การวิเคราะห์ประสิทธิภาพ
เมื่อโปรแกรมหนึ่งเขียนเสร็จแล้ว ความต้องการของเราที่มีต่อมันไม่ใช่เพียงแค่สามารถรันได้เท่านั้น แต่ยังหวังว่ามันจะเป็นแอปพลิเคชันที่มีเสถียรภาพและมีประสิทธิภาพสูง ผ่านการทดสอบต่างๆ เราสามารถรับประกันเสถียรภาพส่วนใหญ่ของโปรแกรมได้ ส่วนโปรแกรมจะมีประสิทธิภาพสูงหรือไม่ จำเป็นต้องเราทำการวิเคราะห์ประสิทธิภาพ ในเนื้อหาก่อนหน้านี้ วิธีการเดียวสำหรับการวิเคราะห์ประสิทธิภาพคือการทดสอบผ่าน Benchmark เพื่อวัดเวลาการทำงานเฉลี่ย การจัดสรรหน่วยความจำ ฯลฯ ของฟังก์ชันหนึ่งๆ อย่างไรก็ตาม ความต้องการในการวิเคราะห์ประสิทธิภาพของโปรแกรมในความเป็นจริงมีมากกว่านั้นมาก บางครั้งเราต้องการวิเคราะห์การใช้ CPU โดยรวมของโปรแกรม การใช้หน่วยความจำ สถานการณ์การจัดสรร heap สถานะ goroutine เส้นทางการทำงานของโค้ดที่เป็น hot spot ฯลฯ ซึ่งสิ่งเหล่านี้ Benchmark ไม่สามารถตอบสนองได้ โชคดีที่เครื่องมือ go ได้รวมเครื่องมือวิเคราะห์ประสิทธิภาพมากมายไว้ให้ผู้พัฒนาได้ใช้ ต่อไปจะอธิบายทีละข้อ
การวิเคราะห์การหนี (Escape Analysis)
ใน go การจัดสรรหน่วยความจำของตัวแปรถูกกำหนดโดยคอมไพเลอร์ โดยทั่วไปจะจัดสรรบน stack และ heap สองที่นี้ หากตัวแปรที่ควรจัดสรรบน stack ถูกจัดสรรบน heap สถานการณ์นี้เรียกว่าการหนี (escape) การวิเคราะห์การหนีคือการวิเคราะห์สถานการณ์การจัดสรรหน่วยความจำในโปรแกรม เนื่องจากมันดำเนินการในช่วงคอมไพล์ จึงเป็นการวิเคราะห์แบบสถิตย์ (static analysis) ชนิดหนึ่ง
TIP
ไปที่บทความ การจัดสรรหน่วยความจำ เพื่อเรียนรู้ว่า go จัดสรรหน่วยความจำอย่างไร
การอ้างอิงพอยน์เตอร์ท้องถิ่น
package main
func main() {
GetPerson()
}
type Person struct {
Name string
Mom *Person
}
func GetPerson() Person {
mom := Person{Name: "lili"}
son := Person{Name: "jack", Mom: &mom}
return son
}ในฟังก์ชัน GetPerson ได้สร้างตัวแปร mom เนื่องจากมันถูกสร้างในฟังก์ชัน เดิมควรจัดสรรบน stack แต่เนื่องจากมันถูกอ้างอิงโดยฟิลด์ Mom ของ son และ son ถูกส่งคืนเป็นค่าส่งกลับของฟังก์ชัน ดังนั้นคอมไพเลอร์จึงจัดสรรมันบน heap นี่เป็นตัวอย่างที่ง่ายมาก ดังนั้นการเข้าใจจึงไม่ต้องใช้แรงมาก แต่หากเป็นโปรเจกต์ที่ใหญ่กว่า มีจำนวนบรรทัดโค้ดหลายหมื่นบรรทัด การวิเคราะห์ด้วยมนุษย์ก็ไม่ใช่เรื่องง่าย ดังนั้นจึงจำเป็นต้องใช้เครื่องมือทำการวิเคราะห์การหนี ดังที่กล่าวไว้ก่อนหน้านี้ การจัดสรรหน่วยความจำถูกควบคุมโดยคอมไพเลอร์ ดังนั้นการวิเคราะห์การหนีก็ดำเนินการโดยคอมไพเลอร์เช่นกัน การใช้งานง่ายมาก เพียงดำเนินการคำสั่งต่อไปนี้:
$ go build -gcflags="-m -m -l"gcflags คือพารามิเตอร์ของคอมไพเลอร์ gc
-mพิมพ์คำแนะนำการปรับปรุงโค้ด หากปรากฏสองตัวจะแสดงรายละเอียดมากขึ้น-lปิดการใช้งานการปรับปรุงแบบ inline
ผลลัพธ์เป็นดังนี้
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:13:2: mom escapes to heap:
./main.go:13:2: flow: son = &mom:
./main.go:13:2: from &mom (address-of) at ./main.go:14:35
./main.go:13:2: from Person{...} (struct literal element) at ./main.go:14:15
./main.go:13:2: from son := Person{...} (assign) at ./main.go:14:6
./main.go:13:2: flow: ~r0 = son:
./main.go:13:2: from return son (return) at ./main.go:15:2
./main.go:13:2: moved to heap: momคอมไพเลอร์บอกเราอย่างชัดเจนว่าตัวแปร mom เกิดการหนี สาเหตุคือค่าส่งกลับมีพอยน์เตอร์ท้องถิ่นในฟังก์ชัน นอกจากสถานการณ์นี้แล้ว ยังมีสถานการณ์อื่นๆ ที่อาจเกิดการหนีได้
::: tips
หากคุณสนใจรายละเอียดของการวิเคราะห์การหนี สามารถดูเนื้อหาเพิ่มเติมได้ในไลบรารีมาตรฐาน cmd/compile/internal/escape/escape.go
:::
การอ้างอิงโดย closure
หาก closure อ้างอิงตัวแปรภายนอกฟังก์ชัน ตัวแปรนั้นก็จะหนีไปยัง heap ด้วย ซึ่งเข้าใจได้ง่าย
package main
func main() {
a := make([]string, 0)
do(func() []string {
return a
})
}
func do(f func() []string) []string {
return f()
}ผลลัพธ์
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:10:9: f does not escape
./main.go:4:2: main capturing by value: a (addr=false assign=false width=24)
./main.go:4:11: make([]string, 0) escapes to heap:
./main.go:4:11: flow: a = &{storage for make([]string, 0)}:
./main.go:4:11: from make([]string, 0) (spill) at ./main.go:4:11
./main.go:4:11: from a := make([]string, 0) (assign) at ./main.go:4:4
./main.go:4:11: flow: ~r0 = a:
./main.go:4:11: from return a (return) at ./main.go:6:3
./main.go:4:11: make([]string, 0) escapes to heap
./main.go:5:5: func literal does not escapeพื้นที่ไม่เพียงพอ
เมื่อพื้นที่ stack ไม่เพียงพอ ก็会发生การหนีเช่นกัน สไลซ์ที่สร้างด้านล่างขอความจุ 1<<15
package main
func main() {
_ = make([]int, 0, 1<<15)
}ผลลัพธ์
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:4:10: make([]int, 0, 32768) escapes to heap:
./main.go:4:10: flow: {heap} = &{storage for make([]int, 0, 32768)}:
./main.go:4:10: from make([]int, 0, 32768) (too large for stack) at ./main.go:4:10
./main.go:4:10: make([]int, 0, 32768) escapes to heapความยาวไม่ทราบค่า
เมื่อความยาวของสไลซ์เป็นตัวแปร เนื่องจากความยาวไม่ทราบค่า จึง会发生การหนี (map ไม่เป็นเช่นนั้น)
package main
func main() {
n := 100
_ = make([]int, n)
}ผลลัพธ์
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:5:10: make([]int, n) escapes to heap:
./main.go:5:10: flow: {heap} = &{storage for make([]int, n)}:
./main.go:5:10: from make([]int, n) (non-constant size) at ./main.go:5:10
./main.go:5:10: make([]int, n) escapes to heapยังมีสถานการณ์พิเศษอีกอย่างหนึ่งคือเมื่อพารามิเตอร์ฟังก์ชันเป็นประเภท ...any ก็อาจเกิดการหนีได้
package main
import "fmt"
func main() {
n := 100
fmt.Println(n)
}ผลลัพธ์
$ go build -gcflags="-m -m -l" .
