Concurrency
Go มีการสนับสนุน concurrency โดยธรรมชาติ ซึ่งเป็นหัวใจหลักของภาษานี้ ความยากในการเริ่มต้นใช้งานค่อนข้างต่ำ ผู้พัฒนาไม่จำเป็นต้องสนใจการนำไปใช้ระดับล่างก็สามารถสร้างแอปพลิเคชัน concurrency ที่ดีได้ ช่วยเพิ่มขีดจำกัดของผู้พัฒนา
Goroutine
Goroutine เป็นเธรดเบา (lightweight thread) หรือที่เรียกว่าเธรดสถานะผู้ใช้ (user-mode thread) ไม่ถูกกำหนดการโดยตรงจาก ระบบปฏิบัติการ แต่ถูกกำหนดการขณะรันไทม์โดยตัวจัดกำหนดการของ Go เอง ดังนั้นค่าใช้จ่ายในการสลับบริบทจึงน้อยมาก ซึ่งเป็นหนึ่งในเหตุผลว่าทำไมประสิทธิภาพ concurrency ของ Go จึงดีมาก แนวคิดของ goroutine ไม่ได้ถูกนำเสนอโดย Go เป็นครั้งแรก และ Go ก็ไม่ใช่ภาษาแรกที่รองรับ goroutine แต่ Go เป็นภาษาแรกที่สามารถรองรับ goroutine และ concurrency ได้อย่างเรียบง่ายและสง่างาม
ใน Go การสร้าง goroutine นั้นง่ายมาก เพียงใช้คำสำคัญ go ก็สามารถเปิด goroutine ได้อย่างรวดเร็ว ต้องตามด้วยการเรียกฟังก์ชัน ตัวอย่างดังนี้
TIP
ฟังก์ชันในตัวที่มีค่าส่งกลับไม่อนุญาตให้ตามหลังคำสำคัญ go เช่นตัวอย่างที่ผิดด้านล่าง
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}สามวิธีในการเปิด goroutine ข้างต้นสามารถใช้ได้ทั้งหมด แต่จริงๆ แล้วหลังจากดำเนินการตัวอย่างนี้แล้ว ในกรณีส่วนใหญ่จะไม่มีอะไรออกมาเลย goroutine ทำงานพร้อมกัน ระบบต้องใช้เวลาในการสร้าง goroutine และก่อนหน้านั้น goroutine หลักได้ทำงานเสร็จแล้ว เมื่อเธรดหลัก退出แล้ว goroutine ย่อยอื่นๆ ก็退出ด้วยเช่นกัน และลำดับการทำงานของ goroutine ก็ไม่แน่นอน ไม่สามารถคาดเดาได้ เช่นตัวอย่างด้านล่าง
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}นี่เป็นตัวอย่างที่เปิด goroutine ในลูป ไม่สามารถคาดเดาได้อย่างแม่นยำว่าจะ输出อะไร อาจเป็นว่า goroutine ย่อยยังไม่ได้เริ่มทำงาน goroutine หลักก็จบแล้ว สถานการณ์เป็นดังนี้
start
endหรืออาจมีเพียงบางส่วนของ goroutine ย่อยที่ทำงานสำเร็จก่อนที่ goroutine หลักจะ退出 สถานการณ์เป็นดังนี้
start
0
1
5
3
4
6
7
endวิธีที่ง่ายที่สุดคือทำให้ goroutine หลักรอชั่วครู่ ต้องใช้ฟังก์ชัน Sleep ในแพ็กเกจ time สามารถทำให้ goroutine ปัจจุบันหยุดชั่วคราวเป็นระยะเวลาหนึ่ง ตัวอย่างดังนี้
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// หยุดชั่วคราว 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}ดำเนินการอีกครั้งผลลัพธ์เป็นดังนี้ จะเห็นว่าตัวเลขทั้งหมดถูก输出อย่างครบถ้วน ไม่มีการ遗漏
start
0
1
5
2
3
4
6
8
9
7
endแต่ลำดับยังคงสับสน ดังนั้นให้รอเล็กน้อยในแต่ละรอบของการลูป ตัวอย่างดังนี้
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}ตอนนี้ผลลัพธ์เป็นลำดับปกติแล้ว
start
0
1
2
3
4
5
6
7
8
9
endในตัวอย่างข้างต้นผลลัพธ์การ输出สมบูรณ์แบบมาก แล้วปัญหาของ concurrency แก้ไขแล้วหรือยัง ไม่ ยังไม่เลยแม้แต่น้อย สำหรับโปรแกรม concurrency แล้ว ปัจจัยที่ไม่สามารถควบคุมได้มีมากมายมาก เวลาที่ดำเนินการ ลำดับก่อนหลัง เวลาที่ใช้ในกระบวนการดำเนินการ ฯลฯ หากงานของ goroutine ย่อยในลูปไม่ใช่แค่การ输出ตัวเลขอย่างง่าย แต่เป็นงานที่巨大และซับซ้อน เวลาที่ใช้ไม่แน่นอน ก็จะ重现ปัญหาก่อนหน้าได้ เช่นโค้ดด้านล่าง
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// จำลองเวลาที่ใช้แบบสุ่ม
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}ผลลัพธ์การ输出ของโค้ดส่วนนี้ยังคงไม่แน่นอน ด้านล่างนี้เป็นหนึ่งในสถานการณ์ที่เป็นไปได้
start
0
3
4
endดังนั้น time.Sleep จึงไม่ใช่วิธีการแก้ปัญหาที่ดี โชคดีที่ Go มีเครื่องมือควบคุม concurrency มากมาย วิธีการควบคุม concurrency ที่ใช้บ่อยมีสามวิธี:
channel: ท่อWaitGroup: สัญญาณContext: บริบท
สามวิธีมีการใช้งานที่เหมาะสมต่างกัน WaitGroup สามารถควบคุม一组ของ goroutine จำนวนที่กำหนดได้อย่างไดนามิก Context เหมาะสมกว่าสำหรับสถานการณ์ที่มี层级ของ goroutine ลึกกว่า ท่อเหมาะสำหรับการสื่อสารระหว่าง goroutine สำหรับการควบคุมด้วยล็อกแบบดั้งเดิม Go ก็มีการสนับสนุนเช่นกัน:
Mutex: ล็อกร่วมกันRWMutex: ล็อกอ่านเขียนร่วมกัน
ท่อ
channel แปลว่าท่อ Go อธิบายหน้าที่ของท่อดังนี้:
Do not communicate by sharing memory; instead, share memory by communicating.
即ใช้ข้อความเพื่อแบ่งปันหน่วยความจำ channel เกิดมาเพื่อสิ่งนี้ เป็นโซลูชันสำหรับการสื่อสารระหว่าง goroutine ในเวลาเดียวกันก็สามารถใช้สำหรับการควบคุม concurrency ได้ มาทำความรู้จักกับไวยากรณ์พื้นฐานของ channel ก่อน ใน Go ใช้คำสำคัญ chan เพื่อแสดงประเภทท่อ และต้องประกาศประเภทการจัดเก็บของท่อเพื่อกำหนดว่าข้อมูลที่จัดเก็บเป็นประเภทอะไร ตัวอย่างด้านล่างเป็นลักษณะของท่อธรรมดา
var ch chan intนี่เป็นคำสั่งประกาศท่อ ขณะนี้ท่อยังไม่ได้เริ่มต้น ค่าเป็น nil ไม่สามารถใช้ได้โดยตรง
การสร้าง
ในการสร้างท่อ มีวิธีเดียวเท่านั้น คือใช้ฟังก์ชันในตัว make สำหรับท่อแล้ว ฟังก์ชัน make รับพารามิเตอร์สองตัว ตัวแรกคือประเภทของท่อ ตัวที่สองเป็นพารามิเตอร์เสริมคือขนาดบัฟเฟอร์ของท่อ ตัวอย่างดังนี้
intCh := make(chan int)
// ท่อที่มีขนาดบัฟเฟอร์เป็น 1
strCh := make(chan string, 1)หลังจากใช้ท่อเสร็จแล้ว ต้องจำไว้ว่าต้องปิดท่อนั้น ใช้ฟังก์ชันในตัว close เพื่อปิดท่อ ฟังก์ชันนี้มีลายเซ็นดังนี้
func close(c chan<- Type)ตัวอย่างการปิดท่อมีดังนี้
func main() {
intCh := make(chan int)
// ทำบางอย่าง
close(intCh)
}บางครั้งการใช้ defer เพื่อปิดท่ออาจดีกว่า
การอ่านเขียน
สำหรับท่อแล้ว Go ใช้ตัวดำเนินการสองตัวที่สื่อความหมายเพื่อแสดงการดำเนินการอ่านเขียน:
ch <-: แสดงการเขียนข้อมูลลงในท่อ
<- ch: แสดงการอ่านข้อมูลจากท่อ
<- แสดงทิศทางการไหลของข้อมูลได้อย่างมีชีวิตชีวา ดูตัวอย่างการอ่านเขียนท่อประเภท int ด้านล่าง
func main() {
// หากไม่มีบัฟเฟอร์จะทำให้เกิด deadlock
intCh := make(chan int, 1)
defer close(intCh)
// เขียนข้อมูล
intCh <- 114514
// อ่านข้อมูล
fmt.Println(<-intCh)
}ในตัวอย่างข้างต้นสร้างท่อประเภท int ที่มีขนาดบัฟเฟอร์เป็น 1 เขียนข้อมูล 114514 ลงไป แล้วอ่านข้อมูลและ输出 สุดท้ายปิดท่อนั้น สำหรับการดำเนินการอ่านแล้ว ยังมีค่าส่งกลับที่สองเป็นค่าบูลีน ใช้表示ว่าข้อมูลอ่านสำเร็จหรือไม่
ints, ok := <-intChวิธีการไหลของข้อมูลในท่อเหมือนกับคิว คือเข้าก่อนออกก่อน (FIFO) การดำเนินการของ goroutine ต่อท่อเป็นแบบซิงโครนัส ในขณะใดขณะหนึ่ง มีเพียง goroutine เดียวเท่านั้นที่สามารถเขียนข้อมูลลงในท่อได้ และในขณะเดียวกันก็มีเพียง goroutine เดียวเท่านั้นที่สามารถอ่านข้อมูลจากท่อได้
ไม่มีบัฟเฟอร์
สำหรับท่อที่ไม่มีบัฟเฟอร์ เนื่องจากความจุของบัฟเฟอร์เป็น 0 จึงไม่เก็บข้อมูลชั่วคราวใดๆ เนื่องจากท่อที่ไม่มีบัฟเฟอร์ไม่สามารถเก็บข้อมูลได้ เมื่อเขียนข้อมูลลงในท่อต้องมี goroutine อื่นมาอ่านข้อมูลทันที มิฉะนั้นจะบล็อกและรอ การอ่านข้อมูลก็เช่นกัน นี่อธิบายว่าทำไมโค้ดที่ดูปกติมากด้านล่างจึงเกิด deadlock
func main() {
// สร้างท่อที่ไม่มีบัฟเฟอร์
ch := make(chan int)
defer close(ch)
