gmp
หนึ่งในคุณสมบัติที่ใหญ่ที่สุดของภาษา Go คือการสนับสนุนการทำงานพร้อมกันโดยธรรมชาติ เพียงแค่ใช้คีย์เวิร์ดเดียวก็สามารถเริ่มต้น coroutine ได้ ดังเช่นตัวอย่างด้านล่าง
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Coroutine ของภาษา Go ใช้งานง่ายมาก สำหรับผู้พัฒนาแทบไม่ต้องทำงานเพิ่มเติมใดๆ นี่เป็นหนึ่งในเหตุผลที่ทำให้มันได้รับความนิยม อย่างไรก็ตามเบื้องหลังความเรียบง่ายนี้มี concurrent scheduler ที่ไม่เรียบง่ายรองรับอยู่ ชื่อของมันเชื่อว่าทุกท่านน่าจะเคยได้ยินมากบ้างน้อยบ้าง เนื่องจากผู้เข้าร่วมหลักประกอบด้วย G (coroutine), M (system thread), P (processor) สามสมาชิก จึงเรียกว่า GMP scheduler การออกแบบของ GMP scheduler มีอิทธิพลต่อการออกแบบ runtime ทั้งหมดของ Go GC, network poller กล่าวได้ว่ามันเป็นหัวใจหลักที่สุดของภาษาทั้งหมด หากมีความเข้าใจเกี่ยวกับมันบ้าง ในการทำงานในอนาคตอาจจะมีประโยชน์บ้าง
ประวัติ
โมเดล concurrent scheduler ของภาษา Go ไม่ได้เป็นต้นฉบับทั้งหมด มันได้ดูดซับประสบการณ์และบทเรียนจากบรรพบุรุษมากมาย ผ่านการพัฒนาและปรับปรุงอย่างต่อเนื่องจึงมีหน้าตาเช่นปัจจุบัน ภาษาที่เคยเรียนรู้มีดังนี้:
- Occam -1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
ที่มีอิทธิพลมากที่สุดคือบทความเกี่ยวกับ CSP (Communicate Sequential Process) ที่ Hall ตีพิมพ์ในปี 1978 ความคิดพื้นฐานของบทความนี้คือกระบวนการแลกเปลี่ยนข้อมูลผ่านการสื่อสารระหว่างกระบวนการ ในภาษาการเขียนโปรแกรมหลายภาษาข้างต้นล้วนได้รับอิทธิพลจากความคิดของ CSP Erlang เป็นตัวอย่างที่โดดเด่นที่สุดของภาษาการเขียนโปรแกรมแบบมุ่งเน้นข้อความ RabbitMQ middleware แบบ open source ที่มีชื่อเสียงก็เขียนด้วย Erlang ในปัจจุบัน ด้วยการพัฒนาคอมพิวเตอร์และอินเทอร์เน็ต การสนับสนุนการทำงานพร้อมกันเกือบกลายเป็นมาตรฐานของภาษาสมัยใหม่ ภาษา Go ที่ผสมผสานความคิด CSP จึงเกิดขึ้น
โมเดลการ schedule
ก่อนอื่นมาแนะนำสมาชิกสามตัวของ GMP อย่างง่าย
- G, Goroutine หมายถึง coroutine ในภาษา Go
- M, Machine หมายถึง system thread หรือ worker thread ซึ่งระบบปฏิบัติการรับผิดชอบในการ schedule
- P, Processor ไม่ได้หมายถึง CPU processor แต่เป็นแนวคิดที่ Go สร้างขึ้นมาเอง หมายถึง processor ที่ทำงานบน system thread ใช้มันเพื่อ schedule coroutine บนแต่ละ system thread
Coroutine เป็น thread ที่เบากว่า ขนาดเล็กกว่า ทรัพยากรที่ต้องการก็น้อยกว่า การสร้างและการทำลายและจังหวะการ schedule ล้วนเสร็จสิ้นโดย Go runtime ไม่ใช่ระบบปฏิบัติการ ดังนั้นต้นทุนการจัดการจึงต่ำกว่า thread มาก อย่างไรก็ตาม coroutine ก็พึ่งพา thread ด้วย time slice ที่ coroutine ต้องการสำหรับการดำเนินการมาจาก thread time slice ที่ thread ต้องการมาจากระบบปฏิบัติการ และการสลับระหว่าง thread ที่ต่างกันมีต้นทุนบางอย่าง ทำให้ coroutine ใช้ time slice ของ thread ให้ดีคือกุญแจสำคัญของการออกแบบ
1:N
วิธีที่ดีที่สุดในการแก้ปัญหาคือการเพิกเฉยต่อปัญหานี้ เนื่องจาก thread switch มีต้นทุน ก็แค่ไม่ switch ก็แล้วกัน จัดสรร coroutine ทั้งหมดให้กับ kernel thread เดียว ดังนั้นจึงเกี่ยวข้องเฉพาะการสลับระหว่าง coroutine
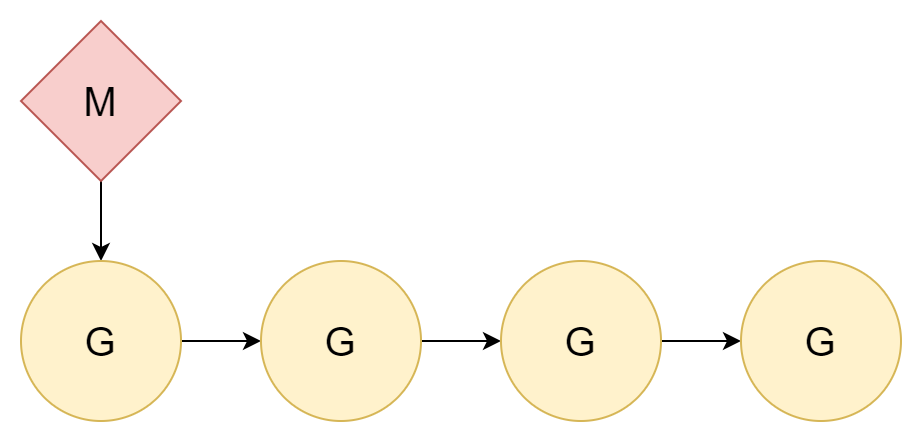
ความสัมพันธ์ระหว่าง thread และ coroutine คือ 1:N การทำเช่นนี้มีข้อเสียที่ชัดเจนมาก คอมพิวเตอร์ในยุคปัจจุบันเกือบทั้งหมดเป็น CPU หลายคอร์ การจัดสรรเช่นนี้ไม่สามารถใช้ประโยชน์จากประสิทธิภาพของ CPU หลายคอร์ได้เต็มที่
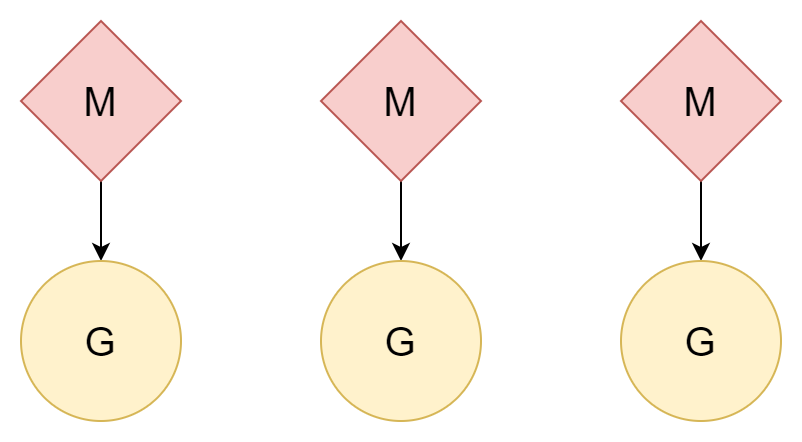
N:N
อีกวิธีหนึ่ง หนึ่ง thread ต่อหนึ่ง coroutine หนึ่ง coroutine สามารถ享受 time slice ทั้งหมดของ thread นั้น หลาย thread ก็สามารถใช้ประโยชน์จากประสิทธิภาพของ CPU หลายคอร์ได้ อย่างไรก็ตาม ต้นทุนการสร้างและสลับ thread ค่อนข้างสูง หากเป็นความสัมพันธ์แบบหนึ่งต่อหนึ่ง กลับไม่ได้ใช้ประโยชน์จากความเบาของ coroutine
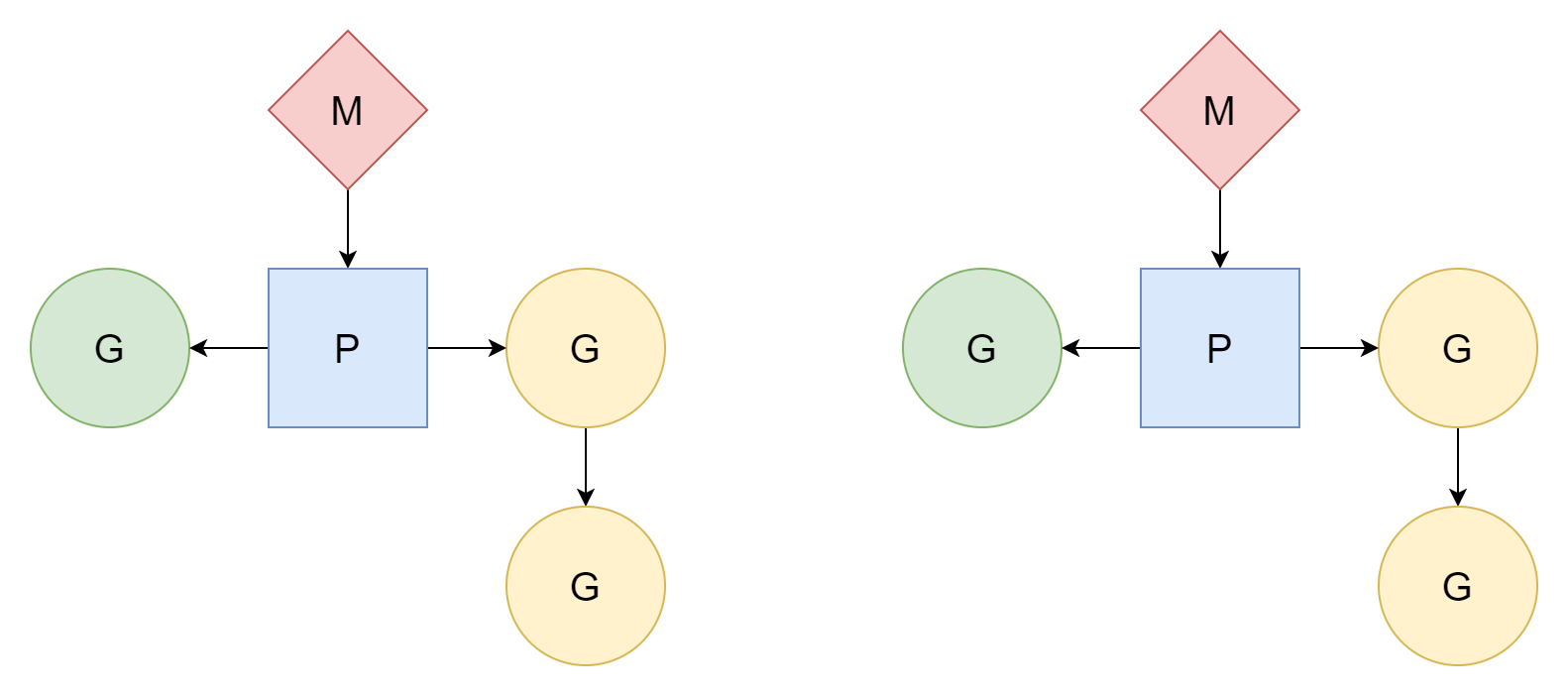
M:N
M thread ต่อ N coroutine และ M น้อยกว่า N หลาย thread ต่อหลาย coroutine แต่ละ thread จะสอดคล้องกับ coroutine จำนวนหนึ่ง processor P รับผิดชอบ schedule ว่า coroutine G จะใช้ time slice ของ thread อย่างไร วิธีนี้เป็นวิธีที่ดี相对而言 และเป็นโมเดลการ schedule ที่ Go ใช้มาจนถึงปัจจุบัน
M สามารถทำงานได้หลังจากเชื่อมโยงกับ processor P เท่านั้น Go จะสร้าง processor จำนวน GOMAXPROCS ดังนั้นจำนวน thread ที่สามารถทำงานได้จริงคือ GOMAXPROCS ค่าเริ่มต้นคือจำนวน logical core ของ CPU ในเครื่องปัจจุบัน เราสามารถตั้งค่า它的ค่าได้ด้วยตนเอง
แก้ไขผ่านโค้ด
runtime.GOMAXPROCS(N)และสามารถปรับแบบไดนามิกได้ใน runtime เรียกแล้ว STW ทันทีตั้งค่า environment variable
export GOMAXPROCS=Nแบบคงที่
ในสถานการณ์จริง จำนวน M จะมากกว่าจำนวน P เนื่องจากใน runtime จะต้องการพวกมันเพื่อจัดการงานอื่นๆ เช่น system calls ค่าสูงสุดคือ 10000
ผู้เข้าร่วมสามตัวของ GMP และ scheduler เองมี type representation ที่สอดคล้องกันใน runtime ทั้งหมดอยู่ในไฟล์ runtime/runtime2.go ด้านล่างนี้จะแนะนำโครงสร้างของมันอย่างง่าย เพื่อความสะดวกในการเข้าใจ在后面
G
G ใน runtime แสดงเป็น type runtime.g structure เป็นหน่วยการ schedule พื้นฐานที่สุดในโมเดลการ schedule โครงสร้างมีดังนี้ เพื่อความสะดวกในการเข้าใจ ได้ลบฟิลด์จำนวนมากออก
