Concorrência
A linguagem Go oferece suporte nativo à concorrência, o que é o cerne da linguagem. Sua curva de aprendizado é relativamente baixa, permitindo que desenvolvedores criem aplicações concorrentes bastante boas sem precisar se preocupar muito com a implementação de baixo nível, elevando assim o patamar mínimo dos desenvolvedores.
Goroutines
Uma goroutine (corrotina) é uma thread leve, ou seja, uma thread em espaço de usuário, não é escalonada diretamente pelo sistema operacional, mas sim pelo próprio escalonador da linguagem Go em tempo de execução. Por isso, o overhead de troca de contexto é muito pequeno, o que é uma das razões pelas quais o desempenho de concorrência do Go é muito bom. O conceito de corrotina não foi proposto pela primeira vez pelo Go, e Go não é a primeira linguagem a suportar corrotinas, mas Go é a primeira linguagem a suportar corrotinas e concorrência de forma bastante concisa e elegante.
Em Go, criar uma goroutine é muito simples, bastando a palavra-chave go para iniciar rapidamente uma goroutine. A palavra-chave go deve ser seguida por uma chamada de função. Exemplo abaixo
TIP
Funções embutidas com valor de retorno não são permitidas após a palavra-chave go, por exemplo, o seguinte exemplo incorreto
go make([]int,10) // go discards result of make([]int, 10) (value of type []int)func main() {
go fmt.Println("hello world!")
go hello()
go func() {
fmt.Println("hello world!")
}()
}
func hello() {
fmt.Println("hello world!")
}As três formas acima de iniciar goroutines são todas válidas, mas na verdade, após a execução deste exemplo, na maioria dos casos nada será impresso. As goroutines são executadas concorrentemente, e o sistema precisa de tempo para criar goroutines. Antes disso, a goroutine principal já terminou sua execução. Uma vez que a thread principal sai, as outras goroutines filhas também saem naturalmente. Além disso, a ordem de execução das goroutines é incerta e imprevisível, como no exemplo abaixo
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
fmt.Println("end")
}Este é um exemplo de iniciar goroutines em um loop. Nunca é possível prever com precisão o que será impresso. Pode ser que as goroutines filhas nem tenham começado a executar e a goroutine principal já tenha terminado, como no caso abaixo
start
endOu pode ser que apenas algumas goroutines filhas tenham conseguido executar antes da goroutine principal sair, como no caso abaixo
start
0
1
5
3
4
6
7
endA solução mais simples é fazer a goroutine principal esperar um pouco, usando a função Sleep do pacote time, que pode pausar a goroutine atual por um período de tempo. Exemplo abaixo
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
}
// Pausar por 1ms
time.Sleep(time.Millisecond)
fmt.Println("end")
}Executando novamente, a saída é a seguinte. Pode-se ver que todos os números foram impressos completamente, sem omissões
start
0
1
5
2
3
4
6
8
9
7
endMas a ordem ainda está bagunçada, então vamos fazer cada iteração do loop esperar um pouco. Exemplo abaixo
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go fmt.Println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}Agora a saída já está na ordem correta
start
0
1
2
3
4
5
6
7
8
9
endNo exemplo acima, o resultado da saída foi perfeito, mas o problema de concorrência foi resolvido? Não, nem um pouco. Para programas concorrentes, há muitos fatores incontroláveis, como o momento da execução, a ordem, o tempo gasto no processo, etc. Se o trabalho da goroutine filha no loop não for apenas imprimir um número simples, mas uma tarefa enorme e complexa com tempo incerto, o problema anterior ainda ocorrerá. Por exemplo, no código abaixo
func main() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// Simula tempo aleatório
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}A saída deste código ainda é incerta, abaixo está uma das possíveis situações
start
0
3
4
endPortanto, time.Sleep não é uma boa solução. Felizmente, Go oferece muitos meios de controle de concorrência. Os métodos de controle de concorrência mais usados são três:
channel: canalWaitGroup: semáforoContext: contexto
Os três métodos têm diferentes situações de aplicação. WaitGroup pode controlar dinamicamente um grupo de goroutines com quantidade especificada. Context é mais adequado para situações onde há muitos níveis de aninhamento de goroutines filhas e netas. Canais são mais adequados para comunicação entre goroutines. Para o controle tradicional com locks, Go também oferece suporte:
Mutex: mutexRWMutex: mutex de leitura e escrita
Canais
channel, traduzido como canal. Go explica o propósito dos canais da seguinte forma:
Do not communicate by sharing memory; instead, share memory by communicating.
Ou seja, compartilhar memória através de mensagens. channel foi criado exatamente para isso. É uma solução de comunicação entre goroutines e também pode ser usado para controle de concorrência. Primeiro, vamos conhecer a sintaxe básica de channel. Em Go, a palavra-chave chan representa o tipo canal, e também é necessário declarar o tipo de armazenamento do canal para especificar que tipo de dados ele armazena. O exemplo abaixo mostra a aparência de um canal comum.
var ch chan intEsta é uma declaração de canal. Neste momento, o canal ainda não foi inicializado, seu valor é nil, e não pode ser usado diretamente.
Criação
Ao criar um canal, há apenas uma maneira, que é usar a função embutida make. Para canais, a função make recebe dois parâmetros: o primeiro é o tipo do canal, e o segundo é um parâmetro opcional para o tamanho do buffer do canal. Exemplo abaixo
intCh := make(chan int)
// Canal com tamanho de buffer 1
strCh := make(chan string, 1)Após terminar de usar um canal, lembre-se sempre de fechá-lo. Use a função embutida close para fechar um canal. A assinatura da função é a seguinte.
func close(c chan<- Type)Um exemplo de fechamento de canal é o seguinte
func main() {
intCh := make(chan int)
// fazer algo
close(intCh)
}Às vezes, usar defer para fechar o canal pode ser melhor.
Leitura e Escrita
Para um canal, Go usa dois operadores bastante intuitivos para representar operações de leitura e escrita:
ch <-: indica escrita de dados em um canal
<- ch: indica leitura de dados de um canal
<- representa de forma bastante vívida a direção do fluxo de dados. Veja um exemplo de leitura e escrita em um canal do tipo int
func main() {
// Se não houver buffer, ocorrerá deadlock
intCh := make(chan int, 1)
defer close(intCh)
// Escrever dados
intCh <- 114514
// Ler dados
fmt.Println(<-intCh)
}No exemplo acima, foi criado um canal do tipo int com tamanho de buffer 1, foram escritos os dados 114514, depois os dados foram lidos e impressos, e finalmente o canal foi fechado. Para a operação de leitura, há um segundo valor de retorno, um valor booleano, que indica se os dados foram lidos com sucesso
ints, ok := <-intChO fluxo de dados no canal é como em uma fila, ou seja, primeiro a entrar, primeiro a sair (FIFO). A operação de goroutines no canal é síncrona. Em um determinado momento, apenas uma goroutine pode escrever dados nele, e também apenas uma goroutine pode ler dados do canal.
