slice
TIP
A leitura deste artigo requer conhecimento da biblioteca padrão unsafe.
O slice é provavelmente a estrutura de dados mais usada na linguagem Go, sem exceção (na verdade, não há muitas estruturas de dados integradas), e pode ser vista em quase todos os lugares. O uso básico foi explicado na introdução à linguagem. Abaixo veremos como é sua estrutura interna e como funciona internamente.
Estrutura
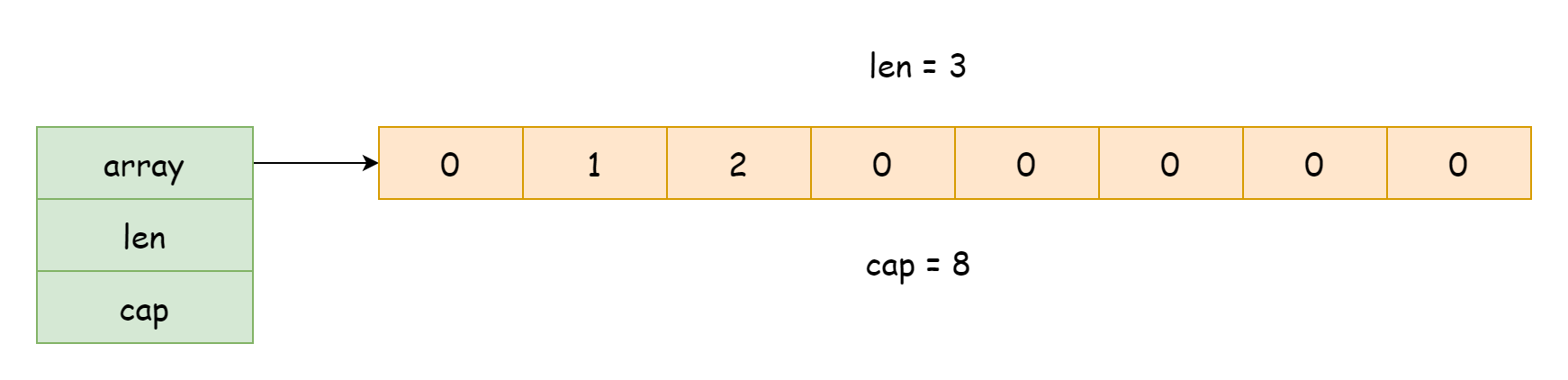
A implementação do slice está localizada no arquivo runtime/slice.go. Em tempo de execução, o slice existe como uma estrutura do tipo runtime.slice, como mostrado abaixo.
type slice struct {
array unsafe.Pointer
len int
cap int
}Esta estrutura possui apenas três campos:
array, ponteiro para o array subjacentelen, comprimento do slice, refere-se ao número de elementos já existentes no arraycap, capacidade do slice, refere-se ao número total de elementos que o array pode容纳
Pelas informações acima, podemos ver que a implementação subjacente do slice ainda depende de um array. Normalmente, é apenas uma estrutura que mantém uma referência ao array, juntamente com registros de capacidade e comprimento. Isso torna a transferência de slices muito eficiente, pois apenas a referência aos dados é copiada, não todos os dados. Além disso, ao usar len e cap para obter o comprimento e capacidade do slice, estamos apenas acessando os valores dos campos, sem necessidade de percorrer o array.
No entanto, isso também traz alguns problemas difíceis de detectar. Veja o exemplo abaixo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]No código acima, s1 é criado através de slicing, mas tanto ele quanto o slice original referenciam o mesmo array subjacente. Modificar os dados em s1 também causa mudanças em s. Portanto, ao copiar um slice, deve-se usar a função copy, que cria um slice independente. Vejamos outro exemplo:
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Novamente usando slicing para copiar, mas desta vez não afeta o slice original. Inicialmente, s1 e s realmente apontavam para o mesmo array, mas posteriormente muitos elementos foram adicionados a s1, excedendo a capacidade do array. Assim, um novo array maior foi alocado para armazenar os elementos, então no final eles apontam para arrays diferentes. Você pode pensar que não há mais problemas, mas vejamos outro exemplo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Embora elementos tenham sido adicionados, o slice impresso está vazio. Na verdade, os dados foram realmente adicionados ao slice, mas escritos no array subjacente. Os parâmetros de função em Go são passados por valor, então o parâmetro s é uma cópia da estrutura do slice original. A operação append retorna um novo slice com comprimento atualizado após adicionar elementos, mas o que é atribuído é o parâmetro s, não o slice original s. Eles não têm realmente nenhuma conexão.
