map
A diferencia de otros lenguajes, Go proporciona soporte para mapas mediante la palabra clave map, no como una biblioteca estándar. El mapa es una estructura de datos muy utilizada con muchas implementaciones posibles. Las dos más comunes son árbol rojo-negro y tabla hash. Go usa implementación con tabla hash.
TIP
La implementación de map involucra muchas operaciones de movimiento de punteros, por lo que leer este artículo requiere conocimiento de la biblioteca estándar unsafe.
Estructura Interna
La estructura runtime.hmap representa un map en Go. Al igual que los slices, la implementación interna de map también es una estructura.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # celdas vivas == tamaño del map. Debe estar primero (usado por len() builtin)
flags uint8
B uint8 // log_2 del # de buckets (puede contener hasta loadFactor * 2^B elementos)
noverflow uint16 // número aproximado de buckets de desbordamiento; ver incrnoverflow para detalles
hash0 uint32 // semilla hash
buckets unsafe.Pointer // array de 2^B Buckets. puede ser nil si count==0.
oldbuckets unsafe.Pointer // array de buckets anterior de la mitad del tamaño, no-nil solo cuando está creciendo
nevacuate uintptr // contador de progreso para evacuación (buckets menores a este han sido evacuados)
extra *mapextra // campos opcionales
}Las anotaciones en inglés ya son muy claras. A continuación se explican los campos más importantes:
count: representa el número de elementos en hmap, el resultado es equivalente alen(map).flags: banderas de hmap, usadas para indicar en qué estado está hmap. Hay las siguientes posibilidades:goconst ( iterator = 1 // el iterador está usando el bucket oldIterator = 2 // el iterador está usando el bucket antiguo hashWriting = 4 // una goroutine está escribiendo en hmap sameSizeGrow = 8 // está creciendo en igual cantidad )B: el número de buckets de hash en hmap es1 << B.noverflow: número aproximado de buckets de desbordamiento en hmap.hash0: semilla hash, especificada cuando se crea hmap, usada para calcular el valor hash.buckets: puntero al array de buckets de hash.oldbuckets: puntero al array de buckets de hash antes de la expansión.extra: almacena los buckets de desbordamiento de hmap. Los buckets de desbordamiento son nuevos buckets creados cuando el bucket actual está lleno para almacenar elementos.
El campo buckets en hmap es un puntero al slice de buckets. En Go, la estructura correspondiente es runtime.bmap:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Como se puede ver, solo tiene un campo tophash, que almacena los 8 bits superiores de cada clave. Pero en realidad, bmap tiene más campos. Esto se debe a que map puede almacenar pares clave-valor de varios tipos, por lo que se necesita inferir el espacio de memoria ocupado según el tipo durante la compilación. La función MapBucketType en cmd/compile/internal/reflectdata/reflect.go construye bmap durante la compilación, realizando una serie de verificaciones, como si el tipo de clave es comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypePor lo tanto, en realidad la estructura de bmap es la siguiente, aunque estos campos no son visibles para nosotros. Go accede a ellos moviendo punteros unsafe en operaciones reales:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Algunas explicaciones de los campos:
tophash: almacena el valor de los 8 bits superiores de cada clave. Para un elemento tophash, hay los siguientes valores especiales:goconst ( emptyRest = 0 // el elemento actual está vacío, y no hay más claves disponibles después de este elemento emptyOne = 1 // el elemento actual está vacío, pero hay claves disponibles después de este elemento evacuatedX = 2 // aparece durante la expansión, solo puede estar en oldbuckets, indica que el elemento actual fue reubicado en la mitad superior del nuevo array de buckets evacuatedY = 3 // aparece durante la expansión, solo puede estar en oldbuckets, indica que el elemento actual fue reubicado en la mitad inferior del nuevo array de buckets evacuatedEmpty = 4 // aparece durante la expansión, el elemento en sí está vacío, fue marcado durante la reubicación minTopHash = 5 // valor mínimo de tophash para una clave normal )Si el valor de
tophash[i]es mayor queminTopHash, indica que existe una clave-valor normal en ese índice.keys: array que almacena claves del tipo especificado.elems: array que almacena valores del tipo especificado.overflow: puntero al bucket de desbordamiento.
Dado que las claves no se pueden acceder directamente a través de los campos de la estructura, Go declara anticipadamente una constante dataoffset, que representa el desplazamiento de memoria de los datos en bmap:
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)En realidad, las claves se almacenan en una dirección de memoria continua, similar a la siguiente estructura. Esto se hace para evitar el desperdicio de espacio debido a la alineación de memoria:
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Por lo tanto, para un bmap, después de mover el puntero dataoffset, mover i*sizeof(keyType) es la dirección de la i-ésima clave:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Obtener la dirección del i-ésimo valor es similar:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))El puntero buckets en hmap apunta a la dirección del primer bucket de hash. Si se desea obtener la dirección del i-ésimo bucket de hash, el desplazamiento es i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))En el contenido posterior, estas operaciones aparecerán con mucha frecuencia.
Hash
Colisión
En hmap, hay un campo extra dedicado a almacenar información de buckets de desbordamiento. Apunta al slice que contiene los buckets de desbordamiento, cuya estructura es:
