gmp
Eine der größten Besonderheiten von Go ist die natürliche Unterstützung für Nebenläufigkeit. Mit nur einem Schlüsselwort kann eine Goroutine gestartet werden, wie das folgende Beispiel zeigt:
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println("hello world!")
}()
go func() {
defer wg.Done()
fmt.Println("hello world too!")
}()
wg.Wait()
}Die Verwendung von Goroutinen in Go ist so einfach, dass Entwickler kaum zusätzliche Arbeit leisten müssen. Dies ist einer der Gründe für ihre Beliebtheit. Hinter der Einfachheit steht jedoch ein komplexer Nebenläufigkeits-Scheduler, der viele Entwickler unter dem Namen GMP-Scheduler kennen dürfte. Die Hauptakteure sind G (Goroutine), M (System-Thread) und P (Prozessor). Das Design des GMP-Schedulers beeinflusst das gesamte Go-Laufzeitsystem, GC und den Netzwerk-Poller. Es ist der Kern der gesamten Sprache.
Geschichte
Das Nebenläufigkeits-Modell von Go ist nicht vollständig originär. Es hat viele Erfahrungen und Lehren von Vorgängern absorbiert und sich kontinuierlich weiterentwickelt. Es wurde von folgenden Sprachen beeinflusst:
- Occam - 1983
- Erlang - 1986
- Newsqueak - 1988
- Concurrent ML - 1993
- Alef - 1995
- Limbo - 1996
Der größte Einfluss ging von Hoare's 1978 veröffentlichter Arbeit über CSP (Communicating Sequential Process) aus. Die Grundidee ist, dass Prozesse durch Kommunikation Daten austauschen. Alle oben genannten Sprachen wurden vom CSP-Gedanken beeinflusst, Erlang ist ein typisches Beispiel für eine nachrichtenorientierte Programmiersprache. Der bekannte Open-Source-Nachrichtenbroker RabbitMQ wurde in Erlang geschrieben. Heute ist Nebenläufigkeitsunterstützung fast ein Standard für moderne Sprachen, und Go mit seinen CSP-Prinzipien wurde geboren.
Scheduler-Modell
Zuerst eine kurze Einführung der drei GMP-Mitglieder:
- G, Goroutine, bezeichnet die Goroutine in Go
- M, Machine, bezeichnet den System-Thread oder Worker-Thread, der vom Betriebssystem geplant wird
- P, Processor, nicht der CPU-Prozessor, sondern ein von Go abstrahiertes Konzept für den Prozessor, der auf System-Threads arbeitet und die Goroutinen auf jedem System-Thread plant
Eine Goroutine ist ein leichterer Thread, kleiner und mit weniger Ressourcen. Erstellung, Zerstörung und Planung werden von der Go-Laufzeitumgebung verwaltet, nicht vom Betriebssystem, wodurch die Verwaltungskosten viel niedriger sind als bei Threads. Goroutinen sind jedoch an Threads gebunden. Das Zeitquantum für die Ausführung einer Goroutine kommt vom Thread, das Zeitquantum des Threads vom Betriebssystem. Das Umschalten zwischen verschiedenen Threads hat gewisse Kosten. Der Schlüssel des Designs liegt darin, wie Goroutinen das Zeitquantum der Threads optimal nutzen.
1:N
Der beste Weg, ein Problem zu lösen, ist, es zu ignorieren. Da Thread-Wechsel Kosten verursacht, einfach nicht wechseln. Alle Goroutinen werden einem Kernel-Thread zugewiesen, sodass nur Goroutine-Wechsel stattfinden.
