slice
TIP
Для чтения этой статьи требуются знания из стандартной библиотеки unsafe.
Срез, вероятно, наиболее часто используемая структура данных в языке Go (на самом деле встроенных структур данных немного). Его можно встретить практически везде. Основное использование среза описано во введении в язык. Ниже рассмотрим его внутреннее устройство и то, как он работает.
Структура
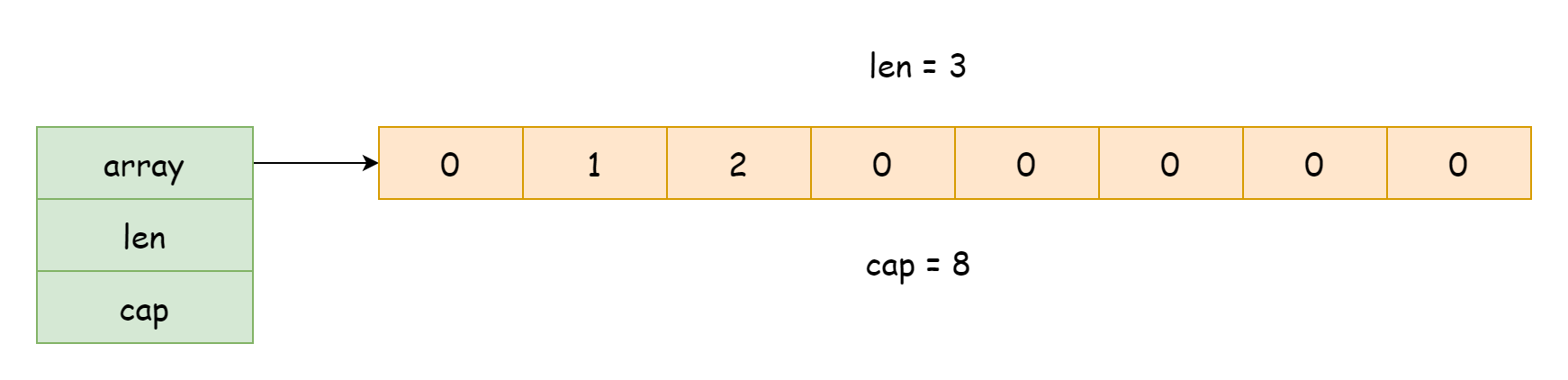
Реализация среза находится в файле runtime/slice.go. Во время выполнения срез существует как структура типа runtime.slice:
type slice struct {
array unsafe.Pointer
len int
cap int
}Эта структура содержит всего три поля:
array— указатель на базовый массивlen— длина среза, количество элементов в массивеcap— ёмкость среза, общее количество элементов, которое может вместить массив
Из этого следует, что底层 реализация среза зависит от массива. В обычном состоянии это просто структура, содержащая ссылку на массив и записи о длине и ёмкости. Передача среза имеет очень низкую стоимость — копируется только ссылка на данные, а не все данные. При использовании len и cap для получения длины и ёмкости среза мы просто получаем значения полей, не перебирая массив.
Однако это также приводит к некоторым неочевидным проблемам. Рассмотрим пример:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]В приведённом коде s1 создаёт новый срез путём разрезания, но и он, и исходный срез ссылаются на один и тот же базовый массив. Изменение данных в s1 также приводит к изменению s. Поэтому при копировании среза следует использовать функцию copy, которая создаёт независимую копию. Рассмотрим ещё один пример:
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]Снова используется разрезание для копирования среза, но на этот раз исходный срез не изменяется. Изначально s1 и s действительно указывали на один и тот же массив, но последующее добавление элементов в s1 превысило ёмкость массива, поэтому был выделен новый больший массив. Таким образом, в конце они указывают на разные массивы.
