gmp
Una delle caratteristiche più importanti del linguaggio Go è il suo supporto nativo per la concorrenza. Basta una sola parola chiave per avviare una coroutine, come dimostrato nell'esempio seguente.
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Le coroutine del linguaggio Go sono così semplici da usare, e per gli sviluppatori non è quasi necessario fare alcun lavoro extra, motivo per cui è così popolare. Tuttavia, dietro questa semplicità c'è uno scheduler di concorrenza non semplice che supporta tutto questo. Il suo nome, come molti di voi avranno sentito più o meno, è composto dai tre componenti principali G (coroutine), M (thread di sistema), P (processore), quindi è anche chiamato scheduler GMP. Il design dello scheduler GMP ha influenzato l'intero design del runtime di Go, incluso il GC e il network poller. Si può dire che è il componente più centrale dell'intero linguaggio, e avere una certa comprensione di esso può essere di grande aiuto nel lavoro futuro.
Storia
Il modello di scheduler di concorrenza del linguaggio Go non è completamente originale, ma ha assorbito molte esperienze e lezioni dei predecessori, sviluppandosi e migliorandosi continuamente per arrivare alla forma attuale. I linguaggi da cui ha preso ispirazione includono:
- Occam - 1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
L'influenza più grande è stata l'articolo di Hoare del 1978 su CSP (Communicating Sequential Processes), il cui concetto fondamentale è che i processi scambiano dati attraverso la comunicazione. Tutti i linguaggi sopra menzionati sono stati influenzati dall'idea di CSP, con Erlang che è il tipico esempio di linguaggio orientato ai messaggi. Il famoso middleware di messaggistica open source RabbitMQ è scritto in Erlang. Al giorno d'oggi, con lo sviluppo dei computer e di Internet, il supporto alla concorrenza è diventato quasi uno standard per i linguaggi moderni, e Go è nato combinando le idee di CSP.
Modello di Scheduler
Introduciamo brevemente i tre componenti di GMP:
- G, Goroutine, si riferisce alle coroutine nel linguaggio Go
- M, Machine, si riferisce ai thread di sistema o thread di lavoro (worker thread), responsabili della schedulazione da parte del sistema operativo
- P, Processor, non si riferisce alla CPU, ma è un concetto astratto di Go, che indica i processori che lavorano sui thread di sistema, attraverso i quali vengono schedulate le coroutine su ogni thread di sistema.
Le coroutine sono thread più leggeri, con una scala più piccola e richiedono meno risorse. La creazione, distruzione e schedulazione sono gestite dal runtime di Go, non dal sistema operativo, quindi il loro costo di gestione è molto inferiore a quello dei thread. Tuttavia, le coroutine dipendono dai thread, e il tempo di esecuzione delle coroutine deriva dai thread, mentre il tempo dei thread deriva dal sistema operativo. Poiché il cambio tra thread diversi ha un certo costo, la chiave del design è come far sfruttare al meglio alle coroutine il tempo dei thread.
1:N
Il modo migliore per risolvere un problema è ignorarlo. Poiché il cambio di thread ha un costo, basta non cambiare thread. Assegnando tutte le coroutine a un singolo thread del kernel, si coinvolge solo il cambio tra coroutine.
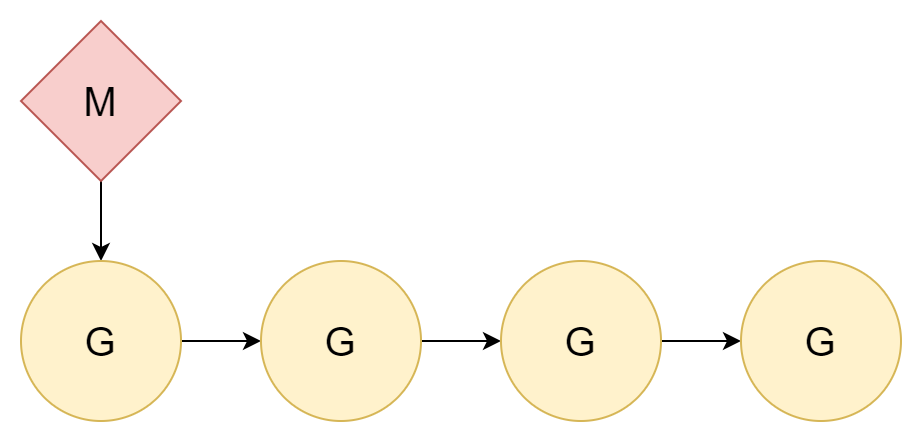
La relazione tra thread e coroutine è 1:N. Questo approccio ha uno svantaggio molto evidente: i computer di oggi sono quasi tutti CPU multi-core, e tale distribuzione non può sfruttare appieno le prestazioni delle CPU multi-core.
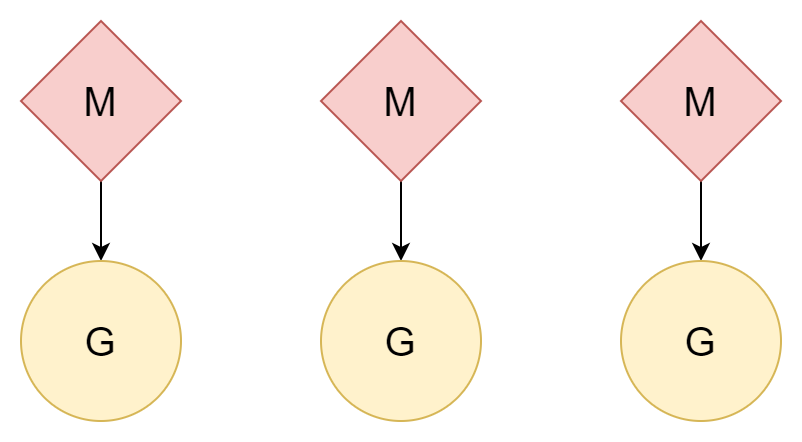
N:N
Un altro metodo è un thread per coroutine, dove una coroutine può godere di tutto il tempo di quel thread, e più thread possono sfruttare le prestazioni di più core CPU. Tuttavia, il costo di creazione e cambio dei thread è relativamente alto, e con una relazione uno-a-uno, non si sfrutta appieno il vantaggio della leggerezza delle coroutine.
