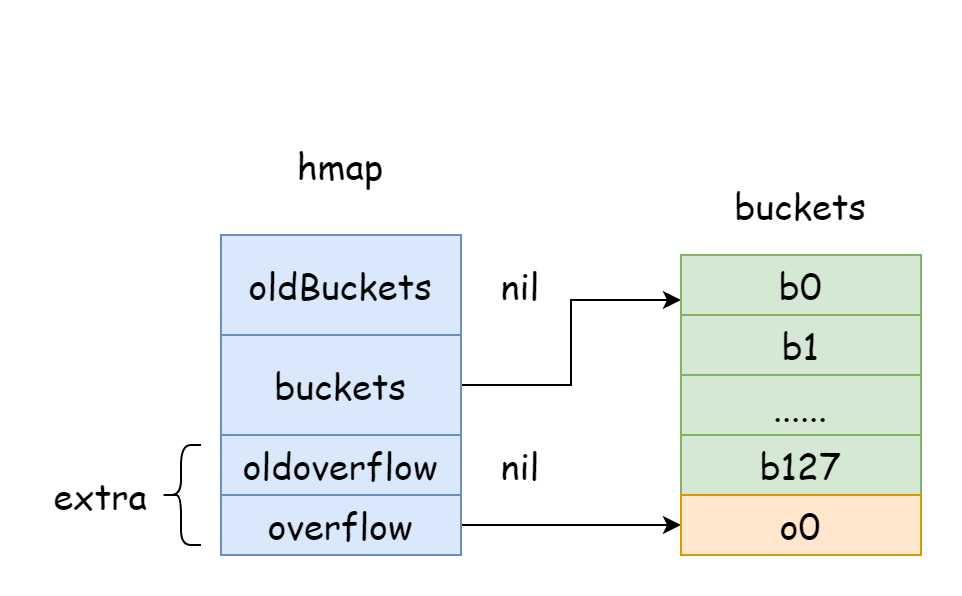
map
Diferentemente de outras linguagens, o suporte a mapas em Go é fornecido pela palavra-chave map, não sendo encapsulado como biblioteca padrão. Mapa é uma estrutura de dados com muitos cenários de uso, existindo muitas implementações diferentes em seu nível inferior. As duas formas mais comuns são árvore rubro-negra e tabela hash. Go utiliza a implementação com tabela hash.
TIP
A implementação do map envolve muitas operações de movimentação de ponteiros, então a leitura deste artigo requer conhecimento da biblioteca padrão unsafe.
Estrutura Interna
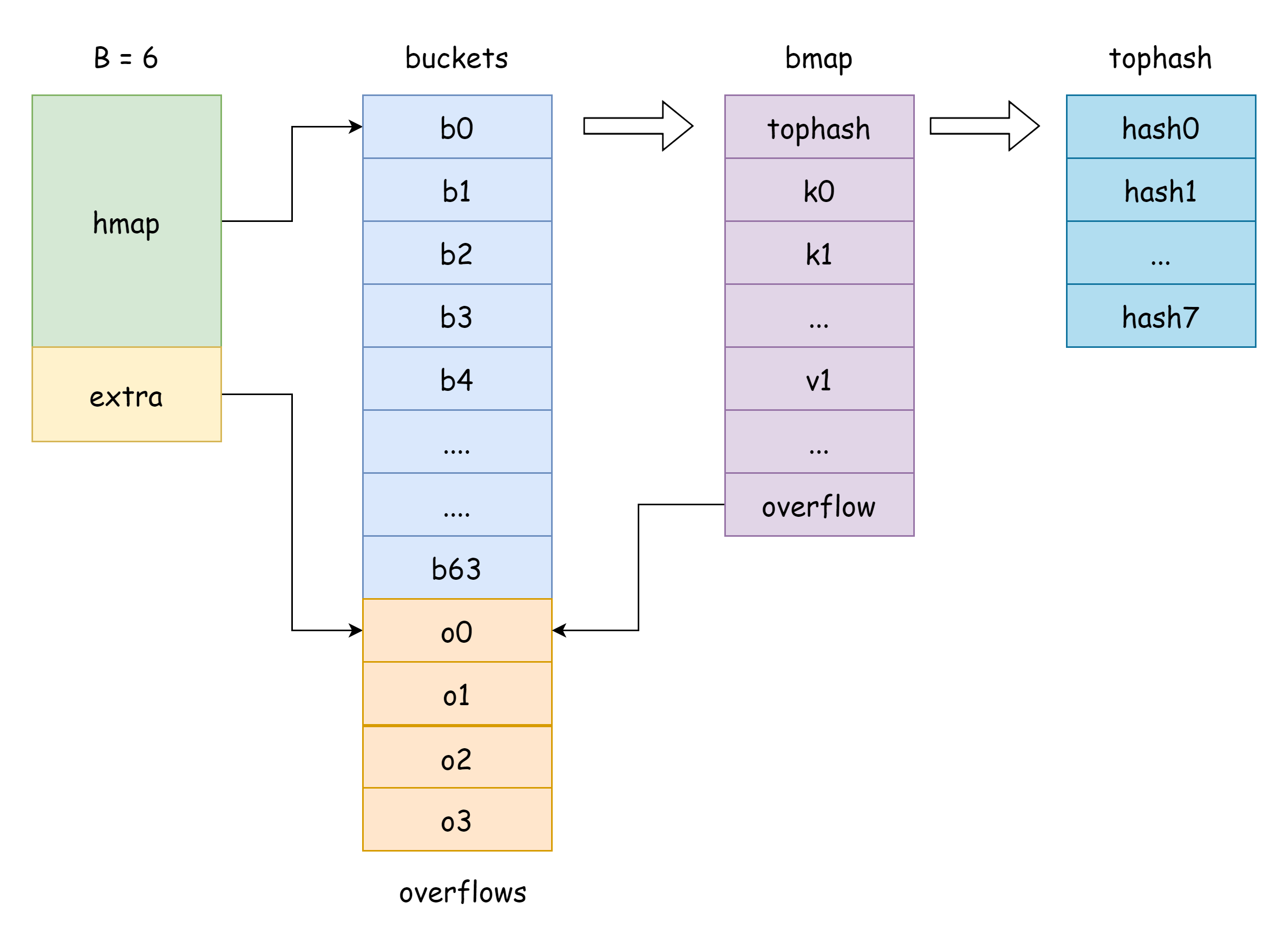
A estrutura runtime.hmap representa o map em Go. Assim como o slice, a implementação interna do map também é uma estrutura.
// A header for a Go map.
type hmap struct {
// Nota: o formato do hmap também está codificado em cmd/compile/internal/reflectdata/reflect.go.
// Certifique-se de que isso permaneça sincronizado com a definição do compilador.
count int // # células vivas == tamanho do map. Deve ser o primeiro (usado pela função len())
flags uint8
B uint8 // log_2 do número de buckets (pode conter até loadFactor * 2^B itens)
noverflow uint16 // número aproximado de buckets de overflow; veja incrnoverflow para detalhes
hash0 uint32 // semente hash
buckets unsafe.Pointer // array de 2^B Buckets. pode ser nil se count==0.
oldbuckets unsafe.Pointer // array de buckets anterior com metade do tamanho, não-nil apenas durante crescimento
nevacuate uintptr // contador de progresso para evacuação (buckets menores que este foram evacuados)
extra *mapextra // campos opcionais
}A注释 em inglês já explica claramente. Abaixo estão explicações simples dos campos mais importantes:
count, representa o número de elementos no hmap, resultado equivalente alen(map).flags, flag do hmap, usada para indicar em que estado o hmap está, com as seguintes possibilidades:goconst ( iterator = 1 // iterador está usando o bucket oldIterator = 2 // iterador está usando o bucket antigo hashWriting = 4 // uma goroutine está escrevendo no hmap sameSizeGrow = 8 // está crescendo com mesma quantidade )B, número de buckets de hash no hmap é1 << B.noverflow, número aproximado de buckets de overflow no hmap.hash0, semente hash, especificada quando o hmap é criado, usada para calcular o valor hash.buckets, ponteiro que armazena o array de buckets de hash.oldbuckets, ponteiro que armazena o array de buckets de hash antes da expansão do hmap.extra, armazena os buckets de overflow do hmap. Buckets de overflow referem-se a quando o bucket atual está cheio, cria-se um novo bucket para armazenar elementos, este novo bucket é o bucket de overflow.
