ميلي ثانية قبل كل قراءة، والكوروتين المسؤول عن الكتابة يمكنه كتابة 5 بيانات كحد أقصى دفعة واحدة، لأن الحد الأقصى لحجم المخزن المؤقت للأنبوب هو 5، وقبل أن يأتي كوروتين للقراءة، لا يمكن إلا الانتظار محجوبًا. لذا إخراج هذا المثال كالتالي:
كتابة 0
كتابة 1
كتابة 2
كتابة 3
كتابة 4 // كُتب 5 دفعة واحدة، المخزن المؤقت ممتلئ، انتظار كوروتينات أخرى للقراءة
قراءة 0
كتابة 5 // اقرأ واحدًا، اكتب واحدًا
قراءة 1
كتابة 6
قراءة 2
كتابة 7
قراءة 3
كتابة 8
كتابة 9
قراءة 4
انتهت الكتابة {} // جميع البيانات أُرسلت، الكوروتين الكاتب انتهى
قراءة 5
قراءة 6
قراءة 7
قراءة 8
قراءة 9
انتهت القراءة {} // جميع البيانات قُرأت، الكوروتين القارئ انتهىيمكن ملاحظة أن الكوروتين المسؤول عن الكتابة أرسل 5 بيانات دفعة واحدة في البداية، وبعد امتلاء المخزن المؤقت بدأ في الانتظار المحجوب حتى يأتي الكوروتين القارئ للقراءة، وبعد ذلك كلما قرأ الكوروتين القارئ بيانات كل 1 ميلي ثانية، وأصبح هناك مكان فارغ في المخزن المؤقت، يكتب الكوروتين الكاتب بيانات واحدة، حتى تنتهي جميع البيانات، وينتهي الكوروتين الكاتب، ثم عندما يقرأ الكوروتين القارئ جميع البيانات من المخزن المؤقت، ينتهي الكوروتين القارئ أيضًا، وأخيرًا يخرج الكوروتين الرئيسي.
TIP
من خلال الدالة المدمجة len يمكن الوصول إلى عدد البيانات في المخزن المؤقت للأنبوب، ومن خلال cap يمكن الوصول إلى حجم المخزن المؤقت للأنبوب.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}الإخراج
3 5باستخدام شروط حظر الأنبوب، يمكن بسهولة كتابة مثال ينتظر فيه الكوروتين الرئيسي انتهاء الكوروتين الفرعي:
func main() {
// إنشاء أنبوب بدون مخزن مؤقت
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// كتابة
ch <- struct{}{}
}()
// حظر وانتظار القراءة
<-ch
fmt.Println(1)
}الإخراج
2
1من خلال الأنبوب بمخزن مؤقت يمكن أيضًا تنفيذ قفل متبادل بسيط، انظر المثال التالي:
var count = 0
// أنبوب بحجم مخزن مؤقت 1
var lock = make(chan struct{}, 1)
func Add() {
// قفل
lock <- struct{}{}
fmt.Println("العدد الحالي", count, "تنفيذ الجمع")
count += 1
// فك القفل
<-lock
}
func Sub() {
// قفل
lock <- struct{}{}
fmt.Println("العدد الحالي", count, "تنفيذ الطرح")
count -= 1
// فك القفل
<-lock
}بما أن حجم المخزن المؤقت للأنبوب هو 1، فلا يمكن تخزين أكثر من بيانات واحدة في المخزن المؤقت. الدالتان Add و Sub قبل كل عملية تحاولان إرسال بيانات إلى الأنبوب، وبما أن حجم المخزن المؤقت هو 1، إذا كان هناك كوروتين آخر قد كتب بيانات بالفعل، يكون المخزن المؤقت ممتلئًا، ويجب على الكوروتين الحالي الانتظار محجوبًا حتى يفرغ مكان في المخزن المؤقت، وهكذا، في لحظة معينة، كوروتين واحد فقط يمكنه تعديل المتغير count، وبهذا يُنفذ قفل متبادل بسيط.
نقاط مهمة
فيما يلي بعض الملخصات، الاستخدام غير الصحيح في الحالات التالية سيؤدي إلى حظر الأنبوب:
القراءة والكتابة على أنبوب بدون مخزن مؤقت
عند إجراء عملية قراءة وكتابة متزامنة مباشرة على أنبوب بدون مخزن مؤقت سيؤدي إلى حظر الكوروتين:
func main() {
// إنشاء أنبوب بدون مخزن مؤقت
intCh := make(chan int)
defer close(intCh)
// إرسال البيانات
intCh <- 1
// قراءة البيانات
ints, ok := <-intCh
fmt.Println(ints, ok)
}القراءة من أنبوب بمخزن مؤقت فارغ
عند القراءة من أنبوب بمخزن مؤقت فارغ، سيؤدي ذلك إلى حظر الكوروتين:
func main() {
// إنشاء أنبوب بمخزن مؤقت
intCh := make(chan int, 1)
defer close(intCh)
// المخزن المؤقت فارغ، حظر وانتظار كوروتينات أخرى لكتابة البيانات
ints, ok := <-intCh
fmt.Println(ints, ok)
}الكتابة إلى أنبوب بمخزن مؤقت ممتلئ
عندما يكون المخزن المؤقت للأنبوب ممتلئًا، فإن الكتابة إليه ستؤدي إلى حظر الكوروتين:
func main() {
// إنشاء أنبوب بمخزن مؤقت
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// ممتلئ، حظر وانتظار كوروتينات أخرى للقراءة
intCh <- 1
}الأنبوب قيمته nil
عندما يكون الأنبوب nil، فإن أي قراءة أو كتابة ستؤدي إلى حظر الكوروتين الحالي:
func main() {
var intCh chan int
// كتابة
intCh <- 1
}func main() {
var intCh chan int
// قراءة
fmt.Println(<-intCh)
}شروط حظر الأنبوب تحتاج إلى إتقانها والتعود عليها جيدًا، في معظم الحالات هذه المشاكل مخفية بشكل جيد، ولن تكون بديهية كما في الأمثلة.
الحالات التالية ستؤدي أيضًا إلى panic:
إغلاق أنبوب قيمته nil
عندما يكون الأنبوب nil، استخدام دالة close لإغلاقه سيؤدي إلى panic:
func main() {
var intCh chan int
close(intCh)
}الكتابة إلى أنبوب مغلق
الكتابة إلى أنبوب مغلق ستؤدي إلى panic:
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}إغلاق أنبوب مغلق
في بعض الحالات، قد يمر الأنبوب عبر عدة طبقات، وقد لا يعرف المتصل من يجب أن يغلق الأنبوب، وبهذا قد يحدث إغلاق أنبوب مغلق بالفعل، مما يسبب panic.