Sem Buffer
Para canais sem buffer, como a capacidade do buffer é 0, nenhum dado pode ser armazenado temporariamente. Justamente porque canais sem buffer não podem armazenar dados, ao escrever dados no canal, deve haver imediatamente outra goroutine para ler os dados, caso contrário haverá bloqueio e espera. O mesmo vale para leitura de dados. Isso também explica por que o código abaixo, aparentemente normal, causa deadlock.
func main() {
// Cria canal sem buffer
ch := make(chan int)
defer close(ch)
// Escreve dados
ch <- 123
// Lê dados
n := <-ch
fmt.Println(n)
}Canais sem buffer não devem ser usados de forma síncrona. O correto é iniciar uma nova goroutine para enviar dados, como no exemplo abaixo
func main() {
// Cria canal sem buffer
ch := make(chan int)
defer close(ch)
go func() {
// Escreve dados
ch <- 123
}()
// Lê dados
n := <-ch
fmt.Println(n)
}Com Buffer
Quando o canal tem um buffer, é como uma fila bloqueante. Ler de um canal vazio e escrever em um canal cheio causam bloqueio. Canais sem buffer, ao enviar dados, devem ter alguém para receber imediatamente, caso contrário ficarão bloqueados. Para canais com buffer, isso não é necessário. Ao escrever dados em um canal com buffer, os dados são primeiro colocados no buffer, e só quando a capacidade do buffer estiver cheia é que haverá bloqueio esperando que uma goroutine leia os dados do canal. Da mesma forma, ao ler de um canal com buffer, os dados são primeiro lidos do buffer, e só quando não há mais dados no buffer é que haverá bloqueio esperando que uma goroutine escreva dados no canal. Portanto, o exemplo que causaria deadlock com canal sem buffer pode ser executado normalmente aqui.
func main() {
// Cria canal com buffer
ch := make(chan int, 1)
defer close(ch)
// Escreve dados
ch <- 123
// Lê dados
n := <-ch
fmt.Println(n)
}Embora possa ser executado normalmente, essa forma de leitura e escrita síncrona é muito perigosa. Uma vez que o buffer do canal esteja vazio ou cheio, haverá bloqueio permanente, pois não há outras goroutines para escrever ou ler dados do canal. Veja o exemplo abaixo
func main() {
// Cria canal com buffer
ch := make(chan int, 5)
// Cria dois canais sem buffer
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
// Responsável por escrever
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("escrito", i)
}
chW <- struct{}{}
}()
// Responsável por ler
go func() {
for i := 0; i < 10; i++ {
// Cada leitura leva 1 milissegundo
time.Sleep(time.Millisecond)
fmt.Println("lido", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("escrita concluída", <-chW)
fmt.Println("leitura concluída", <-chR)
}Aqui foram criados 3 canais no total: um canal com buffer para comunicação entre goroutines, e dois canais sem buffer para sincronizar a ordem de execução das goroutines pai e filho. A goroutine responsável por ler espera 1 milissegundo antes de cada leitura. A goroutine responsável por escrever pode escrever no máximo 5 dados de uma só vez, porque o tamanho máximo do buffer do canal é 5. Antes que outra goroutine venha ler, só pode bloquear e esperar. Portanto, a saída deste exemplo é a seguinte
escrito 0
escrito 1
escrito 2
escrito 3
escrito 4 // escreveu 5 de uma vez, buffer cheio, espera outra goroutine ler
lido 0
escrito 5 // lê um, escreve um
lido 1
escrito 6
lido 2
escrito 7
lido 3
escrito 8
escrito 9
lido 4
escrita concluída {} // todos os dados foram enviados, goroutine de escrita concluída
lido 5
lido 6
lido 7
lido 8
lido 9
leitura concluída {} // todos os dados foram lidos, goroutine de leitura concluídaPode-se ver que a goroutine responsável por escrever enviou 5 dados de uma só vez no início. Depois que o buffer ficou cheio, começou a bloquear esperando a goroutine de leitura ler. Depois, cada vez que a goroutine de leitura lia um dado em 1 milissegundo e o buffer tinha espaço vazio, a goroutine de escrita escrevia um dado, até que todos os dados fossem enviados e a goroutine de escrita terminasse. Em seguida, quando a goroutine de leitura terminasse de ler todos os dados do buffer, a goroutine de leitura também terminaria, e finalmente a goroutine principal sairia.
TIP
Através da função embutida len, você pode acessar a quantidade de dados no buffer do canal, e através de cap pode acessar o tamanho do buffer do canal.
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}Saída
3 5Aproveitando as condições de bloqueio do canal, você pode facilmente escrever um exemplo onde a goroutine principal espera a goroutine filha terminar de executar
func main() {
// Cria um canal sem buffer
ch := make(chan struct{})
defer close(ch)
go func() {
fmt.Println(2)
// Escreve
ch <- struct{}{}
}()
// Bloqueia esperando ler
<-ch
fmt.Println(1)
}Saída
2
1Através de um canal com buffer, você também pode implementar um mutex simples. Veja o exemplo abaixo
var count = 0
// Canal com tamanho de buffer 1
var lock = make(chan struct{}, 1)
func Add() {
// Adquire lock
lock <- struct{}{}
fmt.Println("contagem atual é", count, "executando adição")
count += 1
// Libera lock
<-lock
}
func Sub() {
// Adquire lock
lock <- struct{}{}
fmt.Println("contagem atual é", count, "executando subtração")
count -= 1
// Libera lock
<-lock
}Como o tamanho do buffer do canal é 1, no máximo um dado pode ser armazenado no buffer. As funções Add e Sub tentam enviar dados para o canal antes de cada operação. Como o tamanho do buffer é 1, se outra goroutine já tiver escrito dados e o buffer já estiver cheio, a goroutine atual deve bloquear e esperar até que haja espaço vazio no buffer. Dessa forma, em um determinado momento, no máximo uma goroutine pode modificar a variável count, implementando assim um mutex simples.
Pontos de Atenção
Abaixo estão alguns resumos. Os seguintes casos de uso indevido causarão bloqueio de canal:
Ler e escrever em canal sem buffer
Quando você faz operações de leitura e escrita síncronas diretamente em um canal sem buffer, isso causará bloqueio da goroutine
func main() {
// Criou um canal sem buffer
intCh := make(chan int)
defer close(intCh)
// Envia dados
intCh <- 1
// Lê dados
ints, ok := <-intCh
fmt.Println(ints, ok)
}Ler de canal com buffer vazio
Quando você lê de um canal com buffer vazio, isso causará bloqueio da goroutine
func main() {
// Cria canal com buffer
intCh := make(chan int, 1)
defer close(intCh)
// Buffer vazio, bloqueia esperando outra goroutine escrever dados
ints, ok := <-intCh
fmt.Println(ints, ok)
}Escrever em canal com buffer cheio
Quando o buffer do canal está cheio, escrever dados nele causará bloqueio da goroutine
func main() {
// Cria canal com buffer
intCh := make(chan int, 1)
defer close(intCh)
intCh <- 1
// Cheio, bloqueia esperando outra goroutine ler dados
intCh <- 1
}Canal é nil
Quando o canal é nil, qualquer operação de leitura ou escrita causará bloqueio da goroutine atual
func main() {
var intCh chan int
// Escreve
intCh <- 1
}func main() {
var intCh chan int
// Lê
fmt.Println(<-intCh)
}Você precisa dominar e se familiarizar bem com as condições de bloqueio de canais. Na maioria dos casos, esses problemas estão bem escondidos e não são tão óbvios quanto nos exemplos.
Os seguintes casos também causarão panic:
Fechar um canal nil
Quando o canal é nil, usar a função close para fechá-lo causará panic
func main() {
var intCh chan int
close(intCh)
}Escrever em canal já fechado
Escrever dados em um canal já fechado causará panic
func main() {
intCh := make(chan int, 1)
close(intCh)
intCh <- 1
}Fechar canal já fechado
Em algumas situações, o canal pode ter sido passado por várias camadas, e o chamador talvez não saiba quem deve fechar o canal. Assim, pode acontecer de fechar um canal que já foi fechado, causando panic.
func main() {
ch := make(chan int, 1)
defer close(ch)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Só pode enviar dados para o canal
ch <- 1
close(ch)
}Canal Unidirecional
Canal bidirecional refere-se àquele que pode tanto escrever quanto ler, ou seja, pode operar em ambos os lados do canal. Canal unidirecional refere-se àquele que é apenas de leitura ou apenas de escrita, ou seja, só pode operar em um lado do canal. Criar manualmente um canal apenas de leitura ou apenas de escrita não tem muito sentido, pois não poder ler ou escrever no canal perde sua razão de existir. Canais unidirecionais são geralmente usados para restringir o comportamento do canal, e geralmente aparecem nos parâmetros de função e valores de retorno. Por exemplo, a função embutida close usada para fechar canais tem uma assinatura que usa canal unidirecional.
func close(c chan<- Type)Ou a função After do pacote time frequentemente usada
func After(d Duration) <-chan TimeO parâmetro da função close é um canal apenas de escrita, e o valor de retorno da função After é um canal apenas de leitura. Portanto, a sintaxe do canal unidirecional é a seguinte:
- O símbolo de seta
<-antes, é canal apenas de leitura, como<-chan int - O símbolo de seta
<-depois, é canal apenas de escrita, comochan<- string
Quando você tenta escrever dados em um canal apenas de leitura, a compilação falhará
func main() {
timeCh := time.After(time.Second)
timeCh <- time.Now()
}O erro é o seguinte, o significado é muito claro
invalid operation: cannot send to receive-only channel timeCh (variable of type <-chan time.Time)O mesmo vale para ler dados de um canal apenas de escrita.