O buckets no hmap, ou seja, o ponteiro do slice de buckets, corresponde à estrutura runtime.bmap em Go, como abaixo:
// A bucket for a Go map.
type bmap struct {
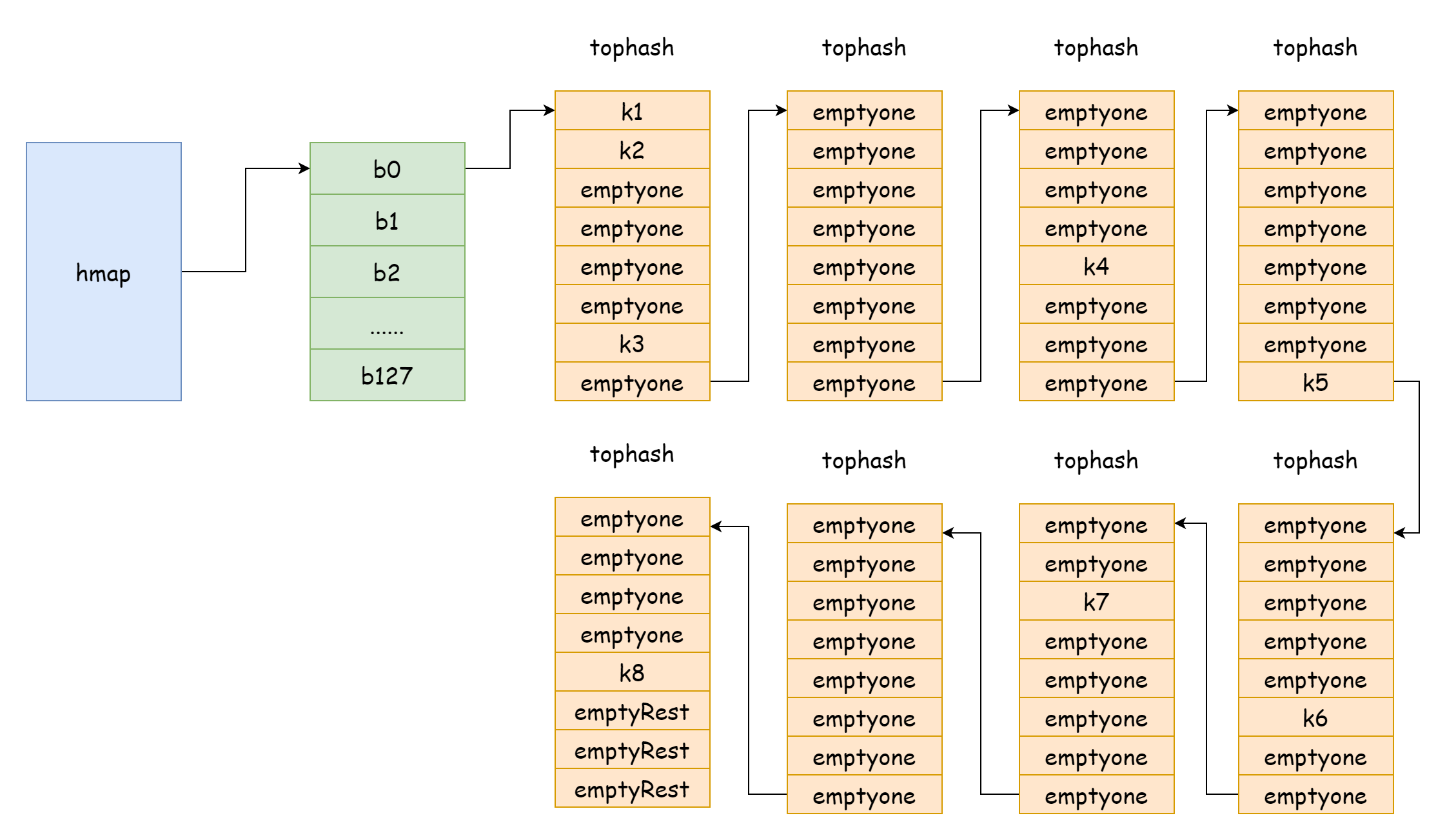
tophash [bucketCnt]uint8
}Podemos ver que ele tem apenas um campo tophash, usado para armazenar os 8 bits superiores de cada chave. Na verdade, bmap tem mais campos do que estes, porque map pode armazenar pares chave-valor de vários tipos, então é necessário inferir o espaço de memória ocupado com base no tipo durante a compilação. A função MapBucketType em cmd/compile/internal/reflectdata/reflect.go constrói bmap durante a compilação, realizando uma série de verificações, como se o tipo da chave é comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypePortanto, na verdade, a estrutura de bmap é a seguinte, mas esses campos não são visíveis para nós. Go acessa através de movimentação de ponteiros unsafe na prática:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Algumas explicações dos campos:
tophash, armazena o valor dos 8 bits superiores de cada chave. Para um elemento tophash, há os seguintes valores especiais:goconst ( emptyRest = 0 // o elemento atual está vazio e não há mais chaves disponíveis após este elemento emptyOne = 1 // o elemento atual está vazio, mas há chaves disponíveis após este elemento evacuatedX = 2 // aparece durante expansão, só pode aparecer em oldbuckets, indica que o elemento foi movido para a metade superior do novo array de buckets de hash evacuatedY = 3 // aparece durante expansão, só pode aparecer em oldbuckets, indica que o elemento foi movido para a metade inferior do novo array de buckets de hash evacuatedEmpty = 4 // aparece durante expansão, o elemento em si está vazio, foi marcado durante a realocação minTopHash = 5 // valor mínimo de tophash para uma chave normal )Sempre que o valor de
tophash[i]for maior queminTopHash, indica que existe uma chave-valor normal no índice correspondente.keys, array que armazena chaves do tipo especificado.elems, array que armazena valores do tipo especificado.overflow, ponteiro para o bucket de overflow.
Como as chaves e valores não podem ser acessados diretamente através dos campos da estrutura, Go declara antecipadamente uma constante dataoffset, que representa o offset de memória dos dados no bmap.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Na verdade, as chaves e valores são armazenados em um endereço de memória contínuo, similar à estrutura abaixo. Isso é feito para evitar desperdício de espaço devido ao alinhamento de memória.
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Portanto, para um bmap, após mover o ponteiro dataoffset, mover i*sizeof(keyType) é o endereço da i-ésima chave:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Obter o endereço do i-ésimo valor é similar:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))O ponteiro buckets no hmap aponta para o endereço do primeiro bucket de hash. Se quiser obter o endereço do i-ésimo bucket de hash, o offset é i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Nas seções seguintes, essas operações aparecerão com muita frequência.
