slice
TIP
La lettura di questo articolo richiede conoscenze della libreria standard unsafe.
Le slice sono probabilmente la struttura dati più comunemente usata nel linguaggio Go (in realtà le strutture dati built-in sono poche), e la si vede quasi ovunque. Il loro uso di base è stato già illustrato nell'introduzione al linguaggio; ora esaminiamo come sono fatte internamente e come funzionano.
Struttura
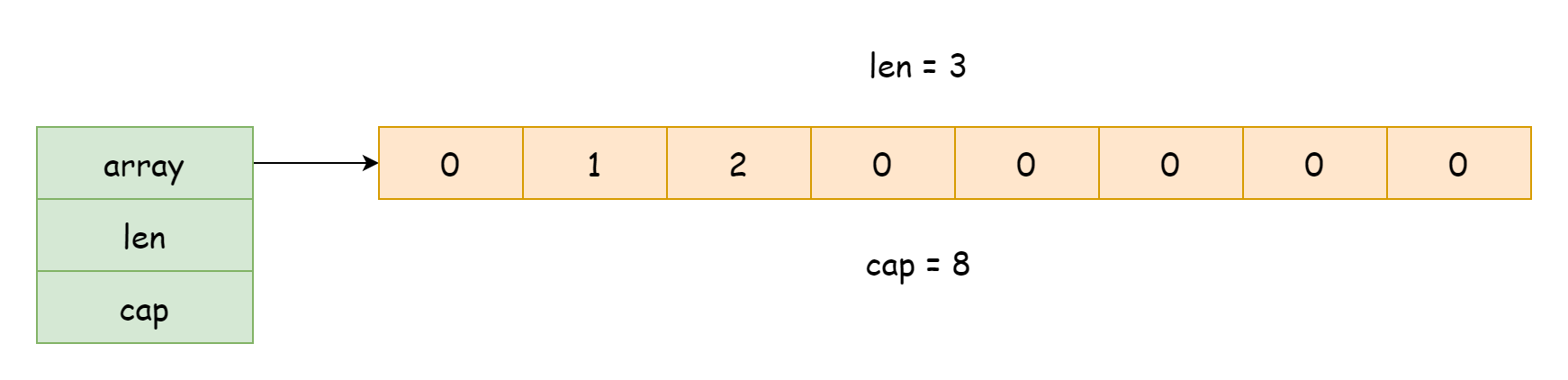
L'implementazione delle slice si trova nel file runtime/slice.go. A runtime, una slice esiste come una struttura di tipo runtime.slice, come mostrato di seguito.
type slice struct {
array unsafe.Pointer
len int
cap int
}Questa struttura ha solo tre campi:
array: puntatore all'array sottostantelen: lunghezza della slice, ovvero il numero di elementi già presenti nell'arraycap: capacità della slice, ovvero il numero totale di elementi che l'array può contenere
Da quanto sopra si evince che l'implementazione sottostante delle slice dipende dagli array. Normalmente è solo una struttura che detiene un riferimento all'array, insieme a capacità e lunghezza. Questo rende il passaggio delle slice molto efficiente: viene copiata solo la referenza ai dati, non tutti i dati stessi. Inoltre, usando len e cap per ottenere lunghezza e capacità, si ottengono direttamente i valori dei campi senza bisogno di iterare l'array.
Tuttavia, questo può causare problemi non sempre evidenti. Consideriamo il seguente esempio:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]Nel codice sopra, s1 è stata creata come nuova slice tramite slicing, ma condivide lo stesso array sottostante con la slice originale. Modificare i dati in s1 causa cambiamenti anche in s. Quindi, quando si copia una slice, si dovrebbe usare la funzione copy, che crea una slice indipendente. Vediamo un altro esempio:
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Anche in questo caso si usa lo slicing per copiare la slice, ma questa volta non influisce sulla slice originale. Inizialmente s1 e s puntavano allo stesso array, ma successivamente sono stati aggiunti troppi elementi a s1, superando la capacità dell'array. È stato quindi allocato un nuovo array più grande, quindi alla fine puntano ad array diversi. Pensate che sia tutto? Vediamo un altro esempio:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Nonostante siano stati aggiunti elementi, la stampa mostra una slice vuota. In realtà i dati sono stati aggiunti alla slice, ma solo nell'array sottostante. In Go i parametri delle funzioni sono passati per valore, quindi il parametro s è una copia della struttura della slice originale. L'operazione append restituisce una slice aggiornata con la nuova lunghezza, ma viene assegnata al parametro s, non alla slice originale, quindi le due non sono collegate.