# golearn/example
./main.go:7:14: n escapes to heap:
./main.go:7:14: flow: {storage for ... argument} = &{storage for n}:
./main.go:7:14: from n (spill) at ./main.go:7:14
./main.go:7:14: from ... argument (slice-literal-element) at ./main.go:7:13
./main.go:7:14: flow: {heap} = {storage for ... argument}:
./main.go:7:14: from ... argument (spill) at ./main.go:7:13
./main.go:7:14: from fmt.Println(... argument...) (call parameter) at ./main.go:7:13
./main.go:7:13: ... argument does not escape
./main.go:7:14: n escapes to heapเหตุผลที่เราต้องทำการวิเคราะห์การหนี ควบคุมการจัดสรรหน่วยความจำอย่างละเอียดเช่นนี้ ส่วนใหญ่เพื่อลดภาระของ GC แต่ go ไม่ใช่ภาษา c อำนาจตัดสินใจสุดท้ายในการจัดสรรหน่วยความจำยังคงอยู่ในมือของคอมไพเลอร์ ยกเว้นในกรณีที่ต้องการประสิทธิภาพสูงมาก ส่วนใหญ่เราไม่จำเป็นต้องใส่ใจรายละเอียดการจัดสรรหน่วยความจำมากเกินไป เพราะจุดประสงค์ของการเกิด GC ก็เพื่อปลดปล่อยผู้พัฒนา
รายละเอียดเล็กน้อย
สำหรับประเภทอ้างอิงบางประเภท เมื่อยืนยันแล้วว่าไม่ใช้มันอีกแล้ว เราสามารถตั้งค่าเป็น nil เพื่อบอก GC ว่าสามารถคืนหน่วยความจำมันได้
type Writer struct {
buf []byte
}
func (w Writer) Close() error {
w.buff = nil
return nil
}pprof
pprof (program profiling) เป็นเครื่องมือวิเคราะห์ประสิทธิภาพของโปรแกรมที่ทรงพลัง มันจะทำการสุ่มตัวอย่างข้อมูลขณะรันไทม์ของโปรแกรม ครอบคลุม cpu หน่วยความจำ goroutine lock ข้อมูล stack ฯลฯ จากนั้นใช้เครื่องมือวิเคราะห์และแสดงผลข้อมูลที่สุ่มตัวอย่าง
ดังนั้นขั้นตอนการใช้ pprof มีเพียงสองขั้นตอน:
- เก็บข้อมูล
- วิเคราะห์ผลลัพธ์
การเก็บข้อมูล
วิธีการเก็บข้อมูลมีสองวิธี คือ อัตโนมัติและแมนนวล (แต่ละวิธีมีข้อดีและข้อเสีย) ก่อนหน้านี้ ให้เขียนฟังก์ชันง่ายๆ เพื่อจำลองการใช้หน่วยความจำและ cpu
func Do() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 24 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}แมนนวล
การเก็บข้อมูลแบบแมนนวลคือการควบคุมผ่านโค้ด ข้อดีคือสามารถควบคุมได้ ยืดหยุ่น สามารถกำหนดเองได้ การใช้ pprof ในโค้ดโดยตรงจำเป็นต้องนำเข้าแพ็กเกจ runtime/pprof
package main
import (
"log"
"os"
"runtime/pprof"
)
func main() {
Do()
w, _ := os.Create("heap.pb")
heapProfile := pprof.Lookup("heap")
err := heapProfile.WriteTo(w, 0)
if err != nil {
log.Fatal(err)
}
}พารามิเตอร์ที่รองรับโดย pprof.Lookup มีดังนี้
profiles.m = map[string]*Profile{
"goroutine": goroutineProfile,
"threadcreate": threadcreateProfile,
"heap": heapProfile,
"allocs": allocsProfile,
"block": blockProfile,
"mutex": mutexProfile,
}ฟังก์ชันนี้จะเขียนข้อมูลที่เก็บได้ลงในไฟล์ที่ระบุ ตัวเลขที่ส่งเข้าไปขณะเขียนมีความหมายดังนี้
0เขียนข้อมูล Protobuf ที่บีบอัดแล้ว ไม่มีความสามารถในการอ่าน1เขียนข้อมูลรูปแบบข้อความ สามารถอ่านได้ http interface ส่งคืนข้อมูลประเภทนี้2ใช้ได้เฉพาะgoroutineแสดงการพิมพ์ข้อมูล stack สไตล์panic
การเก็บข้อมูล cpu ต้องใช้ฟังก์ชัน pprof.StartCPUProfile แยกต่างหาก ต้องใช้เวลาหนึ่งในการสุ่มตัวอย่าง และข้อมูลดิบไม่สามารถอ่านได้ ดังนี้
package main
import (
"log"
"os"
"runtime/pprof"
"time"
)
func main() {
Do()
w, _ := os.Create("cpu.out")
err := pprof.StartCPUProfile(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
pprof.StopCPUProfile()
}การเก็บข้อมูล trace ก็เช่นกัน
package main
import (
"log"
"os"
"runtime/trace"
"time"
)
func main() {
Do()
w, _ := os.Create("trace.out")
err := trace.Start(w)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
trace.Stop()
}อัตโนมัติ
แพ็กเกจ net/http/pprof ได้ห่อหุ้มฟังก์ชันวิเคราะห์ข้างต้นเป็น http interface และลงทะเบียนใน route เริ่มต้น ดังนี้
package pprof
import ...
