map
Contrairement à d'autres langages, en Go, le support des tables de mappage est fourni par le mot-clé map, et non encapsulé dans une bibliothèque standard. Une table de mappage est une structure de données très utilisée, avec de nombreuses implémentations sous-jacentes possibles. Les deux plus courantes sont les arbres rouge-noir et les tables de hachage. Go adopte l'implémentation par table de hachage.
TIP
L'implémentation de map implique de nombreuses opérations de déplacement de pointeurs, donc la lecture de cet article nécessite des connaissances sur la bibliothèque standard unsafe.
Structure interne
La structure runtime.hmap représente un map en Go. Comme pour les slices, l'implémentation interne d'un map est également une structure.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}Les commentaires en anglais expliquent déjà clairement. Voici quelques explications simples pour les champs les plus importants :
count, représente le nombre d'éléments dans le hmap, équivalent àlen(map).flags, bits de drapeau du hmap, utilisés pour indiquer l'état du hmap. Les valeurs possibles sont :goconst ( iterator = 1 // un itérateur utilise les buckets oldIterator = 2 // un itérateur utilise les anciens buckets hashWriting = 4 // une goroutine est en train d'écrire dans le hmap sameSizeGrow = 8 // expansion à taille égale en cours )B, le nombre de buckets de hachage dans le hmap est1 << B.noverflow, nombre approximatif de buckets de débordement dans le hmap.hash0, graine de hachage, spécifiée lors de la création du hmap, utilisée pour calculer les valeurs de hachage.buckets, pointeur vers le tableau de buckets de hachage.oldbuckets, pointeur vers le tableau de buckets de hachage avant expansion.extra, contient les buckets de débordement du hmap. Un bucket de débordement est créé quand le bucket actuel est plein, pour stocker les éléments supplémentaires.
Le champ buckets du hmap est un pointeur vers un slice de buckets, représenté en Go par la structure runtime.bmap, comme montré ci-dessous :
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}On ne voit qu'un seul champ tophash, qui stocke les 8 bits de poids fort de chaque clé. En réalité, bmap a plus de champs, mais comme map peut stocker différents types de paires clé-valeur, la taille mémoire est déduite à la compilation selon le type. La fonction MapBucketType dans cmd/compile/internal/reflectdata/reflect.go construit le bmap à la compilation, en vérifiant notamment si le type de clé est comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeDonc en réalité, la structure de bmap est la suivante, mais ces champs ne sont pas visibles pour nous. Go y accède en déplaçant des pointeurs unsafe :
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Explications :
tophash, stocke les 8 bits de poids fort de chaque clé. Pour un élément de tophash, il y a plusieurs valeurs spéciales :goconst ( emptyRest = 0 // l'élément actuel est vide, et il n'y a plus de clé-valeur disponible après emptyOne = 1 // l'élément actuel est vide, mais il y a des clé-valeur disponibles après evacuatedX = 2 // apparaît lors de l'expansion, seulement dans oldbuckets, indique que l'élément a été déplacé vers la zone supérieure du nouveau tableau evacuatedY = 3 // apparaît lors de l'expansion, seulement dans oldbuckets, indique que l'élément a été déplacé vers la zone inférieure evacuatedEmpty = 4 // apparaît lors de l'expansion, l'élément était déjà vide, marqué lors du déplacement minTopHash = 5 // valeur minimale de tophash pour une clé-valeur normale )Si
tophash[i]est supérieur àminTopHash, cela signifie qu'il y a une clé-valeur normale à cet index.keys, tableau stockant les clés du type spécifié.elems, tableau stockant les valeurs du type spécifié.overflow, pointeur vers un bucket de débordement.
Puisque les clés et valeurs ne peuvent pas être accédées directement via les champs de la structure, Go a déclaré une constante dataOffset, qui représente le décalage mémoire des données dans bmap.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)En réalité, les clés et valeurs sont stockées dans une zone mémoire contiguë, avec une structure similaire à :
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Cela permet d'éviter le gaspillage d'espace dû à l'alignement mémoire.
Pour un bmap, après avoir déplacé le pointeur de dataOffset, déplacer de i*sizeof(keyType) donne l'adresse de la i-ème clé :
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))L'adresse de la i-ème valeur s'obtient de même :
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))Le pointeur buckets dans le hmap pointe vers l'adresse du premier bucket de hachage. Pour obtenir l'adresse du i-ème bucket, le décalage est i*sizeof(bucket).
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Ces opérations apparaîtront très fréquemment dans la suite.
Hachage
Conflits
Dans le hmap, un champ extra est dédié au stockage des informations sur les buckets de débordement. Il pointe vers un slice de pointeurs de buckets de débordement. Sa structure est la suivante :
type mapextra struct {
// slice de pointeurs de buckets de débordement
overflow *[]*bmap
// slice de pointeurs des anciens buckets de débordement avant expansion
