map
Diğer dillerden farklı olarak Go, map desteğini standart kütüphane olarak sarmalamak yerine map anahtar kelimesi aracılığıyla sağlar. Map yaygın olarak kullanılan bir veri yapısıdır ve alt düzeyde birçok implementasyon yöntemi vardır. En yaygın iki yöntem kırmızı-siyah ağaçlar ve hash tablolarıdır. Go hash tablosu implementasyonunu kullanır.
TIP
Map implementasyonu çok sayıda pointer hareket işlemi içerir, bu nedenle bu makaleyi okumak unsafe standart kütüphane bilgisi gerektirir.
İç Yapı
runtime.hmap struct'ı Go'da bir map'i temsil eder. Slice'lar gibi, map'in iç implementasyonu da bir struct'tır.
// A header for a Go map.
type hmap struct {
// Not: hmap formatı cmd/compile/internal/reflectdata/reflect.go içinde de kodlanmıştır.
// Bunun derleyicinin tanımı ile eşleştiğinden emin olun.
count int // # canlı hücre == map'in boyutu. İlk olmalı (len() builtin tarafından kullanılır)
flags uint8
B uint8 // # bucket'ın log_2 değeri (loadFactor * 2^B öğe tutabilir)
noverflow uint16 // yaklaşık taşma bucket sayısı; detaylar için incrnoverflow'a bakın
hash0 uint32 // hash tohumu
buckets unsafe.Pointer // 2^B Bucket dizisi. count==0 ise nil olabilir.
oldbuckets unsafe.Pointer // yarım boyuttaki önceki bucket dizisi, sadece büyürken nil değil
nevacuate uintptr // tahliye için ilerleme sayacı (bundan küçük bucket'lar tahliye edilmiştir)
extra *mapextra // opsiyonel alanlar
}İngilizce yorumlar çok açık bir şekilde açıklamaktadır. Aşağıda daha önemli alanlar için bazı basit açıklamalar bulunmaktadır:
count: hmap'teki eleman sayısını temsil eder,len(map)ile eşdeğerdir.flags: hmap'in hangi durumda olduğunu gösteren hmap bayrakları, aşağıdaki olasılıklar vardır:goconst ( iterator = 1 // Iterator bucket'ları kullanıyor oldIterator = 2 // Iterator eski bucket'ları kullanıyor hashWriting = 4 // Bir goroutine hmap'e yazıyor sameSizeGrow = 8 // Eşit boyutla büyüyor )B: hmap'teki hash bucket sayısı1 << B'dir.noverflow: hmap'teki yaklaşık taşma bucket sayısı.hash0: hash tohumu, hmap oluşturulduğunda belirtilir, hash değerlerini hesaplamak için kullanılır.buckets: hash bucket dizisine pointer.oldbuckets: hmap genişlemeden önceki hash bucket dizisine pointer.extra: hmap'in taşma bucket'larını depolar. Taşma bucket'ları mevcut bucket dolduğunda elemanları depolamak için oluşturulan yeni bucket'lardır.
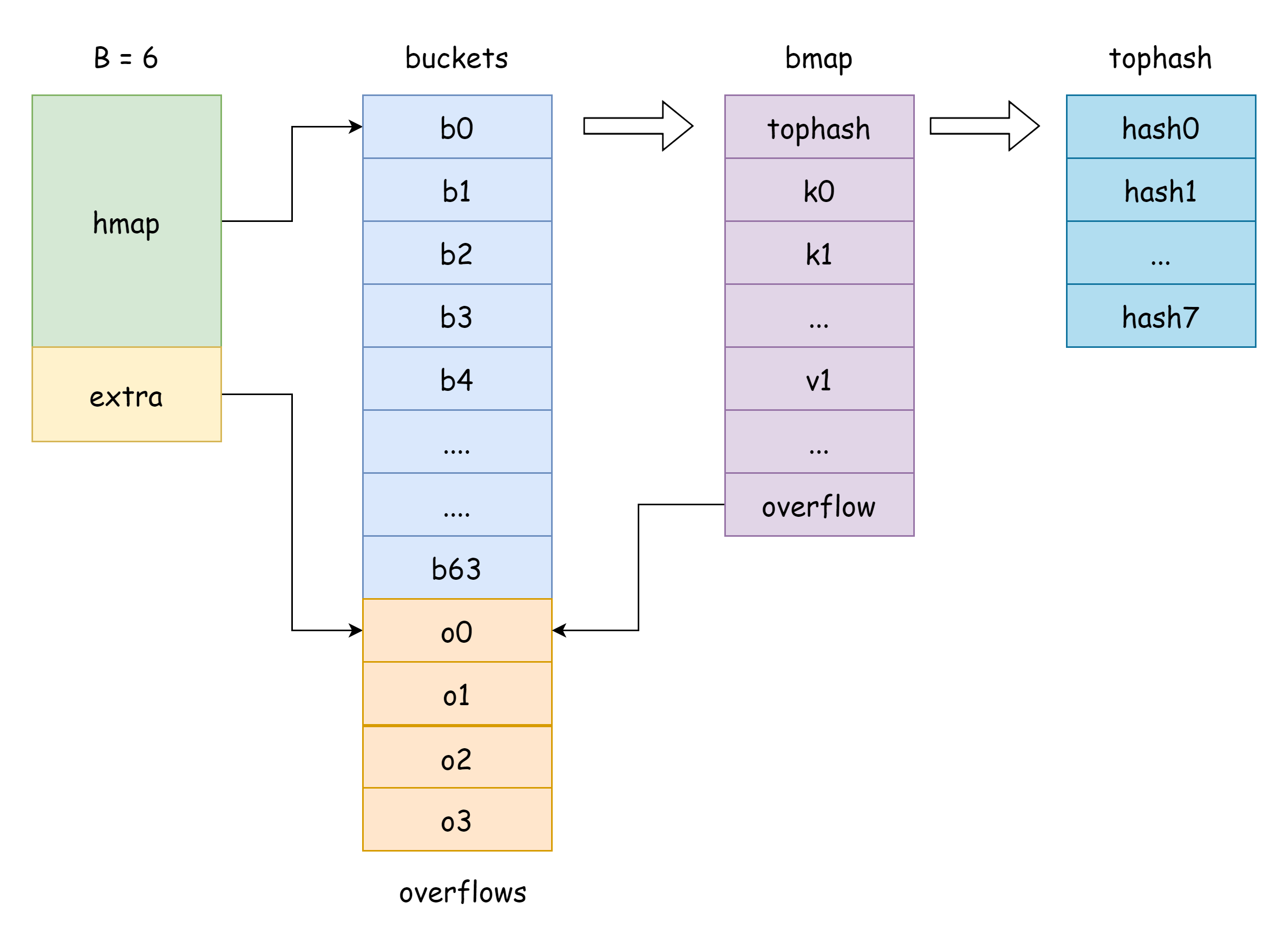
hmap'teki buckets bir bucket slice pointer'ıdır, Go'daki runtime.bmap struct'ına karşılık gelir:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Görüldüğü gibi, sadece bir tophash alanı vardır, her anahtarın yüksek 8 bitini depolar. Ancak, bmap'in bunlardan daha fazla alanı vardır. Bunun nedeni map'in çeşitli tipte anahtar-değer çiftlerini depolayabilmesidir, bu nedenle derleme sırasında tiplere göre bellek alanı türetilmelidir. cmd/compile/internal/reflectdata/reflect.go içindeki MapBucketType fonksiyonu derleme sırasında bmap oluşturur, anahtar tipinin comparable olup olmadığı gibi bir dizi kontrol yapar.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeYani aslında, bmap yapısı şu şekildedir, ancak bu alanlar bize görünmez. Go, unsafe pointer'ları hareket ettirerek bunlara erişir:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Bazı açıklamalar şu şekildedir:
tophash: her anahtarın yüksek 8 bitini depolar. Bir tophash elemanı için aşağıdaki özel değerler vardır:goconst ( emptyRest = 0 // Mevcut eleman boş ve ardından daha fazla kullanılabilir anahtar yok emptyOne = 1 // Mevcut eleman boş ancak ardından kullanılabilir anahtarlar var evacuatedX = 2 // Genişleme sırasında görünür, sadece oldbuckets'ta, elemanın yeni bucket dizisinin üst yarısına taşındığını gösterir evacuatedY = 3 // Genişleme sırasında görünür, sadece oldbuckets'ta, elemanın yeni bucket dizisinin alt yarısına taşındığını gösterir evacuatedEmpty = 4 // Genişleme sırasında görünür, elemanın kendisi boş, yeniden konumlandırma sırasında işaretlenir minTopHash = 5 // Normal bir anahtar-değer için minimum tophash değeri )Eğer
tophash[i]değeriminTopHash'tan büyükse, ilgili indekste normal bir anahtar-değer olduğunu gösterir.keys: belirtilen tipte anahtarları depolayan dizi.elems: belirtilen tipte değerleri depolayan dizi.overflow: taşma bucket'ına pointer.
