並發
Go 語言對於並發的支持是純天然的,這是這門語言的核心所在,其上手難度相對較小,開發人員不太需要關注底層實現就能做出一個相當不錯的並發應用,提高了開發人員的下限。
協程
協程(coroutine)是一種輕量級的線程,或者說是用戶態的線程,不受操作系統直接調度,由 Go 語言自身的調度器進行運行時調度,因此上下文切換開銷非常小,這也是為什麼 Go 的並發性能很不錯的原因之一。協程這一概念並非 Go 首次提出,Go 也不是第一個支持協程的語言,但 Go 是第一個能夠將協程和並發支持的相當簡潔和優雅的語言。
在 Go 中,創建一個協程十分的簡單,僅需要一個 go 關鍵字,就能夠快速開啟一個協程,go 關鍵字後面必須是一個函數調用。例子如下
TIP
具有返回值的內置函數不允許跟隨在 go 關鍵字後面,例如下面的錯誤示范
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}以上三種開啟協程的方式都是可以的,但是其實這個例子執行過後在大部分情況下什麼都不會輸出,協程是並發執行的,系統創建協程需要時間,而在此之前,主協程早已運行結束,一旦主線程退出,其他子協程也就自然退出了。並且協程的執行順序也是不確定的,無法預判的,例如下面的例子
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}這是一個在循環體中開啟協程的例子,永遠也無法精准的預判到它到底會輸出什麼。可能子協程還沒開始運行,主協程就已經結束了,情況如下
start
end又或者只有一部分子協程在主協程退出前成功運行,情況如下
start
0
1
5
3
4
6
7
end最簡單的做法就是讓主協程等一會兒,需要使用到 time 包下的 Sleep 函數,可以使當前協程暫停一段時間,例子如下
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// 暫停1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}再次執行輸出如下,可以看到所有的數字都完整輸出了,沒有遺漏
start
0
1
5
2
3
4
6
8
9
7
end但是順序還是亂的,因此讓每次循環都稍微的等一下。例子如下
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}現在的輸出已經是正常的順序了
start
0
1
2
3
4
5
6
7
8
9
end上面的例子中結果輸出很完美,那麼並發的問題解決了嗎,不,一點也沒有。對於並發的程序而言,不可控的因素非常多,執行的時機,先後順序,執行過程的耗時等等,倘若循環中子協程的工作不只是一個簡單的輸出數字,而是一個非常巨大復雜的任務,耗時的不確定的,那麼依舊會重現之前的問題。例如下方代碼
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// 模擬隨機耗時
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}這段代碼的輸出依舊是不確定的,下面是可能的情況之一
start
0
3
4
end因此 time.Sleep 並不是一種良好的解決辦法,幸運的是 Go 提供了非常多的並發控制手段,常用的並發控制方法有三種:
channel:管道WaitGroup:信號量Context:上下文
三種方法有著不同的適用情況,WaitGroup 可以動態的控制一組指定數量的協程,Context 更適合子孫協程嵌套層級更深的情況,管道更適合協程間通信。對於較為傳統的鎖控制,Go 也對此提供了支持:
Mutex:互斥鎖RWMutex:讀寫互斥鎖
管道
channel,譯為管道,Go 對於管道的作用如下解釋:
Do not communicate by sharing memory; instead, share memory by communicating.
即通過消息來進行內存共享,channel 就是為此而生,它是一種在協程間通信的解決方案,同時也可以用於並發控制,先來認識下 channel 的基本語法。Go 中通過關鍵字 chan 來代表管道類型,同時也必須聲明管道的存儲類型,來指定其存儲的數據是什麼類型,下面的例子是一個普通管道的模樣。
var ch chan int這是一個管道的聲明語句,此時管道還未初始化,其值為 nil,不可以直接使用。
創建
在創建管道時,有且只有一種方法,那就是使用內置函數 make,對於管道而言,make 函數接收兩個參數,第一個是管道的類型,第二個是可選參數為管道的緩沖大小。例子如下
intCh := make(chan int)
// 緩沖區大小為1的管道
strCh := make(chan string, 1)在使用完一個管道後一定要記得關閉該管道,使用內置函數 close 來關閉一個管道,該函數簽名如下。
func close(c chan<- Type)一個關閉管道的例子如下
func main() {
intCh := make(chan int)
// do something
close(intCh)
}有些時候使用 defer 來關閉管道可能會更好。
讀寫
對於一個管道而言,Go 使用了兩種很形象的操作符來表示讀寫操作:
ch <-:表示對一個管道寫入數據
<- ch:表示對一個管道讀取數據
<- 很生動的表示了數據的流動方向,來看一個對 int 類型的管道讀寫的例子
func main() {
// 如果沒有緩沖區則會導致死鎖
intCh := make(chan int, 1)
defer close(intCh)
// 寫入數據
intCh <- 114514
// 讀取數據
fmt.Println(<-intCh)
}上面的例子中創建了一個緩沖區大小為 1 的 int 型管道,對其寫入數據 114514,然後再讀取數據並輸出,最後關閉該管道。對於讀取操作而言,還有第二個返回值,一個布爾類型的值,用於表示數據是否讀取成功
ints, ok := <-intCh管道中的數據流動方式與隊列一樣,即先進先出(FIFO),協程對於管道的操作是同步的,在某一個時刻,只有一個協程能夠對其寫入數據,同時也只有一個協程能夠讀取管道中的數據。
無緩沖
對於無緩沖管道而言,因為緩沖區容量為 0,所以不會臨時存放任何數據。正因為無緩沖管道無法存放數據,在向管道寫入數據時必須立刻有其他協程來讀取數據,否則就會阻塞等待,讀取數據時也是同理,這也解釋了為什麼下面看起來很正常的代碼會發生死鎖。
func main() {
// 創建無緩沖管道
ch := make(chan int)
defer close(ch)
// 寫入數據
ch <- 123
// 讀取數據
n := <-ch
fmt.Println(n)
}無緩沖管道不應該同步的使用,正確來說應該開啟一個新的協程來發送數據,如下例
func main() {
// 創建無緩沖管道
ch := make(chan int)
defer close(ch)
go func() {
// 寫入數據
ch <- 123
}()
// 讀取數據
n := <-ch
fmt.Println(n)
}有緩沖