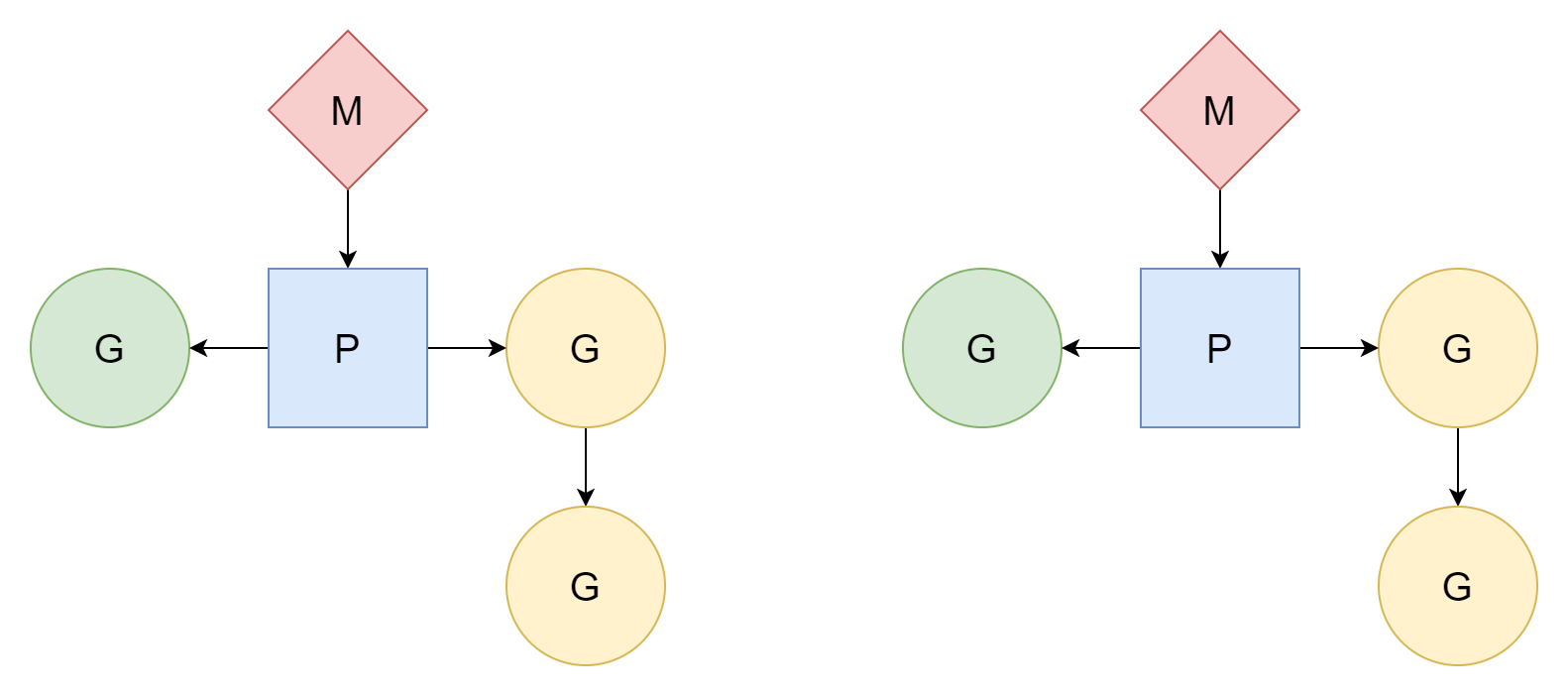
M:N
M thread corrispondono a N coroutine, con M minore di N. Più thread corrispondono a più coroutine, e ogni thread corrisponde a diverse coroutine. Il processore P è responsabile della schedulazione di come le coroutine G utilizzano il tempo dei thread. Questo metodo è relativamente migliore, ed è il modello di scheduler che Go ha utilizzato fino ad oggi.
M può eseguire compiti solo dopo essere associato al processore P. Go crea GOMAXPROCS processori, quindi il numero effettivo di thread che possono eseguire compiti è GOMAXPROCS. Il valore predefinito è il numero di core logici della CPU della macchina corrente, ma possiamo anche impostarlo manualmente.
- Modifica tramite codice
runtime.GOMAXPROCS(N), può essere regolato dinamicamente a runtime, e causa STW immediato dopo la chiamata. - Imposta la variabile d'ambiente
export GOMAXPROCS=N, statico.
Nella pratica, il numero di M è maggiore del numero di P, perché a runtime è necessario per gestire altri compiti, come alcune system call, con un valore massimo di 10000.
I tre partecipanti GMP e lo scheduler stesso hanno le loro rappresentazioni di tipo a runtime, tutte situate nel file runtime/runtime2.go. Di seguito viene presentata una semplice introduzione alle loro strutture per facilitare la comprensione successiva.
G
G nel runtime è rappresentata dalla struttura runtime.g, che è l'unità di schedulazione di base del modello di scheduler. La sua struttura è la seguente, con molti campi rimossi per facilità di comprensione.
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}Il primo campo è l'indirizzo di inizio e fine della memoria dello stack della coroutine.
type stack struct {
lo uintptr
hi uintptr
}_panic e _defer sono puntatori rispettivamente allo stack panic e allo stack defer.
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm è la coroutine M che sta attualmente eseguendo g.
m *m // current m; offset known to arm liblinkpreempt indica se la coroutine corrente deve essere prelazionata, equivalente a g.stackguard0 = stackpreempt.
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus è utilizzato per memorizzare il valore dello stato della coroutine G, con i seguenti valori opzionali:
| Nome | Descrizione |
|---|---|
| _Gidle | Appena allocata, non ancora inizializzata |
| _Grunnable | Indica che la coroutine corrente può essere eseguita, si trova nella coda di attesa |
| _Grunning | Indica che la coroutine corrente sta eseguendo codice utente |
| _Gsyscall | Allocata a una M, utilizzata per eseguire system call |
| _Gwaiting | Coroutine bloccata, motivo del blocco vedi sotto |
| _Gdead | Indica che la coroutine corrente non è in uso, potrebbe essere appena uscita o appena inizializzata |
| _Gcopystack | Indica che lo stack della coroutine si sta spostando, durante questo periodo non esegue codice utente e non si trova nella coda di attesa |
| _Gpreempted | Bloccata in attesa di prelazione, attende di essere risvegliata dalla parte che la prelaziona |
| _Gscan | GC sta scansionando lo spazio dello stack della coroutine, può coesistere con altri stati |
sched è utilizzato per memorizzare le informazioni di contesto della coroutine per ripristinare lo stato di esecuzione della coroutine. Si può vedere che contiene i puntatori sp, pc, ret.
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting indica la coroutine che la coroutine corrente sta aspettando, waitsince registra il momento in cui la coroutine si è bloccata, waitreason indica il motivo del blocco della coroutine, con i valori opzionali seguenti.
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid e parentGoid rappresentano l'identificatore unico della coroutine corrente e della coroutine genitore, startpc rappresenta l'indirizzo della funzione di ingresso della coroutine.
M
M nel runtime è rappresentata dalla struttura runtime.m, che è un'astrazione del thread di lavoro.
