gc
垃圾回收要干的事就是將不再使用的對象內存釋放,騰出空間給其它對象使用。就這麼簡單的一句描述但它實現起來卻非常不簡單,垃圾回收的發展歷史已經有了幾十年,最早在上世紀 60 年代的 Lisp 語言就首次采用了垃圾回收機制,我們所熟知的 Python,Objective-C,其主要的 GC 機制就是引用計數,Java,C#采用的是分代回收。在今天來看垃圾回收,從回收算法來看,可以大致分為下面幾個大類:
- 引用計數:讓每一個對象記錄自身被引用了多少次,當計數為 0 時,就將其回收
- 標記清除:將活動的對象做標記,將未標記的對象進行回收
- 復制算法:將活動對象復制到新的內存中,將舊內存中的所有對象全部回收,達到回收垃圾目的
- 標記壓縮:標記清除的升級版,回收時將活動對象移動到堆的頭部,方便管理
從應用方式來看,可以分為下面幾個大類:
- 全局回收:一次直接回收所有的垃圾
- 分代回收:根據對象的存活時間分成不同的代,然後采用不同的回收算法
- 增量回收:每一次只進行局部的垃圾回收
TIP
前往The Journey of Go's Garbage Collector閱讀英文原文,了解更多有關 Go 垃圾回收的歷史
在剛發布時,Go 的垃圾回收機制十分簡陋,只有簡單的標記清除算法,垃圾回收所造成的 STW(Stop The World,指因垃圾回收暫停整個程序)高達幾秒甚至更久。意識到這一問題的 Go 團隊變開始著手改進垃圾回收算法,在 go1.0 到 go1.8 版本之間,他們先後嘗試過很多設想
- 讀屏障並發復制 GC:讀屏障的開銷有很多不確定性,這種方案被取消了
- 面向請求的收集器(ROC):需要時刻開啟寫屏障,拖累運行速度,拉低了編譯時間
- 分代回收:分代回收在 go 中的效率並不高,因為 go 的編譯器會傾向於將新對象分配到棧上,長期存在的對象分配到堆上,所以新生代對象大多數會被棧直接回收。
- 無寫屏障的卡片標記:通過哈希散列成本來替代寫屏障的成本,需要硬件配合
最後 Go 團隊還是選擇了三色並發標記+寫屏障的組合,並且在後續的版本中不斷的改進和優化,這種做法也一直沿用到現在,下面一組圖展示了從 go1.4 至 go1.9 的 GC 延時變化。
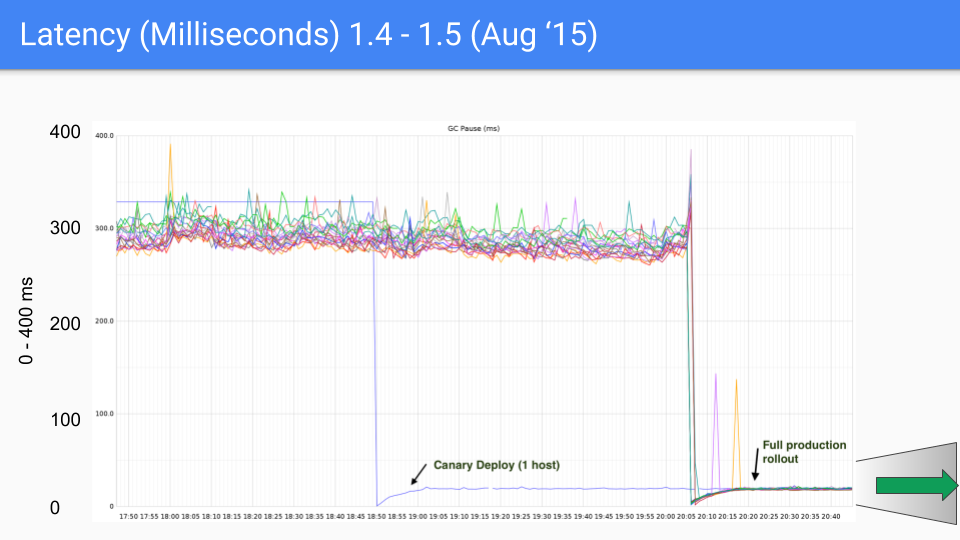
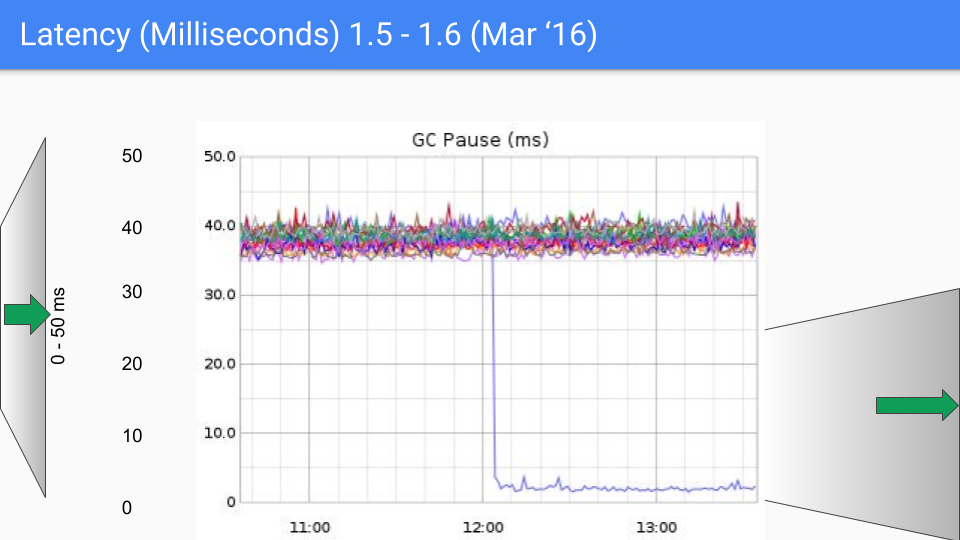
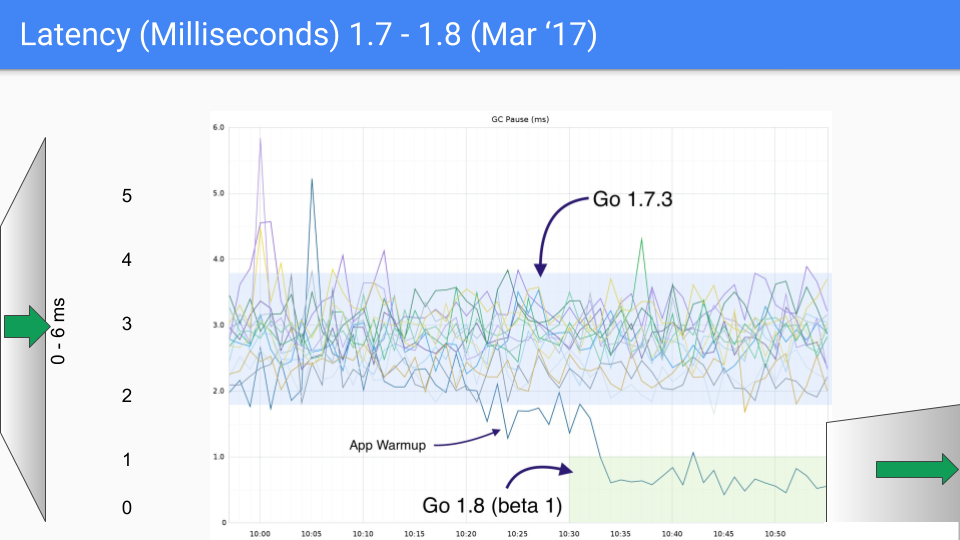
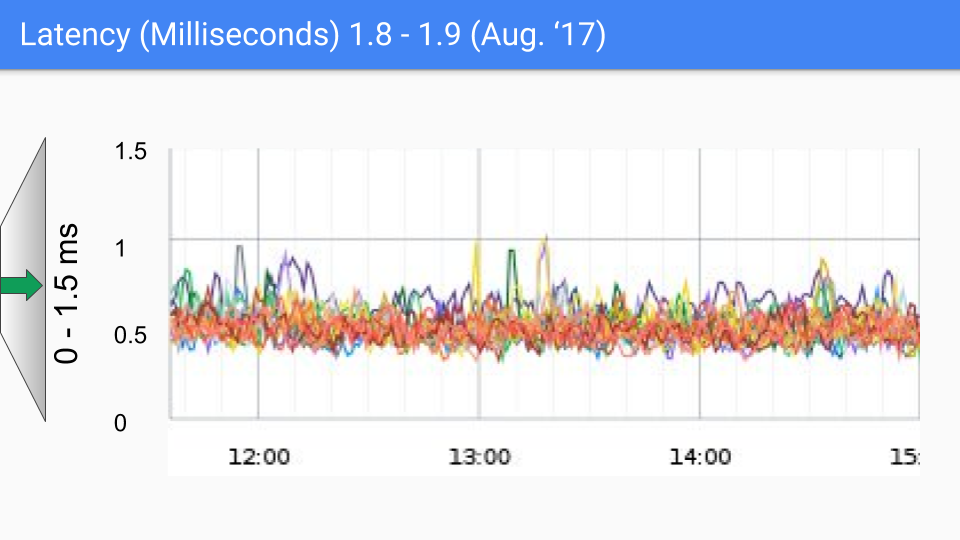
在寫下本文時,go 的最新版本已經快要來到了 go1.23,對於如今的 go 來講,GC 性能早已不算問題了,現在的 GC 延時大部分情況下都低於 100 微秒,滿足絕大部分業務場景的需要。
