Analisi delle Prestazioni
Quando un programma è stato scritto, le nostre aspettative non sono solo che possa essere eseguito, ma speriamo anche che sia un'applicazione stabile ed efficiente. Attraverso vari test, possiamo garantire la maggior parte della stabilità del programma, mentre per sapere se il programma è efficiente, dobbiamo analizzarne le prestazioni. Nel contenuto precedente, l'unico mezzo per l'analisi delle prestazioni era testare il tempo di esecuzione medio e la situazione di allocazione della memoria di una singola unità funzionale tramite Benchmark. Tuttavia, nella realtà, le esigenze di analisi delle prestazioni del programma vanno ben oltre questo. A volte dobbiamo analizzare l'occupazione complessiva della CPU del programma, l'occupazione della memoria, la situazione di allocazione dell'heap, lo stato delle coroutine, i percorsi del codice hot, ecc. Questo è ciò che Benchmark non può soddisfare. Fortunatamente, la toolchain di Go integra molti strumenti di analisi delle prestazioni a disposizione degli sviluppatori. Di seguito verranno spiegati uno per uno.
Analisi di Fuga
In Go, l'allocazione della memoria delle variabili è decisa dal compilatore. Generalmente, vengono allocate sullo stack o sull'heap. Se una variabile che dovrebbe essere allocata sullo stack viene allocata sull'heap, questa situazione è chiamata fuga. L'analisi di fuga serve ad analizzare la situazione di allocazione della memoria nel programma. Poiché viene eseguita durante la compilazione, è un tipo di analisi statica.
TIP
Vai all'articolo Allocazione della Memoria per comprendere come Go alloca la memoria.
Puntatore Locale di Riferimento
package main
func main() {
GetPerson()
}
type Person struct {
Name string
Mom *Person
}
func GetPerson() Person {
mom := Person{Name: "lili"}
son := Person{Name: "jack", Mom: &mom}
return son
}Nella funzione GetPerson viene creata la variabile mom. Poiché è creata all'interno della funzione, originariamente dovrebbe essere allocata sullo stack. Tuttavia, è referenziata dal campo Mom di son, e son viene restituito come valore di ritorno della funzione. Quindi il compilatore la alloca sull'heap. Questo è un esempio molto semplice, quindi non richiede troppo sforzo per comprenderlo. Ma se si tratta di un progetto più grande, con decine di migliaia di righe di codice, l'analisi manuale non è così rilassata. Per questo è necessario utilizzare strumenti per l'analisi di fuga. Come menzionato in precedenza, l'allocazione della memoria è guidata dal compilatore, quindi anche l'analisi di fuga è completata dal compilatore. L'uso è molto semplice, basta eseguire il seguente comando:
$ go build -gcflags="-m -m -l"gcflags sono i parametri del compilatore gc:
-m, stampa i suggerimenti di ottimizzazione del codice. Se presenti due volte, l'output sarà più dettagliato-l, disabilita l'ottimizzazione inline
L'output è il seguente:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:13:2: mom escapes to heap:
./main.go:13:2: flow: son = &mom:
./main.go:13:2: from &mom (address-of) at ./main.go:14:35
./main.go:13:2: from Person{...} (struct literal element) at ./main.go:14:15
./main.go:13:2: from son := Person{...} (assign) at ./main.go:14:6
./main.go:13:2: flow: ~r0 = son:
./main.go:13:2: from return son (return) at ./main.go:15:2
./main.go:13:2: moved to heap: momIl compilatore ci ha detto chiaramente che la variabile mom è scappata. La ragione è che il valore di ritorno include un puntatore locale della funzione. Oltre a questa situazione, ci sono altre circostanze che possono causare fenomeni di fuga.
::: tips
Se sei interessato ai dettagli dell'analisi di fuga, puoi trovare più contenuti nella libreria standard cmd/compile/internal/escape/escape.go.
:::
Riferimento di Chiusura
Se una chiusura riferisce una variabile esterna alla funzione, quella variabile scapperà anche sull'heap. Questo è facile da capire.
package main
func main() {
a := make([]string, 0)
do(func() []string {
return a
})
}
func do(f func() []string) []string {
return f()
}Output:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:10:9: f does not escape
./main.go:4:2: main capturing by value: a (addr=false assign=false width=24)
./main.go:4:11: make([]string, 0) escapes to heap:
./main.go:4:11: flow: a = &{storage for make([]string, 0)}:
./main.go:4:11: from make([]string, 0) (spill) at ./main.go:4:11
./main.go:4:11: from a := make([]string, 0) (assign) at ./main.go:4:4
./main.go:4:11: flow: ~r0 = a:
./main.go:4:11: from return a (return) at ./main.go:6:3
./main.go:4:11: make([]string, 0) escapes to heap
./main.go:5:5: func literal does not escapeSpazio Insufficiente
Quando lo spazio dello stack è insufficiente, si verificherà anche un fenomeno di fuga. La slice creata di seguito richiede una capacità di 1<<15:
package main
func main() {
_ = make([]int, 0, 1<<15)
}Output:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:4:10: make([]int, 0, 32768) escapes to heap:
./main.go:4:10: flow: {heap} = &{storage for make([]int, 0, 32768)}:
./main.go:4:10: from make([]int, 0, 32768) (too large for stack) at ./main.go:4:10
./main.go:4:10: make([]int, 0, 32768) escapes to heapLunghezza Sconosciuta
Quando la lunghezza di una slice è una variabile, poiché la sua lunghezza è sconosciuta, si verificherà un fenomeno di fuga (map non lo farà):
package main
func main() {
n := 100
_ = make([]int, n)
}Output:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:5:10: make([]int, n) escapes to heap:
./main.go:5:10: flow: {heap} = &{storage for make([]int, n)}:
./main.go:5:10: from make([]int, n) (non-constant size) at ./main.go:5:10
./main.go:5:10: make([]int, n) escapes to heapC'è anche una situazione speciale in cui i parametri della funzione sono di tipo ...any, che possono anche causare fuga:
package main
import "fmt"
func main() {
n := 100
fmt.Println(n)
}Output:
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:7:14: n escapes to heap:
./main.go:7:14: flow: {storage for ... argument} = &{storage for n}:
./main.go:7:14: from n (spill) at ./main.go:7:14
./main.go:7:14: from ... argument (slice-literal-element) at ./main.go:7:13
./main.go:7:14: flow: {heap} = {storage for ... argument}:
./main.go:7:14: from ... argument (spill) at ./main.go:7:13
./main.go:7:14: from fmt.Println(... argument...) (call parameter) at ./main.go:7:13
./main.go:7:13: ... argument does not escape
./main.go:7:14: n escapes to heapIl motivo per cui eseguiamo l'analisi di fuga e controlliamo così attentamente l'allocazione della memoria è principalmente per ridurre la pressione sulla GC. Tuttavia, Go non è il linguaggio C. Il potere decisionale finale sull'allocazione della memoria è ancora nelle mani del compilatore. Tranne in casi di esigenze di prestazioni estreme, nella maggior parte delle volte non dobbiamo concentrarci troppo sui dettagli dell'allocazione della memoria. Dopotutto, lo scopo della GC è liberare gli sviluppatori.
