gc
Il compito del garbage collection è rilasciare la memoria degli oggetti non più utilizzati, liberando spazio per altri oggetti. Questa semplice descrizione si traduce in un'implementazione estremamente complessa. Lo sviluppo del garbage collection ha una storia di diversi decenni, già negli anni '60 il linguaggio Lisp ha adottato per primo il meccanismo di garbage collection. Python e Objective-C, che conosciamo, utilizzano principalmente il meccanismo di reference counting, mentre Java e C# utilizzano il garbage collection generazionale. Oggi, gli algoritmi di garbage collection possono essere suddivisi nelle seguenti categorie:
- Reference counting: ogni oggetto registra quante volte viene referenziato, quando il conteggio è 0, viene回收
- Mark-sweep: marca gli oggetti attivi,回收 gli oggetti non marcati
- Copying algorithm: copia gli oggetti attivi in una nuova memoria,回收 tutti gli oggetti nella vecchia memoria
- Mark-compact: versione migliorata del mark-sweep, sposta gli oggetti attivi all'inizio dell'heap per una gestione più facile
Dal punto di vista dell'applicazione, può essere suddiviso nelle seguenti categorie:
- Global collection:回收 tutti i garbage in una volta
- Generational collection: divide gli oggetti in diverse generazioni in base al tempo di vita, utilizzando diversi algoritmi di回收
- Incremental collection: esegue solo il garbage collection locale ogni volta
TIP
Vai a The Journey of Go's Garbage Collector per leggere l'articolo originale in inglese e saperne di più sulla storia del garbage collection di Go
Al momento del rilascio iniziale, il meccanismo di garbage collection di Go era molto rudimentale, con solo un semplice algoritmo mark-sweep, e lo STW (Stop The World, riferito alla pausa dell'intero programma a causa del garbage collection) causato dal garbage collection poteva raggiungere diversi secondi o anche più. Consapevole di questo problema, il team di Go ha iniziato a migliorare l'algoritmo di garbage collection. Tra le versioni Go 1.0 e Go 1.8, hanno provato molte idee:
- Read barrier concurrent copying GC: l'overhead del read barrier ha molte incertezze, questo piano è stato cancellato
- Request-oriented collector (ROC): richiede di abilitare il write barrier in ogni momento, rallentando l'esecuzione e aumentando il tempo di compilazione
- Generational collection: l'efficienza del generational collection in Go non è alta, perché il compilatore Go tende ad allocare nuovi oggetti sullo stack e gli oggetti a lungo termine sull'heap, quindi la maggior parte degli oggetti di nuova generazione viene回收 direttamente dallo stack.
- Card marking senza write barrier: sostituisce il costo del write barrier con il costo dell'hashing, richiede hardware specifico
Alla fine, il team di Go ha scelto la combinazione di three-color concurrent marking + write barrier, e ha continuato a migliorare e ottimizzare nelle versioni successive, e questo approccio è stato utilizzato fino ad oggi. Il seguente gruppo di immagini mostra le variazioni di latenza GC da Go 1.4 a Go 1.9.
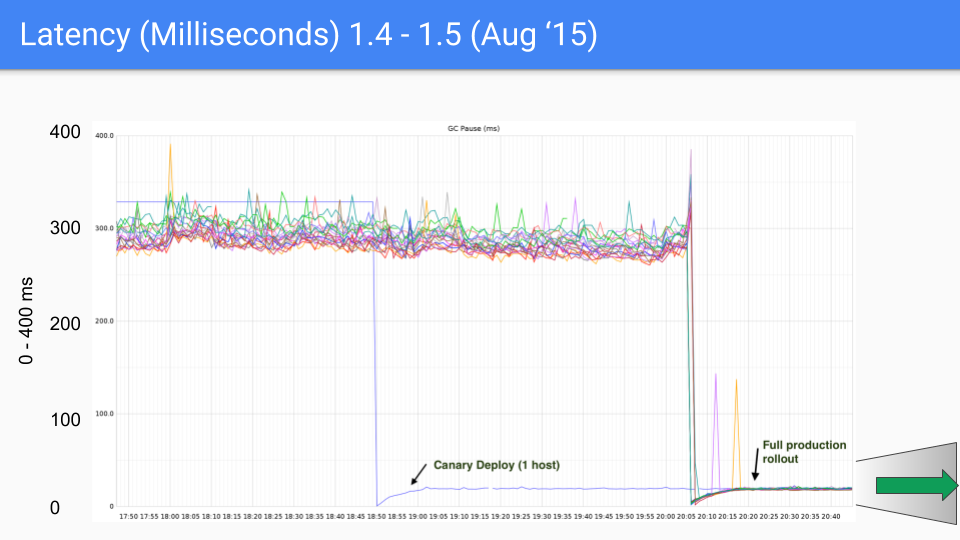
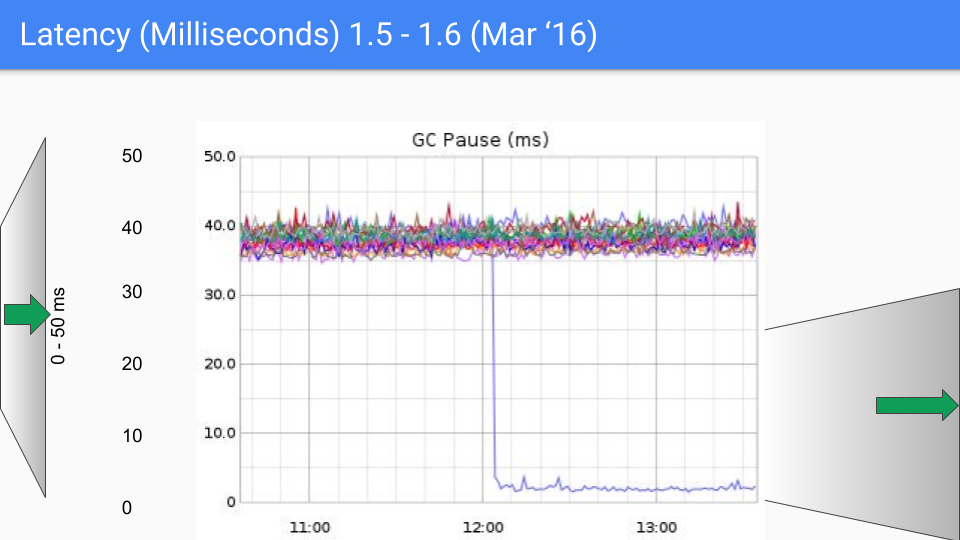
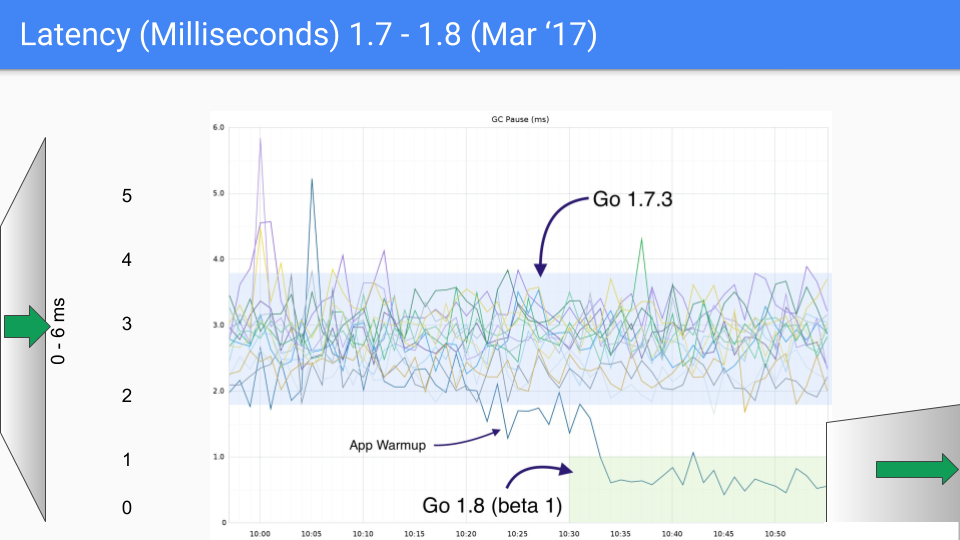
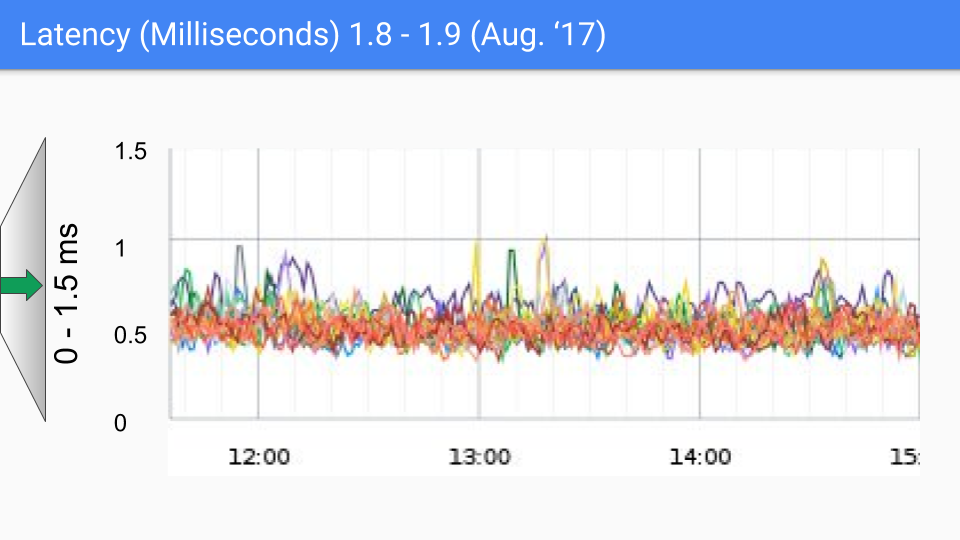
Al momento della stesura di questo articolo, la versione più recente di Go sta per arrivare a Go 1.23, e per l'attuale Go, le prestazioni GC non sono più un problema, la latenza GC è nella maggior parte dei casi inferiore a 100 microsecondi, soddisfacendo le esigenze della maggior parte degli scenari aziendali.
In generale, il garbage collection in Go può essere suddiviso nelle seguenti fasi:
- Fase di scansione: raccoglie gli oggetti root dallo stack e dalle variabili globali
