slice
TIP
La lecture de cet article nécessite des connaissances sur la bibliothèque standard unsafe.
Le slice est probablement la structure de données la plus utilisée en Go, sans exception (en réalité, il n'y a pas beaucoup de structures de données intégrées). On peut le voir presque partout. Son utilisation de base a déjà été expliquée dans l'introduction au langage. Voyons maintenant à quoi il ressemble en interne et comment il fonctionne.
Structure
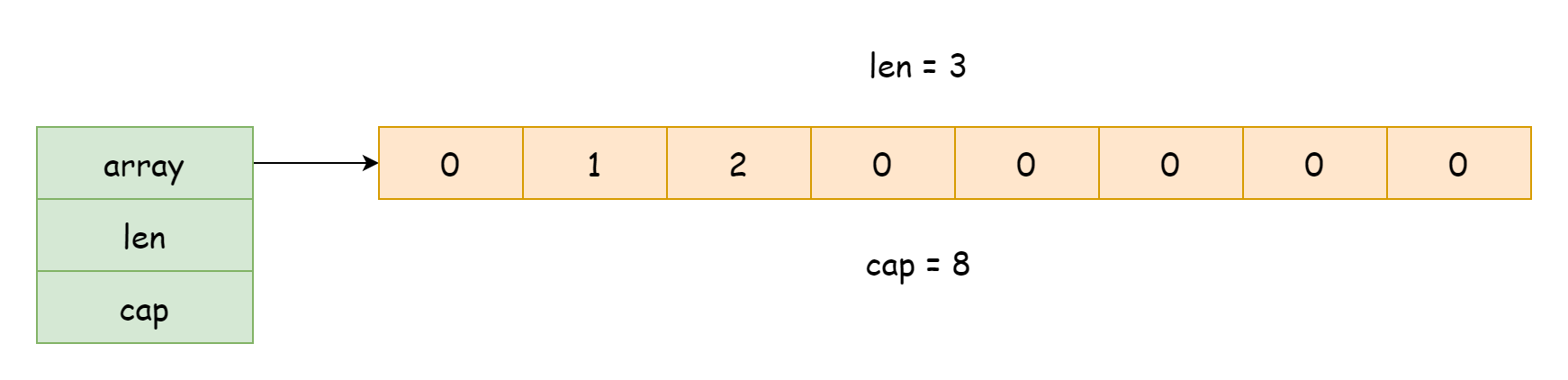
L'implémentation du slice se trouve dans le fichier runtime/slice.go. À l'exécution, le slice existe sous forme d'une structure de type runtime.slice, comme montré ci-dessous.
type slice struct {
array unsafe.Pointer
len int
cap int
}Cette structure n'a que trois champs :
array, pointeur vers le tableau sous-jacentlen, longueur du slice, c'est-à-dire le nombre d'éléments déjà présents dans le tableaucap, capacité du slice, c'est-à-dire le nombre total d'éléments que le tableau peut contenir
D'après les informations ci-dessus, on peut déduire que l'implémentation sous-jacente du slice repose toujours sur un tableau. En temps normal, ce n'est qu'une structure qui ne détient qu'une référence au tableau, ainsi qu'un enregistrement de la capacité et de la longueur. Ainsi, le coût de transmission d'un slice est très faible, il suffit de copier la référence de ses données, sans avoir à copier toutes les données. De plus, lors de l'utilisation de len et cap pour obtenir la longueur et la capacité du slice, cela équivaut à obtenir les valeurs de ses champs, sans avoir à parcourir le tableau.
