Анализ производительности
Когда программа написана, мы требуем от неё не только возможности запуска, но и стабильности и эффективности. С помощью различных тестов мы можем обеспечить большую часть стабильности программы, а для анализа эффективности программы нам нужно провести анализ её производительности. В предыдущих разделах единственным средством анализа производительности было тестирование Benchmark для измерения среднего времени выполнения и распределения памяти определённого функционального модуля. Однако в реальных условиях требования к анализу производительности программ гораздо шире. Иногда нам нужно анализировать общее использование CPU программы, использование памяти, распределение кучи, состояние горутин, пути горячего кода и т.д. Benchmark не может этого обеспечить. К счастью, инструментарий Go интегрирует множество инструментов анализа производительности для разработчиков. Ниже мы рассмотрим их по очереди.
Анализ утечек (Escape Analysis)
В Go распределение памяти переменных определяется компилятором. Обычно переменные распределяются либо в стеке, либо в куче. Если переменная, которая должна была быть распределена в стеке, распределяется в куче, это называется утечкой (escape). Анализ утечек анализирует распределение памяти в программе. Поскольку он выполняется во время компиляции, это вид статического анализа.
TIP
Перейдите к статье Распределение памяти, чтобы узнать, как Go распределяет память.
Локальный указатель
package main
func main() {
GetPerson()
}
type Person struct {
Name string
Mom *Person
}
func GetPerson() Person {
mom := Person{Name: "lili"}
son := Person{Name: "jack", Mom: &mom}
return son
}В функции GetPerson создаётся переменная mom. Поскольку она создана внутри функции, изначально она должна была быть распределена в стеке. Однако на неё ссылается поле Mom переменной son, а son возвращается как значение функции, поэтому компилятор распределяет её в куче. Это очень простой пример, поэтому его нетрудно понять. Но если проект больше, с десятками тысяч строк кода, ручной анализ будет не таким лёгким. Поэтому нужно использовать инструменты для анализа утечек. Как упоминалось ранее, распределение памяти контролируется компилятором, поэтому анализ утечек также выполняется компилятором. Использование очень простое, достаточно выполнить следующую команду:
$ go build -gcflags="-m -m -l"gcflags — это параметры компилятора gc:
-m, выводит рекомендации по оптимизации кода; при указании двух-mвыводится более детально-l, отключает оптимизацию встраивания
Вывод:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:13:2: mom escapes to heap:
./main.go:13:2: flow: son = &mom:
./main.go:13:2: from &mom (address-of) at ./main.go:14:35
./main.go:13:2: from Person{...} (struct literal element) at ./main.go:14:15
./main.go:13:2: from son := Person{...} (assign) at ./main.go:14:6
./main.go:13:2: flow: ~r0 = son:
./main.go:13:2: from return son (return) at ./main.go:15:2
./main.go:13:2: moved to heap: momКомпилятор явно указывает, что переменная mom утекла в кучу из-за того, что возвращаемое значение содержит локальный указатель функции. Помимо этой ситуации, существуют и другие случаи, которые могут вызвать утечку.
::: tips
Если вас интересуют детали анализа утечек, вы можете узнать больше в стандартной библиотеке cmd/compile/internal/escape/escape.go.
:::
Замыкание
Если замыкание ссылается на переменную вне функции, эта переменная также утекает в кучу. Это легко понять.