當管道有了緩沖區,就像是一個阻塞隊列一樣,讀取空的管道和寫入已滿的管道都會造成阻塞。無緩沖管道在發送數據時,必須立刻有人接收,否則就會一直阻塞。對於有緩沖管道則不必如此,對於有緩沖管道寫入數據時,會先將數據放入緩沖區裡,只有當緩沖區容量滿了才會阻塞的等待協程來讀取管道中的數據。同樣的,讀取有緩沖管道時,會先從緩沖區中讀取數據,直到緩沖區沒數據了,才會阻塞的等待協程來向管道中寫入數據。因此,無緩沖管道中會造成死鎖例子在這裡可以順利運行。
func main() {
// 創建有緩沖管道
ch := make(chan int, 1)
defer close(ch)
// 寫入數據
ch <- 123
// 讀取數據
n := <-ch
fmt.Println(n)
}盡管可以順利運行,但這種同步讀寫的方式是非常危險的,一旦管道緩沖區空了或者滿了,將會永遠阻塞下去,因為沒有其他協程來向管道中寫入或讀取數據。來看看下面的一個例子
func main() {
// 創建有緩沖管道
ch := make(chan int, 5)
// 創建兩個無緩沖管道
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// 負責寫
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("寫入", i)
}
chW <- struct{}{}
}()
// 負責讀
go func() {
for i := 0; i < 10; i++ {
// 每次讀取數據都需要花費1毫秒
time.Sleep(time.Millisecond)
fmt.Println("讀取", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("寫入完畢", <-chW)
fmt.Println("讀取完畢", <-chR)
}這裡總共創建了 3 個管道,一個有緩沖管道用於協程間通信,兩個無緩沖管道用於同步父子協程的執行順序。負責讀的協程每次讀取之前都會等待 1 毫秒,負責寫的協程一口氣做多也只能寫入 5 個數據,因為管道緩沖區最大只有 5,在沒有協程來讀取之前,只能阻塞等待。所以該示例輸出如下
寫入 0
寫入 1
寫入 2
寫入 3
寫入 4 // 一下寫了5個,緩沖區滿了,等其他協程來讀
讀取 0
寫入 5 // 讀一個,寫一個
讀取 1
寫入 6
讀取 2
寫入 7
讀取 3
寫入 8
寫入 9
讀取 4
寫入完畢 {} // 所有的數據都發送完畢,寫協程執行完畢
讀取 5
讀取 6
讀取 7
讀取 8
讀取 9
讀取完畢 {} // 所有的數據都讀完了,讀協程執行完畢可以看到負責寫的協程剛開始就一口氣發送了 5 個數據,緩沖區滿了以後就開始阻塞等待讀協程來讀取,後面就是每當讀協程 1 毫秒讀取一個數據,緩沖區有空位了,寫協程就寫入一個數據,直到所有數據發送完畢,寫協程執行結束,隨後當讀協程將緩沖區所有數據讀取完畢後,讀協程也執行結束,最後主協程退出。
TIP
通過內置函數 len 可以訪問管道緩沖區中數據的個數,通過 cap 可以訪問管道緩沖區的大小。
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}輸出
3 5利用管道的阻塞條件,可以很輕易的寫出一個主協程等待子協程執行完畢的例子
func main() {
// 創建一個無緩沖管道
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// 寫入
ch <- struct{}{}
}()
// 阻塞等待讀取
<-ch
fmt.Println(1)
}輸出
2
1通過有緩沖管道還可以實現一個簡單的互斥鎖,看下面的例子
var count = 0
// 緩沖區大小為1的管道
var lock = make(chan struct{}, 1)
func Add() {
// 加鎖
lock <- struct{}{}
fmt.Println("當前計數為", count, "執行加法")
count += 1
// 解鎖
<-lock
}
func Sub() {
// 加鎖
lock <- struct{}{}
fmt.Println("當前計數為", count, "執行減法")
count -= 1
// 解鎖
<-lock
}由於管道的緩沖區大小為 1,最多只有一個數據存放在緩沖區中。Add 和 Sub 函數在每次操作前都會嘗試向管道中發送數據,由於緩沖區大小為 1,倘若有其他協程已經寫入了數據,緩沖區已經滿了,當前協程就必須阻塞等待,直到緩沖區空出位置來,如此一來,在某一個時刻,最多只能有一個協程對變量 count 進行修改,這樣就實現了一個簡單的互斥鎖。
注意點
下面是一些總結,以下幾種情況使用不當會導致管道阻塞:
讀寫無緩沖管道
當對一個無緩沖管道直接進行同步讀寫操作都會導致該協程阻塞
func main() {
// 創建了一個無緩沖管道
intCh := make(chan int)
defer close(intCh)
// 發送數據
intCh <- 1
// 讀取數據
ints, ok := <-intCh
fmt.Println(ints, ok)
}讀取空緩沖區的管道
當讀取一個緩沖區為空的管道時,會導致該協程阻塞
func main() {
// 創建的有緩沖管道
intCh := make(chan int, 1)
defer close(intCh)
// 緩沖區為空,阻塞等待其他協程寫入數據
ints, ok := <-intCh
fmt.Println(ints, ok)
}寫入滿緩沖區的管道
當管道的緩沖區已滿,對其寫入數據會導致該協程阻塞
func main() {
// 創建的有緩沖管道
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// 滿了,阻塞等待其他協程來讀取數據
intCh <- 1
}管道為 nil
當管道為 nil 時,無論怎樣讀寫都會導致當前協程阻塞
func main() {
var intCh chan int
// 寫
intCh <- 1
}func main() {
var intCh chan int
// 讀
fmt.Println(<-intCh)
}關於管道阻塞的條件需要好好掌握和熟悉,大多數情況下這些問題隱藏的十分隱蔽,並不會像例子中那樣直觀。
以下幾種情況還會導致 panic:
關閉一個 nil 管道
當管道為 nil 時,使用 close 函數對其進行關閉操作會導致 panic`
func main() {
var intCh chan int
close(intCh)
}寫入已關閉的管道
對一個已關閉的管道寫入數據會導致 panic
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}關閉已關閉的管道
在一些情況中,管道可能經過層層傳遞,調用者或許也不知道到底該由誰來關閉管道,如此一來,可能會發生關閉一個已經關閉了的管道,就會發生 panic。
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// 只能對管道發送數據
ch <- 1
close(ch)
}單向管道