Cependant, cela pose également certains problèmes difficiles à détecter. Regardons l'exemple suivant :
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]Dans le code ci-dessus, s1 crée un nouveau slice par découpage, mais lui et le slice source font référence au même tableau sous-jacent. Modifier les données dans s1 entraîne également un changement dans s. Donc, lors de la copie d'un slice, il faut utiliser la fonction copy, le slice copié n'aura alors aucun lien avec l'original. Regardons un autre exemple :
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Ici aussi on utilise le découpage pour copier un slice, mais cette fois cela n'affecte pas le slice source. Au début, s1 et s pointaient effectivement vers le même tableau, mais par la suite, l'ajout de trop d'éléments à s1 a dépassé la capacité du tableau, donc un nouveau tableau plus grand a été alloué pour contenir les éléments. À la fin, ils pointent vers des tableaux différents. Pensez-vous que le problème est résolu ? Regardons encore un exemple :
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]On a clairement ajouté des éléments, mais le résultat affiche un slice vide. En réalité, les données ont bien été ajoutées au slice, mais elles ont été écrites dans le tableau sous-jacent. En Go, les arguments de fonction sont passés par valeur, donc le paramètre s est en fait une copie de la structure du slice source. L'opération append retourne une structure de slice avec une longueur mise à jour après l'ajout d'éléments, mais c'est le paramètre s qui est assigné, pas le slice source s. Les deux n'ont en fait pas de lien.
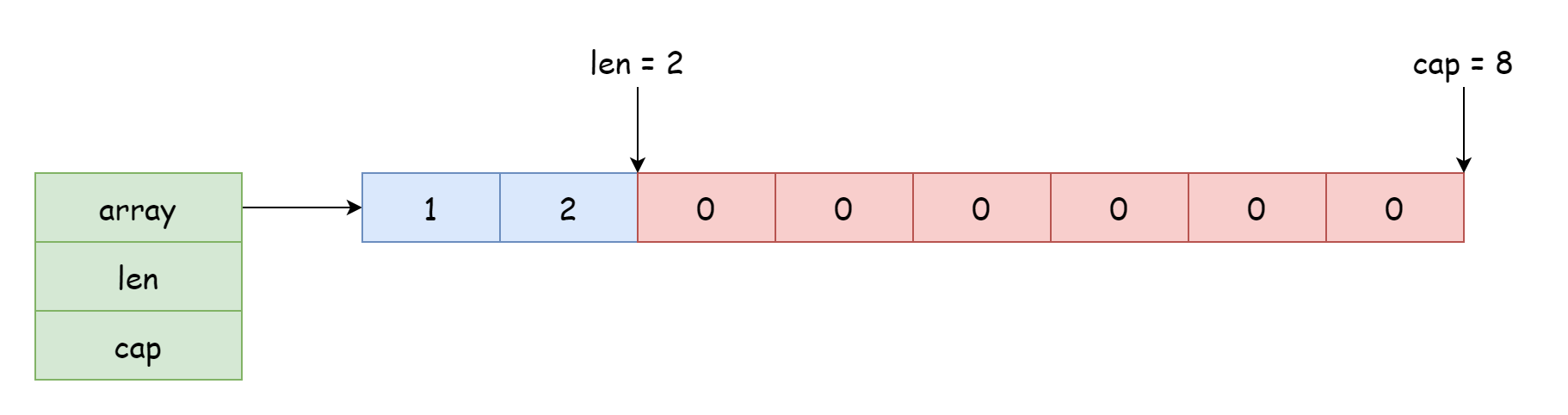
Pour un slice, la position de départ à laquelle il peut accéder et modifier dépend de la position de référence dans le tableau, et le décalage dépend de la longueur enregistrée dans la structure. Le pointeur dans la structure peut pointer vers le début, mais aussi vers le milieu du tableau, comme le montre l'image suivante.
