map
Yang membedakan Go dari bahasa lain adalah dukungan untuk tabel pemetaan disediakan oleh kata kunci map, bukan dikapsulasi sebagai pustaka standar. Tabel pemetaan adalah struktur data yang digunakan dalam banyak skenario, dengan banyak implementasi di tingkat rendah. Dua cara paling umum adalah pohon merah-hitam dan tabel hash, Go menggunakan implementasi tabel hash.
TIP
Implementasi map melibatkan banyak operasi perpindahan pointer, jadi untuk membaca artikel ini diperlukan pengetahuan tentang pustaka standar unsafe.
Struktur Internal
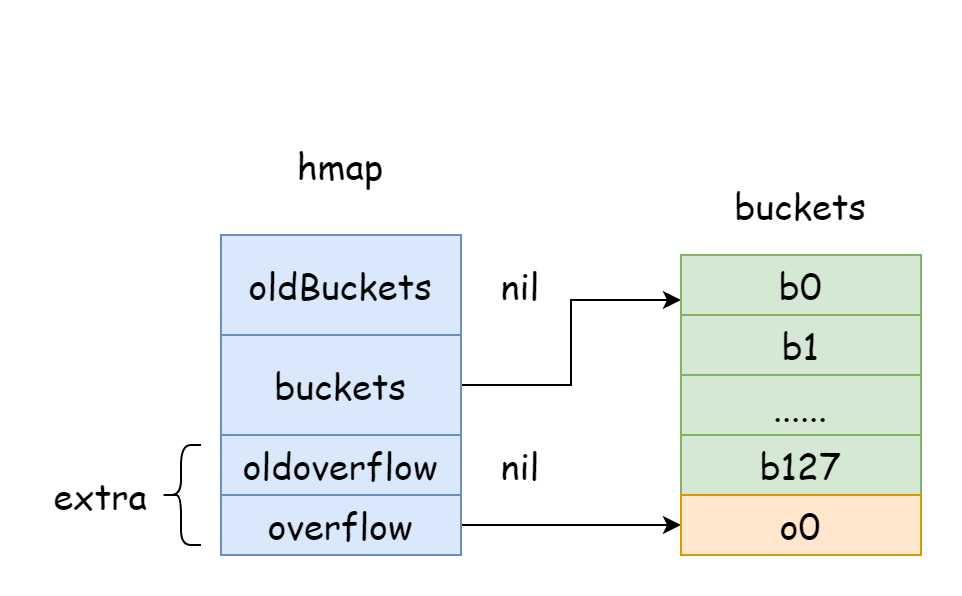
Struktur runtime.hmap merepresentasikan map di Go, seperti slice, implementasi internal map juga merupakan struktur.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}Komentar dalam bahasa Inggris sudah menjelaskan dengan cukup jelas, berikut adalah penjelasan singkat untuk field yang lebih penting
count, menunjukkan jumlah elemen di hmap, hasilnya sama denganlen(map).flags, flag hmap, digunakan untuk menunjukkan status hmap, dengan beberapa kemungkinan berikut.goconst ( iterator = 1 // iterator sedang menggunakan bucket oldIterator = 2 // iterator sedang menggunakan bucket lama hashWriting = 4 // satu goroutine sedang menulis ke hmap sameSizeGrow = 8 // sedang melakukan ekspansi dengan ukuran yang sama )B, jumlah bucket hash di hmap adalah1 << B.noverflow, jumlah perkiraan bucket overflow di hmap.hash0, seed hash, ditentukan saat hmap dibuat, digunakan untuk menghitung nilai hash.buckets, pointer yang menyimpan array bucket hash.oldbuckets, pointer yang menyimpan array bucket hash sebelum ekspansi.extra, menyimpan bucket overflow di hmap. Bucket overflow adalah bucket baru yang dibuat ketika bucket saat ini sudah penuh untuk menyimpan elemen.
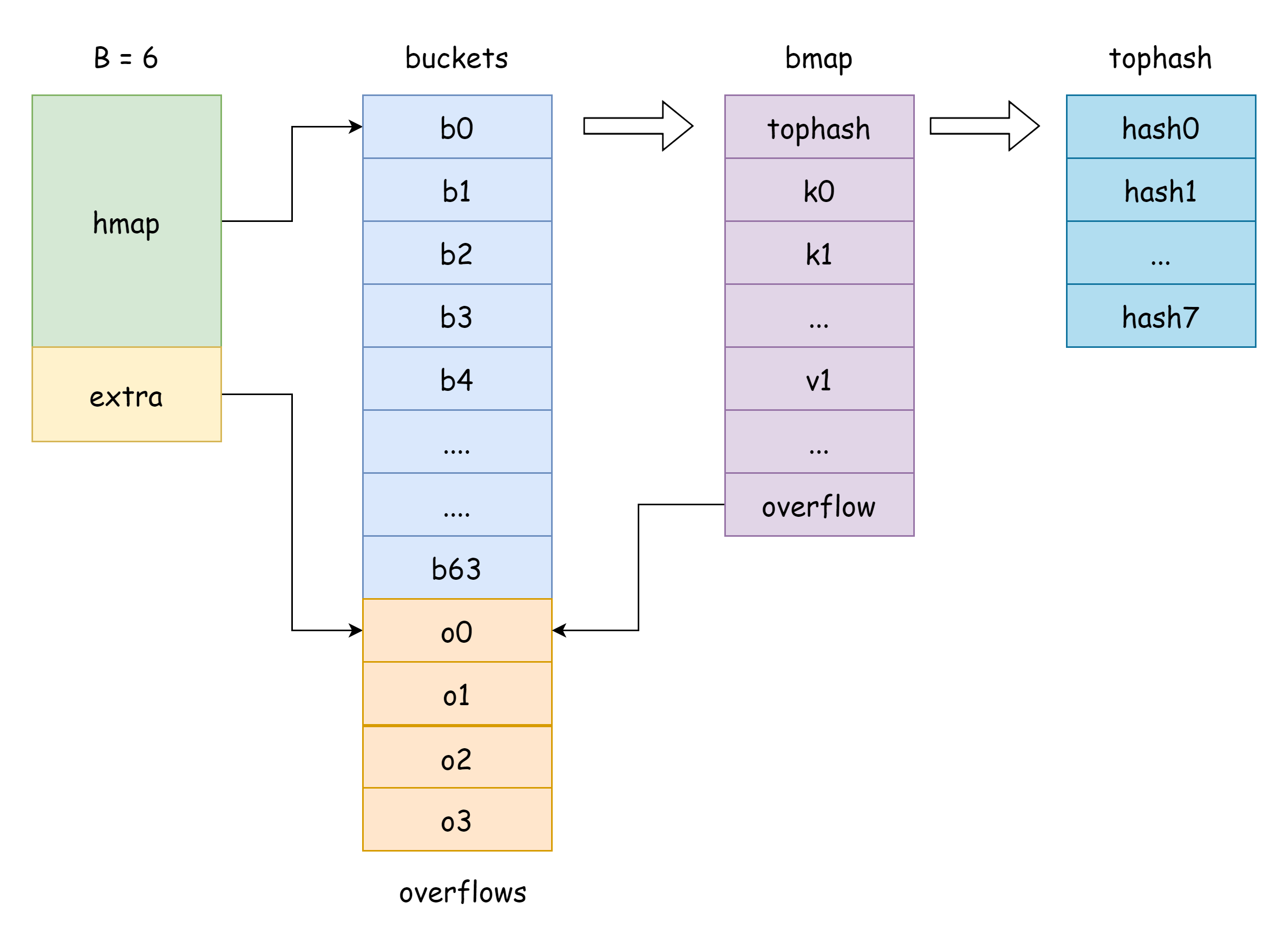
Pointer slice bucket di buckets hmap, sesuai dengan struktur runtime.bmap di Go, seperti berikut
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Dari atas dapat dilihat bahwa ia hanya memiliki field tophash, field ini digunakan untuk menyimpan 8 bit tinggi dari setiap kunci. Namun sebenarnya, bmap memiliki lebih banyak field, ini karena map dapat menyimpan pasangan kunci-nilai dari berbagai tipe, jadi perlu menyimpulkan ruang memori yang digunakan berdasarkan tipe saat kompilasi. Fungsi MapBucketType di cmd/compile/internal/reflectdata/reflect.go mengkonstruksi bmap saat kompilasi, ia akan melakukan serangkaian pemeriksaan, misalnya apakah tipe key comparable.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeJadi sebenarnya, struktur bmap adalah sebagai berikut, namun field-field ini tidak terlihat bagi kita, Go mengaksesnya dengan memindahkan pointer unsafe saat operasi
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Penjelasan untuk beberapa field adalah sebagai berikut
tophash, menyimpan nilai 8 bit tinggi dari setiap kunci. Untuk elemen tophash, ada beberapa nilai khusus berikutgoconst ( emptyRest = 0 // elemen saat ini kosong, dan tidak ada kunci yang tersedia setelah elemen ini emptyOne = 1 // elemen saat ini kosong, tetapi ada kunci yang tersedia setelah elemen ini evacuatedX = 2 // muncul saat ekspansi, hanya bisa muncul di oldbuckets, menunjukkan elemen saat ini dipindahkan ke bagian atas array bucket hash baru evacuatedY = 3 // muncul saat ekspansi, hanya bisa muncul di oldbuckets, menunjukkan elemen saat ini dipindahkan ke bagian bawah array bucket hash baru evacuatedEmpty = 4 // muncul saat ekspansi, elemen itu sendiri kosong, ditandai saat relokasi minTopHash = 5 // nilai minimum tophash untuk kunci normal )Selama nilai
tophash[i]lebih besar dariminTopHash, menunjukkan bahwa ada pasangan kunci-nilai normal pada indeks yang sesuai.keys, array yang menyimpan kunci dari tipe yang ditentukan.elems, array yang menyimpan nilai dari tipe yang ditentukan.overflow, pointer yang menunjuk ke bucket overflow.
