string
string ist ein sehr häufiger grundlegender Datentyp in Go und auch der erste Datentyp, dem ich in Go begegnet bin.
package main
import "fmt"
func main() {
fmt.Println("hello,world!")
}Ich glaube, die meisten Menschen haben diesen Code geschrieben, als sie zum ersten Mal mit Go in Berührung kamen. In builtin/builtin.go gibt es eine einfache Beschreibung von string:
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string stringAus dem oben genannten lassen sich folgende Informationen ableiten:
stringist eine Sammlung von 8-Bit-Bytesstringist normalerweiseUTF-8-kodiertstringkann leer sein, aber nichtnilstringist unveränderlich
Diese Eigenschaften sollten denjenigen, die Go regelmäßig verwenden, längst vertraut sein. Schauen wir uns nun etwas anderes an.
Struktur
In Go wird ein String zur Laufzeit durch die Struktur runtime.stringStruct repräsentiert, die jedoch nicht nach außen hin verfügbar ist. Als Alternative kann reflect.StringHeader verwendet werden.
TIP
Obwohl StringHeader in der Version go.1.21 als veraltet markiert wurde, ist es sehr anschaulich. Im Folgenden wird es weiterhin zur Erläuterung verwendet, was das Verständnis nicht beeinträchtigt. Einzelheiten finden Sie unter Issues · golang/go (github.com).
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
// reflect/value.go
type StringHeader struct {
Data uintptr
Len int
}Die Felder haben folgende Bedeutung:
Data, ein Zeiger auf die Startadresse des String-SpeichersLen, die Anzahl der Bytes im String
Hier ist ein Beispiel für den Zugriff auf die String-Adresse über einen unsafe-Zeiger:
func main() {
str := "hello,world!"
h := *((*reflect.StringHeader)(unsafe.Pointer(&str)))
for i := 0; i < h.Len; i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(unsafe.Pointer(h.Data), uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}Go empfiehlt jedoch jetzt die Verwendung von unsafe.StringData als Ersatz:
func main() {
str := "hello,world!"
ptr := unsafe.Pointer(unsafe.StringData(str))
for i := 0; i < len(str); i++ {
fmt.Printf("%s ", string(*((*byte)(unsafe.Add(ptr, uintptr(i)*unsafe.Sizeof(str[0]))))))
}
}Beide Ausgaben sind identisch:
h e l l o , w o r l d !
Im Wesentlichen ist ein String ein zusammenhängender Speicherbereich, wobei an jeder Adresse ein Byte gespeichert ist. Mit anderen Worten: ein Byte-Array. Das Ergebnis der len-Funktion ist die Anzahl der Bytes, nicht die Anzahl der Zeichen im String. Dies ist besonders wichtig, wenn der String Nicht-ASCII-Zeichen enthält.
string selbst belegt nur sehr wenig Speicher - nämlich einen Zeiger auf die tatsächlichen Daten. Dadurch werden die Kosten für die Übergabe von Strings sehr gering. Meiner Meinung nach: Da nur eine Referenz auf den Speicher gehalten wird, wäre es schwierig zu wissen, ob die ursprüngliche Referenz noch auf die gewünschten Daten verweist, wenn sie beliebig geändert werden könnte (entweder durch Reflexion oder durch das unsafe-Paket). Ein weiterer Vorteil ist die inhärente Nebenläufigkeitssicherheit - niemand kann den String unter normalen Umständen ändern.
