CGO
Como Go precisa de GC, para alguns cenários com requisitos de desempenho mais altos, Go pode não ser muito adequado para processamento. C, como uma linguagem de programação de sistemas tradicional, tem um desempenho excelente, e CGO pode conectar os dois, permitindo chamadas mútuas. Go pode chamar C, delegando tarefas sensíveis ao desempenho para C, enquanto Go fica responsável pela lógica de nível superior. CGO também suporta C chamando Go, embora esse cenário seja menos comum e não seja muito recomendado.
TIP
O ambiente de demonstração do código neste artigo é Windows 10, a linha de comando usa gitbash, e recomenda-se que usuários Windows instalem o mingw com antecedência.
Sobre CGO, há uma introdução simples oficial: C? Go? Cgo! - The Go Programming Language. Se você quiser uma introdução mais detalhada, pode obter informações mais detalhadas na biblioteca padrão cmd/cgo/doc.go, ou pode consultar diretamente a documentação cgo command - cmd/cgo - Go Packages, o conteúdo é exatamente o mesmo.
Chamada de Código
Veja o exemplo abaixo
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}Para usar o recurso CGO, basta ativar através da declaração de importação import "C". Note que C deve ser uma letra maiúscula e o nome da importação não pode ser reescrito. Além disso, certifique-se de que a variável de ambiente CGO_ENABLED esteja definida como 1. Por padrão, essa variável de ambiente já está habilitada.
$ go env | grep CGO
$ go env -w CGO_ENABLED=1Além disso, você precisa garantir que o sistema local tenha a toolchain de construção C/C++, ou seja, gcc. Na plataforma Windows, isso é o mingw, para garantir que o programa compile normalmente. Execute o seguinte comando para compilar. Depois de ativar o CGO, o tempo de compilação será maior do que o Go puro.
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!Outro ponto importante a notar é que, após ativar o CGO, a compilação cruzada não será mais suportada.
Go Incorpora Código C
CGO suporta escrever código C diretamente no arquivo fonte Go e depois chamá-lo diretamente. Veja o exemplo abaixo, onde uma função chamada printSum é escrita e depois chamada na função main do Go.
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}Saída
c:1+2=3Isso é adequado para cenários simples. Se houver muito código C, misturá-lo com o código Go reduz muito a legibilidade, então não é muito adequado fazer isso.
Tratamento de Erros
Em Go, o tratamento de erros é feito através de valores de retorno, mas C não permite múltiplos valores de retorno. Para isso, você pode usar errno em C, que indica que ocorreu um erro durante a chamada da função. CGO é compatível com isso, permitindo que ao chamar funções C você possa tratar erros com valores de retorno como em Go. Para usar errno, primeiro inclua errno.h. Veja o exemplo abaixo
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}Saída
syscall.Errno
The device does not recognize the command.Você pode ver que o tipo de erro é syscall.Errno. errno.h também define muitos outros códigos de erro que você pode explorar por conta própria.
Go Importa Arquivo C
Ao importar arquivos C, você pode resolver bem o problema mencionado acima. Primeiro, crie um arquivo de cabeçalho sum.h com o seguinte conteúdo
int sum(int a, int b);Depois crie sum.c e escreva a função específica
#include "sum.h"
int sum(int a, int b) {
return a + b;
}Depois importe o arquivo de cabeçalho em main.go
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}Agora, para compilar, você precisa especificar a pasta atual, caso contrário o arquivo C não será encontrado, como mostrado abaixo
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3No código, res é uma variável em Go, e C.sum é uma função em C. Seu valor de retorno é int em C, não int em Go. A razão pela qual a chamada é bem-sucedida é porque CGO faz a conversão de tipos.
C Chama Go
C chamando Go refere-se a C chamando Go dentro do CGO, não programas C nativos chamando Go. A cadeia de chamadas é go-cgo-c->cgo->go. Go chama C para aproveitar o ecossistema e o desempenho de C. Quase não há necessidade de programas C nativos chamando Go, e se houver, recomenda-se usar comunicação de rede como alternativa.