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// يمكن فقط إرسال البيانات إلى الأنبوب
ch <- 1
close(ch)
}الأنابيب أحادية الاتجاه
الأنبوب ثنائي الاتجاه يعني أنه يمكن الكتابة والقراءة، أي يمكن العمل على كلا جانبي الأنبوب. الأنبوب أحادي الاتجاه يعني أنبوب للقراءة فقط أو للكتابة فقط، أي يمكن العمل على جانب واحد فقط من الأنبوب. إنشاء أنبوب للقراءة فقط أو للكتابة فقط يدويًا ليس له معنى كبير، لأن عدم القدرة على القراءة أو الكتابة يفقد غرض وجوده. الأنابيب أحادية الاتجاه تُستخدم عادةً لتقييد سلوك القناة، وتظهر غالبًا في معاملات الدوال والقيم المُعادة، مثل توقيع الدالة المدمجة close المستخدمة لإغلاق القناة يستخدم قناة أحادية الاتجاه.
func close(c chan<- Type)أو الدالة After من حزمة time الشائعة الاستخدام:
func After(d Duration) <-chan Timeمعامل دالة close هو قناة للكتابة فقط، وقيمة إرجاع دالة After هي قناة للقراءة فقط، لذا صيغة القناة أحادية الاتجاه كالتالي:
- رمز السهم
<-في المقدمة، يعني قناة للقراءة فقط، مثل<-chan int - رمز السهم
<-في النهاية، يعني قناة للكتابة فقط، مثلchan<- string
عند محاولة الكتابة إلى أنبوب للقراءة فقط، لن ينجح الترجمة:
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}رسالة الخطأ واضحة جدًا:
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)نفس الشيء ينطبق على القراءة من أنبوب للكتابة فقط.
الأنبوب ثنائي الاتجاه يمكن تحويله إلى أنبوب أحادي الاتجاه، لكن العكس غير صحيح. عادةً، عند تمرير أنبوب ثنائي الاتجاه إلى كوروتين أو دالة معينة وعدم الرغبة في أن يقرأ/يرسل بيانات، يمكن استخدام الأنبوب أحادي الاتجاه لتقييد سلوك الطرف الآخر.
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// يمكن فقط إرسال البيانات إلى الأنبوب
ch <- 1
}نفس المبدأ ينطبق على الأنابيب للقراءة فقط.
TIP
chan هو نوع مرجعي، حتى أن معاملات الدوال في Go تُمرر بالقيمة، لكن مرجعها يظل نفسه، وسيتم توضيح هذه النقطة في قسم مبدأ الأنابيب لاحقًا.
for range
من خلال جملة for range، يمكن اجتياز وقراءة البيانات من الأنبوب بمخزن مؤقت، كما في المثال التالي:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}عادةً، عند استخدام for range لاجتياز هياكل بيانات قابلة للتكرار، هناك قيمتان مُعادة، الأولى هي الفهرس، والثانية هي قيمة العنصر، لكن بالنسبة للأنبوب، هناك قيمة مُعادة واحدة فقط، for range سيستمر في قراءة عناصر الأنبوب، عندما يكون المخزن المؤقت للأنبوب فارغًا أو بدون مخزن مؤقت، سيحدث حظر وانتظار، حتى يأتي كوروتين آخر لكتابة البيانات إلى الأنبوب. لذا الإخراج كالتالي:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!يمكن ملاحظة أن الكود أعلاه حدث فيه طريق مسدود، لأن الكوروتين الفرعي قد انتهى بالفعل، والكوروتين الرئيسي لا يزال ينتظر محجوبًا كوروتينات أخرى لكتابة البيانات إلى الأنبوب، لذا يجب إغلاق الأنبوب بعد الانتهاء من الكتابة. التعديل كالتالي:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// إغلاق الأنبوب
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}بعد الكتابة وإغلاق الأنبوب، الكود أعلاه لن يحدث فيه طريق مسدود. ذُكر سابقًا أن قراءة الأنبوب لها قيمتان مُعادة، عند استخدام for range لاجتياز الأنبوب، عند عدم القدرة على قراءة البيانات بنجاح، سينتهي التكرار. القيمة المُعادة الثانية تشير إلى ما إذا كانت قراءة البيانات ناجحة، وليس ما إذا كان الأنبوب مغلقًا، حتى لو كان الأنبوب مغلقًا، بالنسبة للأنبوب بمخزن مؤقت، لا يزال يمكن قراءة البيانات، والقيمة المُعادة الثانية لا تزال true. انظر المثال التالي:
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// إغلاق الأنبوب
close(ch)
// قراءة البيانات مرة أخرى
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}نتيجة الإخراج:
0 true
1 true
2 true
3 true
4 true
0 falseبما أن الأنبوب مغلق، حتى لو كان المخزن المؤقت فارغًا، قراءة البيانات لن تؤدي إلى حظر الكوروتين الحالي، يمكن ملاحظة أن في الاجتياز السادس القيمة المقروءة هي القيمة الصفرية، و ok هي false.
TIP
بخصوص توقيت إغلاق الأنبوب، يجب قدر الإمكان إغلاقه من قبل الطرف الذي يرسل البيانات إلى الأنبوب، وليس من قبل المستقبل، لأن المستقبل في معظم الحالات يعرف فقط استقبال البيانات، ولا يعرف متى يجب إغلاق الأنبوب.
WaitGroup
sync.WaitGroup هو هيكل توفره حزمة sync، WaitGroup تعني انتظار التنفيذ، واستخدامه يمكن بسهولة تحقيق تأثير انتظار مجموعة من الكوروتينات. هذا الهيكل يكشف ثلاث طرق فقط.
طريقة Add تُستخدم لتحديد عدد الكوروتينات التي يجب انتظارها:
func (wg *WaitGroup) Add(delta int)طريقة Done تشير إلى أن الكوروتين الحالي قد انتهى من التنفيذ:
func (wg *WaitGroup) Done()طريقة Wait تنتظر انتهاء الكوروتينات الفرعية، وإلا تظل محجوبة:
func (wg *WaitGroup) Wait()WaitGroup سهل الاستخدام جدًا، جاهز للاستخدام فورًا. تنفيذه الداخلي يعتمد على العداد + الإشارة، عند بدء البرنامج يتم استدعاء Add لتهيئة العد، وكلما انتهى كوروتين من التنفيذ يتم استدعاء Done، فينقص العداد بمقدار 1، حتى يصل إلى 0، وخلال هذه الفترة، استدعاء Wait من الكوروتين الرئيسي سيظل محجوبًا حتى يصل العداد إلى 0، ثم يتم إيقاظه. لنرَ مثالًا بسيطًا على الاستخدام:
func main() {
var wait sync.WaitGroup
// تحديد عدد الكوروتينات الفرعية
wait.Add(1)
go func() {
fmt.Println(1)
// انتهى التنفيذ
wait.Done()
}()
// انتظار الكوروتين الفرعي
wait.Wait()
fmt.Println(2)
}هذا الكود يُخرج دائمًا 1 أولًا ثم 2، الكوروتين الرئيسي سينتظر انتهاء الكوروتين الفرعي قبل الخروج.
