map
В отличие от других языков, в Go поддержка отображения предоставляется ключевым словом map, а не через стандартную библиотеку. Отображение — структура данных с широким использованием, имеющая множество реализаций. Наиболее распространённые — красно-чёрное дерево и хэш-таблица. Go использует реализацию на основе хэш-таблицы.
TIP
Реализация map включает множество операций перемещения указателей, поэтому для чтения этой статьи требуются знания из стандартной библиотеки unsafe.
Внутренняя структура
Структура runtime.hmap представляет map в Go. Как и срез, внутренняя реализация map — это структура.
// Заголовок для Go map.
type hmap struct {
// Примечание: формат hmap также закодирован в cmd/compile/internal/reflectdata/reflect.go.
// Убедитесь, что это синхронизировано с определением компилятора.
count int // # живых ячеек == размер map. Должно быть первым (используется встроенной функцией len())
flags uint8
B uint8 // log_2 количества корзин (может содержать до loadFactor * 2^B элементов)
noverflow uint16 // приблизительное количество корзин переполнения; см. incrnoverflow для деталей
hash0 uint32 // семя хэша
buckets unsafe.Pointer // массив из 2^B корзин. может быть nil, если count==0.
oldbuckets unsafe.Pointer // предыдущий массив корзин половинного размера, не-nil только при расширении
nevacuate uintptr // счётчик прогресса эвакуации (корзины меньше этого были эвакуированы)
extra *mapextra // дополнительные поля
}Английские комментарии объясняют довольно ясно. Ниже приведены простые объяснения важных полей:
count— количество элементов в hmap, результат эквивалентенlen(map).flags— флаги hmap, указывающие состояние hmap, возможны следующие значения:goconst ( iterator = 1 // итератор использует корзину oldIterator = 2 // итератор использует старую корзину hashWriting = 4 // одна горутина записывает в hmap sameSizeGrow = 8 // расширение с сохранением размера )B— количество хэш-корзин в hmap равно1 << B.noverflow— приблизительное количество корзин переполнения в hmap.hash0— семя хэша, указывается при создании hmap, используется для вычисления хэш-значения.buckets— указатель на массив хэш-корзин.oldbuckets— указатель на массив корзин hmap до расширения.extra— хранит корзины переполнения hmap. Корзины переполнения создаются, когда текущая корзина заполнена, для хранения элементов.
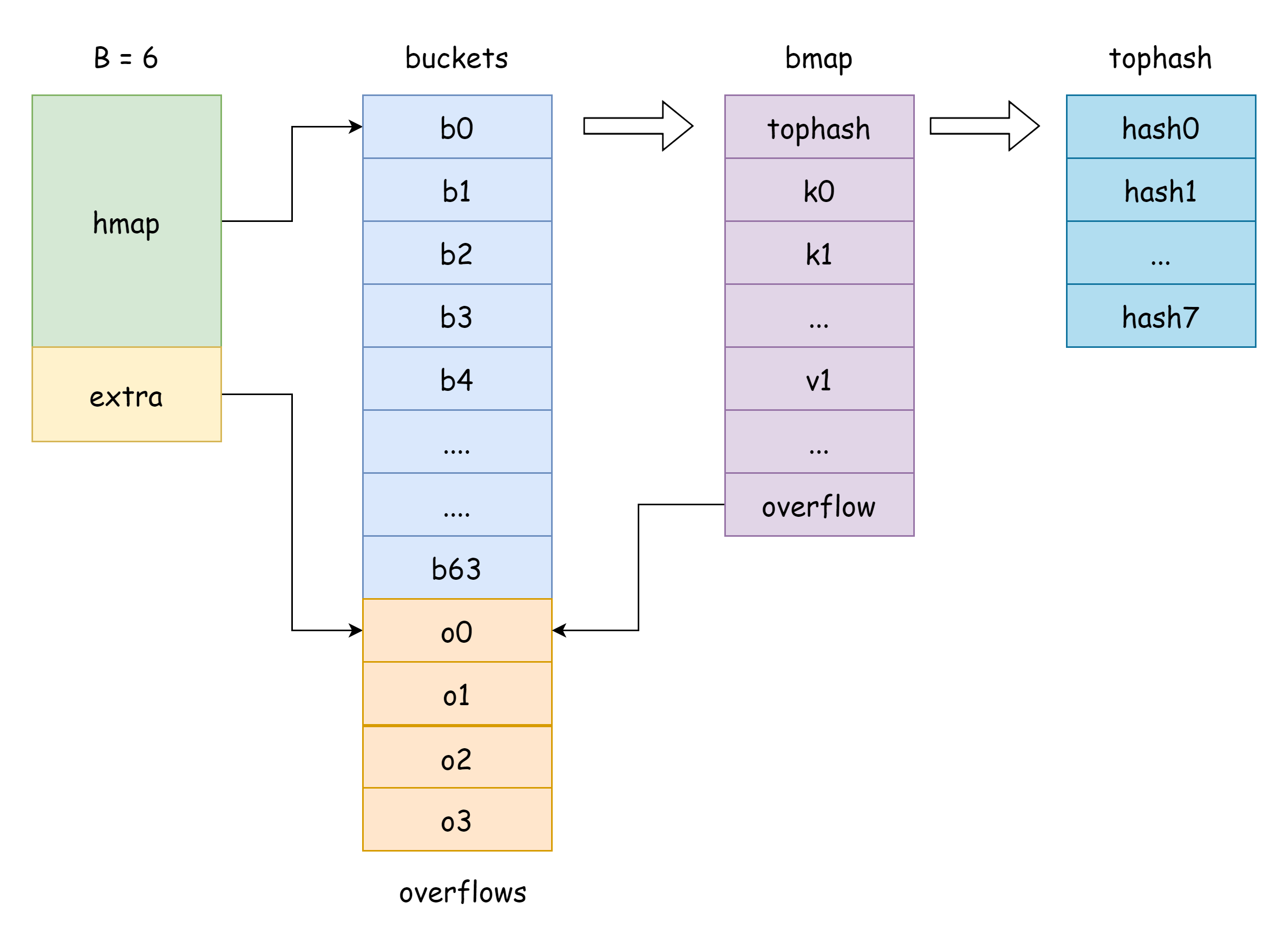
Поле buckets в hmap — указатель на срез корзин, соответствующая структура в Go — runtime.bmap:
// Корзина для Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Видно, что она содержит только поле tophash, которое хранит верхние 8 бит каждого ключа. Но на самом деле полей в bmap больше, поскольку map может хранить пары ключ-значение различных типов, поэтому во время компиляции необходимо выводить занимаемое пространство памяти на основе типа. Функция MapBucketType в cmd/compile/internal/reflectdata/reflect.go конструирует bmap во время компиляции, выполняя серию проверок, например, является ли тип ключа comparable.