Anahtar-değerler struct alanları aracılığıyla doğrudan erişilemediği için, Go dataoffset adlı bir sabit tanımlar, bmap'teki verilerin bellek ofsetini temsil eder:
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Aslında, anahtar-değerler bitişik bir bellek adresinde depolanır, aşağıdaki yapıya benzer. Bu, bellek hizalaması nedeniyle bellek alanı israfını önlemek için yapılır:
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Yani bir bmap için, pointer'ı dataoffset kadar hareket ettirdikten sonra, i*sizeof(keyType) kadar hareket ettirmek i'inci anahtarın adresini verir:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))i'inci değerin adresini almak da aynı şekilde çalışır:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))hmap'teki buckets pointer'ı ilk hash bucket adresine işaret eder. i'inci hash bucket'ın adresini almak için, ofset i*sizeof(bucket)'tır:
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Bu işlemler sonraki içerikte çok sık görünecektir.
Hash
Çarpışma
hmap'te, taşma bucket bilgilerini depolamak için özel bir extra alanı vardır. Taşma bucket'larını depolayan bir slice'a işaret eder, yapısı şu şekildedir:
type mapextra struct {
// Taşma bucket'ları için pointer slice
overflow *[]*bmap
// Genişlemeden önceki eski taşma bucket'ları için pointer slice
oldoverflow *[]*bmap
// Bir sonraki boş taşma bucket'ına pointer
nextOverflow *bmap
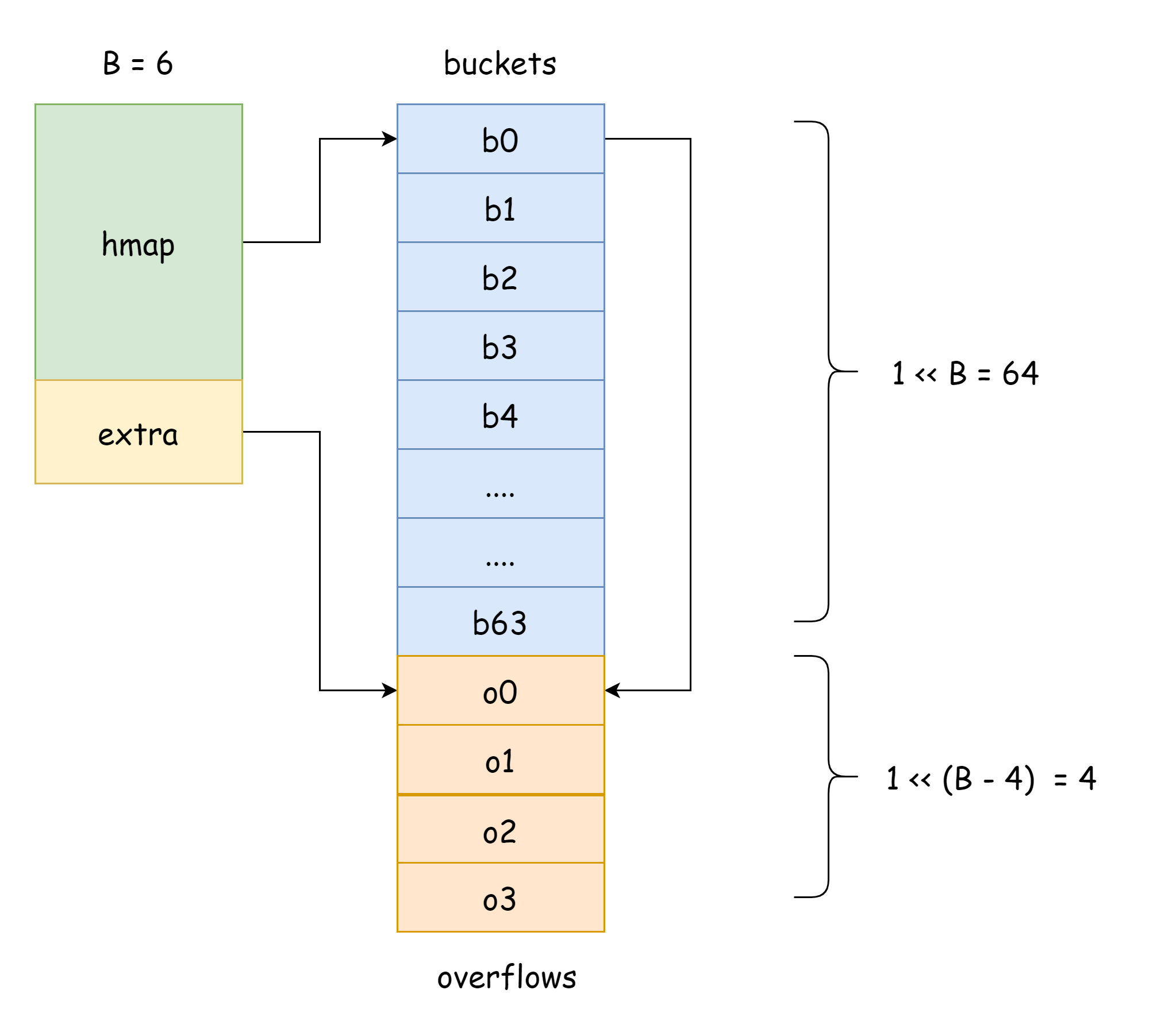
}
TIP
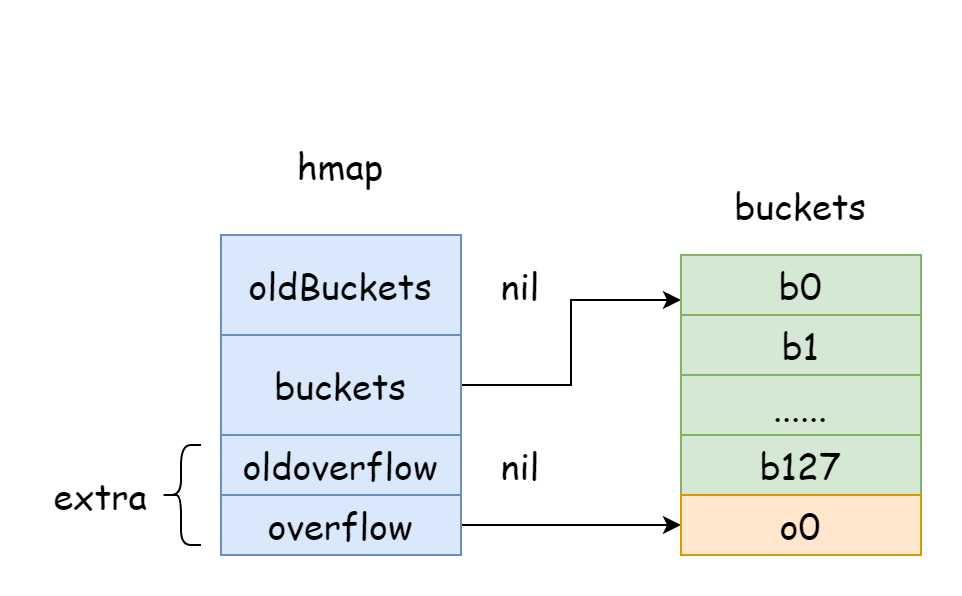
Yukarıdaki şekilde, mavi kısım hash bucket dizisidir ve turuncu kısım taşma hash bucket dizisidir. Taşma bucket'ları aşağıda toplu olarak taşma bucket'ları olarak anılır.