總的來說,Go 中的垃圾回收可以分為下面幾個階段
- 掃描階段:從棧和全局變量中收集根對象
- 標記階段:將對象著色
- 標記終止階段:處理善後工作,關閉屏障
- 回收階段:釋放和回收垃圾對象的內存
概念
在官方文檔和文章中可能會出現以下的一些概念,下面簡單的解釋說明一下
- 賦值器(mutator):一種術語化的表達方式,指的是用戶程序,在 go 中指的是用戶代碼
- 收集器(collector):指的就是負責垃圾回收的程序,在 go 中負責垃圾回收的就是運行時
- 終結器(finalizer):指的是在標記掃描工作完成後,負責回收釋放清理對象內存的代碼
- 控制器:指的是
runtime.gcController全局變量,它的類型為gcControllerState,後者實現了調步算法,負責確認何時進行垃圾回收和執行多少工作量。 - 限制器:指的是
runtime.gcCPULimiter,它負責在垃圾回收時防止 CPU 佔用率過高而影響到用戶程序
觸發
func gcStart(trigger gcTrigger)垃圾回收由runtime.gcStart函數來開啟,它只接收參數runtime.gcTrigger結構體,其中包含了 GC 觸發的原因,當前時間,以及這是第幾輪 GC。
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: current time
n uint32 // gcTriggerCycle: cycle number to start
}其中gcTriggerKind有以下幾種可選值
const (
// gcTriggerHeap indicates that a cycle should be started when
// the heap size reaches the trigger heap size computed by the
// controller.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime indicates that a cycle should be started when
// it's been more than forcegcperiod nanoseconds since the
// previous GC cycle.
gcTriggerTime
// gcTriggerCycle indicates that a cycle should be started if
// we have not yet started cycle number gcTrigger.n (relative
// to work.cycles).