// MapBucketType создаёт тип корзины map с учётом типа map.
func MapBucketType(t *types.Type) *types.TypeФактическая структура bmap следующая, но эти поля невидимы для нас. Go на практике использует перемещение unsafe-указателей для доступа:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Объяснения некоторых полей:
tophash— хранит значение верхних 8 бит каждого ключа. Для элемента tophash возможны следующие специальные значения:goconst ( emptyRest = 0 // текущий элемент пуст, и после него нет доступных ключей emptyOne = 1 // текущий элемент пуст, но после него есть доступные ключи evacuatedX = 2 // появляется при расширении, только в oldbuckets, означает, что элемент перемещён в верхнюю половину нового массива корзин evacuatedY = 3 // появляется при расширении, только в oldbuckets, означает, что элемент перемещён в нижнюю половину нового массива корзин evacuatedEmpty = 4 // появляется при расширении, элемент сам пуст, помечен при перемещении minTopHash = 5 // минимальное значение tophash для нормального ключа )Если значение
tophash[i]большеminTopHash, это означает, что по соответствующему индексу существует нормальный ключ.keys— массив ключей указанного типа.elems— массив значений указанного типа.overflow— указатель на корзину переполнения.
Поскольку ключи нельзя напрямую访问 через поля структуры, Go заранее объявляет константу dataoffset, представляющую смещение памяти данных в bmap:
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)На самом деле ключи хранятся в непрерывной области памяти, примерно так:
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Это сделано для избежания потерь памяти из-за выравнивания. Для bmap после перемещения указателя на dataoffset, перемещение на i*sizeof(keyType) даёт адрес i-го ключа:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Аналогично для получения адреса i-го значения:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))Поле buckets в hmap указывает на адрес первой хэш-корзины. Для получения адреса i-й хэш-корзины смещение равно i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))В дальнейшем эти операции будут встречаться очень часто.
Хэширование
Конфликты
В hmap есть поле extra,专门用于存放溢出桶的信息,它指向存放溢出桶的切片,其结构如下:
type mapextra struct {
// Срез указателей на корзины переполнения
overflow *[]*bmap
// Срез указателей на старые корзины переполнения до расширения
oldoverflow *[]*bmap
// Указатель на следующую свободную корзину переполнения
nextOverflow *bmap
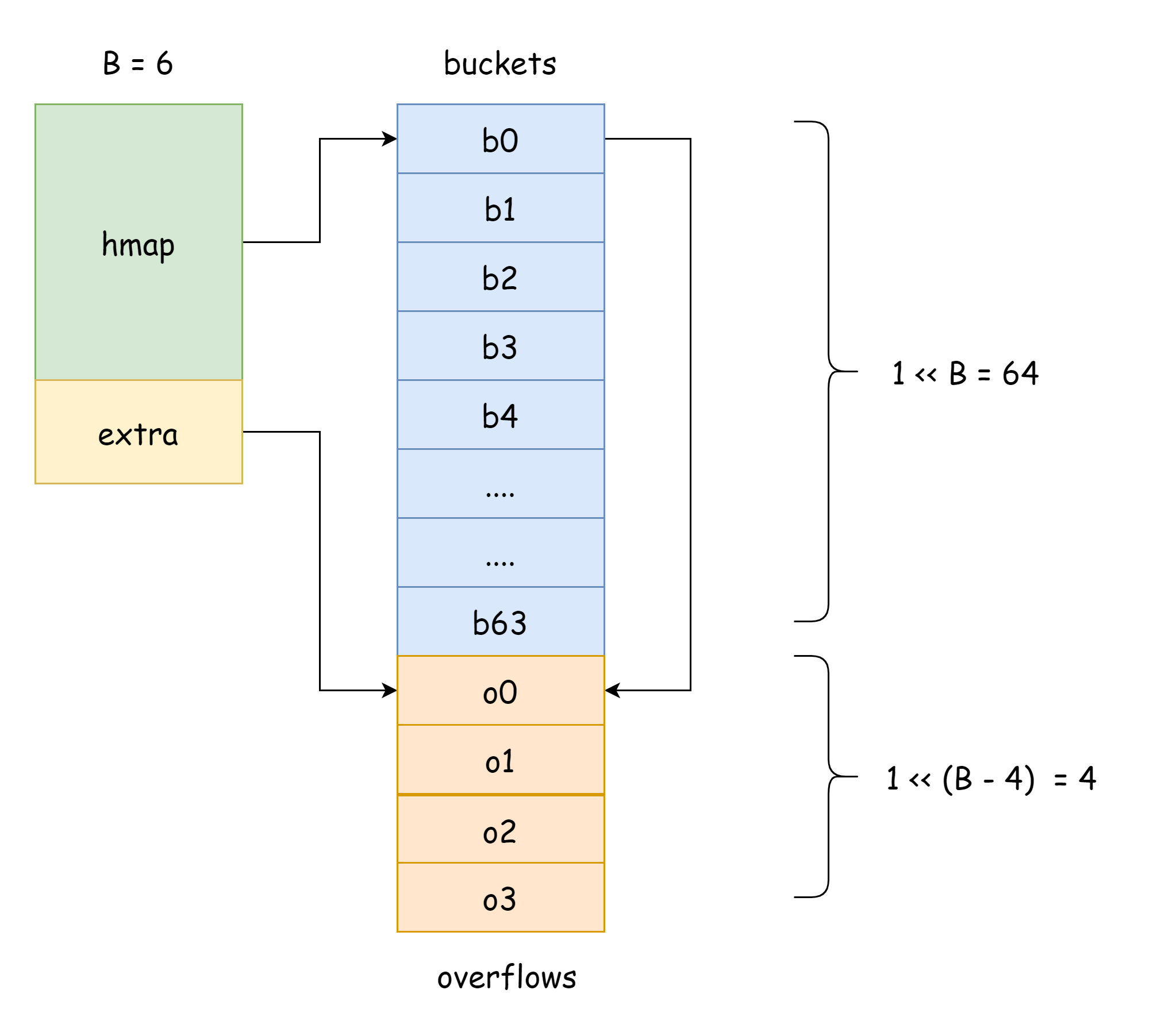
}
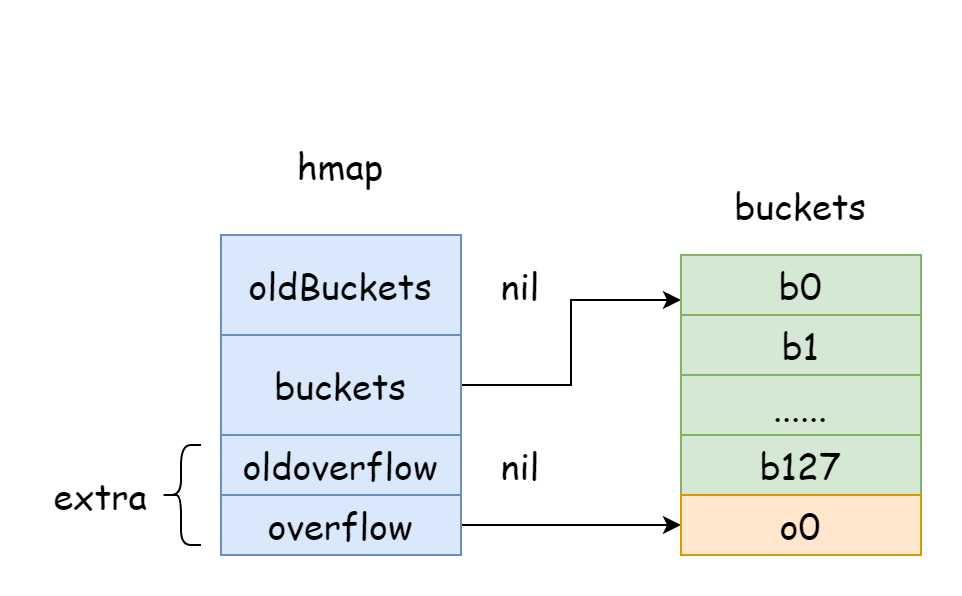
TIP
На рисунке синяя часть — массив хэш-корзин, оранжевая — массив корзин переполнения. Корзины переполнения далее统称为溢出桶。
Рисунок хорошо демонстрирует общую структуру hmap: buckets указывает на массив хэш-корзин, extra — на массив корзин переполнения. Корзина bucket0 указывает на корзину переполнения overflow0. Два разных типа корзин хранятся в двух срезах, память обоих типов непрерывна. Когда два ключа после хэширования распределяются в одну корзину bucket, это называется хэш-конфликтом. Способ решения хэш-конфликтов в Go — метод цепочек. Когда количество конфликтующих ключей превышает вместимость корзины (обычно 8, значение зависит от internal/abi.MapBucketCount), создаётся новая корзина для хранения этих ключей. Эта новая корзина называется корзиной переполнения (overflow bucket), что означает, что оригинальная корзина заполнена, и элементы переполняются в новую корзину. После создания хэш-корзина имеет указатель, указывающий на новую корзину переполнения. Указатели этих корзин соединяются, образуя связный список bmap.
Для метода цепочек используется коэффициент загрузки для измерения конфликтности хэш-таблицы. Формула расчёта:
loadfactor := len(elems) / len(buckets)Чем больше коэффициент загрузки, тем больше хэш-конфликтов, то есть больше корзин переполнения. При чтении/записи хэш-таблицы необходимо перебирать больше корзин переполнения для нахождения指定位置, поэтому производительность ниже. Для улучшения ситуации следует увеличить количество корзин buckets, то есть расширить. Для hmap есть два условия触发 расширения:
- Коэффициент загрузки превышает порог
bucketCnt*13/16, значение как минимум 6.5. - Слишком большое количество корзин переполнения.
Чем меньше коэффициент загрузки, тем ниже эффективность использования памяти hmap, тем больше занимаемой памяти. Функция Go для вычисления коэффициента загрузки — runtime.overLoadFactor:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Где loadFactorNum и loadFactorDen — константы, bucketshift вычисляет 1 << B. Известно:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenУпрощая, получаем:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Где (bucketCnt * 13 / 16) равно 6.5, 1 << B — количество хэш-корзин. Функция вычисляет, превышает ли отношение количества элементов к количеству корзин коэффициент загрузки 6.5.
