map
Điểm khác biệt của Go so với các ngôn ngữ khác là hỗ trợ mapping table được cung cấp bởi từ khóa map, chứ không phải đóng gói thành thư viện chuẩn. Mapping table là một cấu trúc dữ liệu có nhiều tình huống sử dụng, có nhiều cách triển khai底层, hai cách phổ biến nhất là cây đỏ đen và bảng băm, Go áp dụng cách triển khai bảng băm.
TIP
Việc triển khai map liên quan đến rất nhiều thao tác di chuyển con trỏ, nên đọc bài viết này cần kiến thức về thư viện chuẩn unsafe.
Cấu trúc nội bộ
Cấu trúc runtime.hmap biểu diễn map trong Go, cũng như slice, việc triển khai nội bộ của map cũng là cấu trúc.
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}Chú thích tiếng Anh đã giải thích rất rõ ràng, dưới đây giải thích đơn giản các trường quan trọng:
count, biểu thị số lượng phần tử trong hamp, kết quả tương đươnglen(map).flags, flag của hmap, dùng để biểu thị hmap đang ở trạng thái nào, có các khả năng sau:
const (
iterator = 1 // Iterator đang sử dụng bucket
oldIterator = 2 // Iterator đang sử dụng bucket cũ
hashWriting = 4 // Một goroutine đang ghi vào hmap
sameSizeGrow = 8 // Đang mở rộng cùng kích thước
)B, số lượng bucket trong hmap là1 << B.noverflow, số lượng bucket tràn xấp xỉ trong hmap.hash0, hạt giống băm, được chỉ định khi hmap được tạo, dùng để tính giá trị băm.buckets, con trỏ trỏ đến mảng bucket băm.oldbuckets, con trỏ trỏ đến mảng bucket băm trước khi hmap mở rộng.extra, lưu trữ các bucket tràn của hmap, bucket tràn là khi bucket hiện tại đã đầy, tạo bucket mới để lưu trữ phần tử, bucket mới tạo chính là bucket tràn.
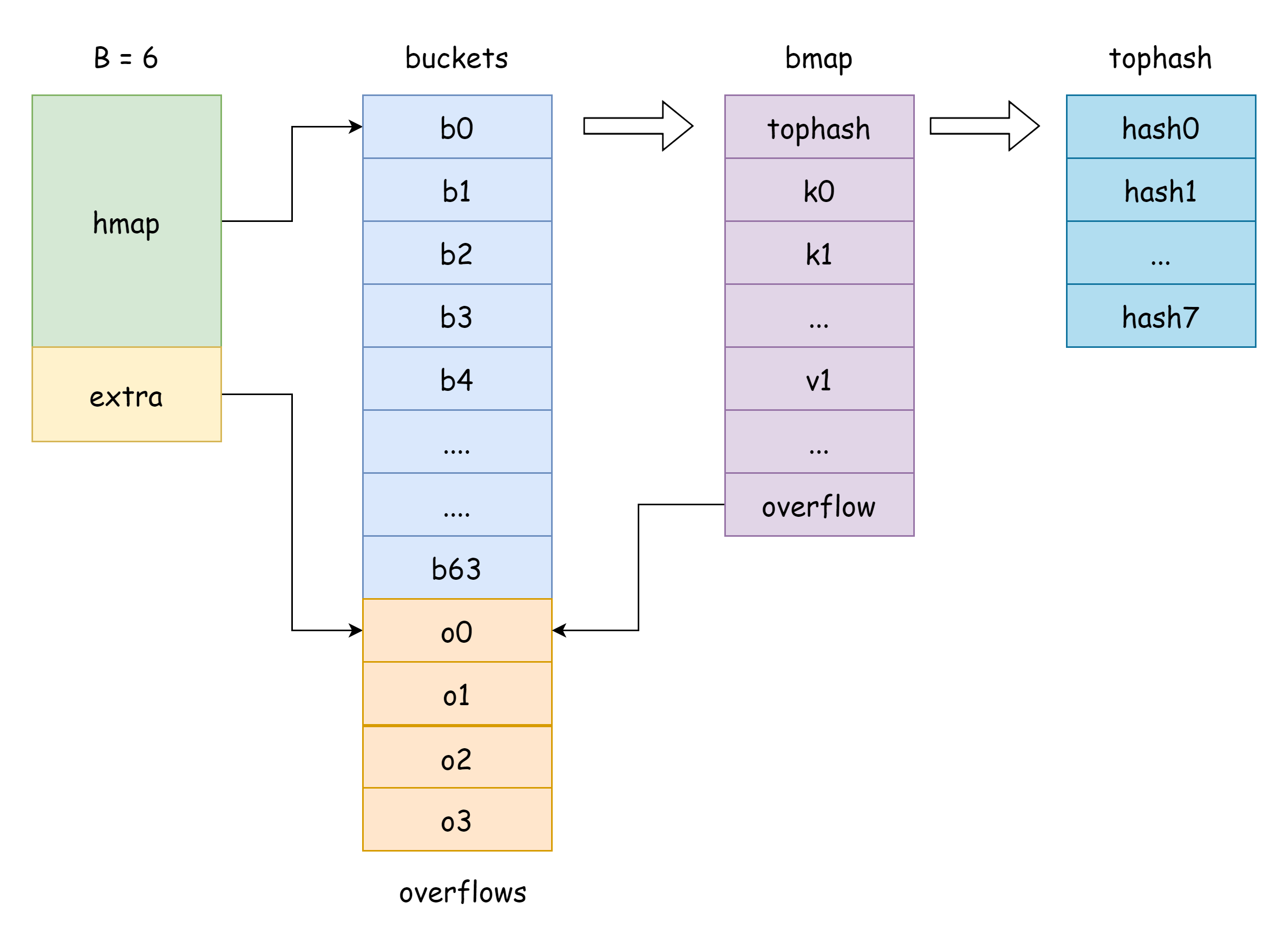
buckets trong hamp chính là con trỏ slice bucket, trong Go tương ứng với cấu trúc runtime.bmap, như sau:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}Từ trên có thể thấy nó chỉ có một trường tophash, trường này dùng để lưu trữ 8 bit cao của mỗi key, nhưng thực tế mà nói, trường của bmap không chỉ có vậy, vì map có thể lưu trữ các cặp key-value thuộc nhiều loại khác nhau, nên cần suy luận không gian bộ nhớ chiếm dụng dựa trên kiểu trong thời gian biên dịch, hàm MapBucketType trong cmd/compile/internal/reflectdata/reflect.go có chức năng xây dựng bmap trong thời gian biên dịch, nó sẽ thực hiện một loạt kiểm tra, ví dụ kiểu key có comparable không.
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.TypeVì vậy thực tế, cấu trúc của bmap như sau, nhưng các trường này đối với chúng ta là không thể nhìn thấy, Go trong thao tác thực tế là thông qua di chuyển con trỏ unsafe để truy cập:
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}Một số giải thích trong đó như sau:
tophash, lưu trữ giá trị 8 bit cao của mỗi key, đối với phần tử tophash而言, có các giá trị đặc biệt sau:
const (
emptyRest = 0 // Phần tử hiện tại là rỗng, và sau phần tử này cũng không có key khả dụng nữa
emptyOne = 1 // Phần tử hiện tại là rỗng, nhưng sau phần tử này có key khả dụng
evacuatedX = 2 // Xuất hiện khi mở rộng, chỉ có thể xuất hiện trong oldbuckets, biểu thị phần tử hiện tại được chuyển đến khu vực trên của mảng bucket băm mới
evacuatedY = 3 // Xuất hiện khi mở rộng chỉ có thể xuất hiện trong oldbuckets, biểu thị phần tử hiện tại được chuyển đến khu vực dưới của mảng bucket băm mới
evacuatedEmpty = 4 // Xuất hiện khi mở rộng, phần tử bản thân là rỗng, được đánh dấu khi chuyển
minTopHash = 5 // Giá trị tối thiểu của tophash đối với một key-value bình thường
)Chỉ cần giá trị tophash[i] lớn hơn minTophash, thì biểu thị chỉ số tương ứng tồn tại key-value bình thường.
keys, mảng lưu trữ key kiểu chỉ định.elems, mảng lưu trữ value kiểu chỉ định.overflow, con trỏ trỏ đến bucket tràn.
Vì key-value không thể truy cập trực tiếp thông qua trường cấu trúc,为此 Go trước tiên khai báo một hằng số dataoffset, nó biểu thị độ lệch bộ nhớ của dữ liệu trong bmap.
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Thực tế, key-value được lưu trữ trong một địa chỉ bộ nhớ liên tục, tương tự như cấu trúc dưới đây, làm như vậy là để tránh lãng phí bộ nhớ do căn chỉnh bộ nhớ.