Piccolo Dettaglio
Per alcuni tipi di riferimento, quando si conferma che non saranno più utilizzati, possiamo impostarli su nil per dire alla GC che possono essere recuperati.
type Writer struct {
buf []byte
}
func (w Writer) Close() error {
w.buff = nil
return nil
}pprof
pprof (program profiling) è uno strumento potente per l'analisi delle prestazioni dei programmi. Campionerà parzialmente i dati runtime del programma, coprendo molti aspetti come CPU, memoria, coroutine, lock, informazioni sullo stack, ecc. Quindi utilizzerà strumenti per analizzare i dati campionati e visualizzare i risultati.
Quindi i passaggi per l'uso di pprof sono solo due:
- Raccolta dei dati
- Analisi dei risultati
Raccolta
Ci sono due modi per raccogliere i dati: automatico e manuale, ognuno con i propri pro e contro. Prima di ciò, scrivi una funzione semplice per simulare il consumo di memoria e CPU:
func Do() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 24 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}Manuale
La raccolta manuale è controllata tramite codice. I vantaggi sono controllabilità, flessibilità e personalizzazione. Utilizzare pprof direttamente nel codice richiede l'importazione del pacchetto runtime/pprof:
package main
import (
"log"
"os"
"runtime/pprof"
)
func main() {
Do()
w, _ := os.Create("heap.pb")
heapProfile := pprof.Lookup("heap")
err := heapProfile.WriteTo(w, 0)
if err != nil {
log.Fatal(err)
}
}I parametri supportati da pprof.Lookup sono mostrati nel seguente codice:
profiles.m = map[string]*Profile{
"goroutine": goroutineProfile,
"threadcreate": threadcreateProfile,
"heap": heapProfile,
"allocs": allocsProfile,
"block": blockProfile,
"mutex": mutexProfile,
}Questa funzione scrive i dati raccolti in un file specificato. Quando si scrive, il numero passato ha i seguenti significati:
0, scrive i dati Protobuf compressi, non leggibili1, scrive i dati in formato testo, leggibili. Questo è il tipo di dati restituito dall'interfaccia HTTP2, disponibile solo pergoroutine, indica la stampa di informazioni sullo stack in stilepanic
La raccolta dei dati CPU richiede l'uso separato della funzione pprof.StartCPUProfile. Richiede un certo tempo per il campionamento e i dati grezzi non sono leggibili, come mostrato di seguito:
package main
import (
"log"
"os"
"runtime/pprof"
"time"
)
func main() {
Do()
w, _ := os.Create("cpu.out")
err := pprof.StartCPUProfile(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
pprof.StopCPUProfile()
}Anche la raccolta dei dati trace è la stessa:
package main
import (
"log"
"os"
"runtime/trace"
"time"
)
func main() {
Do()
w, _ := os.Create("trace.out")
err := trace.Start(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
trace.Stop()
}Automatico
Il pacchetto net/http/pprof incapsula le funzioni di analisi sopra menzionate in interfacce HTTP e le registra nel route predefinito, come mostrato di seguito:
package pprof
import ...
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}Questo ci consente di eseguire direttamente la raccolta dei dati pprof con un solo comando:
package main
import (
"net/http"
// Ricorda di importare questo pacchetto