oldoverflow *[]*bmap
// pointeur vers le prochain bucket de débordement libre
nextOverflow *bmap
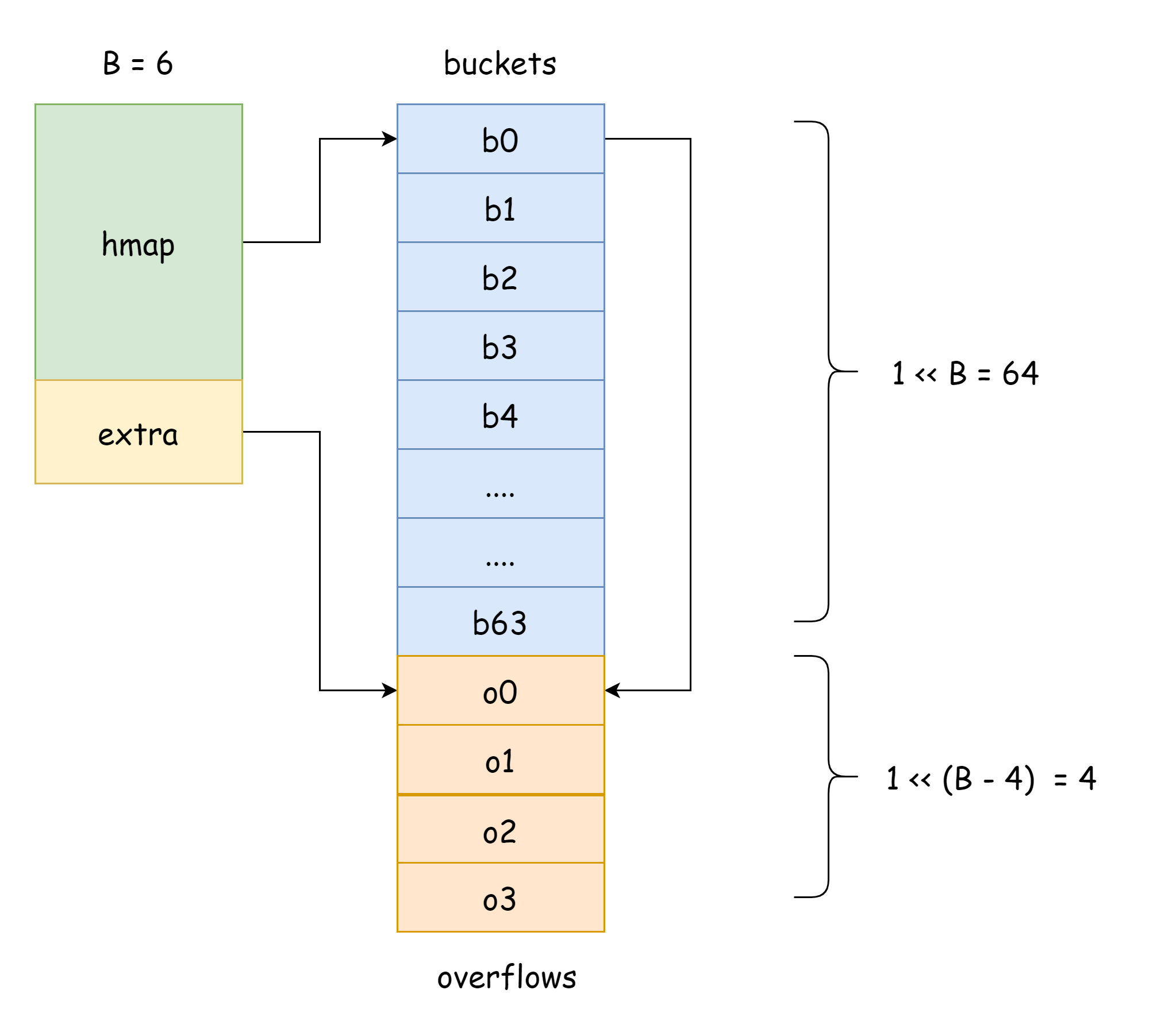
}
TIP
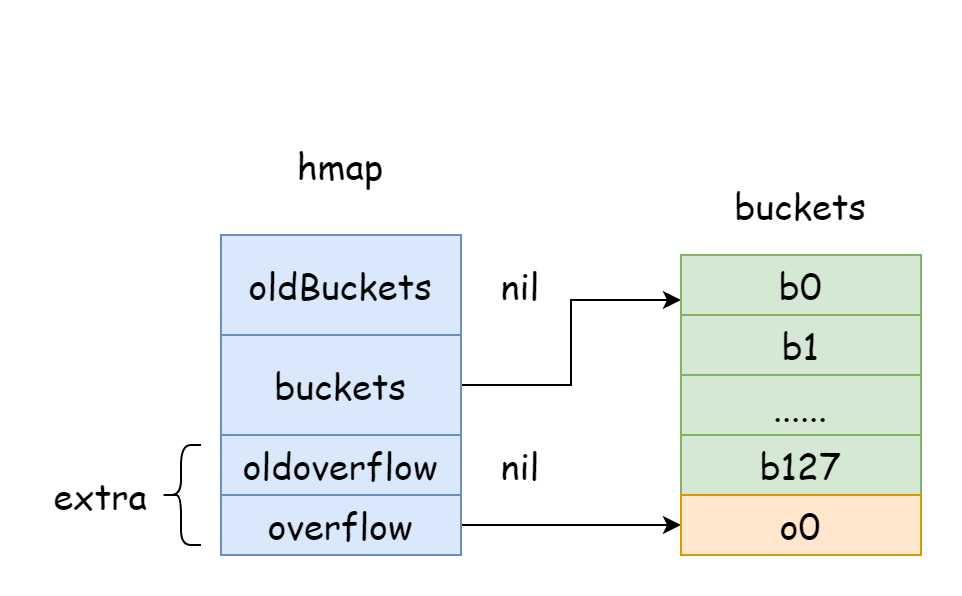
Dans l'image ci-dessus, la partie bleue est le tableau de buckets de hachage, la partie orange est le tableau de buckets de débordement. Nous utiliserons le terme "bucket de débordement" pour désigner ces derniers.
L'image ci-dessus illustre bien la structure générale d'un hmap. buckets pointe vers le tableau de buckets de hachage, extra pointe vers le tableau de buckets de débordement. Le bucket bucket0 pointe vers le bucket de débordement overflow0. Les deux types de buckets sont stockés dans deux slices séparés, avec une mémoire continue pour chaque type.
Quand deux clés sont assignées au même bucket après hachage, c'est ce qu'on appelle un conflit de hachage. Go résout les conflits de hachage par la méthode du chaînage. Quand le nombre de clés en conflit dépasse la capacité du bucket (généralement 8, selon internal/abi.MapBucketCount), un nouveau bucket est créé pour stocker ces clés. Ce nouveau bucket est appelé bucket de débordement. Une fois créé, le bucket de hachage possède un pointeur vers le nouveau bucket de débordement, formant ainsi une liste chaînée de bmap.
Pour la méthode du chaînage, on utilise le facteur de charge pour mesurer les conflits dans la table de hachage. La formule de calcul est :
loadfactor := len(elems) / len(buckets)Quand le facteur de charge est élevé, cela signifie qu'il y a beaucoup de conflits de hachage, donc beaucoup de buckets de débordement. Pour les opérations de lecture/écriture, il faut parcourir plus de listes chaînées de buckets de débordement pour trouver la position spécifiée, donc les performances se dégradent. Pour améliorer la situation, il faut augmenter le nombre de buckets, c'est-à-dire faire une expansion. Pour un hmap, deux conditions déclenchent l'expansion :
- Le facteur de charge dépasse le seuil
bucketCnt*13/16, soit au moins 6.5. - Trop de buckets de débordement
Quand le facteur de charge est faible, cela signifie que le taux d'utilisation mémoire du hmap est bas, donc l'occupation mémoire est plus importante.
La fonction utilisée par Go pour calculer le facteur de charge est runtime.overLoadFactor :
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Où loadFactorNum et loadFactorDen sont des constantes, bucketShift calcule 1 << B, et on sait que :
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenDonc en simplifiant :
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Où (bucketCnt * 13 / 16) vaut 6.5, et 1 << B est le nombre de buckets de hachage. Cette fonction vérifie si le nombre d'éléments divisé par le nombre de buckets dépasse le facteur de charge de 6.5.
Calcul
La fonction interne de Go pour calculer le hachage se trouve dans runtime/alg.go avec f32hash, incluant le traitement des cas NaN et 0 :
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}On voit que la méthode de calcul du hachage pour map n'est pas basée sur le type mais sur la mémoire. Finalement, cela appelle la fonction memhash, implémentée en assembleur dans runtime/asm*.s. Les valeurs de hachage basées sur la mémoire ne devraient pas être persistées, car elles ne doivent être utilisées qu'à l'exécution - on ne peut pas garantir que la distribution mémoire sera identique à chaque exécution.
Dans ce fichier, il y a aussi une fonction typehash qui calcule le hachage selon différents types, mais map n'utilise pas cette fonction :
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrCette implémentation est plus lente mais plus générique, principalement utilisée pour la réflexion et la génération de fonctions à la compilation, comme la fonction suivante :
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Création
L'initialisation d'un map peut se faire de deux façons, comme expliqué dans l'introduction au langage : avec le mot-clé map directement, ou avec la fonction make. Quelle que soit la méthode, c'est finalement runtime.makemap qui crée le map. La signature de cette fonction est :
func makemap(t *maptype, hint int, h *hmap) *hmapParamètres :
t, le type du map, différents types ont des occupations mémoire différenteshint, le deuxième paramètre de la fonctionmake, la capacité estimée d'éléments du maph, un pointeur vers unhmap, peut êtrenil
La valeur de retour est un pointeur vers le hmap initialisé. La fonction effectue plusieurs travaux principaux lors de l'initialisation.
D'abord, vérifier si la mémoire prévue dépasse la mémoire maximale allouable :
// Multiplier la capacité estimée par la taille mémoire du type de bucket
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Débordement numérique ou dépassement de la mémoire maximale allouable
if overflow || mem > maxAlloc {
hint = 0
}Comme mentionné précédemment, un hmap est composé de buckets en interne. Dans le pire cas d'utilisation mémoire, un bucket ne contient qu'un seul élément, occupant le plus de mémoire. Donc l'occupation mémoire maximale estimée est le nombre d'éléments multiplié par la taille mémoire du type correspondant. Si le calcul déborde ou dépasse la mémoire maximale allouable, on met hint à 0.
