Nebenläufigkeit
Go bietet native Unterstützung für Nebenläufigkeit, dies ist der Kern der Sprache. Die Einstiegshürde ist relativ gering, Entwickler müssen sich weniger mit der zugrunde liegenden Implementierung befassen und können dennoch hervorragende nebenläufige Anwendungen erstellen.
Goroutinen
Goroutinen (Coroutines) sind leichtgewichtige Threads oder Threads im Benutzerraum, die nicht direkt vom Betriebssystem gesteuert werden, sondern vom Go-eigenen Scheduler zur Laufzeit verwaltet werden. Daher ist der Kontextwechsel-Overhead sehr gering, was einer der Gründe für die gute Nebenläufigkeitsleistung von Go ist. Das Konzept der Goroutinen wurde nicht erstmals von Go eingeführt, und Go war nicht die erste Sprache, die Goroutinen unterstützte, aber Go ist die erste Sprache, die Goroutinen und Nebenläufigkeit auf eine so einfache und elegante Weise unterstützt.
In Go ist das Erstellen einer Goroutine sehr einfach. Mit nur einem go-Schlüsselwort kann schnell eine Goroutine gestartet werden. Dem go-Schlüsselwort muss ein Funktionsaufruf folgen. Beispiel:
TIP
Eingebaute Funktionen mit Rückgabewerten dürfen nicht dem go-Schlüsselwort folgen, wie im folgenden Fehlerbeispiel gezeigt:
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}Alle drei Methoden zum Starten von Goroutinen sind gültig. In den meisten Fällen wird bei diesem Beispiel jedoch nichts ausgegeben, da Goroutinen parallel ausgeführt werden. Das System benötigt Zeit zum Erstellen der Goroutinen, und在此之前 ist die Haupt-Goroutine bereits beendet. Sobald der Haupt-Thread beendet ist, werden auch alle untergeordneten Goroutinen beendet. Außerdem ist die Ausführungsreihenfolge der Goroutinen unbestimmt und nicht vorhersagbar, wie im folgenden Beispiel:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}Dies ist ein Beispiel für Goroutinen in einer Schleife. Es ist unmöglich, genau vorherzusagen, was ausgegeben wird. Möglicherweise ist die Haupt-Goroutine bereits beendet, bevor die untergeordneten Goroutinen gestartet sind:
start
endOder nur ein Teil der untergeordneten Goroutinen wird vor dem Beenden der Haupt-Goroutine ausgeführt:
start
0
1
5
3
4
6
7
endDie einfachste Lösung besteht darin, die Haupt-Goroutine eine Weile warten zu lassen. Dazu wird die Sleep-Funktion aus dem time-Paket verwendet, die die aktuelle Goroutine für einen bestimmten Zeitraum anhalten kann:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// 1ms pausieren
time.Sleep(time.Millisecond)
fmt.Println("end")
}Die Ausgabe lautet nun wie folgt, alle Zahlen werden vollständig ausgegeben:
start
0
1
5
2
3
4
6
8
9
7
endDie Reihenfolge ist jedoch immer noch durcheinander. Daher sollte bei jeder Iteration kurz gewartet werden:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}Die Ausgabe erfolgt nun in der richtigen Reihenfolge:
start
0
1
2
3
4
5
6
7
8
9
endObwohl die Ausgabe in diesem Beispiel perfekt erscheint, ist das Nebenläufigkeitsproblem nicht gelöst. Für nebenläufige Programme gibt es viele unkontrollierbare Faktoren: Ausführungszeitpunkt, Reihenfolge, Ausführungszeit usw. Wenn die Aufgabe der untergeordneten Goroutine in der Schleife nicht nur eine einfache Ausgabe ist, sondern eine sehr große und komplexe Aufgabe mit unbestimmter Ausführungszeit, treten die vorherigen Probleme erneut auf. Siehe den folgenden Code:
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// Simuliere zufällige Ausführungszeit
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}Die Ausgabe dieses Codes ist immer noch unbestimmt, hier ist eine mögliche Ausgabe:
start
0
3
4
endDaher ist time.Sleep keine gute Lösung. Glücklicherweise bietet Go viele Nebenläufigkeitssteuerungsmethoden. Die drei häufigsten Methoden sind:
channel: PipelineWaitGroup: SemaphorContext: Kontext
Die drei Methoden haben unterschiedliche Anwendungsfälle. WaitGroup kann dynamisch eine bestimmte Anzahl von Goroutinen steuern, Context eignet sich besser für tief verschachtelte Goroutinen-Hierarchien, und Pipelines eignen sich besser für die Kommunikation zwischen Goroutinen. Für traditionelle Sperrensteuerung bietet Go ebenfalls Unterstützung:
Mutex: Gegenseitiger AusschlussRWMutex: Lese-Schreib-Sperre
Pipeline
channel, auf Deutsch Pipeline, wird in Go wie folgt beschrieben:
Do not communicate by sharing memory; instead, share memory by communicating.
Das bedeutet, Speicher wird durch Nachrichtenaustausch gemeinsam genutzt, und channel ist dafür gedacht. Es ist eine Lösung für die Kommunikation zwischen Goroutinen und kann auch zur Nebenläufigkeitssteuerung verwendet werden. Zuerst zur grundlegenden Syntax von channel. In Go wird das Schlüsselwort chan verwendet, um den Pipeline-Typ darzustellen. Gleichzeitig muss der Speichertyp der Pipeline deklariert werden, um anzugeben, welche Art von Daten gespeichert werden. Das folgende Beispiel zeigt eine normale Pipeline:
var ch chan intDies ist eine Pipeline-Deklaration. Zu diesem Zeitpunkt ist die Pipeline nicht initialisiert und ihr Wert ist nil. Sie kann nicht direkt verwendet werden.
Erstellen
Beim Erstellen einer Pipeline gibt es nur eine Methode: die Verwendung der eingebauten Funktion make. Für Pipelines akzeptiert make zwei Parameter: den ersten für den Pipeline-Typ und den zweiten optionalen Parameter für die Puffergröße der Pipeline. Beispiel:
intCh := make(chan int)
// Pipeline mit Puffergröße 1
strCh := make(chan string, 1)Nach der Verwendung einer Pipeline muss diese unbedingt geschlossen werden. Verwenden Sie die eingebaute Funktion close, um eine Pipeline zu schließen. Die Signatur der Funktion lautet:
func close(c chan<- Type)Ein Beispiel zum Schließen einer Pipeline:
func main() {
intCh := make(chan int)
// do something
close(intCh)
}Manchmal ist es besser, defer zum Schließen der Pipeline zu verwenden.
Lesen und Schreiben
In Go werden zwei sehr anschauliche Operatoren verwendet, um Lese- und Schreiboperationen für Pipelines darzustellen:
ch <-: Schreibt Daten in eine Pipeline
<- ch: Liest Daten aus einer Pipeline
<- zeigt sehr anschaulich die Datenflussrichtung an. Hier ein Beispiel für das Lesen und Schreiben einer int-Pipeline:
func main() {
// Ohne Puffer würde ein Deadlock auftreten
intCh := make(chan int, 1)
defer close(intCh)
// Daten schreiben
intCh <- 114514
// Daten lesen
fmt.Println(<-intCh)
}Im obigen Beispiel wurde eine int-Pipeline mit einer Puffergröße von 1 erstellt, der Wert 114514 wurde geschrieben, dann wurden die Daten gelesen und ausgegeben, und schließlich wurde die Pipeline geschlossen. Für Leseoperationen gibt es einen zweiten Rückgabewert, einen booleschen Wert, der angibt, ob das Lesen erfolgreich war:
ints, ok := <-intChDer Datenfluss in einer Pipeline funktioniert wie bei einer Warteschlange, also First-In-First-Out (FIFO). Operationen auf Pipelines durch Goroutinen sind synchron. Zu einem bestimmten Zeitpunkt kann nur eine Goroutine Daten in die Pipeline schreiben, und nur eine Goroutine kann Daten aus der Pipeline lesen.