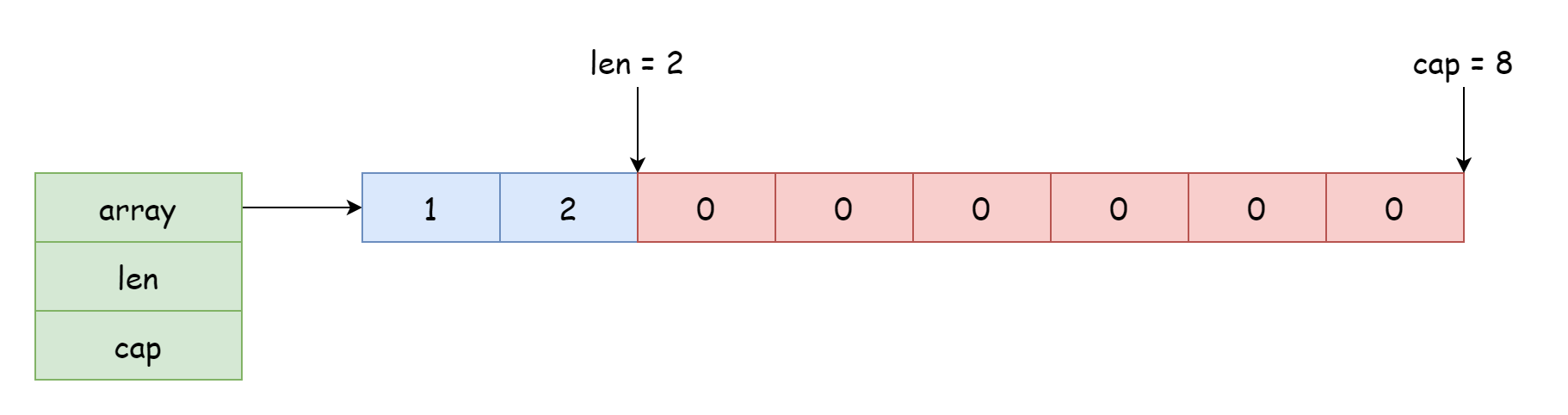
Para um slice, a posição inicial que pode ser acessada e modificada depende da posição de referência ao array. O offset é determinado pelo comprimento registrado na estrutura. O ponteiro na estrutura pode apontar não apenas para o início, mas também para o meio do array, como mostrado na figura abaixo.
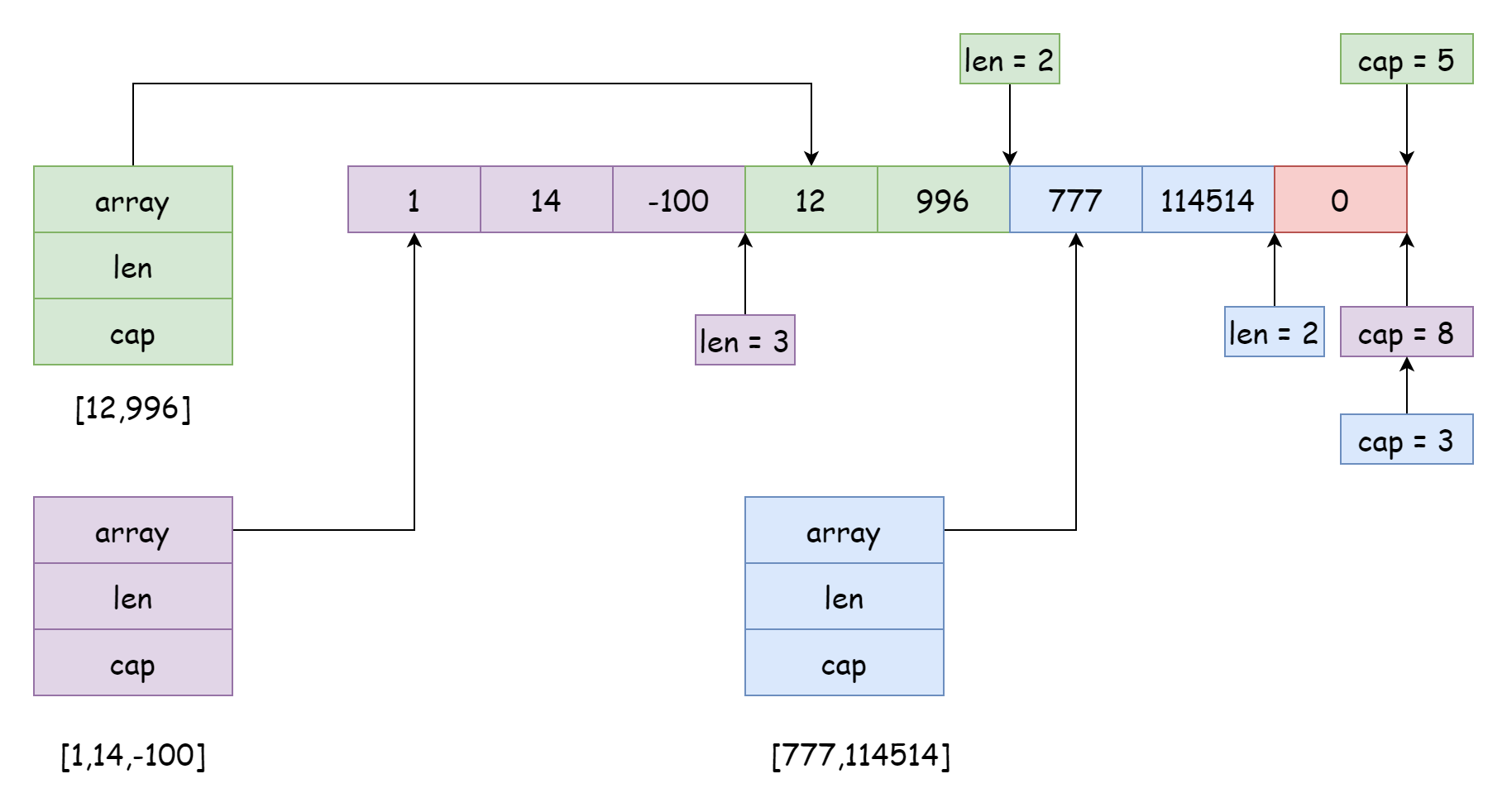
Um array subjacente pode ser referenciado por muitos slices, e as posições e escopos de referência podem ser diferentes, como na figura acima. Essa situação geralmente ocorre ao fazer slicing, como no código abaixo:
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]Ao fazer slicing, a capacidade do novo slice é igual ao comprimento do array menos a posição inicial de referência do novo slice. Por exemplo, a capacidade do novo slice criado por s[4:6] é 6 = 10 - 4. Claro, o escopo de referência do slice não precisa necessariamente ser adjacente, e pode ser entrelaçado, mas isso pode causar grandes problemas. Os dados do slice atual podem ser modificados por outro slice sem conhecimento, como o slice roxo na figura acima. Se elementos forem adicionados usando append posteriormente, pode sobrescrever os dados dos slices verde e azul. Para evitar essa situação, Go permite definir o escopo de capacidade ao fazer slicing, com a sintaxe abaixo:
s4 = s[4:6:6]Neste caso, sua capacidade é limitada a 2, então adicionar elementos acionará a expansão. Após a expansão, torna-se um novo array, sem relação com o array original, evitando efeitos colaterais. Você pensou que os problemas sobre slices terminaram aqui? Na verdade não, vejamos outro exemplo:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// A quantidade de elementos adicionados é exatamente maior que a capacidade
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]O código não tem diferença do exemplo anterior, apenas os parâmetros de entrada foram modificados para que a quantidade de elementos adicionados seja exatamente maior que a capacidade do slice. Isso aciona a expansão durante a adição. Como resultado, os dados não são adicionados ao slice original s, e nem mesmo o array subjacente é escrito. Podemos confirmar isso usando ponteiros unsafe, como no código abaixo:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// A quantidade de elementos adicionados é exatamente maior que a capacidade
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,Como pode ser visto, o array subjacente do slice original está vazio, sem nada. Todos os dados foram escritos no novo array. Mas isso não tem relação com o slice original, porque mesmo que append retorne uma nova referência, apenas o valor do parâmetro s é modificado, sem afetar o slice original s. O slice como estrutura pode ser muito leve, mas os problemas acima não podem ser ignorados, especialmente no código real onde esses problemas geralmente estão bem escondidos e difíceis de detectar.