Вычисление
Функция вычисления хэша в Go находится в файле runtime/alg.go, функция f32hash:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // любой вид NaN
default:
return memhash(p, h, 4)
}
}Видно, что метод хэширования map основан не на типе, а на памяти, в конечном итоге вызывается функция memhash, реализованная на ассемблере, логика находится в runtime/asm*.s. Хэш-значение на основе памяти не должно сохраняться持久化, так как оно используется только во время выполнения, невозможно гарантировать идентичное распределение памяти при каждом запуске.
В этом файле также есть функция typehash, вычисляющая хэш для различных типов, но map не использует эту функцию для хэширования:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrЭта реализация медленнее, но более универсальна, в основном используется для рефлексии и генерации функций во время компиляции, например:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Создание
Инициализация map имеет два способа, что уже описано во введении в язык: создание через ключевое слово map или функцию make. Независимо от способа инициализации, в конечном итоге map создаётся функцией runtime.makemap. Сигнатура функции:
func makemap(t *maptype, hint int, h *hmap) *hmapПараметры:
t— тип map, разные типы требуют разной памяти.hint— второй параметр функцииmake, ожидаемая ёмкость map.h— указатель наhmap, может бытьnil.
Возвращаемое значение — инициализированный указатель hmap. Функция выполняет несколько основных задач при инициализации. Сначала вычисляется, превысит ли ожидаемая память максимальную:
// Умножение ожидаемой ёмкости на размер типа корзины
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Переполнение или превышение максимальной памяти
if overflow || mem > maxAlloc {
hint = 0
}Как упоминалось ранее, hmap состоит из корзин. При минимальной эффективности использования памяти одна корзина содержит один элемент, занимая максимум памяти. Поэтому ожидаемое максимальное использование памяти — количество элементов, умноженное на размер памяти соответствующего типа. Если результат вычисления переполняется или превышает максимальную память для выделения, hint устанавливается в 0, так как далее hint используется для вычисления ёмкости массива корзин.
Второй шаг — инициализация hmap и вычисление случайного хэш-семени:
// Инициализация
if h == nil {
h = new(hmap)
}
// Получение случайного хэш-семени
h.hash0 = fastrand()Затем по значению hint вычисляется ёмкость хэш-корзин:
B := uint8(0)
// Цикл пока hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Присваивание hmap
h.B = BПутём постоянного цикла находится первое значение B, удовлетворяющее (hint / 1 << B) < 6.5, присваивается hmap. После определения ёмкости хэш-корзин выделяется память:
if h.B != 0 {
var nextOverflow *bmap
// Выделенные хэш-корзины и предварительно выделенные свободные корзины переполнения
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Если предварительно выделены свободные корзины переполнения, указываем на них
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}Функция makeBucketArray выделяет память соответствующего размера для хэш-корзин по значению B и предварительно выделяет свободные корзины переполнения. Когда B меньше 4, корзины переполнения не создаются. Если больше 4, создаётся 2^B-4 корзин переполнения. Соответствующий код в функции runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// Меньше 4 — не создаются корзины переполнения
if b >= 4 {
// Ожидаемое количество корзин плюс 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Память, необходимая для корзин переполнения
sz := t.Bucket.Size_ * nbuckets
// Округление памяти вверх
up := roundupsize(sz)
if up != sz {
// Если не равно, пересчитываем с up
nbuckets = up / t.Bucket.Size_
}
}base — ожидаемое количество корзин, nbuckets — фактическое количество корзин, включает количество корзин переполнения.
if base != nbuckets {
// Первая доступная корзина переполнения
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Для уменьшения затрат на отслеживание корзин переполнения, указатель переполнения последней корзины указывает на голову хэш-корзин
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// Последняя корзина переполнения указывает на хэш-корзину
last.setoverflow(t, (*bmap)(buckets))
}Когда они не равны,这意味着 выделены дополнительные корзины переполнения. Указатель nextoverflow указывает на первую доступную корзину переполнения. Таким образом, хэш-корзины и корзины переполнения фактически находятся в одной непрерывной области памяти. Поэтому на рисунке массив хэш-корзин и массив корзин переполнения соседние.