type mapextra struct {
// puntero al slice de buckets de desbordamiento
overflow *[]*bmap
// puntero al slice de buckets de desbordamiento antiguos antes de la expansión
oldoverflow *[]*bmap
// puntero al siguiente bucket de desbordamiento libre
nextOverflow *bmap
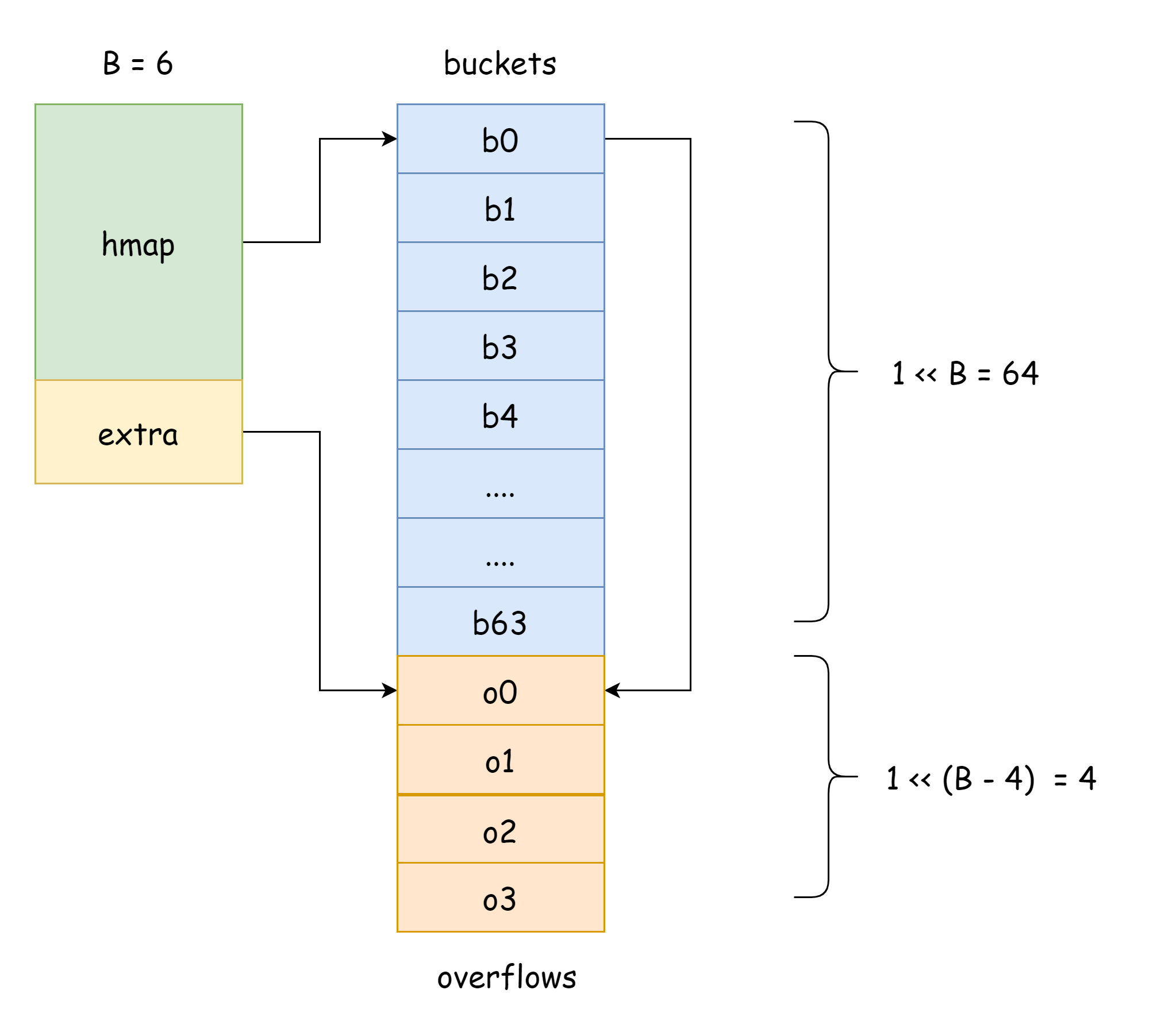
}
TIP
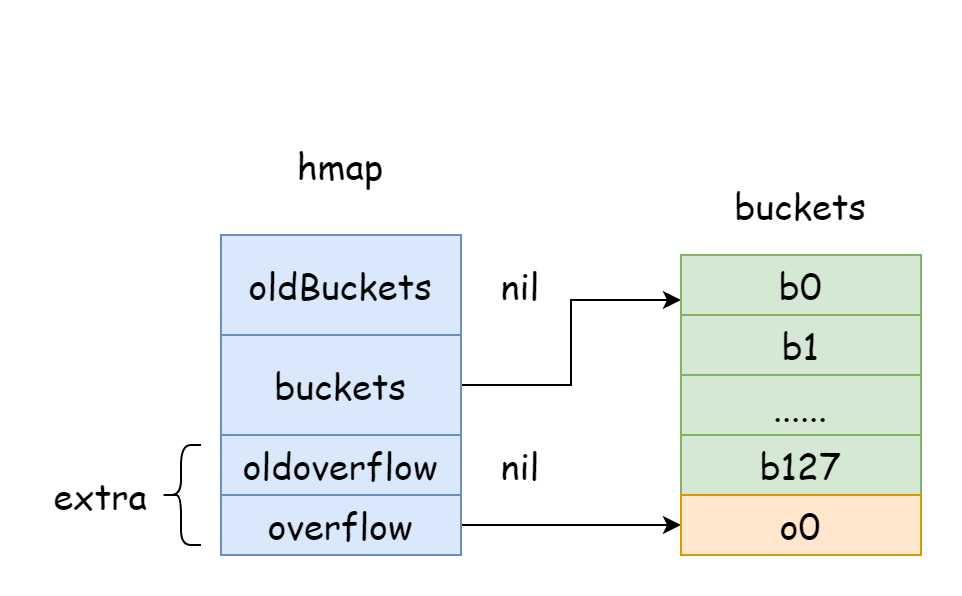
En la figura anterior, la parte azul es el array de buckets de hash, la parte naranja es el array de buckets de desbordamiento. Los buckets de desbordamiento se denominarán colectivamente como overflow buckets a continuación.
La figura anterior muestra bien la estructura general de hmap. buckets apunta al array de buckets de hash, extra apunta al array de buckets de desbordamiento. El bucket bucket0 apunta al bucket de desbordamiento overflow0. Dos tipos diferentes de buckets se almacenan en dos slices separados, y la memoria de ambos tipos de buckets es continua. Cuando dos claves se asignan al mismo bucket después del hash, esto se llama colisión de hash. La forma en que Go resuelve las colisiones de hash es mediante encadenamiento. Cuando el número de claves en conflicto supera la capacidad del bucket, generalmente 8, el valor depende de internal/abi.MapBucketCount. Luego se crea un nuevo bucket para almacenar estas claves, y este bucket se llama bucket de desbordamiento, lo que significa que el bucket original no puede contener más elementos, y los elementos se desbordan a este nuevo bucket. Después de crearlo, el bucket de hash tendrá un puntero apuntando al nuevo bucket de desbordamiento. Los punteros de estos buckets forman una lista enlazada bmap.
Para el método de encadenamiento, se usa el factor de carga para medir las colisiones de la tabla hash. Su fórmula de cálculo es:
loadfactor := len(elems) / len(buckets)Cuando el factor de carga es mayor, significa que hay más colisiones de hash, es decir, más buckets de desbordamiento. Al leer/escribir la tabla hash, se necesita recorrer más buckets de desbordamiento para encontrar la posición especificada, por lo que el rendimiento es peor. Para mejorar esta situación, se debe aumentar el número de buckets buckets, es decir, expandir. Para hmap, hay dos situaciones que pueden desencadenar la expansión:
- El factor de carga supera el umbral
bucketCnt*13/16, cuyo valor es al menos 6.5. - Hay demasiados buckets de desbordamiento.
Cuando el factor de carga es menor, significa que la utilización de memoria de hmap es baja y la memoria ocupada es mayor. La función usada en Go para calcular el factor de carga es runtime.overLoadFactor:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Donde loadFactorNum y loadFactorDen son constantes, bucketshift calcula 1 << B, y se sabe que:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenSimplificando se obtiene:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Donde (bucketCnt * 13 / 16) tiene un valor de 6.5, 1 << B es el número de buckets de hash. Por lo tanto, la función calcula si el número de elementos dividido por el número de buckets es mayor que el factor de carga 6.5.
Cálculo
La función interna de cálculo de hash en Go se encuentra en el archivo runtime/alg.go como f32hash:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // cualquier tipo de NaN
default:
return memhash(p, h, 4)
}
}Como se puede ver, el método de cálculo de hash del map no está basado en tipo, sino en memoria. Finalmente llega a la función memhash, que está implementada en ensamblador, con la lógica ubicada en runtime/asm*.s. El valor hash basado en memoria no debe persistirse, ya que solo debe usarse en tiempo de ejecución. No se puede garantizar que la distribución de memoria sea completamente consistente en cada ejecución.
En este archivo también hay una función llamada typehash, que calcula el valor hash según diferentes tipos, pero map no usa esta función para calcular hash:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrEsta implementación es más lenta que la anterior, pero más genérica. Se usa principalmente para reflexión y generación de funciones en tiempo de compilación, como la siguiente función:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Creación
Hay dos formas de inicializar un map, como se explicó en la introducción al lenguaje. Una es usar directamente la palabra clave map, y la otra es usar la función make. Independientemente del método de inicialización, finalmente runtime.makemap crea el map. La signatura de la función es:
func makemap(t *maptype, hint int, h *hmap) *hmapLos parámetros son:
t: se refiere al tipo del map. Diferentes tipos requieren diferente ocupación de memoria.hint: se refiere al segundo parámetro de la funciónmake, la capacidad esperada de elementos del map.h: se refiere al puntero ahmap, puede sernil.
El valor de retorno es el puntero hmap inicializado. Durante el proceso de inicialización, esta función tiene varios trabajos principales. Primero calcula si la memoria预计分配是否会超出最大分配内存,对应如下代码:
// 将预计容量与桶类型的内存大小相乘
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// 数值溢出或者超出了最大分配内存
if overflow || mem > maxAlloc {
hint = 0
}En la estructura interna anterior se mencionó que hmap está compuesto por buckets. En el caso de menor utilización de memoria, un bucket tiene solo un elemento, ocupando la mayor memoria. Por lo tanto, la ocupación máxima预计 de memoria es el número de elementos multiplicado por la ocupación de memoria del tipo correspondiente. Cuando el resultado del cálculo desborda numéricamente o excede la memoria máxima asignable, se establece hint en 0, porque posteriormente se necesita hint para calcular la capacidad del array de buckets.