Criação
Em tempo de execução, a criação de slices usando a função make é realizada por runtime.makeslice. Sua lógica é bastante simples, e a assinatura da função é:
func makeslice(et *_type, len, cap int) unsafe.PointerRecebe três parâmetros: tipo do elemento, comprimento e capacidade. Após concluir, retorna um ponteiro para o array subjacente. O código é o seguinte:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Calcula a memória total necessária. Se for muito grande, pode causar overflow numérico
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Se estiver tudo bem, aloca memória
return mallocgc(mem, et, true)
}Como pode ser visto, a lógica é muito simples, fazendo apenas duas coisas:
- Calcular a memória necessária
- Alocar espaço de memória
Se a verificação de condições falhar, ocorre panic:
- Overflow numérico ao calcular memória
- Resultado do cálculo maior que a memória máxima alocável
- Comprimento e capacidade inválidos
Se a memória calculada for maior que 32KB, ela será alocada no heap. Após isso, retorna um ponteiro para o array subjacente. A construção da estrutura runtime.slice não é feita pela função makeslice. Na verdade, a construção da estrutura é feita durante a compilação. A função makeslice em tempo de execução é apenas responsável por alocar memória, como no código abaixo:
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capSe estiver interessado, pode verificar o código intermediário gerado, que é semelhante a este:
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8Se usar um array para criar um slice, como abaixo:
var arr [5]int
s := arr[:]O processo é semelhante ao código abaixo:
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo usa diretamente o array como array subjacente do slice, então modificar os dados no slice também afeta os dados do array. Ao criar um slice usando um array, o comprimento é igual a high-low, e a capacidade é igual a max-low, onde max é por padrão o comprimento do array, ou também pode ser especificado manualmente durante o slicing, por exemplo:
var arr [5]int
s := arr[2:3:4]
Acesso
O acesso a slices usa indexação por subscrito, assim como arrays:
elem := s[i]A operação de acesso ao slice é concluída durante a compilação, gerando código intermediário. O código final gerado pode ser entendido como o pseudocódigo abaixo:
p := s.ptr
e := *(p + sizeof(elem(s)) * i)Na verdade, acessa o elemento no índice correspondente através de operação de movimentação de ponteiro, correspondendo à parte do código na função cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Desloca o ponteiro
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)Ao acessar o comprimento e capacidade do slice usando as funções len e cap, o princípio é o mesmo, também correspondendo a parte do código na função cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))No código realmente gerado, acessa o campo len na estrutura do slice movendo o ponteiro, que pode ser entendido como o pseudocódigo abaixo:
p := &s
len := *(p + 8)
cap := *(p + 16)Se houver o seguinte código:
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}Então o código intermediário em uma determinada fase da geração provavelmente será assim:
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9Dá para ver claramente que um adiciona 8 e outro adiciona 16, obviamente acessando os campos do slice através de deslocamento de ponteiro.
Se for possível inferir o comprimento e capacidade durante a compilação, não será necessário deslocar o ponteiro em tempo de execução para obter os valores. Por exemplo, nesta situação não é necessário mover o ponteiro:
s := make([]int, 10, 20)
l := len(s)
c := cap(s)Os valores das variáveis l e c serão diretamente substituídos por 10 e 20.
Escrita
Modificação
s := make([]int, 10)
s[0] = 100Ao modificar o valor de um slice através de índice, durante a compilação é gerado pseudocódigo semelhante através da operação OpStore:
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valO código intermediário em uma determinada fase da geração provavelmente será assim:
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:O código acessa o comprimento do slice para verificar se o índice é válido, e finalmente armazena o elemento movendo o ponteiro.