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}这使得ทำให้เราสามารถรันการเก็บข้อมูล pprof ได้ด้วยคลิกเดียว
package main
import (
"net/http"
// อย่าลืมนำเข้าแพ็กเกจนี้
_ "net/http/pprof"
)
func main() {
go func(){
http.ListenAndServe(":8080", nil)
}
for {
Do()
}
}จากนั้นเปิดเบราว์เซอร์访问 http://127.0.0.1:8080/debug/pprof จะปรากฏหน้าจอดังนี้
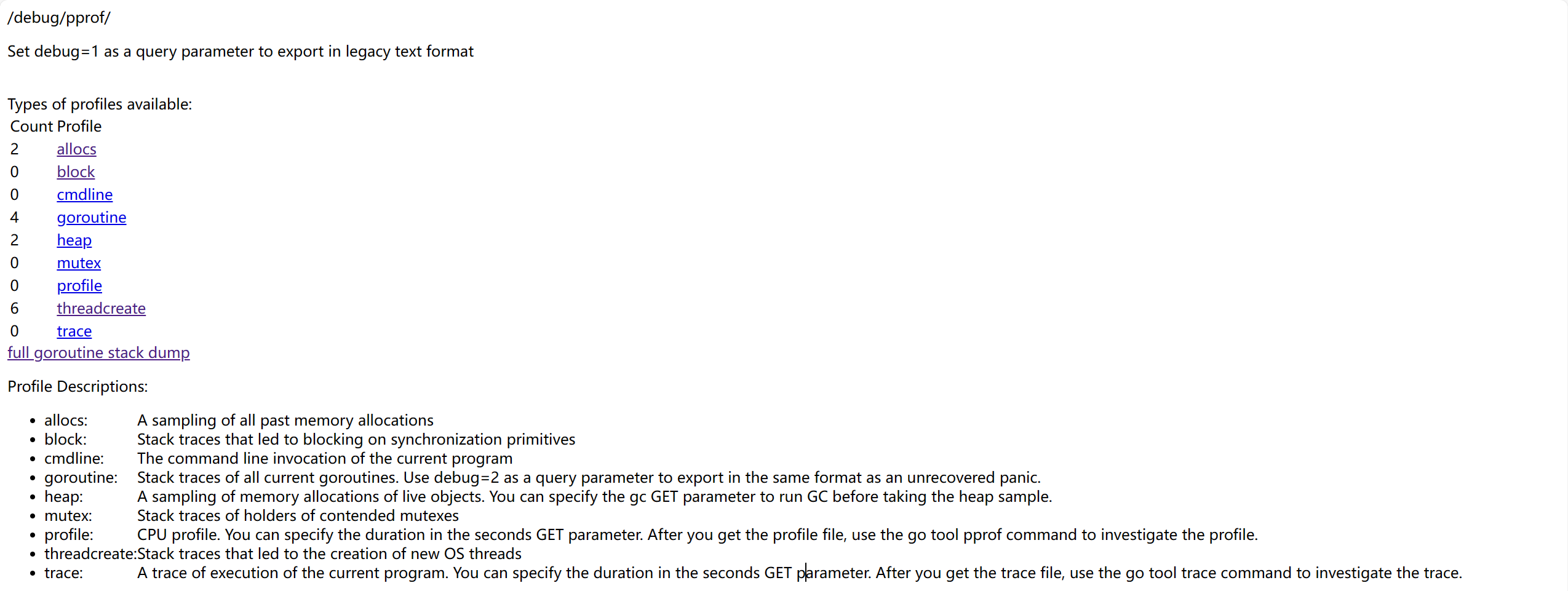
ในหน้ามีตัวเลือกให้เลือกหลายตัว ซึ่งแทนด้วย
allocs: การสุ่มตัวอย่างการจัดสรรหน่วยความจำblock: การติดตามการบล็อกของ synchronization primitivescmdline: การเรียก command line ของโปรแกรมปัจจุบันgoroutine: การติดตาม goroutine ทั้งหมดheap: การสุ่มตัวอย่างการจัดสรรหน่วยความจำสำหรับ对象ที่ยัง存活mutex: การติดตามข้อมูลเกี่ยวกับ mutexprofile: การวิเคราะห์ cpu จะวิเคราะห์ช่วงเวลาหนึ่งและดาวน์โหลดไฟล์threadcreate: การวิเคราะห์สาเหตุที่ทำให้สร้าง OS thread ใหม่trace: การติดตามสถานการณ์การดำเนินการของโปรแกรมปัจจุบัน จะดาวน์โหลดไฟล์เช่นกัน
ข้อมูลที่นี่ส่วนใหญ่มีความสามารถในการอ่านไม่สูง ส่วนใหญ่ใช้สำหรับให้เครื่องมือวิเคราะห์ ดังรูปต่อไปนี้
งานวิเคราะห์เฉพาะต้องเก็บไว้ทำภายหลัง นอกจากตัวเลือก profile และ trace สองตัวแล้ว หากคุณต้องการดาวน์โหลดไฟล์ข้อมูลในเว็บเพจ สามารถลบพารามิเตอร์ query debug=1 ออกได้ นอกจากนี้ยังสามารถรวม interfaces เหล่านี้เข้ากับ route ของคุณเองแทนที่จะใช้ route เริ่มต้น ดังนี้
package main
import (
"net/http"
"net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/trace", pprof.Trace)
servre := &http.Server{
Addr: ":8080",
Handler: mux,
}
servre.ListenAndServe()
}ด้วยวิธีนี้ ยังสามารถรวมเข้ากับ web framework อื่นๆ ได้ เช่น gin, iris เป็นต้น
การวิเคราะห์