- Fase di marking: colora gli oggetti
- Fase di mark termination: gestisce il lavoro di chiusura, chiude le barriere
- Fase di sweeping: rilascia e回收 la memoria degli oggetti garbage
Concetti
Nella documentazione ufficiale e negli articoli possono apparire i seguenti concetti, di seguito una semplice spiegazione:
- Mutator: un termine tecnico che si riferisce al programma utente, in Go si riferisce al codice utente
- Collector: si riferisce al programma responsabile del garbage collection, in Go è il runtime
- Finalizer: si riferisce al codice responsabile del回收 e rilascio della memoria degli oggetti dopo il completamento del lavoro di mark-sweep
- Controller: si riferisce alla variabile globale
runtime.gcController, il cui tipo ègcControllerState, che implementa l'algoritmo di pacing, responsabile di determinare quando eseguire il garbage collection e quanto lavoro eseguire. - Limiter: si riferisce a
runtime.gcCPULimiter, responsabile della prevenzione di un utilizzo eccessivo della CPU durante il garbage collection che potrebbe influenzare il programma utente
Trigger
func gcStart(trigger gcTrigger)Il garbage collection viene avviato dalla funzione runtime.gcStart, che accetta solo il parametro runtime.gcTrigger, che contiene il motivo del trigger GC, il tempo corrente e il numero del ciclo GC.
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: current time
n uint32 // gcTriggerCycle: cycle number to start
}Dove gcTriggerKind ha i seguenti valori opzionali:
const (
// gcTriggerHeap indica che un ciclo dovrebbe essere avviato quando
// la dimensione dell'heap raggiunge la dimensione di trigger calcolata dal
// controller.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime indica che un ciclo dovrebbe essere avviato quando
// è passato più di forcegcperiod nanosecondi dal precedente ciclo GC.
gcTriggerTime
// gcTriggerCycle indica che un ciclo dovrebbe essere avviato se
// non abbiamo ancora avviato il ciclo numero gcTrigger.n (relativo
// a work.cycles).
gcTriggerCycle
)In generale, ci sono tre momenti di trigger del garbage collection:
Quando si crea un nuovo oggetto: quando si alloca memoria chiamando
runtime.mallocgc, se si rileva che l'heap ha raggiunto la soglia (generalmente il doppio dell'ultima GC, questo valore viene anche regolato dall'algoritmo di pacing), viene avviato il garbage collectiongofunc mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }Trigger forzato a tempo: Go avvia una coroutine separata durante l'esecuzione per eseguire la funzione
runtime.forcegchelper, se non viene eseguito il garbage collection per un lungo periodo, forza l'avvio della GC, questo tempo è determinato dalla costanteruntime.forcegcperiod, il cui valore è 2 minuti, e anche nel sistema di monitoraggio della coroutine viene controllato periodicamente se è necessario forzare la GCgofunc forcegchelper() { for { ... gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) ... } }gofunc sysmon() { ... for { ... // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } } }Trigger manuale: attraverso la funzione
runtime.GC, l'utente può triggerare manualmente il garbage collection.gofunc GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
TIP
Se interessati, vai a Go Gc Pacer Re-Design per leggere l'articolo originale in inglese, che spiega il design e i miglioramenti dell'algoritmo di pacing (pacing algorithm) relativo al trigger GC, poiché il contenuto è piuttosto complesso e coinvolge troppe formule matematiche, non viene approfondito nel testo principale.
Marking
Oggi l'algoritmo GC di Go è ancora mark-then-sweep, ma la sua implementazione non è più semplice come prima.