Canais bidirecionais podem ser convertidos em canais unidirecionais, mas o contrário não é possível. Geralmente, quando você passa um canal bidirecional para uma goroutine ou função e não quer que ela leia/envie dados, você pode usar canais unidirecionais para restringir o comportamento da outra parte.
func main() {
ch := make(chan int, 1)
go write(ch)
fmt.Println(<-ch)
}
func write(ch chan<- int) {
// Só pode enviar dados para o canal
ch <- 1
}O mesmo vale para canais apenas de leitura
TIP
chan é um tipo de referência. Embora os argumentos de função em Go sejam passados por valor, a referência continua sendo a mesma. Este ponto será explicado mais adiante na seção sobre princípios de canais.
for range
Através da instrução for range, você pode iterar e ler dados de um canal com buffer, como no exemplo abaixo
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
for n := range ch {
fmt.Println(n)
}
}Geralmente, quando for range itera sobre outras estruturas de dados iteráveis, há dois valores de retorno: o primeiro é o índice, o segundo é o valor do elemento. Mas para canais, há apenas um valor de retorno. for range continuará lendo elementos do canal. Quando o buffer do canal estiver vazio ou não houver buffer, haverá bloqueio e espera até que outra goroutine escreva dados no canal para continuar lendo. Portanto, a saída é a seguinte:
0
1
2
3
4
5
6
7
8
9
fatal error: all goroutines are asleep - deadlock!Pode-se ver que o código acima causou deadlock, porque a goroutine filha já terminou de executar, mas a goroutine principal ainda está bloqueada esperando que outra goroutine escreva dados no canal. Portanto, o canal deve ser fechado após a escrita ser concluída. Modifique o código para o seguinte
func main() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// Fecha o canal
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}Após terminar de escrever, feche o canal, e o código acima não causará mais deadlock. Foi mencionado anteriormente que a leitura do canal tem dois valores de retorno. Quando for range itera sobre o canal, quando não consegue ler dados com sucesso, ele sai do loop. O segundo valor de retorno indica se os dados foram lidos com sucesso, não se o canal já foi fechado. Mesmo que o canal tenha sido fechado, para canais com buffer, ainda é possível ler dados, e o segundo valor de retorno continua sendo true. Veja o exemplo abaixo
func main() {
ch := make(chan int, 10)
for i := 0; i < 5; i++ {
ch <- i
}
// Fecha o canal
close(ch)
// Lê dados novamente
for i := 0; i < 6; i++ {
n, ok := <-ch
fmt.Println(n, ok)
}
}Resultado da saída
0 true
1 true
2 true
3 true
4 true
0 falseComo o canal já foi fechado, mesmo que o buffer esteja vazio, ler dados novamente não causará bloqueio da goroutine atual. Pode-se ver que na sexta iteração, o valor lido é o valor zero, e ok é false.
TIP
Sobre o momento de fechar o canal, deve-se tentar fechá-lo no lado que envia dados para o canal, e não no lado que recebe. Porque na maioria dos casos, o lado que recebe só sabe receber dados, e não sabe quando deve fechar o canal.
WaitGroup
sync.WaitGroup é uma struct fornecida pelo pacote sync. WaitGroup significa esperar a execução. Usá-lo permite facilmente implementar o efeito de esperar por um grupo de goroutines. Esta struct expõe apenas três métodos.
O método Add é usado para indicar a quantidade de goroutines a esperar
func (wg *WaitGroup) Add(delta int)O método Done indica que a goroutine atual terminou de executar
func (wg *WaitGroup) Done()O método Wait espera que as goroutines filhas terminem, caso contrário bloqueia
func (wg *WaitGroup) Wait()WaitGroup é muito simples de usar, pronto para uso. Sua implementação interna é contador + semáforo. No início do programa, chame Add para inicializar a contagem. Cada vez que uma goroutine termina de executar, chame Done, e a contagem diminui em 1, até chegar a 0. Enquanto isso, a goroutine principal que chama Wait ficará bloqueada até que toda a contagem chegue a 0, e então será despertada. Veja um exemplo simples de uso
func main() {
var wait sync.WaitGroup
// Especifica a quantidade de goroutines filhas
wait.Add(1)
go func() {
fmt.Println(1)
// Execução concluída
wait.Done()
}()
// Espera as goroutines filhas
wait.Wait()
fmt.Println(2)
}Este código sempre imprime 1 antes de 2. A goroutine principal espera a goroutine filha terminar de executar antes de sair.
1
2Para o exemplo no início da introdução sobre goroutines, você pode fazer as seguintes modificações
func main() {
var mainWait sync.WaitGroup
var wait sync.WaitGroup
// Conta 10
mainWait.Add(10)
fmt.Println("start")
for i := 0; i < 10; i++ {
// Conta 1 dentro do loop
wait.Add(1)
go func() {
fmt.Println(i)
// Duas contagens diminuem 1
wait.Done()
mainWait.Done()
}()
// Espera a goroutine do loop atual terminar de executar
wait.Wait()
}
// Espera todas as goroutines terminarem de executar
mainWait.Wait()
fmt.Println("end")
}Aqui foi usado sync.WaitGroup para substituir o time.Sleep original. A ordem de execução concorrente das goroutines é mais controlável. Não importa quantas vezes execute, a saída será a seguinte
start
0
1
2
3
4
5
6
7
8
9
endWaitGroup é geralmente adequado para quando você pode ajustar dinamicamente a quantidade de goroutines, por exemplo, quando você sabe de antemão a quantidade de goroutines, ou quando precisa ajustar dinamicamente durante a execução. O valor de WaitGroup não deve ser copiado, e o valor copiado não deve continuar a ser usado, especialmente quando passado como parâmetro de função, deve-se passar o ponteiro e não o valor. Se você usar o valor copiado, a contagem não terá efeito sobre o WaitGroup real, o que pode fazer a goroutine principal bloquear para sempre, e o programa não conseguirá executar normalmente. Por exemplo, o código abaixo
func main() {
var mainWait sync.WaitGroup
mainWait.Add(1)
hello(mainWait)
mainWait.Wait()
fmt.Println("end")
}
func hello(wait sync.WaitGroup) {
fmt.Println("hello")
wait.Done()
}A mensagem de erro indica que todas as goroutines já saíram, mas a goroutine principal ainda está esperando, formando um deadlock. Porque a função hello chama Done em um parâmetro WaitGroup, isso não terá efeito sobre o mainWait original, então você deve usar ponteiro para passar.
hello
fatal error: all goroutines are asleep - deadlock!TIP
Quando a contagem se torna negativa, ou a quantidade de contagem é maior que a quantidade de goroutines filhas, causará panic.
Context
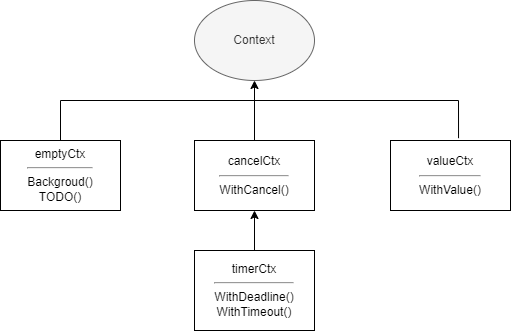
Context traduzido como contexto, é uma solução de controle de concorrência fornecida por Go. Comparado com canais e WaitGroup, ele pode controlar melhor as goroutines filhas e netas, bem como goroutines com níveis mais profundos. Context em si é uma interface, qualquer coisa que implemente essa interface pode ser chamada de contexto, por exemplo, gin.Context no famoso framework web Gin. A biblioteca padrão context também fornece várias implementações, são elas:
emptyCtxcancelCtxtimerCtxvalueCtx
Context
Primeiro vamos ver a definição da interface Context, e depois conhecer suas implementações específicas.