หลังจากได้ไฟล์ข้อมูลที่เก็บแล้ว มีสองวิธีในการวิเคราะห์ คือ command line หรือเว็บเพจ ทั้งสองต้องใช้เครื่องมือ command line pprof go ได้รวมเครื่องมือนี้ไว้โดยค่าเริ่มต้น ดังนั้นไม่ต้องดาวน์โหลดเพิ่มเติม
ที่อยู่โอเพนซอร์สของ pprof: google/pprof: pprof is a tool for visualization and analysis of profiling data (github.com)
Command line
ใช้ไฟล์ข้อมูลที่เก็บไว้ก่อนหน้านี้เป็นพารามิเตอร์
$ go tool pprof heap.pbหากข้อมูลถูกเก็บโดยเว็บ ให้ใช้ web url แทนชื่อไฟล์
$ go tool pprof -http :8080 http://127.0.0.1/debug/pprof/heapจากนั้นจะปรากฏ command line แบบ interactive
15:27:38.3266862 +0800 CST
Type: inuse_space
Time: Apr 15, 2024 at 3:27pm (CST)
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)พิมพ์ help สามารถดูคำสั่งอื่นๆ
Commands:
callgrind Outputs a graph in callgrind format
comments Output all profile comments
disasm Output assembly listings annotated with samples
dot Outputs a graph in DOT format
eog Visualize graph through eog
evince Visualize graph through evince
...ในการดูข้อมูลใน command line โดยทั่วไปใช้คำสั่ง top หรือใช้คำสั่ง traces ก็ได้ แต่ผลลัพธ์ยาวมาก คำสั่ง top ดูคร่าวๆ เท่านั้น
(pprof) top 5
Showing nodes accounting for 117.49MB, 100% of 117.49MB total
flat flat% sum% cum cum%
117.49MB 100% 100% 117.49MB 100% main.makeSlice (inline)
0 0% 100% 117.49MB 100% main.Do
0 0% 100% 117.49MB 100% main.main
0 0% 100% 117.49MB 100% runtime.mainแนะนำตัวชี้วัดบางตัว (cpu เช่นกัน)
flatแทนทรัพยากรที่ฟังก์ชันปัจจุบันใช้cumแทนผลรวมทรัพยากรที่ฟังก์ชันปัจจุบันและ call chain ต่อไปใช้flat%flat/totalcum%cum/total