Mark-Sweep
Iniziamo con il più semplice algoritmo mark-sweep, nella memoria, le relazioni di riferimento tra oggetti formano un grafo, il lavoro del garbage collection viene eseguito su questo grafo, diviso in due fasi:
- Fase di marking: inizia dai nodi root (i nodi root sono solitamente variabili sullo stack, oggetti attivi globali, ecc.), attraversa ogni nodo raggiungibile e lo marca come oggetto attivo, fino a quando tutti i nodi raggiungibili sono stati attraversati
- Fase di sweeping: attraversa tutti gli oggetti nell'heap,回收 gli oggetti non marcati, rilasciando o riutilizzando il loro spazio di memoria
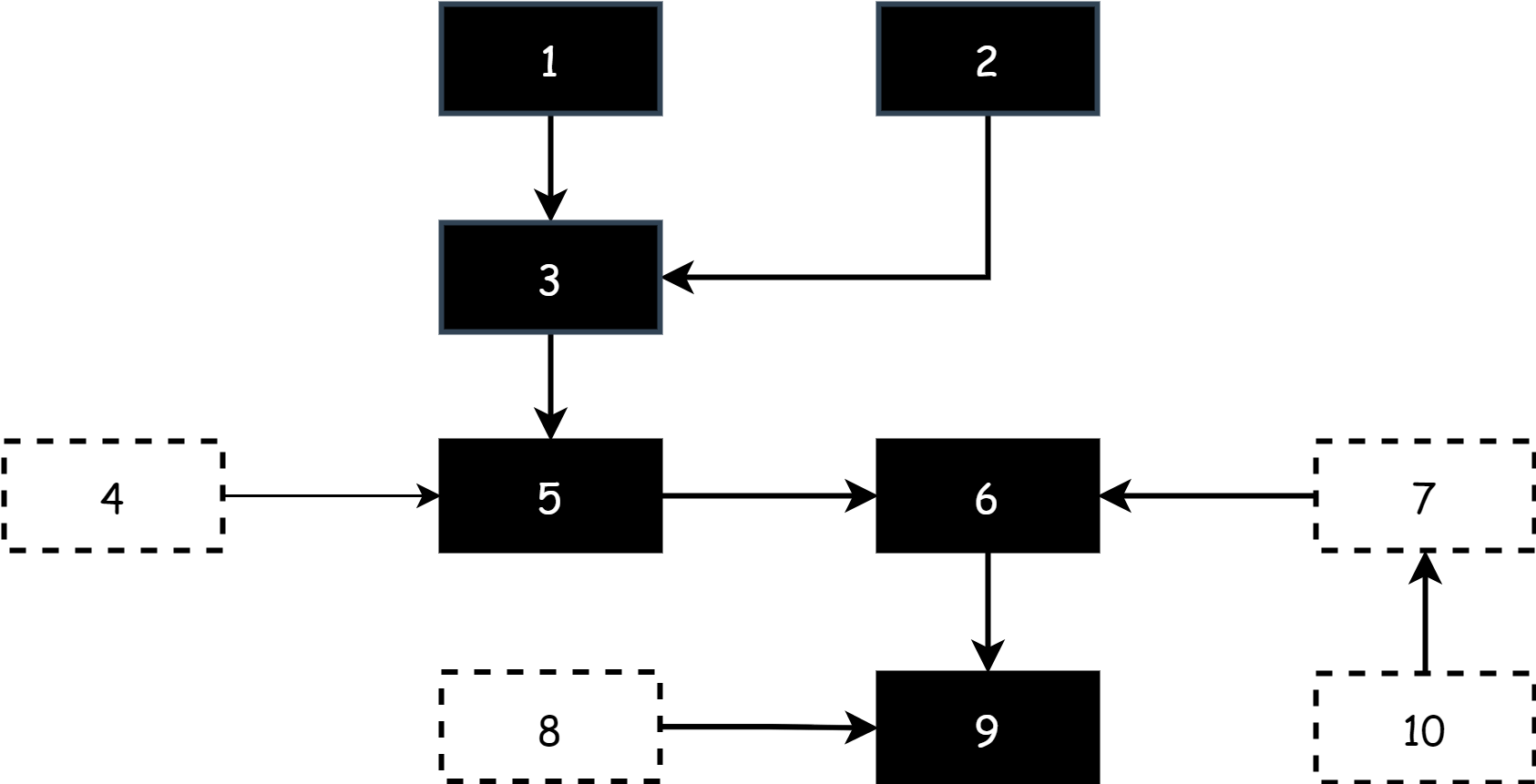
Durante il processo di回收, la struttura del grafo degli oggetti non può essere modificata, quindi l'intero programma deve essere fermato, cioè STW, e può continuare a funzionare solo dopo il completamento del回收. Lo svantaggio di questo algoritmo è che richiede molto tempo, influenzando notevolmente l'efficienza di esecuzione del programma. Questo è l'algoritmo di marking utilizzato nelle versioni iniziali di Go, i suoi svantaggi sono evidenti:
- Produce frammentazione della memoria (a causa della gestione della memoria in stile TCMalloc di Go, l'impatto della frammentazione non è grande)
- Durante la fase di marking scansiona tutti gli oggetti nell'heap
- Causa STW, fermando l'intero programma, e il tempo non è breve
Three-Color Marking
Per migliorare l'efficienza, Go ha adottato il classico algoritmo di three-color marking. I tre colori si riferiscono a nero, grigio e bianco:
- Nero: durante il processo di marking, l'oggetto è stato visitato e tutti gli oggetti che referenzia direttamente sono stati visitati, indicando oggetti attivi
- Grigio: durante il processo di marking, l'oggetto è stato visitato, ma gli oggetti che referenzia direttamente non sono stati tutti visitati, quando tutti sono visitati diventa nero, indicando oggetti attivi
- Bianco: durante il processo di marking non è mai stato visitato, dopo la visita diventa grigio, indicando possibili oggetti garbage
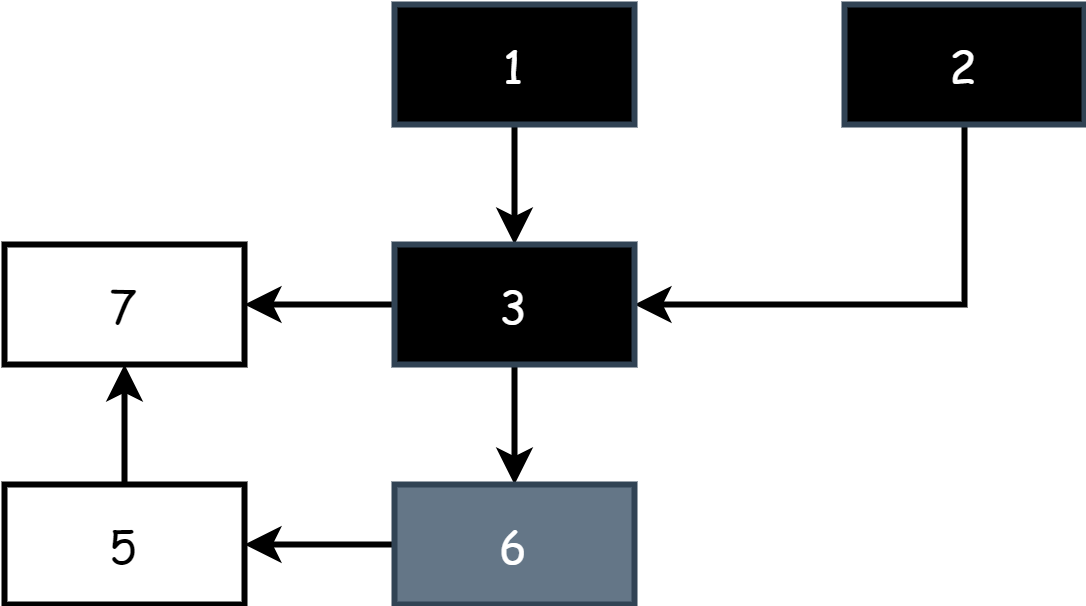
All'inizio del lavoro di three-color marking, ci sono solo oggetti grigi e bianchi, tutti gli oggetti root sono grigi, altri oggetti sono bianchi, come mostrato nella figura seguente:
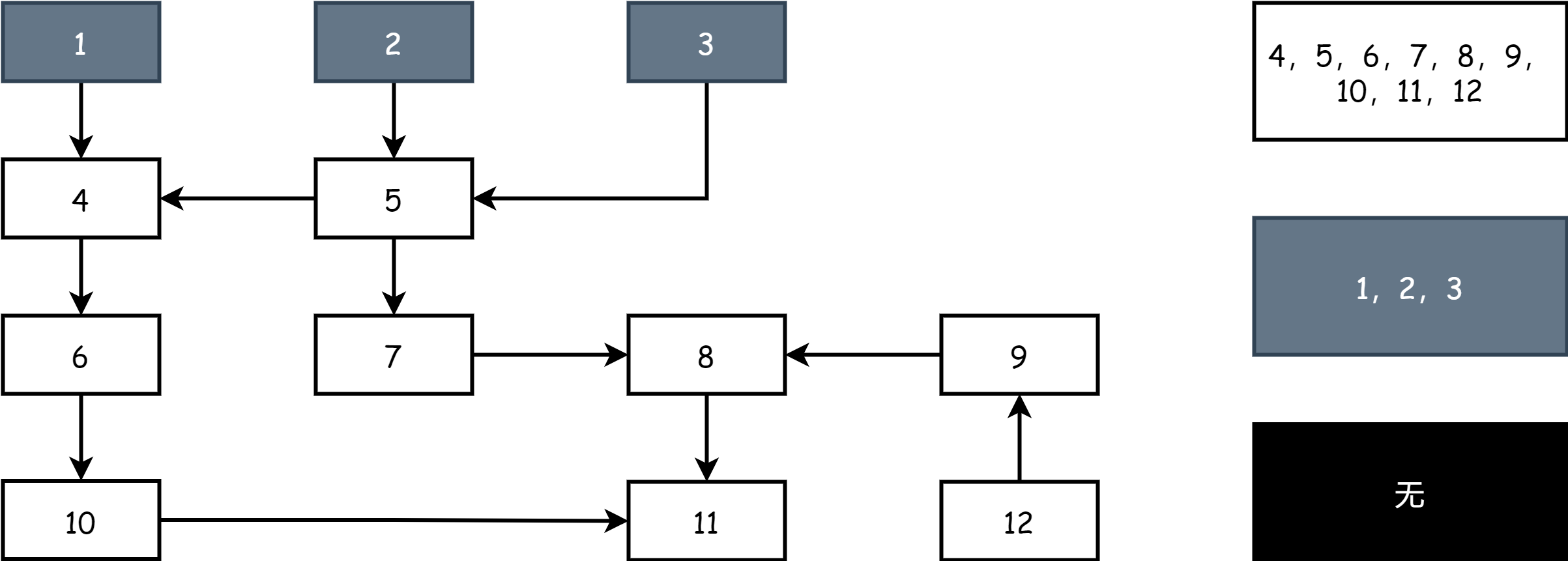
Ogni round di marking inizia dagli oggetti grigi, marca gli oggetti grigi come neri, indicando che sono oggetti attivi, poi marca tutti gli oggetti referenziati direttamente dagli oggetti neri come grigi, il resto è bianco, a questo punto ci sono tre colori: nero, bianco e grigio.
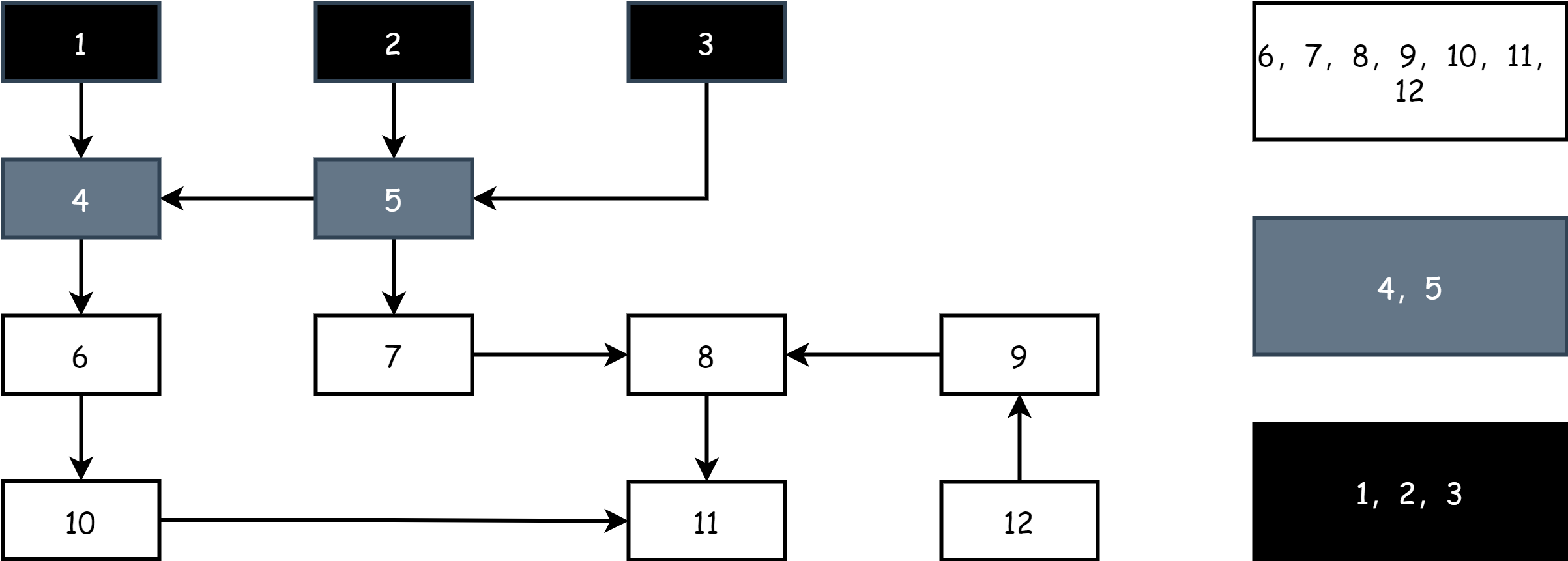
Ripetendo i passaggi sopra, fino a quando rimangono solo oggetti neri e bianchi, quando l'insieme degli oggetti grigi è vuoto, il marking è terminato, come nella figura seguente:
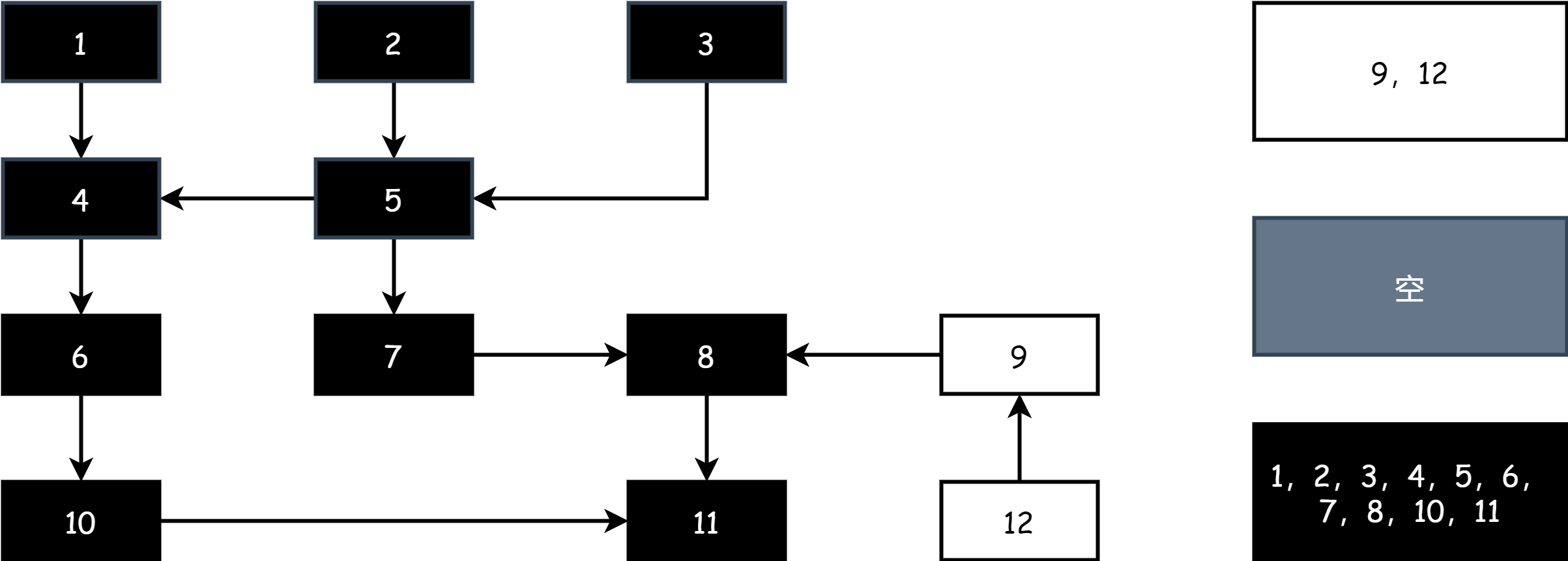
Dopo il marking, nella fase di sweeping basta rilasciare la memoria degli oggetti nell'insieme bianco.