Karena pasangan kunci-nilai tidak dapat diakses langsung melalui field struktur, Go mendeklarasikan konstanta dataoffset sebelumnya, yang mewakili offset memori data di bmap.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Sebenarnya, pasangan kunci-nilai disimpan di alamat memori yang berkelanjutan, mirip dengan struktur berikut, ini dilakukan untuk menghindari pemborosan ruang karena penyelarasan memori.
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Jadi untuk bmap, setelah pointer bergerak dataoffset, bergerak i*sizeof(keyType) adalah alamat key ke-i
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Hal yang sama untuk mendapatkan alamat value ke-i
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))Pointer buckets di hmap, adalah alamat bucket hash pertama. Jika ingin mendapatkan alamat bucket hash ke-i, offsetnya adalah i*sizeof(bucket).
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Operasi ini akan sering muncul di konten berikutnya.
Hash
Konflik
Di hmap, ada field extra yang khusus digunakan untuk menyimpan informasi bucket overflow, ia akan menunjuk ke slice yang menyimpan bucket overflow, strukturnya adalah sebagai berikut.
type mapextra struct {
// pointer slice bucket overflow
overflow *[]*bmap
// pointer slice bucket overflow lama sebelum ekspansi
oldoverflow *[]*bmap
// pointer yang menunjuk ke bucket overflow kosong berikutnya
nextOverflow *bmap
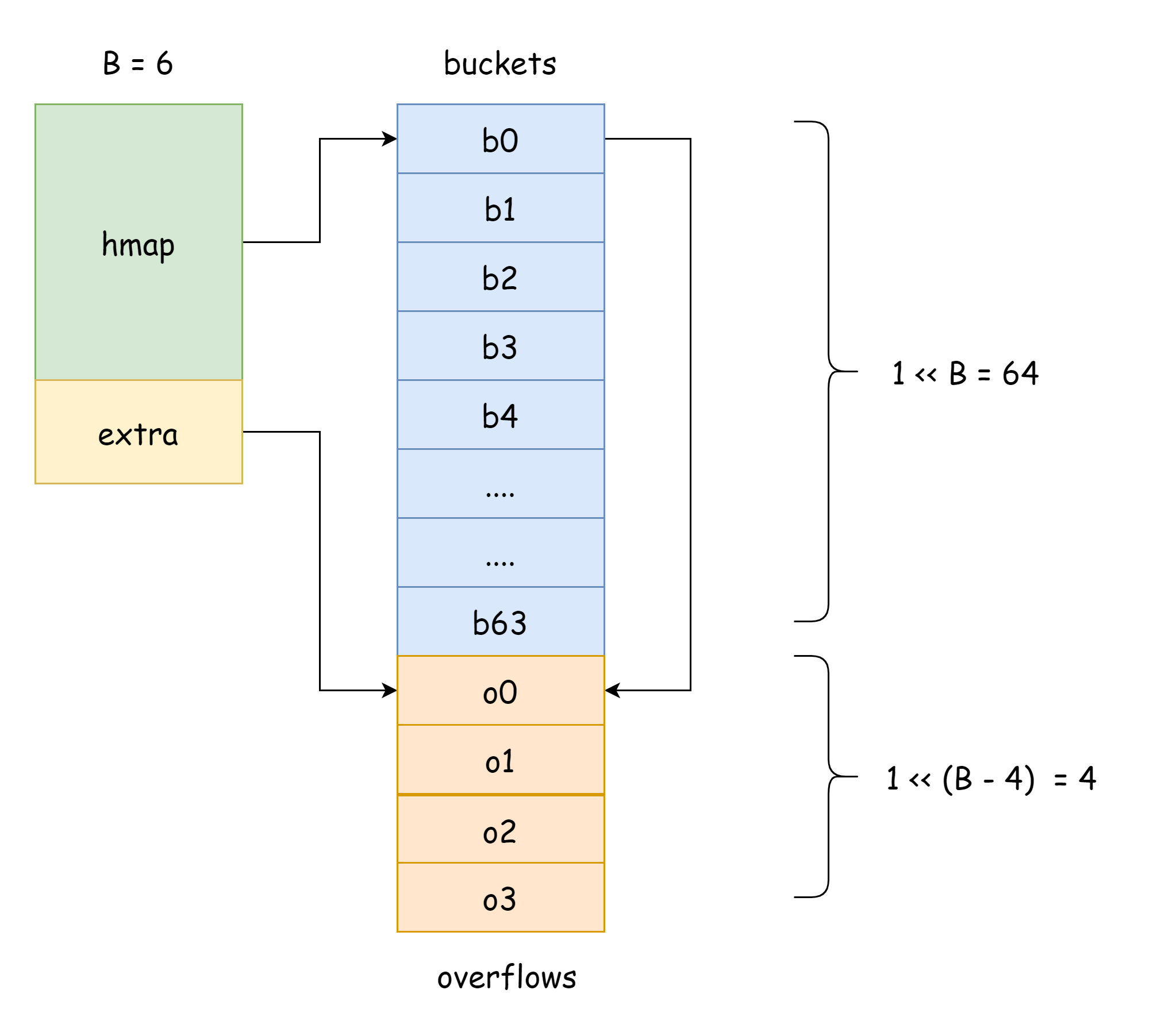
}
TIP
Pada gambar di atas, bagian biru adalah array bucket hash, bagian oranye adalah array bucket hash overflow, bucket overflow di bawah ini secara kolektif disebut bucket overflow.
Gambar di atas dapat menunjukkan struktur umum hmap dengan cukup baik, buckets menunjuk ke array bucket hash, extra menunjuk ke array bucket overflow, bucket bucket0 menunjuk ke bucket overflow overflow0, dua jenis bucket yang berbeda disimpan dalam dua slice, memori dari kedua jenis bucket adalah berkelanjutan. Ketika dua kunci dialokasikan ke bucket yang sama setelah hashing, ini disebut konflik hash. Cara Go menyelesaikan konflik hash adalah chaining. Ketika jumlah kunci yang konflik melebihi kapasitas bucket, biasanya 8, nilainya tergantung pada internal/abi.MapBucketCount. Kemudian bucket baru akan dibuat untuk menyimpan kunci-kunci ini, bucket ini disebut bucket overflow, artinya bucket asli sudah penuh, elemen meluap ke bucket baru ini. Setelah pembuatan selesai, bucket hash akan memiliki pointer yang menunjuk ke bucket overflow baru, pointer-pointer bucket ini terhubung membentuk linked list bmap.