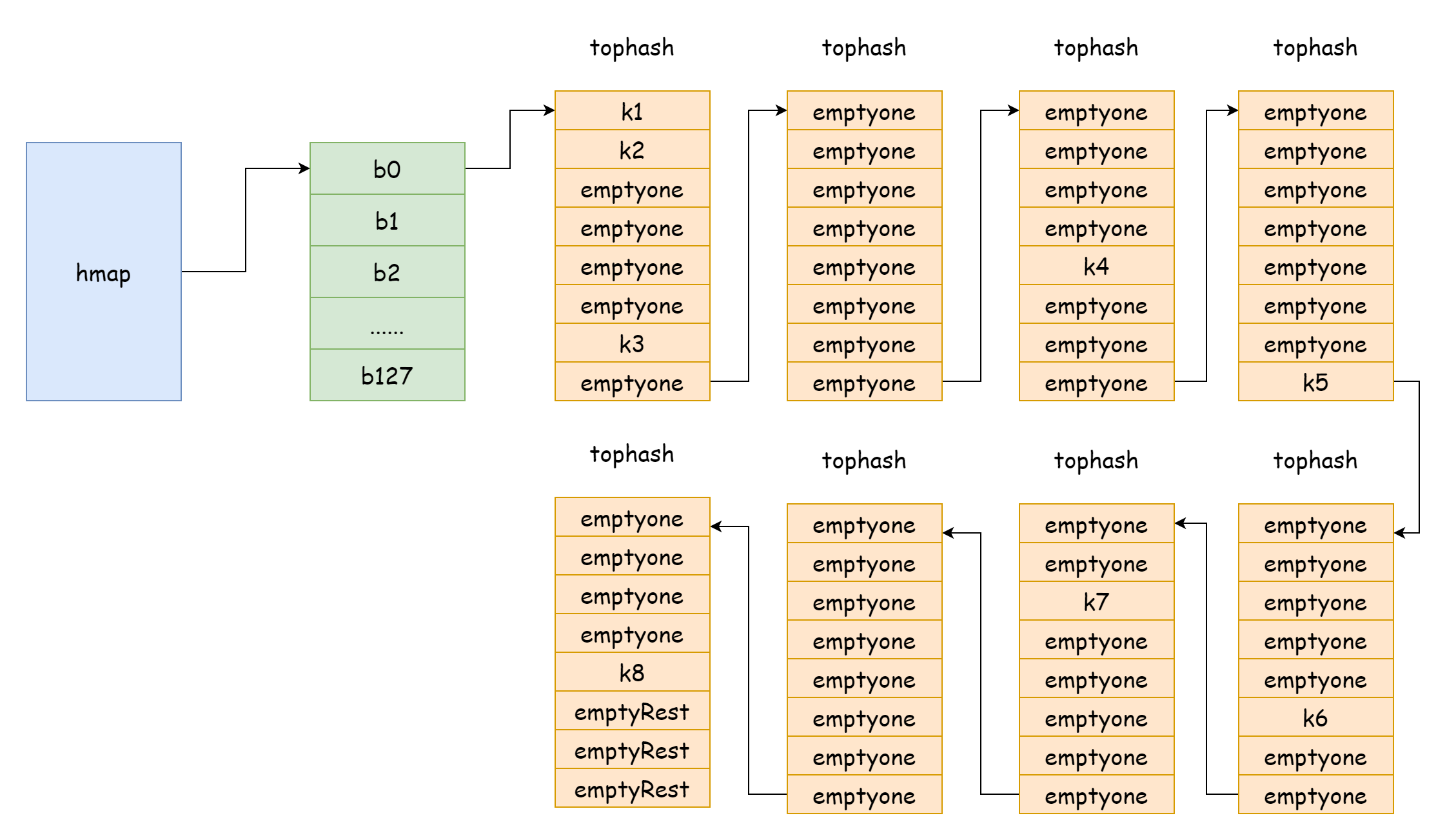
Yukarıdaki şekil hmap'in genel yapısını gösterir. buckets hash bucket dizisine işaret eder, extra taşma bucket dizisine işaret eder, bucket0 taşma bucket'ı overflow0'a işaret eder. İki farklı bucket türü iki slice'ta depolanır ve her iki tür bucket için bellek bitişiktir. İki anahtar hashlendikten sonra aynı bucket'a atandığında, bu bir hash çarpışmasıdır. Go, zincirleme kullanarak hash çarpışmalarını çözer. Çarpışan anahtar sayısı bucket kapasitesini aştığında (genellikle 8, internal/abi.MapBucketCount'a bağlı), bu anahtarları depolamak için yeni bir bucket oluşturulur. Bu yeni bucket'a taşma bucket'ı denir, yani orijinal bucket dolmuştur ve elemanlar bu yeni bucket'a taşar. Oluşturulduktan sonra, hash bucket'ı yeni taşma bucket'ına işaret eden bir pointer'a sahiptir. Bu bucket pointer'larını bağlamak bir bmap bağlantılı listesi oluşturur.
Zincirleme için, yük faktörü hash tablosu çarpışmalarını ölçmek için kullanılır, formül şu şekildedir:
loadfactor := len(elems) / len(buckets)Yük faktörü daha büyük olduğunda, daha fazla hash çarpışması olduğu anlamına gelir, yani daha fazla taşma bucket'ı vardır. Hash tablosunu okurken/yazarken, belirtilen konumu bulmak için daha fazla taşma bucket bağlantılı listesini gezmeniz gerekir, bu da daha düşük performansla sonuçlanır. Bu durumu iyileştirmek için, buckets sayısı artırılmalıdır, yani genişleme. hmap için, iki koşul genişlemeyi tetikler:
- Yük faktörü eşik değeri
bucketCnt*13/16'yı aşar, bu en az 6.5'tir. - Çok fazla taşma bucket'ı
Yük faktörü daha küçük olduğunda, hmap'in düşük bellek kullanımına sahip olduğu ve daha fazla bellek kapladığı anlamına gelir. Go'nun yük faktörünü hesaplamak için kullandığı fonksiyon runtime.overLoadFactor:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Burada loadFactorNum ve loadFactorDen sabitlerdir ve bucketshift 1 << B değerini hesaplar. Verilen:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenBasitleştirildiğinde:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Burada (bucketCnt * 13 / 16) 6.5'e eşittir ve 1 << B hash bucket sayısıdır. Yani bu fonksiyon eleman sayısının bucket sayısına bölümünün yük faktörü 6.5'ten büyük olup olmadığını hesaplar.
Hesaplama
Go'nun dahili hash hesaplama fonksiyonu runtime/alg.go içinde f32hash olarak bulunur:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // her türlü NaN
default:
return memhash(p, h, 4)
}
}Görüldüğü gibi, map hash hesaplama tip bazlı değil bellek bazlıdır, sonunda memhash fonksiyonuna gider, bu assembly ile implemente edilmiştir ve mantık runtime/asm*.s içindedir. Bellek bazlı hash değerleri kalıcı olmamalıdır çünkü sadece çalışma zamanında kullanılmalıdır; her çalıştırmada aynı bellek dağılımını garanti etmek imkansızdır.
Bu dosyada typehash adında bir fonksiyon daha vardır, farklı tiplere göre hash değerlerini hesaplar, ancak map hash için bu fonksiyonu kullanmaz:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrBu implementasyon yukarıdakinden daha yavaştır ancak daha geneldir, öncelikle yansıma ve derleme zamanı fonksiyon oluşturma için kullanılır, örneğin:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Oluşturma
Map başlatmanın iki yöntemi vardır, dil tanıtımında açıklandığı gibi: biri doğrudan map anahtar kelimesini kullanır, diğeri make fonksiyonunu kullanır. Başlatma yöntemi ne olursa olsun, her ikisi de sonunda runtime.makemap tarafından oluşturulur. Fonksiyon imzası:
func makemap(t *maptype, hint int, h *hmap) *hmapParametreler:
t: map tipini ifade eder; farklı tipler farklı bellek kullanımı gerektirir.hint:makefonksiyonunun ikinci parametresini ifade eder, map elemanlarının beklenen kapasitesi.h:hmappointer'ı,nilolabilir.
Dönüş değeri başlatılan hmap pointer'ıdır. Başlatma sırasında, bu fonksiyonun birkaç ana görevi vardır. İlk olarak, beklenen ayrılan belleğin maksimum ayrılan belleği aşılıp aşılmadığını hesaplar:
// Beklenen kapasiteyi bucket tipi bellek boyutuyla çarp
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Sayısal taşma veya maksimum ayrılabilir belleği aşar
if overflow || mem > maxAlloc {
hint = 0
}İç yapı bölümünde belirtildiği gibi, hmap bucket'lardan oluşur. En düşük bellek kullanım durumunda, bir bucket'ta sadece bir eleman vardır ve en fazla belleği kaplar. Yani beklenen maksimum bellek kullanımı eleman sayısı çarpı ilgili tip bellek boyutudur. Hesaplama sonucu taştığında veya maksimum ayrılabilir belleği aştığında, hint'i 0'a ayarla çünkü hint daha sonra bucket dizisi kapasitesini hesaplamak için kullanılacaktır.