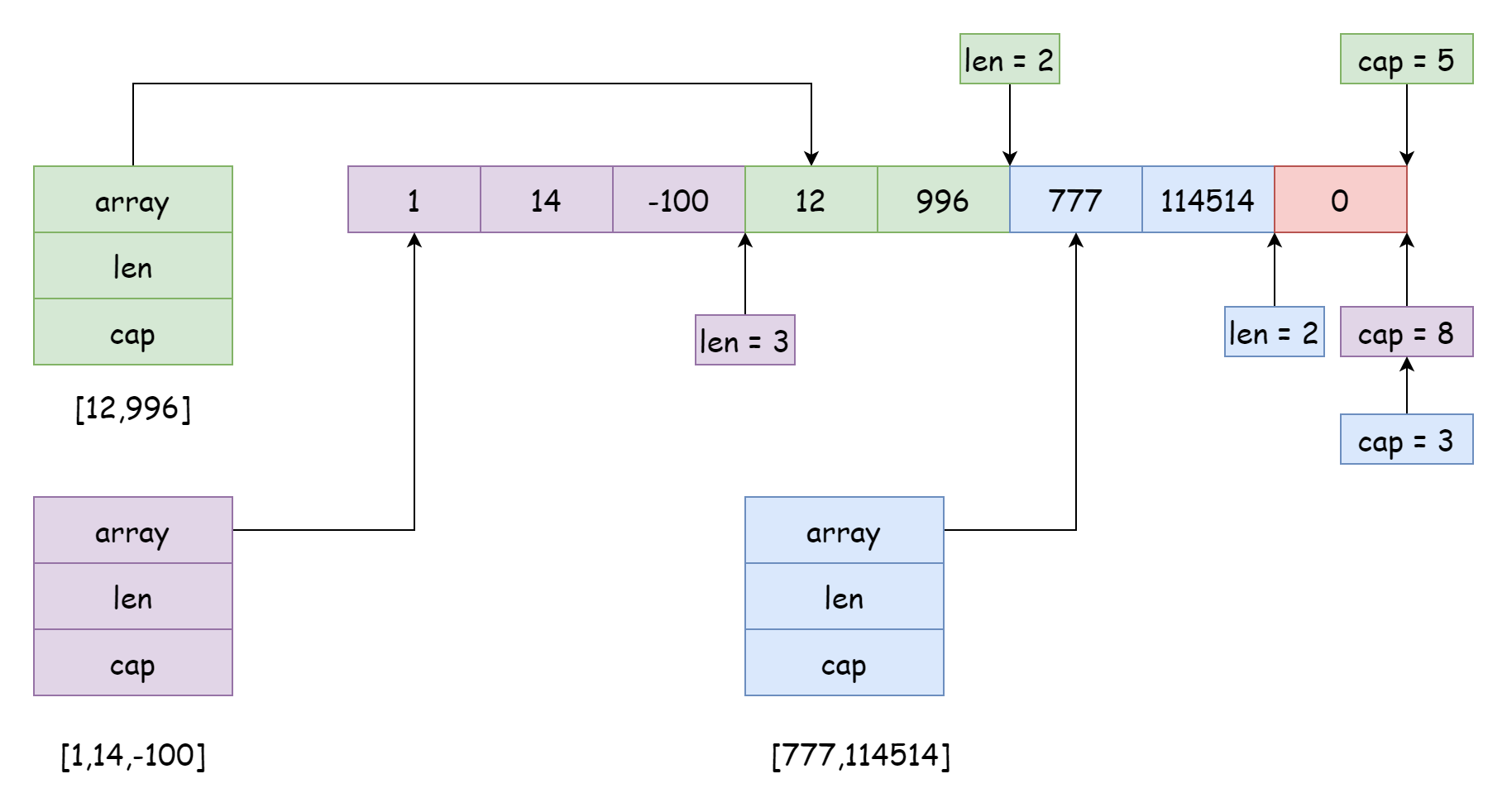
Un même tableau sous-jacent peut être référencé par plusieurs slices, et les positions et étendues des références peuvent être différentes, comme sur l'image ci-dessus. Cette situation se produit généralement lors du découpage d'un slice, avec un code similaire à celui-ci :
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]Lors du découpage, la capacité du nouveau slice généré est égale à la longueur du tableau moins la position de départ de la référence du nouveau slice. Par exemple, s[4:6] génère un nouveau slice avec une capacité de 6 = 10 - 4. Bien sûr, l'étendue de la référence d'un slice n'a pas besoin d'être adjacente, elle peut aussi se chevaucher, mais cela peut créer de gros problèmes. Il est possible que les données d'un slice soient modifiées par un autre slice à l'insu de tous, comme le slice violet sur l'image. Si on utilise append pour ajouter des éléments par la suite, cela pourrait écraser les données des slices vert et bleu. Pour éviter cette situation, Go permet de définir une plage de capacité lors du découpage, avec la syntaxe suivante :
s4 = s[4:6:6]Dans ce cas, sa capacité est limitée à 2, donc l'ajout d'éléments déclenchera une expansion. Après l'expansion, ce sera un nouveau tableau, sans lien avec le tableau source, donc pas d'impact. Vous pensez que les problèmes liés aux slices s'arrêtent là ? Détrompez-vous, regardons encore un exemple :
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// Le nombre d'éléments ajoutés dépasse juste la capacité
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Le code est identique à l'exemple précédent, seuls les paramètres ont été modifiés pour que le nombre d'éléments ajoutés dépasse juste la capacité du slice. Ainsi, lors de l'ajout, une expansion sera déclenchée. De cette façon, non seulement les données n'ont pas été ajoutées au slice source s, mais même le tableau sous-jacent vers lequel il pointe n'a pas reçu de données. Nous pouvons le vérifier avec un pointeur unsafe, comme montré ci-dessous :
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// Le nombre d'éléments ajoutés dépasse juste la capacité