package main
func main() {
a := make([]string, 0)
do(func() []string {
return a
})
}
func do(f func() []string) []string {
return f()
}Вывод:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:10:9: f does not escape
./main.go:4:2: main capturing by value: a (addr=false assign=false width=24)
./main.go:4:11: make([]string, 0) escapes to heap:
./main.go:4:11: flow: a = &{storage for make([]string, 0)}:
./main.go:4:11: from make([]string, 0) (spill) at ./main.go:4:11
./main.go:4:11: from a := make([]string, 0) (assign) at ./main.go:4:4
./main.go:4:11: flow: ~r0 = a:
./main.go:4:11: from return a (return) at ./main.go:6:3
./main.go:4:11: make([]string, 0) escapes to heap
./main.go:5:5: func literal does not escapeНедостаток места
Утечка также происходит, когда недостаточно места в стеке. В следующем примере срез запрашивает ёмкость 1<<15:
package main
func main() {
_ = make([]int, 0, 1<<15)
}Вывод:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:4:10: make([]int, 0, 32768) escapes to heap:
./main.go:4:10: flow: {heap} = &{storage for make([]int, 0, 32768)}:
./main.go:4:10: from make([]int, 0, 32768) (too large for stack) at ./main.go:4:10
./main.go:4:10: make([]int, 0, 32768) escapes to heapНеизвестная длина
Когда длина среза является переменной, происходит утечка (для map это не так):
package main
func main() {
n := 100
_ = make([]int, n)
}Вывод:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:5:10: make([]int, n) escapes to heap:
./main.go:5:10: flow: {heap} = &{storage for make([]int, n)}:
./main.go:5:10: from make([]int, n) (non-constant size) at ./main.go:5:10
./main.go:5:10: make([]int, n) escapes to heapЕсть ещё особый случай: когда параметр функции имеет тип ...any, также может произойти утечка:
package main
import "fmt"
func main() {
n := 100
fmt.Println(n)
}Вывод:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:7:14: n escapes to heap:
./main.go:7:14: flow: {storage for ... argument} = &{storage for n}:
./main.go:7:14: from n (spill) at ./main.go:7:14
./main.go:7:14: from ... argument (slice-literal-element) at ./main.go:7:13
./main.go:7:14: flow: {heap} = {storage for ... argument}:
./main.go:7:14: from ... argument (spill) at ./main.go:7:13
./main.go:7:14: from fmt.Println(... argument...) (call parameter) at ./main.go:7:13
./main.go:7:13: ... argument does not escape
./main.go:7:14: n escapes to heapМы проводим анализ утечек и так детально контролируем распределение памяти в основном для снижения нагрузки на GC. Однако Go — это не C, окончательное решение о распределении памяти остаётся за компилятором. За исключением случаев экстремальных требований к производительности, в большинстве случаев нам не нужно слишком сильно сосредотачиваться на деталях распределения памяти, ведь цель GC — освободить разработчика.
Маленькая деталь
Для некоторых ссылочных типов, когда подтверждено, что они больше не нужны, мы можем установить их в nil, чтобы сообщить GC, что их можно освободить.
type Writer struct {
buf []byte
}
func (w Writer) Close() error {
w.buf = nil
return nil
}pprof
pprof (program profiling) — мощный инструмент анализа производительности программ. Он выполняет выборку данных времени выполнения программы, охватывая CPU, память, горутины, блокировки, информацию о стеке и многие другие аспекты, а затем использует инструменты для анализа и отображения результатов выборки.
Таким образом, использование pprof состоит всего из двух шагов:
- Сбор данных
- Анализ результатов
Сбор
Существует два способа сбора данных: автоматический и ручной, каждый со своими преимуществами и недостатками. Перед этим напишем простую функцию для имитации потребления памяти и CPU:
func Do() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 24 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}Ручной сбор
Ручной сбор контролируется кодом. Его преимущества — контролируемость, гибкость и возможность кастомизации. Для использования pprof в коде нужно импортировать пакет runtime/pprof:
package main
import (
"log"
"os"
"runtime/pprof"
)
func main() {
Do()
w, _ := os.Create("heap.pb")
heapProfile := pprof.Lookup("heap")
err := heapProfile.WriteTo(w, 0)
if err != nil {
log.Fatal(err)
}
}Параметры, поддерживаемые pprof.Lookup, показаны в следующем коде:
profiles.m = map[string]*Profile{
"goroutine": goroutineProfile,
"threadcreate": threadcreateProfile,
"heap": heapProfile,
"allocs": allocsProfile,
"block": blockProfile,
"mutex": mutexProfile,
}Эта функция записывает собранные данные в указанный файл. При записи передаваемое число имеет следующие значения:
0, записывает сжатые данные Protobuf, не читаемые человеком1, записывает данные в текстовом формате, читаемые; HTTP-интерфейс возвращает именно этот формат2, доступно только дляgoroutine, означает вывод информации о стеке в стилеpanic
Для сбора данных CPU нужно отдельно использовать функцию pprof.StartCPUProfile. Ей требуется некоторое время для выборки, и её исходные данные не читаются:
package main
import (
"log"
"os"
"runtime/pprof"
"time"
)
func main() {
Do()
w, _ := os.Create("cpu.out")
err := pprof.StartCPUProfile(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
pprof.StopCPUProfile()
}Сбор данных trace выполняется аналогично:
package main
import (
"log"
"os"
"runtime/trace"
"time"
)
func main() {
Do()
w, _ := os.Create("trace.out")
err := trace.Start(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
trace.Stop()
}Автоматический сбор
Пакет net/http/pprof оборачивает вышеупомянутые функции анализа в HTTP-интерфейсы и регистрирует их в маршруте по умолчанию:
package pprof
import ...