gcTriggerCycle
)總的來說垃圾回收的觸發時機有三種
創建新對象時:在調用
runtime.mallocgc分配內存時,如果監測到堆內存達到了閾值(一般來說是上一次 GC 時的兩倍,該值也會被調步算法進行調整),便會開啟垃圾回收gofunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }定時強制觸發:go 在運行時會啟動一個單獨的協程來運行
runtime.forcegchelper函數,如果長時間沒有進行垃圾回收,它便會強制開啟 GC,這個時間由runtime.forcegcperiod常量決定,其值為 2 分鐘,同時在系統監控協程中也會定時檢查是否需要強制 GCgofunc forcegchelper() { for { ... gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) ... } }gofunc sysmon() { ... for { ... // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } } }手動觸發:通過
runtime.GC函數,用戶可以手動觸發垃圾回收。gofunc GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
TIP
感興趣可以前往Go Gc Pacer Re-Design閱讀英文原文,裡面講解了有關於觸發 GC 的調步算法(pacing algorithm)的設計理念和改進,因其內容比較復雜涉及過多的數學公式,正文中不做過多闡述。
標記
現如今 Go 的 GC 算法依然是先標記後清除這樣一個步驟,但其實現不再像以前一樣簡單。
標記-清除
先從最簡單的標記清除算法開始講起,在內存中,對象與對象之間的引用關系會構成一個圖,垃圾回收的工作就在這個圖上進行,工作分為兩個階段:
- 標記階段:從根節點(根節點通常是棧上的變量,全局變量等活躍對象)開始,逐個遍歷每一個可以到達的節點,並將其標記為活躍對象,直到遍歷完所有可以到達的節點,
- 清除階段:遍歷堆中的所有對象,將未標記的對象回收,將其內存空間釋放或是復用。
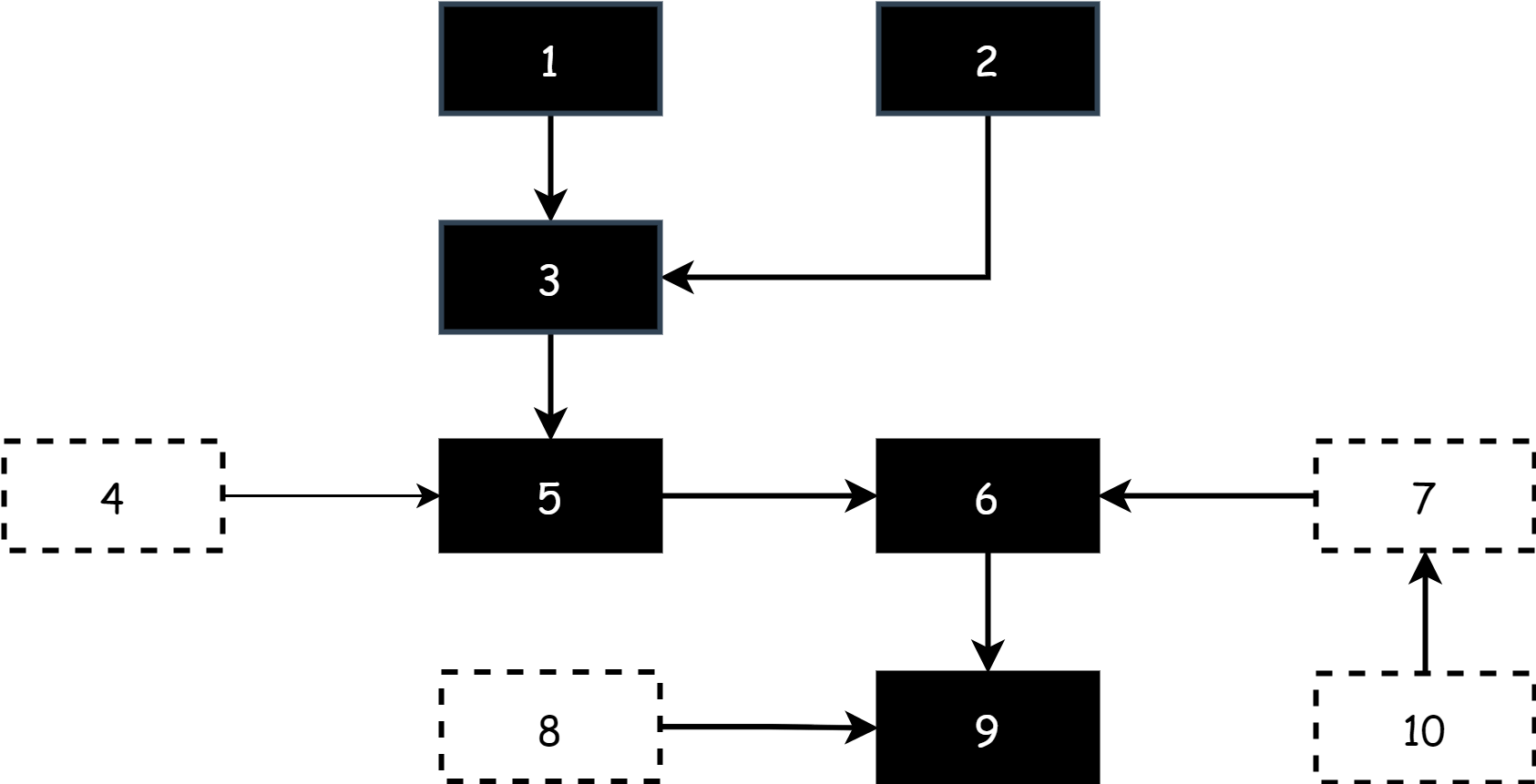
在回收的過程中,對象圖的結構不能被改變,所以要將整個程序停止,也就是 STW,回收完畢以後才能繼續運行,這種算法的缺點就在於耗時較長,比較影響程序的運行效率,這是早期版本 Go 使用的標記算法,它的缺點比較明顯
- 會產生內存碎片(由於 Go TCMalloc 式的內存管理方式,碎片問題的影響並不大)
- 在標記階段會掃描堆的所有對象
- 會導致 STW,暫停整個程序,且時間不短
三色標記