El segundo paso es inicializar hmap y calcular una semilla hash aleatoria, correspondiente al siguiente código:
// 初始化
if h == nil {
h = new(hmap)
}
// 获取一个随机的哈希种子
h.hash0 = fastrand()Luego se calcula la capacidad del bucket de hash según el valor de hint, correspondiente al siguiente código:
B := uint8(0)
// 不断循环直到 hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// 赋值给 hmap
h.B = BMediante un bucle continuo se encuentra el primer valor de B que satisface (hint / 1 << B) < 6.5, y se asigna a hmap. Después de conocer la capacidad del bucket de hash, finalmente se asigna memoria para el bucket de hash:
if h.B != 0 {
var nextOverflow *bmap
// 分配好的哈希桶,和预先分配的空闲溢出桶
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果预先分配了空闲溢出桶,就指向该溢出桶
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}La función makeBucketArray asigna memoria del tamaño correspondiente para el bucket de hash según el valor de B, y pre-asigna buckets de desbordamiento libres. Cuando B es menor que 4, no se crean buckets de desbordamiento. Si es mayor que 4, se crean 2^B-4 buckets de desbordamiento. Correspondiente al siguiente código en la función runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// 小于 4 就不会创建溢出桶
if b >= 4 {
// 预计桶的数量加上 1 << (b-4)
nbuckets += bucketShift(b - 4)
// 溢出桶所需的内存
sz := t.Bucket.Size_ * nbuckets
// 将内存空间向上取整
up := roundupsize(sz)
if up != sz {
// 不相等就采用 up 重新计算
nbuckets = up / t.Bucket.Size_
}
}base se refiere al número预计 de buckets a asignar, nbuckets se refiere al número real de buckets asignados, que incluye el número de buckets de desbordamiento.
if base != nbuckets {
// 第一个可用的溢出桶
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// 为了减少跟踪溢出桶的开销,将最后一个可用溢出桶的溢出指针指向哈希桶的头部
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// 最后一个溢出桶指向哈希桶
last.setoverflow(t, (*bmap)(buckets))
}Cuando ambos no son iguales, significa que se asignaron buckets de desbordamiento adicionales. El puntero nextoverflow apunta al primer bucket de desbordamiento disponible. Como se puede ver, los buckets de hash y los buckets de desbordamiento están en realidad en la misma memoria continua. Esta es la razón por la cual en la figura el array de buckets de hash y el array de buckets de desbordamiento son adyacentes.
Acceso
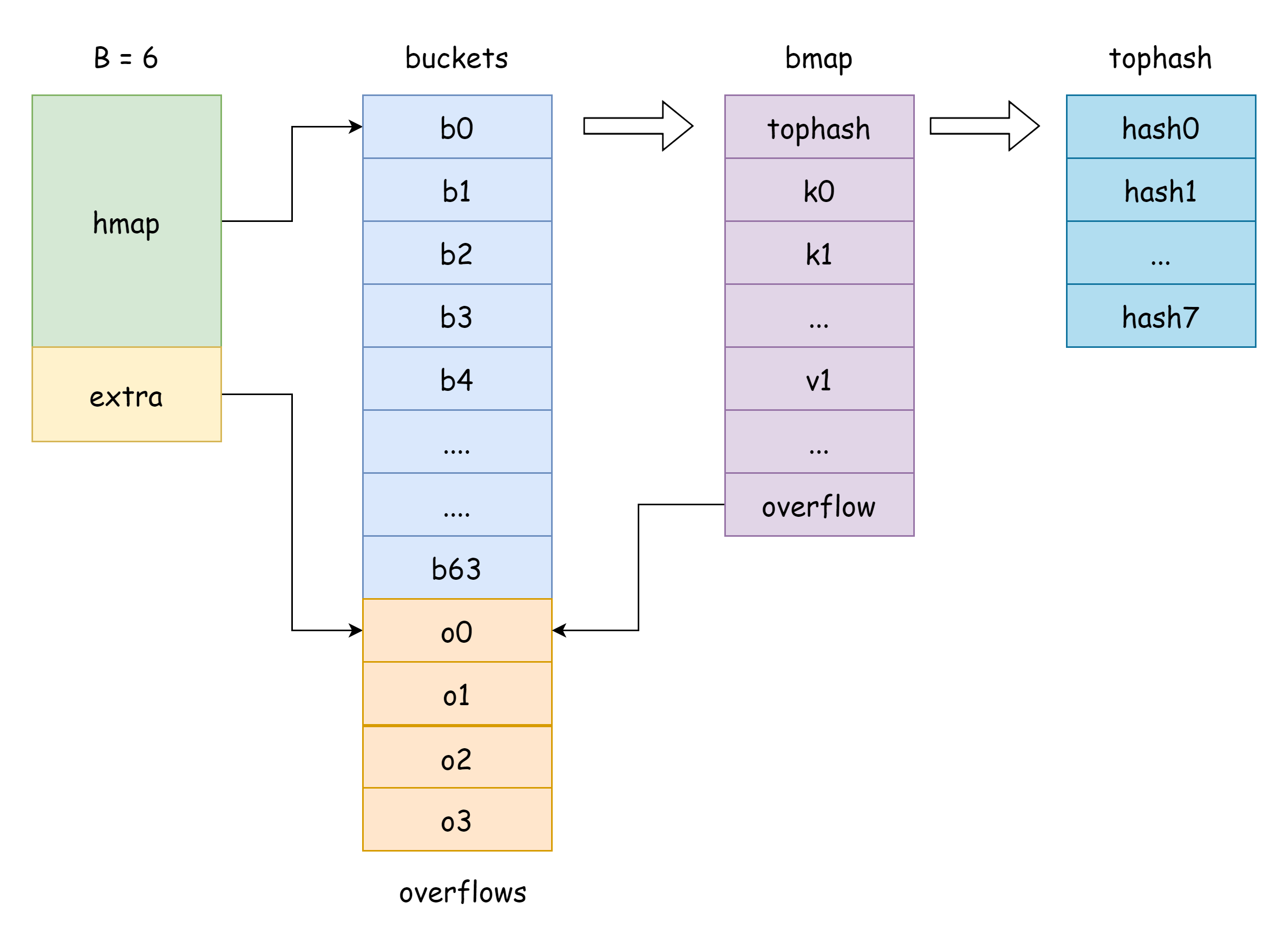
En la introducción de sintaxis se mencionó que hay tres formas de acceder a un map:
# 直接访问值
val := dict[key]
# 访问值以及该键是否存在
val, exist := dict[key]
# 遍历 map
for key, val := range dict{
}Estas tres formas usan funciones diferentes. La forma for range para recorrer un map es la más compleja.
Clave-Valor
Para las dos primeras formas, corresponden dos funciones: runtime.mapaccess1 y runtime.mapaccess2. Las signaturas de las funciones son:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)La clave es un puntero al key de acceso del map, y al devolver solo se devuelve un puntero. Al acceder, primero se debe calcular el valor hash de la clave y ubicar en qué bucket de hash está la clave. Correspondiente al siguiente código:
// 边界处理
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// 防止并发读写
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// 使用指定类型的 hasher 计算哈希值
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// 通过移动指针定位 key 所在的哈希桶
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))Al inicio del acceso se manejan los casos límite y se previene la lectura/escritura concurrente del map. Cuando el map está en estado de lectura/escritura concurrente, se produce un panic. Luego se calcula el valor hash. La función bucketMask calcula (1 << B) - 1, hash & m es igual a hash & (1 << B) - 1, que es una operación de módulo binario, equivalente a hash % (1 << B). El beneficio de usar operaciones de bits es mayor velocidad. Las últimas tres líneas de código calculan el valor hash obtenido de la clave y lo toman módulo con el número actual de buckets en el map para obtener el número del bucket de hash. Luego se mueve el puntero según el número para obtener el puntero del bucket de hash donde está la clave.