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,On peut voir que le tableau sous-jacent du slice source est vide, rien du tout. Toutes les données ont été écrites dans le nouveau tableau. Mais cela n'a rien à voir avec le slice source, car même si append a retourné une nouvelle référence, seule la valeur du paramètre formel s a été modifiée, sans affecter le slice source s. Le slice en tant que structure peut certes être très léger, mais les problèmes ci-dessus ne doivent pas être ignorés, d'autant plus que dans le code réel, ces problèmes sont souvent cachés très profondément et difficiles à découvrir.
Création
À l'exécution, la création d'un slice avec la fonction make est effectuée par runtime.makeslice. Sa logique est relativement simple. La signature de cette fonction est la suivante :
func makeslice(et *_type, len, cap int) unsafe.PointerElle reçoit trois paramètres : le type d'élément, la longueur et la capacité. Elle retourne un pointeur vers le tableau sous-jacent. Son code est le suivant :
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Calculer la mémoire totale nécessaire, si trop grand cela provoque un débordement numérique
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Si pas de problème, allouer la mémoire
return mallocgc(mem, et, true)
}On peut voir que la logique est très simple, elle ne fait que deux choses :
- Calculer la mémoire nécessaire
- Allouer l'espace mémoire
Si la vérification des conditions échoue, une panic est directement déclenchée :
- Débordement numérique lors du calcul de la mémoire
- Le résultat du calcul dépasse la mémoire maximale allouable
- Longueur ou capacité invalide
Si la mémoire calculée est supérieure à 32KB, elle sera allouée sur le tas. Ensuite, un pointeur vers le tableau sous-jacent est retourné. La construction de la structure runtime.slice n'est pas effectuée par la fonction makeslice. En fait, la construction de la structure est effectuée pendant la compilation. La fonction makeslice à l'exécution ne fait qu'allouer la mémoire, avec un code similaire à celui-ci :
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capSi cela vous intéresse, vous pouvez regarder le code intermédiaire généré, qui est similaire à ceci.