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}Allo stesso modo, ci sono molti campi all'interno di M, qui vengono introdotti solo alcuni campi per facilitare la comprensione.
id, identificatore unico di Mg0, coroutine con stack di schedulazionecurg, coroutine utente in esecuzione sul thread di lavorogsignal, coroutine responsabile della gestione dei segnali del threadgoSigStack, spazio stack allocato da Go per la gestione dei segnalip, indirizzo del processore P,oldppunta al P prima dell'esecuzione della system call,nextppunta al nuovo P allocatomallocing, indica se si sta attualmente allocando nuovo spazio di memoriathrowing, indica il tipo di errore che si è verificato su Mpreemptoff, identificatore di prelazione, quando è una stringa vuota indica che la coroutine in esecuzione corrente può essere prelazionatalocks, indica il numero di "lock" correnti su M, quando non è 0 proibisce la prelazionedying, indica che M ha riscontrato unpanicirreparabile, con quattro valori opzionali[0,3], dal basso verso l'alto indica la gravità.spinning, indica che M è in stato idle ed è disponibile.tls, thread local storage
P
P nel runtime è rappresentato da runtime.p, responsabile della schedulazione del lavoro tra M e G, la sua struttura è la seguente:
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status indica lo stato di P, con i seguenti valori opzionali:
| Valore | Descrizione |
|---|---|
| _Pidle | P è in stato idle, può essere allocato a M dallo scheduler, o potrebbe essere solo in transizione tra altri stati |
| _Prunning | P è associato a M e sta eseguendo codice utente |
| _Psyscall | Indica che M associato a P sta eseguendo una system call, durante questo periodo P potrebbe essere prelazionato da altre M |
| _Pgcstop | Indica che P è stato fermato a causa del GC |
| _Pdead | La maggior parte delle risorse di P sono state rimosse e non verrà più utilizzato |
I seguenti campi registrano la coda locale runq in P, si può vedere che la quantità massima della coda locale è 256, oltre questo numero G verrà messo nella coda globale.
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext indica il prossimo G disponibile.
runnext guintptrGli altri campi sono definiti come segue:
id, identificatore unico di Pschedtick, incrementa con il numero di schedulazioni delle coroutine, visibile nella funzioneruntime.execute.syscalltick, incrementa con il numero di system callsysmontick, registra le informazioni osservate l'ultima volta dal monitor di sistemam, M associato a PgFree, lista delle G idlepreempt, indica che P dovrebbe rientrare nella schedulazione
Le informazioni sulla coda globale sono memorizzate nella struttura runtime.schedt, che è la rappresentazione dello scheduler a runtime, come segue.
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}Inizializzazione
L'inizializzazione dello scheduler si trova nella fase di bootstrap del programma Go, responsabile dell'avvio del programma Go è la funzione runtime.rt0_go, implementata in assembly nel file runtime/asm_*.s, parte del codice è la seguente:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RETSi può vedere dalle due righe seguenti la chiamata a runtime·osinit e runtime·schedinit.
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)La prima è responsabile dell'inizializzazione del lavoro relativo al sistema operativo, la seconda è responsabile dell'inizializzazione dello scheduler, ovvero la funzione runtime·schedinit. È responsabile dell'inizializzazione delle risorse necessarie per il funzionamento dello scheduler all'avvio del programma, di seguito il codice semplificato.
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}La funzione runtime.getg è implementata in assembly, la sua funzione è ottenere la rappresentazione runtime della coroutine corrente, ovvero il puntatore alla struttura runtime.g. Attraverso sched.maxmcount = 10000 si può vedere che all'inizializzazione dello scheduler è impostato il numero massimo di M a 10000, questo valore è fisso e non può essere modificato. Successivamente viene inizializzato lo stack, poi la funzione runtime.mcommoninit inizializza M, la sua implementazione è la seguente:
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}Questa funzione pre-inizializza M, principalmente facendo il seguente lavoro:
- Alloca l'id di M
- Alloca separatamente una G per gestire i segnali del thread, completato dalla funzione
runtime.mpreinit - Lo inserisce come testa della lista globale M
runtime.allm
Successivamente inizializza P, il cui numero è per impostazione predefinita il numero di core logici della CPU, altrimenti il valore della variabile d'ambiente.
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}Infine la funzione runtime.procresize è responsabile dell'inizializzazione di P, modifica lo slice globale runtime.allp che memorizza tutti i P in base al numero passato. Prima determina se è necessario espandere la capacità in base alla dimensione.
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}Poi inizializza ogni P.
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}Se il P attualmente utilizzato dalla coroutine deve essere distrutto, viene sostituito con allp[0], e la funzione runtime.acquirep completa l'associazione tra M e il nuovo P.
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}Successivamente distrugge i P non più necessari, durante la distruzione vengono rilasciate tutte le risorse di P, tutte le G nella sua coda locale vengono messe nella coda globale, dopo la distruzione viene fatto lo slice di allp.
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}Infine collega i P idle in una lista e restituisce la testa della lista.
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsDopo di che, l'inizializzazione dello scheduler è completata, e runtime.worldStarted riprende l'esecuzione di tutti i P.
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)Poi viene creata una nuova coroutine tramite la funzione runtime.newproc per avviare il programma Go, successivamente viene chiamata runtime.mstart per avviare ufficialmente lo scheduler, anch'essa implementata in assembly, che internamente chiama la funzione runtime.mstart0 per la creazione, parte del codice è la seguente:
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()A questo punto M ha solo una coroutine g0, che utilizza lo stack di sistema del thread, non uno stack allocato separatamente. La funzione mstart0 inizializza prima i limiti dello stack di G, poi passa a mstart1 per completare il resto del lavoro di inizializzazione.
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()Prima di iniziare, registra il contesto di esecuzione corrente, poiché dopo il successo dell'inizializzazione entra nel ciclo di schedulazione e non tornerà mai, le altre chiamate possono riutilizzare il contesto di esecuzione per tornare dalla funzione mstart1 per uscire dal thread. Dopo aver registrato, le funzioni runtime.asminit e runtime.minit sono responsabili dell'inizializzazione dello stack di sistema, poi la funzione runtime.mstartm0 imposta il callback per la gestione dei segnali. Dopo aver eseguito la funzione di callback m.mstartfn, la funzione runtime.acquirep associa M con il P creato precedentemente, infine entra nel ciclo di schedulazione.
La chiamata a runtime.schedule qui è il primo ciclo di schedulazione del runtime Go, che segna l'inizio ufficiale del lavoro dello scheduler.
Thread
Nello scheduler, G per eseguire codice utente deve affidarsi a P, e P per funzionare correttamente deve essere associato a un M, dove M si riferisce ai thread di sistema.
Creazione
La creazione di M è completata dalla funzione runtime.newm, che accetta una funzione e P e id come parametri, la funzione come parametro non può essere una closure.
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}Prima di iniziare, newm chiama la funzione runtime.allocm per creare la rappresentazione runtime del thread, ovvero M, durante il processo utilizza la funzione runtime.mcommoninit per inizializzare i limiti dello stack di M.
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}Successivamente runtime.newm1 chiama la funzione runtime.newosproc per completare la vera creazione del thread di sistema.