İkinci adım hmap'i başlatır ve rastgele bir hash tohumu hesaplar:
// Başlat
if h == nil {
h = new(hmap)
}
// Rastgele bir hash tohumu al
h.hash0 = fastrand()Ardından hint değerine göre hash bucket kapasitesini hesaplar:
B := uint8(0)
// (hint / 1 << B) < 6.5 olana kadar döngüde devam et
for overLoadFactor(hint, B) {
B++
}
// hmap'e ata
h.B = B(hint / 1 << B) < 6.5 koşulunu sağlayan ilk B değerini bulmak için sürekli döngü yaparak, hmap'e atar. Hash bucket kapasitesini bildikten sonra, sonunda hash bucket'ları için bellek ayırır:
if h.B != 0 {
var nextOverflow *bmap
// Ayrılan hash bucket'ları ve önceden ayrılmış boş taşma bucket'ları
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Önceden ayrılmış boş taşma bucket'ları varsa, onlara işaret et
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}makeBucketArray fonksiyonu B değerine göre hash bucket'ları için ilgili bellek boyutunu ayırır ve boş taşma bucket'ları önceden ayırır. B 4'ten küçük olduğunda, taşma bucket'ları oluşturulmaz. 4'ten büyükse, 2^B-4 taşma bucket'ı oluşturulur. runtime.makeBucketArray içindeki aşağıdaki koda karşılık gelir:
base := bucketShift(b)
nbuckets := base
// 4'ten küçükse taşma bucket'ları oluşturulmaz
if b >= 4 {
// Beklenen bucket sayısı artı 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Taşma bucket'ları için gereken bellek
sz := t.Bucket.Size_ * nbuckets
// Bellek alanını yukarı yuvarla
up := roundupsize(sz)
// Eşit değilse, up kullanarak yeniden hesapla
if up != sz {
nbuckets = up / t.Bucket.Size_
}
}base beklenen bucket sayısını ifade eder, nbuckets gerçek ayrılan bucket sayısını ifade eder, bu taşma bucket sayısını içerir.
if base != nbuckets {
// İlk kullanılabilir taşma bucket'ı
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Taşma bucket izleme yükünü azaltmak için, son kullanılabilir taşma bucket'ının overflow pointer'ını hash bucket başına işaret et
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// Son taşma bucket'ı hash bucket'a işaret eder
last.setoverflow(t, (*bmap)(buckets))
}Eşit olmadıklarında, ekstra taşma bucket'ları ayrıldığı anlamına gelir. nextoverflow pointer'ı ilk kullanılabilir taşma bucket'ına işaret eder. Görüldüğü gibi, hash bucket'ları ve taşma bucket'ları aslında aynı bitişik bellektedir, bu nedenle diyagramda hash bucket dizisi ve taşma bucket dizisi bitişiktir.
Erişim
Sözdizimi tanıtımında belirtildiği gibi, bir map'e erişmenin üç yolu vardır:
# Doğrudan değere eriş
val := dict[key]
# Değere ve anahtarın var olup olmadığına eriş
val, exist := dict[key]
# Map üzerinde yinele
for key, val := range dict{
}Bu üç yol farklı fonksiyonlar kullanır, for range map yinelemesi en karmaşıktır.
Anahtar-Değer
İlk iki yöntem için, iki fonksiyona karşılık gelirler: runtime.mapaccess1 ve runtime.mapaccess2:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Anahtar, erişilen map anahtarına işaret eden bir pointer'dır ve dönüş de bir pointer'dır. Erişim sırasında, önce anahtarın hash değerini hesaplayarak anahtarın hangi hash bucket'ta olduğunu bulur:
// Sınır durumu işleme
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // issue 23734'e bakın
}
return unsafe.Pointer(&zeroVal[0])
}
// Eşzamanlı okuma/yazmayı önle
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Belirtilen tip hasher kullanarak hash hesapla
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Pointer'ı hareket ettirerek anahtarın hash bucket'ını bul
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))Erişim başında, sınır durumlarını işleyin ve eşzamanlı map okuma/yazmayı önleyin. Map eşzamanlı okuma/yazma durumundayken, panic oluşur. Ardından hash değerini hesaplayın. bucketMask fonksiyonu (1 << B) - 1 değerini hesaplar, yani hash & m değeri hash & (1 << B) - 1'e eşittir, bu ikili modülo işlemidir, hash % (1 << B) ile eşdeğerdir. Bitwise işlemleri kullanmak daha hızlıdır. Son üç satır, hash değerinin mevcut map bucket sayısına modülosunu hesaplayarak hash bucket numarasını alır, ardından numara alapján pointer'ı hareket ettirerek anahtarın hash bucket pointer'ını alır.
Anahtarın hangi hash bucket'ta olduğunu bildikten sonra, aramaya başlayabilirsiniz:
// Hash değerinin yüksek 8 bitini al
top := tophash(hash)
bucketloop:
// bmap bağlantılı listesini gez
for ; b != nil; b = b.overflow(t) {
// bmap içindeki elemanlar
for i := uintptr(0); i < bucketCnt; i++ {
// Hesaplanan top'u tophash elemanlarıyla karşılaştır
if b.tophash[i] != top {
// Aşağıdakiler boş, hiçbir şey kalmadı.
if b.tophash[i] == emptyRest {
break bucketloop
}
// Eşit değilse taşma bucket'larını gez
continue
}
// Pointer'ı hareket ettirerek ilgili indekste anahtarı al
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Pointer işleme
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// İki anahtarın eşit olup olmadığını karşılaştır
if t.Key.Equal(key, k) {
// Eşitse, pointer'ı hareket ettirerek k'nın indeksindeki elemanı döndür
// Bu satır anahtar-değer bellek adreslerinin bitişik olduğunu gösterir
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Bulunamadı, sıfır değeri döndür.
return unsafe.Pointer(&zeroVal[0])Hash bucket'ı bulduğunuzda, konumlandırma modülo yoluyla yapılır, bu nedenle anahtarın hangi hash bucket'ta olduğu hash değerinin düşük bitlerine bağlıdır. Kaç düşük bit B'nin boyutuna bağlıdır. Hash bucket'ı bulduktan sonra, tophash hash değerinin yüksek 8 bitini depolar. Düşük bitlerin modülo değerleri aynı olduğundan, anahtarları tek tek karşılamaya gerek yoktur; hash değerinin yüksek 8 bitini karşılaştırmak yeterlidir. Yüksek 8 bit eşitse, ardından anahtarları karşılaştırın. Anahtarlar da eşitse, eleman bulunur. Eşit değilse, tophash dizisini gezmeye devam edin. Hala bulunamadıysa, taşma bucket bmap bağlantılı listesini gezmeye devam edin, bmap'in tophash[i] değeri emptyRest olana kadar, ardından döngüden çıkın ve ilgili tip için sıfır değeri döndürün.
mapaccess2 fonksiyon mantığı mapaccess1 ile tamamen tutarlıdır, sadece elemanın var olup olmadığını gösteren ek bir boolean dönüş değeri vardır.
Yineleme
Map yineleme sözdizimi şu şekildedir:
for key, val := range dict {
// bir şey yap...
}Gerçek yineleme sırasında, Go yineleme bilgilerini depolamak için hiter struct'ını kullanır. hiter, hmap iterator'ın kısaltmasıdır, yani hash tablosu yineleyicisi:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // İlk pozisyonda olmalı. Yineleme sonunu belirtmek için nil yaz (cmd/compile/internal/walk/range.go'ya bak).
elem unsafe.Pointer // İkinci pozisyonda olmalı (cmd/compile/internal/walk/range.go'ya bak).
t *maptype
h *hmap
buckets unsafe.Pointer // hash_iter başlatma zamanında bucket ptr
bptr *bmap // mevcut bucket
overflow *[]*bmap // hmap.buckets'ın taşma bucket'larını canlı tutar
oldoverflow *[]*bmap // hmap.oldbuckets'ın taşma bucket'larını canlı tutar
startBucket uintptr // yinelemenin başladığı bucket
offset uint8 // yineleme sırasında bucket içi ofset (bucketCnt-1'i tutacak kadar büyük olmalı)
wrapped bool // bucket dizisinin sonundan başına zaten sarıldı
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Bazı alanlar için basit açıklamalar:
key,elem:for rangeyinelemesi sırasında elde edilen anahtar-değerbuckets: yineleyici başlatma sırasında belirtilir, hash bucket başına işaret ederbptr: şu anda gezilen bmapstartBucket: yineleme başladığında başlangıç bucket indeksioffset: bucket içi ofset, aralık[0, bucketCnt-1]B: hmap'in B değerii: bucket içi eleman indeksiwrapped: hash bucket dizisinin sonundan başına sarılıp sarılmadığı
Yineleme başlamadan önce, Go yineleyiciyi runtime.mapiterinit fonksiyonu aracılığıyla başlatır, ardından runtime.mapinternext fonksiyonu aracılığıyla map üzerinde yineleme yapar. Her ikisi de hiter struct'ını kullanmalıdır:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Yineleyici başlatma için, önce mevcut map durumunun bir anlık görüntüsünü alın:
it.t = t
it.h = h
// hmap mevcut durumunun anlık görüntüsünü kaydet, sadece B değerini kaydetmek yeterli.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Sonraki yineleme sırasında, gerçekten gezilen şey map'in bir anlık görüntüsüdür, gerçek map değil. Bu nedenle, gezinme sırasında eklenen elemanlar ve bucket'lar gezilmeyecektir. Eşzamanlı gezinme ve yazma fatal tetikleyebilir:
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}İkinci adım gezinme için iki başlangıç pozisyonu belirler: birincisi başlangıç bucket pozisyonu, ikincisi bucket içindeki başlangıç pozisyonu. Her ikisi de rastgele seçilir:
// r bir rastgele sayıdır
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) başlangıç bucket pozisyonunu alır
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 bucket içindeki başlangıç eleman pozisyonunu alır
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Gezilen mevcut bucket indeksini kaydet
it.bucket = it.startBucketfastrand() veya fastrand64() aracılığıyla rastgele bir sayı alın, ardından iki modülo işlemi kullanarak bucket başlangıç pozisyonunu ve bucket içi başlangıç pozisyonunu alın.