Ohne Puffer
Bei Pipelines ohne Puffer beträgt die Pufferkapazität 0, sodass keine Daten temporär gespeichert werden können. Da Pipelines ohne Puffer keine Daten speichern können, müssen beim Schreiben in die Pipeline sofort andere Goroutinen die Daten lesen, andernfalls wird blockiert. Dasselbe gilt beim Lesen. Dies erklärt, warum der folgende anscheinend normale Code einen Deadlock verursacht:
func main() {
// Pipeline ohne Puffer erstellen
ch := make(chan int)
defer close(ch)
// Daten schreiben
ch <- 123
// Daten lesen
n := <-ch
fmt.Println(n)
}Pipelines ohne Puffer sollten nicht synchron verwendet werden. Stattdessen sollte eine neue Goroutine zum Senden von Daten gestartet werden:
func main() {
// Pipeline ohne Puffer erstellen
ch := make(chan int)
defer close(ch)
go func() {
// Daten schreiben
ch <- 123
}()
// Daten lesen
n := <-ch
fmt.Println(n)
}Mit Puffer
Wenn eine Pipeline einen Puffer hat, funktioniert sie wie eine blockierende Warteschlange. Das Lesen einer leeren Pipeline und das Schreiben in eine volle Pipeline führen zu einer Blockierung. Bei Pipelines ohne Puffer muss beim Senden von Daten sofort ein Empfänger vorhanden sein, andernfalls wird blockiert. Bei Pipelines mit Puffer werden die Daten zunächst in den Puffer geschrieben. Nur wenn der Puffer voll ist, wird blockiert, bis eine Goroutine die Daten liest. Beim Lesen einer Pipeline mit Puffer werden zunächst Daten aus dem Puffer gelesen, bis der Puffer leer ist, und dann wird blockiert, bis eine Goroutine Daten in die Pipeline schreibt. Daher kann das folgende Beispiel, das bei Pipelines ohne Puffer einen Deadlock verursachen würde, hier problemlos ausgeführt werden:
func main() {
// Pipeline mit Puffer erstellen
ch := make(chan int, 1)
defer close(ch)
// Daten schreiben
ch <- 123
// Daten lesen
n := <-ch
fmt.Println(n)
}Obwohl dies problemlos ausgeführt werden kann, ist diese synchrone Lese-/Schreibweise gefährlich. Sobald der Puffer der Pipeline leer oder voll ist, wird die Ausführung dauerhaft blockiert, da keine andere Goroutine Daten in die Pipeline schreibt oder daraus liest. Betrachten Sie das folgende Beispiel:
func main() {
// Pipeline mit Puffer erstellen
ch := make(chan int, 5)
// Zwei Pipelines ohne Puffer erstellen
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// Zum Schreiben verantwortlich
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("写入", i)
}
chW <- struct{}{}
}()
// Zum Lesen verantwortlich
go func() {
for i := 0; i < 10; i++ {
// Jedes Lesen dauert 1 Millisekunde
time.Sleep(time.Millisecond)
fmt.Println("读取", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("写入完毕", <-chW)
fmt.Println("读取完毕", <-chR)
}Hier wurden insgesamt 3 Pipelines erstellt: eine mit Puffer für die Kommunikation zwischen Goroutinen und zwei ohne Puffer zur Synchronisation der Ausführungsreihenfolge von über- und untergeordneten Goroutinen. Die lesende Goroutine wartet vor jedem Lesevorgang 1 Millisekunde, und die schreibende Goroutine kann maximal 5 Daten schreiben, da der Puffer maximal 5 fassen kann. Bevor andere Goroutinen die Daten lesen, muss blockiert gewartet werden. Daher lautet die Ausgabe dieses Beispiels:
写入 0
写入 1
写入 2
写入 3
写入 4 // 5 geschrieben, Puffer voll, warte auf lesende Goroutine
读取 0
写入 5 // Eine gelesen, eine geschrieben
读取 1
写入 6
读取 2
写入 7
读取 3
写入 8
写入 9
读取 4
写入完毕 {} // Alle Daten gesendet, schreibende Goroutine beendet
读取 5
读取 6
读取 7
读取 8
读取 9
读取完毕 {} // Alle Daten gelesen, lesende Goroutine beendetWie zu sehen ist, sendet die schreibende Goroutine zunächst 5 Daten auf einmal. Wenn der Puffer voll ist, wird blockiert, bis die lesende Goroutine die Daten liest. Danach schreibt die schreibende Goroutine bei jedem Lesevorgang der lesenden Goroutine (alle 1 Millisekunde) ein neues Datum, bis alle Daten gesendet wurden. Anschließend liest die lesende Goroutine alle verbleibenden Daten aus dem Puffer, und schließlich wird die Haupt-Goroutine beendet.
TIP
Mit der eingebauten Funktion len kann auf die Anzahl der Daten im Puffer der Pipeline zugegriffen werden, und mit cap kann auf die Größe des Puffers zugegriffen werden.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}Ausgabe:
3 5Mithilfe der Blockierungsbedingungen von Pipelines kann leicht ein Beispiel erstellt werden, bei dem die Haupt-Goroutine auf das Ende der untergeordneten Goroutinen wartet:
func main() {
// Eine Pipeline ohne Puffer erstellen
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// Schreiben
ch <- struct{}{}
}()
// Blockierend warten und lesen
<-ch
fmt.Println(1)
}Ausgabe:
2
1Mit einer Pipeline mit Puffer kann auch eine einfache gegenseitige Ausschlusssperre implementiert werden. Siehe das folgende Beispiel:
var count = 0
// Pipeline mit Puffergröße 1
var lock = make(chan struct{}, 1)
func Add() {
// Sperren
lock <- struct{}{}
fmt.Println("当前计数为", count, "执行加法")
count += 1
// Entsperren
<-lock
}
func Sub() {
// Sperren
lock <- struct{}{}
fmt.Println("当前计数为", count, "执行减法")
count -= 1
// Entsperren
<-lock
}Da die Puffergröße der Pipeline 1 beträgt, kann maximal ein Datum im Puffer gespeichert werden. Die Funktionen Add und Sub versuchen vor jeder Operation, Daten in die Pipeline zu senden. Da die Puffergröße 1 beträgt, muss die aktuelle Goroutine blockiert warten, wenn eine andere Goroutine bereits Daten geschrieben hat und der Puffer voll ist, bis eine Position im Puffer frei wird. Auf diese Weise kann zu einem bestimmten Zeitpunkt maximal eine Goroutine die Variable count ändern, wodurch eine einfache gegenseitige Ausschlusssperre implementiert wird.
Hinweise
Im Folgenden sind einige Zusammenfassungen aufgeführt. Diese Situationen können bei unsachgemäßer Verwendung zu Pipeline-Blockierungen führen:
Lesen und Schreiben von Pipelines ohne Puffer
Synchrone Lese- und Schreiboperationen auf einer Pipeline ohne Puffer führen zur Blockierung der aktuellen Goroutine:
func main() {
// Eine Pipeline ohne Puffer erstellen
intCh := make(chan int)
defer close(intCh)
// Daten senden
intCh <- 1
// Daten lesen
ints, ok := <-intCh
fmt.Println(ints, ok)
}Lesen einer Pipeline mit leerem Puffer
Das Lesen einer Pipeline mit leerem Puffer führt zur Blockierung der aktuellen Goroutine:
func main() {
// Eine Pipeline mit Puffer erstellen
intCh := make(chan int, 1)
defer close(intCh)
// Puffer ist leer, blockierend warten, bis andere Goroutinen Daten schreiben
ints, ok := <-intCh
fmt.Println(ints, ok)
}Schreiben in eine Pipeline mit vollem Puffer
Wenn der Puffer der Pipeline voll ist, führt das Schreiben von Daten zur Blockierung der aktuellen Goroutine:
func main() {
// Eine Pipeline mit Puffer erstellen
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// Voll, blockierend warten, bis andere Goroutinen Daten lesen
intCh <- 1
}Pipeline ist nil
Wenn die Pipeline nil ist, führt jedes Lesen oder Schreiben zur Blockierung der aktuellen Goroutine:
func main() {
var intCh chan int
// Schreiben
intCh <- 1
}func main() {
var intCh chan int
// Lesen
fmt.Println(<-intCh)
}Die Bedingungen für Pipeline-Blockierungen sollten gut verstanden und beherrscht werden. In den meisten Fällen sind diese Probleme sehr versteckt und nicht so offensichtlich wie in den Beispielen.