Después de saber en qué bucket de hash está la clave, se puede realizar la búsqueda. Esta parte corresponde al siguiente código:
// 获取哈希值的高八位
top := tophash(hash)
bucketloop:
// 遍历 bmap 链表
for ; b != nil; b = b.overflow(t) {
// bmap 中的元素
for i := uintptr(0); i < bucketCnt; i++ {
// 将计算得出的 top 与 tophash 中的元素进行对比
if b.tophash[i] != top {
// 后续都是空的,没有了。
if b.tophash[i] == emptyRest {
break bucketloop
}
// 不相等就继续遍历溢出桶
continue
}
// 根据 i 移动指针获取对应下标的键
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// 处理下指针
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 比对两个键是否相等
if t.Key.Equal(key, k) {
// 如果相等的话,就移动指针返回 k 对应下标的元素
// 从这行代码就能看出来键值的内存地址是连续的
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 没找到,返回零值。
return unsafe.Pointer(&zeroVal[0])Al ubicar el bucket de hash, se usa el módulo para ubicar. Por lo tanto, en qué bucket de hash está la clave depende de los bits bajos del valor hash. Cuántos bits bajos dependen del tamaño de B. Después de encontrar el bucket de hash, el tophash almacena los 8 bits superiores del valor hash. Dado que los valores de módulo de bits bajos son los mismos, no es necesario comparar uno por uno si las claves son iguales. Solo es necesario comparar los 8 bits superiores del valor hash. Según el valor hash calculado anteriormente, se obtienen sus 8 bits superiores. Se comparan uno por uno en el array tophash en bmap. Si los 8 bits superiores son iguales, se compara si las claves son iguales. Si las claves también son iguales, significa que se encontró el elemento. Si no son iguales, se continúa recorriendo el array tophash. Si aún no se encuentra, se continúa recorriendo la lista enlazada de buckets de desbordamiento bmap, hasta que tophash[i] de bmap sea emptyRest para salir del bucle. Finalmente se devuelve el valor cero del tipo correspondiente.
La función mapaccess2 es completamente consistente con la lógica de la función mapaccess1, solo tiene un valor de retorno booleano adicional para indicar si el elemento existe.
Iteración
La sintaxis para iterar un map es:
for key, val := range dict {
// do somthing...
}Al iterar realmente, Go usa la estructura hiter para almacenar información de iteración. hiter es la abreviatura de hmap iterator, que significa iterador de tabla hash. La estructura es la siguiente:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}A continuación se explican algunos de sus campos:
key,elem: son la clave y el valor obtenidos durante la iteraciónfor rangebuckets: especificado al inicializar el iterador, apunta a la cabeza del bucket de hashbptr: el bmap que se está recorriendo actualmentestartBucket: el número del bucket de inicio al comenzar la iteraciónoffset: desplazamiento dentro del bucket, rango[0, bucketCnt-1]B: es el valor B de hmapi: índice del elemento dentro del bucketwrapped: si ya volvió del final del array de buckets de hash al principio
Antes de comenzar la iteración, Go inicializa el iterador mediante la función runtime.mapiterinit, y luego recorre el map mediante la función runtime.mapiternext. Ambas funciones necesitan usar la estructura hiter. Las signaturas de las dos funciones son:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Para la inicialización del iterador, primero se debe obtener una instantánea actual del map, correspondiente al siguiente código:
it.t = t
it.h = h
// 记录 hmap 当前状态的快照,只需要保存 B 值。
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Durante la iteración posterior, en realidad se recorre una instantánea del map, no el map real. Por lo tanto, los elementos y buckets agregados durante el proceso de iteración no se recorrerán, y la escritura concurrente de elementos puede desencadenar fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}El segundo paso es decidir dos posiciones de inicio para la iteración. La primera es la posición del bucket de inicio, y la segunda es la posición de inicio dentro del bucket. Ambas se seleccionan aleatoriamente, correspondiente al siguiente código:
// r 是一个随机数
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) 得到起始桶的位置
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 得到起始桶内的元素起始位置
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// 记录当前正在遍历的桶序号
it.bucket = it.startBucketSe obtiene un número aleatorio mediante fastrand() o fastrand64(). Dos operaciones de módulo obtienen la posición de inicio del bucket y la posición de inicio dentro del bucket.
TIP
Aunque map no permite lectura/escritura concurrente simultánea, permite iteración concurrente simultánea.
A continuación comienza realmente la iteración del map, cómo recorrer los buckets y la estrategia de salida. Esta parte corresponde al siguiente código:
// hmap
h := it.h
// maptype
t := it.t
// 待遍历的桶的位置
bucket := it.bucket
// 待遍历的 bmap
b := it.bptr
// 桶内序号 i
i := it.i
next:
if b == nil {
// 如果当前桶的位置与起始位置相等,说明是绕了一圈回来,后面的已经遍历过了
// 遍历结束,可以退出了
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// 桶下标后移
bucket++
// bucket == 1 << B,就是走到哈希桶数组的末尾了
if bucket == bucketShift(it.B) {
// 从头开始
bucket = 0
it.wrapped = true
}
i = 0
}La posición de inicio del bucket de hash se selecciona aleatoriamente. Durante la iteración, se itera desde la posición de inicio hacia el final del slice de buckets uno por uno. Al llegar a 1 << B, luego se comienza desde el principio. Cuando se vuelve a la posición de inicio nuevamente, significa que la iteración ha terminado, y luego se sale. El código anterior trata sobre cómo recorrer buckets en un map. El siguiente código describe cómo recorrer dentro de un bucket:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// 如果当前元素是空的就跳过
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// 移动指针获取键
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 移动指针获取值
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// 处理等量扩容的情况,当键值被疏散到了其它位置后,需要重新去寻找键值。
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// 没找到就去溢出桶里面找
b = b.overflow(t)
i = 0
goto nextTIP
En la condición de expansión anterior, hay una expresión que puede causar confusión:
t.Key.Equal(k, k)La razón para juzgar si k es igual a sí mismo es filtrar el caso de clave Nan. Si la clave de un elemento es Nan, entonces no se podrá acceder normalmente a ese elemento. Ya sea iteración, acceso directo o eliminación, no se puede realizar normalmente, porque Nan != Nan siempre es verdadero, por lo que nunca se podrá encontrar esta clave.
Primero se realiza una operación de módulo con los valores i y offset para obtener el índice dentro del bucket a recorrer. Se obtiene la clave-valor moviendo el puntero. Dado que durante la iteración del map, habrá otras operaciones de escritura que desencadenan la expansión del map, por lo que la clave-valor real puede ya no estar en la posición original. En este caso, se necesita usar la función mapaccessK para volver a obtener la clave-valor real. La signatura de esta función es:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Su función es completamente consistente con la función mapaccess1, la diferencia es que la función mapaccessK devuelve simultáneamente el valor de la clave y el valor. Después de obtener finalmente la clave-valor, se asigna a key y elem del iterador, luego se actualiza el índice del iterador. De esta manera se completa una iteración, y la ejecución del código vuelve al bloque de código for range. Si no se encuentra en el bucket, se busca en el bucket de desbordamiento, repitiendo los pasos anteriores, hasta que se complete la iteración de la lista enlazada de buckets de desbordamiento, y luego se continúa iterando el siguiente bucket de hash.