// เขียนข้อมูล
ch <- 123
// อ่านข้อมูล
n := <-ch
fmt.Println(n)
}ท่อที่ไม่มีบัฟเฟอร์ไม่ควรใช้แบบซิงโครนัส อย่างถูกต้องแล้วควรเปิด goroutine ใหม่เพื่อส่งข้อมูล ดังตัวอย่างด้านล่าง
func main() {
// สร้างท่อที่ไม่มีบัฟเฟอร์
ch := make(chan int)
defer close(ch)
go func() {
// เขียนข้อมูล
ch <- 123
}()
// อ่านข้อมูล
n := <-ch
fmt.Println(n)
}มีบัฟเฟอร์
เมื่อท่อมีบัฟเฟอร์ ก็เหมือนกับคิวที่บล็อก การอ่านท่อที่ว่างและการเขียนท่อที่เต็มจะทำให้เกิดการบล็อก ท่อที่ไม่มีบัฟเฟอร์เมื่อส่งข้อมูล ต้องมีคนรับทันที มิฉะนั้นจะบล็อกตลอดไป สำหรับท่อที่มีบัฟเฟอร์ไม่จำเป็นต้องเป็นเช่นนั้น เมื่อเขียนข้อมูลลงในท่อที่มีบัฟเฟอร์ จะนำข้อมูล放入บัฟเฟอร์ก่อน มีเพียงเมื่อความจุของบัฟเฟอร์เต็มแล้วเท่านั้นที่จะบล็อกและรอให้ goroutine มาอ่านข้อมูลจากท่อ ในทำนองเดียวกัน เมื่ออ่านท่อที่มีบัฟเฟอร์ จะอ่านข้อมูลจากบัฟเฟอร์ก่อน จนกว่าข้อมูลในบัฟเฟอร์จะหมด จึงจะบล็อกและรอให้ goroutine มาเขียนข้อมูลลงในท่อ ดังนั้นตัวอย่างที่ทำให้เกิด deadlock ในท่อที่ไม่มีบัฟเฟอร์สามารถรันได้อย่างราบรื่นที่นี่
func main() {
// สร้างท่อที่มีบัฟเฟอร์
ch := make(chan int, 1)
defer close(ch)
// เขียนข้อมูล
ch <- 123
// อ่านข้อมูล
n := <-ch
fmt.Println(n)
}แม้ว่าจะรันได้อย่างราบรื่น แต่การอ่านเขียนแบบซิงโครนัสนี้อันตรายมาก เมื่อบัฟเฟอร์ของท่อว่างหรือเต็ม จะบล็อกตลอดไป เพราะไม่มี goroutine อื่นมาเขียนหรืออ่านข้อมูลจากท่อ ลองดูตัวอย่างด้านล่าง
func main() {
// สร้างท่อที่มีบัฟเฟอร์
ch := make(chan int, 5)
// สร้างท่อที่ไม่มีบัฟเฟอร์สองตัว
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// รับผิดชอบการเขียน
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("เขียน", i)
}
chW <- struct{}{}
}()
// รับผิดชอบการอ่าน
go func() {
for i := 0; i < 10; i++ {
//每次读取数据都需要花费 1 毫秒
time.Sleep(time.Millisecond)
fmt.Println("อ่าน", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("เขียนเสร็จ", <-chW)
fmt.Println("อ่านเสร็จ", <-chR)
}ที่นี่สร้างท่อทั้งหมด 3 ตัว ท่อที่มีบัฟเฟอร์หนึ่งตัวใช้สำหรับการสื่อสารระหว่าง goroutine ท่อที่ไม่มีบัฟเฟอร์สองตัวใช้สำหรับซิงโครไนซ์ลำดับการทำงานของ goroutine หลักและย่อย goroutine ที่รับผิดชอบการอ่านจะรอ 1 มิลลิวินาทีก่อนอ่านแต่ละครั้ง goroutine ที่รับผิดชอบการเขียนสามารถเขียนได้มากที่สุด 5 ข้อมูลในครั้งเดียว เพราะบัฟเฟอร์ของท่อมีขนาดสูงสุดเพียง 5 ก่อนที่จะมี goroutine มาอ่าน สามารถบล็อกและรอได้เท่านั้น ดังนั้นตัวอย่างนี้ผลลัพธ์เป็นดังนี้
เขียน 0
เขียน 1
เขียน 2
เขียน 3
เขียน 4 // เขียน 5 ข้อมูลแล้ว บัฟเฟอร์เต็ม รอให้ goroutine อื่นมาอ่าน
อ่าน 0
เขียน 5 // อ่านหนึ่งข้อมูล เขียนหนึ่งข้อมูล
อ่าน 1
เขียน 6
อ่าน 2
เขียน 7
อ่าน 3
เขียน 8
เขียน 9
อ่าน 4
เขียนเสร็จ {} // ส่งข้อมูลทั้งหมดเสร็จแล้ว goroutine ที่เขียนทำงานเสร็จ
อ่าน 5
อ่าน 6
อ่าน 7
อ่าน 8
อ่าน 9
อ่านเสร็จ {} // อ่านข้อมูลทั้งหมดเสร็จแล้ว goroutine ที่อ่านทำงานเสร็จจะเห็นว่า goroutine ที่รับผิดชอบการเขียนส่ง 5 ข้อมูลทันทีในตอนแรก หลังจากบัฟเฟอร์เต็มก็เริ่มบล็อกและรอให้ goroutine ที่อ่านมาอ่าน หลังจากนั้นทุกครั้งที่ goroutine ที่อ่านอ่านหนึ่งข้อมูลทุก 1 มิลลิวินาที เมื่อบัฟเฟอร์มีที่ว่าง goroutine ที่เขียนก็เขียนหนึ่งข้อมูล จนกว่าจะส่งข้อมูลทั้งหมดเสร็จ goroutine ที่เขียนทำงานเสร็จ หลังจากนั้นเมื่อ goroutine ที่อ่านอ่านข้อมูลทั้งหมดในบัฟเฟอร์เสร็จ goroutine ที่อ่านก็ทำงานเสร็จ สุดท้าย goroutine หลัก退出
TIP
ผ่านฟังก์ชันในตัว len สามารถเข้าถึงจำนวนข้อมูลในบัฟเฟอร์ของท่อได้ ผ่าน cap สามารถเข้าถึงขนาดของบัฟเฟอร์ท่อ
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}ผลลัพธ์
3 5ใช้เงื่อนไขการบล็อกของท่อ สามารถเขียนตัวอย่างที่ goroutine หลัก รอให้ goroutine ย่อยทำงานเสร็จได้ง่ายๆ
func main() {
// สร้างท่อที่ไม่มีบัฟเฟอร์
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// เขียน
ch <- struct{}{}
}()
// บล็อกและรออ่าน
<-ch
fmt.Println(1)
}ผลลัพธ์
2
1ใช้ท่อที่มีบัฟเฟอร์ยังสามารถสร้างล็อกร่วมกันอย่างง่ายได้ ดูตัวอย่างด้านล่าง
var count = 0
// ท่อที่มีขนาดบัฟเฟอร์เป็น 1
var lock = make(chan struct{}, 1)
func Add() {
// ล็อก
lock <- struct{}{}
fmt.Println("计数ปัจจุบันคือ", count, "ดำเนินการบวก")
count += 1
// ปลดล็อก
<-lock
}
func Sub() {
// ล็อก
lock <- struct{}{}
fmt.Println("计数ปัจจุบันคือ", count, "ดำเนินการลบ")
count -= 1
// ปลดล็อก
<-lock
}เนื่องจากขนาดบัฟเฟอร์ของท่อเป็น 1 มีข้อมูล存放在บัฟเฟอร์ได้มากที่สุดหนึ่งข้อมูล ฟังก์ชัน Add และ Sub จะพยายามส่งข้อมูลเข้าท่อก่อนดำเนินการแต่ละครั้ง เนื่องจากขนาดบัฟเฟอร์เป็น 1 หากมี goroutine อื่นเขียนข้อมูลแล้ว บัฟเฟอร์เต็มแล้ว goroutine ปัจจุบันต้องบล็อกและรอ จนกว่าบัฟเฟอร์จะว่าง ด้วยวิธีนี้ ในขณะใดขณะหนึ่ง มีเพียง goroutine เดียวเท่านั้นที่สามารถแก้ไขตัวแปร count ได้ เช่นนี้ก็สร้างล็อกร่วมกันอย่างง่ายได้
ข้อควรระวัง
ด้านล่างนี้เป็นสรุป สถานการณ์ต่อไปนี้หากใช้ไม่เหมาะสมจะทำให้ท่อบล็อก:
อ่านเขียนท่อที่ไม่มีบัฟเฟอร์
เมื่อทำการอ่านเขียนแบบซิงโครนัสโดยตรงกับท่อที่ไม่มีบัฟเฟอร์จะทำให้ goroutine ปัจจุบันบล็อก
func main() {
// สร้างท่อที่ไม่มีบัฟเฟอร์
intCh := make(chan int)
defer close(intCh)
// ส่งข้อมูล
intCh <- 1
// อ่านข้อมูล
ints, ok := <-intCh
fmt.Println(ints, ok)
}อ่านท่อที่มีบัฟเฟอร์ว่าง
เมื่ออ่านท่อที่มีบัฟเฟอร์ว่าง จะทำให้ goroutine ปัจจุบันบล็อก
func main() {
// สร้างท่อที่มีบัฟเฟอร์
intCh := make(chan int, 1)
defer close(intCh)
// บัฟเฟอร์ว่าง บล็อกและรอให้ goroutine อื่นเขียนข้อมูล
ints, ok := <-intCh
fmt.Println(ints, ok)
}เขียนท่อที่มีบัฟเฟอร์เต็ม
เมื่อบัฟเฟอร์ของท่อเต็ม การเขียนข้อมูลจะทำให้ goroutine ปัจจุบันบล็อก
func main() {
// สร้างท่อที่มีบัฟเฟอร์
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// เต็มแล้ว บล็อกและรอให้ goroutine อื่นมาอ่านข้อมูล
intCh <- 1
}ท่อเป็น nil
เมื่อท่อเป็น nil ไม่ว่าอ่านหรือเขียนอย่างไรก็จะทำให้ goroutine ปัจจุบันบล็อก
func main() {
var intCh chan int
// เขียน
intCh <- 1
}func main() {
var intCh chan int
// อ่าน
fmt.Println(<-intCh)
}เกี่ยวกับเงื่อนไขการบล็อกของท่อต้องเข้าใจและคุ้นเคยให้ดี ในกรณีส่วนใหญ่ปัญหาเหล่านี้ซ่อนเร้นมาก ไม่ได้直观เหมือนในตัวอย่าง
สถานการณ์ต่อไปนี้ยังทำให้เกิด panic:
ปิดท่อที่เป็น nil
เมื่อท่อเป็น nil การใช้ฟังก์ชัน close เพื่อปิดจะทำให้เกิด panic
func main() {
var intCh chan int
close(intCh)
}เขียนท่อที่ปิดแล้ว
การเขียนข้อมูลลงในท่อที่ปิดแล้วจะทำให้เกิด panic
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}ปิดท่อที่ปิดแล้ว
ในบางสถานการณ์ ท่ออาจถูกส่งต่อหลายชั้น ผู้เรียกอาจไม่รู้ว่าควรให้ใครปิดท่อ ดังนั้นอาจเกิดการปิดท่อที่ปิดแล้ว จะเกิด panic