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
}ฟิลด์แรกคือที่อยู่เริ่มต้นและที่อยู่สิ้นสุดของ memory ของ stack ที่เป็นของ coroutine นี้
type stack struct {
lo uintptr
hi uintptr
}_panic และ _defer เป็น pointer ที่ชี้ไปยัง panic stack และ defer stack
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm กำลัง execute g ปัจจุบัน
m *m // current m; offset known to arm liblinkpreempt หมายถึง coroutine ปัจจุบันจำเป็นต้องถูก preempt หรือไม่ เทียบเท่ากับ g.stackguard0 = stackpreempt
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus ใช้สำหรับเก็บค่าสถานะของ coroutine G มีค่าที่เป็นไปได้ดังนี้
| ชื่อ | คำอธิบาย |
|---|---|
| _Gidle | เพิ่งถูกจัดสรรและยังไม่ได้ initialize |
| _Grunnable | หมายถึง coroutine ปัจจุบันสามารถทำงานได้ อยู่ใน waiting queue |
| _Grunning | หมายถึง coroutine ปัจจุบันกำลัง execute user code |
| _Gsyscall | ถูกจัดสรร M หนึ่งตัว ใช้สำหรับ execute system call |
| _Gwaiting | coroutine blocked เหตุผลของการ block ดูด้านล่าง |
| _Gdead | หมายถึง coroutine ปัจจุบันไม่ได้ใช้งาน อาจเพิ่ง exit หรือเพิ่ง initialize |
| _Gcopystack | หมายถึง coroutine stack กำลัง move在此期间ไม่ execute user code และไม่อยู่ใน waiting queue |
| _Gpreempted | block ตัวเองเข้าสู่ preemption รอให้ฝ่ายที่ถูก preempt ปลุก |
| _Gscan | GC กำลัง scan coroutine stack space สามารถ coexist กับสถานะอื่น |
sched ใช้สำหรับเก็บ context information ของ coroutine เพื่อ restore execution state ของ coroutine จะเห็นว่าข้างในเก็บ pointer sp, pc, ret
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}waiting หมายถึง coroutine ที่ coroutine ปัจจุบันกำลังรอ waitsince บันทึกเวลาที่ coroutine เกิด block waitreason หมายถึงเหตุผลที่ coroutine block มีค่าที่เป็นไปได้ดังนี้
var waitReasonStrings = [...]string{
waitReasonZero: "",
waitReasonGCAssistMarking: "GC assist marking",
waitReasonIOWait: "IO wait",
waitReasonChanReceiveNilChan: "chan receive (nil chan)",
waitReasonChanSendNilChan: "chan send (nil chan)",
waitReasonDumpingHeap: "dumping heap",
waitReasonGarbageCollection: "garbage collection",
waitReasonGarbageCollectionScan: "garbage collection scan",
waitReasonPanicWait: "panicwait",
waitReasonSelect: "select",
waitReasonSelectNoCases: "select (no cases)",
waitReasonGCAssistWait: "GC assist wait",
waitReasonGCSweepWait: "GC sweep wait",
waitReasonGCScavengeWait: "GC scavenge wait",
waitReasonChanReceive: "chan receive",
waitReasonChanSend: "chan send",
waitReasonFinalizerWait: "finalizer wait",
waitReasonForceGCIdle: "force gc (idle)",
waitReasonSemacquire: "semacquire",
waitReasonSleep: "sleep",
waitReasonSyncCondWait: "sync.Cond.Wait",
waitReasonSyncMutexLock: "sync.Mutex.Lock",
waitReasonSyncRWMutexRLock: "sync.RWMutex.RLock",
waitReasonSyncRWMutexLock: "sync.RWMutex.Lock",
waitReasonTraceReaderBlocked: "trace reader (blocked)",
waitReasonWaitForGCCycle: "wait for GC cycle",
waitReasonGCWorkerIdle: "GC worker (idle)",
waitReasonGCWorkerActive: "GC worker (active)",
waitReasonPreempted: "preempted",
waitReasonDebugCall: "debug call",
waitReasonGCMarkTermination: "GC mark termination",
waitReasonStoppingTheWorld: "stopping the world",
}goid และ parentGoid หมายถึง unique identifier ของ coroutine ปัจจุบันและ parent coroutine startpc หมายถึง address ของ entry function ของ coroutine ปัจจุบัน
M
M ใน runtime แสดงเป็น runtime.m structure เป็นการ abstract ของ worker thread
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}เช่นเดียวกัน ฟิลด์ภายใน M ก็มีมากมายเช่นกัน ที่นี่แนะนำเพียงบางฟิลด์เพื่อความสะดวกในการเข้าใจ
id, unique identifier ของ Mg0, coroutine ที่มี scheduling stackcurg, user coroutine ที่กำลังทำงานบน worker threadgsignal, coroutine ที่รับผิดชอบในการจัดการ thread signalgoSigStack, stack space ที่ Go จัดสรรสำหรับการจัดการ signalp, address ของ processor P,oldpชี้ไปยัง P ก่อน execute system call,nextpชี้ไปยัง P ที่จัดสรรใหม่mallocing, ใช้สำหรับระบุว่าปัจจุบันกำลังจัดสรร memory space ใหม่หรือไม่throwing, หมายถึง type ของ error ที่ M เกิดขึ้นpreemptoff, preemption identifier เมื่อมันเป็น empty string หมายถึง coroutine ที่กำลังทำงานอยู่สามารถถูก preempt ได้locks, หมายถึงจำนวน "lock" ของ M ปัจจุบัน เมื่อไม่เป็น 0 จะห้าม preemptdying, หมายถึง M เกิดpanicที่ไม่สามารถกู้คืนได้ มีค่าที่เป็นไปได้[0,3]สี่ค่า จากต่ำไปสูงหมายถึงระดับความรุนแรงspinning, หมายถึง M อยู่ใน idle state และพร้อมใช้งานตลอดเวลาtls, thread local storage
P
P ใน runtime แสดงด้วย runtime.p รับผิดชอบ schedule งานระหว่าง M กับ G โครงสร้างมีดังนี้
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
...