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}Это позволяет нам запустить сбор данных pprof одной командой:
package main
import (
"net/http"
// Не забудьте импортировать этот пакет
_ "net/http/pprof"
)
func main() {
go func(){
http.ListenAndServe(":8080", nil)
}
for {
Do()
}
}Теперь откройте браузер и перейдите по адресу http://127.0.0.1:8080/debug/pprof. Появится следующая страница:
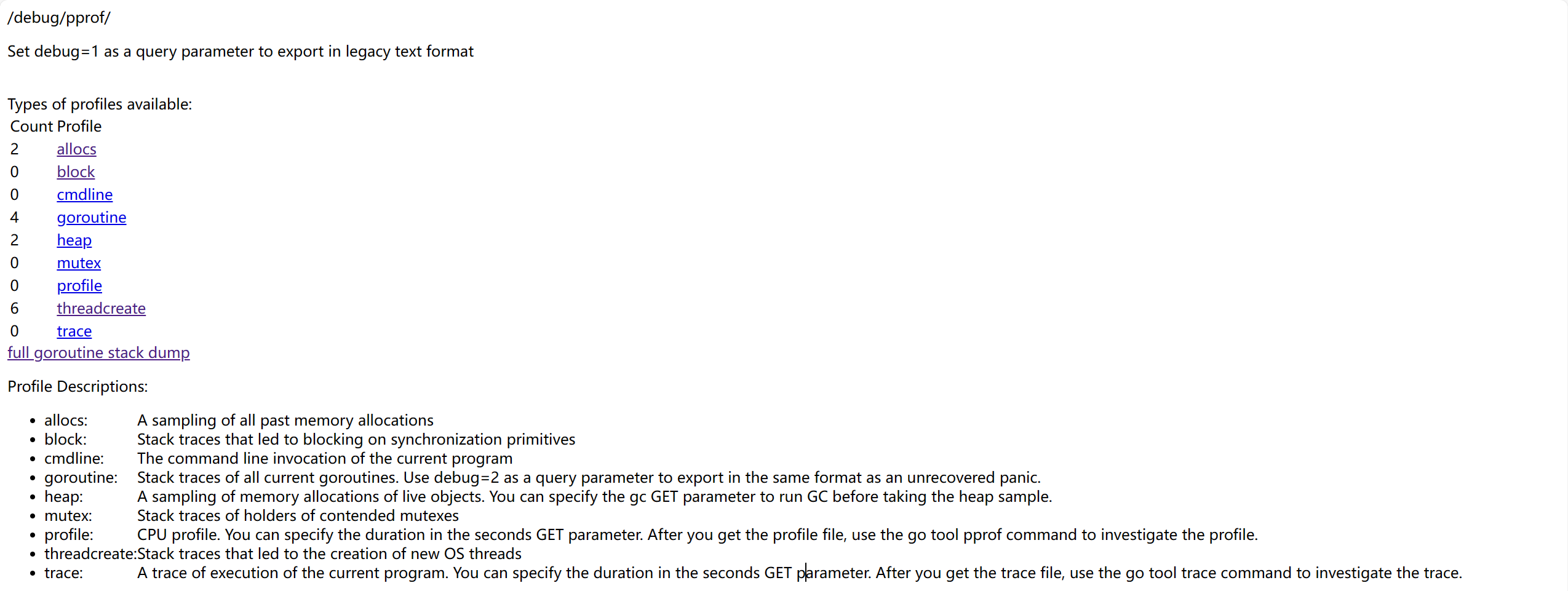
На странице есть несколько опций на выбор:
allocs: выборка распределения памятиblock: отслеживание блокировок синхронизирующих примитивовcmdline: вызов командной строки текущей программыgoroutine: отслеживание всех горутинheap: выборка распределения памяти для живых объектовmutex: отслеживание информации, связанной с мьютексамиprofile: анализ CPU, анализирует некоторое время и загружает файлthreadcreate: анализ причин создания новых потоков OStrace: отслеживание выполнения текущей программы, также загружает файл
Большинство этих данных не имеют высокой читаемости и предназначены для анализа инструментами, как показано на рисунке:
Конкретный анализ будет рассмотрен позже. За исключением опций profile и trace, если вы хотите загрузить файл данных через веб-интерфейс, удалите параметр запроса debug=1. Также можно интегрировать эти интерфейсы в свой собственный маршрут вместо использования маршрута по умолчанию:
package main
import (
"net/http"
"net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/trace", pprof.Trace)
servre := &http.Server{
Addr: ":8080",
Handler: mux,
}
servre.ListenAndServe()
}Таким образом, их можно интегрировать в другие веб-фреймворки, такие как gin, iris и т.д.