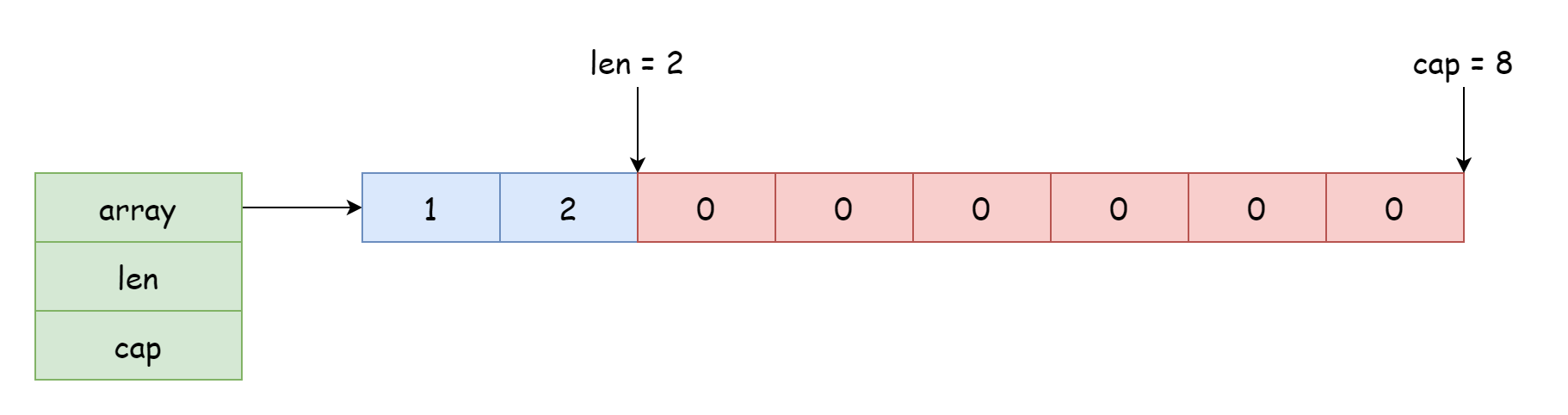
Per una slice, la posizione di accesso e modifica dipende dalla posizione del riferimento all'array. L'offset è determinato dalla lunghezza registrata nella struttura. Il puntatore nella struttura può puntare all'inizio o a metà dell'array, come mostrato nella figura seguente.
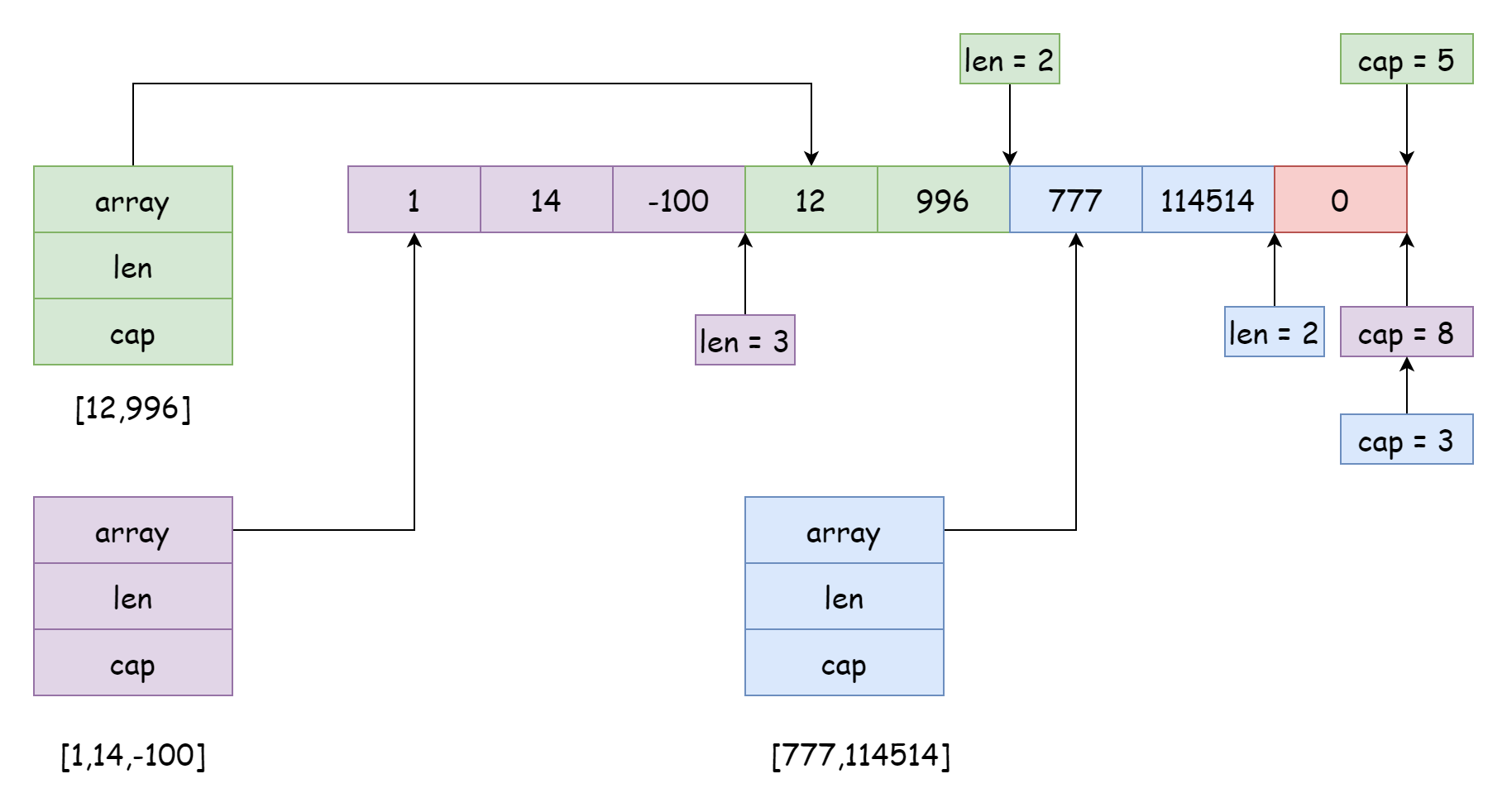
Un array sottostante può essere referenziato da molte slice, con posizioni e intervalli di riferimento diversi, come nella figura sopra. Questa situazione si verifica generalmente quando si effettua lo slicing di una slice, come nel codice seguente:
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]Durante lo slicing, la capacità della nuova slice è uguale alla lunghezza dell'array meno la posizione di inizio della nuova slice. Ad esempio, la capacità della slice creata con s[4:6] è 6 = 10 - 4. Naturalmente, gli intervalli delle slice non devono essere necessariamente adiacenti e possono anche sovrapporsi, ma questo può causare grandi problemi: i dati di una slice potrebbero essere modificati da un'altra slice senza preavviso. Ad esempio, la slice viola nella figura sopra: se si usa append per aggiungere elementi in seguito, potrebbe sovrascrivere i dati delle slice verde e blu. Per evitare questa situazione, Go permette di impostare un limite di capacità durante lo slicing, con la seguente sintassi:
s4 = s[4:6:6]In questo caso, la capacità è limitata a 2, quindi aggiungere elementi attiverà l'espansione. Dopo l'espansione, si tratta di un nuovo array indipendente dall'array originale. Pensate che i problemi delle slice finiscano qui? Non proprio. Vediamo un altro esempio:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// Il numero di elementi da aggiungere è appena superiore alla capacità
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Il codice è identico all'esempio precedente, ma è stato modificato il numero di elementi in input in modo che superi appena la capacità della slice. Questo attiva l'espansione durante l'aggiunta. Di conseguenza, i dati non vengono aggiunti alla slice originale s, e nemmeno l'array sottostante viene scritto. Possiamo verificarlo usando puntatori unsafe, come nel codice seguente:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// Il numero di elementi da aggiungere è appena superiore alla capacità
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,Come si può vedere, l'array sottostante della slice originale è vuoto, senza alcun dato. Tutti i dati sono stati scritti nel nuovo array. Non c'è relazione con la slice originale perché, anche se append restituisce un nuovo riferimento, modifica solo il valore del parametro formale s, senza influenzare la slice originale s. Le slice come strutture possono essere molto leggere, ma i problemi sopra menzionati non vanno sottovalutati, specialmente nel codice reale dove questi problemi sono solitamente nascosti in profondità e difficili da individuare.