}status หมายถึงสถานะของ P มีค่าที่เป็นไปได้ดังนี้
| ค่า | คำอธิบาย |
|---|---|
| _Pidle | P อยู่ใน idle state สามารถถูก scheduler จัดสรร M หรืออาจ只是เปลี่ยนระหว่างสถานะอื่น |
| _Prunning | P เชื่อมโยงกับ M และกำลัง execute user code |
| _Psyscall | หมายถึง M ที่เชื่อมโยงกับ P กำลังทำ system call在此期间 P อาจถูก M อื่น preempt |
| _Pgcstop | หมายถึง P หยุดเนื่องจาก GC |
| _Pdead | ทรัพยากรส่วนใหญ่ของ P ถูกยึดคืน จะไม่ถูกใช้อีก |
ฟิลด์ถัดไปบันทึก runq local queue ใน P จะเห็นว่าจำนวนสูงสุดของ local queue คือ 256 หลังจากเกินจำนวนนี้ G จะถูกใส่ vào global queue
runqhead uint32
runqtail uint32
runq [256]guintptrrunnext หมายถึง G ถัดไปที่พร้อมใช้งาน
runnext guintptrความหมายของฟิลด์อื่นๆ มีดังนี้
id, unique identifier ของ Pschedtick, เพิ่มขึ้นตามจำนวนครั้งที่ coroutine ถูก schedule เห็นได้ในฟังก์ชันruntime.executesyscalltick, เพิ่มขึ้นตามจำนวนครั้งที่ system call เกิดขึ้นsysmontick, บันทึกข้อมูลล่าสุดที่ถูก system monitor สังเกตm, M ที่เชื่อมโยงกับ PgFree, รายการ G ที่ว่างpreempt, หมายถึง P ควรเข้าสู่การ schedule อีกครั้ง
ข้อมูลของ global queue ถูกเก็บไว้ใน runtime.schedt structure เป็นการแสดง形式ของ scheduler ใน runtime ดังนี้
type schedt struct {
...
midle muintptr // idle m's waiting for work
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
// Global runnable queue.
runq gQueue
runqsize int32
...
}การ initialize
การ initialize ของ scheduler อยู่ในขั้นตอน bootstrap ของโปรแกรม Go รับผิดชอบ bootstrap โปรแกรม Go คือฟังก์ชัน runtime.rt0_go มันถูก implement ด้วย assembly อยู่ในไฟล์ runtime/asm_*.s โค้ดบางส่วนมีดังนี้
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
...
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RETสามารถเห็นการเรียก runtime·osinit และ runtime·schedinit จากสองบรรทัดด้านล่าง
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)ตัวแรกรับผิดชอบ initialize งานที่เกี่ยวข้องกับระบบปฏิบัติการ ตัวที่สองรับผิดชอบ initialize scheduler ซึ่งก็คือฟังก์ชัน runtime·schedinit มันจะรับผิดชอบ initialize ทรัพยากรที่จำเป็นสำหรับ scheduler runtime เมื่อโปรแกรมเริ่มต้น ด้านล่างนี้คือโค้ดที่ลดทอนแล้ว
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
...
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
lock(&sched.lock)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
...
// World is effectively started now, as P's can run.
worldStarted()
...
}ฟังก์ชัน runtime.getg ถูก implement ด้วย assembly หน้าที่ของมันคือได้รับ runtime representation ของ coroutine ปัจจุบัน ซึ่งก็คือ pointer ของ runtime.g structure ผ่าน sched.maxmcount = 10000 จะเห็นว่าเมื่อ scheduler initialize ก็ได้ตั้งค่าจำนวนสูงสุดของ M เป็น 10000 ค่านี้เป็นค่าคงที่และไม่สามารถแก้ไขได้ หลังจากนั้นคือ initialize heap stack แล้วจึงเป็นฟังก์ชัน runtime.mcommoninit เพื่อ initialize M การ implement ฟังก์ชันมีดังนี้
func mcommoninit(mp *m, id int64) {
gp := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}ฟังก์ชันนี้ทำ pre-initialize ให้ M ทำงานหลักดังนี้
- จัดสรร id ของ M
- จัดสรร G แยกต่างหากสำหรับจัดการ thread signal เสร็จสิ้นโดยฟังก์ชัน
runtime.mpreinit - ทำให้มันเป็น head node ของ global M linked list
runtime.allm
ถัดไป initialize P จำนวนของมันโดย default คือจำนวน logical core ของ CPU รองลงมาคือค่าของ environment variable
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}สุดท้ายฟังก์ชัน runtime.procresize รับผิดชอบ initialize P มันจะแก้ไข global slice runtime.allp ที่เก็บ P ทั้งหมดตามจำนวนที่ส่งเข้ามา ก่อนอื่นตัดสินว่าจำเป็นต้องขยายขนาดหรือไม่ตามขนาดของจำนวน
if nprocs > int32(len(allp)) {
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}แล้วจึง initialize แต่ละ P
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}หาก P ที่ coroutine ปัจจุบันใช้งานอยู่จำเป็นต้องถูกทำลาย จะแทนที่ด้วย allp[0] เสร็จสิ้นโดยฟังก์ชัน runtime.acquirep เพื่อเชื่อมโยง M กับ P ใหม่
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp)
}จากนั้นทำลาย P ที่ไม่ต้องการอีกต่อไป เมื่อทำลายจะปล่อยทรัพยากรทั้งหมดของ P ใส่ G ทั้งหมดใน local queue ของมันลงใน global queue หลังจากทำลายเสร็จแล้วจึงทำ slice กับ allp
// release resources from unused P's
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
// Trim allp.
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}สุดท้ายเชื่อมโยง P ที่ว่างเป็น linked list และในที่สุดก็ return head node ของ linked list
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
return runnablePsหลังจากนั้น scheduler initialize เสร็จแล้ว runtime.worldStarted จะ restore การทำงานของ P ทั้งหมด
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)จากนั้นจะสร้าง coroutine ใหม่ผ่านฟังก์ชัน runtime.newproc เพื่อเริ่มต้นโปรแกรม Go หลังจากนั้นเรียก runtime.mstart เพื่อ正式启动การทำงานของ scheduler มันก็ถูก implement ด้วย assembly เช่นกัน ภายในจะเรียกฟังก์ชัน runtime.mstart0 เพื่อสร้าง โค้ดบางส่วนมีดังนี้
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()ในขณะนี้มี M เพียง coroutine เดียว g0 coroutine นี้ใช้ system stack ของ thread ไม่ใช่ stack space ที่จัดสรรแยกต่างหาก ฟังก์ชัน mstart0 จะ initialize stack boundary ของ G ก่อน แล้วจึงส่งให้ mstart1 เพื่อเสร็จสิ้นงาน initialize ที่เหลือ
gp := getg()
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
if fn := gp.m.mstartfn; fn != nil {
fn()
}
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
schedule()ก่อนเริ่มต้น จะบันทึก execution state ปัจจุบันก่อน เพราะหลังจาก initialize สำเร็จจะเข้าสู่ scheduling loop และจะไม่ return อีกต่อไป การเรียกอื่นๆ สามารถ reuse execution state เพื่อ return จาก mstart1 เพื่อบรรลุวัตถุประสงค์ในการ exit thread หลังจากบันทึกเสร็จแล้ว ฟังก์ชัน runtime.asminit และ runtime.minit สองฟังก์ชันรับผิดชอบ initialize system stack แล้วฟังก์ชัน runtime.mstartm0 ตั้งค่า callback สำหรับจัดการ signal หลังจาก execute callback function m.mstartfn แล้ว ฟังก์ชัน runtime.acquirep จะเชื่อมโยง M กับ P ที่สร้างไว้ก่อนหน้า สุดท้ายเข้าสู่ scheduling loop
การเรียก runtime.schedule นี้เป็น scheduling loop รอบแรกของ Go runtime ทั้งหมด หมายถึง scheduler เริ่มทำงานอย่างเป็นทางการ
Thread
ใน scheduler G ต้องการ execute user code ต้องอาศัย P และ P ต้องทำงานปกติต้องเชื่อมโยงกับ M M หมายถึง system thread
การสร้าง
การสร้าง M เสร็จสิ้นโดยฟังก์ชัน runtime.newm มันรับฟังก์ชันและ P รวมถึง id เป็น parameter ฟังก์ชันที่เป็น parameter ไม่สามารถเป็น closure ได้
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}ก่อนเริ่มต้น newm จะเรียกฟังก์ชัน runtime.allocm เพื่อสร้าง runtime representation ของ thread ซึ่งก็คือ M ในกระบวนการจะใช้ฟังก์ชัน runtime.mcommoninit เพื่อ initialize stack boundary ของ M
func allocm(pp *p, fn func(), id int64) *m {
allocmLock.rlock()
// The caller owns pp, but we may borrow (i.e., acquirep) it. We must
// disable preemption to ensure it is not stolen, which would make the
// caller lose ownership.