雙向管道指的是既可以寫,也可以讀,即可以在管道兩邊進行操作。單向管道指的是只讀或只寫的管道,即只能在管道的一邊進行操作。手動創建的一個只讀或只寫的管道沒有什麼太大的意義,因為不能對管道讀寫就失去了其存在的作用。單向管道通常是用來限制通道的行為,一般會在函數的形參和返回值中出現,例如用於關閉通道的內置函數 close 的函數簽名就用到了單向通道。
func close(c chan<- Type)又或者說常用到的 time 包下的 After 函數
func After(d Duration) <-chan Timeclose 函數的形參是一個只寫通道,After 函數的返回值是一個只讀通道,所以單向通道的語法如下:
- 箭頭符號
<-在前,就是只讀通道,如<-chan int - 箭頭符號
<-在後,就是只寫通道,如chan<- string
當嘗試對只讀的管道寫入數據時,將會無法通過編譯
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}報錯如下,意思非常明確
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)對只寫的管道讀取數據也是同理。
雙向管道可以轉換為單向管道,反過來則不可以。通常情況下,將雙向管道傳給某個協程或函數並且不希望它讀取/發送數據,就可以用到單向管道來限制另一方的行為。
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// 只能對管道發送數據
ch <- 1
}只讀管道也是一樣的道理
TIP
chan 是引用類型,即便 Go 的函數參數是值傳遞,但其引用依舊是同一個,這一點會在後續的管道原理中說明。
for range
通過 for range 語句,可以遍歷讀取緩沖管道中的數據,如下例
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}通常來說,for range 遍歷其他可迭代數據結構時,會有兩個返回值,第一個是索引,第二個元素值,但是對於管道而言,有且僅有一個返回值,for range 會不斷讀取管道中的元素,當管道緩沖區為空或無緩沖時,就會阻塞等待,直到有其他協程向管道中寫入數據才會繼續讀取數據。所以輸出如下:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!可以看到上面的代碼發生了死鎖,因為子協程已經執行完畢了,而主協程還在阻塞等待其他協程來向管道中寫入數據,所以應該管道在寫入完畢後將其關閉。修改為如下代碼
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// 關閉管道
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}寫完後關閉管道,上述代碼便不再會發生死鎖。前面提到過讀取管道是有兩個返回值的,for range 遍歷管道時,當無法成功讀取數據時,便會退出循環。第二個返回值指的是能否成功讀取數據,而不是管道是否已經關閉,即便管道已經關閉,對於有緩沖管道而言,依舊可以讀取數據,並且第二個返回值仍然為 true。看下面的一個例子
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// 關閉管道
close(ch)
// 再讀取數據
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}輸出結果
0 true
1 true
2 true
3 true
4 true
0 false由於管道已經關閉了,即便緩沖區為空,再讀取數據也不會導致當前協程阻塞,可以看到在第六次遍歷的時候讀取的是零值,並且 ok 為 false。
TIP
關於管道關閉的時機,應該盡量在向管道發送數據的那一方關閉管道,而不要在接收方關閉管道,因為大多數情況下接收方只知道接收數據,並不知道該在什麼時候關閉管道。
WaitGroup
sync.WaitGroup 是 sync 包下提供的一個結構體,WaitGroup 即等待執行,使用它可以很輕易的實現等待一組協程的效果。該結構體只對外暴露三個方法。
Add 方法用於指明要等待的協程的數量
func (wg *WaitGroup) Add(delta int)Done 方法表示當前協程已經執行完畢
func (wg *WaitGroup) Done()Wait 方法等待子協程結束,否則就阻塞
func (wg *WaitGroup) Wait()WaitGroup 使用起來十分簡單,屬於開箱即用。其內部的實現是計數器+信號量,程序開始時調用 Add 初始化計數,每當一個協程執行完畢時調用 Done,計數就-1,直到減為 0,而在此期間,主協程調用 Wait 會一直阻塞直到全部計數減為 0,然後才會被喚醒。看一個簡單的使用例子
func main() {
var wait sync.WaitGroup
// 指定子協程的數量
wait.Add(1)
go func() {
fmt.Println(1)
// 執行完畢
wait.Done()
}()
// 等待子協程
wait.Wait()
fmt.Println(2)
}這段代碼永遠都是先輸出 1 再輸出 2,主協程會等待子協程執行完畢後再退出。
1
2針對協程介紹中最開始的例子,可以做出如下修改
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// 計數10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// 循環內計數1
wait.Add(1)
go func() {
fmt.Println(i)
// 兩個計數-1
wait.Done()
mainWait.Done()
}()
// 等待當前循環的協程執行完畢
wait.Wait()
}
// 等待所有的協程執行完畢
mainWait.Wait()
fmt.Println("end")
}這裡使用了 sync.WaitGroup 替代了原先的 time.Sleep,協程並發執行的的順序更加可控,不管執行多少次,輸出都如下
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup 通常適用於可動態調整協程數量的時候,例如事先知曉協程的數量,又或者在運行過程中需要動態調整。WaitGroup 的值不應該被復制,復制後的值也不應該繼續使用,尤其是將其作為函數參數傳遞時,應該傳遞指針而不是值。倘若使用復制的值,計數完全無法作用到真正的 WaitGroup 上,這可能會導致主協程一直阻塞等待,程序將無法正常運行。例如下方的代碼
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}錯誤提示所有的協程都已經退出,但主協程依舊在等待,這就形成了死鎖,因為 hello 函數內部對一個形參 WaitGroup 調用 Done 並不會作用到原來的 mainWait 上,所以應該使用指針來進行傳遞。
hello
fatal error: all goroutines are asleep - deadlock!TIP