Deuxième étape, initialiser le hmap et calculer une graine de hachage aléatoire :
// Initialisation
if h == nil {
h = new(hmap)
}
// Obtenir une graine de hachage aléatoire
h.hash0 = fastrand()Puis calculer la capacité des buckets de hachage selon la valeur de hint :
B := uint8(0)
// Boucler jusqu'à ce que hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Assigner à hmap
h.B = BOn boucle pour trouver la première valeur B satisfaisant (hint / 1 << B) < 6.5, puis on l'assigne au hmap. Une fois la capacité des buckets connue, on alloue la mémoire pour les buckets :
if h.B != 0 {
var nextOverflow *bmap
// Buckets alloués et buckets de débordement libres pré-alloués
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Si des buckets de débordement libres ont été pré-alloués
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}La fonction makeBucketArray alloue la mémoire pour les buckets selon la valeur de B, ainsi que des buckets de débordement libres pré-alloués. Si B est inférieur à 4, aucun bucket de débordement n'est créé. Si B est supérieur ou égal à 4, on crée 2^B-4 buckets de débordement. Cela correspond au code suivant dans runtime.makeBucketArray :
base := bucketShift(b)
nbuckets := base
// Si inférieur à 4, pas de bucket de débordement
if b >= 4 {
// Ajouter 1 << (b-4) au nombre estimé de buckets
nbuckets += bucketShift(b - 4)
// Mémoire nécessaire pour les buckets de débordement
sz := t.Bucket.Size_ * nbuckets
// Arrondir vers le haut
up := roundupsize(sz)
if up != sz {
// Recalculer avec up si différent
nbuckets = up / t.Bucket.Size_
}
}base est le nombre estimé de buckets à allouer, nbuckets est le nombre réel de buckets alloués, incluant les buckets de débordement.
if base != nbuckets {
// Premier bucket de débordement utilisable
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Pour réduire le coût de suivi des buckets de débordement,
// le pointeur overflow du dernier bucket de débordement pointe vers le premier bucket de hachage
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
last.setoverflow(t, (*bmap)(buckets))
}Quand les deux sont différents, cela signifie que des buckets de débordement supplémentaires ont été alloués. Le pointeur nextOverflow pointe vers le premier bucket de débordement utilisable. On voit donc que les buckets de hachage et les buckets de débordement sont dans le même bloc de mémoire continue, ce qui explique pourquoi sur le schéma, le tableau de buckets de hachage et le tableau de buckets de débordement sont adjacents.
Accès
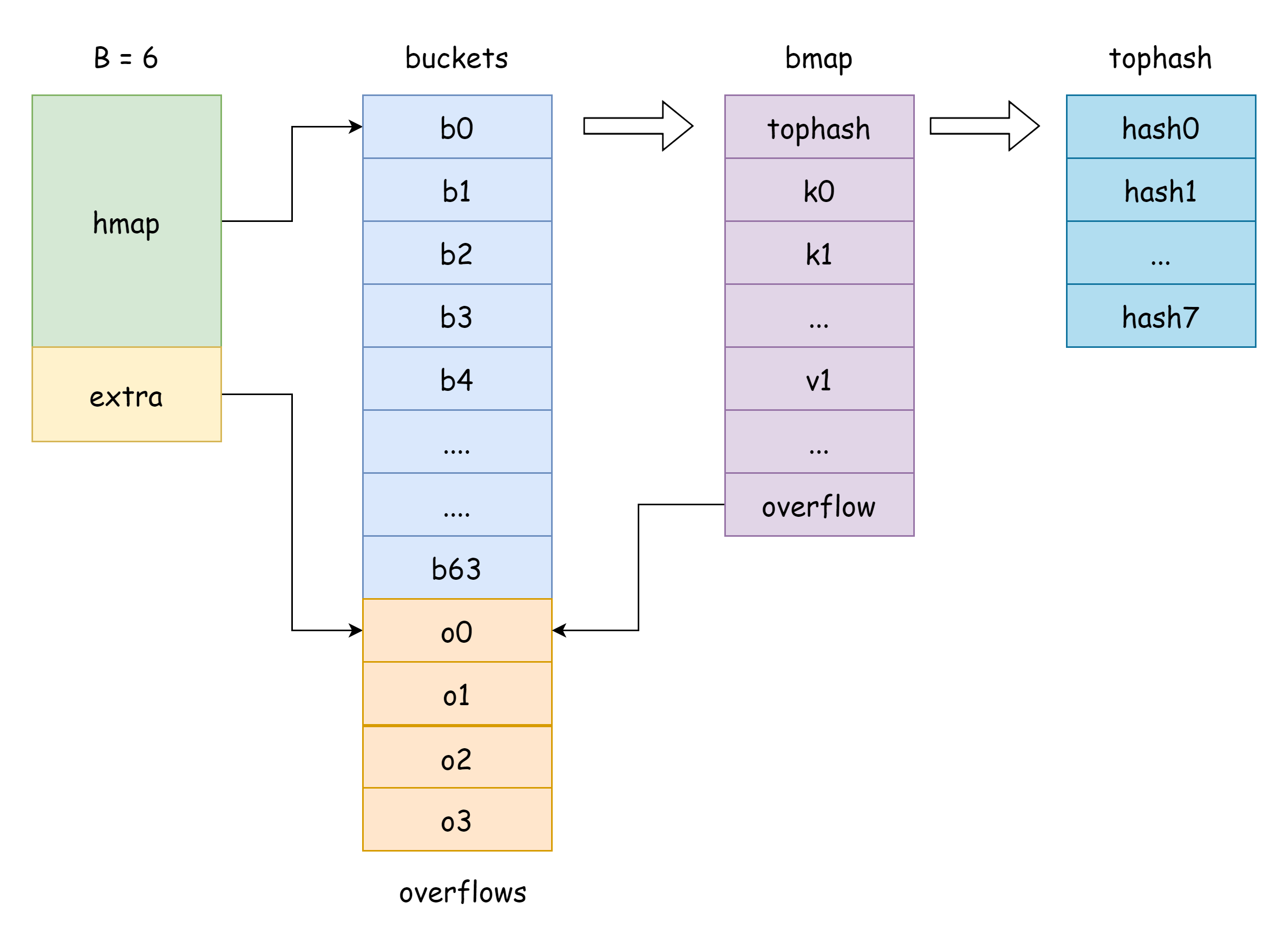
Comme expliqué dans l'introduction au langage, il y a trois façons d'accéder à un map :
# Accès direct à la valeur
val := dict[key]
# Accès à la valeur et vérification de l'existence de la clé
val, exist := dict[key]
# Parcourir le map
for key, val := range dict{
}Chaque méthode utilise des fonctions différentes. Le parcours avec for range est le plus complexe.
Clé-valeur
Pour les deux premières méthodes, deux fonctions sont utilisées : runtime.mapaccess1 et runtime.mapaccess2, avec les signatures suivantes :
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Le paramètre key est un pointeur vers la clé d'accès au map. La fonction retourne uniquement un pointeur. Lors de l'accès, il faut d'abord calculer la valeur de hachage de la clé et localiser le bucket de hachage correspondant :
// Traitement des cas limites
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Prévenir les lectures/écritures concurrentes
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Calculer le hachage avec le hasher du type spécifié
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Localiser le bucket de hachage de la clé en déplaçant le pointeur
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))Au début de l'accès, on traite les cas limites et on empêche les lectures/écritures concurrentes du map. Si le map est en état de lecture/écriture concurrente, une panic se produit. Ensuite, on calcule la valeur de hachage. La fonction bucketMask calcule (1 << B) - 1. hash & m est équivalent à hash % (1 << B), une opération de modulo binaire plus rapide. Les dernières lignes calculent le numéro du bucket en prenant le modulo de la valeur de hachage par le nombre de buckets actuels, puis déplacent le pointeur pour obtenir le pointeur du bucket de hachage.