Die folgenden Situationen führen zusätzlich zu panic:
Schließen einer nil-Pipeline
Wenn die Pipeline nil ist, führt das Schließen mit der close-Funktion zu einem Panic:
func main() {
var intCh chan int
close(intCh)
}Schreiben in eine geschlossene Pipeline
Das Schreiben von Daten in eine geschlossene Pipeline führt zu einem panic:
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}Schließen einer bereits geschlossenen Pipeline
In einigen Fällen kann die Pipeline durch mehrere Ebenen weitergegeben werden, und der Aufrufer weiß möglicherweise nicht, wer die Pipeline schließen soll. In diesem Fall kann es vorkommen, dass eine bereits geschlossene Pipeline erneut geschlossen wird, was zu einem panic führt:
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Kann nur Daten an die Pipeline senden
ch <- 1
close(ch)
}Einseitige Pipelines
Zweiseitige Pipelines können sowohl gelesen als auch geschrieben werden, d. h., Operationen können auf beiden Seiten der Pipeline durchgeführt werden. Einseitige Pipelines sind nur lesbar oder nur schreibbar, d. h., Operationen können nur auf einer Seite der Pipeline durchgeführt werden. Das manuelle Erstellen einer nur lesbaren oder nur schreibbaren Pipeline hat wenig Sinn, da das Lesen und Schreiben der Pipeline deren Existenzgrundlage wäre. Einseitige Pipelines werden normalerweise verwendet, um das Verhalten von Kanälen einzuschränken, und erscheinen im Allgemeinen in Funktionsparametern und Rückgabewerten. Zum Beispiel verwendet die eingebaute Funktion close zum Schließen von Kanälen einen einseitigen Kanal in ihrer Signatur:
func close(c chan<- Type)Oder die After-Funktion im häufig verwendeten time-Paket:
func After(d Duration) <-chan TimeDer Parameter der close-Funktion ist eine schreibgeschützte Pipeline, und der Rückgabewert der After-Funktion ist eine nur lesbare Pipeline. Daher lautet die Syntax für einseitige Pipelines:
- Wenn das Pfeilsymbol
<-vorne steht, handelt es sich um eine nur lesbare Pipeline, z. B.<-chan int - Wenn das Pfeilsymbol
<-hinten steht, handelt es sich um eine nur schreibbare Pipeline, z. B.chan<- string
Der Versuch, Daten in eine nur lesbare Pipeline zu schreiben, führt zu einem Kompilierungsfehler:
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}Die Fehlermeldung ist eindeutig:
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)Dasselbe gilt für das Lesen aus einer nur schreibbaren Pipeline.
Zweiseitige Pipelines können in einseitige Pipelines umgewandelt werden, aber nicht umgekehrt. Normalerweise kann eine einseitige Pipeline verwendet werden, um das Verhalten der anderen Seite einzuschränken, wenn eine zweiseitige Pipeline an eine Goroutine oder Funktion übergeben wird und nicht gelesen/gesendet werden soll.
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Kann nur Daten an die Pipeline senden
ch <- 1
}Dasselbe gilt für nur lesbare Pipelines.
TIP
chan ist ein Referenztyp. Auch wenn Go Funktionsparameter als Wert übergibt, bleibt die Referenz dieselbe. Dies wird in der folgenden Erklärung der Pipeline-Prinzipien erläutert.
for range
Mit der for range-Anweisung können Daten aus einer Pipeline mit Puffer gelesen werden:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}Normalerweise hat for range beim Durchlaufen anderer iterierbarer Datenstrukturen zwei Rückgabewerte: den ersten für den Index und den zweiten für den Elementwert. Bei Pipelines gibt es jedoch nur einen Rückgabewert. for range liest kontinuierlich Elemente aus der Pipeline. Wenn der Puffer leer oder kein Puffer vorhanden ist, wird blockiert, bis andere Goroutinen Daten in die Pipeline schreiben. Daher lautet die Ausgabe:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!Wie zu sehen ist, tritt im obigen Code ein Deadlock auf, da die untergeordnete Goroutine bereits beendet ist, die Haupt-Goroutine jedoch weiterhin blockiert auf andere Goroutinen wartet, um Daten in die Pipeline zu schreiben. Daher sollte die Pipeline nach dem Schreiben aller Daten geschlossen werden. Der Code wird wie folgt geändert:
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// Pipeline schließen
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}Nach dem Schließen der Pipeline tritt im obigen Code kein Deadlock mehr auf. Wie bereits erwähnt, hat das Lesen einer Pipeline zwei Rückgabewerte. Wenn for range keine Daten erfolgreich lesen kann, wird die Schleife beendet. Der zweite Rückgabewert gibt an, ob die Daten erfolgreich gelesen wurden, nicht ob die Pipeline geschlossen ist. Selbst wenn die Pipeline geschlossen ist, können bei einer Pipeline mit Puffer weiterhin Daten gelesen werden, und der zweite Rückgabewert bleibt true. Siehe das folgende Beispiel:
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// Pipeline schließen
close(ch)
// Daten lesen
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}Ergebnis:
0 true
1 true
2 true
3 true
4 true
0 falseDa die Pipeline geschlossen ist, führt das weitere Lesen von Daten auch bei leerem Puffer nicht zur Blockierung der aktuellen Goroutine. Wie zu sehen ist, wird beim sechsten Durchlauf der Nullwert gelesen, und ok ist false.
TIP
Der Zeitpunkt zum Schließen einer Pipeline sollte möglichst auf der Seite liegen, die Daten an die Pipeline sendet, und nicht auf der Empfängerseite, da der Empfänger in den meisten Fällen nur Daten empfängt und nicht weiß, wann die Pipeline geschlossen werden soll.
WaitGroup
sync.WaitGroup ist eine Struktur aus dem sync-Paket. WaitGroup bedeutet Warten auf Ausführung und kann verwendet werden, um das Warten auf eine Gruppe von Goroutinen einfach zu implementieren. Diese Struktur stellt nur drei Methoden öffentlich bereit.
Die Add-Methode wird verwendet, um die Anzahl der zu wartenden Goroutinen anzugeben:
func (wg *WaitGroup) Add(delta int)Die Done-Methode zeigt an, dass die aktuelle Goroutine ausgeführt wurde:
func (wg *WaitGroup) Done()Die Wait-Methode wartet auf das Ende der untergeordneten Goroutinen, andernfalls wird blockiert:
func (wg *WaitGroup) Wait()WaitGroup ist sehr einfach zu verwenden und sofort einsatzbereit. Die interne Implementierung verwendet einen Zähler und ein Semaphor. Zu Beginn des Programms wird Add aufgerufen, um den Zähler zu initialisieren. Jedes Mal, wenn eine Goroutine ausgeführt wird, wird Done aufgerufen, und der Zähler wird um 1 verringert, bis er 0 erreicht. Währenddessen blockiert die Haupt-Goroutine bei Aufruf von Wait, bis alle Zähler auf 0 verringert wurden, und wird dann geweckt. Siehe ein einfaches Verwendungsbeispiel:
func main() {
var wait sync.WaitGroup
// Anzahl der untergeordneten Goroutinen angeben
wait.Add(1)
go func() {
fmt.Println(1)
// Ausführung beendet
wait.Done()
}()
// Auf untergeordnete Goroutine warten
wait.Wait()
fmt.Println(2)
}Dieser Code gibt immer zuerst 1 und dann 2 aus. Die Haupt-Goroutine wartet auf das Ende der untergeordneten Goroutine, bevor sie beendet wird.
1
2Für das erste Beispiel in der Goroutinen-Einführung kann der Code wie folgt geändert werden:
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// Zähler auf 10 setzen
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// In der Schleife Zähler um 1 erhöhen
wait.Add(1)
go func() {
fmt.Println(i)
// Beide Zähler um 1 verringern
wait.Done()
mainWait.Done()
}()
// Warten, bis die aktuelle Goroutine in der Schleife ausgeführt wurde
wait.Wait()
}
// Warten, bis alle Goroutinen ausgeführt wurden
mainWait.Wait()
fmt.Println("end")
}Hier wird sync.WaitGroup anstelle von time.Sleep verwendet. Die Reihenfolge der parallelen Ausführung der Goroutinen ist besser kontrollierbar. Unabhängig davon, wie oft es ausgeführt wird, lautet die Ausgabe:
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup eignet sich normalerweise für Situationen, in denen die Anzahl der Goroutinen dynamisch angepasst werden kann, z. B. wenn die Anzahl der Goroutinen im Voraus bekannt ist oder während der Laufzeit dynamisch angepasst werden muss. Der Wert von WaitGroup sollte nicht kopiert werden, und der kopierte Wert sollte nicht weiter verwendet werden, insbesondere wenn er als Funktionsparameter übergeben wird. Es sollte ein Zeiger und kein Wert übergeben werden. Wenn der kopierte Wert verwendet wird, wirkt sich die Zählung nicht auf das tatsächliche WaitGroup aus. Dies kann dazu führen, dass die Haupt-Goroutine dauerhaft blockiert wartet und das Programm nicht normal ausgeführt werden kann. Siehe den folgenden Code:
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}Die Fehlermeldung besagt, dass alle Goroutinen beendet sind, die Haupt-Goroutine jedoch weiterhin wartet, was einen Deadlock bildet. Der Aufruf von Done innerhalb der hello-Funktion auf dem Parameter WaitGroup wirkt sich nicht auf das ursprüngliche mainWait aus. Daher sollte ein Zeiger zur Übergabe verwendet werden.
hello
fatal error: all goroutines are asleep - deadlock!TIP
Wenn der Zähler negativ wird oder die Anzahl der Zähler die Anzahl der untergeordneten Goroutinen überschreitet, wird ein panic ausgelöst.