Кажется, что проблем больше нет, но рассмотрим ещё один пример:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Несмотря на добавление элементов, выводится пустой срез. На самом деле данные действительно были добавлены в срез, но записаны в базовый массив. В Go параметры функций передаются по значению, поэтому параметр s является копией структуры исходного среза. Операция append возвращает срез с обновлённой длиной после добавления элементов, но присваивание происходит параметру s, а не исходному срезу s, поэтому между ними нет связи.
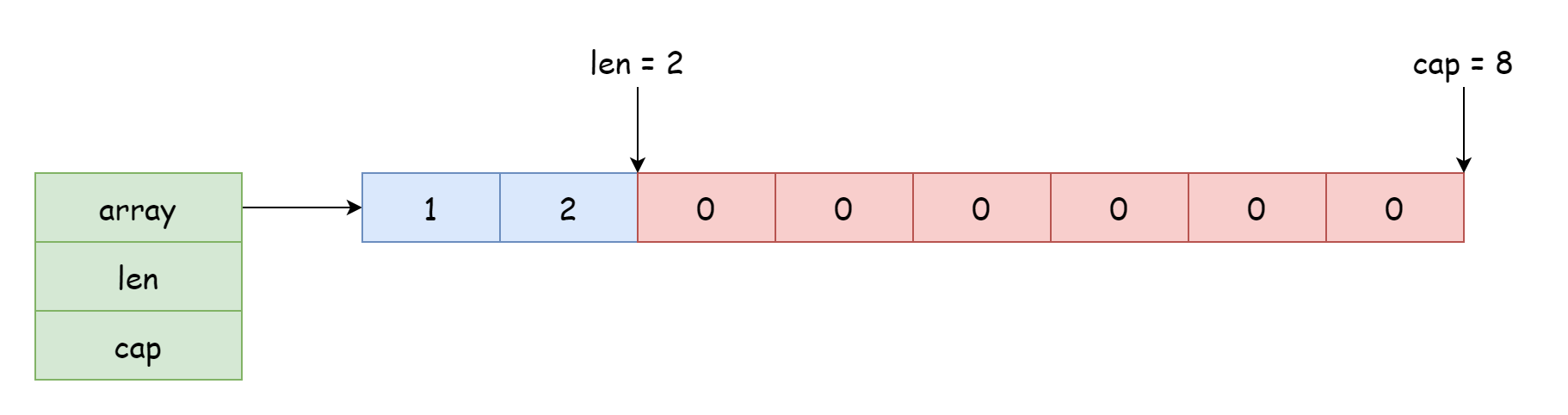
Для среза начальная позиция доступа и изменения зависит от позиции ссылки на массив, смещение определяется длиной, записанной в структуре. Указатель в структуре может указывать не только на начало, но и на середину массива, как показано на рисунке ниже.
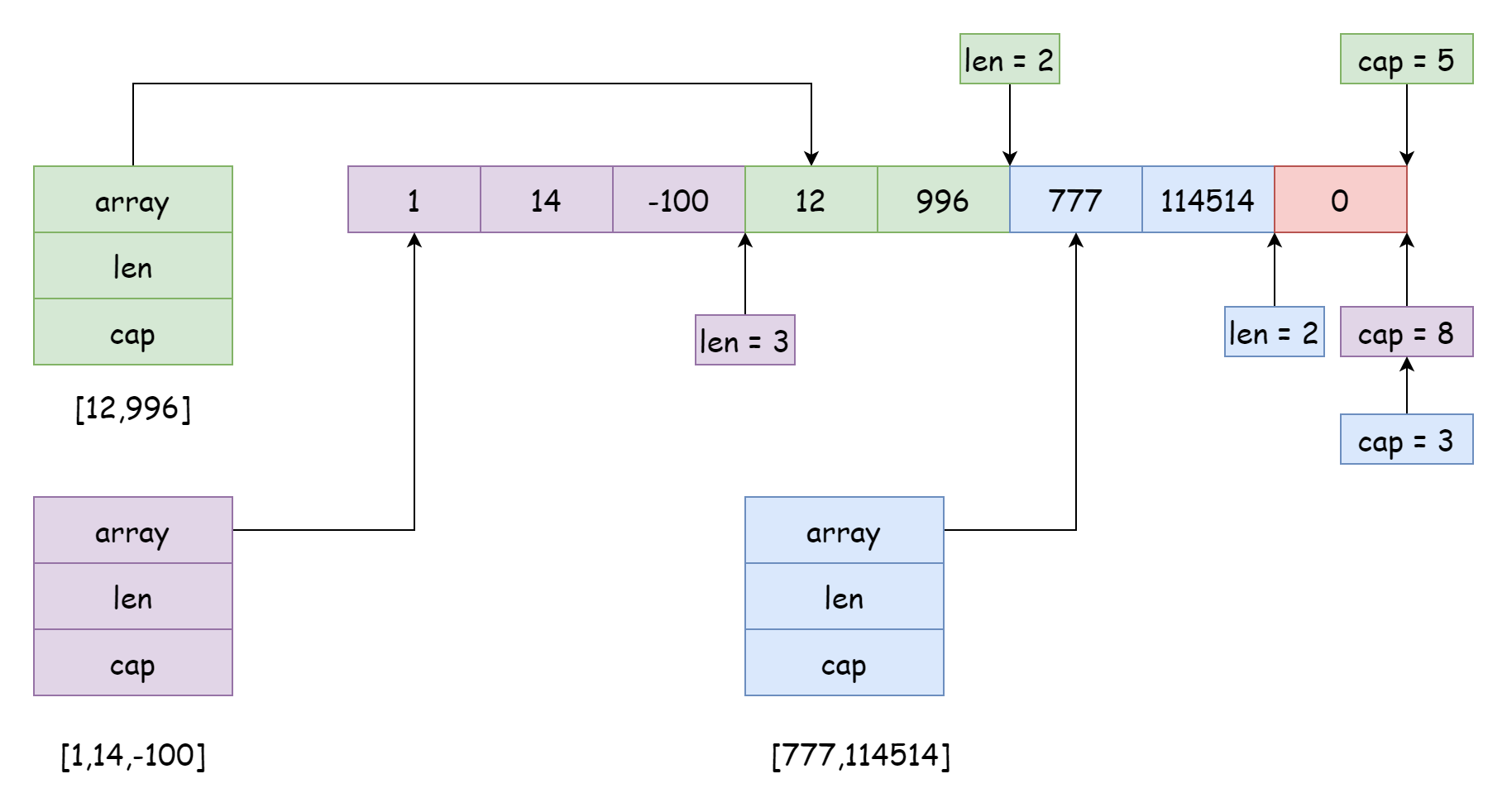
Один базовый массив может быть использован множеством срезов, причём позиции и диапазоны ссылок могут различаться, как показано на рисунке выше. Такая ситуация обычно возникает при разрезании среза, например:
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]При разрезании ёмкость нового среза равна длине массива минус начальная позиция ссылки нового среза. Например, для s[4:6] ёмкость нового среза будет 6 = 10 - 4. Конечно, диапазоны ссылок срезов не обязательно должны быть смежными, они могут пересекаться, но это создаст серьёзные проблемы. Данные текущего среза могут быть изменены другим срезом без ведома разработчика. Например, фиолетовый срез на рисунке выше: если впоследствии использовать append для добавления элементов, можно перезаписать данные зелёного и синего срезов. Чтобы избежать这种情况, Go позволяет устанавливать ёмкость при разрезании:
s4 = s[4:6:6]В этом случае ёмкость ограничивается до 2, поэтому добавление элементов приведёт к расширению, и после расширения это будет новый массив, не связанный с исходным.