Анализ
После получения файлов собранных данных существует два способа анализа: командная строка и веб-интерфейс. Оба используют инструмент командной строки pprof, который по умолчанию интегрирован в Go, поэтому дополнительная загрузка не требуется.
Исходный код pprof: google/pprof: pprof is a tool for visualization and analysis of profiling data (github.com)
Командная строка
Передайте файл собранных данных в качестве параметра:
$ go tool pprof heap.pbЕсли данные собраны через веб-интерфейс, замените имя файла на веб-URL:
$ go tool pprof -http :8080 http://127.0.0.1/debug/pprof/heapЗатем появится интерактивная командная строка:
15:27:38.3266862 +0800 CST
Type: inuse_space
Time: Apr 15, 2024 at 3:27pm (CST)
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)Введите help, чтобы просмотреть другие команды:
Commands:
callgrind Outputs a graph in callgrind format
comments Output all profile comments
disasm Output assembly listings annotated with samples
dot Outputs a graph in DOT format
eog Visualize graph through eog
evince Visualize graph through evince
...Для просмотра данных в командной строке обычно используется команда top. Также можно использовать команду traces, но её вывод очень многословен. Команда top даёт только общее представление:
(pprof) top 5
Showing nodes accounting for 117.49MB, 100% of 117.49MB total