Context
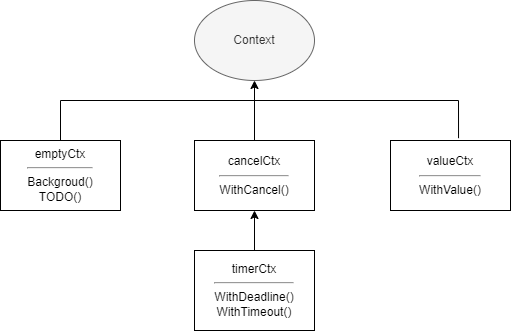
Context, auf Deutsch Kontext, ist eine von Go bereitgestellte Lösung zur Nebenläufigkeitssteuerung. Im Vergleich zu Pipelines und WaitGroup kann es untergeordnete Goroutinen und tiefer verschachtelte Goroutinen besser steuern. Context ist selbst eine Schnittstelle. Jede Implementierung dieser Schnittstelle kann als Kontext bezeichnet werden, z. B. gin.Context im bekannten Web-Framework Gin. Die context-Standardbibliothek bietet mehrere Implementierungen:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
Zuerst zur Definition der Context-Schnittstelle und dann zu ihrer konkreten Implementierung.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
Diese Methode hat zwei Rückgabewerte. deadline ist die Frist, zu der der Kontext abgebrochen werden sollte. Der zweite Wert gibt an, ob eine Frist festgelegt wurde. Wenn keine Frist festgelegt wurde, ist er immer false.
Deadline() (deadline time.Time, ok bool)Done
Der Rückgabewert ist eine schreibgeschützte Pipeline vom Typ leere Struktur. Diese Pipeline dient nur zur Benachrichtigung und überträgt keine Daten. Wenn die Arbeit des Kontexts abgebrochen werden sollte, wird dieser Kanal geschlossen. Für einige Kontexte, die nicht abgebrochen werden können, wird möglicherweise nil zurückgegeben.
Done() <-chan struct{}Err
Diese Methode gibt einen error zurück, der den Grund für das Schließen des Kontexts angibt. Wenn die Done-Pipeline nicht geschlossen ist, wird nil zurückgegeben. Nach dem Schließen wird ein err zurückgegeben, das erklärt, warum der Kontext geschlossen wurde.
Err() errorValue
Diese Methode gibt den entsprechenden Schlüsselwert zurück. Wenn der key nicht existiert oder die Methode nicht unterstützt wird, wird nil zurückgegeben.
Value(key any) anyemptyCtx
Wie der Name schon sagt, ist emptyCtx ein leerer Kontext. Alle Implementierungen im context-Paket sind nicht öffentlich zugänglich, aber es werden entsprechende Funktionen zum Erstellen von Kontexten bereitgestellt. emptyCtx kann über context.Background und context.TODO erstellt werden. Die beiden Funktionen lauten:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}Wie zu sehen ist, wird lediglich ein emptyCtx-Zeiger zurückgegeben. Der zugrunde liegende Typ von emptyCtx ist tatsächlich ein int. Der Grund, warum keine leere Struktur verwendet wird, ist, dass die Instanzen von emptyCtx unterschiedliche Speicheradressen haben müssen. Es kann nicht abgebrochen werden, hat keine Frist und kann keine Werte speichern. Die implementierten Methoden geben alle Nullwerte zurück.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx wird normalerweise als oberster Kontext verwendet und beim Erstellen der anderen drei Kontexttypen als übergeordneter Kontext übergeben. Die Beziehungen zwischen den verschiedenen Implementierungen im context-Paket sind in der folgenden Abbildung dargestellt:
valueCtx
Die Implementierung von valueCtx ist relativ einfach. Sie enthält nur ein Schlüssel-Wert-Paar und ein eingebettetes Feld vom Typ Context.
type valueCtx struct {
Context
key, val any
}Sie implementiert nur die Value-Methode. Die Logik ist ebenfalls einfach: Wenn der aktuelle Kontext den Schlüssel nicht findet, wird im übergeordneten Kontext gesucht.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}Im Folgenden ein einfaches Anwendungsbeispiel für valueCtx:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// Kontext übergeben
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// Timer erstellen
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // Wird niemals ausgeführt
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx wird häufig verwendet, um Daten in mehrstufigen Goroutinen zu übermitteln. Es kann nicht abgebrochen werden, daher gibt ctx.Done immer nil zurück, und select ignoriert nil-Pipelines. Die Ausgabe lautet:
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
Sowohl cancelCtx als auch timerCtx implementieren die canceler-Schnittstelle. Die Schnittstelle lautet:
type canceler interface {
// removeFromParent gibt an, ob das Element aus dem übergeordneten Kontext entfernt werden soll
// err gibt den Grund für den Abbruch an
cancel(removeFromParent bool, err error)
// Done gibt eine Pipeline zurück, die den Abbruchgrund mitteilt
Done() <-chan struct{}
}Die cancel-Methode ist nicht öffentlich zugänglich. Beim Erstellen des Kontexts wird sie über eine Closure als Rückgabewert für externe Aufrufe verpackt, wie im Quellcode von context.WithCancel gezeigt:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// Versuch, sich selbst zu den children des Elternteils hinzuzufügen
propagateCancel(parent, &c)
// Kontext und eine Funktion zurückgeben
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx bedeutet abbrechbarer Kontext. Beim Erstellen wird, wenn der übergeordnete Kontext die canceler-Schnittstelle implementiert, das Element zu den children des Elternteils hinzugefügt, andernfalls wird nach oben gesucht. Wenn alle übergeordneten Kontexte die canceler-Schnittstelle nicht implementieren, wird eine Goroutine gestartet, die auf den Abbruch des Elternteils wartet, und dann wird der aktuelle Kontext beim Ende des Elternteils abgebrochen. Wenn cancelFunc aufgerufen wird, wird der Done-Kanal geschlossen, und alle untergeordneten Kontexte werden ebenfalls abgebrochen. Schließlich wird das Element aus dem übergeordneten Kontext entfernt. Im Folgenden ein einfaches Beispiel:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// Gibt einen cancelCtx und eine cancel-Funktion zurück
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}Ausgabe:
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
context canceledHier ein Beispiel mit tieferer Verschachtelung:
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("正在处理 http 请求...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth 父级取消", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail 父级取消", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}Im Beispiel wurden 3 cancelCtx erstellt. Obwohl das Abbrechen des übergeordneten cancelCtx gleichzeitig seine untergeordneten Kontexte abbricht, sollte aus Sicherheitsgründen nach dem Erstellen eines cancelCtx am Ende des entsprechenden Prozesses die cancel-Funktion aufgerufen werden. Ausgabe:
正在处理 http 请求...
auth...
mail...
mail...
auth...
正在处理 http 请求...
auth...
mail...
正在处理 http 请求...
正在处理 http 请求...
auth...
mail...
auth...
正在处理 http 请求...
mail...
context canceled
auth 父级取消 context canceled
mail 父级取消 context canceledtimerCtx
timerCtx erweitert cancelCtx um einen Timeout-Mechanismus. Das context-Paket bietet zwei Funktionen zum Erstellen: WithDeadline und WithTimeout. Beide Funktionen sind ähnlich. Die erste gibt einen bestimmten Timeout-Zeitpunkt an, z. B. 2023/3/20 16:32:00, die zweite gibt ein Timeout-Intervall an, z. B. 5 Minuten. Die Signaturen der beiden Funktionen lauten:
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx bricht den aktuellen Kontext automatisch nach Ablauf der Zeit ab. Der Abbruchprozess ähnelt dem von cancelCtx, mit dem zusätzlichen Schließen des timers. Im Folgenden ein einfaches Anwendungsbeispiel für timerCtx:
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("上下文取消", ctx.Err())
return
default:
fmt.Println("等待取消中...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}Obwohl der Kontext bei Ablauf automatisch abgebrochen wird, sollte aus Sicherheitsgründen nach Abschluss des entsprechenden Prozesses der Kontext manuell abgebrochen werden. Ausgabe:
等待取消中...