Hash
Conflito
No hmap, há um campo extra usado especificamente para armazenar informações de buckets de overflow. Ele aponta para o slice que armazena os buckets de overflow, com a seguinte estrutura:
type mapextra struct {
// ponteiro do slice de buckets de overflow
overflow *[]*bmap
// ponteiro do slice de buckets de overflow antigos antes da expansão
oldoverflow *[]*bmap
// ponteiro para o próximo bucket de overflow livre
nextOverflow *bmap
}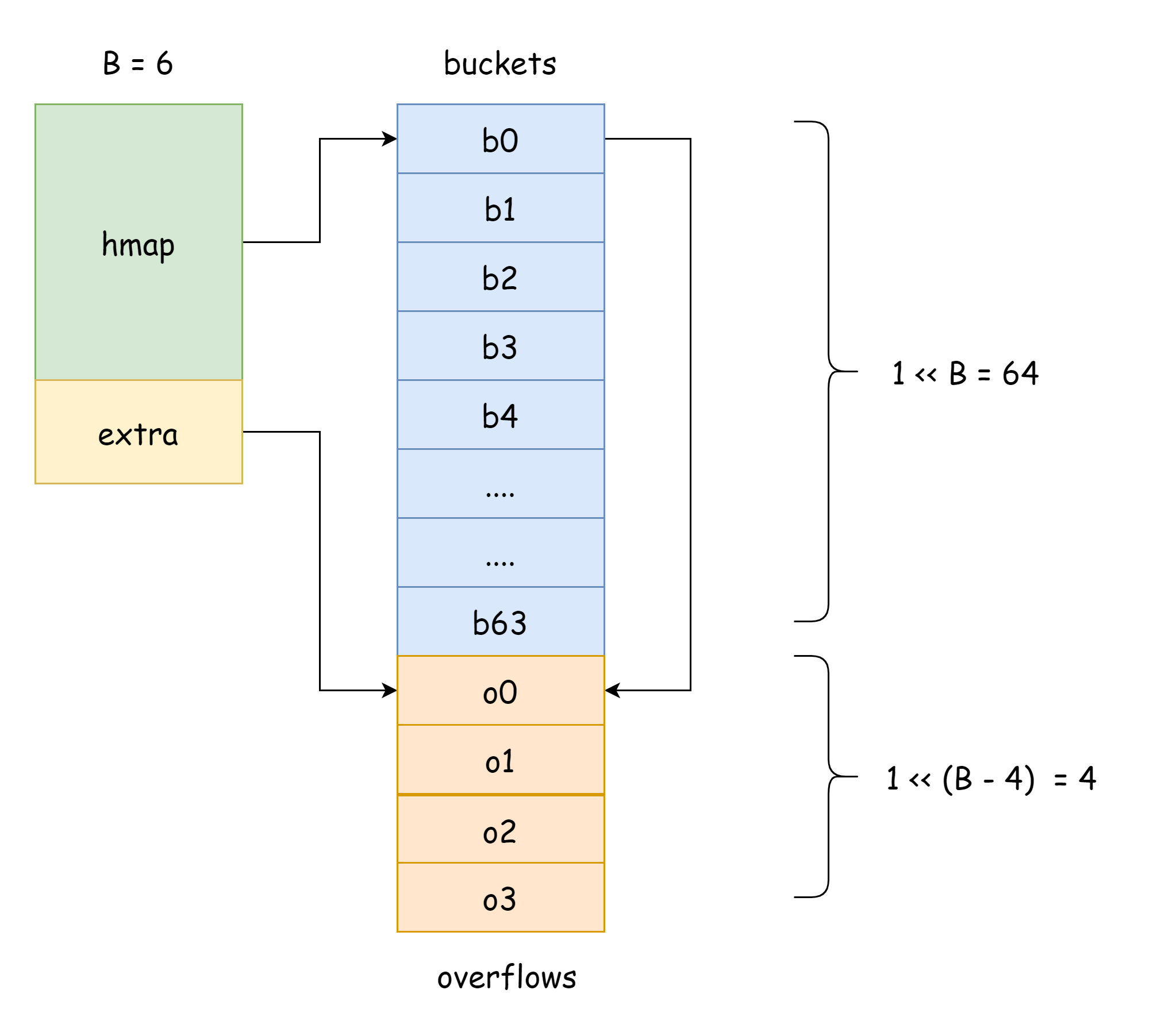
TIP
Na figura acima, a parte azul é o array de buckets de hash, a parte laranja é o array de buckets de overflow de hash. Os buckets de overflow serão referidos coletivamente como buckets de overflow abaixo.
A figura acima pode mostrar bem a estrutura geral do hmap. buckets aponta para o array de buckets de hash, extra aponta para o array de buckets de overflow. O bucket bucket0 aponta para o bucket de overflow overflow0. Dois tipos diferentes de buckets são armazenados em dois slices separados, e a memória de ambos os tipos de buckets é contínua. Quando duas chaves são alocadas no mesmo bucket após hash, isso é chamado de conflito de hash. A maneira como Go resolve conflitos de hash é o método de encadeamento. Quando o número de chaves em conflito excede a capacidade do bucket, geralmente 8, o valor depende de internal/abi.MapBucketCount. Então um novo bucket é criado para armazenar essas chaves, e este bucket é chamado de bucket de overflow, significando que o bucket original não consegue mais armazenar, e os elementos transbordam para este novo bucket. Após a criação, o bucket de hash terá um ponteiro apontando para o novo bucket de overflow. Esses ponteiros de bucket formam uma lista encadeada bmap.
Para o método de encadeamento, usa-se o fator de carga para medir a situação de conflitos na tabela hash, com a fórmula de cálculo:
loadfactor := len(elems) / len(buckets)Quanto maior o fator de carga, mais conflitos de hash ocorrem, ou seja, mais buckets de overflow existem. Ao ler/escrever na tabela hash, é necessário percorrer mais buckets de overflow na lista encadeada para encontrar a posição especificada, então o desempenho é pior. Para melhorar essa situação, deve-se aumentar o número de buckets buckets, ou seja, expansão. Para hmap, há duas situações que podem desencadear expansão:
- Fator de carga excede o limiar
bucketCnt*13/16, cujo valor é pelo menos 6.5. - Número excessivo de buckets de overflow
Quanto menor o fator de carga, menor é a utilização de memória do hmap, e maior é a memória ocupada. A função usada por Go para calcular o fator de carga é runtime.overLoadFactor, com o código:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Onde loadFactorNum e loadFactorDen são constantes, bucketshift calcula 1 << B, e sabe-se que:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenSimplificando, obtemos:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Onde (bucketCnt * 13 / 16) tem valor 6.5, 1 << B é o número de buckets de hash. Portanto, a função desta função é calcular se o número de elementos dividido pelo número de buckets é maior que o fator de carga 6.5.
Cálculo
A função interna de cálculo de hash em Go está localizada no arquivo runtime/alg.go como f32hash, conforme abaixo, incluindo tratamento para os casos NaN e 0.
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // qualquer tipo de NaN
default:
return memhash(p, h, 4)
}
}Podemos ver que o método de cálculo de hash do map não é baseado em tipo, mas baseado em memória, eventualmente chegando à função memhash, que é implementada em assembly, com lógica localizada em runtime/asm*.s. O valor hash baseado em memória não deve ser persistido, pois deve ser usado apenas em tempo de execução, não sendo possível garantir que a distribuição de memória seja completamente consistente em cada execução.
Neste arquivo há também uma função chamada typehash, que calcula o valor hash com base em diferentes tipos, mas o map não usa esta função para calcular hash.
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrEsta implementação é mais lenta que a anterior, mas mais genérica, usada principalmente para reflexão e geração de funções em tempo de compilação, como na função abaixo:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Criação
Há duas maneiras de inicializar um map, o que já foi explicado na introdução à linguagem. Uma é usar diretamente a palavra-chave map, e a outra é usar a função make. Independentemente do método de inicialização, eventualmente runtime.makemap cria o map. A assinatura da função é:
func makemap(t *maptype, hint int, h *hmap) *hmapOnde os parâmetros:
t, refere-se ao tipo do map, diferentes tipos requerem ocupação de memória diferentehint, refere-se ao segundo parâmetro da funçãomake, a capacidade esperada de elementos do map.h, refere-se ao ponteiro dohmap, pode sernil.