Creazione
A runtime, la creazione di una slice tramite la funzione make è gestita da runtime.makeslice. La sua logica è piuttosto semplice. La firma della funzione è la seguente:
func makeslice(et *_type, len, cap int) unsafe.PointerRiceve tre parametri: il tipo di elemento, la lunghezza e la capacità, e restituisce un puntatore all'array sottostante. Il codice è il seguente:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Calcola la memoria totale necessaria; se troppo grande può causare overflow numerico
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Se tutto è ok, alloca la memoria
return mallocgc(mem, et, true)
}La logica è molto semplice: fa solo due cose:
- Calcola la memoria necessaria
- Alloca lo spazio di memoria
Se i controlli delle condizioni falliscono, va direttamente in panic:
- Overflow numerico durante il calcolo della memoria
- Il risultato del calcolo supera la memoria massima allocabile
- Lunghezza e capacità non sono valide
Se la memoria calcolata è maggiore di 32KB, viene allocata sull'heap. Dopodiché, restituisce un puntatore all'array sottostante. La costruzione della struttura runtime.slice non è completata dalla funzione makeslice. In realtà, la costruzione della struttura avviene durante la compilazione; la funzione makeslice a runtime si occupa solo di allocare la memoria, come nel codice seguente:
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capSe siete interessati, potete guardare il codice intermedio generato, simile a questo:
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8Se si usa un array per creare una slice, come nel seguente esempio:
var arr [5]int
s := arr[:]Questo processo è simile al codice seguente:
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo usa direttamente l'array come array sottostante della slice, quindi modificare i dati nella slice influenzerà anche i dati dell'array. Quando si crea una slice da un array, la lunghezza è uguale a high-low e la capacità è uguale a max-low, dove max è per impostazione predefinita la lunghezza dell'array, oppure si può specificare manualmente la capacità durante lo slicing, ad esempio:
var arr [5]int
s := arr[2:3:4]
Accesso
L'accesso a una slice usa l'indicizzazione come per gli array:
elem := s[i]L'operazione di accesso alla slice viene completata durante la compilazione, generando codice intermedio. Il codice finale generato può essere compreso come il seguente pseudocodice:
p := s.ptr
e := *(p + sizeof(elem(s)) * i)In realtà, si accede all'elemento all'indice corrispondente tramite un'operazione di spostamento del puntatore. Questo corrisponde alla seguente parte del codice nella funzione cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Sposta il puntatore
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)Quando si accede alla lunghezza e alla capacità della slice tramite le funzioni len e cap, vale lo stesso principio. Anche questo corrisponde a una parte del codice nella funzione cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))Nel codice effettivamente generato, si accede al campo len della struttura della slice spostando il puntatore, che può essere compreso come il seguente pseudocodice:
p := &s
len := *(p + 8)
cap := *(p + 16)Supponiamo di avere il seguente codice:
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}Allora il codice intermedio in una certa fase della generazione sarà probabilmente simile a questo:
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9Da quanto sopra si può vedere chiaramente che uno aggiunge 8 e l'altro aggiunge 16, indicando che si accede ai campi della slice tramite offset del puntatore.
Se è possibile dedurre la lunghezza e la capacità durante la compilazione, non sarà necessario spostare il puntatore a runtime per ottenere i valori. Ad esempio, in questo caso non è necessario spostare il puntatore:
s := make([]int, 10, 20)
l := len(s)
c := cap(s)I valori delle variabili l e c saranno direttamente sostituiti con 10 e 20.
Scrittura
Modifica
s := make([]int, 10)
s[0] = 100Quando si modifica il valore di una slice tramite indice, durante la compilazione viene generato pseudocodice simile al seguente tramite l'operazione OpStore:
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valIl codice intermedio in una certa fase della generazione sarà probabilmente simile a questo:
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:Il codice accede alla lunghezza della slice per verificare la validità dell'indice, quindi memorizza l'elemento spostando il puntatore.
Aggiunta
La funzione append permette di aggiungere elementi a una slice:
var s []int
s = append(s, 1, 2, 3)Dopo l'aggiunta, restituisce una nuova struttura slice. Se non c'è espansione, rispetto alla slice originale viene aggiornata solo la lunghezza; altrimenti punterà a un nuovo array. I problemi d'uso relativi ad append sono stati spiegati in dettaglio nella sezione Struttura, quindi non ci dilungheremo ulteriormente. Di seguito ci concentreremo su come funziona append.