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Deadline
Este método tem dois valores de retorno. deadline é o tempo limite, ou seja, o momento em que o contexto deve ser cancelado. O segundo valor indica se deadline foi definido. Se não foi definido, sempre será false.
Deadline() (deadline time.Time, ok bool)Done
Seu valor de retorno é um canal apenas de leitura do tipo struct vazia. Este canal serve apenas para notificação, não transmite nenhum dado. Quando o trabalho do contexto deve ser cancelado, este canal será fechado. Para alguns contextos que não suportam cancelamento, pode retornar nil.
Done() <-chan struct{}Err
Este método retorna um error, usado para indicar o motivo do fechamento do contexto. Quando o canal Done não está fechado, retorna nil. Se estiver fechado, retorna um err explicando por que foi fechado.
Err() errorValue
Este método retorna o valor correspondente à chave. Se a key não existir, ou o método não for suportado, retornará nil.
Value(key any) anyemptyCtx
Como o nome sugere, emptyCtx é um contexto vazio. Todas as implementações no pacote context não são expostas externamente, mas são fornecidas funções correspondentes para criar contextos. emptyCtx pode ser criado através de context.Background e context.TODO. As duas funções são as seguintes
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}Pode-se ver que apenas retorna um ponteiro emptyCtx. O tipo subjacente de emptyCtx na verdade é um int. A razão para não usar uma struct vazia é porque as instâncias de emptyCtx devem ter endereços de memória diferentes. Ele não pode ser cancelado, não tem deadline, e não pode obter valores. Os métodos implementados retornam valores zero.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key any) any {
return nil
}emptyCtx é geralmente usado como o contexto de nível mais alto, passado como contexto pai ao criar os outros três tipos de contexto. O relacionamento entre as várias implementações no pacote context é mostrado na figura abaixo
valueCtx
A implementação de valueCtx é relativamente simples. Internamente, contém apenas um par chave-valor e um campo do tipo Context embutido.
type valueCtx struct {
Context
key, val any
}Ele mesmo só implementa o método Value, e a lógica é muito simples: se não encontrar no contexto atual, procura no contexto pai.
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}Abaixo, um caso de uso simples de valueCtx
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(1)
// Passa o contexto
go Do(context.WithValue(context.Background(), 1, 2))
waitGroup.Wait()
}
func Do(ctx context.Context) {
// Cria um novo timer
ticker := time.NewTimer(time.Second)
defer waitGroup.Done()
for {
select {
case <-ctx.Done(): // Nunca será executado
case <-ticker.C:
fmt.Println("timeout")
return
default:
fmt.Println(ctx.Value(1))
}
time.Sleep(time.Millisecond * 100)
}
}valueCtx é mais usado para passar alguns dados entre múltiplos níveis de goroutines. Não pode ser cancelado, então ctx.Done sempre retornará nil, e select ignorará canais nil. A saída final é a seguinte
2
2
2
2
2
2
2
2
2
2
timeoutcancelCtx
cancelCtx e timerCtx ambos implementam a interface canceler. O tipo da interface é o seguinte
type canceler interface {
// removeFromParent indica se deve se remover do contexto pai
// err indica o motivo do cancelamento
cancel(removeFromParent bool, err error)
// Done retorna um canal para notificar o motivo do cancelamento
Done() <-chan struct{}
}O método cancel não é exposto externamente. Ao criar o contexto, ele é encapsulado como valor de retorno através de closure para ser chamado externamente, como mostrado no código fonte de context.WithCancel
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
// Tenta se adicionar aos children do pai
propagateCancel(parent, &c)
// Retorna context e uma função
return &c, func() { c.cancel(true, Canceled) }
}cancelCtx traduzido como contexto cancelável. Ao criar, se o pai implementar canceler, ele se adicionará aos children do pai, caso contrário continuará procurando para cima. Se todos os pais não implementarem canceler, iniciará uma goroutine para esperar o pai cancelar, e quando o pai terminar, cancela o contexto atual. Quando cancelFunc é chamado, o canal Done será fechado, qualquer filho deste contexto também será cancelado, e finalmente se removerá do pai. Abaixo está um exemplo simples:
var waitGroup sync.WaitGroup
func main() {
bkg := context.Background()
// Retorna um cancelCtx e uma função cancel
cancelCtx, cancel := context.WithCancel(bkg)
waitGroup.Add(1)
go func(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("esperando cancelamento...")
}
time.Sleep(time.Millisecond * 200)
}
}(cancelCtx)
time.Sleep(time.Second)
cancel()
waitGroup.Wait()
}Saída
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
context canceledAgora um exemplo com mais níveis de aninhamento
var waitGroup sync.WaitGroup
func main() {
waitGroup.Add(3)
ctx, cancelFunc := context.WithCancel(context.Background())
go HttpHandler(ctx)
time.Sleep(time.Second)
cancelFunc()
waitGroup.Wait()
}
func HttpHandler(ctx context.Context) {
cancelCtxAuth, cancelAuth := context.WithCancel(ctx)
cancelCtxMail, cancelMail := context.WithCancel(ctx)
defer cancelAuth()
defer cancelMail()
defer waitGroup.Done()
go AuthService(cancelCtxAuth)
go MailService(cancelCtxMail)
for {
select {
case <-ctx.Done():
fmt.Println(ctx.Err())
return
default:
fmt.Println("processando requisição http...")
}
time.Sleep(time.Millisecond * 200)
}
}
func AuthService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("auth pai cancelado", ctx.Err())
return
default:
fmt.Println("auth...")
}
time.Sleep(time.Millisecond * 200)
}
}
func MailService(ctx context.Context) {
defer waitGroup.Done()
for {
select {
case <-ctx.Done():
fmt.Println("mail pai cancelado", ctx.Err())
return
default:
fmt.Println("mail...")
}
time.Sleep(time.Millisecond * 200)
}
}No exemplo, foram criados 3 cancelCtx. Embora o cancelCtx pai cancele seus contextos filhos ao ser cancelado, por precaução, se você criou um cancelCtx, deve chamar a função cancel após o fluxo correspondente terminar. A saída é a seguinte
processando requisição http...
auth...
mail...
mail...
auth...
processando requisição http...
auth...
mail...
processando requisição http...
processando requisição http...
auth...
mail...
auth...
processando requisição http...
mail...
context canceled
auth pai cancelado context canceled
mail pai cancelado context canceledtimerCtx
timerCtx adiciona um mecanismo de timeout sobre a base de cancelCtx. O pacote context fornece duas funções para criar: WithDeadline e WithTimeout. Ambas têm funcionalidade similar. A primeira especifica um tempo de timeout específico, como especificar um tempo concreto 2023/3/20 16:32:00. A segunda especifica um intervalo de tempo de timeout, como daqui a 5 minutos. As assinaturas das duas funções são as seguintes
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)timerCtx cancelará automaticamente o contexto atual quando o tempo expirar. O processo de cancelamento, além de precisar fechar o timer adicionalmente, é basicamente consistente com cancelCtx. Abaixo está um exemplo simples de uso de timerCtx
var wait sync.WaitGroup
func main() {
deadline, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Second))
defer cancel()
wait.Add(1)
go func(ctx context.Context) {
defer wait.Done()
for {
select {
case <-ctx.Done():
fmt.Println("contexto cancelado", ctx.Err())
return
default:
fmt.Println("esperando cancelamento...")
}
time.Sleep(time.Millisecond * 200)
}
}(deadline)
wait.Wait()
}Embora o contexto expire e seja cancelado automaticamente, por precaução, após o fluxo relevante terminar, é melhor cancelar o contexto manualmente. A saída é a seguinte
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
esperando cancelamento...
contexto cancelado context deadline exceededWithTimeout na verdade é muito similar a WithDeadline. Sua implementação apenas encapsula um pouco e chama WithDeadline. O uso é o mesmo que WithDeadline no exemplo acima, como mostrado
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}TIP
Assim como alocar memória e não liberar causa vazamento de memória, contexto também é um recurso. Se você criar mas nunca cancelar, também causará vazamento de contexto, então é melhor evitar essa situação.