Доступ
Во введении по синтаксису упоминалось три способа доступа к map:
# Прямой доступ к значению
val := dict[key]
# Доступ к значению и проверка существования ключа
val, exist := dict[key]
# Перебор map
for key, val := range dict{
}Для этих трёх способов используются разные функции. Перебор map через for range наиболее сложен.
Ключ-значение
Для первых двух способов соответствуют две функции: runtime.mapaccess1 и runtime.mapaccess2. Сигнатуры функций:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Где key — указатель на ключ доступа к map, возвращается также указатель. При доступе сначала вычисляется хэш-значение key, определяется корзина key. Соответствующий код:
// Обработка граничных случаев
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // см. issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Предотвращение конкурентного чтения/записи
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Вычисление хэш-значения с помощью hasher指定类型
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Перемещение указателя для определения корзины key
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))В начале доступа обрабатываются граничные случаи и предотвращается конкурентное чтение/запись map. Когда map находится в состоянии конкурентного чтения/записи, происходит panic. Затем вычисляется хэш-значение. Функция bucketMask вычисляет (1 << B) - 1, hash & m равно hash & (1 << B) - 1, это операция взятия остатка в двоичной системе, эквивалентна hash % (1 << B). Преимущество побитовых операций — скорость. Последние три строки кода вычисляют остаток от деления хэш-значения key на количество корзин в текущем map, получая номер хэш-корзины. Затем по номеру перемещается указатель для получения указателя на корзину key.
После определения корзины key можно приступать к поиску. Соответствующий код:
// Получение верхних 8 бит хэш-значения
top := tophash(hash)
bucketloop:
// Перебор связного списка bmap
for ; b != nil; b = b.overflow(t) {
// Элементы в bmap
for i := uintptr(0); i < bucketCnt; i++ {
// Сравнение вычисленного top с элементами tophash
if b.tophash[i] != top {
// Последующие пустые, больше нет.
if b.tophash[i] == emptyRest {
break bucketloop
}
// Если не равно, продолжаем перебор корзин переполнения
continue
}
// Перемещение указателя по i для получения ключа соответствующего индекса
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Обработка указателя
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Сравнение ключей
if t.Key.Equal(key, k) {
// Если равны, перемещаем указатель для возврата элемента соответствующего индекса k
// Из этой строки видно, что адреса памяти ключ-значение непрерывны
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Не найдено, возвращаем нулевое значение.
return unsafe.Pointer(&zeroVal[0])При определении корзины используется взятие остатка, поэтому корзина key зависит от младших бит хэш-значения. Сколько именно младших бит зависит от размера B. После нахождения хэш-корзины tophash хранит верхние 8 бит хэш-значения. Поскольку младшие биты после взятия остатка одинаковы, не нужно сравнивать ключи по одному, достаточно сравнить верхние 8 бит хэш-значения. По вычисленному хэш-значению получаем его верхние 8 бит, сравниваем с элементами массива tophash в bmap. Если верхние 8 бит равны, сравниваем ключи. Если ключи также равны, элемент найден. Если не равны, продолжаем перебор массива tophash. Если не найдено, продолжаем перебор связного списка корзин переполнения bmap, пока tophash[i] bmap не станет emptyRest, затем выходим из цикла, возвращаем нулевое значение соответствующего типа.
Функция mapaccess2 полностью идентична логике mapaccess1, только добавлено булево возвращаемое значение для указания существования элемента.
Перебор
Синтаксис перебора map:
for key, val := range dict {
// do somthing...
}При фактическом переборе Go использует структуру hiter для хранения информации о переборе. hiter — сокращение от hmap iterator,意为哈希表迭代器:
// Структура итерации хэша.
// Если вы изменяете hiter, также измените cmd/compile/internal/reflectdata/reflect.go
// и reflect/value.go, чтобы соответствовать макету этой структуры.
type hiter struct {
key unsafe.Pointer // Должно быть на первой позиции. Запись nil указывает на конец итерации (см. cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Должно быть на второй позиции (см. cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // указатель на корзину во время инициализации итератора
bptr *bmap // текущая корзина
overflow *[]*bmap // хранит корзины переполнения hmap.buckets живыми
oldoverflow *[]*bmap // хранит корзины переполнения hmap.oldbuckets живыми
startBucket uintptr // корзина, с которой началась итерация
offset uint8 // смещение внутри корзины, с которого начинается итерация (должно быть достаточно большим для bucketCnt-1)
wrapped bool // уже выполнен переход от конца массива корзин к началу
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Краткие объяснения полей:
key,elem— ключ-значение, полученные при перебореfor rangebuckets— указывается при инициализации итератора, указывает на голову хэш-корзинbptr— текущий перебираемый bmapstartBucket— номер начальной корзины при итерацииoffset— смещение внутри корзины, диапазон[0, bucketCnt-1]B— значение B hmapi— индекс элемента внутри корзиныwrapped— выполнен ли переход от конца массива хэш-корзин к началу
Перед перебором Go инициализирует итератор функцией runtime.mapiterinit, затем перебирает map функцией runtime.mapinternext. Обе функции используют структуру hiter. Сигнатуры функций:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Для инициализации итератора сначала получается текущий снимок map:
it.t = t
it.h = h
// Запись снимка текущего состояния hmap, нужно сохранить только значение B.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}При последующей итерации фактически перебирается снимок map, а не сам map. Поэтому элементы и корзины, добавленные во время перебора, не будут перебраны. Одновременный конкурентный перебор и запись могут вызвать fatal:
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Затем определяются два начальных位置 перебора: первое —起始位置 корзины, второе —起始位置 внутри корзины. Оба выбираются случайно:
// r — случайное число
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) получаем起始位置 корзины
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 получаем起始位置 элемента внутри корзины
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Запись текущего номера перебираемой корзины
it.bucket = it.startBucketПолучается случайное число через fastrand() или fastrand64(), два взятия остатка дают起始位置 корзины и起始位置 внутри корзины.
TIP
Map не допускает одновременного конкурентного чтения/записи, но допускает одновременный конкурентный перебор.