Konkatenation
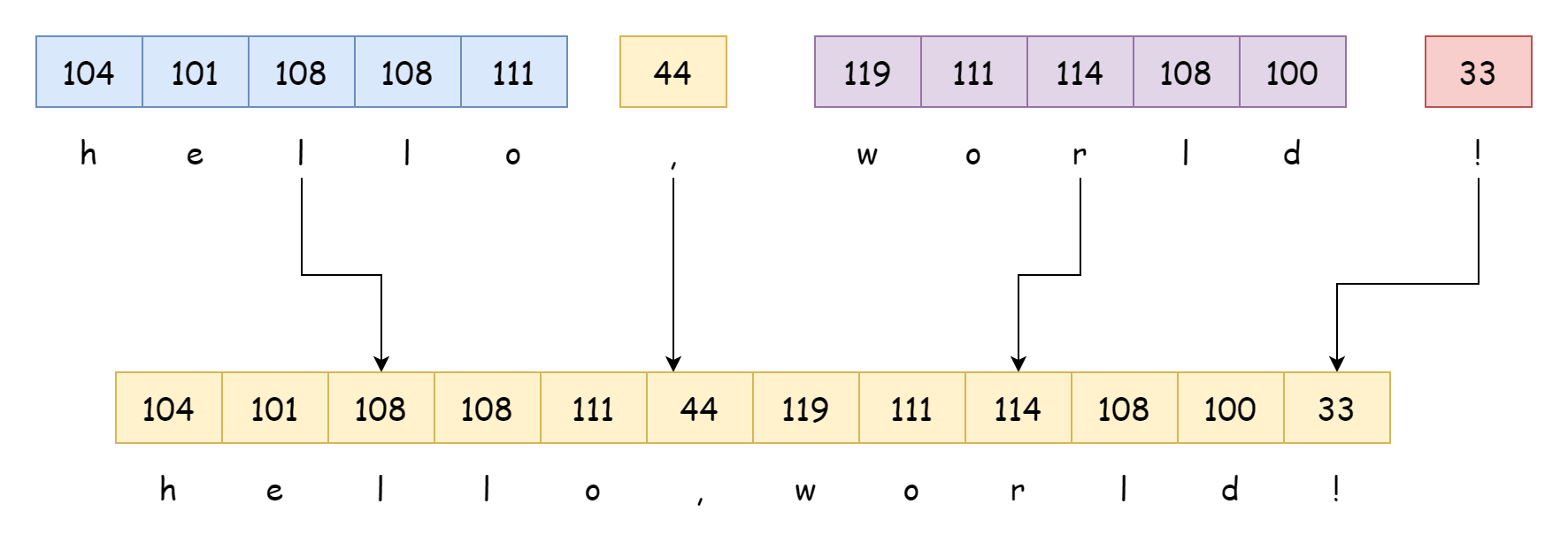
Die Syntax für die String-Konkatenation ist wie folgt: direkte Verwendung des +-Operators.
var (
hello = "hello"
dot = ","
world = "world"
last = "!"
)
str := hello + dot + world + lastDie Konkatenationsoperation wird zur Laufzeit von der Funktion runtime.concatstrings durchgeführt. Bei einer Literal-Konkatenation wie der folgenden leitet der Compiler das Ergebnis direkt ab:
str := "hello" + "," + "world" + "!"
_ = strDurch die Ausgabe des Assembler-Codes lässt sich das Ergebnis erkennen, teilweise wie folgt:
LEAQ go:string."hello,world!"(SB), AX
MOVQ AX, main.str(SP)Es ist offensichtlich, dass der Compiler dies als einen vollständigen String betrachtet, dessen Wert bereits zur Kompilierungszeit feststeht. Die Konkatenation wird nicht zur Laufzeit von runtime.concatstrings durchgeführt. Nur die Konkatenation von String-Variablen wird zur Laufzeit abgeschlossen. Die Funktionssignatur lautet wie folgt - sie empfängt ein Byte-Array und ein String-Slice:
func concatstrings(buf *tmpBuf, a []string) stringWenn die Anzahl der zu konkatinierenden String-Variablen kleiner als 5 ist, werden die folgenden Funktionen als Ersatz verwendet (persönliche Vermutung: Durch Parameter und anonyme Variablen übergeben, die alle auf dem Stack liegen, was im Vergleich zur Laufzeit erstellten Slices besser für GC ist?), obwohl die Konkatenation schließlich immer noch von concatstrings durchgeführt wird.