Select
select no sistema Linux é uma solução de multiplexação de IO. De forma similar, em Go, select é uma estrutura de controle de multiplexação de canais. O que é multiplexação? Em resumo: em um determinado momento, monitorar simultaneamente se múltiplos elementos estão disponíveis. Os elementos monitorados podem ser requisições de rede, IO de arquivos, etc. Em Go, select monitora apenas canais, e nada mais. A sintaxe de select é similar à instrução switch. Veja abaixo como é uma instrução select
func main() {
// Cria três canais
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
default:
fmt.Println("todos os canais estão indisponíveis")
}
}Uso
Similar ao switch, select consiste de múltiplos case e um default. O ramo default pode ser omitido. Cada case só pode operar um canal, e só pode fazer uma operação, ou ler ou escrever. Quando múltiplos case estão disponíveis, select escolherá pseudo-aleatoriamente um case para executar. Se todos os case estiverem indisponíveis, o ramo default será executado. Se não houver ramo default, haverá bloqueio e espera até que pelo menos um case esteja disponível. Como no exemplo acima não foram escritos dados nos canais, naturalmente todos os case estão indisponíveis, então a saída final é o resultado da execução do ramo default. Modificando um pouco, temos:
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
// Inicia uma nova goroutine
go func() {
// Escreve dados no canal A
chA <- 1
}()
select {
case n, ok := <-chA:
fmt.Println(n, ok)
case n, ok := <-chB:
fmt.Println(n, ok)
case n, ok := <-chC:
fmt.Println(n, ok)
}
}No exemplo acima, uma nova goroutine foi iniciada para escrever dados no canal A. Como select não tem ramo padrão, ele ficará bloqueado esperando até que um case esteja disponível. Quando o canal A estiver disponível, após executar o ramo correspondente, a goroutine principal sai diretamente. Para monitorar os canais continuamente, você pode usar em conjunto com um loop for, como abaixo.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
go Send(chA)
go Send(chB)
go Send(chC)
// loop for
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
}
}
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}Assim, os três canais podem ser usados, mas um loop infinito + select fará a goroutine principal bloquear permanentemente. Então você pode colocá-lo em uma nova goroutine separada e adicionar outra lógica.
func main() {
chA := make(chan int)
chB := make(chan int)
chC := make(chan int)
defer func() {
close(chA)
close(chB)
close(chC)
}()
l := make(chan struct{})
go Send(chA)
go Send(chB)
go Send(chC)
go func() {
Loop:
for {
select {
case n, ok := <-chA:
fmt.Println("A", n, ok)
case n, ok := <-chB:
fmt.Println("B", n, ok)
case n, ok := <-chC:
fmt.Println("C", n, ok)
case <-time.After(time.Second): // Define timeout de 1 segundo
break Loop // Sai do loop
}
}
l <- struct{}{} // Diz à goroutine principal que pode sair
}()
<-l
}
func Send(ch chan<- int) {
for i := 0; i < 3; i++ {
time.Sleep(time.Millisecond)
ch <- i
}
}No exemplo acima, através do loop for combinado com select, os três canais são monitorados continuamente. O quarto case é um canal de timeout. Após o timeout, o loop será encerrado e a goroutine filha terminará. A saída final é a seguinte
C 0 true
A 0 true
B 0 true
A 1 true
B 1 true
C 1 true
B 2 true
C 2 true
A 2 trueTimeout
O exemplo anterior usou a função time.After, cujo valor de retorno é um canal apenas de leitura. Esta função usada com select pode implementar um mecanismo de timeout de forma muito simples. Exemplo abaixo
func main() {
chA := make(chan int)
defer close(chA)
go func() {
time.Sleep(time.Second * 2)
chA <- 1
}()
select {
case n := <-chA:
fmt.Println(n)
case <-time.After(time.Second):
fmt.Println("timeout")
}
}Bloqueio Permanente
Quando a instrução select não tem nada dentro, haverá bloqueio permanente. Por exemplo
func main() {
fmt.Println("start")
select {}
fmt.Println("end")
}end nunca será impresso, a goroutine principal ficará bloqueada para sempre. Esta situação geralmente tem usos especiais.
TIP
No case do select, operar em um canal com valor nil não causará bloqueio. Este case será ignorado e nunca será executado. Por exemplo, o código abaixo, não importa quantas vezes execute, só imprimirá timeout.
func main() {
var nilCh chan int
select {
case <-nilCh:
fmt.Println("read")
case nilCh <- 1:
fmt.Println("write")
case <-time.After(time.Second):
fmt.Println("timeout")
}
}Não Bloqueante
Através do uso do ramo default do select combinado com canais, podemos implementar operações de envio e recebimento não bloqueantes, como mostrado abaixo
func TrySend(ch chan int, ele int) bool {
select {
case ch <- ele:
return true
default:
return false
}
}
func TryRecv(ch chan int) (int, bool) {
select {
case ele, ok := <-ch:
return ele, ok
default:
return 0, false
}
}Da mesma forma, também é possível implementar uma verificação não bloqueante se um context já terminou
func IsDone(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}Locks
Primeiro, vamos ver um exemplo
var wait sync.WaitGroup
var count = 0
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Simula tempo de acesso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
// Acessa dados
temp := *data
// Simula tempo de cálculo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(5000)))
ans := 1
// Modifica dados
*data = temp + ans
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("resultado final", count)
}Para o exemplo acima, foram iniciadas dez goroutines para fazer operação +1 em count, e foi usado time.Sleep para simular diferentes tempos gastos. Pela intuição, 10 goroutines executando 10 operações +1, o resultado final deve ser 10. O resultado correto de fato é 10, mas a realidade não é assim. O resultado da execução do exemplo acima é:
1
2
3
3
2
2
3
3
3
4
resultado final 4Pode-se ver que o resultado final é 4, e este é apenas um dos muitos resultados possíveis. Como cada goroutine tem tempos diferentes de acesso e cálculo, a goroutine A gasta 500 milissegundos para acessar os dados, e neste momento o valor de count acessado é 1. Depois gasta mais 400 milissegundos calculando, mas durante esses 400 milissegundos, a goroutine B já completou o acesso e cálculo e atualizou com sucesso o valor de count. Após a goroutine A terminar de calcular, o valor que ela acessou inicialmente já está desatualizado, mas a goroutine A não sabe disso, e ainda assim soma um ao valor acessado originalmente e atribui a count. Assim, o resultado da execução da goroutine B foi sobrescrito. Quando múltiplas goroutines leem e acessam um dado compartilhado, esse tipo de problema é especialmente comum, e para isso precisamos usar locks.
Em Go, Mutex e RWMutex do pacote sync fornecem duas implementações: mutex e mutex de leitura e escrita. Eles fornecem APIs muito simples e fáceis de usar. Para bloquear, basta Lock(), e para desbloquear, basta Unlock(). Note que os locks fornecidos por Go são todos não-recursivos, ou seja, não são reentrantes, então bloquear ou desbloquear repetidamente causará fatal. O significado do lock é proteger invariantes. Bloquear é esperar que os dados não sejam modificados por outras goroutines, como abaixo
func DoSomething() {
Lock()
// Durante este processo, os dados não serão modificados por outras goroutines
Unlock()
}Se fosse um lock recursivo, poderia acontecer a seguinte situação
func DoSomething() {
Lock()
DoOther()
Unlock()
}
func DoOther() {
Lock()
// do other
Unlock()
}A função DoSomething claramente não sabe o que a função DoOther pode fazer com os dados, e pode modificá-los, como abrir mais algumas goroutines filhas destruindo as invariantes. Isso não funciona em Go. Uma vez bloqueado, deve-se garantir a imutabilidade das invariantes. Neste momento, bloquear ou desbloquear repetidamente causará deadlock. Portanto, ao escrever código, deve-se evitar a situação acima. Quando necessário, ao bloquear, use imediatamente a instrução defer para desbloquear.