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// สามารถส่งข้อมูลเข้าท่อได้เท่านั้น
ch <- 1
close(ch)
}ท่อทางเดียว
ท่อสองทางหมายถึงสามารถทั้งเขียนและอ่านได้ คือสามารถดำเนินการที่ทั้งสองข้างของท่อได้ ท่อทางเดียวหมายถึงท่อที่อ่านอย่างเดียวหรือเขียนอย่างเดียว คือสามารถดำเนินการได้ที่ข้างเดียวของท่อเท่านั้น การสร้างท่อที่อ่านอย่างเดียวหรือเขียนอย่างเดียวด้วยตนเองไม่มีความหมายมากนัก เพราะไม่สามารถอ่านเขียนท่อได้ก็สูญเสียหน้าที่ที่มีอยู่ของมัน ท่อทางเดียวมักใช้เพื่อจำกัดพฤติกรรมของช่อง โดยทั่วไปจะปรากฏในพารามิเตอร์ฟังก์ชันและค่าส่งกลับ เช่นฟังก์ชันในตัว close ที่ใช้ปิดช่องใช้ลายเซ็นฟังก์ชันที่มีช่องทางเดียว
func close(c chan<- Type)หรือฟังก์ชัน After ในแพ็กเกจ time ที่ใช้บ่อย
func After(d Duration) <-chan Timeพารามิเตอร์ของฟังก์ชัน close เป็นช่องเขียนอย่างเดียว ค่าส่งกลับของฟังก์ชัน After เป็นช่องอ่านอย่างเดียว ดังนั้นไวยากรณ์ของช่องทางเดียวมีดังนี้:
- เครื่องหมายลูกศร
<-อยู่ข้างหน้า เป็นช่องอ่านอย่างเดียว เช่น<-chan int - เครื่องหมายลูกศร
<-อยู่ข้างหลัง เป็นช่องเขียนอย่างเดียว เช่นchan<- string
เมื่อพยายามเขียนข้อมูลลงในช่องที่อ่านอย่างเดียว จะไม่สามารถผ่านการคอมไพล์ได้
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}ข้อผิดพลาดมีดังนี้ ชัดเจนมาก
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)การอ่านข้อมูลจากช่องที่เขียนอย่างเดียวก็เช่นกัน
ช่องสองทางสามารถแปลงเป็นช่องทางเดียวได้ ในทางกลับกันไม่ได้ โดยปกติแล้ว เมื่อส่งช่องสองทางให้ goroutine หรือฟังก์ชันบางตัวและไม่ต้องการให้อ่าน/ส่งข้อมูล ก็สามารถใช้ช่องทางเดียวเพื่อจำกัดพฤติกรรมของอีกฝ่ายได้
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// สามารถส่งข้อมูลเข้าท่อได้เท่านั้น
ch <- 1
}ช่องอ่านอย่างเดียวก็เช่นกัน
TIP
chan เป็นประเภทอ้างอิง แม้ Go จะส่งพารามิเตอร์ฟังก์ชันแบบค่า แต่การอ้างอิงยังคงเป็นอันเดียวกัน这一点จะอธิบายในหลักการของท่อในภายหลัง
for range
ผ่านคำสั่ง for range สามารถ遍历อ่านข้อมูลในท่อที่มีบัฟเฟอร์ได้ ดังตัวอย่าง
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}โดยปกติแล้ว for range เมื่อ遍历โครงสร้างข้อมูลที่ iterable อื่นๆ จะมีค่าส่งกลับสองตัว ตัวแรกคือดัชนี ตัวที่สองคือค่าองค์ประกอบ แต่สำหรับท่อแล้ว มีค่าส่งกลับเพียงตัวเดียว for range จะอ่านองค์ประกอบในท่ออย่างต่อเนื่อง เมื่อบัฟเฟอร์ของท่อว่างหรือไม่มีบัฟเฟอร์ จะบล็อกและรอ จนกว่าจะมี goroutine อื่นเขียนข้อมูลลงในท่อจึงจะอ่านข้อมูลต่อไปได้ ดังนั้นผลลัพธ์เป็นดังนี้:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!จะเห็นว่าโค้ดข้างต้นเกิด deadlock เพราะ goroutine ย่อยทำงานเสร็จแล้ว แต่ goroutine หลักยังคงบล็อกและรอให้ goroutine อื่นเขียนข้อมูลลงในท่อ ดังนั้นควรปิดท่อหลังจากเขียนข้อมูลเสร็จแล้ว แก้ไขเป็นโค้ดดังนี้
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// ปิดท่อ
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}หลังจากเขียนเสร็จแล้วปิดท่อ โค้ดข้างต้นจะไม่เกิด deadlock อีกต่อไป ก่อนหน้านี้กล่าวว่าการอ่านท่อมีค่าส่งกลับสองตัว เมื่อ for range遍历ท่อไม่สามารถอ่านข้อมูลสำเร็จได้ จะ退出ลูป ค่าส่งกลับที่สองหมายถึงสามารถอ่านข้อมูลสำเร็จหรือไม่ ไม่ใช่ท่อปิดแล้วหรือไม่ แม้ท่อจะปิดแล้ว สำหรับท่อที่มีบัฟเฟอร์แล้ว ยังคงสามารถอ่านข้อมูลได้ และค่าส่งกลับที่สองยังคงเป็น true ดูตัวอย่างด้านล่าง
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// ปิดท่อ
close(ch)
// อ่านข้อมูลอีกครั้ง
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}ผลลัพธ์
0 true
1 true
2 true
3 true
4 true
0 falseเนื่องจากท่อปิดแล้ว แม้บัฟเฟอร์จะว่าง การอ่านข้อมูลอีกครั้งก็ไม่ทำให้ goroutine ปัจจุบันบล็อก จะเห็นว่าในการ遍历ครั้งที่หกอ่านได้ค่าศูนย์ และ ok เป็น false
TIP
เกี่ยวกับจังหวะเวลาในการปิดท่อ ควรปิดท่อที่ฝ่ายส่งข้อมูลเข้าท่อเป็นหลัก ไม่ใช่ที่ฝ่ายรับ เพราะในกรณีส่วนใหญ่ฝ่ายรับรู้เพียงการรับข้อมูลเท่านั้น ไม่รู้ว่าควรปิดท่อเมื่อไหร่
WaitGroup
sync.WaitGroup เป็นสตรักต์ที่จัดให้ในแพ็กเกจ sync WaitGroup即รอการดำเนินการ ใช้สามารถบรรลุผลการรอกลุ่มของ goroutine ได้อย่างง่ายดาย สตรักต์นี้เปิดเผยวิธีการสามวิธีเท่านั้น
วิธีการ Add ใช้ระบุจำนวน goroutine ที่จะรอ
func (wg *WaitGroup) Add(delta int)วิธีการ Done แสดงว่า goroutine ปัจจุบันทำงานเสร็จแล้ว
func (wg *WaitGroup) Done()วิธีการ Wait รอให้ goroutine ย่อยจบ มิฉะนั้นจะบล็อก
func (wg *WaitGroup) Wait()WaitGroup ใช้งานง่ายมาก属于开箱即用 การนำไปใช้ภายในเป็นตัวนับ+สัญญาณ เมื่อโปรแกรมเริ่มต้นเรียก Add เพื่อเริ่มต้นนับ ทุกครั้งที่ goroutine ทำงานเสร็จเรียก Done การนับก็-1 จนกว่าจะลดเป็น 0 และ在此期间 goroutine หลักเรียก Wait จะบล็อกตลอดไปจนกว่าการนับทั้งหมดจะลดเป็น 0 แล้วจึงถูกปลุก ดูตัวอย่างการใช้งานอย่างง่าย
func main() {
var wait sync.WaitGroup
// ระบุจำนวน goroutine ย่อย
wait.Add(1)
go func() {
fmt.Println(1)
// ทำงานเสร็จแล้ว
wait.Done()
}()
// รอ goroutine ย่อย
wait.Wait()
fmt.Println(2)
}โค้ดส่วนนี้จะ输出 1 ก่อนแล้ว输出 2 เสมอ goroutine หลักจะรอให้ goroutine ย่อยทำงานเสร็จก่อนแล้วจึง退出
1
2สำหรับตัวอย่างแรกในบทนำเกี่ยวกับ goroutine สามารถแก้ไขได้ดังนี้
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// นับ 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// ในลูปนับ 1
wait.Add(1)
go func() {
fmt.Println(i)
// สองการนับ-1
wait.Done()
mainWait.Done()
}()
// รอให้ goroutine ในลูปปัจจุบันทำงานเสร็จ
wait.Wait()
}
// รอให้ goroutine ทั้งหมดทำงานเสร็จ
mainWait.Wait()
fmt.Println("end")
}ที่นี่ใช้ sync.WaitGroup แทน time.Sleep เดิม ลำดับการทำงานของ goroutine พร้อมกันสามารถควบคุมได้มากขึ้น ไม่ว่าดำเนินการกี่ครั้ง ผลลัพธ์เป็นดังนี้
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup มักเหมาะสำหรับเมื่อสามารถปรับจำนวน goroutine ได้อย่างไดนามิก เช่น ทราบจำนวน goroutine ล่วงหน้า หรือต้องปรับแบบไดนามิกในระหว่างการทำงาน ค่าของ WaitGroup ไม่ควรถูกคัดลอก ค่าที่คัดลอกแล้วก็ไม่ควรใช้ต่อ โดยเฉพาะเมื่อส่งเป็นพารามิเตอร์ฟังก์ชัน ควรส่งพอยน์เตอร์ไม่ใช่ค่า หากใช้ค่าที่คัดลอก การนับไม่สามารถ作用กับ WaitGroup จริงได้เลย ซึ่งอาจทำให้ goroutine หลักบล็อกและรอตลอดไป โปรแกรมจะไม่สามารถทำงานได้ตามปกติ เช่นโค้ดด้านล่าง
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}ข้อผิดพลาดแสดงว่า goroutine ทั้งหมด退出แล้ว แต่ goroutine หลักยังคงรออยู่ เช่นนี้ก็เกิด deadlock เพราะการเรียก Done ภายในฟังก์ชัน hello กับพารามิเตอร์ WaitGroup ไม่สามารถ作用กับ mainWait เดิมได้ ดังนั้นควรใช้พอยน์เตอร์ในการส่ง
hello
fatal error: all goroutines are asleep - deadlock!TIP