_ "net/http/pprof"
)
func main() {
go func(){
http.ListenAndServe(":8080", nil)
}
for {
Do()
}
}A questo punto, apri il browser e visita http://127.0.0.1:8080/debug/pprof. Apparirà una pagina come questa:
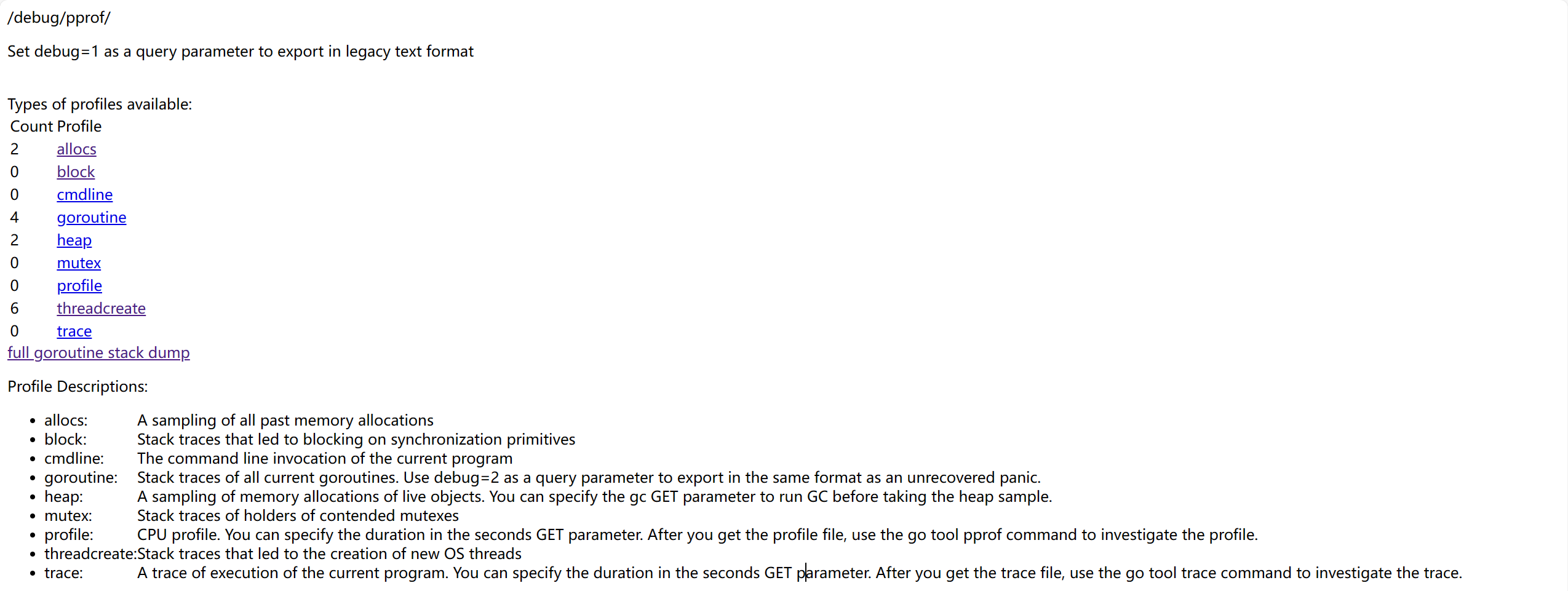
Nella pagina ci sono diverse opzioni selezionabili, che rappresentano rispettivamente:
allocs: campionamento dell'allocazione della memoriablock: tracciamento del blocco dei primitivi di sincronizzazionecmdline: chiamata a riga di comando del programma correntegoroutine: tracciamento di tutte le coroutineheap: campionamento dell'allocazione della memoria per gli oggetti存活mutex: tracciamento delle informazioni relative ai mutexprofile: analisi della CPU, analizzerà per un periodo di tempo e scaricherà un filethreadcreate: analisi delle ragioni che portano alla creazione di nuovi thread OStrace: tracciamento della situazione di esecuzione del programma corrente, scaricherà anche un file
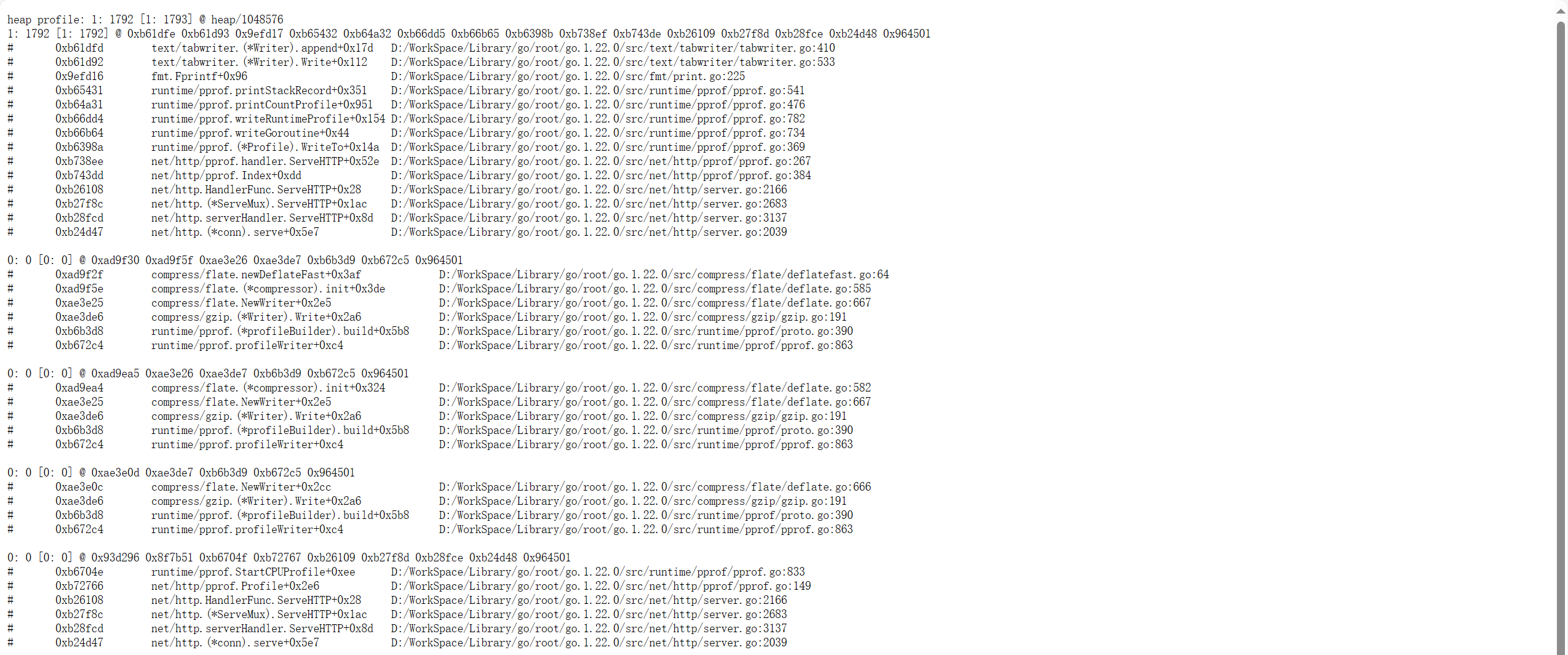
La maggior parte di questi dati non ha una leggibilità elevata. Sono principalmente utilizzati per l'analisi degli strumenti. Come mostrato nella figura seguente:
Il lavoro di analisi specifico verrà lasciato per dopo. Oltre alle due opzioni profile e trace, se desideri scaricare file di dati nel browser, puoi rimuovere il parametro query debug=1. Puoi anche integrare queste interfacce nelle tue route invece di utilizzare le route predefinite, come mostrato di seguito:
package main
import (
"net/http"
"net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/trace", pprof.Trace)
servre := &http.Server{
Addr: ":8080",
Handler: mux,
}
servre.ListenAndServe()
}In questo modo, possono anche essere integrate in altri framework web, come gin, iris, ecc.
Analisi
Dopo aver ottenuto i file di dati raccolti, ci sono due modi per analizzarli: riga di comando o pagina web. Entrambi richiedono l'utilizzo dello strumento a riga di comando pprof. Go integra questo strumento per impostazione predefinita, quindi non è necessario scaricarlo separatamente.
Codice sorgente open source di pprof: google/pprof: pprof is a tool for visualization and analysis of profiling data (github.com)
Riga di Comando
Utilizza il file di dati raccolto in precedenza come parametro:
$ go tool pprof heap.pbSe i dati sono raccolti tramite web, sostituisci il nome del file con l'URL web:
$ go tool pprof -http :8080 http://127.0.0.1/debug/pprof/heapPoi apparirà una riga di comando interattiva:
15:27:38.3266862 +0800 CST
Type: inuse_space
Time: Apr 15, 2024 at 3:27pm (CST)
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)Digita help per visualizzare altri comandi:
Commands:
callgrind Outputs a graph in callgrind format
comments Output all profile comments
disasm Output assembly listings annotated with samples
dot Outputs a graph in DOT format
eog Visualize graph through eog
evince Visualize graph through evince
...Nella riga di comando, per visualizzare i dati si usa generalmente il comando top. Si può anche usare il comando traces, ma il suo output è molto lungo. Il comando top serve solo per avere un'idea generale.
