CGO
Dado que Go requiere GC (Garbage Collection), para algunos escenarios con mayores requisitos de rendimiento, Go puede no ser la mejor opción. C, como lenguaje de programación de sistemas tradicional, tiene un rendimiento excelente, y CGO puede conectar ambos lenguajes permitiendo llamadas mutuas. Go puede llamar a C para delegar tareas sensibles al rendimiento, mientras Go se encarga de la lógica de alto nivel. CGO también soporta que C llame a Go, aunque este escenario es menos común y no se recomienda.
TIP
El entorno de demostración de código en este artículo es Windows 10, usando gitbash como línea de comandos. Se recomienda que los usuarios de Windows instalen mingw previamente.
Sobre CGO, hay una introducción oficial: C? Go? Cgo! - The Go Programming Language. Si desea una introducción más detallada, puede consultar cmd/cgo/doc.go en la biblioteca estándar, o ver directamente la documentación cgo command - cmd/cgo - Go Packages, ambos contenidos son idénticos.
Llamada de código
Veamos el siguiente ejemplo
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}Para usar la funcionalidad CGO, simplemente importe import "C". Tenga en cuenta que C debe estar en mayúscula y el nombre de importación no puede ser reescrito. También debe asegurarse de que la variable de entorno CGO_ENABLED esté configurada como 1, que por defecto está habilitada.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1Además, debe asegurarse de tener la cadena de herramientas de construcción C/C++ localmente, es decir, gcc. En Windows, esto sería mingw, para garantizar que el programa se compile correctamente. Ejecute el siguiente comando para compilar. Tenga en cuenta que después de habilitar CGO, el tiempo de compilación será mayor que el de Go puro.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!Otro punto importante es que después de habilitar CGO, no se podrá realizar compilación cruzada.
Go embebe código C
CGO permite escribir código C directamente en archivos fuente de Go y luego llamarlo directamente. Vea el siguiente ejemplo, donde se escribe una función llamada printSum y luego se llama desde la función main en Go.
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}Salida
c:1+2=3Esto es adecuado para escenarios simples. Si hay mucho código C, mezclarlo con código Go reduce considerablemente la legibilidad, por lo que no se recomienda en esos casos.
Manejo de errores
En Go, el manejo de errores se hace mediante valores de retorno, pero C no permite múltiples valores de retorno. Para esto se puede usar errno de C, que indica que ocurrió un error durante la llamada a la función. CGO es compatible con esto, permitiendo manejar errores con valores de retorno al llamar funciones C, igual que en Go. Para usar errno, primero importe errno.h. Vea el siguiente ejemplo
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}Salida
syscall.Errno
The device does not recognize the command.Puede ver que el tipo de error es syscall.Errno. errno.h define muchos otros códigos de error que puede explorar por su cuenta.
Go importa archivos C
Al importar archivos C, se puede resolver el problema mencionado anteriormente. Primero cree un archivo de encabezado sum.h con el siguiente contenido
int sum(int a, int b);Luego cree sum.c y escriba la función específica
#include "sum.h"
int sum(int a, int b) {
return a + b;
}Luego importe el archivo de encabezado en main.go
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}Ahora para compilar, debe especificar la carpeta actual, de lo contrario no encontrará el archivo C
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3En el código, res es una variable en Go, y C.sum es una función en C. Su valor de retorno es int de C, no int de Go. La llamada es exitosa porque CGO realiza la conversión de tipos.
C llama a Go
C llamando a Go se refiere a C llamando a Go dentro de CGO, no a programas C nativos llamando a Go. La cadena de llamadas es go-cgo-c->cgo->go. Go llama a C para aprovechar el ecosistema y rendimiento de C. Casi no existe la necesidad de programas C nativos llamando a Go; si existe, se recomienda usar comunicación de red en su lugar.