Modificación
La sintaxis para modificar un map es:
dict[key] = valEn Go, la operación de modificación de map es completada por la función runtime.mapassign, cuya signatura es:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerLa lógica de su proceso de acceso es la misma que mapaccess1, pero cuando la clave no existe, se le asignará una posición. Si existe, se actualizará. Finalmente se devuelve el puntero del elemento. Al inicio, se debe hacer algún trabajo de preparación. Esta parte corresponde al siguiente código:
// 不允许写入为 nil 的 map
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 禁止同时并发写
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// 计算 key 哈希值
hash := t.Hasher(key, uintptr(h.hash0))
// 修改 hmap 状态
h.flags ^= hashWriting
// 初始化哈希桶
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}El código anterior principalmente hace las siguientes cosas:
- Verificación del estado de hmap
- Cálculo del valor hash de la clave
- Verificación de si el bucket de hash necesita inicialización
Después, se obtiene la posición del bucket de hash mediante operación de módulo del valor hash, y el tophash de la clave. El código corresponde a:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// 移动指针获取指定位置的 bmap
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// 计算 tophash
top := tophash(hash)Ahora se ha determinado la posición del bucket, bmap, tophash, se puede comenzar a buscar el elemento. Esta parte del código corresponde a:
// 待插入的 tophash
var inserti *uint8
// 待插入的 key 值指针
var insertk unsafe.Pointer
// 待插入的 value 值指针
var elem unsafe.Pointer
bucketloop:
for {
// 遍历桶内的 tophash 数组
for i := uintptr(0); i < bucketCnt; i++ {
// tophash 不相等
if b.tophash[i] != top {
// 如果当前桶内下标是空的,且还没有插入元素,就选取该位置插入
if isEmpty(b.tophash[i]) && inserti == nil {
// 找到了一个合适的位置分配给 key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// 遍历完了就退出循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 如果 tophash 相等的话,则说明 key 可能已经存在了
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 判断 key 是否相等
if !t.Key.Equal(key, k) {
continue
}
// 如果需要更新 key 值的话,就将 key 的内存直接复制到 k 处
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// 得到了元素的指针
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 更新完毕,返回元素指针
goto done
}
// 执行到这里说明没找到 key,遍历溢出桶链表,继续找
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 执行到这里说明 key 没有存在于 map 中,但可能已经找到了一个合适的位置分配给 key,也可能没有
// 没有找到一个合适的位置分配给 key
if inserti == nil {
// 说明当前的哈希桶以及它的溢出桶都满了,那就再分配一个溢出桶
newb := h.newoverflow(t, b)
// 在溢出桶中分配一个位置给 key
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// 如果存放的是 key 指针的话
if t.IndirectKey() {
// 新分配内存,返回的是一个 unsafe 指针
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// 赋值给 insertk,方便后面进行 key 的内存复制
insertk = kmem
}
// 如果存放的是元素指针
if t.IndirectElem() {
// 分配内存
vmem := newobject(t.Elem)
// 让指针指向 vmem
*(*unsafe.Pointer)(elem) = vmem
}
// 将 key 的内存直接复制到 insertk 的位置
typedmemmove(t.Key, insertk, key)
*inserti = top
// 数量加一
h.count++
done:
// 执行到这里说明修改过程已经完成了
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 返回元素指针
return elemEn el gran bloque de código anterior, primero se ingresa al bucle for para intentar buscar en el bucket de hash y el bucket de desbordamiento. La lógica de búsqueda es completamente consistente con mapaccess. En este momento hay tres posibilidades:
- Primero, se encuentra una clave existente en el map, se salta directamente al bloque de código
doney se devuelve el puntero del elemento - Segundo, se encuentra una posición en el map para asignar a la clave, se copia la clave a la posición especificada y se devuelve el puntero del elemento
- Tercero, se han buscado todos los buckets, no se encuentra una posición que se pueda asignar a la clave en el map, se crea un nuevo bucket de desbordamiento, se asigna la clave al bucket, luego se copia la clave a la posición especificada y se devuelve el puntero del elemento
Finalmente, después de obtener el puntero del elemento, se puede asignar. Sin embargo, esta operación no es completada por la función mapassign. Solo es responsable de devolver el puntero del elemento. La operación de asignación se inserta durante el compilador. No se puede ver en el código, pero se puede ver en el código compilado. Supongamos que hay el siguiente código:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Mediante el siguiente comando se obtiene el código ensamblador:
go tool compile -S -N -l main.goLa parte clave está en esta sección:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Como se puede ver, se llama a runtime.mapassign_faststr, cuya lógica es completamente similar a mapassign. LEAQ go:string."world"(SB), CX almacena la dirección de la cadena en CX, MOVQ CX, (AX) luego la almacena en AX, y así se completa la asignación del elemento.
Eliminación
En Go, para eliminar un elemento de un map, solo se puede usar la función incorporada delete:
delete(dict, "abc")Internamente se llama a la función runtime.mapdelete, cuya signatura es:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Elimina el elemento de la clave especificada en el map. No importa si el elemento existe en el map o no, no reaccionará de ninguna manera. La lógica de preparación al inicio de la función es similar, principalmente las siguientes cosas:
- Verificación del estado de hmap
- Cálculo del valor hash de la clave
- Ubicación del bucket de hash
- Cálculo de tophash
Hay mucho contenido repetido anterior, no se repetirá más. Aquí solo se presta atención a su lógica de eliminación. La parte correspondiente del código es:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 没找到就退出循环
if b.tophash[i] == emptyRest {
break search
}
continue
}
// 移动指针找到 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// 删除 key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// 移动指针找到元素的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 删除元素
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// 数量减一
h.count--
// 重置哈希种子,减小冲突发生概率
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Como se puede ver en el código anterior, la lógica de búsqueda es casi completamente consistente con las operaciones anteriores. Se encuentra el elemento, luego se elimina, el número registrado en hmap se reduce en uno. Cuando el número se reduce a 0, se restablece la semilla hash.
Otro punto a tener en cuenta es que después de eliminar el elemento, se debe modificar el estado tophash del índice actual. Esta parte corresponde al siguiente código. Cuando i está al final del bucket, se juzga según el siguiente bucket de desbordamiento si el elemento actual es el último elemento disponible. De lo contrario, se verifica directamente el estado hash del elemento adyacente. Si el elemento actual no es el último disponible, se establece el estado en emptyOne:
// 将当前 tophash 标记为空
b.tophash[i] = emptyOne
// 如果在 tophash 末尾
if i == bucketCnt-1 {
// 溢出桶不为空,且溢出桶内有元素,说明当前元素不是最后一个
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// 相邻元素不为空
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Si el elemento es efectivamente el último elemento, se necesita corregir el valor del array tophash de algunos buckets en la lista enlazada de buckets. De lo contrario, durante la iteración posterior no se podrá salir en la posición correcta. Cuando se creó el bucket de desbordamiento en la creación del map, se mencionó que Go, para reducir el costo de rastrear buckets de desbordamiento, el puntero overflow del último bucket de desbordamiento apunta al bucket de hash de la cabeza. Por lo tanto, en realidad es una lista enlazada circular单向. La "cabeza" de la lista enlazada es el bucket de hash. Y la b aquí es la b después de la búsqueda, muy probablemente sea uno de los buckets de desbordamiento en el medio de la lista enlazada. Se recorre inversamente la lista enlazada circular para buscar el último elemento existente. Aunque el código está escrito como recorrido en orden, dado que la lista enlazada es un anillo, se recorre continuamente en orden hasta el anterior al bucket de desbordamiento actual. En términos de resultado, es efectivamente inverso. Luego se recorre inversamente el array tophash en el bucket, actualizando los elementos con estado emptyOne a emptyRest, hasta encontrar el último elemento existente. Para evitar caer infinitamente en el anillo, cuando se vuelve al bucket inicial, es decir, bOrig, significa que en este momento ya no hay elementos disponibles en la lista enlazada, y se puede salir del bucle:
// 执行到这里说明当前元素后面没有元素了
// 不断的倒序遍历 bmap 链表,倒序遍历桶内的 tophash
// 将状态为 emptyOne 的更新为 emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// 找到当前 bmap 链表的前一个
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Limpieza
En la versión go1.21, se agregó la función incorporada clear, que se puede usar para limpiar todos los elementos en un map. La sintaxis es:
clear(dict)Internamente se llama a la función runtime.mapclear, que es responsable de eliminar todos los elementos en el map. La signatura de la función es:
func mapclear(t *maptype, h *hmap)La lógica de esta función no es compleja. Primero se debe marcar todo el map como vacío. El código correspondiente es:
// 遍历每一个桶以及溢出桶,将所有的 tophash 元素置为 emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Lo que hace el código anterior es recorrer cada bucket y establecer todos los elementos del array tophash en el bucket a emptyRest, marcando el map como vacío. Esto puede evitar que el iterador continúe iterando. Luego se limpia el map. El código correspondiente es:
// 重置哈希种子
h.hash0 = fastrand()
// 重置 extra 结构体
if h.extra != nil {
*h.extra = mapextra{}
}
// 这个操作会清除原来 buckets 的内存,并重新分配新的桶
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// 分配新的空闲溢出桶
h.extra.nextOverflow = nextOverflow
}Mediante makeBucketArray se limpia la memoria de los buckets anteriores, y luego se asigna uno nuevo. De esta manera se completa la limpieza de buckets. Además, hay algunos detalles, como establecer count en 0, y otras operaciones que no se detallarán más.