當計數變為負數,或者計數數量大於子協程數量時,將會引發 panic。
Context
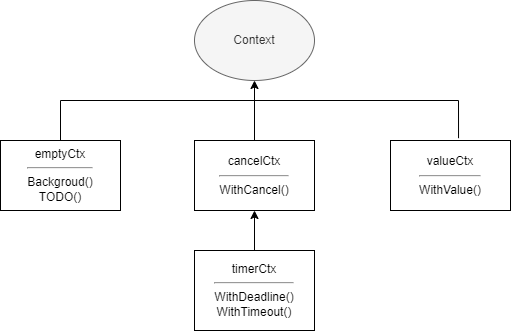
Context 譯為上下文,是 Go 提供的一種並發控制的解決方案,相比於管道和 WaitGroup,它可以更好的控制子孫協程以及層級更深的協程。Context 本身是一個接口,只要實現了該接口都可以稱之為上下文例如著名 Web 框架 Gin 中的 gin.Context。context 標准庫也提供了幾個實現,分別是:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
先來看看 Context 接口的定義,再去了解它的具體實現。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
該方法具有兩個返回值,deadline 是截止時間,即上下文應該取消的時間。第二個值是是否設置 deadline,如果沒有設置則一直為 false。
Deadline() (deadline time.Time, ok bool)Done
其返回值是一個空結構體類型的只讀管道,該管道僅僅起到通知作用,不傳遞任何數據。當上下文所做的工作應該取消時,該通道就會被關閉,對於一些不支持取消的上下文,可能會返回 nil。
Done() <-chan struct{}Err
該方法返回一個 error,用於表示上下關閉的原因。當 Done 管道沒有關閉時,返回 nil,如果關閉過後,會返回一個 err 來解釋為什麼會關閉。
Err() errorValue
該方法返回對應的鍵值,如果 key 不存在,或者不支持該方法,就會返回 nil。
Value(key any) anyemptyCtx
顧名思義,emptyCtx 就是空的上下文,context 包下所有的實現都是不對外暴露的,但是提供了對應的函數來創建上下文。emptyCtx 就可以通過 context.Background 和 context.TODO 來進行創建。兩個函數如下
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}可以看到僅僅只是返回了 emptyCtx 指針。emptyCtx 的底層類型實際上是一個 int,之所以不使用空結構體,是因為 emptyCtx 的實例必須要有不同的內存地址,它沒法被取消,沒有 deadline,也不能取值,實現的方法都是返回零值。
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx 通常是用來當作最頂層的上下文,在創建其他三種上下文時作為父上下文傳入。context 包中的各個實現關系如下圖所示
valueCtx
valueCtx 實現比較簡單,其內部只包含一對鍵值對,和一個內嵌的 Context 類型的字段。
type valueCtx struct {
Context
key, val any
}其本身只實現了 Value 方法,邏輯也很簡單,當前上下文找不到就去父上下文找。
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}下面看一個 valueCtx 的簡單使用案例
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// 傳入上下文
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// 新建定時器
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // 永遠也不會執行
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx 多用於在多級協程中傳遞一些數據,無法被取消,因此 ctx.Done 永遠會返回 nil,select 會忽略掉 nil 管道。最後輸出如下
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx 以及 timerCtx 都實現了 canceler 接口,接口類型如下
type canceler interface {
// removeFromParent 表示是否從父上下文中刪除自身
// err 表示取消的原因
cancel(removeFromParent bool, err error)
// Done 返回一個管道,用於通知取消的原因
Done() <-chan struct{}
}cancel 方法不對外暴露,在創建上下文時通過閉包將其包裝為返回值以供外界調用,就如 context.WithCancel 源代碼中所示
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// 嘗試將自身添加進父級的children中
propagateCancel(parent, &c)
// 返回context和一個函數
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx 譯為可取消的上下文,創建時,如果父級實現了 canceler,就會將自身添加進父級的 children 中,否則就一直向上查找。如果所有的父級都沒有實現 canceler,就會啟動一個協程等待父級取消,然後當父級結束時取消當前上下文。當調用 cancelFunc 時,Done 通道將會關閉,該上下文的任何子級也會隨之取消,最後會將自身從父級中刪除。下面是一個簡單的示例:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// 返回了一個cancelCtx和cancel函數
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}輸出如下
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
context canceled再來一個層級嵌套深一點的示例
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("正在處理http請求...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth 父級取消", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail 父級取消", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}例子中創建了 3 個 cancelCtx,盡管父級 cancelCtx 在取消的同時會取消它的子上下文,但是保險起見,如果創建了一個 cancelCtx,在相應的流程結束後就應該調用 cancel 函數。輸出如下
正在處理http請求...
auth...
mail...
mail...
auth...
正在處理http請求...
auth...
mail...
正在處理http請求...
正在處理http請求...
auth...
mail...
auth...