等待取消中...
等待取消中...
等待取消中...
等待取消中...
上下文取消 context deadline exceededWithTimeout ist sehr ähnlich zu WithDeadline. Die Implementierung ist lediglich eine leichte Kapselung und ruft WithDeadline auf. Die Verwendung ist dieselbe wie im obigen Beispiel mit WithDeadline:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
Wie bei der Speicherzuweisung, die ohne Rückgewinnung zu Speicherlecks führt, ist ein Kontext ebenfalls eine Ressource. Wenn er erstellt, aber nie abgebrochen wird, führt dies zu einem Kontext-Leck. Daher sollte dies vermieden werden.
Select
select ist in Linux-Systemen eine Lösung für IO-Multiplexing. Ähnlich ist select in Go eine Steuerungsstruktur für Pipeline-Multiplexing. Was ist Multiplexing? Einfach gesagt: Zu einem bestimmten Zeitpunkt werden mehrere Elemente auf Verfügbarkeit überwacht. Die überwachten Elemente können Netzwerkanfragen, Datei-IO usw. sein. In Go überwacht select Pipelines und nur Pipelines. Die Syntax von select ist ähnlich der von switch-Anweisungen. Im Folgenden ist eine select-Anweisung dargestellt:
func main() {
// Drei Pipelines erstellen
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("所有管道都不可用")
}
}Verwendung
Ähnlich wie switch besteht select aus mehreren case-Zweigen und einem default-Zweig. Der default-Zweig kann weggelassen werden. Jeder case-Zweig kann nur eine Pipeline und nur eine Operation (entweder Lesen oder Schreiben) ausführen. Wenn mehrere case-Zweige verfügbar sind, wählt select pseudo-zufällig einen case-Zweig zur Ausführung aus. Wenn alle case-Zweige nicht verfügbar sind, wird der default-Zweig ausgeführt. Wenn kein default-Zweig vorhanden ist, wird blockiert, bis mindestens ein case-Zweig verfügbar ist. Da im obigen Beispiel keine Daten in die Pipelines geschrieben wurden, sind natürlich alle case-Zweige nicht verfügbar, sodass schließlich das Ergebnis des default-Zweigs ausgegeben wird. Nach einer kleinen Änderung:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// Eine neue Goroutine starten
go func() {
// Daten in Pipeline A schreiben
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}Im obigen Beispiel wird eine neue Goroutine gestartet, um Daten in Pipeline A zu schreiben. Da select keinen Standardzweig hat, wird es blockiert, bis ein case-Zweig verfügbar ist. Wenn Pipeline A verfügbar ist, wird der entsprechende Zweig ausgeführt, und dann wird die Haupt-Goroutine beendet. Um Pipelines kontinuierlich zu überwachen, kann es mit einer for-Schleife verwendet werden:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// for-Schleife
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Dadurch können alle drei Pipelines verwendet werden, aber die Endlosschleife in Kombination mit select führt zu einer permanenten Blockierung der Haupt-Goroutine. Daher kann es in eine neue Goroutine verschoben und mit anderer Logik kombiniert werden:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // Timeout von 1 Sekunde einstellen
break Loop // Schleife verlassen
}
}
l <- struct{}{} // Haupt-Goroutine mitteilen, dass sie beendet werden kann
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Im obigen Beispiel wird for in Kombination mit select verwendet, um kontinuierlich zu überwachen, ob die drei Pipelines verfügbar sind. Der vierte case-Zweig ist eine Timeout-Pipeline. Nach dem Timeout wird die Schleife verlassen und die untergeordnete Goroutine beendet. Die Ausgabe lautet:
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueTimeout
Im vorherigen Beispiel wurde die time.After-Funktion verwendet, die eine schreibgeschützte Pipeline zurückgibt. Diese Funktion kann in Kombination mit select verwendet werden, um sehr einfach einen Timeout-Mechanismus zu implementieren:
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("超时")
}
}Permanente Blockierung
Wenn die select-Anweisung leer ist, wird permanent blockiert:
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end wird niemals ausgegeben, und die Haupt-Goroutine wird dauerhaft blockiert. Dies hat normalerweise einen speziellen Zweck.
TIP
Wenn in einem case von select auf einer nil-Pipeline operiert wird, führt dies nicht zu einer Blockierung. Dieser case-Zweig wird ignoriert und niemals ausgeführt. Im folgenden Code wird unabhängig von der Ausführungshäufigkeit nur timeout ausgegeben:
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}Nicht blockierend
Durch Verwendung des default-Zweigs von select in Kombination mit Pipelines können nicht blockierende Sende- und Empfangsoperationen implementiert werden:
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}Ebenso kann nicht blockierend überprüft werden, ob ein context beendet ist:
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}Sperren
Betrachten Sie zunächst das folgende Beispiel:
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Simuliere Zugriffszeit
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// Auf Daten zugreifen
temp := *data
// Simuliere Berechnungszeit
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// Daten ändern
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最终结果", count)
}Im obigen Beispiel werden zehn Goroutinen gestartet, um count um 1 zu erhöhen, und time.Sleep wird verwendet, um unterschiedliche Zeiten zu simulieren. Intuitiv sollte das Ergebnis nach 10 Goroutinen mit jeweils +1 Operationen immer 10 sein. Das korrekte Ergebnis ist tatsächlich 10, aber in der Praxis ist dies nicht der Fall. Das Ergebnis des obigen Beispiels lautet:
1
2
3
3
2
2
3
3
3
4
最终结果 4Wie zu sehen ist, ist das Endergebnis 4, was nur eines von vielen möglichen Ergebnissen ist. Da jede Goroutine unterschiedliche Zeiten für den Zugriff und die Berechnung benötigt, greift Goroutine A möglicherweise nach 500 Millisekunden auf die Daten zu und erhält den Wert 1 für count. Anschließend werden 400 Millisekunden für die Berechnung benötigt, aber in diesen 400 Millisekunden hat Goroutine B bereits den Zugriff und die Berechnung abgeschlossen und den Wert von count erfolgreich aktualisiert. Nachdem Goroutine A die Berechnung abgeschlossen hat, ist der ursprünglich von Goroutine A abgerufene Wert veraltet, aber Goroutine A weiß dies nicht und erhöht den Wert immer noch um 1 und weist ihn count zu. Auf diese Weise wird das Ausführungsergebnis von Goroutine B überschrieben. Wenn mehrere Goroutinen auf gemeinsame Daten zugreifen und diese ändern, tritt ein solches Problem häufig auf. Daher werden Sperren benötigt.
Das Mutex und RWMutex im sync-Paket von Go bieten Implementierungen für gegenseitigen Ausschluss und Lese-Schreib-Sperren und stellen sehr einfache und benutzerfreundliche APIs bereit. Zum Sperren wird einfach Lock() aufgerufen, und zum Entsperren wird Unlock() verwendet. Es ist zu beachten, dass die von Go bereitgestellten Sperren nicht rekursive Sperren sind, d. h., sie sind nicht wiederbetretbar. Daher führen wiederholtes Sperren oder Entsperren zu einem fatal. Der Zweck von Sperren besteht darin, Invarianten zu schützen. Beim Sperren soll sichergestellt werden, dass Daten nicht von anderen Goroutinen geändert werden:
func DoSomething() {
Lock()
// Während dieses Prozesses können Daten nicht von anderen Goroutinen geändert werden
Unlock()
}Bei rekursiven Sperren könnte Folgendes passieren:
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}Die DoSomething-Funktion weiß offensichtlich nicht, was die DoOther-Funktion mit den Daten machen könnte, und könnte sie ändern, z. B. durch Starten einiger untergeordneter Goroutinen, die die Invariante破坏. Dies ist in Go nicht zulässig. Nach dem Sperren muss die Unveränderlichkeit der Invariante gewährleistet sein. In diesem Fall führen wiederholtes Sperren und Entsperren zu einem Deadlock. Daher sollte beim Schreiben von Code vermieden werden, dass dies geschieht. Bei Bedarf sollte unmittelbar nach dem Sperren die defer-Anweisung zum Entsperren verwendet werden.