1
2بالنسبة للمثال في باب الكوروتين، يمكن تعديله كالتالي:
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// عداد 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// عداد 1 داخل الحلقة
wait.Add(1)
go func() {
fmt.Println(i)
// كلا العدادين ينقص بمقدار 1
wait.Done()
mainWait.Done()
}()
// انتظار انتهاء الكوروتين في الدورة الحالية
wait.Wait()
}
// انتظار انتهاء جميع الكوروتينات
mainWait.Wait()
fmt.Println("end")
}هنا تم استخدام sync.WaitGroup بدلًا من time.Sleep السابقة، ترتيب تنفيذ الكوروتينات التزامنية أصبح أكثر تحكمًا، مهما تم التنفيذ، الإخراج يكون كالتالي:
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup عادةً ما يُستخدم عندما يمكن تعديل عدد الكوروتينات ديناميكيًا، مثل معرفة عدد الكوروتينات مسبقًا، أو الحاجة إلى تعديل ديناميكي أثناء التشغيل. قيمة WaitGroup لا يجب نسخها، والقيمة المنسوخة لا يجب استخدامها، خاصة عند تمريرها كمعامل دالة، يجب تمرير المؤشر وليس القيمة. إذا تم استخدام قيمة منسوخة، العداد لن يعمل على WaitGroup الحقيقي، مما قد يؤدي إلى انتظار الكوروتين الرئيسي إلى الأبد، ولن يتمكن البرنامج من العمل بشكل طبيعي. مثل الكود التالي:
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}رسالة الخطأ تشير إلى أن جميع الكوروتينات خرجت، لكن الكوروتين الرئيسي لا يزال ينتظر، وهذا يشكل طريق مسدود، لأن استدعاء Done داخل دالة hello على معامل WaitGroup رسمي لن يؤثر على mainWait الأصلية، لذا يجب استخدام المؤشر للتمرير.
hello
fatal error: all goroutines are asleep - deadlock!TIP
عندما يصبح العداد سالبًا، أو عندما يكون عدد العداد أكبر من عدد الكوروتينات الفرعية، سيحدث panic.
Context
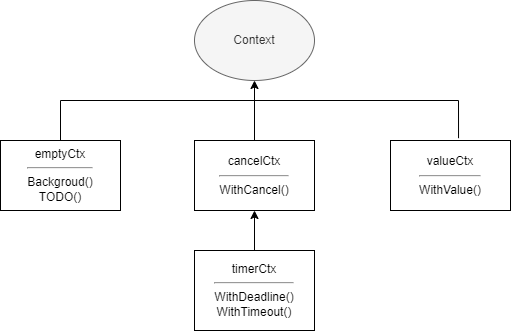
Context تُرجمت كسياق، وهي حل للتحكم في التزامن توفره Go، وبالمقارنة مع الأنابيب و WaitGroup، يمكنها التحكم بشكل أفضل في الكوروتينات الفرعية والذرية والمستويات الأعمق. Context نفسها واجهة، أي شيء يطبق هذه الواجهة يمكن تسميته سياقًا مثل gin.Context في إطار الويب الشهير Gin. حزمة context القياسية توفر أيضًا عدة تطبيقات، وهي:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
لنبدأ بالنظر إلى تعريف واجهة Context، ثم نتعرف على تطبيقاتها المحددة.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
هذه الطريقة لها قيمتان مُعادة، deadline هو وقت الانتهاء، أي الوقت الذي يجب أن يُلغى فيه السياق. القيمة الثانية تشير إلى ما إذا كان deadline قد تم تعيينه، إذا لم يتم تعيينه فستظل false.
Deadline() (deadline time.Time, ok bool)Done
قيمتها المُعادة هي أنبوب للقراءة فقط من نوع هيكل فارغ، هذا الأنبوب ي служي فقط للإشعار، لا ينقل أي بيانات. عندما يجب إلغاء العمل الذي يقوم به السياق، سيُغلق هذا الأنبوب، بالنسبة لبعض السياقات التي لا تدعم الإلغاء، قد تُعيد nil.
Done() <-chan struct{}Err
هذه الطريقة تُعيد error،用于表示关闭上下文的原因。当 Done 管道没有关闭时,返回 nil,如果关闭过后,会返回一个 err 来解释为什么会关闭。
Err() errorValue
هذه الطريقة تُعيد القيمة المقابلة للمفتاح، إذا لم يكن key موجودًا، أو لم تكن هذه الطريقة مدعومة، ستُعيد nil.
Value(key any) anyemptyCtx
كما يوحي الاسم، emptyCtx هو سياق فارغ، جميع التطبيقات في حزمة context غير مكشوفة للخارج، لكنها توفر دوال مقابلة لإنشاء السياقات. يمكن إنشاء emptyCtx من خلال context.Background و context.TODO. الدالتان كالتالي:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}يمكن ملاحظة أنهما فقط تُعيدان مؤشر emptyCtx. النوع الأساسي لـ emptyCtx هو في الواقع int، والسبب في عدم استخدام هيكل فارغ هو أن مثيلات emptyCtx يجب أن يكون لها عناوين ذاكرة مختلفة، ولا يمكن إلغاؤه، وليس لديه deadline، ولا يمكن أخذ قيم منه، والطرق المطبقة جميعها تُعيد قيمًا صفرية.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx يُستخدم عادةً كسياق علوي، ويُمرر كسياق أب عند إنشاء السياقات الثلاثة الأخرى. العلاقة بين التطبيقات المختلفة في حزمة context موضحة في الصورة التالية:
valueCtx
تطبيق valueCtx بسيط نسبيًا، داخله يحتوي فقط على زوج مفتاح-قيمة واحد، وحقل من نوع Context مدمج.
type valueCtx struct {
Context
key, val any
}هو نفسه يطبق فقط طريقة Value، والمنطق بسيط جدًا، إذا لم يُوجد في السياق الحالي يبحث في السياق الأب.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}فيما يلي مثال بسيط على استخدام valueCtx:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// تمرير السياق
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// إنشاء مؤقت جديد
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // لن يُنفذ أبدًا
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx يُستخدم غالبًا لنقل بعض البيانات في الكوروتينات متعددة المستويات، لا يمكن إلغاؤه، لذا ctx.Done سيعيد دائمًا nil، و select سيتجاهل الأنابيب nil. الإخراج النهائي كالتالي:
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx و timerCtx كلاهما يطبق واجهة canceler، نوع الواجهة كالتالي:
type canceler interface {
// removeFromParent 表示是否从父上下文中删除自身
// err 表示取消的原因
cancel(removeFromParent bool, err error)
// Done 返回一个管道,用于通知取消的原因
Done() <-chan struct{}
}طريقة cancel غير مكشوفة للخارج، عند إنشاء السياق يتم تغليفها كقيمة مُعادة عبر الإغلاق لاستدعائها من الخارج، كما هو موضح في الكود المصدري لـ context.WithCancel:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// محاولة إضافة نفسه إلى قائمة children الخاصة بالأب
propagateCancel(parent, &c)
// إرجاع context ودالة
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx تُرجمت كسياق قابل للإلغاء، عند الإنشاء، إذا كان الأب يطبق canceler، سيضيف نفسه إلى قائمة children الخاصة بالأب، وإلا سيستمر في البحث للأعلى. إذا لم يطبق أي من الآباء canceler، سيبدأ كوروتينًا ينتظر إلغاء الأب، ثم عندما ينتهي الأب يُلغي السياق الحالي. عند استدعاء cancelFunc، سيُغلق أنبوب Done، وسيُلغى أي سياق فرعي لهذا السياق، وأخيرًا سيحذف نفسه من الأب. فيما يلي مثال بسيط:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// يعيد cancelCtx ودالة cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("في انتظار الإلغاء...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}الإخراج كالتالي:
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
context canceledمثال آخر بتداخل مستويات أعمق:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("جاري معالجة طلب http...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth ألغى الأب", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail ألغى الأب", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}في المثال تم إنشاء 3 cancelCtx، ورغم أن cancelCtx الأب عند إلغائه سيُلغي سياقاته الفرعية، لكن للاحتياط، إذا تم إنشاء cancelCtx، يجب استدعاء دالة cancel بعد انتهاء العملية المناسبة. الإخراج كالتالي:
جاري معالجة طلب http...
auth...
mail...
mail...
auth...