O valor de retorno é o ponteiro hmap inicializado. Durante o processo de inicialização, esta função tem vários trabalhos principais. Primeiro, calcula se a memória esperada alocada excederá a memória máxima alocável, correspondendo ao código abaixo:
// Multiplica a capacidade esperada pelo tamanho do tipo de bucket
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Overflow numérico ou excede a memória máxima alocável
if overflow || mem > maxAlloc {
hint = 0
}Na estrutura interna mencionada anteriormente, o hmap é composto internamente por buckets. No caso de menor utilização de memória, um bucket tem apenas um elemento, ocupando mais memória. Portanto, a ocupação máxima de memória esperada é o número de elementos multiplicado pelo tamanho de ocupação de memória do tipo correspondente. Quando o resultado do cálculo overflow numérico ou excede a memória máxima alocável, define hint como 0, pois posteriormente é necessário usar hint para calcular a capacidade do array de buckets.
Segundo passo inicializa o hmap e calcula uma semente hash aleatória, correspondendo ao código abaixo:
// Inicializa
if h == nil {
h = new(hmap)
}
// Obtém uma semente hash aleatória
h.hash0 = fastrand()Depois calcula a capacidade dos buckets de hash com base no valor de hint, correspondendo ao código abaixo:
B := uint8(0)
// Loop contínuo até hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Atribui ao hmap
h.B = BAtravés de loop contínuo encontra o primeiro valor B que satisfaz (hint / 1 << B) < 6.5, e o atribui ao hmap. Conhecendo a capacidade dos buckets de hash, finalmente aloca memória para os buckets de hash:
if h.B != 0 {
var nextOverflow *bmap
// Buckets de hash alocados e buckets de overflow livres pré-alocados
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Se buckets de overflow livres foram pré-alocados, aponta para eles
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}A função makeBucketArray aloca memória de tamanho correspondente para os buckets de hash com base no valor de B, e pré-aloca buckets de overflow livres. Quando B é menor que 4, não cria buckets de overflow. Se maior que 4, cria 2^B-4 buckets de overflow. Correspondendo ao código abaixo na função runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// Não cria buckets de overflow se menor que 4
if b >= 4 {
// Número esperado de buckets mais 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Memória necessária para buckets de overflow
sz := t.Bucket.Size_ * nbuckets
// Arredonda o espaço de memória para cima
up := roundupsize(sz)
if up != sz {
// Se não for igual, recalcula usando up
nbuckets = up / t.Bucket.Size_
}
}base refere-se ao número esperado de buckets alocados, nbuckets refere-se ao número real de buckets alocados, que adiciona o número de buckets de overflow.
if base != nbuckets {
// Primeiro bucket de overflow disponível
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Para reduzir o custo de rastrear buckets de overflow, o ponteiro de overflow do último bucket de overflow disponível aponta para o cabeçalho dos buckets de hash
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// Último bucket de overflow aponta para os buckets de hash
last.setoverflow(t, (*bmap)(buckets))
}Quando os dois não são iguais, significa que buckets de overflow adicionais foram alocados. O ponteiro nextoverflow aponta para o primeiro bucket de overflow disponível. Como podemos ver, buckets de hash e buckets de overflow estão na verdade na mesma memória contínua. É por isso que na figura o array de buckets de hash e o array de buckets de overflow são adjacentes.
Acesso
Na introdução à sintaxe foi mencionado que há três maneiras de acessar um map, conforme abaixo:
# Acessa diretamente o valor
val := dict[key]
# Acessa o valor e se a chave existe
val, exist := dict[key]
# Itera sobre o map
for key, val := range dict{
}Estas três maneiras usam funções diferentes. A iteração for range sobre o map é a mais complexa.
Chave-Valor
Para as duas primeiras maneiras, correspondem duas funções: runtime.mapaccess1 e runtime.mapaccess2. As assinaturas das funções são:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Onde key é um ponteiro para a chave de acesso ao map, e o retorno também retorna apenas um ponteiro. Ao acessar, primeiro é necessário calcular o valor hash da key e localizar em qual bucket de hash a key está. Correspondendo ao código abaixo:
// Tratamento de limites
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // veja issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Previne leitura e escrita concorrente
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Usa hasher do tipo especificado para calcular o valor hash
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Localiza o bucket de hash da key através de movimentação de ponteiro
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))No início do acesso, primeiro trata casos de borda e previne leitura e escrita concorrente no map. Quando o map está em estado de leitura e escrita concorrente, ocorre panic. Depois calcula o valor hash. A função bucketMask faz o cálculo (1 << B) - 1, hash & m é igual a hash & (1 << B) - 1, que é uma operação de módulo binário, equivalente a hash % (1 << B). O benefício de usar operação de bits é ser mais rápido. As últimas três linhas de código fazem o seguinte: o valor hash obtido do cálculo da key é calculado com módulo pelo número atual de buckets no map, obtendo o número do bucket de hash. Depois, com base no número, move o ponteiro para obter o ponteiro do bucket de hash onde a key está localizada.
Conhecendo em qual bucket de hash a key está, pode-se prosseguir com a busca. Esta parte corresponde ao código abaixo:
// Obtém os 8 bits superiores do valor hash
top := tophash(hash)
bucketloop:
// Itera sobre a lista encadeada bmap
for ; b != nil; b = b.overflow(t) {
// Elementos no bmap
for i := uintptr(0); i < bucketCnt; i++ {
// Compara o top calculado com os elementos em tophash
if b.tophash[i] != top {
// Os seguintes estão todos vazios, não há mais.
if b.tophash[i] == emptyRest {
break bucketloop
}
// Se não for igual, continua iterando sobre o bucket de overflow
continue
}
// Move o ponteiro para obter a chave do índice correspondente com base em i
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Trata o ponteiro
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Compara se duas chaves são iguais
if t.Key.Equal(key, k) {
// Se forem iguais, move o ponteiro para retornar o elemento correspondente a k
// Desta linha de código podemos ver que os endereços de memória das chaves e valores são contínuos
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Não encontrado, retorna valor zero.
return unsafe.Pointer(&zeroVal[0])Ao localizar o bucket de hash, é feito através de módulo. Portanto, em qual bucket de hash a key está depende dos bits inferiores do valor hash. Quantos bits inferiores dependem do tamanho de B. Após encontrar o bucket de hash, o tophash nele armazena os 8 bits superiores do valor hash. Como os valores de módulo dos bits inferiores são os mesmos, não é necessário comparar um por um se as keys são iguais. Basta comparar os 8 bits superiores do valor hash. Com base no valor hash calculado anteriormente, obtém seus 8 bits superiores e compara um por um no array tophash no bmap. Se os 8 bits superiores forem iguais, compara se as chaves são iguais. Se as chaves também forem iguais, significa que encontrou o elemento. Se não forem iguais, continua iterando sobre o array tophash. Se ainda não encontrar, continua iterando sobre a lista encadeada de buckets de overflow bmap, até que tophash[i] do bmap seja emptyRest e sai do loop. Finalmente retorna o valor zero do tipo correspondente.
A função mapaccess2 é completamente consistente com a lógica da função mapaccess1, apenas tem um valor de retorno booleano adicional, usado para indicar se o elemento existe.
Iteração
A sintaxe para iterar sobre um map é:
for key, val := range dict {
// do somthing...