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}L'implementazione di runtime.newosproc varia a seconda del sistema operativo, come viene creato esattamente non è ciò di cui dobbiamo preoccuparci, è responsabilità del sistema operativo, poi runtime.mstart avvia il lavoro di M.
Uscita
runtime.gogo(&mp.g0.sched)All'inizio è stato menzionato che durante la chiamata a mstart1 il contesto di esecuzione è stato salvato nel campo sched di g0, passando questo campo alla funzione runtime.gogo (implementata in assembly) permette al thread di saltare al contesto di esecuzione per continuare l'esecuzione, poiché al momento del salvataggio è stato utilizzato getcallerpc(), quindi quando si ripristina il contesto si torna alla funzione mstart0.
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)Dopo il ripristino del contesto di esecuzione, secondo l'ordine di esecuzione si entra nella funzione mexit per uscire dal thread.
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)Fa principalmente le seguenti cose:
- Chiama
runtime.uminitper annullare il lavoro diruntime.minit - Rimuove M dalla variabile globale
allm - Imposta
freemdello scheduler per puntare a M corrente - La funzione
runtime.releasepdisassocia P da M corrente, eruntime.handoffpfa sì che P si associ ad altre M per continuare il lavoro - La funzione
runtime.destroyè responsabile del rilascio delle risorse di M - Infine il sistema operativo esce dal thread
A questo punto M è uscito con successo.
Pausa
Quando è necessario sospendere M a causa di schedulazione dello scheduler, GC, system call o altri motivi, viene chiamata la funzione runtime.stopm per sospendere il thread, di seguito il codice semplificato.
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}Per prima cosa inserisce M nella lista globale delle M idle, poi mPark() blocca il thread corrente su notesleep(&gp.m.park), quando viene risvegliato la funzione ritorna.
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}M dopo essere stato risvegliato cercherà un P da associare per continuare l'esecuzione del compito.
Coroutine
Il ciclo di vita di una coroutine corrisponde esattamente ai suoi stati, comprendere il ciclo di vita delle coroutine è molto utile per capire lo scheduler, dopotutto l'intero scheduler è progettato attorno alle coroutine, l'intero ciclo di vita delle coroutine è mostrato nella figura seguente.
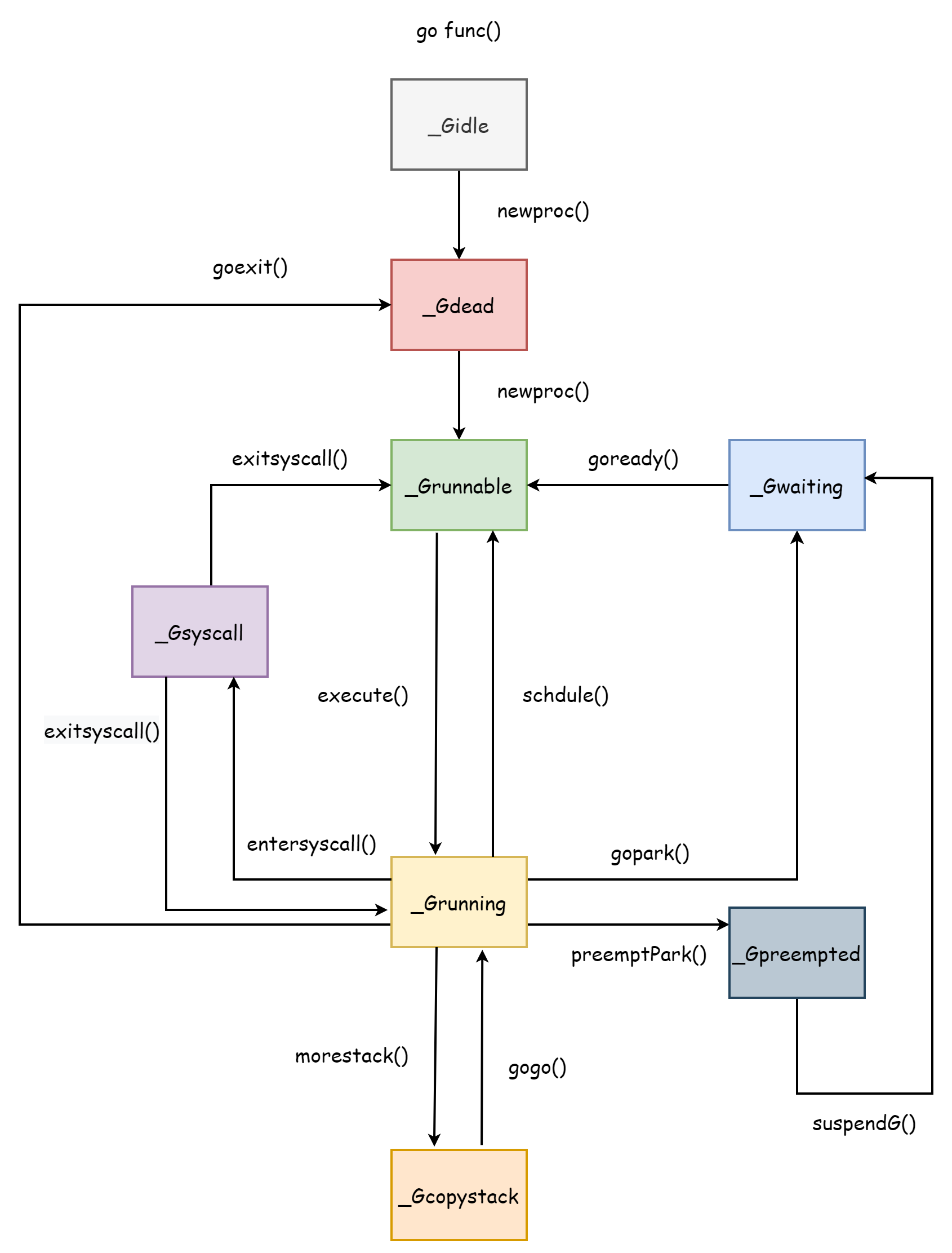
_Gcopystack è lo stato che la coroutine ha durante l'espansione dello stack, discusso nella sezione Stack delle Coroutine.
Creazione
La creazione di una coroutine dal punto di vista sintattico richiede solo una parola chiave go e una funzione.
go doSomething()Dopo la compilazione diventa una chiamata alla funzione runtime.newproc.
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1 completa la creazione effettiva, durante la creazione per prima cosa blocca M, proibisce la prelazione, poi cerca G idle dalla lista locale gfree di P per riutilizzare, se non ne trova crea una nuova G tramite runtime.malg, allocando 2kb di spazio stack. A questo punto lo stato di G è _Gdead.
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}In Go 1.18 e successive, la copia dei parametri non è più completata dalla funzione newproc1, prima di questo veniva utilizzato runtime.memmove per copiare i parametri della funzione. Ora è solo responsabile del reset dello stack della coroutine, impostando runtime.goexit come base dello stack per gestire l'uscita della coroutine, poi imposta il PC della funzione di ingresso newg.startpc = fn.fn per indicare l'inizio dell'esecuzione, dopo aver impostato, lo stato di G è _Grunnable.