เราจะเห็นได้ชัดเจนว่าการใช้หน่วยความจำของ call chain ทั้งหมดคือ 117.49MB เนื่องจากฟังก์ชัน Do เองไม่ทำอะไรเลย เพียงเรียกฟังก์ชันอื่น ดังนั้นตัวชี้วัด flat ของมันคือ 0 การสร้างสไลซ์ถูกจัดการโดยฟังก์ชัน makeSlice ดังนั้นตัวชี้วัด flat ของมันคือ 100%
เราสามารถแปลงเป็นรูปแบบ visualization pprof รองรับรูปแบบมากมาย เช่น pdf, svg, png, gif ฯลฯ (ต้องติดตั้ง Graphviz)
(pprof) png
Generating report in profile001.png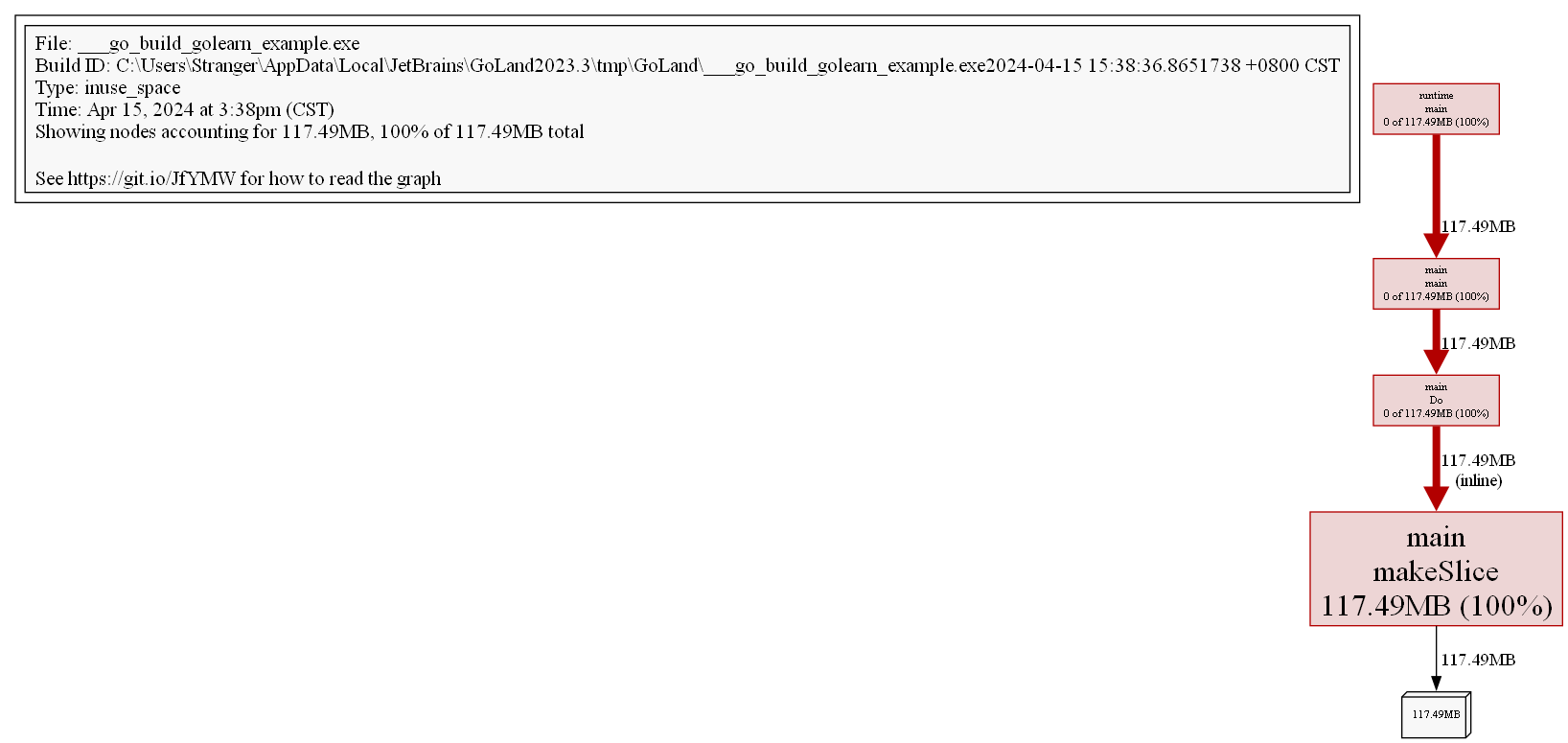
ผ่านรูปภาพเราสามารถเห็นสถานการณ์การใช้หน่วยความจำของ call chain ทั้งหมดได้ชัดเจนขึ้น
ดูผ่านคำสั่ง list ในรูปแบบซอร์สโค้ด
(pprof) list Do
Total: 117.49MB
ROUTINE ======================== main.Do in D:\WorkSpace\Code\GoLeran\golearn\example\main.go
0 117.49MB (flat, cum) 100% of Total
. . 21:func Do() {
. . 22: for i := 0; i < 10; i++ {
. 117.49MB 23: slice := makeSlice()
. . 24: sortSlice(slice)
. . 25: }
. . 26:}
. . 27:
. . 28:func makeSlice() []int {สำหรับรูปภาพและซอร์สโค้ด ยังสามารถใช้คำสั่ง web และ weblist เพื่อดูรูปภาพและซอร์สโค้ดในเบราว์เซอร์ได้
เว็บเพจ
ก่อนนี้เพื่อให้ความหลากหลายของข้อมูลมากขึ้น ให้แก้ไขฟังก์ชันจำลองเล็กน้อย
func Do1() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func Do2() {
for i := 0; i < 10; i++ {
slice := makeSlice()
sortSlice(slice)
}
}
func makeSlice() []int {
var s []int
for range 1 << 12 {
s = append(s, rand.Int())
}
return s
}
func sortSlice(s []int) {
slices.Sort(s)
}การวิเคราะห์ผ่านเว็บเพจสามารถแสดงผลแบบ visualization ไม่ต้องดำเนินการ command line ด้วยตนเอง เมื่อใช้การวิเคราะห์ผ่านเว็บเพจ เพียงดำเนินการคำสั่งต่อไปนี้
$ go tool pprof -http :8080 heap.pbหากข้อมูลถูกเก็บโดยเว็บ ให้ใช้ web url แทนชื่อไฟล์
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/heap