Une fois le bucket connu, on peut commencer la recherche :
// Obtenir les 8 bits de poids fort de la valeur de hachage
top := tophash(hash)
bucketloop:
// Parcourir la liste chaînée de bmap
for ; b != nil; b = b.overflow(t) {
// Éléments dans le bmap
for i := uintptr(0); i < bucketCnt; i++ {
// Comparer le tophash calculé avec les éléments du tableau tophash
if b.tophash[i] != top {
// Le reste est vide, rien d'autre
if b.tophash[i] == emptyRest {
break bucketloop
}
// Pas égal, continuer à parcourir les buckets de débordement
continue
}
// Déplacer le pointeur pour obtenir la clé à l'index correspondant
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Traiter les pointeurs
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Comparer si les deux clés sont égales
if t.Key.Equal(key, k) {
// Si égal, déplacer le pointeur pour retourner l'élément correspondant
// On voit ici que les adresses mémoire des clés et valeurs sont continues
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Non trouvé, retourner la valeur zéro
return unsafe.Pointer(&zeroVal[0])Pour localiser le bucket de hachage, on utilise le modulo sur la valeur de hachage, donc le bucket dépend des bits de poids faible de la valeur de hachage. Le nombre exact de bits dépend de la valeur de B. Une fois le bucket trouvé, son tophash contient les 8 bits de poids fort des valeurs de hachage. Comme les bits de poids faible donnent le même résultat de modulo, on n'a pas besoin de comparer les clés une par une - il suffit de comparer les 8 bits de poids fort.
On obtient les 8 bits de poids fort à partir de la valeur de hachage calculée, puis on compare avec chaque élément du tableau tophash du bmap. Si les 8 bits de poids fort correspondent, on compare si les clés sont égales. Si les clés correspondent aussi, on a trouvé l'élément. Sinon, on continue à parcourir le tableau tophash, et si on ne trouve toujours pas, on continue avec la liste chaînée de buckets de débordement jusqu'à ce que tophash[i] du bmap soit emptyRest, puis on sort de la boucle et on retourne la valeur zéro du type correspondant.
La fonction mapaccess2 a exactement la même logique que mapaccess1, avec simplement une valeur de retour booléenne supplémentaire indiquant si l'élément existe.
Parcours
La syntaxe pour parcourir un map est :
for key, val := range dict {
// do somthing...
}Lors du parcours réel, Go utilise la structure hiter pour stocker les informations de parcours. hiter est l'abréviation de hmap iterator, signifiant itérateur de table de hachage. Sa structure est :
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Explication de certains champs :
key,elemsont les clés et valeurs obtenues lors du parcoursfor rangebuckets, spécifié lors de l'initialisation de l'itérateur, pointe vers le premier bucket de hachagebptr, le bmap en cours de parcoursstartBucket, le numéro du bucket de départ au début de l'itérationoffset, le décalage dans le bucket, dans la plage[0, bucketCnt-1]B, la valeur B du hmapi, l'index de l'élément dans le bucketwrapped, indique si on est revenu au début après avoir atteint la fin du tableau de buckets
Avant le début du parcours, Go initialise l'itérateur avec runtime.mapiterinit, puis parcourt le map avec runtime.mapiternext. Les deux utilisent la structure hiter. Les signatures sont :
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Pour l'initialisation de l'itérateur, on commence par obtenir un instantané du map actuel :
it.t = t
it.h = h
// Enregistrer un instantané de l'état actuel du hmap, il suffit de sauvegarder la valeur B
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Lors de l'itération, on parcourt en fait un instantané du map, pas le map réel. Donc les éléments et buckets ajoutés pendant le parcours ne seront pas visités. De plus, si on écrit simultanément pendant le parcours, cela peut déclencher un fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}La deuxième étape consiste à déterminer les deux positions de départ du parcours : la position du bucket de départ et la position de départ dans le bucket. Ces deux positions sont choisies aléatoirement :
// r est un nombre aléatoire
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) donne la position du bucket de départ
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 donne la position de départ des éléments dans le bucket
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Enregistrer le numéro du bucket en cours de parcours
it.bucket = it.startBucketOn obtient un nombre aléatoire via fastrand() ou fastrand64(), puis deux opérations modulo donnent la position de départ du bucket et la position de départ dans le bucket.
TIP
Bien que le map ne permette pas les lectures/écritures concurrentes simultanées, il permet les parcours concurrents simultanés.
Ensuite commence réellement l'itération du map. Comment parcourir les buckets et la stratégie de sortie :
// hmap
h := it.h
// maptype
t := it.t
// Position du bucket à parcourir
bucket := it.bucket
// bmap à parcourir
b := it.bptr
// Index i dans le bucket
i := it.i
next:
if b == nil {
// Si la position actuelle du bucket est égale à la position de départ,
// cela signifie qu'on a fait un tour complet
// Le parcours est terminé
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Avancer l'index du bucket
bucket++
// bucket == 1 << B signifie qu'on a atteint la fin du tableau de buckets
if bucket == bucketShift(it.B) {
// Recommencer au début
bucket = 0
it.wrapped = true
}
i = 0
}La position de départ du bucket de hachage est choisie aléatoirement. Lors du parcours, on itère depuis la position de départ vers la fin du slice de buckets, et quand on atteint 1 << B, on recommence au début. Quand on revient à la position de départ, le parcours est terminé.
Le code ci-dessus concerne la façon de parcourir les buckets dans le map. Le code suivant décrit comment parcourir à l'intérieur d'un bucket :
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Si l'élément actuel est vide, passer
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Déplacer le pointeur pour obtenir la clé
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Déplacer le pointeur pour obtenir la valeur
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Traiter le cas de l'expansion à taille égale
// Quand la clé-valeur a été déplacée ailleurs, il faut la rechercher à nouveau
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Si non trouvé, chercher dans les buckets de débordement
b = b.overflow(t)
i = 0
goto nextTIP
Dans la condition d'expansion ci-dessus, une expression peut sembler confusing :
t.Key.Equal(k, k)On vérifie si k est égal à lui-même pour filtrer le cas où la clé est NaN. Si la clé d'un élément est NaN, on ne peut pas accéder normalement à cet élément, que ce soit par parcours ou accès direct, ou même suppression, car NaN != NaN est toujours vrai, donc on ne peut jamais trouver cette clé.
D'abord, on calcule l'index dans le bucket à partir de i et offset par opération modulo. On obtient la clé et la valeur en déplaçant les pointeurs. Comme le map peut être en expansion pendant le parcours (déclenché par d'autres écritures), la clé-valeur réelle peut ne plus être à sa position d'origine. Dans ce cas, on utilise mapaccessK pour récupérer la clé-valeur réelle.
La fonction mapaccessK a la signature suivante :
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Elle fonctionne exactement comme mapaccess1, mais retourne à la fois la clé et la valeur.
Une fois la clé-valeur obtenue, on l'assigne aux champs key et elem de l'itérateur, puis on met à jour les index de l'itérateur. Une itération est ainsi terminée, et l'exécution revient au bloc de code du for range. Si on ne trouve pas dans le bucket, on cherche dans les buckets de débordement, en répétant les étapes ci-dessus jusqu'à ce que la liste chaînée de buckets de débordement soit entièrement parcourue, puis on passe au bucket de hachage suivant.