flat flat% sum% cum cum%
117.49MB 100% 100% 117.49MB 100% main.makeSlice (inline)
0 0% 100% 117.49MB 100% main.Do
0 0% 100% 117.49MB 100% main.main
0 0% 100% 117.49MB 100% runtime.mainКраткое описание некоторых показателей (аналогично для CPU):
flat: ресурсы, потреблённые текущей функциейcum: общая сумма ресурсов, потреблённых текущей функцией и её последующими вызовамиflat%: flat/totalcum%: cum/total
Мы явно видим, что использование памяти во всём стеке вызовов составляет 117.49MB. Поскольку функция Do сама ничего не делает, а только вызывает другие функции, её показатель flat равен 0. Создание среза выполняется функцией makeSlice, поэтому её показатель flat равен 100%.
Мы можем преобразовать данные в визуальный формат. pprof поддерживает множество форматов, таких как pdf, svg, png, gif и т.д. (требуется установка Graphviz):
(pprof) png
Generating report in profile001.png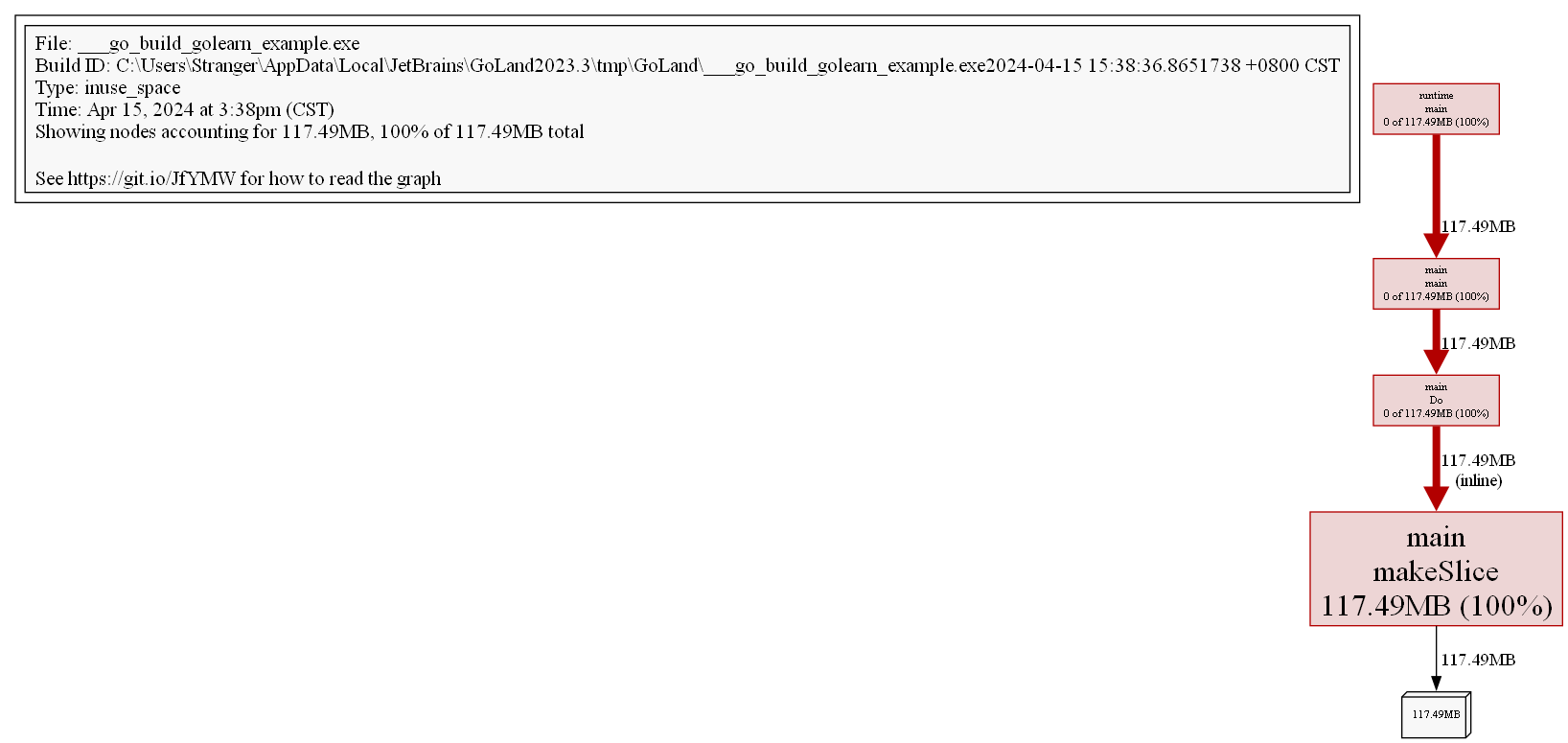
На изображении мы можем чётко увидеть ситуацию использования памяти во всём стеке вызовов.
Просмотр в виде исходного кода с помощью команды list:
(pprof) list Do
Total: 117.49MB
ROUTINE ======================== main.Do in D:\WorkSpace\Code\GoLeran\golearn\example\main.go
0 117.49MB (flat, cum) 100% of Total
. . 21:func Do() {
. . 22: for i := 0; i < 10; i++ {
. 117.49MB 23: slice := makeSlice()