acquirem()
gp := getg()
if gp.m.p == 0 {
acquirep(pp) // temporarily borrow p for mallocs in this function
}
mp := new(m)
mp.mstartfn = fn
mcommoninit(mp, id)
mp.g0.m = mp
releasem(gp.m)
allocmLock.runlock()
return mp
}หลังจากนั้น runtime.newm1 เรียกฟังก์ชัน runtime.newosproc เพื่อเสร็จสิ้นการสร้าง system thread จริง
func newm1(mp *m) {
execLock.rlock()
newosproc(mp)
execLock.runlock()
}การ implement ของ runtime.newosproc จะแตกต่างกันไปตามระบบปฏิบัติการ วิธีการสร้างที่เฉพาะเจาะจงไม่ใช่สิ่งที่เราต้องกังวล ระบบปฏิบัติการรับผิดชอบ แล้ว runtime.mstart จะเริ่มต้นการทำงานของ M
การ exit
runtime.gogo(&mp.g0.sched)ในตอน initialize ได้กล่าวไว้แล้วว่า เมื่อเรียกฟังก์ชัน mstart1 จะบันทึก execution state ไว้ในฟิลด์ sched ของ g0 ส่งฟิลด์นี้ให้ฟังก์ชัน runtime.gogo (implement ด้วย assembly) ก็可以让 thread กระโดดไป execute ต่อที่ execution state เมื่อบันทึกใช้ getcallerpc() ดังนั้นเมื่อ restore execution state จะกลับไปที่ฟังก์ชัน mstart0
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)หลังจาก restore execution state แล้ว ตามลำดับการ execute จะเข้าสู่ฟังก์ชัน mexit เพื่อ exit thread
mp := getg().m
unminit()
lock(&sched.lock)
for pprev := &allm; *pprev != nil; pprev = &(*pprev).alllink {
if *pprev == mp {
*pprev = mp.alllink
}
}
mp.freeWait.Store(freeMWait)
mp.freelink = sched.freem
sched.freem = mp
unlock(&sched.lock)
handoffp(releasep())
mdestroy(mp)
exitThread(&mp.freeWait)มันทำงานหลักดังนี้
- เรียก
runtime.uninitเพื่อยกเลิกงานของruntime.minit - ลบ M นี้จาก global variable
allm - ทำให้
freemของ scheduler ชี้ไปยัง M ปัจจุบัน - โดย
runtime.releasepจะแยก P กับ M ปัจจุบัน และโดยruntime.handoffpทำให้ P เชื่อมโยงกับ M อื่นเพื่อทำงานต่อ - โดย
runtime.destroyรับผิดชอบทำลายทรัพยากรของ M - สุดท้ายระบบปฏิบัติการ exit thread
至此 M ก็ exit สำเร็จ
การ pause
เมื่อจำเป็นต้อง pause M เนื่องจาก scheduler schedule, GC, system call ฯลฯ จะเรียกฟังก์ชัน runtime.stopm เพื่อ pause thread ด้านล่างนี้คือโค้ดที่ลดทอนแล้ว
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}มันจะใส่ M เข้าไปใน global idle M list ก่อน แล้วโดย mPark() จะ block thread ปัจจุบันที่ notesleep(&gp.m.park) นี้ เมื่อถูก wake up ฟังก์ชันนี้จะ return
func mPark() {
gp := getg()
notesleep(&gp.m.park)
noteclear(&gp.m.park)
}M ที่ถูก wake up จะค้นหา P เพื่อ bind และทำงานต่อ
Coroutine
Lifecycle ของ coroutine สอดคล้องกับสถานะหลายสถานะของ coroutine พอดี การเข้าใจ lifecycle ของ coroutine จะมีประโยชน์ต่อการเข้าใจ scheduler แน่นอนว่าทั้ง scheduler ออกแบบมาเพื่อ coroutine lifecycle ทั้งหมดของ coroutine มีดังนี้
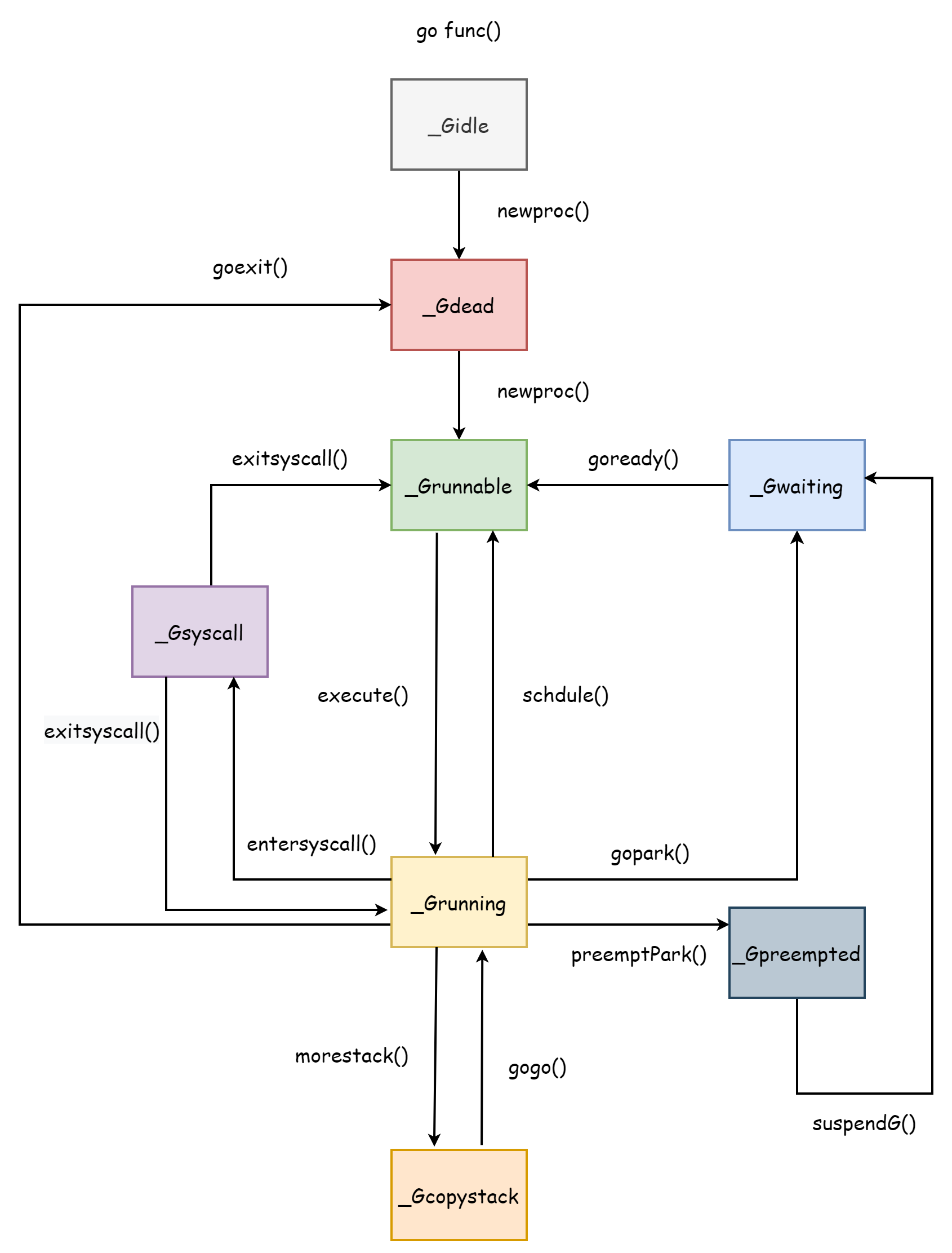
_Gcopystack เป็นสถานะที่ coroutine stack ขยาย จะอธิบายในส่วน Coroutine Stack
การสร้าง
การสร้าง coroutine จากมุมมองของ syntax只需要คีย์เวิร์ด go หนึ่งตัวและฟังก์ชันหนึ่งตัว
go doSomething()หลังจาก compile จะกลายเป็นการเรียกฟังก์ชัน runtime.newproc
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}โดย runtime.newproc1 เสร็จสิ้นการสร้างจริง ในการสร้างก่อนอื่นจะ lock M ห้าม preempt แล้วจะไปค้นหา G ที่ว่างใน gfree list ท้องถิ่นของ P เพื่อ reuse หากไม่พบจะสร้าง G ใหม่โดย runtime.malg และจัดสรร stack space 2kb ให้มัน ในขณะนั้นสถานะของ G คือ _Gdead
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}หลังจาก Go1.18 เป็นต้นไป การคัดลอก parameter ไม่เสร็จสิ้นโดยฟังก์ชัน newproc1 อีกต่อไป ก่อนหน้านี้จะใช้ runtime.memmove เพื่อคัดลอก parameter ของฟังก์ชัน ตอนนี้รับผิดชอบเพียง reset stack space ของ coroutine ทำให้ runtime.goexit เป็น stack bottom โดยมันจัดการการ exit ของ coroutine แล้วตั้งค่า PC ของ entry function newg.startpc = fn.fn หมายถึงเริ่ม execute จากตรงนี้ หลังจากตั้งค่าเสร็จแล้ว ในขณะนั้นสถานะของ G คือ _Grunnable
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
casgstatus(newg, _Gdead, _Grunnable)สุดท้ายตั้งค่า unique identifier ของ G แล้วปล่อย M return coroutine G ที่สร้าง
newg.goid = pp.goidcache
pp.goidcache++
releasem(mp)
return newgหลังจากสร้าง coroutine เสร็จแล้ว จะลองใส่ลงใน local queue ของ P โดยฟังก์ชัน runtime.runqput หากใส่ไม่ได้ก็จะใส่ลงใน global queue ในกระบวนการสร้าง coroutine ทั้งหมด สถานะของมันเปลี่ยนจาก _Gidle เป็น _Gdead ก่อน หลังจากตั้งค่า entry function แล้วเปลี่ยนจาก _Gdead เป็น _Grunnable
การ exit
ในการสร้าง Go ได้ตั้งค่าฟังก์ชัน runtime.goexit เป็น stack bottom ของ coroutine แล้วเมื่อ coroutine execute เสร็จสุดท้ายจะเข้าสู่ฟังก์ชันนี้ ผ่าน call chain goexit->goexit1->goexit0 สุดท้ายโดย runtime.goexit0 รับผิดชอบงาน exit ของ coroutine
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
dropg()
...