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)Infine imposta l'identificatore unico di G, poi rilascia M e restituisce la coroutine G creata.
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgDopo la creazione della coroutine, prova a inserirla nella coda locale di P tramite la funzione runtime.runqput, se non c'è spazio la mette nella coda globale. Durante l'intero processo di creazione della coroutine, il suo stato cambia prima da _Gidle a _Gdead, dopo aver impostato la funzione di ingresso cambia da _Gdead a _Grunnable.
Uscita
Durante la creazione, Go ha già impostato la funzione runtime.goexit come base dello stack della coroutine, quindi quando la coroutine ha finito di eseguire alla fine entra in questa funzione, attraverso la catena di chiamate goexit->goexit1->goexit0, infine runtime.goexit0 è responsabile del lavoro di uscita della coroutine.
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}Questa funzione fa principalmente le seguenti cose:
- Imposta lo stato a
_Gdead - Reimposta i valori dei campi
dropg()taglia il collegamento tra M e Ggfput(pp, gp)inserisce G corrente nella lista locale idle di Pschedule()esegue una nuova schedulazione, cedendo il diritto di esecuzione di M ad altre G
Dopo l'uscita, lo stato della coroutine cambia da _Grunning a _Gdead, e potrebbe essere riutilizzata in futuro quando si creano nuove coroutine.
System Call
Quando la coroutine G esegue codice utente e effettua una system call, ci sono due modi per triggerare una system call:
- System call della libreria standard
syscall - Chiamata cgo
Poiché la system call blocca il thread di lavoro, prima è necessario fare准备工作, completato dalla funzione runtime.entersyscall, ma la prima è solo una semplice chiamata alla funzione runtime.reentersyscall, il lavoro effettivo è completato da quest'ultima. Per prima cosa blocca M corrente, durante la preparazione G non può essere prelazionato, e l'espansione dello stack è proibita, impostando gp.stackguard0 = stackPreempt per indicare che dopo il completamento della preparazione il diritto di esecuzione di P sarà prelazionato da altre G, poi conserva il contesto di esecuzione della coroutine,方便 per il ripristino dopo il ritorno della system call.
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcSuccessivamente, per prevenire un blocco prolungato che influisce sull'esecuzione di altre G, M e P si disassociano, M e G dopo il disaccoppiamento si bloccano a causa dell'esecuzione della system call, mentre P dopo il disaccoppiamento potrebbe associarsi ad altre M idle per permettere ad altre G nella coda locale di P di continuare il lavoro.
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--Dopo il completamento della preparazione, rilascia il lock di M, durante questo periodo lo stato di G cambia da _Grunning a _Gsyscall, lo stato di P cambia a _Psyscall.
Quando la system call ritorna, il thread M non è più bloccato, e la G corrispondente deve essere schedulata nuovamente per eseguire il codice utente, completato dalla funzione runtime.exitsyscall. Per prima cosa blocca M corrente, ottiene il riferimento al vecchio P.
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0A questo punto si divide in due casi per gestire, il primo caso è se c'è un P direttamente disponibile, la funzione runtime.exitsyscallfast determina se il P originale è disponibile, cioè se lo stato di P è _Psyscall, altrimenti cerca un P idle.
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}Se trova con successo un P disponibile, M si associa a P, G cambia dallo stato _Gsyscall a _Grunning, poi attraverso runtime.Gosched G cede attivamente il diritto di esecuzione, P entra nel ciclo di schedulazione per cercare altre G disponibili.
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}Se non trova, M si disassocia da G, G cambia dallo stato _Gsyscall a _Grunnable, poi prova nuovamente a trovare un P idle, se non trova mette direttamente G nella coda globale, poi entra in un nuovo ciclo di schedulazione, la vecchia M entra nello stato idle tramite runtime.stopm, aspettando nuovi compiti in futuro. Se P è trovato, la vecchia M e G si associano al nuovo P, poi continuano a eseguire codice utente, lo stato cambia da _Grunnable a _Grunning.
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}Dopo l'uscita dalla system call, lo stato di G ha due possibili risultati, uno è _Grunnable in attesa di essere schedulato, l'altro è _Grunning che continua l'esecuzione.
Sospensione
Quando la coroutine corrente si sospende per alcuni motivi, lo stato cambia da _Grunnable a _Gwaiting, ci sono molti motivi per la sospensione, può essere a causa di blocco del channel, select, lock o time.sleep, per più motivi vedi Struttura G. Prendiamo time.Sleep come esempio, è effettivamente collegato a runtime.timesleep, il codice seguente.
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}Si può vedere che ottiene la coroutine corrente tramite getg, poi sospende la coroutine corrente tramite runtime.gopark. runtime.gopark aggiorna il motivo del blocco di G e M, rilascia il lock di M.
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)Poi cambia sullo stack di sistema e runtime.park_m cambia lo stato di G a _Gwaiting, poi taglia il collegamento tra M e G ed entra in un nuovo ciclo di schedulazione per cedere il diritto di esecuzione ad altre G. Dopo la sospensione, G non esegue codice utente e non si trova nella coda locale, ma mantiene un riferimento a M e P.
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()Nella funzione runtime.timesleep c'è questa riga di codice, che specifica il valore di t.f.
t.f = goroutineReadyQuesta funzione runtime.goroutineReady è utilizzata per risvegliare la coroutine sospesa, chiama la funzione runtime.ready per risvegliare la coroutine.
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)Dopo il risveglio, cambia lo stato di G a _Grunnable, poi mette G nella coda locale di P in attesa di essere schedulata in futuro.
Stack delle Coroutine
Le coroutine nel linguaggio Go sono tipiche coroutine con stack, ogni volta che si avvia una coroutine viene allocato uno stack indipendente sull'heap, e cambia con l'uso crescendo o riducendosi. Durante l'inizializzazione dello scheduler, la funzione runtime.stackinit è responsabile dell'inizializzazione della cache globale dello stack stackpool e stackLarge.
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}Oltre a questo, ogni P ha la propria cache indipendente dello stack mcache.
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}La cache dei thread mcache è indipendente per ogni thread e non è allocata sulla memoria heap, non richiede lock durante l'accesso, queste tre cache dello stack verranno utilizzate durante l'allocazione dello spazio successivo.
Allocazione
Quando si crea una coroutine, se non ci sono coroutine riutilizzabili, viene allocato un nuovo stack, la cui dimensione predefinita è 2KB.
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}La funzione responsabile dell'allocazione dello stack è runtime.stackalloc.
func stackalloc(n uint32) stackIn base alla dimensione della memoria dello stack richiesta se è inferiore a 32KB si dividono due casi, 32KB è anche lo standard in Go per distinguere tra oggetti piccoli e grandi. Se inferiore a questo valore si ottiene dalla cache stackpool, quando M è associato a P e M non può essere prelazionato, si ottiene dalla cache locale dei thread.