Invarianza
L'algoritmo di three-color marking non può eseguire marking concorrente (il programma esegue il marking mentre è in esecuzione), se la struttura del grafo degli oggetti cambia durante il marking, questo può portare a due situazioni:
- Over-marking: dopo che un oggetto è stato marcato come nero, il programma utente elimina tutti i riferimenti a quell'oggetto, allora dovrebbe essere un oggetto bianco e deve essere pulito
- Under-marking: dopo che un oggetto è stato marcato come bianco, altri oggetti nel programma utente referenziano quell'oggetto, allora dovrebbe essere un oggetto nero e non dovrebbe essere pulito
Il primo caso è accettabile, perché gli oggetti non puliti possono essere gestiti nel round successivo di回收. Ma il secondo caso non è accettabile, la memoria di un oggetto in uso viene rilasciata erroneamente, causando gravi errori di programma, questo è un problema che deve essere evitato.
Il concetto di three-color invariance proviene dall'articolo 《Barrier Techniques for Incremental Tracing》 pubblicato da Pekka P. Pirinen nel 1998, si riferisce alle due invarianze del colore degli oggetti durante il marking concorrente:
Strong tricolor invariance: gli oggetti neri non possono referenziare direttamente oggetti bianchi
Weak tricolor invariance: quando un oggetto nero referenzia direttamente un oggetto bianco, deve esserci un altro oggetto grigio che può accedere direttamente o indirettamente a quell'oggetto grigio, chiamato protezione dell'oggetto grigio
Per la strong tricolor invariance, è noto che l'oggetto nero 3 è un oggetto già visitato, e i suoi oggetti figlio sono stati tutti visitati e marcati come oggetti grigi, se in questo momento il programma utente aggiunge concorrentemente un nuovo riferimento all'oggetto bianco 7 all'oggetto nero 3, normalmente l'oggetto bianco 7 dovrebbe essere marcato come grigio, ma poiché l'oggetto nero 3 è già stato visitato, l'oggetto 7 non verrà visitato, quindi rimane sempre un oggetto bianco e alla fine viene erroneamente pulito.

Per la weak tricolor invariance, è simile alla strong tricolor invariance, perché l'oggetto grigio può accedere direttamente o indirettamente a quell'oggetto bianco, durante il processo di marking successivo verrà infine marcato come oggetto grigio, evitando così di essere erroneamente pulito.
Attraverso l'invarianza, si può garantire che nessun oggetto venga erroneamente pulito durante il processo di marking, garantendo così la correttezza del lavoro di marking in condizioni concorrenti, permettendo così al three-color marking di lavorare concorrentemente, migliorando notevolmente l'efficienza del marking rispetto all'algoritmo mark-sweep. Per garantire l'invarianza tricolor in condizioni concorrenti, la chiave sta nella tecnologia delle barriere.
Lavoro di Marking
Nella fase di scansione GC, c'è una variabile globale runtime.gcphase utilizzata per indicare lo stato GC, con i seguenti valori opzionali:
_GCoff: il lavoro di marking non è iniziato_GCmark: il lavoro di marking è iniziato_GCmarktermination: il lavoro di marking sta per terminare
Quando il lavoro di marking inizia, lo stato di runtime.gcphase è _GCmark, il lavoro di marking è eseguito dalla funzione runtime.gcDrain, dove il parametro runtime.gcWork è un buffer pool che contiene i puntatori agli oggetti da tracciare.
func gcDrain(gcw *gcWork, flags gcDrainFlags)Durante il lavoro, tenta di ottenere puntatori tracciabili dal buffer pool, se ce ne sono, chiama la funzione runtime.scanobject per continuare il lavoro di scansione, il cui scopo è scansionare continuamente gli oggetti nel buffer, marcandoli come neri.
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
scanobject(b, gcw)Il lavoro di scansione si ferma solo quando P viene prelazionato o quando sta per verificarsi STW:
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork è una coda che adotta il modello produttore/consumatore, responsabile della memorizzazione degli oggetti grigi in attesa di scansione, ogni processore P ha una tale coda locale, corrispondente al campo runtime.p.gcw.
func scanobject(b uintptr, gcWork *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}La funzione runtime.scanobject durante la scansione marca continuamente gli oggetti bianchi raggiungibili come grigi, poi li mette nella coda locale chiamando gcw.put, mentre la funzione gcDrain tenta continuamente di ottenere oggetti grigi attraverso gcw.tryget per continuare la scansione. Il processo di mark-scan è incrementale, non è necessario completare tutto il lavoro di marking in una volta, quando il compito di marking viene prelazionato per alcuni motivi si interrompe, e dopo il ripristino può continuare a completare il lavoro di marking in base agli oggetti grigi rimanenti nella coda.
Marking in Background
Il lavoro di marking non viene eseguito immediatamente all'inizio della GC, quando viene triggerata la GC, Go crea tanti task di marking quanti sono i processori P correnti, vengono aggiunti alla coda globale dei task, poi entrano in休眠 fino a quando vengono risvegliati durante la fase di marking. A runtime, runtime.gcBgMarkStartWorkers esegue la distribuzione dei task, il task di marking si riferisce effettivamente alla funzione runtime.gcBgMarkWorker, dove le variabili globali di runtime gcBgMarkWorkerCount e gomaxprocs indicano rispettivamente il numero corrente di worker e il numero di processori P.
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has
// a background GC G.
//
// Worker Gs don't exit if gomaxprocs is reduced. If it is raised
// again, we can reuse the old workers; no need to create new workers.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// The worker is now guaranteed to be added to the pool before
// its P's next findRunnableGCWorker.
gcBgMarkWorkerCount++
}
}Dopo l'avvio del worker, crea una struttura runtime.gcBgMarkWorkerNode, la aggiunge al pool globale di worker runtime.gcBgMarkWorkerPool, poi chiama la funzione runtime.gopark per far addormentare la coroutine:
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// Go to sleep until woken by
// gcController.findRunnableGCWorker.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// Release this G to the pool.
gcBgMarkWorkerPool.push(&node.node)
// Note that at this point, the G may immediately be
// rescheduled and may be running.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}Ci sono due situazioni che possono risvegliare il worker:
- Durante la fase di marking, il ciclo di schedulazione risveglia i worker dormienti attraverso la funzione
runtime.gcController.findRunnableGCWorker - Durante la fase di marking, se il processore P è attualmente idle, il ciclo di schedulazione tenta di ottenere direttamente worker disponibili dal pool globale di worker
gcBgMarkWorkerPool
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// Try to schedule a GC worker.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}La struttura del processore P ha un campo gcMarkWorkerMode che indica la modalità di esecuzione del task di marking, con i seguenti valori opzionali:
gcMarkWorkerNotWorker: indica che il processore P corrente non sta eseguendo task di markinggcMarkWorkerDedicatedMode: indica che il processore P corrente è dedicato all'esecuzione del task di marking e non può essere prelazionato durante il periodo.gcMarkWorkerFractionalMode: indica che il processore corrente esegue il task di marking perché l'utilizzo GC non soddisfa lo standard (25% è lo standard), può essere prelazionato durante l'esecuzione. Supponiamo che il numero corrente di processori P sia 5, secondo la formula di calcolo, a questo punto è necessario un processore P dedicato al marking, l'utilizzo ha raggiunto solo il 20%, il restante 5% di utilizzo richiede l'attivazione di un processore P in modalitàFractionalModeper compensare. Il codice di calcolo specifico è il seguente:gofunc (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // Too many dedicated workers. dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode: indica che il processore corrente esegue il task di marking perché è idle, può essere prelazionato durante l'esecuzione.