Далее начинается собственно итерация map, перебор корзин и стратегия выхода. Соответствующий код:
// hmap
h := it.h
// maptype
t := it.t
// Позиция перебираемой корзины
bucket := it.bucket
// Перебираемый bmap
b := it.bptr
// Индекс i внутри корзины
i := it.i
next:
if b == nil {
// Если текущая позиция корзины равна起始位置, значит выполнен круг,后续已 перебрано
// Перебор завершён, можно выйти
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Смещение индекса корзины вперёд
bucket++
// bucket == 1 << B, достигнут конец массива хэш-корзин
if bucket == bucketShift(it.B) {
// Начать сначала
bucket = 0
it.wrapped = true
}
i = 0
}起始位置 хэш-корзин выбирается случайно. При переборе происходит итерация от起始位置 к концу среза корзин по одному. При достижении 1 << B начинается сначала. При возвращении к起始位置 означает завершение перебора, затем выход. Приведённый код описывает перебор корзин в map. Ниже описывается перебор внутри корзины:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Если текущий элемент пуст, пропускаем
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Перемещение указателя для получения ключа
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Перемещение указателя для получения значения
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Обработка случая расширения с сохранением размера. После перемещения ключа в другое位置 нужно заново найти ключ.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Если не найдено, ищем в корзине переполнения
b = b.overflow(t)
i = 0
goto nextTIP
В условии расширения выше есть выражение, которое может вызвать недоумение:
t.Key.Equal(k, k)Проверка равенства k самому себе нужна для фильтрации случая ключа Nan. Если ключ элемента — Nan, то正常访问 этого элемента невозможен. Ни перебор, ни прямой доступ, ни удаление не могут正常进行, поскольку Nan != Nan всегда истинно, и этот ключ никогда не будет найден.
Сначала по значениям i и offset через взятие остатка получаем индекс внутри корзины для перебора. Перемещением указателя получаем ключ-значение. Поскольку во время перебора map другие операции записи могут触发 расширение map, фактический ключ может быть не на оригинальном位置. В этом случае нужно использовать функцию mapaccessK для повторного получения фактического ключа. Сигнатура функции:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Её функция完全 идентична mapaccess1, отличие в том, что mapaccessK возвращает одновременно ключ и значение. После получения ключа присваиваем его key, elem итератора, затем обновляем индекс итератора. Так завершается одна итерация, код执行 возвращается в блок кода for range. Если в корзине не найдено, ищем в корзине переполнения, повторяя шаги выше. После завершения перебора связного списка корзин переполнения продолжаем итерацию следующей хэш-корзины.
Изменение
Синтаксис изменения map:
dict[key] = valВ Go операция изменения map выполняется функцией runtime.mapassign. Сигнатура функции:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerЛогика процесса доступа идентична mapaccess1, но когда ключ не существует, для него выделяется位置. Если существует — обновляется. В конечном итоге возвращается указатель на элемент. В начале нужно выполнить подготовительные работы. Соответствующий код:
// Запись в nil map не разрешена
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Запрет одновременной конкурентной записи
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Вычисление хэш-значения key
hash := t.Hasher(key, uintptr(h.hash0))
// Изменение состояния hmap
h.flags ^= hashWriting
// Инициализация хэш-корзин
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Приведённый код выполняет следующие действия:
- Проверка состояния hmap
- Вычисление хэш-значения key
- Проверка необходимости инициализации хэш-корзин
Затем через взятие остатка хэш-значения определяется位置 хэш-корзины и tophash key. Соответствующий код:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Перемещение указателя для получения bmap指定位置
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Вычисление tophash
top := tophash(hash)Теперь определена位置 корзины, bmap, tophash, можно приступать к поиску элемента. Соответствующий код:
// tophash для вставки
var inserti *uint8
// Указатель на ключ для вставки
var insertk unsafe.Pointer
// Указатель на значение для вставки
var elem unsafe.Pointer
bucketloop:
for {
// Перебор массива tophash внутри корзины
for i := uintptr(0); i < bucketCnt; i++ {
// tophash не равен
if b.tophash[i] != top {
// Если текущий индекс корзины пуст и ещё нет вставленного элемента, выбираем это位置 для вставки
if isEmpty(b.tophash[i]) && inserti == nil {
// Найдено подходящее место для key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Если перебор завершён, выходим из цикла
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// Если tophash равны, значит key возможно уже существует
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Проверка равенства key
if !t.Key.Equal(key, k) {
continue
}
// Если нужно обновить key, копируем память key в k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Получен указатель на элемент
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Обновление завершено, возвращаем указатель на элемент
goto done
}
// Если дошли сюда, значит key не найден. Перебираем связный список корзин переполнения, продолжаем поиск
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Если дошли сюда, значит key не найден в map. Но возможно найдено подходящее место для key, а возможно и нет.
// Не найдено подходящего места для key
if inserti == nil {
// Значит текущая хэш-корзина и её корзина переполнения заполнены. Выделяем новую корзину переполнения
newb := h.newoverflow(t, b)
// Выделяем место для key в корзине переполнения
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Если хранится указатель на key
if t.IndirectKey() {
// Выделение новой памяти, возвращается unsafe-указатель
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Присваивание insertk для удобства копирования памяти key
insertk = kmem
}
// Если хранится указатель на элемент
if t.IndirectElem() {
// Выделение памяти
vmem := newobject(t.Elem)
// Указатель указывает на vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Копирование памяти key в位置 insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// Увеличение количества на один
h.count++
done:
// Если дошли сюда, значит процесс изменения завершён
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Возврат указателя на элемент
return elemВ приведённом большом блоке кода сначала进入 for-цикл для попытки поиска в хэш-корзине и корзине переполнения. Логика поиска完全 идентична mapaccess. Возможны три случая:
- Первый: в map найден существующий key, переходим к блоку кода
done, возвращаем указатель на элемент. - Второй: в map найдено место для key, копируем key в指定位置, возвращаем указатель на элемент.
- Третий: все корзины перебраны, в map не найдено места для key. Создаётся новая корзина переполнения, key распределяется в корзину. Затем key копируется в指定位置, возвращаем указатель на элемент.
После получения указателя на элемент можно присваивать значение. Но эта операция выполняется не функцией mapassign, она только возвращает указатель на элемент. Операция присваивания вставляется компилятором во время компиляции, не видна в коде, но видна в скомпилированном коде. Предположим следующий код:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Получаем ассемблерный код командой:
go tool compile -S -N -l main.goКлючевые места:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Видно, что вызывается runtime.mapassign_faststr, логика完全 идентична mapassign. LEAQ go:string."world"(SB), CX сохраняет адрес строки в CX, MOVQ CX, (AX) сохраняет его в AX, так завершается присваивание элемента.