Думаете, на этом проблемы со срезами заканчиваются? Вовсе нет. Рассмотрим ещё один пример:
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// Количество добавляемых элементов немного больше ёмкости
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]Код аналогичен предыдущему примеру, но изменено количество добавляемых элементов, чтобы оно немного превышало ёмкость среза. Это приведёт к расширению при добавлении. В результате данные не будут добавлены в исходный срез s, и даже в его базовый массив не будут записаны данные. Это можно подтвердить с помощью указателей unsafe:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// Количество добавляемых элементов немного больше ёмкости
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,Как видно, базовый массив исходного среза пуст, данные были записаны в новый массив. Но это не имеет отношения к исходному срезу, поскольку даже если append вернул новую ссылку, изменяется только значение параметра s, что не влияет на исходный срез s. Срез как структура действительно делает его очень лёгким, но проблемы, описанные выше, нельзя игнорировать, особенно в реальном коде, где эти проблемы обычно скрыты глубоко и их трудно обнаружить.
Создание
Во время выполнения создание среза функцией make выполняется функцией runtime.makeslice. Её логика довольно проста. Сигнатура функции:
func makeslice(et *_type, len, cap int) unsafe.PointerОна принимает три параметра: тип элемента, длину, ёмкость, и возвращает указатель на базовый массив. Код:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// Вычисление необходимого объёма памяти, если слишком большой, может привести к переполнению
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// Если всё в порядке, выделяем память
return mallocgc(mem, et, true)
}Логика очень проста, выполняется всего две вещи:
- Вычисление необходимого объёма памяти
- Выделение памяти
Если проверка условий не проходит, происходит panic:
- Переполнение при вычислении памяти
- Результат вычисления больше максимально допустимой памяти
- Длина и ёмкость нелегальны
Если вычисленная память больше 32KB, она выделяется в куче. После этого возвращается указатель на базовый массив. Построение структуры runtime.slice выполняется не функцией makeslice, а во время компиляции. Функция makeslice во время выполнения только выделяет память, примерно так:
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = capЕсли интересно, можно посмотреть на сгенерированный промежуточный код, который выглядит примерно так:
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8Если для создания среза используется массив, например:
var arr [5]int
s := arr[:]Этот процесс аналогичен следующему коду:
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capGo напрямую использует массив как базовый массив среза, поэтому изменение данных среза также влияет на данные массива. При создании среза из массива длина равна high-low, ёмкость равна max-low, где max по умолчанию равен длине массива, или можно вручную указать ёмкость при разрезании, например:
var arr [5]int
s := arr[2:3:4]
Доступ
Доступ к срезу осуществляется через индексацию, как к массиву:
elem := s[i]Операция доступа к срезу выполняется во время компиляции путём генерации промежуточного кода. В итоге сгенерированный код можно представить следующим псевдокодом:
p := s.ptr
e := *(p + sizeof(elem(s)) * i)Фактически это операция перемещения указателя для доступа к элементу по индексу, что соответствует части кода в функции cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// Смещение указателя
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)При доступе к длине и ёмкости среза через функции len и cap также используется аналогичный подход, что соответствует части кода в функции cmd/compile/internal/ssagen.exprCheckPtr:
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))В фактически сгенерированном коде доступ к полю len структуры среза осуществляется путём перемещения указателя, что можно представить следующим псевдокодом:
p := &s
len := *(p + 8)
cap := *(p + 16)Если есть следующий код:
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}То на определённой стадии промежуточный код, вероятно, будет выглядеть так:
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9Из этого видно, что одно значение со смещением +8, другое +16, очевидно, что доступ к полям среза осуществляется через смещение указателя.
Если во время компиляции можно определить длину и ёмкость, то во время выполнения не потребуется смещение указателя для получения значения. Например, в следующей ситуации не нужно перемещать указатель:
s := make([]int, 10, 20)
l := len(s)
c := cap(s)Значения переменных l и c будут напрямую заменены на 10 и 20.
Запись
Изменение
s := make([]int, 10)
s[0] = 100При изменении значения среза по индексу во время компиляции генерируется псевдокод с операцией OpStore:
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = valНа определённой стадии промежуточный код, вероятно, будет выглядеть так:
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:Видно, что код обращается к длине среза для проверки легальности индекса, затем через перемещение указателя сохраняет элемент.