Il team di Go non desidera che la GC occupi troppe prestazioni influenzando il normale funzionamento del programma utente, eseguendo il lavoro di marking secondo queste diverse modalità, può completare la GC senza sprecare prestazioni e senza influenzare il programma utente. Si può notare che l'unità di base di distribuzione del task di marking è il processore P, quindi il lavoro di marking viene eseguito concorrentemente, più task di marking e il programma utente eseguono concorrentemente senza influenzarsi a vicenda.
Marking Assist
La coroutine G ha un campo gcAssistBytes a runtime, qui chiamato GC assist credit. Durante lo stato di marking GC, quando una coroutine tenta di allocare una certa dimensione di memoria, viene detratto un credito pari alla dimensione della memoria allocata. Se a questo punto il credito è negativo, la coroutine deve assistere nel completare una quantità fissa di lavoro di scansione GC per ripagare il credito, quando il credito è positivo, la coroutine non ha bisogno di completare il task di marking assist.
La funzione che detrae il credito è runtime.deductAssistCredit, viene chiamata prima che la funzione runtime.mallocgc allochi memoria.
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
return assistG
}Tuttavia, quando la coroutine completa una quantità fissa di lavoro di scansione assist, ripaga una quantità fissa di credito alla coroutine corrente, la funzione effettivamente responsabile del marking assist è runtime.gcDrainN.
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// 完成工作了
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}Poiché la scansione è concorrente, solo una parte del lavoro registrato appartiene alla coroutine corrente, il resto del lavoro viene ripagato alle altre coroutine in base all'ordine della coda assist, se c'è ancora un surplus, viene aggiunto al credito globale gcController.assistBytesPerWork.
func gcFlushBgCredit(scanWork int64) {
// 如果队列为空则直接添加到全局积分中
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// 还有剩余
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}Corrispondentemente, quando il credito da ripagare è troppo elevato (memoria allocata troppo grande), si può anche usare il credito globale per compensare parte del proprio debito:
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// 用全局积分抵押
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}Il marking assist è un mezzo di bilanciamento in condizioni di alto carico, la velocità di allocazione della memoria del programma utente è molto superiore alla velocità di marking, si esegue tanto lavoro di marking quanta memoria viene allocata.
Mark Termination
Quando tutti gli oggetti grigi raggiungibili sono stati marcati come neri, si passa dallo stato _GCmark allo stato _GCmarktermination, questo processo è completato dalla funzione runtime.gcMarkDone. All'inizio, controlla se ci sono ancora task da eseguire:
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// 将所有因写屏障拦截的标记操作全部批量的执行
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}Quando non ci sono task globali e locali da eseguire, chiama runtime.stopTheWorldWithSema per STW, poi esegue alcuni lavori di chiusura:
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Notify the CPU limiter that GC assists will now cease.
gcCPULimiter.startGCTransition(false, now)
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Perform mark termination. This will restart the world.
gcMarkTermination(stw)Per prima cosa imposta runtime.gcBlackenEnabled a 0, indicando che il lavoro di marking è terminato, notifica al limiter che il marking assist è terminato, chiude le barriere di memoria, risveglia tutte le coroutine dormienti a causa del marking assist, poi risveglia tutte le coroutine utente, deve anche raccogliere vari dati del lavoro di scansione di questo round per regolare l'algoritmo di pacing per prepararsi alla scansione del round successivo, dopo il completamento del lavoro di chiusura, chiama la funzione runtime.gcSweep per pulire gli oggetti garbage, infine chiama runtime.startTheWorldWithSema per ripristinare l'esecuzione del programma.
Barriere
Lo scopo delle barriere di memoria può essere inteso come hook del comportamento di assegnazione degli oggetti, eseguendo alcune operazioni designate prima dell'assegnazione, questo codice hook viene solitamente inserito nel codice dal compilatore durante la compilazione. Come menzionato in precedenza, l'aggiunta e l'eliminazione di riferimenti agli oggetti in condizioni concorrenti durante il three-color marking causano problemi, poiché entrambe sono operazioni di scrittura (l'eliminazione è assegnazione di valore nullo), le barriere che le intercettano sono collettivamente chiamate write barrier. Ma il meccanismo delle barriere non è privo di costi, intercettare le operazioni di scrittura in memoria causa overhead aggiuntivo, quindi il meccanismo delle barriere funziona solo sull'heap, considerando la complessità di implementazione e il degrado delle prestazioni, non funziona per stack e registri.
TIP
Per maggiori dettagli sull'applicazione della tecnologia delle barriere in Go, vai a Eliminate STW stack rescan per leggere l'articolo originale in inglese, questo articolo fa riferimento a molto contenuto.
Insertion Write Barrier
L'insertion write barrier è stata proposta da Dijkstra, soddisfa la strong tricolor invariance. Quando un oggetto nero aggiunge un nuovo riferimento a un oggetto bianco, l'insertion write barrier intercetta questa operazione, marca l'oggetto bianco come grigio, questo evita che gli oggetti neri referenzino direttamente oggetti bianchi, garantendo la strong tricolor invariance, questo è abbastanza facile da capire.

Come menzionato in precedenza, il write barrier non viene applicato allo stack, se le relazioni di riferimento degli oggetti stack cambiano durante il processo di marking concorrente, ad esempio un oggetto nero nello stack referenzia un oggetto bianco nell'heap, quindi per garantire la correttezza degli oggetti stack, si possono solo marcare tutti gli oggetti nello stack come oggetti grigi dopo la fine del marking, poi scansionare di nuovo, equivale a scansionare lo spazio stack due volte per un round di marking, e la seconda scansione deve STW, se nel programma esistono contemporaneamente centinaia o migliaia di stack di coroutine, allora il tempo di consumo di questo processo di scansione non può essere ignorato, secondo i dati statistici ufficiali, il tempo di consumo della nuova scansione è di circa 10-100 millisecondi.
Vantaggi: non è necessario STW durante la scansione
Svantaggi: è necessario scansionare due volte lo spazio stack per garantire la correttezza, è necessario STW
Deletion Write Barrier
La deletion write barrier è stata proposta da Yuasa, anche chiamata snapshot-at-the-beginning barrier, questo metodo richiede STW all'inizio per scattare una snapshot degli oggetti root, e marca tutti gli oggetti root come neri, tutti gli oggetti figlio di primo livello come grigi, in modo che tutti gli altri oggetti figlio bianchi siano sotto la protezione degli oggetti grigi. Il team di Go non ha applicato direttamente la deletion write barrier, ma ha scelto di usarla in combinazione con l'insertion write barrier, quindi per facilitare la comprensione successiva, qui va comunque spiegata. La regola della deletion write barrier per garantire la correttezza in condizioni concorrenti è: quando si elimina un riferimento a un oggetto bianco da un oggetto grigio o bianco, si marca direttamente l'oggetto bianco come grigio.