A runtime non esiste una funzione come runtime.appendslice corrispondente. Il lavoro di aggiunta degli elementi viene effettuato durante la compilazione: la funzione append viene espansa nel codice intermedio corrispondente. Il codice di判断 si trova nella funzione cmd/compile/internal/walk/assign.go walkassign:
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}Come si vede, ci sono tre casi:
- Aggiunta di diversi elementi
- Aggiunta di una slice
- Aggiunta di una slice creata temporaneamente
Di seguito verrà illustrato come appare il codice generato, così da capire come funziona effettivamente append. Se siete interessati al processo di generazione del codice, potete approfondire autonomamente.
Aggiunta di elementi
s = append(s, x, y, z)Se si aggiungono solo un numero limitato di elementi, la funzione walkAppend li espande nel seguente codice:
// Numero di elementi da aggiungere
const argc = len(args) - 1
newLen := s.len + argc
// È necessaria l'espansione?
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zPer prima cosa calcola il numero di elementi da aggiungere, poi verifica se è necessaria l'espansione, infine assegna i valori uno per uno.
Aggiunta di una slice
s = append(s, s1...)Se si aggiunge direttamente una slice, la funzione appendSlice la espande nel seguente codice:
newLen := s.len + s1.len
// Confronta come uint così growslice può andare in panic su overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Come prima, calcola la nuova lunghezza, verifica se è necessaria l'espansione. La differenza è che Go non aggiunge gli elementi della slice originale uno per uno, ma sceglie di copiare direttamente la memoria.
Aggiunta di una slice temporanea
s = append(s, make([]T, l2)...)Se si aggiunge una slice creata temporaneamente, la funzione extendslice la espande nel seguente codice:
if l2 >= 0 {
// Blocco if vuoto qui per un node.SetLikely(true) più significativo
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// Pulisce la nuova porzione dell'array sottostante.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)Per le slice aggiunte temporaneamente, Go ottiene la lunghezza della slice temporanea. Se la capacità della slice corrente non è sufficiente a contenerla, tenterà l'espansione. Dopodiché, pulirà la parte corrispondente della memoria.
Espansione
Dalla sezione sulla struttura sappiamo che le slice sono sottostantemente degli array. Gli array sono strutture a lunghezza fissa, ma le slice hanno lunghezza variabile. Quando la capacità dell'array non è sufficiente, la slice richiede più memoria per i dati, ovvero un nuovo array, copia i vecchi dati nel nuovo, e il riferimento della slice punterà al nuovo array. Questo processo è chiamato espansione. Il lavoro di espansione viene completato a runtime dalla funzione runtime.growslice, la cui firma è la seguente:
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceSpiegazione breve dei parametri:
oldPtr: puntatore al vecchio arraynewLen: lunghezza del nuovo array,newLen = oldLen + numoldCap: capacità della vecchia slice, uguale alla lunghezza del vecchio arrayet: tipo di elemento
Il valore di ritorno è una nuova slice, completamente indipendente dalla slice originale. L'unico punto in comune è che i dati salvati sono gli stessi.
var s []int
s = append(s, elems...)Quando si usa append per aggiungere elementi, si richiede che il valore di ritorno sovrascriva la slice originale. Se avviene un'espansione, viene restituita una nuova slice.
Durante l'espansione, per prima cosa si determinano la nuova lunghezza e capacità, come nel codice seguente:
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Doppia capacità
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Overflow numerico
if newcap <= 0 {
newcap = newLen
}
}
}Dal codice sopra si evince che per le slice con capacità inferiore a 256, la capacità raddoppia. Per le slice con capacità maggiore o uguale a 256, la capacità sarà almeno 1,25 volte quella originale. Quando la slice è piccola, raddoppiare direttamente ogni volta evita espansioni frequenti. Quando la slice è grande, il moltiplicatore di espansione diminuisce per evitare di allocare troppa memoria e sprecarla.
Dopo aver ottenuto la nuova lunghezza e capacità, si calcola la memoria necessaria, come nel codice seguente:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Capacità finale
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}La formula per il calcolo della memoria è mem = cap * sizeof(et). Per facilitare l'allineamento della memoria, durante il processo la memoria calcolata viene arrotondata per eccesso a una potenza intera di 2, e si ricalcola la nuova capacità. Se la nuova capacità è troppo grande e causa overflow numerico durante il calcolo, o se la nuova memoria supera la memoria massima allocabile, si va in panic.
var p unsafe.Pointer
// Alloca memoria
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}Dopo aver calcolato i risultati necessari, si alloca memoria della dimensione specificata, si pulisce la memoria nell'intervallo da newLen a newCap, si copiano i dati del vecchio array nella nuova slice, e infine si costruisce la struttura della slice.