為了改進效率,Go 采用了經典的三色標記算法,所謂三色,指的是黑灰白三色:
- 黑色:在標記過程中對象已訪問過,並且它所直接引用的對象也都已經訪問過,表示活躍的對象
- 灰色:在標記過程中對象已訪問過,但它所直接引用的對象並未全部訪問,當全部訪問完後會轉變為黑色,表示活躍的對象
- 白色:在標記過程中從未被訪問過,在訪問過後會變為灰色,表示可能為垃圾對象,
在三色標記工作開始時,場上只有灰色和白色對象,所有根對象都是灰色,其它對象都是白色,如下圖所示
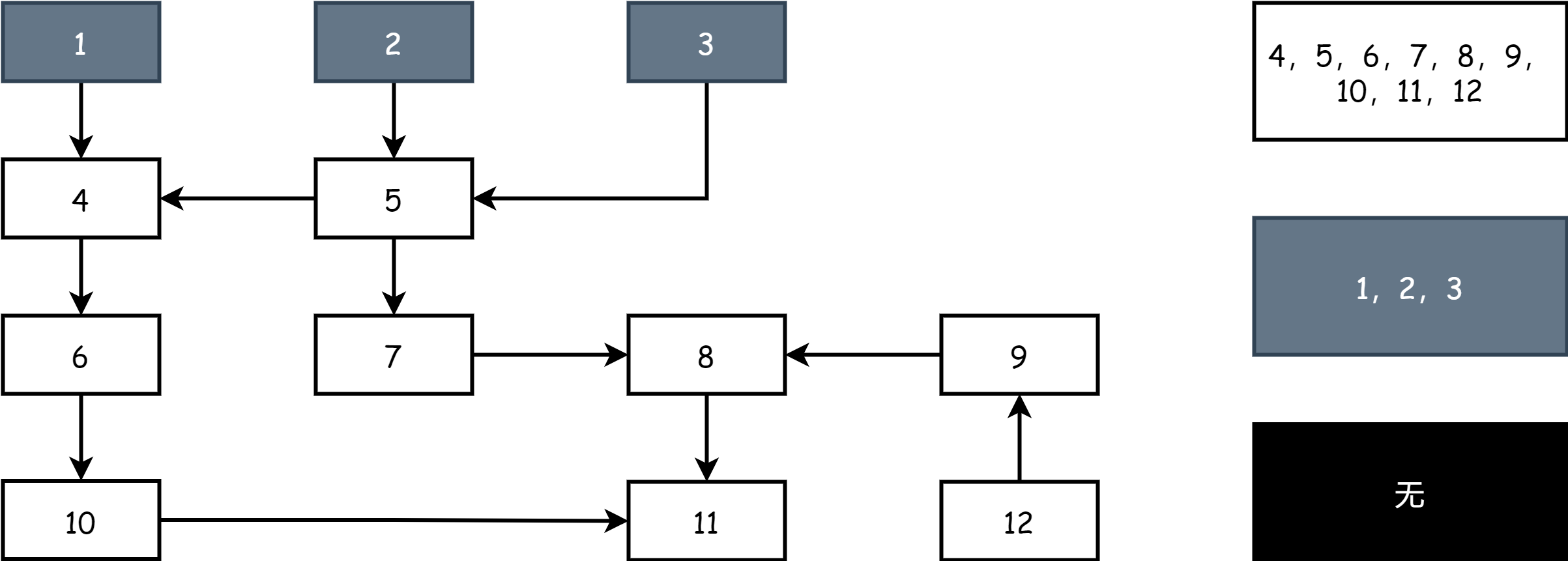
每一輪標記開始時,先從灰色對象開始,將灰色對象標記為黑色,表示其為活躍對象,然後再將黑色對象所有直接引用的對象標記為灰色,剩下的就是白色,此時場上就有了黑白灰三種顏色。
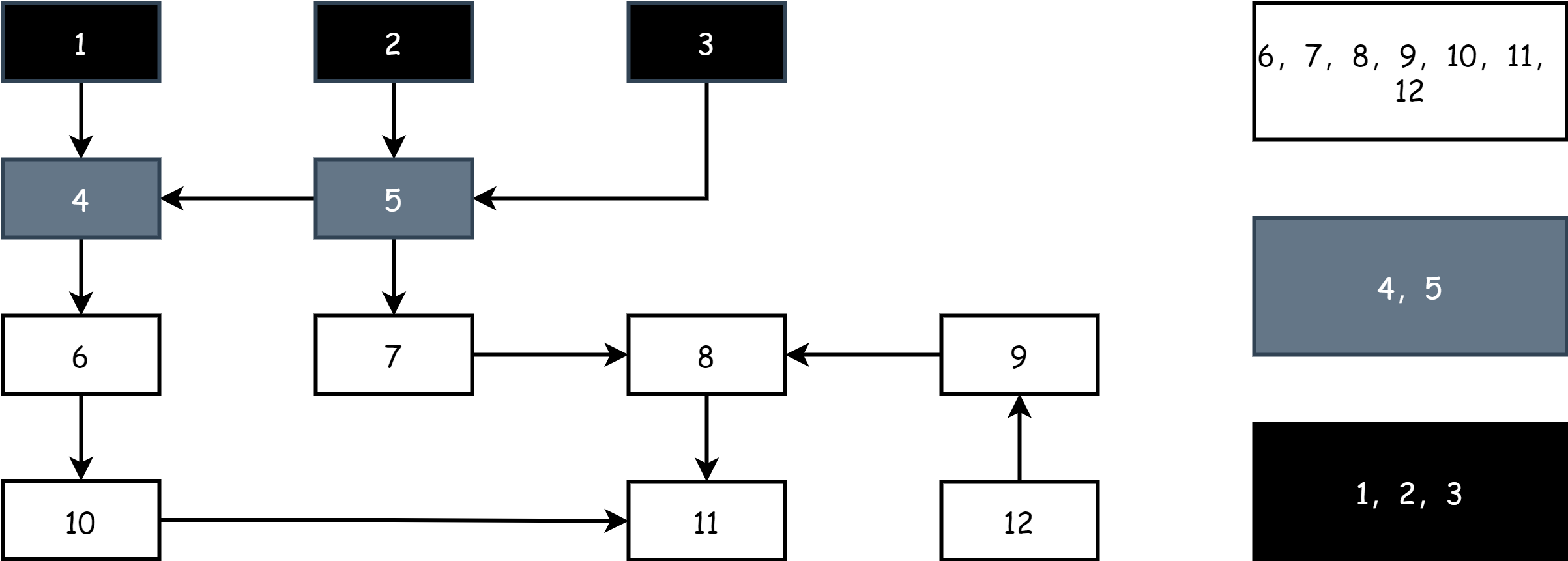
不斷重復上述步驟,直到場上只剩下黑色和白色對象,當灰色對象集合為空時,就代表著標記結束,如下圖
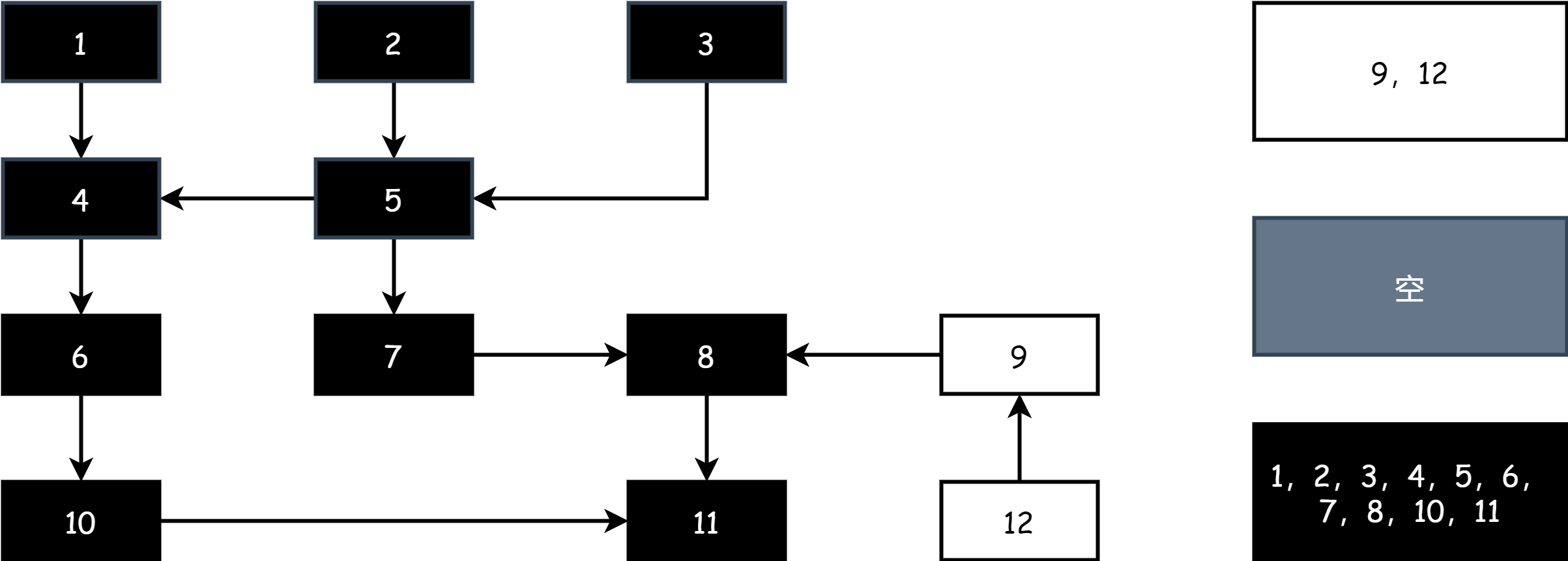
在標記結束後,在清除階段只需將白色集合中對象的內存釋放即可。
不變性
三色標記法本身沒法進行並發標記(指程序一邊運行一邊標記),如果在標記時對象圖結構發生了改變,這可能會導致兩種情況
- 多標:在對象被標記為黑色對象後,用戶程序刪除了對於該對象的所有引用,那麼它應該是白色對象需要被清除
- 漏標:在對象被標記為白色對象後,用戶程序中有其它對象引用了該對象,那麼它應該是黑色對象不應該被清除
對於第一種情況其實可以接受,因為未被清理的對象可以在下一輪回收中被處理掉。但第二種情況就沒法接受了,正在使用中的對象內存被錯誤的釋放,會造成嚴重的程序錯誤,這是必須要避免的問題。
三色不變性這一概念來自於 Pekka P. Pirinen 於 1998 年發表的論文《Barrier techniques for incremental tracing》,它指在並發標記時的對象顏色的兩個不變性:
強三色不變性:黑色對象不可以直接引用白色對象
弱三色不變性:當黑色對象直接引用白色對象時,必須有另一個灰色對象可以直接或間接訪問到該灰色對象,稱作受到灰色對象的保護
對於強三色不變性而言,已知黑色對象 3 是已經訪問過的對象,且其子對象也全都訪問過並標記為灰色對象,如果此時用戶程序並發的給黑色對象 3 添加白色對象 7 的新引用,正常來說白色對象 7 應該被標記為灰色,但由於黑色對象 3 已經被訪問過了,對象 7 不會被訪問,所以它始終都是白色對象,並最終被錯誤的清理掉。

對於弱三色不變性而言,它其實跟強三色不變性同理,因為灰色對象能夠直接或間接的訪問到該白色對象,後續標記過程中它最終會被標記為灰色對象,從而避免被誤清理。