Mutex
sync.Mutex é a implementação de mutex fornecida por Go. Ela implementa a interface sync.Locker
type Locker interface {
// Bloquear
Lock()
// Desbloquear
Unlock()
}Usar mutex pode resolver perfeitamente o problema acima. Exemplo abaixo
var wait sync.WaitGroup
var count = 0
var lock sync.Mutex
func main() {
wait.Add(10)
for i := 0; i < 10; i++ {
go func(data *int) {
// Bloqueia
lock.Lock()
// Simula tempo de acesso
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
// Acessa dados
temp := *data
// Simula tempo de cálculo
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
ans := 1
// Modifica dados
*data = temp + ans
// Desbloqueia
lock.Unlock()
fmt.Println(*data)
wait.Done()
}(&count)
}
wait.Wait()
fmt.Println("resultado final", count)
}Cada goroutine, antes de acessar os dados, primeiro bloqueia. Após completar a atualização, desbloqueia. Outras goroutines que quiserem acessar precisam primeiro obter o lock, caso contrário bloqueiam e esperam. Assim, o problema mencionado acima não existe mais, e a saída é a seguinte
1
2
3
4
5
6
7
8
9
10
resultado final 10RWMutex
Mutex é adequado para situações onde a frequência de operações de leitura e escrita é similar. Para dados com muitas leituras e poucas escritas, se usar mutex, causará muita competição desnecessária de locks por goroutines, o que consumirá muitos recursos do sistema. Neste caso, é necessário usar mutex de leitura e escrita, ou seja, RWMutex. Para uma goroutine:
- Se obteve lock de leitura, outras goroutines serão bloqueadas ao fazer operações de escrita, mas não serão bloqueadas ao fazer operações de leitura
- Se obteve lock de escrita, outras goroutines serão bloqueadas ao fazer operações de escrita, e também serão bloqueadas ao fazer operações de leitura
A implementação de RWMutex em Go é sync.RWMutex. Ela também implementa a interface Locker, mas fornece mais métodos disponíveis, como abaixo:
// Adquire lock de leitura
func (rw *RWMutex) RLock()
// Tenta adquirir lock de leitura
func (rw *RWMutex) TryRLock() bool
// Libera lock de leitura
func (rw *RWMutex) RUnlock()
// Adquire lock de escrita
func (rw *RWMutex) Lock()
// Tenta adquirir lock de escrita
func (rw *RWMutex) TryLock() bool
// Libera lock de escrita
func (rw *RWMutex) Unlock()Entre eles, TryRlock e TryLock são operações não bloqueantes de tentativa de bloqueio. Se conseguir bloquear com sucesso, retorna true. Se não conseguir obter o lock, não bloqueia, mas retorna false. A implementação interna do RWMutex ainda é um mutex. Não é porque há lock de leitura e lock de escrita que há dois locks. Do início ao fim, há apenas um lock. Abaixo, vejamos um caso de uso de RWMutex
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
func main() {
wait.Add(12)
// Muitas leituras, poucas escritas
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Espera as goroutines filhas terminarem
wait.Wait()
fmt.Println("resultado final", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("obteve lock de leitura")
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("liberou lock de leitura", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("obteve lock de escrita")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("liberou lock de escrita", *i)
rw.Unlock()
wait.Done()
}Este exemplo iniciou 3 goroutines de escrita e 7 goroutines de leitura. Ao ler dados, primeiro adquire o lock de leitura. Goroutines de leitura podem adquirir o lock de leitura normalmente, mas bloquearão goroutines de escrita. Ao adquirir o lock de escrita, bloqueará tanto goroutines de leitura quanto de escrita, até que o lock de escrita seja liberado. Assim, implementou-se exclusão mútua entre goroutines de leitura e escrita, garantindo a correção dos dados. A saída do exemplo é:
obteve lock de leitura
obteve lock de leitura
obteve lock de leitura
obteve lock de leitura
liberou lock de leitura 0
liberou lock de leitura 0
liberou lock de leitura 0
liberou lock de leitura 0
obteve lock de escrita
liberou lock de escrita 1
obteve lock de leitura
obteve lock de leitura
obteve lock de leitura
liberou lock de leitura 1
liberou lock de leitura 1
liberou lock de leitura 1
obteve lock de escrita
liberou lock de escrita 2
obteve lock de escrita
liberou lock de escrita 3
resultado final 3TIP
Para locks, não devem ser passados e armazenados como valores, deve-se usar ponteiros.
Variável de Condição
Variável de condição, aparece e é usada junto com mutex, então algumas pessoas podem chamá-la incorretamente de lock de condição, mas não é um lock, é um mecanismo de comunicação. Go fornece implementação através de sync.Cond. A assinatura da função para criar uma variável de condição é:
func NewCond(l Locker) *CondPode-se ver que a pré-condição para criar uma variável de condição é criar um lock. sync.Cond fornece os seguintes métodos para uso
// Bloqueia esperando a condição ser satisfeita, até ser despertado
func (c *Cond) Wait()
// Desperta uma goroutine bloqueada pela condição
func (c *Cond) Signal()
// Desperta todas as goroutines bloqueadas pela condição
func (c *Cond) Broadcast()O uso de variável de condição é muito simples. Modificando ligeiramente o exemplo de RWMutex acima
var wait sync.WaitGroup
var count = 0
var rw sync.RWMutex
// Variável de condição
var cond = sync.NewCond(rw.RLocker())
func main() {
wait.Add(12)
// Muitas leituras, poucas escritas
go func() {
for i := 0; i < 3; i++ {
go Write(&count)
}
wait.Done()
}()
go func() {
for i := 0; i < 7; i++ {
go Read(&count)
}
wait.Done()
}()
// Espera as goroutines filhas terminarem
wait.Wait()
fmt.Println("resultado final", count)
}
func Read(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(500)))
rw.RLock()
fmt.Println("obteve lock de leitura")
// Condição não satisfeita, bloqueia
for *i < 3 {
cond.Wait()
}
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println("liberou lock de leitura", *i)
rw.RUnlock()
wait.Done()
}
func Write(i *int) {
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
rw.Lock()
fmt.Println("obteve lock de escrita")
temp := *i
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
*i = temp + 1
fmt.Println("liberou lock de escrita", *i)
rw.Unlock()
// Desperta todas as goroutines bloqueadas pela variável de condição
cond.Broadcast()
wait.Done()
}Ao criar a variável de condição, como aqui a variável de condição atua sobre as goroutines de leitura, o lock de leitura é passado como mutex. Se passar o RWMutex diretamente, causará problema de desbloqueio repetido nas goroutines de escrita. O que é passado aqui é sync.rlocker, obtido através do método RWMutex.RLocker.
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }Pode-se ver que rlocker apenas encapsula as operações de lock de leitura do RWMutex. Na verdade, é a mesma referência, ainda é o mesmo lock. Quando a goroutine de leitura lê dados, se for menor que 3, bloqueia e espera até que os dados sejam maiores que 3. A goroutine de escrita, após atualizar os dados, tenta despertar todas as goroutines bloqueadas pela variável de condição. A saída final é
obteve lock de leitura
obteve lock de leitura
obteve lock de leitura
obteve lock de leitura
obteve lock de escrita
liberou lock de escrita 1
obteve lock de leitura
obteve lock de escrita
liberou lock de escrita 2
obteve lock de leitura
obteve lock de leitura
obteve lock de escrita
liberou lock de escrita 3 // terceira goroutine de escrita terminou
liberou lock de leitura 3
liberou lock de leitura 3
liberou lock de leitura 3
liberou lock de leitura 3
liberou lock de leitura 3
liberou lock de leitura 3
liberou lock de leitura 3
resultado final 3Pode-se ver no resultado que, após a terceira goroutine de escrita terminar de atualizar os dados, as sete goroutines de leitura bloqueadas pela variável de condição foram todas retomadas.
TIP
Para variáveis de condição, deve-se usar for e não if. Deve-se usar um loop para verificar se a condição está satisfeita, porque quando a goroutine é despertada, não se pode garantir que a condição atual já esteja satisfeita.
for !condition {
cond.Wait()
}sync
Grande parte das ferramentas relacionadas à concorrência em Go são fornecidas pela biblioteca padrão sync. Já foram apresentados sync.WaitGroup, sync.Locker, etc. Além disso, o pacote sync tem algumas outras ferramentas disponíveis.