TIP
Map eşzamanlı okuma/yazmaya izin vermese de, eşzamanlı gezinmeye izin verir.
Ardından, yineleme gerçekten başlar. Bucket'ları nasıl gezeceğiniz ve çıkış stratejisi aşağıdaki koda karşılık gelir:
// hmap
h := it.h
// maptype
t := it.t
// Gezilecek bucket pozisyonu
bucket := it.bucket
// Gezilen bmap
b := it.bptr
// Bucket içi indeks i
i := it.i
next:
if b == nil {
// Mevcut bucket pozisyonu başlangıç pozisyonuna eşitse, tam tur dönüldüğü anlamına gelir, ardından gelenler zaten gezildi
// Yineleme tamamlandı, çıkılabilir
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Bucket indeksini ileri taşı
bucket++
// bucket == 1 << B, hash bucket dizisinin sonuna ulaşıldı
if bucket == bucketShift(it.B) {
// Baştan başla
bucket = 0
it.wrapped = true
}
i = 0
}Hash bucket başlangıç pozisyonu rastgele seçilir. Gezirme sırasında, başlangıç pozisyonundan bucket slice sonuna doğru tek tek yineleyin. 1 << B değerine ulaştığınızda, ardından baştan başlayın. Başlangıç pozisyonuna tekrar döndüğünüzde, gezinmenin tamamlandığı anlamına gelir, ardından çıkın. Yukarıdaki kod map'te bucket'ları nasıl gezeceğinizi açıklar. Aşağıdaki kod bir bucket içinde nasıl gezileceğini açıklar:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Mevcut eleman boşsa atla
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Pointer'ı hareket ettirerek anahtarı al
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Pointer'ı hareket ettirerek değeri al
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Eşit boyutlu genişleme durumunu işle. Anahtar-değer başka pozisyonlara tahliye edildiğinde, anahtar-değeri yeniden bulmak gerekir.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Bucket içinde bulunamadıysa, taşma bucket'ında ara
b = b.overflow(t)
i = 0
goto nextTIP
Yukarıdaki genişleme yargılama koşulunda, bir ifade kafa karıştırıcı olabilir:
t.Key.Equal(k, k)k'nın kendisine eşit olup olmadığını kontrol etme nedeni Nan anahtar durumlarını filtrelemektir. Bir elemanın anahtarı Nan ise, o elemana doğrudan erişmek imkansız hale gelir. Yineleme, doğrudan erişim veya silme是否正常 olarak devam edemez çünkü Nan != Nan her zaman doğrudur, bu nedenle bu anahtar asla bulunamaz.
İlk olarak, i ve offset değerlerini modülo işlemiyle bucket içi indeksi alın. Pointer'ı hareket ettirerek anahtar-değeri alın. Map gezinmesi sırasında, diğer yazma işlemleri map genişlemesini tetikleyebilir, bu nedenle gerçek anahtar-değer artık orijinal pozisyonda olmayabilir. Bu durumda, gerçek anahtar-değeri yeniden almak için mapaccessK fonksiyonunu kullanmak gerekir. Fonksiyon imzası:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)İşlevselliği mapaccess1 ile tamamen tutarlıdır, ancak mapaccessK hem anahtarı hem de değeri döndürür. Sonunda anahtar-değeri aldıktan sonra, yineleyicinin key ve elem'ine atayın, ardından yineleyici indeksini güncelleyin. Bu bir yinelemeyi tamamlar ve kod yürütme for range kod bloğuna döner. Bucket içinde bulunamadıysa, taşma bucket'ında arayın ve taşma bucket bağlantılı listesi gezinmesi tamamlanana kadar yukarıdaki adımları tekrarlayın, ardından bir sonraki hash bucket'ı gezmeye devam edin.
Değiştirme
Map değiştirme sözdizimi şu şekildedir:
dict[key] = valGo'da, map değiştirme işlemleri runtime.mapassign fonksiyonu tarafından tamamlanır:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerErişim süreci mantığı mapaccess1 ile aynıdır, ancak anahtar mevcut olmadığında, onun için bir pozisyon ayrılır. Mevcutsa, güncellenir. Son olarak, eleman pointer'ı döndürülür. Başlangıçta, bazı hazırlık çalışmaları yapılmalıdır:
// nil map'e yazmaya izin verilmez
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Eşzamanlı yazmalar yasaktır
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Anahtar hash değerini hesapla
hash := t.Hasher(key, uintptr(h.hash0))
// hmap durumunu değiştir
h.flags ^= hashWriting
// Hash bucket'ı başlat
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Yukarıdaki kod şunları yapar:
- hmap durum kontrolü
- Anahtar hash değerini hesapla
- Hash bucket'ın başlatılması gerekip gerekmediğini kontrol et
Ardından hash değeri modülo işlemini kullanarak hash bucket pozisyonunu ve anahtarın tophash'ini alın:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Belirtilen pozisyonda bmap almak için pointer'ı hareket ettir
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// tophash hesapla
top := tophash(hash)Artık bucket pozisyonu, bmap ve tophash belirlendi, bu nedenle eleman aramasına başlanabilir:
// Eklenecek tophash
var inserti *uint8
// Eklenecek anahtar değer pointer'ı
var insertk unsafe.Pointer
// Eklenecek değer değer pointer'ı
var elem unsafe.Pointer
bucketloop:
for {
// Bucket içindeki tophash dizisini gez
for i := uintptr(0); i < bucketCnt; i++ {
// tophash eşit değil
if b.tophash[i] != top {
// Mevcut bucket indeksi boşsa ve henüz eleman eklenmediyse, bu pozisyonu ekleme için seç
if isEmpty(b.tophash[i]) && inserti == nil {
// Anahtar için uygun bir pozisyon bulundu
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Gezme tamamlandıktan sonra döngüden çık
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash eşitse, anahtar zaten mevcut olabilir
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Anahtarların eşit olup olmadığını kontrol et
if !t.Key.Equal(key, k) {
continue
}
// Anahtar değeri güncellenmesi gerekiyorsa, anahtar belleğini doğrudan k pozisyonuna kopyala
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Eleman pointer'ı alındı
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Güncelleme tamamlandı, eleman pointer'ı döndür
goto done
}
// Buraya ulaşıldıysa anahtar bulunamadı, taşma bucket bağlantılı listesini gezerek aramaya devam et
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Buraya ulaşıldıysa anahtar map'te mevcut değil, ancak anahtar için uygun bir pozisyon bulunmuş olabilir veya bulunmamış olabilir
// Anahtar için uygun bir pozisyon bulunamadı
if inserti == nil {
// Mevcut hash bucket ve onun taşma bucket'ı dolu, yeni bir taşma bucket'ı ayır
newb := h.newoverflow(t, b)
// Taşma bucket'ında anahtar için bir pozisyon ayır
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Anahtar pointer'ı depolanıyorsa
if t.IndirectKey() {
// Yeni bellek ayır, unsafe pointer döndürür
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Daha sonra anahtar bellek kopyalaması için insertk'ya ata
insertk = kmem
}
// Eleman pointer'ı depolanıyorsa
if t.IndirectElem() {
// Bellek ayır
vmem := newobject(t.Elem)
// Pointer'ı vmem'e işaret et
*(*unsafe.Pointer)(elem) = vmem
}
// Anahtar belleğini doğrudan insertk pozisyonuna kopyala
typedmemmove(t.Key, insertk, key)
*inserti = top
// Sayımı artır
h.count++
done:
// Buraya ulaşıldıysa değiştirme süreci tamamlandı
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Eleman pointer'ı döndür
return elemYukarıdaki büyük kod bloğunda, önce hash bucket ve taşma bucket'ta aramayı denemek için for döngüsüne girin. Arama mantığı mapaccess ile tamamen tutarlıdır. Bu noktada, üç olasılık vardır:
- Birincisi, map'te mevcut anahtar bulundu, doğrudan
donebloğuna atla, eleman pointer'ı döndür - İkincisi, map'te anahtar için bir pozisyon bulundu, anahtarı belirtilen pozisyona kopyala ve eleman pointer'ı döndür
- Üçüncüsü, tüm bucket'lar arandı, map'te anahtar için pozisyon bulunamadı, yeni bir taşma bucket'ı oluştur, anahtarı bucket'a ata, ardından anahtarı belirtilen pozisyona kopyala ve eleman pointer'ı döndür
Sonunda eleman pointer'ı aldıktan sonra, atama yapılabilir. Ancak, bu işlem mapassign fonksiyonu tarafından tamamlanmaz; sadece eleman pointer'ı döndürür. Atama işlemi derleme sırasında eklenir, kaynak kodda görünmez ancak derlenmiş kodda görünür. Aşağıdaki koda sahip olduğumuzu varsayalım:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Aşağıdaki komutla assembly kodunu alın:
go tool compile -S -N -l main.goAnahtar kısımlar burada:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Görüldüğü gibi, runtime.mapassign_faststr çağrılır. LEAQ go:string."world"(SB), CX string adresini CX'e depolar ve MOVQ CX, (AX) onu AX'e depolar, böylece eleman ataması tamamlanır.