正在處理http請求...
mail...
context canceled
auth 父級取消 context canceled
mail 父級取消 context canceledtimerCtx
timerCtx 在 cancelCtx 的基礎之上增加了超時機制,context 包下提供了兩種創建的函數,分別是 WithDeadline 和 WithTimeout,兩者功能類似,前者是指定一個具體的超時時間,比如指定一個具體時間 2023/3/20 16:32:00,後者是指定一個超時的時間間隔,比如 5 分鐘後。兩個函數的簽名如下
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx 會在時間到期後自動取消當前上下文,取消的流程除了要額外的關閉 timer 之外,基本與 cancelCtx 一致。下面是一個簡單的 timerCtx 的使用示例
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("上下文取消", ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}盡管上下文到期會自動取消,但是為了保險起見,在相關流程結束後,最好手動取消上下文。輸出如下
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
上下文取消 context deadline exceededWithTimeout 其實與 WithDealine 非常相似,它的實現也只是稍微封裝了一下並調用 WithDeadline,和上面例子中的 WithDeadline 用法一樣,如下
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
就跟內存分配後不回收會造成內存洩漏一樣,上下文也是一種資源,如果創建了但從來不取消,一樣會造成上下文洩露,所以最好避免此種情況的發生。
Select
select 在 Linux 系統中,是一種 IO 多路復用的解決方案,類似的,在 Go 中,select 是一種管道多路復用的控制結構。什麼是多路復用,簡單的用一句話概括:在某一時刻,同時監測多個元素是否可用,被監測的可以是網絡請求,文件 IO 等。在 Go 中的 select 監測的元素就是管道,且只能是管道。select 的語法與 switch 語句類似,下面看看一個 select 語句長什麼樣
func main() {
// 創建三個管道
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("所有管道都不可用")
}
}使用
與 switch 類似,select 由多個 case 和一個 default 組成,default 分支可以省略。每一個 case 只能操作一個管道,且只能進行一種操作,要麼讀要麼寫,當有多個 case 可用時,select 會偽隨機的選擇一個 case 來執行。如果所有 case 都不可用,就會執行 default 分支,倘若沒有 default 分支,將會阻塞等待,直到至少有一個 case 可用。由於上例中沒有對管道寫入數據,自然所有的 case 都不可用,所以最終輸出為 default 分支的執行結果。稍微修改下後如下:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// 開啟一個新的協程
go func() {
// 向A管道寫入數據
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}上例開啟了一個新的協程來向管道 A 寫入數據,select 由於沒有默認分支,所以會一直阻塞等待直到有 case 可用。當管道 A 可用時,執行完對應分支後主協程就直接退出了。要想一直監測管道,可以配合 for 循環使用,如下。
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// for循環
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}這樣確實三個管道都能用上了,但是死循環+select 會導致主協程永久阻塞,所以可以將其單獨放到新協程中,並且加上一些其他的邏輯。
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // 設置1秒的超時時間
break Loop // 退出循環
}
}
l <- struct{}{} // 告訴主協程可以退出了
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}上例中通過 for 循環配合 select 來一直監測三個管道是否可以用,並且第四個 case 是一個超時管道,超時過後便會退出循環,結束子協程。最終輸出如下
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 true超時
上一個例子用到了 time.After 函數,其返回值是一個只讀的管道,該函數配合 select 使用可以非常簡單的實現超時機制,例子如下
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("超時")
}
}永久阻塞
當 select 語句中什麼都沒有時,就會永久阻塞,例如
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end 永遠也不會輸出,主協程會一直阻塞,這種情況一般是有特殊用途。
TIP
在 select 的 case 中對值為 nil 的管道進行操作的話,並不會導致阻塞,該 case 則會被忽略,永遠也不會被執行。例如下方代碼無論執行多少次都只會輸出 timeout。
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}非阻塞
通過使用select的default分支配合管道,我們可以實現非阻塞的收發操作,如下所示
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}同理,也可以實現非阻塞的判斷一個context是否已經結束
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}鎖
先來看看的一個例子
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// 模擬訪問耗時
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// 訪問數據
temp := *data
// 模擬計算耗時
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// 修改數據
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最終結果", count)
}對於上面的例子,開啟了十個協程來對 count 進行 +1 操作,並且使用了 time.Sleep 來模擬不同的耗時,根據直覺來講,10 個協程執行 10 個 +1 操作,最終結果一定是 10,正確結果也確實是 10,但事實並非如此,上面的例子執行結果如下:
1
2
3
3
2
2
3
3
3
4
最終結果 4可以看到最終結果為 4,而這只是眾多可能結果中的一種。由於每個協程訪問和計算所需的時間不同,A 協程訪問數據耗費 500 毫秒,此時訪問到的 count 值為 1,隨後又花費了 400 毫秒計算,但在這 400 毫秒內,B 協程已經完成了訪問和計算並成功更新了 count 的值,A 協程在計算完畢後,A 協程最初訪問到的值已經過時了,但 A 協程並不知道這件事,依舊在原先訪問到的值基礎上加一,並賦值給 count,這樣一來,B 協程的執行結果被覆蓋了。多個協程讀取和訪問一個共享數據時,尤其會發生這樣的問題,為此就需要用到鎖。