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/profile
$ go tool pprof -http :8080 http://127.0.0.1:9090/debug/pprof/goroutineTIP
เกี่ยวกับวิธีการวิเคราะห์ข้อมูล ไปที่ pprof: How to read the graph เพื่อเรียนรู้เพิ่มเติม
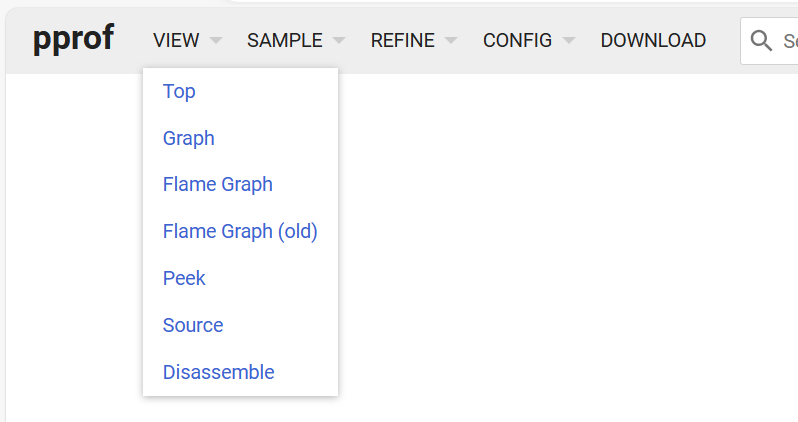
ในเว็บเพจมี 6 รายการที่สามารถดูได้
- Top เหมือนคำสั่ง top
- Graph กราฟเส้น
- Flame Graph กราฟเปลวไฟ
- Peek
- Source ดูซอร์สโค้ด
- Disassemble ดูการ disassemble
สำหรับหน่วยความจำสามารถวิเคราะห์ได้สี่มิติ
alloc_objects: จำนวน对象 ทั้งหมดที่จัดสรรแล้ว รวมถึงที่ปล่อยแล้วalloc_spcae: พื้นที่หน่วยความจำทั้งหมดที่จัดสรรแล้ว รวมถึงที่ปล่อยแล้วinuse_objects: จำนวน对象 ที่กำลังใช้inuse_space: พื้นที่หน่วยความจำที่กำลังใช้
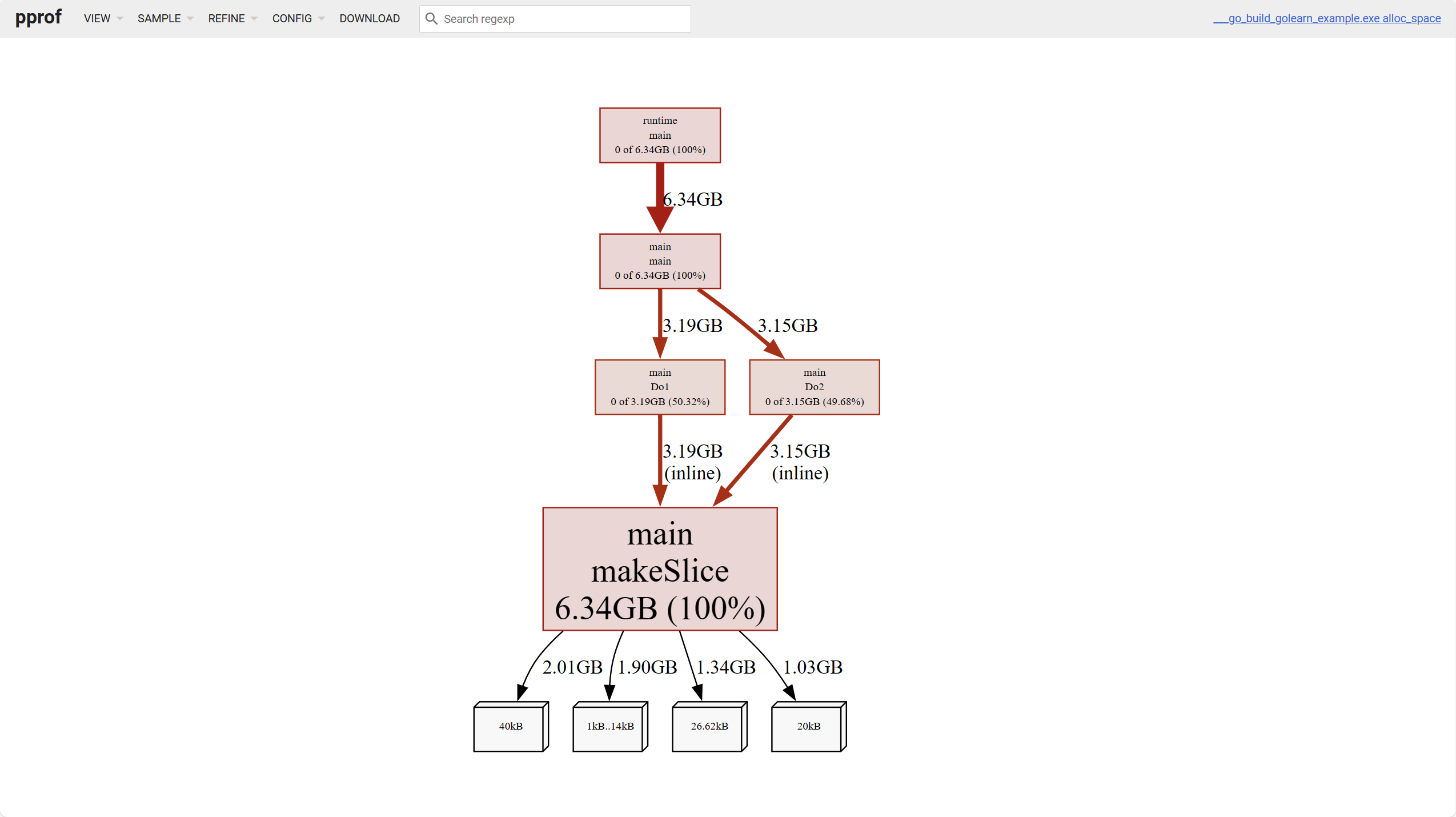
โหนดใบสีขาวด้านล่างสุดในภาพแทนการ占用ของ对象ขนาดต่างๆ
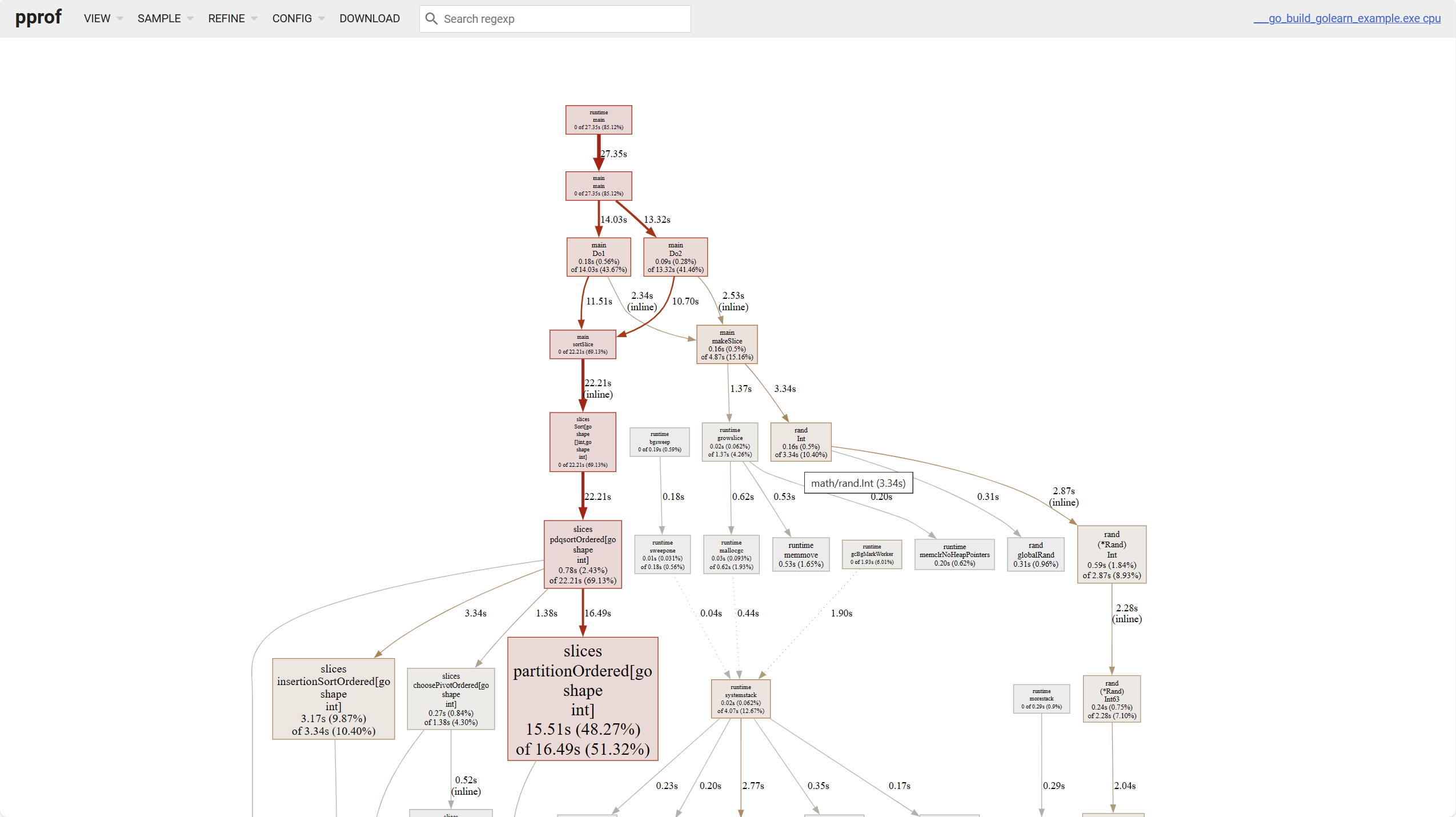
เกี่ยวกับกราฟเส้น มี几点ที่ควรสังเกต
- สีของบล็อกยิ่งเข้ม การ占用ยิ่งสูง เส้นยิ่งหนา การ占用ยิ่งสูง
- เส้นทึบแทนการเรียกโดยตรง เส้นประแทนการข้าม call chain บางส่วน

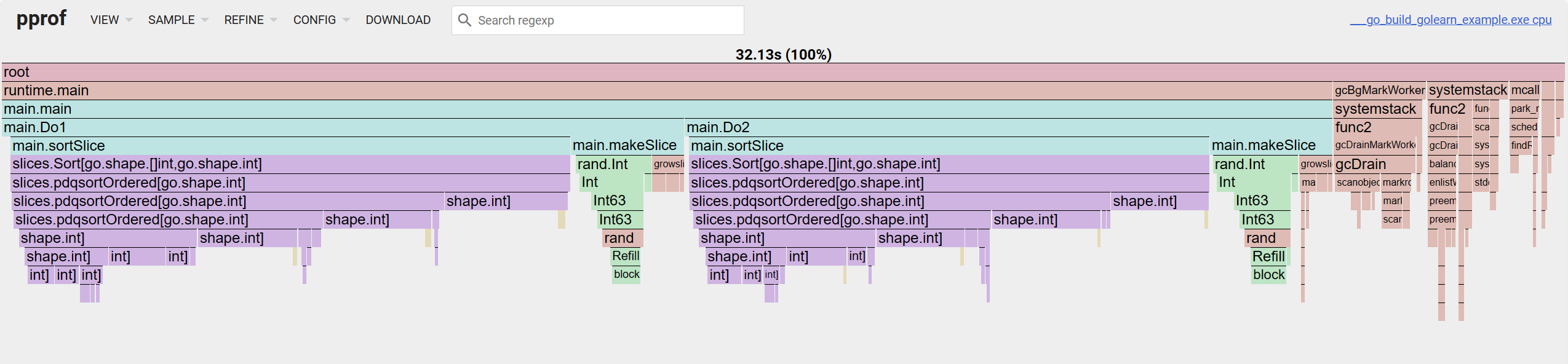
สำหรับกราฟเปลวไฟ มองจากบนลงล่างคือ call chain มองจากซ้ายไปขวาคือเปอร์เซ็นต์การ占用ของ cum
trace
pprof 主要负责การวิเคราะห์การใช้ทรัพยากรของโปรแกรม ส่วน trace เหมาะสมกว่าสำหรับการติดตามรายละเอียดการดำเนินการของโปรแกรม ไฟล์ข้อมูลของมันไม่เข้ากันกับ pprof งานวิเคราะห์ที่เกี่ยวข้องดำเนินการโดยคำสั่ง go tool trace
หากเป็นข้อมูลที่เก็บแบบแมนนวล สามารถใช้ชื่อไฟล์เป็นพารามิเตอร์
$ go tool trace trace.outหากเป็นข้อมูลที่เก็บแบบอัตโนมัติ ก็เช่นกัน
$ curl http://127.0.0.1:8080/debug/pprof/trace > trace.out && go tool trace trace.outหลังจากดำเนินการจะเปิด web server
2024/04/15 17:15:40 Preparing trace for viewer...