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}Se superiore a 32KB, si ottiene dalla cache stackLarge, se ancora non basta si alloca direttamente memoria sull'heap.
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}Alla fine restituisce l'indirizzo basso e alto dello spazio stack.
return stack{uintptr(v), uintptr(v) + uintptr(n)}Espansione
La dimensione predefinita dello stack della coroutine è 2KB, sufficientemente leggera, quindi il costo di creazione di una coroutine è molto basso, ma questo potrebbe non essere sufficiente, quando lo stack non è sufficiente è necessario espanderlo. Il compilatore inserisce la funzione runtime.morestack all'inizio delle funzioni per controllare se la coroutine corrente necessita di espansione dello stack, se necessario chiama la funzione runtime.newstack per completare la vera operazione di espansione.
TIP
Poiché morestack viene inserito quasi all'inizio di tutte le funzioni, il punto di controllo dell'espansione dello stack è anche un punto di prelazione della coroutine.
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)Si può vedere che la capacità dello stack calcolata è il doppio dell'originale, la funzione runtime.copystack completa il lavoro di copia dello stack, prima della copia lo stato di G cambia da _Grunning a _Gcopystack.
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}Questa funzione fa principalmente i seguenti lavori:
- Alloca un nuovo spazio stack
- Copia direttamente la memoria del vecchio stack nel nuovo spazio stack tramite
runtime.memmove - Regola le strutture che contengono puntatori allo stack, come defer, panic, ecc.
- Aggiorna i campi dello stack di G
- Regola i puntatori che puntano alla vecchia memoria stack tramite
runtime.adjustframe - Rilascia la memoria del vecchio stack
Dopo il completamento, lo stato di G cambia da _Gcopystack a _Grunning, e la funzione runtime.gogo fa continuare G a eseguire codice utente. Proprio grazie all'esistenza dell'espansione dello stack delle coroutine, la memoria in Go è instabile.
Contrazione
Quando lo stato di G è _Grunnable, _Gsyscall, _Gwaiting, GC scannerà lo spazio di memoria dello stack della coroutine.
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}Il lavoro effettivo di contrazione dello stack è completato da runtime.shrinkstack.
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}Quando lo spazio stack utilizzato è inferiore a 1/4 dell'originale, viene ridotto a 1/2 dell'originale tramite runtime.copystack, il resto del lavoro è simile a prima.
Stack Segmentati
Dal processo di copystack si può vedere che copia la memoria del vecchio stack in uno spazio stack più grande, sia il vecchio stack che il nuovo stack hanno indirizzi di memoria continui. Nell'antico linguaggio Go, l'espansione dello stack era diversa, all'epoca si pensava che la copia di memoria consumasse troppe prestazioni, si adottava l'approccio dello stack segmentato, se la memoria dello stack non era sufficiente, si richiedeva un nuovo spazio stack, la memoria dello stack originale non veniva rilasciata né copiata, collegata tramite puntatori, formando una lista concatenata di stack, questa è l'origine dello stack segmentato, come mostrato nella figura seguente.
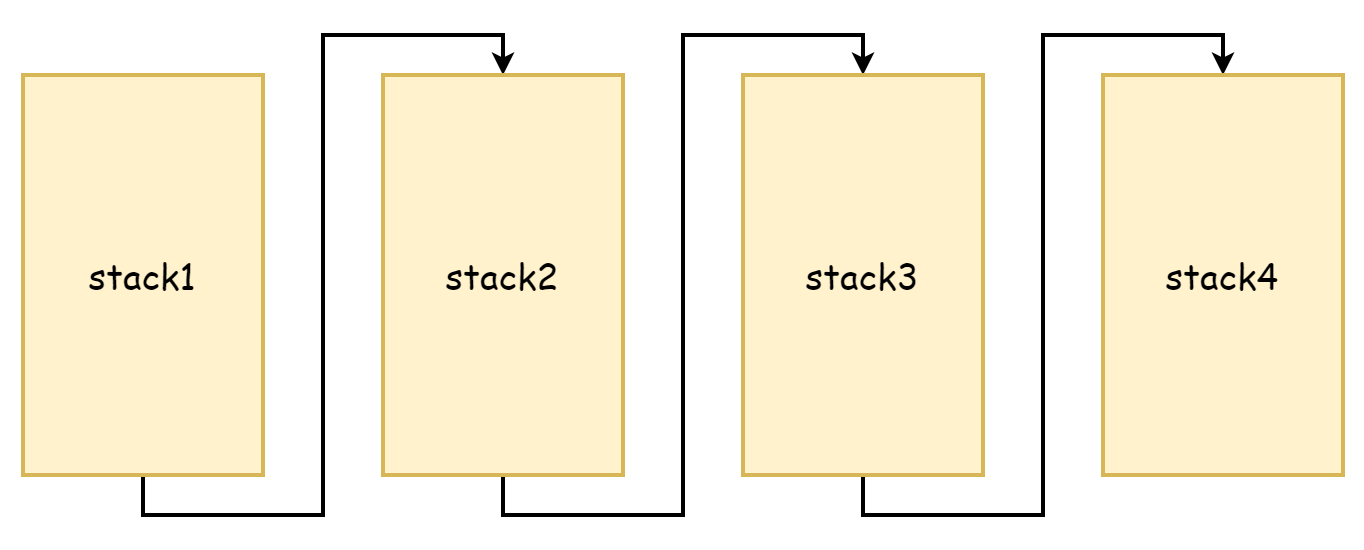
Il vantaggio di questo approccio è che non è necessario copiare lo stack originale, ma lo svantaggio è molto evidente, cioè triggera molto frequentemente l'espansione e contrazione dello stack. Quando la memoria libera dello stack è quasi esaurita, una nuova chiamata di funzione triggera l'espansione dello stack, quando queste funzioni ritornano, non è più necessario il nuovo spazio stack e triggera di nuovo la contrazione, se la frequenza di queste chiamate di funzione è molto alta, allora l'espansione e contrazione frequenti causano un consumo di prestazioni molto grande.
Quindi dopo Go 1.4 si è passati allo stack continuo, lo stack continuo poiché alloca uno spazio stack di capacità maggiore, non si verifica la situazione in cui la memoria utilizzata raggiunge il valore critico a causa delle chiamate di funzione che triggerano frequenti espansioni e contrazioni, e poiché gli indirizzi di memoria sono continui, secondo il principio di località spaziale della cache, lo stack continuo è anche più favorevole alla cache della CPU.