Untuk chaining, faktor beban digunakan untuk mengukur konflik tabel hash, rumus perhitungannya adalah sebagai berikut
loadfactor := len(elems) / len(buckets)Semakin besar faktor beban, semakin banyak konflik hash, yaitu semakin banyak jumlah bucket overflow. Saat membaca dan menulis tabel hash, perlu menelusuri lebih banyak linked list bucket overflow untuk menemukan posisi yang ditentukan, jadi performanya lebih buruk. Untuk memperbaiki situasi ini, jumlah bucket buckets harus ditingkatkan, yaitu ekspansi. Untuk hmap, ada dua kondisi yang akan memicu ekspansi
- Faktor beban melebihi ambang batas
bucketCnt*13/16, nilainya setidaknya 6.5. - Jumlah bucket overflow terlalu banyak
Semakin kecil faktor beban, semakin rendah utilisasi memori hmap, semakin besar memori yang digunakan. Fungsi yang digunakan Go untuk menghitung faktor beban adalah runtime.overLoadFactor, kodenya adalah sebagai berikut
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Di mana loadFactorNum dan loadFactorDen adalah konstanta, bucketshift menghitung 1 << B, dan diketahui
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenJadi setelah disederhanakan dapat diperoleh
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Di mana nilai (bucketCnt * 13 / 16) adalah 6.5, 1 << B adalah jumlah bucket hash, jadi fungsi ini menghitung apakah jumlah elemen dibagi jumlah bucket lebih besar dari faktor beban 6.5.
Perhitungan
Fungsi hash internal Go terletak di file runtime/alg.go dalam f32hash, seperti berikut, termasuk penanganan untuk NaN dan 0.
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}Dapat dilihat bahwa metode perhitungan hash map tidak berdasarkan tipe, tetapi berdasarkan memori, akhirnya akan masuk ke fungsi memhash, yang diimplementasikan oleh assembly, logika terletak di runtime/asm*.s. Nilai hash berbasis memori tidak boleh dipersistenkan, karena hanya boleh digunakan saat runtime, tidak mungkin menjamin distribusi memori setiap kali berjalan sama.
Di file yang sama ada fungsi bernama typehash, fungsi ini menghitung nilai hash berdasarkan tipe yang berbeda, namun map tidak menggunakan fungsi ini untuk menghitung hash.
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrImplementasi ini lebih lambat daripada yang di atas, tetapi lebih umum, terutama digunakan untuk refleksi dan pembuatan fungsi saat kompilasi, seperti fungsi berikut.
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Pembuatan
Inisialisasi map memiliki dua cara, hal ini telah dijelaskan dalam pengenalan bahasa, satu adalah menggunakan kata kunci map langsung, yang lain adalah menggunakan fungsi make. Tidak peduli cara mana yang digunakan untuk inisialisasi, akhirnya runtime.makemap yang membuat map, signature fungsi ini adalah sebagai berikut
func makemap(t *maptype, hint int, h *hmap) *hmapParameter di antaranya
t, mengacu pada tipe map,占用 memori yang berbeda untuk tipe yang berbedahint, mengacu pada parameter kedua fungsimake, kapasitas perkiraan elemen map.h, mengacu pada pointerhmap, bisanil.
Nilai return adalah pointer hmap yang telah diinisialisasi. Fungsi ini memiliki beberapa pekerjaan utama selama proses inisialisasi. Pertama adalah menghitung apakah alokasi memori yang diperkirakan akan melebihi memori alokasi maksimum, sesuai dengan kode berikut
// mengalikan kapasitas perkiraan dengan ukuran memori tipe bucket
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// nilai overflow atau melebihi memori alokasi maksimum
if overflow || mem > maxAlloc {
hint = 0
}Dalam struktur internal sebelumnya telah disebutkan, hmap terdiri dari bucket, dalam kasus utilisasi memori terendah, satu bucket hanya memiliki satu elemen,占用 memori paling banyak, jadi perkiraan占用 memori maksimum adalah jumlah elemen dikali ukuran占用 memori tipe yang sesuai. Ketika hasil perhitungan nilai overflow, atau melebihi memori yang dapat dialokasikan maksimum, set hint menjadi 0, karena后续 perlu menggunakan hint untuk menghitung kapasitas array bucket.
Langkah kedua adalah menginisialisasi hmap, dan menghitung seed hash acak, sesuai dengan kode berikut
// inisialisasi
if h == nil {
h = new(hmap)
}
// mendapatkan seed hash acak
h.hash0 = fastrand()Kemudian menghitung kapasitas bucket hash berdasarkan nilai hint, kode yang sesuai adalah sebagai berikut
B := uint8(0)
// terus loop sampai hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// assign ke hmap
h.B = BMelalui loop terus menerus untuk menemukan nilai B pertama yang memenuhi (hint / 1 << B) < 6.5, assign ke hmap. Setelah mengetahui kapasitas bucket hash, terakhir adalah mengalokasikan memori untuk bucket hash
if h.B != 0 {
var nextOverflow *bmap
// bucket hash yang dialokasikan, dan bucket overflow kosong yang dialokasikan sebelumnya
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// jika bucket overflow kosong dialokasikan sebelumnya, tunjuk ke bucket overflow tersebut
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}Fungsi makeBucketArray akan mengalokasikan memori dengan ukuran yang sesuai untuk bucket hash berdasarkan nilai B, dan mengalokasikan bucket overflow kosong sebelumnya. Ketika B kurang dari 4, tidak akan membuat bucket overflow, jika lebih besar dari 4 maka akan membuat 2^B-4 bucket overflow. Sesuai dengan fungsi runtime.makeBucketArray dalam kode berikut
base := bucketShift(b)
nbuckets := base
// tidak akan membuat bucket overflow jika kurang dari 4
if b >= 4 {
// jumlah perkiraan bucket ditambah 1 << (b-4)
nbuckets += bucketShift(b - 4)
// memori yang dibutuhkan bucket overflow
sz := t.Bucket.Size_ * nbuckets
// bulatkan ruang memori ke atas
up := roundupsize(sz)
if up != sz {
// tidak sama gunakan up untuk menghitung ulang
nbuckets = up / t.Bucket.Size_
}
}base mengacu pada jumlah bucket yang akan dialokasikan, nbuckets mengacu pada jumlah bucket yang sebenarnya dialokasikan, ia menambahkan jumlah bucket overflow.
if base != nbuckets {
// bucket overflow yang pertama tersedia
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// untuk mengurangi biaya pelacakan bucket overflow, pointer overflow bucket overflow terakhir menunjuk ke kepala bucket hash
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// bucket overflow terakhir menunjuk ke bucket hash
last.setoverflow(t, (*bmap)(buckets))
}Ketika keduanya tidak sama, menunjukkan bahwa bucket overflow tambahan dialokasikan, pointer nextoverflow menunjuk ke bucket overflow yang pertama tersedia. Dari sini dapat dilihat bahwa bucket hash dan bucket overflow sebenarnya berada di blok memori yang berkelanjutan, ini juga alasan mengapa array bucket hash dan array bucket overflow berdekatan dalam gambar.
Akses
Dalam pengenalan sintaks telah disebutkan, ada tiga cara untuk mengakses map, seperti berikut
# akses nilai langsung
val := dict[key]
# akses nilai dan apakah kunci tersebut ada
val, exist := dict[key]
# iterasi map
for key, val := range dict{
}Ketiga cara ini menggunakan fungsi yang berbeda, di antaranya for range untuk iterasi map adalah yang paling kompleks.
Kunci-Nilai
Untuk dua cara pertama, sesuai dengan dua fungsi, masing-masing adalah runtime.mapaccess1 dan runtime.mapaccess2, signature fungsi adalah sebagai berikut
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Di mana key adalah pointer yang menunjuk ke kunci untuk mengakses map, saat return hanya akan mengembalikan pointer. Saat mengakses, pertama perlu menghitung nilai hash key, memposisikan key di bucket hash mana, sesuai dengan kode berikut
// penanganan batas
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // lihat issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// mencegah baca/tulis konkuren
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// gunakan hasher tipe yang ditentukan untuk menghitung nilai hash
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// posisikan pointer bucket hash tempat key berada dengan memindahkan pointer
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))Pada awal akses, lakukan penanganan situasi batas, dan mencegah map dibaca/ditulis secara konkuren. Ketika map dalam status baca/tulis konkuren, akan terjadi panic. Kemudian hitung nilai hash, fungsi bucketMask melakukan perhitungan (1 << B) - 1, hash & m sama dengan hash & (1 << B) - 1, ini adalah operasi modulus biner, setara dengan hash % (1 << B), keuntungan menggunakan operasi bit adalah lebih cepat. Tiga baris kode terakhir melakukan hal berikut: nilai hash yang dihitung dari key di-modulus dengan jumlah bucket di map saat ini, mendapatkan nomor bucket hash, kemudian memindahkan pointer berdasarkan nomor tersebut untuk mendapatkan pointer bucket hash tempat key berada.