CGO suporta exportar funções Go para C chamar. Para exportar uma função Go, adicione o comentário //export func_name acima da assinatura da função, e seus parâmetros e valores de retorno devem ser tipos suportados pelo CGO. Exemplo abaixo
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Reescreva o arquivo sum.c com o seguinte conteúdo
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}E modifique o arquivo de cabeçalho sum.h
void do_sum();Depois exporte a função em Go
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}Agora a função sum usada em C é realmente fornecida por Go. O resultado da saída é
20O ponto chave é a importação de _cgo_export.h no arquivo sum.c, que contém informações sobre todos os tipos exportados por Go. Se não importar, não será possível usar as funções exportadas por Go. Outro ponto de atenção é que _cgo_export.h não pode ser importado em arquivos Go, porque a pré-condição para gerar esse arquivo de cabeçalho é que todos os arquivos fonte Go possam ser compilados. Portanto, a seguinte forma de escrever está errada
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}O compilador indicará que o arquivo de cabeçalho não existe
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.Se a função Go tiver múltiplos valores de retorno, C receberá uma estrutura ao chamá-la.
A propósito, podemos passar ponteiros Go para C através de parâmetros de função C. Durante a chamada da função C, CGO tentará garantir a segurança da memória, mas o valor de retorno de funções Go exportadas não pode conter ponteiros, porque nesse caso CGO não consegue determinar se está sendo referenciado, e também não consegue fixar a memória. Se a memória retornada for referenciada e depois essa memória for coletada pelo GC em Go ou sofrer deslocamento, isso resultará em ponteiro fora dos limites, como mostrado abaixo.
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}A forma de escrever acima não é permitida por padrão na compilação. Se quiser desativar essa verificação, pode configurar da seguinte forma.
GODEBUG=cgocheck=0Existem dois níveis de verificação, que podem ser definidos como 1 ou 2. Quanto maior o nível, maior o overhead de tempo de execução causado pela verificação. Você pode visitar cgo command - passing_pointer para mais detalhes.
Conversão de Tipos
CGO faz um mapeamento entre os tipos de C e Go para facilitar suas chamadas em tempo de execução. Para tipos em C, após importar import "C" em Go, na maioria dos casos você pode acessá-los diretamente através de
C.typenamePor exemplo
C.int(1)
C.char('a')Mas tipos em C podem ser compostos por múltiplas palavras-chave, como
unsigned charNesse caso, não é possível acessá-los diretamente. No entanto, você pode usar a palavra-chave typedef em C para dar um alias ao tipo, o que é equivalente ao alias de tipo em Go. Como abaixo
typedef unsigned char byte;Dessa forma, você pode acessar o tipo unsigned char através de C.byte. Exemplo abaixo
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}Saída
a
b
cNa maioria dos casos, CGO já definiu aliases para tipos comuns (tipos básicos, etc.). Você também pode definir seus próprios aliases seguindo o método acima, sem conflitos.
char
O tipo char em C corresponde ao tipo int8 em Go, e unsigned char corresponde ao tipo uint8 em Go, que é o tipo byte.
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}Saída
type: main._Ctype_char, val: 99Se você mudar o parâmetro de set para C.char(math.MaxInt8 + 1), a compilação falhará com o seguinte erro
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_charStrings
CGO fornece algumas pseudo-funções para passar strings e slices de bytes entre C e Go. Essas funções na verdade não existem, e você não consegue encontrar suas definições. Assim como import "C", o pacote C também não existe, é apenas para conveniência dos desenvolvedores. Após a compilação, elas serão convertidas em outras operações.
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byteStrings em Go são essencialmente uma struct que contém uma referência a um array subjacente. Ao passar para uma função C, você precisa usar C.CString() para criar uma "string" em C usando malloc, alocando espaço de memória para ela, e então retornar um ponteiro C. Como C não tem um tipo string, geralmente se usa char* para representar strings, que é um ponteiro para um array de caracteres. Lembre-se de usar free para liberar a memória após o uso.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}Também pode ser do tipo array de char, ambos são iguais, são ponteiros para o elemento inicial.
void printfGoString(char s[]) {
puts(s);
}Você também pode passar slices de bytes. Como C.CBytes() retorna um unsafe.Pointer, antes de passar para a função C, você precisa convertê-lo para o tipo *C.char.