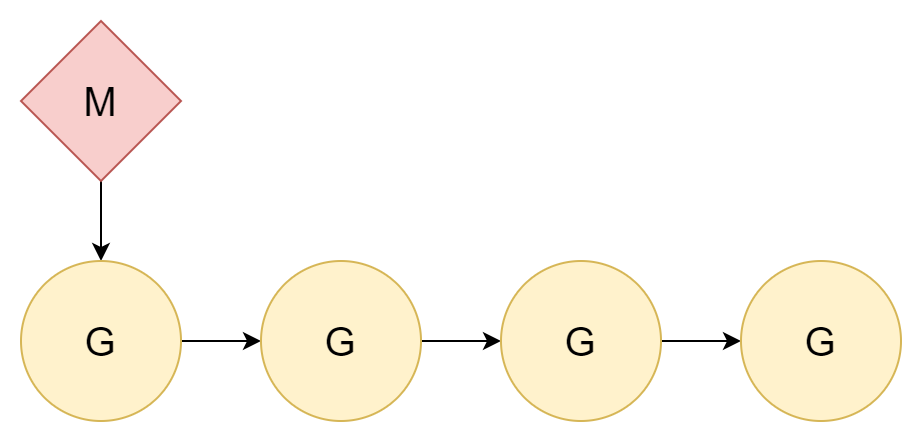
Die Beziehung zwischen Thread und Goroutine ist 1:N. Ein offensichtlicher Nachteil: Heutige Computer haben fast alle Multi-Core-CPUs, diese Zuweisung kann die Multi-Core-CPU-Leistung nicht vollständig nutzen.
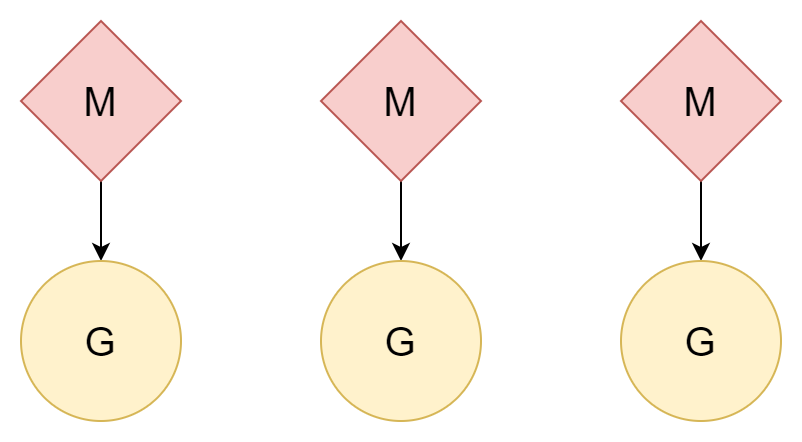
N:N
Eine andere Methode: Ein Thread entspricht einer Goroutine. Eine Goroutine kann das gesamte Zeitquantum dieses Threads nutzen, mehrere Threads können auch die Multi-Core-CPU-Leistung gut nutzen. Aber die Erstellungs- und Wechselkosten von Threads sind relativ hoch. Bei einer 1:1-Beziehung wird der Vorteil der leichten Goroutine nicht genutzt.