جاري معالجة طلب http...
auth...
mail...
جاري معالجة طلب http...
جاري معالجة طلب http...
auth...
mail...
auth...
جاري معالجة طلب http...
mail...
context canceled
auth ألغى الأب context canceled
mail ألغى الأب context canceledtimerCtx
timerCtx يضيف آلية انتهاء المهلة على أساس cancelCtx، حزمة context توفر دالتين للإنشاء، هما WithDeadline و WithTimeout، وظيفتهما متشابهة، الأولى تحدد وقت انتهاء محدد، مثل تحديد وقت محدد 2023/3/20 16:32:00، والثانية تحدد فاصل زمني للانتهاء، مثل بعد 5 دقائق. توقيع الدالتين كالتالي:
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx سيُلغي السياق الحالي تلقائيًا عند انتهاء الوقت، وعملية الإلغاء بالإضافة إلى إغلاق timer إضافي، هي نفسها أساسًا مثل cancelCtx. فيما يلي مثال بسيط على استخدام timerCtx:
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("أُلغي السياق", ctx.Err())
return
default:
fmt.Println("في انتظار الإلغاء...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}رغم أن السياق سيُلغى تلقائيًا عند انتهاء وقته، لكن للاحتياط، بعد انتهاء العملية المناسبة، من الأفضل إلغاء السياق يدويًا. الإخراج كالتالي:
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
في انتظار الإلغاء...
أُلغي السياق context deadline exceededWithTimeout تشبه جدًا WithDeadline، وتطبيقها هو فقط تغليف بسيط واستدعاء WithDeadline، والاستخدام مثل WithDeadline في المثال أعلاه، كالتالي:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
تمامًا كما أن عدم استرداد الذاكرة بعد تخصيصها يسبب تسربًا في الذاكرة، السياق أيضًا مورد، إذا تم إنشاؤه ولم يُلغَ أبدًا، سيحدث تسرب في السياق، لذا من الأفضل تجنب هذا الموقف.
Select
select في نظام Linux هو حل لتعدد إرسال IO، وبالمثل، في Go، select هو هيكل تحكم لتعدد إرسال الأنابيب. ما هو تعدد الإرسال، باختصار في جملة واحدة: في لحظة معينة، مراقبة عناصر متعددة في نفس الوقت لمعرفة ما إذا كانت متاحة، يمكن أن تكون العناصر المراقبة طلبات شبكة، أو IO للملفات، وما إلى ذلك. في Go، العناصر التي يراقبها select هي الأنابيب، وأنابيب فقط. صيغة select تشبه جملة switch، لنرَ كيف تبدو جملة select:
func main() {
// إنشاء ثلاثة أنابيب
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("جميع الأنابيب غير متاحة")
}
}الاستخدام
مثل switch، يتكون select من عدة case و default واحد، وفرع default يمكن حذفه. كل case يمكنه تشغيل أنبوب واحد فقط، وإجراء عملية واحدة فقط، إما قراءة أو كتابة، عندما يكون عدة case متاحة، سيختار select عشوائيًا زائفًا case واحد للتنفيذ. إذا كانت جميع case غير متاحة، سيُنفذ فرع default، وإذا لم يكن هناك فرع default، سيحدث حظر وانتظار حتى يكون case واحد متاح على الأقل. بما أن المثال أعلاه لم يكتب بيانات إلى الأنابيب، فبطبيعة الحال جميع case غير متاحة، لذا الإخراج النهائي هو نتيجة تنفيذ فرع default. بعد تعديل بسيط:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// بدء كوروتين جديد
go func() {
// كتابة بيانات إلى الأنبوب A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}في المثال أعلاه تم بدء كوروتين جديد لكتابة البيانات إلى الأنبوب A، وبما أن select ليس له فرع افتراضي، سيظل محجوبًا في انتظار حتى يكون case متاح. عندما يكون الأنبوب A متاحًا، بعد تنفيذ الفرع المقابل يخرج الكوروتين الرئيسي مباشرة. لمراقبة الأنابيب باستمرار، يمكن استخدام حلقة for، كالتالي:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// حلقة for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}هذا بالفعل يجعل الأنابيب الثلاثة جميعها متاحة، لكن حلقة لا نهائية + select ستجعل الكوروتين الرئيسي محجوبًا للأبد، لذا يمكن وضعه في كوروتين جديد منفصل، وإضافة بعض المنطق الآخر.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // تعيين وقت انتهاء مهلة 1 ثانية
break Loop // الخروج من الحلقة
}
}
l <- struct{}{} // إخبار الكوروتين الرئيسي أنه يمكن الخروج
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}في المثال أعلاه، من خلال حلقة for مع select لمراقبة الأنابيب الثلاثة باستمرار، والـ case الرابع هو أنبوب انتهاء مهلة، وبعد انتهاء المهلة سيخرج من الحلقة وينهي الكوروتين الفرعي. الإخراج النهائي كالتالي:
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueانتهاء المهلة
المثال السابق استخدم دالة time.After، قيمتها المُعادة هي أنبوب للقراءة فقط، هذه الدالة مع select يمكنها تنفيذ آلية انتهاء المهلة ببساطة شديدة، المثال التالي:
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("انتهت المهلة")
}
}حظر دائم
عندما تكون جملة select فارغة تمامًا، سيحدث حظر دائم، مثل:
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end لن تُخرج أبدًا، الكوروتين الرئيسي سيظل محجوبًا، وهذا الموقف عادةً ما يكون له استخدامات خاصة.
TIP
إذا تمت عملية على أنبوب قيمته nil في case داخل select، فلن يسبب ذلك حظرًا، بل سيتم تجاهل هذا case ولن يُنفذ أبدًا. مثل الكود التالي مهما نُفذ سيُخرج timeout فقط.