Go 中 sync 包下的 Mutex 與 RWMutex 提供了互斥鎖與讀寫鎖兩種實現,且提供了非常簡單易用的 API,加鎖只需要 Lock(),解鎖也只需要 Unlock()。需要注意的是,Go 所提供的鎖都是非遞歸鎖,也就是不可重入鎖,所以重復加鎖或重復解鎖都會導致 fatal。鎖的意義在於保護不變量,加鎖是希望數據不會被其他協程修改,如下
func DoSomething() {
Lock()
// 在這個過程中,數據不會被其他協程修改
Unlock()
}倘若是遞歸鎖的話,就可能會發生如下情況
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}DoSomthing 函數顯然不知道 DoOther 函數可能會對數據做點什麼,從而修改了數據,比如再開幾個子協程破壞了不變量。這在 Go 中是行不通的,一旦加鎖以後就必須保證不變量的不變性,此時重復加鎖解鎖都會導致死鎖。所以在編寫代碼時應該避免上述情況,必要時在加鎖的同時立即使用 defer 語句解鎖。
互斥鎖
sync.Mutex 是 Go 提供的互斥鎖實現,其實現了 sync.Locker 接口
type Locker interface {
// 加鎖
Lock()
// 解鎖
Unlock()
}使用互斥鎖可以非常完美的解決上述問題,例子如下
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// 加鎖
lock.Lock()
// 模擬訪問耗時
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// 訪問數據
temp := *data
// 模擬計算耗時
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// 修改數據
*data = temp + ans
// 解鎖
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最終結果", count)
}每一個協程在訪問數據前,都先上鎖,更新完成後再解鎖,其他協程想要訪問就必須要先獲得鎖,否則就阻塞等待。如此一來,就不存在上述問題了,所以輸出如下
1
2
3
4
5
6
7
8
9
10
最終結果 10讀寫鎖
互斥鎖適合讀操作與寫操作頻率都差不多的情況,對於一些讀多寫少的數據,如果使用互斥鎖,會造成大量的不必要的協程競爭鎖,這會消耗很多的系統資源,這時候就需要用到讀寫鎖,即讀寫互斥鎖,對於一個協程而言:
- 如果獲得了讀鎖,其他協程進行寫操作時會阻塞,其他協程進行讀操作時不會阻塞
- 如果獲得了寫鎖,其他協程進行寫操作時會阻塞,其他協程進行讀操作時會阻塞
Go 中讀寫互斥鎖的實現是 sync.RWMutex,它也同樣實現了 Locker 接口,但它提供了更多可用的方法,如下:
// 加讀鎖
func (rw *RWMutex) RLock()
// 嘗試加讀鎖
func (rw *RWMutex) TryRLock() bool
// 解讀鎖
func (rw *RWMutex) RUnlock()
// 加寫鎖
func (rw *RWMutex) Lock()
// 嘗試加寫鎖
func (rw *RWMutex) TryLock() bool
// 解寫鎖
func (rw *RWMutex) Unlock()其中 TryRlock 與 TryLock 兩個嘗試加鎖的操作是非阻塞式的,成功加鎖會返回 true,無法獲得鎖時並不會阻塞而是返回 false。讀寫互斥鎖內部實現依舊是互斥鎖,並不是說分讀鎖和寫鎖就有兩個鎖,從始至終都只有一個鎖。下面來看一個讀寫互斥鎖的使用案例
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// 讀多寫少
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// 等待子協程結束
wait.Wait()
fmt.Println("最終結果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到讀鎖")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("釋放讀鎖", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到寫鎖")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("釋放寫鎖", *i)
rw.Unlock()
wait.Done()
}該例開啟了 3 個寫協程,7 個讀協程,在讀數據的時候都會先獲得讀鎖,讀協程可以正常獲得讀鎖,但是會阻塞寫協程,獲得寫鎖的時候,則會同時阻塞讀協程和寫協程,直到釋放寫鎖,如此一來實現了讀協程與寫協程互斥,保證了數據的正確性。例子輸出如下:
拿到讀鎖
拿到讀鎖
拿到讀鎖
拿到讀鎖
釋放讀鎖 0
釋放讀鎖 0
釋放讀鎖 0
釋放讀鎖 0
拿到寫鎖
釋放寫鎖 1
拿到讀鎖
拿到讀鎖
拿到讀鎖
釋放讀鎖 1
釋放讀鎖 1
釋放讀鎖 1
拿到寫鎖
釋放寫鎖 2
拿到寫鎖
釋放寫鎖 3
最終結果 3TIP
對於鎖而言,不應該將其作為值傳遞和存儲,應該使用指針。
條件變量
條件變量,與互斥鎖一同出現和使用,所以有些人可能會誤稱為條件鎖,但它並不是鎖,是一種通訊機制。Go 中的 sync.Cond 對此提供了實現,而創建條件變量的函數簽名如下:
func NewCond(l Locker) *Cond可以看到創建一個條件變量前提就是需要創建一個鎖,sync.Cond 提供了如下的方法以供使用
// 阻塞等待條件生效,直到被喚醒
func (c *Cond) Wait()
// 喚醒一個因條件阻塞的協程
func (c *Cond) Signal()
// 喚醒所有因條件阻塞的協程
func (c *Cond) Broadcast()條件變量使用起來非常簡單,將上面的讀寫互斥鎖的例子稍微修改下即可
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// 條件變量
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// 讀多寫少
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// 等待子協程結束
wait.Wait()
fmt.Println("最終結果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到讀鎖")
// 條件不滿足就一直阻塞
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("釋放讀鎖", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到寫鎖")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("釋放寫鎖", *i)
rw.Unlock()
// 喚醒所有因條件變量阻塞的協程
cond.Broadcast()
wait.Done()
}在創建條件變量時,因為在這裡條件變量作用的是讀協程,所以將讀鎖作為互斥鎖傳入,如果直接傳入讀寫互斥鎖會導致寫協程重復解鎖的問題。這裡傳入的是 sync.rlocker,通過 RWMutex.RLocker 方法獲得。
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }可以看到 rlocker 也只是把讀寫互斥鎖的讀鎖操作封裝了一下,實際上是同一個引用,依舊是同一個鎖。讀協程讀取數據時,如果小於 3 就會一直阻塞等待,直到數據大於 3,而寫協程在更新數據後都會嘗試喚醒所有因條件變量而阻塞的協程,所以最後的輸出如下