}Ao iterar na prática, Go usa a estrutura hiter para armazenar informações de iteração. hiter é abreviação de hmap iterator, significando iterador de tabela hash. A estrutura é:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Deve estar na primeira posição. Escreva nil para indicar fim da iteração (veja cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Deve estar na segunda posição (veja cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // ponteiro do bucket no momento da inicialização do hash_iter
bptr *bmap // bucket atual
overflow *[]*bmap // mantém os buckets de overflow de hmap.buckets vivos
oldoverflow *[]*bmap // mantém os buckets de overflow de hmap.oldbuckets vivos
startBucket uintptr // bucket onde a iteração começou
offset uint8 // offset intra-bucket para começar durante a iteração (deve ser grande o suficiente para conter bucketCnt-1)
wrapped bool // já voltou do fim do array de buckets para o início
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Abaixo estão algumas explicações simples dos campos:
key,elemsão as chaves e valores obtidos durante a iteraçãofor rangebuckets, especificado durante a inicialização do iterador, aponta para o cabeçalho dos buckets de hashbptr, o bmap que está sendo iterado atualmentestartBucket, número do bucket inicial quando a iteração começaoffset, offset dentro do bucket, intervalo[0, bucketCnt-1]B, é o valor B do hmapi, índice do elemento dentro do bucketwrapped, se voltou do fim do array de buckets de hash para o início
Antes de começar a iterar, Go inicializa o iterador através da função runtime.mapiterinit, e depois itera sobre o map através da função runtime.mapiternext. Ambas precisam usar a estrutura hiter. As assinaturas das duas funções são:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Para inicialização do iterador, primeiro é necessário obter um snapshot atual do map, correspondendo ao código abaixo:
it.t = t
it.h = h
// Registra um snapshot do estado atual do hmap, precisa apenas salvar o valor B.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Durante a iteração subsequente, na verdade itera-se sobre um snapshot do map, não o map real. Portanto, elementos e buckets adicionados durante o processo de iteração não serão iterados. E iterar e escrever elementos concorrentemente ao mesmo tempo pode potencialmente acionar fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Segundo passo decide duas posições iniciais de iteração: a primeira é a posição do bucket inicial, a segunda é a posição inicial dentro do bucket. Ambas são escolhidas aleatoriamente, correspondendo ao código abaixo:
// r é um número aleatório
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) obtém a posição do bucket inicial
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 obtém a posição inicial do elemento dentro do bucket inicial
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Registra o número do bucket que está sendo iterado atualmente
it.bucket = it.startBucketObtém um número aleatório através de fastrand() ou fastrand64(), e através de duas operações de módulo obtém a posição inicial do bucket e a posição inicial dentro do bucket.
TIP
Embora o map não permita leitura e escrita concorrente simultaneamente, permite iteração concorrente simultaneamente.
Agora realmente começa a iterar sobre o map. Como iterar sobre os buckets e a estratégia de saída correspondem ao código abaixo:
// hmap
h := it.h
// maptype
t := it.t
// Posição do bucket a ser iterado
bucket := it.bucket
// bmap a ser iterado
b := it.bptr
// Índice i dentro do bucket
i := it.i
next:
if b == nil {
// Se a posição do bucket atual for igual à posição inicial, significa que deu uma volta completa e já iterou sobre o que vem depois
// Iteração terminada, pode sair
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Incrementa o índice do bucket
bucket++
// bucket == 1 << B, chegou ao fim do array de buckets de hash
if bucket == bucketShift(it.B) {
// Começa do início
bucket = 0
it.wrapped = true
}
i = 0
}A posição inicial dos buckets de hash é escolhida aleatoriamente. Durante a iteração, itera-se da posição inicial para o fim do slice de buckets um por um. Ao chegar em 1 << B, depois começa do início. Quando retorna novamente à posição inicial, significa que a iteração foi concluída e sai. O código acima trata de como iterar buckets no map. O código abaixo descreve como iterar dentro de um bucket:
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Se o elemento atual estiver vazio, pula
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Move o ponteiro para obter a chave
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Move o ponteiro para obter o valor
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Trata o caso de crescimento de mesma quantidade. Quando a chave-valor foi疏散 para outras posições, precisa buscar novamente a chave-valor.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Se não encontrou, busca no bucket de overflow
b = b.overflow(t)
i = 0
goto nextTIP
Na condição de julgamento de expansão acima, há uma expressão que pode causar confusão:
t.Key.Equal(k, k)A razão para julgar se k é igual a si mesmo é filtrar o caso onde a chave é Nan. Se a chave de um elemento for Nan, então não será possível acessar o elemento normalmente. Seja iteração, acesso direto ou remoção, não podem ser realizados normalmente, porque Nan != Nan sempre será verdadeiro, então nunca será possível encontrar esta chave.
Primeiro, através da operação de módulo dos valores i e offset, obtém o índice dentro do bucket a ser iterado. Obtém a chave-valor através de movimentação de ponteiro. Como durante a iteração do map, outras operações de escrita podem ocorrer desencadeando expansão do map, então a chave-valor real pode não estar mais na posição original. Neste caso, é necessário usar a função mapaccessK para buscar novamente a chave-valor real. A assinatura desta função é:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Sua função é completamente consistente com a função mapaccess1, a diferença é que a função mapaccessK retorna simultaneamente o valor da chave e o valor. Após obter finalmente a chave-valor, atribui ao key e elem do iterador, depois atualiza o índice do iterador. Assim completa uma iteração, e a execução do código retorna ao bloco de código for range. Se não encontrar dentro do bucket, busca no bucket de overflow, repetindo os passos acima até que a lista encadeada de buckets de overflow seja iterada completamente. Depois continua iterando sobre o próximo bucket de hash.
Modificação
A sintaxe para modificar um map é:
dict[key] = valEm Go, a operação de modificar um map é completada pela função runtime.mapassign, cuja assinatura é:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerA lógica do processo de acesso é a mesma que mapaccess1, mas quando a chave não existe, aloca uma posição para ela. Se existir, atualiza. Finalmente retorna o ponteiro do elemento. No início, é necessário fazer alguns preparativos. Esta parte corresponde ao código abaixo:
// Não permite escrita em map nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Proíbe escrita concorrente simultânea
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Calcula o valor hash da key
hash := t.Hasher(key, uintptr(h.hash0))
// Modifica o estado do hmap
h.flags ^= hashWriting
// Inicializa os buckets de hash
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}O código acima faz principalmente as seguintes coisas:
- Verificação do estado do hmap
- Calcula o valor hash da key
- Verifica se os buckets de hash precisam ser inicializados
Depois, através da operação de módulo do valor hash, obtém a posição do bucket de hash e o tophash da key. O código corresponde ao abaixo:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Move o ponteiro para obter o bmap na posição especificada
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Calcula tophash
top := tophash(hash)Agora determinada a posição do bucket, bmap, tophash, pode-se começar a buscar o elemento. Esta parte do código corresponde ao abaixo:
// tophash a ser inserido
var inserti *uint8
// Ponteiro da chave a ser inserida
var insertk unsafe.Pointer
// Ponteiro do valor a ser inserido
var elem unsafe.Pointer
bucketloop:
for {
// Itera sobre o array tophash dentro do bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash não é igual
if b.tophash[i] != top {
// Se o índice atual dentro do bucket está vazio e ainda não inseriu elemento, seleciona esta posição para inserir
if isEmpty(b.tophash[i]) && inserti == nil {
// Encontra uma posição adequada para alocar à key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Se terminou de iterar, sai do loop
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// Se tophash for igual, significa que a key pode já existir
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Julga se a key é igual
if !t.Key.Equal(key, k) {
continue
}
// Se precisar atualizar o valor da key, copia diretamente a memória da key para k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// Obtém o ponteiro do elemento
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Atualização concluída, retorna o ponteiro do elemento
goto done
}
// Chegar aqui significa que não encontrou a key. Itera sobre a lista encadeada de buckets de overflow e continua buscando
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Chegar aqui significa que a key não existe no map, mas pode ter encontrado uma posição adequada para alocar à key, ou não
// Não encontrou uma posição adequada para alocar à key
if inserti == nil {
// Significa que o bucket de hash atual e seus buckets de overflow estão cheios. Então aloca um novo bucket de overflow
newb := h.newoverflow(t, b)
// Aloca uma posição no bucket de overflow para a key
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Se armazenar ponteiro de key
if t.IndirectKey() {
// Aloca nova memória, retorna um ponteiro unsafe
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Atribui a insertk para facilitar a cópia de memória da key posteriormente
insertk = kmem
}
// Se armazenar ponteiro de elemento
if t.IndirectElem() {
// Aloca memória
vmem := newobject(t.Elem)
// Faz o ponteiro apontar para vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Copia diretamente a memória da key para a posição insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// Incrementa a quantidade em um
h.count++
done:
// Chegar aqui significa que o processo de modificação foi concluído
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Retorna o ponteiro do elemento
return elemNo grande trecho de código acima, primeiro entra no loop for tentando buscar no bucket de hash e no bucket de overflow. A lógica de busca é completamente consistente com mapaccess. Neste momento há três possibilidades:
- Primeiro, encontra uma key já existente no map, pula diretamente para o bloco de código
donee retorna o ponteiro do elemento - Segundo, encontra uma posição no map para alocar à key, copia a key para a posição especificada e retorna o ponteiro do elemento
- Terceiro, todos os buckets foram buscados e não encontrou uma posição que possa ser alocada à key no map. Cria um novo bucket de overflow e aloca a key no bucket. Depois copia a key para a posição especificada e retorna o ponteiro do elemento
Finalmente, após obter o ponteiro do elemento, pode-se atribuir. No entanto, esta operação não é completada pela função mapassign. Ela é apenas responsável por retornar o ponteiro do elemento. A operação de atribuição é inserida durante o compilador, não visível no código, mas visível no código compilado. Suponha que haja o código abaixo:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Através do comando abaixo obtém o código assembly:
go tool compile -S -N -l main.goAs partes críticas estão nestas:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Podemos ver que chama runtime.mapassign_faststr, cuja lógica é completamente similar a mapassign. LEAQ go:string."world"(SB), CX armazena o endereço da string em CX, MOVQ CX, (AX) armazena em AX, completando assim a atribuição do elemento.