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}عدم الحظر
من خلال استخدام فرع default في select مع الأنابيب، يمكننا تنفيذ عمليات إرسال واستقبال غير حظرية، كالتالي:
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}وبالمثل، يمكن تنفيذ حظر غيري للحكم على ما إذا كان context قد انتهى:
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}الأقفال
لنبدأ بمثال:
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// محاكاة وقت الوصول
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// الوصول إلى البيانات
temp := *data
// محاكاة وقت الحساب
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// تعديل البيانات
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("النتيجة النهائية", count)
}بالنسبة للمثال أعلاه، تم فتح عشرة كوروتينات لإجراء عملية +1 على count، واستُخدم time.Sleep لمحاكاة أوقات مختلفة، حسب الحدس، 10 كوروتينات تنفذ 10 عمليات +1، النتيجة النهائية يجب أن تكون 10، والنتيجة الصحيحة هي بالفعل 10، لكن الواقع ليس كذلك، نتيجة تنفيذ المثال أعلاه كالتالي:
1
2
3
3
2
2
3
3
3
4
النتيجة النهائية 4يمكن ملاحظة أن النتيجة النهائية هي 4، وهذه واحدة فقط من النتائج المحتملة العديدة. نظرًا لاختلاف الوقت الذي تحتاجه كل كوروتين للوصول والحساب، الكوروتين A يستغرق 500 ميلي ثانية للوصول إلى البيانات، وفي هذه اللحظة قيمة count المقروءة هي 1، ثم يستغرق 400 ميلي ثانية أخرى للحساب، لكن خلال هذه الـ 400 ميلي ثانية، الكوروتين B قد أكمل الوصول والحساب وحدّث قيمة count بنجاح، وبعد انتهاء الكوروتين A من الحساب، القيمة التي قرأها الكوروتين A في البداية أصبحت قديمة، لكن الكوروتين A لا يعرف هذا، وما زال يضيف واحدًا على القيمة التي قرأها أصلاً ويعينها لـ count، وبهذا يتم استبدال نتيجة تنفيذ الكوروتين B. عند قراءة وكتابة عدة كوروتينات لبيانات مشتركة، تحدث هذه المشكلة بشكل خاص، ولهذا نحتاج إلى استخدام الأقفال.
Go توفر Mutex و RWMutex من حزمة sync كتطبيقين للقفل المتبادل وقفل القراءة والكتابة، وتوفر واجهات برمجة تطبيقات سهلة الاستخدام جدًا، للقفل يكفي Lock()، ولفتح القفل يكفي Unlock(). يجب الانتباه إلى أن الأقفال التي توفرها Go كلها أقفال غير عودية، أي أقفال غير قابلة لإعادة الدخول، لذا فإن القفل المتكرر أو فتح القفل المتكرر سيؤدي إلى fatal. معنى القفل هو حماية الثوابت، والقفل هو أمل ألا يتم تعديل البيانات بواسطة كوروتينات أخرى، كالتالي:
func DoSomething() {
Lock()
// خلال هذه العملية، لن يتم تعديل البيانات بواسطة كوروتينات أخرى
Unlock()
}إذا كان قفلًا عوديًا، فقد يحدث الموقف التالي:
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}دالة DoSomething بوضوح لا تعرف ماذا قد تفعل دالة DoOther بالبيانات، وبالتالي تعدلها، مثل فتح عدة كوروتينات فرعية تكسر الثوابت. هذا غير ممكن في Go، بمجرد القفل يجب ضمان ثبات الثوابت، وفي هذه الحالة القفل المتكرر أو فتح القفل المتكرر سيؤدي إلى طريق مسدود. لذا عند كتابة الكود يجب تجنب الموقف أعلاه، وعند الضرورة يمكن استخدام جملة defer لفتح القفل فورًا عند القفل.
القفل المتبادل
sync.Mutex هو تطبيق القفل المتبادل الذي توفره Go، وهو يطبق واجهة sync.Locker:
type Locker interface {
// قفل
Lock()
// فتح القفل
Unlock()
}استخدام القفل المتبادل يمكن أن يحل المشكلة أعلاه بشكل مثالي، المثال التالي:
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// قفل
lock.Lock()
// محاكاة وقت الوصول
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// الوصول إلى البيانات
temp := *data
// محاكاة وقت الحساب
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// تعديل البيانات
*data = temp + ans
// فتح القفل
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("النتيجة النهائية", count)
}كل كوروتين قبل الوصول إلى البيانات، يقفل أولًا، وبعد الانتهاء من التحديث يفتح القفل، والكوروتينات الأخرى التي تريد الوصول يجب أن تحصل على القفل أولًا، وإلا تنتظر محجوبة. وبهذا، لا وجود للمشكلة أعلاه، والإخراج كالتالي:
1
2
3
4
5
6
7
8
9
10
النتيجة النهائية 10قفل القراءة والكتابة
القفل المتبادل مناسب للحالات التي يكون فيها تكرار عمليات القراءة والكتابة متقاربًا، بالنسبة لبعض البيانات التي تكون فيها القراءة أكثر من الكتابة، إذا استُخدم القفل المتبادل، سيؤدي ذلك إلى تنافس كبير وغير ضروري من الكوروتينات على القفل، مما يستهلك الكثير من موارد النظام، وفي هذه الحالة نحتاج إلى استخدام قفل القراءة والكتابة، أي القفل المتبادل للقراءة والكتابة، بالنسبة لكوروتين واحد:
- إذا حصل على قفل القراءة، الكوروتينات الأخرى ستُحجب عند إجراء عمليات كتابة، والكوروتينات الأخرى لن تُحجب عند إجراء عمليات قراءة
- إذا حصل على قفل الكتابة، الكوروتينات الأخرى ستُحجب عند إجراء عمليات كتابة، والكوروتينات الأخرى ستُحجب عند إجراء عمليات قراءة
تطبيق القفل المتبادل للقراءة والكتابة في Go هو sync.RWMutex، وهو أيضًا يطبق واجهة Locker، لكنه يوفر طرقًا أكثر可用,كالتالي:
// قفل القراءة
func (rw *RWMutex) RLock()
// محاولة قفل القراءة
func (rw *RWMutex) TryRLock() bool
// فتح قفل القراءة
func (rw *RWMutex) RUnlock()
// قفل الكتابة
func (rw *RWMutex) Lock()
// محاولة قفل الكتابة
func (rw *RWMutex) TryLock() bool
// فتح قفل الكتابة
func (rw *RWMutex) Unlock()من بينها، عمليتا TryRlock و TryLock للمحاولة غير حظرية، نجاح القفل سيعيد true، وعدم القدرة على الحصول على القفل لن يسبب حظرًا بل سيعيد false. التنفيذ الداخلي للقفل المتبادل للقراءة والكتابة لا يزال قفلًا متبادلًا، ليس الأمر أن وجود قفل للقراءة وقفل للكتابة يعني وجود قفلين، من البداية إلى النهاية لا يوجد إلا قفل واحد. لنرَ مثالًا على استخدام القفل المتبادل للقراءة والكتابة:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// قراءة أكثر وكتابة أقل
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// انتظار انتهاء الكوروتينات الفرعية
wait.Wait()
fmt.Println("النتيجة النهائية", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("تم الحصول على قفل القراءة")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("تحرير قفل القراءة", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("تم الحصول على قفل الكتابة")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("تحرير قفل الكتابة", *i)
rw.Unlock()
wait.Done()
}هذا المثال يفتح 3 كوروتينات للكتابة، و7 كوروتينات للقراءة، عند قراءة البيانات يتم الحصول على قفل القراءة أولًا، والكوروتينات القراءة يمكنها الحصول على قفل القراءة بشكل طبيعي، لكنها ستحجب الكوروتينات الكتابة، وعند الحصول على قفل الكتابة، ستحجب في نفس الوقت كوروتينات القراءة والكتابة، حتى يتم تحرير قفل الكتابة، وبهذا يتحقق التبادل بين كوروتينات القراءة والكتابة، ويضمن صحة البيانات. إخراج المثال كالتالي:
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تحرير قفل القراءة 0
تحرير قفل القراءة 0
تحرير قفل القراءة 0
تحرير قفل القراءة 0
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 1
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تحرير قفل القراءة 1
تحرير قفل القراءة 1
تحرير قفل القراءة 1
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 2
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 3
النتيجة النهائية 3TIP
بالنسبة للأقفال، لا يجب تمريرها وتخزينها كقيم، بل يجب استخدام المؤشرات.