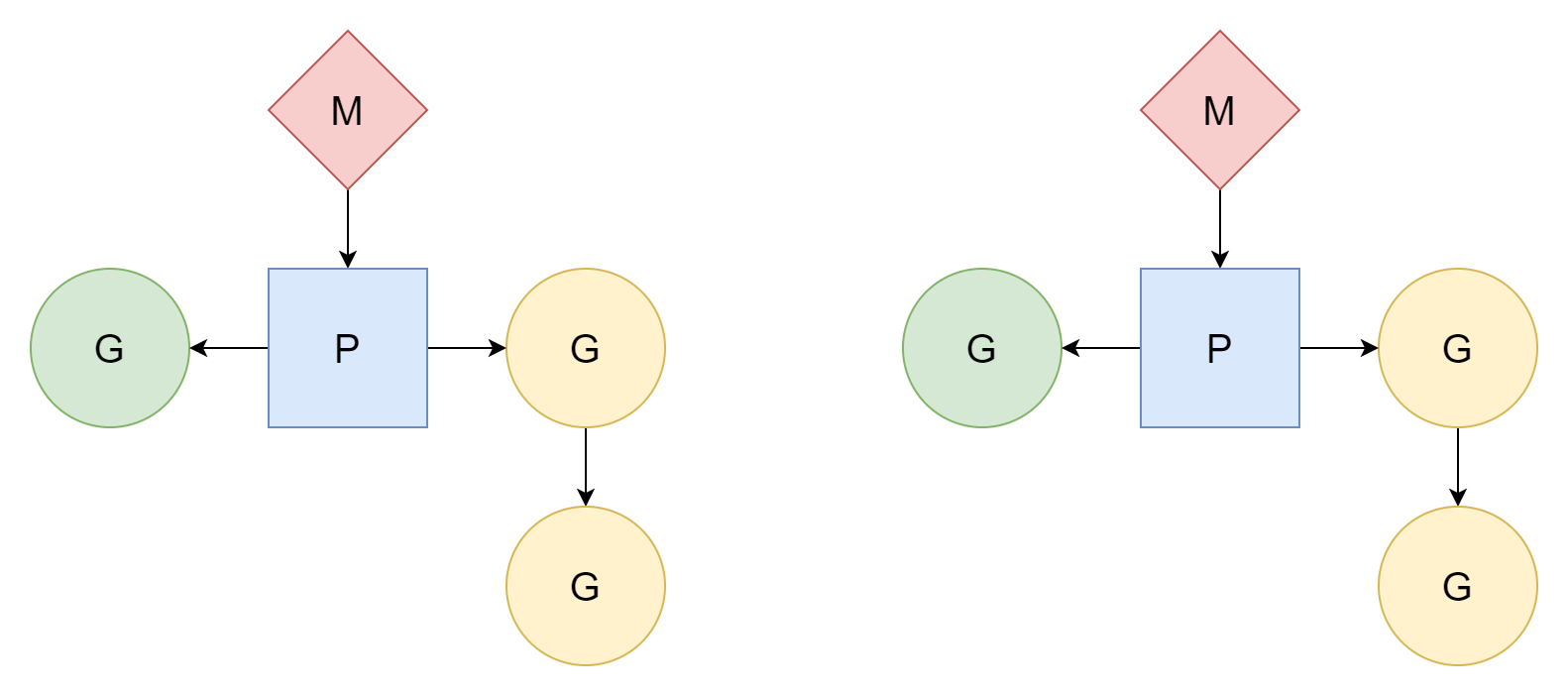
M:N
M Threads entsprechen N Goroutinen, wobei M kleiner als N ist. Mehrere Threads entsprechen mehreren Goroutinen, jeder Thread entspricht mehreren Goroutinen. Der Prozessor P ist für die Planung zuständig, wie Goroutinen G das Zeitquantum der Threads nutzen. Dies ist die relativ beste Methode und das Scheduler-Modell, das Go bis heute verwendet.
M kann nur Aufgaben ausführen, wenn es mit einem Prozessor P verknüpft ist. Go erstellt GOMAXPROCS Prozessoren, daher ist die Anzahl der Threads, die tatsächlich Aufgaben ausführen können, GOMAXPROCS. Der Standardwert ist die Anzahl der logischen CPU-Kerne des aktuellen Computers. Wir können diesen Wert auch manuell setzen:
- Durch Code:
runtime.GOMAXPROCS(N), kann zur Laufzeit dynamisch angepasst werden, führt zu STW - Durch Umgebungsvariable:
export GOMAXPROCS=N, statisch
In der Praxis ist die Anzahl von M größer als die von P, da die Laufzeitumgebung sie für andere Aufgaben benötigt, wie Systemaufrufe. Der Maximalwert ist 10000.
G, M und P sowie der Scheduler selbst haben entsprechende Typen in der Laufzeitumgebung. Sie befinden sich in der Datei runtime/runtime2.go.