เมื่อการนับเป็นลบ หรือจำนวนการนับมากกว่าจำนวน goroutine ย่อย จะเกิด panic
Context
Context แปลว่าบริบท เป็นโซลูชันการควบคุม concurrency ที่ Go จัดให้ เทียบกับท่อและ WaitGroup แล้ว สามารถควบคุม goroutine ลูกหลานและ goroutine ที่มี层级ลึกกว่าได้ดีกว่า Context เองเป็นอินเทอร์เฟซ ตราบใดที่ใช้อินเทอร์เฟซนี้สามารถเรียกว่าบริบทได้ เช่น gin.Context ในเฟรมเวิร์ก Web ที่มีชื่อเสียง Gin ไลบรารีมาตรฐาน context ก็จัดให้มีการนำไปใช้หลายอย่าง分别是:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
มาดูคำจำกัดความของอินเทอร์เฟซ Context ก่อน แล้วจึงทำความเข้าใจกับการนำไปใช้เฉพาะ
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
วิธีการนี้มีค่าส่งกลับสองตัว deadline คือเวลาสิ้นสุด คือเวลาที่บริบทควรถูกยกเลิก ค่าที่สองคือ是否ตั้งค่า deadline แล้ว หากไม่ได้ตั้งค่าจะเป็น false ตลอด
Deadline() (deadline time.Time, ok bool)Done
ค่าส่งกลับเป็นช่องอ่านอย่างเดียวประเภทสตรักต์ว่าง ช่องนี้ทำหน้าที่เป็นเพียงการแจ้งเตือน ไม่ส่งข้อมูลใดๆ เมื่อการทำงานที่บริบททำควรจะถูกยกเลิก ช่องนี้จะถูกปิด สำหรับบริบทที่ไม่สนับสนุนการยกเลิก อาจส่งคืน nil
Done() <-chan struct{}Err
วิธีการนี้ส่งคืน error ใช้แสดงสาเหตุของการปิดบริบท เมื่อช่อง Done ไม่ได้ปิด จะส่งคืน nil หากปิดแล้ว จะส่งคืน err เพื่ออธิบายว่าทำไมจึงปิด
Err() errorValue
วิธีการนี้ส่งคืนค่าคีย์ที่สอดคล้องกัน หาก key ไม่มีอยู่ หรือไม่รองรับวิธีการนี้ จะส่งคืน nil
Value(key any) anyemptyCtx
顾名思义 emptyCtx คือบริบทว่าง การนำไปใช้ทั้งหมดในแพ็กเกจ context ไม่เปิดเผยต่อภายนอก แต่จัดให้มีฟังก์ชันสำหรับสร้างบริบท emptyCtx สามารถสร้างผ่าน context.Background และ context.TODO ได้ ฟังก์ชันสองฟังก์ชันมีดังนี้
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}จะเห็นว่าเพียงส่งคืนพอยน์เตอร์ emptyCtx เท่านั้น ประเภทพื้นฐานของ emptyCtx จริงๆ แล้วเป็น int เหตุผลที่ไม่ใช้สตรักต์ว่างเป็นเพราะอินสแตนซ์ของ emptyCtx ต้องมีที่อยู่หน่วยความจำที่แตกต่างกัน ไม่สามารถถูกยกเลิกได้ ไม่มี deadline และไม่สามารถ取值 วิธีการที่นำไปใช้ล้วนส่งคืนค่าศูนย์
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx มักใช้เป็นบริบทระดับบนสุด เมื่อสร้างบริบทอีกสามประเภทจะส่งเป็นบริบทพ่อ ความสัมพันธ์ของการนำไปใช้ต่างๆ ในแพ็กเกจ context แสดงดังรูปด้านล่าง
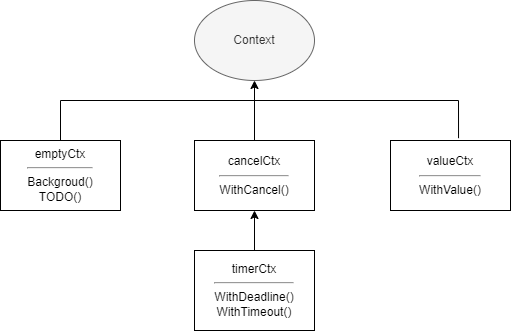
valueCtx
การนำไปใช้ของ valueCtx ค่อนข้างง่าย ภายในมีคู่คีย์-ค่าเพียงหนึ่งคู่ และฟิลด์ประเภท Context ที่ฝังอยู่
type valueCtx struct {
Context
key, val any
}ตัวมันเองนำไปใช้เพียงวิธีการ Value ตรรกะก็ง่ายมาก หากบริบทปัจจุบันหาไม่พบก็去找ในบริบทพ่อ
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}ด้านล่างดูตัวอย่างการใช้งานอย่างง่ายของ valueCtx
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// ส่งบริบท
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// สร้างตัวจับเวลาใหม่
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // ไม่มีทางดำเนินการ
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx มักใช้สำหรับการส่งข้อมูลใน goroutine หลายระดับ ไม่สามารถถูกยกเลิกได้ ดังนั้น ctx.Done จะส่งคืน nil เสมอ select จะละเว้นช่อง nil สุดท้ายผลลัพธ์เป็นดังนี้
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx และ timerCtx ล้วนใช้อินเทอร์เฟซ canceler ประเภทอินเทอร์เฟซมีดังนี้
type canceler interface {
// removeFromParent แสดงว่า是否ลบตัวเองออกจากบริบทพ่อ
// err แสดงสาเหตุของการยกเลิก
cancel(removeFromParent bool, err error)
// Done ส่งคืนช่องหนึ่งช่อง ใช้แจ้งเตือนสาเหตุของการยกเลิก
Done() <-chan struct{}
}วิธีการ cancel ไม่เปิดเผยต่อภายนอก เมื่อสร้างบริบทจะห่อเป็นค่าส่งกลับผ่าน closure เพื่อให้ภายนอกเรียกใช้ เช่นในซอร์สโค้ด context.WithCancel แสดงไว้
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// พยายามเพิ่มตัวเองเข้าไปใน children ของพ่อ
propagateCancel(parent, &c)
// ส่งคืน context และฟังก์ชัน
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx แปลว่าบริบทที่สามารถยกเลิกได้ เมื่อสร้าง หากพ่อใช้อินเทอร์เฟซ canceler จะเพิ่มตัวเองเข้าไปใน children ของพ่อ มิฉะนั้นจะค้นหาขึ้นไปเรื่อยๆ หากบริบทพ่อทั้งหมดไม่ใช้อินเทอร์เฟซ canceler จะเปิด goroutine หนึ่งรอให้พ่อยกเลิก แล้วเมื่อพ่อจบลงก็ยกเลิกบริบทปัจจุบัน เมื่อเรียก cancelFunc ช่อง Done จะถูกปิด goroutine ใดๆ ของบริบทนี้ก็จะถูกยกเลิกด้วย สุดท้ายจะลบตัวเองออกจากพ่อ ด้านล่างนี้เป็นตัวอย่างอย่างง่าย:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// ส่งคืน cancelCtx และฟังก์ชัน cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("กำลังรอการยกเลิก...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}ผลลัพธ์เป็นดังนี้
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
context canceledมาดูตัวอย่างที่มี层级嵌套ลึกกว่านี้อีกตัวอย่าง
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("กำลังประมวลผลคำขอ http...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth พ่อ取消", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail พ่อ取消", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}ในตัวอย่างสร้าง cancelCtx 3 ตัว แม้บริบทพ่อ cancelCtx จะยกเลิกบริบทลูกของมันในเวลาเดียวกัน แต่เพื่อความมั่นใจ หากสร้าง cancelCtx แล้ว หลังจาก流程ที่เกี่ยวข้องจบลง就应该เรียกฟังก์ชัน cancel ผลลัพธ์เป็นดังนี้
กำลังประมวลผลคำขอ http...
auth...
mail...
mail...
auth...
กำลังประมวลผลคำขอ http...
auth...
mail...
กำลังประมวลผลคำขอ http...
กำลังประมวลผลคำขอ http...
auth...
mail...
auth...
กำลังประมวลผลคำขอ http...
mail...
context canceled
auth พ่อ取消 context canceled
mail พ่อ取消 context canceledtimerCtx
timerCtx เพิ่มกลไกเวลา超时บนพื้นฐานของ cancelCtx แพ็กเกจ context จัดให้มีฟังก์ชันสร้างสองฟังก์ชัน分别是 WithDeadline และ WithTimeout ทั้งสองฟังก์ชันมีหน้าที่คล้ายกัน ตัวแรกระบุเวลา超时ที่เจาะจง เช่นระบุเวลาเฉพาะ 2023/3/20 16:32:00 ตัวหลังไประยะเวลา超时 เช่น 5 นาทีต่อมา ลายเซ็นของฟังก์ชันทั้งสองมีดังนี้
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx จะยกเลิกบริบทปัจจุบันโดยอัตโนมัติเมื่อเวลา到期 กระบวนการยกเลิก除了要ปิด timer เพิ่มเติมแล้ว พื้นฐานเหมือนกับ cancelCtx ด้านล่างนี้เป็นตัวอย่างการใช้งานอย่างง่ายของ timerCtx
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("บริบทยกเลิก", ctx.Err())
return
default:
fmt.Println("กำลังรอการยกเลิก...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}แม้บริบทจะ到期โดยอัตโนมัติ แต่เพื่อความมั่นใจ หลังจาก流程ที่เกี่ยวข้องจบลง最好ยกเลิกบริบทด้วยตนเอง ผลลัพธ์เป็นดังนี้
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
กำลังรอการยกเลิก...