CGO permite exportar funciones Go para que C las llame. Para exportar una función Go, agregue el comentario //export func_name encima de la firma de la función, y tanto sus parámetros como valores de retorno deben ser tipos soportados por CGO. Ejemplo
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Modifique el archivo sum.c con el siguiente contenido
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}También modifique el archivo de encabezado sum.h
void do_sum();Luego exporte la función en Go
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Ahora la función sum usada en C es realmente proporcionada por Go. La salida es
20El punto clave es el archivo _cgo_export.h importado en sum.c, que contiene información sobre todos los tipos exportados de Go. Si no lo importa, no podrá usar las funciones exportadas de Go. Otro punto importante es que _cgo_export.h no puede importarse en archivos Go, porque este archivo de encabezado se genera solo cuando todos los archivos fuente de Go pueden compilar. Por lo tanto, la siguiente forma de escribir es incorrecta
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}El compilador indicará que el archivo de encabezado no existe
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.Si una función Go tiene múltiples valores de retorno, C recibirá una estructura al llamarla.
Por cierto, podemos pasar punteros de Go a C a través de parámetros de funciones C. Durante la llamada a la función C, CGO intentará garantizar la seguridad de memoria, pero el valor de retorno de una función Go exportada no puede contener punteros, porque en este caso CGO no puede determinar si está siendo referenciado ni fijar la memoria. Si la memoria retornada es referenciada y luego esta memoria es recolectada por el GC en Go o se desplaza, resultará en un puntero fuera de límites, como se muestra a continuación.
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}La forma de escribir anterior no está permitida por defecto. Si desea desactivar esta verificación, puede configurar
GODEBUG=cgocheck=0Tiene dos niveles de verificación, puede establecerlo como 1 o 2. Cuanto mayor sea el nivel, mayor será el costo de verificación en tiempo de ejecución. Puede consultar cgo command - passing_pointer para más detalles.
Conversión de tipos
CGO crea un mapeo entre los tipos de C y Go para facilitar sus llamadas en tiempo de ejecución. Para los tipos de C, después de importar import "C" en Go, en la mayoría de los casos puede acceder directamente a través de
C.typenamePor ejemplo
C.int(1)
C.char('a')Pero los tipos de C pueden estar compuestos por múltiples palabras clave, como
unsigned charEn este caso no se puede acceder directamente, pero puede usar la palabra clave typedef de C para dar un alias al tipo, lo cual es equivalente a los alias de tipo en Go. Por ejemplo
typedef unsigned char byte;Así, puede acceder al tipo unsigned char a través de C.byte. Ejemplo
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}Salida
a
b
cEn la mayoría de los casos, CGO ya ha creado alias para los tipos comunes (tipos básicos, etc.). También puede definir los suyos propios según el método anterior, no habrá conflictos.
char
El tipo char de C corresponde al tipo int8 de Go, y unsigned char corresponde al tipo uint8 de Go, que es el tipo byte.
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}Salida
type: main._Ctype_char, val: 99Si cambia el parámetro de set a C.char(math.MaxInt8 + 1), la compilación fallará con el siguiente error
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charCadenas
CGO proporciona algunas pseudo-funciones para pasar cadenas y slices de bytes entre C y Go. Estas funciones en realidad no existen, no puede encontrar su definición. Al igual que import "C", el paquete C tampoco existe, solo es para conveniencia de los desarrolladores. Después de la compilación, se convertirán en otras operaciones.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteLas cadenas en Go son esencialmente una estructura que contiene una referencia a un array subyacente. Al pasar a una función C, necesita usar C.CString() para crear una "cadena" en C usando malloc, asignando espacio de memoria y retornando un puntero C. Como C no tiene un tipo cadena, generalmente se usa char* para representar cadenas, que es un puntero a un array de caracteres. Recuerde usar free para liberar la memoria después de usarla.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}También puede ser del tipo array de char, ambos son esencialmente lo mismo, punteros al primer elemento.