Expansión
En todas las operaciones anteriores, para prestar más atención a la lógica en sí, se ocultó mucho contenido relacionado con la expansión. Esto lo hace más simple. La lógica de expansión es en realidad más compleja. Se coloca al final para no causar interferencia. Ahora veamos cómo Go expande el map. Ya se mencionó anteriormente que hay dos condiciones para desencadenar la expansión:
- El factor de carga supera 6.5
- El número de buckets de desbordamiento es demasiado grande
La función para juzgar si el factor de carga supera el umbral es la función runtime.overLoadFactor, que ya se explicó en la parte de conflicto de hash. La función para juzgar si el número de buckets de desbordamiento es demasiado grande es runtime.tooManyOverflowBuckets. Su principio de funcionamiento también es muy simple. El código es:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}El código anterior se puede simplificar a la siguiente expresión, que se puede entender de un vistazo:
overflow >= 1 << (min(15,B) % 16)Aquí, la definición de Go para "demasiados" es: el número de buckets de desbordamiento es aproximadamente igual al número de buckets de hash. Si el umbral es bajo, se hará trabajo extra. Si el umbral es alto, se ocupará mucha memoria durante la expansión. Al modificar y eliminar elementos, es posible desencadenar la expansión. El código para juzgar si se necesita expansión es:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}Como se puede ver, estas tres condiciones limitan:
- No se puede estar expandiendo actualmente
- El factor de carga debe ser menor que 6.5
- El número de buckets de desbordamiento no debe ser demasiado grande
La función responsable de la expansión es naturalmente runtime.hashGrow, cuya signatura es:
func hashGrow(t *maptype, h *hmap)En realidad, la expansión también tiene tipos. Según diferentes condiciones desencadenantes, los tipos de expansión también son diferentes. Se dividen en los siguientes dos tipos:
- Expansión incremental
- Expansión de igual cantidad
Expansión Incremental
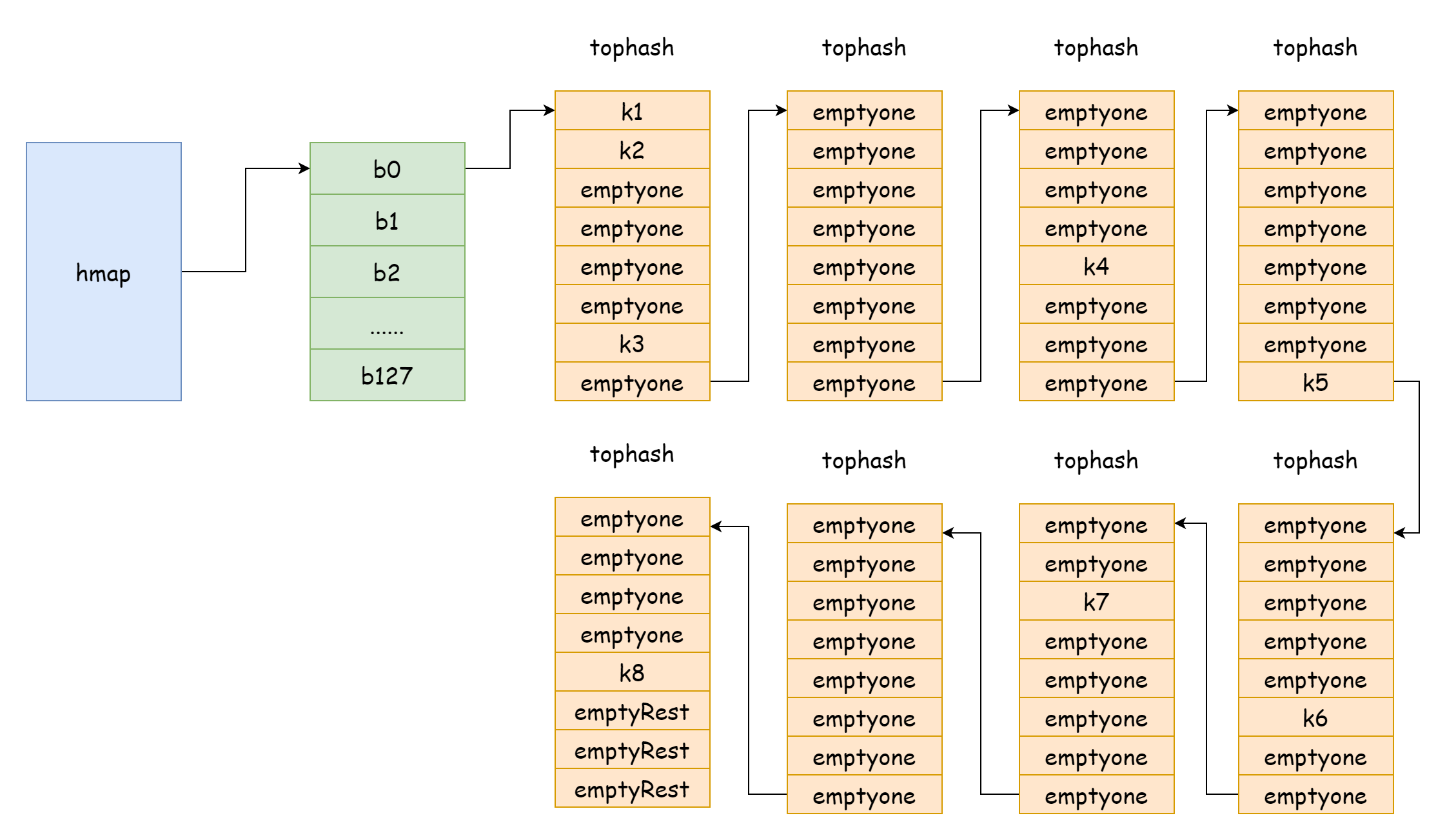
Cuando el factor de carga es demasiado grande, es decir, el número de elementos es mayor que el número de buckets de hash, cuando el conflicto de hash es severo, se formarán muchas listas enlazadas de buckets de desbordamiento. Esto causará que el rendimiento de lectura/escritura del map disminuya, porque se necesita recorrer más buckets de desbordamiento para encontrar un elemento. El tiempo de complejidad de recorrer es O(n). El tiempo de complejidad de búsqueda de la tabla hash depende principalmente del tiempo de cálculo del valor hash y del tiempo de recorrido. Cuando el tiempo de recorrido es mucho menor que el tiempo de cálculo del hash, el tiempo de complejidad de búsqueda puede considerarse O(1). Si el conflicto de hash es frecuente, demasiadas claves se asignan al mismo bucket de hash. La lista enlazada de buckets de desbordamiento demasiado larga causa un aumento en el tiempo de recorrido, lo que lleva a un aumento en el tiempo de búsqueda. Las operaciones de agregar/eliminar/modificar necesitan primero realizar operaciones de búsqueda. De esta manera, el rendimiento de todo el map disminuirá severamente.