บริบทยกเลิก context deadline exceededWithTimeout จริงๆ แล้วคล้ายกับ WithDeadline มาก การนำไปใช้เพียง封装เล็กน้อยแล้วเรียก WithDeadline และการใช้งานเหมือนกับ WithDeadline ในตัวอย่างข้างต้น มีดังนี้
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
เช่นเดียวกับการจัดสรรหน่วยความจำแล้วไม่回收จะทำให้เกิดหน่วยความจำรั่วไหล บริบทก็เป็นทรัพยากรชนิดหนึ่ง หากสร้างแต่ไม่เคยยกเลิก ก็จะทำให้เกิดบริบทรั่วไหลเช่นกัน ดังนั้น最好หลีกเลี่ยงสถานการณ์นี้
Select
select ในระบบ Linux เป็นโซลูชัน IO multiplexing ในทำนองเดียวกัน ใน Go select เป็นโครงสร้างควบคุม multiplexing ของท่อ Multiplexing คืออะไร อธิบายง่ายๆ ในประโยคเดียว: ในขณะใดขณะหนึ่ง ตรวจสอบว่าองค์ประกอบหลายตัวพร้อมใช้งานหรือไม่ องค์ประกอบที่ตรวจสอบอาจเป็นคำขอเครือข่าย ไฟล์ IO ฯลฯ ใน select ของ Go องค์ประกอบที่ตรวจสอบคือท่อ และเป็นท่อเท่านั้น ไวยากรณ์ของ select คล้ายกับคำสั่ง switch ด้านล่างนี้ดูว่าคำสั่ง select มีลักษณะอย่างไร
func main() {
// สร้างท่อสามตัว
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("ท่อทั้งหมดไม่พร้อมใช้งาน")
}
}การใช้งาน
คล้ายกับ switch select ประกอบด้วย case หลายตัวและ default หนึ่งตัว สาขา default สามารถละเว้นได้ แต่ละ case สามารถดำเนินการท่อได้เพียงหนึ่งตัว และสามารถดำเนินการได้เพียงหนึ่งอย่างเท่านั้น คืออ่านหรือเขียน เมื่อมี case หลายตัวพร้อมใช้งาน select จะสุ่มเลือก case หนึ่งตัวเพื่อดำเนินการ หาก case ทั้งหมดไม่พร้อมใช้งาน จะดำเนินการสาขา default หากไม่มีสาขา default จะบล็อกและรอ จนกว่าอย่างน้อยหนึ่ง case จะพร้อมใช้งาน เนื่องจากในตัวอย่างข้างต้นไม่ได้เขียนข้อมูลเข้าท่อ แน่นอนว่า case ทั้งหมดไม่พร้อมใช้งาน ดังนั้นสุดท้ายผลลัพธ์เป็นผลการดำเนินการของสาขา default แก้ไขเล็กน้อยเป็นดังนี้:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// เปิด goroutine ใหม่
go func() {
// เขียนข้อมูลเข้าท่อ A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}ตัวอย่างข้างต้นเปิด goroutine ใหม่เพื่อเขียนข้อมูลเข้าท่อ A select เนื่องจากไม่มีสาขา default จึงบล็อกและรอตลอดไปจนกว่าจะมี case พร้อมใช้งาน เมื่อท่อ A พร้อมใช้งาน หลังจากดำเนินการสาขาที่สอดคล้องกันแล้ว goroutine หลักก็退出โดยตรง หากต้องการตรวจสอบท่อตลอด สามารถใช้ร่วมกับลูป for ได้ ดังนี้
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// ลูป for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}เช่นนี้确实ใช้ท่อทั้งสามได้ทั้งหมด แต่ลูปไม่สิ้นสุด+select จะทำให้ goroutine หลักบล็อกตลอดไป ดังนั้นสามารถแยกไปไว้ใน goroutine ใหม่ และเพิ่มตรรกะอื่นๆ บ้าง
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // ตั้งเวลา超时 1 วินาที
break Loop // ออกจากลูป
}
}
l <- struct{}{} // บอก goroutine หลักว่าสามารถ退出ได้แล้ว
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}ในตัวอย่างข้างต้นใช้ลูป for ร่วมกับ select เพื่อตรวจสอบท่อสามตัวว่าพร้อมใช้งานหรือไม่ตลอดเวลา และ case ที่สี่เป็นท่อ超时 เมื่อ超时แล้วจะ退出ลูป จบ goroutine ย่อย สุดท้ายผลลัพธ์เป็นดังนี้
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 true超时
ตัวอย่างก่อนหน้าใช้ฟังก์ชัน time.After ค่าส่งกลับเป็นช่องอ่านอย่างเดียว ฟังก์ชันนี้ใช้ร่วมกับ select สามารถบรรลุกลไก超时ได้อย่างง่ายดาย ตัวอย่างดังนี้
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("超时")
}
}บล็อกตลอดไป
เมื่อคำสั่ง select ไม่มีอะไรเลย จะบล็อกตลอดไป เช่น
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end ไม่มีทางถูก输出 goroutine หลักจะบล็อกตลอดไป สถานการณ์นี้มักมีวัตถุประสงค์พิเศษ
TIP
ในการดำเนินการ case ของ select กับท่อที่มีค่าเป็น nil จะไม่ทำให้บล็อก case นี้จะถูกละเว้น ไม่มีทางถูกดำเนินการ ตัวอย่างด้านล่างไม่ว่าดำเนินการกี่ครั้งจะ输出 timeout เท่านั้น
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}ไม่บล็อก
通过使用 default สาขาของ select ร่วมกับท่อ เราสามารถบรรลุการส่งรับแบบไม่บล็อกได้ ดังแสดงด้านล่าง
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}ในทำนองเดียวกัน ยังสามารถบรรลุการตัดสินแบบไม่บล็อกว่า context จบลงแล้วหรือไม่
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}ล็อก
มาดูตัวอย่างหนึ่งก่อน
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// จำลองเวลาเข้าถึงข้อมูล
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// เข้าถึงข้อมูล
temp := *data
// จำลองเวลาคำนวณ
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// แก้ไขข้อมูล
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("ผลลัพธ์สุดท้าย", count)
}สำหรับตัวอย่างข้างต้น เปิดสิบ goroutine เพื่อดำเนินการ +1 กับ count และใช้ time.Sleep เพื่อจำลองเวลาที่ใช้ต่างกัน ตามสัญชาตญาณแล้ว 10 goroutine ดำเนินการ +1 10 ครั้ง ผลลัพธ์สุดท้ายต้องเป็น 10 ผลลัพธ์ที่ถูกต้องก็确实是 10 แต่ความจริงไม่เป็นเช่นนั้น ผลลัพธ์การดำเนินการของตัวอย่างข้างต้นมีดังนี้:
1
2
3
3
2
2
3
3
3
4
ผลลัพธ์สุดท้าย 4จะเห็นว่าผลลัพธ์สุดท้ายเป็น 4 และนี่เป็นเพียงหนึ่งในผลลัพธ์ที่เป็นไปได้มากมาย เนื่องจากแต่ละ goroutine ใช้เวลาในการเข้าถึงและคำนวณต่างกัน goroutine A ใช้เวลา 500 มิลลิวินาทีในการเข้าถึงข้อมูล ขณะนี้ค่า count ที่เข้าถึงได้เป็น 1 หลังจากนั้นใช้เวลา 400 มิลลิวินาทีในการคำนวณ แต่ในช่วง 400 มิลลิวินาทีนี้ goroutine B ได้เข้าถึงและคำนวณเสร็จแล้วและอัปเดตค่า count สำเร็จแล้ว หลังจาก goroutine A คำนวณเสร็จแล้ว ค่าที่ goroutine A เข้าถึงในตอนแรกล้าสมัยแล้ว แต่ goroutine A ไม่รู้เรื่องนี้ ยังคงบวกหนึ่งบนพื้นฐานของค่าที่เข้าถึงในตอนแรก และกำหนดค่าให้ count เช่นนี้ ผลลัพธ์การดำเนินการของ goroutine B ถูกทับ เมื่อมี goroutine หลายตัวอ่านและเข้าถึงข้อมูลร่วมกันหนึ่งชิ้น มักเกิดปัญหาเช่นนี้ ดังนั้นจึงต้องใช้ล็อก
ใน Go Mutex และ RWMutex ในแพ็กเกจ sync จัดให้มีการนำไปใช้สองแบบคือล็อกร่วมกันและล็อกอ่านเขียน และจัดให้มี API ที่ง่ายและใช้งานง่ายมาก การล็อกเพียง Lock() การปลดล็อกก็เพียง Unlock() ควรทราบว่า ล็อกที่ Go จัดให้เป็น non-recursive lock คือ不可重入锁 ดังนั้นการล็อกซ้ำหรือปลดล็อกซ้ำจะทำให้เกิด fatal ความหมายของล็อกอยู่ที่การปกป้อง invariant การล็อกคือหวังว่าข้อมูลจะไม่ถูกแก้ไขโดย goroutine อื่น ดังนี้
func DoSomething() {
Lock()
// ในระหว่างนี้ ข้อมูลจะไม่ถูกแก้ไขโดย goroutine อื่น
Unlock()
}หากเป็น recursive lock แล้ว อาจเกิดสถานการณ์ดังนี้
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// ทำอย่างอื่น
Unlock()
}ฟังก์ชัน DoSomthing ไม่รู้ว่าฟังก์ชัน DoOther อาจทำอะไรกับข้อมูลบ้าง จึงแก้ไขข้อมูล เช่นเปิด goroutine ย่อยอีกสองสามตัวทำลาย invariant สิ่งนี้ใช้ไม่ได้ใน Go เมื่อล็อกแล้วต้องรับประกันความไม่เปลี่ยนแปลงของ invariant ในเวลานี้การล็อกซ้ำปลดล็อกซ้ำจะทำให้เกิด deadlock ดังนั้นเมื่อเขียนโค้ดควรหลีกเลี่ยงสถานการณ์ข้างต้น เมื่อจำเป็นให้ใช้คำสั่ง defer ปลดล็อกทันทีในขณะที่ล็อก