通過不變性,可以確保在標記過程中不會有對象被誤清理,也就能保證並發條件下的標記工作的正確性,從而可以使得三色標記並發的工作,這樣一來其標記效率相比於標記-清除算法會提升相當多。要在並發情況下保證三色不變性,關鍵就在於屏障技術。
標記工作
在 GC 掃描階段時,有一個全局變量runtime.gcphase用於表示 GC 的狀態,有如下可選值:
_GCoff:標記工作未開始_GCmark:標記工作已開始_GCmarktermination:標記工作將要終止
當標記工作開始時,runtime.gcphase的狀態為_GCmark,執行標記工作的是runtime.gcDrain函數,其中runtime.gcWork參數是一個緩沖池,它存放著要追蹤的對象指針。
func gcDrain(gcw *gcWork, flags gcDrainFlags)在工作時,它會嘗試從緩沖池去獲取可追蹤的指針,如果有的話則會調用runtime.scanobject函數繼續執行掃描任務,它的作用是不斷的掃描緩沖區中的對象,將它們染黑。
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
scanobject(b, gcw)當 P 被搶佔或將發生 STW 時,掃描工作才會停止
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork是一個采用了生產者/消費者模型的隊列,該隊列負責存放待掃描的灰色對象,每一個處理器 P 本地都有這樣一個隊列,對應``runtime.p.gcw`字段。
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}runitme.scanobject函數在掃描時會不斷的將可達的白色對象標記為灰色,然後通過調用gcw.put放入本地的隊列中,同時gcDrain函數也會不斷的通過gcw.tryget來嘗試獲取灰色對象以繼續掃描。標記掃描的過程是增量式的,不需要一口氣完成所有的標記工作,標記任務因一些原因被搶佔時就會中斷,等到恢復後可以根據隊列中剩余的灰色對象繼續完成標記工作。
後台標記
標記工作並不會在 GC 開始時立即執行,在剛觸發 GC 時,go 會創建與當前處理器 P 總數量相同的標記任務,它們會被添加到全局任務隊列中,然後進入休眠直到在標記階段被喚醒。在運行時,由runtime.gcBgMarkStartWorkers來進行任務的分配,標記任務實際上指的就是runtime.gcBgMarkWorker函數,其中gcBgMarkWorkerCount和gomaxprocs兩個運行時全局變量分別表示當前 worker 的數量和處理器 P 的數量。
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has
// a background GC G.