متغير الشرط
متغير الشرط، يظهر ويُستخدم مع القفل المتبادل، لذا قد يخطئ البعض في تسميته قفل الشرط، لكنه ليس قفلًا، بل هو آلية اتصال. Go توفر تطبيقًا لذلك من خلال sync.Cond، وتوقيع الدالة لإنشاء متغير الشرط كالتالي:
func NewCond(l Locker) *Condيمكن ملاحظة أن الشرط المسبق لإنشاء متغير شرط هو إنشاء قفل، sync.Cond يوفر الطرق التالية للاستخدام:
// حظر وانتظار تحقق الشرط، حتى يتم الإيقاظ
func (c *Cond) Wait()
// إيقاظ كوروتين واحد محجوب بسبب الشرط
func (c *Cond) Signal()
// إيقاظ جميع الكوروتينات المحجوبة بسبب الشرط
func (c *Cond) Broadcast()استخدام متغير الشرط بسيط جدًا، يمكن تعديل مثال القفل المتبادل للقراءة والكتابة أعلاه قليلًا:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// متغير الشرط
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// قراءة أكثر وكتابة أقل
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// انتظار انتهاء الكوروتينات الفرعية
wait.Wait()
fmt.Println("النتيجة النهائية", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("تم الحصول على قفل القراءة")
// إذا لم يتحقق الشرط يستمر في الحظر
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("تحرير قفل القراءة", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("تم الحصول على قفل الكتابة")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("تحرير قفل الكتابة", *i)
rw.Unlock()
// إيقاظ جميع الكوروتينات المحجوبة بسبب متغير الشرط
cond.Broadcast()
wait.Done()
}عند إنشاء متغير الشرط، لأن متغير الشرط هنا يعمل على الكوروتينات القراءة، تم تمرير قفل القراءة كقفل متبادل، إذا تم تمرير القفل المتبادل للقراءة والكتابة مباشرة سيؤدي ذلك إلى مشكلة فتح القفل المتكرر من الكوروتينات الكتابة. ما تم تمريره هنا هو sync.rlocker، ويُحصل عليه من خلال طريقة RWMutex.RLocker:
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }يمكن ملاحظة أن rlocker هو فقط تغليف لعمليات قفل القراءة للقفل المتبادل للقراءة والكتابة، وهو في الواقع نفس المرجع، ونفس القفل. عند قراءة البيانات، إذا كانت أقل من 3 ستظل محجوبة في انتظار، حتى تصبح البيانات أكبر من 3، والكوروتينات الكتابة بعد تحديث البيانات ستحاول إيقاظ جميع الكوروتينات المحجوبة بسبب متغير الشرط، لذا الإخراج النهائي كالتالي:
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 1
تم الحصول على قفل القراءة
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 2
تم الحصول على قفل القراءة
تم الحصول على قفل القراءة
تم الحصول على قفل الكتابة
تحرير قفل الكتابة 3 // الكوروتين الكاتب الثالث انتهى من التنفيذ
تحرير قفل القراءة 3
تحرير قفل القراءة 3
تحرير قفل القراءة 3
تحرير قفل القراءة 3
تحرير قفل القراءة 3
تحرير قفل القراءة 3
تحرير قفل القراءة 3
النتيجة النهائية 3من النتائج يمكن ملاحظة أنه بعد انتهاء الكوروتين الكاتب الثالث من تحديث البيانات، استأنفت الكوروتينات القراءة السبع المحجوبة بسبب متغير الشرط عملها.
TIP
بالنسبة لمتغير الشرط، يجب استخدام for وليس if، يجب استخدام حلقة للحكم على ما إذا كان الشرط قد تحقق، لأن الكوروتين عند إيقاظه لا يمكن ضمان أن الشرط الحالي قد تحقق بالفعل.
for !condition {
cond.Wait()
}sync
معظم أدوات التزامن في Go توفرها حزمة sync القياسية، وقد تم تقديم sync.WaitGroup و sync.Locker أعلاه، وبالإضافة إلى ذلك، توفر حزمة sync بعض الأدوات الأخرى للاستخدام.
Once
عند استخدام بعض هياكل البيانات، إذا كانت هذه الهياكل ضخمة جدًا، يمكن النظر في استخدام التحميل الكسول، أي تهيئة هيكل البيانات فقط عند الحاجة الفعلية إليه. مثل المثال التالي:
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// عند استخدام الشريحة فعليًا، سيتم النظر في تهيئتها
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}لكن المشكلة هنا، إذا كان كوروتين واحد يستخدمها فبالتأكيد لا توجد أي مشكلة، لكن إذا وصل إليها عدة كوروتينات فقد تحدث مشاكل. مثلًا الكوروتينان A و B استدعيا طريقة Add في نفس الوقت، A نفذ أسرع قليلًا، وقد انتهى من التهيئة بالفعل، وأضاف البيانات بنجاح، ثم الكوروتين B يهيئ مرة أخرى، وبهذا يتم استبدال البيانات التي أضافها الكوروتين A مباشرة، وهذه هي المشكلة.