ล็อกร่วมกัน
sync.Mutex เป็นการนำไปใช้ล็อกร่วมกันที่ Go จัดให้ ใช้อินเทอร์เฟซ sync.Locker
type Locker interface {
// ล็อก
Lock()
// ปลดล็อก
Unlock()
}ใช้ล็อกร่วมกันสามารถแก้ปัญหาข้างต้นได้อย่างสมบูรณ์แบบ ตัวอย่างดังนี้
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// ล็อก
lock.Lock()
// จำลองเวลาเข้าถึงข้อมูล
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// เข้าถึงข้อมูล
temp := *data
// จำลองเวลาคำนวณ
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// แก้ไขข้อมูล
*data = temp + ans
// ปลดล็อก
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("ผลลัพธ์สุดท้าย", count)
}ทุก goroutine ก่อนเข้าถึงข้อมูล จะล็อกก่อน หลังจากอัปเดตเสร็จแล้วจึงปลดล็อก goroutine อื่นต้องการเข้าถึงต้องได้รับล็อกก่อน มิฉะนั้นจะบล็อกและรอ เช่นนี้ก็ไม่มีปัญหาข้างต้นแล้ว ดังนั้นผลลัพธ์เป็นดังนี้
1
2
3
4
5
6
7
8
9
10
ผลลัพธ์สุดท้าย 10ล็อกอ่านเขียน
ล็อกร่วมกันเหมาะสำหรับสถานการณ์ที่ความถี่ในการอ่านและการเขียนใกล้เคียงกัน สำหรับข้อมูลที่อ่านมากเขียนน้อย หากใช้ล็อกร่วมกัน จะทำให้มีการแข่งขันล็อกของ goroutine จำนวนมากที่ไม่จำเป็น ซึ่งจะทำให้消耗ทรัพยากรระบบมาก ในเวลานี้ต้องใช้ล็อกอ่านเขียน คือล็อกอ่านเขียนร่วมกัน สำหรับ goroutine หนึ่งตัว:
- หากได้รับล็อกอ่าน goroutine อื่นดำเนินการเขียนจะบล็อก goroutine อื่นดำเนินการอ่านจะไม่บล็อก
- หากได้รับล็อกเขียน goroutine อื่นดำเนินการเขียนจะบล็อก goroutine อื่นดำเนินการอ่านจะบล็อก
การนำไปใช้ล็อกอ่านเขียนร่วมกันใน Go คือ sync.RWMutex它也ใช้อินเทอร์เฟซ Locker เช่นกัน แต่จัดให้มีวิธีการที่ใช้ได้มากขึ้น ดังนี้:
// ล็อกอ่าน
func (rw *RWMutex) RLock()
// พยายามล็อกอ่าน
func (rw *RWMutex) TryRLock() bool
// ปลดล็อกอ่าน
func (rw *RWMutex) RUnlock()
// ล็อกเขียน
func (rw *RWMutex) Lock()
// พยายามล็อกเขียน
func (rw *RWMutex) TryLock() bool
// ปลดล็อกเขียน
func (rw *RWMutex) Unlock()ในนี้การดำเนินการล็อกสองตัว TryRlock และ TryLock เป็นแบบไม่บล็อก เมื่อล็อกสำเร็จจะส่งคืน true เมื่อไม่สามารถได้รับล็อกจะไม่บล็อกแต่ส่งคืน false การนำไปใช้ภายในของล็อกอ่านเขียนยังคงเป็นล็อกร่วมกัน ไม่ได้หมายความว่าแบ่งล็อกอ่านและล็อกเขียน就有สองล็อก ตั้งแต่เริ่มต้นจนจบมีล็อกเพียงหนึ่งตัวเท่านั้น ด้านล่างนี้ดูตัวอย่างการใช้งานล็อกอ่านเขียนร่วมกัน
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// อ่านมากเขียนน้อย
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// รอให้ goroutine ย่อยจบ
wait.Wait()
fmt.Println("ผลลัพธ์สุดท้าย", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("ได้ล็อกอ่านแล้ว")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("ปลดล็อกอ่าน", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("ได้ล็อกเขียนแล้ว")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("ปลดล็อกเขียน", *i)
rw.Unlock()
wait.Done()
}ในตัวอย่างนี้เปิด goroutine เขียน 3 ตัว goroutine อ่าน 7 ตัว เมื่ออ่านข้อมูลจะได้รับล็อกอ่านก่อน goroutine อ่านสามารถได้รับล็อกอ่านได้ตามปกติ แต่จะบล็อก goroutine เขียน เมื่อได้ล็อกเขียนแล้ว จะบล็อกทั้ง goroutine อ่านและ goroutine เขียนพร้อมกัน จนกว่าจะปลดล็อกเขียน เช่นนี้ก็บรรลุการร่วมกันระหว่าง goroutine อ่านและ goroutine เขียน รับประกันความถูกต้องของข้อมูล ตัวอย่างผลลัพธ์เป็นดังนี้:
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ปลดล็อกอ่าน 0
ปลดล็อกอ่าน 0
ปลดล็อกอ่าน 0
ปลดล็อกอ่าน 0
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 1
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ปลดล็อกอ่าน 1
ปลดล็อกอ่าน 1
ปลดล็อกอ่าน 1
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 2
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 3
ผลลัพธ์สุดท้าย 3TIP
สำหรับล็อกแล้ว ไม่ควรส่งและเก็บเป็นค่า ควรใช้พอยน์เตอร์
ตัวแปรเงื่อนไข
ตัวแปรเงื่อนไข ปรากฏและใช้ร่วมกับล็อกร่วมกัน ดังนั้นบางคนอาจเข้าใจผิดเรียกว่าล็อกเงื่อนไข แต่ไม่ใช่ล็อก เป็นกลไกการสื่อสารหนึ่ง การนำไปใช้ใน Go คือ sync.Cond และลายเซ็นฟังก์ชันสำหรับสร้างตัวแปรเงื่อนไขมีดังนี้:
func NewCond(l Locker) *Condจะเห็นว่า前提ในการสร้างตัวแปรเงื่อนไขหนึ่งตัวคือต้องสร้างล็อกหนึ่งตัว sync.Cond จัดให้มีวิธีการดังต่อไปนี้สำหรับใช้งาน
// บล็อกและรอให้เงื่อนไขมีผล จนกว่าจะถูกปลุก
func (c *Cond) Wait()
// ปลุก goroutine หนึ่งตัวที่บล็อกเนื่องจากเงื่อนไข
func (c *Cond) Signal()
// ปลุก goroutine ทั้งหมดที่บล็อกเนื่องจากเงื่อนไข
func (c *Cond) Broadcast()ตัวแปรเงื่อนไขใช้งานง่ายมาก แก้ไขตัวอย่างล็อกอ่านเขียนข้างต้นเล็กน้อย即可
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// ตัวแปรเงื่อนไข
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// อ่านมากเขียนน้อย
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// รอให้ goroutine ย่อยจบ
wait.Wait()
fmt.Println("ผลลัพธ์สุดท้าย", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("ได้ล็อกอ่านแล้ว")
// เงื่อนไขไม่พอใจก็บล็อกตลอด
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("ปลดล็อกอ่าน", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("ได้ล็อกเขียนแล้ว")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("ปลดล็อกเขียน", *i)
rw.Unlock()
// ปลุก goroutine ทั้งหมดที่บล็อกเนื่องจากตัวแปรเงื่อนไข
cond.Broadcast()
wait.Done()
}เมื่อสร้างตัวแปรเงื่อนไข เนื่องจากในที่นี้ตัวแปรเงื่อนไข作用กับ goroutine อ่าน จึงส่งล็อกอ่านเป็นล็อกร่วมกันเข้าไป หากส่งล็อกอ่านเขียนร่วมกันโดยตรงจะทำให้ goroutine เขียนปลดล็อกซ้ำ的问题 ที่นี่ส่งเข้าไปคือ sync.rlocker ได้ผ่านวิธีการ RWMutex.RLocker
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }จะเห็นว่า rlocker เพียง封装การดำเนินการล็อกอ่านของล็อกอ่านเขียนร่วมกันเท่านั้น จริงๆ แล้วเป็นการอ้างอิงอันเดียวกัน ยังคงเป็นล็อกเดียวกัน เมื่อ goroutine อ่านอ่านข้อมูล หากน้อยกว่า 3 จะบล็อกตลอดไป จนกว่าข้อมูลจะมากกว่า 3 และ goroutine เขียนหลังจากอัปเดตข้อมูลแล้วจะพยายามปลุก goroutine ทั้งหมดที่บล็อกเนื่องจากตัวแปรเงื่อนไข ดังนั้นสุดท้ายผลลัพธ์เป็นดังนี้
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 1
ได้ล็อกอ่านแล้ว
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 2
ได้ล็อกอ่านแล้ว
ได้ล็อกอ่านแล้ว
ได้ล็อกเขียนแล้ว
ปลดล็อกเขียน 3 // goroutine เขียนตัวที่สามทำงานเสร็จแล้ว
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ปลดล็อกอ่าน 3
ผลลัพธ์สุดท้าย 3จากผลลัพธ์จะเห็นว่า เมื่อ goroutine เขียนตัวที่สามอัปเดตข้อมูลเสร็จแล้ว goroutine อ่านเจ็ดตัวที่บล็อกเนื่องจากตัวแปรเงื่อนไขก็恢复การดำเนินการ
TIP
สำหรับตัวแปรเงื่อนไข ควรใช้ for ไม่ใช่ if ควรใช้ลูปเพื่อตัดสินว่าเงื่อนไขพอใจหรือไม่ เพราะเมื่อ goroutine ถูกปลุกแล้วไม่สามารถรับประกันว่าเงื่อนไขปัจจุบันพอใจแล้ว
for !condition {
cond.Wait()