Silme
Go'da, bir map elemanını silmek için sadece yerleşik delete fonksiyonunu kullanabilirsiniz:
delete(dict, "abc")Dahili olarak, runtime.mapdelete fonksiyonunu çağırır:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Map'te belirtilen anahtara sahip elemanı siler. Elemanın map'te mevcut olup olmadığına bakılmaksızın, tepki vermez. Başlangıçtaki fonksiyon hazırlık mantığı benzerdir:
- hmap durum kontrolü
- Anahtar hash değerini hesapla
- Hash bucket'ı bul
- Tophash hesapla
Çok fazla tekrarlayan içerik var, bu nedenle daha fazla ayrıntıya girmiyoruz. Burada sadece silme mantığına odaklanıyoruz:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Bulunamadıysa döngüden çık
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Pointer'ı hareket ettirerek anahtar pozisyonunu bul
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Anahtarı sil
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Pointer'ı hareket ettirerek eleman pozisyonunu bul
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Elemanı sil
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Sayımı azalt
h.count--
// Çarpışma olasılığını azaltmak için hash tohumunu sıfırla
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Yukarıdaki koddan görebileceğiniz gibi, arama mantığı önceki işlemlerle neredeyse tamamen tutarlıdır. Elemanı bul, ardından sil, hmap kayıtlı sayısı bir azalır. Sayı 0 olduğunda, hash tohumunu sıfırla.
Dikkat edilmesi gereken bir diğer nokta, eleman silindikten sonra, mevcut indeksin tophash durumunun değiştirilmesi gerektiğidir:
// Mevcut tophash'i boş olarak işaretle
b.tophash[i] = emptyOne
// Tophash'in sonundaysa
if i == bucketCnt-1 {
// Taşma bucket boş değilse ve elemanları varsa, mevcut eleman sonuncusu değildir
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Bitişik eleman boş değil
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Eğer eleman gerçekten son eleman ise, bucket bağlantılı listesindeki bazı bucket'ların tophash dizi değerleri düzeltilmelidir. Aksi takdirde, sonraki gezinme doğru pozisyonda çıkamaz. Map'te taşma bucket'ları oluştururken, taşma bucket izleme yükünü azaltmak için, son taşma bucket'ının overflow pointer'ı baş hash bucket'a işaret eder, bu nedenle aslında tek yönlü dairesel bir listedir. Listenin "başı" hash bucket'tır. Burada b, aramadan sonraki b'dir, büyük olasılıkla listedeki ortadaki bir taşma bucket'ıdır. Dairesel bağlantılı listeyi ters sırayla gezerek son mevcut elemanı bulun. Kod ileri gezme yazsa da, liste bir halka olduğu için, mevcut taşma bucket'ından önceye kadar sürekli ileri gezer. Sonuç açısından, gerçekten ters yöndedir. Ardından bucket içindeki tophash dizisini ters sırayla gezin, emptyOne durumundaki elemanları emptyRest olarak güncelleyin, son mevcut elemanı bulana kadar. Halkada sonsuz döngüyü önlemek için, başlangıç bucket'ına döndüğünüzde, yani bOrig, listede daha fazla kullanılabilir eleman olmadığı anlamına gelir, bu nedenle döngüden çıkın:
// Buraya ulaşıldıysa mevcut elemandan sonra eleman yok
// Sürekli olarak bmap bağlantılı listesini ters sırayla gez, bucket içinde tophash'i ters sırayla gez
// emptyOne durumundaki elemanları emptyRest olarak güncelle
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Mevcut bmap bağlantılı listesindeki önceki bmap'i bul
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Temizleme
go1.21 sürümünde, map'teki tüm elemanları temizlemek için yerleşik clear fonksiyonu eklendi:
clear(dict)Dahili olarak, runtime.mapclear fonksiyonunu çağırır, map'teki tüm elemanları silmekten sorumludur:
func mapclear(t *maptype, h *hmap)Bu fonksiyonun mantığı karmaşık değildir. İlk olarak, tüm map'i boş olarak işaretleyin:
// Her bucket ve taşma bucket'ı gez, tüm tophash elemanlarını emptyRest olarak ayarla
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Yukarıdaki kod her bucket'ı gezer ve bucket'ın tophash dizisindeki tüm elemanları emptyRest olarak ayarlar, map'i boş olarak işaretler. Bu, yineleyicinin yinelemeye devam etmesini önler, ardından map'i temizle:
// Hash tohumunu sıfırla
h.hash0 = fastrand()
// extra struct'ı sıfırla
if h.extra != nil {
*h.extra = mapextra{}
}
// Bu işlem orijinal buckets belleğini temizler ve yeni buckets ayırır
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Yeni boş taşma bucket'ları ayır
h.extra.nextOverflow = nextOverflow
}makeBucketArray aracılığıyla önceki bucket belleğini temizle, ardından yeni ones ayır. Bu bucket temizlemeyi tamamlar. Ek olarak, count'u 0'a ayarlama gibi bazı detaylar ve diğer işlemler ayrıntılandırılmamıştır.
Genişleme
Önceki tüm işlemlerde, mantığın kendisine daha fazla odaklanmak için, çok fazla genişleme ile ilgili içerik gizlendi, bu daha basit hale getirdi. Genişleme mantığı aslında oldukça karmaşıktır, müdahaleyi önlemek için sona yerleştirildi. Şimdi Go'nun map'leri nasıl genişlettiğini görelim. Daha önce belirtildiği gibi, genişleme iki koşul tarafından tetiklenir:
- Yük faktörü 6.5'i aşar
- Çok fazla taşma bucket'ı
Yük faktörünün eşiği aşıp aşmadığını kontrol eden fonksiyon runtime.overLoadFactor'dır, hash çarpışma bölümünde açıklanmıştır. Taşma bucket sayısının çok fazla olup olmadığını kontrol eden fonksiyon runtime.tooManyOverflowBuckets'tır, basitçe çalışır:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Yukarıdaki kod aşağıdaki ifadeye basitleştirilebilir, hemen anlaşılabilir:
overflow >= 1 << (min(15,B) % 16)Burada, Go'nun "çok fazla" tanımı şudur: taşma bucket sayısı hash bucket sayısı ile yaklaşık olarak aynıdır. Eşik çok düşükse, ekstra iş yapılır. Eşik çok yüksekse, genişleme çok fazla bellek tüketir. Genişleme değiştirme ve silme sırasında tetiklenebilir. Genişlemenin gerekip gerekmediğini kontrol eden kod:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Tabloyu büyütmek her şeyi geçersiz kılar, bu yüzden tekrar dene
}Görüldüğü gibi, bu üç koşul kısıtlar:
- Şu anda genişliyor olamaz
- Yük faktörü 6.5'ten küçük olmalı
- Taşma bucket sayısı çok fazla olamaz
Genişlemeden sorumlu fonksiyon doğal olarak runtime.hashGrow'dır:
func hashGrow(t *maptype, h *hmap)Aslında, genişleme farklı tetikleme koşullarına göre farklı türlere sahiptir:
- Artımlı genişleme
- Eşit boyutlu genişleme
Artımlı Genişleme
Yük faktörü çok büyük olduğunda, yani eleman sayısı hash bucket sayısından çok daha büyük olduğunda, hash çarpışmaları şiddetli olduğunda, çok fazla taşma bucket bağlantılı listesi oluşur. Bu, map okuma/yazma performansının düşmesine neden olur çünkü bir elemanı bulmak için daha fazla taşma bucket bağlantılı listesini gezmeniz gerekir. Gezme zaman karmaşıklığı O(n)'dir. Hash tablosu arama zaman karmaşıklığı öncelikle hash hesaplama zamanı ve gezme zamanına bağlıdır. Gezme zamanı hash hesaplama zamanından çok daha az olduğunda, arama zaman karmaşıklığı O(1) olarak kabul edilebilir. Hash çarpışmaları sık olursa ve çok fazla anahtar aynı hash bucket'a atanırsa, taşma bucket bağlantılı listesi çok uzun hale gelir, gezme zamanını artırır, bu da arama zamanını artırır. Ekleme/silme/değiştirme işlemlerinin tümü önce arama yapması gerektiğinden, bu tüm map performansının ciddi şekilde düşmesine neden olur.