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...Vì vậy đối với một bmap而言, sau khi di chuyển con trỏ dataoffset, di chuyển i*sizeof(keyType) là địa chỉ của key thứ i:
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))Lấy địa chỉ của value thứ i cũng tương tự:
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))Con trỏ buckets trong hamp, chính là trỏ đến địa chỉ bucket băm đầu tiên, nếu muốn lấy địa chỉ của bucket băm thứ i, độ lệch là i*sizeof(bucket):
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))Trong nội dung sau, các thao tác này sẽ xuất hiện rất thường xuyên.
Băm
Xung đột
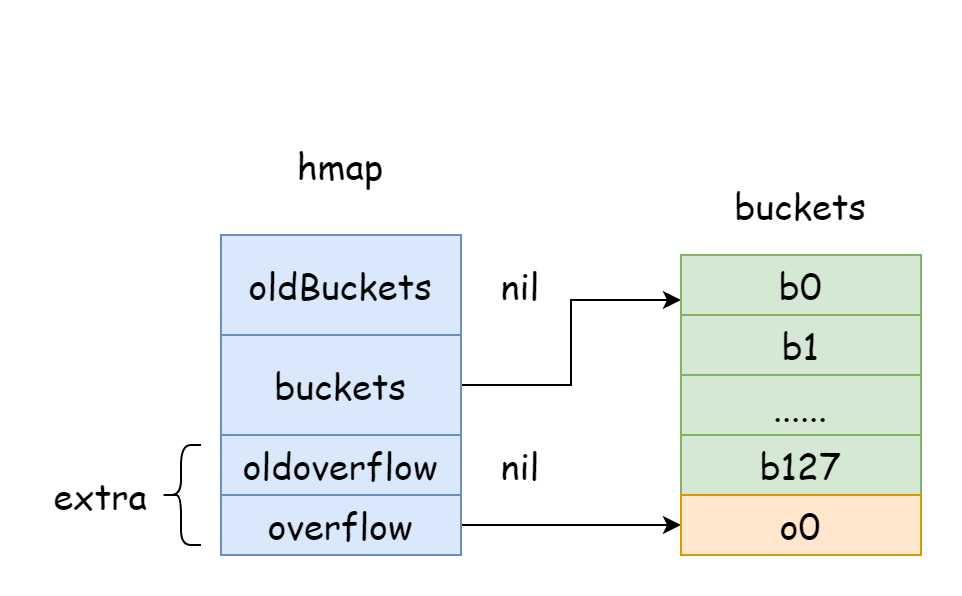
Trong hmap, có một trường extra chuyên dùng để lưu trữ thông tin bucket tràn, nó sẽ trỏ đến slice lưu trữ bucket tràn, cấu trúc như sau:
type mapextra struct {
// Con trỏ slice của bucket tràn
overflow *[]*bmap
// Con trỏ slice của bucket tràn cũ trước khi mở rộng
oldoverflow *[]*bmap
// Con trỏ trỏ đến bucket tràn rảnh tiếp theo
nextOverflow *bmap
}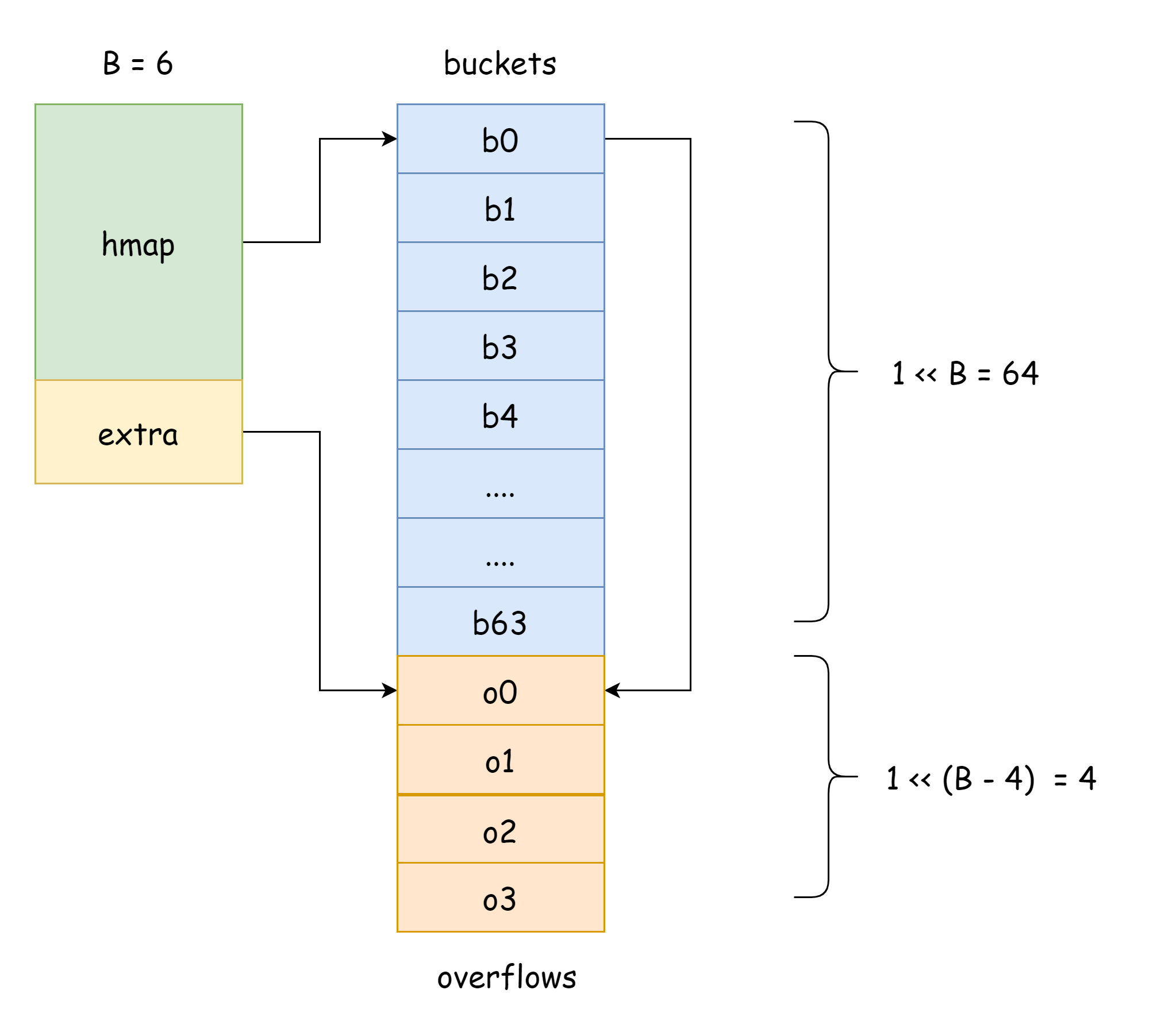
TIP
Trong hình trên, phần màu xanh lam là mảng bucket băm, phần màu cam là mảng bucket băm tràn, bucket tràn dưới đây gọi chung là bucket tràn.
Hình trên có thể biểu diễn khá tốt cấu trúc đại khái của hmap, buckets trỏ đến mảng bucket băm, extra trỏ đến mảng bucket tràn, bucket bucket0 trỏ đến bucket tràn overflow0, hai loại bucket khác nhau được lưu trữ trong hai slice, bộ nhớ của hai loại bucket đều liên tục. Khi hai key được phân phối vào cùng một bucket thông qua băm, trường hợp này chính là xảy ra xung đột băm. Cách Go giải quyết xung đột băm là phương pháp chaining, khi số lượng key xảy ra xung đột lớn hơn dung lượng bucket, thường là 8, giá trị này phụ thuộc vào internal/abi.MapBucketCount. Sau đó sẽ tạo một bucket mới để lưu trữ các key này, bucket này gọi là bucket tràn, ý là bucket ban đầu không chứa nổi, phần tử tràn ra bucket mới này, sau khi tạo xong, bucket băm sẽ có một con trỏ trỏ đến bucket tràn mới, các con trỏ của các bucket này nối lại tạo thành một danh sách liên kết bmap.