gfput(pp, gp)
...
schedule()
}ฟังก์ชันนี้ทำงานหลักดังนี้
- ตั้งค่าสถานะเป็น
_Gdead - reset ค่าฟิลด์
dropg()ตัดการเชื่อมโยงระหว่าง M กับ Ggfput(pp, gp)ใส่ G ปัจจุบันลงใน local idle list ของ Pschedule()ทำการ schedule รอบใหม่ ส่ง execution right ให้ G อื่น
หลังจาก exit สถานะของ coroutine เปลี่ยนจาก _Grunning เป็น _Gdead ในอนาคตเมื่อสร้าง coroutine ใหม่ยังอาจถูก reuse
System call
เมื่อ coroutine G กำลัง execute user code หากทำ system call มีวิธี trigger system call สองวิธี
- System call ของ
syscallstandard library - cgo call
เนื่องจาก system call จะ block worker thread ดังนั้นก่อนหน้านั้นจำเป็นต้องเตรียมงาน เสร็จสิ้นโดยฟังก์ชัน runtime.entersyscall แต่ตัวแรกก็เป็นเพียงการเรียกฟังก์ชัน runtime.reentersyscall อย่างง่าย งานจริงเสร็จสิ้นโดยตัวหลัง ก่อนอื่นจะ lock M ปัจจุบัน ในระหว่างการเตรียม G ห้ามถูก preempt และห้าม stack expansion ตั้งค่า gp.stackguard0 = stackPreempt หมายถึงหลังจากเตรียมงานเสร็จ execution right ของ P จะถูก G อื่น preempt แล้วรักษา execution state ของ coroutine เพื่อความสะดวกในการ restore หลังจาก system call return
gp := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
gp.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pcหลังจากนั้น เพื่อป้องกัน block ยาวนาน而影响 G อื่น execute M กับ P จะแยกกัน M และ G ที่แยกกันจะ block เนื่องจาก execute system call ส่วน P หลังจากแยกกันอาจ bind กับ M idle อื่นเพื่อให้ G อื่นใน local queue ของ P ทำงานต่อได้
casgstatus(gp, _Grunning, _Gsyscall)
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--หลังจากเตรียมงานเสร็จ ปล่อย lock ของ M在此期间สถานะของ G เปลี่ยนจาก _Grunning เป็น _Gsyscall สถานะของ P เปลี่ยนเป็น _Psyscall
เมื่อ system call return แล้ว thread M ไม่ block อีกต่อไป G ที่สอดคล้องกันก็ต้องถูก schedule อีกครั้งเพื่อ execute user code เสร็จสิ้นโดยฟังก์ชัน runtime.exitsyscall ก่อนอื่น lock M ปัจจุบัน ได้รับ reference ของ P เก่า
gp := getg()
gp.waitsince = 0
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0ในขณะนั้นแบ่งเป็นสองกรณี来处理 กรณีแรกคือมี P ที่สามารถใช้ได้โดยตรงหรือไม่ ฟังก์ชัน runtime.exitsyscallfast จะตัดสินว่า P เดิมสามารถใช้ได้หรือไม่ นั่นคือสถานะของ P เป็น _Psyscall หรือไม่ มิฉะนั้นก็จะหา P idle
func exitsyscallfast(oldp *p) bool {
gp := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
})
if ok {
return true
}
}
return false
}หากหา P ที่ใช้ได้สำเร็จ M จะ bind กับ P G เปลี่ยนสถานะจาก _Gsyscall เป็น _Grunning แล้วโดย runtime.Gosched G主动ส่ง execution right P เข้าสู่ scheduling loop เพื่อหา G อื่นที่ใช้ได้
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
if exitsyscallfast(oldp) {
// There's a cpu for us, so we can run.
gp.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(gp, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
// restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
} else {
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}หากหาไม่ได้ M จะแยกกับ G G เปลี่ยนจาก _Gsyscall เป็น _Grunnable แล้วลองหา P idle อีกครั้ง หากหาไม่ได้ก็ใส่ G ลงใน global queue แล้วเข้าสู่ scheduling loop รอบใหม่ M เก่าโดย runtime.stopm เข้าสู่ idle state รองานใหม่ในอนาคต หากหา P ได้ M เก่าและ G จะเชื่อมโยงกับ P ใหม่ แล้ว execute user code ต่อ สถานะเปลี่ยนจาก _Grunnable เป็น _Grunning
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
globrunqput(gp)
}
unlock(&sched.lock)
if pp != nil {
acquirep(pp)
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}หลังจาก exit system call แล้ว สถานะของ G สุดท้ายมีสองผลลัพธ์ หนึ่งคือ _Grunnable ที่รอถูก schedule อีกหนึ่งคือ _Grunning ที่ทำงานต่อ
Suspend
เมื่อ coroutine ปัจจุบัน suspend เนื่องจากบางเหตุผล สถานะจะเปลี่ยนจาก _Grunnable เป็น _Gwaiting เหตุผลของการ suspend มีมากมาย อาจเป็นเพราะ channel block, select, lock หรือ time.sleep เหตุผลเพิ่มเติมดูที่ G structure ยกตัวอย่าง time.Sleep มันจริงๆ แล้วเชื่อมต่อกับ runtime.timesleep โค้ดของตัวหลังมีดังนี้
func timeSleep(ns int64) {
if ns <= 0 {
return
}
gp := getg()
t := gp.timer
if t == nil {
t = new(timer)
gp.timer = t
}
t.f = goroutineReady
t.arg = gp
t.nextwhen = nanotime() + ns
if t.nextwhen < 0 { // check for overflow.
t.nextwhen = maxWhen
}
gopark(resetForSleep, unsafe.Pointer(t), waitReasonSleep, traceBlockSleep, 1)
}จะเห็นว่ามันได้รับ coroutine ปัจจุบันผ่าน getg แล้วทำให้ coroutine ปัจจุบัน suspend โดย runtime.gopark runtime.gopark จะ update เหตุผล block ของ G และ M ปล่อย lock ของ M
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)แล้วสลับไปยัง system stack โดย runtime.park_m เพื่อเปลี่ยนสถานะของ G เป็น _Gwaiting แล้วตัดการเชื่อมโยงระหว่าง M กับ G และเข้าสู่ scheduling loop ใหม่เพื่อส่ง execution right ให้ G อื่น หลังจาก suspend แล้ว G ไม่ execute user code และไม่อยู่ใน local queue เพียงแต่รักษา reference ของ M และ P
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()ในฟังก์ชัน runtime.timesleep มีบรรทัดนี้ ระบุค่าของ t.f
t.f = goroutineReadyฟังก์ชัน runtime.goroutineReady นี้ใช้สำหรับ wake up coroutine ที่ suspend มันจะเรียกฟังก์ชัน runtime.ready เพื่อ wake up coroutine
status := readgstatus(gp)
// Mark runnable.
mp := acquirem()
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)หลังจาก wake up แล้ว เปลี่ยนสถานะของ G เป็น _Grunnable แล้วใส่ G ลงใน local queue ของ P รออนาคตถูก schedule
Coroutine Stack
Coroutine ในภาษา Go เป็น typical stacked coroutine ทุกครั้งที่เปิด coroutine จะจัดสรร stack space อิสระบน heap给它 และมันจะเติบโตหรือหดตัวตามการใช้งาน เมื่อ scheduler initialize ฟังก์ชัน runtime.stackinit รับผิดชอบ initialize global stack space cache stackpool และ stackLarge
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
stackpool[i].item.span.init()
lockInit(&stackpool[i].item.mu, lockRankStackpool)
}
for i := range stackLarge.free {
stackLarge.free[i].init()
lockInit(&stackLarge.lock, lockRankStackLarge)
}
}นอกจากนี้ แต่ละ P มี stack space cache mcache ของตัวเอง
type p struct {
...
mcache *mcache
...