void printfGoString(char s[]) {
puts(s);
}También puede pasar slices de bytes. Como C.CBytes() retorna un unsafe.Pointer, debe convertirlo a tipo *C.char antes de pasarlo a la función C.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}La salida de los ejemplos anteriores es la misma
this is a go stringEstos métodos de pasar cadenas involucran una copia de memoria. Después de pasar, en realidad hay una copia tanto en la memoria de C como en la de Go, lo cual es más seguro. Dicho esto, aún podemos pasar punteros directamente a funciones C, y también podemos modificar cadenas de Go directamente desde C. Vea el siguiente ejemplo
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}Salida
this is a go stringEl ejemplo usa unsafe.SliceData para obtener directamente el puntero al array subyacente de la cadena, y lo convierte a un puntero C antes de pasarlo a la función C. La memoria de esta cadena es gestionada por Go, por lo que no necesita free. La ventaja es que el proceso de paso no requiere copia, pero tiene cierto riesgo. El siguiente ejemplo demuestra cómo modificar una cadena de Go desde C
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}Salida
this is a go string
this is c go string
this is c go stringEnteros
La relación de mapeo de enteros entre Go y C se muestra en la siguiente tabla. Puede encontrar más información sobre el mapeo de tipos de enteros en la biblioteca estándar cmd/cgo/gcc.go.
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
Código de ejemplo
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO también proporciona soporte para los tipos de enteros de <stdint.h>, donde el tamaño de memoria de los tipos es más claro y definido, y su estilo de nomenclatura es muy similar al de Go.
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
Al usar CGO, se recomienda usar los tipos de enteros de <stdint.h>.
Números de punto flotante
El mapeo de tipos de punto flotante entre Go y C es el siguiente
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
Código de ejemplo
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}Slices
La situación de los slices es similar a la de las cadenas mencionadas anteriormente. La diferencia es que CGO no proporciona pseudo-funciones para copiar slices. Si quiere que C acceda a un slice de Go, solo puede pasar el puntero del slice. Vea el siguiente ejemplo
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}Salida
0 1 2 3 4 5 6 7 8 9Aquí se pasa el puntero al array subyacente del slice a la función C. Como la memoria de este array es gestionada por Go, no se recomienda que C mantenga una referencia a su puntero por mucho tiempo. Por el contrario, el ejemplo de usar un array de C como array subyacente de un slice de Go es el siguiente
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}Salida
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7A través de la función unsafe.Slice puede convertir un puntero de array en un slice. Por intuición, un array en C es solo un puntero al primer elemento, así que normalmente debería usarse así
goslice := unsafe.Slice(&C.s, l)A través de la salida puede ver que si hace esto, excepto por el primer elemento, toda la memoria restante está fuera de límites.
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]Aunque un array en C es solo un puntero de cabeza, después de ser envuelto por CGO se convierte en un array de Go con su propia dirección, por lo que debe tomar la dirección del primer elemento del array.
goslice := unsafe.Slice(&C.s[0], l)Estructuras
A través del prefijo C.struct_ más el nombre de la estructura, puede acceder a estructuras de C. Las estructuras de C no pueden ser embebidas como estructuras anónimas en estructuras de Go. El siguiente es un ejemplo simple de una estructura de C
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}Salida
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}Si algunos miembros de una estructura de C contienen bit-field, CGO ignorará esos miembros. Por ejemplo, modifique person de la siguiente manera
struct person {
int32_t age: 1;
char* name;
};Al ejecutar nuevamente, se producirá un error
p.age undefined (type _Ctype_struct_person has no field or method age)Las reglas de alineación de memoria de los campos de estructuras en C y Go no son las mismas. Si CGO está habilitado, en la mayoría de los casos C será el predominante.