G
G wird zur Laufzeit durch die Struktur runtime.g repräsentiert. Sie ist die grundlegendste Planungseinheit des Scheduler-Modells:
type g struct {
stack stack // offset known to runtime/cgo
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
goid uint64
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
atomicstatus atomic.Uint32
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
startpc uintptr // pc of goroutine function
parentGoid uint64 // goid of goroutine that created this goroutine
waiting *sudog // sudog structures this g is waiting on
}Das erste Feld ist die Start- und Endadresse des Stacks dieser Goroutine:
type stack struct {
lo uintptr
hi uintptr
}_panic und _defer sind Zeiger auf den Panic-Stack bzw. Defer-Stack:
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost deferm ist der Thread, der gerade diese G ausführt:
m *m // current m; offset known to arm liblinkpreempt gibt an, ob die aktuelle Goroutine präemptiert werden muss:
preempt bool // preemption signal, duplicates stackguard0 = stackpreemptatomicstatus speichert den Status der Goroutine G mit folgenden möglichen Werten:
| Name | Beschreibung |
|---|---|
| _Gidle | Gerade zugewiesen, noch nicht initialisiert |
| _Grunnable | Die aktuelle Goroutine kann ausgeführt werden, befindet sich in der Warteschlange |
| _Grunning | Die aktuelle Goroutine führt Benutzercode aus |
| _Gsyscall | Ein M wurde zugewiesen für Systemaufrufe, |
| _Gwaiting | Goroutine blockiert, Grund siehe unten |
| _Gdead | Die aktuelle Goroutine wird nicht verwendet, möglicherweise gerade beendet oder initialisiert |
| _Gcopystack | Der Goroutine-Stack wird verschoben, währenddessen wird kein Benutzercode ausgeführt, befindet sich nicht in der Warteschlange |
| _Gpreempted | Blockiert sich selbst für Präemption, wartet auf Erwachen |
| _Gscan | GC scannt den Goroutine-Stack, kann mit anderen Status koexistieren |
sched speichert den Kontext der Goroutine für die Wiederherstellung des Ausführungszustands:
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}M
M wird zur Laufzeit durch die Struktur runtime.m repräsentiert, eine Abstraktion des Worker-Threads:
type m struct {
id int64
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
p puintptr // attached p for executing go code
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
spinning bool // m is out of work and is actively looking for work
tls [tlsSlots]uintptr
...
}Wichtige Felder:
id, die eindeutige Kennung von Mg0, die Goroutine mit Planungs-Stackcurg, die Benutzer-Goroutine, die gerade auf dem Worker-Thread läuftgsignal, die Goroutine für Signalverarbeitungp, die Adresse des Prozessors Pspinning, gibt an, dass M im Leerlauf ist und verfügbar
P
P wird zur Laufzeit durch runtime.p repräsentiert und ist für die Planung zwischen M und G zuständig:
type p struct {
id int32
status uint32 // one of pidle/prunning/...
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
m muintptr // back-link to associated m
// Queue of runnable goroutines
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
preempt bool
...
}status gibt den Status von P an:
| Wert | Beschreibung |
|---|---|
| _Pidle | P ist im Leerlauf, kann vom Scheduler einem M zugewiesen werden |
| _Prunning | P ist mit M verknüpft und führt Benutzercode aus |
| _Psyscall | Das mit P verknüpfte M führt einen Systemaufruf durch, P kann von anderen M übernommen werden |
| _Pgcstop | P wurde wegen GC angehalten |
| _Pdead | Die meisten Ressourcen von P wurden entzogen, wird nicht mehr verwendet |
Die lokalen Warteschlangen-Felder:
runqhead uint32
runqtail uint32
runq [256]guintptrDie maximale Anzahl der lokalen Warteschlange ist 256. Wird dieser Wert überschritten, wird G in die globale Warteschlange verschoben.