拿到讀鎖
拿到讀鎖
拿到讀鎖
拿到讀鎖
拿到寫鎖
釋放寫鎖 1
拿到讀鎖
拿到寫鎖
釋放寫鎖 2
拿到讀鎖
拿到讀鎖
拿到寫鎖
釋放寫鎖 3 // 第三個寫協程執行完畢
釋放讀鎖 3
釋放讀鎖 3
釋放讀鎖 3
釋放讀鎖 3
釋放讀鎖 3
釋放讀鎖 3
釋放讀鎖 3
最終結果 3從結果中可以看到,當第三個寫協程更新完數據後,七個因條件變量而阻塞的讀協程都恢復了運行。
TIP
對於條件變量,應該使用 for 而不是 if,應該使用循環來判斷條件是否滿足,因為協程被喚醒時並不能保證當前條件就已經滿足了。
for !condition {
cond.Wait()
}sync
Go 中很大一部分的並發相關的工具都是 sync 標准庫提供的,上述已經介紹過了 sync.WaitGroup,sync.Locker 等,除此之外,sync 包下還有一些其他的工具可以使用。
Once
當在使用一些數據結構時,如果這些數據結構太過龐大,可以考慮采用懶加載的方式,即真正要用到它的時候才會初始化該數據結構。如下面的例子
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// 當真正用到切片的時候,才會考慮去初始化
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}那麼問題就來了,如果只有一個協程使用肯定是沒有任何問題的,但是如果有多個協程訪問的話就可能會出現問題了。比如協程 A 和 B 同時調用了 Add 方法,A 執行的稍微快一些,已經初始化完畢了,並且將數據成功添加,隨後協程 B 又初始化了一遍,這樣一來將協程 A 添加的數據直接覆蓋掉了,這就是問題所在。
而這就是 sync.Once 要解決的問題,顧名思義,Once 譯為一次,sync.Once 保證了在並發條件下指定操作只會執行一次。它的使用非常簡單,只對外暴露了一個 Do 方法,簽名如下:
func (o *Once) Do(f func())在使用時,只需要將初始化操作傳入 Do 方法即可,如下
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// 當真正用到切片的時候,才會考慮去初始化
m.o.Do(func() {
fmt.Println("初始化")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}輸出如下
初始化
4從輸出結果中可以看到,所有的數據等正常添加進切片,初始化操作只執行了一次。其實 sync.Once 的實現相當簡單,去除注釋真正的代碼邏輯只有 16 行,其原理就是鎖+原子操作。源代碼如下:
type Once struct {
// 用於判斷操作是否已經執行
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// 原子加載數據
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// 加鎖
o.m.Lock()
// 解鎖
defer o.m.Unlock()
// 判斷是否執行
if o.done == 0 {
// 執行完畢後修改done
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
sync.Pool 的設計目的是用於存儲臨時對象以便後續的復用,是一個臨時的並發安全對象池,將暫時用不到的對象放入池中,在後續使用中就不需要再額外的創建對象可以直接復用,減少內存的分配與釋放頻率,最重要的一點就是降低 GC 壓力。sync.Pool 總共只有兩個方法,如下:
// 申請一個對象
func (p *Pool) Get() any
// 放入一個對象
func (p *Pool) Put(x any)並且 sync.Pool 有一個對外暴露的 New 字段,用於對象池在申請不到對象時初始化一個對象
New func() any下面以一個例子演示
var wait sync.WaitGroup
// 臨時對象池
var pool sync.Pool
// 用於計數過程中總共創建了多少個對象
var numOfObject atomic.Int64
// BigMemData 假設這是一個佔用內存很大的結構體
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"大內存"}
}
wait.Add(1000)
// 這裡開啟1000個協程
for i := 0; i < 1000; i++ {
go func() {
// 申請對象
val := pool.Get()
// 使用對象
_ = val.(BigMemData)
// 用完之後再釋放對象
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}例子中開啟了 1000 個協程不斷的在池中申請和釋放對象,如果不采用對象池,那麼 1000 個協程都需要各自實例化對象,並且這 1000 個實例化後的對象在使用完畢後都需要由 GC 來釋放內存,如果有幾十萬個協程或者說創建該對象的成本十分的高昂,這種情況下就會佔用很大的內存並且給 GC 帶來非常大的壓力,采用對象池後,可以復用對象減少實例化的頻率,比如上述的例子輸出可能如下:
5即便開啟了 1000 個協程,整個過程中也只創建了 5 個對象,如果不采用對象池的話 1000 個協程將會創建 1000 個對象,這種優化帶來的提升是顯而易見的,尤其是在並發量特別大和實例化對象成本特別高的時候更能體現出優勢。
在使用 sync.Pool 時需要注意幾個點:
- 臨時對象:
sync.Pool只適合存放臨時對象,池中的對象可能會在沒有任何通知的情況下被 GC 移除,所以並不建議將網絡鏈接,數據庫連接這類存入sync.Pool中。 - 不可預知:
sync.Pool在申請對象時,無法預知這個對象是新創建的還是復用的,也無法知曉池中有幾個對象 - 並發安全:官方保證
sync.Pool一定是並發安全,但並不保證用於創建對象的New函數就一定是並發安全的,New函數是由使用者傳入的,所以New函數的並發安全性要由使用者自己來維護,這也是為什麼上例中對象計數要用到原子值的原因。
TIP
最後需要注意的是,當使用完對象後,一定要釋放回池中,如果用了不釋放那麼對象池的使用將毫無意義。
標准庫 fmt 包下就有一個對象池的使用案例,在 fmt.Fprintf 函數中
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// 申請一個打印緩沖區
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// 使用完畢後釋放
p.free()
return
}其中 newPointer 函數和 free 方法的實現如下
func newPrinter() *pp {
// 向對象池申請的一個對象
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// 為了讓對象池中的緩沖區大小大致相同以便更好的彈性控制緩沖區大小
// 過大的緩沖區就不用放回對象池
if cap(p.buf) > 64<<10 {
return
}
// 字段重置後釋放對象到池中
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map 是官方提供的一種並發安全 Map 的實現,開箱即用,使用起來十分的簡單,下面是該結構體對外暴露的方法:
// 根據一個key讀取值,返回值會返回對應的值和該值是否存在
func (m *Map) Load(key any) (value any, ok bool)
// 存儲一個鍵值對