Setelah mengetahui key berada di bucket hash mana, dapat mulai mencari, bagian ini sesuai dengan kode berikut
// dapatkan 8 bit tinggi dari nilai hash
top := tophash(hash)
bucketloop:
// iterasi linked list bmap
for ; b != nil; b = b.overflow(t) {
// elemen di bmap
for i := uintptr(0); i < bucketCnt; i++ {
// bandingkan top yang dihitung dengan elemen di tophash
if b.tophash[i] != top {
// selanjutnya kosong, tidak ada lagi.
if b.tophash[i] == emptyRest {
break bucketloop
}
// tidak sama lanjutkan iterasi bucket overflow
continue
}
// pindahkan pointer berdasarkan i untuk mendapatkan kunci pada indeks yang sesuai
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// tangani pointer
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// bandingkan apakah dua kunci sama
if t.Key.Equal(key, k) {
// jika sama, pindahkan pointer untuk mengembalikan elemen pada k yang sesuai
// dari baris kode ini dapat dilihat bahwa alamat memori kunci-nilai berkelanjutan
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// tidak ditemukan, kembalikan nilai nol.
return unsafe.Pointer(&zeroVal[0])Saat memposisikan bucket hash, dilakukan melalui modulus, jadi key berada di bucket hash mana tergantung pada bit rendah nilai hash,至于 berapa bit rendah tergantung pada ukuran B. Setelah menemukan bucket hash, tophash di dalamnya menyimpan 8 bit tinggi nilai hash, karena nilai modulus bit rendah sama, jadi tidak perlu membandingkan satu per satu apakah key sama, cukup bandingkan 8 bit tinggi nilai hash. Berdasarkan nilai hash yang dihitung sebelumnya, dapatkan 8 bit tingginya, bandingkan satu per satu di array tophash di bmap. Jika 8 bit tinggi sama, bandingkan apakah kunci sama. Jika kunci juga sama, menunjukkan bahwa elemen telah ditemukan. Jika tidak sama, lanjutkan iterasi array tophash. Jika masih tidak ditemukan, lanjutkan iterasi linked list bmap bucket overflow, sampai tophash[i] dari bmap adalah emptyRest keluar dari loop, akhirnya kembalikan nilai nol dari tipe yang sesuai.
Fungsi mapaccess2 sama persis dengan fungsi mapaccess1, hanya menambahkan nilai return boolean, digunakan untuk menunjukkan apakah elemen ada.
Iterasi
Sintaks untuk iterasi map adalah sebagai berikut
for key, val := range dict {
// lakukan sesuatu...
}Saat melakukan iterasi, Go menggunakan struktur hiter untuk menyimpan informasi iterasi, hiter adalah singkatan dari hmap iterator, yang berarti iterator tabel hash, strukturnya adalah sebagai berikut.
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Harus berada di posisi pertama. Tulis nil untuk menunjukkan akhir iterasi (lihat cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Harus berada di posisi kedua (lihat cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // pointer bucket saat inisialisasi hash_iter
bptr *bmap // bucket saat ini
overflow *[]*bmap // menjaga bucket overflow hmap.buckets tetap hidup
oldoverflow *[]*bmap // menjaga bucket overflow hmap.oldbuckets tetap hidup
startBucket uintptr // bucket tempat iterasi dimulai
offset uint8 // offset dalam bucket untuk mulai dari selama iterasi (harus cukup besar untuk menampung bucketCnt-1)
wrapped bool // sudah kembali dari akhir array bucket ke awal
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Berikut adalah penjelasan singkat untuk beberapa field-nya
key,elemadalah pasangan kunci-nilai yang diperoleh saat iterasifor rangebuckets, ditentukan saat inisialisasi iterator, menunjuk ke kepala bucket hashbptr, bmap yang sedang diiterasistartBucket, nomor bucket awal saat iterasi dimulaioffset, offset dalam bucket, rentang[0, bucketCnt-1]B, adalah nilai B dari hmapi, indeks elemen dalam bucketwrapped, apakah sudah kembali dari akhir array bucket hash ke kepala
Sebelum iterasi dimulai, Go menginisialisasi iterator melalui fungsi runtime.mapiterinit, kemudian melakukan iterasi map melalui fungsi runtime.mapiternext, keduanya perlu menggunakan struktur hiter, signature dua fungsi adalah sebagai berikut.
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Untuk inisialisasi iterator, pertama perlu mendapatkan snapshot map saat ini, sesuai dengan kode berikut.
it.t = t
it.h = h
// catat snapshot status hmap saat ini, hanya perlu menyimpan nilai B.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Saat iterasi berikutnya, sebenarnya yang diiterasi adalah snapshot map, bukan map yang sebenarnya, jadi elemen dan bucket yang ditambahkan selama iterasi tidak akan diiterasi, dan jika secara bersamaan menulis elemen, mungkin memicu fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Langkah kedua adalah menentukan dua posisi awal iterasi, pertama adalah posisi bucket awal, kedua adalah posisi awal dalam bucket, keduanya dipilih secara acak, sesuai dengan kode berikut
// r adalah angka acak
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) mendapatkan posisi bucket awal
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 mendapatkan posisi elemen awal dalam bucket awal
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// catat nomor bucket yang sedang diiterasi saat ini
it.bucket = it.startBucketMelalui fastrand() atau fastrand64() mendapatkan angka acak, dua operasi modulus mendapatkan posisi bucket awal dan posisi awal dalam bucket.
TIP
Map tidak mengizinkan baca/tulis konkuren secara bersamaan, tetapi mengizinkan iterasi konkuren secara bersamaan.
Selanjutnya baru benar-benar mulai iterasi map, bagaimana iterasi bucket, dan strategi keluar, bagian ini sesuai dengan kode berikut
// hmap
h := it.h
// maptype
t := it.t
// posisi bucket yang akan diiterasi
bucket := it.bucket
// bmap yang sedang diiterasi
b := it.bptr
// indeks i dalam bucket
i := it.i
next:
if b == nil {
// jika posisi bucket saat ini sama dengan posisi awal, menunjukkan sudah kembali, yang berikutnya sudah diiterasi
// iterasi selesai, dapat keluar
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// geser indeks bucket
bucket++
// bucket == 1 << B, sudah mencapai akhir array bucket hash
if bucket == bucketShift(it.B) {
// mulai dari awal
bucket = 0
it.wrapped = true
}
i = 0
}Posisi awal bucket hash dipilih secara acak, saat iterasi, iterasi satu per satu dari posisi awal ke akhir slice bucket, ketika mencapai 1 << B, kemudian mulai dari awal, ketika kembali ke posisi awal lagi, menunjukkan bahwa iterasi selesai, kemudian keluar. Kode di atas adalah tentang bagaimana iterasi bucket di map, sedangkan kode di bawah menjelaskan bagaimana iterasi dalam bucket.
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// jika elemen saat ini kosong, lewati
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// pindahkan pointer untuk mendapatkan kunci
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// pindahkan pointer untuk mendapatkan nilai
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// tangani kasus ekspansi ukuran yang sama, setelah kunci dipindahkan ke posisi lain, perlu mencari kunci lagi.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// jika tidak ditemukan, cari di bucket overflow
b = b.overflow(t)
i = 0
goto nextTIP
Dalam kondisi判断 ekspansi di atas, ada ekspresi yang mungkin membingungkan, seperti berikut
t.Key.Equal(k, k)Alasan判断 k sama dengan dirinya sendiri adalah untuk memfilter kasus kunci adalah Nan. Jika kunci suatu elemen adalah Nan, maka tidak akan dapat mengakses elemen tersebut dengan normal, baik iterasi, akses langsung, atau penghapusan tidak dapat dilakukan dengan normal, karena Nan != Nan selalu benar, jadi tidak akan pernah dapat menemukan kunci ini.
Pertama, melalui operasi modulus nilai i dan offset mendapatkan indeks dalam bucket yang akan diiterasi, dapatkan pasangan kunci-nilai dengan memindahkan pointer. Karena selama iterasi map, akan ada operasi tulis lain yang memicu ekspansi map, jadi kunci aktual mungkin sudah tidak di posisi semula. Dalam kasus ini, perlu menggunakan fungsi mapaccessK untuk mendapatkan kembali kunci aktual, signature fungsi ini adalah sebagai berikut
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Fungsinya sama persis dengan fungsi mapaccess1, perbedaannya adalah fungsi mapaccessK akan mengembalikan nilai key dan value secara bersamaan. Setelah mendapatkan pasangan kunci-nilai, assign ke key, elem iterator, kemudian update indeks iterator, sehingga menyelesaikan satu iterasi, eksekusi kode kembali ke blok kode for range. Jika tidak ditemukan dalam bucket, cari di bucket overflow, ulangi langkah di atas, sampai iterasi linked list bucket overflow selesai, kemudian lanjutkan iterasi bucket hash berikutnya.