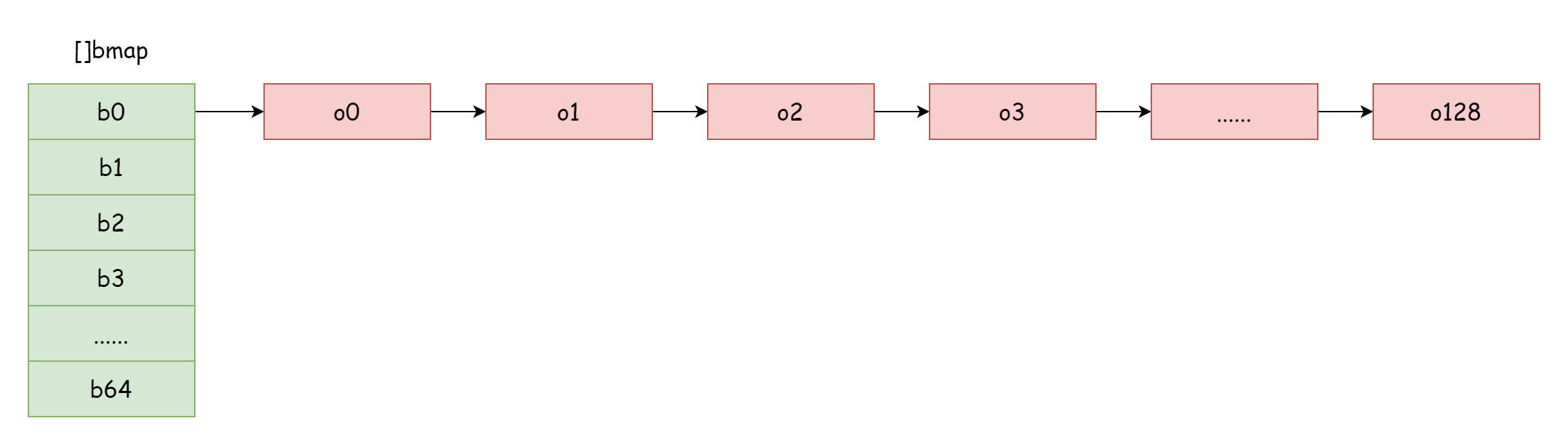
Şekilde gösterilen böyle aşırı durumlarda, arama zaman karmaşıklığı temelde O(n)'den farklı değildir. Bunu çözmek için, çözüm çok uzun taşma bucket bağlantılı listeleri oluşmasını önlemek için daha fazla hash bucket eklemektir. Bu yöntem artımlı genişleme olarak da adlandırılır.
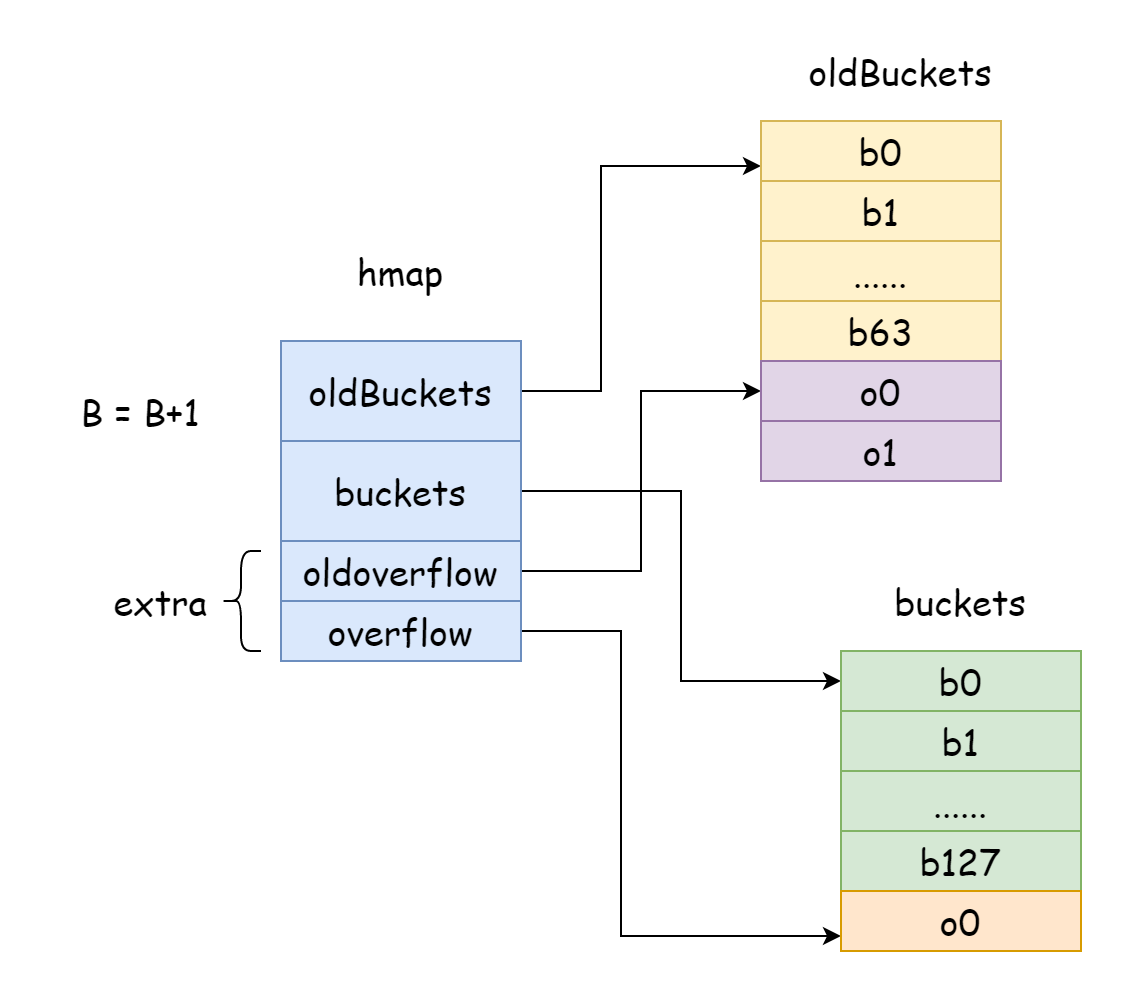
Go'da, artımlı genişleme her seferinde B'ye bir ekler, yani hash bucket ölçeği her seferinde iki katına çıkar. Genişlemeden sonra, eski veriler yeni map'e yeniden konumlandırılmalıdır. Map eleman sayısı onlarca veya yüz milyonlarca ise, hepsini bir seferde yeniden konumlandırmak çok uzun sürer. Bu nedenle Go, kademeli yeniden konumlandırma stratejisi benimser. Bunun için, Go hmap'in oldBuckets'ını orijinal hash bucket dizisine işaret eder, bunun eski veri olduğunu belirtir. Ardından daha büyük kapasiteli hash bucket dizisi oluşturur, hmap'in buckets'ını yeni hash bucket dizisine işaret eder. Her değiştirme ve silme sırasında, eski bucket'tan yeni bucket'a bazı elemanları yeniden konumlandırır, yeniden konumlandırma tamamlanana kadar, ardından eski bucket belleği serbest bırakılır.