Copia
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)Quando si usa la funzione copy per copiare una slice, la funzione cmd/compile/internal/walk.walkcopy determina durante la compilazione come effettuare la copia. Se viene chiamata a runtime, si usa la funzione runtime.slicecopy, che si occupa di copiare le slice. La firma della funzione è la seguente:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intRiceve i puntatori e le lunghezze della slice di origine e di destinazione, nonché la lunghezza da copiare width. La logica di questa funzione è molto semplice, come mostrato di seguito:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Calcola il numero di byte da copiare
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}Il valore di width dipende dal minimo delle lunghezze delle due slice. Come si vede, durante la copia di una slice non si iterano gli elementi uno per uno, ma si copia direttamente un blocco intero della memoria dell'array sottostante. Quando la slice è grande, la copia della memoria può avere un impatto significativo sulle prestazioni.
Se non viene chiamata a runtime, viene espansa in codice nella seguente forma:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Entrambi i modi hanno lo stesso principio: copiano la slice copiando la memoria. La funzione memmove è implementata in assembly; se interessati, potete visualizzare i dettagli in runtime/memmove_amd64.s.
Pulizia
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}Nella versione go1.21, è stata aggiunta la funzione built-in clear per pulire il contenuto di una slice, ovvero impostare tutti gli elementi al loro valore zero. Quando la funzione clear agisce su una slice, il compilatore la espande durante la compilazione tramite la funzione cmd/compile/internal/walk.arrayClear nella seguente forma:
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}Per prima cosa verifica se la lunghezza della slice è 0, poi calcola il numero di byte da pulire, e infine gestisce due casi a seconda che l'elemento sia un puntatore o meno. Alla fine viene usata la funzione memclrNoHeapPointers, la cui firma è la seguente:
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)Riceve due parametri: un puntatore all'indirizzo di inizio e un offset, ovvero il numero di byte da pulire. L'indirizzo di inizio della memoria è l'indirizzo del riferimento detenuto dalla slice, e l'offset n = sizeof(et) * len. Questa funzione è implementata in assembly; se interessati, potete查看 i dettagli in runtime/memclr_amd64.s.
Vale la pena menzionare che se nel codice sorgente si tenta di pulire un array tramite iterazione, ad esempio:
for i := range s {
s[i] = ZERO_val
}Prima dell'introduzione della funzione clear, si usava solitamente questo metodo per pulire le slice. Durante la compilazione, questo codice viene ora ottimizzato dalla funzione cmd/compile/internal/walk.arrayRangeClear nella seguente forma:
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Ferma il ciclo
i = len(s) - 1
}
}La logica è identica a quella sopra, con l'aggiunta della riga i = len(s)-1, il cui scopo è fermare il ciclo dopo la pulizia della memoria.
Iterazione
for i, e := range s {
fmt.Println(i, e)
}Quando si usa for range per iterare su una slice, la funzione walkRange in cmd/compile/internal/walk/range.go la espande nella seguente forma:
// Copia la struttura
hs := s
// Ottieni il puntatore all'array sottostante
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... corpo del ciclo ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}Come si vede, l'implementazione di for range itera sugli elementi spostando il puntatore. Per evitare che la slice venga aggiornata durante l'iterazione, viene preventivamente copiata la struttura hs. Per evitare che il puntatore punti a memoria fuori limite dopo l'iterazione, hu usa il tipo uintptr per memorizzare l'indirizzo, convertendolo in unsafe.Pointer solo quando necessario accedere agli elementi.
La variabile v2, ovvero e in for range, è durante tutto il processo sempre la stessa variabile: viene solo sovrascritta, non ricreata. Questo ha causato il problema delle variabili di ciclo che ha困扰 gli sviluppatori Go per un decennio. Nella versione go1.21, i responsabili hanno finalmente deciso di risolvere il problema. Si prevede che negli aggiornamenti delle versioni successive, la creazione di v2 potrebbe diventare come segue:
v2 := *hpIl processo di costruzione del codice intermedio è omesso qui, poiché non rientra nelle conoscenze sulle slice. Se interessati, potete approfondire autonomamente.