Modification
La syntaxe pour modifier un map est :
dict[key] = valEn Go, la modification d'un map est effectuée par la fonction runtime.mapassign, avec la signature suivante :
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerLa logique d'accès est identique à mapaccess1, mais si la clé n'existe pas, un emplacement lui est attribué. Si elle existe, elle est mise à jour. Finalement, un pointeur vers l'élément est retourné.
Au début, quelques préparatifs sont nécessaires :
// Interdire l'écriture dans un map nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Interdire les écritures concurrentes
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Calculer la valeur de hachage de la clé
hash := t.Hasher(key, uintptr(h.hash0))
// Modifier l'état du hmap
h.flags ^= hashWriting
// Initialiser les buckets de hachage si nécessaire
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Le code ci-dessus fait principalement :
- Vérifier l'état du hmap
- Calculer la valeur de hachage de la clé
- Vérifier si les buckets de hachage doivent être initialisés
Ensuite, par opération modulo sur la valeur de hachage, on obtient la position du bucket de hachage et le tophash de la clé :
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Déplacer le pointeur pour obtenir le bmap à la position spécifiée
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Calculer le tophash
top := tophash(hash)Maintenant que la position du bucket, le bmap et le tophash sont déterminés, on peut commencer la recherche :
// tophash à insérer
var inserti *uint8
// Pointeur vers la clé à insérer
var insertk unsafe.Pointer
// Pointeur vers la valeur à insérer
var elem unsafe.Pointer
bucketloop:
for {
// Parcourir le tableau tophash dans le bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash différent
if b.tophash[i] != top {
// Si l'index actuel dans le bucket est vide et qu'aucun élément n'a été inséré
// on choisit cette position pour l'insertion
if isEmpty(b.tophash[i]) && inserti == nil {
// Trouvé une position appropriée pour la clé
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Parcours terminé, sortir de la boucle
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// Si tophash est égal, la clé existe peut-être déjà
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Vérifier si les clés sont égales
if !t.Key.Equal(key, k) {
continue
}
// Si la clé doit être mise à jour, copier la mémoire de la clé directement à l'emplacement k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Pointeur vers l'élément obtenu
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Mise à jour terminée, retourner le pointeur de l'élément
goto done
}
// Arrivé ici, la clé n'a pas été trouvée, parcourir la liste chaînée de buckets de débordement
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Arrivé ici, la clé n'existe pas dans le map
// Mais une position appropriée a peut-être été trouvée, ou non
// Aucune position appropriée trouvée
if inserti == nil {
// Le bucket de hachage actuel et ses buckets de débordement sont pleins
// Allouer un nouveau bucket de débordement
newb := h.newoverflow(t, b)
// Allouer une position dans le bucket de débordement pour la clé
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Si on stocke des pointeurs de clé
if t.IndirectKey() {
// Allouer une nouvelle mémoire
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Assigner à insertk pour faciliter la copie mémoire de la clé
insertk = kmem
}
// Si on stocke des pointeurs d'éléments
if t.IndirectElem() {
// Allouer la mémoire
vmem := newobject(t.Elem)
// Faire pointer le pointeur vers vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Copier la mémoire de la clé à la position insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// Incrémenter le compteur
h.count++
done:
// Arrivé ici, la modification est terminée
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Retourner le pointeur de l'élément
return elemDans le code ci-dessus, on entre d'abord dans une boucle for pour rechercher dans le bucket de hachage et les buckets de débordement. La logique de recherche est identique à mapaccess. À ce stade, il y a trois possibilités :
- La clé existe déjà dans le map - on saute directement au bloc
doneet on retourne le pointeur de l'élément - Une position disponible a été trouvée dans le map pour la clé - on copie la clé à cette position et on retourne le pointeur de l'élément
- Tous les buckets ont été parcourus sans trouver de position disponible - on crée un nouveau bucket de débordement, on y place la clé, puis on retourne le pointeur de l'élément
Une fois le pointeur de l'élément obtenu, l'assignation peut avoir lieu. Cependant, cette opération n'est pas effectuée par la fonction mapassign - elle ne fait que retourner le pointeur de l'élément. L'assignation est insérée par le compilateur. Ce n'est pas visible dans le code source, mais on peut le voir dans le code compilé. Par exemple :
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}En obtenant le code assembleur avec la commande :
go tool compile -S -N -l main.goLa partie clé est :
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)On voit l'appel à runtime.mapassign_faststr (logique similaire à mapassign). LEAQ go:string."world"(SB), CX stocke l'adresse de la chaîne dans CX, puis MOVQ CX, (AX) la stocke à l'adresse pointée par AX, complétant ainsi l'assignation de l'élément.
Suppression
En Go, pour supprimer un élément d'un map, on utilise la fonction intégrée delete :
delete(dict, "abc")En interne, cela appelle la fonction runtime.mapdelete, avec la signature suivante :
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Elle supprime l'élément avec la clé spécifiée du map. Que l'élément existe ou non, elle ne réagira pas. La logique de préparation en début de fonction est similaire : vérification de l'état du hmap, calcul de la valeur de hachage de la clé, localisation du bucket de hachage, calcul du tophash. Ces contenus répétés ne seront pas détaillés ici.
La logique de suppression est la suivante :
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Non trouvé, sortir de la boucle
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Déplacer le pointeur pour trouver la position de la clé
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Supprimer la clé
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Déplacer le pointeur pour trouver la position de l'élément
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Supprimer l'élément
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Décrémenter le compteur
h.count--
// Réinitialiser la graine de hachage pour réduire la probabilité de conflits
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}La logique de recherche est presque identique aux opérations précédentes. On trouve l'élément, on le supprime, on décrémente le compteur du hmap. Quand le compteur atteint 0, on réinitialise la graine de hachage.
Un autre point important est qu'après suppression de l'élément, il faut modifier l'état du tophash à l'index actuel. Le code correspondant est le suivant. Quand i est à la fin du bucket, on utilise le bucket de débordement suivant pour déterminer si l'élément actuel est le dernier disponible, sinon on vérifie directement l'état de hachage de l'élément adjacent. Si l'élément actuel n'est pas le dernier disponible, on met l'état à emptyOne.
// Marquer le tophash actuel comme vide
b.tophash[i] = emptyOne
// Si à la fin du tophash
if i == bucketCnt-1 {
// Le bucket de débordement n'est pas vide et contient des éléments
// donc l'élément actuel n'est pas le dernier
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// L'élément adjacent n'est pas vide
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Si l'élément est bien le dernier, il faut corriger les valeurs du tableau tophash de certains buckets dans la liste chaînée, sinon les parcours ultérieurs ne pourront pas se terminer à la bonne position.
Lors de la création des buckets de débordement, Go fait pointer le pointeur overflow du dernier bucket de débordement vers le premier bucket de hachage pour réduire le coût de suivi des buckets de débordement. C'est donc une liste chaînée circulaire simple, dont la "tête" est le bucket de hachage. Ici, b est le b après recherche, qui peut être n'importe quel bucket de débordement au milieu de la liste. On parcourt la liste circulaire à l'envers pour trouver le dernier élément existant. Bien que le code écrive un parcours en sens normal, comme la liste est un cercle, le parcours continue jusqu'au bucket précédent le bucket actuel, ce qui revient effectivement à un parcours à l'envers. On parcourt ensuite à l'envers le tableau tophash du bucket, mettant à jour les éléments avec l'état emptyOne en emptyRest jusqu'à trouver le dernier élément existant. Pour éviter de rester infiniment dans la boucle, quand on revient au bucket initial bOrig, cela signifie qu'il n'y a plus d'éléments disponibles dans la liste, et on peut sortir de la boucle.