Modifikasi
Sintaks untuk memodifikasi map adalah sebagai berikut
dict[key] = valDi Go, untuk operasi modifikasi map, diselesaikan oleh fungsi runtime.mapassign, signature fungsi ini adalah sebagai berikut
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerLogika proses aksesnya sama dengan mapaccess1, namun ketika key tidak ada akan dialokasikan posisi, jika ada akan diupdate, akhirnya mengembalikan pointer elemen. Pada awalnya, perlu melakukan beberapa pekerjaan persiapan, bagian ini sesuai dengan kode berikut
// tidak mengizinkan menulis ke map yang nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// melarang tulis konkuren secara bersamaan
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// hitung nilai hash key
hash := t.Hasher(key, uintptr(h.hash0))
// ubah status hmap
h.flags ^= hashWriting
// inisialisasi bucket hash
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Kode di atas melakukan beberapa hal berikut
- Pemeriksaan status hmap
- Menghitung nilai hash key
- Memeriksa apakah bucket hash perlu diinisialisasi
Setelah itu, melalui operasi modulus nilai hash mendapatkan posisi bucket hash, dan tophash key, kode sesuai dengan berikut
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// pindahkan pointer untuk mendapatkan bmap pada posisi yang ditentukan
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// hitung tophash
top := tophash(hash)Sekarang posisi bucket sudah ditentukan, bmap, tophash, dapat mulai mencari elemen, bagian ini sesuai dengan kode berikut
// tophash yang akan disisipkan
var inserti *uint8
// pointer nilai key yang akan disisipkan
var insertk unsafe.Pointer
// pointer nilai value yang akan disisipkan
var elem unsafe.Pointer
bucketloop:
for {
// iterasi array tophash dalam bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash tidak sama
if b.tophash[i] != top {
// jika indeks dalam bucket saat ini kosong, dan belum ada elemen yang disisipkan, pilih posisi ini untuk disisipkan
if isEmpty(b.tophash[i]) && inserti == nil {
// menemukan posisi yang cocok untuk dialokasikan ke key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// keluar loop setelah iterasi selesai
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// jika tophash sama, menunjukkan key mungkin sudah ada
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
//判断 apakah key sama
if !t.Key.Equal(key, k) {
continue
}
// jika perlu mengupdate nilai key, salin memori key ke k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// dapatkan pointer elemen
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// update selesai, kembalikan pointer elemen
goto done
}
// sampai di sini menunjukkan key tidak ditemukan, iterasi linked list bucket overflow, lanjutkan mencari
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// sampai di sini menunjukkan key tidak ada di map, tetapi mungkin sudah menemukan posisi yang cocok untuk key, atau mungkin tidak
// tidak menemukan posisi yang cocok untuk key
if inserti == nil {
// menunjukkan bucket hash saat ini dan bucket overflow-nya sudah penuh, alokasikan bucket overflow baru
newb := h.newoverflow(t, b)
// alokasikan posisi di bucket overflow untuk key
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// jika menyimpan pointer key
if t.IndirectKey() {
// alokasikan memori baru, mengembalikan pointer unsafe
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// assign ke insertk, memudahkan replikasi memori key di belakang
insertk = kmem
}
// jika menyimpan pointer elemen
if t.IndirectElem() {
// alokasikan memori
vmem := newobject(t.Elem)
// buat pointer menunjuk ke vmem
*(*unsafe.Pointer)(elem) = vmem
}
// salin memori key langsung ke posisi insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// jumlah bertambah satu
h.count++
done:
// sampai di sini menunjukkan proses modifikasi selesai
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// kembalikan pointer elemen
return elemDalam satu bagian besar kode di atas, pertama masuk ke loop for untuk mencoba mencari di bucket hash dan bucket overflow, logika pencarian sama persis dengan mapaccess, saat ini ada tiga kemungkinan
- Pertama, menemukan key yang sudah ada di map, langsung lompat ke blok kode
done, kembalikan pointer elemen - Kedua, menemukan posisi di map untuk dialokasikan ke key, salin key ke posisi yang ditentukan, dan kembalikan pointer elemen
- Ketiga, semua bucket sudah dicari, tidak menemukan posisi yang dapat dialokasikan ke key di map, buat bucket overflow baru, dan assign key ke bucket, kemudian salin key ke posisi yang ditentukan, dan kembalikan pointer elemen
Setelah mendapatkan pointer elemen, dapat melakukan assignment, namun operasi ini tidak diselesaikan oleh fungsi mapassign, ia hanya bertanggung jawab untuk mengembalikan pointer elemen, operasi assignment disisipkan saat kompilasi, tidak terlihat di dalam kode, tetapi dapat dilihat setelah kompilasi. Misalkan ada kode berikut
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Melalui perintah berikut mendapatkan kode assembly
go tool compile -S -N -l main.goBagian kuncinya ada di sini
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Dapat dilihat memanggil runtime.mapassign_faststr, logikanya sama persis dengan mapassign, LEAQ go:string."world"(SB), CX adalah menyimpan alamat string ke CX, MOVQ CX, (AX) kemudian menyimpannya ke AX, sehingga menyelesaikan assignment elemen.
Penghapusan
Di Go, untuk menghapus elemen map, hanya dapat menggunakan fungsi built-in delete, seperti berikut
delete(dict, "abc")Panggilan internalnya adalah fungsi runtime.mapdelete, signature fungsi ini adalah sebagai berikut
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Ia akan menghapus elemen dengan key yang ditentukan di map, tidak peduli apakah elemen ada di map, ia tidak akan bereaksi. Logika pekerjaan persiapan di awal fungsi mirip dengan yang sebelumnya, tidak lain adalah beberapa hal berikut
- Pemeriksaan status hmap
- Menghitung nilai hash key
- Memposisikan bucket hash
- Menghitung tophash
Ada banyak konten yang berulang di depan, tidak akan dijelaskan lagi di sini, di sini hanya memperhatikan logika penghapusannya, bagian kode yang sesuai adalah sebagai berikut.
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// jika tidak ditemukan keluar loop
if b.tophash[i] == emptyRest {
break search
}
continue
}
// pindahkan pointer untuk menemukan posisi key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// hapus key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// pindahkan pointer untuk menemukan posisi elemen
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// hapus elemen
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// jumlah berkurang satu
h.count--
// reset seed hash, kurangi probabilitas konflik
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Melalui kode di atas dapat dilihat, logika pencarian hampir sama persis dengan operasi di depan, menemukan elemen, kemudian hapus, jumlah yang dicatat hmap berkurang satu, ketika jumlah berkurang menjadi 0, reset seed hash.
Hal lain yang perlu diperhatikan adalah, setelah menghapus elemen, perlu memodifikasi status tophash pada indeks saat ini, bagian ini sesuai dengan kode berikut. Ketika i di akhir bucket,判断 berdasarkan bucket overflow berikutnya apakah elemen saat ini adalah elemen terakhir yang tersedia, jika tidak langsung lihat status hash elemen yang berdekatan. Jika elemen saat ini bukan yang terakhir yang tersedia, set status ke emptyOne.
// tandai tophash saat ini sebagai kosong
b.tophash[i] = emptyOne
// jika di akhir tophash
if i == bucketCnt-1 {
// bucket overflow tidak kosong, dan ada elemen di bucket overflow, menunjukkan elemen saat ini bukan yang terakhir
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// elemen berdekatan tidak kosong
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Jika elemen memang elemen terakhir, perlu memperbaiki nilai tophash array dari beberapa bucket di linked list bucket, jika tidak akan menyebabkan tidak dapat keluar di posisi yang benar saat iterasi berikutnya. Saat membuat bucket overflow di map, telah disebutkan bahwa Go untuk mengurangi biaya pelacakan bucket overflow, pointer overflow bucket overflow terakhir menunjuk ke bucket hash kepala, jadi sebenarnya ini adalah linked list siklik单向, "kepala" linked list adalah bucket hash. Dan b di sini adalah b setelah pencarian, sangat mungkin adalah salah satu bucket overflow di tengah linked list, iterasi terbalik linked list siklik untuk mencari elemen terakhir yang ada. Meskipun kode menulis iterasi maju, karena linked list adalah cincin, ia terus iterasi maju sampai sebelum bucket overflow saat ini, dari hasil memang terbalik. Kemudian iterasi terbalik array tophash dalam bucket, update elemen dengan status emptyOne menjadi emptyRest, sampai menemukan elemen terakhir yang ada. Untuk menghindari terjebak dalam cincin tanpa batas, ketika kembali ke bucket awal, yaitu bOrig, menunjukkan bahwa tidak ada elemen yang tersedia di linked list saat ini, dapat keluar dari loop.