Удаление
В Go для удаления элемента map можно использовать только встроенную функцию delete:
delete(dict, "abc")Внутри вызывается функция runtime.mapdelete. Сигнатура функции:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Она удаляет指定 key элемент из map, независимо от существования элемента в map, не реагирует никак. Логика подготовительной работы в начале функции аналогична:
- Проверка состояния hmap
- Вычисление хэш-значения key
- Определение хэш-корзины
- Вычисление tophash
Много повторяющегося контента, не будем подробно останавливаться. Здесь关注 только логика удаления. Соответствующий код:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Не найдено, выходим из цикла
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Перемещение указателя для нахождения位置 key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Удаление key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Перемещение указателя для нахождения位置 элемента
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Удаление элемента
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Уменьшение количества на один
h.count--
// Сброс хэш-семени для уменьшения вероятности конфликтов
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Из приведённого кода видно, что логика поиска почти完全 идентична предыдущим операциям. Находим элемент, затем удаляем, количество записей в hmap уменьшается на один. При уменьшении до 0 сбрасывается хэш-семя.
Другой важный момент: после удаления элемента нужно изменить состояние tophash текущего индекса. Соответствующий код:
// Помечаем текущий tophash как пустой
b.tophash[i] = emptyOne
// Если в конце tophash
if i == bucketCnt-1 {
// Если корзина переполнения не пуста и содержит элементы, значит текущий элемент не последний
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Соседний элемент не пуст
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Если элемент действительно последний, нужно исправить значения массива tophash部分 корзин в связном списке корзин. Иначе при последующем переборе невозможно будет выйти в правильном位置. При создании корзин переполнения в map упоминалось, что Go для уменьшения затрат на отслеживание корзин переполнения, указатель overflow последней корзины переполнения указывает на головную хэш-корзину. Фактически это односторонний циклический связный список, «голова» списка — хэш-корзина. Здесь b — bmap после поиска,很可能 одна из корзин в середине списка. Обратный перебор циклического списка для нахождения последнего существующего элемента. Несмотря на то, что код написан как прямой перебор, поскольку список циклический, он постоянно перебирает вперёд до предыдущей корзины переполнения перед текущей. С результата — действительно обратный. Затем обратный перебор массива tophash внутри корзины, обновление элементов со статусом emptyOne на emptyRest, пока не найден последний существующий элемент. Для избежания бесконечного陷入 в цикле, при возвращении к начальной корзине bOrig, означает, что в списке больше нет доступных элементов, можно выйти из цикла.
// Если дошли сюда, значит после текущего элемента нет элементов
// Постоянный обратный перебор связного списка bmap, обратный перебор tophash внутри корзины
// Обновление элементов со статусом emptyOne на emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Нахождение предыдущего bmap в списке
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Очистка
В версии go1.21 добавлена встроенная функция clear для очистки всех элементов map. Синтаксис:
clear(dict)Внутри вызывается функция runtime.mapclear, отвечающая за удаление всех элементов map. Сигнатура функции:
func mapclear(t *maptype, h *hmap)Логика функции не сложна. Сначала весь map помечается как пустой. Соответствующий код:
// Перебор каждой корзины и корзины переполнения, установка всех элементов tophash в emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Приведённый код перебирает каждую корзину, устанавливает все элементы массива tophash в emptyRest, помечая map как пустой. Это阻止ляет итератору继续 итерацию. Затем очищается map. Соответствующий код:
// Сброс хэш-семени
h.hash0 = fastrand()
// Сброс структуры extra
if h.extra != nil {
*h.extra = mapextra{}
}
// Эта операция очищает память оригинальных buckets и выделяет новые корзины
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Выделение новых свободных корзин переполнения
h.extra.nextOverflow = nextOverflow
}Через makeBucketArray очищается память предыдущих корзин, затем выделяется новая. Так завершается очистка корзин. Помимо этого есть некоторые детали, например, установка count в 0 и другие операции, не будем подробно останавливаться.
Расширение
Во всех предыдущих операциях для большего внимания к самой логике было屏蔽ровано много контента, связанного с расширением, что упрощало понимание. Логика расширения на самом деле довольно сложна, размещена в конце, чтобы не создавать помех. Теперь рассмотрим, как Go выполняет расширение map. Ранее упоминалось два условия触发 расширения:
- Коэффициент загрузки превышает 6.5
- Слишком большое количество корзин переполнения
Функция для判断 превышения порога коэффициента загрузки — runtime.overLoadFactor, описана в части о хэш-конфликтах. Функция для判断 чрезмерного количества корзин переполнения — runtime.tooManyOverflowBuckets. Принцип работы прост:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Приведённый код можно упростить до следующего выражения, сразу понятного:
overflow >= 1 << (min(15,B) % 16)Здесь определение Go для «too many»: количество корзин переполнения примерно равно количеству хэш-корзин. Если порог низкий, выполняется лишняя работа. Если порог высокий, при расширении占用ляется много памяти. При изменении и удалении элементов возможно触发 расширения. Код判断 необходимости расширения:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Расширение таблицы делает всё недействительным, поэтому пробуем снова
}Видны три ограничения:
- В данный момент не должно быть расширения
- Коэффициент загрузки меньше 6.5
- Количество корзин переполнения не должно быть чрезмерным
Функция, отвечающая за расширение — runtime.hashGrow. Сигнатура функции:
func hashGrow(t *maptype, h *hmap)На самом деле расширение делится на виды. В зависимости от условий触发 разные типы расширения:
- Инкрементное расширение
- Расширение с сохранением размера
Инкрементное расширение
Когда коэффициент загрузки слишком велик, то есть количество элементов значительно превышает количество хэш-корзин, при серьёзных хэш-конфликтах образуется много связных списков корзин переполнения. Это приводит к снижению производительности чтения/записи map, поскольку для поиска элемента нужно перебирать больше корзин переполнения. Время перебора — O(n). Время поиска в хэш-таблице в основном зависит от времени вычисления хэш-значения и времени перебора. Когда время перебора значительно меньше времени вычисления хэша, сложность поиска можно считать O(1). Если хэш-конфликты часты,过多 key распределяются в одну хэш-корзину,过长 связный список корзин переполнения увеличивает время перебора, что увеличивает время поиска. Операции вставки/удаления/изменения требуют сначала поиска, что приводит к серьёзному снижению производительности всего map.