. . 24: sortSlice(slice)
. . 25: }
. . 26:}
. . 27:
. . 28:func makeSlice() []int {Для изображений и исходного кода можно использовать команды web и weblist для просмотра в браузере.
Веб-интерфейс
Для более разнообразных данных изменим имитирующую функцию:
func Do1() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func Do2() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 12 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}Веб-анализ визуализирует результаты, избавляя от необходимости вручную работать с командной строкой. При использовании веб-анализа достаточно выполнить следующую команду:
$ go tool pprof -http :8080 heap.pbЕсли данные собраны через веб-интерфейс, замените имя файла на веб-URL:
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/heap
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/profile
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/goroutineTIP
О том, как анализировать данные, узнайте больше в разделе pprof: How to read the graph.
В веб-интерфейсе всего 6 элементов для просмотра:
- Top, аналогично команде top
- Graph, линейный график
- Flame Graph, огненный график
- Peek,
- Source, просмотр исходного кода
- Disassemble, дизассемблирование
Для памяти можно анализировать по четырём измерениям:
alloc_objects: количество всех распределённых объектов на данный момент, включая освобождённыеalloc_space: всё распределённое пространство памяти на данный момент, включая освобождённоеinuse_objects: количество используемых объектовinuse_space: используемое пространство памяти
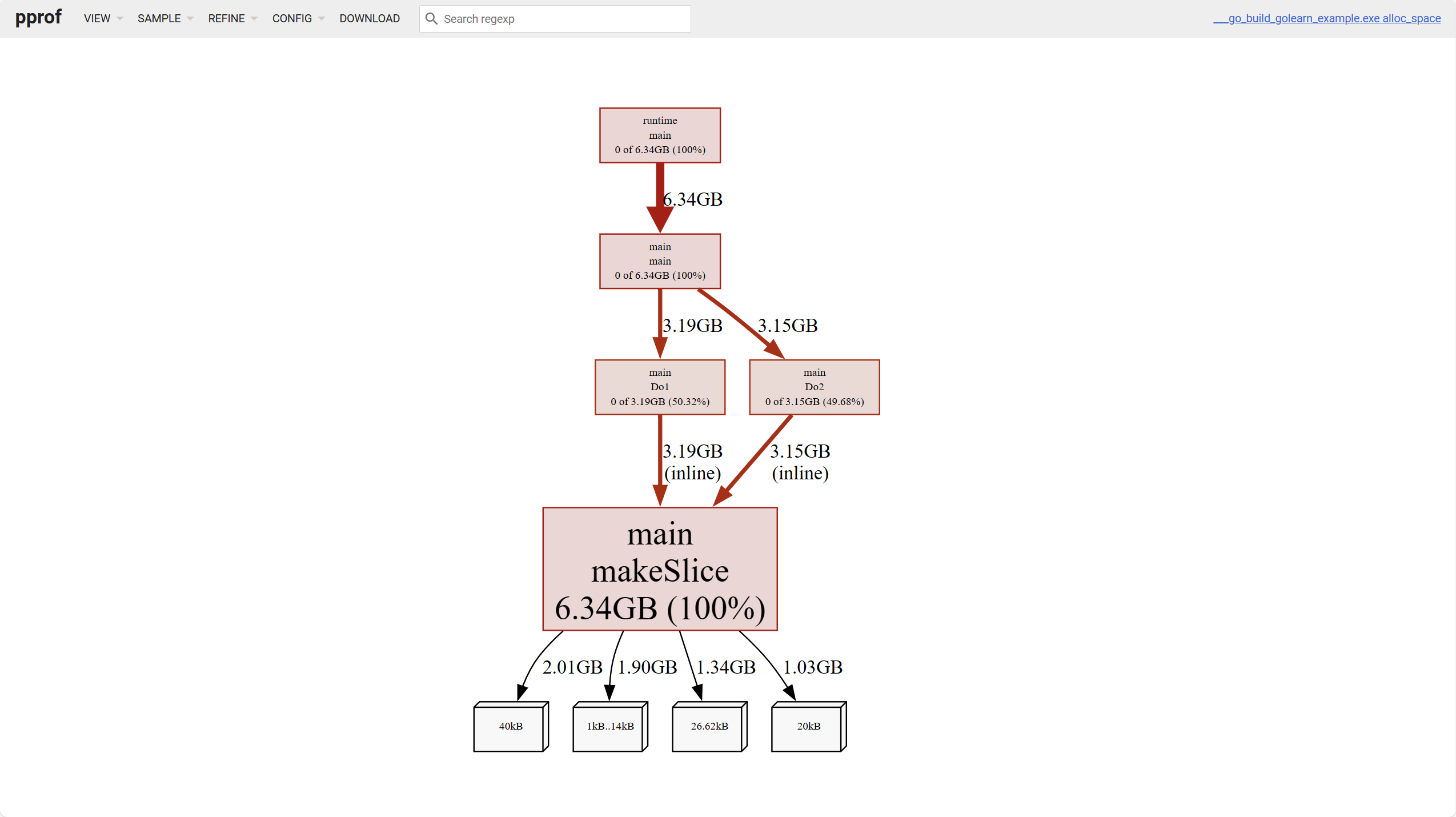
Белые листовые узлы внизу графика представляют объекты разного размера.
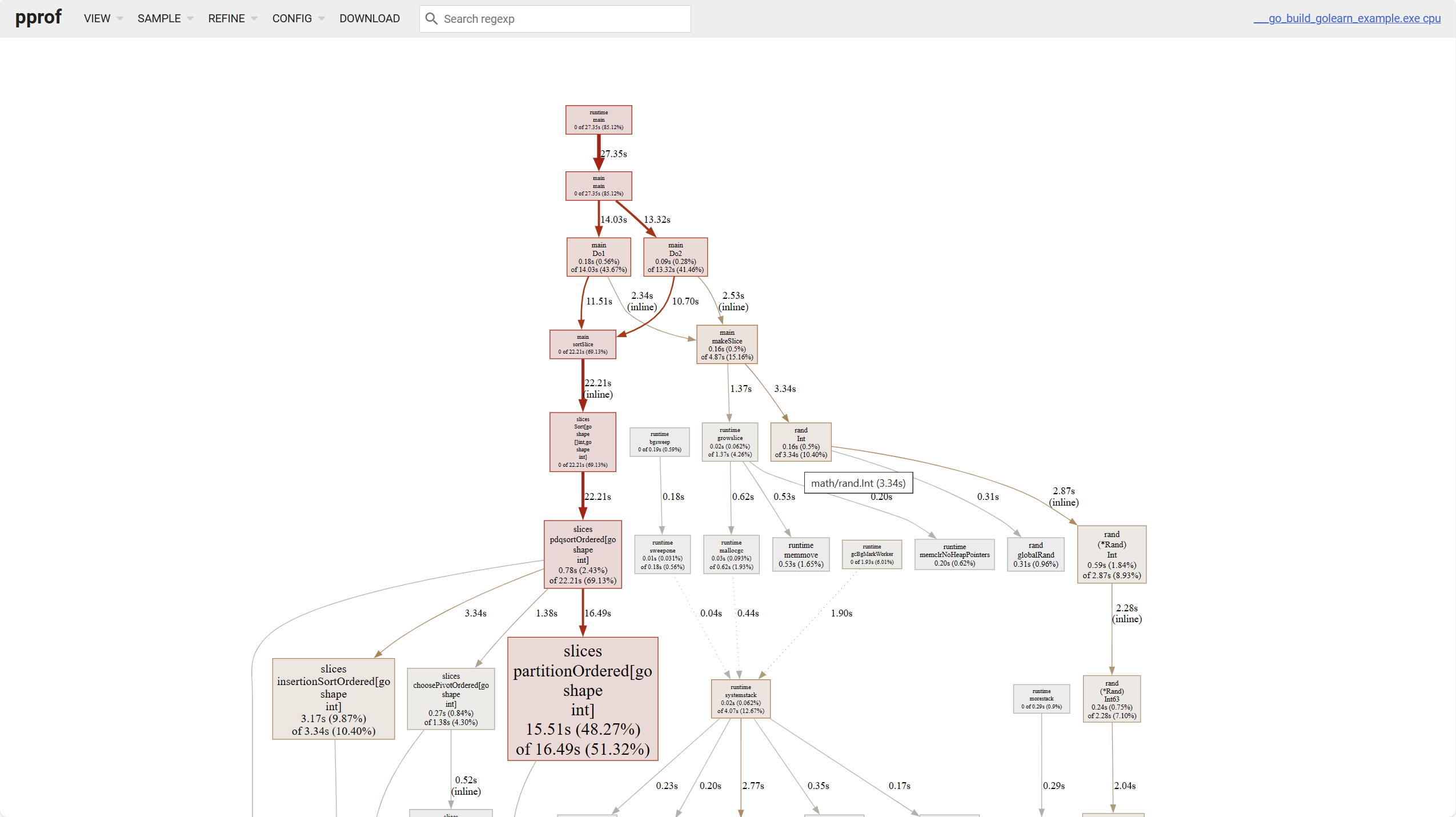
Что касается линейного графика, следует отметить несколько моментов:
- Чем темнее цвет блока, тем выше потребление; чем толще линия, тем выше потребление
- Сплошная линия означает прямой вызов, пунктирная линия означает пропуск некоторых звеньев вызова.

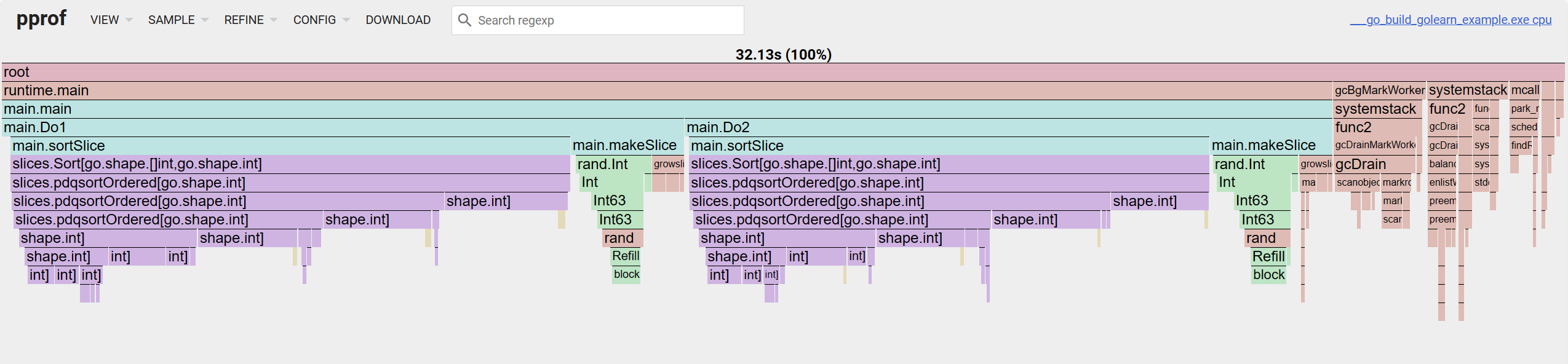
Для огненного графика: если смотреть сверху вниз — это цепочка вызовов, слева направо — процент потребления cum.
trace
pprof в основном отвечает за анализ потребления ресурсов программы, а trace больше подходит для отслеживания деталей выполнения программы. Его файлы данных несовместимы с pprof, и анализ выполняется командой go tool trace.
Для данных, собранных вручную, передайте имя файла в качестве параметра:
$ go tool trace trace.outДля данных, собранных автоматически, аналогично:
$ curl http://127.0.0.1:8080/debug/pprof/trace > trace.out && go tool trace trace.outПосле выполнения запускается веб-сервер:
2024/04/15 17:15:40 Preparing trace for viewer...