//
// Worker Gs don't exit if gomaxprocs is reduced. If it is raised
// again, we can reuse the old workers; no need to create new workers.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// The worker is now guaranteed to be added to the pool before
// its P's next findRunnableGCWorker.
gcBgMarkWorkerCount++
}
}在 worker 啟動後,它會創建一個runtime.gcBgMarkWorkerNode結構體,將其加入全局的 worker 池runitme.gcBgMarkWorkerPool,然後調用runtime.gopark函數讓協程其陷入休眠
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// Go to sleep until woken by
// gcController.findRunnableGCWorker.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// Release this G to the pool.
gcBgMarkWorkerPool.push(&node.node)
// Note that at this point, the G may immediately be
// rescheduled and may be running.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}有兩種情況可以喚醒 worker
- 處於標記階段時,調度循環會通過
runtime.runtime.gcController.findRunnableGCWorker函數來喚醒休眠的 worker - 處於標記階段時,如果處理器 P 當前為空閒狀態,調度循環會嘗試直接從全局 worker 池
gcBgMarkWorkerPool中獲取可用的 worker
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// Try to schedule a GC worker.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}處理器 P 有結構體中有一個字段gcMarkWorkerMode來表示標記任務的執行模式,它有以下幾個可選值:
gcMarkWorkerNotWorker:表示當前處理器 P 沒有正在執行標記任務gcMarkWorkerDedicatedMode:表示當前處理器 P 專門用於執行標記任務,且期間不會被搶佔。gcMarkWorkerFractionalMode:表示當前處理器是因為 GC 利用率不達標(25%達標)才執行的標記任務,執行期間可以被搶佔。假設當前處理器 P 數量為 5,根據計算公式此時需要一個專用處理標記任務的處理器 P,利用率只達到了 20%,剩下 5%的利用率就需要開啟一個FractionalMode的處理器 P 來彌補。具體的計算代碼如下所示gofunc (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // Too many dedicated workers. dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode:表示當前處理器是因為空閒才執行標記任務,執行期間可以被搶佔。
Go 團隊不希望 GC 佔用過多的性能從而影響用戶程序的正常運行,根據這些不同的模式進行標記工作,可以在不浪費性能也不影響用戶程序的情況下完成 GC。可以注意到的是標記任務的基本分配單位是處理器 P,所以標記工作是並發進行的,多個標記任務和用戶程序之間並發的執行,互不影響。
標記輔助
協程 G 在運行時有一個字段gcAssistBytes,這裡將其稱為 GC 輔助積分。處於 GC 標記狀態時,當一個協程嘗試申請若干大小的內存,它會被扣除與申請內存大小相同的積分。如果此時積分為負數,那麼該協程必須輔助完成定量的 GC 掃描任務來償還積分,當積分為正數時,協程就可以不需要去完成輔助標記任務了。
扣除積分的函數為runtime.deductAssistCredit,它會在runtime.mallocgc函數分配內存前被調用。
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
return assistG
}然而當協程完成定量的輔助掃描工作後,就會償還定量的積分給當前協程,實際負責輔助標記的函數是runtime.gcDrainN。
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// 完成工作了
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}由於掃描是並發的,記錄下來的工作量中只有一部分是當前協程的,余下的工作量會根據輔助隊列的順序來逐個償還給其它協程,如果還有剩余的話,就會添加到全局積分gcController.assistBytesPerWork中。
func gcFlushBgCredit(scanWork int64) {
// 如果隊列為空則直接添加到全局積分中
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// 還有剩余
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}相應的,當需要償還的積分過多時(申請的內存過大),也可以使用全局積分來抵消部分自己的借債
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// 用全局積分抵押
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}標記輔助是在高負載的情況下的一種平衡手段,用戶程序分配內存的速度遠高於標記的速度,分配多少內存就進行多少標記工作。
標記終止
當所有可達的灰色對象都被染黑了過後,此時就由_GCmark狀態過渡到_GCmarktermination狀態,這個過程由runtime.gcMarkDone函數來完成。在開始時,它會檢查是否仍有任務要執行,
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// 將所有因寫屏障攔截的標記操作全部批量的執行
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}當沒有任何全局任務和本地任務要執行後,調用runtime.stopTheWorldWithSema進行 STW,然後做一些收尾的工作
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Notify the CPU limiter that GC assists will now cease.
gcCPULimiter.startGCTransition(false, now)
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Perform mark termination. This will restart the world.