Gegenseitiger Ausschluss (Mutex)
sync.Mutex ist die von Go bereitgestellte Implementierung für gegenseitigen Ausschluss und implementiert die sync.Locker-Schnittstelle:
type Locker interface {
// Sperren
Lock()
// Entsperren
Unlock()
}Mit einer Sperre für gegenseitigen Ausschluss kann das obige Problem perfekt gelöst werden. Beispiel:
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Sperren
lock.Lock()
// Simuliere Zugriffszeit
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Auf Daten zugreifen
temp := *data
// Simuliere Berechnungszeit
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// Daten ändern
*data = temp + ans
// Entsperren
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("最终结果", count)
}Jede Goroutine sperrt vor dem Zugriff auf die Daten und entsperrt nach dem Aktualisieren. Andere Goroutinen müssen zuerst die Sperre erhalten, andernfalls wird blockiert. Auf diese Weise treten die oben genannten Probleme nicht auf, und die Ausgabe lautet:
1
2
3
4
5
6
7
8
9
10
最终结果 10Lese-Schreib-Sperre (RWMutex)
Eine Sperre für gegenseitigen Ausschluss eignet sich für Situationen, in denen Lese- und Schreiboperationen ähnlich häufig sind. Für Daten mit vielen Lese- und wenigen Schreiboperationen würde die Verwendung einer Sperre für gegenseitigen Ausschluss zu vielen unnötigen Konkurrenzen um die Sperre führen, was viele Systemressourcen verbrauchen würde. In diesem Fall wird eine Lese-Schreib-Sperre benötigt. Für eine Goroutine gilt:
- Wenn eine Lesesperre erhalten wurde, werden andere Goroutinen beim Schreiben blockiert, aber beim Lesen nicht blockiert.
- Wenn eine Schreibsperre erhalten wurde, werden andere Goroutinen sowohl beim Schreiben als auch beim Lesen blockiert.
Die Implementierung der Lese-Schreib-Sperre in Go ist sync.RWMutex. Sie implementiert ebenfalls die Locker-Schnittstelle, bietet jedoch mehr verfügbare Methoden:
// Lesesperre hinzufügen
func (rw *RWMutex) RLock()
// Versuch, Lesesperre hinzuzufügen
func (rw *RWMutex) TryRLock() bool
// Lesesperre aufheben
func (rw *RWMutex) RUnlock()
// Schreibsperre hinzufügen
func (rw *RWMutex) Lock()
// Versuch, Schreibsperre hinzuzufügen
func (rw *RWMutex) TryLock() bool
// Schreibsperre aufheben
func (rw *RWMutex) Unlock()Die beiden Versuch-Sperren-Operationen TryRLock und TryLock sind nicht blockierend. Bei erfolgreichem Sperren wird true zurückgegeben. Wenn die Sperre nicht erhalten werden kann, wird nicht blockiert, sondern false zurückgegeben. Die interne Implementierung der Lese-Schreib-Sperre ist immer noch eine Sperre für gegenseitigen Ausschluss. Es gibt nicht zwei Sperren, nur weil es Lesesperren und Schreibsperren gibt. Von Anfang bis Ende gibt es nur eine Sperre. Im Folgenden ein Anwendungsbeispiel für eine Lese-Schreib-Sperre:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// Viele Lese-, wenige Schreiboperationen
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Warten auf Ende der untergeordneten Goroutinen
wait.Wait()
fmt.Println("最终结果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到读锁")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("释放读锁", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到写锁")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("释放写锁", *i)
rw.Unlock()
wait.Done()
}Im Beispiel werden 3 Schreib-Goroutinen und 7 Lese-Goroutinen gestartet. Beim Lesen von Daten wird zuerst eine Lesesperre angefordert. Lese-Goroutinen können die Lesesperre normal erhalten, aber Schreib-Goroutinen werden blockiert. Beim Anfordern einer Schreibsperre werden sowohl Lese- als auch Schreib-Goroutinen blockiert, bis die Schreibsperre freigegeben wird. Auf diese Weise wird der gegenseitige Ausschluss zwischen Lese- und Schreib-Goroutinen implementiert und die Korrektheit der Daten gewährleistet. Die Ausgabe des Beispiels lautet:
拿到读锁
拿到读锁
拿到读锁
拿到读锁
释放读锁 0
释放读锁 0
释放读锁 0
释放读锁 0
拿到写锁
释放写锁 1
拿到读锁
拿到读锁
拿到读锁
释放读锁 1
释放读锁 1
释放读锁 1
拿到写锁
释放写锁 2
拿到写锁
释放写锁 3
最终结果 3TIP
Sperren sollten nicht als Wert übergeben und gespeichert werden. Es sollten Zeiger verwendet werden.
Bedingungsvariablen
Bedingungsvariablen werden zusammen mit Sperren für gegenseitigen Ausschluss verwendet und erscheinen. Daher könnten einige sie fälschlicherweise als Bedingungssperren bezeichnen, aber sie sind keine Sperren, sondern ein Kommunikationsmechanismus. sync.Cond in Go bietet eine Implementierung dafür. Die Signatur der Funktion zum Erstellen einer Bedingungsvariablen lautet:
func NewCond(l Locker) *CondWie zu sehen ist, ist die Voraussetzung für das Erstellen einer Bedingungsvariablen das Erstellen einer Sperre. sync.Cond stellt die folgenden Methoden zur Verfügung:
// Blockierend warten, bis die Bedingung erfüllt ist, bis geweckt
func (c *Cond) Wait()
// Eine Goroutine wecken, die aufgrund der Bedingung blockiert ist
func (c *Cond) Signal()
// Alle Goroutinen wecken, die aufgrund der Bedingung blockiert sind
func (c *Cond) Broadcast()Bedingungsvariablen sind sehr einfach zu verwenden. Das obige Beispiel für Lese-Schreib-Sperren kann wie folgt geändert werden:
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// Bedingungsvariable
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// Viele Lese-, wenige Schreiboperationen
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Warten auf Ende der untergeordneten Goroutinen
wait.Wait()
fmt.Println("最终结果", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("拿到读锁")
// Blockieren, solange die Bedingung nicht erfüllt ist
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("释放读锁", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("拿到写锁")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("释放写锁", *i)
rw.Unlock()
// Alle Goroutinen wecken, die aufgrund der Bedingungsvariablen blockiert sind
cond.Broadcast()
wait.Done()
}Beim Erstellen der Bedingungsvariablen wird die Lesesperre als Sperre für gegenseitigen Ausschluss übergeben, da die Bedingungsvariable hier auf Lese-Goroutinen wirkt. Wenn die Lese-Schreib-Sperre direkt übergeben würde, würde dies zu einem Problem mit wiederholtem Entsperren durch Schreib-Goroutinen führen. Hier wird sync.rlocker verwendet, das über die RWMutex.RLocker-Methode erhalten wird.
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }Wie zu sehen ist, kapselt rlocker lediglich die Leseoperation der Lese-Schreib-Sperre. Tatsächlich handelt es sich um dieselbe Referenz und dieselbe Sperre. Beim Lesen von Daten durch Lese-Goroutinen wird blockiert, wenn der Wert kleiner als 3 ist, bis der Wert größer als 3 ist. Schreib-Goroutinen versuchen nach dem Aktualisieren der Daten, alle Goroutinen zu wecken, die aufgrund der Bedingungsvariablen blockiert sind. Daher lautet die endgültige Ausgabe:
拿到读锁
拿到读锁
拿到读锁
拿到读锁
拿到写锁
释放写锁 1
拿到读锁
拿到写锁
释放写锁 2
拿到读锁
拿到读锁
拿到写锁
释放写锁 3 // Dritte Schreib-Goroutine abgeschlossen
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
释放读锁 3
最终结果 3Wie aus dem Ergebnis zu sehen ist, werden nach dem Aktualisieren der Daten durch die dritte Schreib-Goroutine alle sieben aufgrund der Bedingungsvariablen blockierten Lese-Goroutinen wieder ausgeführt.
TIP
Bei Bedingungsvariablen sollte for anstelle von if verwendet werden. Es sollte eine Schleife verwendet werden, um zu überprüfen, ob die Bedingung erfüllt ist, da beim Wecken einer Goroutine nicht garantiert werden kann, dass die aktuelle Bedingung bereits erfüllt ist.
for !condition {
cond.Wait()
}sync
Ein großer Teil der nebenläufigen Tools in Go wird von der Standardbibliothek sync bereitgestellt. Oben wurden bereits sync.WaitGroup, sync.Locker usw. vorgestellt. Darüber hinaus bietet das sync-Paket einige weitere Tools.