Remoção
Em Go, para remover um elemento de um map, só é possível usar a função integrada delete:
delete(dict, "abc")Internamente chama a função runtime.mapdelete, cuja assinatura é:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Ela remove o elemento da chave especificada no map. Independentemente de o elemento existir ou não no map, ela não terá qualquer reação. A lógica de preparação no início da função é similar, nada mais que as seguintes coisas:
- Verificação do estado do hmap
- Calcula o valor hash da key
- Localiza o bucket de hash
- Calcula tophash
Há muito conteúdo repetido anteriormente, não será mais explicado em detalhes. Aqui focamos apenas na lógica de remoção. A parte correspondente do código é:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Se não encontrou, sai do loop
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Move o ponteiro para encontrar a posição da key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Remove a key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Move o ponteiro para encontrar a posição do elemento
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Remove o elemento
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Decrementa a quantidade em um
h.count--
// Reseta a semente hash, reduz a probabilidade de conflitos
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Podemos ver através do código acima que a lógica de busca é quase completamente consistente com as operações anteriores. Encontra o elemento, depois remove, decrementa a quantidade registrada no hmap em um. Quando a quantidade é reduzida a 0, reseta a semente hash.
Outro ponto a notar é que, após remover o elemento, é necessário modificar o estado tophash do índice atual. Esta parte corresponde ao código abaixo. Quando i está no final do bucket, julga com base no próximo bucket de overflow se o elemento atual é o último elemento disponível. Caso contrário, verifica diretamente o estado hash dos elementos adjacentes. Se o elemento atual não for o último disponível, define o estado como emptyOne:
// Marca o tophash atual como vazio
b.tophash[i] = emptyOne
// Se estiver no final do tophash
if i == bucketCnt-1 {
// Se o bucket de overflow não estiver vazio e houver elementos no bucket de overflow, significa que o elemento atual não é o último
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Elemento adjacente não está vazio
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Se o elemento for de fato o último elemento, é necessário corrigir os valores do array tophash de alguns buckets na lista encadeada de buckets. Caso contrário, iterações subsequentes não poderão sair na posição correta. Ao criar buckets de overflow no map, foi mencionado que Go, para reduzir o custo de rastrear buckets de overflow, o ponteiro overflow do último bucket de overflow aponta para o bucket de hash do cabeçalho. Portanto, é na verdade uma lista encadeada circular unidirecional. A "cabeça" da lista encadeada é o bucket de hash. E o b aqui é o b após a busca, muito provavelmente é um bucket de overflow no meio da lista. Itera逆序 sobre a lista encadeada circular para buscar o último elemento existente. Embora o código esteja escrito como iteração正序, como a lista encadeada é um anel, itera constantemente正序 até o bucket anterior ao bucket de overflow atual. Em termos de resultado, é de fato逆序. Depois itera逆序 sobre o array tophash no bucket, atualizando elementos com estado emptyOne para emptyRest, até encontrar o último elemento existente. Para evitar ficar preso infinitamente no anel, quando retorna ao bucket inicial, ou seja, bOrig, significa que não há mais elementos disponíveis na lista encadeada, e pode sair do loop:
// Chegar aqui significa que não há elementos após o elemento atual
// Itera constantemente逆序 sobre a lista encadeada bmap,逆序 sobre o tophash dentro do bucket
// Atualiza elementos com estado emptyOne para emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Encontra o anterior na lista bmap atual
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Limpeza
Na versão go1.21, foi adicionada a função integrada clear, que pode ser usada para limpar todos os elementos em um map. A sintaxe é:
clear(dict)Internamente chama a função runtime.mapclear, que é responsável por remover todos os elementos do map. A assinatura da função é:
func mapclear(t *maptype, h *hmap)A lógica desta função não é muito complexa. Primeiro é necessário marcar todo o map como vazio, correspondendo ao código abaixo:
// Itera sobre cada bucket e bucket de overflow, define todos os elementos tophash como emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))O que o código acima faz é iterar sobre cada bucket, definindo todos os elementos do array tophash no bucket como emptyRest, marcando o map como vazio. Isso impede que o iterador continue iterando. Depois limpa o map, correspondendo ao código abaixo:
// Reseta a semente hash
h.hash0 = fastrand()
// Reseta a estrutura extra
if h.extra != nil {
*h.extra = mapextra{}
}
// Esta operação limpa a memória dos buckets anteriores e aloca novos buckets
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Aloca novos buckets de overflow livres
h.extra.nextOverflow = nextOverflow
}Através de makeBucketArray limpa a memória dos buckets anteriores, depois aloca novos. Assim completa a limpeza dos buckets. Além disso, há alguns detalhes, como definir count para 0, e outras operações não serão explicadas em detalhes.
Expansão
Em todas as operações anteriores, para focar mais na lógica em si,屏蔽了很多与扩容相关的内容,这样会简单很多。扩容的逻辑其实比较复杂,放在最后就是不希望产生干扰,那么现在就来看看 go 是如何对 map 进行扩容的,前面已经提到过,触发扩容有两个条件:
- Fator de carga excede 6.5
- Número de buckets de overflow é excessivo
A função que julga se o fator de carga excede o limiar é a função runtime.overLoadFactor, já explicada na parte de conflitos de hash. A função que julga se o número de buckets de overflow é excessivo é runtime.tooManyOverflowBuckets, cujo princípio de funcionamento também é muito simples. O código é:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}O código acima pode ser simplificado para a seguinte expressão, fácil de entender de uma vez:
overflow >= 1 << (min(15,B) % 16)Aqui, a definição de Go para "too many" é: o número de buckets de overflow é aproximadamente igual ao número de buckets de hash. Se o limiar for baixo, fará trabalho desnecessário. Se o limiar for alto, ocupará muita memória durante a expansão. É possível desencadear expansão durante operações de modificação e remoção de elementos. O código que julga se é necessário expansão é:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}Podemos ver estas três condições de restrição:
- Não pode estar em expansão atualmente
- Fator de carga menor que 6.5
- Número de buckets de overflow não pode ser excessivo
A função responsável pela expansão naturalmente é runtime.hashGrow, cuja assinatura é:
func hashGrow(t *maptype, h *hmap)Na verdade, expansão também tem tipos. Diferentes condições desencadeiam diferentes tipos de expansão, divididos nos seguintes dois tipos:
- Expansão incremental
- Expansão de mesma quantidade
Expansão Incremental
Quando o fator de carga é muito grande, ou seja, o número de elementos é maior que o número de buckets de hash, quando os conflitos de hash são muito severos, formar-se-ão muitas listas encadeadas de buckets de overflow. Isso levará à diminuição do desempenho de leitura/escrita do map, porque é necessário percorrer mais buckets de overflow na lista encadeada para encontrar um elemento. O tempo de complexidade de iteração é O(n). O tempo de complexidade de busca na tabela hash depende principalmente do tempo de cálculo do valor hash e do tempo de iteração. Quando o tempo de iteração é muito menor que o tempo de cálculo do hash, a complexidade de tempo de busca pode ser considerada O(1). Se conflitos de hash forem frequentes, muitas chaves são alocadas no mesmo bucket de hash. Lista encadeada de buckets de overflow muito longa leva ao aumento do tempo de iteração, resultando em aumento do tempo de busca. Como operações de inserção, remoção e modificação precisam primeiro realizar operações de busca, isso leva a uma queda severa no desempenho de todo o map.