// sampai di sini menunjukkan tidak ada elemen setelah elemen saat ini
// terus iterasi terbalik linked list bmap, iterasi terbalik tophash dalam bucket
// update status emptyOne menjadi emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// temukan bucket sebelumnya di linked list bmap saat ini
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Pengosongan
Di versi go1.21, ditambahkan fungsi built-in clear, dapat digunakan untuk mengosongkan semua elemen di map, sintaksnya adalah sebagai berikut
clear(dict)Internalnya memanggil fungsi runtime.mapclear, yang bertanggung jawab untuk menghapus semua elemen di map, signature fungsinya adalah sebagai berikut
func mapclear(t *maptype, h *hmap)Logika fungsi ini tidak terlalu kompleks, pertama perlu menandai seluruh map sebagai kosong, kode yang sesuai adalah sebagai berikut.
// iterasi setiap bucket dan bucket overflow, set semua elemen tophash menjadi emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Hal yang dilakukan kode di atas adalah iterasi setiap bucket, set semua elemen array tophash di bucket menjadi emptyRest, tandai map sebagai kosong, sehingga dapat mencegah iterator继续 iterasi, kemudian kosongkan map, kode yang sesuai adalah sebagai berikut.
// reset seed hash
h.hash0 = fastrand()
// reset struktur extra
if h.extra != nil {
*h.extra = mapextra{}
}
// operasi ini akan menghapus memori buckets sebelumnya, dan alokasikan bucket baru
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// alokasikan bucket overflow kosong baru
h.extra.nextOverflow = nextOverflow
}Melalui makeBucketArray menghapus memori bucket sebelumnya, kemudian alokasikan yang baru, dengan demikian menyelesaikan penghapusan bucket, selain itu ada beberapa detail, seperti set count menjadi 0, dan beberapa operasi lainnya tidak akan dijelaskan lebih lanjut.
Ekspansi
Dalam semua operasi sebelumnya, untuk lebih memperhatikan logika itu sendiri, jadi banyak konten terkait ekspansi disembunyikan, ini akan lebih sederhana. Logika ekspansi sebenarnya cukup kompleks, diletakkan di akhir adalah agar tidak mengganggu, sekarang mari lihat bagaimana Go melakukan ekspansi map, telah disebutkan sebelumnya, ada dua kondisi yang memicu ekspansi:
- Faktor beban melebihi 6.5
- Jumlah bucket overflow terlalu banyak
Fungsi yang判断 apakah faktor beban melebihi ambang batas adalah fungsi runtime.overLoadFactor, telah dijelaskan di bagian konflik hash, dan fungsi yang判断 apakah jumlah bucket overflow terlalu banyak adalah runtime.tooManyOverflowBuckets, prinsip kerjanya juga sangat sederhana, kodenya adalah sebagai berikut
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Kode di atas dapat disederhanakan menjadi ekspresi berikut, langsung dapat dipahami.
overflow >= 1 << (min(15,B) % 16)Di sini, definisi Go untuk too many adalah: jumlah bucket overflow hampir sama dengan jumlah bucket hash. Jika ambang batas rendah, akan melakukan pekerjaan tambahan, jika ambang batas tinggi, akan占用 banyak memori saat ekspansi. Saat modifikasi dan penghapusan elemen mungkin memicu ekspansi, kode yang判断 apakah perlu ekspansi adalah sebagai berikut.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Ekspansi tabel membuat semuanya tidak valid, coba lagi
}Dapat dilihat ada tiga kondisi pembatas ini
- Saat ini tidak sedang dalam ekspansi
- Faktor beban kurang dari 6.5
- Jumlah bucket overflow tidak boleh terlalu banyak
Fungsi yang bertanggung jawab untuk ekspansi tentu saja runtime.hashGrow, signature fungsinya adalah sebagai berikut
func hashGrow(t *maptype, h *hmap)Sebenarnya, ekspansi juga memiliki jenis, ekspansi yang dipicu oleh kondisi berbeda juga memiliki tipe berbeda, dibagi menjadi dua berikut
- Ekspansi inkremental
- Ekspansi ukuran sama
Ekspansi Inkremental
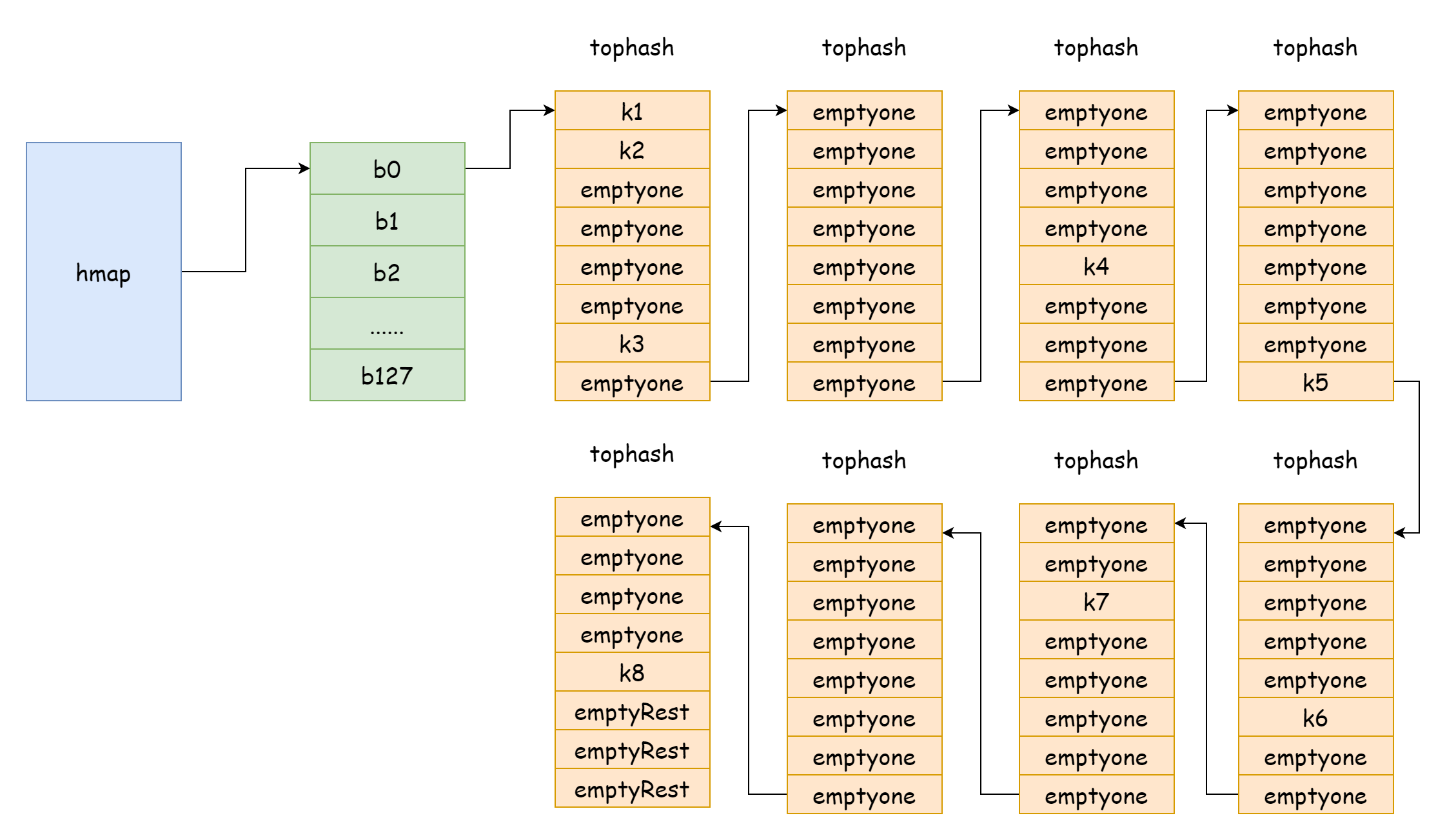
Ketika faktor beban terlalu besar, yaitu jumlah elemen lebih besar dari jumlah bucket hash, ketika konflik hash cukup parah, akan membentuk banyak linked list bucket overflow, ini akan menyebabkan performa baca/tulis map menurun, karena perlu iterasi lebih banyak linked list bucket overflow untuk menemukan elemen, sedangkan kompleksitas waktu iterasi adalah O(n), kompleksitas waktu pencarian tabel hash terutama tergantung pada waktu perhitungan nilai hash dan waktu iterasi, ketika waktu iterasi jauh lebih kecil dari waktu perhitungan hash, kompleksitas waktu pencarian baru dapat disebut O(1). Jika konflik hash cukup sering, terlalu banyak key dialokasikan ke bucket hash yang sama, linked list bucket overflow yang terlalu panjang menyebabkan waktu iterasi meningkat, akan menyebabkan waktu pencarian meningkat, dan operasi tambah/hapus/ubah perlu melakukan operasi pencarian terlebih dahulu, dengan demikian akan menyebabkan performa seluruh map menurun drastis.