Đối với phương pháp chaining而言, sử dụng hệ số tải để đo lường tình trạng xung đột của bảng băm, công thức tính như sau:
loadfactor := len(elems) / len(buckets)Khi hệ số tải càng lớn, biểu thị xung đột băm càng nhiều,也就是 số lượng bucket tràn càng nhiều, thì khi đọc ghi bảng băm, cần duyệt danh sách liên kết bucket tràn nhiều hơn, mới có thể tìm thấy vị trí chỉ định, nên hiệu suất càng kém. Để cải thiện tình trạng này, nên tăng số lượng bucket buckets,也就是 mở rộng, đối với hmap而言, có hai trường hợp sẽ kích hoạt mở rộng:
- Hệ số tải vượt quá ngưỡng
bucketCnt*13/16, giá trị này ít nhất là 6.5. - Số lượng bucket tràn quá nhiều
Khi hệ số tải càng nhỏ, biểu thị tỷ lệ sử dụng bộ nhớ của hmap thấp, bộ nhớ chiếm dụng càng lớn. Hàm dùng để tính hệ số tải trong Go là runtime.overLoadFactor, code như sau:
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}Trong đó loadFactorNum và loadFactorDen đều là hằng số, bucketshift là tính 1 << B, và đã biết:
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDenVì vậy rút gọn một chút sẽ được:
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)Trong đó (bucketCnt * 13 / 16) giá trị là 6.5, 1 << B chính là số lượng bucket băm, nên chức năng của hàm này là tính giá trị số lượng phần tử chia cho số lượng bucket có lớn hơn hệ số tải 6.5 không.
Tính toán
Hàm tính băm nội bộ trong Go nằm trong file runtime/alg.go với hàm f32hash, như sau, bao gồm xử lý cho hai trường hợp NaN và 0:
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}Có thể thấy rằng, phương pháp tính băm của map không dựa trên kiểu, mà dựa trên bộ nhớ, cuối cùng sẽ đi đến hàm memhash, hàm này được triển khai bằng assembly, logic nằm trong runtime/asm*.s. Giá trị băm dựa trên bộ nhớ không nên được lưu trữ bền vững, vì nó chỉ nên được sử dụng trong runtime, không thể đảm bảo mỗi lần chạy phân phối bộ nhớ đều hoàn toàn nhất quán.
Trong file này còn có một hàm tên là typehash, hàm này sẽ tính giá trị băm dựa trên các kiểu khác nhau, nhưng map sẽ không sử dụng hàm này để tính băm:
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptrCách triển khai này so với cách trên chậm hơn, nhưng phổ biến hơn, chủ yếu dùng cho reflection và tạo hàm thời gian biên dịch, ví dụ như hàm dưới đây:
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}Tạo
Khởi tạo map có hai cách, điểm này đã được trình bày trong phần nhập môn ngôn ngữ, một là sử dụng từ khóa map để tạo trực tiếp, hai là sử dụng hàm make, bất kể dùng cách nào để khởi tạo, cuối cùng đều do runtime.makemap tạo map, chữ ký hàm như sau:
func makemap(t *maptype, hint int, h *hmap) *hmapTrong đó các tham số:
t, chỉ kiểu của map, kiểu khác nhau chiếm dụng bộ nhớ cần thiết khác nhauhint, chỉ tham số thứ hai của hàmmake, dung lượng phần tử dự kiến của map.h, chỉ con trỏ củahmap, có thể lànil.
Giá trị trả về chính là con trỏ hmap đã khởi tạo xong. Hàm này trong quá trình khởi tạo có một vài công việc chính. Đầu tiên là tính toán bộ nhớ phân phối dự kiến có vượt quá bộ nhớ phân phối tối đa không, tương ứng với code sau:
// Nhân dung lượng dự kiến với kích thước bộ nhớ của kiểu bucket
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// Tràn số hoặc vượt quá bộ nhớ phân phối tối đa
if overflow || mem > maxAlloc {
hint = 0
}Trong cấu trúc nội bộ trước đó đã đề cập, hmap nội bộ được cấu thành bởi bucket, trong trường hợp tỷ lệ sử dụng bộ nhớ thấp nhất, một bucket chỉ có một phần tử, chiếm dụng bộ nhớ nhiều nhất, nên bộ nhớ chiếm dụng tối đa dự kiến là số lượng phần tử nhân với kích thước bộ nhớ của kiểu tương ứng. Khi kết quả tính toán bị tràn số, hoặc vượt quá bộ nhớ có thể phân phối tối đa, sẽ đặt hint thành 0, vì sau này cần dùng hint để tính dung lượng mảng bucket.
Bước thứ hai khởi tạo hmap, và tính toán hạt giống băm ngẫu nhiên, tương ứng với code sau:
// Khởi tạo
if h == nil {
h = new(hmap)
}
// Lấy hạt giống băm ngẫu nhiên
h.hash0 = fastrand()Sau đó tính toán dung lượng bucket băm dựa trên giá trị hint, code tương ứng như sau:
B := uint8(0)
// Liên tục vòng lặp cho đến khi hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// Gán cho hmap
h.B = BThông qua vòng lặp liên tục tìm giá trị B đầu tiên thỏa mãn (hint / 1 << B) < 6.5, gán giá trị này cho hmap, sau khi biết dung lượng bucket băm, cuối cùng là phân phối bộ nhớ cho bucket băm:
if h.B != 0 {
var nextOverflow *bmap
// Bucket băm đã phân phối, và bucket tràn rảnh được phân phối trước
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// Nếu đã phân phối trước bucket tràn rảnh, thì trỏ đến bucket tràn này
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}Hàm makeBucketArray sẽ dựa trên giá trị B, phân phối bộ nhớ có kích thước tương ứng cho bucket băm, và phân phối trước bucket tràn rảnh, khi B nhỏ hơn 4, sẽ không tạo bucket tràn, nếu lớn hơn 4 thì sẽ tạo 2^B-4 bucket tràn. Tương ứng với code sau trong hàm runtime.makeBucketArray:
base := bucketShift(b)
nbuckets := base
// Nhỏ hơn 4 sẽ không tạo bucket tràn
if b >= 4 {
// Số lượng bucket dự kiến cộng với 1 << (b-4)
nbuckets += bucketShift(b - 4)
// Bộ nhớ bucket tràn cần thiết
sz := t.Bucket.Size_ * nbuckets
// Làm tròn lên không gian bộ nhớ
up := roundupsize(sz)
if up != sz {
// Không bằng nhau thì dùng up để tính toán lại
nbuckets = up / t.Bucket.Size_
}
}base chỉ số lượng bucket dự kiến phân phối, nbuckets chỉ số lượng bucket thực tế phân phối, nó cộng thêm số lượng bucket tràn.
if base != nbuckets {
// Bucket tràn khả dụng đầu tiên
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// Để giảm chi phí theo dõi bucket tràn, con trỏ overflow của bucket tràn khả dụng cuối cùng trỏ đến đầu bucket băm
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// Bucket tràn cuối cùng trỏ đến bucket băm
last.setoverflow(t, (*bmap)(buckets))
}Khi hai cái không bằng nhau, biểu thị đã phân phối bucket tràn bổ sung, con trỏ nextoverflow trỏ đến bucket tràn khả dụng đầu tiên. Từ đây có thể thấy, bucket băm và bucket tràn thực tế nằm trong cùng một khối bộ nhớ liên tục, đây cũng là lý do tại sao trong hình mảng bucket băm và mảng bucket tràn liền kề nhau.
Truy cập
Trong phần nhập môn cú pháp đã nói qua, truy cập map tổng cộng có ba cách, như sau:
# Trực tiếp truy cập value
val := dict[key]
# Truy cập value và key này có tồn tại không
val, exist := dict[key]
# Duyệt map
for key, val := range dict{
}Ba cách này sử dụng các hàm khác nhau, trong đó for range duyệt map phức tạp nhất.
Key-value
Đối với hai cách đầu而言, tương ứng với hai hàm,分别是 runtime.mapaccess1 và runtime.mapaccess2, chữ ký hàm như sau:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)Trong đó key là con trỏ trỏ đến key truy cập map, khi trả về cũng chỉ trả về con trỏ. Khi truy cập, đầu tiên cần tính giá trị băm của key, định vị key ở bucket nào, code tương ứng như sau:
// Xử lý biên
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// Ngăn chặn đọc ghi đồng thời
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// Sử dụng hasher chỉ định kiểu để tính giá trị băm
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// Định vị bucket của key thông qua di chuyển con trỏ
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))Khi bắt đầu truy cập trước tiên xử lý tình huống biên, và ngăn chặn map đọc ghi đồng thời, khi map ở trạng thái đọc ghi đồng thời, sẽ xảy ra panic. Sau đó tính giá trị băm, hàm bucketMask làm là tính (1 << B) - 1 , hash & m就等于 hash & (1 << B) - 1 , đây là thao tác lấy dư nhị phân, tương đương hash % (1 << B), lợi ích của việc sử dụng phép toán bit là nhanh hơn. Ba dòng code cuối cùng làm là lấy dư giá trị băm tính được từ key với số lượng bucket trong map hiện tại,得到 số thứ tự bucket băm, sau đó dựa vào số thứ tự này di chuyển con trỏ để lấy con trỏ bucket của key.