Uniones
Usando C.union_ más el nombre puede acceder a uniones de C. Como Go no soporta uniones, estas existen como arrays de bytes en Go. El siguiente es un ejemplo simple
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}Salida
[4]uint8 [0 0 0 0]A través de unsafe.Pointer puede acceder y modificar
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}Salida
0
1024
[0 4 0 0]Enumeraciones
A través del prefijo C.enum_ más el nombre del tipo de enumeración puede acceder a tipos de enumeración de C. El siguiente es un ejemplo simple
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}Salida
0 alive
1 deadPunteros
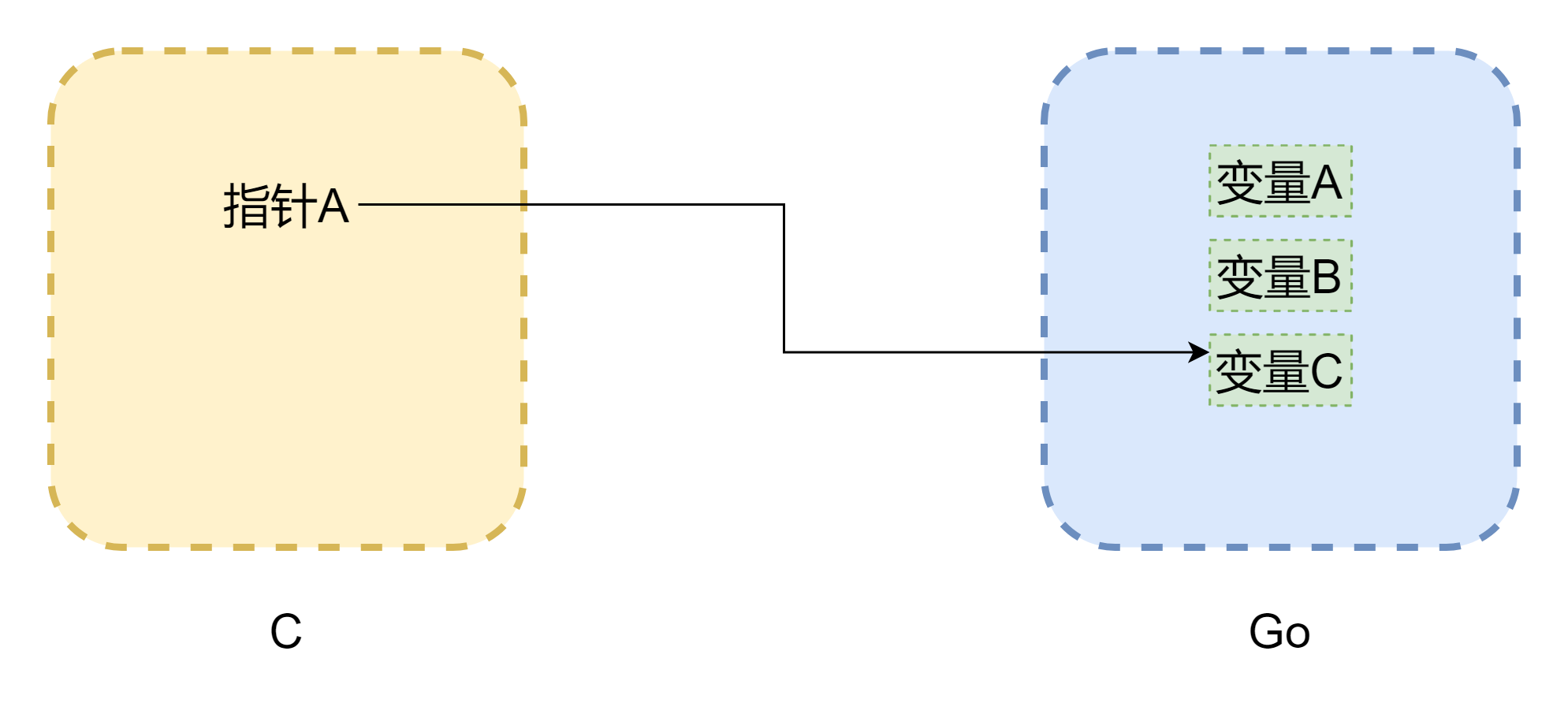
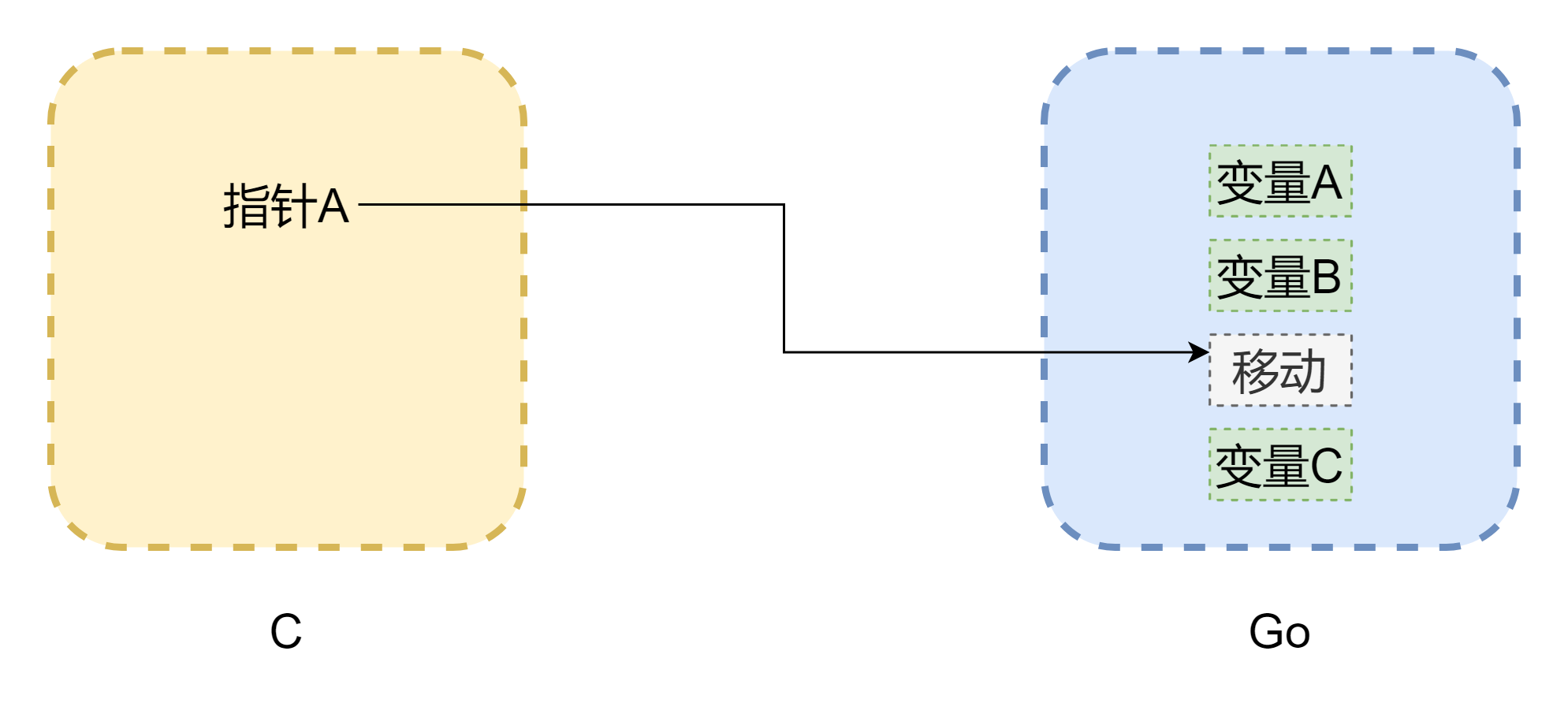
Cuando se habla de punteros, no se puede evitar el tema de la memoria. El mayor problema de las llamadas mutuas entre CGO es que los modelos de memoria de los dos lenguajes son diferentes. La memoria de C es completamente gestionada manualmente por el desarrollador, usando malloc() para asignar memoria y free() para liberarla. Si no se libera manualmente, nunca se liberará por sí misma, por lo que la gestión de memoria de C es muy estable. Go es diferente, tiene GC, y el espacio de pila de las Goroutines se ajusta dinámicamente. Cuando el espacio de pila es insuficiente, crece, lo que puede causar que las direcciones de memoria cambien, como se muestra en la figura anterior (el dibujo no es riguroso). Los punteros pueden convertirse en punteros colgados comunes en C. Aunque CGO puede evitar el movimiento de memoria en la mayoría de los casos (usando runtime.Pinner para fijar la memoria), la documentación oficial de Go no recomienda que C mantenga referencias a memoria de Go por mucho tiempo. Por el contrario, es más seguro que punteros de Go referencien memoria de C, a menos que llame manualmente C.free(), esta memoria no será liberada automáticamente.