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}A saída dos exemplos acima é a mesma
this is a go stringEsses métodos de passagem de string envolvem uma cópia de memória. Após a passagem, na verdade, há uma cópia na memória C e outra na memória Go, o que é mais seguro. Dito isso, ainda podemos passar ponteiros diretamente para funções C, e também podemos modificar strings Go diretamente em C. Veja o exemplo abaixo
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}Saída
this is a go stringO exemplo usa unsafe.SliceData para obter diretamente o ponteiro do array subjacente da string, e depois de convertê-lo para um ponteiro C, passa para a função C. A memória dessa string é gerenciada por Go, então naturalmente não há necessidade de free. A vantagem de fazer isso é que o processo de passagem não requer cópia, mas há certo risco. O exemplo abaixo demonstra a modificação de uma string Go em C
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}Saída
this is a go string
this is c go string
this is c go stringInteiros
A relação de mapeamento de inteiros entre Go e C é mostrada na tabela abaixo. Informações sobre o mapeamento de tipos inteiros também podem ser encontradas na biblioteca padrão cmd/cgo/gcc.go.
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
Código de exemplo
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}CGO também oferece suporte aos tipos inteiros de <stdint.h>, onde os tamanhos de memória dos tipos são mais claros e definidos, e o estilo de nomenclatura é muito semelhante ao de Go.
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
Ao usar CGO, recomenda-se usar os tipos inteiros de <stdint.h>.
Números de Ponto Flutuante
O mapeamento de tipos de números de ponto flutuante entre Go e C é o seguinte
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
Código de exemplo
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}Slices
A situação dos slices é na verdade semelhante à das strings mencionadas acima, mas a diferença é que CGO não fornece pseudo-funções para copiar slices. Para que C acesse slices em Go, você só pode passar o ponteiro do slice. Veja o exemplo abaixo
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}Saída
0 1 2 3 4 5 6 7 8 9Aqui o ponteiro do array subjacente do slice é passado para a função C. Como a memória desse array é gerenciada por Go, não é recomendado que C mantenha uma referência de ponteiro por muito tempo. Por outro lado, um exemplo de usar um array C como array subjacente de um slice Go é mostrado abaixo
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}Saída
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7Através da função unsafe.Slice, você pode converter um ponteiro de array em um slice. Por intuição, um array em C é apenas um ponteiro para o elemento inicial, então normalmente deveria ser usado assim
goslice := unsafe.Slice(&C.s, l)Através da saída, você pode ver que se fizer isso, exceto pelo primeiro elemento, toda a memória restante estará fora dos limites.
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]Mesmo que um array em C seja apenas um ponteiro inicial, depois de ser envolvido pelo CGO, ele se torna um array Go com seu próprio endereço, então você deve obter o endereço do elemento inicial do array.
goslice := unsafe.Slice(&C.s[0], l)Structs
Através do prefixo C.struct_ mais o nome da struct, você pode acessar structs C. Structs C não podem ser incorporadas como structs anônimas em structs Go. Abaixo está um exemplo simples de uma struct C
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}Saída
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}Se alguns membros da struct C contiverem bit-field, CGO ignorará esses membros da struct. Por exemplo, modifique person para o seguinte
struct person {
int32_t age: 1;
char* name;
};Ao executar novamente, ocorrerá um erro
p.age undefined (type _Ctype_struct_person has no field or method age)As regras de alinhamento de memória dos campos de struct em C e Go não são as mesmas. Se o CGO estiver ativado, na maioria dos casos C será o predominante.