Sau khi biết key ở bucket nào, có thể展开 tìm kiếm, phần này tương ứng với code sau:
// Lấy 8 bit cao của giá trị băm
top := tophash(hash)
bucketloop:
// Duyệt danh sách liên kết bmap
for ; b != nil; b = b.overflow(t) {
// Phần tử trong bmap
for i := uintptr(0); i < bucketCnt; i++ {
// So sánh top tính được với phần tử trong tophash
if b.tophash[i] != top {
// Sau này đều là rỗng, không còn nữa
if b.tophash[i] == emptyRest {
break bucketloop
}
// Không bằng nhau thì tiếp tục duyệt bucket tràn
continue
}
// Di chuyển con trỏ dựa vào i để lấy key của chỉ số tương ứng
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// Xử lý con trỏ
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// So sánh hai key có bằng nhau không
if t.Key.Equal(key, k) {
// Nếu bằng nhau, thì di chuyển con trỏ trả về phần tử của chỉ số k tương ứng
// Từ dòng code này có thể thấy địa chỉ bộ nhớ của key-value là liên tục
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// Không tìm thấy, trả về giá trị零.
return unsafe.Pointer(&zeroVal[0])Khi định vị bucket băm, là thông qua lấy dư để định vị, nên key ở bucket nào phụ thuộc vào bit thấp của giá trị băm, còn到底是 thấp mấy bit thì phụ thuộc vào kích thước của B, mà sau khi tìm thấy bucket băm, tophash trong đó lưu trữ 8 bit cao của giá trị băm, vì bit thấp lấy dư đều giống nhau, như vậy không cần phải so sánh từng key có bằng nhau không, chỉ cần so sánh 8 bit cao của giá trị băm là đủ. Dựa vào giá trị băm tính được trước đó để lấy 8 bit cao của nó, so sánh từng cái trong mảng tophash trong bmap, nếu 8 bit cao bằng nhau, thì so sánh key có bằng nhau không, nếu key cũng bằng nhau thì biểu thị đã tìm thấy phần tử, không bằng nhau thì tiếp tục duyệt mảng tophash, vẫn không tìm thấy thì tiếp tục duyệt danh sách liên kết bmap bucket tràn, cho đến khi tophash[i] của bmap là emptyRest thì thoát vòng lặp, cuối cùng trả về giá trị零 của kiểu tương ứng.
Hàm mapaccess2 hoàn toàn nhất quán với logic của hàm mapaccess1, chỉ thêm một giá trị trả về boolean, dùng để biểu thị phần tử có tồn tại không.
Duyệt
Cú pháp duyệt map như sau:
for key, val := range dict {
// do somthing...
}Khi thực tế duyệt, Go sử dụng cấu trúc hiter để lưu trữ thông tin duyệt, hiter là viết tắt của hmap iterator, ý là iterator bảng băm, cấu trúc như sau:
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}Dưới đây giải thích đơn giản một số trường của nó:
key,elemchính là key-value lấy được khi duyệtfor rangebuckets, được chỉ định khi khởi tạo iterator, trỏ đến đầu bucket bămbptr, bmap đang duyệt hiện tạistartBucket, số thứ tự bucket bắt đầu khi duyệtoffset, độ lệch trong bucket, phạm vi[0, bucketCnt-1]B, chính là giá trị B của hmapi, chỉ số phần tử trong bucketwrapped, có từ cuối mảng bucket băm quay về đầu không
Trước khi bắt đầu duyệt, Go thông qua hàm runtime.mapiterinit để khởi tạo iterator, sau đó thông qua hàm runtime.mapiternext để duyệt map, cả hai đều cần dùng đến cấu trúc hiter, chữ ký hai hàm như sau:
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)Đối với khởi tạo iterator而言, đầu tiên cần lấy snapshot hiện tại của map, tương ứng với code sau:
it.t = t
it.h = h
// Ghi lại snapshot trạng thái hiện tại của hmap, chỉ cần lưu giá trị B.
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}Sau này khi duyệt, thực tế duyệt là snapshot của map, chứ không phải map thực tế, nên trong quá trình duyệt các phần tử và bucket được thêm vào sẽ không được duyệt đến, và đồng thời duyệt ghi phần tử đồng thời, có thể kích hoạt fatal.
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}Bước thứ hai quyết định hai vị trí bắt đầu duyệt, đầu tiên là vị trí bucket bắt đầu, thứ hai là vị trí bắt đầu trong bucket, cả hai đều được chọn ngẫu nhiên, tương ứng với code sau:
// r là một số ngẫu nhiên
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B)得到 vị trí bucket bắt đầu
it.startBucket = r & bucketMask(h.B)
// r >> B % 8得到 vị trí bắt đầu phần tử trong bucket bắt đầu
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// Ghi lại số thứ tự bucket đang duyệt hiện tại
it.bucket = it.startBucketThông qua fastrand() hoặc fastrand64() để lấy một số ngẫu nhiên, hai lần lấy模运算得到 vị trí bucket bắt đầu và vị trí bắt đầu trong bucket.
TIP
Map tuy không cho phép đồng thời đọc ghi, nhưng cho phép đồng thời duyệt.
Tiếp theo mới thực sự bắt đầu duyệt map, làm thế nào để duyệt bucket, và chiến lược thoát, phần này tương ứng với code sau:
// hmap
h := it.h
// maptype
t := it.t
// Vị trí bucket待 duyệt
bucket := it.bucket
// bmap待 duyệt
b := it.bptr
// Chỉ số i trong bucket
i := it.i
next:
if b == nil {
// Nếu vị trí bucket hiện tại bằng vị trí bắt đầu, biểu thị đã đi một vòng quay lại, sau này đã duyệt qua
// Duyệt kết thúc, có thể thoát
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// Dịch chuyển chỉ số bucket
bucket++
// bucket == 1 << B, là đi đến cuối mảng bucket băm
if bucket == bucketShift(it.B) {
// Bắt đầu từ đầu
bucket = 0
it.wrapped = true
}
i = 0
}Vị trí bắt đầu của bucket băm được chọn ngẫu nhiên, khi duyệt, từ vị trí bắt đầu duyệt逐个 đến cuối slice bucket, khi đi đến 1 << B, sau đó bắt đầu từ đầu, khi quay lại vị trí bắt đầu lần nữa, biểu thị đã duyệt xong, sau đó thoát. Code trên là về làm thế nào để duyệt bucket trong map, còn code dưới đây mô tả làm thế nào để duyệt trong bucket.
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// Nếu phần tử hiện tại là rỗng thì bỏ qua
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// Di chuyển con trỏ lấy key
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Di chuyển con trỏ lấy value
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// Xử lý trường hợp mở rộng cùng kích thước, khi key-value được sơ tán đến vị trí khác, cần tìm lại key-value.
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// Không tìm thấy thì đi tìm trong bucket tràn
b = b.overflow(t)
i = 0
goto nextTIP
Trong điều kiện phán đoán mở rộng trên, có một biểu thức có thể khiến người ta cảm thấy khó hiểu, như sau:
t.Key.Equal(k, k)Lý do phải phán đoán k có bằng với chính nó không, là để lọc trường hợp key là Nan, nếu key của một phần tử là Nan, thì sẽ无法正常 truy cập phần tử đó, cho dù là duyệt hay trực tiếp truy cập, hoặc là xóa都无法 bình thường tiến hành, vì Nan != Nan永远 thành lập,也就永远 không thể tìm thấy key này.
Đầu tiên dựa vào giá trị i và offset lấy模运算得到 chỉ số trong bucket待 duyệt, thông qua di chuyển con trỏ để lấy key-value, vì trong quá trình duyệt map, sẽ có các thao tác ghi khác kích hoạt mở rộng map, nên key-value thực tế có thể không còn ở vị trí ban đầu nữa, trong trường hợp này cần sử dụng hàm mapaccessK để lấy lại key-value thực tế, chữ ký hàm này như sau:
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)Chức năng của nó hoàn toàn nhất quán với hàm mapaccess1, khác biệt là hàm mapaccessK sẽ đồng thời trả về giá trị key và value. Cuối cùng sau khi lấy được key-value, gán chúng cho key, elem của iterator, sau đó cập nhật chỉ số của iterator, như vậy là hoàn thành một lần duyệt, code thực thi sẽ quay lại khối code for range. Nếu không tìm thấy trong bucket, thì đi tìm trong bucket tràn, tiếp tục lặp lại các bước trên, cho đến khi duyệt xong danh sách liên kết bucket tràn, sau đó tiếp tục duyệt bucket băm tiếp theo.