2024/04/15 17:15:40 Splitting trace for viewer...
2024/04/15 17:15:40 Opening browser. Trace viewer is listening on http://127.0.0.1:51805หลังจากเปิดหน้าประมาณดังนี้
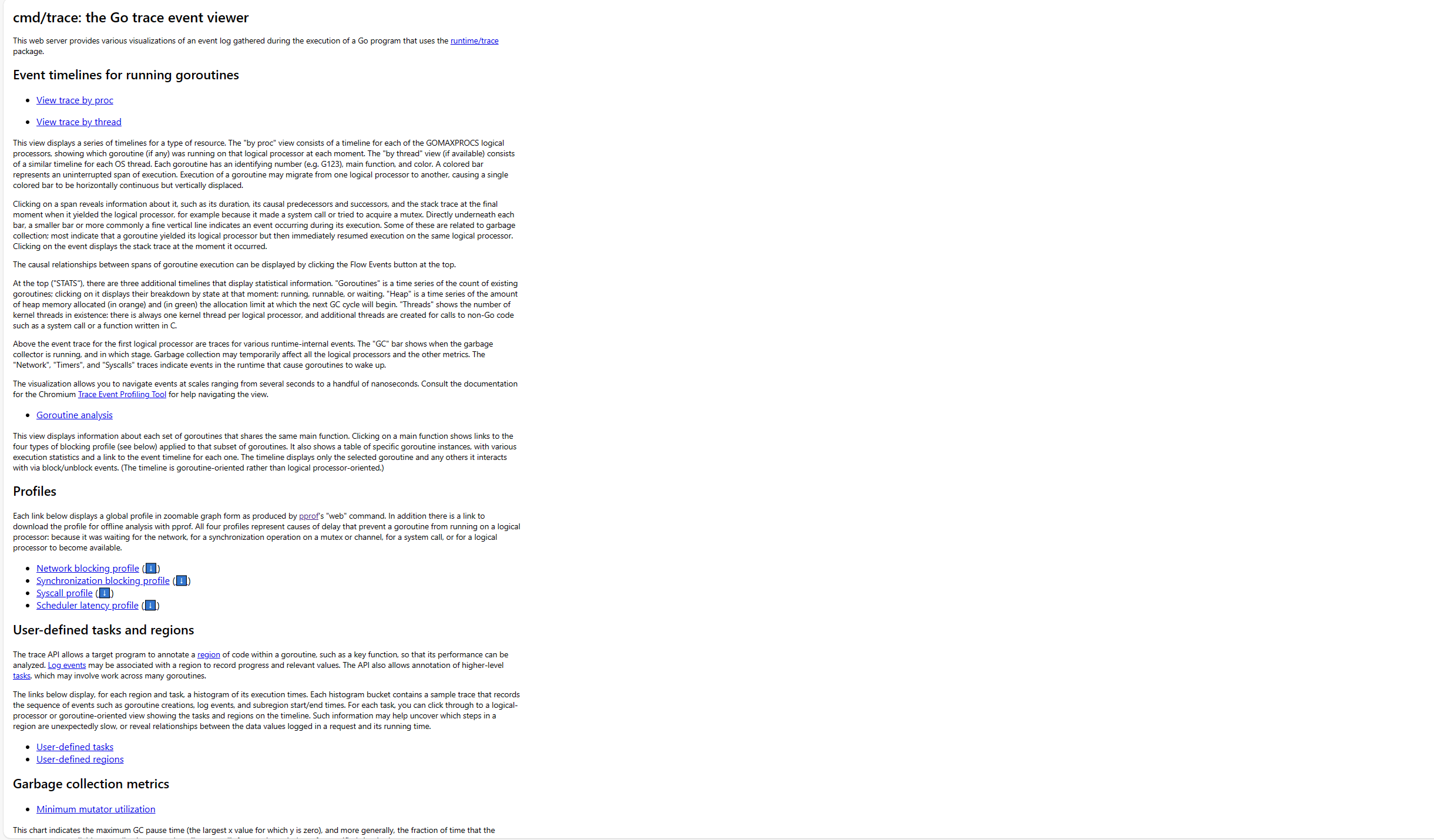
这里面ประกอบด้วยส่วนต่อไปนี้ ข้อมูลเหล่านี้ค่อนข้างเข้าใจยาก
Event timelines for running goroutines
trace by proc: แสดง timeline ของ goroutine ที่ทำงานบน processor นั้นๆ ในแต่ละช่วงเวลา
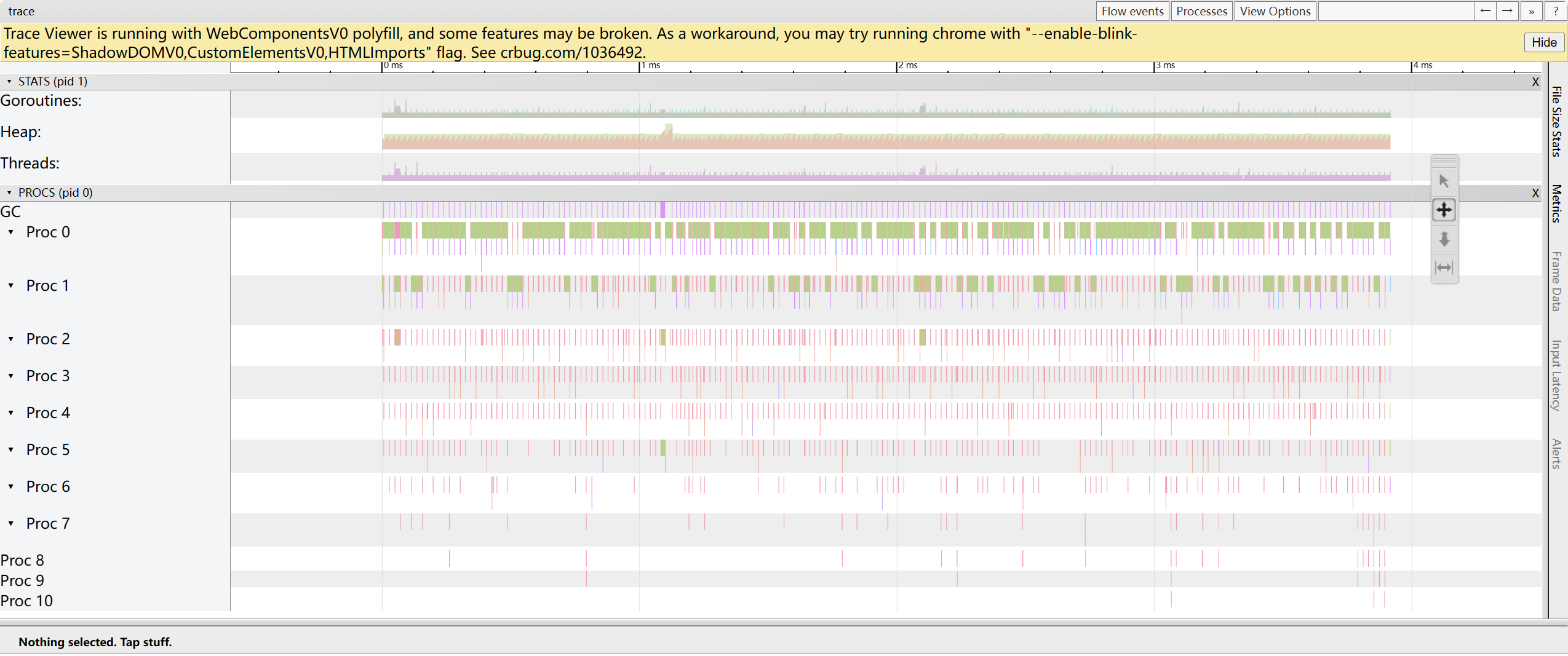
trace by thread: แสดง timeline ของ goroutine ที่ทำงานบน OS thread ในแต่ละช่วงเวลา
Goroutine analysis: แสดงข้อมูลสถิติเกี่ยวกับ goroutine ของ每组 main function