2024/04/15 17:15:40 Splitting trace for viewer...
2024/04/15 17:15:40 Opening browser. Trace viewer is listening on http://127.0.0.1:51805После открытия страница выглядит примерно так:
Здесь содержится несколько разделов. Эти данные не так легко понять.
Event timelines for running goroutines
trace by proc: отображает временную шкалу горутин, работающих на процессоре в каждый момент времени
trace by thread: отображает временную шкалу горутин, работающих на потоке OS в каждый момент времени
Goroutine analysis: отображает статистику горутин для каждой группы главных функций


Profiles
- Network blocking profile: информация о горутинах, заблокированных из-за сетевого IO
- Synchronization blocking profile: информация о горутинах, заблокированных из-за синхронизирующих примитивов
- Syscall profile: информация о горутинах, заблокированных из-за системных вызовов
User-defined tasks and regions
- User-defined tasks: информация о горутинах для пользовательских задач
- User-defined regions: информация о горутинах для пользовательских областей кода
Garbage collection metrics
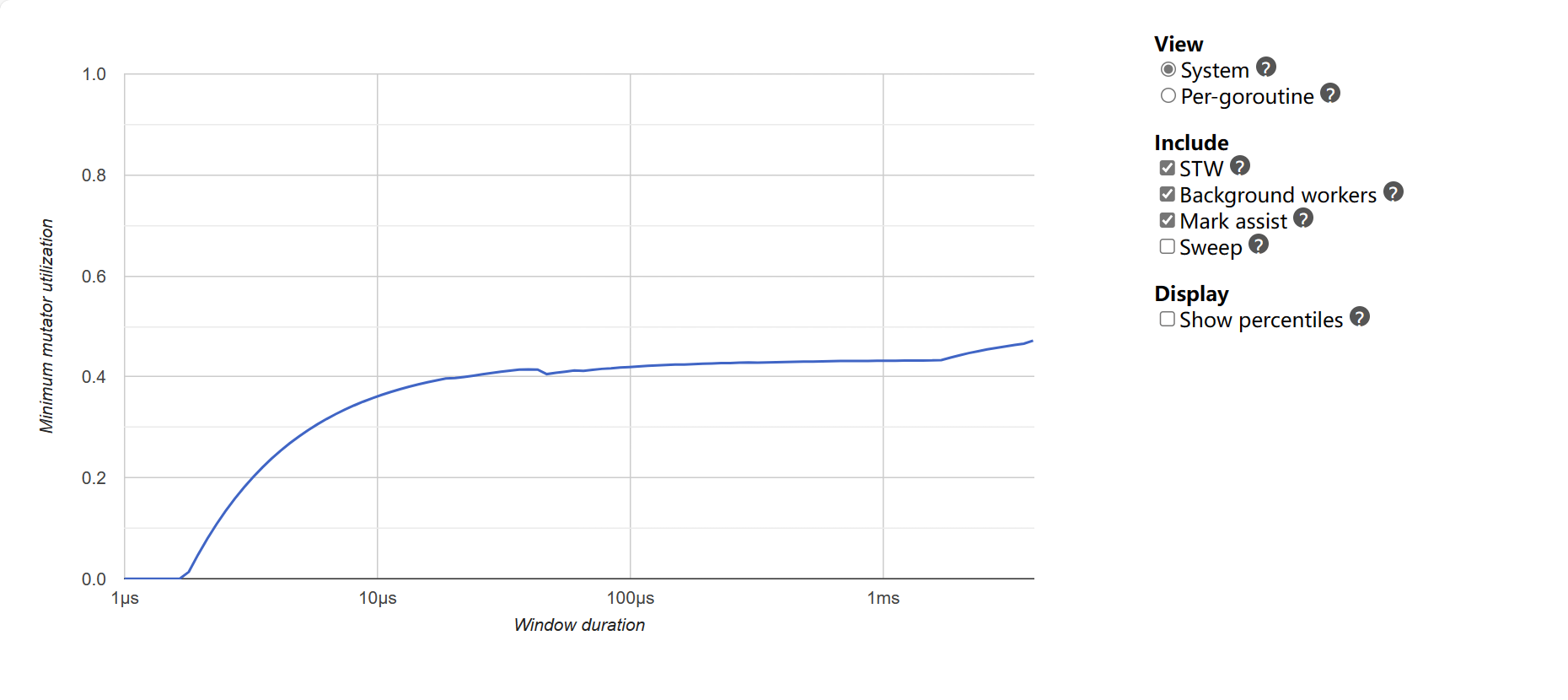
Minimum mutator utilization: отображает максимальное время последнего GC