Once
Ao usar algumas estruturas de dados, se essas estruturas forem muito grandes, você pode considerar usar carregamento preguiçoso, ou seja, inicializar a estrutura de dados apenas quando realmente precisar usá-la. Como no exemplo abaixo
type MySlice []int
func (m *MySlice) Get(i int) (int, bool) {
if *m == nil {
return 0, false
} else {
return (*m)[i], true
}
}
func (m *MySlice) Add(i int) {
// Só considera inicializar quando realmente usar o slice
if *m == nil {
*m = make([]int, 0, 10)
}
*m = append(*m, i)
}Mas surge um problema: se apenas uma goroutine usar, certamente não há problema. Mas se múltiplas goroutines acessarem, podem surgir problemas. Por exemplo, as goroutines A e B chamam o método Add ao mesmo tempo. A executa um pouco mais rápido, já terminou a inicialização e adicionou os dados com sucesso. Depois a goroutine B inicializa novamente, sobrescrevendo diretamente os dados adicionados pela goroutine A. Esse é o problema.
E é isso que sync.Once resolve. Como o nome sugere, Once significa uma vez. sync.Once garante que, em condições de concorrência, uma operação especificada seja executada apenas uma vez. Seu uso é muito simples, expondo apenas um método Do, com a seguinte assinatura:
func (o *Once) Do(f func())Ao usar, basta passar a operação de inicialização para o método Do, como abaixo
var wait sync.WaitGroup
func main() {
var slice MySlice
wait.Add(4)
for i := 0; i < 4; i++ {
go func() {
slice.Add(1)
wait.Done()
}()
}
wait.Wait()
fmt.Println(slice.Len())
}
type MySlice struct {
s []int
o sync.Once
}
func (m *MySlice) Get(i int) (int, bool) {
if m.s == nil {
return 0, false
} else {
return m.s[i], true
}
}
func (m *MySlice) Add(i int) {
// Só considera inicializar quando realmente usar o slice
m.o.Do(func() {
fmt.Println("inicializando")
if m.s == nil {
m.s = make([]int, 0, 10)
}
})
m.s = append(m.s, i)
}
func (m *MySlice) Len() int {
return len(m.s)
}Saída
inicializando
4Pode-se ver no resultado que todos os dados foram adicionados normalmente ao slice, e a operação de inicialização foi executada apenas uma vez. Na verdade, a implementação de sync.Once é bastante simples. Removendo os comentários, a lógica real do código tem apenas 16 linhas. Seu princípio é lock + operação atômica. O código fonte é:
type Once struct {
// Usado para julgar se a operação já foi executada
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
// Carrega dados atomicamente
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// Bloqueia
o.m.Lock()
// Desbloqueia
defer o.m.Unlock()
// Verifica se já foi executado
if o.done == 0 {
// Após executar, modifica done
defer atomic.StoreUint32(&o.done, 1)
f()
}
}Pool
O objetivo do design de sync.Pool é armazenar objetos temporários para reutilização posterior. É um pool de objetos temporários seguro para concorrência. Colocar objetos temporariamente não usados no pool permite reutilizá-los diretamente em usos posteriores sem precisar criar novos objetos, reduzindo a frequência de alocação e liberação de memória. O ponto mais importante é reduzir a pressão sobre o GC. sync.Pool tem apenas dois métodos, como abaixo:
// Solicita um objeto
func (p *Pool) Get() any
// Coloca um objeto no pool
func (p *Pool) Put(x any)E sync.Pool tem um campo New exposto externamente, usado para inicializar um objeto quando o pool não consegue fornecer um
New func() anyAbaixo, um exemplo de demonstração
var wait sync.WaitGroup
// Pool de objetos temporários
var pool sync.Pool
// Usado para contar quantos objetos foram criados durante o processo
var numOfObject atomic.Int64
// BigMemData supõe-se que seja uma struct que ocupa muita memória
type BigMemData struct {
M string
}
func main() {
pool.New = func() any {
numOfObject.Add(1)
return BigMemData{"memória grande"}
}
wait.Add(1000)
// Aqui inicia 1000 goroutines
for i := 0; i < 1000; i++ {
go func() {
// Solicita objeto
val := pool.Get()
// Usa objeto
_ = val.(BigMemData)
// Após usar, libera o objeto de volta
pool.Put(val)
wait.Done()
}()
}
wait.Wait()
fmt.Println(numOfObject.Load())
}O exemplo iniciou 1000 goroutines solicitando e liberando objetos constantemente no pool. Se não usar o pool de objetos, as 1000 goroutines precisariam instanciar seus próprios objetos, e esses 1000 objetos instanciados, após o uso, precisariam ter sua memória liberada pelo GC. Se houver centenas de milhares de goroutines, ou se o custo de criar esse objeto for muito alto, essa situação ocuparia muita memória e traria muita pressão para o GC. Usando o pool de objetos, é possível reutilizar objetos e reduzir a frequência de instanciação. Por exemplo, a saída do exemplo acima pode ser:
5Mesmo iniciando 1000 goroutines, apenas 5 objetos foram criados durante todo o processo. Se não usar o pool de objetos, 1000 goroutines criariam 1000 objetos. Essa otimização traz uma melhoria óbvia, especialmente quando a concorrência é muito alta e o custo de instanciar objetos é muito alto.
Ao usar sync.Pool, note alguns pontos:
- Objetos temporários:
sync.Poolsó é adequado para armazenar objetos temporários. Objetos no pool podem ser removidos pelo GC sem qualquer notificação, então não é recomendado colocar conexões de rede, conexões de banco de dados, etc., nosync.Pool. - Imprevisibilidade: Ao solicitar objetos do
sync.Pool, não é possível prever se o objeto é recém-criado ou reutilizado, nem saber quantos objetos há no pool. - Segurança para concorrência: O oficial garante que
sync.Poolé seguro para concorrência, mas não garante que a funçãoNewusada para criar objetos seja segura para concorrência. A funçãoNewé passada pelo usuário, então a segurança de concorrência da funçãoNewdeve ser mantida pelo próprio usuário. É por isso que, no exemplo acima, a contagem de objetos usa valores atômicos.
TIP
Finalmente, note que após terminar de usar o objeto, deve-se liberá-lo de volta para o pool. Se usar e não liberar, o uso do pool de objetos não terá sentido.