Uniões
Usando C.union_ mais o nome, você pode acessar uniões em C. Como Go não suporta uniões, elas existem em Go na forma de arrays de bytes. Abaixo está um exemplo simples
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}Saída
[4]uint8 [0 0 0 0]Através de unsafe.Pointer, você pode acessar e modificar
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}Saída
0
1024
[0 4 0 0]Enumerações
Através do prefixo C.enum_ mais o nome do tipo de enumeração, você pode acessar tipos de enumeração em C. Abaixo está um exemplo simples
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}Saída
0 alive
1 deadPonteiros
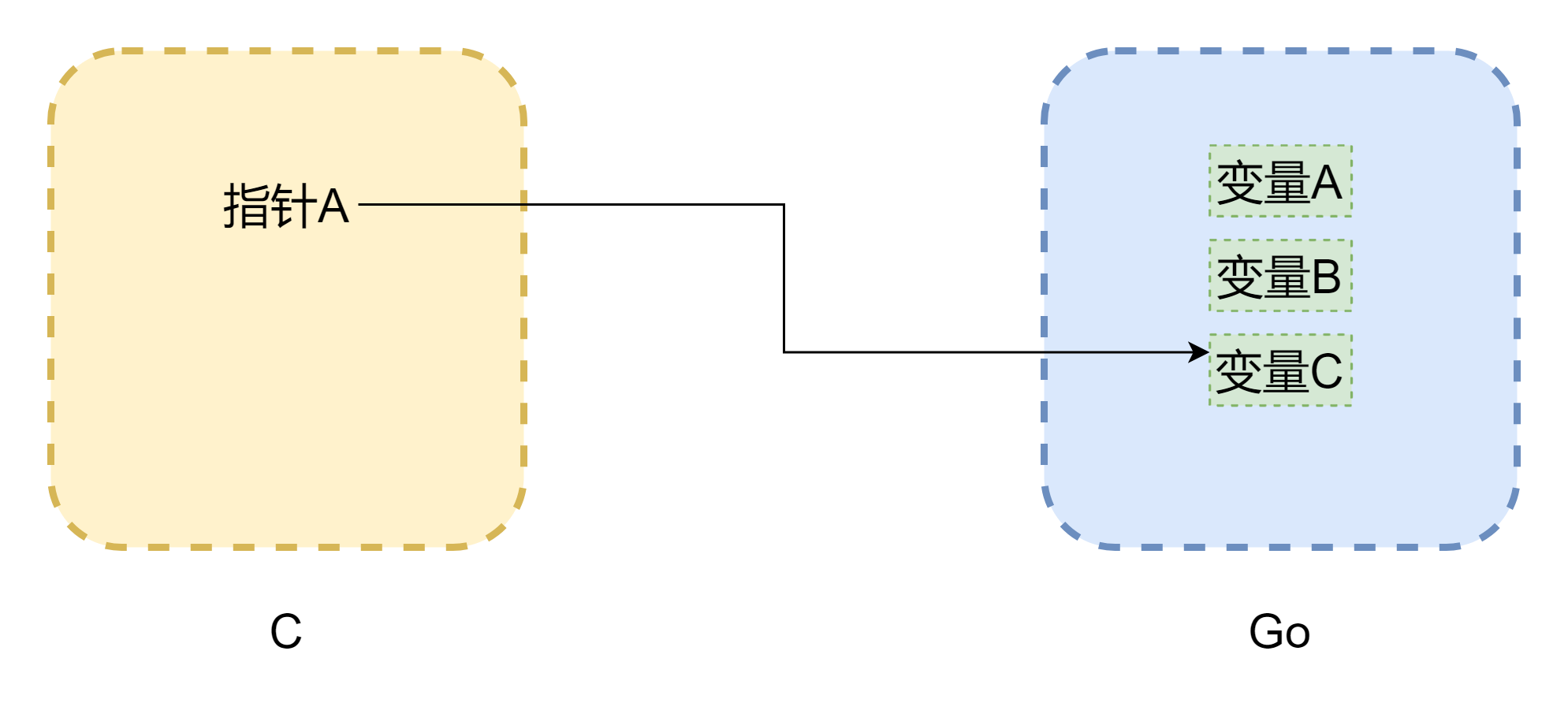
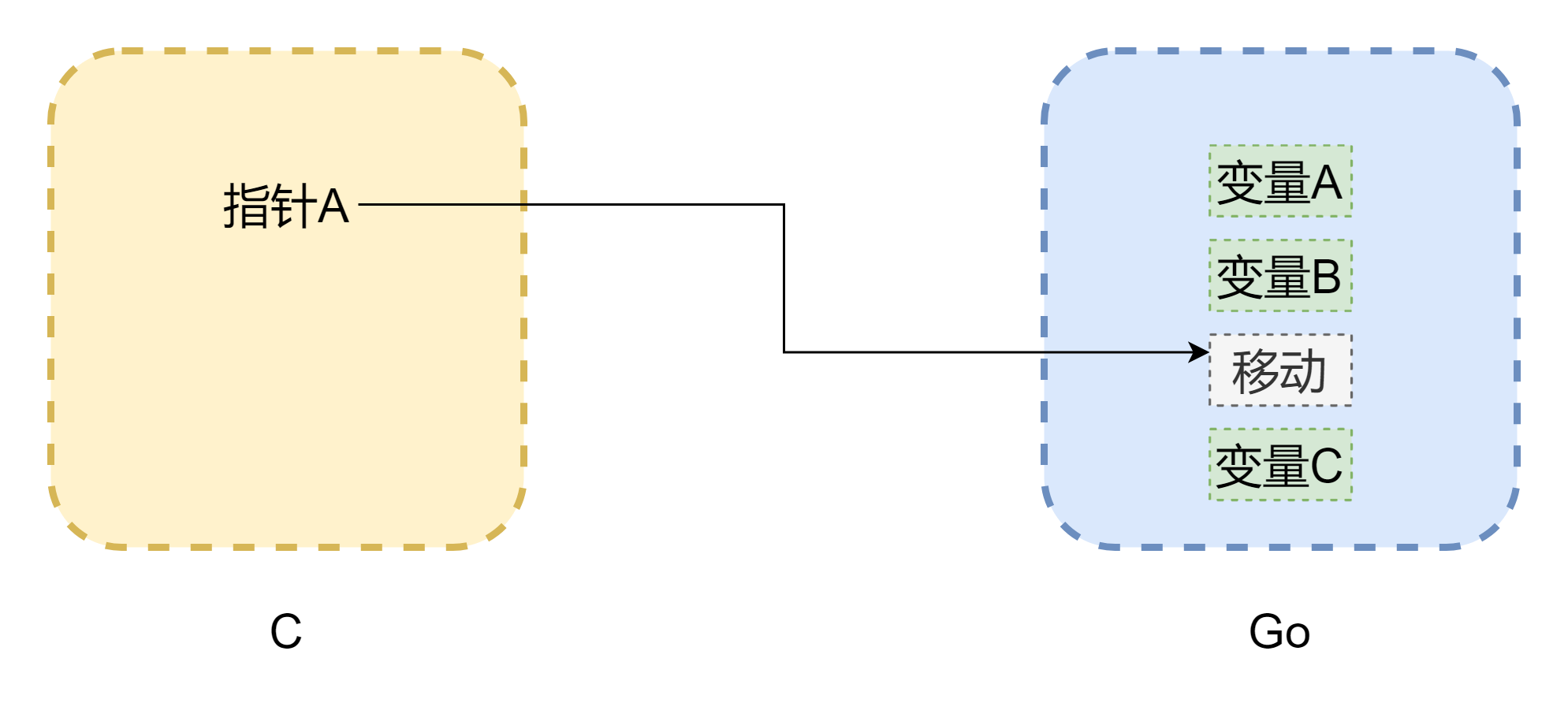
Quando se fala de ponteiros, não se pode evitar o assunto da memória. O maior problema das chamadas mútuas entre CGO é que os modelos de memória das duas linguagens não são os mesmos. A memória em C é completamente gerenciada manualmente pelo desenvolvedor, usando malloc() para alocar memória e free() para liberar memória. Se não for liberada manualmente, ela nunca será liberada por si só, então o gerenciamento de memória em C é muito estável. Go é diferente, pois tem GC, e o espaço de stack das Goroutines é ajustado dinamicamente. Quando o espaço de stack é insuficiente, ele cresce, e assim o endereço de memória pode mudar, como mostrado na figura acima (a figura não é rigorosa). O ponteiro pode se tornar um ponteiro pendente comum em C. Mesmo que CGO possa evitar a movimentação de memória na maioria dos casos (usando runtime.Pinner para fixar a memória), a equipe oficial de Go também não recomenda que C mantenha referências de memória Go por muito tempo. Por outro lado, é mais seguro quando ponteiros em Go referenciam memória em C, a menos que você chame C.free() manualmente, caso contrário essa memória não será liberada automaticamente.
Se você quiser passar ponteiros entre C e Go, primeiro precisa convertê-los para unsafe.Pointer, e depois convertê-los para o tipo de ponteiro correspondente, assim como void* em C. Veja dois exemplos. O primeiro é um exemplo de ponteiro C referenciando uma variável Go, e também modificando a variável.