(pprof) top 5
Showing nodes accounting for 117.49MB, 100% of 117.49MB total
flat flat% sum% cum cum%
117.49MB 100% 100% 117.49MB 100% main.makeSlice (inline)
0 0% 100% 117.49MB 100% main.Do
0 0% 100% 117.49MB 100% main.main
0 0% 100% 117.49MB 100% runtime.mainIntroduciamo brevemente alcuni degli indicatori (lo stesso per la CPU):
flat: rappresenta le risorse consumate dalla funzione correntecum: rappresenta il totale delle risorse consumate dalla funzione corrente e dalla sua catena di chiamate successiveflat%: flat/totalcum%: cum/total
Possiamo vedere chiaramente che l'occupazione della memoria dell'intera catena di chiamate è 117.49MB. Poiché la funzione Do non fa nulla, chiama solo altre funzioni, il suo indicatore flat è 0. La creazione della slice è gestita dalla funzione makeSlice, quindi il suo indicatore flat è 100%.
Possiamo convertire in un formato visualizzabile. pprof supporta molti formati, come pdf, svg, png, gif, ecc. (è necessario installare Graphviz):
(pprof) png
Generating report in profile001.png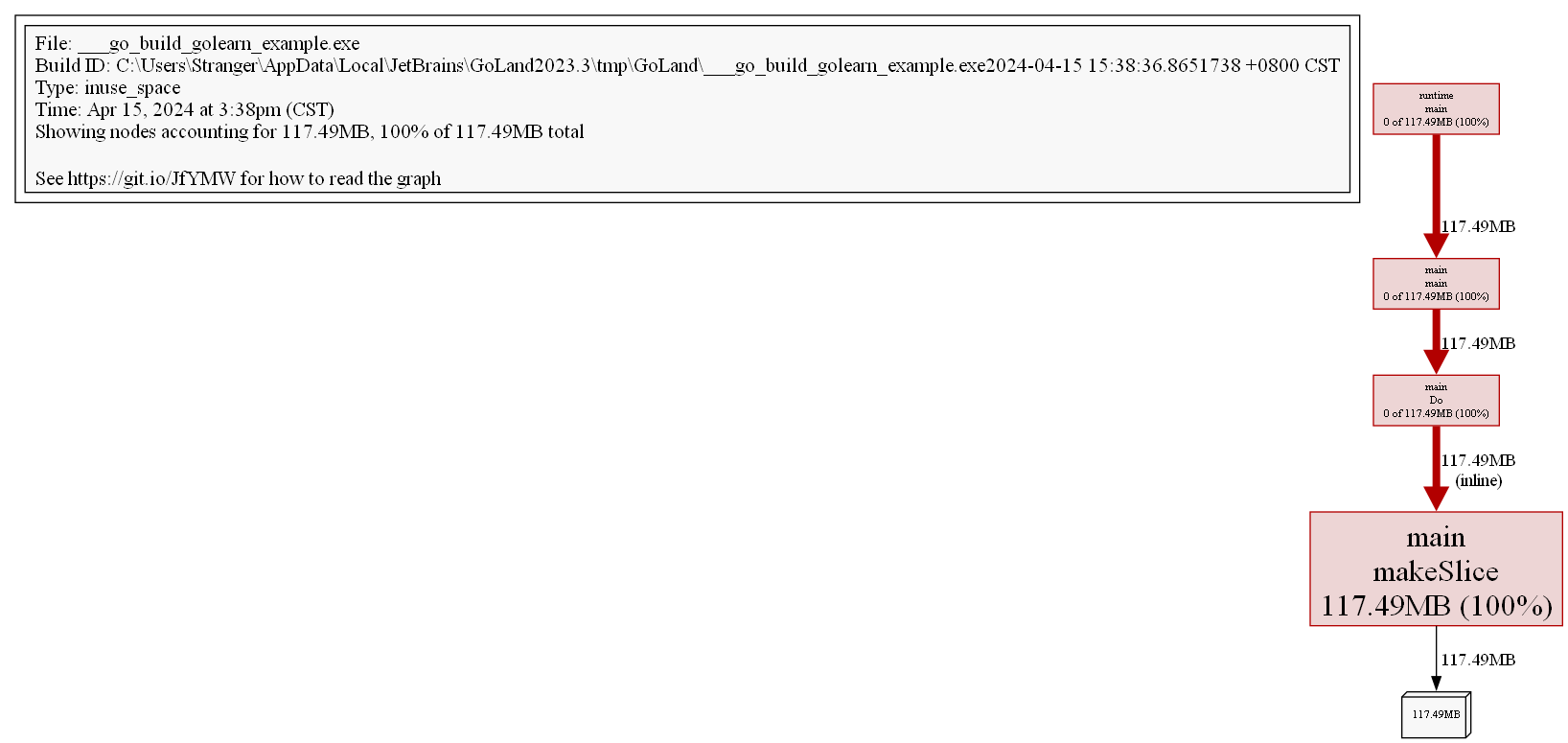
Attraverso l'immagine possiamo vedere più chiaramente la situazione di occupazione della memoria dell'intera catena di chiamate.
Per visualizzare il codice sorgente, usa il comando list:
(pprof) list Do
Total: 117.49MB
ROUTINE ======================== main.Do in D:\WorkSpace\Code\GoLeran\golearn\example\main.go
0 117.49MB (flat, cum) 100% of Total
. . 21:func Do() {
. . 22: for i := 0; i < 10; i++ {
. 117.49MB 23: slice := makeSlice()
. . 24: sortSlice(slice)
. . 25: }
. . 26:}
. . 27:
. . 28:func makeSlice() []int {Per immagini e codice sorgente, puoi anche usare i comandi web e weblist per visualizzare immagini e codice sorgente nel browser.
Pagina Web
Prima di ciò, per rendere i dati più diversificati, modifica leggermente la funzione simulata:
func Do1() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func Do2() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 12 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}L'analisi della pagina web può visualizzare i risultati, eliminando la necessità di operare manualmente la riga di comando. Quando si utilizza l'analisi della pagina web, basta eseguire il seguente comando:
$ go tool pprof -http :8080 heap.pbSe i dati sono raccolti tramite web, sostituisci il nome del file con l'URL web:
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/heap
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/profile
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/goroutineTIP
Per come analizzare i dati, vai a pprof: How to read the graph per ulteriori informazioni.