}
type mcache struct {
_ sys.NotInHeap
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}Thread cache mcache เป็นอิสระของแต่ละ thread และไม่จัดสรรบน heap memory เมื่อเข้าถึงไม่จำเป็นต้อง lock ทั้งสาม stack cache นี้จะใช้ในการจัดสรร space ในภายหลัง
การจัดสรร
เมื่อสร้าง coroutine หากไม่มี coroutine ที่สามารถ reuse ได้ จะเลือกจัดสรร stack space ใหม่ให้มัน ขนาดโดย default คือ 2KB
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}ฟังก์ชันที่รับผิดชอบจัดสรร stack space คือ runtime.stackalloc
func stackalloc(n uint32) stackแบ่งเป็นสองกรณีตามขนาดของ stack memory ที่ขอว่าน้อยกว่า 32KB หรือไม่ 32KB เป็นมาตรฐานที่ Go ใช้ตัดสินว่าเป็น small object หรือ large object หากน้อยกว่าค่านี้จะได้รับจาก stackpool cache เมื่อ M bind กับ P และ M ไม่อนุญาตให้ preempt จะได้รับจาก thread cache ท้องถิ่น
if n < fixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
}หากมากกว่า 32KB จะได้รับจาก stackLarge cache หากยังไม่พอจะจัดสรร memory บน heap โดยตรง
else {
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}หลังจากนั้น return low address และ high address ของ stack space
return stack{uintptr(v), uintptr(v) + uintptr(n)}การขยาย
ขนาด default ของ coroutine stack คือ 2KB เบามาก ดังนั้นต้นทุนการสร้าง coroutine ต่ำมาก แต่นี่อาจไม่เพียงพอ เมื่อ stack space ไม่พอจะต้องขยาย Compiler จะแทรกฟังก์ชัน runtime.morestack ที่จุดเริ่มต้นของฟังก์ชันเพื่อตรวจสอบว่า coroutine ปัจจุบันจำเป็นต้องขยาย stack หรือไม่ หากจำเป็นจะเรียก runtime.newstack เพื่อเสร็จสิ้นการขยายจริง
TIP
เนื่องจาก morestack แทบจะถูกแทรกที่จุดเริ่มต้นของทุกฟังก์ชัน ดังนั้นจังหวะตรวจสอบ stack expansion ก็เป็น coroutine preemption point ด้วย
thisg := getg()
gp := thisg.m.curg
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)จะเห็นว่า capacity ของ stack space ที่คำนวณคือสองเท่าของเดิม เสร็จสิ้นโดยฟังก์ชัน runtime.copystack ก่อน copy G เปลี่ยนสถานะจาก _Grunning เป็น _Gcopystack
func copystack(gp *g, newsize uintptr) {
old := gp.stack
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + stackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
var u unwinder
for u.init(gp, 0); u.valid(); u.next() {
adjustframe(&u.frame, &adjinfo)
}
stackfree(old)
}ฟังก์ชันนี้ทำงานดังนี้
- จัดสรร stack space ใหม่
- copy old stack memory ไปยัง new stack space โดยตรงผ่าน
runtime.memmove - ปรับ structure ที่มี stack pointer เช่น defer, panic เป็นต้น
- update ฟิลด์ stack space ของ G
- ปรับ pointer ที่ชี้ไปยัง old stack memory ผ่าน
runtime.adjustframe - ปล่อย memory ของ old stack
หลังจากเสร็จแล้ว สถานะของ G เปลี่ยนจาก _Gcopystack เป็น _Grunning และโดยฟังก์ชัน runtime.gogo ให้ G execute user code ต่อ เนื่องจากมี coroutine stack expansion ดังนั้น memory ใน Go จึงไม่เสถียร
การหด
เมื่อสถานะของ G เป็น _Grunnable, _Gsyscall, _Gwaiting GC จะ scan memory space ของ coroutine stack
func scanstack(gp *g, gcw *gcWork) int64 {
switch readgstatus(gp) &^ _Gscan {
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
...
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
}
...
}งาน shrink stack จริงเสร็จสิ้นโดย runtime.shrinkstack
func shrinkstack(gp *g) {
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}เมื่อ stack space ที่ใช้น้อยกว่า 1/4 ของเดิม จะหดเป็น 1/2 ของเดิมผ่าน runtime.copystack งานหลังจากนั้นก็ไม่ต่างจากก่อนหน้า
Segmented Stack
จากกระบวนการ copystack จะเห็นว่ามันจะ copy old stack memory ไปยัง stack space ที่ใหญ่กว่า ไม่ว่าจะเป็น stack เดิมหรือ stack ใหม่ memory address ของพวกมันต่อเนื่องกัน ในภาษา Go ยุคโบราณ วิธีการขยาย stack ไม่เหมือนตอนนี้ ตอนนั้นคิดว่า memory copy กิน performance มากเกินไป ใช้แนวคิด segmented stack เมื่อ stack space memory ไม่พอ ก็ขอ stack space ใหม่ memory ของ stack space เดิมจะไม่ปล่อยและไม่ถูก copy เชื่อมต่อกันผ่าน pointer เกิดเป็น stack linked list นี่คือที่มาของ segmented stack ดังรูปด้านล่าง
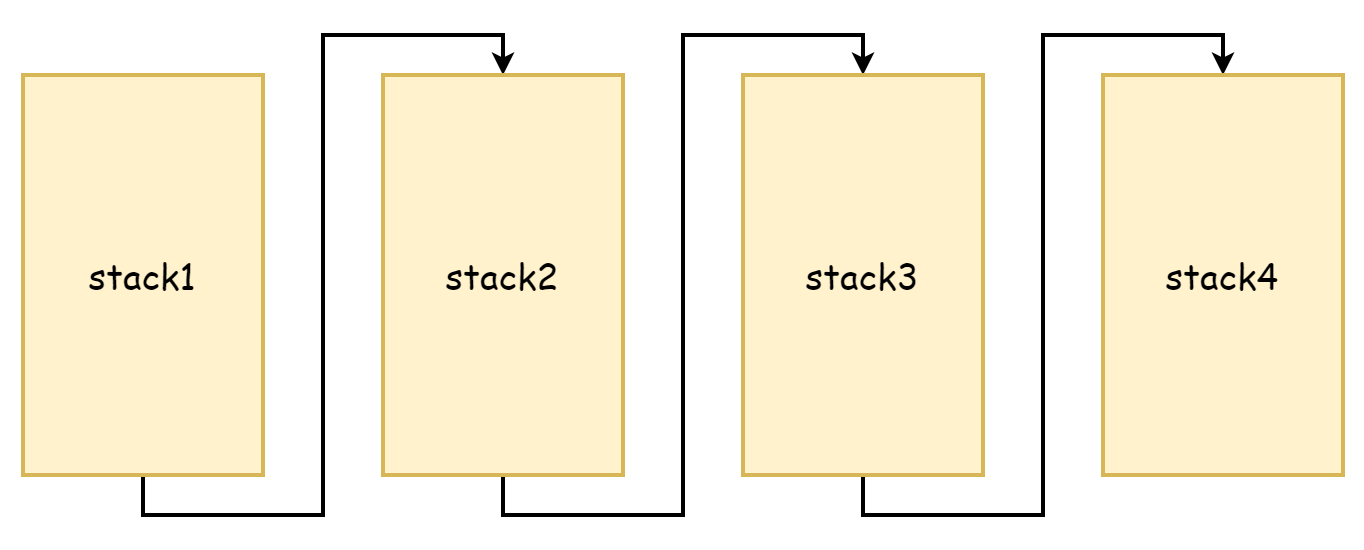
ข้อดีของการทำเช่นนี้คือไม่ต้อง copy stack เดิม แต่ข้อเสียก็ชัดเจนมาก คือจะ trigger stack expansion และ shrink บ่อยมาก เมื่อ idle memory ของ stack space เหลือ无几 function call ใหม่จะ trigger stack expansion เมื่อ function เหล่านี้ return ไม่ต้องการ stack space ใหม่แล้วก็จะ trigger shrink อีก หากความถี่ของ function call เหล่านี้สูงมาก การดำเนินการเช่นนี้จะทำให้ performance loss มาก
ดังนั้นหลังจาก Go1.4 เปลี่ยนเป็น continuous stack continuous stack เนื่องจากจัดสรร stack space ที่มีความจุมากกว่า จะไม่เกิดกรณีที่ used memory ถึง critical value แล้ว trigger expansion/shrink บ่อยเนื่องจาก function call และเนื่องจาก memory address ต่อเนื่อง ตามหลักการ spatial locality ของ cache continuous stack ก็เป็น friendly ต่อ CPU cache มากกว่า
Scheduling Loop
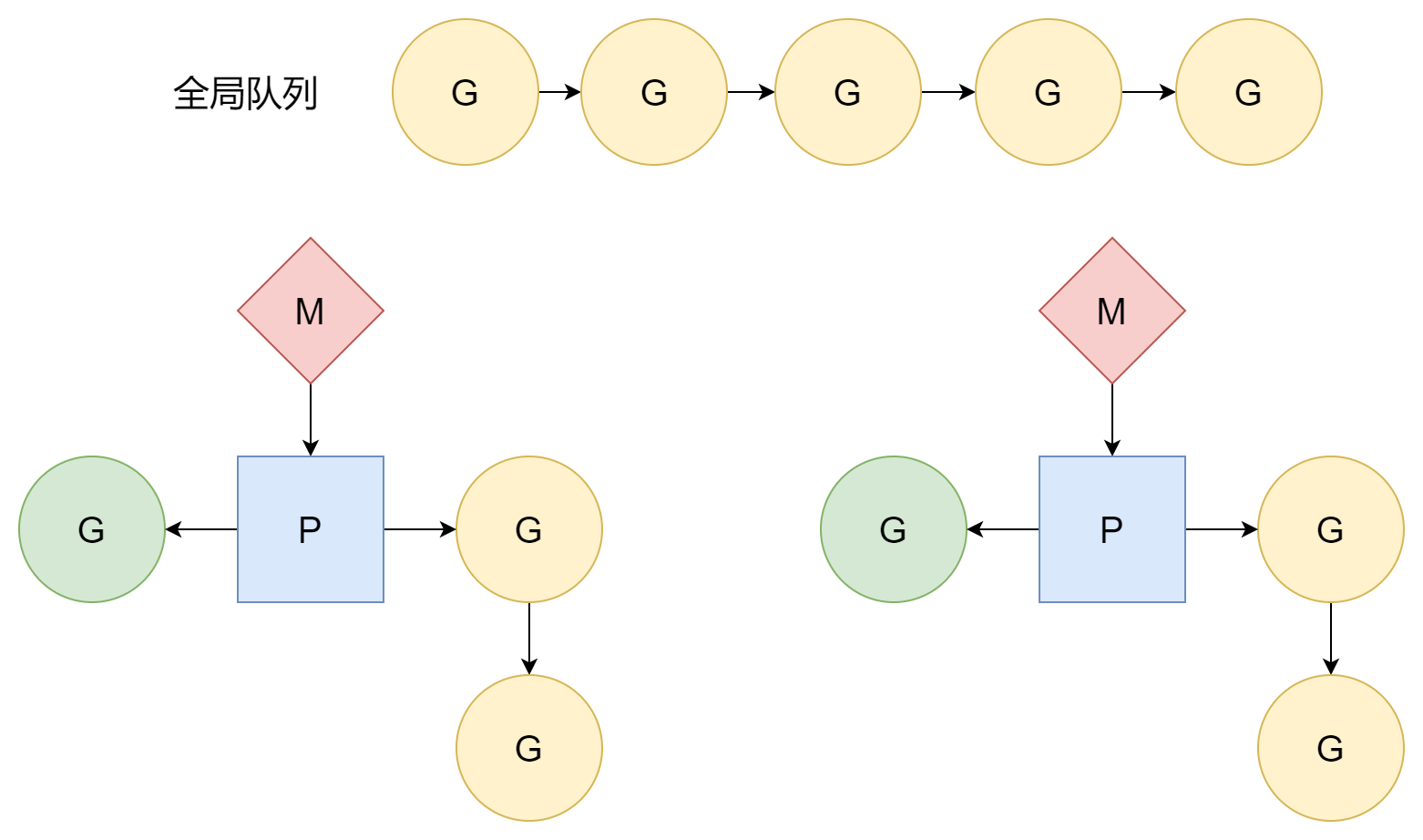
ในส่วน scheduler initialize ได้กล่าวไว้แล้วว่า ในฟังก์ชัน runtime.mstart1 หลังจาก M bind กับ P สำเร็จ จะเข้าสู่ runtime.schedule scheduling loop แรก正式开始 schedule G เพื่อ execute user code ใน scheduling loop ส่วนนี้ P มีบทบาทหลัก M สอดคล้องกับ system thread G สอดคล้องกับ entry function ซึ่งคือ user code แต่ P ไม่เหมือน M และ G ที่มี entity ที่สอดคล้องกัน มันเป็นเพียง abstract concept เป็นคนกลางจัดการความสัมพันธ์ระหว่าง M และ G