Initialisierung
Die Initialisierung des Schedulers erfolgt in der Boot-Phase des Go-Programms. Verantwortlich ist die Funktion runtime.rt0_go, die in Assembler implementiert ist:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// start this M
CALL runtime·mstart(SB)runtime.schedinit initialisiert die Ressourcen, die der Scheduler benötigt:
func schedinit() {
...
gp := getg()
sched.maxmcount = 10000
stackinit()
mallocinit()
mcommoninit(gp.m, -1)
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}Die maximale Anzahl von M wird auf 10000 gesetzt. Dann werden Stack, Speicher und M initialisiert. Schließlich wird runtime.procresize aufgerufen, um P zu initialisieren.
Threads
Erstellung
Die Erstellung von M erfolgt durch die Funktion runtime.newm:
func newm(fn func(), pp *p, id int64) {
acquirem()
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
newm1(mp)
releasem(getg().m)
}runtime.allocm erstellt die Laufzeit-Repräsentation von M. runtime.newm1 ruft runtime.newosproc auf, um den tatsächlichen System-Thread zu erstellen.
Beendigung
Wenn ein Thread beendet wird, erfolgt dies durch runtime.mexit:
runtime.uminitmacht die Arbeit vonruntime.minitrückgängig- Löscht M aus der globalen Liste
allm - Setzt den
freem-Zeiger des Schedulers auf das aktuelle M runtime.releaseptrennt P vom aktuellen Mruntime.destroygibt die Ressourcen von M frei- Das Betriebssystem beendet den Thread
Pause
Wenn M wegen Scheduler, GC oder Systemaufrufen pausiert werden muss, wird runtime.stopm aufgerufen:
func stopm() {
gp := getg()
lock(&sched.lock)
mput(gp.m)
unlock(&sched.lock)
mPark()
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}Es setzt M in die globale freie M-Liste und blockiert den aktuellen Thread.
Goroutinen
Der Lebenszyklus einer Goroutine entspricht ihren verschiedenen Zuständen.
Erstellung
Goroutine-Erstellung erfordert syntaktisch nur ein go-Schlüsselwort:
go doSomething()Nach der Kompilierung wird dies zu einem Aufruf von runtime.newproc:
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}runtime.newproc1 führt die tatsächliche Erstellung durch. Zuerst wird M gesperrt, dann wird versucht, eine freie G aus der lokalen gfree-Liste von P wiederzuverwenden. Wenn keine gefunden wird, wird eine neue G mit runtime.malg erstellt und mit 2KB Stack ausgestattet. Der Status ist dann _Gdead.
mp := acquirem()
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg)
}Nach der Einrichtung wechselt der Status von _Gdead zu _Grunnable.
Beendigung
Bei der Erstellung wurde runtime.goexit als Stack-Boden gesetzt. Wenn die Goroutine fertig ist, wird diese Funktion aufgerufen. Über die Aufrufkette goexit->goexit1->goexit0 ist runtime.goexit0 für die Beendigung zuständig:
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
...
casgstatus(gp, _Grunning, _Gdead)
...
dropg()
gfput(pp, gp)
schedule()
}Die Funktion führt folgende Schritte aus:
- Setzt den Status auf
_Gdead - Setzt Felder zurück
dropg()trennt die Verbindung zwischen M und Ggfput(pp, gp)setzt G in die lokale freie Liste von Pschedule()startet eine neue Planungsrunde
Systemaufrufe
Wenn eine Goroutine während der Ausführung einen Systemaufruf tätigt, muss runtime.entersyscall aufgerufen werden:
gp := getg()
gp.m.locks++
gp.stackguard0 = stackPreempt
gp.throwsplit = true
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pc
casgstatus(gp, _Grunning, _Gsyscall)
pp := gp.m.p.ptr()
pp.m = 0
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
gp.m.locks--Während eines Systemaufrufs wird M von P getrennt. P kann mit einem anderen freien M verknüpft werden.