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8Si on utilise un tableau pour créer un slice, comme ci-dessous :
var arr [5]int
s := arr[:]Ce processus est similaire au code suivant :
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo utilisera directement ce tableau comme tableau sous-jacent du slice, donc modifier les données dans le slice affectera également les données du tableau. Lors de la création d'un slice à partir d'un tableau, la longueur est égale à high-low, et la capacité est égale à max-low, où max est par défaut la longueur du tableau, ou peut être spécifié manuellement lors du découpage, par exemple :
var arr [5]int
s := arr[2:3:4]
Accès
Accéder à un slice se fait comme pour un tableau, en utilisant un index :
elem := s[i]L'opération d'accès à un slice est effectuée pendant la compilation en générant du code intermédiaire. Le code finalement généré peut être compris comme le pseudo-code suivant :
p := s.ptr
e := *(p + sizeof(elem(s)) * i)En réalité, l'accès se fait en déplaçant un pointeur vers l'élément correspondant à l'index. Cela correspond à la partie suivante du code dans la fonction cmd/compile/internal/ssagen.exprCheckPtr :
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Décaler le pointeur
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)Lors de l'accès à la longueur et à la capacité d'un slice avec les fonctions len et cap, c'est le même principe. Cela correspond également à une partie du code dans la fonction cmd/compile/internal/ssagen.exprCheckPtr :
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))Dans le code réellement généré, on accède au champ len de la structure du slice en déplaçant un pointeur. Cela peut être compris comme le pseudo-code suivant :
p := &s
len := *(p + 8)
cap := *(p + 16)Supposons le code suivant :
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}Alors, à un certain stade de la génération, le code intermédiaire ressemblera probablement à ceci :
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9On peut voir clairement ci-dessus qu'un ajout de 8 et un ajout de 16 indiquent clairement un accès aux champs du slice par décalage de pointeur.
Si la longueur et la capacité peuvent être déduites pendant la compilation, il n'est pas nécessaire de décaler un pointeur à l'exécution pour obtenir les valeurs. Par exemple, dans le cas suivant, il n'est pas nécessaire de déplacer le pointeur :
s := make([]int, 10, 20)
l := len(s)
c := cap(s)Les valeurs des variables l et c seront directement remplacées par 10 et 20.
Écriture
Modification
s := make([]int, 10)
s[0] = 100Lors de la modification de la valeur d'un slice via un index, pendant la compilation, une opération OpStore générera un pseudo-code similaire à celui-ci :
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valÀ un certain stade de la génération, le code intermédiaire ressemblera probablement à ceci :
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:On peut voir que le code accède à la longueur du slice pour vérifier si l'index est valide, puis stocke l'élément en déplaçant un pointeur.
Ajout
La fonction append permet d'ajouter des éléments à un slice :
var s []int
s = append(s, 1, 2, 3)Après l'ajout d'éléments, elle retourne une nouvelle structure de slice. S'il n'y a pas eu d'expansion, par rapport au slice source, seule la longueur a été mise à jour. Sinon, elle pointera vers un nouveau tableau. Les problèmes liés à l'utilisation de append ont déjà été expliqués en détail dans la section Structure, nous n'y reviendrons pas. Ci-dessous, nous nous concentrerons sur le fonctionnement de append.
À l'exécution, il n'existe pas de fonction comme runtime.appendslice correspondante. Le travail d'ajout d'éléments est en fait effectué pendant la compilation. La fonction append sera développée en code intermédiaire correspondant. Le code de jugement se trouve dans la fonction cmd/compile/internal/walk/assign.go walkassign :
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}On peut voir qu'il y a trois cas :
- Ajouter plusieurs éléments
- Ajouter un slice
- Ajouter un slice temporaire créé
Ci-dessous, nous expliquerons à quoi ressemble le code généré, afin de comprendre comment append fonctionne réellement. Le processus de génération de code peut être exploré par vous-même si vous êtes intéressé.
Ajouter des éléments
s = append(s, x, y, z)Si on ajoute seulement un nombre limité d'éléments, la fonction walkAppend développera le code comme suit :
// Nombre d'éléments à ajouter
const argc = len(args) - 1
newLen := s.len + argc
// Vérifier si une expansion est nécessaire
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zD'abord, on calcule le nombre d'éléments à ajouter, puis on vérifie si une expansion est nécessaire, et enfin on assigne les valeurs une par une.