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}Schauen wir uns an, was die Funktion concatstrings macht:
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
// Länge 0 überspringen
if n == 0 {
continue
}
// Numerischer Überlauf
if l+n < l {
throw("string concatenation too long")
}
l += n
// Zählen
count++
idx = i
}
// Kein String, leeren String zurückgeben
if count == 0 {
return ""
}
// Wenn nur ein String vorhanden ist, direkt zurückgeben
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
// Speicher für neuen String zuweisen
s, b := rawstringtmp(buf, l)
for _, x := range a {
// Kopieren
copy(b, x)
// Abschneiden
b = b[len(x):]
}
return s
}Zunächst wird die Gesamtlänge und Anzahl der zu konkatinierenden Strings ermittelt. Dann wird Speicher basierend auf der Gesamtlänge zugewiesen. Die Funktion rawstringtmp gibt einen String s und ein Byte-Slice b zurück. Obwohl ihre Länge feststeht, haben sie keinen Inhalt, da sie im Wesentlichen zwei Zeiger auf eine neue Speicheradresse sind. Der Code für die Speicherzuweisung lautet:
func rawstring(size int) (s string, b []byte) {
// Kein Typ angegeben
p := mallocgc(uintptr(size), nil, false)
// Obwohl Speicher zugewiesen wurde, ist dort nichts
return unsafe.String((*byte)(p), size), unsafe.Slice((*byte)(p), size)
}Der zurückgegebene String s dient der einfacheren Darstellung, das Byte-Slice b dient der einfacheren Änderung des Strings - beide verweisen auf dieselbe Speicheradresse.
for _, x := range a {
// Kopieren
copy(b, x)
// Abschneiden
b = b[len(x):]
}Die copy-Funktion ruft zur Laufzeit runtime.slicecopy auf. Sie kopiert den Speicher von src direkt an die Adresse von dst. Nachdem alle Strings kopiert wurden, ist der gesamte Konkatenationsprozess abgeschlossen. Wenn die zu kopierenden Strings sehr groß sind, ist dieser Prozess recht performanceintensiv.
Konvertierung
Wie bereits erwähnt, sind Strings selbst nicht veränderbar. Wenn man versucht, einen String zu ändern, wird sogar die Kompilierung fehlschlagen. Go wird folgenden Fehler melden:
str := "hello" + "," + "world" + "!"
str[0] = '1'cannot assign to string (neither addressable nor a map index expression)Um einen String zu ändern, muss man ihn zuerst in ein Byte-Slice []byte konvertieren. Die Verwendung ist sehr einfach:
bs := []byte(str)Intern wird die Funktion runtime.stringtoslicebyte aufgerufen. Die Logik ist sehr einfach, der Code lautet:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}Wenn die String-Länge kleiner als die Puffer-Länge ist, wird direkt das Byte-Slice des Puffers zurückgegeben. Dies spart Speicher bei der Konvertierung kleiner Strings. Andernfalls wird ein Speicherbereich zugewiesen, der der String-Länge entspricht, und der String wird in die neue Speicheradresse kopiert. Die Funktion rawbyteslice(len(s)) macht ähnliches wie die zuvor erwähnte rawstring-Funktion - beide weisen Speicher zu.
Ebenso lässt sich ein Byte-Slice syntaktisch sehr einfach in einen String konvertieren:
str := string([]byte{'h','e','l','l','o'})Intern wird die Funktion runtime.slicebytetostring aufgerufen, die ebenfalls leicht verständlich ist:
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string {
if n == 0 {
return ""
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if goarch.BigEndian {
p = add(p, 7)
}
return unsafe.String((*byte)(p), 1)
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return unsafe.String((*byte)(p), n)
}Zuerst werden die Sonderfälle behandelt, wenn die Slice-Länge 0 oder 1 ist. In diesen Fällen ist keine Speicherkopie erforderlich. Wenn die Länge kleiner als die Puffer-Länge ist, wird der Speicher des Puffers verwendet, andernfalls wird neuer Speicher zugewiesen. Schließlich wird der Speicher mit der memmove-Funktion direkt kopiert. Der kopierte Speicher hat keine Verbindung mehr zum Quellspeicher, sodass er beliebig geändert werden kann.