Sửa đổi
Cú pháp sửa đổi map như sau:
dict[key] = valTrong Go, đối với thao tác sửa đổi map, do hàm runtime.mapassign hoàn thành, chữ ký hàm như sau:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.PointerLogic quá trình truy cập của nó tương tự như mapaccess1, nhưng khi key không tồn tại sẽ phân phối một vị trí cho nó, nếu tồn tại thì cập nhật, cuối cùng trả về con trỏ phần tử. Khi bắt đầu, cần làm một số công việc chuẩn bị, phần này tương ứng với code sau:
// Không cho phép ghi vào map nil
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// Cấm đồng thời ghi
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// Tính giá trị băm của key
hash := t.Hasher(key, uintptr(h.hash0))
// Sửa đổi trạng thái hmap
h.flags ^= hashWriting
// Khởi tạo bucket băm
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}Code trên chủ yếu làm các việc sau:
- Kiểm tra trạng thái hmap
- Tính giá trị băm của key
- Kiểm tra bucket băm có cần khởi tạo không
Sau đó thông qua lấy模运算 giá trị băm để得到 vị trí bucket, và tophash của key, code tương ứng như sau:
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// Di chuyển con trỏ lấy bmap ở vị trí chỉ định
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// Tính tophash
top := tophash(hash)Bây giờ đã xác định vị trí bucket, bmap, tophash, có thể bắt đầu tìm kiếm phần tử, phần code này tương ứng như sau:
// tophash待 chèn
var inserti *uint8
// Con trỏ key待 chèn
var insertk unsafe.Pointer
// Con trỏ value待 chèn
var elem unsafe.Pointer
bucketloop:
for {
// Duyệt mảng tophash trong bucket
for i := uintptr(0); i < bucketCnt; i++ {
// tophash không bằng nhau
if b.tophash[i] != top {
// Nếu chỉ số trong bucket hiện tại là rỗng, và chưa chèn phần tử, thì chọn vị trí này để chèn
if isEmpty(b.tophash[i]) && inserti == nil {
// Tìm thấy một vị trí thích hợp để phân phối cho key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// Duyệt xong thì thoát vòng lặp
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// Nếu tophash bằng nhau, thì biểu thị key có thể đã tồn tại
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// Phán đoán key có bằng nhau không
if !t.Key.Equal(key, k) {
continue
}
// Nếu cần cập nhật key, thì sao chép bộ nhớ của key trực tiếp đến vị trí k
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
//得到 con trỏ phần tử
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Cập nhật xong, trả về con trỏ phần tử
goto done
}
// Thực thi đến đây biểu thị không tìm thấy key, duyệt danh sách liên kết bucket tràn, tiếp tục tìm
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Thực thi đến đây biểu thị key không tồn tại trong map, nhưng có thể đã tìm thấy một vị trí thích hợp để phân phối cho key, cũng có thể không có
// Không tìm thấy vị trí thích hợp để phân phối cho key
if inserti == nil {
// Biểu thị bucket băm hiện tại và bucket tràn của nó đều đã đầy, thì phân phối một bucket tràn mới
newb := h.newoverflow(t, b)
// Phân phối một vị trí cho key trong bucket tràn
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// Nếu lưu trữ là con trỏ key
if t.IndirectKey() {
// Phân phối bộ nhớ mới, trả về là con trỏ unsafe
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// Gán cho insertk, tiện cho việc sao chép bộ nhớ key sau này
insertk = kmem
}
// Nếu lưu trữ là con trỏ phần tử
if t.IndirectElem() {
// Phân phối bộ nhớ
vmem := newobject(t.Elem)
// Để con trỏ trỏ đến vmem
*(*unsafe.Pointer)(elem) = vmem
}
// Sao chép bộ nhớ của key trực tiếp đến vị trí insertk
typedmemmove(t.Key, insertk, key)
*inserti = top
// Số lượng tăng một
h.count++
done:
// Thực thi đến đây biểu thị quá trình sửa đổi đã hoàn thành
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// Trả về con trỏ phần tử
return elemTrong một đoạn code lớn trên, đầu tiên vào vòng lặp for thử tìm kiếm trong bucket băm và bucket tràn, logic tìm kiếm hoàn toàn nhất quán với mapaccess, lúc này có ba khả năng:
- Thứ nhất, tìm thấy key đã tồn tại trong map, trực tiếp nhảy đến khối code
done, trả về con trỏ phần tử - Thứ hai, tìm thấy một vị trí trong map để phân phối cho key sử dụng, sao chép key vào vị trí chỉ định, và trả về con trỏ phần tử
- Thứ ba, tất cả bucket đều tìm xong, không tìm thấy vị trí có thể phân phối cho key trong map, tạo một bucket tràn mới, và phân phối key vào bucket, sau đó sao chép key vào vị trí chỉ định, và trả về con trỏ phần tử
Cuối cùng sau khi得到 con trỏ phần tử, có thể gán giá trị, nhưng phần thao tác này không do hàm mapassign hoàn thành, nó chỉ负责 trả về con trỏ phần tử, thao tác gán giá trị được chèn vào trong thời gian biên dịch, không thể nhìn thấy trong code, nhưng code sau khi biên dịch có thể nhìn thấy, giả sử có code sau:
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}Thông qua lệnh sau得到 code assembly:
go tool compile -S -N -l main.goPhần then chốt nằm ở phần này:
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)Có thể thấy đã gọi runtime.mapassign_faststr, logic của nó hoàn toàn tương tự mapassign, LEAQ go:string."world"(SB), CX là lưu trữ địa chỉ string vào CX, MOVQ CX, (AX) sau đó lưu trữ nó vào AX, thế là hoàn thành việc gán giá trị phần tử.
Xóa
Trong Go, muốn xóa một phần tử của map, chỉ có thể sử dụng hàm built-in delete, như sau:
delete(dict, "abc")Nội bộ nó gọi là hàm runtime.mapdelete, chữ ký hàm như sau:
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)Nó sẽ xóa phần tử của key chỉ định trong map, bất kể phần tử có tồn tại trong map không, nó đều không có phản ứng gì. Logic làm công việc chuẩn bị ở đầu hàm đều tương tự, không ngoài mấy việc sau:
- Kiểm tra trạng thái hmap
- Tính giá trị băm của key
- Định vị bucket băm
- Tính tophash
Phía trước có rất nhiều nội dung trùng lặp, không nói lại nữa, ở đây chỉ quan tâm logic xóa của nó, phần code tương ứng như sau:
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// Không tìm thấy thì thoát vòng lặp
if b.tophash[i] == emptyRest {
break search
}
continue
}
// Di chuyển con trỏ tìm vị trí của key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// Xóa key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// Di chuyển con trỏ tìm vị trí của phần tử
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// Xóa phần tử
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// Số lượng giảm một
h.count--
// Đặt lại hạt giống băm, giảm xác suất xảy ra xung đột
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}Thông qua code trên có thể thấy, logic tìm kiếm gần như hoàn toàn nhất quán với các thao tác trước đó, tìm thấy phần tử, sau đó xóa, số lượng ghi lại của hmap giảm một, khi số lượng giảm về 0, thì đặt lại hạt giống băm.
Một điểm cần chú ý khác là, sau khi xóa phần tử xong, cần sửa đổi trạng thái tophash của chỉ số hiện tại, phần code tương ứng như sau. Khi i ở cuối bucket, phán đoán dựa vào bucket tràn tiếp theo xem phần tử hiện tại có phải là phần tử khả dụng cuối cùng không, nếu không thì trực tiếp xem trạng thái băm của phần tử liền kề. Nếu phần tử hiện tại không phải là khả dụng cuối cùng, thì đặt trạng thái thành emptyOne.
// Đánh dấu tophash hiện tại là rỗng
b.tophash[i] = emptyOne
// Nếu ở cuối tophash
if i == bucketCnt-1 {
// Bucket tràn không rỗng, và trong bucket tràn có phần tử, biểu thị phần tử hiện tại không phải là cuối cùng
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// Phần tử liền kề không rỗng
if b.tophash[i+1] != emptyRest {
goto notLast
}
}Nếu phần tử thực sự là phần tử cuối cùng, thì cần sửa đổi một chút giá trị của mảng tophash của một số bucket trong danh sách bucket, nếu không thì khi duyệt sau này sẽ导致 không thể thoát ở vị trí chính xác. Khi tạo bucket tràn trong map đã nói qua, Go để giảm chi phí theo dõi bucket tràn, con trỏ overflow của bucket tràn cuối cùng chính là trỏ đến bucket băm ở đầu, nên nó thực tế là một danh sách liên kết vòng một chiều, "đầu" của danh sách liên kết chính là bucket băm. Mà b ở đây là b sau khi tìm kiếm, rất có thể là một bucket nào đó ở giữa danh sách liên kết, duyệt ngược danh sách liên kết vòng để tìm phần tử khả dụng cuối cùng. Mặc dù code viết là duyệt xuôi, vì danh sách liên kết là một vòng, nó không ngừng duyệt xuôi cho đến trước bucket tràn hiện tại, về kết quả mà nói确实 là duyệt ngược. Sau đó duyệt ngược mảng tophash trong bucket, cập nhật phần tử có trạng thái emptyOne thành emptyRest, cho đến khi tìm thấy phần tử khả dụng cuối cùng. Để tránh rơi vào vòng lặp vô hạn trong vòng, khi quay lại bucket ban đầu,也就是 bOrig, biểu thị lúc này trong danh sách liên kết không còn phần tử khả dụng nữa, có thể thoát vòng lặp.