Ajouter un slice
s = append(s, s1...)Si on ajoute directement un slice, la fonction appendSlice développera le code comme suit :
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Comme précédemment, on calcule la nouvelle longueur, on vérifie si une expansion est nécessaire. La différence est que Go n'ajoute pas les éléments du slice source un par un, mais choisit de copier directement la mémoire.
Ajouter un slice temporaire
s = append(s, make([]T, l2)...)Si on ajoute un slice créé temporairement, la fonction extendslice développera le code comme suit :
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)Pour un slice temporaire ajouté, Go obtient la longueur du slice temporaire. Si la capacité du slice actuel est insuffisante, une expansion sera tentée. Ensuite, la mémoire correspondante sera effacée.
Expansion
Comme on l'a vu dans la section Structure, le sous-sol d'un slice reste un tableau. Un tableau est une structure de données de longueur fixe, mais la longueur d'un slice est variable. Lorsque la capacité du tableau est insuffisante, le slice demandera un espace mémoire plus grand pour stocker les données, c'est-à-dire un nouveau tableau, puis y copiera les anciennes données. La référence du slice pointera alors vers le nouveau tableau. Ce processus est appelé expansion. L'expansion est effectuée à l'exécution par la fonction runtime.growslice, dont la signature est la suivante :
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceExplication simple des paramètres :
oldPtr, pointeur vers l'ancien tableaunewLen, longueur du nouveau tableau,newLen = oldLen + numoldCap, capacité de l'ancien slice, égale à la longueur de l'ancien tableauet, type d'élément
Sa valeur de retour est un nouveau slice. Le nouveau slice n'a aucun lien avec l'ancien slice, le seul point commun est que les données stockées sont les mêmes.
var s []int
s = append(s, elems...)Lors de l'utilisation de append pour ajouter des éléments, il faut assigner sa valeur de retour au slice original. Si une expansion a eu lieu, la valeur retournée est un nouveau slice.
Lors de l'expansion, il faut d'abord déterminer la nouvelle longueur et capacité, correspondant au code suivant :
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Double capacité
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Débordement numérique
if newcap <= 0 {
newcap = newLen
}
}
}D'après le code ci-dessus, pour les slices de capacité inférieure à 256, la capacité double. Pour les slices de capacité supérieure ou égale à 256, la capacité sera au moins 1,25 fois la capacité originale. Lorsque le slice actuel est petit, le doublement à chaque fois permet d'éviter des expansions fréquentes. Lorsque le slice est grand, le taux d'expansion diminue pour éviter de demander trop de mémoire et provoquer du gaspillage.
Après avoir obtenu la nouvelle longueur et capacité, on calcule la mémoire nécessaire, correspondant au code suivant :
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Capacité finale
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}La formule de calcul de la mémoire est mem = cap * sizeof(et). Pour faciliter l'alignement de la mémoire, la mémoire calculée sera arrondie à la puissance de 2 supérieure, et la nouvelle capacité sera recalculée. Si la nouvelle capacité est trop grande et provoque un débordement lors du calcul, ou si la nouvelle mémoire dépasse la mémoire maximale allouable, une panic sera déclenchée.
var p unsafe.Pointer
// Allouer la mémoire
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}Après avoir calculé les résultats nécessaires, on alloue une mémoire de la taille spécifiée, puis on efface la mémoire dans l'intervalle newLen à newCap, on copie les données de l'ancien tableau dans le nouveau slice, et enfin on construit la structure du slice.