Nella pagina web ci sono un totale di 6 elementi visualizzabili:
- Top, come il comando top
- Graph, grafico lineare
- Flame Graph, grafico a fiamma
- Peek
- Source, visualizza il codice sorgente
- Disassemble, disassemblaggio
Per la memoria, ci sono quattro dimensioni da analizzare:
alloc_objects: numero totale di oggetti allocati finora, inclusi quelli rilasciatialloc_spcae: spazio di memoria totale allocato finora, inclusi quelli rilasciatiinuse_objects: numero di oggetti in usoinuse_space: spazio di memoria in uso
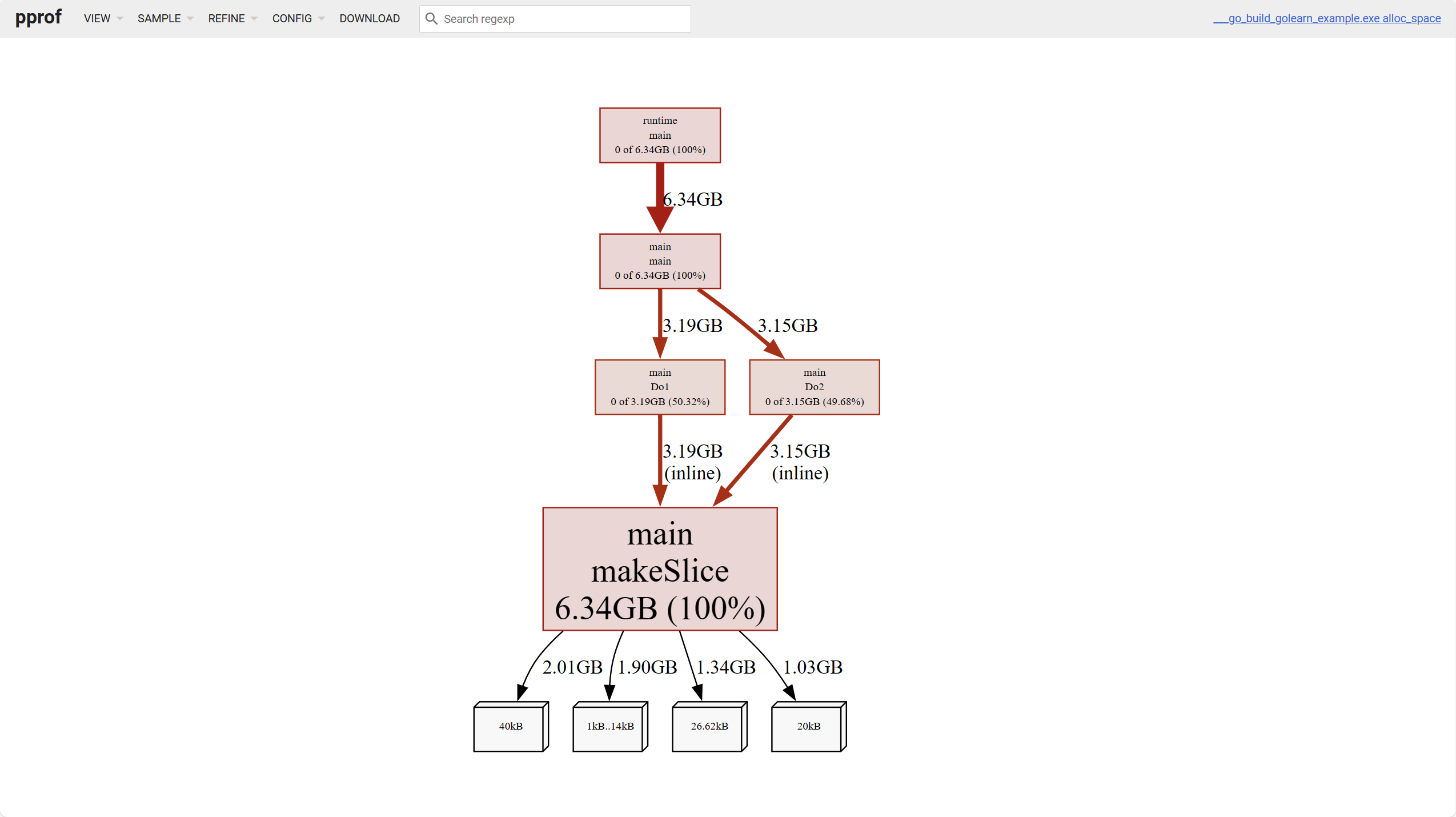
I nodi foglia bianchi nella parte inferiore della figura rappresentano oggetti di diverse dimensioni occupati.
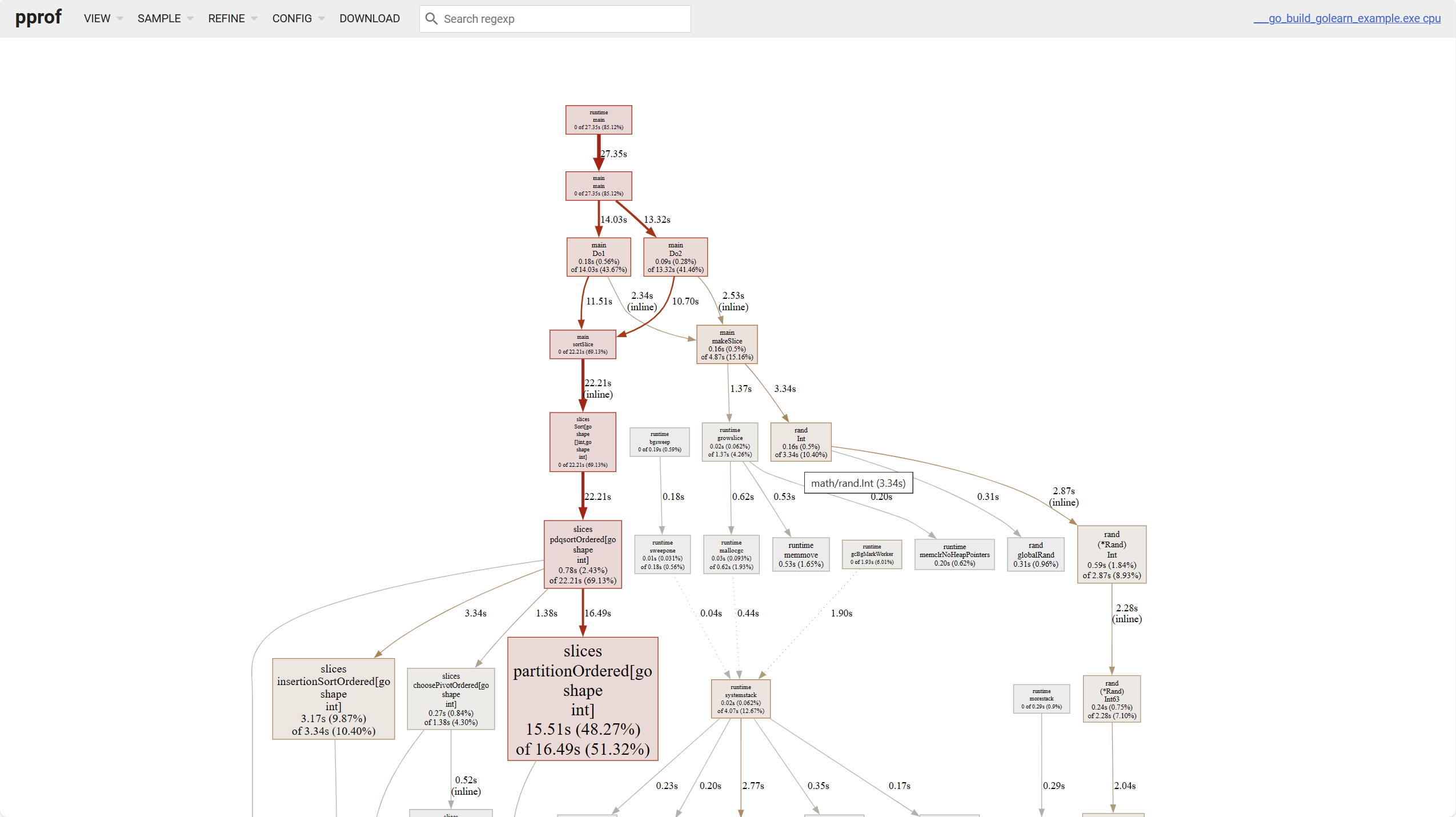
Per il grafico lineare, ci sono alcuni punti da notare:
- Più scuro è il colore del blocco, maggiore è l'occupazione. Più spessa è la linea, maggiore è l'occupazione.