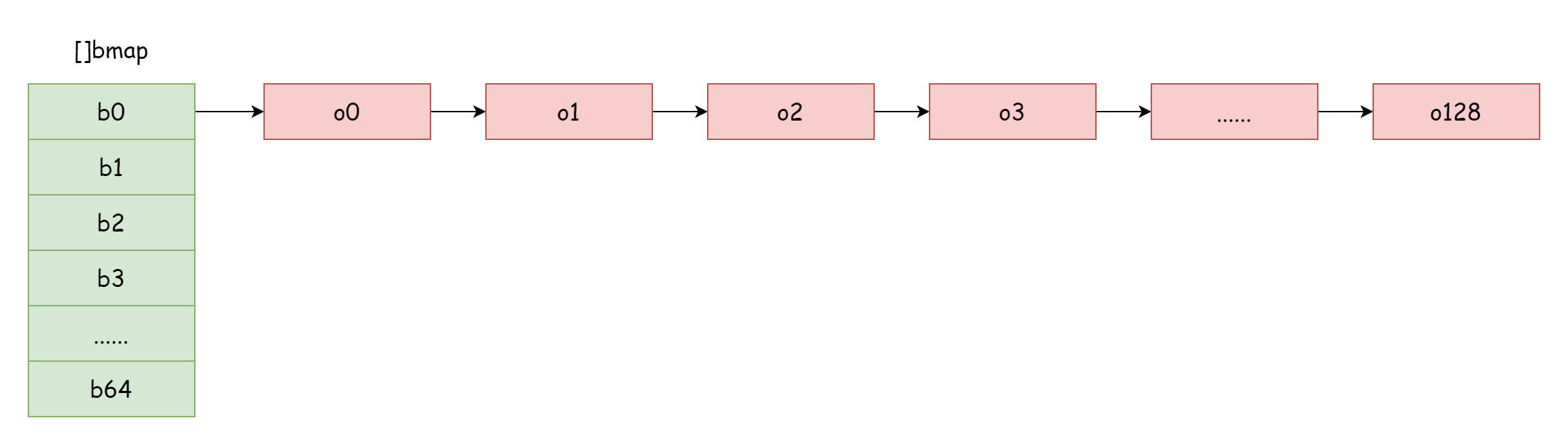
En una situación tan extrema como en la figura, el tiempo de complejidad de búsqueda es básicamente igual a O(n). Frente a esta situación, la solución es agregar más buckets de hash para evitar formar listas enlazadas de buckets de desbordamiento demasiado largas. Este método también se conoce como expansión incremental.
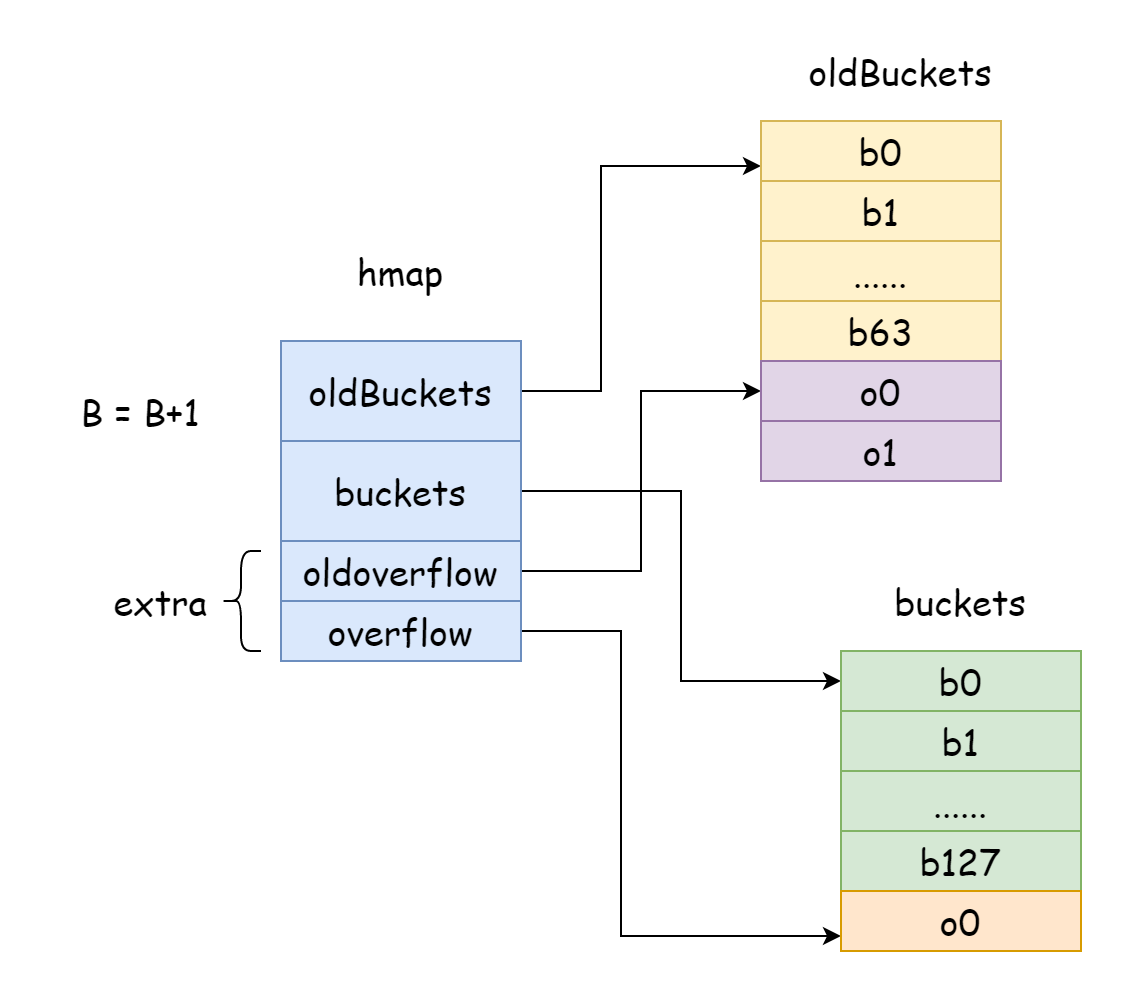
En Go, la expansión incremental aumenta B en uno cada vez, es decir, la escala de buckets de hash se expande al doble cada vez. Después de la expansión, se deben reubicar los datos antiguos al nuevo map. Si el número de elementos en el map es de decenas de millones o incluso cientos de millones, reubicar todo de una vez tomará mucho tiempo. Por lo tanto, Go adopta la estrategia de reubicación gradual. Para esto, Go hará que oldBuckets en hamp apunte al array de buckets de hash original, indicando que estos son datos antiguos. Luego se crea un array de buckets de hash de mayor capacidad, y hmap en buckets apunta al nuevo array de buckets de hash. Luego, en cada modificación y eliminación de elementos, se reubican algunos elementos del bucket antiguo al nuevo bucket, hasta que se complete la reubicación. Solo entonces se liberará la memoria del bucket antiguo.