// Thực thi đến đây biểu thị sau phần tử hiện tại không còn phần tử nào nữa
// Liên tục duyệt ngược danh sách liên kết bmap, duyệt ngược mảng tophash trong bucket
// Cập nhật phần tử có trạng thái emptyOne thành emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// Tìm bucket trước đó của danh sách liên kết bmap hiện tại
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}Xóa toàn bộ
Trong phiên bản go1.21, đã thêm hàm built-in clear, có thể dùng để xóa tất cả phần tử trong map, cú pháp như sau:
clear(dict)Nội bộ nó gọi hàm runtime.mapclear, nó负责 xóa tất cả phần tử trong map, chữ ký hàm như sau:
func mapclear(t *maptype, h *hmap)Logic của hàm này không phức tạp, đầu tiên cần đánh dấu toàn bộ map là rỗng, code tương ứng như sau:
// Duyệt từng bucket và bucket tràn, đặt tất cả phần tử tophash thành emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))Code trên làm là duyệt từng bucket, đặt các phần tử của mảng tophash trong bucket thành emptyRest, đánh dấu map là rỗng, như vậy có thể ngăn iterator tiếp tục duyệt, sau đó xóa map, code tương ứng như sau:
// Đặt lại hạt giống băm
h.hash0 = fastrand()
// Đặt lại cấu trúc extra
if h.extra != nil {
*h.extra = mapextra{}
}
// Thao tác này sẽ xóa bộ nhớ của buckets trước đó, và phân phối bucket mới
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// Phân phối bucket tràn rảnh mới
h.extra.nextOverflow = nextOverflow
}Thông qua makeBucketArray xóa bộ nhớ của bucket trước đó, sau đó phân phối một cái mới, như vậy là hoàn thành việc xóa bucket, ngoài ra còn một số chi tiết khác, ví dụ như đặt count thành 0, và một số thao tác khác không nói nhiều.
Mở rộng
Trong tất cả các thao tác trước đó, để quan tâm hơn đến logic bản thân của nó, nên đã che chắn rất nhiều nội dung liên quan đến mở rộng, như vậy sẽ đơn giản hơn nhiều. Logic mở rộng thực tế khá phức tạp, đặt ở cuối là không hy vọng bị quấy rầy, vậy bây giờ hãy xem Go làm thế nào để mở rộng map, trước đó đã đề cập, kích hoạt mở rộng có hai điều kiện:
- Hệ số tải vượt quá 6.5
- Số lượng bucket tràn quá nhiều
Hàm phán đoán hệ số tải có vượt quá ngưỡng không là hàm runtime.overLoadFactor, đã trình bày trong phần xung đột băm, còn hàm phán đoán số lượng bucket tràn có quá nhiều không là runtime.tooManyOverflowBuckets, nguyên lý làm việc của nó cũng rất đơn giản, code như sau:
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}Code trên có thể đơn giản hóa thành biểu thức sau,一眼就能看懂:
overflow >= 1 << (min(15,B) % 16)Ở đây, định nghĩa too many của Go là: số lượng bucket tràn gần bằng số lượng bucket băm, nếu ngưỡng thấp, sẽ làm công việc thừa, nếu ngưỡng cao, thì khi mở rộng sẽ chiếm dụng bộ nhớ lớn. Khi sửa đổi và xóa phần tử thì có thể kích hoạt mở rộng, code phán đoán có cần mở rộng không như sau:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}Có thể thấy ba điều kiện hạn chế này:
- Hiện tại không thể đang mở rộng
- Hệ số tải nhỏ hơn 6.5
- Số lượng bucket tràn không được quá nhiều
Hàm负责 mở rộng tự nhiên là runtime.hashGrow, chữ ký hàm như sau:
func hashGrow(t *maptype, h *hmap)Thực tế, mở rộng cũng phân loại, dựa trên điều kiện khác nhau kích hoạt mở rộng loại khác nhau, phân thành hai loại sau:
- Mở rộng tăng dần
- Mở rộng cùng kích thước
Mở rộng tăng dần
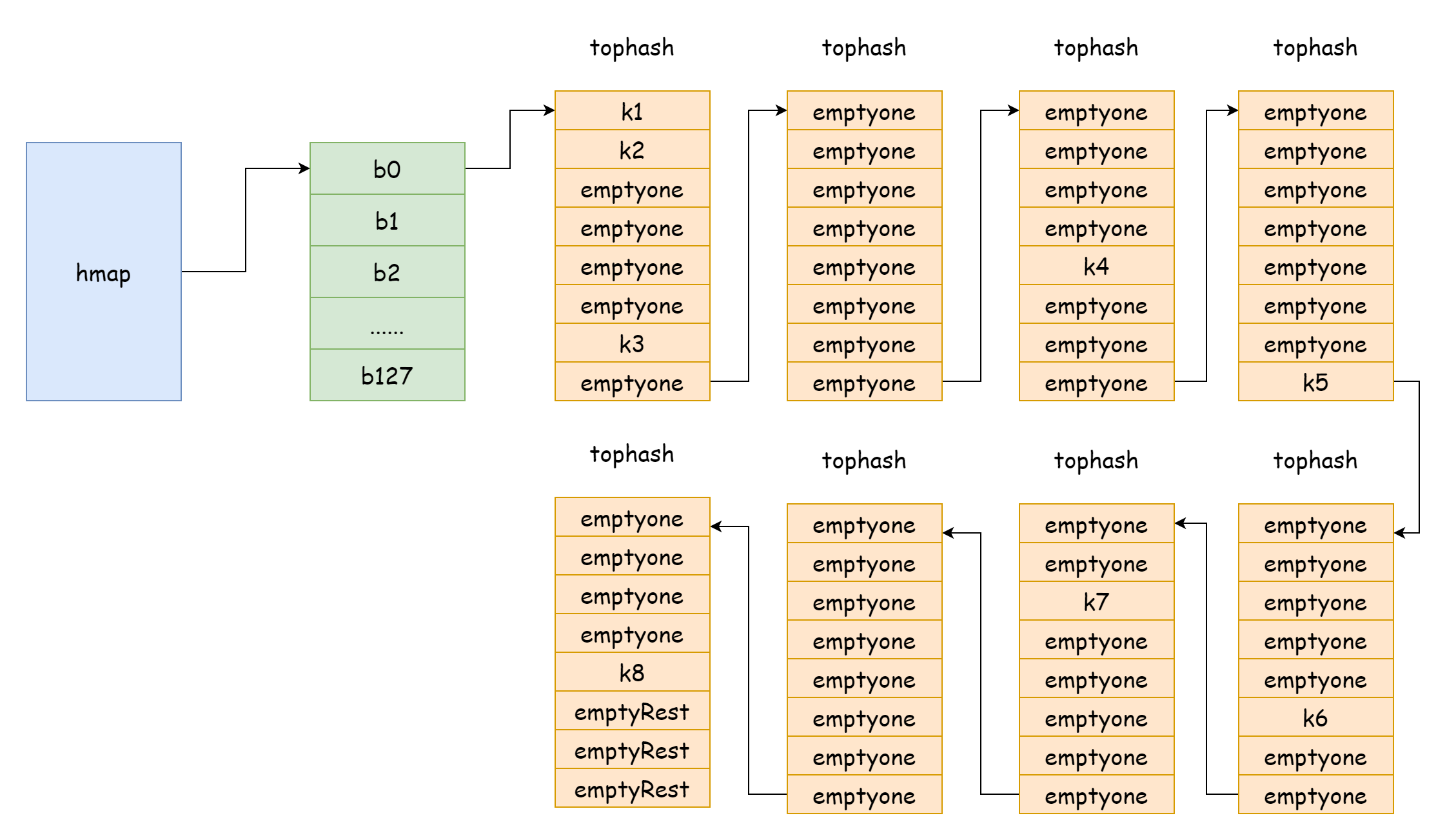
Khi hệ số tải quá lớn, tức số lượng phần tử lớn hơn số lượng bucket băm, khi xung đột băm nghiêm trọng, sẽ hình thành rất nhiều danh sách liên kết bucket tràn, như vậy sẽ导致 hiệu suất đọc ghi của map giảm xuống, vì cần tìm một phần tử duyệt nhiều danh sách liên kết bucket tràn hơn, mà độ phức tạp thời gian duyệt là O(n), độ phức tạp thời gian tìm kiếm của bảng băm chủ yếu phụ thuộc vào thời gian tính giá trị băm và thời gian duyệt, khi thời gian duyệt nhỏ hơn rất nhiều so với thời gian tính giá trị băm, độ phức tạp thời gian tìm kiếm mới có thể gọi là O(1). Nếu xung đột băm khá thường xuyên, quá nhiều key được phân phối vào cùng một bucket băm, danh sách liên kết bucket tràn quá dài导致 thời gian duyệt tăng lên, sẽ导致 thời gian tìm kiếm tăng lên, mà các thao tác tăng sửa đổi xóa đều cần thực hiện thao tác tìm kiếm trước, như vậy sẽ导致 hiệu suất của toàn bộ map giảm xuống nghiêm trọng.