func (m *Map) Store(key, value any)
// 刪除一個鍵值對
func (m *Map) Delete(key any)
// 如果該key已存在,就返回原有的值,否則將新的值存入並返回,當成功讀取到值時,loaded為true,否則為false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// 刪除一個鍵值對,並返回其原有的值,loaded的值取決於key是否存在
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// 遍歷Map,當f()返回false時,就會停止遍歷
func (m *Map) Range(f func(key, value any) bool)下面用一個簡單的示例來演示下 sync.Map 的基本使用
func main() {
var syncMap sync.Map
// 存入數據
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// 讀取數據
fmt.Println(syncMap.Load("a"))
// 讀取並刪除
fmt.Println(syncMap.LoadAndDelete("a"))
// 讀取或存入
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// 遍歷map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}輸出
a true
a true
hello world false
a hello world
b goodbye world接下來看一個並發使用 map 的例子:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}上例中使用的普通 map,開了 10 個協程不斷的存入數據,顯然這很可能會觸發 fatal,結果大概率會如下
fatal error: concurrent map writes使用 sync.Map 就可以避免這個問題
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}輸出如下
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4為了並發安全肯定需要做出一定的犧牲,sync.Map 的性能要比 map 低 10-100 倍左右。
原子
在計算機學科中,原子或原語操作,通常用於表述一些不可再細化分割的操作,由於這些操作無法再細化為更小的步驟,在執行完畢前,不會被其他的任何協程打斷,所以執行結果要麼成功要麼失敗,沒有第三種情況可言,如果出現了其他情況,那麼它就是不是原子操作。例如下方的代碼:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}上方的代碼是一個簡單的判斷分支,盡管代碼很少,但也不是原子操作,真正的原子操作是由硬件指令層面支持的。
類型
好在大多情況下並不需要自行編寫匯編,Go 標准庫 sync/atomic 包下已經提供了原子操作相關的 API,其提供了以下幾種類型以供進行原子操作。
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}其中 Pointer 原子類型支持泛型,Value 類型支持存儲任何類型,除此之外,還提供了許多函數來方便操作。因為原子操作的粒度過細,在大多數情況下,更適合處理這些基礎的數據類型。
TIP
atmoic 包下原子操作只有函數簽名,沒有具體實現,具體的實現是由 plan9 匯編編寫。
使用
每一個原子類型都會提供以下三個方法:
Load():原子的獲取值Swap(newVal type) (old type):原子的交換值,並且返回舊值Store(val type):原子的存儲值
不同的類型可能還會有其他的額外方法,比如整型類型都會提供 Add 方法來實現原子加減操作。下面以一個 int64 類型演示為例:
func main() {
var aint64 atomic.Uint64
// 存儲值
aint64.Store(64)
// 交換值
aint64.Swap(128)
// 增加
aint64.Add(112)
// 加載值
fmt.Println(aint64.Load())
}或者也可以直接使用函數
func main() {
var aint64 int64
// 存儲值
atomic.StoreInt64(&aint64, 64)
// 交換值
atomic.SwapInt64(&aint64, 128)
// 增加
atomic.AddInt64(&aint64, 112)
// 加載
fmt.Println(atomic.LoadInt64(&aint64))
}其他的類型的使用也是十分類似的,最終輸出為:
240CAS
atomic 包還提供了 CompareAndSwap 操作,也就是 CAS。它是實現樂觀鎖和無鎖數據結構的核心。樂觀鎖本身並不是鎖,是一種並發條件下無鎖化並發控制方式:線程/協程在修改數據前,不會先加鎖,而是先讀取數據,進行計算,然後在提交修改時使用CAS來判斷在此期間是否有其他線程修改過該數據。如果沒有(值仍等於之前讀取的值),則修改成功;否則,失敗並重試。因此之所以被稱作樂觀鎖,是因為它總是樂觀的假設共享數據不會被修改,僅當發現數據未被修改時才會去執行對應操作,而前面了解到的互斥量就是悲觀鎖,互斥量總是悲觀的認為共享數據肯定會被修改,所以在操作時會加鎖,操作完畢後就會解鎖。由於無鎖化實現的並發,其安全性和效率相對於鎖要高一些,許多並發安全的數據結構都采用了 CAS 來進行實現,不過真正的效率要結合具體使用場景來看。看下面的一個例子:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}這是一個使用互斥鎖的例子,每次增加數字前都會先上鎖,執行完畢後就會解鎖,過程中會導致其他協程阻塞,接下來使用 CAS 改造一下:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}對於 CAS 而言,有三個參數,內存值,期望值,新值。執行時,CAS 會將期望值與當前內存值進行比較,如果內存值與期望值相同,就會執行後續的操作,否則的話什麼也不做。對於 Go 中 atomic 包下的原子操作,CAS 相關的函數則需要傳入地址,期望值,新值,且會返回是否成功替換的布爾值。例如 int64 類型的 CAS 操作函數簽名如下:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)在 CAS 的例子中,首先會通過 LoadInt64 來獲取期望值,隨後使用 CompareAndSwapInt64 來進行比較交換,如果不成功的話就不斷循環,直到成功。這樣無鎖化的操作雖然不會導致協程阻塞,但是不斷的循環對於 CPU 而言依舊是一個不小的開銷,所以在一些實現中失敗達到了一定次數可能會放棄操作。但是對於上面的操作而言,僅僅只是簡單的數字相加,涉及到的操作並不復雜,所以完全可以考慮無鎖化實現。
TIP
大多數情況下,僅僅只是比較值是無法做到並發安全的,比如因 CAS 引起 ABA 問題,就需要使用額外加入 version 來解決問題。
Value
atomic.Value 結構體,可以存儲任意類型的值,結構體如下
type Value struct {
// any類型
v any
}盡管可以存儲任意類型,但是它不能存儲 nil,並且前後存儲的值類型應當一致,下面兩個例子都無法通過編譯
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into Value除此之外,它的使用與其他的原子類型並無太大的差別,並且需要注意的是,所有的原子類型都不應該復制值,而是應該使用它們的指針。