- La linea solida rappresenta una chiamata diretta, la linea tratteggiata rappresenta che alcune catene di chiamate sono state saltate.

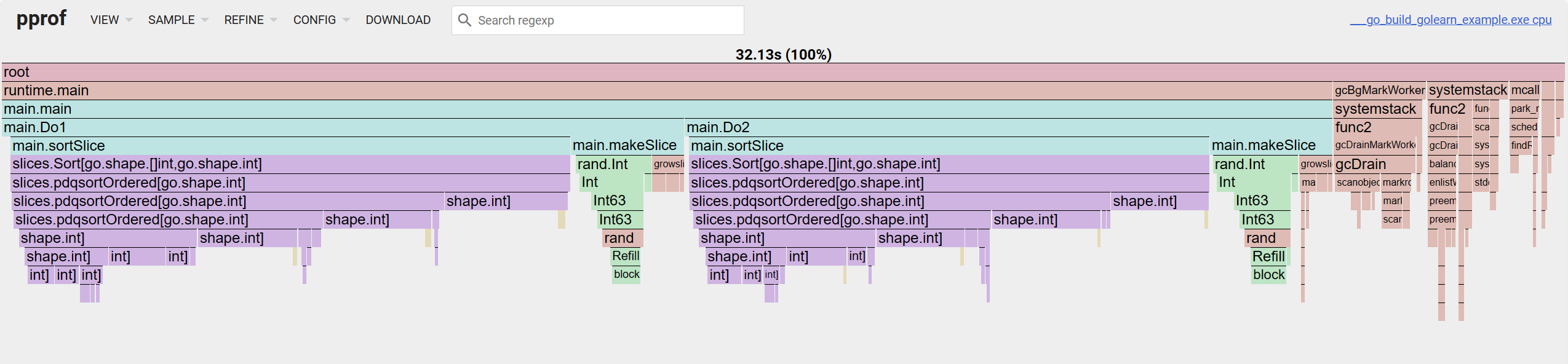
Per il grafico a fiamma, guardando dall'alto verso il basso è la catena di chiamate. Guardando da sinistra a destra è la percentuale di occupazione cum.
trace
pprof è principalmente responsabile dell'analisi dell'occupazione delle risorse del programma, mentre trace è più adatto per tracciare i dettagli di esecuzione del programma. I suoi file di dati sono incompatibili con i precedenti. Il lavoro di analisi correlato è completato dal comando go tool trace.
Se i dati sono raccolti manualmente, puoi usare il nome del file come parametro:
$ go tool trace trace.outSe i dati sono raccolti automaticamente, è lo stesso principio:
$ curl http://127.0.0.1:8080/debug/pprof/trace > trace.out && go tool trace trace.outDopo l'esecuzione, verrà avviato un server web:
2024/04/15 17:15:40 Preparing trace for viewer...
2024/04/15 17:15:40 Splitting trace for viewer...
2024/04/15 17:15:40 Opening browser. Trace viewer is listening on http://127.0.0.1:51805Dopo aver aperto, la pagina è approssimativamente come mostrato di seguito:
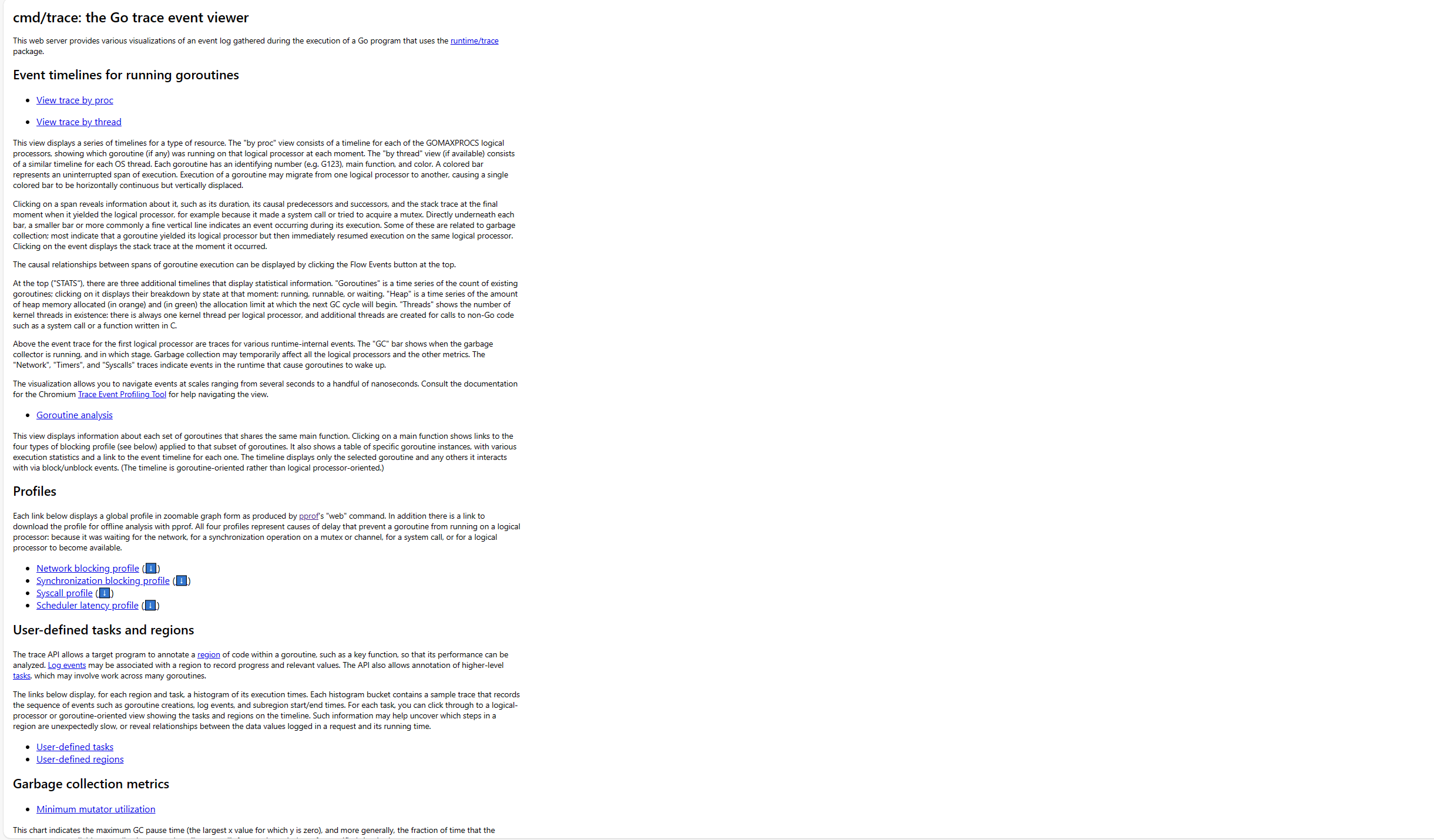
Questo contiene principalmente le seguenti parti. Non è facile comprendere questi dati:
Event timelines for running goroutines
trace by proc: mostra la timeline delle coroutine in esecuzione su quel processore in ogni momento
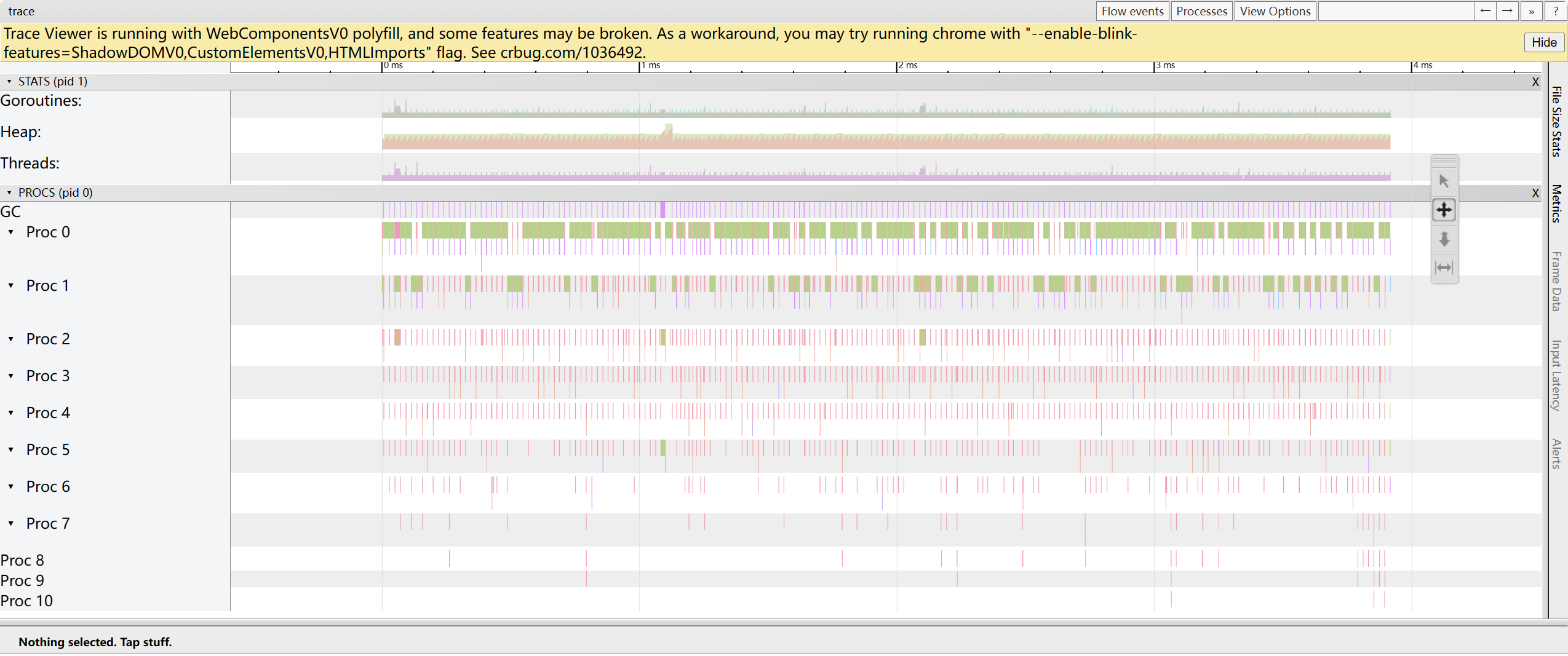
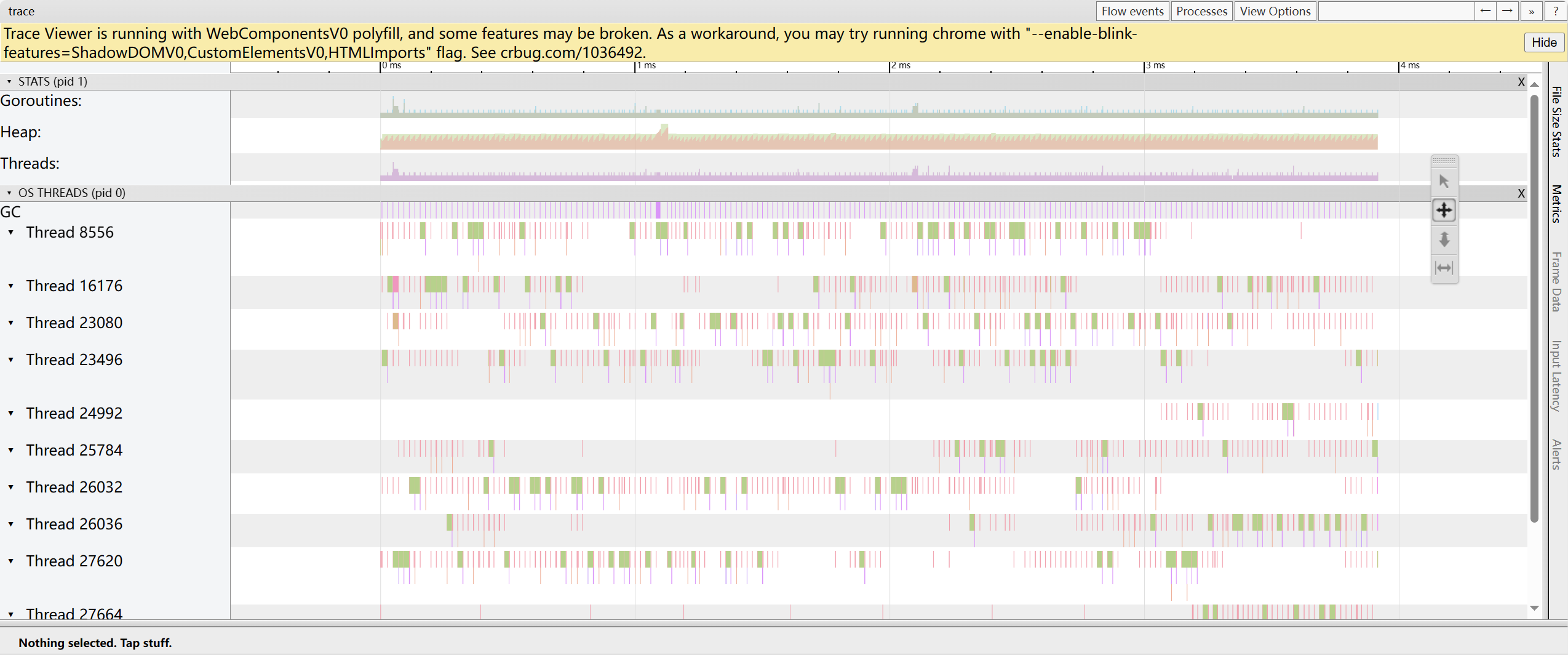
trace by thread: mostra la timeline delle coroutine in esecuzione sui thread OS in ogni momento