Once
Bei der Verwendung einiger Datenstrukturen kann, wenn diese zu groß sind, eine Lazy-Loading-Methode in Betracht gezogen werden, d. h., die Datenstruktur wird erst initialisiert, wenn sie tatsächlich verwendet wird. Im folgenden Beispiel:
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// Initialisierung nur bei tatsächlicher Verwendung des Slices
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}Das Problem ist, dass bei Verwendung durch nur eine Goroutine kein Problem besteht. Wenn jedoch mehrere Goroutinen zugreifen, können Probleme auftreten. Wenn beispielsweise Goroutine A und B gleichzeitig die Add-Methode aufrufen und A etwas schneller ist, wurde bereits initialisiert und die Daten erfolgreich hinzugefügt. Anschließend initialisiert Goroutine B erneut, wodurch die von Goroutine A hinzugefügten Daten direkt überschrieben werden. Dies ist das Problem.
Dies ist das Problem, das sync.Once löst. Wie der Name schon sagt, bedeutet Once einmal. sync.Once stellt sicher, dass unter Nebenläufigkeitsbedingungen eine bestimmte Operation nur einmal ausgeführt wird. Die Verwendung ist sehr einfach. Es stellt nur eine Do-Methode öffentlich bereit. Die Signatur lautet:
func (o *Once) Do(f func())Bei der Verwendung muss lediglich die Initialisierungsoperation an die Do-Methode übergeben werden:
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// Initialisierung nur bei tatsächlicher Verwendung des Slices
m.o.Do(func() {
fmt.Println("初始化")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}Ausgabe:
初始化
4Wie aus der Ausgabe zu sehen ist, werden alle Daten normal zum Slice hinzugefügt, und die Initialisierungsoperation wird nur einmal ausgeführt. Die Implementierung von sync.Once ist tatsächlich sehr einfach. Der eigentliche Code-Logik ohne Kommentare besteht nur aus 16 Zeilen. Das Prinzip ist Sperre + atomare Operation. Der Quellcode lautet:
type Once struct {
// Wird verwendet, um zu判断, ob die Operation bereits ausgeführt wurde
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Atomares Laden der Daten
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// Sperren
o.m.Lock()
// Entsperren
defer o.m.Unlock()
// Überprüfen, ob ausgeführt
if o.done == 0 {
// Nach der Ausführung done ändern
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
Der Zweck von sync.Pool ist die Speicherung temporärer Objekte zur späteren Wiederverwendung. Es ist ein temporärer, nebenläufig sicherer Objektpool. Objekte, die vorübergehend nicht verwendet werden, werden im Pool gespeichert. Bei der späteren Verwendung müssen keine zusätzlichen Objekte erstellt werden, sondern können direkt wiederverwendet werden. Dies reduziert die Häufigkeit der Speicherzuweisung und -freigabe und最重要的是 senkt den GC-Druck. sync.Pool hat nur zwei Methoden:
// Ein Objekt anfordern
func (p *Pool) Get() any
// Ein Objekt in den Pool legen
func (p *Pool) Put(x any)Außerdem hat sync.Pool ein öffentliches New-Feld, das verwendet wird, um ein Objekt zu initialisieren, wenn kein Objekt aus dem Pool angefordert werden kann:
New func() anyIm Folgenden ein Beispiel zur Veranschaulichung:
var wait sync.WaitGroup
// Temporärer Objektpool
var pool sync.Pool
// Wird verwendet, um zu zählen, wie viele Objekte insgesamt erstellt wurden
var numOfObject atomic.Int64
// BigMemData Angenommen, dies ist eine Struktur mit großem Speicherbedarf
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"大内存"}
}
wait.Add(1000)
// Hier werden 1000 Goroutinen gestartet
for i := 0; i < 1000; i++ {
go func() {
// Objekt anfordern
val := pool.Get()
// Objekt verwenden
_ = val.(BigMemData)
// Objekt nach der Verwendung wieder in den Pool legen
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}Im Beispiel werden 1000 Goroutinen gestartet, die kontinuierlich Objekte aus dem Pool anfordern und freigeben. Wenn kein Objektpool verwendet würde, müssten alle 1000 Goroutinen各自 Objekte instanziieren, und diese 1000 instanziierten Objekte müssten nach der Verwendung von GC freigegeben werden. Wenn es Zehntausende von Goroutinen gibt oder die Erstellung des Objekts sehr kostspielig ist, würde dies viel Speicher belegen und großen Druck auf GC ausüben. Nach der Verwendung eines Objektpools können Objekte wiederverwendet werden, um die Häufigkeit der Instanziierung zu reduzieren. Im obigen Beispiel könnte die Ausgabe wie folgt lauten:
5Obwohl 1000 Goroutinen gestartet wurden, wurden im gesamten Prozess nur 5 Objekte erstellt. Ohne Verwendung eines Objektpools würden 1000 Goroutinen 1000 Objekte erstellen. Die durch diese Optimierung erzielte Verbesserung ist offensichtlich, insbesondere bei besonders hoher Nebenläufigkeit und besonders hohen Kosten für die Instanziierung von Objekten.
Bei der Verwendung von sync.Pool sind einige Punkte zu beachten:
- Temporäre Objekte:
sync.Pooleignet sich nur zur Speicherung temporärer Objekte. Objekte im Pool können ohne Benachrichtigung von GC entfernt werden. Daher wird nicht empfohlen, Netzwerkverbindungen, Datenbankverbindungen usw. insync.Poolzu speichern. - Nicht vorhersagbar: Bei der Anforderung von Objekten aus
sync.Poolkann nicht vorhergesagt werden, ob das Objekt neu erstellt oder wiederverwendet wird, und es kann auch nicht festgestellt werden, wie viele Objekte sich im Pool befinden. - Nebenläufige Sicherheit: Offiziell wird garantiert, dass
sync.Poolnebenläufig sicher ist. Es wird jedoch nicht garantiert, dass die zum Erstellen von Objekten verwendeteNew-Funktion nebenläufig sicher ist. DieNew-Funktion wird vom Benutzer übergeben, daher muss die nebenläufige Sicherheit derNew-Funktion vom Benutzer selbst gewartet werden. Aus diesem Grund wird im obigen Beispiel für die Objektzählung ein atomarer Wert verwendet.
TIP
Zuletzt ist zu beachten, dass Objekte nach der Verwendung unbedingt in den Pool zurückgegeben werden müssen. Wenn sie nicht zurückgegeben werden, ist die Verwendung des Objektpools sinnlos.
Die Standardbibliothek fmt-Paket verwendet einen Objektpool. In der fmt.Fprintf-Funktion:
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// Einen Druckpuffer anfordern
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// Nach der Verwendung freigeben
p.free()
return
}Die Implementierung der newPrinter-Funktion und der free-Methode lautet:
func newPrinter() *pp {
// Ein Objekt aus dem Objektpool anfordern
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// Um die Puffergröße im Objektpool ungefähr gleich zu halten und die Puffergröße besser elastisch steuern zu können
// Zu große Puffer werden nicht in den Objektpool zurückgegeben
if cap(p.buf) > 64<<10 {
return
}
// Felder zurücksetzen und Objekt in den Pool freigeben
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map ist eine von der offiziellen Seite bereitgestellte Implementierung einer nebenläufig sicheren Map. Sie ist sofort einsatzbereit und sehr einfach zu verwenden. Im Folgenden sind die Methoden aufgeführt, die diese Struktur öffentlich bereitstellt:
// Einen Wert anhand eines Schlüssels lesen. Der Rückgabewert gibt den entsprechenden Wert und an, ob der Wert existiert
func (m *Map) Load(key any) (value any, ok bool)
// Ein Schlüssel-Wert-Paar speichern
func (m *Map) Store(key, value any)
// Ein Schlüssel-Wert-Paar löschen
func (m *Map) Delete(key any)
// Wenn der Schlüssel bereits existiert, wird der ursprüngliche Wert zurückgegeben. Andernfalls wird der neue Wert gespeichert und zurückgegeben. Wenn der Wert erfolgreich gelesen wird, ist loaded true, andernfalls false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// Ein Schlüssel-Wert-Paar löschen und den ursprünglichen Wert zurückgeben. Der Wert von loaded hängt davon ab, ob der Schlüssel existiert
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Map durchlaufen. Wenn f() false zurückgibt, wird das Durchlaufen gestoppt
func (m *Map) Range(f func(key, value any) bool)Im Folgenden ein einfaches Beispiel zur Veranschaulichung der grundlegenden Verwendung von sync.Map:
func main() {
var syncMap sync.Map
// Daten speichern
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// Daten lesen
fmt.Println(syncMap.Load("a"))
// Lesen und löschen
fmt.Println(syncMap.LoadAndDelete("a"))
// Lesen oder speichern
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// Map durchlaufen
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Ausgabe:
a true
a true
hello world false
a hello world
b goodbye worldIm Folgenden ein Beispiel für die nebenläufige Verwendung einer Map:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}Im obigen Beispiel wird eine normale Map verwendet, und es werden 10 Goroutinen gestartet, die kontinuierlich Daten speichern. Dies führt sehr wahrscheinlich zu einem Fatal. Das Ergebnis lautet wahrscheinlich:
fatal error: concurrent map writesDie Verwendung von sync.Map kann dieses Problem vermeiden:
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Ausgabe:
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4Für nebenläufige Sicherheit müssen bestimmte Opfer gebracht werden. Die Leistung von sync.Map ist etwa 10-100 Mal niedriger als die von Map.