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning {
resetspinning()
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}โค้ดด้านบนลดทอนแล้ว ลบ condition judgment มากมาย จุดสำคัญที่สุดมีเพียงสองจุด runtime.findRunnable และ runtime.execute ตัวแรกรับผิดชอบหา G และจะ return G ที่ใช้ได้เสมอ ตัวที่สองรับผิดชอบให้ G execute user code ต่อ
สำหรับฟังก์ชัน findRunnable แหล่งที่มาของ G แรกคือ local queue ของ P
// local runq
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}หาก local queue ไม่มี G ก็ลองได้รับจาก global queue
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}หากหาไม่พบทั้ง local และ global queue จะลองได้รับจาก network poller
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}หากยังหาไม่พบ สุดท้ายจะไป "ขโมย" G จาก local queue ของ P อื่น ในการสร้าง coroutine ได้กล่าวไว้แล้วว่า แหล่งที่มาใหญ่ของ G ใน local queue ของ P คือ sub coroutine ที่ spawn โดย coroutine ปัจจุบัน อย่างไรก็ตาม ไม่ใช่ทุก coroutine จะสร้าง sub coroutine เช่นนี้อาจเกิดสถานการณ์ที่ P บางส่วนยุ่งมาก อีกบางส่วน P idle นี่จะทำให้เกิดสถานการณ์ G บางตัวเพราะรออยู่ตลอดจึงไม่สามารถถูก execute ได้ ส่วนอีกฝั่ง P ว่างมาก ไม่มีอะไรทำ เพื่อที่จะใช้ P ทั้งหมดให้เต็มที่ ให้พวกมันทำงานได้มีประสิทธิภาพสูงสุด เมื่อ P หา G ไม่พบ ก็จะไปยัง local queue ของ P อื่นเพื่อ "ขโมย" G ที่สามารถ execute ได้ เช่นนี้แต่ละ P จึงมี G queue ที่ค่อนข้างสม่ำเสมอ นานๆ จะเกิดสถานการณ์ P กับ P มองตากัน
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}runtime.stealWork จะสุ่มเลือก Pหนึ่งตัวเพื่อขโมย งานขโมยจริงเสร็จสิ้นโดยฟังก์ชัน runtime.runqgrab มันจะลองขโมย G ครึ่งหนึ่งของ local queue ของ P นั้น
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
n = n - n/2
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}งานขโมยทั้งหมดจะทำสี่ครั้ง หากสี่ครั้งก็ขโมยไม่ได้ก็ return หากสุดท้ายหาไม่พบ M ปัจจุบันจะถูก runtime.stopm pause จนกว่าจะถูก wake up แล้วทำขั้นตอนข้างต้นซ้ำ เมื่อหาและ return G แล้ว จะส่งให้ runtime.execute เพื่อรัน G
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched)ก่อนอื่น update curg ของ M แล้ว update สถานะของ G เป็น _Grunning สุดท้ายส่งให้ runtime.gogo เพื่อ restore การทำงานของ G
โดยสรุปแล้ว ใน scheduling loop แหล่งที่มาของ G แบ่งตาม priority มีสี่อย่าง
- Local queue ของ P
- Global queue
- Network poller
- ขโมยจาก local queue ของ P อื่น
runtime.execute หลังจาก execute แล้วจะไม่ return G ที่ได้รับมาก็ไม่ execute ตลอดไป ในบางจังหวะ trigger schedule แล้ว execution right ของมันจะถูกยึด แล้วเข้าสู่ scheduling loop รอบใหม่ ส่ง execution right ให้ G อื่น
Scheduling Strategy
G ที่ต่างกัน execute user code อาจใช้เวลานานต่างกัน G บางตัวอาจใช้เวลานานมาก G บางตัวใช้เวลานานสั้น G ที่ execute นานอาจทำให้ G อื่นไม่สามารถถูก execute ได้ ดังนั้นการ execute G สลับกัน才是วิธีที่ถูกต้อง ในระบบปฏิบัติการวิธีการทำงานเช่นนี้เรียกว่า concurrency
Cooperative Scheduling
ความคิดพื้นฐานของ cooperative scheduling คือให้ G ส่ง execution right ให้ G อื่นเอง มีสองวิธีหลัก
วิธีแรกคือ主动ส่ง execution right ใน user code Go มีฟังก์ชัน runtime.Gosched() ผู้ใช้สามารถตัดสินใจได้ว่าจะส่ง execution right เมื่อไหร่ อย่างไรก็ตามในหลายครั้งรายละเอียดการทำงานของ scheduler ภายในเป็น black box สำหรับผู้ใช้ ยากที่จะตัดสินว่าเมื่อไหร่ควร主动ส่ง execution right ความต้องการสำหรับผู้ใช้ค่อนข้างสูง และ Go scheduler พยายาม屏蔽รายละเอียดส่วนใหญ่สำหรับผู้ใช้ แสวงหาวิธีการใช้งานที่ง่ายกว่า ในสถานการณ์เช่นนี้ให้ผู้ใช้มีส่วนร่วมในงาน scheduling ไม่ใช่เรื่องดี
วิธีที่สองคือ preemption mark แม้ชื่อของมันมีคำว่า preemption แต่โดย essence แล้วมันยังเป็น cooperative scheduling strategy ความคิดคือแทรก preemption detection code runtime.morestack() ที่หัวของฟังก์ชัน กระบวนการแทรกเสร็จสิ้นในช่วง compile ก่อนหน้านี้ได้กล่าวไว้แล้วว่าเดิมทีมันเป็นฟังก์ชันที่ใช้สำหรับ stack expansion detection เนื่องจาก detection point ของมันคือการ call ของทุกฟังก์ชัน นี่ก็เป็นจังหวะที่ดีสำหรับ preemption detection ฟังก์ชัน runtime.newstack ครึ่งบนกำลังทำ preemption detection ครึ่งล่างกำลังทำ stack expansion detection ก่อนหน้าเพื่อหลีกเลี่ยงการรบกวนจึงลบส่วนนี้ออก ตอนนี้มาดูส่วนนี้ทำอะไร ก่อนอื่นจะตัดสิน preemption ตาม gp.stackguard0 หากไม่จำเป็นก็จะ execute user code ต่อ
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
preempt := stackguard0 == stackPreempt
if preempt {
if !canPreemptM(thisg.m) {
gp.stackguard0 = gp.stack.lo + stackGuard
gogo(&gp.sched) // never return
}
}เมื่อ g.stackguard0 == stackPreempt โดยฟังก์ชัน runtime.canPreemptM() ตัดสินว่าเงื่อนไขของ coroutine จำเป็นต้องถูก preempt หรือไม่ โค้ดมีดังนี้
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}จะเห็นว่าสามารถถูก preempt ต้องเป็นไปตามสี่เงื่อนไข
- M ไม่ถูก lock
- ไม่กำลังจัดสรร memory
- ไม่ disable preemption
- P อยู่ในสถานะ
_Prunning
ในสองสถานการณ์ต่อไปนี้จะตั้งค่า g.stackguard0 เป็น stackPreempt
- เมื่อจำเป็นต้องทำ garbage collection
- เมื่อเกิด system call
if preempt {
if gp.preemptShrink {
gp.preemptShrink = false
shrinkstack(gp)
}
// Act like goroutine called runtime.Gosched.