Adição
A função append pode adicionar elementos a um slice:
var s []int
s = append(s, 1, 2, 3)Após adicionar elementos, retorna uma nova estrutura de slice. Se não houver expansão, apenas o comprimento é atualizado em relação ao slice original; caso contrário, apontará para um novo array. Os problemas de uso de append foram explicados em detalhes na parte Estrutura. Abaixo focaremos em como append funciona.
Em tempo de execução, não há uma função como runtime.appendslice correspondente. O trabalho de adicionar elementos é feito durante a compilação. A função append é expandida para código intermediário correspondente. O código de julgamento está na função cmd/compile/internal/walk/assign.go walkassign:
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}Podemos ver que são divididos em três situações:
- Adicionar vários elementos
- Adicionar um slice
- Adicionar um slice criado temporariamente
Abaixo explicaremos como o código gerado se parece, para entender como append realmente funciona. Se estiver interessado no processo de geração de código, pode pesquisar por conta própria.
Adicionar elementos
s = append(s, x, y, z)Se estiver adicionando um número limitado de elementos, será expandido pela função walkAppend para o seguinte código:
// Quantidade de elementos a serem adicionados
const argc = len(args) - 1
newLen := s.len + argc
// É necessário expandir?
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zPrimeiro calcula a quantidade de elementos a serem adicionados, depois julga se é necessário expandir, e finalmente atribui um por um.
Adicionar slice
s = append(s, s1...)Se estiver adicionando diretamente um slice, será expandido pela função appendSlice para o seguinte código:
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Ainda como antes, calcula o novo comprimento, julga se é necessário expandir. A diferença é que Go não adiciona os elementos do slice original um por um, mas escolhe copiar diretamente a memória.
Adicionar slice temporário
s = append(s, make([]T, l2)...)Se estiver adicionando um slice criado temporariamente, será expandido pela função extendslice para o seguinte código:
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)Para slices adicionados temporariamente, Go obtém o comprimento do slice temporário. Se a capacidade do slice atual não for suficiente para acomodar, tentará expandir. Após concluir, também limpará a parte correspondente da memória.
Expansão
Pelo conteúdo da parte de estrutura, sabemos que o slice subjacente ainda é um array. O array é uma estrutura de dados de comprimento fixo, mas o comprimento do slice é variável. Quando a capacidade do array é insuficiente, o slice solicitará uma área de memória maior para armazenar dados, ou seja, um novo array. Em seguida, copia os dados antigos para o novo array, e a referência do slice apontará para o novo array. Esse processo é chamado de expansão. O trabalho de expansão é realizado em tempo de execução pela função runtime.growslice, cuja assinatura é:
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceExplicação simples dos parâmetros:
oldPtr, ponteiro para o array antigonewLen, comprimento do novo array,newLen = oldLen + numoldCap, capacidade do slice antigo, que é igual ao comprimento do array antigoet, tipo do elemento
Seu retorno é um novo slice, que não tem nenhuma relação com o slice original. O único ponto em comum é que os dados salvos são os mesmos.
var s []int
s = append(s, elems...)Ao usar append para adicionar elementos, é solicitado que o valor retornado sobrescreva o slice original. Se ocorrer expansão, o retornado é um novo slice.
Na expansão, primeiro é necessário determinar o novo comprimento e capacidade, correspondendo ao código abaixo:
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Dobrar capacidade
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Overflow numérico
if newcap <= 0 {
newcap = newLen
}
}
}Pelo código acima, para slices com capacidade menor que 256, a capacidade dobra. Para slices com capacidade maior ou igual a 256, será pelo menos 1,25 vezes a capacidade original. Quando o slice é menor, aumentar diretamente o dobro a cada vez pode evitar expansões frequentes. Quando o slice é maior, a taxa de expansão será reduzida, evitando solicitar muita memória e causar desperdício.