gcMarkTermination(stw)首先將runtime.BlackenEnabled置為 0,表示標記工作已經結束了,通知限制器標記輔助已經結束了,關閉內存屏障,喚醒所有因輔助標記而休眠的協程,然後再重新喚醒所有的用戶協程,還要收集本輪掃描工作的各種數據來調整調步算法來為下一輪掃描做准備,收尾工作完成後,調用runtime.gcSweep函數清理垃圾對象,最後再調用runtime.startTheWorldWithSema讓程序恢復運行。
屏障
內存屏障的作用可以理解為 hook 了對象的賦值行為,在賦值前做一些指定的操作,這種 hook 代碼通常在編譯期間由編譯器插入到代碼中。前面提到過,三色標記在並發情況下添加和刪除對象引用都會導致問題,由於這兩個都是寫操作(刪除就是賦空值),所以攔截它們的屏障被統稱為寫屏障。但屏障機制並非毫無成本,攔截內存寫操作會造成額外的開銷,因此屏障機制只在堆上生效,考慮到實現復雜度和性能損耗,對於棧和寄存器則不起作用范圍內。
TIP
想要了解更多 Go 對於屏障技術的應用細節,前往Eliminate STW stack rescan閱讀英文原文,本文參考了許多內容。
插入寫屏障
插入寫屏障由 Dijkstra 提出的,它滿足強三色不變式。當給黑色對象添加了一個新的白色對象引用時,插入寫屏障會攔截此操作,將該白色對象標記為灰色,這樣可以避免黑色對象直接引用白色對象,保證了強三色不變性,這個相當好理解。

前面提到過寫屏障不會應用在棧上,如果在並發標記的過程中棧對象的引用關系發生了變化,比如棧中的黑色對象引用了堆中的白色對象,所以為了確保棧對象的正確性,只能在標記結束後再次將棧中的所有對象全部標記為灰色對象,然後重新掃描一遍,等於是一輪標記要掃描兩次棧空間,並且第二次掃描時必須要 STW,假如程序中同時存在成百上千個協程棧,那麼這一掃描過程的耗時將不容忽視,根據官方統計的數據,重新掃描的耗時大概在 10-100 毫秒左右。
優點:掃描時不需要 STW
缺點:需要二次掃描棧空間保證正確性,需要 STW
刪除寫屏障
刪除寫屏障由 Yuasa 提出,又稱基於起始快照的屏障,該方式在開始時需要 STW 來對根對象進行快照記錄,並且它會將所有根對象標黑,所有的一級子對象標灰,這樣其余的白色子對象都會處於灰色對象的保護之下。Go 團隊並沒有直接應用刪除寫屏障,而是選擇了將其與插入寫屏障混合使用,所以為了方便後續的理解,這裡還是要講一下。刪除寫屏障在並發條件下保證正確性的規則是:當從灰色或白色對象刪除對白色對象的引用時,都會直接將白色對象標記為灰色對象。
分兩種情況來解讀:
刪除灰色對象對於白色對象的引用:由於不知道白色對象下游是否被黑色對象引用,此舉可能會切斷灰色對象對於白色對象的保護
刪除白色對象對於白色對象的引用:由於不知道白色對象上游是否被灰色保護,下游是否被黑色對象引用,此舉也可能會切斷灰色對於白色對象的保護
不管是哪種情況,刪除寫屏障都會將被引用的白色對象標記為灰色,這樣一來就能滿足弱三色不變式。這是一種保守的做法,因為上下游情況未知,將其標記為灰色就等於不再視其為垃圾對象,就算刪除引用後會導致該對象不可達也就是成為垃圾對象時,也仍然會將其標記為灰色,它會在下輪掃描中被釋放掉,這總好過對象被誤清理而導致的內存錯誤。

優點:由於棧對象全黑,所以不需要二次掃描棧空間
缺點:在掃描開始時需要 STW 來對棧空間的根對象進行快照
混合寫屏障
go1.8 版本引用了新的屏障機制:混合寫屏障,即插入寫屏障與刪除寫屏障的混合,結合了它們兩個的優點:
- 插入寫屏障起始時不需要 STW 來進行快照
- 刪除寫屏障不需要 STW 來二次掃描棧空間
下面是官方給出的的偽代碼:
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
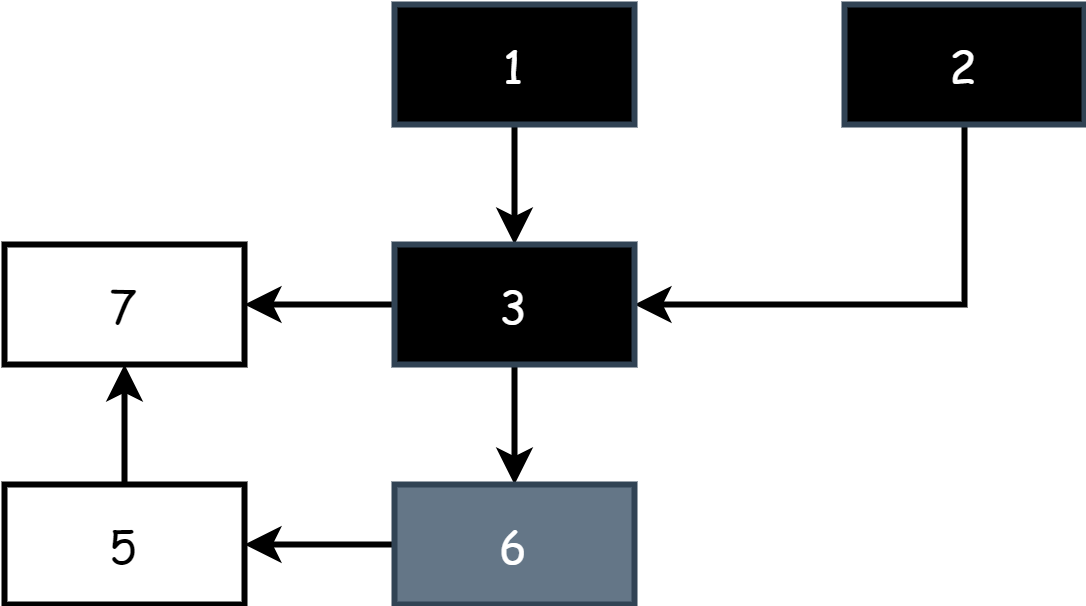
*slot = ptr簡單講解下裡面的一些概念,其中slot是一個指針,表示對其它對象的引用,*slot是原對象,ptr是新對象,*slot=ptr是一次賦值操作,等於修改對象的引用,賦空值就是刪除引用,shade()表示將一個對象標記為灰色,shade(*slot)就是將原對象標記為灰色,shade(ptr)就是將新對象標記為灰色,下面是一個例圖,假設對象 1 原來引用著對象 2,然後用戶程序修改了引用,讓對象 1 引用了對象 3,混合寫屏障捕捉到了這一行為,其中*slot代表的就是對象 2,ptr代表的就是對象 1。
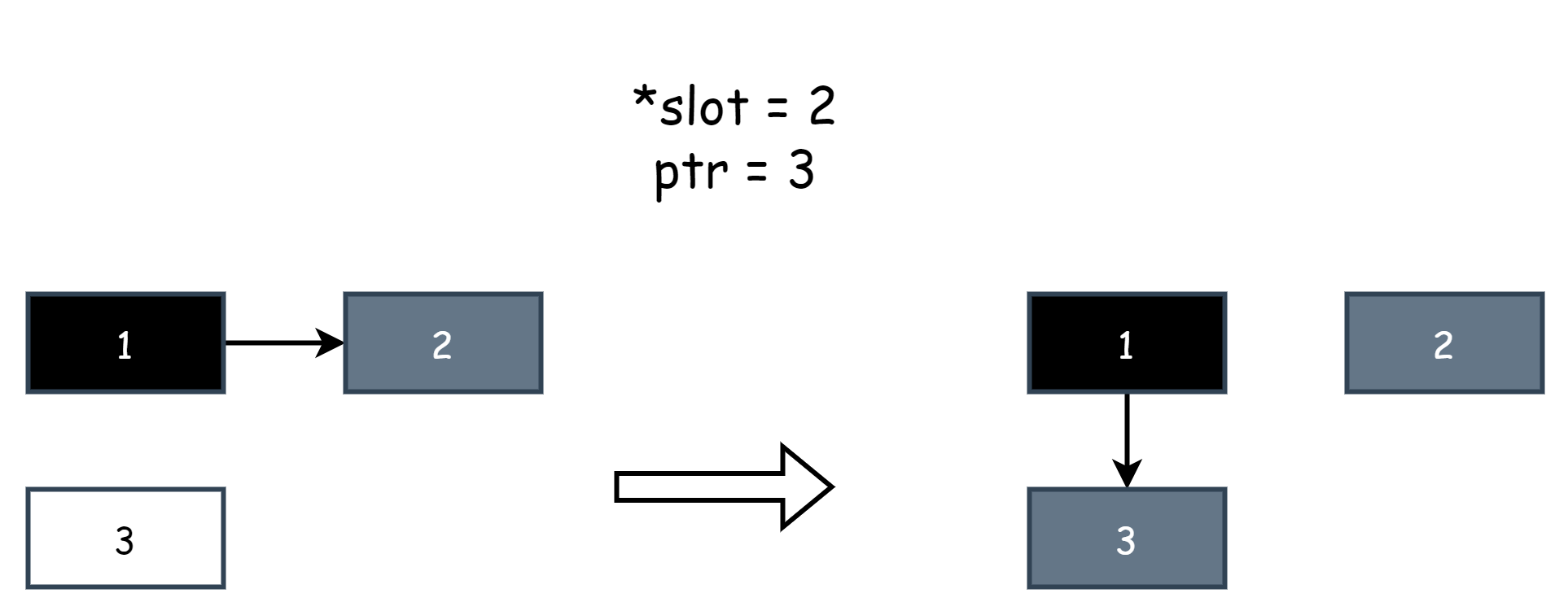
官方用一句話概括了上面偽代碼的作用
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