Добавление
Функция append позволяет добавлять элементы в срез:
var s []int
s = append(s, 1, 2, 3)После добавления элементов она возвращает новую структуру среза. Если расширения не произошло, по сравнению с исходным срезом обновляется только длина, иначе указывается новый массив. Вопросы использования append подробно описаны в разделе Структура, поэтому не будем останавливаться на них. Ниже рассмотрим, как работает append.
Во время выполнения нет функции типа runtime.appendslice. Добавление элементов выполняется на этапе компиляции, функция append разворачивается в соответствующий промежуточный код. Код проверки находится в функции cmd/compile/internal/walk/assign.go walkassign:
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // также работает для append(slice, string).
default:
r = walkAppend(call, init, as)
}Видно три случая:
- Добавление нескольких элементов
- Добавление среза
- Добавление временно созданного среза
Ниже рассмотрим, как выглядит сгенерированный код, чтобы понять, как на самом деле работает append. Процесс генерации кода можно изучить самостоятельно, если интересно.
Добавление элементов
s = append(s, x, y, z)Если добавляется ограниченное количество элементов, функция walkAppend разворачивает это в следующий код:
// Количество добавляемых элементов
const argc = len(args) - 1
newLen := s.len + argc
// Нужно ли расширение
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = zСначала вычисляется количество добавляемых элементов, затем проверяется необходимость расширения, наконец, присваиваются значения по одному.
Добавление среза
s = append(s, s1...)Если добавляется срез, функция appendSlice разворачивает это в следующий код:
newLen := s.len + s1.len
// Сравниваем как uint, чтобы growslice мог panic при переполнении.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))Как и раньше, вычисляется новая длина, проверяется необходимость расширения. Но Go не добавляет элементы исходного среза по одному, а выбирает прямое копирование памяти.
Добавление временного среза
s = append(s, make([]T, l2)...)Если добавляется временно созданный срез, функция extendslice разворачивает это в следующий код:
if l2 >= 0 {
// Пустой блок if здесь для более осмысленного node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// Очистка новой части базового массива.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)Для временно добавляемого среза Go получает длину временного среза. Если ёмкость текущего среза недостаточна, происходит расширение. После этого очищается соответствующая часть памяти.
Расширение
Из раздела о структуре известно, что底层 реализация среза — массив. Массив — структура данных фиксированной длины, но длина среза изменяема. При недостаточной ёмкости массива срез запрашивает большую область памяти для размещения данных — новый массив, копирует в него старые данные, и ссылка среза начинает указывать на новый массив. Этот процесс называется расширением. Расширение выполняется во время выполнения функцией runtime.growslice. Сигнатура функции:
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) sliceКраткое объяснение параметров:
oldPtr— указатель на старый массивnewLen— длина нового массива,newLen = oldLen + numoldCap— ёмкость старого среза, равна длине старого массиваet— тип элемента
Возвращаемое значение — новый срез, который не связан со старым срезом, единственное общее — сохранённые данные.
var s []int
s = append(s, elems...)При добавлении элементов через append требуется, чтобы возвращаемое значение перезаписывало исходный срез. Если произошло расширение, возвращается новый срез.
При расширении сначала необходимо определить новую длину и ёмкость, что соответствует следующему коду:
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// Двойная ёмкость
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// Переполнение
if newcap <= 0 {
newcap = newLen
}
}
}Из приведённого кода следует, что для срезов с ёмкостью меньше 256 ёмкость увеличивается вдвое, а для срезов с ёмкостью 256 и более — как минимум в 1.25 раза. Когда срез мал,每次 увеличение вдвое позволяет избежать частого расширения. Когда срез велик, коэффициент расширения уменьшается, чтобы избежать выделения излишней памяти.