Nach Rückkehr vom Systemaufruf übernimmt runtime.exitsyscall die Nachbearbeitung. Es gibt zwei Möglichkeiten:
- Ein P ist direkt verfügbar (das alte P oder ein freies P)
- Kein P verfügbar - G wird in die globale Warteschlange gesetzt
Aufhängen
Wenn eine Goroutine aufgehängt wird, wechselt der Status von _Grunnable zu _Gwaiting. Gründe können Channel-Blockierung, select, Sperren oder time.Sleep sein.
runtime.gopark aktualisiert den Blockierungsgrund von G und M:
mp := acquirem()
gp := mp.curg
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
releasem(mp)
mcall(park_m)runtime.park_m wechselt den Status von G zu _Gwaiting:
mp := getg().m
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
schedule()Zum Aufwecken wird runtime.ready verwendet, das den Status von _Gwaiting zu _Grunnable ändert und G in die lokale Warteschlange von P setzt.
Goroutine-Stack
Jede Goroutine erhält einen eigenen Stack im Heap, der sich je nach Nutzung vergrößert oder verkleinert.
Zuweisung
Beim Erstellen einer neuen Goroutine wird standardmäßig ein 2KB-Stack zugewiesen:
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg)
}runtime.stackalloc ist für die Stack-Zuweisung zuständig. Bei weniger als 32KB wird aus dem stackpool-Cache genommen, sonst aus stackLarge oder direkt vom Heap.
Erweiterung
Der Compiler fügt am Anfang jeder Funktion runtime.morestack ein, um zu prüfen, ob eine Stack-Erweiterung nötig ist. Der neue Stack ist doppelt so groß wie der alte:
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
casgstatus(gp, _Grunning, _Gcopystack)
copystack(gp, newsize)
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)runtime.copystack kopiert den alten Stack in den neuen:
- Neuen Stack zuweisen
- Alten Stack in den neuen kopieren
- Strukturen mit Stack-Zeigern anpassen
- G's Stack-Felder aktualisieren
- Alten Stack freigeben
Verkleinerung
Wenn G den Status _Grunnable, _Gsyscall oder _Gwaiting hat, scannt GC den Stack. Wenn weniger als 1/4 des Stacks genutzt wird, wird er auf die Hälfte verkleinert:
func shrinkstack(gp *g) {
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
if newsize < fixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
if used := gp.stack.hi - gp.sched.sp + stackNosplit; used >= avail/4 {
return
}
copystack(gp, newsize)
}Planungsschleife
In der Planungsschleife sucht P nach ausführbaren G:
func schedule() {
mp := getg().m
top:
pp := mp.p.ptr()
pp.preempt = false
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
execute(gp, inheritTime)
}G kommt aus folgenden Quellen (nach Priorität):
- Lokale Warteschlange von P
- Globale Warteschlange
- Netzwerk-Poller
- Von anderen P's "stehlen"
runtime.execute führt G aus:
mp := getg().m
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
gogo(&gp.sched)Planungsstrategien
Kooperative Planung
Bei der kooperativen Planung gibt G freiwillig die Ausführung an andere G ab. Zwei Methoden:
runtime.Gosched()- Benutzer ruft explizit auf- Präemptionsmarkierung - Der Compiler fügt
runtime.morestack()am Funktionsanfang ein
Präemptive Planung
Seit Go 1.14 gibt es signalbasierte asynchrone Präemption. Wenn G länger als 10ms läuft, sendet der System-Monitor ein Präemptionssignal:
func retake(now int64) uint32 {
for i := 0; i < len(allp); i++ {
pp := allp[i]
if s == _Prunning || s == _Psyscall {
if pd.schedwhen+forcePreemptNS <= now {
preemptone(pp)
}
}
}
}Auch bei GC kann Präemption ausgelöst werden.
Zusammenfassung
Auslöser für Planung:
- Funktionsaufrufe
- Systemaufrufe
- System-Monitor
- Garbage Collection
- Goroutine-Aufhängung (Channel, Sperren, etc.)
Es gibt zwei Hauptstrategien: kooperative und präemptive Planung. Beide koexistieren im aktuellen Scheduler.