Si divide in due situazioni per interpretare:
Eliminazione del riferimento di un oggetto grigio a un oggetto bianco: poiché non si sa se l'oggetto bianco è referenziato da un oggetto nero a valle, questo potrebbe tagliare la protezione dell'oggetto grigio all'oggetto bianco
Eliminazione del riferimento di un oggetto bianco a un oggetto bianco: poiché non si sa se l'oggetto bianco è protetto da un oggetto grigio a monte, se è referenziato da un oggetto nero a valle, questo potrebbe anche tagliare la protezione dell'oggetto grigio all'oggetto bianco
Indipendentemente dalla situazione, la deletion write barrier marca l'oggetto bianco referenziato come grigio, in questo modo si soddisfa la weak tricolor invariance. Questo è un approccio conservativo, perché le situazioni a monte e a valle sono sconosciute, marcarlo come grigio equivale a non considerarlo più come oggetto garbage, anche se dopo l'eliminazione del riferimento l'oggetto diventa irraggiungibile cioè diventa un oggetto garbage, viene comunque marcato come grigio, verrà rilasciato nel round di scansione successivo, questo è meglio degli errori di memoria causati dalla pulizia errata degli oggetti.

Vantaggi: poiché gli oggetti stack sono tutti neri, non è necessario scansionare due volte lo spazio stack
Svantaggi: all'inizio della scansione è necessario STW per scattare una snapshot degli oggetti root nello spazio stack
Hybrid Write Barrier
La versione Go 1.8 ha introdotto un nuovo meccanismo di barriera: hybrid write barrier, cioè la combinazione di insertion write barrier e deletion write barrier, combinando i vantaggi di entrambi:
- L'insertion write barrier non richiede STW per scattare una snapshot all'inizio
- La deletion write barrier non richiede STW per scansionare due volte lo spazio stack
Di seguito il pseudocodice fornito ufficialmente:
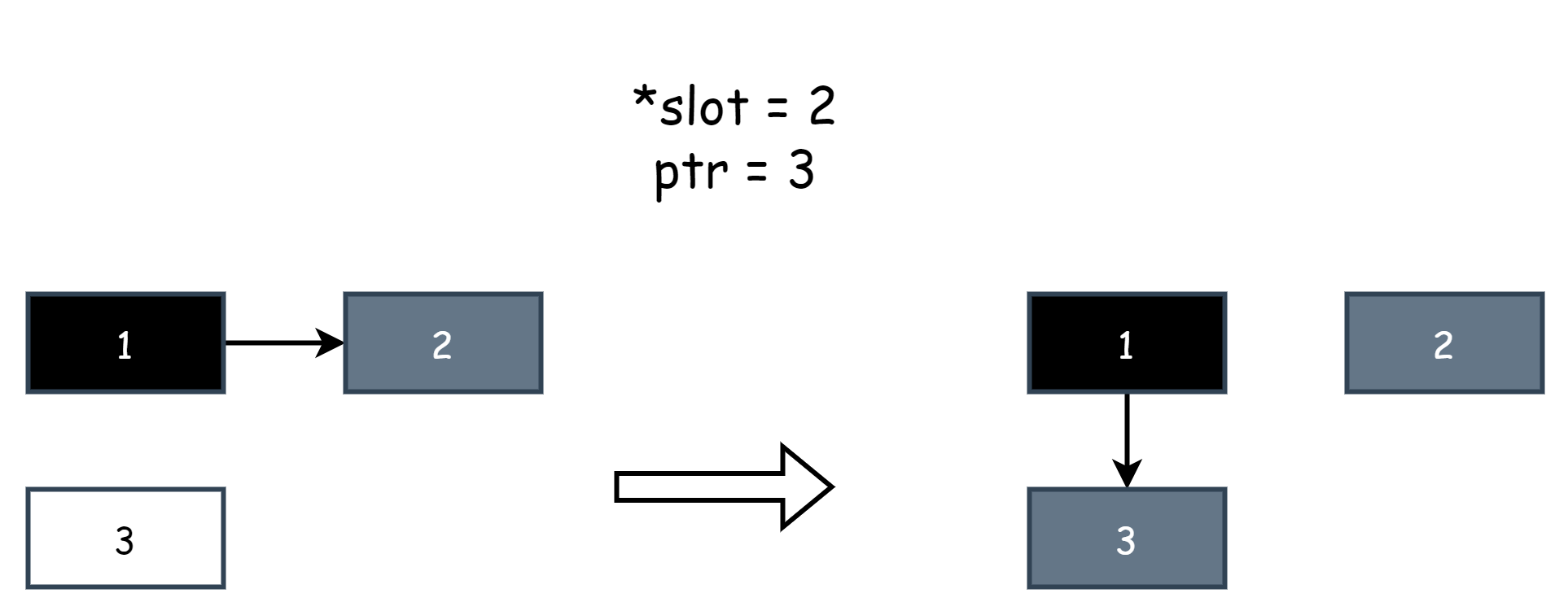
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptrUna semplice spiegazione di alcuni concetti all'interno, dove slot è un puntatore, indica un riferimento ad altri oggetti, *slot è l'oggetto originale, ptr è il nuovo oggetto, *slot=ptr è un'operazione di assegnazione, equivale a modificare il riferimento dell'oggetto, assegnare un valore nullo è eliminare il riferimento, shade() indica marcare un oggetto come grigio, shade(*slot) significa marcare l'oggetto originale come grigio, shade(ptr) significa marcare il nuovo oggetto come grigio, di seguito un esempio di immagine, supponiamo che l'oggetto 1 originariamente referenziasse l'oggetto 2, poi il programma utente modifica il riferimento, facendo referenziare all'oggetto 1 l'oggetto 3, l'hybrid write barrier intercetta questo comportamento, dove *slot rappresenta l'oggetto 2, ptr rappresenta l'oggetto 1.
L'ufficiale ha riassunto l'effetto del pseudocodice sopra in una frase:
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
Tradotto, quando l'hybrid write barrier intercetta un'operazione di scrittura, marca l'oggetto originale come grigio, se lo stack della coroutine corrente non è stato ancora scansionato, marca anche il nuovo oggetto come grigio.