Ciclo di Schedulazione
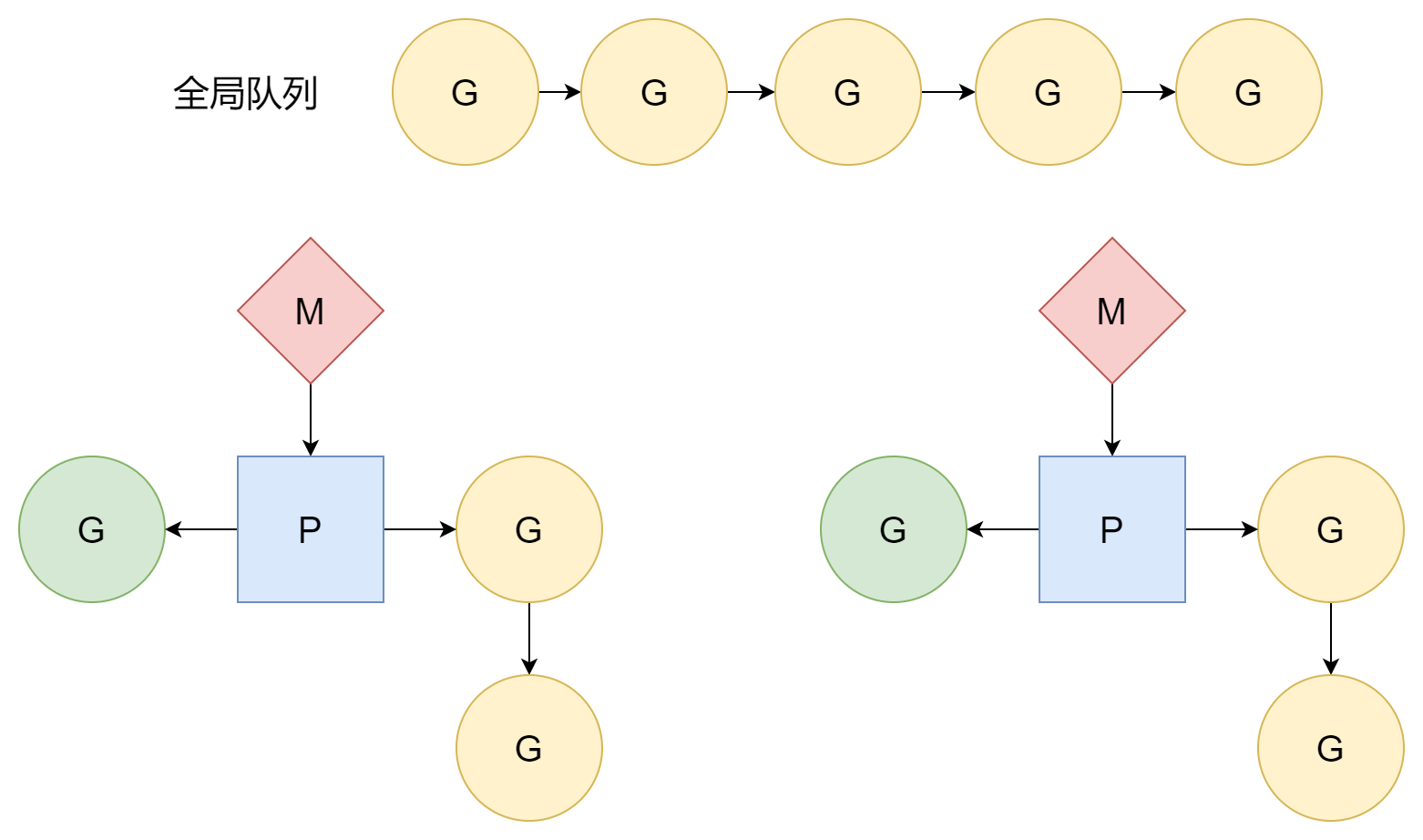
Nella parte di inizializzazione dello scheduler è stato menzionato che nella funzione runtime.mstart1, dopo che M e P sono associati con successo, si entra nel primo ciclo di schedulazione runtime.schedule per iniziare ufficialmente la schedulazione di G per eseguire codice utente. Nel ciclo di schedulazione, questa parte è principalmente P che gioca un ruolo. M corrisponde al thread di sistema, G corrisponde alla funzione di ingresso ovvero al codice utente, ma P non ha un'entità corrispondente come M e G, è solo un concetto astratto, come intermediario gestisce la relazione tra M e G.
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}Il codice sopra è semplificato, sono stati rimossi molti giudizi condizionali, i punti più centrali sono solo due runtime.findRunnable e runtime.execute, il primo è responsabile di trovare una G, e restituisce sicuramente una G disponibile, il secondo è responsabile di far continuare G a eseguire codice utente.
Per la funzione findRunnable, la prima fonte di G è la coda locale di P.
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}Se la coda locale non ha G, allora prova a ottenere dalla coda globale.
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}Se non si trova né nella coda locale né in quella globale, prova a ottenere dal network poller.
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}Se ancora non si trova, alla fine si cerca di rubare G dalla coda locale di altri P. Quando si crea una coroutine è stato menzionato che una grande fonte di G nella coda locale di P sono le coroutine figlie derivate dalla coroutine corrente, tuttavia non tutte le coroutine creano coroutine figlie, così potrebbe verificarsi una situazione in cui una parte di P è molto occupata, un'altra parte di P è idle, questo porta a una situazione in cui alcune G aspettano sempre e non possono essere eseguite, mentre dall'altra parte P è molto libero, niente da fare. Per poter sfruttare tutti i P al massimo della loro efficienza, quando P non trova G, va a "rubare" G eseguibili dalla coda locale di altri P, in questo modo ogni P può avere una coda di G più uniforme, e raramente si verifica la situazione in cui P guardano l'un l'altro senza fare nulla.
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork seleziona casualmente un P per rubare, il vero lavoro di furto è completato dalla funzione runtime.runqgrab, che prova a rubare metà delle G dalla coda locale di quel P.
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}L'intero lavoro di furto viene eseguito quattro volte, se dopo quattro volte non si riesce a rubare G allora ritorna. Se alla fine non si riesce a trovare, M corrente viene sospeso da runtime.stopm, fino a quando non viene risvegliato e continua a ripetere i passaggi precedenti. Quando si trova e restituisce una G, viene passata a runtime.execute per eseguire G.
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)Per prima cosa aggiorna curg di M, poi aggiorna lo stato di G a _Grunning, infine passa a runtime.gogo per ripristinare l'esecuzione di G.
In sintesi, nel ciclo di schedulazione le fonti di G secondo la priorità sono quattro:
- Coda locale di P
- Coda globale
- Network poller
- Rubare dalla coda locale di altri P
runtime.execute dopo l'esecuzione non ritorna, e la G appena ottenuta non esegue per sempre, a un certo momento triggera la schedulazione, il suo diritto di esecuzione viene privato, poi entra in un nuovo ciclo di schedulazione, cedendo il diritto di esecuzione ad altre G.