وهذا هو ما يحله sync.Once، كما يوحي الاسم، Once تعني مرة واحدة، sync.Once يضمن أن العملية المحددة ستُنفذ مرة واحدة فقط في ظروف التزامن. استخدامه بسيط جدًا، يكشف للخارج طريقة واحدة فقط Do، وتوقيعها كالتالي:
func (o *Once) Do(f func())عند الاستخدام، يكفي تمرير عملية التهيئة إلى طريقة Do، كالتالي:
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// عند استخدام الشريحة فعليًا، سيتم النظر في تهيئتها
m.o.Do(func() {
fmt.Println("تهيئة")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}الإخراج كالتالي:
تهيئة
4من نتيجة الإخراج يمكن ملاحظة أن جميع البيانات أُضيفت بشكل طبيعي إلى الشريحة، وتم تنفيذ عملية التهيئة مرة واحدة فقط. في الواقع، تنفيذ sync.Once بسيط جدًا، بعد إزالة التعليقات الكود الفعلي لا يتجاوز 16 سطرًا، ومبدأه هو القفل + العمليات الذرية. الكود المصدري كالتالي:
type Once struct {
// 用于判断操作是否已经执行
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// 原子加载数据
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// 加锁
o.m.Lock()
// 解锁
defer o.m.Unlock()
// 判断是否执行
if o.done == 0 {
// 执行完毕后修改done
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
الغرض من تصميم sync.Pool هو تخزين الكائنات المؤقتة لإعادة استخدامها لاحقًا، وهو تجمع كائنات مؤقتة آمن للتزامن، وضع الكائنات غير المستخدمة حاليًا في التجمع، وعند الاستخدام اللاحق لا حاجة لإنشاء كائنات إضافية ويمكن إعادة استخدامها مباشرة، مما يقلل من تكرار تخصيص وتحرير الذاكرة، والأهم من ذلك تقليل ضغط GC. sync.Pool لديه طريقتان فقط، كالتالي:
// طلب كائن
func (p *Pool) Get() any
// وضع كائن
func (p *Pool) Put(x any)كما أن sync.Pool لديه حقل New مكشوف للخارج،用于初始化 كائن عندما لا يتمكن تجمع الكائنات من الحصول على كائن:
New func() anyفيما يلي مثال توضيحي:
var wait sync.WaitGroup
// تجمع الكائنات المؤقتة
var pool sync.Pool
// 用于计数过程中总共创建了多少个对象
var numOfObject atomic.Int64
// BigMemData 假设这是一个占用内存很大的结构体
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"ذاكرة كبيرة"}
}
wait.Add(1000)
// هنا يتم فتح 1000 كوروتين
for i := 0; i < 1000; i++ {
go func() {
// طلب كائن
val := pool.Get()
// استخدام الكائن
_ = val.(BigMemData)
// بعد الانتهاء من استخدامه يتم تحرير الكائن
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}المثال يفتح 1000 كوروتين تتقدم وتحرر الكائنات باستمرار في التجمع، إذا لم يُستخدم تجمع الكائنات، فكل كوروتين من الـ 1000 يحتاج إلى إنشاء مثيل لكائن خاص به، وهذه الـ 1000 كائن بعد الانتهاء من استخدامها تحتاج جميعها إلى أن يحررها GC من الذاكرة، إذا كان هناك مئات الآلاف من الكوروتينات أو كانت تكلفة إنشاء هذا الكائن باهظة جدًا، في هذه الحالة ستُشغل ذاكرة كبيرة وسيُسبب ضغطًا كبيرًا جدًا على GC، وباستخدام تجمع الكائنات، يمكن إعادة استخدام الكائنات وتقليل تكرار الإنشاء، مثل إخراج المثال أعلاه قد يكون كالتالي:
5حتى مع فتح 1000 كوروتين، لم يُنشأ خلال العملية بأكملها إلا 5 كائنات، وإذا لم يُستخدم تجمع الكائنات فالـ 1000 كوروتين ستُنشئ 1000 كائن، وهذا التحسين واضح، خاصة عندما يكون حجم التزامن كبيرًا جدًا وتكلفة إنشاء الكائنات عالية جدًا.
عند استخدام sync.Pool يجب الانتباه لعدة نقاط:
- الكائنات المؤقتة:
sync.Poolمناسب فقط لتخزين الكائنات المؤقتة، وقد تُزال الكائنات في التجمع بواسطة GC في أي وقت دون أي إشعار، لذا لا يُنصح بوضع اتصالات الشبكة، اتصالات قواعد البيانات وغيرها فيsync.Pool. - عدم القدرة على التنبؤ: عند طلب كائن من
sync.Pool، لا يمكن التنبؤ بما إذا كان هذا الكائن جديدًا أو معاد استخدامه، ولا يمكن معرفة عدد الكائنات في التجمع. - الأمان للتزامن: الموقع الرسمي يضمن أن
sync.Poolآمن للتزامن بالتأكيد، لكنه لا يضمن أن دالةNewالمستخدمة لإنشاء الكائنات آمنة للتزامن، دالةNewيمررها المستخدم، لذا أمان التزامن لدالةNewيجب أن يتحمله المستخدم نفسه، ولهذا السبب في المثال أعلاه استُخدمت قيمة ذرية لعد الكائنات.
TIP
أخيرًا يجب الانتباه، عند الانتهاء من استخدام الكائن، يجب تحريره وإعادته إلى التجمع، إذا استُخدم ولم يُحرر فإن استخدام تجمع الكائنات لن يكون له معنى.
حزمة fmt القياسية لديها حالة استخدام لتجمع الكائنات، في دالة fmt.Fprintf:
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// طلب مخزن طباعة مؤقت
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// بعد الانتهاء من الاستخدام يتم التحرير
p.free()
return
}تنفيذ دالة newPointer وطريقة free كالتالي:
func newPrinter() *pp {
// طلب كائن من تجمع الكائنات
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// لجعل حجم المخزن المؤقت في تجمع الكائنات متقاربًا للتحكم المرن بشكل أفضل في حجم المخزن المؤقت
// المخازن المؤقتة كبيرة الحجم لا توضع في تجمع الكائنات
if cap(p.buf) > 64<<10 {
return
}
// إعادة تعيين الحقول ثم تحرير الكائن إلى التجمع
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map هي خريطة آمنة للتزامن يوفرها الموقع الرسمي، جاهزة للاستخدام فورًا، واستخدامها بسيط جدًا، فيما يلي الطرق التي يكشفها هذا الهيكل للخارج:
// قراءة قيمة بناءً على مفتاح، القيمة المُعادة ستُرجع القيمة المقابلة وما إذا كانت القيمة موجودة
func (m *Map) Load(key any) (value any, ok bool)
// تخزين زوج مفتاح-قيمة
func (m *Map) Store(key, value any)
// حذف زوج مفتاح-قيمة
func (m *Map) Delete(key any)
// إذا كان المفتاح موجودًا بالفعل، تُرجع القيمة الأصلية، وإلا تُخزن القيمة الجديدة وتُرجع، عند القراءة بنجاح، loaded تكون true، وإلا false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// حذف زوج مفتاح-قيمة، وإرجاع قيمته الأصلية، قيمة loaded تعتمد على وجود المفتاح
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// اجتياز الخريطة، عندما تُرجع f() القيمة false، سيتوقف الاجتياز
func (m *Map) Range(f func(key, value any) bool)فيما يلي مثال بسيط لتوضيح الاستخدام الأساسي لـ sync.Map:
func main() {
var syncMap sync.Map
// إدخال بيانات
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// قراءة البيانات
fmt.Println(syncMap.Load("a"))
// قراءة وحذف
fmt.Println(syncMap.LoadAndDelete("a"))
// قراءة أو تخزين
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// اجتياز الخريطة
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}الإخراج:
a true
a true
hello world false
a hello world
b goodbye worldبعد ذلك لنرَ مثالًا على استخدام الخريطة في التزامن:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}في المثال أعلاه استُخدمت خريطة عادية، وفُتحت 10 كوروتينات لتخزين البيانات باستمرار، وبوضوح هذا من المحتمل جدًا أن يثير fatal، والنتيجة على الأرجح ستكون:
fatal error: concurrent map writesاستخدام sync.Map يمكن تجنب هذه المشكلة:
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}الإخراج كالتالي:
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4من أجل الأمان للتزامن يجب بالتأكيد تقديم بعض التنازلات، أداء sync.Map أقل بـ 10-100 مرة تقريبًا من الخريطة العادية.