}sync
ใน Go เครื่องมือที่เกี่ยวข้องกับ concurrency จำนวนมากจัดให้โดยไลบรารีมาตรฐาน sync ข้างต้นได้แนะนำ sync.WaitGroup, sync.Locker เป็นต้นไปแล้ว นอกจากนั้น แพ็กเกจ sync ยังมีเครื่องมืออื่นๆ ที่สามารถใช้ได้
Once
เมื่อใช้โครงสร้างข้อมูลบางชนิด หากโครงสร้างข้อมูลเหล่านี้ใหญ่เกินไป สามารถพิจารณาใช้วิธี lazy loading คือจะเริ่มต้นโครงสร้างข้อมูลนี้ก็ต่อเมื่อ真的要ใช้มัน เช่นตัวอย่างด้านล่าง
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// เมื่อ真的要ใช้สไลซ์แล้ว จึงพิจารณาเริ่มต้น
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}ปัญหาก็มา หากมี goroutine เดียวใช้แน่นอนไม่มีปัญหา แต่ถ้ามี goroutine หลายตัวเข้าถึงก็อาจเกิดปัญหาได้ เช่น goroutine A และ B เรียกวิธีการ Add พร้อมกัน A ดำเนินการเร็วเล็กน้อย เริ่มต้นเสร็จแล้ว และเพิ่มข้อมูลสำเร็จแล้ว หลังจากนั้น goroutine B เริ่มต้นอีกครั้ง เช่นนี้ก็ทับข้อมูลที่ goroutine A เพิ่มโดยตรง นี่คือปัญหา所在
และนี่คือปัญหาที่ sync.Once ต้องแก้ไข顾名思义 Once แปลว่าครั้งเดียว sync.Once รับประกันว่าการดำเนินการที่กำหนดจะดำเนินการเพียงครั้งเดียวภายใต้เงื่อนไข concurrency การใช้งานง่ายมาก เปิดเผยวิธีการ Do หนึ่งวิธีเท่านั้น ลายเซ็นมีดังนี้:
func (o *Once) Do(f func())เมื่อใช้ เพียงส่งการดำเนินการเริ่มต้นเข้าไปในวิธีการ Do即可 ดังนี้
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// เมื่อ真的要ใช้สไลซ์แล้ว จึงพิจารณาเริ่มต้น
m.o.Do(func() {
fmt.Println("เริ่มต้น")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}ผลลัพธ์เป็นดังนี้
เริ่มต้น
4จากผลลัพธ์การ输出จะเห็นว่า ข้อมูลทั้งหมดถูกเพิ่มเข้าสไลซ์ตามปกติ การดำเนินการเริ่มต้นดำเนินการเพียงครั้งเดียว จริงๆ แล้วการนำไปใช้ของ sync.Once ง่ายมาก ลบคำอธิบายแล้วตรรกะโค้ดจริงมีเพียง 16 บรรทัด หลักการคือล็อก+การดำเนินการอะตอมิก ซอร์สโค้ดมีดังนี้:
type Once struct {
// ใช้ตัดสินว่าการดำเนินการดำเนินการแล้วหรือไม่
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// โหลดข้อมูลแบบอะตอมิก
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// ล็อก
o.m.Lock()
// ปลดล็อก
defer o.m.Unlock()
// ตัดสินว่า是否ดำเนินการ
if o.done == 0 {
// หลังจากดำเนินการเสร็จแล้วแก้ไข done
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
sync.Pool ออกแบบมาเพื่อเก็บออบเจกต์ชั่วคราวสำหรับการนำกลับมาใช้ใหม่ในอนาคต เป็นพูลออบเจกต์ชั่วคราวที่ปลอดภัยสำหรับ concurrency เก็บออบเจกต์ที่ยังไม่ได้ใช้ชั่วคราวลงในพูล ในการใช้งานในภายหลังไม่ต้องสร้างออบเจกต์เพิ่มเติมสามารถนำกลับมาใช้ใหม่ได้โดยตรง ลดความถี่ในการจัดสรรและปล่อยหน่วยความจำ จุดสำคัญที่สุดคือลดแรงกดดัน GC sync.Pool มีเพียงสองวิธีการเท่านั้น ดังนี้:
// ขอออบเจกต์หนึ่งตัว
func (p *Pool) Get() any
// ใส่ออบเจกต์หนึ่งตัว
func (p *Pool) Put(x any)และ sync.Pool มีฟิลด์ New ที่เปิดเผยต่อภายนอกหนึ่งฟิลด์ ใช้เริ่มต้นออบเจกต์หนึ่งตัวเมื่อพูลขอออบเจกต์ไม่ได้
New func() anyด้านล่างสาธิตด้วยตัวอย่างหนึ่ง
var wait sync.WaitGroup
// พูลออบเจกต์ชั่วคราว
var pool sync.Pool
// ใช้สำหรับนับว่าในระหว่างกระบวนการสร้างออบเจกต์ทั้งหมดกี่ตัว
var numOfObject atomic.Int64
// BigMemData สมมติว่าเป็นสตรักต์ที่ใช้หน่วยความจำมาก
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"หน่วยความจำใหญ่"}
}
wait.Add(1000)
// ที่นี่เปิด 1000 goroutine
for i := 0; i < 1000; i++ {
go func() {
// ขอออบเจกต์
val := pool.Get()
// ใช้ออบเจกต์
_ = val.(BigMemData)
// หลังจากใช้เสร็จแล้วปล่อยออบเจกต์กลับ
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}ในตัวอย่างเปิด 1000 goroutine ไม่หยุดขอและปล่อยออบเจกต์ในพูล หากไม่ใช้พูลออบเจกต์ แล้ว 1000 goroutine ต่างต้องสร้างออบเจกต์各自 และออบเจกต์ 1000 ตัวที่สร้างหลังจากใช้งานเสร็จแล้วต่างต้องให้ GC ปล่อยหน่วยความจำ หากมี goroutine หลายแสนตัวหรือต้นทุนในการสร้างออบเจกต์นี้สูงมาก ในสถานการณ์เช่นนี้จะใช้หน่วยความจำมากและสร้างแรงกดดันให้ GC มาก ใช้พูลออบเจกต์后可以นำออบเจกต์กลับมาใช้ใหม่ลดความถี่ในการสร้าง实例 เช่นตัวอย่างข้างต้นผลลัพธ์อาจเป็นดังนี้:
5แม้เปิด 1000 goroutine แต่ในระหว่างกระบวนการทั้งหมดสร้างออบเจกต์เพียง 5 ตัว หากไม่ใช้พูลออบเจกต์ 1000 goroutine จะสร้างออบเจกต์ 1000 ตัว การปรับปรุงที่นำมาซึ่งการยกระดับนี้เห็นได้ชัด โดยเฉพาะเมื่อปริมาณ concurrency มากมากและต้นทุนในการสร้าง实例สูงมากจะแสดงข้อได้เปรียบมากขึ้น
เมื่อใช้ sync.Pool ต้องสังเกต几点:
- ออบเจกต์ชั่วคราว:
sync.Poolเหมาะสำหรับการ存放ออบเจกต์ชั่วคราวเท่านั้น ออบเจกต์ในพูลอาจถูก GC ลบออกโดยไม่มีการแจ้งเตือนใดๆ ดังนั้นไม่แนะนำให้เก็บการเชื่อมต่อเครือข่าย การเชื่อมต่อฐานข้อมูลประเภทนี้ลงในsync.Pool - ไม่สามารถคาดเดาได้:
sync.Poolเมื่อขอออบเจกต์ ไม่สามารถคาดเดาได้ว่าออบเจกต์นี้是新创建的หรือนำกลับมาใช้ใหม่ ไม่สามารถรู้ได้ว่าในพูลมีออบเจกต์กี่ตัว - ปลอดภัยสำหรับ concurrency: ทางการรับประกันว่า
sync.Poolต้องปลอดภัยสำหรับ concurrency แต่ไม่รับประกันว่าฟังก์ชันNewที่ใช้สร้างออบเจกต์ต้องปลอดภัยสำหรับ concurrency ฟังก์ชันNewส่งโดยผู้ใช้ ดังนั้นความปลอดภัยสำหรับ concurrency ของฟังก์ชันNewต้อง由ผู้ใช้ดูแลเอง这也是为什么在ตัวอย่างข้างต้นการนับออบเจกต์ต้องใช้ค่าอะตอมิก
TIP
สุดท้ายต้องสังเกตว่า เมื่อใช้ออบเจกต์เสร็จแล้ว ต้องปล่อยกลับเข้าพูล หากใช้แล้วไม่ปล่อย การใช้พูลออบเจกต์จะไร้ความหมาย
ในไลบรารีมาตรฐานแพ็กเกจ fmt มีตัวอย่างการใช้งานพูลออบเจกต์หนึ่งตัวอย่าง ในฟังก์ชัน fmt.Fprintf
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// ขอบัฟเฟอร์พิมพ์หนึ่งตัว
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// ปล่อยหลังจากใช้เสร็จแล้ว
p.free()
return
}ในนี้การนำไปใช้ของฟังก์ชัน newPointer และวิธีการ free มีดังนี้
func newPrinter() *pp {
// ออบเจกต์หนึ่งที่ขอจากพูลออบเจกต์
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// เพื่อให้ขนาดบัฟเฟอร์ในพูลออบเจกต์大致相同以便ควบคุมขนาดบัฟเฟอร์ได้ดีขึ้น
// บัฟเฟอร์ที่ใหญ่เกินไป就不用放回พูลออบเจกต์
if cap(p.buf) > 64<<10 {
return
}
// รีเซ็ตฟิลด์แล้วปล่อยออบเจกต์เข้าพูล
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map เป็นการนำไปใช้ Map ที่ปลอดภัยสำหรับ concurrency ที่ทางการจัดให้开箱即用 ใช้งานง่ายมาก ด้านล่างนี้เป็นวิธีการที่สตรักต์นี้เปิดเผย:
// อ่านค่าตาม key หนึ่งตัว ค่าส่งกลับจะส่งคืนค่าที่สอดคล้องกันและว่าค่านั้นมีอยู่หรือไม่
func (m *Map) Load(key any) (value any, ok bool)
// เก็บคู่คีย์-ค่าหนึ่งคู่
func (m *Map) Store(key, value any)
// ลบคู่คีย์-ค่าหนึ่งคู่
func (m *Map) Delete(key any)
// หาก key นั้นมีอยู่แล้ว ก็ส่งคืนค่าเดิม มิฉะนั้นเก็บค่าใหม่และส่งคืน เมื่ออ่านค่าได้สำเร็จ loaded เป็น true มิฉะนั้นเป็น false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// ลบคู่คีย์-ค่าหนึ่งคู่ และส่งคืนค่าเดิม loaded的值取决于key是否存在
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