A biblioteca padrão fmt tem um caso de uso de pool de objetos. Na função fmt.Fprintf
func Fprintf(w io.Writer, format string, a ...any) (n int, err error) {
// Solicita um buffer de impressão
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
// Após usar, libera
p.free()
return
}A implementação da função newPointer e do método free é a seguinte
func newPrinter() *pp {
// Solicita um objeto do pool de objetos
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
// Para que o tamanho do buffer no pool seja aproximadamente o mesmo, permitindo melhor controle elástico do tamanho do buffer
// Buffers muito grandes não são colocados de volta no pool
if cap(p.buf) > 64<<10 {
return
}
// Após redefinir os campos, libera o objeto de volta para o pool
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}Map
sync.Map é uma implementação de Map seguro para concorrência fornecida oficialmente. Pronto para uso, é muito simples de usar. Abaixo estão os métodos expostos por esta struct:
// Lê um valor baseado em uma chave, retorna o valor correspondente e se o valor existe
func (m *Map) Load(key any) (value any, ok bool)
// Armazena um par chave-valor
func (m *Map) Store(key, value any)
// Deleta um par chave-valor
func (m *Map) Delete(key any)
// Se a chave já existe, retorna o valor original, caso contrário armazena o novo valor e retorna. Quando lê o valor com sucesso, loaded é true, caso contrário é false
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool)
// Deleta um par chave-valor e retorna seu valor original, o valor de loaded depende se a chave existe
func (m *Map) LoadAndDelete(key any) (value any, loaded bool)
// Itera sobre o Map, quando f() retorna false, para de iterar
func (m *Map) Range(f func(key, value any) bool)Abaixo, um exemplo simples para demonstrar o uso básico de sync.Map
func main() {
var syncMap sync.Map
// Armazena dados
syncMap.Store("a", 1)
syncMap.Store("a", "a")
// Lê dados
fmt.Println(syncMap.Load("a"))
// Lê e deleta
fmt.Println(syncMap.LoadAndDelete("a"))
// Lê ou armazena
fmt.Println(syncMap.LoadOrStore("a", "hello world"))
syncMap.Store("b", "goodbye world")
// Itera sobre o map
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Saída
a true
a true
hello world false
a hello world
b goodbye worldAgora vejamos um exemplo de uso concorrente de map:
func main() {
myMap := make(map[int]int, 10)
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
myMap[n] = n
}
wait.Done()
}(i)
}
wait.Wait()
}No exemplo acima, foi usado um map comum. Foram abertas 10 goroutines armazenando dados constantemente. Claramente, isso muito provavelmente vai disparar um fatal. O resultado provavelmente será
fatal error: concurrent map writesUsando sync.Map você pode evitar esse problema
func main() {
var syncMap sync.Map
var wait sync.WaitGroup
wait.Add(10)
for i := 0; i < 10; i++ {
go func(n int) {
for i := 0; i < 100; i++ {
syncMap.Store(n, n)
}
wait.Done()
}(i)
}
wait.Wait()
syncMap.Range(func(key, value any) bool {
fmt.Println(key, value)
return true
})
}Saída
8 8
3 3
1 1
9 9
6 6
5 5
7 7
0 0
2 2
4 4Para segurança de concorrência, certamente é necessário fazer alguns sacrifícios. O desempenho de sync.Map é cerca de 10-100 vezes menor que o de map.
Operações Atômicas
Na ciência da computação, operações atômicas ou primitivas são geralmente usadas para descrever algumas operações que não podem ser mais subdivididas. Como essas operações não podem ser divididas em passos menores, antes de terminar a execução, não serão interrompidas por nenhuma outra goroutine. Portanto, o resultado da execução ou é sucesso ou é falha, não há terceira possibilidade. Se aparecer outra situação, então não é uma operação atômica. Por exemplo, o código abaixo:
func main() {
a := 0
if a == 0 {
a = 1
}
fmt.Println(a)
}O código acima é um simples ramo de julgamento. Embora o código seja pouco, não é uma operação atômica. Operações atômicas reais são suportadas no nível de instruções de hardware.
Tipos
Felizmente, na maioria dos casos, não é necessário escrever assembly por conta própria. A biblioteca padrão sync/atomic de Go já fornece APIs relacionadas a operações atômicas. Ela fornece os seguintes tipos para operações atômicas.
atomic.Bool{}
atomic.Pointer[]{}
atomic.Int32{}
atomic.Int64{}
atomic.Uint32{}
atomic.Uint64{}
atomic.Uintptr{}
atomic.Value{}Entre eles, o tipo atômico Pointer suporta genéricos, e o tipo Value suporta armazenar qualquer tipo. Além disso, também fornece muitas funções para facilitar as operações. Como a granularidade das operações atômicas é muito fina, na maioria dos casos, é mais adequado para lidar com esses tipos de dados básicos.
TIP
No pacote atomic, as operações atômicas têm apenas assinaturas de função, sem implementação concreta. A implementação concreta é escrita em assembly plan9.
Uso
Cada tipo atômico fornecerá os seguintes três métodos:
Load(): obtém valor atomicamenteSwap(newVal type) (old type): troca valor atomicamente e retorna o valor antigoStore(val type): armazena valor atomicamente
Tipos diferentes podem ter outros métodos extras, como tipos inteiros que fornecem o método Add para implementar operações atômicas de adição e subtração. Abaixo, um exemplo com tipo int64:
func main() {
var aint64 atomic.Uint64
// Armazena valor
aint64.Store(64)
// Troca valor
aint64.Swap(128)
// Adiciona
aint64.Add(112)
// Carrega valor
fmt.Println(aint64.Load())
}Ou também pode usar funções diretamente
func main() {
var aint64 int64
// Armazena valor
atomic.StoreInt64(&aint64, 64)
// Troca valor
atomic.SwapInt64(&aint64, 128)
// Adiciona
atomic.AddInt64(&aint64, 112)
// Carrega
fmt.Println(atomic.LoadInt64(&aint64))
}O uso de outros tipos é muito similar, e a saída final é:
240CAS
O pacote atomic também fornece a operação CompareAndSwap, ou seja, CAS. É o núcleo para implementar locks otimistas e estruturas de dados sem lock. O lock otimista em si não é um lock, é um método de controle de concorrência sem lock: threads/goroutines, antes de modificar dados, não bloqueiam primeiro, mas leem os dados, fazem cálculos, e ao submeter a modificação usam CAS para julgar se durante este período outros threads modificaram os dados. Se não (o valor ainda é igual ao valor lido anteriormente), a modificação é bem-sucedida; caso contrário, falha e tenta novamente. Portanto, é chamado de lock otimista porque sempre assume otimisticamente que dados compartilhados não serão modificados, e só executa a operação correspondente quando descobre que os dados não foram modificados. O mutex mencionado anteriormente é um lock pessimista, que sempre assume pessimisticamente que dados compartilhados certamente serão modificados, então bloqueia ao operar e desbloqueia após terminar. Como a concorrência é implementada sem lock, sua segurança e eficiência são maiores que as de locks. Muitas estruturas de dados seguras para concorrência usam CAS para implementação, mas a eficiência real depende do cenário de uso específico. Veja o exemplo abaixo:
var lock sync.Mutex
var count int
func Add(num int) {
lock.Lock()
count += num
lock.Unlock()
}Este é um exemplo usando mutex. Antes de cada incremento, bloqueia primeiro, e após terminar, desbloqueia. Durante o processo, outras goroutines serão bloqueadas. Agora vamos modificar usando CAS:
var count int64
func Add(num int64) {
for {
expect := atomic.LoadInt64(&count)
if atomic.CompareAndSwapInt64(&count, expect, expect+num) {
break
}
}
}Para CAS, há três parâmetros: valor na memória, valor esperado, novo valor. Ao executar, CAS compara o valor esperado com o valor atual na memória. Se o valor na memória for igual ao valor esperado, executa a operação subsequente; caso contrário, não faz nada. Para operações atômicas no pacote atomic de Go, funções relacionadas a CAS precisam receber endereço, valor esperado, novo valor, e retornam um booleano indicando se a substituição foi bem-sucedida. Por exemplo, a assinatura da função de operação CAS para tipo int64 é:
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)No exemplo de CAS, primeiro obtém o valor esperado através de LoadInt64, depois usa CompareAndSwapInt64 para comparar e trocar. Se não for bem-sucedido, continua no loop até conseguir. Essa operação sem lock, embora não cause bloqueio de goroutines, o loop constante ainda é um overhead considerável para a CPU, então em algumas implementações, após um certo número de falhas, pode desistir da operação. Mas para a operação acima, que é apenas uma simples adição de números, as operações envolvidas não são complexas, então pode-se considerar a implementação sem lock.
TIP
Na maioria dos casos, apenas comparar valores não é suficiente para garantir segurança de concorrência. Por exemplo, o problema ABA causado por CAS requer adicionar version extra para resolver.
Value
A struct atomic.Value pode armazenar valores de qualquer tipo. A struct é:
type Value struct {
// tipo any
v any
}Embora possa armazenar qualquer tipo, não pode armazenar nil, e os tipos dos valores armazenados consecutivamente devem ser consistentes. Os dois exemplos abaixo não podem ser compilados
func main() {
var val atomic.Value
val.Store(nil)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of nil value into Valuefunc main() {
var val atomic.Value
val.Store("hello world")
val.Store(114514)
fmt.Println(val.Load())
}
// panic: sync/atomic: store of inconsistently typed value into ValueAlém disso, seu uso não é muito diferente de outros tipos atômicos, e note que todos os tipos atômicos não devem ter seus valores copiados, mas sim usar seus ponteiros.