Copie
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)Lors de la copie d'un slice avec la fonction copy, le code généré pendant la compilation par cmd/compile/internal/walk.walkcopy détermine la méthode de copie. Si l'appel se fait à l'exécution, la fonction runtime.slicecopy sera utilisée. Cette fonction est responsable de la copie du slice, avec la signature suivante :
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intElle reçoit les pointeurs et longueurs du slice source et du slice destination, ainsi que la longueur à copier width. La logique de cette fonction est très simple, comme montré ci-dessous :
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Calculer le nombre d'octets à copier
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}La valeur de width dépend du minimum des longueurs des deux slices. On peut voir que lors de la copie d'un slice, on ne parcourt pas les éléments un par un, mais on choisit de copier directement toute la mémoire du tableau sous-jacent. Lorsque le slice est grand, la copie de mémoire peut avoir un impact non négligeable sur les performances.
Si l'appel ne se fait pas à l'exécution, le code sera développé sous la forme suivante :
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Les deux méthodes ont le même principe : copier le slice en copiant la mémoire. La fonction memmove est implémentée en assembleur. Si vous êtes intéressé, vous pouvez consulter les détails dans runtime/memmove_amd64.s.
Effacement
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}Dans la version go1.21, la nouvelle fonction intégrée clear a été ajoutée pour effacer le contenu d'un slice, ou plus précisément pour mettre tous les éléments à leur valeur zéro. Lorsque la fonction clear agit sur un slice, le compilateur développe pendant la compilation via la fonction cmd/compile/internal/walk.arrayClear le code sous la forme suivante :
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}D'abord, on vérifie si la longueur du slice est 0, puis on calcule le nombre d'octets à effacer. Ensuite, selon que l'élément est un pointeur ou non, on traite de deux manières différentes. Mais finalement, la fonction memclrNoHeapPointers sera utilisée, avec la signature suivante :
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)Elle reçoit deux paramètres : un pointeur vers l'adresse de départ, et le décalage, c'est-à-dire le nombre d'octets à effacer. L'adresse de départ de la mémoire est l'adresse de la référence détenue par le slice, et le décalage n = sizeof(et) * len. Cette fonction est implémentée en assembleur. Si vous êtes intéressé, vous pouvez consulter les détails dans runtime/memclr_amd64.s.
Il est à noter que si le code source tente d'utiliser une boucle pour effacer un tableau, par exemple :
for i := range s {
s[i] = ZERO_val
}Avant l'existence de la fonction clear, c'était ainsi qu'on effaçait un slice. À la compilation, ce code est maintenant optimisé par la fonction cmd/compile/internal/walk.arrayRangeClear sous la forme suivante :
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Arrêter la boucle
i = len(s) - 1
}
}La logique est exactement la même que précédemment. Il y a une ligne supplémentaire i = len(s)-1, dont le but est d'arrêter la boucle après l'effacement de la mémoire.
Parcours
for i, e := range s {
fmt.Println(i, e)
}Lors de l'utilisation de for range pour parcourir un slice, la fonction walkRange dans cmd/compile/internal/walk/range.go développe le code sous la forme suivante :
// Copier la structure
hs := s
// Obtenir le pointeur du tableau sous-jacent
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}On peut voir que l'implémentation de for range parcourt toujours les éléments en déplaçant un pointeur. Pour éviter que le slice ne soit modifié pendant le parcours, une copie de la structure hs a été faite au préalable. Pour éviter que le pointeur ne pointe vers une mémoire hors limites après la fin du parcours, hu utilise le type uintptr pour stocker l'adresse, et ne convertit en unsafe.Pointer que lorsque l'accès à un élément est nécessaire.
La variable v2, c'est-à-dire e dans for range, est toujours la même variable tout au long du parcours. Elle ne fait qu'être écrasée, jamais recréée. Cela a provoqué le problème des variables de boucle qui a préoccupé les développeurs Go pendant dix ans. C'est seulement dans la version go.1.21 que l'équipe officielle a décidé de s'attaquer à ce problème. Dans les mises à jour futures, la création de v2 pourrait devenir :
v2 := *hpLe processus de construction du code intermédiaire est omis ici, car cela ne relève pas des connaissances sur les slices. Si vous êtes intéressé, vous pouvez l'explorer par vous-même.