//遍历Map เมื่อ f() ส่งคืน false จะหยุด遍历
func (m *Map) Range(f func(key, value any) bool)ด้านล่างใช้ตัวอย่างอย่างง่ายเพื่อสาธิตการใช้งานพื้นฐานของ sync.Map
func main() {
var syncMap sync.Map
// เก็บข้อมูล
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// อ่านข้อมูล
fmt.Println(syncMap.Load("a"))
// อ่านและลบ
fmt.Println(syncMap.LoadAndDelete("a"))
// อ่านหรือเก็บ
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
//遍历 map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}ผลลัพธ์
a true
a true
hello world false
a hello world
b goodbye worldต่อไปดูตัวอย่างการใช้ map แบบ concurrency:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}ในตัวอย่างข้างต้นใช้ map ธรรมดา เปิด 10 goroutine ไม่หยุดเก็บข้อมูล แน่นอนว่านี่อาจทำให้เกิด fatal ได้มาก ผลลัพธ์น่าจะเป็นดังนี้
fatal error: concurrent map writesใช้ sync.Map สามารถหลีกเลี่ยงปัญหานี้ได้
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}ผลลัพธ์เป็นดังนี้
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4เพื่อความปลอดภัยสำหรับ concurrency แน่นอนต้องเสียสละบางอย่าง ประสิทธิภาพของ sync.Map ต่ำกว่า map 10-100 เท่า左右
อะตอมิก
ในสาขาวิทยาศาสตร์คอมพิวเตอร์ การดำเนินการอะตอมิกหรือการดำเนินการระดับปฐมภูมิ มักใช้แสดงการดำเนินการที่ไม่สามารถแบ่งย่อยเพิ่มเติมได้ เนื่องจาก การดำเนินการเหล่านี้ไม่สามารถแบ่งเป็นขั้นตอนที่เล็กลงได้ ก่อนดำเนินการเสร็จแล้ว จะไม่ถูก goroutine อื่นใดๆ ขัดจังหวะ ดังนั้นผลลัพธ์การดำเนินการ要么สำเร็จ要么ล้มเหลว ไม่มีสถานการณ์ที่สาม หากปรากฏสถานการณ์อื่น แล้วมันไม่ใช่การดำเนินการอะตอมิก เช่นโค้ดด้านล่าง:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}โค้ดข้างต้นเป็นสาขาตัดสินอย่างง่าย แม้โค้ดจะน้อยมาก แต่ก็ไม่ใช่การดำเนินการอะตอมิก การดำเนินการอะตอมิกจริงได้รับการสนับสนุนจากระดับคำสั่งฮาร์ดแวร์
ประเภท
โชคดีที่ในกรณีส่วนใหญ่ไม่จำเป็นต้องเขียนแอสเซมบลีด้วยตนเอง แพ็กเกจไลบรารีมาตรฐาน sync/atomic ของ Go ได้จัดให้มี API ที่เกี่ยวข้องกับการดำเนินการอะตอมิก จัดให้มีประเภทดังต่อไปนี้สำหรับการดำเนินการอะตอมิก
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}ในนี้ประเภทอะตอมิก Pointer รองรับ generics ประเภท Value รองรับการจัดเก็บประเภทใดๆ นอกจากนั้น ยังจัดให้มีฟังก์ชันมากมายเพื่ออำนวยความสะดวกในการดำเนินการ เนื่องจาก粒度ของการดำเนินการอะตอมิกละเอียดเกินไป ในกรณีส่วนใหญ่ เหมาะสำหรับการจัดการข้อมูลพื้นฐานเหล่านี้มากกว่า
TIP
การดำเนินการอะตอมิกในแพ็กเกจ atmoic มีเพียงลายเซ็นฟังก์ชัน ไม่มีการนำไปใช้เฉพาะ การนำไปใช้เฉพาะเขียนโดยแอสเซมบลี plan9
การใช้งาน
แต่ละประเภทอะตอมิกจะจัดให้มีวิธีการสามวิธีต่อไปนี้:
Load(): รับค่าแบบอะตอมิกSwap(newVal type) (old type): แลกเปลี่ยนค่าแบบอะตอมิก และส่งคืนค่าเดิมStore(val type): เก็บค่าแบบอะตอมิก
ประเภทที่ต่างกันอาจมีวิธีการเพิ่มเติมอื่นๆ เช่น ประเภทจำนวนเต็มจะจัดให้มีวิธีการ Add เพื่อบวกและลบแบบอะตอมิก ด้านล่างนี้เป็นตัวอย่างด้วยประเภท int64:
func main() {
var aint64 atomic.Uint64
// เก็บค่า
aint64.Store(64)
// แลกเปลี่ยนค่า
aint64.Swap(128)
// เพิ่ม
aint64.Add(112)
// โหลดค่า
fmt.Println(aint64.Load())
}หรือสามารถใช้ฟังก์ชันโดยตรงได้
func main() {
var aint64 int64
// เก็บค่า
atomic.StoreInt64(&aint64, 64)
// แลกเปลี่ยนค่า
atomic.SwapInt64(&aint64, 128)
// เพิ่ม
atomic.AddInt64(&aint64, 112)
// โหลด
fmt.Println(atomic.LoadInt64(&aint64))
}การใช้งานประเภทอื่นๆ ก็คล้ายกันมาก สุดท้ายผลลัพธ์เป็น:
240CAS
แพ็กเกจ atomic ยังจัดให้มีการดำเนินการ CompareAndSwap หรือที่เรียกว่า CAS它是核心ของการ实现 optimistic lock และโครงสร้างข้อมูลที่ไม่มีล็อก optimistic lock เองไม่ใช่ล็อก เป็นวิธีการควบคุม concurrency แบบไม่มีล็อกภายใต้เงื่อนไข concurrency: เธรด/goroutine ก่อนแก้ไขข้อมูล ไม่ล็อกก่อน แต่จะอ่านข้อมูลก่อน ดำเนินการคำนวณ แล้วเมื่อส่งการแก้ไขใช้ CAS เพื่อตัดสินว่า在此期间มีเธรดอื่นแก้ไขข้อมูลนี้หรือไม่ หากไม่มี (ค่ายังเท่ากับค่าที่อ่านก่อนหน้า) ก็แก้ไขสำเร็จ มิฉะนั้น ล้มเหลวและลองใหม่ ดังนั้นเหตุผลที่เรียกว่า optimistic lock เป็นเพราะมันมักoptimisticว่าข้อมูลร่วมกันจะไม่ถูกแก้ไข จะดำเนินการดำเนินการที่สอดคล้องกันก็ต่อเมื่อพบว่าข้อมูลไม่ได้ถูกแก้ไขเท่านั้น และ interlock ที่เข้าใจก่อนหน้านี้คือ pessimistic lock interlock มักoptimistic认为ข้อมูลร่วมกันจะถูกแก้ไขแน่นอน ดังนั้นเมื่อดำเนินการจะล็อก หลังจากดำเนินการเสร็จแล้วจะปลดล็อก เนื่องจาก concurrency ที่实现โดยไม่มีล็อกมีความปลอดภัยและประสิทธิภาพสูงกว่าล็อก โครงสร้างข้อมูลที่ปลอดภัยสำหรับ concurrency จำนวนมากใช้ CAS ในการ实现 แต่ประสิทธิภาพที่แท้จริงต้อง结合สถานการณ์การใช้งานเฉพาะ来看 ดูตัวอย่างด้านล่าง:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}นี่เป็นตัวอย่างที่ใช้ล็อกร่วมกัน ทุกครั้งก่อนเพิ่มตัวเลขจะล็อกก่อน หลังจากดำเนินการเสร็จแล้วจะปลดล็อก ในระหว่างกระบวนการจะทำให้ goroutine อื่นบล็อก ต่อไปใช้ CAS ปรับปรุง:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}สำหรับ CAS แล้ว มีพารามิเตอร์สามตัว ค่าหน่วยความจำ ค่าที่คาดหวัง ค่าใหม่ เมื่อดำเนินการ CAS จะเปรียบเทียบค่าที่คาดหวังกับค่าหน่วยความจำปัจจุบัน หากค่าหน่วยความจำเหมือนกับค่าที่คาดหวัง จะดำเนินการดำเนินการที่ตามมา มิฉะนั้นไม่ทำอะไรเลย สำหรับ การดำเนินการอะตอมิกในแพ็กเกจ atomic ของ Go ฟังก์ชันที่เกี่ยวข้องกับ CAS ต้องส่งที่อยู่ ค่าที่คาดหวัง ค่าใหม่ และจะส่งคืนค่าบูลีนว่าแทนที่สำเร็จหรือไม่ เช่นลายเซ็นฟังก์ชันการดำเนินการ CAS ประเภท int64 มีดังนี้:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)ในตัวอย่าง CAS ก่อนอื่นจะรับค่าที่คาดหวังผ่าน LoadInt64 หลังจากนั้นใช้ CompareAndSwapInt64 เพื่อเปรียบเทียบแลกเปลี่ยน หากไม่สำเร็จก็วนลูปไม่หยุด จนกว่าจะสำเร็จ การดำเนินการแบบไม่มีล็อกเช่นนี้แม้ไม่ทำให้ goroutine บล็อก แต่การวนลูปไม่หยุดสำหรับ CPU แล้ว仍是ค่าใช้จ่ายไม่น้อย ดังนั้นในบางการ实现เมื่อล้มเหลวถึงจำนวนครั้งหนึ่งอาจ放弃การดำเนินการ แต่สำหรับการดำเนินการข้างต้นแล้ว เพียงแค่บวกตัวเลขอย่างง่าย การดำเนินการที่เกี่ยวข้องไม่ซับซ้อน ดังนั้นสามารถพิจารณา实现แบบไม่มีล็อกได้
TIP
ในกรณีส่วนใหญ่ เพียงแค่เปรียบเทียบค่าไม่สามารถ做到ปลอดภัยสำหรับ concurrency ได้ เช่นปัญหา ABA ที่เกิดจาก CAS ต้องใช้ version เพิ่มเติมเพื่อแก้ปัญหา
Value
สตรักต์ atomic.Value สามารถเก็บค่าประเภทใดๆ ได้ สตรักต์มีดังนี้
type Value struct {
// ประเภท any
v any
}แม้สามารถเก็บประเภทใดๆ ได้ แต่ไม่สามารถเก็บ nil ได้ และค่าที่เก็บก่อนหลังควรมีประเภท一致 ตัวอย่างสองตัวอย่างด้านล่างไม่สามารถผ่านการคอมไพล์ได้
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into Valueนอกจากนั้น การใช้งานไม่แตกต่างจากประเภทอะตอมิกอื่นๆ มากนัก และต้องสังเกตว่า ประเภทอะตอมิกทั้งหมดไม่ควรคัดลอกค่า แต่ควรใช้พอยน์เตอร์ของพวกมัน