// Arrivé ici, il n'y a plus d'éléments après l'élément actuel
// Parcourir la liste de bmap à l'envers, parcourir le tophash du bucket à l'envers
// Mettre à jour les états emptyOne en emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Trouver le précédent dans la liste chaînée de bmap
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Vidage
Dans la version go1.21, une nouvelle fonction intégrée clear a été ajoutée pour vider tous les éléments d'un map. La syntaxe est :
clear(dict)En interne, elle appelle la fonction runtime.mapclear, responsable de supprimer tous les éléments du map. Sa signature est :
func mapclear(t *maptype, h *hmap)La logique de cette fonction n'est pas complexe. D'abord, il faut marquer tout le map comme vide :
// Parcourir chaque bucket et bucket de débordement, mettre tous les éléments tophash à emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Le code ci-dessus parcourt chaque bucket et met tous les éléments du tableau tophash à emptyRest, marquant le map comme vide. Cela empêche les itérateurs de continuer à itérer. Ensuite, on vide le map :
// Réinitialiser la graine de hachage
h.hash0 = fastrand()
// Réinitialiser la structure extra
if h.extra != nil {
*h.extra = mapextra{}
}
// Cette opération efface la mémoire des buckets précédents et réalloue de nouveaux buckets
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Allouer de nouveaux buckets de débordement libres
h.extra.nextOverflow = nextOverflow
}Via makeBucketArray, on efface la mémoire des anciens buckets et on en alloue de nouveaux, complétant ainsi le vidage des buckets. Il y a d'autres détails comme mettre count à 0 et d'autres opérations qui ne seront pas détaillées.
Expansion
Dans toutes les opérations précédentes, pour se concentrer sur leur logique propre, beaucoup de contenu lié à l'expansion a été masqué. La logique d'expansion est assez complexe et est placée à la fin pour éviter les interférences. Voyons maintenant comment Go effectue l'expansion d'un map.
Comme mentionné précédemment, deux conditions déclenchent l'expansion :
- Le facteur de charge dépasse 6.5
- Trop de buckets de débordement
La fonction pour vérifier si le facteur de charge dépasse le seuil est runtime.overLoadFactor, déjà expliquée dans la section sur les conflits de hachage. La fonction pour vérifier si le nombre de buckets de débordement est trop élevé est runtime.tooManyOverflowBuckets :
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Ce code peut être simplifié en l'expression suivante :
overflow >= 1 << (min(15,B) % 16)Ici, Go définit "trop" comme : le nombre de buckets de débordement est à peu près égal au nombre de buckets de hachage. Si le seuil est trop bas, on fera du travail superflu. S'il est trop haut, l'expansion occupera beaucoup de mémoire.
L'expansion peut être déclenchée lors de la modification ou la suppression d'éléments. Le code vérifiant si une expansion est nécessaire est :
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}On voit trois conditions :
- Pas d'expansion en cours
- Facteur de charge inférieur à 6.5
- Nombre de buckets de débordement pas trop élevé
La fonction responsable de l'expansion est naturellement runtime.hashGrow, avec la signature :
func hashGrow(t *maptype, h *hmap)En réalité, l'expansion est de deux types selon les conditions qui la déclenchent :
- Expansion incrémentale
- Expansion à taille égale
Expansion incrémentale
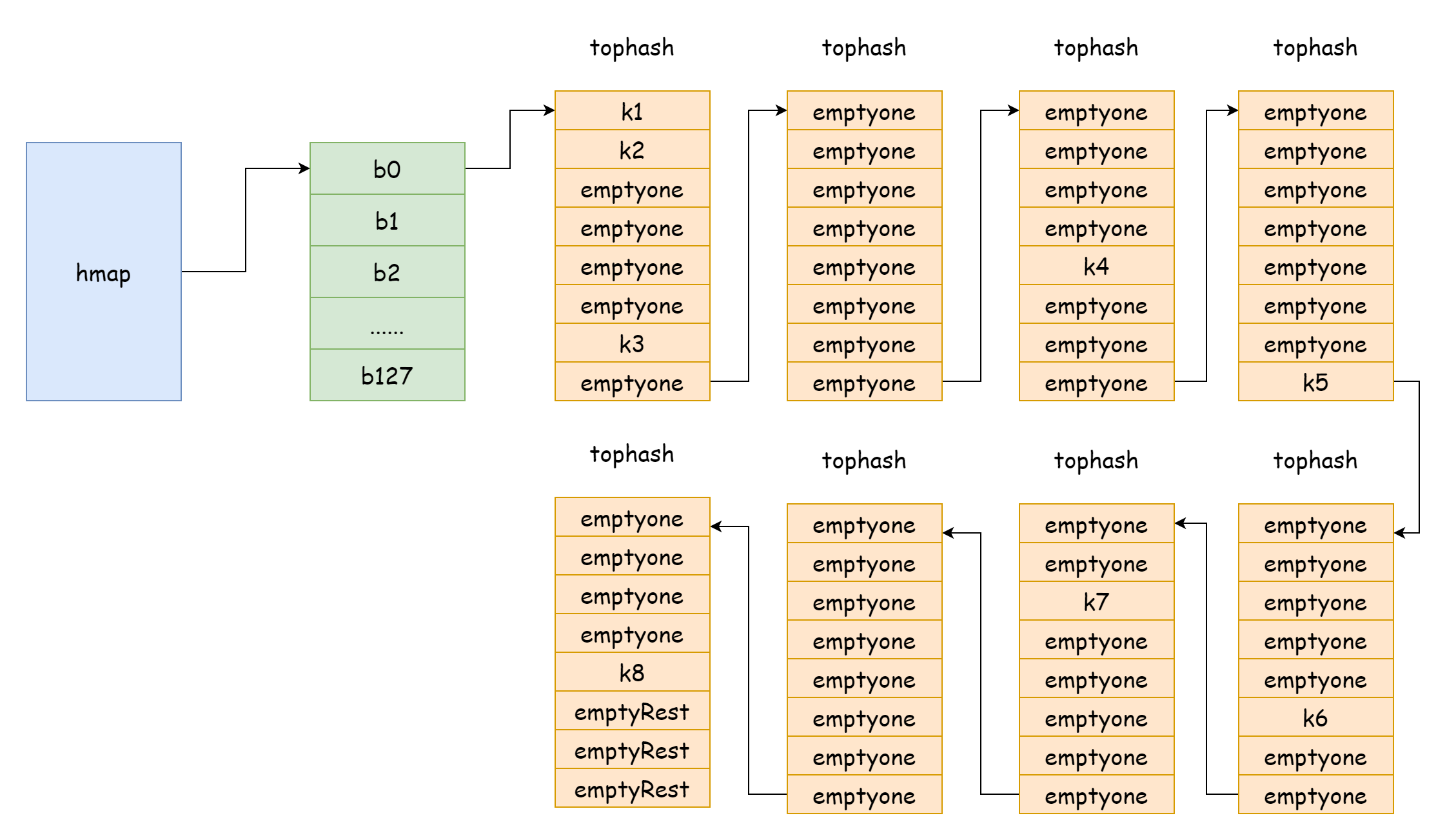
Quand le facteur de charge est trop élevé (beaucoup plus d'éléments que de buckets de hachage), les conflits de hachage sont fréquents, créant de nombreuses listes chaînées de buckets de débordement. Cela dégrade les performances de lecture/écriture du map car il faut parcourir plus de listes chaînées pour trouver un élément. La complexité temporelle du parcours est O(n). La complexité de recherche dans une table de hachage dépend principalement du temps de calcul du hachage et du temps de parcours. Quand le temps de parcours est bien inférieur au temps de calcul du hachage, on peut parler de complexité O(1). Si les conflits de hachage sont fréquents et que trop de clés sont assignées au même bucket de hachage, la liste chaînée de débordement s'allonge, augmentant le temps de parcours et donc le temps de recherche. Comme les opérations d'ajout, suppression et modification nécessitent d'abord une recherche, toutes les performances du map se dégradent.