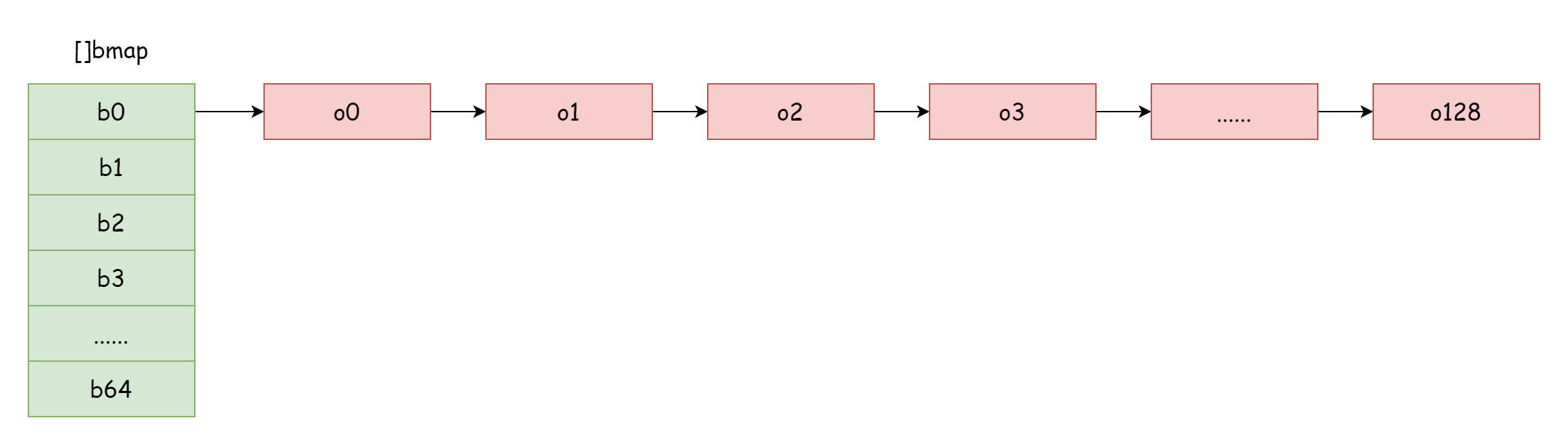
Seperti kasus ekstrem dalam gambar, kompleksitas waktu pencarian pada dasarnya tidak berbeda dengan O(n). Menghadapi situasi ini, solusinya adalah menambahkan lebih banyak bucket hash, menghindari pembentukan linked list bucket overflow yang terlalu panjang, metode ini juga disebut ekspansi inkremental.
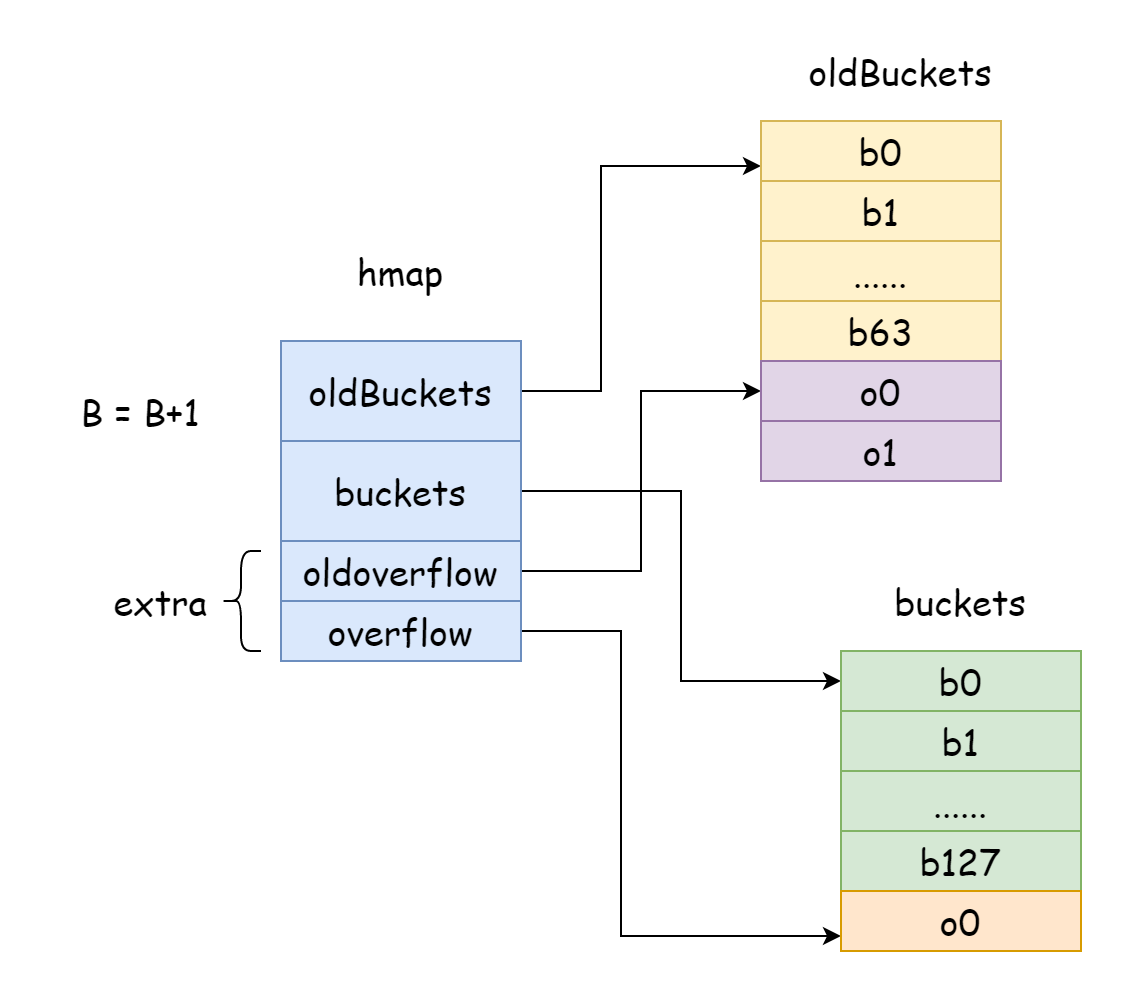
Di Go, ekspansi inkremental setiap kali akan menambahkan B sebesar satu, yaitu skala bucket hash setiap kali diperluas dua kali lipat. Setelah ekspansi, perlu memindahkan data lama ke map baru, jika jumlah elemen di map dihitung dalam puluhan juta bahkan ratusan juta, jika dipindahkan sekaligus akan memakan waktu lama, jadi Go mengadopsi strategi pemindahan bertahap. Untuk itu, Go akan membuat oldBuckets di hamp menunjuk ke array bucket hash asli, menunjukkan ini adalah data lama, kemudian buat array bucket hash dengan kapasitas lebih besar, buat hmap di buckets menunjuk ke array bucket hash baru, kemudian setiap kali memodifikasi dan menghapus elemen, pindahkan sebagian elemen dari bucket lama ke bucket baru, sampai pemindahan selesai, memori bucket lama akan dilepaskan.
func hashGrow(t *maptype, h *hmap) {
// selisih
bigger := uint8(1)
// bucket lama
oldbuckets := h.buckets
// bucket hash baru
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// bucket overflow juga perlu menentukan bucket lama dan baru
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Hal yang dilakukan kode di atas adalah membuat bucket hash baru dengan kapasitas dua kali lipat lebih besar, kemudian tentukan referensi bucket hash lama dan baru, serta referensi bucket overflow lama dan baru, sedangkan pekerjaan pemindahan aktual tidak diselesaikan oleh fungsi hashGrow, ia hanya bertanggung jawab untuk menentukan bucket lama dan baru, dan update beberapa status hmap. Pekerjaan ini sebenarnya diselesaikan oleh fungsi runtime.growWork, signature fungsinya adalah sebagai berikut
func growWork(t *maptype, h *hmap, bucket uintptr)Ia akan dipanggil di fungsi mapassign dan mapdelete dalam bentuk berikut, fungsinya adalah jika map saat ini sedang dalam ekspansi, lakukan pemindahan sebagian.
if h.growing() {
growWork(t, h, bucket)
}Saat melakukan operasi modifikasi dan penghapusan, perlu判断 apakah saat ini dalam ekspansi, ini terutama diselesaikan oleh metode hmap.growing, kontennya sangat sederhana, yaitu判断 apakah oldbuckets tidak kosong, sesuai dengan kode berikut.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Mari lihat apa yang dilakukan fungsi growWork.