func hashGrow(t *maptype, h *hmap) {
// Fark
bigger := uint8(1)
// Eski bucket'lar
oldbuckets := h.buckets
// Yeni hash bucket'ları
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Taşma bucket'ları da eski ve yeni bucket'ları belirtmelidir
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Yukarıdaki kod iki kat kapasiteli yeni hash bucket'ları oluşturur, ardından eski ve yeni hash bucket'larına ve eski ve yeni taşma bucket'larına referansları belirtir. Gerçek yeniden konumlandırma işi hashGrow fonksiyonu tarafından tamamlanmaz; sadece eski ve yeni bucket'ları belirtir ve bazı hmap durumlarını günceller. Bu iş aslında runtime.growWork fonksiyonu tarafından tamamlanır:
func growWork(t *maptype, h *hmap, bucket uintptr)Aşağıdaki formda mapassign ve mapdelete fonksiyonlarında çağrılır. Rolü, mevcut map genişliyorsa kısmi yeniden konumlandırma yapmaktır:
if h.growing() {
growWork(t, h, bucket)
}Değiştirme ve silme sırasında, şu anda genişliyor olup olmadığını kontrol etmek gerekir, öncelikle hmap.growing metodu tarafından yapılır. İçerik basittir: oldbuckets'ın boş olup olmadığını kontrol eder:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}growWork fonksiyonunun ne yaptığını görelim:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}bucket&h.oldbucketmask() işlemi eski bucket pozisyonunu hesaplar, yeniden konumlandırılacak bucket'ın mevcut bucket'ın eski bucket'ı olduğundan emin olur. Fonksiyondan, yeniden konumlandırmadan gerçekten sorumlu fonksiyonun runtime.evacuate olduğunu görebilirsiniz. Yeniden konumlandırma sırasında yeni bucket'ları yinelemek için evaDst struct'ını kullanır:
type evacDst struct {
b *bmap // Yeniden konumlandırma hedefindeki yeni bucket
i int // Bucket içi indeks
k unsafe.Pointer // Yeni anahtar hedefine pointer
e unsafe.Pointer // Yeni değer hedefine pointer
}Yeniden konumlandırma başlamadan önce, Go iki evacDst struct'ı ayırır: biri yeni hash bucket'ın üst yarısına işaret eder, diğeri yeni hash bucket'ın alt yarısına işaret eder:
// Eski bucket'larda belirtilen hash bucket'ı bul
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Eski bucket uzunluğu = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Yeni bucket'ın üst yarısına işaret eder
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// Eşit boyutlu genişlemeyi kontrol et
if !h.sameSizeGrow() {
y := &xy[1]
// Yeni bucket'ın alt yarısına işaret eder
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Eski bucket yeniden konumlandırma hedefleri iki yeni bucket'tır. Yeniden konumlandırmadan sonra, bucket'taki verilerin bir kısmı üst yarısında, diğer kısmı alt yarısında olacaktır. Bu, genişletilen verilerin daha eşit dağılmasını sağlamak için yapılır. Ne kadar eşit dağılırsa, map arama performansı o kadar iyi olur. Go verileri iki yeni bucket'a nasıl yeniden konumlandırır aşağıdaki koda karşılık gelir:
// Taşma bucket bağlantılı listesini gez
for ; b != nil; b = b.overflow(t) {
// Her bucket'taki ilk anahtar-değer çiftini al
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Bucket'taki her anahtar-değer çiftini gez
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Boşsa atla
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Yeni hash bucket yeniden konumlandırma durumunda olmamalıdır
// Aksi takdirde bir şeyler yanlış
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Bu değişken mevcut anahtar-değer çiftinin üst veya alt yarısına yeniden konumlandırılıp konumlandırılmadığını belirler
// Değeri sadece 0 veya 1 olabilir
var useY uint8
if !h.sameSizeGrow() {
// Hash değerini yeniden hesapla
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 özel durumunu işle
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Sabit değerleri kontrol et
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Eski bucket tophash'i güncelle, mevcut elemanın yeniden konumlandırıldığını belirt
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// Yeniden konumlandırma hedefini belirt
dst := &xy[useY] // tahliye hedefi
// Yeni bucket kapasitesi yetersizse, bir taşma bucket'ı oluştur
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // dst.i'yi maskele, sınır kontrolünü önlemek için optimizasyon
// Anahtarı kopyala
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // pointer'ı kopyala
} else {
typedmemmove(t.Key, dst.k, k) // elemanı kopyala
}
// Değeri kopyala
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Yeni bucket hedef pointer'ını ileri taşı, bir sonraki anahtar-değer için hazırlan
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Yukarıdaki koddan, Go eski bucket bağlantılı listesindeki her bucket'taki her elemanı gezerek, verileri yeni bucket'a taşır. Verilerin üst veya alt yarısına gidip gitmeyeceği yeniden hesaplanan hash değerine bağlıdır:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Yeniden konumlandırmadan sonra, mevcut elemanın tophash'i evacuatedX veya evacuatedY olarak ayarlanır. Genişleme sırasında veri aramaya çalışırsanız, bu durum verinin yeniden konumlandırıldığını gösterir, bu nedenle ilgili veriyi yeni bucket'ta aramanız gerektiğini bilirsiniz. Bu mantık runtime.mapaccess1 içindeki aşağıdaki koda karşılık gelir:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// Eskiden yarı kadar bucket vardı; iki'nin bir kuvvetini daha maskele.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Eski bucket yeniden konumlandırıldıysa, orada arama
if !evacuated(oldb) {
b = oldb
}
}Elemana erişirken, şu anda genişleme durumundaysa, önce eski bucket'ta aramayı deneyin. Eski bucket yeniden konumlandırıldıysa, eski bucket'ta aramayın. Yeniden konumlandırmaya geri dönün, hedef belirlendi. Ardından verileri yeni bucket'a kopyalayın, ardından evacDst struct'ının bir sonraki hedefe işaret etmesini sağlayın:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Bu mevcut bucket tamamen yeniden konumlandırılana kadar devam eder. Ardından Go tüm eski bucket anahtar-değer veri belleğini temizler, sadece hash bucket tophash dizisini bırakır (tophash dizisi daha sonra yeniden konumlandırma durumunu yargılamak için gerektiğinden bırakılır). Eski bucket'taki taşma bucket belleği artık referans verilmez ve GC tarafından geri dönüştürülür. hmap'in yeniden konumlandırma ilerlemesini kaydetmek için bir nevacuate alanı vardır. Eski bir hash bucket'ı yeniden konumlandırdıktan sonra, bir artar. Değeri eski bucket sayısına eşit olduğunda, tüm map genişlemesinin tamamlandığı anlamına gelir. Ardından, runtime.advanceEvacuationMark fonksiyonu genişleme sonlandırma işlemlerini yapar:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Yeniden konumlandırılan miktarı sayar ve eski bucket sayısına eşit olup olmadığını onaylar. Eşitse, eski bucket'lara ve eski taşma bucket'larına tüm referansları temizle. Böylece genişleme tamamlanır.
growWork fonksiyonunda, evacuate fonksiyonu toplamda iki kez çağrılır. İlk seferinde erişilen bucket'ın eski bucket'ını yeniden konumlandırır. İkinci seferinde h.nevacuate tarafından işaret edilen eski bucket'ı yeniden konumlandırır. Toplamda iki bucket yeniden konumlandırılır, yani kademeli yeniden konumlandırma sırasında, her seferinde iki bucket yeniden konumlandırılır.
Eşit Boyutlu Genişleme
Daha önce belirtildiği gibi, eşit boyutlu genişleme taşma bucket sayısı çok fazla olduğunda tetiklenir. Map'in önce çok sayıda eleman eklediğini, ardından çok sayıda eleman sildiğini varsayalım. Çok sayıda bucket boş olabilir, bazı bucket'ların çok fazla elemanı olabilir, veri dağılımı çok eşitsizdir ve oldukça fazla taşma bucket'ı boştur, considerable bellek kaplar. Bu tür sorunları çözmek için, eşit kapasiteli yeni bir map oluşturmak, hash bucket'ları yeniden ayırmak gerekir. Bu sürece eşit boyutlu genişleme denir. Yani aslında bir genişleme işlemi değil, tüm elemanları yeniden dağıtarak veri dağılımını daha eşit hale getirmektir. Eşit boyutlu genişleme mantığı artımlı genişleme işlemine birleştirilmiştir, yeni ve eski map kapasiteleri tamamen eşittir.
hashGrow fonksiyonunda, yük faktörü eşiği aşmadıysa, eşit boyutlu genişleme yapılır. Go h.flags durumunu sameSizeGrow olarak günceller, h.B bir artmayacaktır, bu nedenle newly oluşturulan hash bucket kapasitesi değişmeyecektir:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)evacuate fonksiyonunda, başlangıçta eavcDst struct'ı oluştururken, eşit boyutlu genişleme varsa, sadece yeni bucket'a işaret eden bir struct oluşturulur:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Ve eleman yeniden konumlandırma sırasında, eşit boyutlu genişleme hash değerini yeniden hesaplamaz, üst/alt yarısı seçimi yoktur:
if !h.sameSizeGrow() {
// Hash değerini yeniden hesapla
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 != k2 özel durumunu işle
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Bunlar dışında, diğer mantık artımlı genişleme ile tamamen tutarlıdır. Eşit boyutlu genişleme ve hash bucket yeniden tahsisinden sonra, taşma bucket sayısı azalır. Eski taşma bucket'ların tümü GC tarafından geri dönüştürülür.