Goroutine analysis: mostra le informazioni statistiche relative alle coroutine per ogni gruppo di funzioni principali


Profiles
- Network blocking profile: informazioni sulle coroutine bloccate a causa di IO di rete
- Synchronization blocking profile: informazioni sulle coroutine bloccate a causa di primitivi di sincronizzazione
- Syscall profile: informazioni sulle coroutine bloccate a causa di chiamate di sistema
User-defined tasks and regions
- User-defined tasks: informazioni relative alle coroutine per le attività definite dall'utente
- User-defined regions: informazioni relative alle coroutine per le aree di codice definite dall'utente
Garbage collection metrics
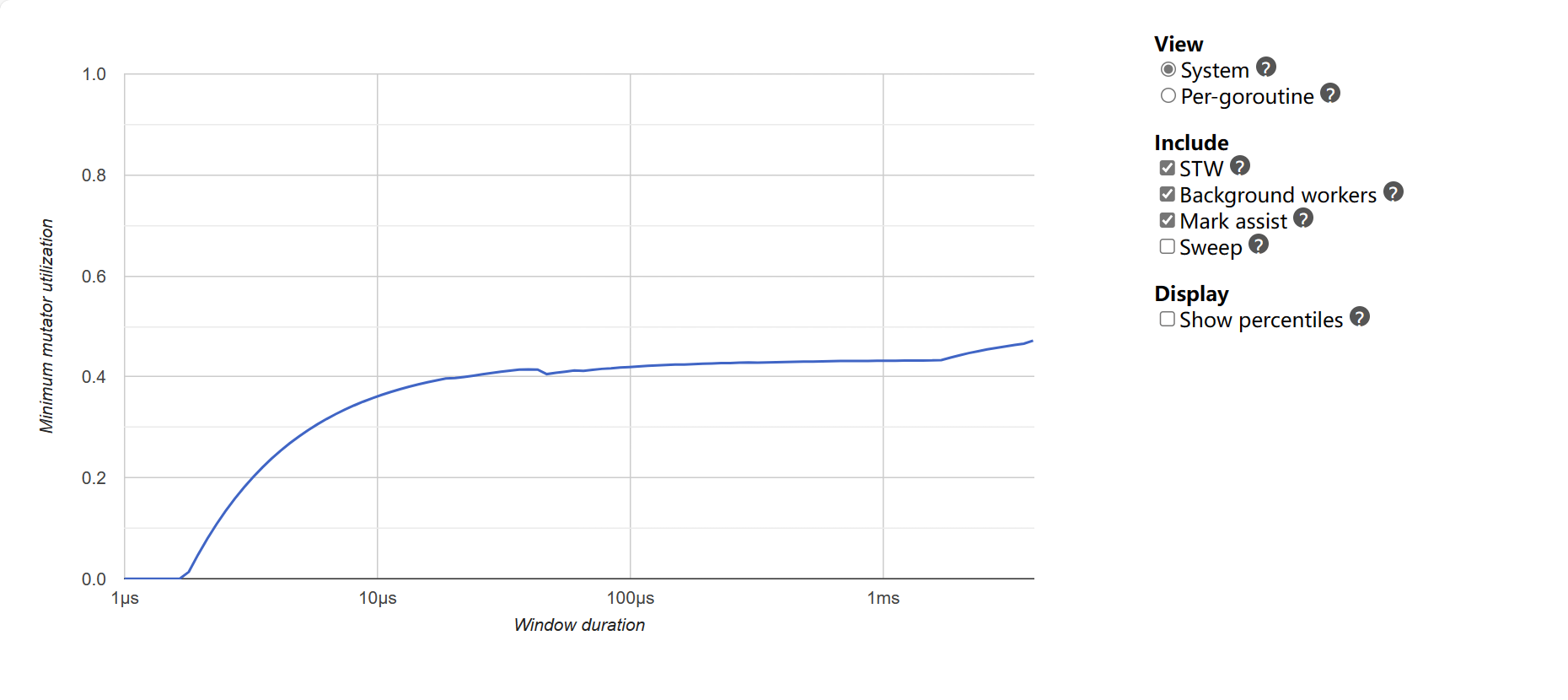
Minimum mutator utilization: mostra il tempo massimo di GC recente