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}Di antaranya operasi bucket&h.oldbucketmask() adalah menghitung posisi bucket lama, memastikan bucket lama yang akan dipindahkan adalah bucket saat ini. Dari fungsi dapat dilihat bahwa yang benar-benar bertanggung jawab untuk pekerjaan pemindahan adalah fungsi runtime.evacuate, di antaranya menggunakan struktur evaDst untuk menunjukkan tujuan pemindahan, fungsi utamanya adalah iterasi bucket baru selama proses pemindahan, strukturnya adalah sebagai berikut.
type evacDst struct {
b *bmap // bucket baru tujuan pemindahan
i int // indeks dalam bucket
k unsafe.Pointer // pointer yang menunjuk ke tujuan kunci baru
e unsafe.Pointer // pointer yang menunjuk ke tujuan nilai baru
}Sebelum pemindahan dimulai, Go akan mengalokasikan dua struktur evacDst, satu menunjuk ke bagian atas bucket hash baru, yang lain menunjuk ke bagian bawah bucket hash baru, kode yang sesuai adalah sebagai berikut
// posisikan bucket hash yang ditentukan di bucket lama
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// panjang bucket lama = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// menunjuk ke bagian atas bucket baru
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
//判断 apakah ekspansi ukuran sama
if !h.sameSizeGrow() {
y := &xy[1]
// menunjuk ke bagian bawah bucket baru
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Tujuan pemindahan bucket lama adalah dua bucket baru, setelah pemindahan, sebagian data di bucket akan berada di bagian atas, sebagian data lainnya akan berada di bagian bawah, ini dilakukan agar data setelah ekspansi dapat didistribusikan lebih merata, semakin merata distribusinya, performa pencarian map akan semakin baik. Bagaimana Go memindahkan data ke dua bucket baru, sesuai dengan kode berikut.
// iterasi linked list bucket overflow
for ; b != nil; b = b.overflow(t) {
// dapatkan pasangan kunci-nilai pertama di setiap bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// iterasi setiap pasangan kunci-nilai dalam bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// jika kosong lewati
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// bucket hash baru tidak boleh dalam status pemindahan
// jika tidak pasti ada masalah
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// variabel ini menentukan pasangan kunci-nilai saat ini dipindahkan ke bagian atas atau bawah
// nilainya hanya bisa 0 atau 1
var useY uint8
if !h.sameSizeGrow() {
// hitung ulang nilai hash
hash := t.Hasher(k2, uintptr(h.hash0))
// tangani kasus khusus k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// periksa nilai konstanta
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// update tophash bucket lama, menunjukkan elemen saat ini sudah dipindahkan
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// tentukan tujuan pemindahan
dst := &xy[useY] // tujuan evakuasi
// kapasitas bucket baru tidak cukup, buat bucket overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i sebagai optimasi, untuk menghindari pemeriksaan batas
// salin kunci
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // salin pointer
} else {
typedmemmove(t.Key, dst.k, k) // salin elemen
}
// salin nilai
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// geser pointer tujuan bucket baru, persiapan untuk pasangan kunci berikutnya
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Dari kode di atas dapat dilihat, Go akan iterasi setiap elemen di setiap bucket di linked list bucket lama, pindahkan data di dalamnya ke bucket baru, menentukan data到底是 pergi ke bagian atas atau bawah tergantung pada nilai hash yang dihitung ulang
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Setelah pemindahan, akan set tophash elemen saat ini menjadi evacuatedX atau evacuatedY, jika mencoba mencari data selama ekspansi, melalui status ini dapat mengetahui bahwa data sudah dipindahkan, jadi tahu harus mencari data yang sesuai di bucket baru. Bagian logika ini sesuai dengan kode berikut di fungsi runtime.mapaccess1.
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// Dulu ada setengah dari jumlah bucket; modulus satu kekuatan dua lagi.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// jika bucket lama sudah dipindahkan tidak perlu mencari lagi
if !evacuated(oldb) {
b = oldb
}
}Saat mengakses elemen, jika saat ini dalam status ekspansi, akan先去 mencoba mencari di bucket lama, jika bucket lama sudah dipindahkan tidak perlu mencari di bucket lama. Kembali ke bagian pemindahan, saat ini sudah menentukan tujuan pemindahan, selanjutnya adalah salin data ke bucket baru, kemudian buat struktur evacDst menunjuk ke tujuan berikutnya.
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Operasi seperti ini sampai bucket saat ini selesai dipindahkan, kemudian Go akan menghapus semua data kunci-nilai bucket lama, hanya menyisakan array tophash bucket hash (ditinggalkan karena后续 perlu bergantung pada array tophash untuk判断 status pemindahan), memori bucket overflow di bucket lama karena tidak lagi direferensikan selanjutnya akan direclaim oleh GC. Field nevacuate di hmap digunakan untuk mencatat progres pemindahan, setiap kali selesai memindahkan bucket hash lama, akan bertambah satu, ketika nilainya sama dengan jumlah bucket lama, menunjukkan bahwa ekspansi seluruh map sudah selesai, selanjutnya oleh fungsi runtime.advanceEvacuationMark melakukan pekerjaan收尾 ekspansi.
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Ia akan menghitung jumlah yang sudah dipindahkan dan konfirmasi apakah sama dengan jumlah bucket lama, jika sama akan menghapus semua referensi ke bucket lama dan bucket overflow lama,至此 ekspansi selesai.
Di fungsi growWork, total memanggil fungsi evacuate dua kali, pertama adalah memindahkan bucket lama dari bucket yang sedang diakses saat ini, kedua adalah memindahkan bucket lama yang ditunjuk oleh h.nevacuate, total memindahkan dua bucket, menunjukkan bahwa saat pemindahan bertahap, setiap kali akan memindahkan dua bucket.
Ekspansi Ukuran Sama
Telah disebutkan sebelumnya, kondisi pemicu ekspansi ukuran sama adalah jumlah bucket overflow terlalu banyak. Misalkan map terlebih dahulu menambahkan banyak elemen, kemudian menghapus banyak elemen, dengan demikian mungkin banyak bucket kosong, mungkin beberapa bucket memiliki banyak elemen, distribusi data sangat tidak merata, ada相当 banyak bucket overflow yang kosong,占用 cukup banyak memori. Untuk menyelesaikan masalah seperti ini, perlu membuat map baru dengan kapasitas yang sama, alokasikan bucket hash lagi, proses ini disebut ekspansi ukuran sama. Jadi sebenarnya bukan operasi ekspansi, hanya mengalokasikan ulang semua elemen agar distribusi data lebih merata, operasi ekspansi ukuran sama digabungkan dalam operasi ekspansi inkremental, logikanya sama persis dengan ekspansi inkremental, kapasitas map lama dan baru sama persis.
Di fungsi hashGrow, jika faktor beban tidak melebihi ambang batas, melakukan ekspansi ukuran sama, Go update status h.flags menjadi sameSizeGrow, h.B juga tidak akan bertambah satu, jadi kapasitas bucket hash yang dibuat baru juga tidak akan berubah, sesuai dengan kode berikut.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)Di fungsi evacuate, saat baru membuat struktur eavcDst, jika ekspansi ukuran sama hanya akan membuat satu struktur yang menunjuk ke bucket baru, sesuai dengan kode berikut.
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Dan saat memindahkan elemen, ekspansi ukuran sama tidak akan menghitung ulang nilai hash, juga tidak ada pilihan bagian atas dan bawah
if !h.sameSizeGrow() {
// hitung ulang nilai hash
hash := t.Hasher(k2, uintptr(h.hash0))
// tangani kasus khusus k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Selain ini, logika lainnya sama persis dengan ekspansi inkremental. Setelah ekspansi ukuran sama bucket hash dialokasikan ulang, jumlah bucket overflow akan berkurang, bucket overflow lama akan direclaim oleh GC.