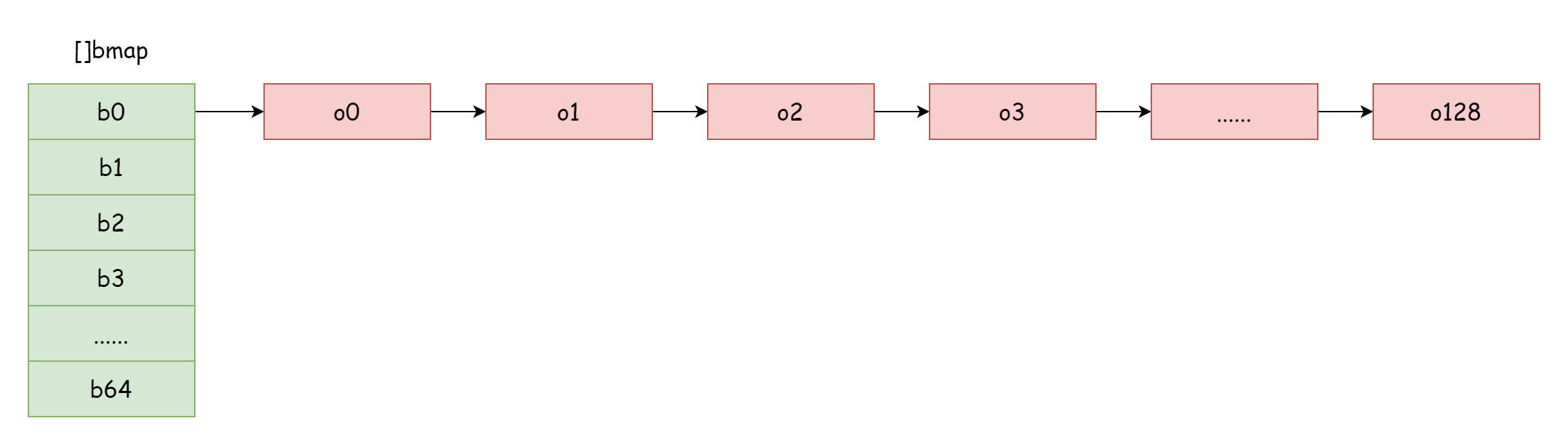
В такой крайней ситуации, как на рисунке, сложность поиска практически не отличается от O(n). Решение — добавление большего количества хэш-корзин, избежание образования过长 связных списков корзин переполнения. Этот метод называется инкрементным расширением.
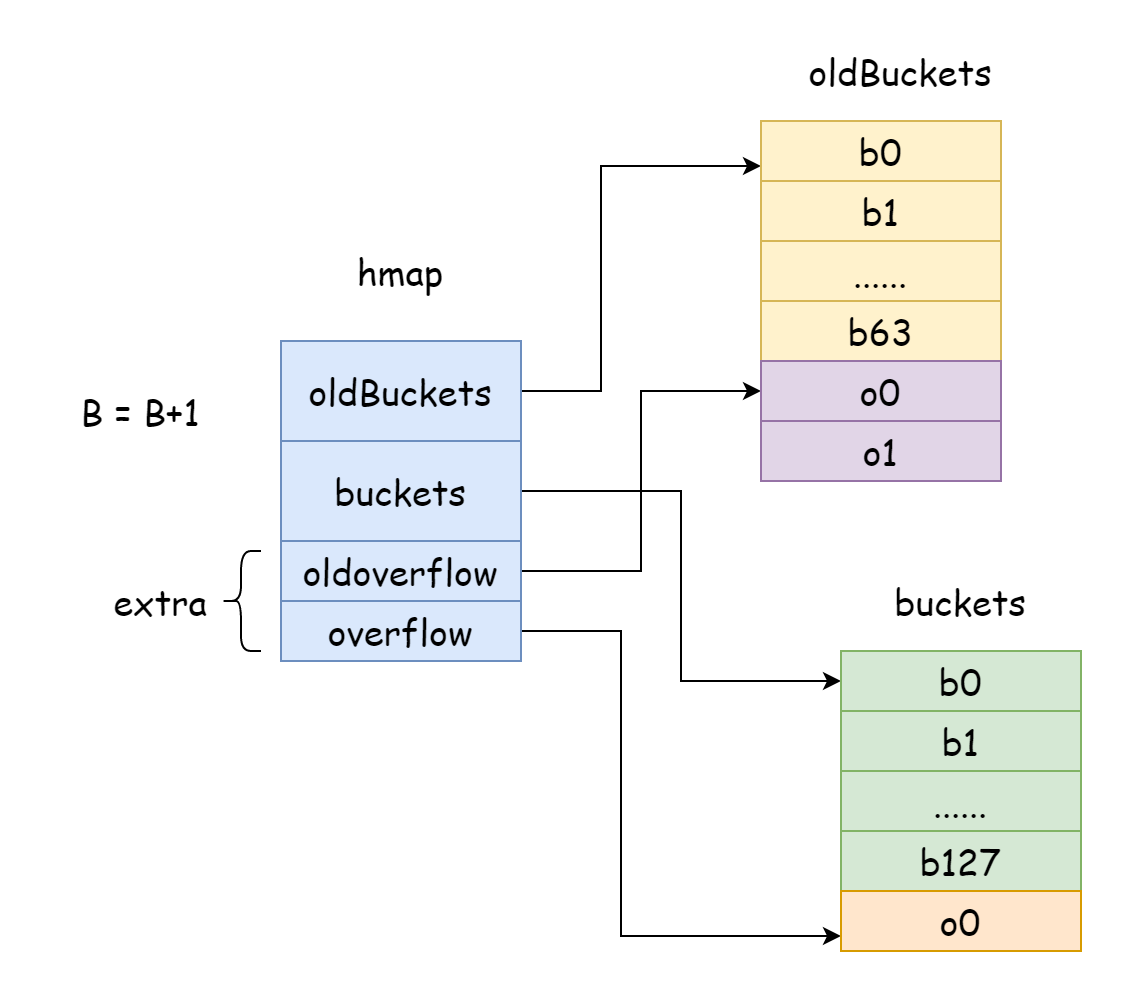
В Go при инкрементном расширении B увеличивается на один, то есть масштаб хэш-корзин每次 расширяется вдвое. После расширения старые данные нужно переместить в новый map. Если количество элементов в map исчисляется миллионами или даже сотнями миллионов,一次性全部 перемещение займёт много времени. Поэтому Go использует стратегию постепенного перемещения. Для этого oldBuckets в hamp указывает на оригинальный массив хэш-корзин, обозначая старые данные. Затем создаётся массив хэш-корзин большей ёмкости, buckets в hmap указывает на новый массив хэш-корзин. При каждом изменении и удалении элемента部分 элементов перемещается из старой корзины в новую. До завершения перемещения память старых корзин не освобождается.
func hashGrow(t *maptype, h *hmap) {
// Разница
bigger := uint8(1)
// Старые корзины
oldbuckets := h.buckets
// Новые хэш-корзины
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Корзины переполнения также нужно指定 старые и новые
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Приведённый код создаёт новые хэш-корзины вдвое большей ёмкости, затем指定 ссылки на старые и новые корзины хэша, а также старые и новые корзины переполнения. Фактическое перемещение выполняется не функцией hashGrow, она только指定 старые и новые корзины и обновляет некоторые состояния hmap. Эта работа выполняется функцией runtime.growWork. Сигнатура функции:
func growWork(t *maptype, h *hmap, bucket uintptr)Она вызывается в функциях mapassign и mapdelete в следующей форме,作用 — если当前 map находится в расширении, выполняется部分 перемещение.