func hashGrow(t *maptype, h *hmap) {
// 差值
bigger := uint8(1)
// 旧桶
oldbuckets := h.buckets
// 新的哈希桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 溢出桶也要指定旧桶和新桶
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Lo que hace el código anterior es crear un nuevo bucket de hash con el doble de capacidad, luego especificar las referencias de buckets antiguos y nuevos, y las referencias de buckets de desbordamiento antiguos y nuevos. El trabajo real de reubicación no es completado por la función hashGrow. Solo es responsable de especificar buckets antiguos y nuevos, y actualizar algunos estados de hmap. Estos trabajos son en realidad completidos por la función runtime.growWork, cuya signatura es:
func growWork(t *maptype, h *hmap, bucket uintptr)Se llamará en las funciones mapassign y mapdelete de la siguiente forma. Su función es que si el map actual está en expansión, realizar un trabajo de reubicación parcial:
if h.growing() {
growWork(t, h, bucket)
}Al modificar y eliminar elementos, se debe juzgar si se está actualmente en expansión. Esto se completa principalmente por el método hmap.growing. El contenido es muy simple, solo juzgar si oldbuckets no es vacío. Correspondiente al siguiente código:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Veamos qué hace la función growWork:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}La operación bucket&h.oldbucketmask() calcula la posición del bucket antiguo, asegurando que se reubique el bucket antiguo del bucket actual que se va a reubicar. Como se puede ver en la función, el trabajo real de reubicación es completado por la función runtime.evacuate. Se usa la estructura evaDst para representar el destino de reubicación. Su función principal es iterar el nuevo bucket durante el proceso de reubicación. Su estructura es:
type evacDst struct {
b *bmap // 搬迁目的地的新桶
i int // 桶内下标
k unsafe.Pointer // 指向新键目的地的指针
e unsafe.Pointer // 指向新值目的地的指针
}Antes de comenzar la reubicación, Go asignará dos estructuras evacDst. Una apunta a la mitad superior del nuevo bucket de hash, y la otra apunta a la mitad inferior del nuevo bucket de hash. El código correspondiente es:
// 定位旧桶中指定的哈希桶
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// 旧桶的长度 = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// 指向新桶的上半区
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// 判断是不是等量扩容
if !h.sameSizeGrow() {
y := &xy[1]
// 指向新桶的下半区
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}El destino de reubicación del bucket antiguo son dos nuevos buckets. Después de la reubicación, parte de los datos en el bucket estará en la mitad superior, y otra parte de los datos estará en la mitad inferior. Esto se hace con la esperanza de que los datos después de la expansión se distribuyan de manera más uniforme. Cuanto más uniforme sea la distribución, mejor será el rendimiento de búsqueda del map. Cómo Go reubica los datos a dos nuevos buckets corresponde al siguiente código:
// 遍历溢出桶链表
for ; b != nil; b = b.overflow(t) {
// 拿到每个桶的第一键值对
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// 遍历桶中的每一个键值对
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// 如果是空的就跳过
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// 新哈希桶不应该处于搬迁状态
// 否则的话肯定是出问题了
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 该变量决定了当前键值对被搬迁到上半区还是下半区
// 它的值只能是 0 或 1
var useY uint8
if !h.sameSizeGrow() {
// 重新计算哈希值
hash := t.Hasher(k2, uintptr(h.hash0))
// 处理 k2 != k2 的特殊情况,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// 检查常量的值
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 更新旧桶的 tophash,表示当前元素已被搬迁
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 指定搬迁目的地
dst := &xy[useY] // evacuation destination
// 新桶容量不够用了建个溢出桶
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 复制键
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// 复制值
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// 后移新桶目的指针,为下一个键值做准备
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Desde el código anterior se puede ver que Go recorrerá cada elemento en cada bucket en la lista enlazada de buckets antiguos, y moverá los datos al nuevo bucket. Decidir si los datos van a la mitad superior o inferior depende del valor hash recalculado:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Después de la reubicación, se establecerá el tophash del elemento actual en evacuatedX o evacuated. Si se intenta buscar datos durante el proceso de expansión, se puede saber a través de este estado que los datos han sido reubicados, y se sabe que se debe buscar en el nuevo bucket. Esta parte de la lógica corresponde al siguiente código en la función runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// 如果旧桶已经被搬迁了就不找了
if !evacuated(oldb) {
b = oldb
}
}Al acceder al elemento, si actualmente se está en estado de expansión, se intentará buscar primero en el bucket antiguo. Si el bucket antiguo ya ha sido reubicado, no se buscará en el bucket antiguo. Volviendo a la reubicación, en este momento se ha determinado el destino de la reubicación. Lo siguiente es copiar los datos al nuevo bucket, y luego hacer que la estructura evacDst apunte al siguiente destino:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Esta operación continúa hasta que se complete la reubicación del bucket actual. Luego Go limpiará toda la memoria de los datos de clave-valor del bucket antiguo, dejando solo un array tophash de bucket de hash (se deja porque posteriormente se depende del array tophash para juzgar el estado de reubicación). La memoria de los buckets de desbordamiento en el bucket antiguo será reciclada por GC posteriormente ya que不再被引用。En hmap hay un campo nevacuate usado para registrar el progreso de reubicación. Cada vez que se reubica un bucket de hash antiguo, se incrementa en uno. Cuando su valor es igual al número de buckets antiguos, significa que se ha completado la expansión de todo el map. A continuación, la función runtime.advanceEvacuationMark realiza el trabajo de finalización de la expansión:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Estadísticas la cantidad reubicada y confirma si es igual al número de buckets antiguos. Si son iguales, se eliminan todas las referencias a buckets antiguos y buckets de desbordamiento antiguos. Hasta aquí se completa la expansión.
En la función growWork, se llama a la función evacuate un total de dos veces. La primera vez es reubicar el bucket antiguo del bucket que se está访问 actualmente. La segunda vez es reubicar el bucket antiguo apuntado por h.nevacuate. Se reubican dos buckets en total, lo que significa que en cada reubicación gradual se reubican dos buckets.
Expansión de Igual Cantidad
Se mencionó anteriormente que la condición desencadenante de la expansión de igual cantidad es que el número de buckets de desbordamiento es demasiado grande. Supongamos que el map primero agrega una gran cantidad de elementos, y luego elimina una gran cantidad de elementos. En este caso, muchos buckets pueden estar vacíos, y algunos buckets pueden tener muchos elementos. La distribución de datos es muy desigual, y相当多的 buckets de desbordamiento están vacíos, ocupando mucha memoria. Para resolver este tipo de problemas, se necesita crear un nuevo map de la misma capacidad, y reasignar buckets de hash. Este proceso se llama expansión de igual cantidad. Por lo tanto, en realidad no es una operación de expansión, solo es una redistribución secundaria de todos los elementos para hacer que la distribución de datos sea más uniforme. La operación de expansión de igual cantidad se combina en la operación de expansión incremental, y la lógica es completamente consistente con la expansión incremental. La capacidad del map antiguo y nuevo es completamente igual.
En la función hashGrow, si el factor de carga no supera el umbral, se realiza la expansión de igual cantidad. Go actualiza el estado de h.flags a sameSizeGrow, y h.B no se incrementa en uno. Por lo tanto, la capacidad del nuevo bucket de hash creado tampoco cambiará. Correspondiente al siguiente código:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)En la función evacuate, al crear inicialmente la estructura eavcDst, si es expansión de igual cantidad, solo se creará una estructura apuntando al nuevo bucket. Correspondiente al siguiente código:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Y al reubicar elementos, la expansión de igual cantidad no recalculará el valor hash, y no hay selección de mitad superior e inferior:
if !h.sameSizeGrow() {
// 重新计算哈希值
hash := t.Hasher(k2, uintptr(h.hash0))
// 处理 k2 != k2 的特殊情况,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Excepto por esto, el resto de la lógica es completamente consistente con la expansión incremental. Después de la reasignación de buckets de hash mediante la expansión de igual cantidad, el número de buckets de desbordamiento disminuirá, y los buckets de desbordamiento antiguos serán reciclados por GC.