翻譯過來就是,當混合寫屏障攔截到寫操作時,會將原對象標記為灰色,如果當前協程棧還未被掃描過時,就將新對象也標記為灰色。
標記工作開始時,需要掃描棧空間以收集根對象,這時會直接將其全部標記為黑色,在此期間任何新創建對象也會被標記為黑色,保證棧中的所有都是黑色對象,所以偽代碼中的current stack is grey表示的就是當前協程棧還未被掃描過,所以協程棧只有兩種狀態,要麼全黑要麼全灰,在由全灰變為全黑的過程中是需要暫停當前協程的,所以在混合寫屏障下依然會有局部的 STW。當協程棧全黑時,此時一定滿足強三色不變式,因為掃描後棧中的黑色對象只會引用灰色對象,不會存在黑色對象直接引用白色對象的情況,所以此時不需要插入寫屏障,對應偽代碼
if current stack is grey:
shade(ptr)但仍然需要刪除寫屏障來滿足弱三色不變式,也就是
shade(*slot)在掃描完畢後,由於棧空間的對象已經是全黑的了,就不再需要去二次掃描棧空間了,可以節省掉 STW 的時間。
至此,也就是 go1.8 版本往後,Go 大體上確立了垃圾回收的基本框架,後續版本有關垃圾回收的優化也都是建立在混合寫屏障的基礎之上的,由於已經消除了大部分的 STW,此時垃圾回收的平均延時已經降低到了微秒級別。
著色緩存
在之前提到的屏障機制中,在攔截到寫操作時都是立即標記對象顏色,在采用混合寫屏障後,由於需要對原對象和新對象都行進行標記,所以工作量會翻倍,同時編譯器插入的代碼也會增加。為了進行優化,在 go1.10 版本中,寫屏障在進行著色時不再會立即標記對象顏色,而是會將原對象和新對象存入一個緩存池中,等積攢到了一定數量後,再進行批量標記,這樣做效率更高。
負責緩存的結構是runtime.wbBuf,它實際上是一個數組,大小為 512。
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}每一個 P 本地都有這樣一個緩存
type p struct {
...
wbBuf wbBuf
...
}在標記工作進行時,如果gcw隊列中沒有可用的灰色對象,就會將緩存中的對象放入本地隊列中。
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 刷新寫屏障緩存
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}另外一種情況是,當標記終止時,也會檢查每一個 P 本地的wbBuf是否有剩下的灰色對象
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}回收
在垃圾回收中,最重要的部分在於如何找出垃圾對象,也就是掃描標記工作,而在標記工作完成後,回收工作就相對沒那麼復雜,它只需要將未標記的對象回收釋放就行。這部分代碼主要在runtime/mgcsweep.go文件中,根據文件中注釋可以得知 Go 中的回收算法分為兩種。
對象回收
對象回收的工作會在標記終止階段,由runtime.sweepone來完成清理工作,過程是異步的。在清理時,它會嘗試在內存單元中尋找未標記的對象,然後回收掉。倘若整個內存單元都未被標記,那麼這一個單元都會被回收掉。
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// 嘗試獲取回收器
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// 清理
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}對於對象回收算法而言,回收整個單元比較的困難,所以就有了第二個回收算法。
單元回收
單元回收的工作是在內存分配前進行的,由runtime.mheap.reclaim方法來完成,它會在堆中尋找所有對象都未被標記的內存單元,然後將整個單元回收。
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}對於內存單元而言,有一個sweepgen字段用於表明其回收狀態
mspan.sweepgen == mheap.sweepgen - 2:該內存單元需要回收mspan.sweepgen == mheap.sweepgen - 1:該內存單元正在被回收mspan.sweepgen == mheap.sweepgen:該內存單元已經被回收了,可以正常使用mspan.sweepgen == mheap.sweepgen + 1:內存單元在緩存中,且需要回收mspan.sweepgen == mheap.sweepgen + 3:內存單元已經被回收了,但仍然在緩存中
mheap.sweepgen會隨著 GC 輪次而增加,並且每一次都會+2。