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}Saída
1
3
3O segundo é um exemplo de ponteiro Go referenciando uma variável C e modificando-a.
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}Saída
10
11A propósito, CGO não suporta ponteiros de função em C.
Bibliotecas de Link
C não tem um gerenciamento de dependências como Go. Para usar bibliotecas escritas por outras pessoas diretamente, além de obter o código fonte diretamente, há outra maneira que é usar bibliotecas de link estático e dinâmico. CGO também suporta isso. Graças a isso, podemos importar bibliotecas escritas por outras pessoas em programas Go sem precisar do código fonte.
Biblioteca de Link Dinâmico
Uma biblioteca de link dinâmico não pode ser executada sozinha. Ela é carregada na memória junto com o executável em tempo de execução. Abaixo demonstraremos como criar uma biblioteca de link dinâmico simples e usá-la com CGO. Primeiro, prepare um arquivo lib/sum.c com o seguinte conteúdo
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}Escreva o arquivo de cabeçalho lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);Em seguida, use gcc para criar a biblioteca de link dinâmico. Primeiro, compile para gerar o arquivo objeto
$ cd lib
$ gcc -c sum.c -o sum.oDepois crie a biblioteca de link dinâmico
$ gcc -shared -o libsum.dll sum.oApós a criação, importe o arquivo de cabeçalho sum.h no código Go, e também precisa informar ao CGO através de macros onde encontrar os arquivos de biblioteca
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -Irefere-se ao caminho relativo para buscar arquivos de cabeçalho-Lrefere-se ao caminho de busca da biblioteca,${SRCDIR}representa o caminho absoluto do caminho atual, porque seu parâmetro deve ser um caminho absoluto-lrefere-se ao nome do arquivo da biblioteca, sum ésum.dll.
CFFLAGS e LDFLAGS são ambas opções de compilação do gcc. Por questões de segurança, CGO desabilitou alguns parâmetros. Visite cgo command para mais detalhes.
Coloque a biblioteca dinâmica no mesmo diretório do exe
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.goFinalmente, compile e execute o programa Go
$ go build main.go && ./main.exe
3A chamada da biblioteca de link dinâmico foi bem-sucedida.
Biblioteca de Link Estático
Diferente da biblioteca de link dinâmico, ao usar CGO para importar uma biblioteca de link estático, ela será linkada junto com o arquivo objeto Go em um único executável. Ainda usando sum.c como exemplo, primeiro compile o arquivo fonte em um arquivo objeto
$ gcc -o sum.o -c sum.cDepois empacote o arquivo objeto em uma biblioteca de link estático (deve começar com o prefixo lib, caso contrário não será encontrada)
$ ar rcs libsum.a sum.oConteúdo do arquivo Go
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}Compile
$ go build && ./main.exe
3A chamada da biblioteca de link estático foi bem-sucedida.
Conclusão
Embora o objetivo de usar CGO seja o desempenho, alternar entre C e Go também causa uma perda de desempenho não insignificante. Para algumas tarefas muito simples, a eficiência do CGO não é tão boa quanto a do Go puro. Veja um exemplo
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}Este é um teste muito simples. Funções de soma de dois números foram escritas em C e Go respectivamente, e cada uma foi executada 1 milhão de vezes para calcular o tempo médio. Os resultados do teste são
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/opA partir dos resultados, você pode ver que o tempo médio do CGO é mais de vinte vezes maior do que o do Go puro. Se o que está sendo executado não é apenas uma simples soma de dois números, mas uma tarefa mais demorada, a vantagem do CGO será maior. Além disso, usar CGO tem as seguintes desvantagens
- Muitas ferramentas da cadeia de ferramentas Go não poderão ser usadas, como gotest, pprof. O exemplo de teste acima não pode usar gotest, só pode ser escrito manualmente.
- A velocidade de compilação fica mais lenta, e a compilação cruzada integrada também não pode mais ser usada
- Problemas de segurança de memória
- Problemas de dependência, se outros usarem sua biblioteca, também precisarão ativar o CGO.
Antes de considerar completamente, não introduza CGO em seus projetos. Para algumas tarefas muito complexas, usar CGO pode realmente trazer benefícios, mas se for apenas para tarefas simples, é melhor continuar usando Go puro.