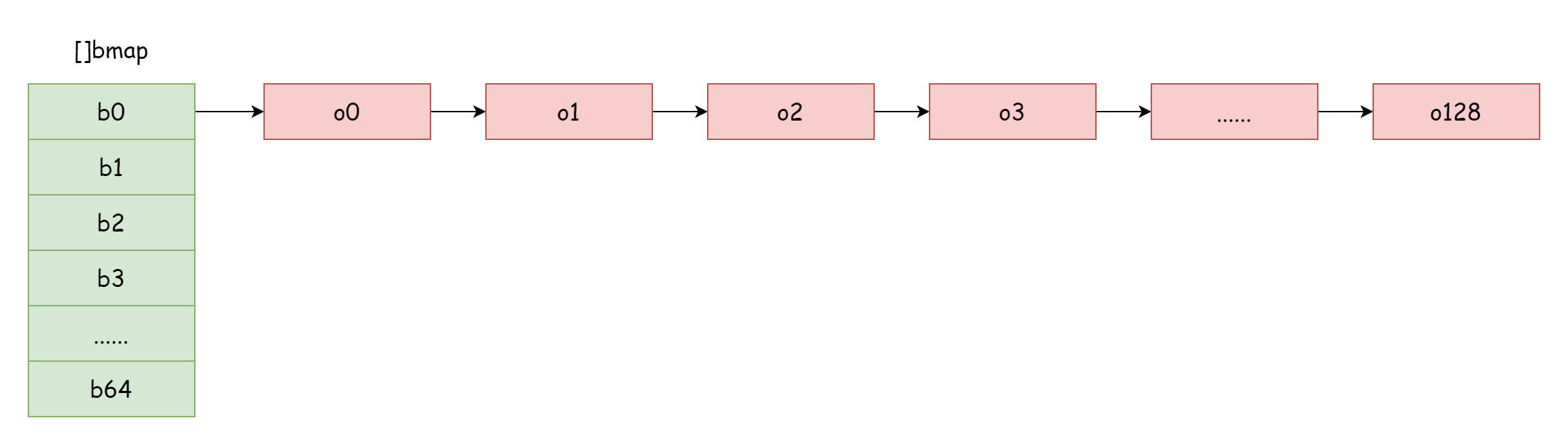
Como nesta situação extrema mostrada na figura, a complexidade de tempo de busca é basicamente equivalente a O(n). Para lidar com esta situação, a solução é adicionar mais buckets de hash, evitando formar listas encadeadas de buckets de overflow muito longas. Este método também é chamado de expansão incremental.
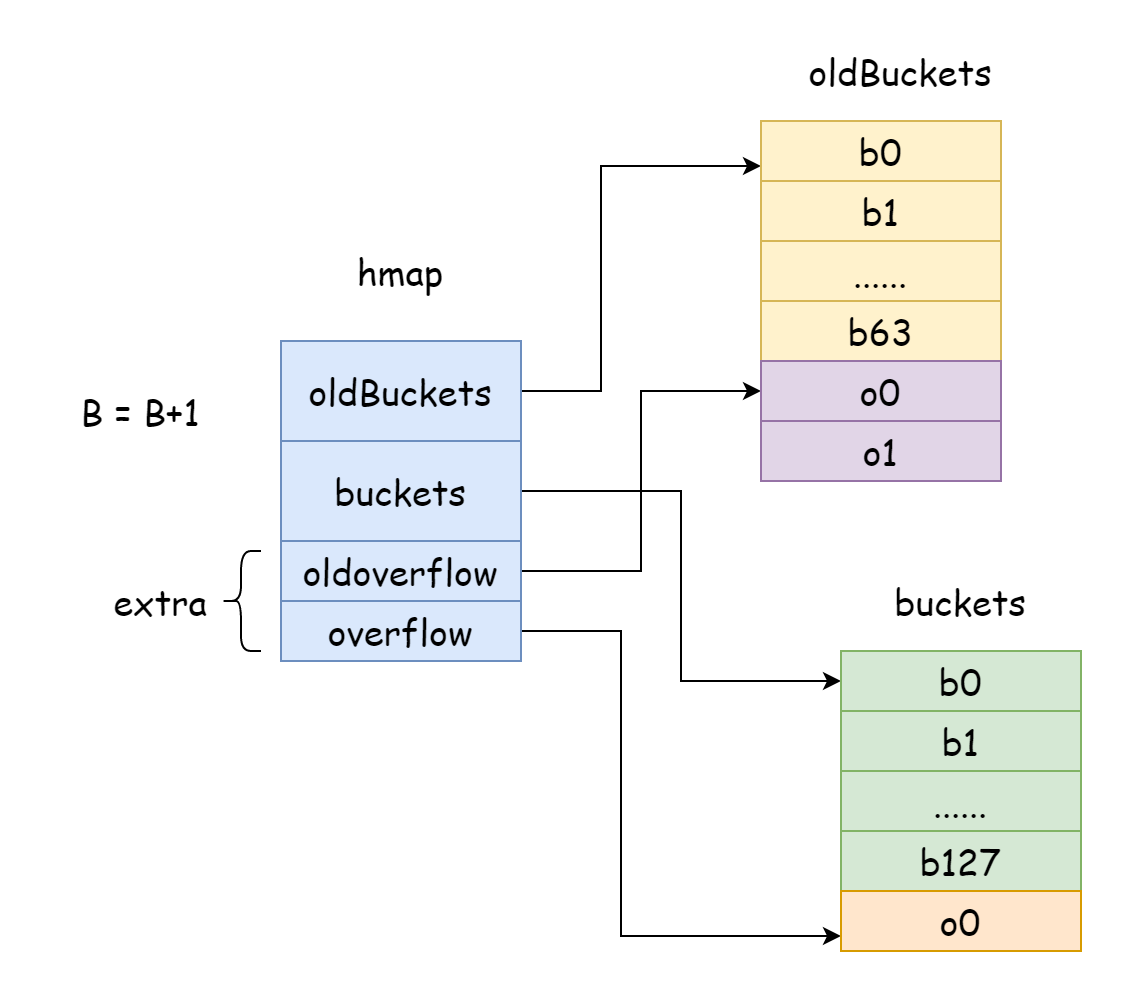
Em Go, a expansão incremental sempre adiciona um ao B, ou seja, a escala dos buckets de hash é expandida para o dobro a cada vez. Após a expansão, é necessário mover os dados antigos para o novo map. Se o número de elementos no map for de milhões ou até centenas de milhões, mover tudo de uma vez levaria muito tempo. Portanto, Go adota a estratégia de movimento gradual. Para isso, Go faz com que oldBuckets no hamp aponte para o array original de buckets de hash, indicando que estes são dados antigos. Depois cria um array de buckets de hash de maior capacidade, fazendo com que buckets no hmap aponte para o novo array de buckets de hash. Durante cada modificação e remoção de elementos, move parcialmente os elementos do bucket antigo para o novo bucket, até que o movimento seja concluído. Só então a memória do bucket antigo é liberada.