Profiles
- Network blocking profile: ข้อมูล goroutine ที่ถูกบล็อกเนื่องจาก network IO
- Synchronization blocking profile: ข้อมูล goroutine ที่ถูกบล็อกเนื่องจาก synchronization primitives
- Syscall profile: ข้อมูล goroutine ที่ถูกบล็อกเนื่องจาก system call
User-defined tasks and regions
- User-defined tasks: ข้อมูล goroutine ของ tasks ที่ผู้ใช้กำหนด
- User-defined regions: ข้อมูล goroutine ของ regions ของโค้ดที่ผู้ใช้กำหนด
Garbage collection metrics
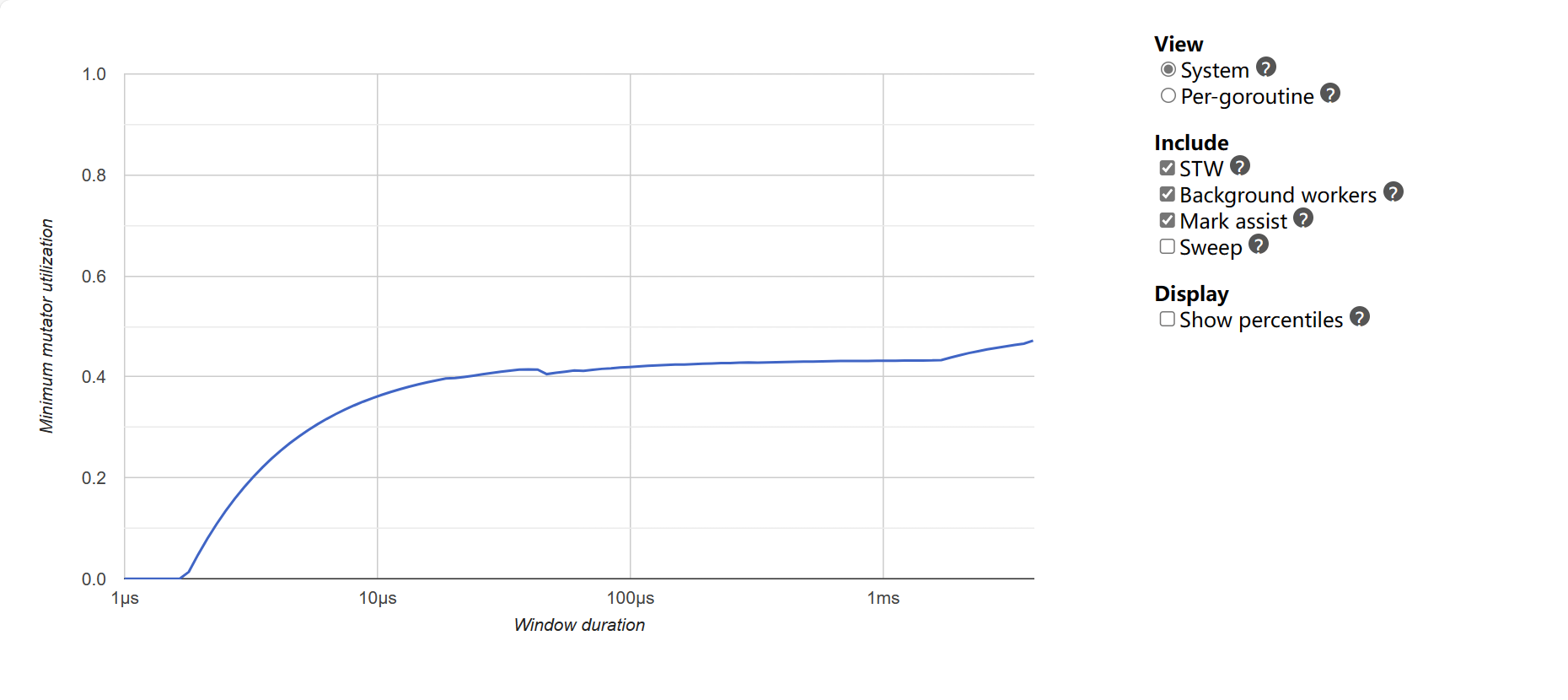
Minimum mutator utilization: แสดงเวลาสูงสุดของ GC ล่าสุด