Bemerkenswert ist, dass bei beiden oben genannten Konvertierungsmethoden Speicher kopiert werden muss. Wenn der zu kopierende Speicher sehr groß ist, ist der Performance-Verbrauch ebenfalls erheblich. Bei der Aktualisierung auf Version go1.20 wurden im unsafe-Paket folgende Funktionen hinzugefügt:
// Übergibt einen Typzeiger auf eine Speicheradresse und Datenlänge, gibt deren Slice-Darstellung zurück
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
// Übergibt ein Slice, erhält einen Zeiger auf das zugrunde liegende Array
func SliceData(slice []ArbitraryType) *ArbitraryType
// Gibt basierend auf der übergebenen Adresse und Länge einen String zurück
func String(ptr *byte, len IntegerType) string
// Übergibt einen String, gibt dessen Startspeicheradresse zurück, aber die zurückgegebenen Bytes können nicht geändert werden
func StringData(str string) *byteBesonders die Funktionen String und StringData ermöglichen eine Konvertierung ohne Speicherkopie. Es ist jedoch zu beachten, dass die Voraussetzung für ihre Verwendung ist, dass die Daten schreibgeschützt sind und später nicht geändert werden. Andernfalls wird sich der String ändern. Betrachten Sie das folgende Beispiel:
func main() {
bs := []byte("hello,world!")
s := unsafe.String((*byte)(unsafe.SliceData(bs)), len(bs))
bs[0] = 'b'
fmt.Println(s)
}Zunächst wird über SliceData die Adresse des zugrunde liegenden Arrays des Byte-Slices abgerufen, dann wird über String dessen String-Darstellung erhalten. Wenn anschließend das Byte-Slice direkt geändert wird, ändert sich auch der String. Dies widerspricht offensichtlich dem ursprünglichen Zweck von Strings. Betrachten wir ein weiteres Beispiel:
func main() {
str := "hello,world!"
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
// fatal
bytes[0] = 'b'
fmt.Println(str)
}Nachdem die Slice-Darstellung des Strings erhalten wurde, führt der Versuch, das Byte-Slice zu ändern, direkt zu einem fatal. Schauen wir uns an, was passiert, wenn wir die Art der String-Deklaration ändern:
func main() {
var str string
fmt.Scanln(&str)
bytes := unsafe.Slice(unsafe.StringData(str), len(str))
fmt.Println(bytes)
bytes[0] = 'b'
fmt.Println(str)
}hello,world!
[104 101 108 108 111 44 119 111 114 108 100 33]
bello,world!Aus dem Ergebnis ist ersichtlich, dass die Änderung tatsächlich erfolgreich war. Der Grund für das vorherige fatal lag daran, dass die Variable str ein String-Literal speicherte. String-Literale werden im schreibgeschützten Datensegment gespeichert, nicht auf dem Heap oder Stack. Dies verhindert grundlegend die Möglichkeit, dass ein durch ein Literal deklarierter String später geändert werden kann. Für eine gewöhnliche String-Variable kann sie im Wesentlichen geändert werden, aber diese Schreibweise wird vom Compiler nicht zugelassen. Zusammenfassend lässt sich sagen, dass die Verwendung von unsafe-Funktionen für String-Konvertierungen nicht sicher ist, es sei denn, man kann garantieren, dass die Daten niemals geändert werden.
Iteration
s := "hello world!"
for i, r := range s {
fmt.Println(i, r)
}Um mit Mehrbyte-Zeichen umzugehen, wird für die Iteration über Strings normalerweise eine for range-Schleife verwendet. Bei der Verwendung von for range zur Iteration über einen String wird der Compiler den Code während der Kompilierung in folgende Form expandieren:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
// Prüfen, ob es sich um ein Einbyte-Zeichen handelt
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
i, r = hv1t, hv2
// Schleifenkörper
}Im expandierten Code wird die for range-Schleife durch eine klassische for-Schleife ersetzt. In der Schleife wird geprüft, ob das aktuelle Byte ein Einbyte-Zeichen ist. Wenn es sich um ein Mehrbyte-Zeichen handelt, wird die Laufzeitfunktion runtime.decoderune aufgerufen, um die vollständige Kodierung zu erhalten. Diese wird dann i und r zugewiesen. Nach der Verarbeitung wird der im Quellcode definierte Schleifenkörper ausgeführt.
Die Konstruktion des Zwischencodes wird von der Funktion walkRange in cmd/compile/internal/walk/range.go durchgeführt. Diese Funktion ist auch für die Verarbeitung aller Typen zuständig, die mit for range durchlaufen werden können. Hier wird nicht weiter darauf eingegangen - wer interessiert ist, kann sich selbst weiter informieren.