После получения новой длины и ёмкости вычисляется необходимая память, что соответствует следующему коду:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// Конечная ёмкость
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}Формула вычисления памяти: mem = cap * sizeof(et). Для удобства выравнивания памяти в процессе вычисленная память округляется вверх до степени двойки, и повторно вычисляется новая ёмкость. Если новая ёмкость слишком велика и приводит к переполнению при вычислении, или новая память превышает максимально допустимую для выделения, происходит panic.
var p unsafe.Pointer
// Выделение памяти
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}После вычисления необходимых результатов выделяется память указанного размера, затем очищается область памяти от newLen до newCap, данные старого массива копируются в новый срез, наконец, строится структура среза.
Копирование
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)При копировании среза функцией copy способ копирования определяется кодом, сгенерированным во время компиляции cmd/compile/internal/walk.walkcopy. Если вызов происходит во время выполнения, используется функция runtime.slicecopy, отвечающая за копирование среза. Сигнатура функции:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) intОна принимает указатели и длины исходного и целевого срезов, а также длину копирования width. Логика этой функции очень проста:
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// Вычисление количества копируемых байт
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}Значение width определяется минимальной длиной двух срезов. Видно, что при копировании среза элементы не копируются перебором, а напрямую копируется блок памяти базового массива. При большом размере среза копирование памяти оказывает значительное влияние на производительность.
Если вызов происходит не во время выполнения, разворачивается следующий код:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}Принцип обоих способов одинаков — копирование среза через копирование памяти. Функция memmove реализована на ассемблере, детали можно посмотреть в runtime/memmove_amd64.s.
Очистка
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}В версии go1.21 добавлена встроенная функция clear для очистки содержимого среза, то есть обнуления всех элементов. Когда функция clear применяется к срезу, компилятор во время компиляции функцией cmd/compile/internal/walk.arrayClear разворачивает это в следующую форму:
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}Сначала проверяется длина среза, затем вычисляется количество очищаемых байт, затем обработка разделяется на два случая в зависимости от того, является ли элемент указателем. Но в конечном итоге используется функция memclrNoHeapPointers. Сигнатура:
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)Она принимает два параметра: указатель на начальный адрес и смещение, то есть количество очищаемых байт. Начальный адрес памяти — адрес ссылки, удерживаемой срезом, смещение n = sizeof(et) * len. Функция реализована на ассемблере, детали можно посмотреть в runtime/memclr_amd64.s.
Стоит отметить, что если в исходном коде попытаться очистить массив перебором, например:
for i := range s {
s[i] = ZERO_val
}До появления функции clear обычно так и очищали срез. При компиляции этот код теперь оптимизируется функцией cmd/compile/internal/walk.arrayRangeClear:
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// Остановка цикла
i = len(s) - 1
}
}Логика та же, что и выше, добавлена строка i = len(s)-1 для остановки цикла после очистки памяти.
Перебор
for i, e := range s {
fmt.Println(i, e)
}При переборе среза через for range функция walkRange из cmd/compile/internal/walk/range.go разворачивает это в следующую форму:
// Копирование структуры
hs := s
// Получение указателя на базовый массив
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... тело цикла ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}Видно, что реализация for range осуществляется через перемещение указателя для перебора элементов. Чтобы избежать обновления среза во время перебора, заранее копируется структура hs. Чтобы избежать выхода указателя за границы памяти после завершения перебора, hu использует тип uintptr для хранения адреса, преобразуясь в unsafe.Pointer только при доступе к элементу.
Переменная v2, то есть e в for range, на протяжении всего перебора остаётся одной и той же переменной, она только перезаписывается, не создаётся заново. Это вызвало проблему переменной цикла,困扰вшую разработчиков Go десятилетие. В версии go1.21官方 наконец решила исправить это. В будущих версиях создание v2, вероятно, будет выглядеть так:
v2 := *hpПроцесс построения промежуточного кода здесь опущен, это не относится к знаниям о срезах, при желании можно изучить самостоятельно.