Após obter o novo comprimento e capacidade, calcula-se a memória necessária, correspondendo ao código abaixo:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Capacidade final
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}A fórmula de cálculo de memória é mem = cap * sizeof(et). Para facilitar o alinhamento de memória, durante o processo a memória calculada será arredondada para cima para uma potência de 2, e o novo容量 será recalculado. Se o novo容量 for muito grande causando overflow numérico no cálculo, ou se a nova memória exceder a memória máxima alocável, ocorrerá panic.
var p unsafe.Pointer
// Alocar memória
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}Após calcular os resultados necessários, aloca-se memória do tamanho especificado, limpa-se a memória da região de newLen a newCap, copia-se os dados do array antigo para o novo slice, e finalmente constrói-se a estrutura do slice.
Cópia
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)Ao usar a função copy para copiar slices, a função cmd/compile/internal/walk.walkcopy determina durante a compilação de que forma o código será gerado para copiar. Se for chamado em tempo de execução, usará a função runtime.slicecopy, responsável por copiar slices. A assinatura da função é:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intRecebe os ponteiros e comprimentos dos slices de origem e destino, bem como o comprimento a ser copiado width. A lógica desta função é muito simples, como mostrado abaixo:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Calcula o número de bytes a serem copiados
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}O valor de width depende do mínimo dos comprimentos dos dois slices. Podemos ver que, ao copiar slices, não se percorre elemento por elemento para copiar, mas escolhe copiar diretamente blocos inteiros de memória do array subjacente. Quando o slice é grande, o impacto de desempenho da cópia de memória não é pequeno.
Se não for chamado em tempo de execução, será expandido para código na seguinte forma:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Ambas as formas têm o mesmo princípio, ambas copiam slices copiando memória. A função memmove é implementada em assembly. Se estiver interessado, pode visualizar os detalhes em runtime/memmove_amd64.s.
Limpeza
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}Na versão go1.21, foi adicionada a função integrada clear que pode ser usada para limpar o conteúdo de um slice, ou seja, definir todos os elementos como valor zero. Quando a função clear age sobre um slice, o compilador expande durante a compilação através da função cmd/compile/internal/walk.arrayClear para a forma abaixo:
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}Primeiro julga se o comprimento do slice é 0, depois calcula o número de bytes a serem limpos, e divide em duas situações dependendo se o elemento é um ponteiro. Mas no final usará a função memclrNoHeapPointers, cuja assinatura é:
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)Recebe dois parâmetros: um é o ponteiro para o endereço inicial, e outro é o offset, ou seja, o número de bytes a serem limpos. O endereço inicial da memória é o endereço da referência mantida pelo slice, e o offset n = sizeof(et) * len. Esta função é implementada em assembly. Se estiver interessado, pode verificar os detalhes em runtime/memclr_amd64.s.
Vale mencionar que, se o código fonte tentar limpar o array usando iteração, como este:
for i := range s {
s[i] = ZERO_val
}Antes da função clear, normalmente era assim que se limpava slices. Durante a compilação, agora este código será otimizado pela função cmd/compile/internal/walk.arrayRangeClear para a forma abaixo:
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Parar o loop
i = len(s) - 1
}
}A lógica é exatamente a mesma que acima, com uma linha extra i = len(s)-1, cujo propósito é parar o loop após a limpeza da memória.
Iteração
for i, e := range s {
fmt.Println(i, e)
}Ao iterar sobre um slice usando for range, a função walkRange em cmd/compile/internal/walk/range.go expande para a forma abaixo:
// Copiar estrutura
hs := s
// Obter ponteiro do array subjacente
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}Podemos ver que a implementação de for range ainda itera sobre os elementos movendo o ponteiro. Para evitar que o slice seja atualizado durante a iteração, uma cópia da estrutura hs é feita antecipadamente. Para evitar que o ponteiro aponte para memória fora dos limites após a iteração, hu usa o tipo uintptr para armazenar o endereço, convertendo para unsafe.Pointer apenas quando necessário acessar elementos.
A variável v2 é o e em for range. Durante todo o processo de iteração, é sempre a mesma variável, apenas será sobrescrita, não recriada. Este ponto causou o problema de variáveis de loop que困扰了 desenvolvedores Go por dez anos. Até a versão go1.21, o oficial finalmente decidiu resolver. Prevê-se que em atualizações de versões futuras, a criação de v2 pode se tornar assim:
v2 := *hpO processo de construção do código intermediário foi omitido aqui, pois não pertence ao conhecimento sobre slices. Se estiver interessado, pode pesquisar por conta própria.