العمليات الذرية
في علوم الحاسوب، العمليات الذرية أو البدائية، تُستخدم عادةً للتعبير عن بعض العمليات التي لا يمكن تقسيمها إلى أجزاء أصغر، وبما أن هذه العمليات لا يمكن تقسيمها إلى خطوات أصغر، فقبل الانتهاء من تنفيذها لن تُقاطع من قبل أي كوروتين آخر، لذا فإن نتيجة التنفيذ إما نجاح أو فشل، ولا توجد حالة ثالثة، وإذا ظهرت حالات أخرى فليست عملية ذرية. مثل الكود التالي:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}الكود أعلاه هو عبارة عن شرط بسيط، ورغم أن الكود قليل، لكنه ليس عملية ذرية، العمليات الذرية الحقيقية مدعومة من مستوى تعليمات العتاد.
الأنواع
لحسن الحظ في معظم الحالات لا حاجة لكتابة التجميع بنفسك، حزمة sync/atomic القياسية في Go توفر بالفعل واجهات برمجة تطبيقات للعمليات الذرية، وتوفر الأنواع التالية لإجراء العمليات الذرية:
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}من بينها، النوع الذري Pointer يدعم الأنواع العامة، والنوع Value يدعم تخزين أي نوع، وبالإضافة إلى ذلك، توفر العديد من الدوال لتسهيل العمليات. لأن دقة العمليات الذرية دقيقة جدًا، في معظم الحالات، تكون أكثر ملاءمة للتعامل مع أنواع البيانات الأساسية هذه.
TIP
العمليات الذرية في حزمة atmoic لها توقيعات دوال فقط، وليس لها تطبيق محدد، والتطبيق الفعلي مكتوب بتجميع plan9.
الاستخدام
كل نوع ذري يوفر الطرق الثلاث التالية:
Load(): الحصول على القيمة ذريًاSwap(newVal type) (old type): تبديل القيمة ذريًا، وإرجاع القيمة القديمةStore(val type): تخزين القيمة ذريًا
الأنواع المختلفة قد يكون لديها طرق إضافية أخرى، مثل الأنواع الصحيحة توفر جميعها طريقة Add لتنفيذ عمليات الجمع والطرح الذرية. فيما يلي مثال على النوع int64:
func main() {
var aint64 atomic.Uint64
// تخزين القيمة
aint64.Store(64)
// تبديل القيمة
aint64.Swap(128)
// زيادة
aint64.Add(112)
// تحميل القيمة
fmt.Println(aint64.Load())
}أو يمكن أيضًا استخدام الدوال مباشرة:
func main() {
var aint64 int64
// تخزين القيمة
atomic.StoreInt64(&aint64, 64)
// تبديل القيمة
atomic.SwapInt64(&aint64, 128)
// زيادة
atomic.AddInt64(&aint64, 112)
// تحميل
fmt.Println(atomic.LoadInt64(&aint64))
}استخدام الأنواع الأخرى مشابه جدًا، والإخراج النهائي:
240CAS
حزمة atomic توفر أيضًا عملية CompareAndSwap، أي CAS. وهي جوهر تنفيذ القفل المتفائل وهياكل البيانات بدون أقفال. القفل المتفائل نفسه ليس قفلًا، بل هو طريقة للتحكم في التزامن بدون أقفال في ظروف التزامن: الخيط/الكوروتين قبل تعديل البيانات، لا يقفل أولًا، بل يقرأ البيانات أولًا، ويجري الحسابات، ثم عند تقديم التعديل يستخدم CAS للحكم على ما إذا كان هناك خيط آخر قد عدل البيانات خلال هذه الفترة. إذا لم يكن كذلك (القيمة لا تزال مساوية للقيمة المقروءة سابقًا)، فالتعديل ناجح؛ وإلا، يفشل ويعيد المحاولة. لذلك سُمي قفلًا متفائلًا لأنه يفترض دائمًا بشكل متفائل أن البيانات المشتركة لن تُعدل، وفقط عند اكتشاف أن البيانات لم تُعدل سيقوم بتنفيذ العملية المقابلة، والقفل المتبادل الذي تعرفنا عليه سابقًا هو قفل متشائم، القفل المتبادل يفترض دائمًا بشكل متشائم أن البيانات المشتركة ستُعدل بالتأكيد، لذا عند العمل يقفل، وبعد الانتهاء من العملية يفتح القفل. نظرًا لأن التزامن المُنفذ بدون أقفال، فإن أمانه وكفاءته أعلى نسبيًا من الأقفال، والعديد من هياكل البيانات الآمنة للتزامن تستخدم CAS في تنفيذها، لكن الكفاءة الحقيقية تعتمد على سيناريو الاستخدام المحدد. لنرَ المثال التالي:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}هذا مثال يستخدم القفل المتبادل، قبل كل زيادة للرقم يقفل أولًا، وبعد الانتهاء من التنفيذ يفتح القفل، وخلال العملية سيؤدي ذلك إلى حظر الكوروتينات الأخرى، الآن سنستخدم CAS للتعديل:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}بالنسبة لـ CAS، هناك ثلاثة معاملات، قيمة الذاكرة، القيمة المتوقعة، القيمة الجديدة. عند التنفيذ، سيقارن CAS القيمة المتوقعة مع قيمة الذاكرة الحالية، إذا كانت قيمة الذاكرة مساوية للقيمة المتوقعة، سيقوم بالعملية اللاحقة، وإلا لا يفعل شيئًا. بالنسبة للعمليات الذرية في حزمة atomic في Go، دوال CAS تتطلب تمرير العنوان، والقيمة المتوقعة، والقيمة الجديدة، وستُعيد قيمة منطقية تشير إلى نجاح الاستبدال. مثل توقيع دالة CAS للنوع int64 كالتالي:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)في مثال CAS، أولًا يتم الحصول على القيمة المتوقعة من خلال LoadInt64، ثم استخدام CompareAndSwapInt64 للمقارنة والتبديل، إذا لم ينجح يستمر في التكرار حتى ينجح. هذه العملية بدون أقفال رغم أنها لن تسبب حظر الكوروتينات، لكن التكرار المستمر لا يزال يمثل عبئًا كبيرًا على CPU، لذا في بعض التطبيقات إذا فشل الوصول إلى عدد معين من المرات قد يتم التخلي عن العملية. لكن بالنسبة للعملية أعلاه، هي مجرد جمع أرقام بسيط، والعمليات المتضمنة ليست معقدة، لذا يمكن بالتأكيد النظر في التنفيذ بدون أقفال.
TIP
في معظم الحالات، مجرد مقارنة القيم لا يمكن تحقيق الأمان للتزامن، مثل مشكلة ABA الناتجة عن CAS، تحتاج إلى استخدام version إضافي لحل المشكلة.
Value
هيكل atomic.Value، يمكنه تخزين قيم من أي نوع، الهيكل كالتالي:
type Value struct {
// نوع any
v any
}رغم أنه يمكن تخزين أي نوع، لكنه لا يمكن تخزين nil، والأنواع قبل وبعد التخزين يجب أن تكون متسقة، المثالان التاليان لا يمكن ترجمتهما:
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into Valueبخلاف ذلك، استخدامه لا يختلف كثيرًا عن الأنواع الذرية الأخرى، ويجب الانتباه إلى أن جميع الأنواع الذرية لا يجب نسخ قيمها، بل يجب استخدام مؤشراتها.