func hashGrow(t *maptype, h *hmap) {
// Diferença
bigger := uint8(1)
// Buckets antigos
oldbuckets := h.buckets
// Novos buckets de hash
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Buckets de overflow também precisam especificar buckets antigos e novos
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}O código acima faz o seguinte: cria novos buckets de hash com capacidade dobrada, depois especifica as referências dos buckets antigos e novos de hash, bem como as referências dos buckets de overflow antigos e novos. O trabalho real de realocação não é completado pela função hashGrow. Ela é apenas responsável por especificar buckets antigos e novos e atualizar alguns estados do hmap. Estes trabalhos são na verdade completados pela função runtime.growWork, cuja assinatura é:
func growWork(t *maptype, h *hmap, bucket uintptr)Ela será chamada nas funções mapassign e mapdelete da seguinte forma. Sua função é: se o map atual estiver em expansão, realiza um trabalho de realocação parcial:
if h.growing() {
growWork(t, h, bucket)
}Ao modificar e remover elementos, é necessário julgar se está atualmente em expansão. Isso é completado principalmente pelo método hmap.growing. O conteúdo é muito simples, apenas julga se oldbuckets não está vazio. Correspondendo ao código abaixo:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Vamos ver o que a função growWork faz:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}Onde a operação bucket&h.oldbucketmask() calcula a posição do bucket antigo, garantindo que o bucket antigo a ser movido é o bucket atual. Podemos ver no código que a função realmente responsável pelo trabalho de realocação é a função runtime.evacuate. Ela usa a estrutura evaDst para representar o destino da realocação. Seu papel principal é iterar sobre o novo bucket durante o processo de realocação. Sua estrutura é:
type evacDst struct {
b *bmap // novo bucket de destino da realocação
i int // índice dentro do bucket
k unsafe.Pointer // ponteiro para o destino da nova chave
e unsafe.Pointer // ponteiro para o destino do novo valor
}Antes de começar a realocação, Go aloca duas estruturas evacDst. Uma aponta para a metade superior do novo bucket de hash, e outra aponta para a metade inferior do novo bucket de hash. O código correspondente é:
// Localiza o bucket de hash especificado no bucket antigo
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Comprimento do bucket antigo = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Aponta para a metade superior do novo bucket
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// Julga se é expansão de mesma quantidade
if !h.sameSizeGrow() {
y := &xy[1]
// Aponta para a metade inferior do novo bucket
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}O destino de realocação do bucket antigo são dois novos buckets. Após a realocação, parte dos dados no bucket estará na metade superior, e outra parte dos dados estará na metade inferior. Isso é feito na esperança de que os dados após a expansão sejam distribuídos de forma mais uniforme. Quanto mais uniforme a distribuição, melhor será o desempenho de busca do map. Como Go move os dados para dois novos buckets corresponde ao código abaixo:
// Itera sobre a lista encadeada de buckets de overflow
for ; b != nil; b = b.overflow(t) {
// Obtém o primeiro par chave-valor de cada bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Itera sobre cada par chave-valor no bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Se estiver vazio, pula
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Novo bucket de hash não deve estar em estado de realocação
// Caso contrário, definitivamente há um problema
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Esta variável decide se o par chave-valor atual é movido para a metade superior ou inferior
// Seu valor só pode ser 0 ou 1
var useY uint8
if !h.sameSizeGrow() {
// Recalcula o valor hash
hash := t.Hasher(k2, uintptr(h.hash0))
// Trata o caso especial k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Verifica o valor da constante
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Atualiza o tophash do bucket antigo, indicando que o elemento atual foi movido
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// Especifica o destino da realocação
dst := &xy[useY] // destino da evacuação
// Se a capacidade do novo bucket não for suficiente, cria um bucket de overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mascara dst.i como otimização para evitar verificação de limites
// Copia a chave
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copia ponteiro
} else {
typedmemmove(t.Key, dst.k, k) // copia elemento
}
// Copia o valor
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Move o ponteiro de destino do novo bucket para o próximo, preparando para a próxima chave-valor
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Podemos ver no código acima que Go itera sobre cada elemento de cada bucket na lista encadeada de buckets antigos, movendo os dados para o novo bucket. Decidir se os dados vão para a metade superior ou inferior depende do valor hash recalculado:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Após a realocação, define o tophash do elemento atual como evacuatedX ou evacuatedY. Se tentar buscar dados durante o processo de expansão, através deste estado pode-se saber que os dados já foram movidos, e sabe-se que deve buscar os dados correspondentes no novo bucket. Esta parte da lógica corresponde ao código abaixo na função runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// Havia metade dos buckets antes; mascara mais uma potência de dois.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Se o bucket antigo já foi movido, não busca mais
if !evacuated(oldb) {
b = oldb
}
}Ao acessar o elemento, se estiver atualmente em estado de expansão, primeiro tenta buscar no bucket antigo. Se o bucket antigo já foi movido, não busca mais no bucket antigo. Voltando à realocação, agora determinado o destino da realocação, o próximo passo é copiar os dados para o novo bucket, e depois fazer a estrutura evacDst apontar para o próximo destino:
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Assim opera até que o bucket atual seja completamente movido. Depois Go limpa completamente os dados de memória do bucket antigo, deixando apenas um array tophash de bucket de hash (deixa porque posteriormente depende do array tophash para julgar o estado de realocação). A memória dos buckets de overflow no bucket antigo será reciclada pelo GC posteriormente, pois não é mais referenciada. Há um campo nevacuate no hmap usado para registrar o progresso da realocação. Cada vez que um bucket de hash antigo é movido, incrementa em um. Quando seu valor é igual ao número de buckets antigos, significa que a expansão de todo o map foi concluída. Em seguida, a função runtime.advanceEvacuationMark realiza o trabalho de finalização da expansão:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Ela estatística a quantidade movida e confirma se é igual ao número de buckets antigos. Se for igual, limpa todas as referências para todos os buckets antigos e buckets de overflow antigos. Até aqui a expansão está concluída.
Na função growWork, chama a função evacuate duas vezes no total. A primeira vez move o bucket antigo do bucket que está sendo acessado atualmente. A segunda vez move o bucket antigo apontado por h.nevacuate. Move dois buckets no total a cada vez durante a realocação gradual.
Expansão de Mesma Quantidade
Foi mencionado anteriormente que a condição de acionamento da expansão de mesma quantidade é o número excessivo de buckets de overflow. Suponha que o map primeiro adicione uma grande quantidade de elementos, e depois remova uma grande quantidade de elementos. Neste caso, muitos buckets podem estar vazios, alguns buckets podem ter muitos elementos, a distribuição de dados é muito desigual, e muitos buckets de overflow estão vazios, ocupando considerável memória. Para resolver este tipo de problema, é necessário criar um novo map de mesma capacidade, realocar os buckets de hash, e este processo é chamado de expansão de mesma quantidade. Portanto, na verdade não é uma operação de expansão, apenas redistribui todos os elementos para tornar a distribuição de dados mais uniforme. A operação de expansão de mesma quantidade é combinada na operação de expansão incremental, e a lógica é completamente consistente com a expansão incremental. A capacidade do map antigo e novo é completamente igual.
Na função hashGrow, se o fator de carga não exceder o limiar, realiza-se a expansão de mesma quantidade. Go atualiza o estado de h.flags para sameSizeGrow, e h.B não incrementa em um. Portanto, a capacidade dos buckets de hash recém-criados também não muda. Correspondendo ao código abaixo:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)Na função evacuate, ao criar a estrutura eavcDst inicialmente, se for expansão de mesma quantidade, apenas cria uma estrutura apontando para o novo bucket. Correspondendo ao código abaixo:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}E durante a realocação de elementos, a expansão de mesma quantidade não recalcula o valor hash, e não há escolha entre metade superior e inferior:
if !h.sameSizeGrow() {
// Recalcula o valor hash
hash := t.Hasher(k2, uintptr(h.hash0))
// Trata o caso especial k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Exceto por estas diferenças, o resto da lógica é completamente consistente com a expansão incremental. Após a expansão de mesma quantidade e realocação dos buckets de hash, o número de buckets de overflow será reduzido. Os buckets de overflow antigos serão reciclados pelo GC.