Atome
In der Informatik werden atomare oder primitive Operationen normalerweise verwendet, um Operationen zu beschreiben, die nicht weiter in kleinere Schritte unterteilt werden können. Da diese Operationen nicht weiter unterteilt werden können, werden sie vor dem Abschluss nicht von anderen Goroutinen unterbrochen. Daher ist das Ergebnis entweder erfolgreich oder fehlgeschlagen. Es gibt keinen dritten Fall. Wenn andere Fälle auftreten, handelt es sich nicht um eine atomare Operation. Im folgenden Code:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}Der obige Code ist eine einfache Verzweigung. Obwohl der Code sehr kurz ist, handelt es sich nicht um eine atomare Operation. Echte atomare Operationen werden auf Hardware-Befehlsebene unterstützt.
Typen
Glücklicherweise müssen in den meisten Fällen keine Assembly-Sprachen selbst geschrieben werden. Das Paket sync/atomic der Go-Standardbibliothek bietet APIs für atomare Operationen. Es stellt die folgenden Typen für atomare Operationen bereit:
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}Der atomare Typ Pointer unterstützt Generika, und der Typ Value unterstützt das Speichern beliebiger Typen. Darüber hinaus werden viele Funktionen zur einfachen Bedienung bereitgestellt. Da die Granularität atomarer Operationen zu fein ist, eignen sie sich in den meisten Fällen besser für die Verarbeitung dieser grundlegenden Datentypen.
TIP
Atomare Operationen im atomic-Paket haben nur Funktionssignaturen, aber keine konkreten Implementierungen. Die konkreten Implementierungen werden in plan9-Assembly geschrieben.
Verwendung
Jeder atomare Typ stellt die folgenden drei Methoden bereit:
Load(): Atomares Abrufen des WertsSwap(newVal type) (old type): Atomares Austauschen des Werts und Zurückgeben des alten WertsStore(val type): Atomares Speichern des Werts
Verschiedene Typen können zusätzliche Methoden haben. Zum Beispiel stellen Ganzzahltypen die Add-Methode für atomare Additions- und Subtraktionsoperationen bereit. Im Folgenden ein Beispiel für den Typ int64:
func main() {
var aint64 atomic.Uint64
// Wert speichern
aint64.Store(64)
// Wert austauschen
aint64.Swap(128)
// Erhöhen
aint64.Add(112)
// Wert laden
fmt.Println(aint64.Load())
}Oder es können direkt Funktionen verwendet werden:
func main() {
var aint64 int64
// Wert speichern
atomic.StoreInt64(&aint64, 64)
// Wert austauschen
atomic.SwapInt64(&aint64, 128)
// Erhöhen
atomic.AddInt64(&aint64, 112)
// Laden
fmt.Println(atomic.LoadInt64(&aint64))
}Die Verwendung anderer Typen ist sehr ähnlich. Die endgültige Ausgabe lautet:
240CAS
Das atomic-Paket bietet auch die CompareAndSwap-Operation, auch CAS genannt. Sie ist der Kern der Implementierung von optimistischen Sperren und lockenfreien Datenstrukturen. Optimistische Sperren sind selbst keine Sperren, sondern eine lockenfreie Nebenläufigkeitssteuerungsmethode unter Nebenläufigkeitsbedingungen: Threads/Goroutinen sperren nicht zuerst, bevor sie Daten ändern, sondern lesen zuerst die Daten, führen Berechnungen durch und verwenden dann CAS, um zu判断, ob andere Threads die Daten während dieser Zeit geändert haben. Wenn nicht (der Wert entspricht immer noch dem zuvor gelesenen Wert), ist die Änderung erfolgreich. Andernfalls schlägt sie fehl und es wird erneut versucht. Daher wird sie als optimistische Sperre bezeichnet, weil sie immer optimistisch annimmt, dass gemeinsame Daten nicht geändert werden, und nur dann die entsprechende Operation ausführt, wenn festgestellt wird, dass die Daten nicht geändert wurden. Die zuvor kennengelernten Mutexe sind pessimistische Sperren. Mutexe gehen immer pessimistisch davon aus, dass gemeinsame Daten geändert werden, und sperren daher während der Operation und entsperren nach Abschluss der Operation. Da die lockenfreie Implementierung von Nebenläufigkeit eine höhere Sicherheit und Effizienz als Sperren aufweist, verwenden viele nebenläufige sichere Datenstrukturen CAS zur Implementierung. Die tatsächliche Effizienz hängt jedoch vom jeweiligen Verwendungsszenario ab. Im Folgenden ein Beispiel:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}Dies ist ein Beispiel für die Verwendung einer Sperre für gegenseitigen Ausschluss. Vor jedem Erhöhen der Zahl wird gesperrt, und nach der Ausführung wird entsperrt. Während des Prozesses werden andere Goroutinen blockiert. Als Nächstes wird es mit CAS umgeschrieben:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}Für CAS gibt es drei Parameter: Speicherwert, Erwartungswert und neuer Wert. Bei der Ausführung vergleicht CAS den Erwartungswert mit dem aktuellen Speicherwert. Wenn der Speicherwert mit dem Erwartungswert übereinstimmt, wird die nachfolgende Operation ausgeführt. Andernfalls wird nichts unternommen. Für atomare Operationen im atomic-Paket von Go müssen bei CAS-bezogenen Funktionen die Adresse, der Erwartungswert und der neue Wert übergeben werden. Außerdem wird ein boolescher Wert zurückgegeben, der angibt, ob der Austausch erfolgreich war. Zum Beispiel lautet die Signatur der CAS-Operationsfunktion für den Typ int64:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)Im CAS-Beispiel wird zunächst LoadInt64 verwendet, um den Erwartungswert abzurufen. Anschließend wird CompareAndSwapInt64 zum Vergleichen und Austauschen verwendet. Wenn dies nicht erfolgreich ist, wird kontinuierlich wiederholt, bis es erfolgreich ist. Solche lockenfreien Operationen führen nicht zur Blockierung von Goroutinen, aber das kontinuierliche Wiederholen ist immer noch ein erheblicher Overhead für die CPU. Daher wird in einigen Implementierungen die Operation nach einer bestimmten Anzahl von Fehlversuchen aufgegeben. Für die obige Operation, bei der es sich nur um eine einfache Addition von Zahlen handelt und die beteiligten Operationen nicht komplex sind, kann jedoch eine lockenfreie Implementierung in Betracht gezogen werden.
TIP
In den meisten Fällen reicht der Vergleich von Werten allein nicht aus, um nebenläufige Sicherheit zu gewährleisten. Zum Beispiel das ABA-Problem, das durch CAS verursacht wird, erfordert die Verwendung einer zusätzlichen version, um das Problem zu lösen.
Value
Die Struktur atomic.Value kann Werte beliebiger Typen speichern. Die Struktur lautet:
type Value struct {
// any-Typ
v any
}Obwohl sie beliebige Typen speichern kann, kann sie nil nicht speichern, und die Typen der zuvor und danach gespeicherten Werte sollten konsistent sein. Die folgenden beiden Beispiele können nicht kompiliert werden:
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into ValueAbgesehen davon ist die Verwendung nicht sehr unterschiedlich zu anderen atomaren Typen. Es ist zu beachten, dass bei allen atomaren Typen keine Werte kopiert werden sollten, sondern ihre Zeiger verwendet werden sollten.