Si desea pasar punteros entre C y Go, primero debe convertirlos a unsafe.Pointer, y luego convertirlos al tipo de puntero correspondiente, igual que void* en C. Veamos dos ejemplos. El primero es un ejemplo de un puntero de C referenciando una variable de Go, y además modificando la variable.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}Salida
1
3
3El segundo es un ejemplo de un puntero de Go referenciando una variable de C y modificándola.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}Salida
10
11Por cierto, CGO no soporta punteros de función de C.
Bibliotecas enlazadas
C no tiene gestión de dependencias como Go. Para usar bibliotecas escritas por otros, además de obtener directamente el código fuente, hay otra opción: bibliotecas de enlace estático y dinámico. CGO también soporta esto, lo que nos permite importar bibliotecas escritas por otros en programas Go sin necesidad del código fuente.
Bibliotecas de enlace dinámico
Las bibliotecas de enlace dinámico no pueden ejecutarse solas. Se cargan en memoria junto con el ejecutable en tiempo de ejecución. A continuación se demuestra cómo crear una biblioteca de enlace dinámico simple y usarla con CGO. Primero prepare un archivo lib/sum.c con el siguiente contenido
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}Escriba el archivo de encabezado lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);Luego use gcc para crear la biblioteca de enlace dinámico. Primero compile para generar el archivo objeto
$ cd lib
$ gcc -c sum.c -o sum.oLuego cree la biblioteca de enlace dinámico
$ gcc -shared -o libsum.dll sum.oUna vez creada, importe el archivo de encabezado sum.h en el código Go, y también debe indicar a CGO a través de macros dónde encontrar los archivos de biblioteca
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Iindica la ruta relativa para buscar archivos de encabezado-Lindica la ruta de búsqueda de bibliotecas,${SRCDIR}representa la ruta absoluta del directorio actual, porque su parámetro debe ser una ruta absoluta-lindica el nombre del archivo de biblioteca, sum essum.dll
CFFLAGS y LDFLAGS son opciones de compilación de gcc. Por razones de seguridad, CGO deshabilita algunos parámetros. Consulte cgo command para más detalles.
Coloque la biblioteca dinámica en el mismo directorio que el exe
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goFinalmente compile el programa Go y ejecútelo
$ go build main.go && ./main.exe
3La llamada a la biblioteca de enlace dinámico fue exitosa.
Bibliotecas de enlace estático
A diferencia de las bibliotecas de enlace dinámico, al importar una biblioteca de enlace estático con CGO, se enlazará con el archivo objeto de Go para formar un solo ejecutable. Usemos sum.c como ejemplo. Primero compile el archivo fuente en un archivo objeto
$ gcc -o sum.o -c sum.cLuego empaquete el archivo objeto en una biblioteca de enlace estático (debe comenzar con el prefijo lib, de lo contrario no se encontrará)
$ ar rcs libsum.a sum.oContenido del archivo Go
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}Compile
$ go build && ./main.exe
3La llamada a la biblioteca de enlace estático fue exitosa.
Conclusión
Aunque el propósito de usar CGO es el rendimiento, el cambio entre C y Go también causa una pérdida de rendimiento no menor. Para algunas tareas muy simples, la eficiencia de CGO no es tan buena como la de Go puro. Veamos un ejemplo
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}Esta es una prueba muy simple. Se escribió una función de suma de dos números tanto en C como en Go, y cada una se ejecutó 1 millón de veces para calcular el tiempo promedio. Los resultados de la prueba son
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opDe los resultados se puede ver que el tiempo promedio de CGO es más de veinte veces mayor que el de Go puro. Si lo que se ejecuta no es una simple suma de dos números, sino una tarea más costosa, la ventaja de CGO será mayor. Además, usar CGO tiene las siguientes desventajas
- Muchas herramientas de la cadena de Go no podrán usarse, como gotest, pprof. El ejemplo de prueba anterior no puede usar gotest, solo se puede escribir manualmente.
- La velocidad de compilación se ralentiza, y la compilación cruzada incorporada ya no se puede usar
- Problemas de seguridad de memoria
- Problemas de dependencias, si otros usan su biblioteca, también deben habilitar CGO
Antes de considerar cuidadosamente, no introduzca CGO en su proyecto. Para algunas tareas muy complejas, usar CGO puede traer beneficios, pero si son solo tareas simples, es mejor quedarse con Go puro.