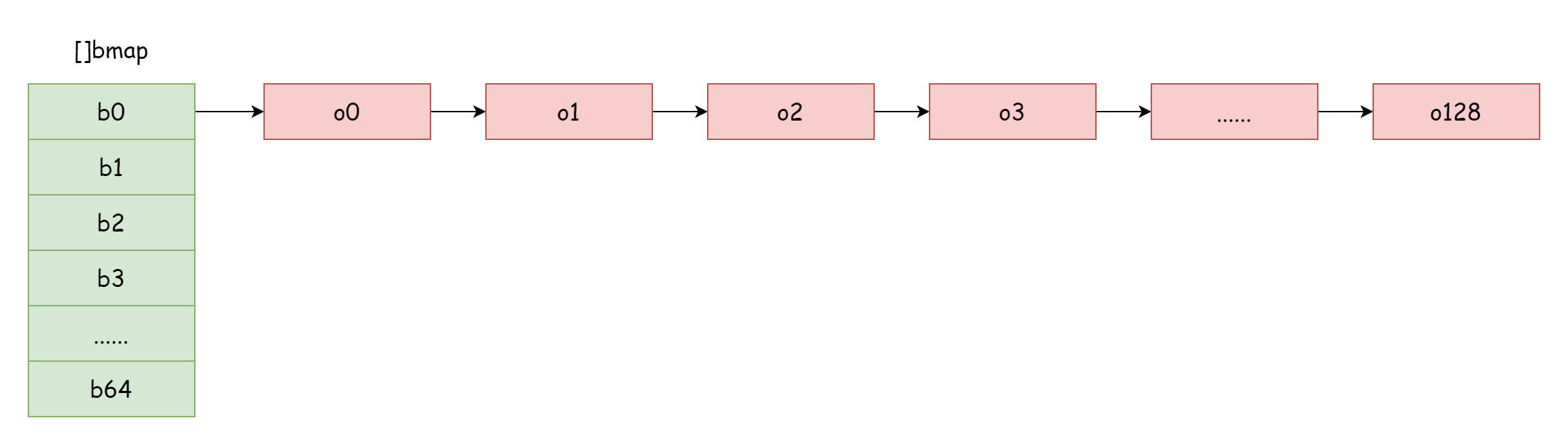
Dans un cas extrême comme sur l'image, la complexité de recherche est essentiellement O(n). La solution est d'ajouter plus de buckets de hachage pour éviter les listes chaînées trop longues. Cette méthode est appelée expansion incrémentale.
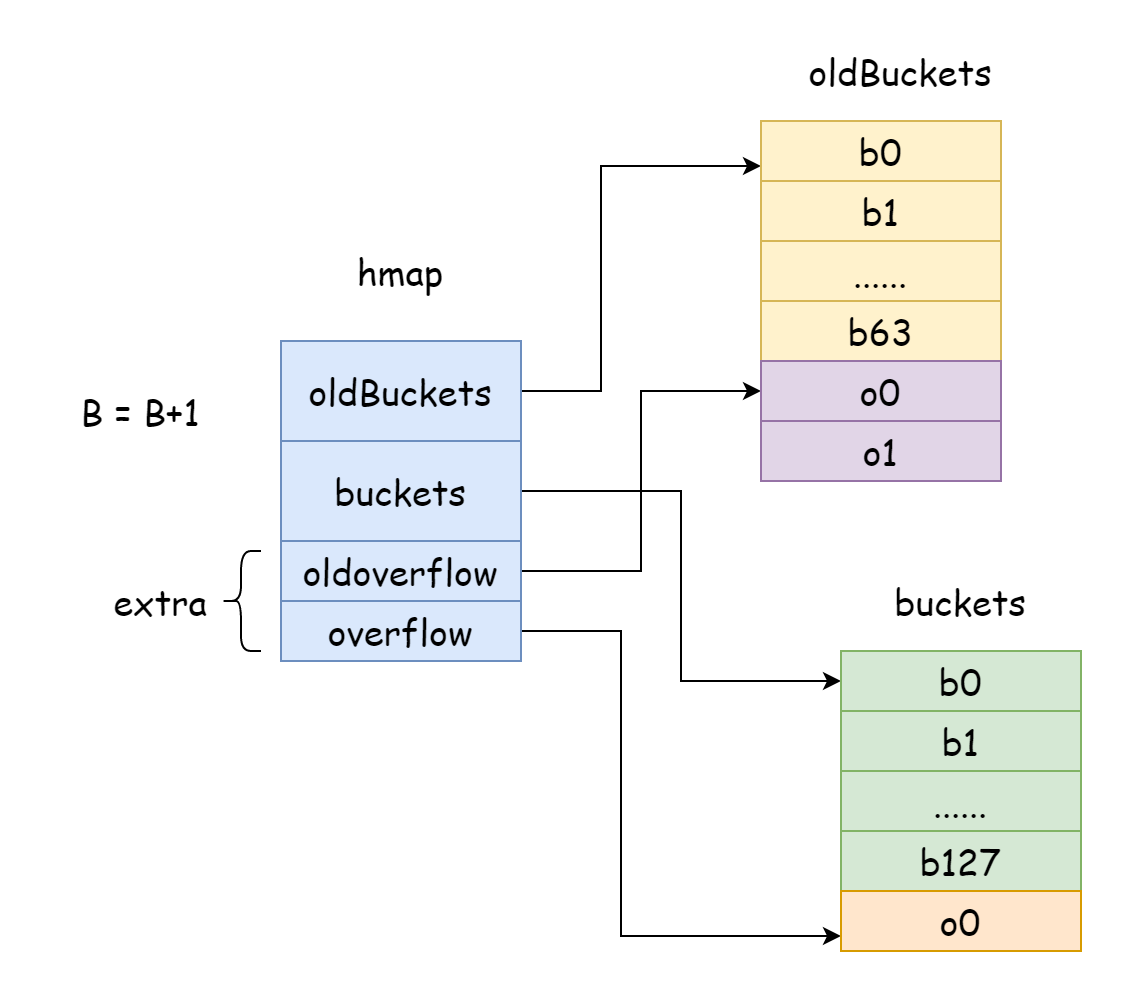
En Go, l'expansion incrémentale double la valeur B à chaque fois, donc la taille des buckets de hachage double. Après expansion, il faut déplacer les anciennes données vers le nouveau map. Si le map contient des millions voire des milliards d'éléments, un déplacement complet prendrait très longtemps. Go adopte donc une stratégie de déplacement progressif. Pour cela, Go fait pointer oldBuckets du hmap vers l'ancien tableau de buckets de hachage (indiquant que ce sont les anciennes données), puis crée un nouveau tableau de buckets de plus grande capacité et fait pointer buckets du hmap vers ce nouveau tableau. À chaque modification ou suppression d'élément, une partie des éléments est déplacée des anciens buckets vers les nouveaux, jusqu'à ce que le déplacement soit terminé. Ce n'est qu'alors que la mémoire des anciens buckets est libérée.
func hashGrow(t *maptype, h *hmap) {
// Différence
bigger := uint8(1)
// Anciens buckets
oldbuckets := h.buckets
// Nouveaux buckets de hachage
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Spécifier aussi les anciens et nouveaux buckets de débordement
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Ce code crée un nouveau tableau de buckets de hachage de capacité double, spécifie les références des anciens et nouveaux buckets de hachage et de débordement, et met à jour certains états du hmap. Le travail réel de déplacement n'est pas effectué par hashGrow - elle ne fait que spécifier les anciens et nouveaux buckets.