Strategie di Schedulazione
Diverse G possono avere tempi di esecuzione del codice utente diversi, alcune G possono richiedere molto tempo, altre G richiedono poco tempo, G con tempi di esecuzione lunghi possono causare ritardi nell'esecuzione di altre G, quindi l'esecuzione alternata di G è il modo corretto, questo modo di lavorare nel sistema operativo è chiamato concorrenza.
Schedulazione Collaborativa
L'idea di base della schedulazione collaborativa è far cedere volontariamente il diritto di esecuzione alle altre G, ci sono principalmente due metodi.
Il primo metodo è cedere attivamente nel codice utente, Go fornisce la funzione runtime.Gosched(), l'utente può decidere autonomamente quando cedere il diritto di esecuzione, ma spesso i dettagli interni del lavoro dello scheduler sono una scatola nera per l'utente, è difficile giudicare quando cedere attivamente, richiede requisiti più alti per l'utente, e lo scheduler di Go cerca di schermare la maggior parte dei dettagli per l'utente, perseguendo un metodo di utilizzo più semplice, in questo caso far partecipare anche l'utente al lavoro di schedulazione non è una buona cosa.
Il secondo metodo è il标记 di prelazione, sebbene il suo nome abbia la parola prelazione, ma essenzialmente è ancora una strategia di schedulazione collaborativa. L'idea è inserire codice di rilevamento della prelazione all'inizio delle funzioni runtime.morestack(), il processo di inserimento è completato durante il periodo di compilazione, è stato menzionato prima che originariamente era una funzione utilizzata per il rilevamento dell'espansione dello stack, poiché il suo punto di rilevamento è la chiamata di ogni funzione, questo è anche un buon momento per eseguire il rilevamento della prelazione. La parte superiore della funzione runtime.newstack è tutta dedicata al rilevamento della prelazione, la parte inferiore è dedicata al rilevamento dell'espansione dello stack, per evitare interferenze prima è stata omessa questa parte, ora vediamo cosa fa questa parte. Per prima cosa giudica la prelazione in base a gp.stackguard0, se non è necessario continua a eseguire il codice utente.
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}Quando g.stackguard0 == stackPreempt, la funzione runtime.canPreemptM() giudica se le condizioni della coroutine necessitano di essere prelazionate, il codice è il seguente:
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}Si può vedere che per essere prelazionabile è necessario soddisfare quattro condizioni:
- M non è bloccato
- Non si sta allocando memoria
- Non è disabilitata la prelazione
- P è nello stato
_Prunning
E nei seguenti due casi g.stackguard0 viene impostato a stackPreempt:
- Quando è necessario il garbage collection
- Quando si verifica una system call
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}Infine si arriva a runtime.gopreempt_m() per cedere attivamente il diritto di esecuzione della coroutine corrente. Per prima cosa taglia il collegamento tra M e G, lo stato diventa _Grunnable, poi mette G nella coda globale, infine entra nel ciclo di schedulazione per cedere il diritto di esecuzione ad altre G.
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()In questo modo, tutte le coroutine durante la chiamata di funzione potrebbero entrare in questa funzione per il rilevamento della prelazione, questa strategia deve dipendere dal momento della chiamata di funzione per triggerare la prelazione e cedere attivamente il diritto. Prima di Go 1.14, Go ha sempre utilizzato questa strategia di schedulazione, ma questo ha un problema, se non ci sono chiamate di funzione, non si può rilevare, ad esempio il seguente codice classico, che dovrebbe apparire in molti tutorial:
func main() {
// Limita il numero di P a 1
runtime.GOMAXPROCS(1)
// Coroutine 1
go func() {
for {
// Questa coroutine gira a vuoto continuamente
}
}()
// Entra nella system call, la coroutine principale cede il diritto ad altre coroutine
time.Sleep(time.Millisecond)
println("exit")
}Il codice crea una coroutine 1 che gira a vuoto, poi la coroutine principale cede attivamente il diritto a causa della system call, a questo punto la coroutine 1 è in schedulazione, ma poiché non chiama affatto funzioni, non può eseguire il rilevamento della prelazione, poiché c'è solo un P, non ci sono altri P idle, questo porta alla situazione in cui la coroutine principale non può mai essere schedulata, exit non viene mai stampato, ma questo problema è limitato a prima di Go 1.14.
Schedulazione Prelazionabile
Go 1.14 ha aggiunto la strategia di schedulazione prelazionabile basata su segnali, questa è una strategia di prelazione asincrona, attraverso l'invio di segnali tramite thread asincroni per prelazionare i thread, la schedulazione prelazionabile basata su segnali ha attualmente due ingressi,分别是 il monitor di sistema e GC.
Nel ciclo del monitor di sistema, attraversa ogni P, se il tempo di esecuzione di G che P sta schedulando supera i 10ms, triggera forzatamente la prelazione. Questo lavoro è completato dalla funzione runtime.retake, di seguito il codice semplificato.
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}Quando è necessario eseguire il garbage collection, se lo stato di G è _Grunning, cioè è ancora in esecuzione, triggera anche la prelazione.
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}I due ingressi di prelazione alla fine entrano nella funzione runtime.preemptM, che completa l'invio del segnale di prelazione. Quando il segnale viene inviato con successo, il callback del gestore di segnali registrato da runtime.initsig durante runtime.mstart, ovvero runtime.sighandler, viene utilizzato, se rileva che il segnale inviato è un segnale di prelazione, inizia la prelazione.
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt modifica il contesto della coroutine target, iniettando la chiamata a runtime.asyncPreempt.
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...In questo modo quando si ritorna al codice utente, la coroutine target arriva alla funzione runtime.asyncPreempt, che coinvolge la chiamata a runtime.asyncPreempt2.
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RETFa sì che la coroutine corrente smetta di lavorare ed esegua un nuovo ciclo di schedulazione per cedere il diritto di esecuzione ad altre coroutine.
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}Questo processo avviene tutto nella funzione runtime.asyncPreempt, implementata in assembly (situata in runtime/preempt_*.s) e ripristina il contesto della coroutine modificato precedentemente dopo il completamento della schedulazione, per permettere alla coroutine di riprendersi normalmente in futuro. Dopo l'adozione della strategia di prelazione asincrona, l'esempio precedente non blocca più permanentemente la coroutine principale, quando la coroutine che gira a vuoto esegue per un certo tempo viene forzata a eseguire il ciclo di schedulazione, cedendo così il diritto di esecuzione alla coroutine principale, permettendo infine al programma di terminare normalmente.
Riepilogo
In sintesi, i momenti che triggerano la schedulazione sono i seguenti:
- Chiamata di funzione
- System call
- Monitor di sistema
- Garbage collection, anche per le coroutine con tempi di esecuzione lunghi viene eseguita la prelazione
- La coroutine si sospende a causa di channel, lock o altri motivi
Le strategie di schedulazione sono principalmente due categorie, collaborativa e prelazionabile, la collaborativa cede attivamente il diritto di esecuzione, la prelazionabile prelaziona asincronamente il diritto di esecuzione, le due coesistono per formare lo scheduler di oggi.