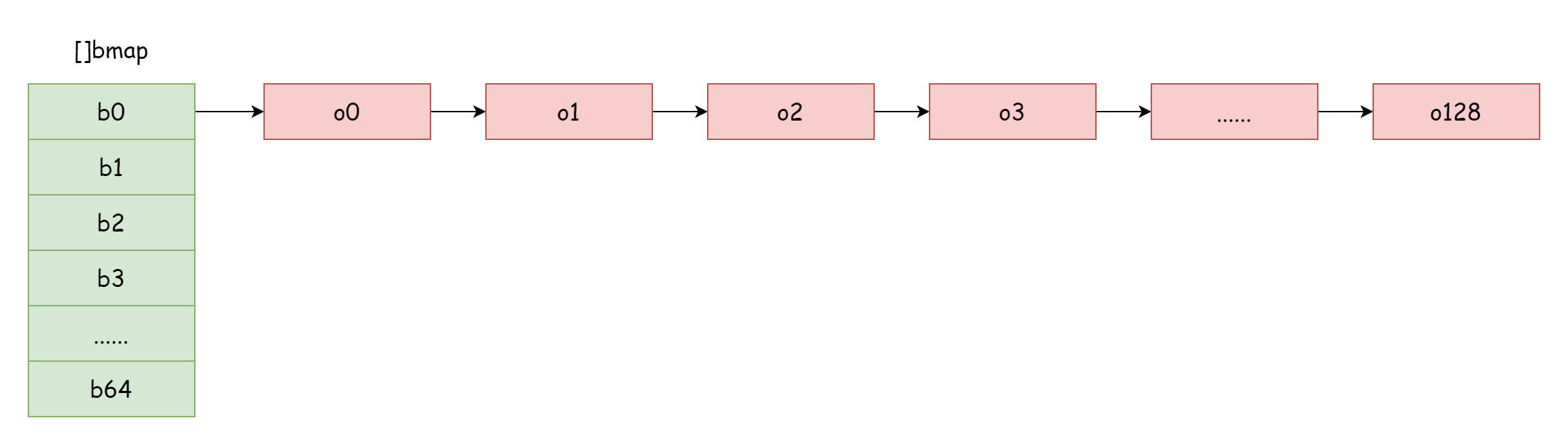
Giống như trường hợp cực đoan trong hình này, độ phức tạp thời gian tìm kiếm cơ bản không khác gì O(n) rồi. Đối mặt với tình huống này, cách giải quyết là thêm nhiều bucket băm hơn, tránh hình thành danh sách liên kết bucket tràn quá dài, phương pháp này cũng được gọi là mở rộng tăng dần.
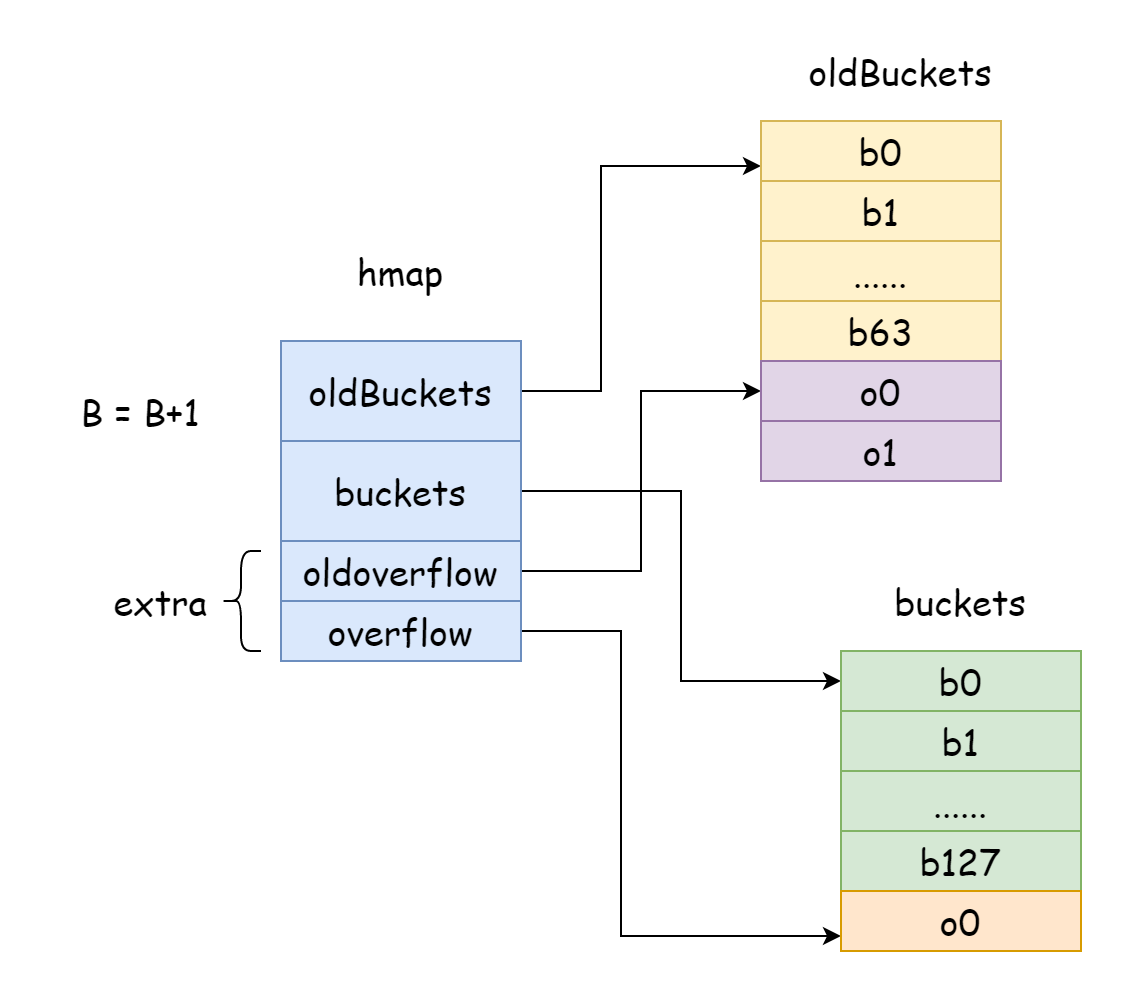
Trong Go, mở rộng tăng dần mỗi lần đều thêm một vào B,也就是 quy mô bucket băm mỗi lần mở rộng gấp đôi. Sau khi mở rộng, cần chuyển dữ liệu cũ vào map mới, nếu số lượng phần tử trong map tính bằng triệu thậm chí trăm triệu, một lần chuyển toàn bộ sẽ mất thời gian rất lâu, nên Go áp dụng chiến lược chuyển dần dần,为此, Go sẽ để oldBuckets trong hamp trỏ đến mảng bucket băm ban đầu, biểu thị đây là dữ liệu cũ, sau đó tạo mảng bucket băm có dung lượng lớn hơn, để buckets trong hmap trỏ đến mảng bucket băm mới, sau đó mỗi lần sửa đổi và xóa phần tử, chuyển một phần phần tử từ bucket cũ sang bucket mới, cho đến khi chuyển xong, bộ nhớ của bucket cũ mới được giải phóng.
func hashGrow(t *maptype, h *hmap) {
// Hiệu số
bigger := uint8(1)
// Bucket cũ
oldbuckets := h.buckets
// Bucket băm mới
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// Bucket tràn cũng cần chỉ định bucket cũ và bucket mới
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}Code trên làm là tạo bucket băm mới có dung lượng lớn gấp đôi, sau đó chỉ định tham chiếu bucket cũ mới của bucket băm, và tham chiếu bucket tràn cũ mới, mà công việc chuyển thực tế không do hàm hashGrow hoàn thành, nó chỉ负责 chỉ định bucket cũ mới, và cập nhật một số trạng thái của hmap. Những công việc này thực tế do hàm runtime.growWork hoàn thành, chữ ký hàm như sau:
func growWork(t *maptype, h *hmap, bucket uintptr)Nó sẽ được gọi trong hàm mapassign và mapdelete dưới hình thức sau, tác dụng của nó là nếu map hiện tại đang trong quá trình mở rộng, thì thực hiện một phần công việc chuyển.