Ce travail est effectué par la fonction runtime.growWork, avec la signature :
func growWork(t *maptype, h *hmap, bucket uintptr)Elle est appelée dans mapassign et mapdelete sous la forme suivante, effectuant un déplacement partiel si le map est en cours d'expansion :
if h.growing() {
growWork(t, h, bucket)
}Pour vérifier si le map est en cours d'expansion, on utilise la méthode hmap.growing, qui vérifie simplement si oldbuckets n'est pas vide :
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Voyons ce que fait growWork :
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}L'opération bucket&h.oldbucketmask() calcule la position de l'ancien bucket. La fonction réellement responsable du déplacement est runtime.evacuate. Elle utilise la structure evacDst pour représenter la destination du déplacement, principalement pour itérer sur les nouveaux buckets pendant le déplacement. Sa structure est :
type evacDst struct {
b *bmap // Nouveau bucket de destination
i int // Index dans le bucket
k unsafe.Pointer // Pointeur vers la destination de la nouvelle clé
e unsafe.Pointer // Pointeur vers la destination de la nouvelle valeur
}Avant le début du déplacement, Go alloue deux structures evacDst, une pointant vers la zone supérieure du nouveau bucket de hachage, l'autre vers la zone inférieure :
// Localiser le bucket de hachage spécifié dans les anciens buckets
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Longueur des anciens buckets = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Pointer vers la zone supérieure des nouveaux buckets
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// Vérifier si c'est une expansion à taille égale
if !h.sameSizeGrow() {
y := &xy[1]
// Pointer vers la zone inférieure des nouveaux buckets
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}La destination du déplacement de l'ancien bucket est deux nouveaux buckets. Après le déplacement, une partie des données sera dans la zone supérieure, l'autre dans la zone inférieure. Cela permet une distribution plus uniforme des données après expansion, ce qui améliore les performances de recherche.
Le code montrant comment Go déplace les données vers les deux nouveaux buckets est le suivant :
// Parcourir la liste chaînée de buckets de débordement
for ; b != nil; b = b.overflow(t) {
// Obtenir la première paire clé-valeur de chaque bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Parcourir chaque paire clé-valeur dans le bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Si vide, passer
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Le nouveau bucket de hachage ne devrait pas être en cours de déplacement
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Cette variable détermine si la paire actuelle va dans la zone supérieure ou inférieure
// Sa valeur ne peut être que 0 ou 1
var useY uint8
if !h.sameSizeGrow() {
// Recalculer la valeur de hachage
hash := t.Hasher(k2, uintptr(h.hash0))
// Traiter le cas spécial k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Vérifier les constantes
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Mettre à jour le tophash de l'ancien bucket, indiquant que l'élément a été déplacé
b.tophash[i] = evacuatedX + useY
// Spécifier la destination
dst := &xy[useY]
// Si le nouveau bucket est plein, créer un bucket de débordement
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// Copier la clé
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2
} else {
typedmemmove(t.Key, dst.k, k)
}
// Copier la valeur
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Avancer les pointeurs de destination pour la prochaine paire
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Le code montre que Go parcourt chaque élément de chaque bucket de la liste chaînée d'anciens buckets, déplaçant les données vers les nouveaux buckets. La décision d'aller dans la zone supérieure ou inférieure dépend de la valeur de hachage recalculée :
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Après le déplacement, le tophash de l'élément actuel est mis à evacuatedX ou evacuatedY. Si on essaie de rechercher des données pendant l'expansion, cet état permet de savoir que les données ont été déplacées et qu'il faut les chercher dans les nouveaux buckets. Cette logique correspond au code suivant dans runtime.mapaccess1 :
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Si l'ancien bucket a été déplacé, ne pas chercher dedans
if !evacuated(oldb) {
b = oldb
}
}Lors de l'accès aux éléments, si le map est en cours d'expansion, on essaie d'abord de chercher dans les anciens buckets. Si l'ancien bucket a déjà été déplacé, on ne cherche pas dedans.
Revenons au déplacement : une fois la destination déterminée, on copie les données vers le nouveau bucket, puis on fait pointer la structure evacDst vers la destination suivante :
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Cette opération continue jusqu'à ce que le bucket actuel soit entièrement déplacé. Go efface ensuite toute la mémoire des données clé-valeur de l'ancien bucket, ne laissant que le tableau tophash du bucket de hachage (laissé pour déterminer l'état du déplacement ultérieurement). La mémoire des buckets de débordement dans l'ancien bucket sera récupérée par le GC car elle n'est plus référencée.
Le champ nevacuate du hmap enregistre la progression du déplacement. À chaque bucket d'ancien bucket déplacé, il est incrémenté. Quand sa valeur égale le nombre d'anciens buckets, l'expansion du map est terminée. La fonction runtime.advanceEvacuationMark effectue ensuite le travail de finalisation de l'expansion :
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit {
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Elle compte le nombre de buckets déplacés et vérifie s'il est égal au nombre d'anciens buckets. Si égal, elle efface toutes les références aux anciens buckets et anciens buckets de débordement. L'expansion est ainsi terminée.
Dans la fonction growWork, evacuate est appelée deux fois : la première pour déplacer l'ancien bucket du bucket actuellement accédé, la seconde pour déplacer l'ancien bucket pointé par h.nevacuate. Deux buckets sont donc déplacés à chaque fois.
Expansion à taille égale
Comme mentionné précédemment, l'expansion à taille égale est déclenchée quand il y a trop de buckets de débordement. Par exemple, si le map a d'abord beaucoup d'éléments ajoutés, puis beaucoup d'éléments supprimés, beaucoup de buckets peuvent être vides tandis que d'autres ont beaucoup d'éléments. La distribution des données est très inégale, avec beaucoup de buckets de débordement vides occupant beaucoup de mémoire. Pour résoudre ce problème, on crée un nouveau map de même capacité et on réalloue les buckets de hachage. Ce processus est appelé expansion à taille égale. Ce n'est pas vraiment une expansion, mais une redistribution de tous les éléments pour une distribution plus uniforme. L'expansion à taille égale est intégrée dans l'expansion incrémentale, avec une logique identique mais des capacités de l'ancien et du nouveau map parfaitement égales.
Dans la fonction hashGrow, si le facteur de charge ne dépasse pas le seuil, c'est une expansion à taille égale. Go met à jour l'état h.flags à sameSizeGrow, et h.B n'est pas incrémenté, donc la capacité des nouveaux buckets de hachage reste inchangée :
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)Dans la fonction evacuate, au début lors de la création des structures evacDst, si c'est une expansion à taille égale, une seule structure est créée pointant vers le nouveau bucket :
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Et lors du déplacement des éléments, l'expansion à taille égale ne recalcule pas la valeur de hachage et n'a pas de choix entre zones supérieure et inférieure :
if !h.sameSizeGrow() {
// Recalculer la valeur de hachage
hash := t.Hasher(k2, uintptr(h.hash0))
// Traiter le cas spécial k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Mis à part ces différences, la logique est identique à l'expansion incrémentale. Après l'expansion à taille égale et la réallocation des buckets de hachage, le nombre de buckets de débordement diminue, et les anciens buckets de débordement sont récupérés par le GC.