gopreempt_m(gp) // never return
}สุดท้ายจะไปถึง runtime.gopreempt_m()主动ส่ง execution right ของ coroutine ปัจจุบัน ก่อนอื่นตัดการเชื่อมโยงระหว่าง M กับ G สถานะเปลี่ยนเป็น _Grunnable แล้วใส่ G ลงใน global queue สุดท้ายเข้าสู่ scheduling loop ส่ง execution right ให้ G อื่น
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()เช่นนี้ ทุก coroutine เมื่อทำ function call อาจเข้าสู่ฟังก์ชันนี้เพื่อทำ preemption detection strategy นี้ต้องพึ่งพาจังหวะ function call จึงสามารถ trigger preemption และ主动ส่ง execution right ได้ ก่อน 1.14 Go ยังใช้ scheduling strategy นี้ แต่จะมีปัญหาหนึ่ง หากไม่มี function call ก็ไม่สามารถ detect ได้ เช่นโค้ดคลาสสิกด้านล่างนี้ ควรปรากฏใน tutorial หลายแห่ง
func main() {
// จำกัดจำนวน P ให้เป็น 1
runtime.GOMAXPROCS(1)
// coroutine 1
go func() {
for {
// coroutine นี้หมุนว่าง不停
}
}()
// เข้า system call主 coroutine ส่ง execution right ให้ coroutine อื่น
time.Sleep(time.Millisecond)
println("exit")
}โค้ดสร้าง coroutine 1 ที่หมุนว่าง แล้ว主 coroutine เพราะ system call主动ส่ง execution right ในขณะนั้น coroutine 1 กำลังถูก schedule แต่เพราะมันไม่เรียกฟังก์ชันเลย จึงไม่สามารถทำ preemption detection ได้ เนื่องจาก P มีเพียงหนึ่งเดียว ไม่มี P idle อื่น นี่จะทำให้主 coroutine ไม่สามารถถูก schedule ได้ตลอดไป exit จึงไม่สามารถ output ได้ อย่างไรก็ตามปัญหานี้จำกัดอยู่แค่ก่อน Go1.14
Preemptive Scheduling
ทางการเพิ่ม preemptive scheduling strategy แบบ signal-based ใน Go1.14 นี่เป็น async preemption strategy ผ่าน async thread ส่ง signal เพื่อทำ preemption thread signal-based preemptive scheduling ปัจจุบันมีสอง entry คือ system monitor และ GC
ใน loop ของ system monitor จะ traverse ทุก P หาก G ที่ P กำลัง schedule ใช้เวลานานกว่า 10ms จะ强制 trigger preemption งานส่วนนี้เสร็จสิ้นโดยฟังก์ชัน runtime.retake ด้านล่างนี้คือโค้ดที่ลดทอนแล้ว
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
sysretake = true
}
}
}
unlock(&allpLock)
return uint32(n)
}เมื่อจำเป็นต้องทำ garbage collection หากสถานะของ G เป็น _Grunning นั่นคือยังทำงานอยู่ ก็จะ trigger preemption เช่นกัน
func suspendG(gp *g) suspendGState {
for i := 0; ; i++ {
switch s := readgstatus(gp); s {
case _Grunning:
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
......
......
func preemptM(mp *m) {
if mp.signalPending.CompareAndSwap(0, 1) {
if GOOS == "darwin" || GOOS == "ios" {
pendingPreemptSignals.Add(1)
}
signalM(mp, sigPreempt)
}
}สอง preemption entry สุดท้ายจะเข้าสู่ฟังก์ชัน runtime.preemptM โดยมันเสร็จสิ้นการส่ง preemption signal เมื่อ signal ส่งสำเร็จแล้ว ใน runtime.mstart โดย runtime.initsig ลงทะเบียน signal handler callback function runtime.sighandler จะมีประโยชน์ หาก detect ว่าส่งเป็น preemption signal ก็จะเริ่ม preemption
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
if sig == sigPreempt && debug.asyncpreemptoff == 0 && !delayedSignal {
// Might be a preemption signal.
doSigPreempt(gp, c)
}
...
}doSigPreempt จะแก้ไข context ของ target coroutine inject เรียก runtime.asyncPreempt
func doSigPreempt(gp *g, ctxt *sigctxt) {
// Check if this G wants to be preempted and is safe to
// preempt.
if wantAsyncPreempt(gp) {
if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok {
// Adjust the PC and inject a call to asyncPreempt.
ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc)
}
}
...เช่นนี้เมื่อสลับกลับไปยัง user code อีกครั้ง target coroutine จะไปถึงฟังก์ชัน runtime.asyncPreempt ในฟังก์ชันนี้เกี่ยวข้องกับการเรียก runtime.asyncPreempt2
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0
PUSHQ BP
MOVQ SP, BP
// Save flags before clobbering them
PUSHFQ
// obj doesn't understand ADD/SUB on SP, but does understand ADJSP
ADJSP $368
// But vet doesn't know ADJSP, so suppress vet stack checking
...
CALL ·asyncPreempt2(SB)
...
RETมันจะทำให้ coroutine ปัจจุบันหยุดทำงานและทำ scheduling loop รอบใหม่เพื่อส่ง execution right ให้ coroutine อื่น
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}กระบวนการนี้เกิดขึ้นในฟังก์ชัน runtime.asyncPreempt มันถูก implement ด้วย assembly (อยู่ใน runtime/preempt_*.s) และหลังจาก schedule เสร็จจะ restore context ของ coroutine ที่ถูกแก้ไขก่อนหน้า เพื่อให้ coroutine นี้สามารถ restore ปกติในอนาคต หลังจากใช้ async preemption strategy แล้ว ตัวอย่างก่อนหน้าจะไม่ block主 coroutine ตลอดไปอีก เมื่อ coroutine ที่หมุนว่างทำงานไปสักพักก็จะถูกบังคับให้ทำ scheduling loop เพื่อส่ง execution right ให้主 coroutine สุดท้ายทำให้โปรแกรมสามารถจบปกติได้
สรุป
โดยสรุปแล้ว จังหวะที่ trigger schedule มีดังนี้:
- Function call
- System call
- System monitor
- Garbage collection สำหรับ coroutine ที่ใช้เวลานานเกินไปก็จะทำ preemption
- Coroutine suspend เนื่องจาก channel, lock ฯลฯ
Scheduling strategy มีสองประเภทหลัก cooperative และ preemptive cooperative คือ主动ส่ง execution right preemptive คือ async preempt execution right ทั้งสองอยู่ร่วมกันจึงเกิด scheduler ในปัจจุบัน