if h.growing() {
growWork(t, h, bucket)
}Khi thực hiện thao tác sửa đổi và xóa, cần phán đoán hiện tại có đang trong quá trình mở rộng không, điều này chủ yếu do phương thức hmap.growing hoàn thành, nội dung rất đơn giản, là phán đoán oldbuckets có rỗng không, code tương ứng như sau:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Hãy xem hàm growWork đã làm những gì:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}Trong đó thao tác bucket&h.oldbucketmask() là tính得到 vị trí bucket cũ, đảm bảo bucket cũ của bucket hiện tại sẽ được chuyển. Từ hàm có thể thấy hàm thực sự负责 công việc chuyển là hàm runtime.evacuate, trong đó sử dụng cấu trúc evaDst để biểu thị đích đến của việc chuyển, tác dụng chính là duyệt bucket mới trong quá trình chuyển, cấu trúc của nó như sau:
type evacDst struct {
b *bmap // Bucket mới của đích đến chuyển
i int // Chỉ số trong bucket
k unsafe.Pointer // Con trỏ trỏ đến đích đến key mới
e unsafe.Pointer // Con trỏ trỏ đến đích đến value mới
}Trước khi bắt đầu chuyển, Go sẽ phân phối hai cấu trúc evacDst, một trỏ đến khu vực trên của bucket băm mới, một trỏ đến khu vực dưới của bucket băm mới, code tương ứng như sau:
// Định vị bucket băm chỉ định trong bucket cũ
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// Độ dài bucket cũ = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// Trỏ đến khu vực trên của bucket mới
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// Phán đoán có phải mở rộng cùng kích thước không
if !h.sameSizeGrow() {
y := &xy[1]
// Trỏ đến khu vực dưới của bucket mới
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Đích đến chuyển của bucket cũ là hai bucket mới, sau khi chuyển, một phần dữ liệu trong bucket sẽ ở khu vực trên, một phần dữ liệu khác sẽ ở khu vực dưới, làm như vậy là hy vọng dữ liệu sau khi mở rộng có thể phân phối đều hơn, phân phối càng đều, hiệu suất tìm kiếm của map càng tốt. Go làm thế nào để chuyển dữ liệu vào hai bucket mới, tương ứng với code sau:
// Duyệt danh sách liên kết bucket tràn
for ; b != nil; b = b.overflow(t) {
// Lấy key-value đầu tiên của mỗi bucket
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// Duyệt từng key-value trong bucket
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// Nếu là rỗng thì bỏ qua
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// Bucket băm mới không nên ở trạng thái chuyển
// Nếu không thì chắc chắn có vấn đề
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// Biến này quyết định key-value hiện tại được chuyển đến khu vực trên hay khu vực dưới
// Giá trị của nó chỉ có thể là 0 hoặc 1
var useY uint8
if !h.sameSizeGrow() {
// Tính lại giá trị băm
hash := t.Hasher(k2, uintptr(h.hash0))
// Xử lý trường hợp đặc biệt k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// Kiểm tra giá trị hằng số
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// Cập nhật tophash của bucket cũ, biểu thị phần tử hiện tại đã được chuyển
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// Chỉ định đích đến chuyển
dst := &xy[useY] // evacuation destination
// Dung lượng bucket mới không đủ dùng thì tạo bucket tràn
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// Sao chép key
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// Sao chép value
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// Dịch chuyển con trỏ đích đến bucket mới, chuẩn bị cho key-value tiếp theo
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}Từ code trên có thể thấy, Go sẽ duyệt từng phần tử của từng bucket trong danh sách liên kết bucket cũ, chuyển dữ liệu trong đó đến bucket mới, quyết định dữ liệu到底是 đi khu vực trên hay khu vực dưới phụ thuộc vào giá trị băm tính lại sau:
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}Sau khi chuyển, sẽ đặt tophash của phần tử hiện tại thành evacuatedX hoặc evacuated, nếu trong quá trình mở rộng thử tìm kiếm dữ liệu, thông qua trạng thái này có thể biết dữ liệu đã được chuyển,就知道 phải đi tìm dữ liệu tương ứng trong bucket mới. Phần logic này tương ứng với code sau trong hàm runtime.mapaccess1:
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// Nếu bucket cũ đã được chuyển thì không tìm nữa
if !evacuated(oldb) {
b = oldb
}
}Khi truy cập phần tử, nếu hiện tại đang trong trạng thái mở rộng, sẽ先去 thử tìm trong bucket cũ, nếu bucket cũ đã được chuyển thì không tìm trong bucket cũ nữa. Quay lại phần chuyển này, lúc này đã xác định đích đến chuyển, tiếp theo cần làm là sao chép dữ liệu vào bucket mới, sau đó để cấu trúc evacDst trỏ đến đích đến tiếp theo.
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}Thao tác như vậy cho đến khi bucket hiện tại chuyển xong, sau đó Go sẽ xóa toàn bộ dữ liệu key-value của bucket cũ hiện tại, chỉ để lại một mảng tophash bucket băm (để lại là vì sau này cần dựa vào mảng tophash để phán đoán trạng thái chuyển), bộ nhớ bucket tràn trong bucket cũ vì không còn được tham chiếu sau này sẽ được GC thu hồi. Trong hmap có một trường nevacuate dùng để ghi lại tiến độ chuyển, mỗi khi chuyển xong một bucket băm cũ, sẽ tăng một, khi giá trị của nó bằng với số lượng bucket cũ, thì biểu thị toàn bộ mở rộng của map đã hoàn thành, tiếp theo do hàm runtime.advanceEvacuationMark thực hiện công việc kết thúc mở rộng.
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Nó sẽ thống kê số lượng đã chuyển và xác nhận có bằng với số lượng bucket cũ không, nếu bằng thì xóa tham chiếu đối với tất cả bucket cũ và bucket tràn cũ, đến đây mở rộng hoàn tất.
Trong hàm growWork, tổng cộng gọi hai lần hàm evacuate, lần đầu là chuyển bucket cũ của bucket đang truy cập hiện tại, lần thứ hai là chuyển bucket cũ do h.nevacuate trỏ đến, tổng cộng chuyển hai lần, biểu thị mỗi lần chuyển dần dần sẽ chuyển hai bucket.
Mở rộng cùng kích thước
Trước đó đã đề cập, điều kiện kích hoạt mở rộng cùng kích thước là số lượng bucket tràn quá nhiều, giả sử map trước tiên thêm một lượng lớn phần tử, sau đó lại xóa một lượng lớn phần tử, như vậy có thể rất nhiều bucket là rỗng, có thể một số bucket có rất nhiều phần tử, phân phối dữ liệu rất không đều, có khá nhiều bucket tràn là rỗng, chiếm dụng không ít bộ nhớ. Để giải quyết loại vấn đề này, cần tạo một map mới có cùng dung lượng, phân phối lại bucket băm một lần, quá trình này gọi là mở rộng cùng kích thước. Nên thực tế không phải là thao tác mở rộng, chỉ là phân phối lại tất cả phần tử để phân phối dữ liệu càng đều hơn, thao tác mở rộng cùng kích thước được trộn lẫn trong thao tác mở rộng tăng dần, logic hoàn toàn nhất quán với mở rộng tăng dần, dung lượng map cũ mới hoàn toàn bằng nhau.
Trong hàm hashGrow, nếu hệ số tải không vượt quá ngưỡng, thực hiện chính là mở rộng cùng kích thước, Go cập nhật trạng thái h.flags thành sameSizeGrow, h.B cũng không tăng một, nên dung lượng bucket băm mới tạo cũng không có thay đổi, code tương ứng như sau:
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)Trong hàm evacuate, khi刚开始 tạo cấu trúc eavcDst, nếu là mở rộng cùng kích thước thì chỉ tạo một cấu trúc trỏ đến bucket mới, code tương ứng như sau:
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}Và khi chuyển phần tử, mở rộng cùng kích thước không tính lại giá trị băm, cũng không có lựa chọn khu vực trên dưới:
if !h.sameSizeGrow() {
// Tính lại giá trị băm
hash := t.Hasher(k2, uintptr(h.hash0))
// Xử lý trường hợp đặc biệt k2 != k2
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}Ngoài những điều này, các logic khác hoàn toàn nhất quán với mở rộng tăng dần. Sau khi mở rộng cùng kích thước bucket băm được phân phối lại, số lượng bucket tràn sẽ giảm, bucket tràn cũ đều sẽ được GC thu hồi.