if h.growing() {
growWork(t, h, bucket)
}При изменении и удалении нужно判断当前是否 в расширении. Это в основном выполняется методом hmap.growing. Содержимое простое —判断 oldbuckets не nil:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Рассмотрим, что делает функция growWork:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}Операция bucket&h.oldbucketmask() вычисляет位置 старой корзины,确保将要 перемещается当前 корзина старой корзины. Из функции видно, что фактическое перемещение выполняется функцией runtime.evacuate. Используется структура evaDst для обозначения назначения перемещения,主要作用 — итерация новых корзин во время перемещения. Структура:
type evacDst struct {
b *bmap // Новая корзина назначения перемещения
i int // Индекс внутри корзины
k unsafe.Pointer // Указатель на назначение нового ключа
e unsafe.Pointer // Указатель на назначение нового значения
}Перед началом перемещения Go выделяет две структуры evacDst: одна указывает на верхнюю половину новой хэш-корзины, другая — на нижнюю половину. Соответствующий код:
// Определение指定旧 корзины
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Длина旧 корзины = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Указывает на верхнюю половину новой корзины
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
//判断是否 расширение с сохранением размера
if !h.sameSizeGrow() {
y := &xy[1]
// Указывает на нижнюю половину новой корзины
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Назначение перемещения旧 корзины — две новые корзины. После перемещения部分 данных корзины будет в верхней половине, другая部分 — в нижней половине. Это сделано для более равномерного распределения данных после расширения. Чем равномернее распределение, тем лучше производительность поиска map. Как Go перемещает данные в две новые корзины, соответствует следующий код:
// Перебор связного списка корзин переполнения
for ; b != nil; b = b.overflow(t) {
// Получение первой пары ключ-значение каждой корзины
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Перебор каждой пары ключ-значение в корзине
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Если пусто, пропускаем
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Новая хэш-корзина не должна быть в состоянии перемещения
// Иначе что-то не так
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Эта переменная决定当前 пара ключ-значение перемещается в верхнюю или нижнюю половину
// Её значение может быть только 0 или 1
var useY uint8
if !h.sameSizeGrow() {
// Перевычисление хэш-значения
hash := t.Hasher(k2, uintptr(h.hash0))
// Обработка特殊 случая k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Проверка значения константы
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Обновление tophash旧 корзины,表示当前 элемент已被 перемещён
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
//指定 назначение перемещения
dst := &xy[useY] // назначение эвакуации
// Если ёмкость новой корзины недостаточна, создаём корзину переполнения
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// Копирование ключа
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// Копирование значения
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Перемещение указателя назначения новой корзины вперёд, подготовка к следующему ключу
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Из приведённого кода видно, что Go перебирает каждую корзину в связном списке旧 корзин, каждый элемент в корзине, перемещая данные в новую корзину. Решение, в какую половину (верхнюю или нижнюю) перемещаются данные, зависит от перевычисленного хэш-значения:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}После перемещения tophash текущего элемента устанавливается в evacuatedX или evacuated. Если во время расширения尝试 найти данные, по этому состоянию можно узнать, что данные已被 перемещены, и нужно искать соответствующие данные в новой корзине. Эта логика соответствует следующему коду в функции runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// Раньше было вдвое меньше корзин; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Если旧 корзина已被 перемещена, не ищем
if !evacuated(oldb) {
b = oldb
}
}При доступе к элементу, если当前 в состоянии расширения, сначала尝试 найти в旧 корзине. Если旧 корзина已被 перемещена, не ищем в旧 корзине. Возвращаясь к перемещению, теперь определено назначение перемещения. Далее нужно скопировать данные в новую корзину, затем让 структура evacDst указывает на следующее назначение:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Так操作 до полного завершения перемещения当前 корзины. Затем Go полностью очищает память данных ключ-значение当前旧 корзины, оставляя только массив tophash хэш-корзины (оставлен потому, что后续 нужно по массиву tophash判断 состояние перемещения). Память корзин переполнения в旧 корзине, поскольку больше не используется, впоследствии будет собрана GC. В hmap есть поле nevacuate для записи прогресса перемещения. После перемещения каждой旧 хэш-корзины увеличивается на один. Когда его значение равно количеству旧 корзин, означает завершение расширения всего map. Далее функция runtime.advanceEvacuationMark выполняет завершающую работу расширения:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Она подсчитывает количество перемещённых и подтверждает равенство с количеством旧 корзин. При равенстве очищаются все ссылки на旧 корзины и旧 корзины переполнения. На этом расширение завершено.
В функции growWork总共 вызывается дважды функция evacuate: первый раз — перемещение旧 корзины当前访问 корзины, второй раз — перемещение旧 корзины, на которую указывает h.nevacuate.总共 перемещается две корзины,说明 при постепенном перемещении每次 перемещаются две корзины.
Расширение с сохранением размера
Ранее упоминалось, что условием触发 расширения с сохранением размера является чрезмерное количество корзин переполнения. Предположим, map сначала добавляет большое количество элементов, затем大量 удаляет элементы. В результате многие корзины могут быть пустыми, некоторые корзины могут иметь много элементов, распределение данных очень неравномерно. Довольно много корзин переполнения пусты, занимая немало памяти. Для решения这类 проблем нужно создать новый map той же ёмкости, повторно分配 хэш-корзины. Этот процесс называется расширением с сохранением размера. На самом деле это не операция расширения, а повторное распределение всех элементов для более равномерного распределения данных. Логика расширения с сохранением размера объединена в логику инкрементного расширения, ёмкость新旧 map完全 равна.
В функции hashGrow, если коэффициент загрузки не превысил порог, выполняется расширение с сохранением размера. Go обновляет состояние h.flags в sameSizeGrow, h.B не увеличивается на один, поэтому ёмкость newly created хэш-корзин также не изменится. Соответствующий код:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)В функции evacuate, при初始创建 структуры eavcDst, если это расширение с сохранением размера, создаётся только одна структура, указывающая на новую корзину. Соответствующий код:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}При перемещении элементов расширение с сохранением размера не перевычисляет хэш-значение, нет выбора между верхней и нижней половиной:
if !h.sameSizeGrow() {
// Перевычисление хэш-значения
hash := t.Hasher(k2, uintptr(h.hash0))
// Обработка特殊 случая k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Помимо этого, остальная логика完全 идентична инкрементному расширению. После повторного分配 хэш-корзин при расширении с сохранением размера количество корзин переполнения уменьшается,旧 корзины переполнения будут собраны GC.