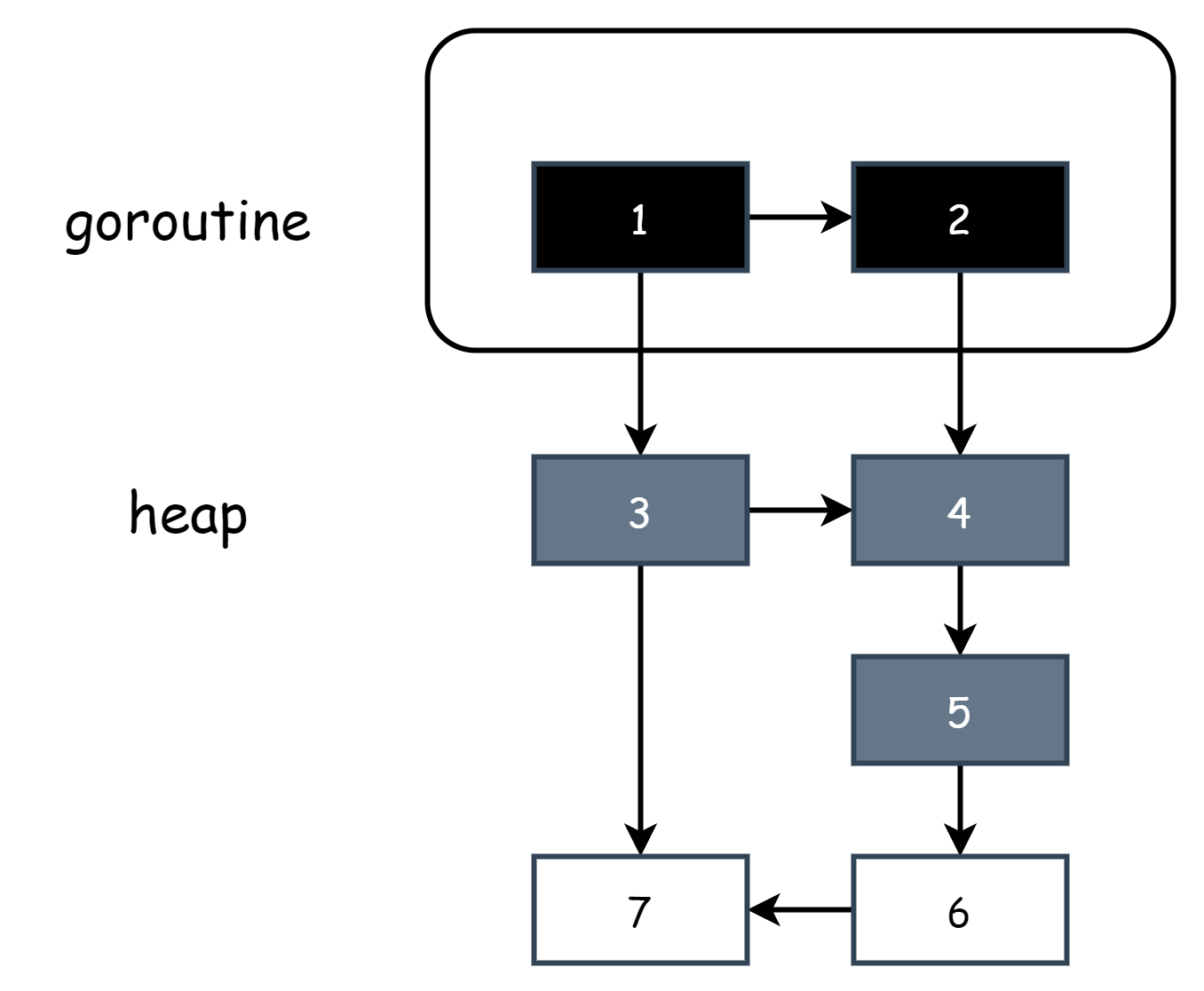
Quando inizia il lavoro di marking, è necessario scansionare lo spazio stack per raccogliere gli oggetti root, a questo punto vengono marcati direttamente tutti come neri, durante questo periodo qualsiasi nuovo oggetto creato viene anche marcato come nero, garantendo che tutti gli oggetti nello stack siano neri, quindi current stack is grey nel pseudocodice indica che lo stack della coroutine corrente non è stato ancora scansionato, quindi lo stack della coroutine ha solo due stati, o tutto nero o tutto grigio, durante il processo di transizione da tutto grigio a tutto nero è necessario sospendere la coroutine corrente, quindi sotto l'hybrid write barrier ci sono ancora STW locali. Quando lo stack della coroutine è tutto nero, a questo punto deve soddisfare la strong tricolor invariance, perché dopo la scansione gli oggetti neri nello stack referenziano solo oggetti grigi, non esiste una situazione in cui un oggetto nero referenzia direttamente un oggetto bianco, quindi a questo punto non è necessario l'insertion write barrier, corrispondente al pseudocodice:
if current stack is grey:
shade(ptr)Ma è ancora necessaria la deletion write barrier per soddisfare la weak tricolor invariance, cioè:
shade(*slot)Dopo il completamento della scansione, poiché gli oggetti nello spazio stack sono già tutti neri, non è più necessario scansionare due volte lo spazio stack, si può risparmiare il tempo di STW.
Fin qui, cioè dalla versione Go 1.8 in poi, Go ha fondamentalmente stabilito il quadro di base del garbage collection, le ottimizzazioni relative al garbage collection nelle versioni successive sono anche basate sull'hybrid write barrier, poiché la maggior parte degli STW è stata eliminata, a questo punto la latenza media del garbage collection è stata ridotta al livello di microsecondi.
Write Buffer
Nel meccanismo di barriera menzionato in precedenza, quando si intercetta un'operazione di scrittura, si marca immediatamente il colore dell'oggetto, dopo l'adozione dell'hybrid write barrier, poiché è necessario marcare sia l'oggetto originale che il nuovo oggetto, il lavoro raddoppia, e il codice inserito dal compilatore aumenta anche. Per ottimizzare, nella versione Go 1.10, il write barrier non marca immediatamente il colore dell'oggetto durante la colorazione, ma memorizza l'oggetto originale e il nuovo oggetto in un buffer pool, dopo aver accumulato una certa quantità, esegue la marking in batch, questo è più efficiente.
La struttura responsabile della cache è runtime.wbBuf, che è effettivamente un array, di dimensione 512.
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}Ogni P locale ha una tale cache:
type p struct {
...
wbBuf wbBuf
...
}Durante il lavoro di marking, se non ci sono oggetti grigi disponibili nella coda gcw, mette gli oggetti nel buffer nella coda locale.
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 刷新写屏障缓存
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}Un'altra situazione è che, quando si termina il marking, controlla anche se ogni wbBuf locale di P ha oggetti grigi rimanenti:
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}Sweep
Nel garbage collection, la parte più importante sta nel trovare gli oggetti garbage, cioè il lavoro di scanning e marking, e dopo il completamento del lavoro di marking, il lavoro di sweep è relativamente meno complesso, deve solo回收 e rilasciare gli oggetti non marcati. Questo codice si trova principalmente nel file runtime/mgcsweep.go, secondo i commenti nel file si può sapere che gli algoritmi di sweep in Go sono di due tipi.
Sweep di Oggetti
Il lavoro di sweep degli oggetti viene eseguito durante la fase di mark termination, completato da runtime.sweepone per pulire, il processo è asincrono. Durante la pulizia, tenta di cercare oggetti non marcati nell'unità di memoria, poi li回收. Se un'intera unità di memoria non è marcata, allora tutta l'unità viene回收.
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// 尝试获取回收器
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// 清理
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}Per l'algoritmo di sweep degli oggetti,回收 un'intera unità è più difficile, quindi c'è un secondo algoritmo di sweep.
Sweep di Span
Il lavoro di sweep degli span viene eseguito prima dell'allocazione della memoria, completato dal metodo runtime.mheap.reclaim, che cerca nell'heap tutte le unità di memoria i cui oggetti non sono marcati, poi回收 l'intera unità.
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}Per le unità di memoria, c'è un campo sweepgen utilizzato per indicare il loro stato di sweep:
mspan.sweepgen == mheap.sweepgen - 2: l'unità di memoria deve essere回收mspan.sweepgen == mheap.sweepgen - 1: l'unità di memoria sta venendo回收mspan.sweepgen == mheap.sweepgen: l'unità di memoria è stata回收 e può essere utilizzata normalmentemspan.sweepgen == mheap.sweepgen + 1: l'unità di memoria è nella cache e deve essere回收mspan.sweepgen == mheap.sweepgen + 3: l'unità di memoria è stata回收 ma è ancora nella cache
mheap.sweepgen aumenta con i round di GC, e ogni volta aumenta di +2.